
Discrete Multi-Objective Grey Wolf Algorithm Applied to Dynamic Distributed Flexible Job Shop Scheduling Problem with Variable Processing Times


Abstract
1. Introduction
- (1)
- A multi-objective DDFJSP-VPT mathematical model is established with the objectives of simultaneously minimizing the makespan, total factory load, and tardiness, in which the processing time fluctuation follows a normal distribution.
- (2)
- Based on the chance-constrained programming theory, the actual processing times are predicted utilizing the quantiles of the given normal distribution and the permissible violation degree of the constraints. This approach enhances the robustness of the obtained initial scheduling solution, reducing the impact of dynamic events on the original schedule.
- (3)
- We propose a heuristic scheduling method to solve the associated model. Using this method, a left-shift adjustment strategy, an insertion-based local adjustment strategy, and a global adjustment strategy based on a discrete multi-objective grey wolf algorithm (DMOGWO) are developed.
- (4)
- An initialization strategy that combines multiple heuristic rules is designed to generate the initial populations with certain levels of quality and diversity. Additionally, discrete crossover and mutation operators are used for position updates in the wolf pack, enabling the GWO to adaptively resolve the scheduling problem.
- (5)
- To evaluate the effectiveness of the proposed methods, a series of experiments are conducted with four main purposes: (i) conducting a sensitivity analysis of the population size in DMOGWO to investigate its impact on the algorithm’s performance; (ii) comparing the performance of DMOGWO with other representative algorithms on solving a static DFJSP and DDFJSP-VPT to assess its competitiveness in terms of both static and dynamic scenarios; (iii) evaluating the performance of the proposed scheduling method against other dynamic scheduling methods with regard to dynamic environments; and (iv) analyzing the impact of the prediction scheme on scheduling efficiency and robustness.
