
Text Removal for Trademark Images Based on Self-Prompting Mechanisms and Multi-Scale Texture Aggregation


Abstract
1. Introduction
- (1)
- Proposing an auto-prompting model that combines a text detection network, SAM, and a diffusion model to achieve better trademark text erasure.
- (2)
- Introducing an integrated differentiating feature pyramid that improves the model’s expressive power by integrating multi-layer features and capturing potential regularities among intra-layer features.
- (3)
- Presenting a texture fusion module that fuses features across different scales to accurately represent multi-scale text instances, thereby enhancing the model’s robustness and generalization ability in complex scenes.

2. Related Work
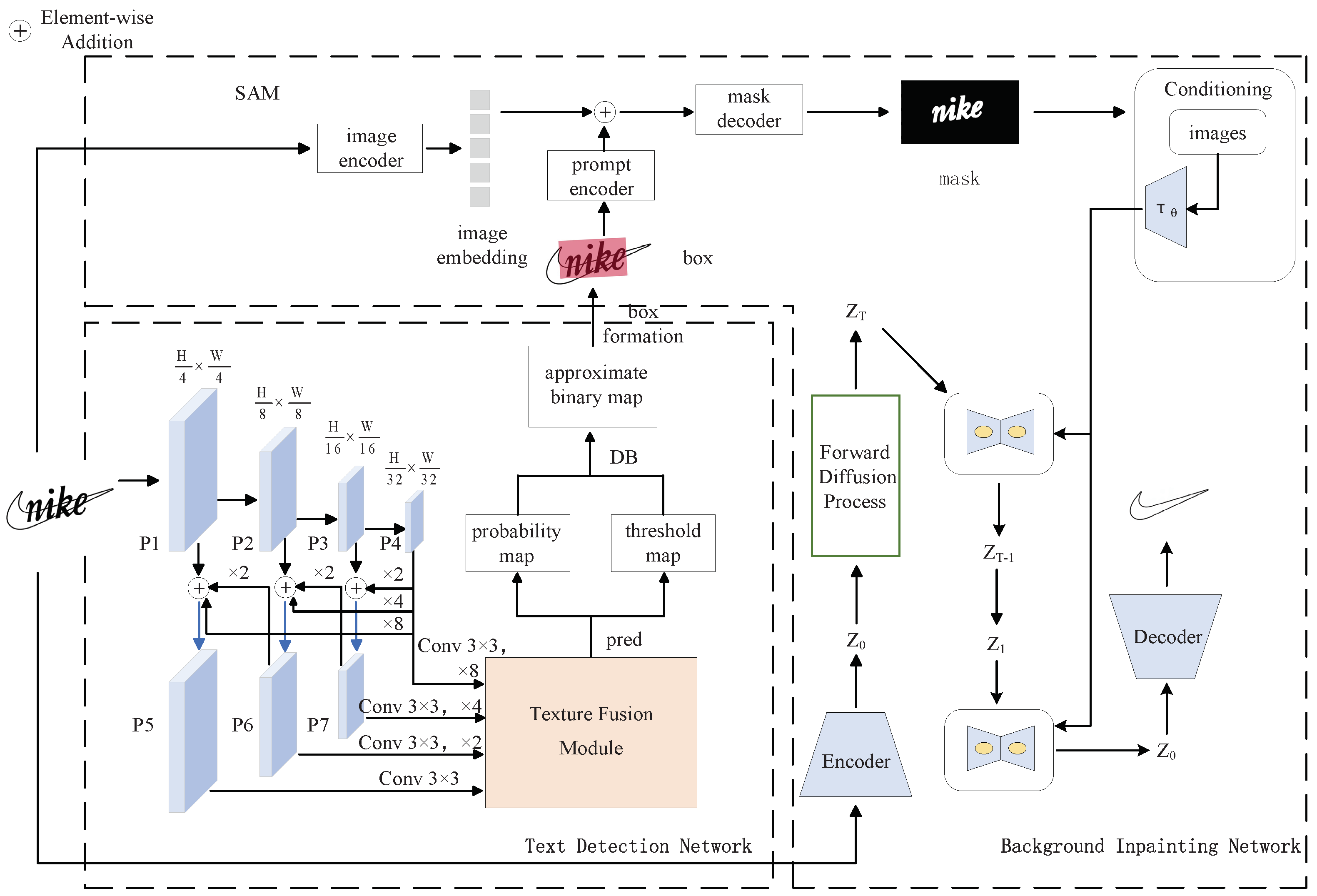
3. Methodology
3.1. Overall Framework
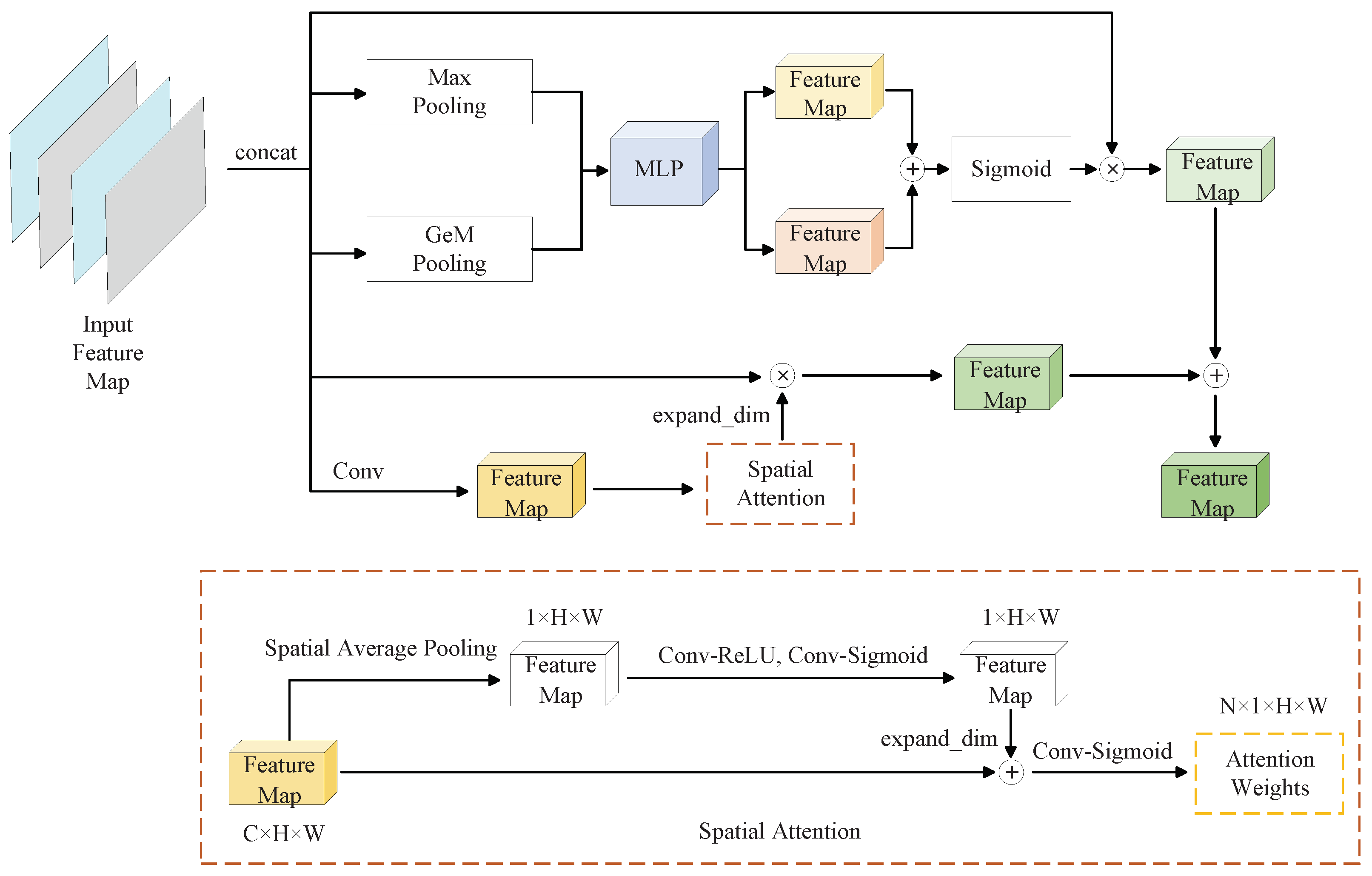
3.2. Comprehensive Differentiating Feature Pyramid
3.3. Texture Aggregation Module
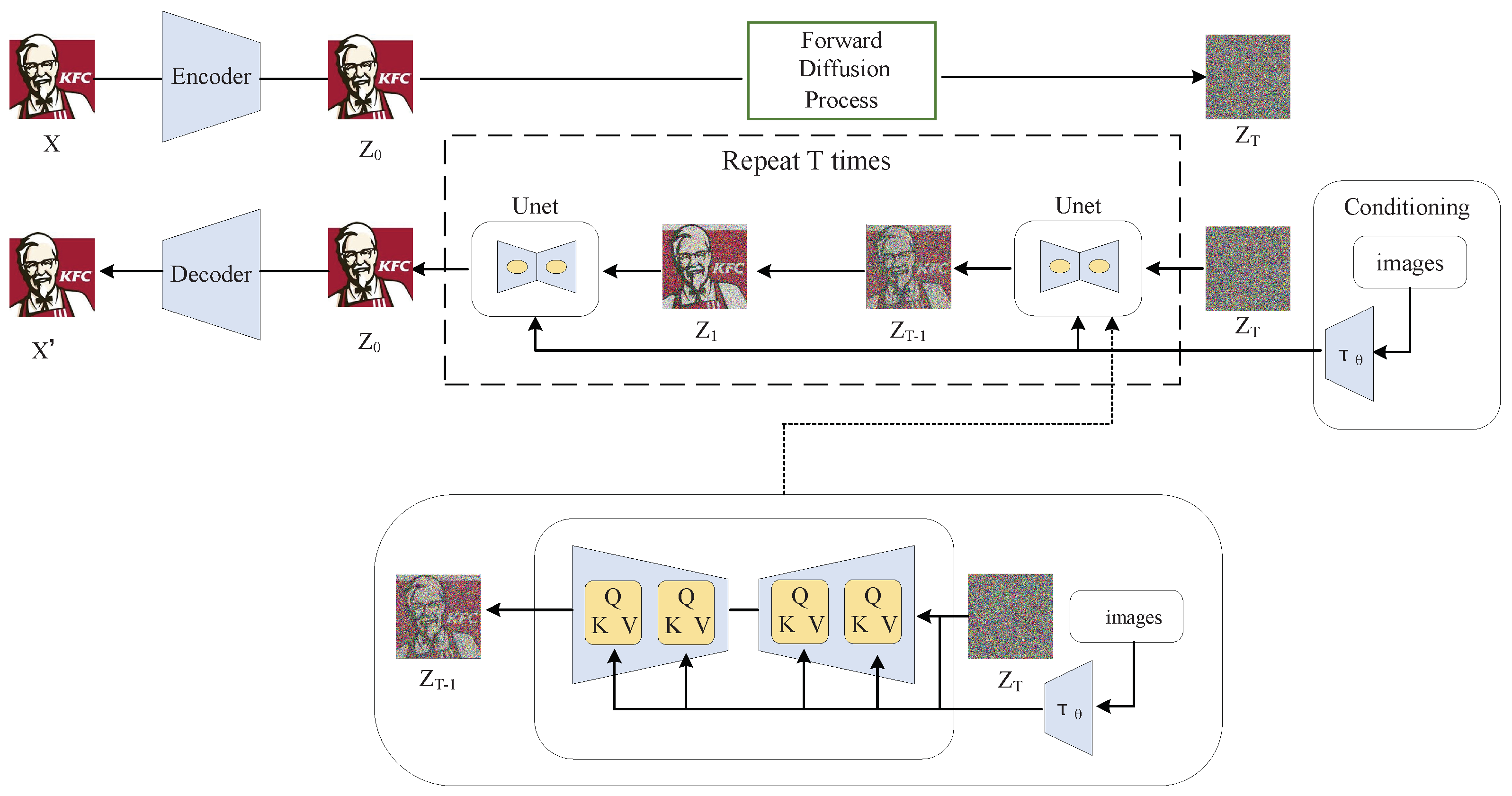
3.4. Diffusion Module
3.5. Loss Function
4. Experiments
4.1. Datasets and Evaluation Criteria
4.2. Experimental Configuration
4.3. Comparative Experiments
4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Feng, Y.; Shi, C.; Qi, C.; Xu, J.; Xiao, B.; Wang, C. Aggregation of reversal invariant features from edge images for large-scale trademark retrieval. In Proceedings of the 2018 4th International Conference on Control, Automation and Robotics (ICCAR), Auckland, New Zealand, 14 June 2018; pp. 384–388. [Google Scholar]
- Tursun, O.; Denman, S.; Sivapalan, S.; Sridharan, S.; Fookes, C.; Mau, S. Component-based attention for large-scale trademark retrieval. IEEE Trans. Inf. Forensics Secur. 2019, 17, 2350–2363. [Google Scholar] [CrossRef]
