
A Road Extraction Algorithm for the Guided Fusion of Spatial and Channel Features from Multi-Spectral Images

Abstract
1. Introduction
- (1)
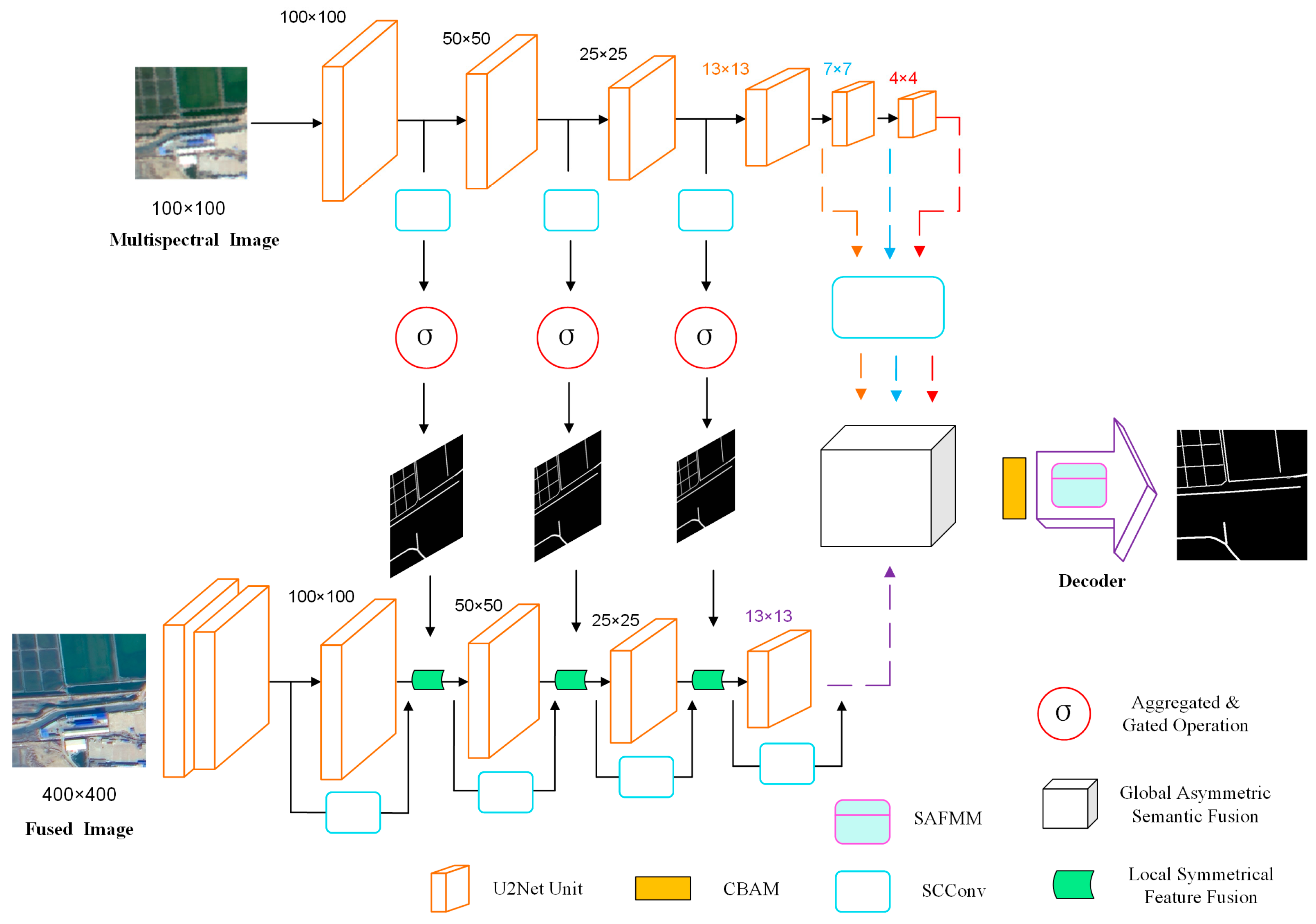
- Based on the MSNet network, for the problem of low utilization of spectral features from HR-RSIs, we propose a refined road extraction algorithm for the guided fusion of spatial and channel features in Multi-spectral images (SC-FMNet);
- (2)
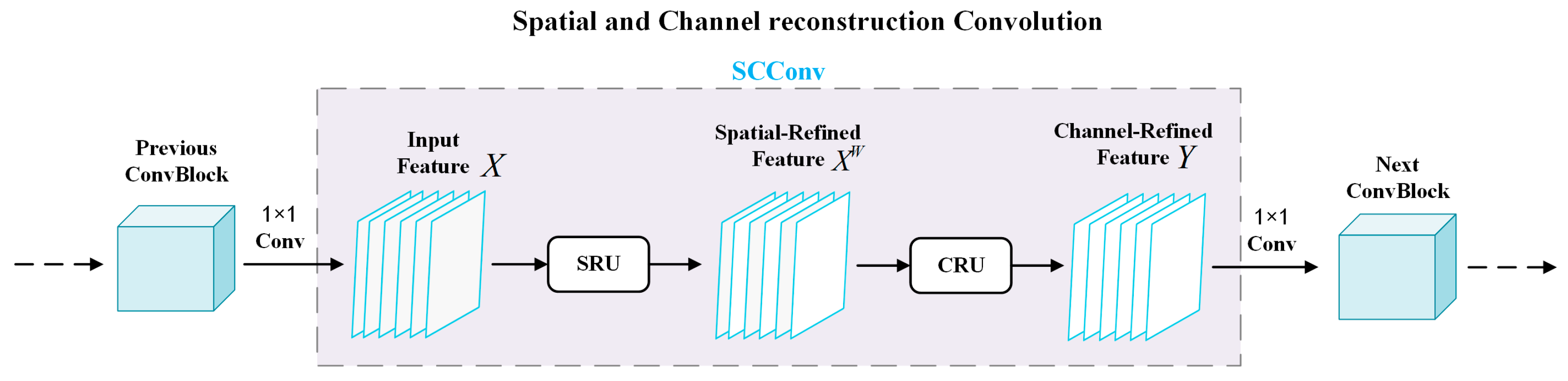
- A Multi-spectral branch structure is designed on the basis of fused image branches. The Spatial and Channel reconstruction Convolution (SCConv) module is merged into the two branches, respectively, which cascades the spatial reconstruction unit and the channel reconstruction unit to remove redundant features through reconstruction.
- (3)
- The Spatially Adaptive Feature Modulation Mechanism (SAFMM) module is embedded into the decoding structure, which mainly consists of a Spatially Adaptive Feature Modulation (SAFM) unit and a Convolutional Channel Mixer (CCM) unit. The SAFM unit learns the multi-scale features and uses the non-local information to adaptively modulate the features so as to select the most suitable modulation for each pixel position.
2. Materials and Methods
2.1. SC-FMNet
2.2. Space and Channel Reconstruction Convolution (SCConv)
2.2.1. Spatial Reconstruction Unit (SRU)
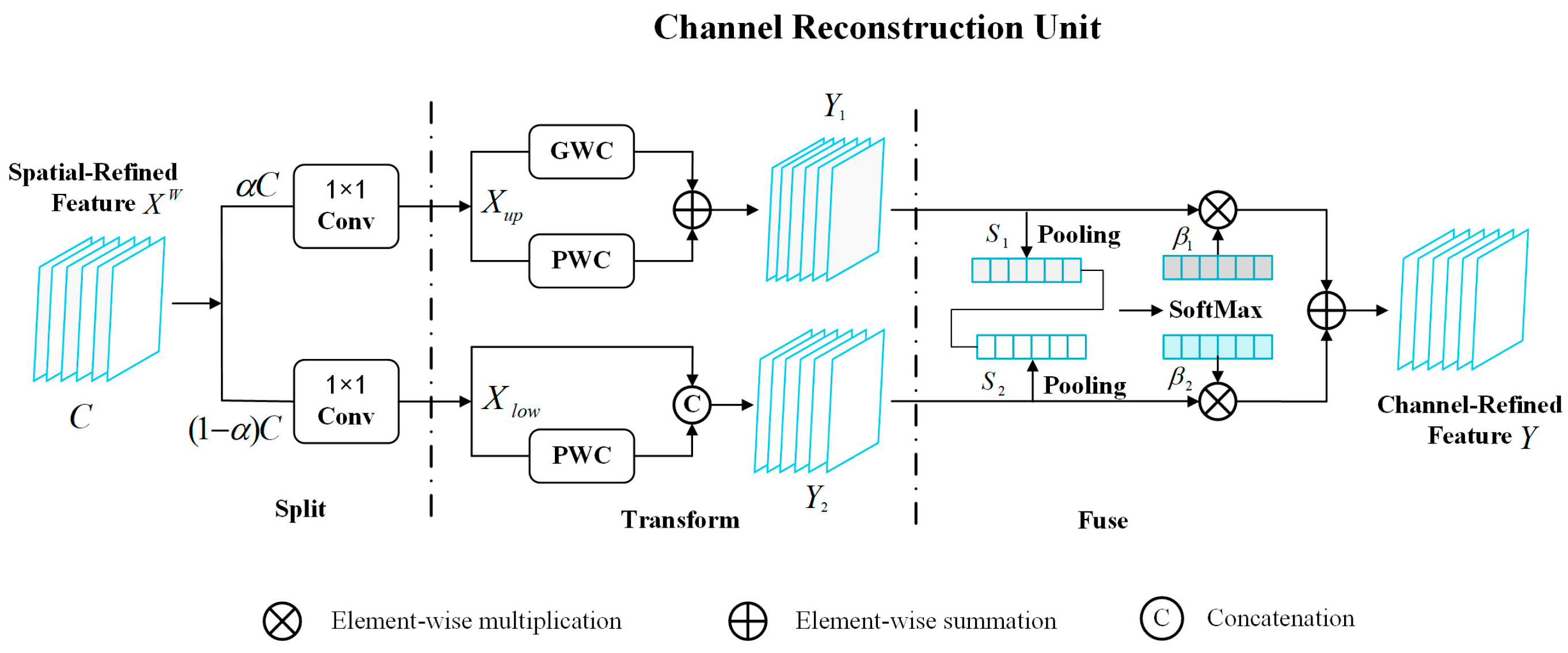
2.2.2. Channel Reconstruction Unit (CRU)
2.3. Spatial Adaptive Feature Modulation Mechanism (SAFMM)
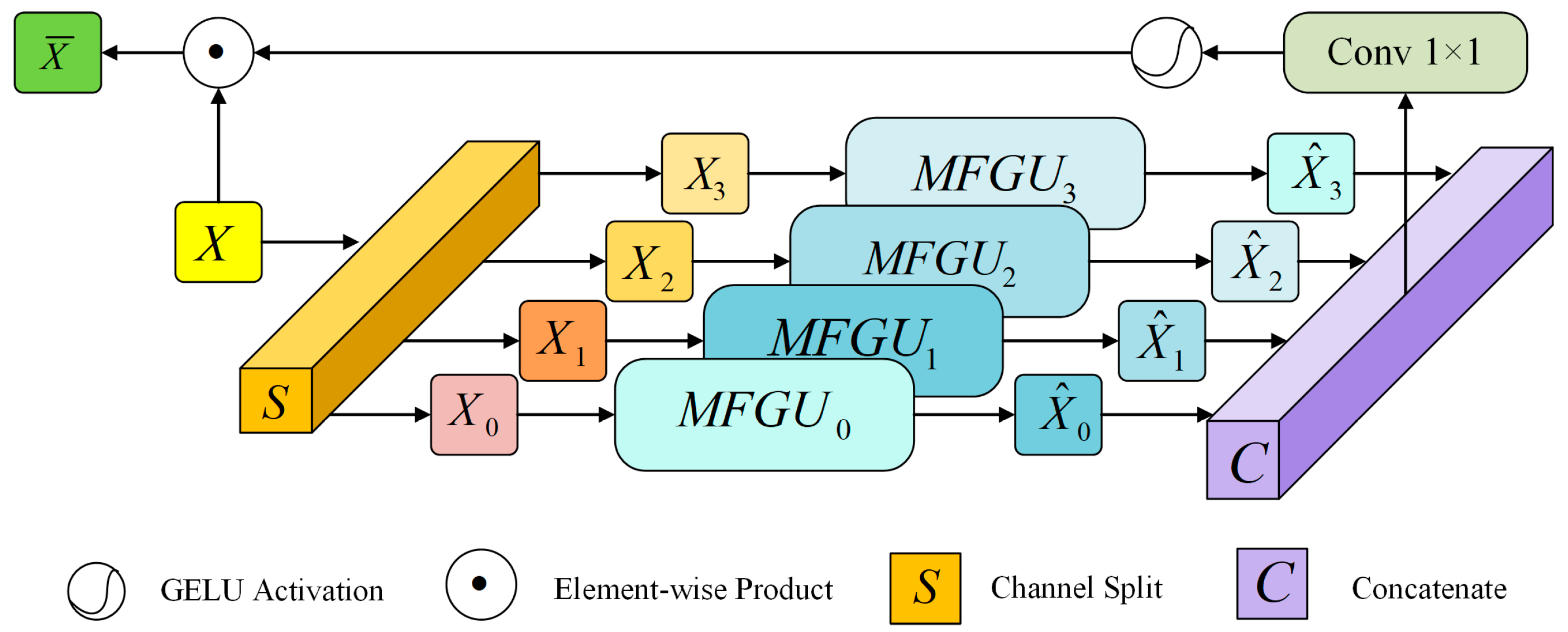
2.3.1. Space Adaptive Feature Modulation Unit (SAFM)
2.3.2. Feature Blending Module (FMM)
