
Road Extraction from Remote Sensing Images Using a Skip-Connected Parallel CNN-Transformer Encoder-Decoder Model


 and
and
Abstract
1. Introduction
- Novel Stepped Parallel Architecture: We propose a stepped parallel encoder architecture that integrates the CNN Encoder Module (CEM) and Transformer Encoder Module (TEM), enabling the fusion of local and global information, compensating for the limitations of conventional CNNs.
- Enhanced Encoder Module Design: We redesign the CNN and Transformer encoder modules from classic models to focus on local feature capture and global context collection, respectively. This design maintains their feature-capturing strengths while enabling integration into a parallel architecture.
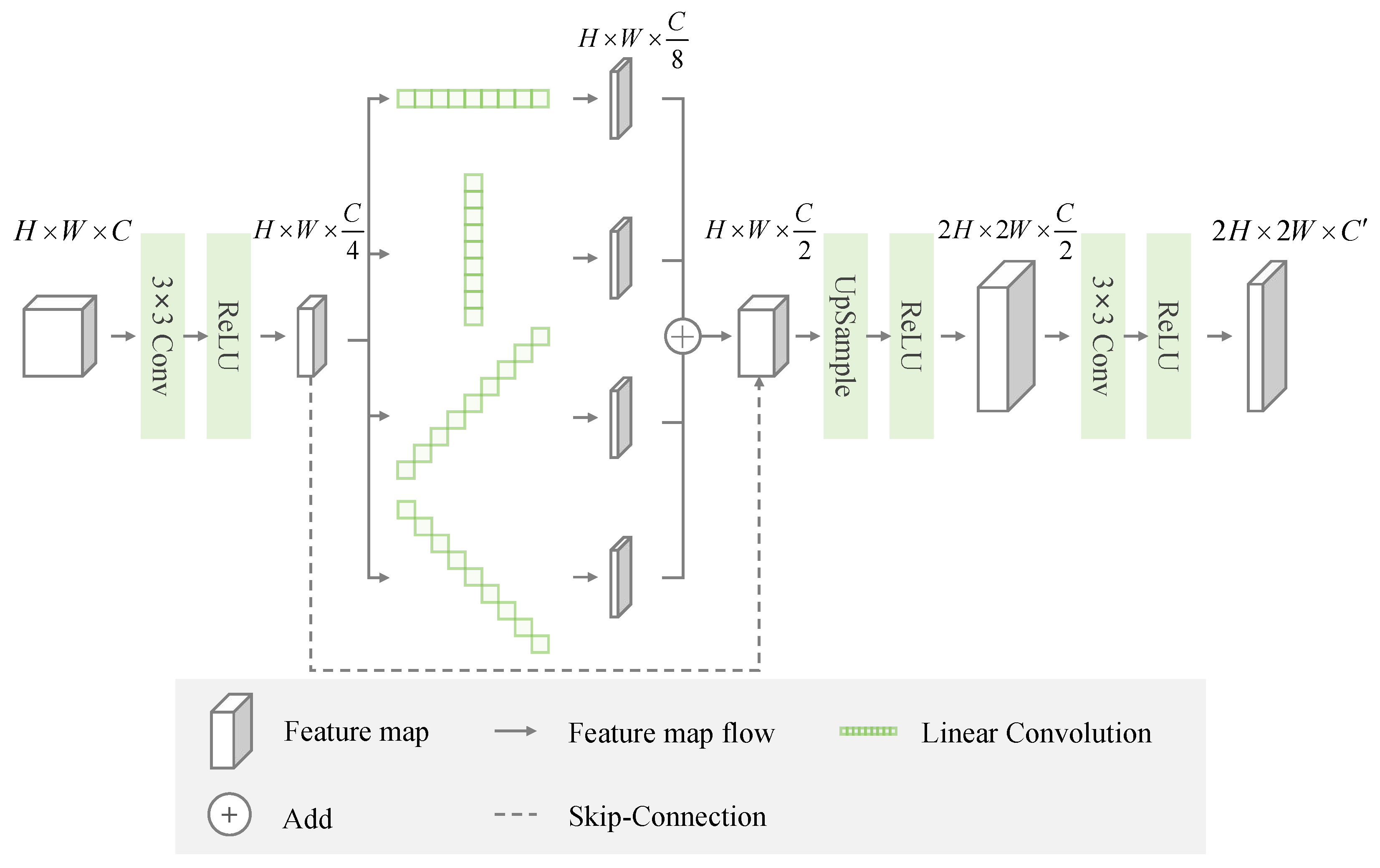
- Innovative Linear Decoder Module: We specifically design the Linear Convolution Module (LCM) in the decoder for linear shape characteristics and large-span distribution features of roads, which improves the edge integrity while reducing computational complexity.
