
EHC-GCN: Efficient Hierarchical Co-Occurrence Graph Convolution Network for Skeleton-Based Action Recognition


Abstract
1. Introduction
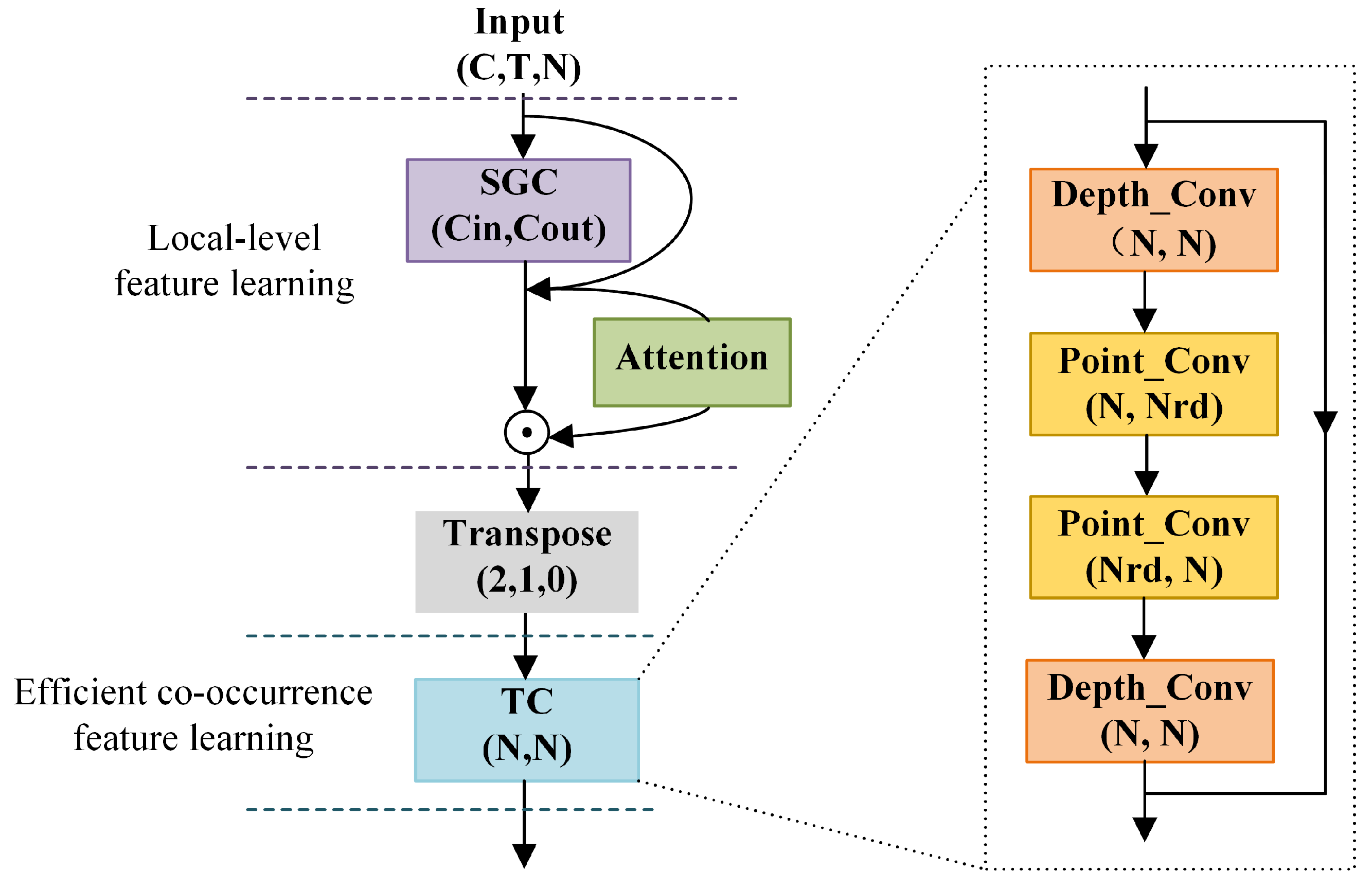
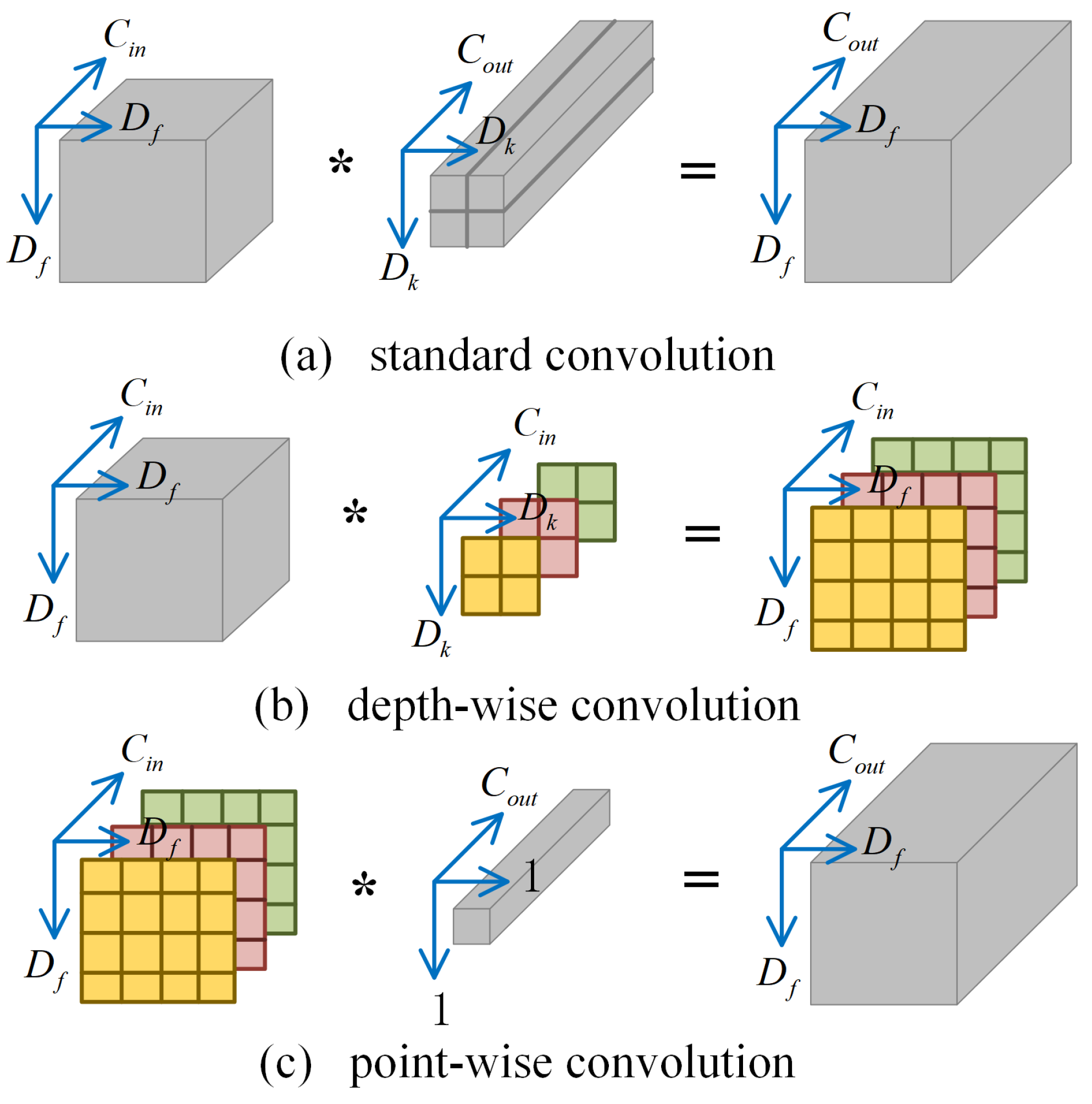
- We designed a hierarchical co-occurrence feature learning module, which achieves performance improvement with a minimal number of parameters. Firstly, SGC operations are employed to learn the local features of body joints. Then, after transposing the dimensions, CNN characteristics are utilized to aggregate the global features of the joints.
- By introducing the advanced depth-wise separable layer into the model, we further enhance the efficiency of the model.
- Our method achieved higher accuracy with fewer parameters and computational complexity on the NTU RGB+D 60 and 120 datasets. Compared with the SOTA methods, it achieves a better balance between accuracy and efficiency.
2. Related Work
2.1. Skeleton-Based Action Recognition