- Zheng, L.; Lei, Y.; Qiu, G.; Huang, J. Near-duplicate image detection in a visually salient riemannian space. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1578–1593. [Google Scholar] [CrossRef]
- Liu, Y.; Jin, L.; Zhang, S.; Luo, C.; Zhang, S. Curved scene text detection via transverse and longitudinal sequence connection. Pattern Recognit. 2019, 90, 337–345. [Google Scholar] [CrossRef]
- Tursun, O.; Aker, C.; Kalkan, S. A large-scale dataset and benchmark for similar trademark retrieval. arXiv 2017, arXiv:1701.05766. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 15 January 2023; pp. 4015–4026. [Google Scholar]
- Carreira-Perpinán, M.A. Generalised blurring mean-shift algorithms for nonparametric clustering. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Shi, J.; Qi, C. Sparse modeling based image inpainting with local similarity constraint. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 1371–1375. [Google Scholar]
- Nakamura, T.; Zhu, A.; Yanai, K.; Uchida, S. Scene text eraser. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 832–837. [Google Scholar]
- Liu, C.; Liu, Y.; Jin, L.; Zhang, S.; Luo, C.; Wang, Y. Erasenet: End-to-end text removal in the wild. IEEE Trans. Image Process. 2020, 29, 8760–8775. [Google Scholar] [CrossRef] [PubMed]
- Tursun, O.; Zeng, R.; Denman, S.; Sivapalan, S.; Sridharan, S.; Fookes, C. Mtrnet: A generic scene text eraser. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 39–44. [Google Scholar]
- Tursun, O.; Denman, S.; Zeng, R.; Sivapalan, S.; Sridharan, S.; Fookes, C. MTRNet++: One-stage mask-based scene text eraser. Comput. Vis. Image Underst. 2020, 201, 103066. [Google Scholar] [CrossRef]
