
Enhanced Location Prediction for Wargaming with Graph Neural Networks and Transformers

Abstract
1. Introduction
- Temporal sequence modeling with transformers: ELP-Net incorporates a transformer module to handle temporal sequence data, enabling the simultaneous consideration of information from multiple units across different time steps. This results in richer feature extraction by capturing the temporal dynamics within the wargame.
- Spatial–temporal GNN-based model: The core advantage lies in the combination of a temporal module with a graph convolution module, incorporating the novel mix-hop attention propagation layers. This design outperforms traditional CNNs in handling sparse data and capturing complex node relationships, providing a more robust solution for location prediction.
- End-to-end graph sequence learning framework: The graph structure learning layer, the graph convolution, the temporal convolution modules, and the transformer architecture are integrated and jointly optimized within an end-to-end learning framework.
- Enhanced location prediction performance: Numerical experiments have demonstrated that ELP-Net consistently outperforms baseline models, underscoring the effectiveness of its integrated architecture in accurately capturing spatial–temporal dependencies and providing reliable predictions in complex wargaming scenarios.
2. Background
2.1. Tactical Wargame Platform
2.2. Dataset Description
3. Methodology
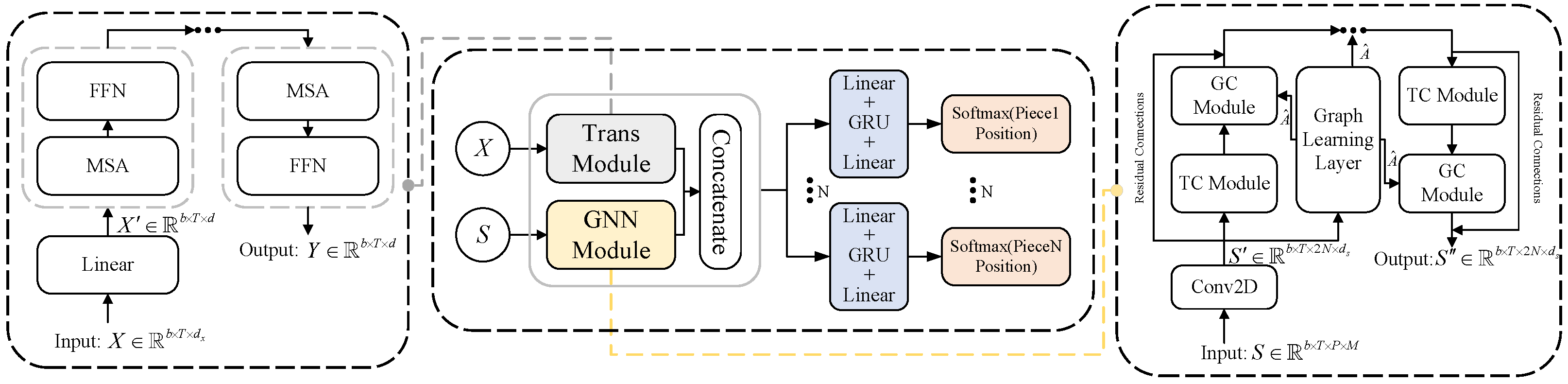
3.1. Framework
3.2. Transformer Module
3.3. Spatial–Temporal Graph Neural Network
3.3.1. Graph Learning Layer
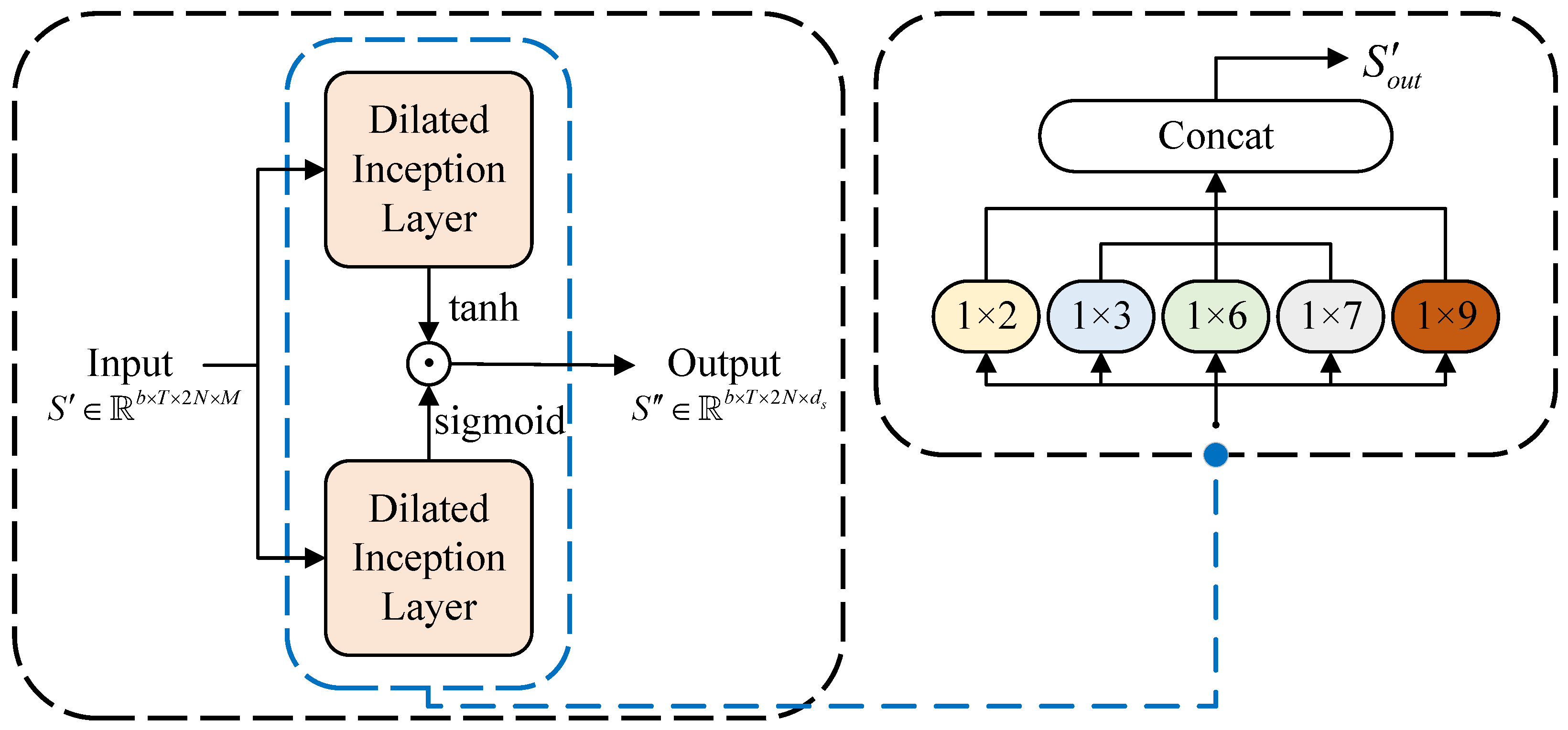
3.3.2. Temporal Convolution Module
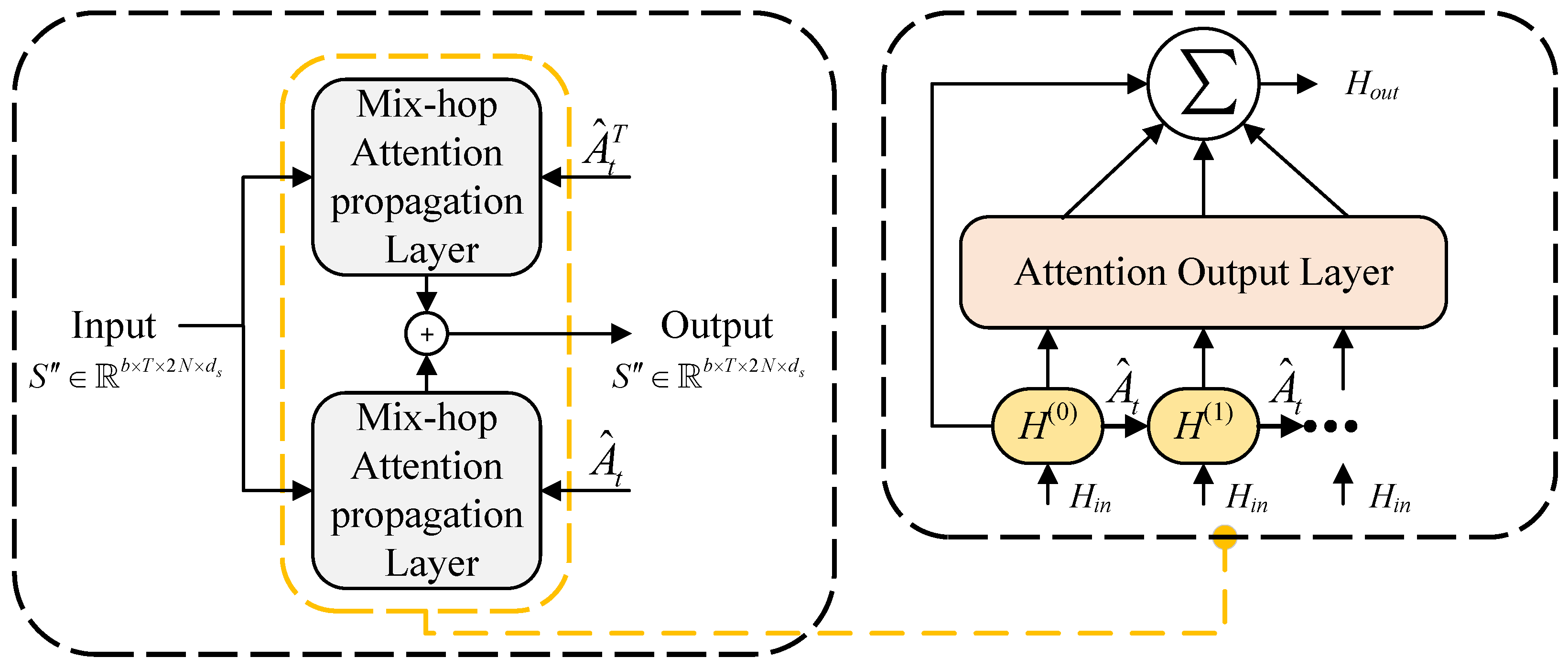
3.3.3. Graph Convolution Module
3.4. Optimization
| Algorithm 1 The predictive algorithm of ELP-Net |
Input: batch of sampled data (); initialized graph learning layer ; initialized temporal convolution module ; initialized graph convolution module ; parameter set ; learning rate .
|
4. Experimental Results
4.1. Experimental Setting
4.2. Baseline Methods for Comparison
- CNN-GRU: The model proposed by Liu et al. [19], combining convolutional neural networks (CNNs) and gated recurrent units (GRUs).
- CNN-MSA-GRU: An enhanced version of the CNN-GRU model with the addition of a multi-head self-attention (MSA) module.
- ELP-Net: Our proposed model, integrating a graph learning layer, graph convolution, temporal convolution modules, and transformer architecture for improved feature representation and prediction accuracy.
