
Cross-Domain Feature Fusion Network: A Lightweight Road Extraction Model Based on Multi-Scale Spatial-Frequency Feature Fusion

Abstract
1. Introduction
- (1)
- Lightweight Backbone Network: The advantages of using the modified Xception as the backbone network are more apparent in scenarios where the segmented images have diverse semantic labels and the dataset size is sufficient for training. In contrast, the MobileNetV2 network has a simpler structure, fewer parameters, lower computational complexity, and faster training speed. For tasks like road extraction with fewer semantic label categories, MobileNetV2 achieves better segmentation accuracy.
- (2)
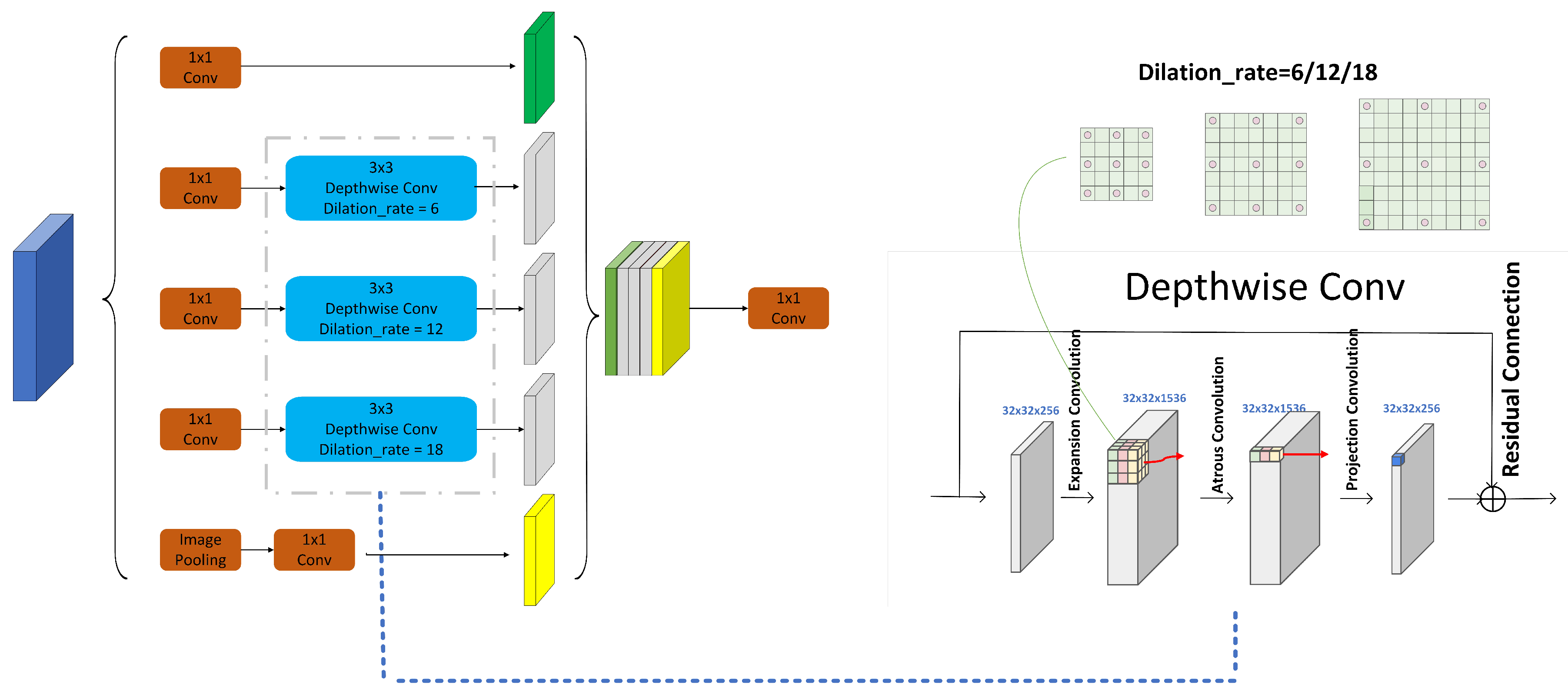
- Atrous Bottleneck Pyramid Module (ABPM): The original ASPP module extracts feature maps with different receptive fields by parallel atrous convolutions with various dilation rates. However, its spaced and sparse sampling leads to a lack of correlation between convolution results, causing issues like checkerboard artifacts, feature discontinuities, and spatial gaps. A common solution is to apply upsampling before convolution to avoid these artifacts. Inspired by MobileNetV2’s inverted residual structure, which first expands dimensions, then applies convolution, and finally reduces dimensions while maintaining low computational costs through depthwise separable convolution, this study designs the ABPM. This module extracts features using atrous convolutions in high-dimensional spaces, improving the correlation between extracted features.