2.2. Efficient Models
3. Efficient Hierarchical Co-Occurrence Graph Convolution Networks
3.1. Model Architecture
3.2. Data Preprocessing
- Motion velocity consists of fast motion and slow motion .
- Bone features consists of skeletal length and skeletal angle .where represents the adjacent joint of the i-th joint and represents the 3D coordinates of joint.
3.3. Spatio-Temporal Graph Convolution
3.4. Efficient Hierarchical Co-Occurrence Convolution
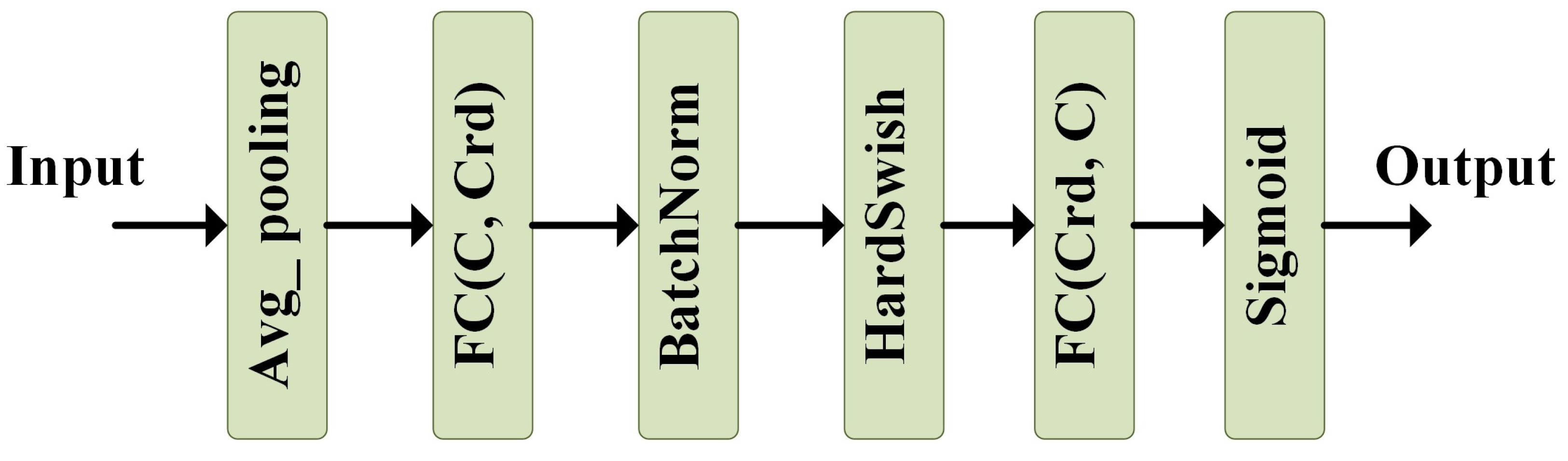
3.5. Channel Attention Module
3.6. Loss Function
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
- The NTU dataset has a maximum of 300 frames for each video clip. To unify the dimension of input frames, skeleton sequences with fewer than 300 frames were padded with zeros. At most, the skeleton data of two individuals were selected for each action sequence; if there were fewer than two individuals, they were padded with zeros.