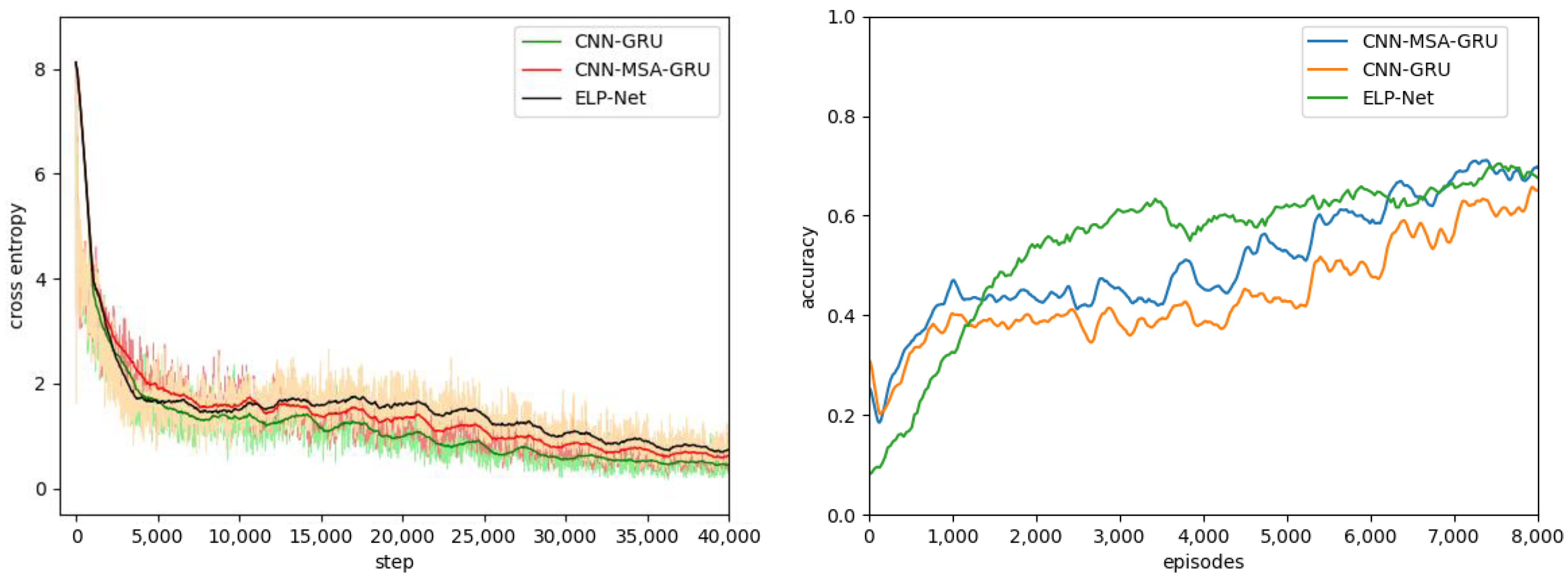
4.3. Train Results
4.4. Test Results
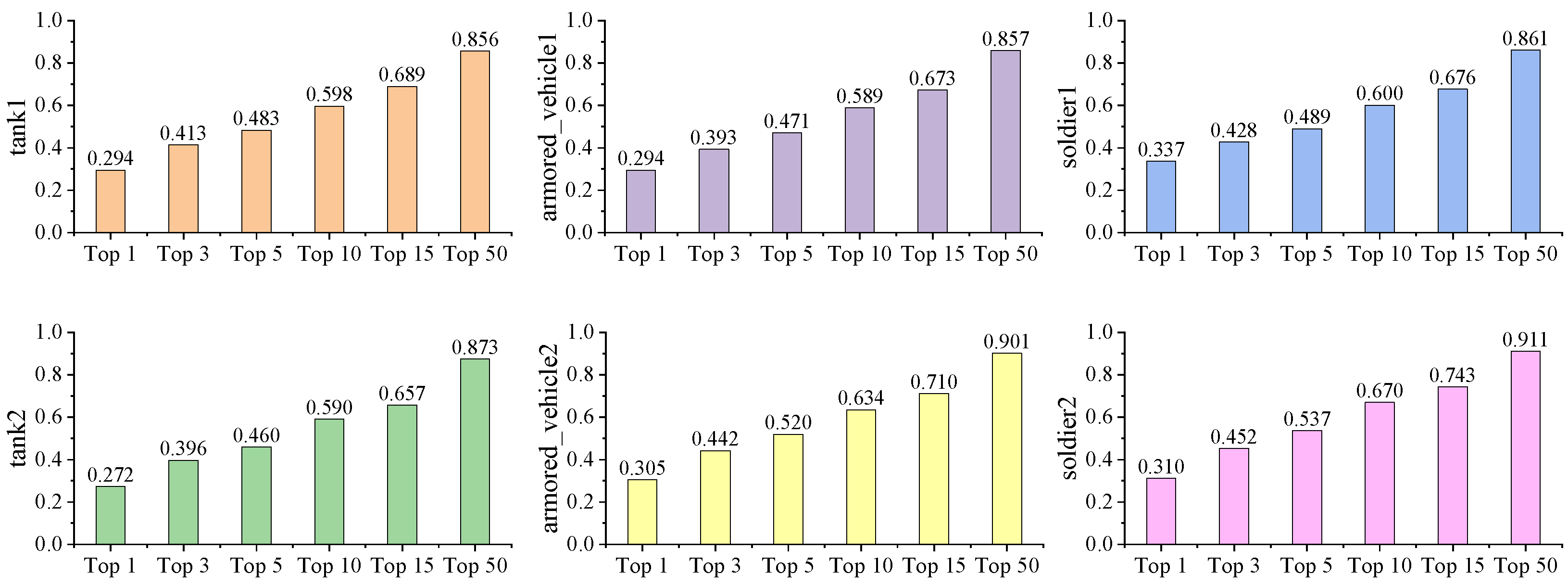
4.4.1. Top-x Accuracy Between Different Pieces
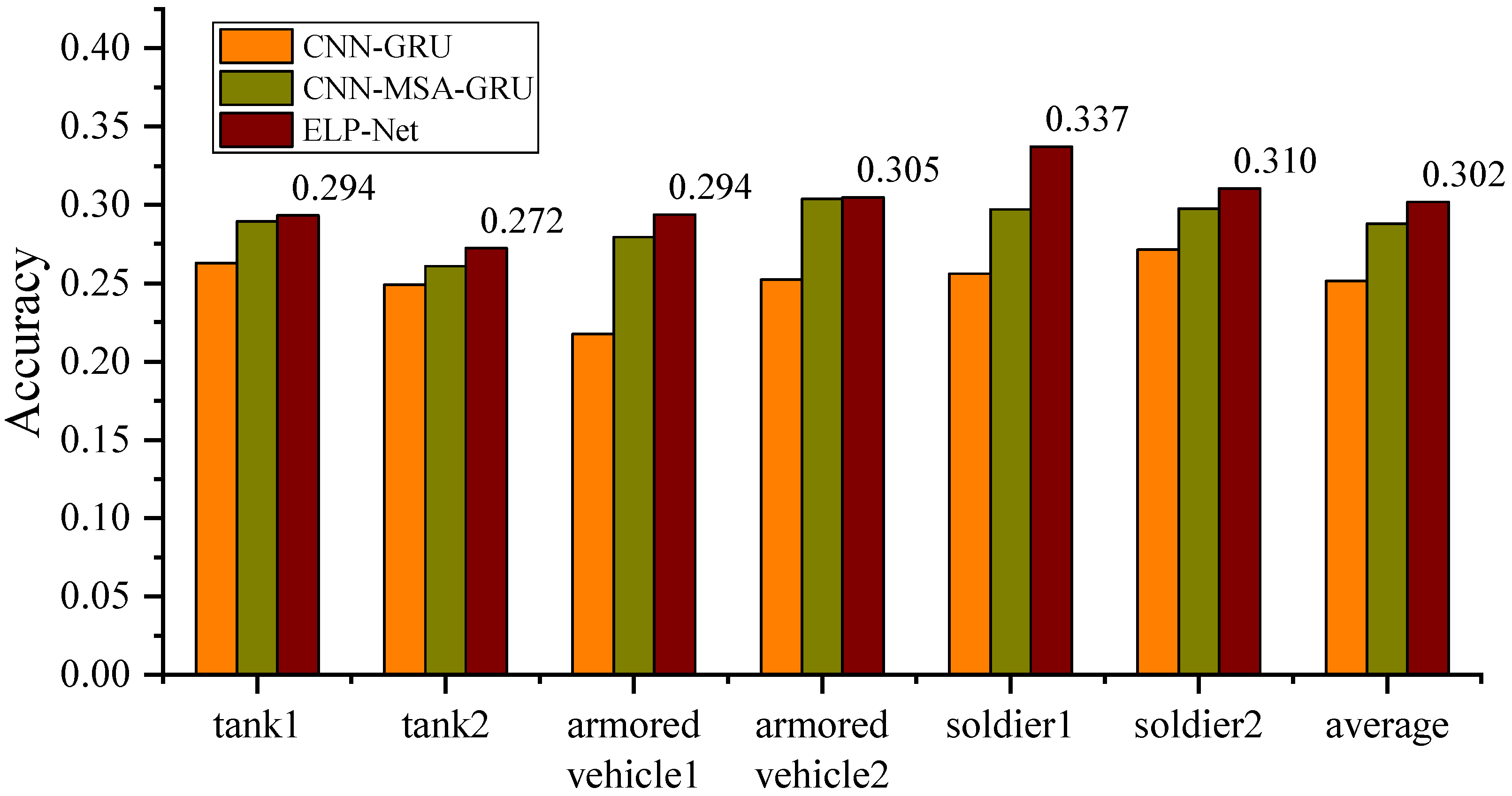
4.4.2. Top 1 Accuracy Among Different Models
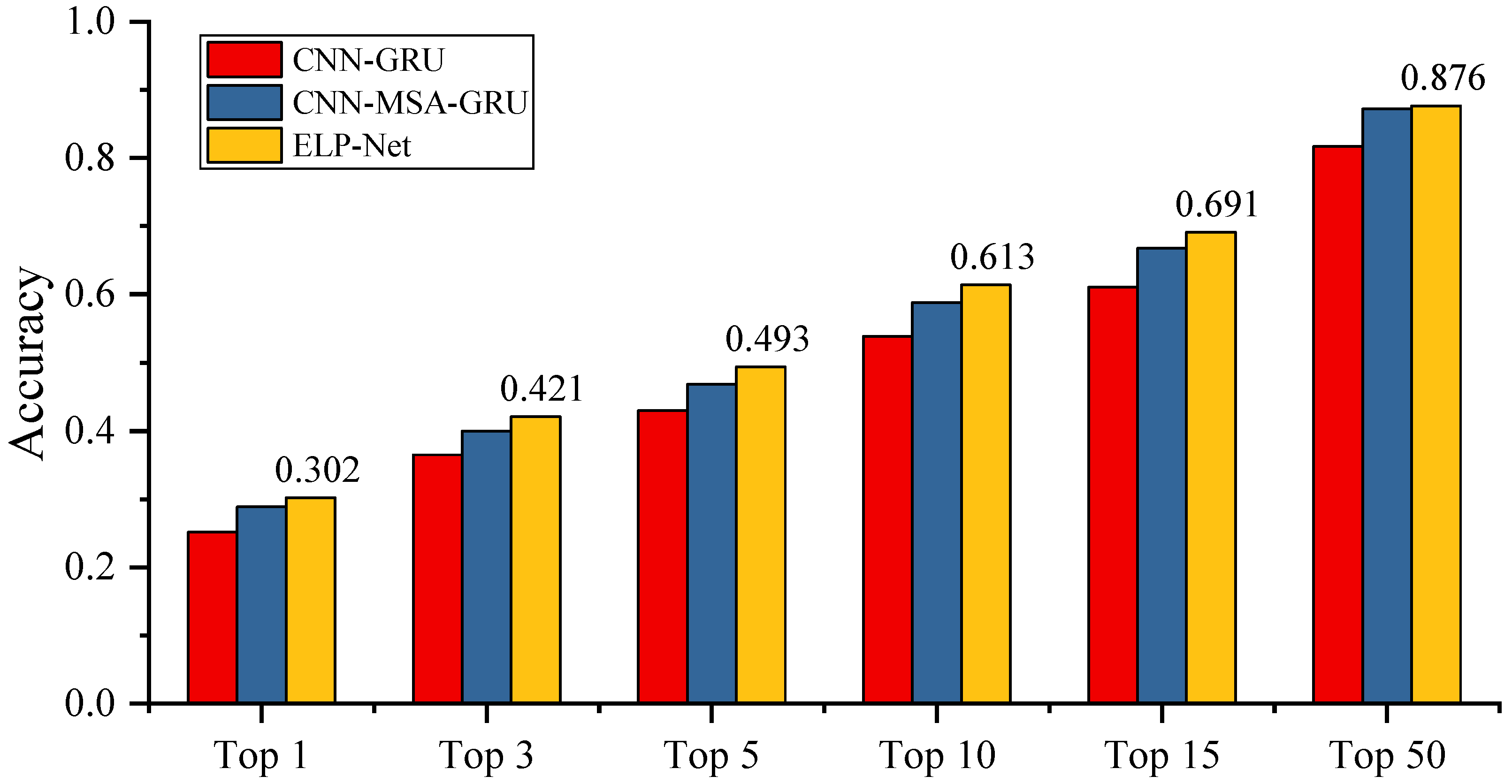
4.4.3. Averaged Top-x Accuracy Comparison Between Competitors
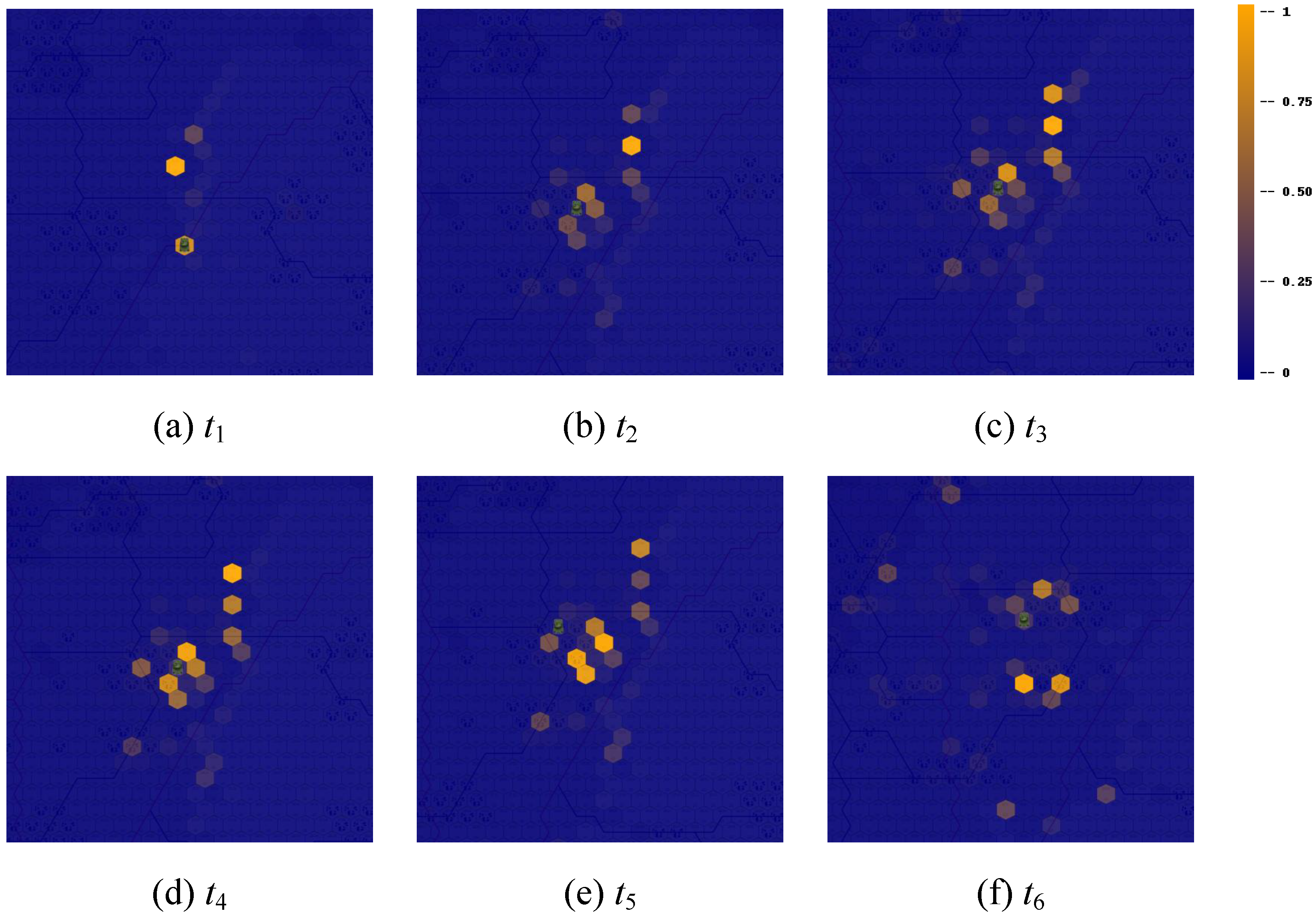
4.4.4. Enemy Location Prediction Heatmap
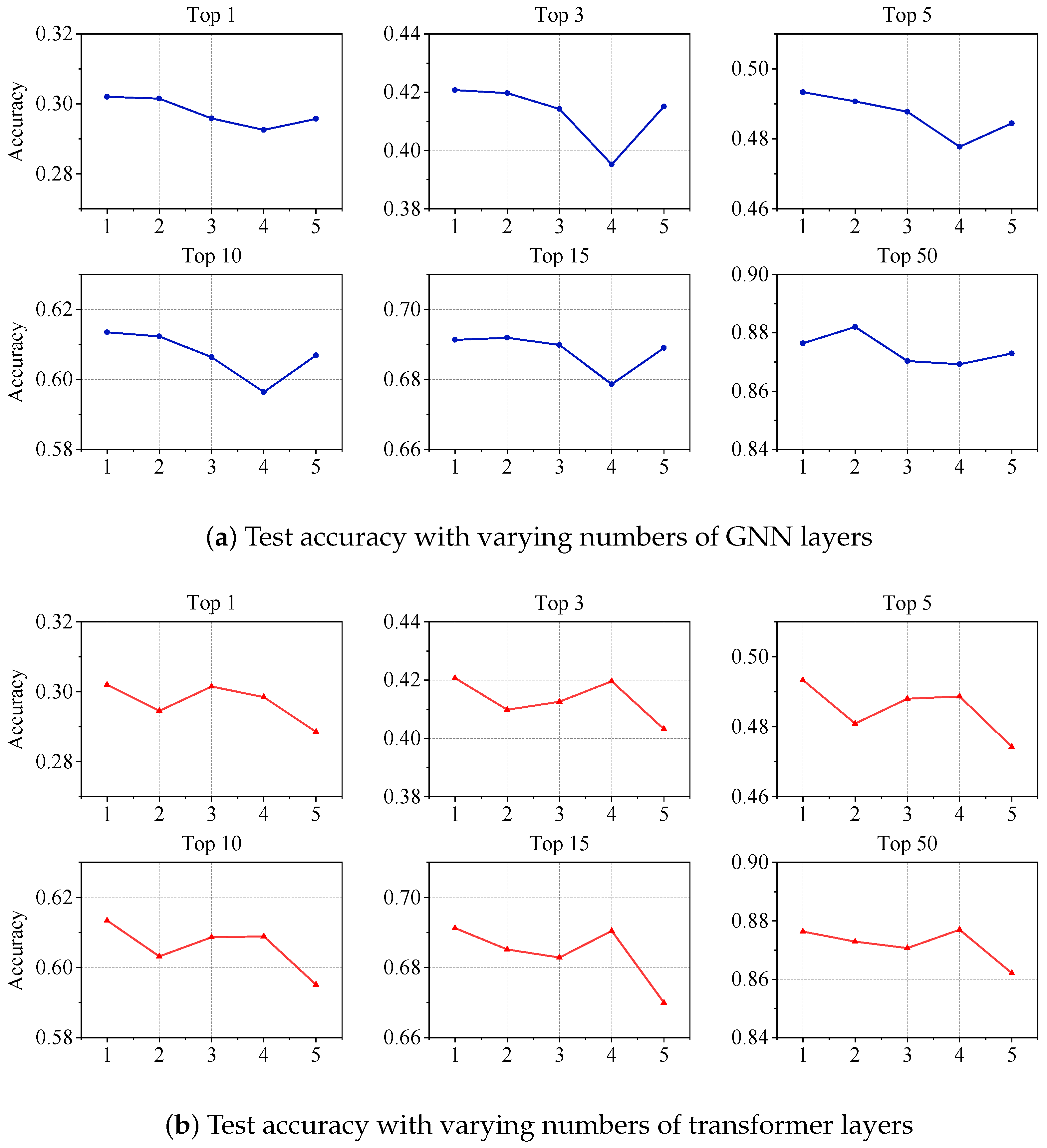
4.5. Network Depth Influence
4.6. Ablation Study
- Base model: a version of the model without transformer and GNN modules.
- +Transformer: the base model with the addition of transformer module.
- +GNN: the base model with the GNN module added.
- Full model: the complete ELP-Net, with both the transformer and GNN modules.
5. Discussion
- Generalization of the graph learning layer: The current approach of constructing a graph adjacency matrix for each time step of the situational graph using the graph learning layer shows limitations in generalizability. Future research could explore the impact of diverse graph topologies on model performance and develop adaptive graph construction methods that automatically select the optimal graph structure based on the data. This enhancement would improve the model applicability across diverse datasets.
- Optimization of the temporal convolution module: While employing multiple-sized dilated convolution filters aims to capture temporal patterns more comprehensively, it also increases model complexity. Future work could focus on refining the temporal convolution mechanism, potentially exploring alternative architectures or mechanisms that balance performance improvement with model simplicity.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Experimental Setup
Appendix B. Implementation Details
