Abstract
Building on advances in promptable segmentation models, this work introduces a framework that integrates Large Vision-Language Model (LVLM) bounding box priors with prototype-based region of interest (ROI) selection to improve zero-shot medical image segmentation. Unlike prior methods such as SaLIP, which often misidentify regions due to reliance on text–image CLIP similarity, the proposed approach leverages visual prototypes to mitigate language bias and enhance ROI ranking, resulting in more accurate segmentation. Bounding box estimation is further strengthened through systematic prompt engineering to optimize LVLM performance across diverse datasets and imaging modalities. Evaluation was conducted on three publicly available benchmark datasets—CC359 (brain MRI), HC18 (fetal head ultrasound), and CXRMAL (chest X-ray)—without any task-specific fine-tuning. The proposed method achieved substantial improvements over prior approaches. On CC359, it reached a Dice score of 0.95 ± 0.06 and a mean Intersection-over-Union (mIoU) of 0.91 ± 0.10. On HC18, it attained a Dice score of 0.82 ± 0.20 and mIoU of 0.74 ± 0.22. On CXRMAL, the model achieved a Dice score of 0.90 ± 0.08 and mIoU of 0.83 ± 0.12. These standard deviations reflect variability across test images within each dataset, indicating the robustness of the proposed zero-shot framework. These results demonstrate that integrating LVLM-derived bounding box priors with prototype-based selection substantially advances zero-shot medical image segmentation.
1. Introduction
Accurate anatomical segmentation is critical for medical image analysis, underpinning diagnosis, treatment planning, and disease monitoring. Yet traditional methods require large annotated datasets and supervised training—often impractical due to annotation cost, domain variability, and privacy constraints [1,2]. Even well-trained models frequently fail to generalize across institutions, scanner vendors, and patient demographics because of domain shift, leading to degraded performance and costly retraining.
Zero-shot segmentation enables deployment without task-specific fine-tuning, allowing immediate use on new modalities and targets. This reduces clinician burden and supports scalable solutions where annotations are scarce, such as rural hospitals or underrepresented populations. Leveraging foundation models like SAM and LVLMs, zero-shot methods offer a training-free, adaptable, and equitable path for medical AI [3,4,5]. Their robustness under data scarcity and domain variability makes them well suited for clinical translation.
Recent advances in foundation vision models, such as SAM [6] and CLIP [7], show strong generalization on natural images. However, direct application to medical imaging is limited by domain-specific differences in texture, contrast, and anatomy. SaLIP [8] narrows this gap by integrating CLIP-based text and image similarity into the SAM pipeline, using enriched anatomical descriptions to guide mask selection. While effective, SaLIP relies on language-based supervision, which can introduce bias and reduce robustness when text is ambiguous or poorly aligned with medical anatomy.
This paper proposes LVLM Prototype Segmentation, a framework that removes language dependence by combining prototype-based visual similarity with LVLM-generated bounding boxes in the SAM pipeline. Using structured prompts with Gemini Pro 2.5 [9], we extract accurate anatomical bounding boxes and use class-specific visual prototypes (rather than text) to select the correct SAM masks.
Our contributions are as follows:
- A prompt engineering strategy for improving LVLM-based bounding box estimation across diverse medical imaging modalities.
- A prototype-based similarity ranking method that mitigates language bias and enhances segmentation accuracy, especially in anatomically ambiguous regions.
- Comprehensive zero-shot segmentation evaluation on three public datasets including brain MRI, fetal ultrasound, and chest X-ray, performed without any fine-tuning or task-specific training
- Public release of code, bounding box annotations, and prompt templates to facilitate reproducibility and future work.
By combining LVLM-generated spatial priors with prototype-based visual retrieval, our framework outperforms prior zero-shot methods such as SaLIP [8] and approaches the performance of ground truth-assisted methods, providing a robust and training-free path forward for medical image segmentation.
The remainder of this paper is organized as follows. Section 2 reviews related works and foundational advances in vision–language and prototype-based segmentation. Section 3 presents the proposed framework, including the LVLM-driven bounding box estimation and prototype-based retrieval modules. Section 4 describes the experimental setup, datasets, and evaluation metrics, followed by performance comparisons and ablation studies. Section 5 provides a detailed discussion of the findings, advantages, and limitations of the approach. Finally, Section 6 concludes the paper and outlines potential directions for future research.
2. Background and Related Work
The Segment Anything Model (SAM) [6] has emerged as a versatile, prompt-driven segmentation framework capable of producing masks in a zero-shot manner. Its ability to segment without retraining has sparked interest in medical imaging, where annotation is costly. However, direct application to medical data often yields suboptimal results due to domain gaps in appearance and structure boundaries [3,5]. To address this, recent work has focused on test-time prompting strategies and semantic guidance without fine-tuning.
SaLIP [8] exemplifies this direction by combining SAM with CLIP [7] in a cascade. SAM first generates candidate masks, CLIP ranks them using text prompts enriched with GPT-3.5 descriptions of the target anatomy, and the top match is re-segmented with SAM for refinement. This approach improves zero-shot segmentation across modalities without retraining but relies on text-based similarity, which can introduce language bias and ambiguity when anatomical terms are imprecise or underrepresented in CLIP’s training data.
Other approaches automate prompt generation to guide SAM. SimSAM [10] simulates extensive point prompts and aggregates resulting masks to refine boundaries, while EviPrompt [4] places prompts in high-uncertainty regions using evidential reasoning. These methods improve mask quality without retraining but still depend on effective prompt placement and often require multiple SAM inferences per image.