- (3)
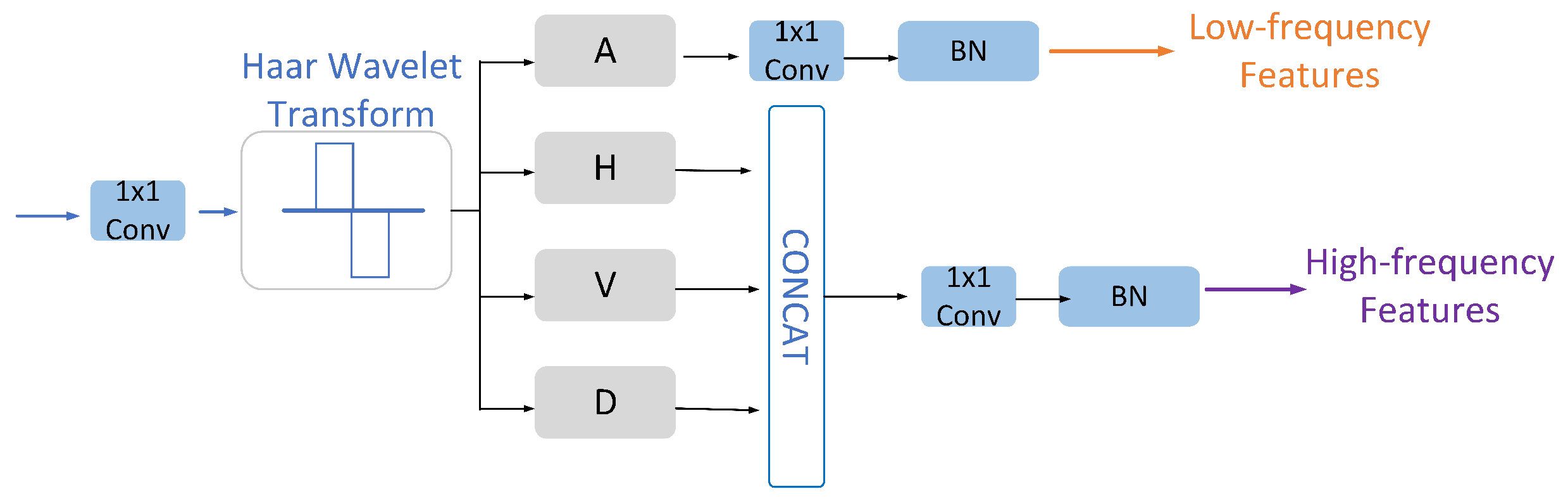
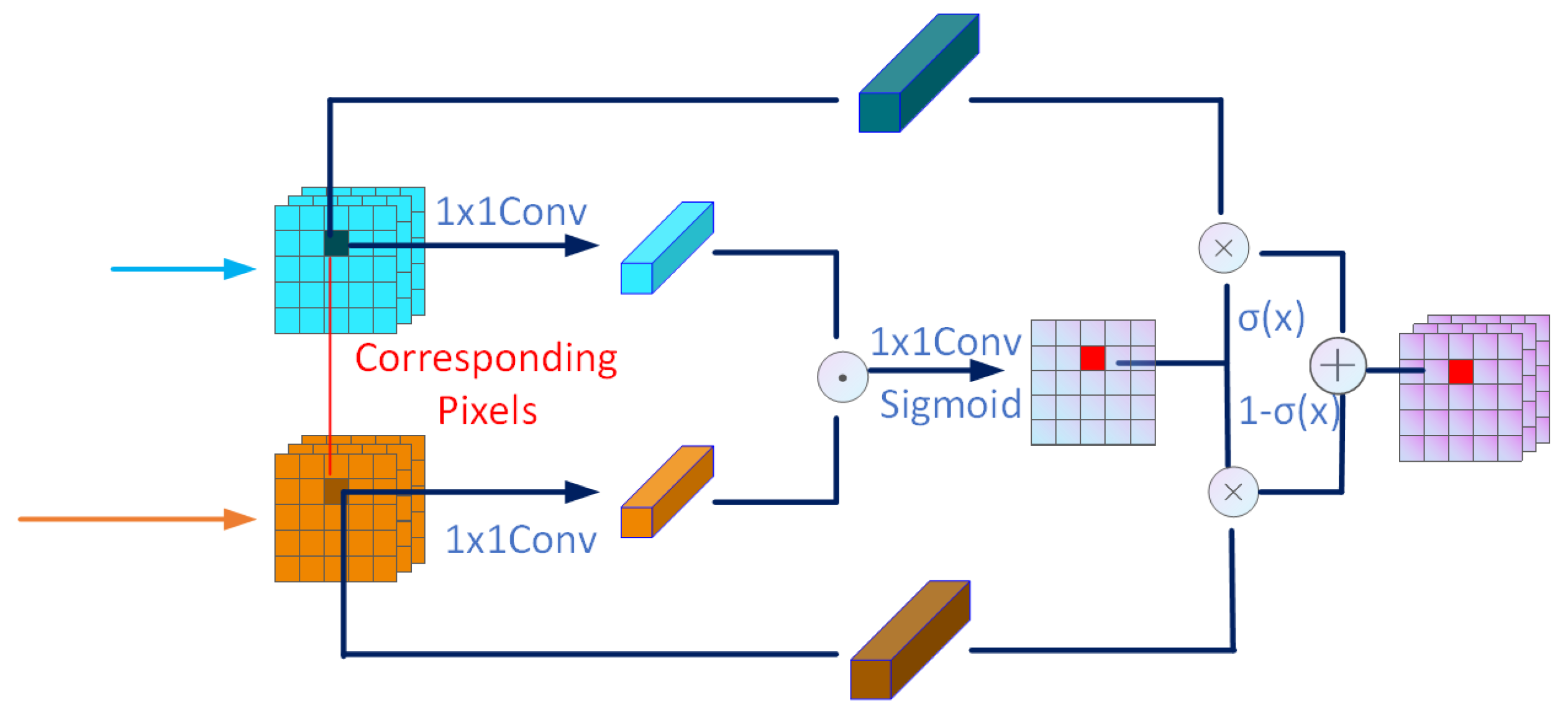
- Introducing Frequency Domain Information: A Frequency Band Feature Separator (FBFS) is designed to split the frequency domain features into high-frequency and low-frequency components using Haar wavelet transform. High-frequency features focus on local edges, while low-frequency features emphasize large-area continuous regions and regions. Subsequently, a Domain Fusion Module (DFM) aligns and fuses frequency domain and spatial domain features. High-frequency features are integrated with deep spatial features that carry semantic information, whereas low-frequency features are linked with shallow spatial features that encode positional information. DFM can select features between the frequency domain and spatial domain, effectively bridge the semantic gap between the two features, and make full use of the frequency domain and spatial domain feature information.
2. Materials and Methods
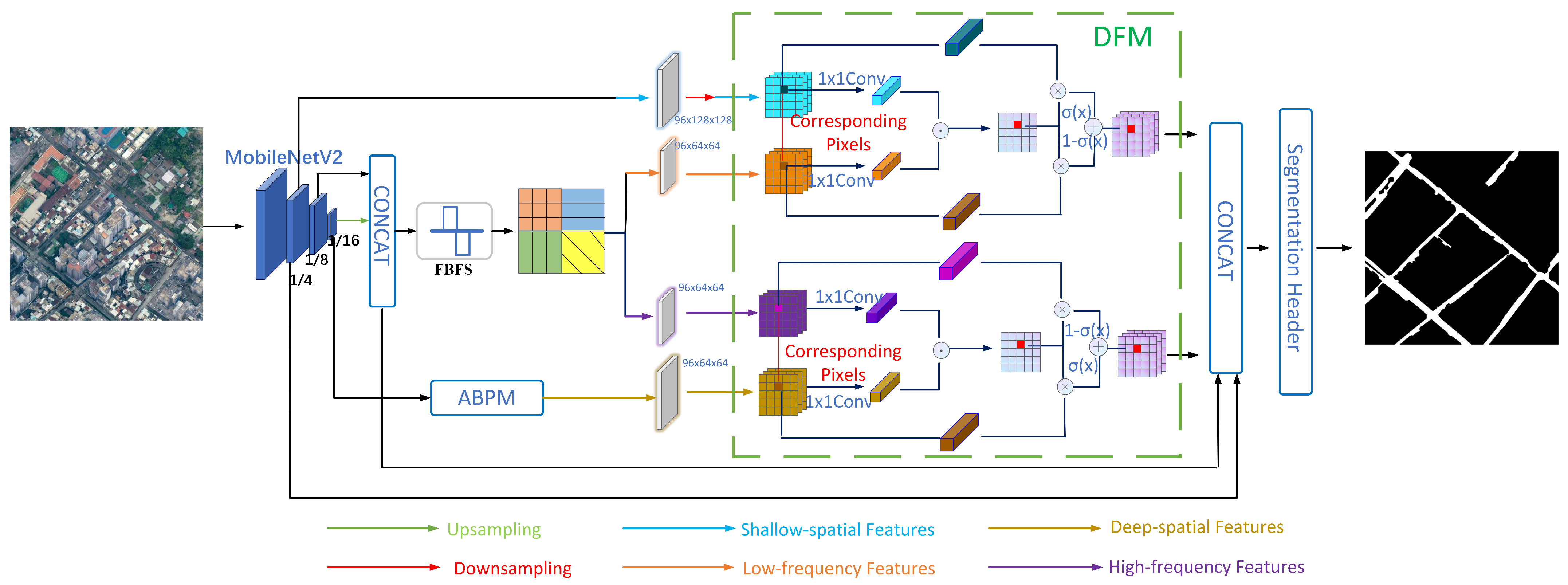
2.1. The Overall Structure of CDFFNet
2.2. Improved Network Module
2.2.1. Atrous Bottleneck Pyramid Module (ABPM)
2.2.2. Frequency Band Feature Separator (FBFS)
2.2.3. Domain Fusion Module (DFM)
3. Experiments and Analysis
3.1. Experimental Settings
3.1.1. Datasets
3.1.2. Evaluation Metrics
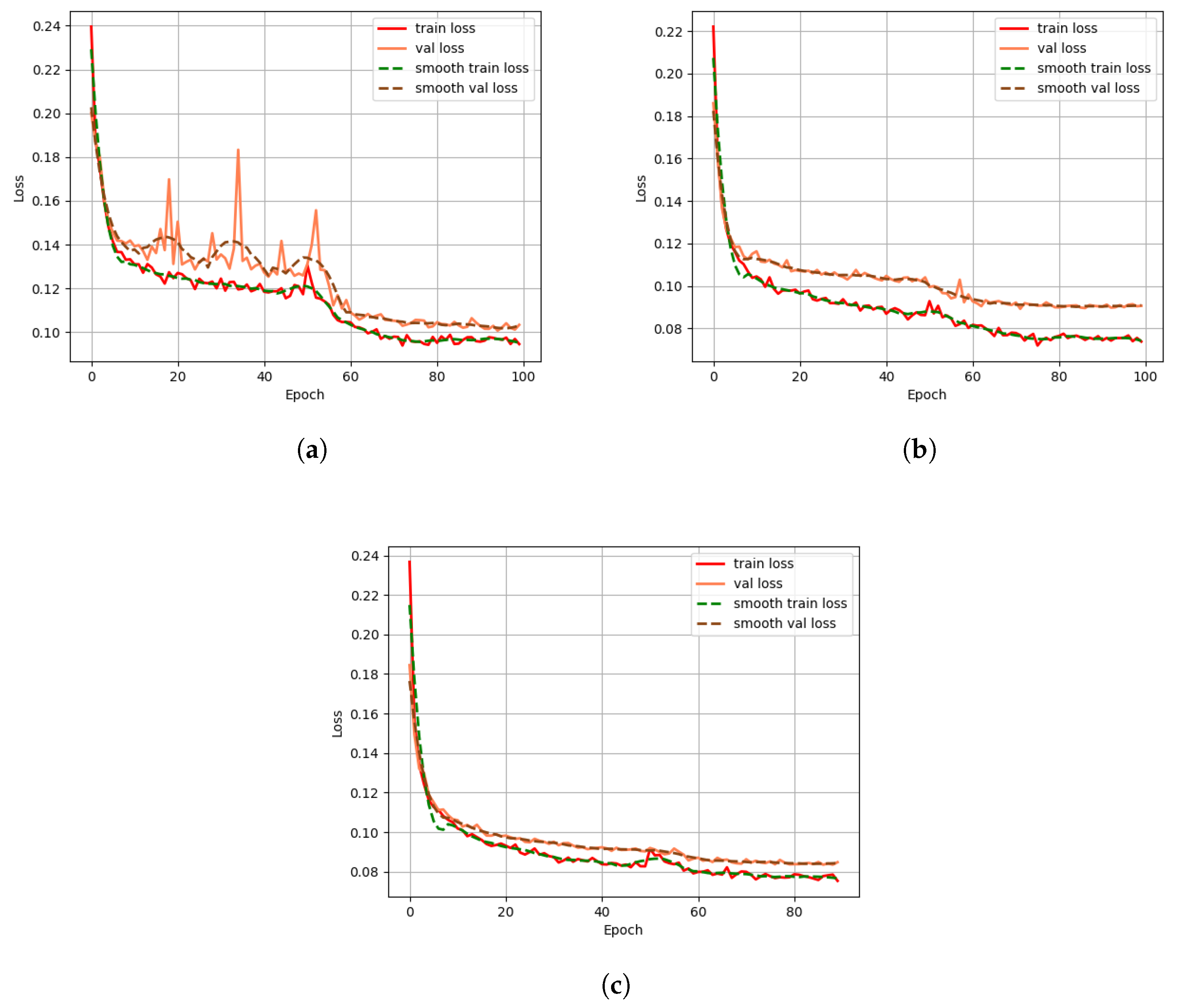
3.1.3. Implementation Details
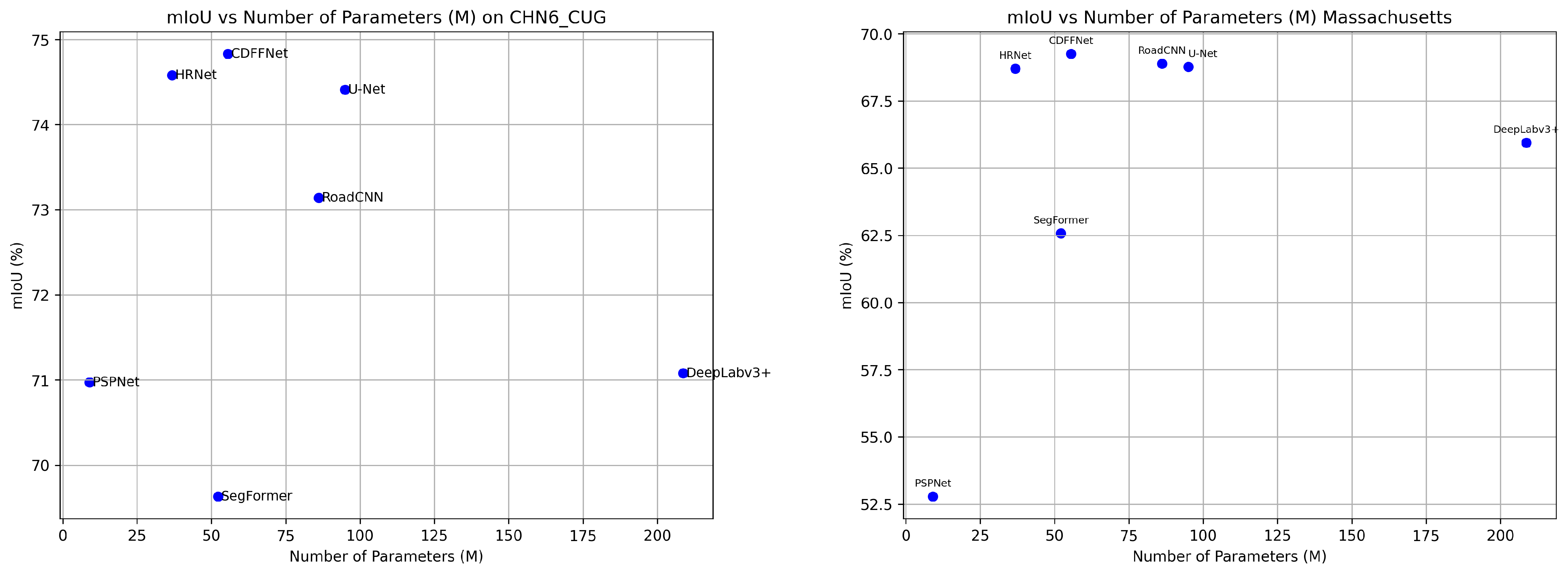
3.2. Comparison with Other Methods
