
Data-Driven Machine-Learning-Based Seismic Response Prediction and Damage Classification for an Unreinforced Masonry Building

 ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Methodology of the Study
2.1. Database Creation
2.2. Data Partition and Pre-Processing
2.3. Model Training and Performance Evaluation
3. Database Development
3.1. Finite-Element Modelling of the Benchmark URM Building
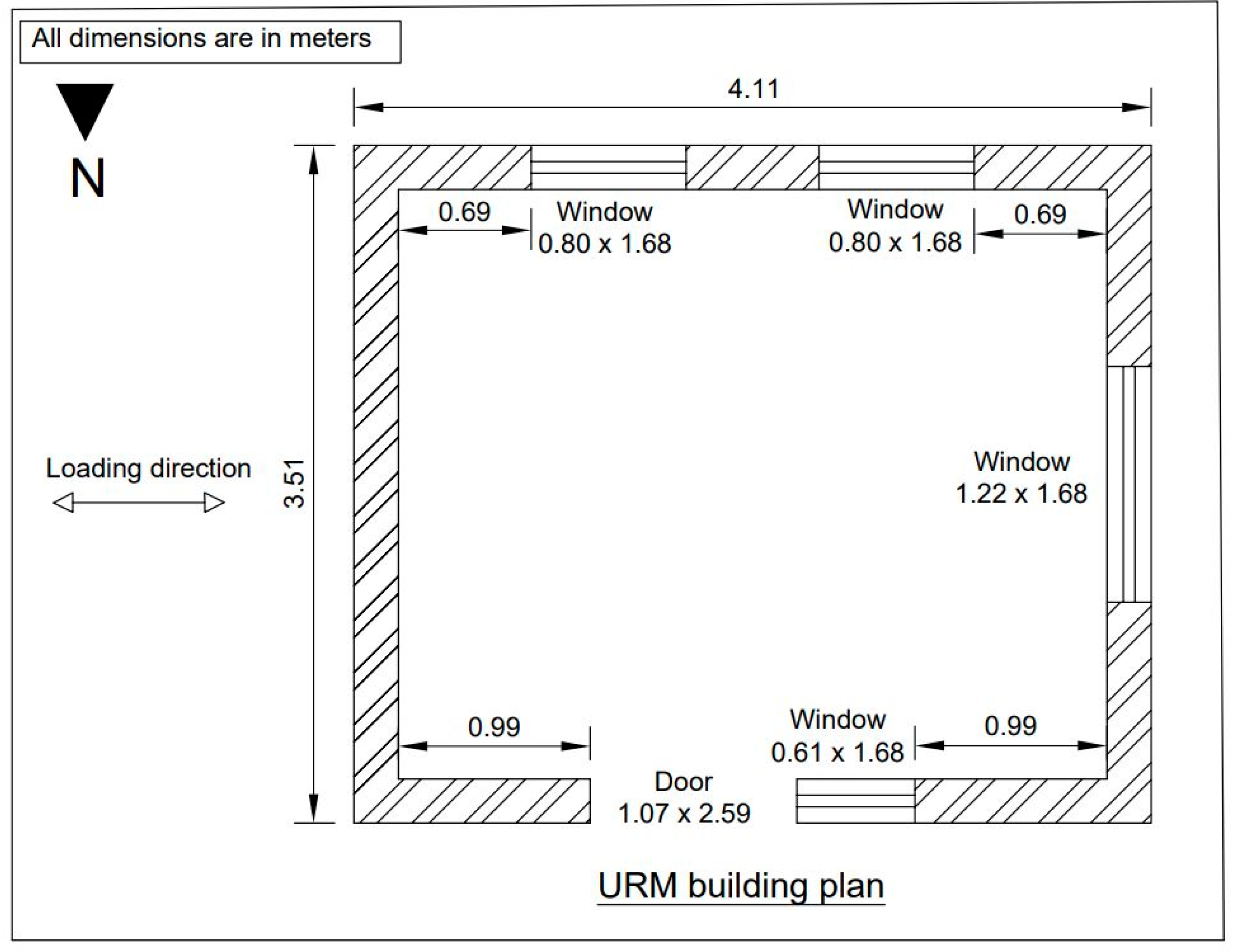
3.1.1. Benchmark Building
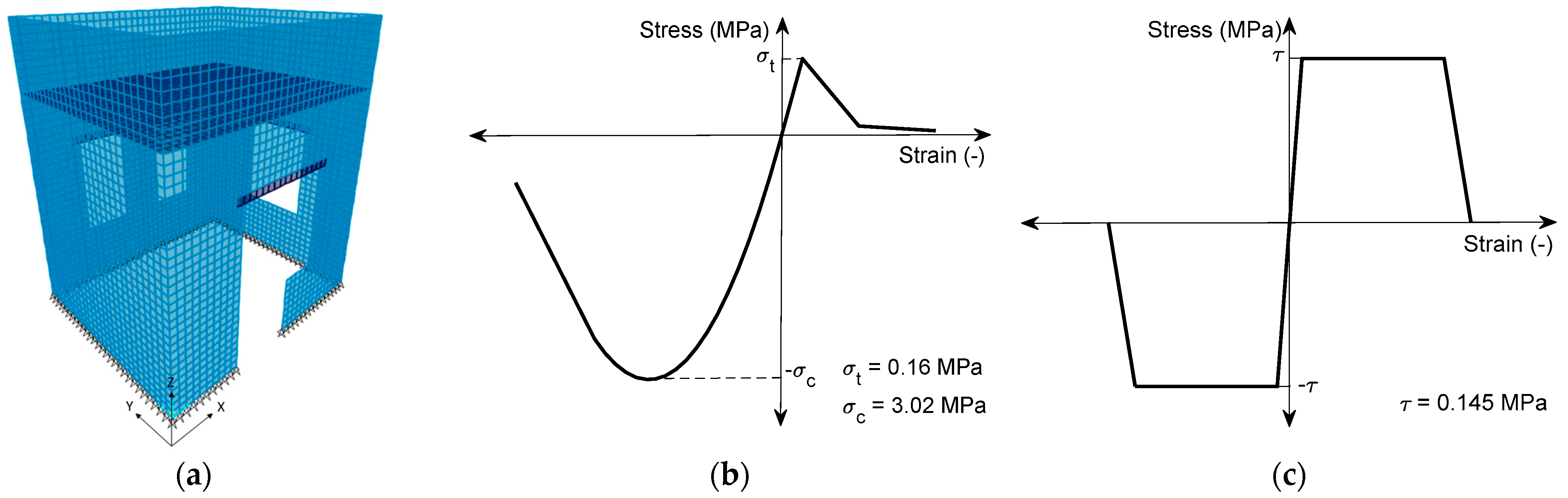
3.1.2. Development of the Simplified Numerical Model
3.1.3. Model Validation
3.2. Ground-Motion Selection
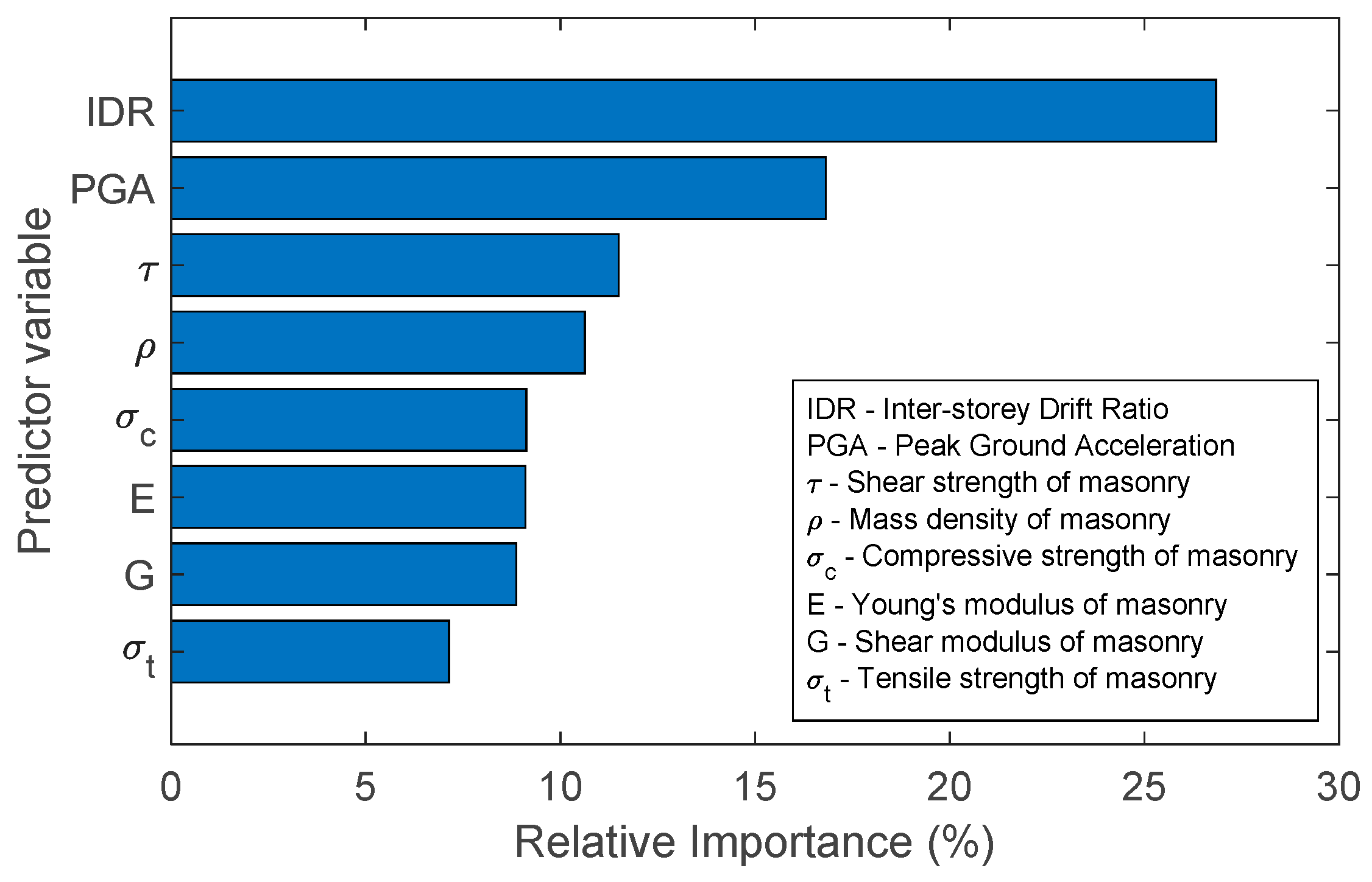
3.3. Material Properties
3.4. Damage States
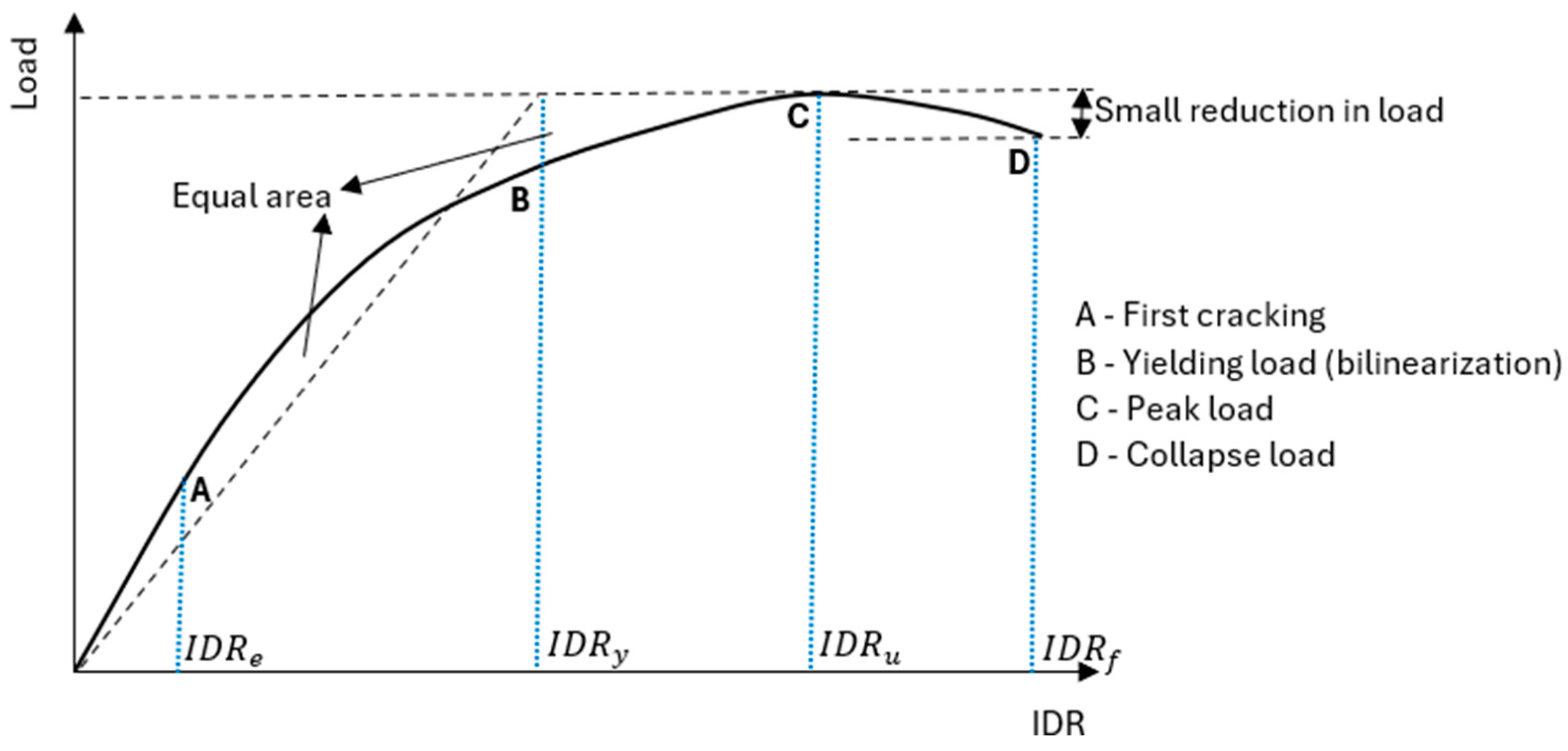
3.5. Numerical Analyses of Probabilistic Models
3.6. Database Development and Processing
4. Development of Machine Learning Models
4.1. Regression-Based Machine Learning Techniques
4.1.1. Linear Regression (LR)
4.1.2. Stepwise Linear Regression (SLR)
4.1.3. Ridge Regression (RR)
4.1.4. Decision Tree (DT)
4.1.5. Random Forest (RF)
4.1.6. Support Vector Machine (SVM)
4.1.7. Gaussian Process Regression (GPR)
4.1.8. Neural Networks (NN)
4.2. Classification-Based Machine Learning Techniques
4.2.1. Naïve Bayes (NB)
4.2.2. Discriminant Analysis (DA)
4.2.3. K-Nearest Neighbours (KNN)
4.2.4. Adaptive Boosting (AB)
