
The Fruit Recognition and Evaluation Method Based on Multi-Model Collaboration


Abstract
1. Introduction
- (1)
- This paper proposes a multi-model collaborative method for fruit recognition and evaluation, which separates the detection and classification tasks and optimizes the classification results through a feature matching network. The proposed method can achieve more accurate fruit recognition and is also suitable for fruit ripeness assessment.
- (2)
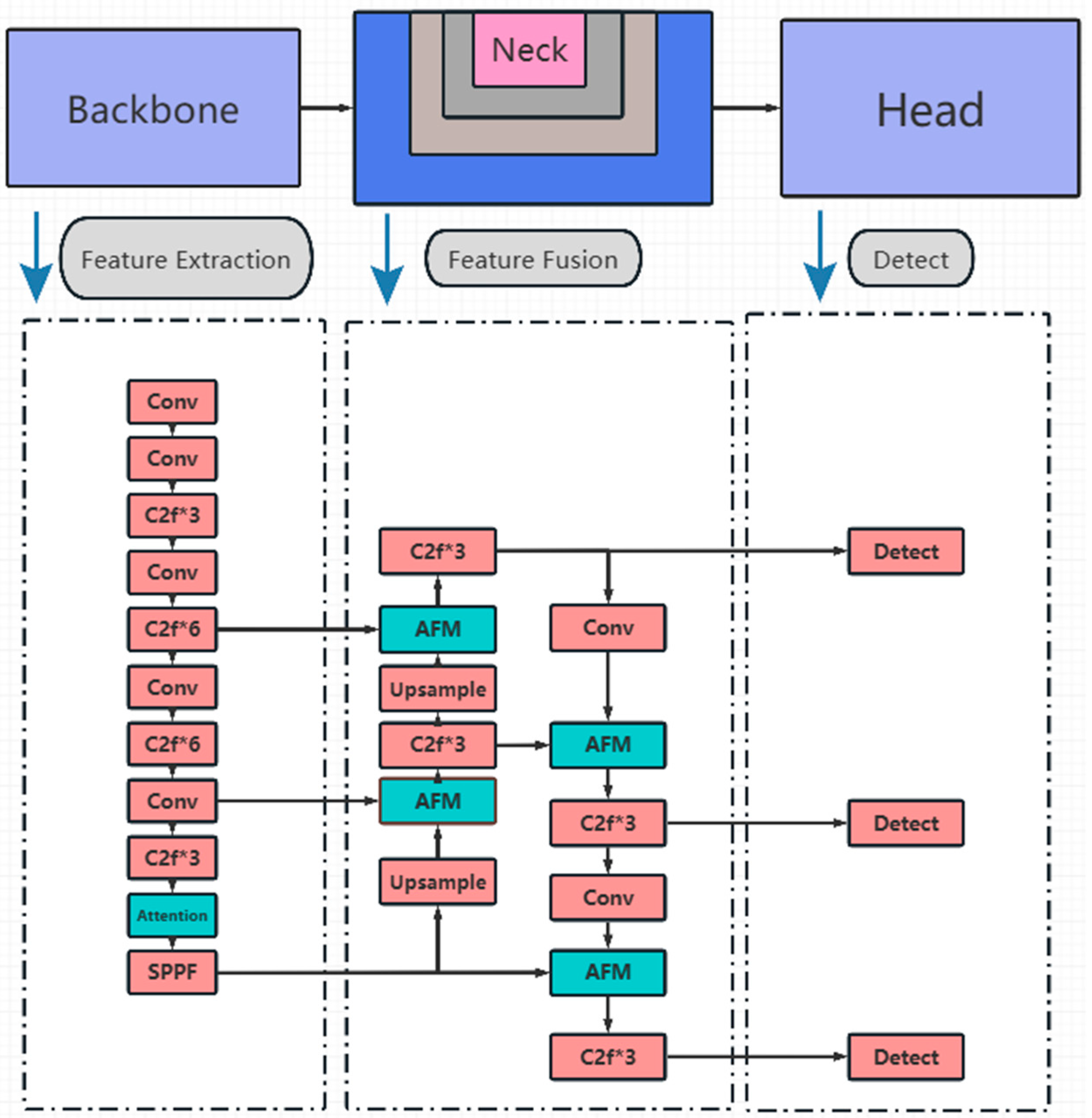