2. Literature Review
2.1. Dynamic Distributed Flexible Job Shop Scheduling Problems
2.2. Flexible Job Shop Scheduling Problems with Variable Processing Time
3. Formulation of Multi-Criteria Optimization Problem
3.1. Problem Description
3.2. Mathematical Modeling for the DDFJSP-VPT
4. Chance-Constrained Approach for Processing Time Predictions
5. Heuristic Scheduling Method
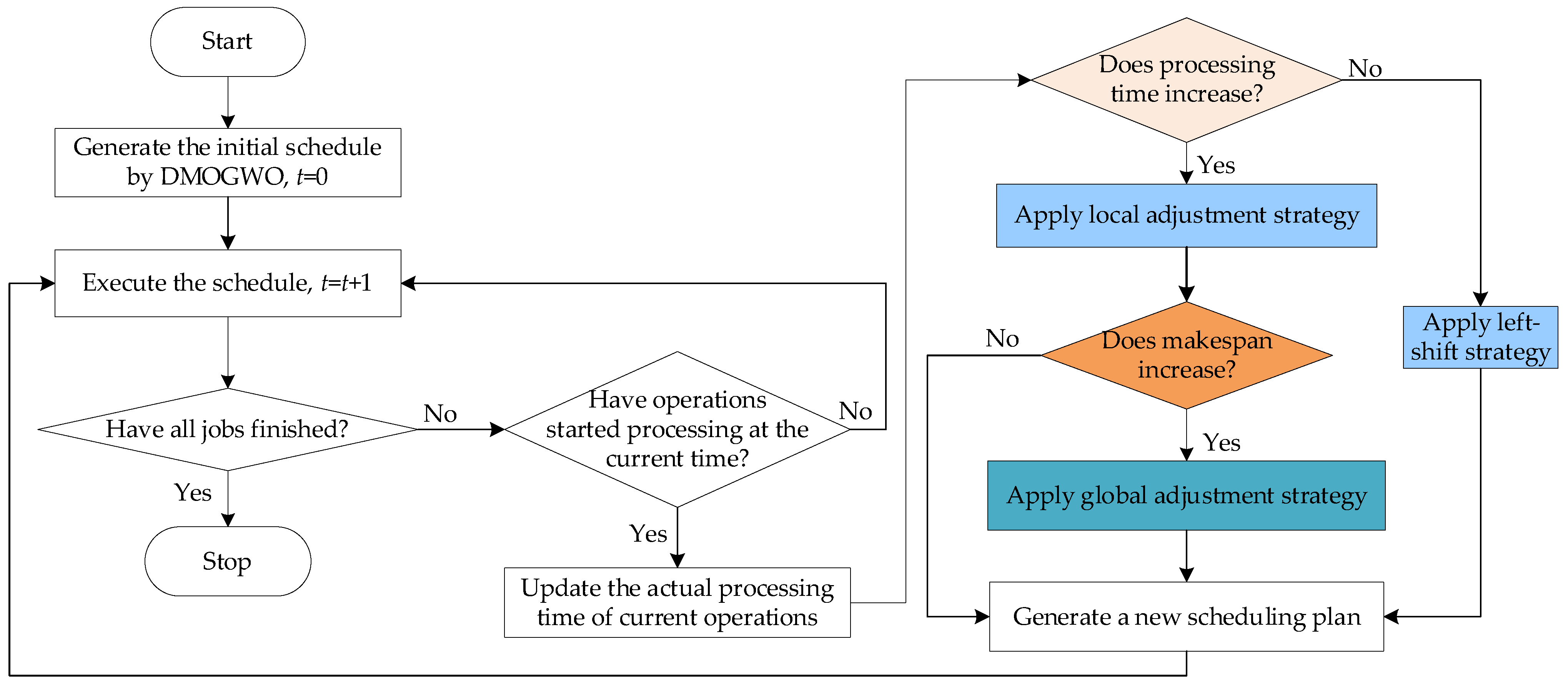
5.1. Framework of the Heuristic Scheduling Method
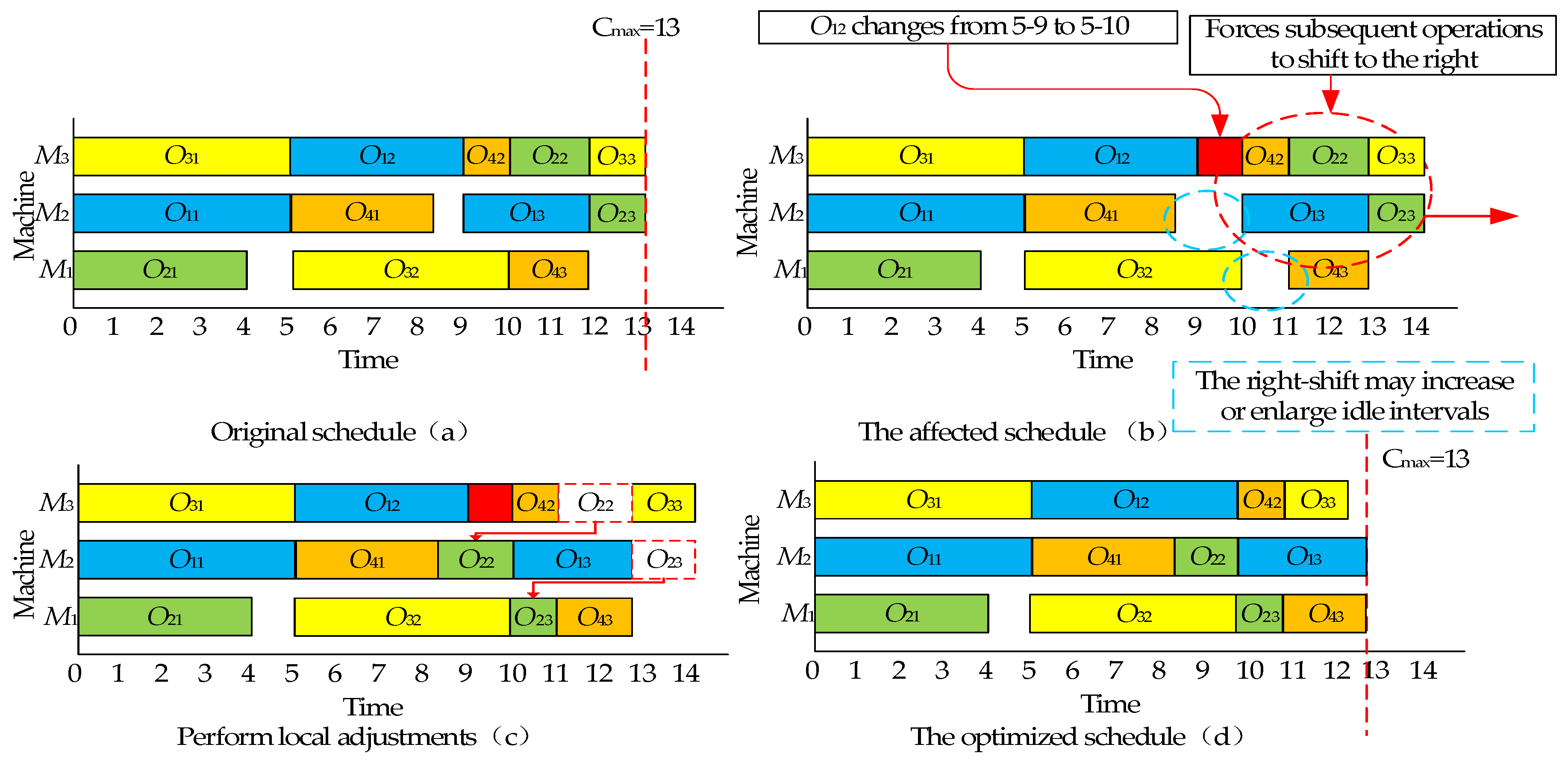
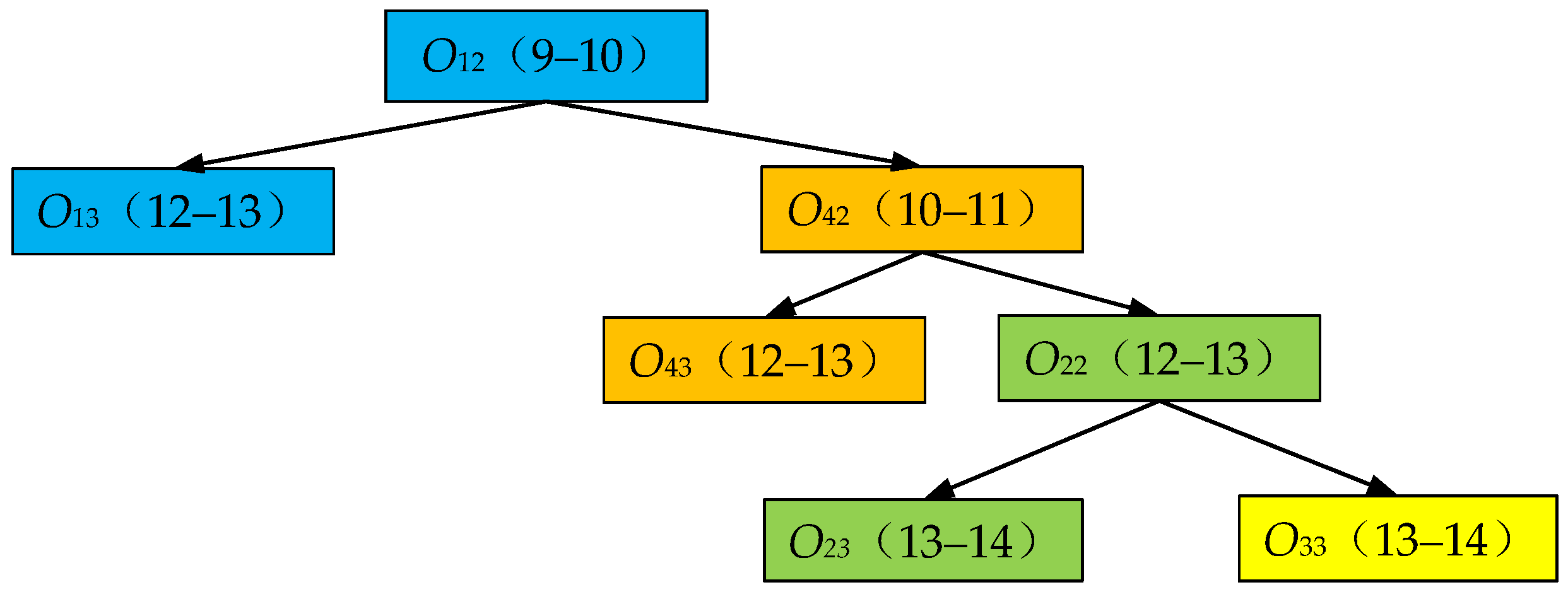
5.2. Insertion-Based Local Adjustment Strategy
5.3. DMOGWO-Based Global Adjustment Strategy
| Algorithm 1: Framework of the DMOGWO algorithm |
| 1: Initialize a wolf group P0 |
| 2: Determine leader wolf packs according to non-dominated sorting |
| 3: t = 0 |
| 4: while (stop criterion is not satisfied) do |
| 5: Pnew = Ø |
| 6: for each wolf St ∈ Pt do |
| 7: determine Sα, Sβ, Sδ as Sleader from leader wolf packs |
| 8: off ← Crossover (St, Sleader) |
| 9: if rand < Pm then |
| 10: off ← Mutation (off) |
| 11: end if |
| 12: Pnew ← Pnew ∪ off |
| 13: end for |
| 14: {F1, F2, …, Flast} ← Non-dominated sorting and crowding distance(Pt ∪ Pnew) |
| 15: Pt+1 ← Environmental Selection (F1,F2,…,Flast) |
| 16: Determine leader wolf packs according to different ranks |
| 17: t = t + 1 |
| 18: end while |
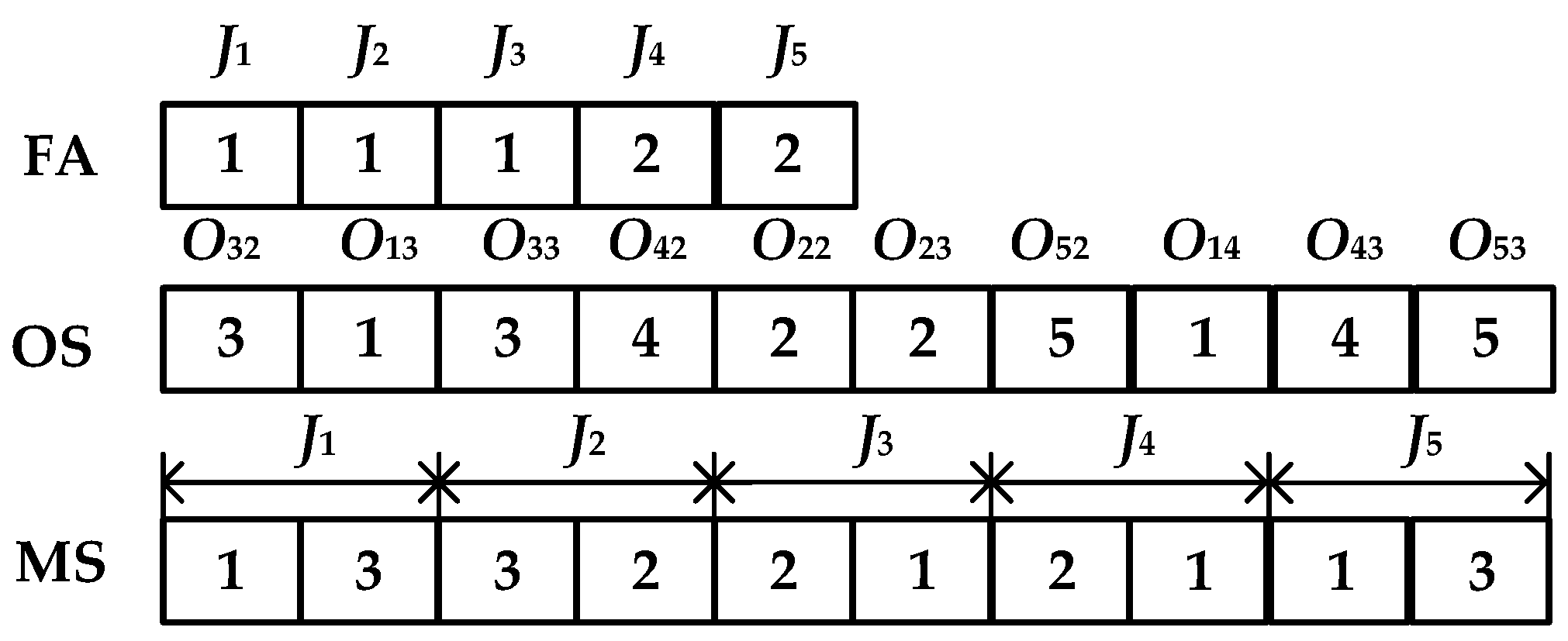
5.3.1. Chromosome Encoding
5.3.2. Chromosome Decoding
5.3.3. Population Initialization
5.3.4. Social Structure of the Wolf Pack
- If the population consists of a single non-dominated rank, the leader wolves , , and are randomly selected from this rank.