3.2.1. Accuracy Comparison Experiment
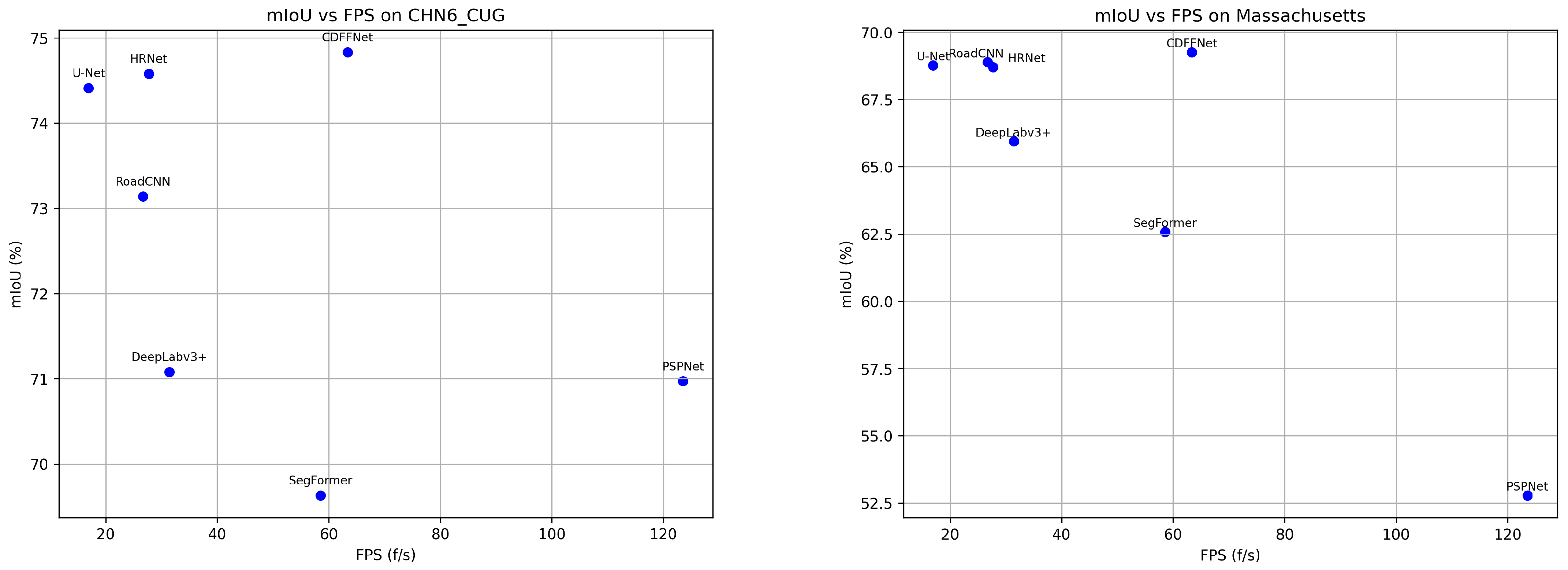
3.2.2. Inference Efficiency Comparison Experiment
3.2.3. Comparison Experiment Prediction Results
3.3. Ablation Experiments
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hou, Z.Q.; Chen, Y.; Yuan, W.H.; Chen, J.M. The Study on the Recent Suspended Sediment Variation Characteristics in Yangshan Deepwater Port Area Based on Landsat 8 Satellite Data. Port Waterw. Eng. 2024, 27–33+40. [Google Scholar] [CrossRef]
- Yang, A.Q.; Yu, X.H.; Chen, L.; Yan, S.M.; Zhu, L.Y.; Guo, W.; Li, M.M.; Li, Y.Y.; Li, Y.; He, J.Y. Long-term Trend of HCHO Column Concentration in Shanxi Based on Satellite Remote Sensing. China Environ. Sci. 2024, 44, 6608–6616. [Google Scholar] [CrossRef]
- Xu, Q.; Long, C.; Yu, L.; Zhang, C. Road extraction with satellite images and partial road maps. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4501214. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J.; Li, T.; Sun, K. Road Extraction and Intersection Detection Based on Tensor Voting. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1587–1590. [Google Scholar]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Bastani, F.; He, S.; Abbar, S.; Alizadeh, M.; Balakrishnan, H.; Chawla, S.; Madden, S.; DeWitt, D. Roadtracer: Automatic Extraction of Road Networks from Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4720–4728. [Google Scholar]
