
RL–Fusion: The Large Language Model Fusion Method Based on Reinforcement Learning for Task Enhancing


Abstract
1. Introduction
- Reinforcement learning-based model fusion is employed to optimize parameter selection during fusion by rewarding the results, which allows for effective exploration of optimal parameter combinations and enhances model performance.
- The evaluation feedback module of the LLM provides real-time dynamic feedback, adjusting the evaluation dataset according to the reinforcement learning results, thereby effectively enhancing the fusion model’s performance.
- Effectiveness testing on multiple datasets demonstrates that the method provides modeling capabilities for task enhancement.
2. Related Works
2.1. Weight Alignment
2.2. Task Enhancing for Model Fusion
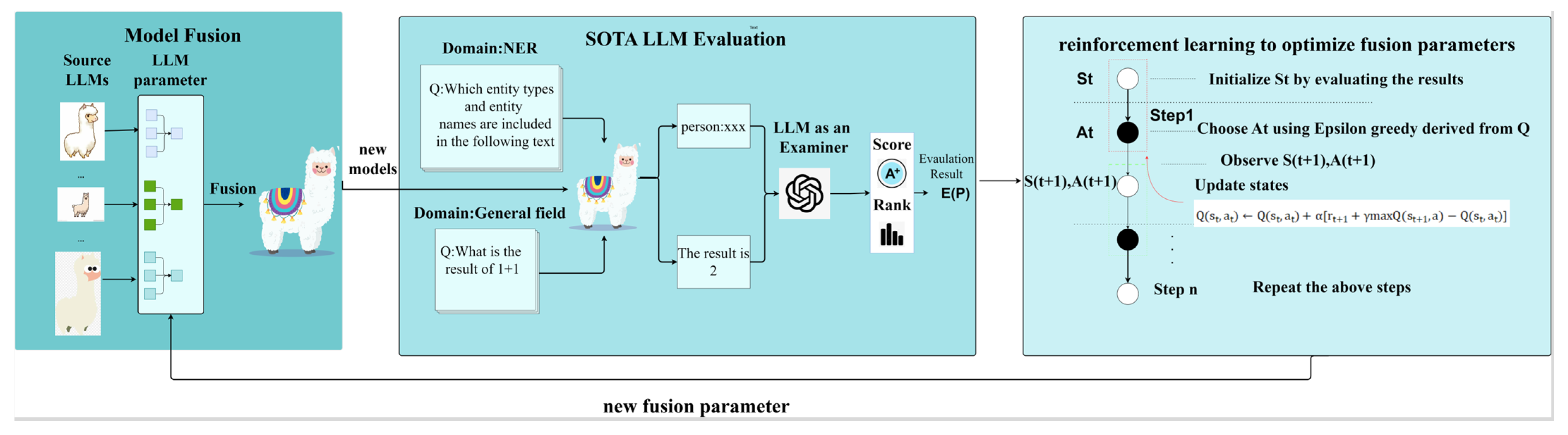
3. Method
3.1. Model Fusion
3.1.1. Slerp
3.1.2. TIES
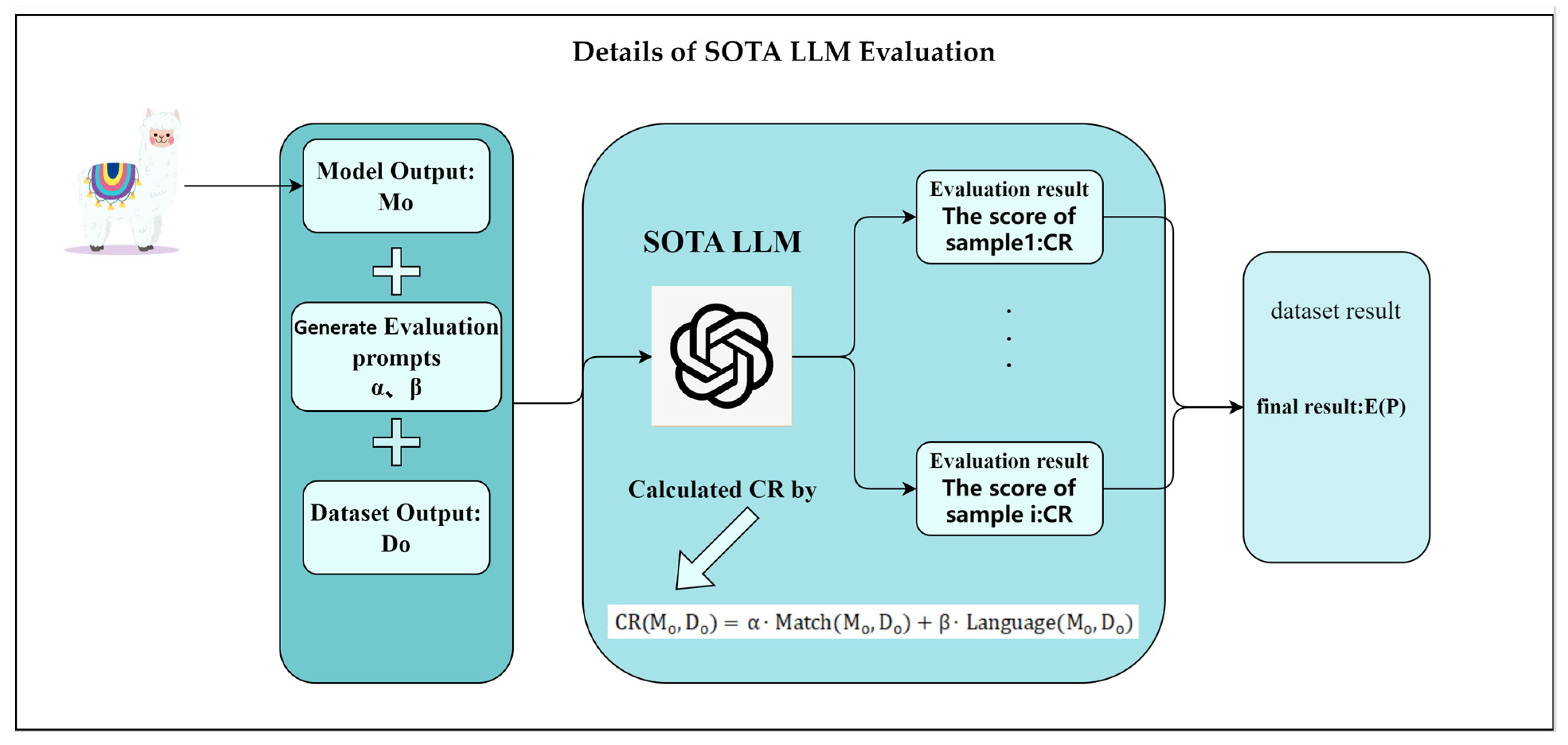
3.2. SOTA LLM Evaluation
- Generate Evaluation Prompt
- 2.
- Contextual relevance
- 3.
- Performance Evaluation
3.3. Reinforcement Learning to Optimize Fusion Parameters
3.3.1. State Representation
3.3.2. Action Definition
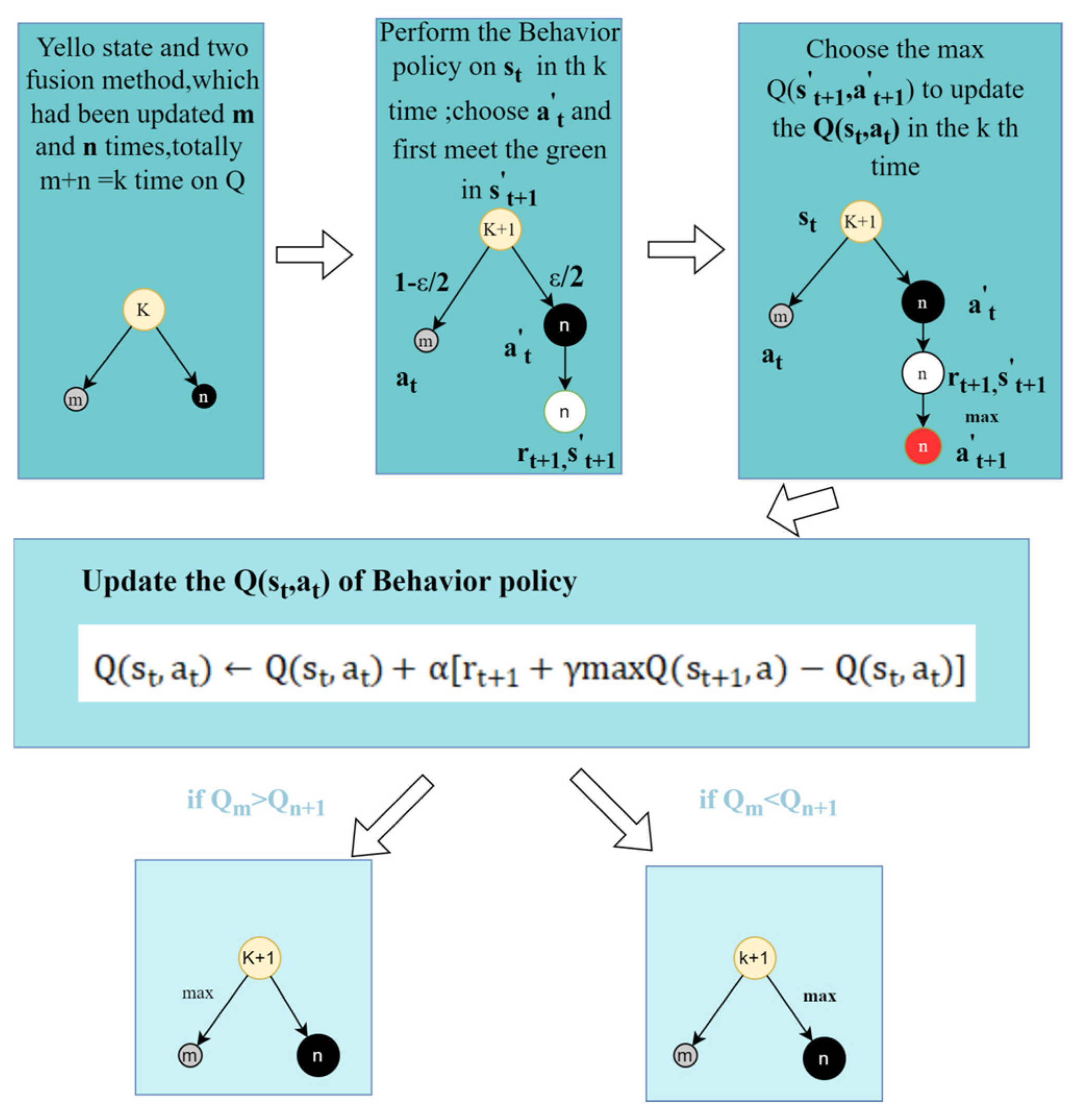
3.3.3. Q-Learning in RL–Fusion
- Reward Feedback
- 2.
- active selection
- 3.
- Q-value Update
3.4. Algorithmic Process
| Algorithm 1: Model Fusion and Optimization with Q-Learning |
| Input: Base models BaseModels = {} Number of epochs for training: epochs Output: Best_Model and Best_Performance 1: Initialize model parameters and metrics (The base model before fusion was obtained using SOTA LLM evaluation). 2: Initialize Q-table Q for reinforcement learning. 3: Set Best_Model = , Best_Performance = −∞ Training and Optimization: 4: for episode = 1 to epochs: 5: Fuse BaseModels using TIES/Slerp method, adjust model weights. 6: Evaluate the fusion model using SOTA LLM evaluation module for current parameter configuration Calculated from Equation (5). 7: Calculate r using Equation (10) 8: Select action a using Equation (11) 9: Update Q-value using Equation (12) 10: Update Q-value for selected action a in state s. 11: if > BestPerformance: 12: BestModel = current model configuration 13: BestPerformance = |
4. Experiments and Results
4.1. Datasets
4.2. Model Evaluation Metrics
- For each discipline , calculate the accuracy for that disciplinewhere is 1 when otherwise 0.