- If the population has two non-dominated ranks, is randomly selected from the first rank, while and are chosen randomly from the second rank.
- If the population contains more than two non-dominated ranks, , , and are randomly selected from the first, second, and third ranks, respectively.
5.3.5. Wolf Pack Position Update Method
6. Experiments and Results
6.1. Experimental Instances and Processing Time Variability
6.2. Experimental Metrics
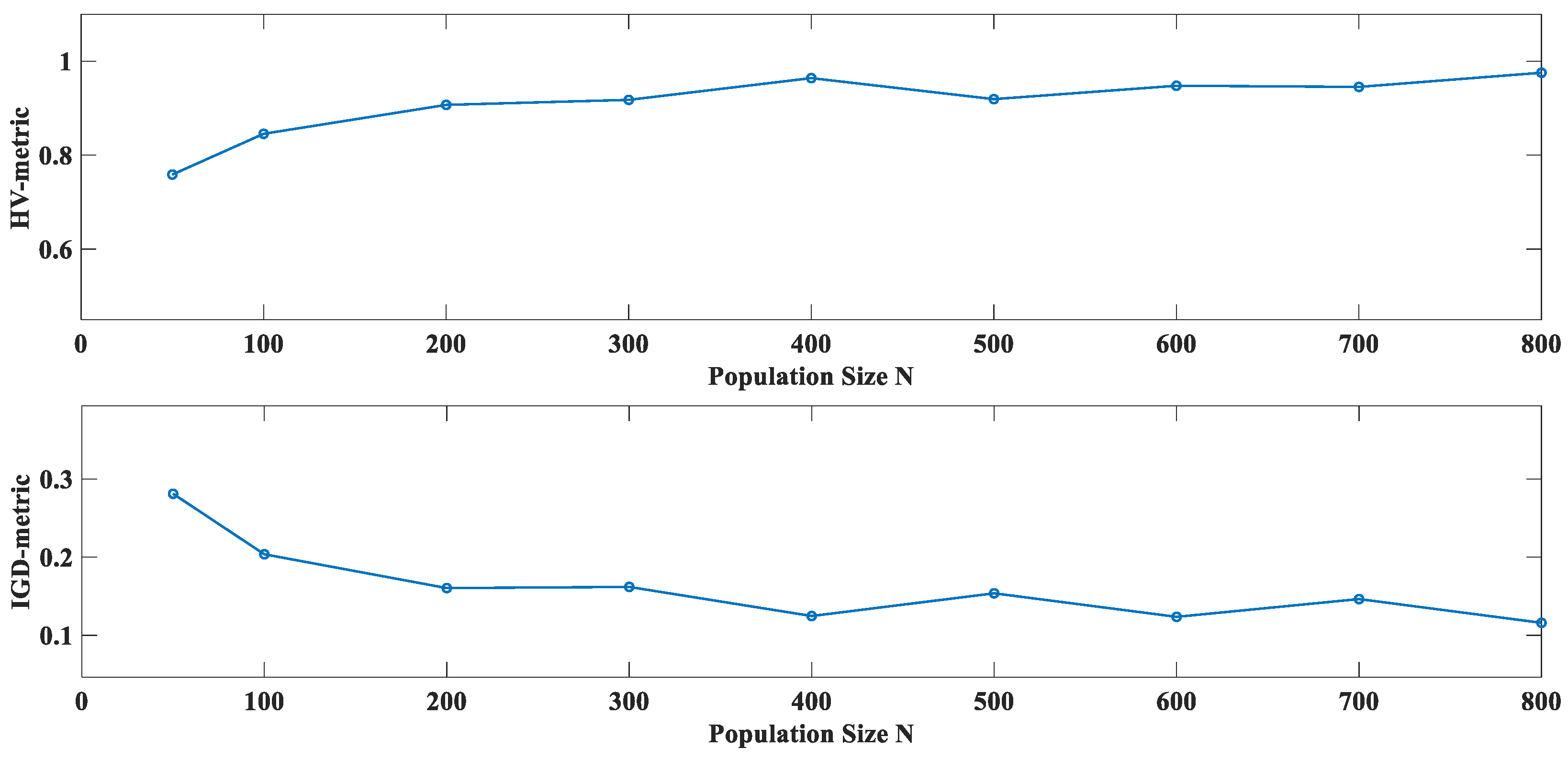
6.3. Sensitivity Analysis of Population Size
6.4. Performance Evaluation of the DMOGWO Algorithm
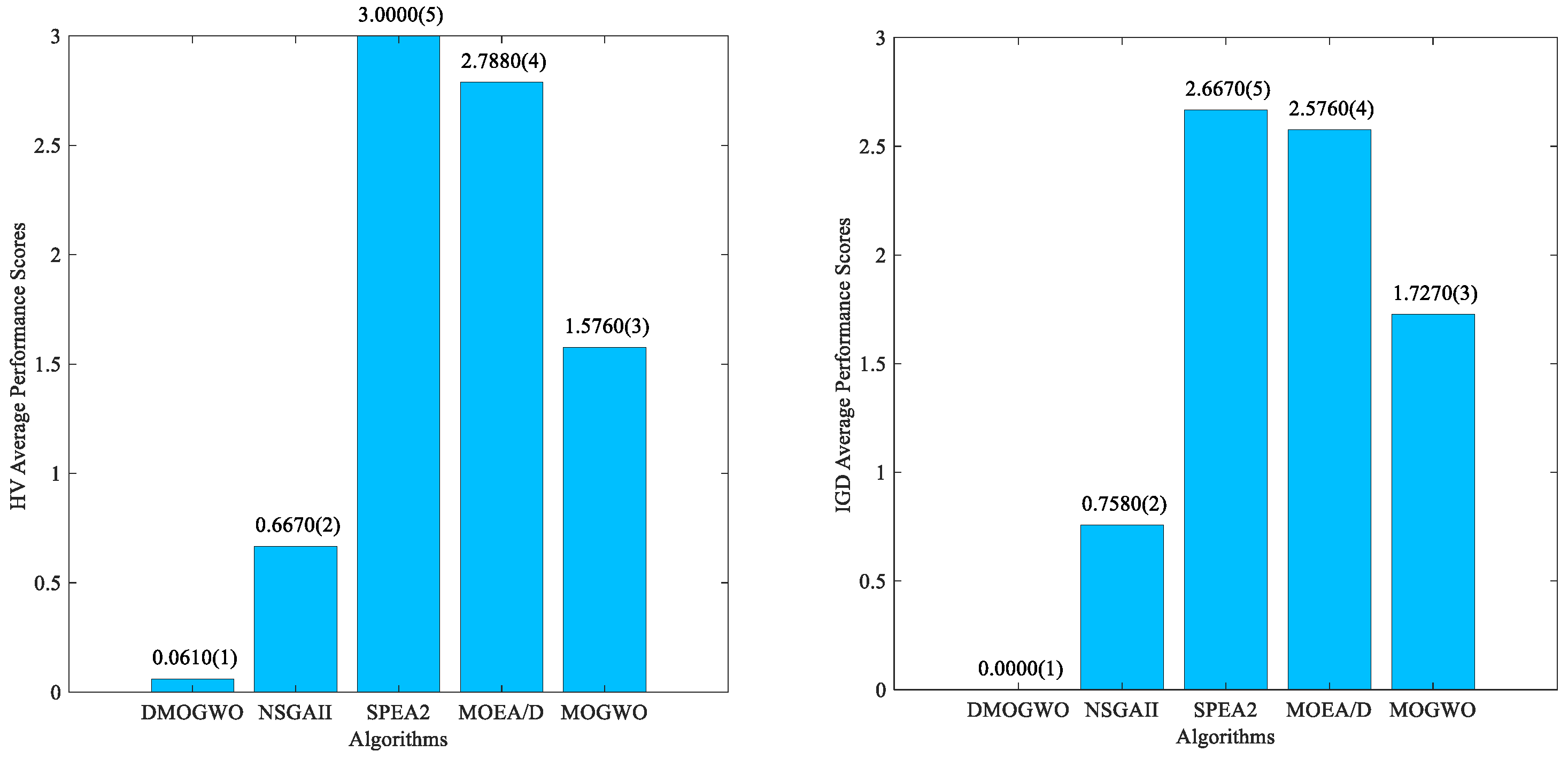
6.4.1. Performance Comparisons in the Initial Static Problem
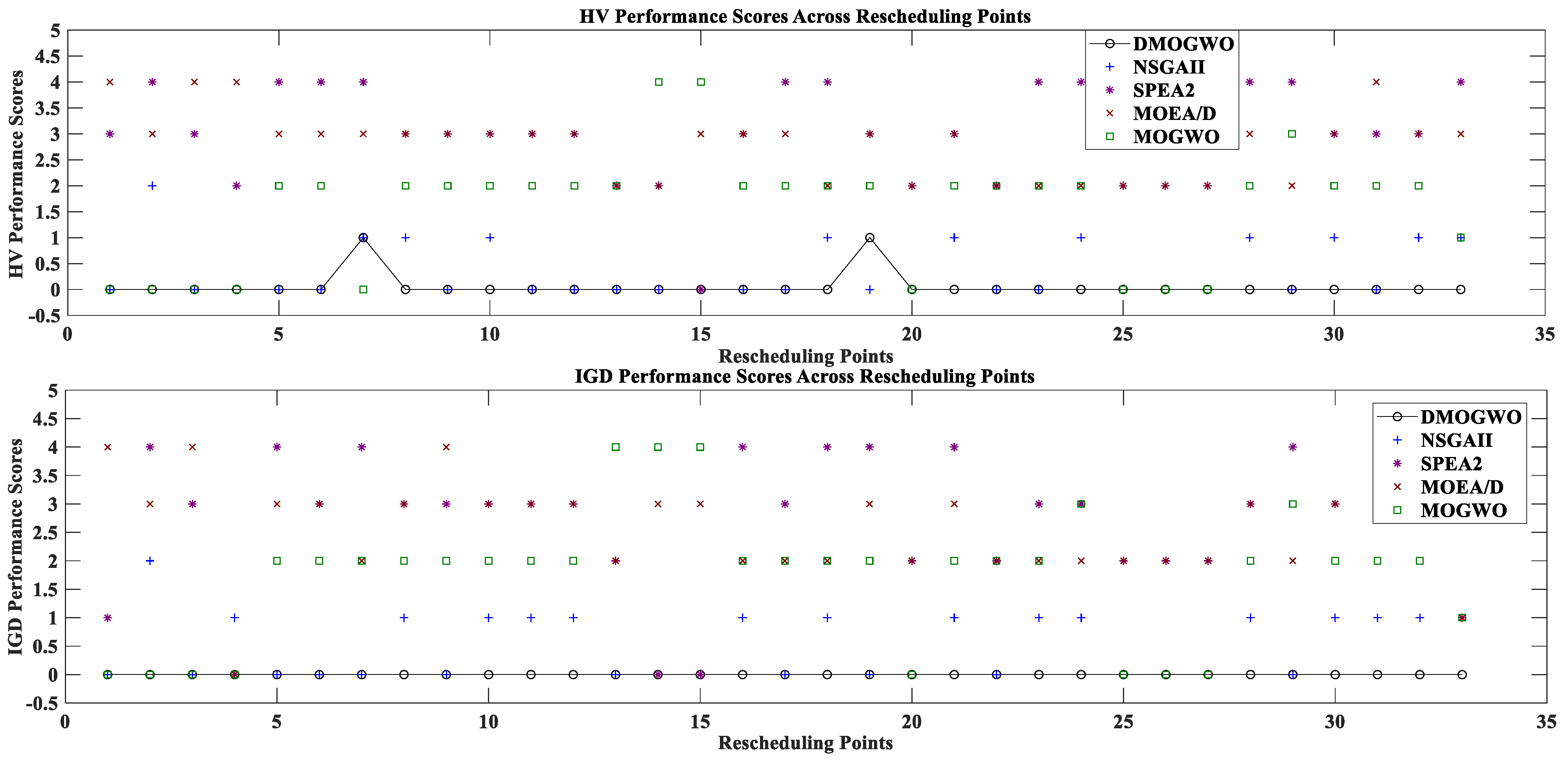
6.4.2. Performance Comparisons for the Dynamic Problem

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instance | HV | IGD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| DMOGWO | NSGA-II | SPEA2 | MOEA/D | MOGWO | DMOGWO | NSGA-II | SPEA2 | MOEA/D | MOGWO | |
| MK01 | 0.7738 | 0.7603 (=) | 0.7069 (+) | 0.6521 (+) | 0.7827 (=) | 0.0199 | 0.0281 (=) | 0.0810 (+) | 0.1016 (+) | 0.0294 (=) |
| MK02 | 0.7362 | 0.6903 (+) | 0.6421 (+) | 0.5926 (+) | 0.7433 (=) | 0.0536 | 0.0699 (=) | 0.0767 (+) | 0.1154 (+) | 0.0502 (=) |
| MK03 | 1.2031 | 1.2032 (=) | 0.8313 (+) | 1.0458 (+) | 1.1829 (+) | 0.0114 | 0.0138 (=) | 0.1450 (+) | 0.0713 (+) | 0.0254 (+) |
| MK04 | 0.7616 | 0.7588 (=) | 0.5943 (+) | 0.6655 (+) | 0.7495 (+) | 0.0141 | 0.0153 (=) | 0.0848 (+) | 0.0661 (+) | 0.0310 (+) |
| MK05 | 1.2028 | 1.1762 (+) | 0.9385 (+) | 0.9083 (+) | 1.0734 (+) | 0.0487 | 0.0622 (+) | 0.1579 (+) | 0.1776 (+) | 0.1188 (+) |
| MK06 | 0.8062 | 0.8098 (=) | 0.7011 (+) | 0.6305 (+) | 0.6290 (+) | 0.0449 | 0.0402 (=) | 0.1082 (+) | 0.2068 (+) | 0.2008 (+) |
| MK07 | 1.0272 | 0.9310 (+) | 0.6847 (+) | 0.7477 (+) | 0.9003 (+) | 0.0282 | 0.0399 (+) | 0.1691 (+) | 0.1240 (+) | 0.1036 (+) |
| MK08 | 0.7434 | 0.6699 (+) | 0.5093 (+) | 0.5493 (+) | 0.6314 (+) | 0.0391 | 0.0523 (+) | 0.1373 (+) | 0.1116 (+) | 0.1193 (+) |
| MK09 | 1.1828 | 1.1618 (+) | 0.8553 (+) | 1.0261 (+) | 1.0592 (+) | 0.0249 | 0.0362 (+) | 0.2166 (+) | 0.1188 (+) | 0.1233 (+) |
| MK10 | 0.9470 | 0.9171 (+) | 0.7176 (+) | 0.7122 (+) | 0.8573 (+) | 0.0966 | 0.1132 (+) | 0.1949 (+) | 0.2087 (+) | 0.1508 (+) |
| Instance | DMOGWO(A) vs. NSGA-II(B) | DMOGWO(A) vs. SPEA2(C) | DMOGWO(A) vs. MOEA/D(D) | DMOGWO(A) vs. MOGWO(E) | ||||
|---|---|---|---|---|---|---|---|---|
| C(A,B) | C(B,A) | C(A,C) | C(C,A) | C(A,D) | C(D,A) | C(A,E) | C(E,A) | |
| MK01 | 0.5935 | 0.1726 (+) | 0.5529 | 0.1225 (+) | 0.8733 | 0.0013 (+) | 0.5433 | 0.2716 (=) |
| MK02 | 0.3980 | 0.1988 (=) | 0.3878 | 0.1490 (+) | 0.7365 | 0.0741 (+) | 0.2245 | 0.2506 (=) |
| MK03 | 0.3518 | 0.2705 (=) | 0.7693 | 0.0053 (+) | 0.9975 | 0.0000 (+) | 0.8019 | 0.0615 (+) |
| MK04 | 0.2371 | 0.1816 (=) | 0.3468 | 0.0085 (+) | 0.7244 | 0.0020 (+) | 0.8439 | 0.0273 (+) |
| MK05 | 0.5026 | 0.2026 (+) | 0.6285 | 0.0110 (+) | 0.9455 | 0.0000 (+) | 0.9486 | 0.0016 (+) |
| MK06 | 0.4142 | 0.4544 (=) | 0.5509 | 0.2141 (+) | 0.9366 | 0.0132 (+) | 0.9973 | 0.0008 (+) |
| MK07 | 0.3051 | 0.1891 (=) | 0.6516 | 0.0036 (+) | 0.8308 | 0.0031 (+) | 0.7515 | 0.0037 (+) |
| MK08 | 0.3425 | 0.1452 (+) | 0.3881 | 0.0111 (+) | 0.5692 | 0.0006 (+) | 0.5635 | 0.0153 (+) |