- Wang, Y.; Tong, L.; Luo, S.; Xiao, F.; Yang, J. A Multi-Scale and Multi-Direction Feature Fusion Network for Road Detection From Satellite Imagery. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5615718. [Google Scholar]
- Chen, H.; Li, Z.; Wu, J.; Xiong, W.; Du, C. SemiRoadExNet: A semi-supervised network for road extraction from remote sensing imagery via adversarial learning. ISPRS J. Photogramm. Remote Sens. 2023, 198, 169–183. [Google Scholar] [CrossRef]
- Bose, S.; Chowdhury, R.S.; Pal, D.; Bose, S.; Banerjee, B.; Chaudhuri, S. Multiscale probability map guided index pooling with attention-based learning for road and building segmentation. ISPRS J. Photogramm. Remote Sens. 2023, 206, 132–148. [Google Scholar] [CrossRef]
- Zhang, L.; Lan, M.; Zhang, J.; Tao, D. Stagewise unsupervised domain adaptation with adversarial self-training for road segmentation of remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5609413. [Google Scholar] [CrossRef]
- Ding, L.; Bruzzone, L. DiResNet: Direction-aware residual network for road extraction in VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 10243–10254. [Google Scholar] [CrossRef]
- Sun, W.; Wang, R. Fully convolutional networks for semantic segmentation of very high resolution remotely sensed images combined with DSM. IEEE Geosci. Remote Sens. Lett. 2018, 15, 474–478. [Google Scholar] [CrossRef]
- Weng, W.; Zhu, X. UNet: Convolutional networks for biomedical image segmentation. IEEE Access 2021, 9, 16591–16603. [Google Scholar] [CrossRef]