- Calculate the average accuracy across all disciplines
- Calculate weighted average accuracy across all disciplines:
4.3. Model Parameter Setups
4.4. Experiments
4.4.1. Ablation Experiment
4.4.2. Comparison with the Original Model
4.4.3. Comparison with Fine-Tuned Models on Computational Resources
4.4.4. Comparison with the Other Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A Survey of Large Language Models. arXiv 2024, arXiv:2303.18223. [Google Scholar] [CrossRef]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020, arXiv:2001.08361. [Google Scholar] [CrossRef]
- Hoffmann, J.; Borgeaud, S.; Mensch, A.; Buchatskaya, E.; Cai, T.; Rutherford, E.; Casas, D.D.L.; Hendricks, L.A.; Welbl, J.; Clark, A.; et al. Training Compute-Optimal Large Language Models. arXiv 2022, arXiv:2203.15556. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar] [CrossRef]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar] [CrossRef]
- Yang, E.; Shen, L.; Guo, G.; Wang, X.; Cao, X.; Zhang, J.; Tao, D. Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications and Opportunities. arXiv 2024, arXiv:2408.07666. [Google Scholar] [CrossRef]
- Ortiz-Jimenez, G.; Favero, A.; Frossard, P. Task Arithmetic in the Tangent Space: Improved Editing of Pre-Trained Models. arXiv 2023, arXiv:2305.12827. [Google Scholar] [CrossRef]
- Avrahami, O.; Lischinski, D.; Fried, O. Gan Cocktail: Mixing GANs Without Dataset Access; Springer: Berlin/Heidelberg, Germany, 2022; Volume 13683, pp. 205–221. [Google Scholar] [CrossRef]
- Nguyen, D.; Nguyen, T.; Nguyen, K.; Phung, D.; Bui, H.; Ho, N. On Cross-Layer Alignment for Model Fusion of Heterogeneous Neural Networks. arXiv 2023, arXiv:2110.15538. [Google Scholar] [CrossRef]
- Akiba, T.; Shing, M.; Tang, Y.; Sun, Q.; Ha, D. Evolutionary Optimization of Model Merging Recipes. arXiv 2024, arXiv:2403.13187. [Google Scholar] [CrossRef]
- Liu, D.; Wang, Z.; Wang, B.; Chen, W.; Li, C.; Tu, Z.; Chu, D.; Li, B.; Sui, D. Checkpoint Merging via Bayesian Optimization in LLM Pretraining. arXiv 2024, arXiv:2403.19390. [Google Scholar] [CrossRef]
- Zhou, Z.; Yang, Y.; Yang, X.; Yan, J.; Hu, W. Going Beyond Linear Mode Connectivity: The Layerwise Linear Feature Connectivity. arXiv 2023, arXiv:2307.08286. [Google Scholar] [CrossRef]
- Yadav, P.; Tam, D.; Choshen, L.; Raffel, C.; Bansal, M. TIES-Merging: Resolving Interference When Merging Models. arXiv 2023, arXiv:2306.01708. [Google Scholar] [CrossRef]
- Aiello, E.; Yu, L.; Nie, Y.; Aghajanyan, A.; Oguz, B. Jointly Training Large Autoregressive Multimodal Models. arXiv 2023, arXiv:2309.15564. [Google Scholar] [CrossRef]
- Chen, C.; Du, Y.; Fang, Z.; Wang, Z.; Luo, F.; Li, P.; Yan, M.; Zhang, J.; Huang, F.; Sun, M.; et al. Model Composition for Multimodal Large Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Bangkok, Thailand, 11–16 August 2024; Ku, L.-W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 11246–11262. [Google Scholar] [CrossRef]
- Sung, Y.-L.; Li, L.; Lin, K.; Gan, Z.; Bansal, M.; Wang, L. An Empirical Study of Multimodal Model Merging. arXiv 2023, arXiv:2304.14933. [Google Scholar] [CrossRef]
- Shukor, M.; Dancette, C.; Rame, A.; Cord, M. UnIVAL: Unified Model for Image, Video, Audio and Language Tasks. arXiv 2023, arXiv:2307.16184. [Google Scholar] [CrossRef]
- Minsky, M. Steps toward Artificial Intelligence. In Proceedings of the IRE; IEEE: New York, NY, USA, 1961; Volume 49, pp. 8–30. [Google Scholar] [CrossRef]
- Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring Massive Multitask Language Understanding. arXiv 2021, arXiv:2009.03300. [Google Scholar] [CrossRef]
- Huang, Y.; Bai, Y.; Zhu, Z.; Zhang, J.; Zhang, J.; Su, T.; Liu, J.; Lv, C.; Zhang, Y.; Lei, J.; et al. C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models. arXiv 2023, arXiv:2305.08322. [Google Scholar] [CrossRef]
- Luo, Y.; Kong, Q.; Xu, N.; Cao, J.; Hao, B.; Qu, B.; Chen, B.; Zhu, C.; Zhao, C.; Zhang, D.; et al. YAYI 2: Multilingual Open-Source Large Language Models. arXiv 2023, arXiv:2312.14862. [Google Scholar] [CrossRef]
- Goddard, C.; Siriwardhana, S.; Ehghaghi, M.; Meyers, L.; Karpukhin, V.; Benedict, B.; McQuade, M.; Solawetz, J. Arcee’s MergeKit: A Toolkit for Merging Large Language Models. arXiv 2024, arXiv:2403.13257. [Google Scholar] [CrossRef]
- Tang, A.; Shen, L.; Luo, Y.; Hu, H.; Du, B.; Tao, D. FusionBench: A Comprehensive Benchmark of Deep Model Fusion. arXiv 2024, arXiv:2406.03280. [Google Scholar] [CrossRef]
- Singh, S.P.; Jaggi, M. Model Fusion via Optimal Transport. arXiv 2023, arXiv:1910.05653. [Google Scholar] [CrossRef]
- Tatro, N.J.; Chen, P.-Y.; Das, P.; Melnyk, I.; Sattigeri, P.; Lai, R. Optimizing Mode Connectivity via Neuron Alignment. arXiv 2020, arXiv:2009.02439. [Google Scholar] [CrossRef]
- Xu, Z.; Yuan, K.; Wang, H.; Wang, Y.; Song, M.; Song, J. Training-Free Pretrained Model Merging. arXiv 2024, arXiv:2403.01753. [Google Scholar] [CrossRef]
- Jordan, K.; Sedghi, H.; Saukh, O.; Entezari, R.; Neyshabur, B. Repair: Renormalizing Permuted Activations for Interpolation Repair. arXiv 2023, arXiv:2211.08403. [Google Scholar] [CrossRef]
- Crisostomi, D.; Fumero, M.; Baieri, D.; Bernard, F.; Rodolà, E. C2M3: Cycle-Consistent Multi-Model Merging. arXiv 2024, arXiv:2405.17897. [Google Scholar] [CrossRef]
- Ramé, A.; Couairon, G.; Shukor, M.; Dancette, C.; Gaya, J.-B.; Soulier, L.; Cord, M. Rewarded soups: Towards Pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards. arXiv 2023, arXiv:2306.04488. [Google Scholar] [CrossRef]
- Shoemake, K. Animating rotation with quaternion curves. In SIGGRAPH ’85: Proceedings of the 12th Annual Conference on Computer Graphics and Interactive Techniques; Association for Computing Machinery: New York, NY, USA, 1985; pp. 245–254. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A. Automatic differentiation in PyTorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2021. [Google Scholar] [CrossRef]
- Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Yang, A.; Fan, A.; et al. The Llama 3 Herd of Models. arXiv 2024, arXiv:2407.21783. [Google Scholar] [CrossRef]
- Jiang, A.Q.; Sablayrolles, A.; Roux, A.; Mensch, A.; Savary, B.; Bamford, C.; Chaplot, D.S.; Casas, D.D.L.; Hanna, E.B.; Bressand, F.; et al. Mixtral of Experts. arXiv 2024, arXiv:2401.04088. [Google Scholar] [CrossRef]
- Bai, J.; Bai, S.; Chu, Y.; Cui, Z.; Dang, K.; Deng, X.; Fan, Y.; Ge, W.; Han, Y.; Huang, F.; et al. Qwen Technical Report. arXiv 2023, arXiv:2309.16609. [Google Scholar] [CrossRef]
- Peng, B.; Alcaide, E.; Anthony, Q.; Albalak, A.; Arcadinho, S.; Biderman, S.; Cao, H.; Cheng, X.; Chung, M.; Grella, M.; et al. RWKV: Reinventing RNNs for the Transformer Era. arXiv 2023, arXiv:2305.13048. [Google Scholar] [CrossRef]
- Almazrouei, E.; Alobeidli, H.; Alshamsi, A.; Cappelli, A.; Cojocaru, R.; Debbah, M.; Goffinet, É.; Hesslow, D.; Launay, J.; Malartic, Q.; et al. The Falcon Series of Open Language Models. arXiv 2023, arXiv:2311.16867. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action Category | Action Description | Parameter Range | Specific Adjustment Method |