4.3. Performance Evaluation Metrics
5. Results and Discussion
5.1. Building Response Prediction Models
- After examining several models, the RF, GPR, and NN models demonstrated effective performance in predicting the IDR of the URM building. This is evidenced by their higher values and the lower RMSE values associated with the training data, the least being the RMSE of the RF model. However, the GPR model exhibits comparatively lower RMSE relative to the test data. The RF model showed a lower value for the test set compared to the training set (3.6% reduction), indicating poor performance or high variance relative to the new dataset. On the other hand, the GPR model performed better in both the training and test sets (less than 0.2% variation), which is again evident from the RMSE values associated with the training and test sets of the model. This highlights the efficiency of GPR model in capturing the complex relationships in data.
- The performance levels of the DT and SVM were found to be effective while examining the and RMSE values of the training set. However, the results obtained from the test set of DT and SVM models showed a slightly poor performance, with comparatively smaller values of 0.923 and 0.958, and larger RMSE values of 0.476 and 0.327, respectively, compared to other non-parametric models (RF, GPR, and NN). This indicates the overfitting of the DT model and the instability of the model relative to changes in the data.
- The LR, SLR, and RR models are ineffective in accurately predicting structural response due to the nonlinearity in the relationship between the predictor and response variables. The findings also indicate a tendency for these linear models to overfit the data. The relatively poor performance of the linear models in comparison to their nonlinear counterparts may also be a result of their sensitivity to outliers in the seismic response data, despite the implementation of cross-validation and regularization techniques during the model development phase.
- Even though the variation in the value of the parametric models (LR, SLR, and RR) exhibits a variation from the best performing GPR model by 10% to 17%, a notable variation in the RMSE of the training set (55% to 65%) can be observed. This fact was also established by comparing the actual and predicted response (in natural logarithmic scale) of the test set obtained through various ML algorithms, as illustrated in Figure 8. It is also clear that non-parametric models, particularly the GPR model, show a much better fit. With its high RMSE values (0.70), and the least fit in the regression graph, the RR exhibits comparatively poor performance among the parametric models.
