
Harnessing Spatial-Frequency Information for Enhanced Image Restoration



Abstract
1. Introduction
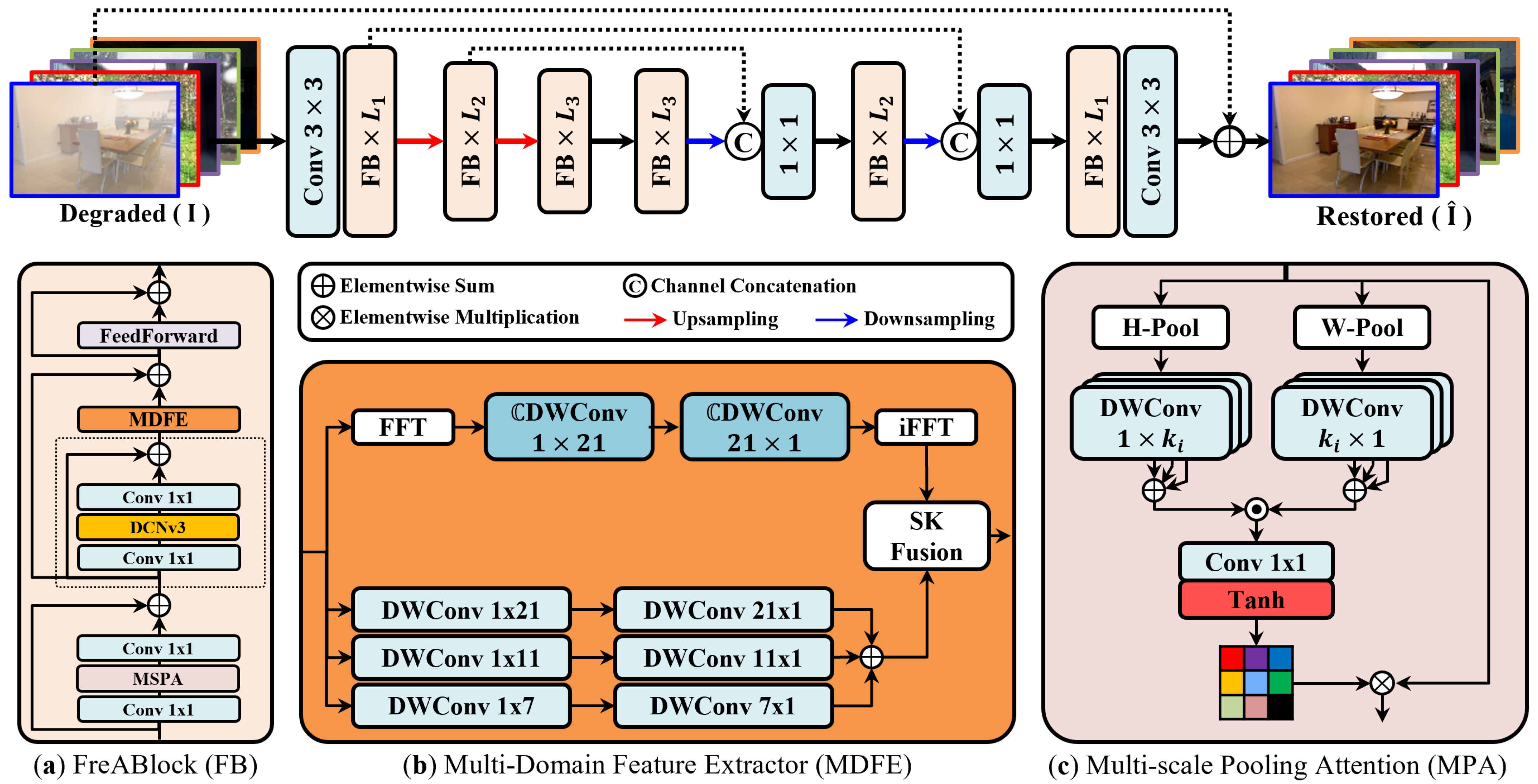
- We propose a multi-domain feature extractor (MDFE) that selectively integrates spatial and frequency information for different types of degradation and is designed to operate appropriately in the corresponding domain.
- To efficiently capture global information, we propose a multi-scale pooling attention (MPA) mechanism, which utilizes unidirectional pooling functions and convolutions with multiple strip kernels, thereby reducing the computational complexity of vanilla attention from to .