Appendix C. Complexity Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Components | Time Complexity |
|---|---|
| Multi-head self-attention | |
| Position-wise feed-forward | |
| Graph learning layer | |
| Graph convolution module | |
| Temporal convolution module |
References
- Dunnigan, J.F. Wargames Handbook: How to Play and Design Commercial and Professional Wargames; IUniverse: Bloomington, IN, USA, 2000. [Google Scholar]
- Bolling, R.H. The Joint Theater Level Simulation in military operations other than war. In Proceedings of the 27th Conference on Winter Simulation, Arlington, VA, USA, 3–6 December 1995; pp. 1134–1138. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Shao, K.; Zhu, Y.; Zhao, D. Starcraft micromanagement with reinforcement learning and curriculum transfer learning. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 3, 73–84. [Google Scholar] [CrossRef]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- Davis, P.K. Applying Artificial Intelligence Techniques to Strategic-Level Gaming and Simulation; Technical Reports; Rand Corporation: Santa Monica, CA, USA, 1988; Volume 2752. [Google Scholar]
- Bowling, M.; Fürnkranz, J.; Graepel, T.; Musick, R. Machine learning and games. Mach. Learn. 2006, 63, 211–215. [Google Scholar] [CrossRef]
- Langreck, J.; Wong, H.; Hernandez, A.; Upton, S.; McDonald, M.; Pollman, A.; Hatch, W. Modeling and simulation of future capabilities with an automated computer-aided wargame. J. Def. Model. Simul. 2021, 18, 407–416. [Google Scholar] [CrossRef]
- Hieb, M.; Hille, D.; Tecuci, G. Designing a Computer Opponent for War Games: Integrating Planning, Learning and Knowledge Acquisition in WARGLES. In Proceedings of the 1993 AAAI Fall Symposium on Games: Learning and Planning, Raleigh, NC, USA, 22–24 October 1993. [Google Scholar]