| MK09 | 0.3675 | 0.1086 (+) | 0.4876 | 0.0028 (+) | 0.6810 | 0.0054 (+) | 0.9464 | 0.0093 (+) |
| MK10 | 0.5974 | 0.0697 (+) | 0.7001 | 0.0065 (+) | 0.7878 | 0.0003 (+) | 0.8402 | 0.0310 (+) |
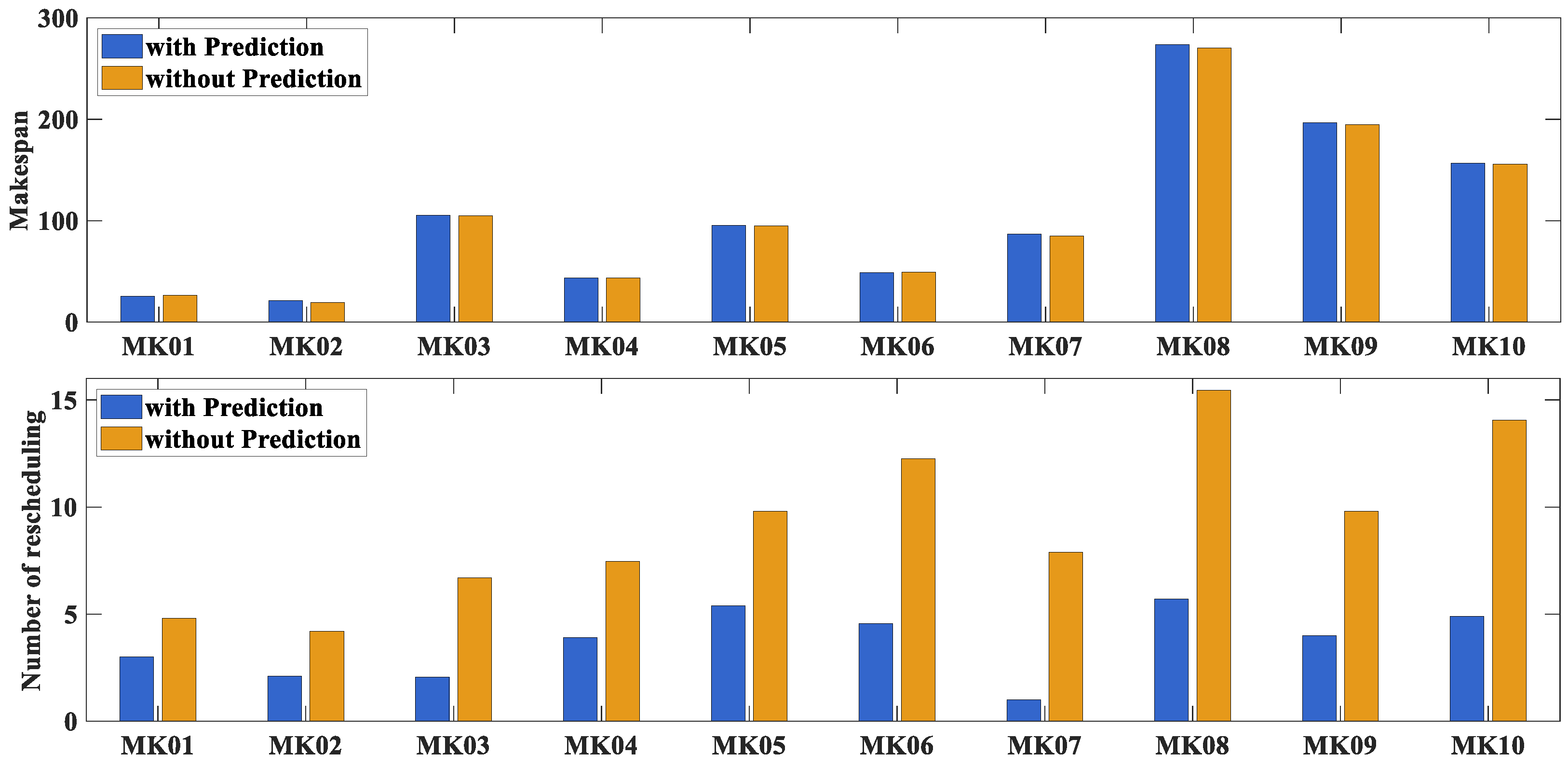
6.5. Performance Evaluation of the Heuristic Scheduling Method
6.6. Further Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Luo, C.; Gong, W.; Lu, C. Knowledge-driven two-stage memetic algorithm for energy-efficient flexible job shop scheduling with machine breakdowns. Expert Syst. Appl. 2024, 235, 121149. [Google Scholar] [CrossRef]
- Zhang, G.; Sun, J.; Liu, X.; Wang, G.; Yang, Y. Solving flexible job shop scheduling problems with transportation time based on improved genetic algorithm. Math. Biosci. Eng. 2019, 16, 1334–1347. [Google Scholar] [CrossRef] [PubMed]
- Du, B.; Han, S.; Guo, J.; Li, Y. A hybrid estimation of distribution algorithm for solving assembly flexible job shop scheduling in a distributed environment. Eng. Appl. Artif. Intell. 2024, 133, 108491. [Google Scholar] [CrossRef]
- Wang, L.; Deng, J.; Wang, S.-Y. Survey on optimization algorithms for distributed shop scheduling (Review). Control Decis. 2016, 31, 1–11. [Google Scholar] [CrossRef]
- Caldeira, R.; Honnungar, S.; Kumar, G.C.M. Feasibility study for converting traditional line assembly into work cells for termination of fiber optics cable. AIP Conf. Proc. 2018, 1943, 020047. [Google Scholar] [CrossRef]
- Mula, J.; Poler, R.; García-Sabater, J.P.; Lario, F.C. Models for production planning under uncertainty: A review. Int. J. Prod. Econ. 2006, 103, 271–285. [Google Scholar] [CrossRef]
- Gu, J.; Jiang, T.; Zhu, H.; Zhang, C. Low-Carbon Job Shop Scheduling Problem with Discrete Genetic-Grey Wolf Optimization Algorithm. J. Adv. Manuf. Syst. 2020, 19, 1–14. [Google Scholar] [CrossRef]
- Luo, S.; Zhang, L.; Fan, Y. Energy-efficient scheduling for multi-objective flexible job shops with variable processing speeds by grey wolf optimization. J. Clean. Prod. 2019, 234, 1365–1384. [Google Scholar] [CrossRef]
- Zhu, Z.; Zhou, X. An efficient evolutionary grey wolf optimizer for multi-objective flexible job shop scheduling problem with hierarchical job precedence constraints. Comput. Ind. Eng. 2020, 140, 106280. [Google Scholar] [CrossRef]
- Kong, X.; Yao, Y.; Yang, W.; Yang, Z.; Su, J. Solving the Flexible Job Shop Scheduling Problem Using a Discrete Improved Grey Wolf Optimization Algorithm. Machines 2022, 10, 1100. [Google Scholar] [CrossRef]
- Komaki, G.M.; Kayvanfar, V. Grey Wolf Optimizer algorithm for the two-stage assembly flow shop scheduling problem with release time. J. Comput. Sci. 2015, 8, 109–120. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, Y.; Zhang, Y.; Xu, G. Energy-Saving Distributed Flexible Job Shop Scheduling Optimization with Dual Resource Constraints Based on Integrated Q-Learning Multi-Objective Grey Wolf Optimizer. Comput. Model. Eng. 2024, 140, 1459–1483. [Google Scholar] [CrossRef]
- Li, X.; Xie, J.; Ma, Q.; Gao, L.; Li, P. Improved gray wolf optimizer for distributed flexible job shop scheduling problem. Sci. China Technol. Sci. 2022, 65, 2105–2115. [Google Scholar] [CrossRef]
- Zhu, K.; Gong, G.; Peng, N.; Zhang, L.; Huang, D.; Luo, Q.; Li, X. Dynamic distributed flexible job-shop scheduling problem considering operation inspection. Expert Syst. Appl. 2023, 224, 119840. [Google Scholar] [CrossRef]