- The proposed FreANet is evaluated on 11 benchmark datasets for various restoration tasks, demonstrating remarkable performance compared to other algorithms.
2. Related Works
2.1. Image Restoration
2.2. Modeling Frequency Information
2.3. Attention Mechanisms
3. Methodology
3.1. Overall Architecture
3.2. Multi-Domain Feature Extractor (MDFE)
3.3. Multi-Scale Pooling Attention (MPA)
3.4. Loss Function
4. Experiments
4.1. Single-Image Defocus Deblurring Results
4.2. Motion Deblurring Results
4.3. Dehazing Results
4.4. Low-Light Enhancement Results
5. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Li, C.Y.; Guo, J.C.; Cong, R.M.; Pang, Y.W.; Wang, B. Underwater image enhancement by dehazing with minimum information loss and histogram distribution prior. IEEE Trans. Image Process. 2016, 25, 5664–5677. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.H. Gated Fusion Network for Single Image Dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3253–3261. [Google Scholar]
- Chen, L.; Lu, X.; Zhang, J.; Chu, X.; Chen, C. HINet: Half Instance Normalization Network for Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 182–192. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision transformers for single image dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef] [PubMed]
- Cui, Y.; Tao, Y.; Bing, Z.; Ren, W.; Gao, X.; Cao, X.; Huang, K.; Knoll, A. Selective frequency network for image restoration. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Cui, Y.; Ren, W.; Cao, X.; Knoll, A. Focal network for image restoration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 13001–13011. [Google Scholar]
- Yang, H.H.; Fu, Y. Wavelet u-net and the chromatic adaptation transform for single image dehazing. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2736–2740. [Google Scholar]
- Li, R.; Dong, H.; Wang, L.; Liang, B.; Guo, Y.; Wang, F. Frequency-aware deep dual-path feature enhancement network for image dehazing. In Proceedings of the International Conference on Pattern Recognition, Montreal, QC, Canada, 21–25 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3406–3412. [Google Scholar]
- Zhou, M.; Huang, J.; Guo, C.L.; Li, C. Fourmer: An efficient global modeling paradigm for image restoration. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 42589–42601. [Google Scholar]
- Mao, X.; Liu, Y.; Liu, F.; Li, Q.; Shen, W.; Wang, Y. Intriguing findings of frequency selection for image deblurring. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 1905–1913. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Hou, Q.; Liu, Z.; Cheng, M.M.; Hu, S.M. Segnext: Rethinking convolutional attention design for semantic segmentation. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 1140–1156. [Google Scholar]
- Trabelsi, C.; Bilaniuk, O.; Zhang, Y.; Serdyuk, D.; Subramanian, S.; Santos, J.F.; Mehri, S.; Rostamzadeh, N.; Bengio, Y.; Pal, C.J. Deep complex networks. arXiv 2017, arXiv:1705.09792. [Google Scholar]
- Cui, Y.; Ren, W.; Yang, S.; Cao, X.; Knoll, A. IRNeXt: Rethinking Convolutional Network Design for Image Restoration. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Cui, Y.; Ren, W.; Knoll, A. Omni-Kernel Network for Image Restoration. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 1426–1434. [Google Scholar]