- The NTU RGB+3D skeleton data were obtained from the Kinect v2 camera, which can sense the 3D positions of 25 body joints. Therefore, each skeleton sequence contains the coordinates of 25 body joints for 300 frames, with 3 input channels consisting of 2D pixel coordinates (x, y) and depth coordinate z.
- The NTU RGB+2D skeleton data were obtained using the HRNet-w32 [37] pose estimation algorithm, which provides 2D coordinates for 17 body joints. Thus, each skeleton sequence contains the coordinates of 17 body joints for 300 frames. Following reference [11], we set three input channels consisting of 2D pixel coordinates (x, y) and confidence score.
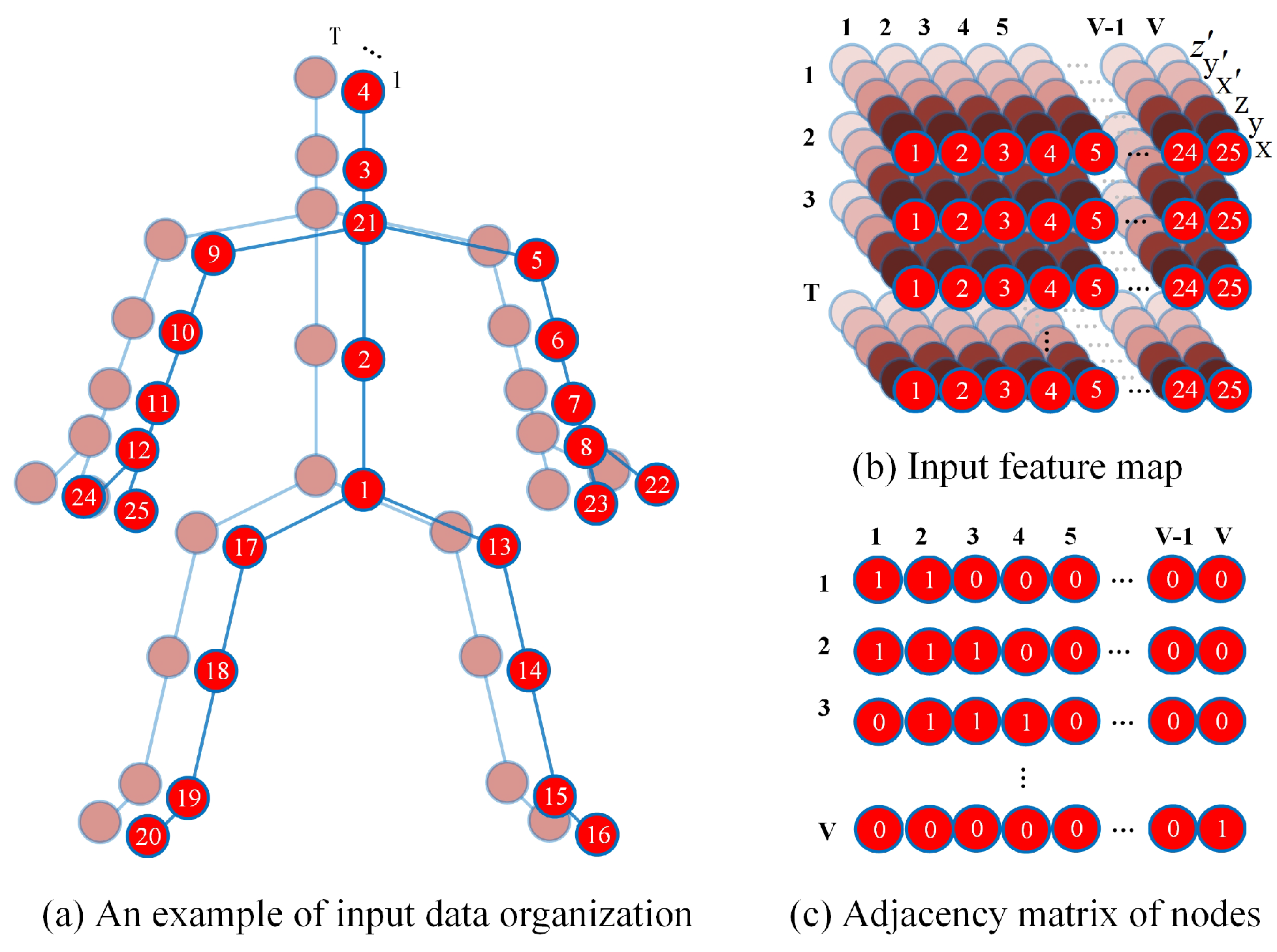
- The different methods of obtaining skeleton data resulted in variations in the number of body joints and their adjacency relationships. When using GCN operations to process skeleton data, it is necessary to customize the adjacency matrix between joints (as shown in Figure 3c). Therefore, when dealing with skeleton data from different sources, it is necessary to reset the adjacency matrix to reflect the current body joint connectivity.