- Zdenek, J.; Nakayama, H. Erasing scene text with weak supervision. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Seattle, WA, USA, 13–19 June 2020; pp. 2238–2246. [Google Scholar]
- Tang, Z.; Miyazaki, T.; Sugaya, Y.; Omachi, S. Stroke-based scene text erasing using synthetic data for training. IEEE Trans. Image Process. 2021, 30, 9306–9320. [Google Scholar] [CrossRef] [PubMed]
- Conrad, B.; Chen, P.I. Two-stage seamless text erasing on real-world scene images. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1309–1313. [Google Scholar]
- Kwon, H.; Lee, S. Toward backdoor attacks for image captioning model in deep neural networks. Secur. Commun. Netw. 2022, 2022, 1525052. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Liao, M.; Zou, Z.; Wan, Z.; Yao, C.; Bai, X. Real-time scene text detection with differentiable binarization and adaptive scale fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 919–931. [Google Scholar] [CrossRef] [PubMed]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10819–10829. [Google Scholar]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized feature pyramid for object detection. IEEE Trans. Image Process. 2023, 32, 4341–4354. [Google Scholar] [CrossRef] [PubMed]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local Features Coupling Global Representations for Visual Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 367–376. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Wang, Z.; Li, Z.; Sun, J.; Xu, Y. Selective convolutional features based generalized-mean pooling for fine-grained image retrieval. In Proceedings of the 2018 IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018; pp. 1–4. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 2256–2265. [Google Scholar]