3. Results and Analysis
3.1. Experimental Setup
- (1)
- Recall
- (2)
- Precision
- (3)
- F1-score
- (4)
- OA
- (5)
- IoU
3.2. Datasets and Proprecessing
- A.
- GF2-FC road dataset
- B.
- CHN6-CUG road dataset
3.3. Ablation Experiments
- (1)
- GF2-FC road dataset
- (2)
- CHN6-CUG road dataset
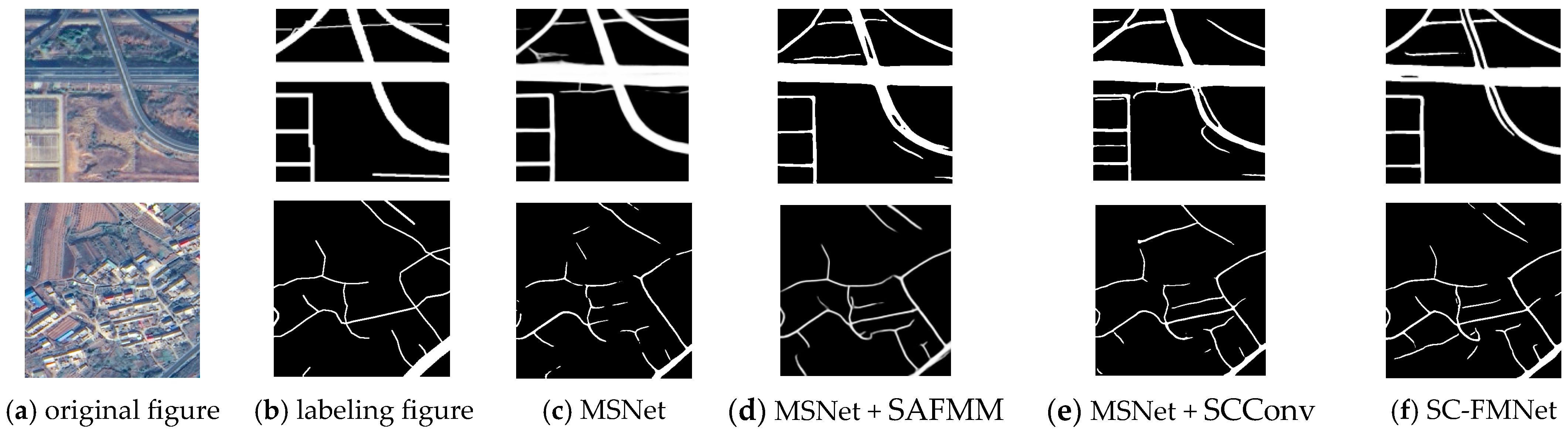
3.4. Results and Comparison
- (1)
- GF2-FC road dataset
- (2)
- CHN6-CUG road dataset
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road extraction methods in high-resolution remote sensing images: A comprehensive review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Qian, W.; Li, Y.; Ye, Q.; Ding, W.; Shu, W. Disambiguation-based partial label feature selection via feature dependency and label consistency. Inf. Fusion 2023, 94, 152–168. [Google Scholar] [CrossRef]
- Parlak, B.; Uysal, A.K. A novel filter feature selection method for text classification: Extensive Feature Selector. J. Inf. Sci. 2023, 49, 59–78. [Google Scholar] [CrossRef]
- Gui, Y.; Li, D.; Fang, R. A fast adaptive algorithm for training deep neural networks. Appl. Intell. 2023, 53, 4099–4108. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; part III 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Wang, B.; Chen, Z.; Wu, L. Road extraction from high-resolution remote sensing images with U-Net network taking connectivity into account. J. Remote Sens. 2020, 24, 1488–1499. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, Y.; Li, W.; Alexandropoulos, G.C.; Yu, J.; Ge, D.; Xiang, W. DDU-Net: Dual-decoder-U-Net for road extraction using high-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Gao, L.; Song, W.; Dai, J.; Chen, Y. Road extraction from high-resolution remote sensing imagery using refined deep residual convolutional neural network. Remote Sens. 2019, 11, 552. [Google Scholar] [CrossRef]