- Schwarz, J.O.; Ram, C.; Rohrbeck, R. Combining scenario planning and business wargaming to better anticipate future competitive dynamics. Futures 2019, 105, 133–142. [Google Scholar] [CrossRef]
- Moy, G.; Shekh, S. The application of AlphaZero to wargaming. In AI 2019: Advances in Artificial Intelligence, Proceedings of the 32nd Australasian Joint Conference, Adelaide, SA, Australia, 2–5 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 3–14. [Google Scholar]
- Wu, K.; Liu, M.; Cui, P.; Zhang, Y. A training model of wargaming based on imitation learning and deep reinforcement learning. In Proceedings of the Chinese Intelligent Systems Conference, Beijing, China, 15–16 October 2022; Springer: Singapore, 2022; pp. 786–795. [Google Scholar]
- Chen, L.; Liang, X.; Feng, Y.; Zhang, L.; Yang, J.; Liu, Z. Online intention recognition with incomplete information based on a weighted contrastive predictive coding model in wargame. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 7515–7528. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kahng, H.; Jeong, Y.; Cho, Y.S.; Ahn, G.; Park, Y.J.; Jo, U.; Lee, H.; Do, H.; Lee, J.; Choi, H.; et al. Clear the fog: Combat value assessment in incomplete information games with convolutional encoder-decoders. arXiv 2018, arXiv:1811.12627. [Google Scholar]
- Synnaeve, G.; Lin, Z.; Gehring, J.; Gant, D.; Mella, V.; Khalidov, V.; Carion, N.; Usunier, N. Forward modeling for partial observation strategy games-a starcraft defogger. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, Montreal, QC, Canada, 3–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Cho, K.; Van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Liu, M.; Zhang, H.; Hao, W.; Qi, X.; Cheng, K.; Jin, D.; Feng, X. Introduction of a new dataset and method for location predicting based on deep learning in wargame. J. Intell. Fuzzy Syst. 2021, 40, 9259–9275. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2018, arXiv:1412.3555. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representations (ICLR-17), Toulon, France, 24–26 April 2017. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2017, 1050, 10-48550. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Connecting the dots: Multivariate time series forecasting with graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 753–763. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Girgis, R.; Golemo, F.; Codevilla, F.; Weiss, M.; D’Souza, J.A.; Kahou, S.E.; Heide, F.; Pal, C. Latent variable sequential set transformers for joint multi-agent motion prediction. arXiv 2021, arXiv:2104.00563. [Google Scholar]
- Zhou, Z.; Ye, L.; Wang, J.; Wu, K.; Lu, K. Hivt: Hierarchical vector transformer for multi-agent motion prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–22 June 2022; pp. 8823–8833. [Google Scholar]
- Yuan, Y.; Weng, X.; Ou, Y.; Kitani, K.M. Agentformer: Agent-aware transformers for socio-temporal multi-agent forecasting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9813–9823. [Google Scholar]
- Yao, K.; Han, F.; Zhao, S. Attention Enhanced Transformer for Multi-agent Trajectory Prediction. In Proceedings of the International Conference on Intelligent Computing, Tianjin, China, 5–8 August 2024; Springer: Singapore, 2024; pp. 275–286. [Google Scholar]
- Lee, S.; Lee, J.; Yu, Y.; Kim, T.; Lee, K. MART: MultiscAle Relational Transformer Networks for Multi-agent Trajectory Prediction. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Cham, Switzerland, 2024; pp. 89–107. [Google Scholar]
- Wen, M.; Kuba, J.; Lin, R.; Zhang, W.; Wen, Y.; Wang, J.; Yang, Y. Multi-agent reinforcement learning is a sequence modeling problem. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, New Orleans, LA, USA, 28 November–9 December 2022; Curran Associates Inc.: Red Hook, NY, USA, 2022; Volume 35, pp. 16509–16521. [Google Scholar]