2. Methods
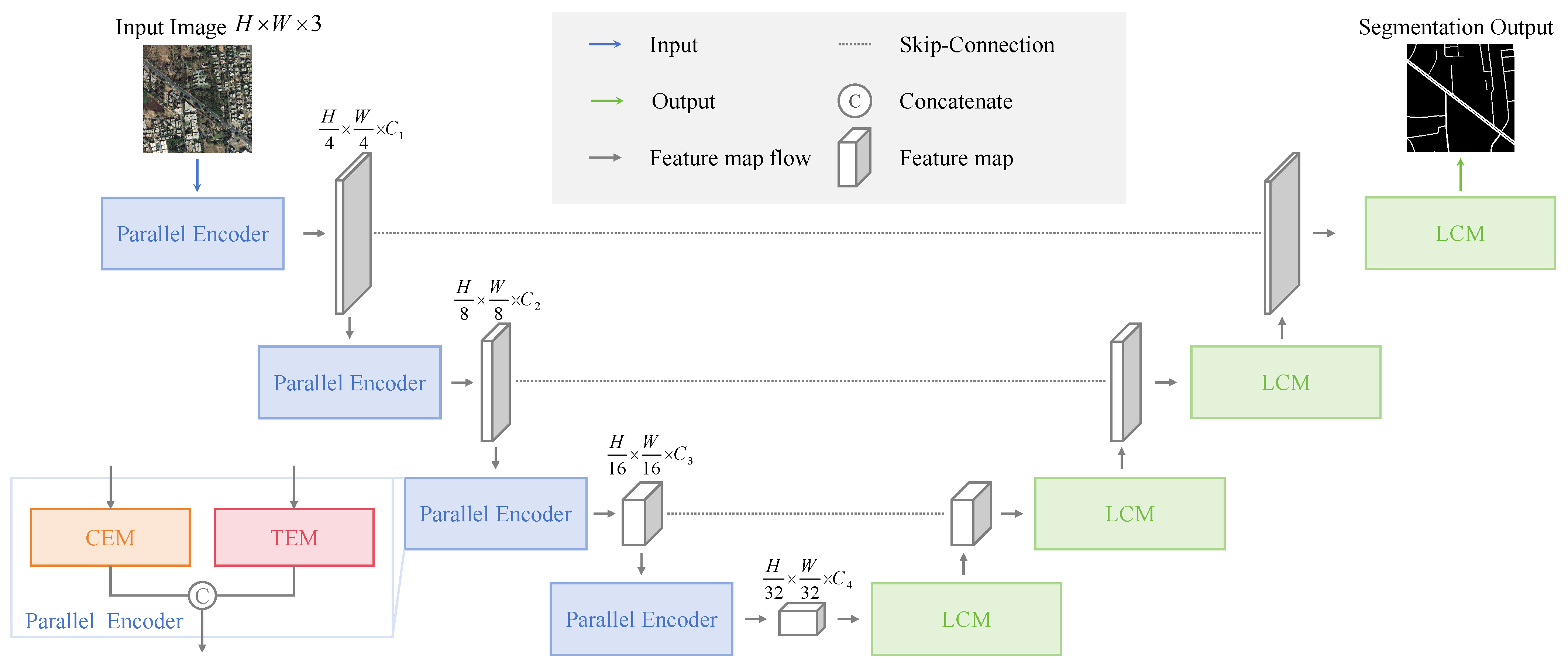
2.1. Architecture Overview
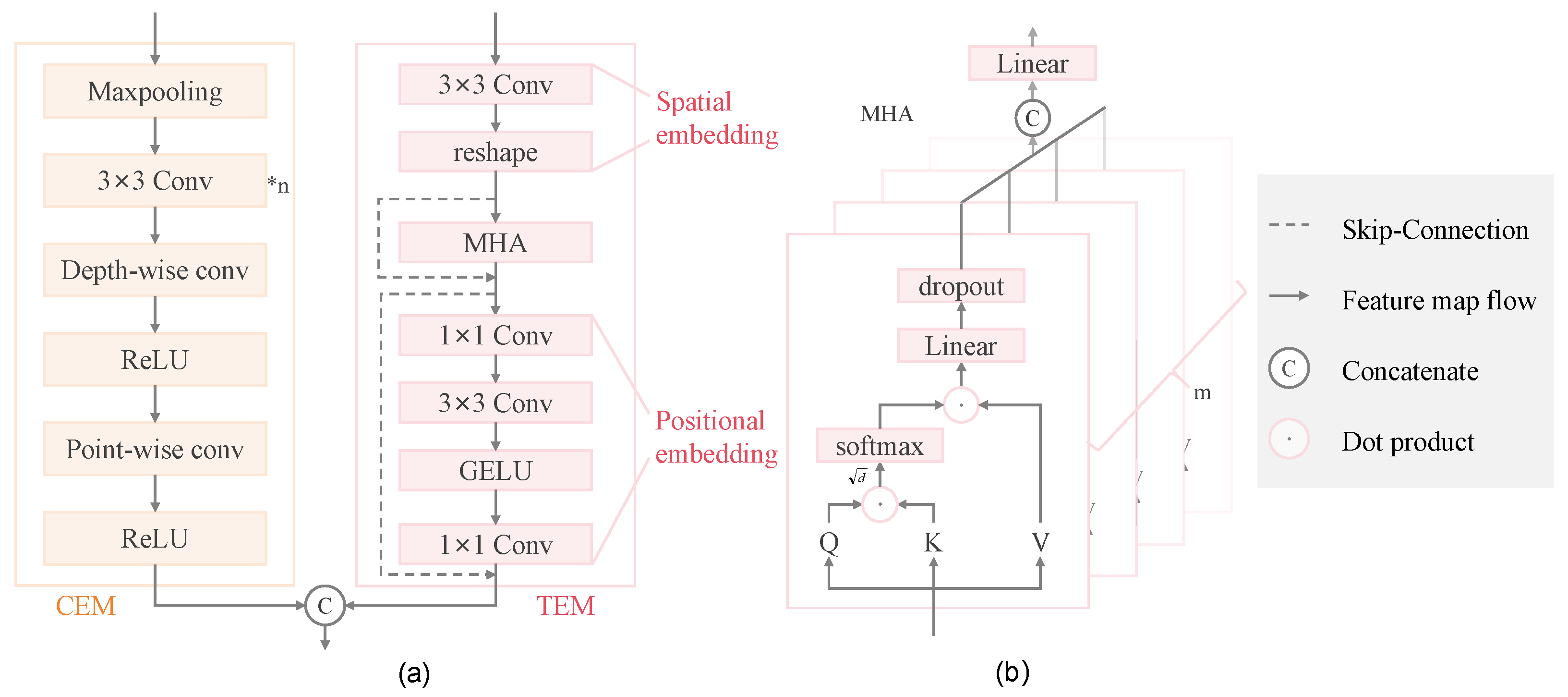
2.2. CNN Encoder Module
2.3. Transformer Encoder Module
2.4. Linear Convolution Decoder Module
3. Results
3.1. Dataset Introduction
- The German-Street dataset, a subset of the CITY-OSM dataset, was published by Kaiser et al. [35] and includes images from various cities and regions, with annotations generated via OpenStreetMap. It consists of 4000 street images measuring 512 × 512 pixels, divided into 3600 for training, 40 for validation, and 360 for testing.
- The Massachusetts Roads dataset, created by Mnih et al. [36], consists of 1171 aerial images of Massachusetts, each measuring 1500 × 1500 pixels and covering an area of 2.25 square kilometers. The dataset includes a wide range of landscapes such as urban, suburban, and rural areas and is randomly split into 1108 for training, 14 for validation, and 49 for testing.