- Wu, H.; Qu, Y.; Lin, S.; Zhou, J.; Qiao, R.; Zhang, Z.; Xie, Y.; Ma, L. Contrastive learning for compact single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10551–10560. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning enriched features for real image restoration and enhancement. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 492–511. [Google Scholar]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated Context Aggregation Network for Image Dehazing and Deraining. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 7–11 January 2019. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. MAXIM: Multi-axis MLP for image processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5769–5780. [Google Scholar]
- Zheng, Y.; Zhan, J.; He, S.; Dong, J.; Du, Y. Curricular contrastive regularization for physics-aware single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5785–5794. [Google Scholar]
- Anwar, S.; Barnes, N. Densely residual laplacian super-resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1192–1204. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Lee, E.; Hwang, Y. Decomformer: Decompose Self-Attention of Transformer for Efficient Image Restoration. IEEE Access 2024, 12, 38672–38684. [Google Scholar] [CrossRef]
- Tian, C.; Zheng, M.; Zuo, W.; Zhang, B.; Zhang, Y.; Zhang, D. Multi-stage image denoising with the wavelet transform. Pattern Recognit. 2023, 134, 109050. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.L.; Zhou, M.; Liang, Z.; Zhou, S.; Feng, R.; Loy, C.C. Embedding Fourier for Ultra-High-Definition Low-Light Image Enhancement. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zheng, C.; Liu, X.; Qi, G.J.; Chen, C. Potter: Pooling attention transformer for efficient human mesh recovery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1611–1620. [Google Scholar]
- Cooley, J.W.; Lewis, P.A.; Welch, P.D. The fast Fourier transform and its applications. IEEE Trans. Educ. 1969, 12, 27–34. [Google Scholar] [CrossRef]
- Wang, W.; Dai, J.; Chen, Z.; Huang, Z.; Li, Z.; Zhu, X.; Hu, X.; Lu, T.; Lu, L.; Li, H.; et al. Internimage: Exploring large-scale vision foundation models with deformable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14408–14419. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Abuolaim, A.; Brown, M.S. Defocus deblurring using dual-pixel data. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 111–126. [Google Scholar]
- Ruan, L.; Chen, B.; Li, J.; Lam, M.L. Aifnet: All-in-focus image restoration network using a light field-based dataset. IEEE Trans. Comput. Imaging 2021, 7, 675–688. [Google Scholar] [CrossRef]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Shen, Z.; Wang, W.; Lu, X.; Shen, J.; Ling, H.; Xu, T.; Shao, L. Human-aware motion deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5572–5581. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef] [PubMed]
- Ancuti, C.O.; Ancuti, C.; Sbert, M.; Timofte, R. Dense-haze: A benchmark for image dehazing with dense-haze and haze-free images. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1014–1018. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; Timofte, R. NH-HAZE: An image dehazing benchmark with non-homogeneous hazy and haze-free images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 444–445. [Google Scholar]
- Zhang, J.; Cao, Y.; Zha, Z.J.; Tao, D. Nighttime dehazing with a synthetic benchmark. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2355–2363. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. In Proceedings of the BMVC, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Yang, W.; Wang, W.; Huang, H.; Wang, S.; Liu, J. Sparse gradient regularized deep retinex network for robust low-light image enhancement. IEEE Trans. Image Process. 2021, 30, 2072–2086. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Lee, J.; Son, H.; Rim, J.; Cho, S.; Lee, S. Iterative filter adaptive network for single image defocus deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2034–2042. [Google Scholar]