- Lin, Z.; Feng, M.; dos Santos, C.N.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A structured self-attentive sentence embedding. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Pan, Y.; Ni, W.; Yang, Y. An algorithm to estimate enemy’s location in WarGame based on pheromone. In Proceedings of the 2018 33rd Youth Academic Annual Conference of Chinese Association of Automation (YAC), Nanjing, China, 18–20 May 2018; pp. 749–753. [Google Scholar]
- Xing, S.; Ni, W.; Zhang, H.; Zhao, M. Spatial-Temporal Heterogeneous Graph Modeling for Opponent’s Location Prediction in War-game. In Proceedings of the 2022 7th International Conference on Computer and Communication Systems (ICCCS), Wuhan, China, 22–25 April 2022; pp. 97–103. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Chen, J.; Gao, K.; Li, G.; He, K. NAGphormer: A Tokenized Graph Transformer for Node Classification in Large Graphs. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Liu, J.; Li, C.; Liang, F.; Lin, C.; Sun, M.; Yan, J.; Ouyang, W.; Xu, D. Inception convolution with efficient dilation search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11486–11495. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
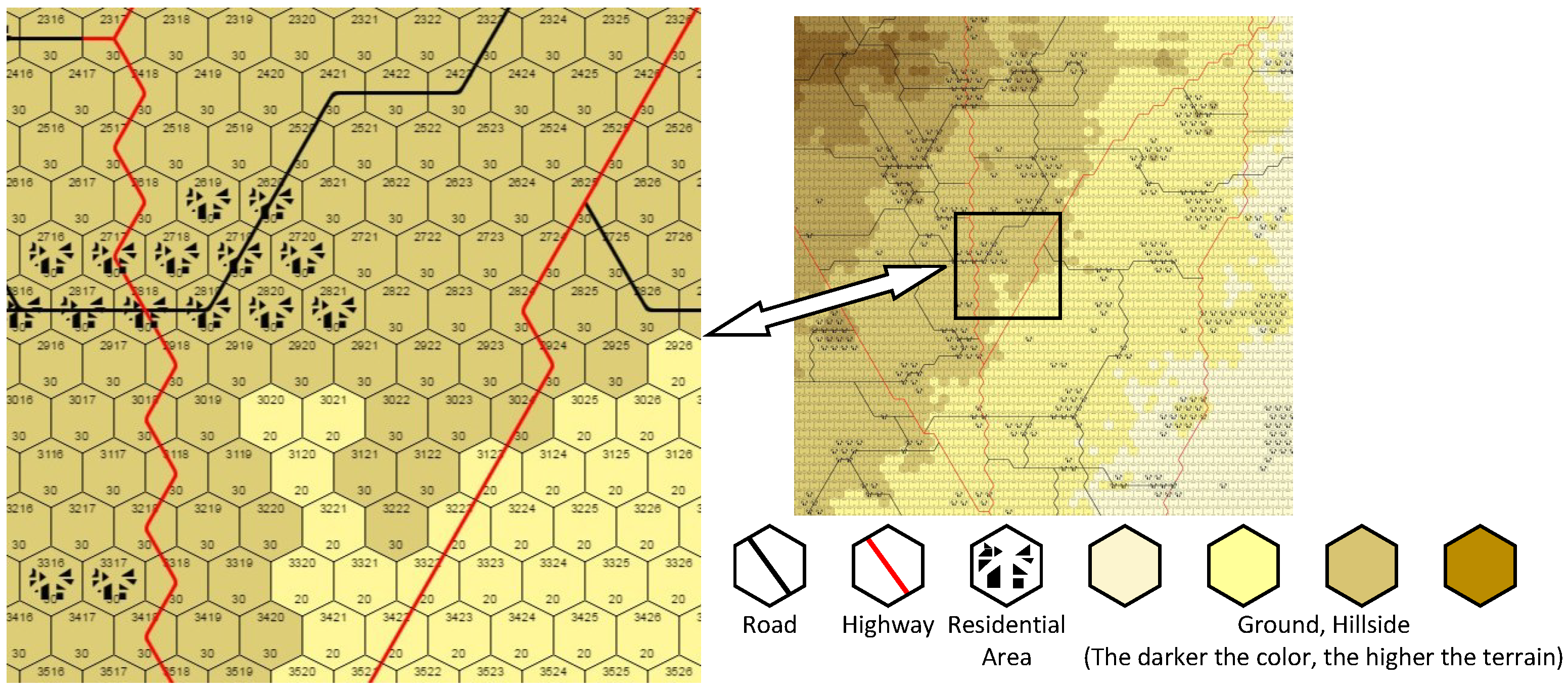
| Features | Sub-Features | Size | Description |
|---|---|---|---|
| Attribute vectors | Stage | 20 bits | Stage of the wargame. |
| Occupation points | 4 bits | Status of occupation points. | |
| Our piece attributes | 23 bits | 138 bits total for 6 pieces. | |
| Enemy piece attributes | 23 bits | 138 bits total for 6 pieces. | |
| Result | 1 bit | Labeled data for model training. | |
| Spatial tensors | Player color | Red (0) or blue (1). | |
| Our pieces location | Locations of 6 pieces. | ||