3.2. Evaluation Metrics
3.3. Implementation Details
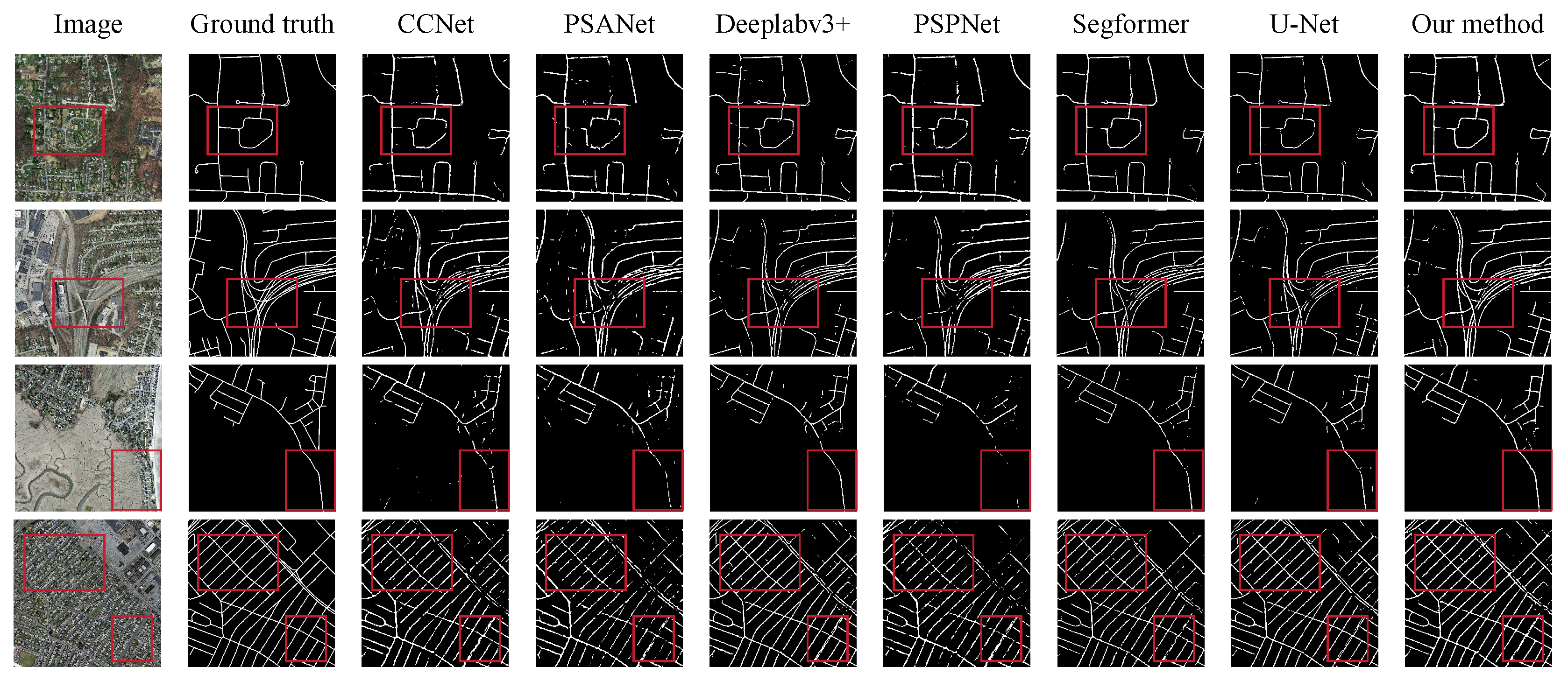
3.4. Experimental Data and Result Visualization
3.4.1. Experiments Based on the German-Street Dataset
3.4.2. Experiments Based on the Massachusetts Roads Dataset
3.4.3. Ablation Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Number of Road Pixels | Number of Background Pixels | Positive and Negative Sample Ratio (%) | Positive Sample Ratio (%) |
|---|---|---|---|---|
| CHN6-CUG | 85,356,849 | 1,097,174,735 | 7.78 | 7.22 |
| DeepGlobe | 276,640,131 | 6,251,794,045 | 4.42 | 4.24 |
| Massachusetts | 58,409,723 | 1,169,472,773 | 4.99 | 4.76 |
| German-Street | 115,195,161 | 933,380,839 | 12.34 | 10.99 |
References
- Sun, Z.; Wu, J.; Yang, J.; Huang, Y.; Li, C.; Li, D. Path Planning for GEO-UAV Bistatic SAR Using Constrained Adaptive Multiobjective Differential Evolution. IEEE Trans. Geoence Remote Sens. 2016, 54, 6444–6457. [Google Scholar] [CrossRef]
- Mckeown, D.M. The Role of Artificial Intelligence in the Integration of Remotely Sensed Data with Geographic Information Systems. IEEE Trans. Geosci. Remote Sens. 1987, GE-25, 330–348. [Google Scholar] [CrossRef]
- Xu, W.; Wei, J.; Dolan, J.M.; Zhao, H.; Zha, H. A Real-Time Motion Planner with Trajectory Optimization for Autonomous Vehicles. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012. [Google Scholar]
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Engin. (Eng. Ed.) 2016, 3, 271–282. [Google Scholar] [CrossRef]
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road Extraction Methods in High-Resolution Remote Sensing Images: A Comprehensive Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Mo, S.; Shi, Y.; Yuan, Q.; Li, M. A Survey of Deep Learning Road Extraction Algorithms Using High-Resolution Remote Sensing Images. Sensors 2024, 24, 1708. [Google Scholar] [CrossRef] [PubMed]
- Anil, P.N.; Natarajan, S. A Novel Approach Using Active Contour Model for Semi-Automatic Road Extraction from High Resolution Satellite Imagery. In Proceedings of the Second International Conference on Machine Learning & Computing, Bangalore, India, 9–11 February 2010. [Google Scholar]
- Abraham, L.; Sasikumar, M. A fuzzy based road network extraction from degraded satellite images. In Proceedings of the 2013 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Mysore, India, 22–25 August 2013. [Google Scholar]
- Mnih, V.; Hinton, G.E. Learning to Detect Roads in High-Resolution Aerial Images; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. DLMIA ML-CDS 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Jha, D.; Smedsrud, P.H.; Johansen, D.; De Lange, T.; Johansen, H.D.; Halvorsen, P.; Riegler, M.A. A Comprehensive Study on Colorectal Polyp Segmentation with ResUNet++, Conditional Random Field and Test-Time Augmentation. arXiv 2021, arXiv:2107.12435. [Google Scholar] [CrossRef]