4.3. Ablation Study
4.4. Comparisons with SOTA Methods
4.5. Speed
5. Discussion
5.1. The Application of the EHC-GCN Model in Human–Computer Interaction Scenarios
5.2. Discussion on Noisy/Incomplete Skeleton Data
5.3. Future Work
- Fine-grained data augmentation: Integrating more detailed hand joint data features is beneficial for the recognition of finger-level action categories. Moreover, augmenting face keypoint data can help in identifying the emotional states of individuals during behavioral processes.
- Multi-modal learning: By integrating multi-modal data (such as skeleton data, RGB videos, depth information, and audio signals), we can achieve mutual complementarity between different types of data. This allows for a more comprehensive understanding of the context of actions, thereby improving the recognition accuracy.
- Deployment in practical applications: To transition the action recognition model from experimental simulation to real-world application, it is necessary to test and validate it in actual human–robot interaction scenarios. This includes integration with industrial robot systems, on-site trials, and performance evaluation.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
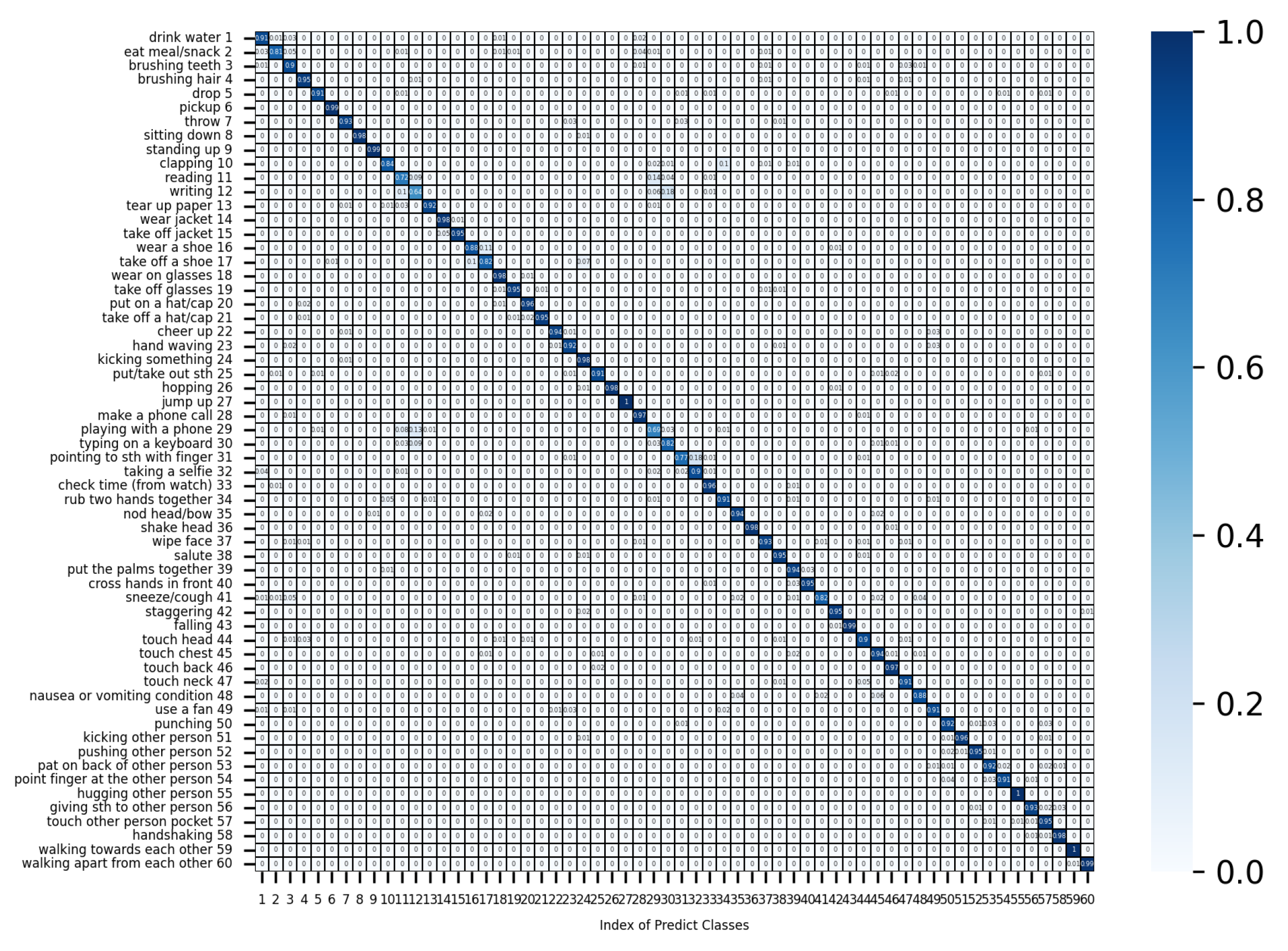
Appendix A. Confusion Matrix on the NTU 60 Dataset
Appendix B. Network Architecture

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Motion Velocities | Bone Features | Output | |
|---|---|---|---|---|
| Input | Fast motion; slow motion | Skeleton length; skeleton angle | M: 6 × 300 × 25 B: 6 × 300 × 25 | |
| Norm | Batch Norm | Batch Norm | M: 6 × 300 × 25 B: 6 × 300 × 25 | |
| STGCN Block | SGC | Adjacency matrix; D = 2 (1, 1), 64, stride (1, 1) | Adjacency matrix; D = 2 (1, 1), 64, stride (1, 1) | M: 64 × 300 × 25 B: 64 × 300 × 25 |
| TC | (5, 1), 64, stride (1, 1) | (5, 1), 64, stride (1, 1) | M: 64 × 300 × 25 B: 64 × 300 × 25 | |
| EHC-GCN Block | SGC | Adjacency matrix; D = 2 (1, 1), 48, stride (1, 1) | Adjacency matrix; D = 2 (1, 1), 48, stride (1, 1) | M: 48 × 300 × 25 B: 48 × 300 × 25 |
| Attention | Channel attention module | Channel attention module | M: 48 × 300 × 25 B: 48 × 300 × 25 | |
| Transpose | (2, 1, 0) | (2, 1, 0) | M: 25 × 300 × 48 B: 25 × 300 × 48 | |
| EC-TC | D_conv: (5, 1), 48, stride (1, 1) P_conv: (1, 1), 24, stride (1, 1) P_conv: (1, 1), 48, stride (1,1) D_conv: (5, 1), 48, stride (1, 1) | D_conv: (5, 1), 48, stride (1, 1) P_conv: (1, 1), 24, stride (1, 1) P_conv: (1, 1), 48, stride (1, 1) D_conv: (5, 1), 48, stride (1, 1) | M: 25 × 300 × 48 B: 25 × 300 × 48 | |
| Concate | Concate, dim = 2 | 25 × 300 × 96 | ||
| Transpose | (2, 1, 0) | 96 × 300 × 25 | ||
| EHC-GCN Block | SGC | Adjacency matrix; D = 2; (1, 1), 64, stride (1, 1) | 64 × 300 × 25 | |
| Attention | Channel attention module | 64 × 300 × 25 | ||
| Transpose | (2, 1, 0) | 25 × 300 × 64 | ||
| EC-TC | D_conv: (5, 1), 64, stride (1, 1) P_conv: (1, 1), 32, stride (1, 1) P_conv: (1, 1), 64, stride (1, 1) D_conv: (5, 1), 64, stride (2, 1) | 25 × 150 × 64 | ||
| Transpose | (2, 1, 0) | 64 × 150 × 25 | ||
| EHC-GCN Block | SGC | Adjacency matrix; D = 2; (1, 1), 128, stride (1, 1) | 128 × 150 × 25 | |
| Attention | Channel attention module | 128 × 150 × 25 | ||
| Transpose | (2, 1, 0) | 25 × 150 × 128 | ||