- Zhang, S.; Liu, Y.; Jin, L.; Huang, Y.; Lai, S. Ensnet: Ensconce text in the wild. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 801–808. [Google Scholar]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; i Bigorda, L.G.; Mestre, S.R.; Mas, J.; Mota, D.F.; Almazan, J.A.; De Las Heras, L.P. ICDAR 2013 robust reading competition. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Athens, Greece, 30 August–4 September 2013; pp. 1484–1493. [Google Scholar]
- Nayef, N.; Yin, F.; Bizid, I.; Choi, H.; Feng, Y.; Karatzas, D.; Luo, Z.; Pal, U.; Rigaud, C.; Chazalon, J.; et al. Icdar2017 robust reading challenge on multi-lingual scene text detection and script identification-rrc-mlt. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 1454–1459. [Google Scholar]
- Long, S.; Ruan, J.; Zhang, W.; He, X.; Wu, W.; Yao, C. Textsnake: A flexible representation for detecting text of arbitrary shapes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 20–36. [Google Scholar]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8440–8449. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Bian, X.; Wang, C.; Quan, W.; Ye, J.; Zhang, X.; Yan, D.M. Scene text removal via cascaded text stroke detection and erasing. Comput. Vis. Media 2022, 8, 273–287. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision | Recall | F-Score |
|---|---|---|---|
| TextSnake [30] | 67.9 | 85.3 | 75.6 |
| TLOC [4] | 77.4 | 69.8 | 73.4 |
| PAN [31] | 86.4 | 81.2 | 83.7 |