- Kumar, P.; Nagar, P.; Arora, C.; Gupta, A. U-SegNet: Fully Convolutional Neural Network based Automated Brain tissue segmentation Tool. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Wang, Y.; Seo, J.; Jeon, T. NL-LinkNet: Toward Lighter But More Accurate Road Extraction With Nonlocal Operations. IEEE Geosci. Remote Sens. Lett. 2021, 19, 3000105. [Google Scholar] [CrossRef]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Liu, Y.; Zhang, Y.; Wang, Y.; Hou, F.; Yuan, J.; Tian, J.; Zhang, Y.; Shi, Z.; Fan, J.; He, Z. A Survey of Visual Transformers. arXiv 2021, arXiv:2111.06091. [Google Scholar] [CrossRef] [PubMed]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Tao, D. A Survey on Visual Transformer. arXiv 2023, arXiv:2012.12556. [Google Scholar]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient Transformers: A Survey. ACM Comput. Surv. 2023, 55, 109.1–109.28. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Zhang, L. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. arXiv 2020, arXiv:2012.15840. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. arXiv 2021, arXiv:2102.12122. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the Design of Spatial Attention in Vision Transformers. arXiv 2021, arXiv:2104.13840. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Xu, Z.; Liu, Y.; Gan, L.; Sun, Y.; Liu, M.; Wang, L. RNGDet: Road Network Graph Detection by Transformer in Aerial Images. arXiv 2022, arXiv:2202.07824. [Google Scholar] [CrossRef]
- Wang, C.; Xu, R.; Xu, S.; Meng, W.; Wang, R.; Zhang, J.; Zhang, X. Towards accurate and efficient road extraction by leveraging the characteristics of road shapes. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4404616. [Google Scholar] [CrossRef]
- Hetang, C.; Xue, H.; Le, C.; Yue, T.; Wang, W.; He, Y. Segment Anything Model for Road Network Graph Extraction. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17–18 June 2024. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Islam, M.A.; Jia, S.; Bruce, N.D.B. How Much Position Information Do Convolutional Neural Networks Encode? arXiv 2020, arXiv:2001.08248. [Google Scholar]
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.K. Learning Aerial Image Segmentation From Online Maps. IEEE Trans. Geosci. Remote Sensing. 2017, 55, 6054–6068. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016; pp. 6230–6239. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. PSANet: Point-Wise Spatial Attention Network for Scene Parsing; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar]

| Model Name | Background | Road | Overall | |||||
|---|---|---|---|---|---|---|---|---|