- Cui, Y.; Ren, W.; Cao, X.; Knoll, A. Image Restoration via Frequency Selection. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 1093–1108. [Google Scholar] [CrossRef]
- Cui, Y.; Knoll, A. Dual-domain strip attention for image restoration. Neural Netw. 2024, 171, 429–439. [Google Scholar] [CrossRef] [PubMed]
- Tsai, F.J.; Peng, Y.T.; Lin, Y.Y.; Tsai, C.C.; Lin, C.W. Stripformer: Strip transformer for fast image deblurring. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 146–162. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar]
- Wang, T.; Tao, G.; Lu, W.; Zhang, K.; Luo, W.; Zhang, X.; Lu, T. Restoring vision in hazy weather with hierarchical contrastive learning. Pattern Recognit. 2024, 145, 109956. [Google Scholar] [CrossRef]
- Cai, Y.; Bian, H.; Lin, J.; Wang, H.; Timofte, R.; Zhang, Y. Retinexformer: One-stage retinex-based transformer for low-light image enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12504–12513. [Google Scholar]
- Yang, W.; Wang, S.; Fang, Y.; Wang, Y.; Liu, J. Band representation-based semi-supervised low-light image enhancement: Bridging the gap between signal fidelity and perceptual quality. IEEE Trans. Image Process. 2021, 30, 3461–3473. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Wang, R.; Fu, C.W.; Jia, J. SNR-aware low-light image enhancement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17714–17724. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Dataset | Test Subname | #Train | #Test |
|---|---|---|---|---|
| Defocus Deblurring | DPDD [37] | - | 350 | 76 |
| LFDOF [38] | - | 11,261 | 725 | |
| Motion Deblurring | GoPro [39] | - | 2103 | 1111 |
| HIDE [40] | - | 0 | 2025 | |
| Dehazing | RESIDE-ITS [41] | SOTS-Indoor | 13,990 | 500 |
| RESIDE-OTS [41] | SOTS-Outdoor | 313,950 | 500 | |
| Dense-Haze [42] | - | 45 | 5 | |
| NH-HAZE [43] | - | 45 | 5 | |
| NHR [44] | - | 16,146 | 1794 | |
| Enhancement | LOLv1 [45] | - | 485 | 15 |
| LOLv2-real [46] | - | 689 | 100 | |
| LOLv2-syn [46] | - | 900 | 100 |
| Methods | Indoor Scenes | Outdoor Scenes | Combined | #Params | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | MAE↓ | LPIPS↓ | PSNR↑ | SSIM↑ | MAE↓ | LPIPS↓ | PSNR↑ | SSIM↑ | MAE↓ | LPIPS↓ | (M) | |
| IFAN [49] | 28.11 | 0.861 | 0.026 | 0.179 | 22.76 | 0.720 | 0.052 | 0.254 | 25.37 | 0.789 | 0.039 | 0.217 | 10.47 |
| Restormer [7] | 28.87 | 0.882 | 0.025 | 0.145 | 23.24 | 0.743 | 0.050 | 0.209 | 25.98 | 0.811 | 0.038 | 0.178 | 26.13 |
| SFNet [10] | 29.16 | 0.878 | 0.023 | 0.168 | 23.45 | 0.747 | 0.049 | 0.244 | 26.23 | 0.811 | 0.037 | 0.207 | 13.27 |
| FocalNet [11] | 29.10 | 0.876 | 0.024 | 0.173 | 23.41 | 0.743 | 0.049 | 0.246 | 26.18 | 0.808 | 0.037 | 0.210 | 12.82 |
| IRNeXt [18] | 29.22 | 0.879 | 0.024 | 0.167 | 23.53 | 0.752 | 0.049 | 0.244 | 26.30 | 0.814 | 0.037 | 0.206 | 14.75 |
| OKNet [19] | 28.99 | 0.877 | 0.024 | 0.169 | 23.51 | 0.751 | 0.049 | 0.241 | 26.18 | 0.812 | 0.037 | 0.206 | 14.02 |
| FSNet [50] | 29.14 | 0.878 | 0.024 | 0.166 | 23.45 | 0.747 | 0.050 | 0.246 | 26.22 | 0.811 | 0.037 | 0.207 | 13.28 |
| DSANet [51] | 29.27 | 0.881 | 0.024 | 0.158 | 23.50 | 0.749 | 0.049 | 0.231 | 26.31 | 0.813 | 0.036 | 0.195 | 13.16 |
| FreANet | 29.32 | 0.881 | 0.023 | 0.131 | 23.55 | 0.757 | 0.049 | 0.195 | 26.36 | 0.817 | 0.036 | 0.164 | 12.74 |
| Methods | GoPro [39] | HIDE [40] | #Params | ||