| EC-TC | D_conv: (5, 1), 128, stride (1, 1) P_conv: (1, 1), 64, stride (1, 1) P_conv: (1, 1), 128, stride (1, 1) D_conv: (5, 1), 128, stride (2, 1) | 25 × 75 × 128 | ||
| Transpose Pool | (2, 1, 0) | 128 × 75 × 25 | ||
| Global average pooling | 128 | |||
| Classifier | Fully connected layer | number of classes | ||
References
- Yu, X.; Zhang, X.; Xu, C.; Ou, L. Human–robot collaborative interaction with human perception and action recognition. Neurocomputing 2024, 563, 126827. [Google Scholar] [CrossRef]
- Gammulle, H.; Ahmedt-Aristizabal, D.; Denman, S.; Tychsen-Smith, L.; Petersson, L.; Fookes, C. Continuous human action recognition for human-machine interaction: A review. Acm Comput. Surv. 2023, 55, 272. [Google Scholar] [CrossRef]
- Moutinho, D.; Rocha, L.F.; Costa, C.M.; Teixeira, L.F.; Veiga, G. Deep learning-based human action recognition to leverage context awareness in collaborative assembly. Robot. Comput.-Integr. Manuf. 2023, 80, 102449. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, C.; Dong, X. A Multi-Scale Video Longformer Network for Action Recognition. Appl. Sci. 2024, 14, 1061. [Google Scholar] [CrossRef]
- Delamou, M.; Bazzi, A.; Chafii, M.; Amhoud, E.M. Deep learning-based estimation for multitarget radar detection. In Proceedings of the 2023 IEEE 97th Vehicular Technology Conference (VTC2023-Spring), Florence, Italy, 20–23 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–5. [Google Scholar]
- Du, Y.; Fu, Y.; Wang, L. Skeleton based action recognition with convolutional neural network. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; IEEE: New York, NY, USA, 2015; pp. 579–583. [Google Scholar]
- Sun, Z.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G.; Liu, J. Human action recognition from various data modalities: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3200–3225. [Google Scholar] [CrossRef] [PubMed]
- Kong, Y.; Fu, Y. Human action recognition and prediction: A survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Wang, L. Richly activated graph convolutional network for action recognition with incomplete skeletons. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: New York, NY, USA, 2019; pp. 1–5. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3595–3603. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Richly activated graph convolutional network for robust skeleton-based action recognition. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1915–1925. [Google Scholar] [CrossRef]
- Cheng, K.; Zhang, Y.; He, X.; Chen, W.; Cheng, J.; Lu, H. Skeleton-based action recognition with shift graph convolutional network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 183–192. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 143–152. [Google Scholar]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. arXiv 2018, arXiv:1804.06055. [Google Scholar]
- Ye, F.; Pu, S.; Zhong, Q.; Li, C.; Xie, D.; Tang, H. Dynamic gcn: Context-enriched topology learning for skeleton-based action recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 55–63. [Google Scholar]
- Si, C.; Jing, Y.; Wang, W.; Wang, L.; Tan, T. Skeleton-based action recognition with hierarchical spatial reasoning and temporal stack learning network. Pattern Recognit. 2020, 107, 107511. [Google Scholar] [CrossRef]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1227–1236. [Google Scholar]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 32–39. [Google Scholar] [CrossRef]