- Zhu, N.; Gong, G.; Lu, D.; Huang, D.; Peng, N.; Qi, H. An effective reformative memetic algorithm for distributed flexible job-shop scheduling problem with order cancellation. Expert Syst. Appl. 2024, 237, 121205. [Google Scholar] [CrossRef]
- Zhang, H.; Qin, C.; Xu, G.; Chen, Y.; Gao, Z. An energy-saving distributed flexible job shop scheduling with machine breakdowns. Appl. Soft Comput. 2024, 167, 112276. [Google Scholar] [CrossRef]
- Chen, Y.; Liao, X.; Chen, G.; Hou, Y. Dynamic Intelligent Scheduling in Low-Carbon Heterogeneous Distributed Flexible Job Shops with Job Insertions and Transfers. Sensors 2024, 24, 2251. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Y.; Ren, S.; Wang, C.; Wang, W. Evolutionary game based real-time scheduling for energy-efficient distributed and flexible job shop. J. Clean. Prod. 2021, 293, 126093. [Google Scholar] [CrossRef]
- Lin, C.; Cao, Z.; Zhou, M. Learning-Based Grey Wolf Optimizer for Stochastic Flexible Job Shop Scheduling. IEEE Trans. Autom. Sci. Eng. 2022, 19, 3659–3671. [Google Scholar] [CrossRef]
- Jin, L.; Zhang, C.; Wen, X.; Sun, C.; Fei, X. A neutrosophic set-based TLBO algorithm for the flexible job-shop scheduling problem with routing flexibility and uncertain processing times. Complex Intell. Syst. 2021, 7, 2833–2853. [Google Scholar] [CrossRef]
- Caldeira, R.H.; Gnanavelbabu, A. A simheuristic approach for the flexible job shop scheduling problem with stochastic processing times. Simulation 2020, 97, 215–236. [Google Scholar] [CrossRef]
- Sun, L.; Lin, L.; Li, H.; Gen, M. Cooperative Co-Evolution Algorithm with an MRF-Based Decomposition Strategy for Stochastic Flexible Job Shop Scheduling. Mathematics 2019, 7, 318. [Google Scholar] [CrossRef]
- Mokhtari, H.; Dadgar, M. Scheduling optimization of a stochastic flexible job-shop system with time-varying machine failure rate. Comput. Oper. Res. 2015, 61, 31–45. [Google Scholar] [CrossRef]
- Shahgholi Zadeh, M.; Katebi, Y.; Doniavi, A. A heuristic model for dynamic flexible job shop scheduling problem considering variable processing times. Int. J. Prod. Res. 2018, 57, 3020–3035. [Google Scholar] [CrossRef]
- Zhong, X.; Han, Y.; Yao, X.; Gong, D.; Sun, Y. An evolutionary algorithm for the multi-objective flexible job shop scheduling problem with uncertain processing time. Sci. Sin. Inform. 2023, 53, 737–757. [Google Scholar] [CrossRef]
- Zhang, L.; Feng, Y.; Xiao, Q.; Xu, Y.; Li, D.; Yang, D.; Yang, Z. Deep reinforcement learning for dynamic flexible job shop scheduling problem considering variable processing times. J. Manuf. Syst. 2023, 71, 257–273. [Google Scholar] [CrossRef]
- Fu, Y.; Gao, K.; Wang, L.; Huang, M.; Liang, Y.-C.; Dong, H. Scheduling stochastic distributed flexible job shops using an multi-objective evolutionary algorithm with simulation evaluation. Int. J. Prod. Res. 2024, 63, 86–103. [Google Scholar] [CrossRef]
- Charnes, A.; Cooper, W.W. Chance-Constrained Programming. Manage. Sci. 1959, 6, 73–79. [Google Scholar] [CrossRef]
- Muralidhar, K.; Swenseth, S.R.; Wilson, R.I. Describing processing time when simulating JIT environments. Int. J. Prod. Res. 1992, 30, 1. [Google Scholar] [CrossRef]