- Makhlouf, Y.; Daamouche, A.; Melgani, F. Convolutional Encoder-Decoder Network for Road Extraction from Remote Sensing Images. In Proceedings of the 2024 IEEE Mediterranean and Middle-East Geoscience and Remote Sensing Symposium (M2GARSS), Oran, Algeria, 15–17 April 2024; pp. 11–15. [Google Scholar]
- Song, Y.; Huang, T.; Fu, X.; Jiang, Y.; Xu, J.; Zhao, J.; Yan, W.; Wang, X. A novel lane line detection algorithm for driverless geographic information perception using mixed-attention mechanism ResNet and row anchor classification. ISPRS Int. J. Geo Inf. 2023, 12, 132. [Google Scholar] [CrossRef]
- Li, S.; Liao, C.; Ding, Y.; Hu, H.; Jia, Y.; Chen, M.; Xu, B.; Ge, X.; Liu, T.; Wu, D. Cascaded residual attention enhanced road extraction from remote sensing images. ISPRS Int. J. Geo Inf. 2022, 11, 9. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; 2017; Volume 30, Available online: https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 2 February 2025).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhang, Z.; Miao, C.; Liu, C.; Tian, Q. DCS-TransUperNet: Road segmentation network based on CSwin transformer with dual resolution. Appl. Sci. 2022, 12, 3511. [Google Scholar] [CrossRef]
- He, B.; Song, Y.; Zhu, Y.; Sha, Q.; Shen, Y.; Yan, T.; Nian, R.; Lendasse, A. Local receptive fields based extreme learning machine with hybrid filter kernels for image classification. Multidimens. Syst. Signal Process. 2019, 30, 1149–1169. [Google Scholar] [CrossRef]