- The variations of the and RMSE values associated with the prediction models are illustrated in Figure 9. The values of the training and test sets for all the non-parametric models (DT, RF, SVM, GPR, and NN) ranged between 0.9 and 1.0, indicating the best performance, as compared to parametric models (LR, SLR, and RR). Furthermore, the RMSE values for SVM, GPR, and NN were all below 0.4, demonstrating their better performance.
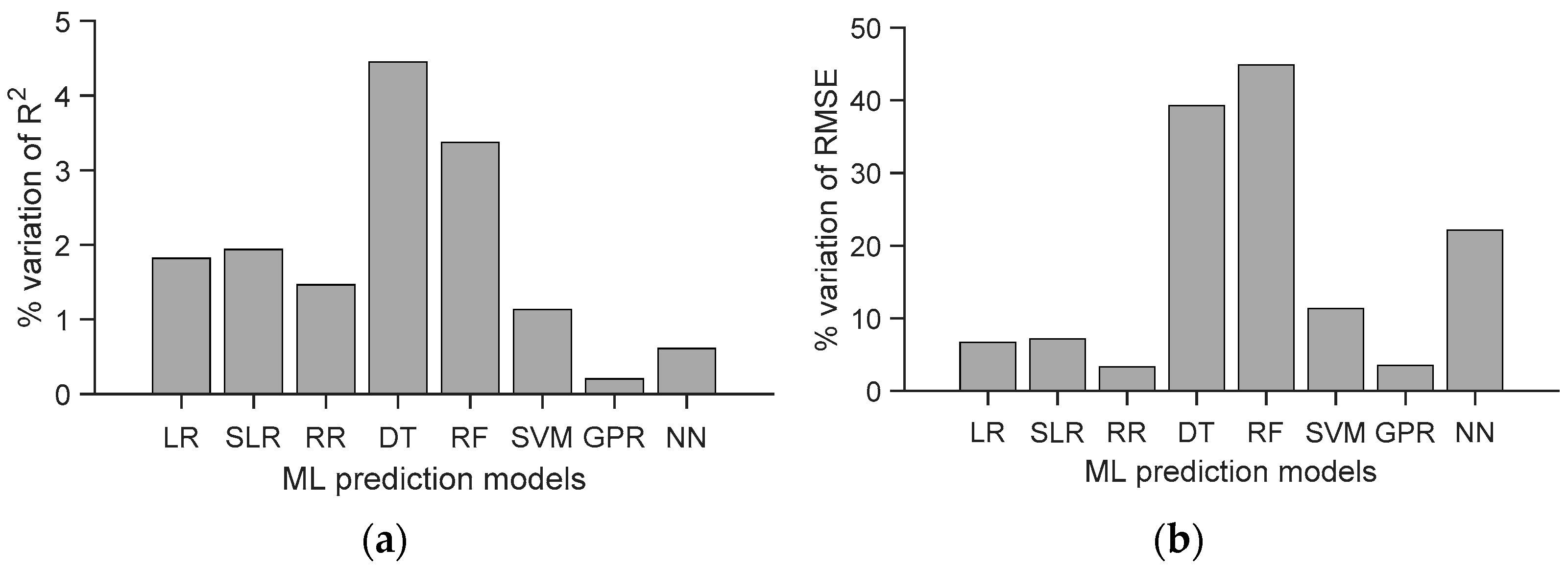
- Furthermore, the percentage variation in the and RMSE values of the training and test sets of the ML models were calculated, and the results are compared in Figure 10. The lowest percentage variations for both the and RMSE values were found in the GPR model, which again substantiates the effective performance of the model in predicting the response. Based on these results, the performance of SVM model was found to be relatively better than the DT, RF and NN models. Even though the percentage variations associated with the results of the parametric models (LR, SLR, and RR) were comparatively lower than those of the non-parametric models, the values were quantitatively higher than those of the values reported by non-parametric models.
- The performance of the ML models can be influenced by the underlying database, which in turn is impacted by factors such as building type, input variables, dataset size, and output variables in structural-engineering applications. The existing literature contains consistent findings which demonstrate that non-parametric regression models outperform parametric regression models. Specifically, RF, SVM, and DT have demonstrated superior performance in accurately estimating the structural responses of steel moment-resisting frame buildings [6].