Parallel work leverages prototype-based segmentation for generalization. Bian et al. [11] transferred learned relation prototypes between modalities to achieve cross-domain zero-shot segmentation, while Liu et al. [12] used CLIP-derived textual prototypes to unify organ and tumor segmentation in a single universal model. Such approaches demonstrate the utility of visual prototypes for removing language dependence but have not been combined with SAM’s mask proposal capabilities.
Current zero-shot medical segmentation methods either (1) depend heavily on text-based CLIP similarity (e.g., SaLIP [8]), risking bias and poor coverage for rare terms, or (2) focus on prompt engineering without integrating strong semantic priors from LVLM model. Prototype-based methods mitigate language bias but lack the flexible mask generation and refinement pipeline of SAM. Additionally, existing works rarely exploit LVLMs capabilities (e.g., Gemini Vision) for precise bounding box estimation as priors to guide SAM prompting. The proposed framework addresses this gap by replacing textual prompts with visual prototypes for selecting the correct segmentation and leveraging LVLM-generated bounding boxes to drive targeted point prompting, improving both localization and segmentation accuracy in a fully zero-shot setting.
3. Methodology
3.1. Overview of the Proposed Framework
The proposed pipeline begins with prompt-engineered Gemini Pro to estimate precise bounding boxes for the target anatomical structure. From these bounding boxes, SAM is used to generate segmentation candidates by point prompting within the predicted region, while an additional candidate is generated directly from the initial Gemini-derived bounding box. Candidate selection is performed using CLIP, which computes similarity scores against a prototype embedding derived from multiple representative segmentation masks. The whole process is depicted in Figure 1.
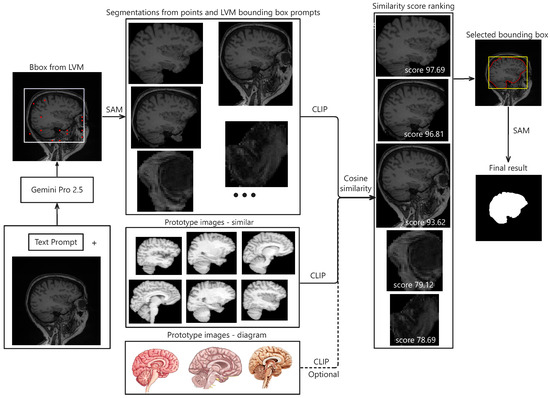
Figure 1.
Illustration of segmentation results using the proposed framework. The pipeline begins with an input image and a corresponding text prompt, which are packaged and sent to Gemini Pro 2.5 via its API. The model returns bounding box coordinates indicating the estimated target region. Within this region of interest (ROI), a set of evenly spaced points, along with the bounding box, are used as prompts for the SAM model to generate candidate segmentations. Each candidate is embedded using CLIP. Separately, prototype embeddings are computed by averaging embeddings from similar ROIs or target diagrams across various datasets. These prototypes are then compared to the candidate embeddings to compute similarity scores. The segmentations are ranked based on these scores, and the top-ranked result is selected. Finally, a refined bounding box derived from this selection is used to generate the final segmentation via SAM.
To facilitate reproducibility, we provide pseudocode describing the two principal components of the proposed framework: (1) prompt engineering and bounding box estimation using the Large Vision-Language Model (Gemini Pro 2.5), and (2) prototype-based segmentation candidate selection, as detailed in Section 3.3.
Algorithms 1 and 2 make explicit the key steps used for LVLM-driven bounding box estimation and prototype-based retrieval, thereby providing sufficient detail for independent reproduction of the study.
| Algorithm 1 Prompt-Engineered Bounding Box Estimation using Gemini Pro 2.5 |
| Require: Input image I, anatomical description D, dimension variable DIMENSIONS Ensure: Bounding box coordinates
|
| Algorithm 2 Prototype-Based Segmentation Candidate Selection |
| Require: Candidate masks from SAM, prototype set , CLIP encoder Ensure: Selected segmentation mask
|
3.2. Bounding Box Estimation with Prompt-Engineered Large Vision-Language Models
Bounding box priors were generated using the Gemini Pro 2.5 API. To support large-scale annotation at a manageable cost, we implemented a batch inference pipeline, enabling the generation of approximately 10,000 bounding boxes in a single run. A systematic prompt design strategy was employed to ensure tight and anatomically relevant bounding boxes while minimizing the inclusion of irrelevant structures. Each input image was paired with a customized prompt and submitted to various vision–language models (VLMs), which returned bounding box coordinates representing the region of interest. Multiple prompt formulations were explored, incorporating modality-specific cues and spatial constraints. Certain designs improved box precision and reduced false positives, while others degraded performance or introduced ambiguity.
GPT-4o [13] demonstrated performance comparable to Gemini Pro 2.5 [9] in our internal evaluations; however, Gemini Pro 2.5, available from Google, was chosen for downstream experiments due to its consistent accuracy, stable API access, and available research funding for sustained API usage. It also outperformed LLaMA-based models, as shown in Figure 2. Model outputs were returned in JSON format and integrated directly into our segmentation pipeline. While the bounding box estimations generated by Gemini across multiple datasets were not sufficiently precise to serve as final segmentations, they consistently localized the region of interest. Despite occasional boundary inaccuracies, these estimations provided reliable spatial priors that effectively guided the SAM model towards more accurate segmentations, as illustrated in Figure 3.
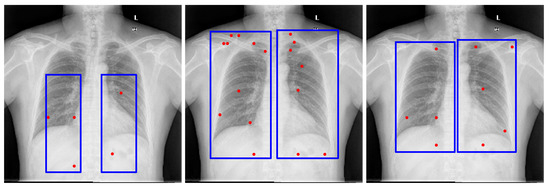
Figure 2.