| IoU (%) | Recall (%) | IoU (%) | Recall (%) | mIoU (%) | mPA (%) | Accuracy (%) | f1-Score (%) | |
| PSPNet [39] | 92.26 | 96.91 | 47.84 | 59.58 | 70.03 | 78.25 | 92.74 | 84.88 |
| PSANet [40] | 92.22 | 97.11 | 47.05 | 57.83 | 69.63 | 77.47 | 92.72 | 84.41 |
| CCNet [27] | 92.32 | 97.33 | 46.95 | 56.91 | 69.64 | 77.12 | 92.81 | 84.24 |
| Deeplabv3+ [12] | 91.95 | 96.49 | 47.51 | 60.75 | 69.73 | 78.62 | 92.49 | 84.99 |
| Unet [13] | 92.52 | 96.76 | 50.57 | 63.57 | 71.54 | 80.17 | 93.05 | 86.13 |
| Segformer [41] | 92.48 | 96.83 | 50.05 | 62.66 | 71.72 | 79.75 | 93.01 | 85.87 |
| Our method | 92.85 | 96.68 | 53.24 | 67.29 | 73.05 | 81.98 | 93.39 | 87.31 |
| Model Name | Background | Road | Overall | |||||
|---|---|---|---|---|---|---|---|---|
| IoU (%) | Recall (%) | IoU (%) | Recall (%) | mIoU (%) | mPA (%) | Accuracy (%) | f1-Score (%) | |
| PSPNet | 96.31 | 98.88 | 38.06 | 46.61 | 67.19 | 72.75 | 96.39 | 82.92 |
| PSANet | 96.07 | 98.34 | 39.65 | 52.86 | 67.86 | 75.6 | 96.17 | 84.65 |
| CCNet | 96.35 | 98.59 | 41.66 | 53.44 | 69 | 76.01 | 96.44 | 85.01 |
| Deeplabv3+ | 96.77 | 99.06 | 46.55 | 57.51 | 71.66 | 78.17 | 96.86 | 85.52 |
| Unet | 96.97 | 99.36 | 44.85 | 50.63 | 70.91 | 74.99 | 97.04 | 84.6 |
| Segformer | 97 | 99.48 | 44.19 | 48.76 | 70.59 | 74.12 | 97.07 | 84.06 |
| Our method | 96.83 | 98.58 | 49.71 | 63.85 | 73.27 | 81.21 | 96.93 | 88.38 |
| Dataset | CEM | TEM | LCM | Road Iou | Overall Miou |
|---|---|---|---|---|---|
| German-Street | ✓ | 50.76 | 71.71 | ||
| ✓ | 49.77 | 71.33 | |||
| ✓ | ✓ | 52.4 | 72.42 | ||
| ✓ | ✓ | ✓ | 53.24 | 73.05 | |
| Massachusetts | ✓ | 46.69 | 71.86 | ||
| ✓ | 45.98 | 71.27 | |||
| ✓ | ✓ | 48.07 | 72.52 | ||
| ✓ | ✓ | ✓ | 49.71 | 73.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gui, L.; Gu, X.; Huang, F.; Ren, S.; Qin, H.; Fan, C. Road Extraction from Remote Sensing Images Using a Skip-Connected Parallel CNN-Transformer Encoder-Decoder Model. Appl. Sci. 2025, 15, 1427. https://doi.org/10.3390/app15031427
Gui L, Gu X, Huang F, Ren S, Qin H, Fan C. Road Extraction from Remote Sensing Images Using a Skip-Connected Parallel CNN-Transformer Encoder-Decoder Model. Applied Sciences. 2025; 15(3):1427. https://doi.org/10.3390/app15031427
Chicago/Turabian StyleGui, Linger, Xingjian Gu, Fen Huang, Shougang Ren, Huanhuan Qin, and Chengcheng Fan. 2025. "Road Extraction from Remote Sensing Images Using a Skip-Connected Parallel CNN-Transformer Encoder-Decoder Model" Applied Sciences 15, no. 3: 1427. https://doi.org/10.3390/app15031427
APA StyleGui, L., Gu, X., Huang, F., Ren, S., Qin, H., & Fan, C. (2025). Road Extraction from Remote Sensing Images Using a Skip-Connected Parallel CNN-Transformer Encoder-Decoder Model. Applied Sciences, 15(3), 1427. https://doi.org/10.3390/app15031427