5.2. Damage Levels Classification Models
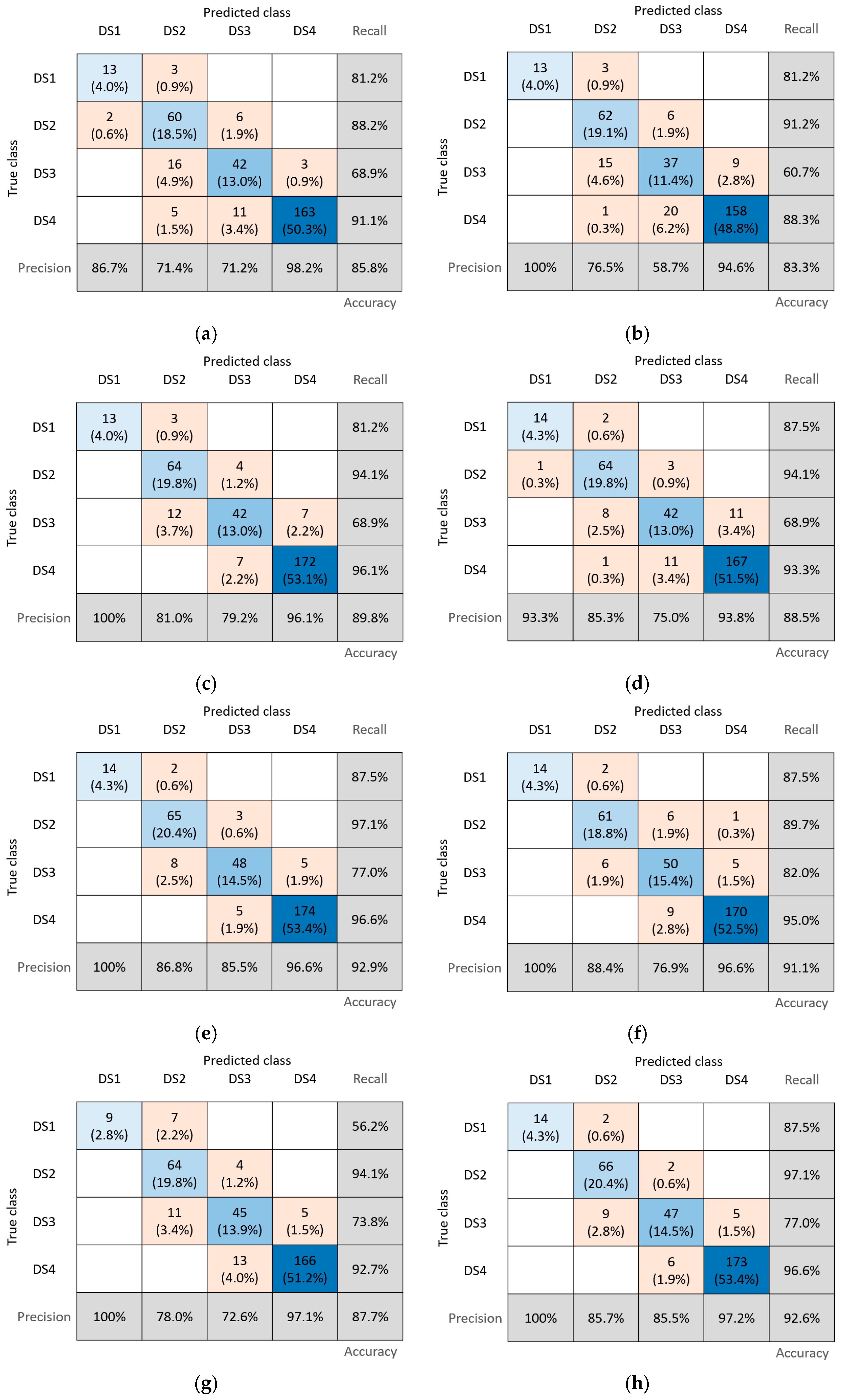
- The results show that the RF model had the highest accuracy rate, at 92.9%, followed by the NN and AB models. The good performance of the tree-based models suggests that there are non-linear decision boundaries between the failure modes. The results clearly indicate that the non-parametric tree-based models performed better overall than did parametric non-tree-based models like NB.
- Identifying damage state DS4, which indicates the collapse of the URM building, is critical. The RF model had a precision and recall rate of 96.6% in identifying DS4 in the test set. Similarly, the NN model showed a high recall rate for DS4 and slightly higher precision than the RF model.
- Compared to other ML models, the RF model had a higher F1 score for all damage states, followed by the NN and AB models. These models also had lower misclassification rates. The F1 score of the DA model for all damage states was comparatively lower than other models, indicating poor performance in classifying the damage states. The AB model had 1.8% lower accuracy and 1.6% lower DS4 recall than the RF model. Based on the results, it can be clearly seen the bagging-based RF model outperforms gradient-based methods like AB in terms of accuracy.
- Despite having a lower training error, the SVM model was outperformed by the neural network model in terms of accuracy, precision, and recall on the test set. Additionally, the KNN model with zero training error had lower accuracy than the tree-based models. This highlights the importance of splitting the data into training and test sets to evaluate model performance accurately.
- In Figure 12, the accuracy, F1 score, precision, and recall of the classification models are compared. It is evident that the RF, SVM, and NN models demonstrate higher accuracy levels, ranging from 90% to 100%. Additionally, the F1 score values for these models exceed 75.0% across all damage states. While accurate classification of DS3 and DS4 is crucial, models exhibiting superior performance in classifying all damage states will significantly aid in the post-earthquake risk assessment of URM buildings. Notably, the precision values of the NB, DA, KNN, DT, and SVM models fall below 70% for damage states DS1 and DS3, indicating their poor performance. Furthermore, the recall values also reflect the inferior performance of NB and DA models, with recall values below 70% for the damage state DS3.
- The results clearly demonstrate the superior performance of RF, AB, and NN models in categorizing the damage states of the URM building. Comparable findings validating the efficacy of these classification models can be found in the existing literature. For instance, the AB model achieved over 80% accuracy in classifying failure modes of reinforced concrete frames with infills [9]. Furthermore, the RF and AB models utilized for the collapse status classification of RC frame buildings exhibited enhanced performance [10]. Similarly, the RF model employed for identifying the flexure–shear failure mode of concrete shear walls attained the highest accuracy, with 70% recall and 84% precision [11].