Examples of lung bounding box estimations generated by different models: LLaMA-4-Maverick-17B-128E, GPT-4o, and Gemini Pro 2.5. The blue rectangles indicate the bounding-box prompts, and the red dots represent the point prompts. Both are provided as inputs to the Segment Anything Model (SAM) to generate segmentation candidates.
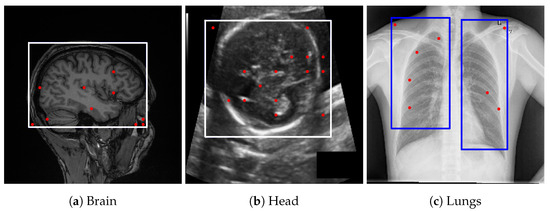
Figure 3.
Bounding box estimations by Gemini Pro 2.5 across different datasets. Blue rectangles and red dots indicate the prompts provided to SAM for generating segmentation candidates.
To further refine bounding box accuracy, we examined prompt engineering strategies. Three key elements were found to be critical: (1) a coordinate-setting variable (DIMENSIONS) that dynamically adjusts to image size, with the origin fixed at the top-left corner; (2) a precise anatomical description of the target region; and (3) a clearly specified output format. Full prompt templates are detailed in Appendix B.
3.3. LVLM SAM Segmentation Generator and Prototype-Based Retrieval
We employed SAM ViT-H [6] as the base segmentation model, using bounding boxes produced by the vision-language model (LVLM) to localize candidate regions of interest. Each bounding box was resized to match SAM’s input resolution, after which SAM generated multiple candidate masks per box using both the LVLM-derived bounding box prompt and a set of evenly distributed point prompts within the box.
To generate evenly spaced point prompts within each LVLM-derived bounding box, we used a deterministic grid sampling strategy to ensure reproducibility. For a bounding box , the width and height are defined as and . A two-dimensional grid of points is created inside B, where the coordinates of each point are given by the following:
for and . The complete set of prompts is then defined as .
In all experiments, a uniform grid of was employed, resulting in 256 evenly distributed point prompts within each LVLM-predicted bounding box. This grid density was empirically chosen to ensure comprehensive spatial coverage for candidate mask generation. Increasing the grid resolution beyond this level did not yield additional unique segmentations, as many neighboring prompts produced identical or near-identical SAM masks. A fixed random seed (seed = 123) was used to ensure deterministic point-based prompting during SAM inference, thereby guaranteeing full reproducibility of the segmentation results. The generated grid points, together with the LVLM-derived bounding box, served as spatial prompts for SAM to produce all unique candidate segmentation masks.
To identify the correct segmentation, we replaced CLIP-based text prompts with a prototype-based similarity retrieval strategy. Representative prototype images for each target class, drawn from different dataset cohorts to support zero-shot segmentation, were encoded using CLIP to compute an average class embedding. Each candidate image crop was also encoded with CLIP, and cosine similarity was computed between these crop embeddings and the corresponding class prototype embedding. The candidate with the highest similarity score was selected as the final segmentation, enabling robust anatomical alignment while reducing reliance on text prompt engineering as used in [8]. To make this process explicit, we formalize the computation of prototype embeddings and the retrieval of the most semantically similar crop in the shared embedding space as follows.
Let be the set of target classes, and let denote the set of candidate crop images extracted from the input. For each class , we define a set of prototype (reference) images .
Let denote the image encoder (e.g., CLIP), which maps an image to a d-dimensional embedding space. The embedding of each prototype image is computed as follows:
The class prototype embedding is obtained by averaging the normalized embeddings:
Each candidate crop is encoded and normalized as follows:
The cosine similarity between each crop embedding and the prototype embedding is as follows:
The final selected crop for class is as follows:
This approach selects the crop most semantically aligned with the class prototype in the shared embedding space, enabling robust segmentation without dependence on text prompts for mask selection. The procedure is summarized in Algorithm 2.
4. Experiments
4.1. Datasets and Evaluation Metrics
4.1.1. Evaluation Datasets
The framework was evaluated on three datasets: (1) Calgary–Campinas Brain MRI for skull stripping, (2) HC18 fetal ultrasound for head circumference estimation, and (3) a chest X-ray dataset for lung field segmentation. Performance metrics included Dice similarity coefficient (DSC) and mean Intersection-over-Union (mIoU). Experiments are conducted on three publicly available medical image segmentation datasets:
- CC359 Brain MRI [14]: T1-weighted brain MRI scans from multiple scanners (GE 1.5T, GE 3T, Philips 1.5T, Philips 3T, Siemens 1.5T).
- HC18 Fetal Head Ultrasound [15]: A total of 999 ultrasound images with manual fetal head annotations.
- Chest X-ray Masks and Labels (CXRMALs) [16]: A total of 704 chest radiographs with lung masks.
All prototype subsets were strictly separated from the evaluation data to prevent any data leakage or subject overlap. For volumetric datasets, the division was performed at the subject level to ensure that no slices from the same patient were used simultaneously for prototype construction and evaluation. This protocol guarantees objective performance assessment under both few-shot and zero-shot conditions.
4.1.2. Reference Prototype Sets
To evaluate the impact of different prototype sources on retrieval-based segmentation performance, we conducted controlled experiments using three distinct types of prototypes. For each dataset, only one prototype source was used at a time to isolate its contribution to the final segmentation results:
- Internal subsets (few-shot): A small portion of each evaluation dataset was held out and used exclusively as prototypes. These samples were strictly excluded from the evaluation set to simulate a few-shot setting.
- External datasets (zero-shot): A limited number of representative samples were selected from publicly available datasets of the same imaging modality but derived from different cohorts, enabling a zero-shot prototype setup.