- Weinland, D.; Özuysal, M.; Fua, P. Making Action Recognition Robust to Occlusions and Viewpoint Changes. In Proceedings of the Computer Vision—ECCV 2010, Heraklion, Greece, 5–11 September 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 635–648. [Google Scholar]
- Li, S.; Yi, J.; Farha, Y.A.; Gall, J. Pose refinement graph convolutional network for skeleton-based action recognition. IEEE Robot. Autom. Lett. 2021, 6, 1028–1035. [Google Scholar] [CrossRef]
- Plizzari, C.; Cannici, M.; Matteucci, M. Spatial temporal transformer network for skeleton-based action recognition. In Proceedings of the Pattern Recognition. ICPR International Workshops and Challenges, Virtual Event, 10–15 January 2021; Proceedings, Part III. Springer: Berlin/Heidelberg, Germany, 2021; pp. 694–701. [Google Scholar]
- Liu, Y.; Zhang, H.; Xu, D.; He, K. Graph transformer network with temporal kernel attention for skeleton-based action recognition. Knowl.-Based Syst. 2022, 240, 108146. [Google Scholar] [CrossRef]
- Moon, G.; Kwon, H.; Lee, K.M.; Cho, M. Integralaction: Pose-driven feature integration for robust human action recognition in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3339–3348. [Google Scholar]
- Guo, F.; Jin, T.; Zhu, S.; Xi, X.; Wang, W.; Meng, Q.; Song, W.; Zhu, J. B2c-afm: Bi-directional co-temporal and cross-spatial attention fusion model for human action recognition. IEEE Trans. Image Process. 2023, 32, 4989–5003. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Q.; Ren, Z.; Cheng, J.; Zhang, Q.; Yan, H.; Liu, J. Skeleton-based action recognition with multi-scale spatial-temporal convolutional neural network. In Proceedings of the 2021 IEEE International Conference on Real-time Computing and Robotics (RCAR), Xining, China, 15–19 July 2021; IEEE: New York, NY, USA, 2021; pp. 957–962. [Google Scholar]
- Zhang, P.; Lan, C.; Zeng, W.; Xing, J.; Xue, J.; Zheng, N. Semantics-guided neural networks for efficient skeleton-based human action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1112–1121. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Constructing stronger and faster baselines for skeleton-based action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1474–1488. [Google Scholar] [CrossRef]
- Hedegaard, L.; Heidari, N.; Iosifidis, A. Continual spatio-temporal graph convolutional networks. Pattern Recognit. 2023, 140, 109528. [Google Scholar] [CrossRef]
- Wu, L.; Zhang, C.; Zou, Y. SpatioTemporal focus for skeleton-based action recognition. Pattern Recognit. 2023, 136, 109231. [Google Scholar] [CrossRef]
- Shi, F.; Lee, C.; Qiu, L.; Zhao, Y.; Shen, T.; Muralidhar, S.; Han, T.; Zhu, S.C.; Narayanan, V. Star: Sparse transformer-based action recognition. arXiv 2021, arXiv:2107.07089. [Google Scholar]
- Zhou, D.; Hou, Q.; Chen, Y.; Feng, J.; Yan, S. Rethinking bottleneck structure for efficient mobile network design. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 680–697. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A large scale dataset for 3D human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Guo, J.; Li, Y.; Lin, W.; Chen, Y.; Li, J. Network decoupling: From regular to depthwise separable convolutions. arXiv 2018, arXiv:1808.05517. [Google Scholar]