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AB | Adaptive Boosting |
| CoV | Coefficient of Variation |
| DA | Discriminant Analysis |
| DS | Damage State |
| DT | Decision Tree |
| ELM | Ensemble Learning Method |
| ERTR | Extremely Randomized Tree Regressor |
| FE | Finite Element |
| GDI | Gini’s Diversity Index |
| GPR | Gaussian Process Regression |
| IDR | Inter-story drift ratio |
| IM | Intensity Measure |
| IRTS | Iteratively Reweighted Least Squares |
| KNN | K-Nearest Neighbors |
| LHS | Latin Hypercube Sampling |
| LR | Linear Regression |
| ML | Machine Learning |
| NB | Naïve Bayes |
| NN | Neural Networks |
| PGA | Peak Ground Acceleration |
| RC | Reinforced Concrete |
| RF | Random Forest |
| RMSE | Root Mean Square Error |
| RR | Ridge Regression |
| SLR | Stepwise Linear Regression |
| SVM | Support Vector Machine |
| URM | Unreinforced Masonry |
References
- Arya, A.S.; Boen, T.; Ishiyama, Y. Guidelines for Earthquake Resistant Non-Engineered Construction; UNESCO: Paris, France, 2014. [Google Scholar]
- Ravichandran, N.; Losanno, D.; Parisi, F. Low-cost base isolation systems for unreinforced masonry buildings in developing countries. In Proceedings of the 8th International Conference on Computational Methods in Structural Dynamics and Earthquake Engineering Methods in Structural Dynamics and Earthquake Engineering, Eccomas Proceedia, Athens, Greece, 28–30 June 2021. [Google Scholar]
- Choudhury, T.; Milani, G.; Kaushik, H.B. Comprehensive numerical approaches for the design and safety assessment of masonry buildings retrofitted with steel bands in developing countries: The case of India. Constr. Build. Mater. 2015, 85, 227–246. [Google Scholar] [CrossRef]
- Michalski, R.S.; Carbonell, J.G.; Mitchell, T.M. Machine Learning an Artificial Intelligence Approach; Springer: Berlin/Heidelberg, Germany; New York, NY, USA; Tokyo, Japan, 1984. [Google Scholar]
- Sun, H.; Burton, H.V.; Huang, H. Machine learning applications for building structural design and performance assessment: State-of-the-art review. J. Build. Eng. 2021, 33, 101816. [Google Scholar] [CrossRef]
- Kiani, J.; Camp, C.; Pezeshk, S. On the application of machine learning techniques to derive seismic fragility curves. Comput. Struct. 2019, 218, 108–122. [Google Scholar] [CrossRef]
- Thai, H.T. Machine learning for structural engineering: A state-of-the-art review. Structures 2022, 38, 448–491. [Google Scholar] [CrossRef]
- Wang, X.; Mazumder, R.K.; Salarieh, B.; Salman, A.M.; Shafieezadeh, A.; Li, Y. Machine learning for risk and resilience assessment in structural engineering: Progress and future trends. J. Struct. Eng. 2022, 148, 03122003. [Google Scholar] [CrossRef]
- Huang, H.; Burton, H.V. Classification of in-plane failure modes for reinforced concrete frames with infills using machine learning. J. Build. Eng. 2019, 25, 100767. [Google Scholar] [CrossRef]
- Hwang, S.H.; Mangalathu, S.; Shin, J.; Jeon, J.S. Machine learning-based approaches for seismic demand and collapse of ductile reinforced concrete building frames. J. Build. Eng. 2021, 34, 101905. [Google Scholar] [CrossRef]
- Mangalathu, S.; Jang, H.; Hwang, S.H.; Jeon, J.S. Data-driven machine-learning-based seismic failure mode identification of reinforced concrete shear walls. Eng. Struct. 2020, 208, 110331. [Google Scholar] [CrossRef]
- Mangalathu, S.; Jeon, J.S. Classification of failure mode and prediction of shear strength for reinforced concrete beam-column joints using machine learning techniques. Eng. Struct. 2018, 160, 85–94. [Google Scholar] [CrossRef]
- Charalampakis, A.E.; Tsiatas, G.C.; Kotsiantis, S.B. Machine learning and nonlinear models for the estimation of fundamental period of vibration of masonry infilled RC frame structures. Eng. Struct. 2020, 216, 110765. [Google Scholar] [CrossRef]
- Latif, I.; Banerjee, A.; Surana, M. Explainable machine learning aided optimization of masonry infilled reinforced concrete frames. Structures 2022, 44, 1751–1766. [Google Scholar] [CrossRef]
- Wu, J.R.; Di Sarno, L. A machine-learning method for deriving state-dependent fragility curves of existing steel moment frames with masonry infills. Eng. Struct. 2023, 276, 115345. [Google Scholar] [CrossRef]
- Mojaddadi, H.; Pradhan, B.; Nampak, H.; Ahmad, N.; Ghazali, A.H.B. Ensemble machine-learning-based geospatial approach for flood risk assessment using multi-sensor remote-sensing data and GIS. Geomat. Nat. Hazards Risk 2017, 8, 1080–1102. [Google Scholar] [CrossRef]
- Zhang, Y.; Burton, H.V.; Sun, H.; Shokrabadi, M. A machine learning framework for assessing post-earthquake structural safety. Struct. Saf. 2018, 72, 1–16. [Google Scholar] [CrossRef]
- Zhu, J.; Zhang, W. Probabilistic fatigue damage assessment of coastal slender bridges under coupled dynamic loads. Eng. Struct. 2018, 166, 274–285. [Google Scholar] [CrossRef]
- Chomacki, L.; Rusek, J.; Słowi, L. Machine Learning Methods in Damage Prediction of Masonry Development Exposed to the Industrial Environment of Mines. Energies 2022, 15, 3958. [Google Scholar] [CrossRef]