- Anatomical diagrams (zero-shot): Educational illustrations and schematic anatomical diagrams were used as prototypes. These were manually adjusted via geometric transformations such as flipping, rotation, or separation of left/right anatomical structures to better align with the spatial orientation of the evaluation data.
Brain MRI (CC359). Experiments were conducted using three prototype sources: internal CC359 samples, Subject S01 from the LPBA40 dataset (T1 weighted sagittal) [17], and schematic brain diagrams that were flipped when needed to serve as diagram-based prototypes. For internal sample selection, seven slices (indices 0, 14, 28, 42, 56, 70, and 84) from the first subject in the Site 6 test subset were used as prototype images, corresponding to approximately 0.6% of all test slices. These prototypes were then applied to evaluate segmentation across all remaining sites. No other slices from this subject or site were included in the evaluation phase.
Fetal Head Ultrasound (HC18). Independent runs were performed using prototypes drawn either from internal HC18 samples or from a small set of annotated cases in the PSFHS dataset [18]. Because no suitable anatomically faithful diagrams of the fetal head were available, diagram-based prototypes were not used. For few-shot evaluation, three cases (001_HC, 282_HC, and 567_2HC) were selected as prototypes, representing approximately 0.3% of the dataset to capture diversity in head size and orientation. The remaining 996 images were reserved exclusively for evaluation.
Lung (CXRMAL). Experiments used prototypes from internal data, external chest X-ray samples from the Darwin dataset [19], or stylized lung diagrams in which the left and right lungs were separated to match the evaluation orientation. For the few-shot setting, we used the last five images (indices 561–565) as prototypes (0.7% of the dataset) and removed them from the evaluation pool.
By testing each prototype source in isolation, we were able to directly compare the performance impact of internal, external, and anatomical diagrams as prototypes. This design disentangles their contributions and highlights the strengths and limitations of each prototype strategy for zero-shot segmentation.
4.1.3. Evaluation Metrics
All images are first normalized to the range and converted to three channels if originally grayscale. For volumetric modalities such as brain MRI and ultrasound, processing is performed on a slice-by-slice basis. Bounding boxes are expressed in pixel coordinates relative to each slice. Dice Similarity Coefficient (DSC) and mean Intersection-over-Union (mIoU) are computed for each task:
where P and G denote predicted and ground truth masks.
4.2. Performance
The Large Vision-Language Model bounding box priors improve localization, while prototype-based similarity ranking refines mask selection, particularly in challenging scenarios involving low contrast, partial occlusion, or anatomical ambiguity. The proposed Gemini CLIP SAM framework achieves substantial improvements over baseline methods that rely solely on SAM point or text prompts.
Table 1 summarizes the quantitative results across all datasets, comparing our zero-shot framework with U-Net, SaLIP [8], GT-SAM (using ground truth bounding boxes), and unprompted SAM (automatic segmentation of the entire image). To ensure consistency, we report both the original scores from SaLIP (as published) and rerun results obtained using the same prompts. We found that some previously reported scores could not be fully replicated, highlighting the challenges of prompt reproducibility and reinforcing the need for more robust alternatives such as prototype-based retrieval.

Table 1.
Performance comparison (DSC and mIoU) across models for different datasets.
Our method demonstrates consistent gains in both DSC and mIoU across all imaging modalities. For lung segmentation, DSC improves from 0.82 with SaLIP reruns to 0.90, and mIoU from 0.74 to 0.83. In fetal head segmentation, performance rises from DSC 0.80 to 0.82 () and mIoU from 0.72 to 0.74 (). Brain MRI benefits the most, with DSC improvements ranging from 0.02 to 0.14 depending on the scanner type. For example, Philips 1.5T improves from 0.80 to 0.94 in DSC and from 0.72 to 0.89 in mIoU. Siemens 3T scans achieve the highest overall performance, with our method reaching DSC 0.95 and mIoU 0.91 using zero-shot prototype-based similarity guided by LVLM priors. To ensure that these improvements are statistically robust, we performed two-tailed paired t-tests on per-sample Dice and mIoU values from matched cases across six dataset pairs (brain MRI subsets, chest X-ray lungs, and fetal head ultrasound). The proposed LVLM prototype method showed consistently higher scores with large effect sizes: Dice increased by 0.12–0.23 and mIoU by 0.15–0.30 on average across pairs, with all comparisons achieving . For example, on the GE 1.5 T brain subset (), Dice improved from to and mIoU from to . These results confirm that the performance advantages of our method over SaLIP are statistically significant across all datasets.
In several cases, our method closely matches GT-SAM accuracy in Table 1. For example, both methods achieve DSC 0.93 and mIoU 0.88 on Philips 3T, while our approach attains DSC 0.94 and mIoU 0.90 on GE 3T compared with GT-SAM’s 0.96 and 0.93. Similarly, on Siemens 3T, our method reaches DSC 0.95 and mIoU 0.91, approaching GT-SAM (0.96 DSC, 0.90 mIoU). These results demonstrate the effectiveness of combining LVLM-generated bounding boxes with prototype-based similarity in narrowing the gap to an oracle bounding box setup.
Although U-Net achieves the highest performance in several brain MRI subsets (e.g., DSC 0.98 on GE 1.5T) in Table 1, it is important to note that U-Net was fully supervised and trained on the target domain, whereas our method operates in a purely zero-shot setting without any retraining or fine-tuning. This highlights the strength of our approach in scenarios where annotated training data is limited or unavailable.
Overall, the integration of LVLM priors and prototype-based ranking not only improves over text-based baselines such as SaLIP [8] but also achieves segmentation quality comparable to that of GT-SAM, demonstrating strong generalization without the need for domain-specific training.