- Chen, L.C. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting Encoder Representations for Efficient Semantic Segmentation. In Proceedings of the 2017 IEEE visual communications and image processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 182–186. [Google Scholar]
- Mei, J.; Li, R.J.; Gao, W.; Cheng, M.M. CoANet: Connectivity attention network for road extraction from satellite imagery. IEEE Trans. Image Process. 2021, 30, 8540–8552. [Google Scholar] [CrossRef]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic Snake Convolution Based on Topological Geometric Constraints for Tubular Structure Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 6070–6079. [Google Scholar]
- Oner, D.; Koziński, M.; Citraro, L.; Dadap, N.C.; Konings, A.G.; Fua, P. Promoting connectivity of network-like structures by enforcing region separation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5401–5413. [Google Scholar] [CrossRef]
- Yang, Z.; Zhou, D.; Yang, Y.; Zhang, J.; Chen, Z. Road extraction from satellite imagery by road context and full-stage feature. IEEE Geosci. Remote Sens. Lett. 2022, 20, 8000405. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, X.; Li, X.; Ye, Y.; Lau, R.Y.; Zhang, X.; Huang, X. Road detection and centerline extraction via deep recurrent convolutional neural network U-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7209–7220. [Google Scholar] [CrossRef]
- Zhipeng, S.; Jingwen, L.; Jianwu, J.; Yanling, L.; Ming, Z. Remote Sensing Image Semantic Segmentation Method Based on Improved DeepLabV3+. Laser Optoelectron. Prog. 2023, 60, 0628003. [Google Scholar]
- Wulamu, A.; Shi, Z.; Zhang, D.; He, Z. Multiscale road extraction in remote sensing images. Comput. Intell. Neurosci. 2019, 2019, 2373798. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Cai, M.; Xia, Z. A lightweight high-resolution RS image road extraction method combining multi-scale and attention mechanism. IEEE Access 2023, 11, 108956–108966. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Valanarasu, J.M.J.; Patel, V.M. Spin Road Mapper: Extracting Roads from Aerial Images via Spatial and Interaction Space Graph Reasoning for Autonomous Driving. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 343–350. [Google Scholar]
- Gao, F.; Wang, X.; Gao, Y.; Dong, J.; Wang, S. Sea ice change detection in SAR images based on convolutional-wavelet neural networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1240–1244. [Google Scholar] [CrossRef]
- Zhao, C.; Xia, B.; Chen, W.; Guo, L.; Du, J.; Wang, T.; Lei, B. Multi-scale wavelet network algorithm for pediatric echocardiographic segmentation via hierarchical feature guided fusion. Appl. Soft Comput. 2021, 107, 107386. [Google Scholar] [CrossRef]
- Xu, C.; Jia, W.; Wang, R.; Luo, X.; He, X. Morphtext: Deep morphology regularized accurate arbitrary-shape scene text detection. IEEE Trans. Multimed. 2022, 25, 4199–4212. [Google Scholar] [CrossRef]