- Shahroudy, A.; Ng, T.T.; Gong, Y.; Wang, G. Deep multimodal feature analysis for action recognition in rgb+ d videos. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1045–1058. [Google Scholar] [CrossRef] [PubMed]
- Luvizon, D.C.; Picard, D.; Tabia, H. 2d/3d pose estimation and action recognition using multitask deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5137–5146. [Google Scholar]
- Baradel, F.; Wolf, C.; Mille, J.; Taylor, G.W. Glimpse clouds: Human activity recognition from unstructured feature points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 469–478. [Google Scholar]
- Zhang, P.; Xue, J.; Lan, C.; Zeng, W.; Gao, Z.; Zheng, N. EleAtt-RNN: Adding attentiveness to neurons in recurrent neural networks. IEEE Trans. Image Process. 2019, 29, 1061–1073. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Zhang, L.; Guan, L.; Liu, M. Gfnet: A lightweight group frame network for efficient human action recognition. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: New York, NY, USA, 2020; pp. 2583–2587. [Google Scholar]
- Li, L.; Wang, M.; Ni, B.; Wang, H.; Yang, J.; Zhang, W. 3d human action representation learning via cross-view consistency pursuit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4741–4750. [Google Scholar]
- Peng, W.; Hong, X.; Zhao, G. Tripool: Graph triplet pooling for 3D skeleton-based action recognition. Pattern Recognit. 2021, 115, 107921. [Google Scholar] [CrossRef]
- Nikpour, B.; Armanfard, N. Spatio-temporal hard attention learning for skeleton-based activity recognition. Pattern Recognit. 2023, 139, 109428. [Google Scholar] [CrossRef]


| Model | Acc (%) | GFLOP | Params (M) |
|---|---|---|---|
| Non-HC | 86.9 | 1.89 | 0.15 |
| Non-Attention | 87.6 | 2.07 | 0.14 |
| EHC-GCN | 88.5 | 2.09 | 0.16 |
| Inputs | Acc (%) | GFLOP | Params (M) |
|---|---|---|---|
| Velocity | 84.9 | 1.37 | 0.11 |
| Bone | 85.6 | 1.37 | 0.11 |
| Velocity + Bone | 88.5 | 2.09 | 0.16 |
| Layer | Acc (%) | GFLOP | Params (M) |
|---|---|---|---|
| Basic Conv | 88.5 | 2.43 | 0.16 |
| Separable Conv | 88.5 | 2.09 | 0.16 |
| Kernel Size | Acc (%) | GFLOP | Params (M) |
|---|---|---|---|
| 3 × 1 | 88.4 | 1.84 | 0.14 |
| 5 × 1 | 88.5 | 2.09 | 0.16 |
| 7 × 1 | 88.5 | 2.34 | 0.17 |
| EHC-GCN Module | Acc (%) | GFLOP | Params (M) |
|---|---|---|---|
| 3 (channel = 48|64, 128) | 88.5 | 2.09 | 0.16 |
| 4 (channel = 48, 24|64, 128) | 88.1 | 2.22 | 0.18 |
| Model | Year | Data | X-Sub | X-View | GFLOP | Params (M) |
|---|---|---|---|---|---|---|
| DSSCA-SSLM [41] | 2017 | RGB + Pose | 74.9 | - | ||
| 2D-3D-Softargma [42] | 2018 | RGB | 85.5 | - | - | - |
| Glimpse Clouds [43] | 2018 | RGB | 86.6 | 93.2 | - | - |
| IntegralAction [25] | 2021 | RGB | 91.7 | - | - | - |
| B2C-AFM [26] | 2023 | RGB + Pose | 91.7 | - | - | - |
| HCN [16] | 2018 | 3D Skeleton | 86.5 | 91.1 | - | - |
| ST-GCN [9] | 2018 | 3D Skeleton | 81.5 | 88.3 | 16.32 | 3.10 |
| SR-TSL [18] | 2018 | 3D Skeleton | 84.8 | 92.4 | 4.20 | 19.07 |
| RA-GCNv1 [10] | 2019 | 3D Skeleton | 85.9 | 93.5 | 32.80 | 6.21 |
| AS-GCN [11] | 2019 | 3D Skeleton | 86.8 | 94.2 | 26.76 | 9.50 |
| 2s-AGCN [12] | 2019 | 3D Skeleton | 88.5 | 95.1 | 37.32 | 6.94 |
| AGC-LSTM [19] | 2019 | 3D Skeleton | 89.2 | 95.0 | 54.40 | 22.89 |
| EleAtt-GRU [44] * | 2020 | 3D Skeleton | 79.8 | 87.1 | - | 0.3 |
| GFNet [45] * | 2020 | 3D Skeleton | 82.0 | 89.9 | 48.7 | 1.6 |