4.3. Prototype-Based Similarity and LVLM Bounding Box
Table 2 compares CLIP similarity based on text prompts, as used in SaLIP [8], with our prototype-based similarity retrieval integrated with a large vision-language model (LVLM). Our approach consistently outperforms the text-based method across all datasets. The LVLM expands the candidate segmentation pool by incorporating outputs from bounding box prompts alongside point-based ones, while the prototype-based retrieval mechanism more effectively selects the most accurate segmentation. These quantitative improvements are shown in Table 2.
Table 2.
Performance comparison between zero-shot text-based and prototype-based similarity retrieval with and without LVLM-generated bounding boxes (LVLM Bbox). Metrics are reported as Dice (DSC) and mIoU.
Moreover, incorporating a few labeled examples from the target dataset (few-shot) significantly improves performance across a range of modalities in Table 3. In scenarios where no closely related dataset is available, simple anatomical diagrams representing the segmentation target can serve as effective prototypes. Although this results in a slight reduction in accuracy, the performance remains competitive, as shown in the Proto-diagram column of in Table 2.
Table 3.
Comparison of segmentation performance (DSC and mIoU) among SaLIP rerun baseline, prototype-only, LVLM-only, combine zero-shot, and combine few-shot methods.
As shown in Figure A1, the text-based model frequently selects overly inclusive masks (e.g., covering most of the head in brain MRI), while the prototype-based approach more reliably identifies the correct segmentation. Other Figure A2 and Figure A3 provide representative examples from chest X-ray lung segmentation (CXRMAL), and fetal head ultrasound (HC18), highlighting the qualitative differences between our method, the SaLIP baseline, and the ground truth. The performance gains stem from both an improved pool of segmentation candidates and a more effective selection mechanism based on prototype similarity.
4.4. Bounding Box Estimation with Prompt-Engineered Large Vision-Language Models
To quantify computational and economic efficiency, we analyzed token usage and cost associated with bounding box generation using the Gemini 2.5 Pro API [9]. Each image query required approximately 548 input tokens and 20 output tokens. Given the current pricing rates for requests under 200,000 tokens (input: USD 1.25 per million tokens; output: USD 10.00 per million tokens), the per-image cost is as follows:
The total cost per image is USD 0.000885. To further optimize efficiency, we utilized the Gemini Batch API [20], which allows simultaneous processing of multiple queries and reduces tokenization overhead. In practice, this batch strategy lowered the effective per-image cost by roughly 50%, resulting in an average of USD 0.00044 per image. For large-scale annotation, generating 10,000 bounding boxes therefore costs approximately USD 4.40, highlighting the economic scalability of the proposed approach.
4.5. Ablations
To better understand the contribution of individual components in our method, we conducted a series of ablation studies. These experiments explore several design choices, including the role of prototype similarity in separating left and right lung regions, the effect of constraining point prompts to LVLM-derived bounding boxes, and the impact of prompt engineering and model selection for bounding box estimation. Through these targeted investigations, we aim to isolate the effects of each component and provide insight into how they contribute to the overall performance of the system.
4.5.1. Component-Wise Study
To isolate the contribution of each module, we performed a quantitative ablation across all datasets comparing the following: (i) LVLM-only, where the LVLM–SAM segmentation generator produces candidates and the final mask is chosen via text-based retrieval; (ii) Prototype-only, where candidates are generated without LVLM spatial priors and the final mask is selected via prototype similarity in the shared embedding space; (iii) Combined (zero-shot), which integrates LVLM–SAM candidate generation with prototype-based retrieval; and (iv) Combined (few-shot), which uses the prototype bank with a small number of in-domain exemplars selected from the target dataset (e.g., per class).
Table 3 reports the DSC and mIoU for all configurations. Across brain MRI, lung X-ray, and fetal head ultrasound, the Combined configuration consistently outperforms both LVLM-only and Prototype-only, demonstrating the complementary strengths of LVLM-derived spatial priors and prototype-based selection. The few-shot augmentation further enhances accuracy while adding negligible computational overhead and requiring no parameter updates.
An exception is observed in the fetal head dataset, where the LVLM-only configuration achieves higher scores than the Combined model. This may be attributed to the dataset choice, as PSFHS differs considerably from HC18 in terms of contrast and imaging characteristics, reducing cross dataset generalization. However, when the few-shot approach is applied using prototypes sampled directly from the target dataset (HC18), the Combined configuration achieves significantly higher performance than LVLM-only, highlighting the importance of prototype relevance and quality in driving segmentation accuracy.
4.5.2. Prototype Similarity for Separating Left and Right Lung
Previous work, such as SaLIP [8], has shown that text-based similarity alone is insufficient for distinguishing between left and right lung regions, largely because CLIP lacks spatial semantic understanding—specifically, it struggles to differentiate objects based on spatial alignment (i.e., left vs. right). In our experiments, we observed similar limitations: text-based CLIP similarity frequently resulted in overlapping or incorrect lung assignments, particularly in cases with ambiguous anatomical boundaries.
In contrast, our method leverages the LVLMs to explicitly estimate bounding boxes for the left and right lungs at the outset. This enables the formation of distinct candidate pools for each lung, allowing prototype-based similarity to more effectively retrieve the correct segmentation candidate. This approach significantly mitigates the ambiguity observed in purely text-based methods.
The quantitative results demonstrate the effectiveness of our approach. When integrated with text-based similarity, the LVLM achieves a Dice score of and an IoU of , surpassing the previously reported SaLIP baseline, which attained a Dice score of and an IoU of without incorporating the LVLM, as shown in Table 2. However, the performance gain from using our prototype-based model () was not substantially greater than that of the LVLM-enhanced text-based model (), likely due to the high similarity among segmentation candidates generated from the same prompt applied to SAM. Nonetheless, more substantial performance improvements with the prototype-based model are observed on other datasets, as illustrated in Figure A3.