- Chang, P.; Chen, S.; Lin, K. Two-phase sub population genetic algorithm for parallel machine-scheduling problem. Expert Syst. Appl. 2005, 29, 705–712. [Google Scholar] [CrossRef]
- Bitar, A.; Dauze’re-Pe’re’s, S.; Yugma, C.; Roussel, R. A memetic algorithm to solve an unrelated parallel machine scheduling problem with auxiliary resources in semiconductor manufacturing. J. Sched. 2016, 19, 367–376. [Google Scholar] [CrossRef]
- He, W.; Sun, D.-h. Scheduling flexible job shop problem subject to machine breakdown with route changing and right-shift strategies. Int. J. Adv. Manuf. Technol. 2012, 66, 501–514. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Gao, K.Z.; Suganthan, P.N.; Pan, Q.K.; Chua, T.J.; Cai, T.X.; Chong, C.S. Pareto-based grouping discrete harmony search algorithm for multi-objective flexible job shop scheduling. Inf. Sci. 2014, 289, 76–90. [Google Scholar] [CrossRef]
- Lu, C.; Gao, L.; Li, X.; Xiao, S. A hybrid multi-objective grey wolf optimizer for dynamic scheduling in a real-world welding industry. Eng. Appl. Artif. Intell. 2017, 57, 61–79. [Google Scholar] [CrossRef]
- Wang, X.; Gao, L.; Zhang, C.; Shao, X. A multi-objective genetic algorithm based on immune and entropy principle for flexible job-shop scheduling problem. Int. J. Adv. Manuf. Technol. 2010, 51, 757–767. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, G.; Xu, Y.; Liu, M. An enhanced Pareto-based artificial bee colony algorithm for the multi-objective flexible job-shop scheduling. Int. J. Adv. Manuf. Technol. 2012, 60, 1111–1123. [Google Scholar] [CrossRef]
- Brandimarte, P. Routing and scheduling in a flexible job shop by tabu search. Ann. Oper. Res. 1993, 41, 157–183. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L.; Laumanns, M.; Fonseca, C.M.; Da Fonseca, V.G. Performance assessment of multiobjective optimizers: An analysis and review. IEEE Trans. Evol. Comput. 2003, 7, 117–132. [Google Scholar] [CrossRef]
- Tang, J.; Gong, G.; Peng, N.; Zhu, K.; Huang, D.; Luo, Q. An effective memetic algorithm for distributed flexible job shop scheduling problem considering integrated sequencing flexibility. Expert Syst. Appl. 2024, 242, 122734. [Google Scholar] [CrossRef]
- Qingfu, Z.; Hui, L. MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the Strength Pareto Evolutionary Algorithm for Multiobjective Optimization; Technical Report Gloriastrasse; 103, TIK-Rep; Swiss Federal Institute of Technology: Lausanne, Switzerland, 2001; pp. 1–20. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Shen, X.-N.; Yao, X. Mathematical modeling and multi-objective evolutionary algorithms applied to dynamic flexible job shop scheduling problems. Inf. Sci. 2015, 298, 198–224. [Google Scholar] [CrossRef]
- Bader, J.; Zitzler, E. HypE: An Algorithm for Fast Hypervolume-Based Many-Objective Optimization. Evol. Comput. 2011, 19, 45–76. [Google Scholar] [CrossRef] [PubMed]
- Chuanjun, Z.; Wen, Q.; Mengzhou, Z.; Guang, C.; Chaoyong, Z. Multi-objective flexible job shops robust scheduling problem under stochastic processing times. China Mech. Eng. 2016, 27, 1667–1672. [Google Scholar] [CrossRef]
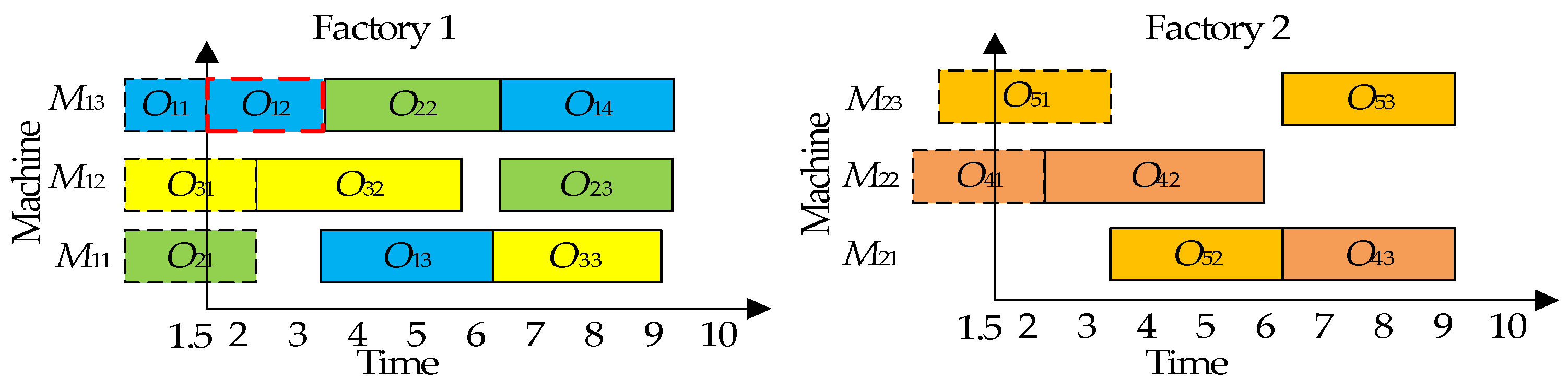
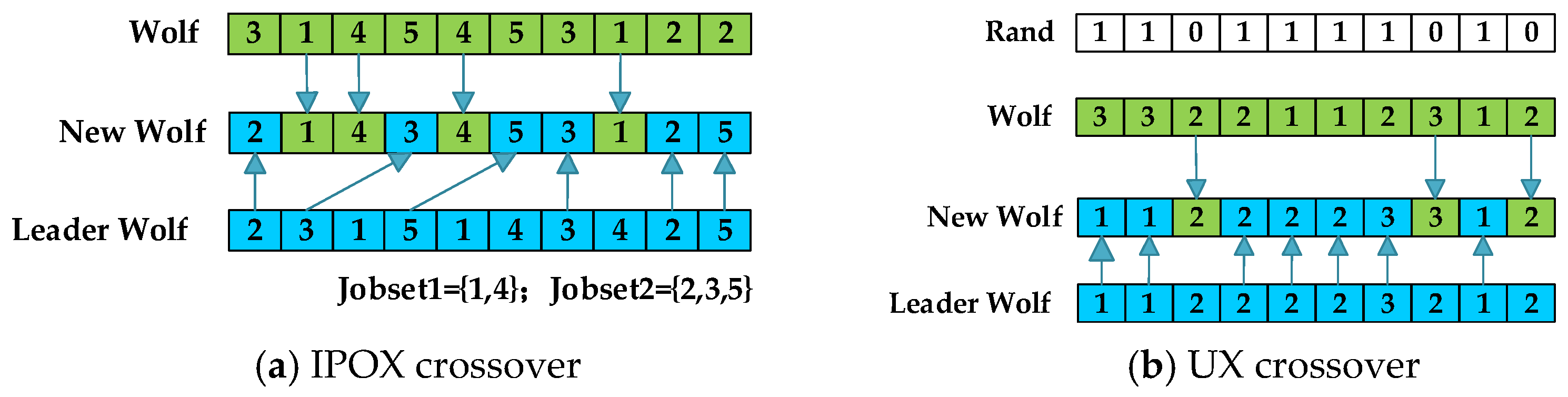

| Notation | Description |
|---|---|
| Parameters: | |
| Number of jobs | |
| The ith job | |
| w | Number of factories |
| The lth factory | |