- Du, Y.; Sheng, Q.; Zhang, W.; Zhu, C.; Li, J.; Wang, B. From local context-aware to non-local: A road extraction network via guidance of multi-spectral image. ISPRS J. Photogramm. Remote Sens. 2023, 203, 230–245. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Li, J.; Wen, Y.; He, L. Scconv: Spatial and channel reconstruction convolution for feature redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6153–6162. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 510–519. [Google Scholar]
- Sun, L.; Dong, J.; Tang, J.; Pan, J. Spatially-adaptive feature modulation for efficient image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 13190–13199. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnetv2: Smaller models and faster training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Ren, B.; Ma, S.; Hou, B.; Hong, D.; Chanussot, J.; Wang, J.; Jiao, L. A dual-stream high resolution network: Deep fusion of GF-2 and GF-3 data for land cover classification. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102896. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Y.; Wang, L.; Zhong, Y.; Guan, Q.; Lu, X.; Zhang, L.; Li, D. A global context-aware and batch-independent network for road extraction from VHR satellite imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 353–365. [Google Scholar] [CrossRef]
- Li, R.; Wang, L.; Zhang, C.; Duan, C.; Zheng, S. A2-FPN for semantic segmentation of fine-resolution remotely sensed images. Int. J. Remote Sens. 2022, 43, 1131–1155. [Google Scholar] [CrossRef]