| DBNet++ [18] | 87.9 | 82.8 | 85.3 |
| MTF-STTR | 89.9 | 85.6 | 87.7 |
| Method | MSE | PSNR | pEPs | pCEPs |
|---|---|---|---|---|
| EnsNet [27] | 0.0021 | 29.5 | 0.0069 | 0.002 |
| EraseNet [10] | 0.0002 | 38.3 | 0.0048 | 0.0004 |
| Pix2Pix [32] | 0.0027 | 26.8 | 0.0473 | 0.0244 |
| Bain [33] | 0.0159 | 20.8 | 0.1021 | 0.5996 |
| MTF-STTR | 0.0003 | 40.1 | 0.004 | 0.0003 |
| DB | IDFP | TFM | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| 84.3 | 75.2 | 80.6 | |||
| ✓ | 86.1 | 81.4 | 84.5 | ||
| ✓ | 87.6 | 80.3 | 84.9 | ||
| ✓ | 85.8 | 81.3 | 84.1 | ||
| ✓ | ✓ | 88.2 | 83 | 85.9 | |
| ✓ | ✓ | 86.8 | 82.9 | 85.4 | |
| ✓ | ✓ | 88.7 | 84.2 | 87.3 | |
| ✓ | ✓ | ✓ | 89.9 | 85.6 | 87.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, W.; Wang, X.; Zhou, B.; Li, L. Text Removal for Trademark Images Based on Self-Prompting Mechanisms and Multi-Scale Texture Aggregation. Appl. Sci. 2025, 15, 1553. https://doi.org/10.3390/app15031553
Zhou W, Wang X, Zhou B, Li L. Text Removal for Trademark Images Based on Self-Prompting Mechanisms and Multi-Scale Texture Aggregation. Applied Sciences. 2025; 15(3):1553. https://doi.org/10.3390/app15031553
Chicago/Turabian StyleZhou, Wenchao, Xiuhui Wang, Boxiu Zhou, and Longwen Li. 2025. "Text Removal for Trademark Images Based on Self-Prompting Mechanisms and Multi-Scale Texture Aggregation" Applied Sciences 15, no. 3: 1553. https://doi.org/10.3390/app15031553
APA StyleZhou, W., Wang, X., Zhou, B., & Li, L. (2025). Text Removal for Trademark Images Based on Self-Prompting Mechanisms and Multi-Scale Texture Aggregation. Applied Sciences, 15(3), 1553. https://doi.org/10.3390/app15031553