4.5.3. Restricting Point Prompts to LVLM Bounding Boxes
In the original SaLIP approach [8], point prompts were sampled uniformly across the entire image. In our modified version, point prompts were restricted to the region within the bounding box generated by the LVLM, with the aim of narrowing the search space to more relevant areas. However, this restriction did not result in a statistically significant improvement in Dice or mIoU. One possible explanation, particularly in the case of the lungs dataset, is that sampling point prompts across the entire image, as done in SaLIP, does not generate enough misleading segmentation candidates to confuse the final selection process. Nonetheless, this modification has shown more substantial performance gains on other datasets, as presented in Table 2.
4.5.4. Prompt Engineering and Choice of Large Vision-Language Models for Bounding Box Estimation
To derive reliable bounding box priors, we designed structured prompts that explicitly defined both the target anatomical structures and the spatial constraints of the bounding box. The final prompts used in our pipeline are provided in Appendix B. These prompts were tested across several LVLMs, including maverick-llama-4, GPT-4V, and Gemini Vision. While multiple models could generate bounding boxes, we selected Gemini Pro 2.5 for its consistent alignment with regions of interest and compatibility with available computational resources. In contrast, alternative models often produced loose or misaligned boxes, which degraded downstream segmentation accuracy. Representative bounding box results from different models with the same prompt are shown in Figure 2, underscoring the importance of prompt engineering and the sensitivity of the pipeline to LVLM choice.
5. Discussion
We propose a prototype-guided zero-shot segmentation framework that pairs LVLM-generated spatial priors with visual prototype retrieval to improve SAM mask selection. By decoupling selection from language embeddings and using low-cost LVLM proposals to constrain SAM’s search space, the method improves localization and yields high-quality segmentation candidates without task-specific training. With systematic prompting of Gemini Pro 2.5, we obtain anatomically consistent bounding boxes across modalities.
Relative to SaLIP [8], which ranks candidates via CLIP-based text and image similarity, prototype retrieval yields greater robustness and generalization. Text prompts can miss spatial context and are sensitive to phrasing; prototype embeddings, built from representative image crops or schematic diagrams, provide more discriminative results. Across brain MRIs, fetal head ultrasounds, and chest X-rays, our method consistently outperforms zero-shot baselines and approaches GT-SAM. The approach is also scalable; with Gemini Pro 2.5 we generated 10,000 bounding boxes in a single batch, supporting semi-automated annotation.
Despite these advantages, limitations remain. Bounding box quality depends on the LVLM models; errors can propagate to segmentation, causing failures. Contributing factors include low-contrast or occluded anatomy, and domain shift from natural-image pretraining. These issues reflect the broader opacity of LVLM decision making. Multi-prompt ensembles and coordinate averaging may improve the localization but increased compute cost. We explored iterative prompting for bounding box refinement: the LVLM generated a box, self-evaluated it, proposed adjustments, and repeated until a predefined quality threshold was met. In practice, this loop often oscillated without converging, offered diminishing returns, and drove inference costs sharply higher.
Prototype retrieval is also sensitive to prototype quality. Non-representative sets reduce accuracy. Promising extensions include automatic prototype selection, adaptive updates, and augmentation via class-conditional diffusion. We currently use a CLIP encoder to compute embeddings, but domain-specific encoders (e.g., MedCLIP [21], BioCLIP [22]) may further improve similarity estimation.
Reproducibility is a practical concern. Our pipeline currently relies on the closed source Gemini 2.5 Pro but is modular and compatible with open models. In exploratory tests, LLaMA 7B and Maverick 17B produced inaccurate and inconsistent bounding boxes on a small number of images, likely reflecting limited visual reasoning capacity. We also tested GPT-4o briefly, but cost limited extensive evaluation; in our preliminary trials, Gemini 2.5 Pro yielded the most consistent and accurate results. We could not assess larger open models (e.g., LLaMA 70B, GPT OSS 120B) due to hardware constraints (typically requiring GPU for efficient inference). Future work will evaluate such models on high memory systems to improve transparency and local usability.
Finally, ethical use of clinical data is essential. Although our datasets are public and anonymized, deployment should comply with privacy regulations and institutional review. Local or on-premise LVLM inference can reduce data exposure and operational cost.
In summary, LVLM-derived spatial priors combined with prototype-based selection substantially improve zero-shot medical image segmentation while eliminating manual annotations. The framework is flexible, scalable across modalities, and well positioned for further gains as LVLMs and domain-specific encoders advance.
6. Conclusions
This study presents a novel framework for zero-shot medical image segmentation that integrates bounding box priors from a large vision-language model (Gemini Pro 2.5), prototype-guided mask retrieval using CLIP embeddings, and segmentation candidate generation via the Segment Anything Model (SAM). The method removes the need for modality-specific fine-tuning or task-specific annotations, enabling robust and scalable deployment across diverse imaging modalities, including brain MRIs, fetal ultrasounds, and chest X-rays.
Quantitatively, the proposed prototype-guided LVLM Bbox framework achieves notable improvements over the SaLIP rerun baseline across all datasets. For example, on CC359 brain MRI, Dice and mIoU scores increased from / to / on GE 1.5T and from / to / on GE 3T. Similar gains were observed for lung segmentation ( to Dice) and fetal head ultrasound ( to Dice). These results demonstrate consistent and substantial improvements in both localization and boundary accuracy, outperforming previous zero-shot methods such as SaLIP [8].