- Tsai, F.J.; Peng, Y.T.; Tsai, C.C.; Lin, Y.Y.; Lin, C.W. Banet: A blur-aware attention network for dynamic scene deblurring. IEEE Trans. Image Process. 2022, 31, 6789–6799. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- He, P.; Jiao, L.; Shang, R.; Wang, S.; Liu, X.; Quan, D.; Yang, K.; Zhao, D. MANet: Multi-scale aware-relation network for semantic segmentation in aerial scenes. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, H.; Shen, C.; He, T.; Jin, L.; Wang, L. Abcnet: Real-time scene text spotting with adaptive bezier-curve network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9809–9818. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | OA (%) | P (%) | R (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|---|
| MSNet | 94.84 | 79.91 | 63.12 | 70.18 | 54.06 |
| MSNet + SAFMM | 95.95 | 79.64 | 70.35 | 73.77 | 58.44 |
| MSNet + SCConv | 95.02 | 79.50 | 66.69 | 71.41 | 55.53 |
| SC-FMNet | 98.57 | 80.74 | 72.47 | 76.01 | 61.30 |
| Methods | OA (%) | P (%) | R (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|---|
| MSNet | 95.46 | 78.83 | 62.91 | 66.93 | 56.00 |
| MSNet + SAFMM | 96.08 | 79.44 | 65.38 | 71.80 | 57.00 |
| MSNet + SCConv | 95.54 | 76.98 | 62.96 | 69.37 | 56.25 |
| SC-FMNet | 96.16 | 79.60 | 66.86 | 72.61 | 63.10 |
| Methods | OA (%) | P (%) | R (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|---|
| A2FPN [26] | 94.81 | 79.62 | 61.83 | 70.03 | 53.89 |
| BANet [27] | 93.96 | 79.03 | 51.05 | 62.21 | 45.15 |
| DCSwin [28] | 93.80 | 77.46 | 51.36 | 61.77 | 44.68 |
| MANet [29] | 94.77 | 78.62 | 58.56 | 69.45 | 53.20 |
| UNetFormer [30] | 94.40 | 72.46 | 57.37 | 66.62 | 49.95 |