- Loverdos, D.; Sarhosis, V. Automatic image-based brick segmentation and crack detection of masonry walls using machine learning. Autom. Constr. 2022, 140, 104389. [Google Scholar] [CrossRef]
- Mishra, M.; Bhatia, A.S.; Maity, D. Predicting the compressive strength of unreinforced brick masonry using machine learning techniques validated on a case study of a museum through nondestructive testing. J. Civ. Struct. Health Monit. 2020, 10, 389–403. [Google Scholar] [CrossRef]
- Rezaie, A.; Godio, M.; Achanta, R.; Beyer, K. Machine-learning for damage assessment of rubble stone masonry piers based on crack patterns. Autom. Constr. 2022, 140, 104313. [Google Scholar] [CrossRef]
- Siam, A.; Ezzeldin, M.; El-Dakhakhni, W. Machine learning algorithms for structural performance classifications and predictions: Application to reinforced masonry shear walls. Structures 2019, 22, 252–265. [Google Scholar] [CrossRef]
- Loverdos, D.; Sarhosis, V. Geometrical digital twins of masonry structures for documentation and structural assessment using machine learning. Eng. Struct. 2023, 275, 115256. [Google Scholar] [CrossRef]
- Harirchian, E.; Hosseini, S.E.A.; Novelli, V.; Lahmer, T.; Rasulzade, S. Utilizing advanced machine learning approaches to assess the seismic fragility of non-engineered masonry structures. Results Eng. 2024, 21, 101750. [Google Scholar] [CrossRef]
- Zain, M.; Dackermann, U.; Prasittisopin, L. Machine learning (ML) algorithms for seismic vulnerability assessment of school buildings in high-intensity seismic zones. Structures 2024, 70, 107639. [Google Scholar] [CrossRef]
- Coskun, O.; Aldemir, A. Machine learning network suitable for accurate rapid seismic risk estimation of masonry building stocks. Nat. Hazards 2023, 115, 261–287. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Farhangi, V. Determination of piers shear capacity using numerical analysis and machine learning for generalization to masonry large scale walls. Structures 2023, 49, 443–466. [Google Scholar] [CrossRef]
- Valero, E.; Forster, A.; Bosché, F.; Hyslop, E.; Wilson, L.; Turmel, A. Automated defect detection and classification in ashlar masonry walls using machine learning. Autom. Constr. 2019, 106, 102846. [Google Scholar] [CrossRef]
- Shahzada, K.; Khan, A.N.; Elnashai, A.S.; Ashraf, M.; Javed, M.; Naseer, A.; Alam, B. Experimental seismic performance evaluation of unreinforced brick masonry buildings. Earthq. Spectra 2012, 28, 1269–1290. [Google Scholar] [CrossRef]
- Ravichandran, N.; Losanno, D.; Parisi, F. Comparative assessment of finite element macro-modelling approaches for seismic analysis of non-engineered masonry constructions. Bull. Earthq. Eng. 2021, 19, 5565–5607. [Google Scholar] [CrossRef]
- CSI. Analysis Reference Manual; Computers and Structures Inc.: Berkeley, CA, USA, 2014. [Google Scholar]
- Thuyet, V.N.; Deb, S.K.; Dutta, A. Mitigation of seismic vulnerability of prototype low-rise masonry building using U-FREIs. J. Perform. Constr. Facil. 2018, 32, 04017136. [Google Scholar] [CrossRef]
- Losanno, D.; Ravichandran, N.; Parisi, F. Seismic fragility of base-isolated single-storey unreinforced masonry buildings equipped with classical and recycled rubber bearings in Himalayan regions. J. Build. Eng. 2022, 45, 103648. [Google Scholar] [CrossRef]
- Kaushik, H.B.; Rai, D.C.; Jain, S.K. Uniaxial compressive stress–strain model for clay brick masonry. Curr. Sci. 2017, 92, 497–501. [Google Scholar]
- Akhaveissy, A.H.; Milani, G. Pushover analysis of large scale unreinforced masonry structures by means of a fully 2D non-linear model. Constr. Build. Mater. 2013, 41, 276–295. [Google Scholar] [CrossRef]
- CESMD. Center for Engineering Strong Motion Data, Strong Motion Virtual Data Center. Available online: www.strongmotioncenter.org (accessed on 10 October 2023).
- Su, L.; Li, X.L.; Jiang, Y.P. Comparison of methodologies for seismic fragility analysis of unreinforced masonry buildings considering epistemic uncertainty. Eng. Struct. 2020, 205, 110059. [Google Scholar] [CrossRef]
- Bakhshi, A.; Karimi, K. Performance evaluation of masonry buildings using a probabilistic approach. Sci. Iran. 2008, 15, 295–307. [Google Scholar]
- Choudhury, T.; Milani, G.; Kaushik, H.B. Experimental and numerical analyses of unreinforced masonry wall components and building. Constr. Build. Mater. 2020, 257, 119599. [Google Scholar] [CrossRef]
- Giordano, N.; De Luca, F.; Sextos, A. Analytical fragility curves for masonry school building portfolios in Nepal. Bull. Earthq. Eng. 2021, 19, 1121–1150. [Google Scholar] [CrossRef]
- Habieb, A.B.; Milani, G.; Tavio, T. Two-step advanced numerical approach for the design of low-cost unbonded fiber reinforced elastomeric seismic isolation systems in new masonry buildings. Eng. Fail. Anal. 2018, 90, 380–396. [Google Scholar] [CrossRef]
- Kadam, S.B.; Singh, Y.; Bing, L. Seismic fragility reduction of an unreinforced masonry school building through retrofit using ferrocement overlay. Earthq. Eng. Eng. Vib. 2020, 19, 397–412. [Google Scholar] [CrossRef]