By replacing language-based similarity with visual prototypes and leveraging spatial priors generated by the vision-language model, the proposed approach addresses two fundamental limitations of current prompt-based segmentation methods: language bias and unreliable localization. The integration of LVLM priors with prototype-based retrieval not only improved mean Dice and mIoU scores by up to and , respectively, but also produced anatomically consistent boundaries across modalities.
Extensive experiments confirm that the method narrows the gap between zero-shot and oracle-guided (GT-SAM) segmentation, offering near-supervised accuracy without requiring labeled data. The framework achieves these results in a purely zero-shot setting, relying only on small prototype sets and general-purpose LVLMs. The use of prompt-engineered queries for bounding box generation proved both accurate and cost-efficient, enabling large-scale region proposal with minimal human input.
In conclusion, the combination of LVLM-based localization and prototype-driven visual retrieval establishes a new benchmark for training-free segmentation, achieving state-of-the-art zero-shot performance across brain MRI, fetal ultrasound, and chest X-ray datasets.
Author Contributions
Conceptualization, H.P. and S.C.; methodology, H.P.; software, H.P.; validation, H.P. and S.C.; writing—original draft preparation, H.P.; writing—review and editing, S.C.; supervision, S.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Vice President for Research and Partnerhsips, the Data Institute for Societal Challenges, and the Stephenson Cancer Center at the University of Oklahoma through the 2021 DISC/SCC Seed Grant Award.
Data Availability Statement
All research data used in this study were sourced from publicly available data on public websites. The source codes developed for this study are accessible at: ProtoSAM https://github.com/hngpham/ProtoSAM (accessed on 1 October 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Visual Results

Figure A1.
Brain MRI segmentation results. From left to right: (a) input image with ground truth overlay, (b) SaLIP segmentation, (c) LVLM with text-based retrieval, (d) LVLM with a similar target segmentation as prototype, and (e) LVLM with an anatomical illustration of the brain as prototype.

Figure A2.
Fetal ultrasound segmentation results. From left to right: (a) input image with ground truth overlay, (b) SaLIP segmentation, (c) LVLM with a similar target segmentation as prototype (ours), (d) LVLM with text-based retrieval.

Figure A3.
Chest X-ray segmentation results. From left to right: (a) input image with ground truth overlay, (b) SaLIP segmentation, (c) LVLM with text-based retrieval, (d) LVLM with a similar target segmentation as prototype, and (e) LVLM with an anatomical illustration of the lungs as prototype.
Appendix B. Prompt Engineering
Among all other model, we can see the best model for this task is Gemini Pro 2.5. All the prompts below would be used for this model.
Appendix B.1. Brain
- Identity and Purpose
You are an expert radiologist specializing in brain anatomy. You will be provided with a sagittal medical image of a human brain. Your task is to identify and provide the coordinates for a bounding box that isolates the brain based on the specific anatomical landmarks defined below.
The origin for coordinates is the top-left corner of the image. Assume the input image has dimensions of DIMENSIONS pixels.
- Guidelines for Identifying the Bounding Box
- Top Edge (): The top edge of the bounding box must be horizontally aligned with the superior-most (highest) point of the frontal lobe.
- Right Edge (): The right edge must be vertically aligned with the anterior-most (rightmost) point of the frontal lobe.
- Left Edge (): The left edge must be vertically aligned with the posterior-most (leftmost) point of the occipital lobe.
- Bottom Edge (): The bottom edge must be horizontally aligned with the inferior-most (lowest) point of the cerebellum.
- Output Instructions
The values must be in the following order:
Do not include any extra text, explanation, or formatting—only the list in square brackets.
- Input
INPUT: [Insert the sagittal brain MRI image here]
Appendix B.2. Lungs
- Identity and Purpose
You are an expert radiologist specializing in thoracic anatomy. You will be provided with coronal or axial medical images (e.g., CT scans). Your task is to identify and provide the tightest possible bounding box coordinates for the left lung and the right lung individually. The goal is to obtain an accurate estimation of the lung positions for later segmentation.
The origin of the x and y coordinates is the top-left corner of the image. Assume the input image has dimensions of DIMENSIONS pixels.
- Guidelines for Identifying the Bounding Boxes
- Each bounding box must tightly enclose the entirety of its respective lung parenchyma.
- The boxes must strictly exclude the heart, mediastinum, great vessels, trachea, diaphragm, chest wall (ribs, muscle), and other non-lung tissues.
- Provide two distinct bounding boxes: one for the left lung and one for the right lung.
- Aim for the most compact bounding boxes possible to minimize empty space around the lung tissue.
- Output Instructions
Provide the output as a single object with: left lung first, then right lung. Each bounding box must be represented as a list of four integers in the following order:
Do not include any extra text, explanation.
Example output format:
- Input
INPUT: [Insert the coronal or axial chest image here]
Appendix B.3. Fetal Heads
- Objective
As an expert obstetric sonographer, your task is to analyze a DIMENSIONS pixel axial ultrasound image of a fetal head and return its tightest possible bounding box coordinates. The coordinate origin is the top-left corner of the image.
- Bounding Box Criteria
- Target Feature: Identify the fetal head by its skull, which appears as a continuous, bright, elliptical boundary. This structure surrounds the darker brain tissue and is set against black amniotic fluid.
- Enclosure: The bounding box must completely enclose the entire fetal head, defined by the outer contour of the skull (calvarium).
- Precise Fit: The bounding box must be perfectly snug. All four edges of the box (top, bottom, left, and right) must touch the outer boundary of the fetal skull, ensuring there is no extra space between the box and the skull.
- Output Instructions
Provide the output as a single list containing one list of four integers in the order:
Do not include any additional text, explanations, or labels.