| Observed enemy locations | Locations of 6 enemy pieces. | ||
| Enemy vehicle vision | Vision range of enemy vehicles. | ||
| Enemy soldier vision | Vision range of enemy soldiers. | ||
| Map tensor | Elevation of the map. | ||
| Previous stage enemy locations | Labeled data for model training. |
| Module | Parameters | Value |
|---|---|---|
| Transformer | Number of heads H | 8 |
| Dropout | 0.1 | |
| GNN | Depth L of mix-hop | 3 |
| Retain ratio of mix-hop | 0.05 | |
| Others | Learning rate | 0.001 |
| Learning decay rate | 0.7 | |
| Time steps T | 10 | |
| Weight decay | 0.0001 | |
| Mini-batch size b | 32 | |
| Epochs | 15 |
| Model Variant | Top 1 | Top 3 | Top 5 | Top 10 | Top 15 | Top 50 | Average |
|---|---|---|---|---|---|---|---|
| Base model | 0.251 | 0.365 | 0.430 | 0.539 | 0.610 | 0.817 | 0.502 |
| +Transformer | 0.288 | 0.399 | 0.468 | 0.588 | 0.667 | 0.872 | 0.547 |
| +GNN | 0.291 | 0.394 | 0.462 | 0.579 | 0.677 | 0.867 | 0.545 |
| Full model | 0.302 | 0.421 | 0.493 | 0.613 | 0.691 | 0.876 | 0.566 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, D.; Li, J.; Yin, J. Enhanced Location Prediction for Wargaming with Graph Neural Networks and Transformers. Appl. Sci. 2025, 15, 1723. https://doi.org/10.3390/app15041723
Liang D, Li J, Yin J. Enhanced Location Prediction for Wargaming with Graph Neural Networks and Transformers. Applied Sciences. 2025; 15(4):1723. https://doi.org/10.3390/app15041723
Chicago/Turabian StyleLiang, Dingge, Junliang Li, and Junping Yin. 2025. "Enhanced Location Prediction for Wargaming with Graph Neural Networks and Transformers" Applied Sciences 15, no. 4: 1723. https://doi.org/10.3390/app15041723
APA StyleLiang, D., Li, J., & Yin, J. (2025). Enhanced Location Prediction for Wargaming with Graph Neural Networks and Transformers. Applied Sciences, 15(4), 1723. https://doi.org/10.3390/app15041723