|---|---|---|---|
| Weight adjustment | Reconfigure the weights of each base model in the fusion model to enhance or attenuate the impact of a particular model. | Increase or reduce the weight of a base model, the step size is , For example, the current weight , the action will adjust to 0.55 and to 0.45. | |
| Fusion method selection | Different model fusion methods were chosen, Slerp, TIES | {Slerp, TIES} | Choose a new fusion method. For example, switch from the current TIES to Slerp. |
| Learning rate adjustment | The learning rate during the model fusion is dynamically adjusted to control the pace of parameter updates. | A linear or exponential adjustment based on the current learning rate, for example, from = 0.01 was increased to = 0.02 Or reduced to = 0.005. |
| Method | MMLU | C-Eval | Yayi(NER) |
|---|---|---|---|
| Baseline | 68.2% | 76.7% | 2.1 |
| RL | 70.1% | 77.9% | 2.4 |
| RL–Fusion | 70.8% | 78.6% | 2.5 |
| RL–Fusion+FineTune | 69.5% | 80.2% | 3.8 |
| Task | llama-3-8b-Instruct | llama-3-Chinese-8b-Instruct-v3 | RL–Fusion LLM |
|---|---|---|---|
| formal_logic | 54.0% | 50.8% | 53.2% |
| high_school_government_and_politics | 92.2% | 90.2% | 94.8% |
| international_law | 81.0% | 80.2% | 86.8% |
| jurisprudence | 79.6% | 76.9% | 82.0% |
| logical_fallacies | 74.8% | 74.2% | 76.1% |
| management | 84.5% | 77.7% | 82.5% |
| marketing | 91.0% | 90.2% | 91.5% |
| Weighted_accuracy | 79.6% | 77.2% | 81.0% |
| Task | llama-3-8b-Instruct | llama-3-Chinese-8b-Instruct-v3 | RL–Fusion LLM |
|---|---|---|---|
| stem | 67.9% | 63.2% | 65.2% |
| average(Hard) | 59.8% | 57.4% | 60.7% |
| Social Science | 82.8% | 84.5% | 85.0% |
| Humanity | 78.4% | 82.2% | 83.9% |
| Other | 70.8% | 71.1% | 72.3% |
| Average | 75.1% | 77.2% | 78.6% |
| Task | llama-3-8b-Instruct | llama-3-Chinese-8b-Instruct-v3 | RL–Fusion LLM |
|---|---|---|---|
| NER | 1.8 | 2.1 | 2.5 |
| Time | Hardware Resource | MMLU | C-Eval | |
|---|---|---|---|---|
| FineTune | 60 min | RTX4090 24G | 68.5% | 79.2% |
| RL–Fusion | 15 min | cpu | 70.8% | 78.6% |
| Model | MMLU | C-Eval |
|---|---|---|
| RL–Fusion | 70.8% | 78.6% |
| Slerp [30] | 68.7% | 74.1% |
| TIES [13] | 66.9% | 76.2% |
| Llama 3.1-8B [33] | 73.0% | 81.2% |
| LLaMA 2-7B [5] | 45.3% | 75.2% |
| Mixtral 8x7B [34] | 70.6% | 74.7% |
| Qwen 7B [35] | 56.7% | 59.6% |
| GPT-3 6.7B [19] | 43.2% | 54.4% |
| RWKV v5 Eagle 7B [36] | 31% | 46.7% |
| Falcon 7B [37] | 28.0% | 39.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Li, J.; Liu, Y.; Li, X.; Yan, C.; Zhang, Y. RL–Fusion: The Large Language Model Fusion Method Based on Reinforcement Learning for Task Enhancing. Appl. Sci. 2025, 15, 2186. https://doi.org/10.3390/app15042186
Wang Z, Li J, Liu Y, Li X, Yan C, Zhang Y. RL–Fusion: The Large Language Model Fusion Method Based on Reinforcement Learning for Task Enhancing. Applied Sciences. 2025; 15(4):2186. https://doi.org/10.3390/app15042186
Chicago/Turabian StyleWang, Zijian, Jiayong Li, Yu Liu, Xuhang Li, Cairong Yan, and Yanting Zhang. 2025. "RL–Fusion: The Large Language Model Fusion Method Based on Reinforcement Learning for Task Enhancing" Applied Sciences 15, no. 4: 2186. https://doi.org/10.3390/app15042186
APA StyleWang, Z., Li, J., Liu, Y., Li, X., Yan, C., & Zhang, Y. (2025). RL–Fusion: The Large Language Model Fusion Method Based on Reinforcement Learning for Task Enhancing. Applied Sciences, 15(4), 2186. https://doi.org/10.3390/app15042186