- Park, J.; Towashiraporn, P.; Craig, J.I.; Goodno, B.J. Seismic fragility analysis of low-rise unreinforced masonry structures. Eng. Struct. 2009, 31, 125–137. [Google Scholar] [CrossRef]
- Sarkar, A.; Halder, L.; Sharma, R.P. Seismic damage evaluation of unreinforced masonry buildings in high seismic zone using the nonlinear static method. Adv. Struct. Eng. Dynam 2015, 2, 1039–1053. [Google Scholar]
- Cross, T.; De Luca, F.; De Risi, R.; Camata, G.; Petracca, M. Micro-modelling of stone masonry template buildings as a strategy for seismic risk assessment in developing countries. Eng. Struct. 2023, 274, 114910. [Google Scholar] [CrossRef]
- Castaldo, P.; Palazzo, B.; Della Vecchia, P. Seismic reliability of base-isolated structures with friction pendulum bearings. Eng. Struct. 2015, 95, 80–93. [Google Scholar] [CrossRef]
- Betti, M.; Galano, L.; Vignoli, A. Time-history seismic analysis of masonry buildings: A comparison between two non-linear modelling approaches. Buildings 2015, 5, 597–621. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Leo, B.; Jerome, F.; Charles, J.S.; Olshen, R.A. Classification and Regression Trees, 1st ed.; Taylor & Francis: New York, NY, USA; Routledge: Oxfordshire, UK, 2017. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning; MIT Press: Cambridge, UK, 2006. [Google Scholar]
- Haykin, S. Neural Networks—A Comprehensive Foundation, 2nd ed.; Pearson Prentice Hall: Noida, India, 2004. [Google Scholar]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian network classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef]
- Lachenbruch, P.A.; Goldstein, M. Discriminant analysis. Biometrics 1979, 35, 69–85. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Hu, L.Y.; Huang, M.W.; Ke, S.W.; Tsai, C.F. The distance function effect on k-nearest neighbor classification for medical datasets. SpringerPlus 2016, 5, 1304. [Google Scholar] [CrossRef]
- Hastie, T.; Rosset, S.; Zhu, J.; Zou, H. Multi-class adaboost. Stat. Interface 2009, 2, 349–360. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mode | Frequency (Hz) | |
|---|---|---|
| Detailed 3D Solid Element Model [31] | Layered Shell Element Model [Present Study] | |
| 1 | 8.60 | 8.61 |
| 2 | 9.43 | 9.68 |
| 3 | 14.04 | 15.04 |
| Material Properties | Mean | CoV | Range |
|---|---|---|---|
| Mass density (kg/m3) | 1778 | 0.07 | [1272, 2013] |
| Compressive strength (MPa) | 4.79 | 0.39 | [1.11, 8.67] |
| Tensile strength (MPa) | 0.25 | 0.61 | [0.03, 0.43] |
| Shear strength (MPa) | 0.20 | 0.58 | [0.02, 0.63] |
| Young’s modulus (MPa) | 1669 | 0.62 | [620, 2982] |
| Model | Training | Test | ||||
|---|---|---|---|---|---|---|
| RMSE | RMSE | |||||
| Linear Regression (LR) | 0.878 | 0.877 | 0.556 | 0.862 | 0.858 | 0.596 |
| Stepwise Linear Regression (SLR) | 0.877 | 0.876 | 0.558 | 0.860 | 0.857 | 0.601 |
| Ridge Regression (RR) | 0.806 | 0.804 | 0.700 | 0.818 | 0.814 | 0.677 |
| Decision Tree (DT) | 0.966 | 0.966 | 0.289 | 0.923 | 0.921 | 0.476 |
| Random Forest (RF) | 0.978 | 0.978 | 0.226 | 0.945 | 0.943 | 0.410 |
| Support Vector Machine (SVM) | 0.969 | 0.968 | 0.281 | 0.958 | 0.957 | 0.317 |
| Gaussian Process Regression (GPR) | 0.976 | 0.976 | 0.248 | 0.974 | 0.973 | 0.257 |
| Neural Networks (NN) | 0.978 | 0.977 | 0.239 | 0.972 | 0.972 | 0.307 |
| Model | Accuracy (%) | Misclassification Rate | Training Error | F1 Score | |||
|---|---|---|---|---|---|---|---|
| DS1 | DS2 | DS3 | DS4 | ||||
| NB | 85.8 | 0.1420 | 0.1098 | 83.86 | 78.92 | 70.03 | 94.52 |
| DA | 83.3 | 0.1667 | 0.1032 | 89.62 | 83.21 | 59.68 | 91.34 |
| KNN | 89.8 | 0.1019 | 0 | 89.62 | 87.06 | 73.69 | 96.10 |
| DT | 88.5 | 0.1142 | 0.0503 | 90.31 | 89.48 | 71.82 | 93.55 |
| RF | 92.9 | 0.0710 | 0 | 93.33 | 91.66 | 81.03 | 96.60 |
| AB | 91.1 | 0.0895 | 0.0013 | 93.33 | 89.05 | 79.37 | 95.79 |
| SVM | 87.7 | 0.1235 | 0.0026 | 71.96 | 85.30 | 73.20 | 94.85 |
| NN | 92.6 | 0.0741 | 0.1323 | 93.33 | 91.04 | 81.03 | 96.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ravichandran, N.; Bidorn, B.; Mercan, O.; Paneerselvam, B. Data-Driven Machine-Learning-Based Seismic Response Prediction and Damage Classification for an Unreinforced Masonry Building. Appl. Sci. 2025, 15, 1686. https://doi.org/10.3390/app15041686
Ravichandran N, Bidorn B, Mercan O, Paneerselvam B. Data-Driven Machine-Learning-Based Seismic Response Prediction and Damage Classification for an Unreinforced Masonry Building. Applied Sciences. 2025; 15(4):1686. https://doi.org/10.3390/app15041686
Chicago/Turabian StyleRavichandran, Nagavinothini, Butsawan Bidorn, Oya Mercan, and Balamurugan Paneerselvam. 2025. "Data-Driven Machine-Learning-Based Seismic Response Prediction and Damage Classification for an Unreinforced Masonry Building" Applied Sciences 15, no. 4: 1686. https://doi.org/10.3390/app15041686
APA StyleRavichandran, N., Bidorn, B., Mercan, O., & Paneerselvam, B. (2025). Data-Driven Machine-Learning-Based Seismic Response Prediction and Damage Classification for an Unreinforced Masonry Building. Applied Sciences, 15(4), 1686. https://doi.org/10.3390/app15041686