| L | A sufficiently large constant |
| Decision Variables: | |
| Instance | Number of Jobs | Number of Machines | Operations Range per job | Machines Range per Operation | Time Range per Operation |
|---|---|---|---|---|---|
| MK01 | 10 | 6 | 5–7 | 3 | 1–7 |
| MK02 | 10 | 6 | 5–7 | 6 | 1–7 |
| MK03 | 15 | 8 | 10–10 | 5 | 1–20 |
| MK04 | 15 | 8 | 3–10 | 3 | 1–10 |
| MK05 | 15 | 4 | 5–10 | 2 | 5–10 |
| MK06 | 15 | 15 | 15–15 | 5 | 1–10 |
| MK07 | 20 | 5 | 5–5 | 5 | 1–20 |
| MK08 | 20 | 10 | 10–5 | 2 | 5–20 |
| MK09 | 20 | 10 | 10–15 | 5 | 5–20 |
| MK10 | 20 | 15 | 10–15 | 5 | 5–20 |
| Instance | HV | IGD | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| DMOGWO | NSGA-II | SPEA2 | MOEA/D | MOGWO | DMOGWO | NSGA-II | SPEA2 | MOEA/D | MOGWO | |
| MK01 | 1.1540 | 1.1710 (=) | 1.1023 (=) | 0.9855 (+) | 1.1375 (=) | 0.0961 | 0.1153 (=) | 0.1356 (=) | 0.2074 (+) | 0.1110 (=) |
| MK02 | 1.1931 | 1.2018 (=) | 1.1931 (=) | 1.0917 (+) | 1.1828 (=) | 0.0606 | 0.0691 (=) | 0.0717 (=) | 0.1428 (+) | 0.0660 (=) |
| MK03 | 1.1957 | 1.1864 (=) | 0.8034 (+) | 1.0246 (+) | 1.1695 (+) | 0.0054 | 0.0106 (+) | 0.1285 (+) | 0.0713 (+) | 0.0173 (+) |
| MK04 | 1.2296 | 1.2200 (=) | 0.8787 (+) | 1.0839 (+) | 1.1936 (+) | 0.0269 | 0.0284 (=) | 0.1871 (+) | 0.1038 (+) | 0.0410 (+) |
| MK05 | 1.2017 | 1.1597 (+) | 0.9441 (+) | 0.8984 (+) | 1.0950 (+) | 0.0798 | 0.0870 (=) | 0.1849 (+) | 0.2087 (+) | 0.1181 (+) |
| MK06 | 0.9401 | 0.9308 (=) | 0.6488 (+) | 0.6670 (+) | 0.8155 (+) | 0.1009 | 0.1244 (=) | 0.2416 (+) | 0.4040 (+) | 0.2064 (+) |
| MK07 | 1.1766 | 1.1614 (=) | 0.9137 (+) | 0.9957 (+) | 1.0828 (+) | 0.0581 | 0.0603 (=) | 0.1621 (+) | 0.1264 (+) | 0.1023 (+) |
| MK08 | 1.0795 | 1.0231 (+) | 0.6900 (+) | 0.7983 (+) | 0.8964 (+) | 0.1546 | 0.1864 (+) | 0.3765 (+) | 0.2664 (+) | 0.2419 (+) |
| MK09 | 1.1729 | 1.1435 (+) | 0.8046 (+) | 0.9028 (+) | 1.0436 (+) | 0.0470 | 0.0657 (+) | 0.2167 (+) | 0.1705 (+) | 0.1215 (+) |
| MK10 | 1.2095 | 1.1896 (+) | 0.9888 (+) | 1.0388 (+) | 1.1530 (+) | 0.0292 | 0.0448 (+) | 0.1447 (+) | 0.1421 (+) | 0.0805 (+) |
| Instance | DMOGWO(A) vs. NSGA-II(B) | DMOGWO(A) vs. SPEA2(C) | DMOGWO(A) vs. MOEA/D(D) | DMOGWO(A) vs. MOGWO(E) | ||||
|---|---|---|---|---|---|---|---|---|
| C(A,B) | C(B,A) | C(A,C) | C(C,A) | C(A,D) | C(D,A) | C(A,E) | C(E,A) | |
| MK01 | 0.3510 | 0.1023 (=) | 0.4863 | 0.2005 (=) | 0.8003 | 0.0500 (+) | 0.4998 | 0.0508 (+) |
| MK02 | 0.3493 | 0.2493 (=) | 0.2500 | 0.1993 (=) | 0.8743 | 0.0000 (+) | 0.1505 | 0.2490 (=) |
| MK03 | 0.5139 | 0.1800 (+) | 0.7280 | 0.0020 (+) | 0.9120 | 0.0000 (+) | 0.9221 | 0.0153 (+) |
| MK04 | 0.3998 | 0.3409 (=) | 0.5450 | 0.0139 (+) | 0.9896 | 0.0013 (+) | 0.8029 | 0.0482 (+) |
| MK05 | 0.4897 | 0.1953 (=) | 0.8113 | 0.0540 (+) | 1.0000 | 0.0000 (+) | 0.8153 | 0.0043 (+) |
| MK06 | 0.6443 | 0.2040 (+) | 0.7053 | 0.0533 (+) | 0.9483 | 0.0015 (+) | 0.8963 | 0.0520 (+) |
| MK07 | 0.4985 | 0.1663 (+) | 0.8110 | 0.0000 (+) | 0.9406 | 0.0000 (+) | 0.9034 | 0.0088 (+) |
| MK08 | 0.5628 | 0.2493 (+) | 0.7720 | 0.0008 (+) | 0.9643 | 0.0040 (+) | 0.9578 | 0.0013 (+) |
| MK09 | 0.4925 | 0.2305 (+) | 0.8505 | 0.0010 (+) | 0.9256 | 0.0003 (+) | 0.9530 | 0.0098 (+) |
| MK10 | 0.5868 | 0.1933 (+) | 0.7725 | 0.0492 (+) | 0.9970 | 0.0000 (+) | 0.9608 | 0.0033 (+) |
| Method | Avg Makespan | Avg Tardiness | Avg Factory Load |