- Xu, C.; Fu, H.; Ma, L.; Jia, W.; Zhang, C.; Xia, F.; Ai, X.; Li, B.; Zhang, W. Seeing Text in the Dark: Algorithm and Benchmark. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, Australia, 28 October–1 November 2024; pp. 2870–2878. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ross, T.Y.; Dollár, G. Focal Loss for Dense Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | mIoU/% | mPA/% | Recall/% | Accuracy/% |
|---|---|---|---|---|
| PSPNet (mobileNetV2) | 70.97 | 77.60 | 56.63 | 96.18 |
| U-Net (VGG16) | 74.41 | 81.06 | 63.41 | 96.68 |
| HRNet (hrnetv2_w18) | 74.58 | 80.88 | 62.96 | 96.74 |
| SegFormer (MixViTb1) | 69.63 | 75.42 | 52.08 | 96.09 |
| RoadCNN | 73.14 | 80.78 | 62.15 | 96.39 |
| DeepLabv3+ (Xception) | 71.08 | 78.77 | 59.25 | 96.05 |
| CDFFNet (MobileNetV2) | 74.83 | 81.86 | 65.10 | 96.70 |
| Methods | mIoU/% | mPA/% | Recall/% | Accuracy/% |
|---|---|---|---|---|
| PSPNet (mobileNetV2) | 52.78 | 55.02 | 10.43 | 96.03 |
| U-Net (VGG16) | 68.77 | 73.13 | 46.95 | 97.21 |
| HRNet (hrnetv2_w18) | 68.70 | 74.56 | 45.98 | 97.13 |
| SegFormer (MixViTb1) | 62.57 | 66.35 | 40.32 | 96.88 |
| Road CNN | 68.88 | 74.17 | 47.22 | 97.12 |
| DeepLabv3+ (Xception) | 65.94 | 70.94 | 42.8 | 96.82 |
| CDFFNet (MobileNetV2) | 69.25 | 73.8 | 48.3 | 97.24 |
| Methods | PSPNet | U-Net | HRNet | SegFormer | RoadCNN | v3+ | CDFFNet |
|---|---|---|---|---|---|---|---|