Example output:
- Input
INPUT: [Insert the axial fetal head ultrasound image here]
References
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A Survey on Deep Learning in Medical Image Analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar] [CrossRef]
- Fan, K.; Liang, L.; Li, H.; Situ, W.; Zhao, W.; Li, G. Research on Medical Image Segmentation Based on SAM and Its Future Prospects. Bioengineering 2025, 12, 608. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Tang, J.; Men, A.; Chen, Q. EviPrompt: A Training-Free Evidential Prompt Generation Method for Segment Anything Model in Medical Images. arXiv 2023, arXiv:2311.06400. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Zhang, Y.; Zhou, Y.; Wu, Y.; Gong, C. Can SAM Segment Polyps? arXiv 2023, arXiv:2304.07583. [Google Scholar] [CrossRef]
- Ravi, N.; Gabeur, V.; Hu, Y.T.; Hu, R.; Ryali, C.; Ma, T.; Khedr, H.; Rädle, R.; Rolland, C.; Gustafson, L.; et al. SAM 2: Segment Anything in Images and Videos. arXiv 2024, arXiv:2408.00714. [Google Scholar] [PubMed]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. arXiv 2021, arXiv:2103.00020. [Google Scholar] [CrossRef]
- Aleem, S.; Wang, F.; Maniparambil, M.; Arazo, E.; Dietlmeier, J.; Silvestre, G.; Curran, K.; O’Connor, N.E.; Little, S. Test-Time Adaptation with SaLIP: A Cascade of SAM and CLIP for Zero shot Medical Image Segmentation. arXiv 2024, arXiv:2404.06362. [Google Scholar]
- Google. We’re Expanding Our Gemini 2.5 Family of Models. 2025. Available online: https://blog.google/products/gemini/gemini-2-5-model-family-expands/ (accessed on 17 June 2025).
- Towle, B.; Chen, X.; Zhou, K. SimSAM: Zero-shot Medical Image Segmentation via Simulated Interaction. arXiv 2024, arXiv:2406.00663. [Google Scholar]
- Bian, C.; Yuan, C.; Ma, K.; Yu, S.; Wei, D.; Zheng, Y. Domain Adaptation Meets Zero-Shot Learning: An Annotation-Efficient Approach to Multi-Modality Medical Image Segmentation. IEEE Trans. Med. Imaging 2022, 41, 1043–1056. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Zhang, Y.; Chen, J.N.; Xiao, J.; Lu, Y.; Landman, B.A.; Yuan, Y.; Yuille, A.; Tang, Y.; Zhou, Z. CLIP-Driven Universal Model for Organ Segmentation and Tumor Detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 21095–21107. [Google Scholar] [CrossRef]
- OpenAI. Introducing GPT-4o and More Tools to ChatGPT Free Users. 2024. Available online: https://openai.com/index/gpt-4o-and-more-tools-to-chatgpt-free/ (accessed on 13 May 2024).
- Souza, R.; Lucena, O.; Garrafa, J.; Gobbi, D.; Saluzzi, M.; Appenzeller, S.; Rittner, L.; Frayne, R.; Lotufo, R. An open, multi-vendor, multi-field-strength brain MR dataset and analysis of publicly available skull stripping methods agreement. NeuroImage 2018, 170, 482–494. [Google Scholar] [CrossRef] [PubMed]
- van den Heuvel, T.L.A.; de Bruijn, D.; de Korte, C.L.; van Ginneken, B. Automated measurement of fetal head circumference using 2D ultrasound images. PLoS ONE 2018, 13, e0200412. [Google Scholar] [CrossRef] [PubMed]
- Sharma, N. Segmentation-Based Classification Deep Learning Model for Classifying the Severity of COVID-19 on Chest X-ray Images. Diagnostics 2022, 12, 2132. [Google Scholar] [CrossRef]
- Shattuck, D.W.; Mirza, M.; Adisetiyo, V.; Hojatkashani, C.; Salamon, G.; Narr, K.L.; Poldrack, R.A.; Bilder, R.M.; Toga, A.W. LPBA40 Subjects Native Space: MRI Data and Brain Masks in Native Space. Laboratory of Neuro Imaging (LONI), University of Southern California. 2007. Available online: https://www.loni.usc.edu/research/atlas_downloads (accessed on 23 January 2025).
- Chen, G.; Bai, J.; Ou, Z.; Lu, Y.; Wang, H. PSFHS: Intrapartum ultrasound image dataset for AI-based segmentation of pubic symphysis and fetal head. Sci. Data 2024, 11, 436. [Google Scholar] [CrossRef] [PubMed]
- Danilov, V.; Proutski, A.; Kirpich, A.; Litmanovich, D.; Gankin, Y. Chest X-Ray Dataset for Lung Segmentation. Mendeley Data, Version 2, 2022. Available via Mendeley Data—Chest X-Ray Dataset for Lung Segmentation. Available online: https://data.mendeley.com/datasets/8gf9vpkhgy/2 (accessed on 23 January 2025).
- Google. Gemini Batch API. 2025. Available online: https://ai.google.dev/gemini-api/docs/batch-api/ (accessed on 17 June 2025).
- Wang, Z.; Wu, Z.; Agarwal, D.; Sun, J. MedCLIP: Contrastive Learning from Unpaired Medical Images and Text. arXiv 2022, arXiv:2210.10163. [Google Scholar] [CrossRef]
- Stevens, S.; Wu, J.; Thompson, M.J.; Campolongo, E.G.; Song, C.H.; Carlyn, D.E.; Dong, L.; Dahdul, W.M.; Stewart, C.; Berger-Wolf, T.; et al. BioCLIP: A Vision Foundation Model for the Tree of Life. arXiv 2024, arXiv:2311.18803. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).