|---|---|---|---|
| FAR1 + MAR1 + SPT | 152.5570 ± 10.3291 | 340.3910 ± 40.8320 | 658.8920 ± 0.3928 |
| FAR1 + MAR2 + SPT | 120.6490 ± 8.3210 | 212.2750 ± 41.7754 | 771.1400 ± 16.2458 |
| FAR1 + MAR3 + SPT | 133.3275 ± 14.4204 | 348.8570 ± 82.0908 | 942.0190 ± 42.2810 |
| FAR2 + MAR1 + SPT | 149.5850 ± 10.5789 | 331.1560 ± 63.8415 | 659.0110 ± 0.4405 |
| FAR2 + MAR2 + SPT | 120.3770 ± 12.0717 | 200.5355 ± 50.2503 | 764.2850 ± 25.3700 |
| FAR2 + MAR3 + SPT | 132.5515 ± 10.5213 | 332.6000 ± 63.9346 | 929.0045 ± 22.8944 |
| FAR1 + MAR1 + EDD | 141.3315 ± 7.4195 | 404.9715 ± 52.0484 | 659.3950 ± 0.6024 |
| FAR1 + MAR2 + EDD | 124.3380 ± 12.2159 | 292.2310 ± 46.5486 | 775.6655 ± 15.2888 |
| FAR1 + MAR3 + EDD | 137.9690 ± 13.8511 | 429.9040 ± 78.6745 | 968.0980 ± 38.5276 |
| FAR2 + MAR1 + EDD | 145.7560 ± 9.9641 | 430.5280 ± 48.5627 | 659.5075 ± 0.6525 |
| FAR2 + MAR2 + EDD | 118.6630 ± 9.3815 | 291.9735 ± 57.8797 | 776.2800 ± 21.3636 |
| FAR2 + MAR3 + EDD | 136.9060 ± 13.6345 | 416.4960 ± 69.3839 | 965.7185 ± 43.6098 |
| FAR1 + MAR1 + LCR | 131.3435 ± 8.4095 | 397.8990 ± 38.0280 | 659.0970 ± 0.6666 |
| FAR1 + MAR2 + LCR | 116.6145 ± 7.3871 | 281.7150 ± 58.0040 | 778.3695 ± 25.7305 |
| FAR1 + MAR3 + LCR | 129.0545 ± 10.2834 | 404.3545 ± 65.9814 | 958.8905 ± 32.4785 |
| FAR2 + MAR1 + LCR | 133.1555 ± 9.4063 | 415.0705 ± 77.6714 | 658.8705 ± 0.6640 |
| FAR2 + MAR2 + LCR | 112.7030 ± 8.2004 | 256.8070 ± 37.8803 | 793.5140 ± 20.7099 |
| FAR2 + MAR3 + LCR | 133.6625 ± 10.9616 | 434.4575 ± 64.0533 | 974.2605 ± 35.5795 |
| FAR1 + MAR1 + RAND | 124.0835 ± 7.5009 | 288.9380 ± 49.3850 | 659.4990 ± 1.0215 |
| FAR1 + MAR2 + RAND | 112.8370 ± 11.7223 | 197.1655 ± 42.9895 | 784.8950 ± 19.6604 |
| FAR1 + MAR3 + RAND | 135.7470 ± 11.9744 | 392.2830 ± 73.1358 | 984.9805 ± 39.3767 |
| FAR2 + MAR1 + RAND | 121.0080 ± 6.6896 | 287.0665 ± 54.8079 | 659.0645 ± 0.6109 |
| FAR2 + MAR2 + RAND | 115.0515 ± 10.4489 | 214.7640 ± 43.8436 | 785.8260 ± 18.6741 |
| FAR2 + MAR3 + RAND | 134.6400 ± 14.9668 | 392.6080 ± 104.4888 | 988.4450 ± 48.9537 |
| Hybrid-shift strategy | 88.1500 ± 0 | 50.7400 ± 0 | 665.9400 ± 0 |
| Proposed scheduling method | 83.6725 ± 2.1910 | 39.5960 ± 11.6871 | 695.2530 ± 6.8797 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Wang, C.; Xu, B.; Liu, S. Discrete Multi-Objective Grey Wolf Algorithm Applied to Dynamic Distributed Flexible Job Shop Scheduling Problem with Variable Processing Times. Appl. Sci. 2025, 15, 2281. https://doi.org/10.3390/app15052281
Chen J, Wang C, Xu B, Liu S. Discrete Multi-Objective Grey Wolf Algorithm Applied to Dynamic Distributed Flexible Job Shop Scheduling Problem with Variable Processing Times. Applied Sciences. 2025; 15(5):2281. https://doi.org/10.3390/app15052281
Chicago/Turabian StyleChen, Jiapeng, Chun Wang, Binzi Xu, and Sheng Liu. 2025. "Discrete Multi-Objective Grey Wolf Algorithm Applied to Dynamic Distributed Flexible Job Shop Scheduling Problem with Variable Processing Times" Applied Sciences 15, no. 5: 2281. https://doi.org/10.3390/app15052281
APA StyleChen, J., Wang, C., Xu, B., & Liu, S. (2025). Discrete Multi-Objective Grey Wolf Algorithm Applied to Dynamic Distributed Flexible Job Shop Scheduling Problem with Variable Processing Times. Applied Sciences, 15(5), 2281. https://doi.org/10.3390/app15052281