|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | (M) | |
| MPRNet [3] | 32.66 | 0.959 | 30.96 | 0.939 | 20.1 |
| HINet [5] | 32.71 | 0.959 | 30.32 | 0.932 | 20.1 |
| Restormer [7] | 32.92 | 0.961 | 31.22 | 0.942 | 26.13 |
| Uformer-B [53] | 33.06 | 0.967 | 30.90 | 0.953 | 50.88 |
| Stripformer [52] | 33.08 | 0.962 | 31.03 | 0.940 | 20 |
| IRNeXt [18] | 33.16 | 0.962 | - | - | 14.75 |
| FreANet | 33.21 | 0.962 | 31.11 | 0.937 | 12.74 |
| Methods | SOTS-Indoor [41] | SOTS-Outdoor [41] | Dense-Haze [42] | NH-HAZE [43] | Overheads | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | #Params (M) | FLOPs (G) | |
| GridDehazeNet [54] | 32.16 | 0.984 | 30.86 | 0.982 | - | - | 13.80 | 0.54 | 0.956 | 21.49 |
| FFA-Net [6] | 36.39 | 0.989 | 33.57 | 0.984 | 14.39 | 0.45 | 19.87 | 0.69 | 4.45 | 287.8 |
| AECR-Net [20] | 37.17 | 0.990 | - | - | 15.80 | 0.47 | 19.88 | 0.72 | 2.61 | 52.20 |
| MAXIM [23] | 38.11 | 0.991 | 34.19 | 0.985 | - | - | - | - | 14.1 | - |
| Fourmer [14] | 37.32 | 0.990 | - | - | 15.95 | 0.49 | 19.91 | 0.72 | 1.29 | 20.6 |
| OKNet-S [19] | 37.59 | 0.994 | 35.45 | 0.992 | 16.85 | 0.62 | 20.29 | 0.80 | 2.40 | 17.88 |
| OKNet [19] | 40.79 | 0.996 | 37.68 | 0.995 | 16.92 | 0.64 | 20.48 | 0.80 | 4.72 | 39.71 |
| FreANet-S | 39.54 | 0.995 | 36.46 | 0.993 | 17.39 | 0.65 | 20.11 | 0.81 | 1.79 | 19.77 |
| FreANet | 41.62 | 0.997 | 38.39 | 0.995 | 17.53 | 0.67 | 20.52 | 0.82 | 5.37 | 40.29 |
| Method | OFSD | HCD | FocalNet | FSNet | OKNet | FreANet |
|---|---|---|---|---|---|---|
| [44] | [55] | [11] | [50] | [19] | (Ours) | |
| PSNR↑ | 21.32 | 23.43 | 25.35 | 26.30 | 27.92 | 28.76 |
| SSIM↑ | 0.804 | 0.953 | 0.969 | 0.976 | 0.979 | 0.978 |
| Method | LOLv1 [45] | LOLv2-Real [46] | LOLv2-Syn [46] | #Params | |||
|---|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | (M) | |
| DRBN [57] | 20.13 | 0.830 | 20.29 | 0.831 | 23.22 | 0.927 | 5.27 |
| Restormer [7] | 22.43 | 0.823 | 19.94 | 0.827 | 21.41 | 0.830 | 26.13 |
| MIRNet [21] | 24.14 | 0.830 | 20.02 | 0.820 | 21.94 | 0.876 | 31.76 |
| UHDFour [29] | 23.09 | 0.870 | 21.78 | 0.870 | - | - | 28.52 |
| SNR-Net [58] | 24.61 | 0.842 | 21.48 | 0.849 | 24.14 | 0.928 | 4.01 |
| FreANet | 23.60 | 0.836 | 21.78 | 0.860 | 25.91 | 0.939 | 2.45 |
| Variant | MPA | RDB | MDFE | SOTS-Indoor | |||
|---|---|---|---|---|---|---|---|
| Spatial | Frequency | PSNR↑ | SSIM↑ | #Params | |||
| (a) | ✔ | 30.75 | 0.976 | 0.81 M | |||
| (b) | ✔ | 36.29 | 0.991 | 1.40 M | |||
| (c) | ✔ | ✔ | 37.06 | 0.993 | 1.59 M | ||
| (d) | ✔ | 33.36 | 0.984 | 0.66 M | |||
| (e) | ✔ | 25.06 | 0.941 | 0.66 M | |||
| (f) | ✔ | ✔ | 35.83 | 0.991 | 0.81 M | ||
| (g) | ✔ | ✔ | ✔ | 36.65 | 0.992 | 1.01 M | |
| (h) | ✔ | ✔ | ✔ | 39.18 | 0.994 | 1.59 M | |
| (i) | ✔ | ✔ | ✔ | ✔ | 39.54 | 0.995 | 1.78 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, C.-H.; Choi, H.-D.; Lim, M.-T. Harnessing Spatial-Frequency Information for Enhanced Image Restoration. Appl. Sci. 2025, 15, 1856. https://doi.org/10.3390/app15041856
Park C-H, Choi H-D, Lim M-T. Harnessing Spatial-Frequency Information for Enhanced Image Restoration. Applied Sciences. 2025; 15(4):1856. https://doi.org/10.3390/app15041856
Chicago/Turabian StylePark, Cheol-Hoon, Hyun-Duck Choi, and Myo-Taeg Lim. 2025. "Harnessing Spatial-Frequency Information for Enhanced Image Restoration" Applied Sciences 15, no. 4: 1856. https://doi.org/10.3390/app15041856
APA StylePark, C.-H., Choi, H.-D., & Lim, M.-T. (2025). Harnessing Spatial-Frequency Information for Enhanced Image Restoration. Applied Sciences, 15(4), 1856. https://doi.org/10.3390/app15041856