| ABCNet [31] | 93.71 | 76.74 | 50.82 | 61.15 | 44.04 |
| MSNet | 94.84 | 79.91 | 63.12 | 70.18 | 54.06 |
| A2FPN [26] | 98.57 | 80.74 | 72.47 | 76.01 | 61.30 |
| Methods | OA (%) | P (%) | R (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|---|
| A2FPN | 95.38 | 77.22 | 59.20 | 63.25 | 55.29 |
| BANet | 94.99 | 54.03 | 52.81 | 58.13 | 47.98 |
| DCSwin | 93.77 | 69.39 | 42.50 | 52.71 | 45.79 |
| MANet | 94.11 | 72.98 | 44.19 | 55.05 | 49.20 |
| UNetFormer | 93.10 | 72.39 | 45.11 | 55.58 | 48.49 |
| ABCNet | 94.04 | 70.18 | 47.03 | 56.32 | 40.98 |
| MSNet | 95.46 | 78.83 | 62.91 | 66.93 | 56.00 |
| SC-FMNet | 96.16 | 79.60 | 66.86 | 72.61 | 63.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, L.; Zhang, Y.; Jiao, A.; Zhang, L. A Road Extraction Algorithm for the Guided Fusion of Spatial and Channel Features from Multi-Spectral Images. Appl. Sci. 2025, 15, 1684. https://doi.org/10.3390/app15041684
Gao L, Zhang Y, Jiao A, Zhang L. A Road Extraction Algorithm for the Guided Fusion of Spatial and Channel Features from Multi-Spectral Images. Applied Sciences. 2025; 15(4):1684. https://doi.org/10.3390/app15041684
Chicago/Turabian StyleGao, Lin, Yongqi Zhang, Aolin Jiao, and Lincong Zhang. 2025. "A Road Extraction Algorithm for the Guided Fusion of Spatial and Channel Features from Multi-Spectral Images" Applied Sciences 15, no. 4: 1684. https://doi.org/10.3390/app15041684
APA StyleGao, L., Zhang, Y., Jiao, A., & Zhang, L. (2025). A Road Extraction Algorithm for the Guided Fusion of Spatial and Channel Features from Multi-Spectral Images. Applied Sciences, 15(4), 1684. https://doi.org/10.3390/app15041684