| PN/M | 9.06 | 94.95 | 36.76 | 52.18 | 86.15 | 208.70 | 55.57 |
| FPS (f/s) | 123.54 | 16.95 | 27.74 | 58.55 | 26.69 | 31.41 | 63.36 |
| Method | mIoU/% | mPA/% | Recall% | Accuracy/% | PN/M |
|---|---|---|---|---|---|
| DeepLabV3+ | 71.08 | 78.77 | 59.25 | 96.05 | 208.70 |
| +MobileNetV2 | 72.74 | 79.21 | 59.74 | 96.46 | 22.18 |
| +ABPM | 73.65 | 80.81 | 63.08 | 96.52 | 31.76 |
| +FBFS | 74.58 | 81.56 | 64.83 | 96.65 | 55.64 |
| +DFM | 74.83 | 81.86 | 65.10 | 96.70 | 55.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, L.; Shi, T.; Zhang, L. Cross-Domain Feature Fusion Network: A Lightweight Road Extraction Model Based on Multi-Scale Spatial-Frequency Feature Fusion. Appl. Sci. 2025, 15, 1968. https://doi.org/10.3390/app15041968
Gao L, Shi T, Zhang L. Cross-Domain Feature Fusion Network: A Lightweight Road Extraction Model Based on Multi-Scale Spatial-Frequency Feature Fusion. Applied Sciences. 2025; 15(4):1968. https://doi.org/10.3390/app15041968
Chicago/Turabian StyleGao, Lin, Tianyang Shi, and Lincong Zhang. 2025. "Cross-Domain Feature Fusion Network: A Lightweight Road Extraction Model Based on Multi-Scale Spatial-Frequency Feature Fusion" Applied Sciences 15, no. 4: 1968. https://doi.org/10.3390/app15041968
APA StyleGao, L., Shi, T., & Zhang, L. (2025). Cross-Domain Feature Fusion Network: A Lightweight Road Extraction Model Based on Multi-Scale Spatial-Frequency Feature Fusion. Applied Sciences, 15(4), 1968. https://doi.org/10.3390/app15041968