| SGN [28] * | 2020 | 3D Skeleton | 89.0 | 94.5 | - | 0.69 |
| DGNN [17] | 2020 | 3D Skeleton | 89.9 | 96.1 | - | 26.24 |
| 4s-ShiftGCN [14] | 2020 | 3D Skeleton | 90.7 | 96.5 | 10.0 | 2.76 |
| MS-G3D [15] | 2020 | 3D Skeleton | 91.5 | 96.2 | 48.88 | 6.40 |
| PRGCN [22] * | 2021 | 3D Skeleton | 85.2 | 91.7 | 1.7 | 0.5 |
| RA-GCNv2 [13] | 2021 | 3D Skeleton | 87.3 | 93.6 | 32.80 | 6.21 |
| 3s-CrosSCLR [46] | 2021 | 3D Skeleton | 86.2 | 92.5 | - | 2.55 |
| Tripool [47] | 2021 | 3D Skeleton | 88.0 | 95.3 | 11.76 | - |
| STAR [32] | 2021 | 3D Skeleton | 83.4 | 89.0 | - | 1.26 |
| ST-TR [23] | 2021 | 3D Skeleton | 89.9 | 96.1 | - | - |
| KA-AGTN [24] | 2022 | 3D Skeleton | 90.4 | 96.1 | - | - |
| CoST-GCN [30] * | 2023 | 3D Skeleton | 85.3 | 93.1 | 0.27 | 3.14 |
| CoAGCN [30] * | 2023 | 3D Skeleton | 86.0 | 93.9 | 0.30 | 3.47 |
| CoS-TR [30] * | 2023 | 3D Skeleton | 86.5 | 93.3 | 0.22 | 3.09 |
| STF-Net [31] * | 2023 | 3D Skeleton | 88.8 | 95.0 | 7.5 | 1.7 |
| STH-DRL [48] | 2023 | 3D Skeleton | 90.8 | 96.7 | - | - |
| EfficientGCN-B0 [29] * | 2023 | 3D Skeleton | 90.2 | 94.9 | 2.73 | 0.29 |
| EHC-GCN | 2024 | 3D Skeleton | 88.5 | 93.4 | 2.09 | 0.16 |
| EHC-GCN | 2024 | Pose | 92.0 | 94.2 | 1.40 | 0.15 |
| Model | Year | Data | X-Sub | X-Set |
|---|---|---|---|---|
| ST-GCN [9] | 2018 | 3D Skeleton | 70.7 | 73.2 |
| SR-TSL [18] | 2018 | 3D Skeleton | 74.1 | 79.9 |
| RA-GCNv1 [10] | 2019 | 3D Skeleton | 74.4 | 79.4 |
| AS-GCN [11] | 2019 | 3D Skeleton | 77.9 | 78.5 |
| 2s-AGCN [12] | 2019 | 3D Skeleton | 82.5 | 84.2 |
| SGN [28] * | 2020 | 3D Skeleton | 79.2 | 81.5 |
| RA-GCNv2 [13] | 2021 | 3D Skeleton | 81.1 | 82.7 |
| 3s-CrosSCLR [46] | 2021 | 3D Skeleton | 80.5 | 80.4 |
| Tripool [47] | 2021 | 3D Skeleton | 80.1 | 82.8 |
| STAR [32] | 2021 | 3D Skeleton | 78.3 | 78.5 |
| ST-TR [23] | 2021 | 3D Skeleton | 81.9 | 84.1 |
| CoST-GCN [30] * | 2023 | 3D Skeleton | 83.7 | 85.1 |
| CoAGCN [30] * | 2023 | 3D Skeleton | 84.0 | 85.3 |
| CoS-TR [30] * | 2023 | 3D Skeleton | 84.8 | 86.1 |
| EfficientGCN-B0 [29] * | 2023 | 3D Skeleton | 86.6 | 85.0 |
| EHC-GCN | 2024 | 3D Skeleton | 84.6 | 85.6 |
| EHC-GCN | 2024 | Pose | 83.7 | 87.0 |
| Model | Frames per pred | CPU (preds/s) | GPU (preds/s) |
|---|---|---|---|
| EfficientGCN-B0 [29] | 300 | 11.5 | 204.7 |
| EHC-GCN (3D Skeleton) | 300 | 12.1 | 210.2 |
| EHC-GCN (Pose) | 300 | 16.6 | 291.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, Y.; Yang, D.; Xu, J.; Xu, L.; Wang, H. EHC-GCN: Efficient Hierarchical Co-Occurrence Graph Convolution Network for Skeleton-Based Action Recognition. Appl. Sci. 2025, 15, 2109. https://doi.org/10.3390/app15042109
Bai Y, Yang D, Xu J, Xu L, Wang H. EHC-GCN: Efficient Hierarchical Co-Occurrence Graph Convolution Network for Skeleton-Based Action Recognition. Applied Sciences. 2025; 15(4):2109. https://doi.org/10.3390/app15042109
Chicago/Turabian StyleBai, Ying, Dongsheng Yang, Jing Xu, Lei Xu, and Hongliang Wang. 2025. "EHC-GCN: Efficient Hierarchical Co-Occurrence Graph Convolution Network for Skeleton-Based Action Recognition" Applied Sciences 15, no. 4: 2109. https://doi.org/10.3390/app15042109
APA StyleBai, Y., Yang, D., Xu, J., Xu, L., & Wang, H. (2025). EHC-GCN: Efficient Hierarchical Co-Occurrence Graph Convolution Network for Skeleton-Based Action Recognition. Applied Sciences, 15(4), 2109. https://doi.org/10.3390/app15042109