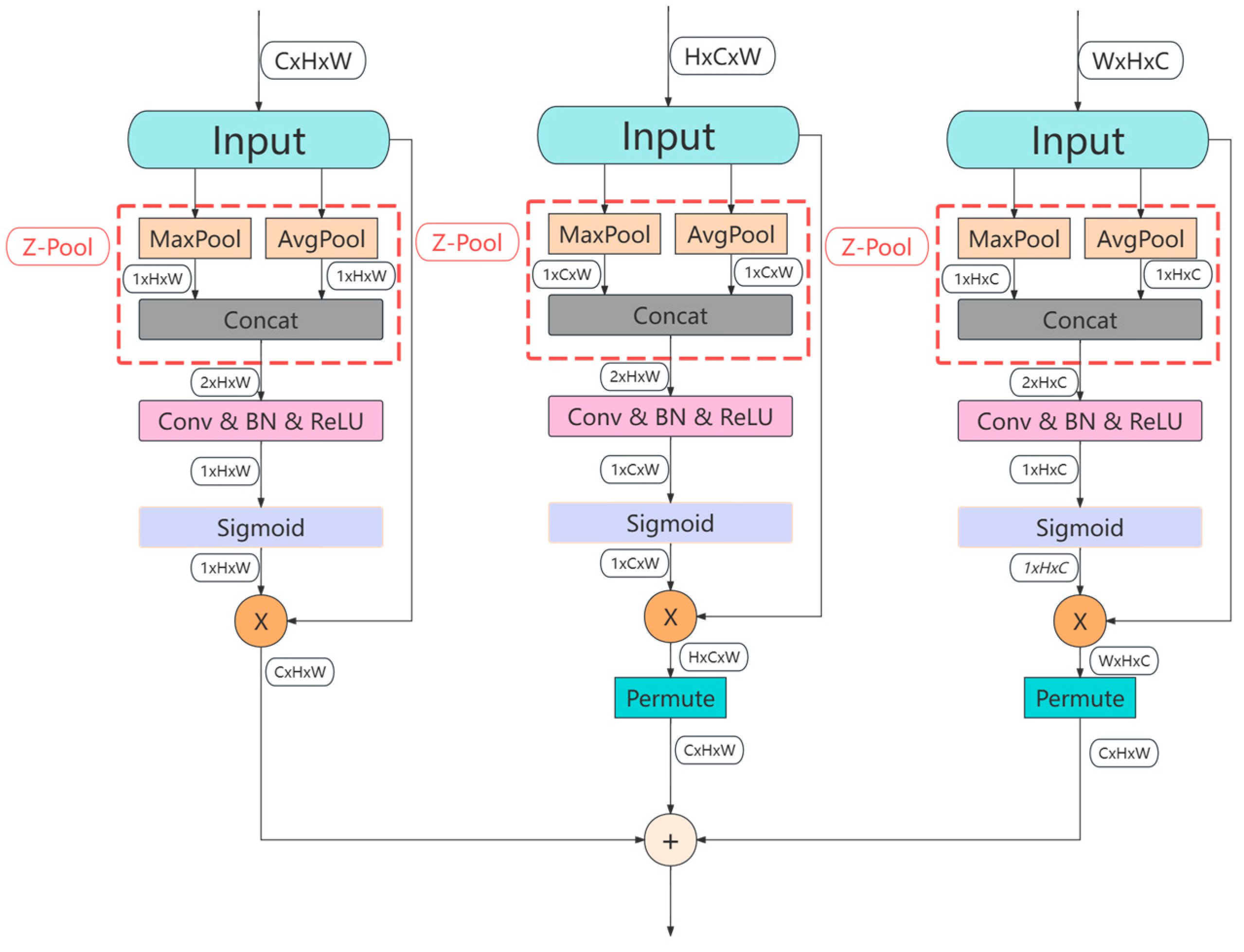
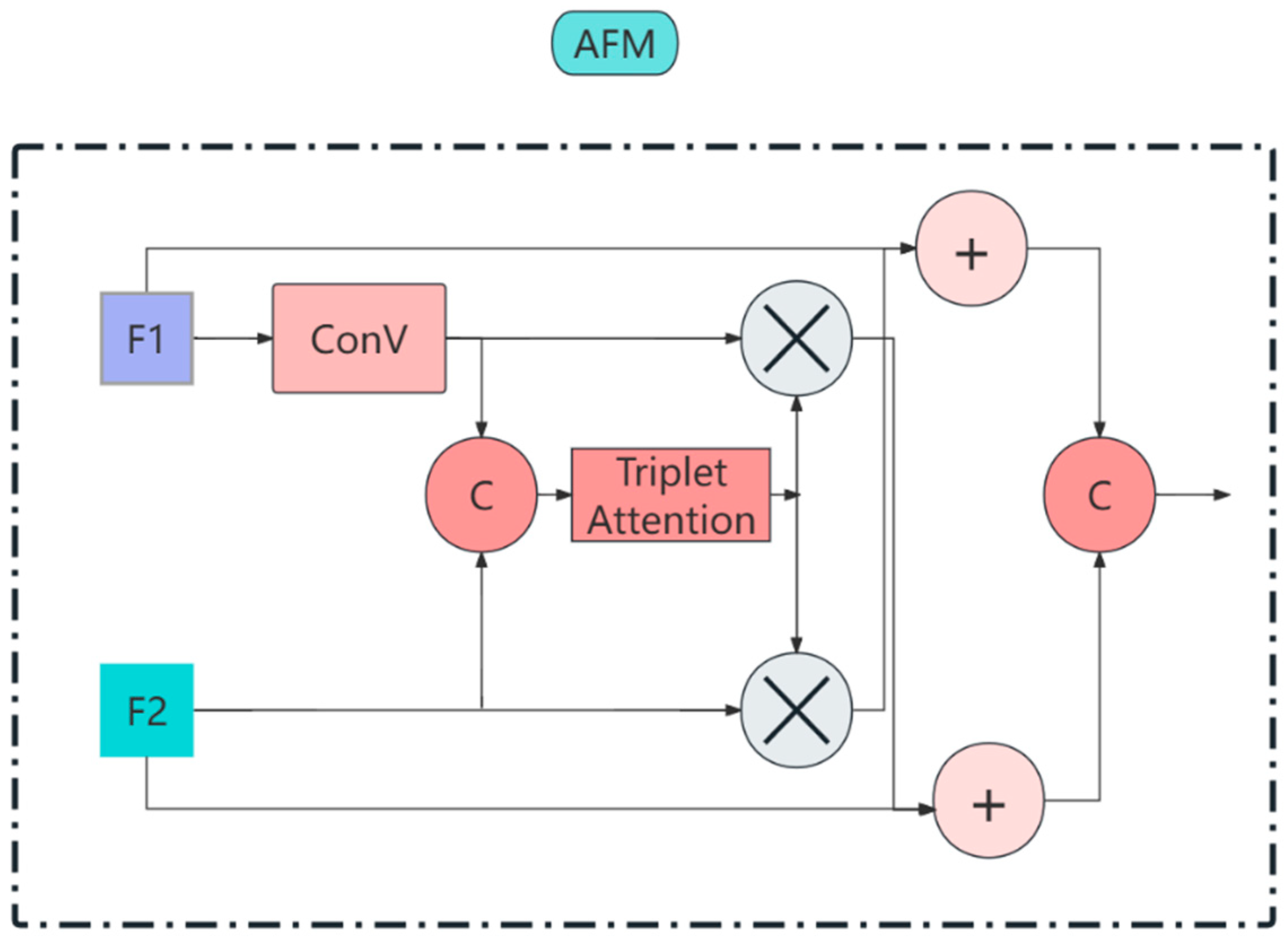
- An attention-based fusion module is designed to achieve interactive fusion and enhancement of input features, which helps improve the performance and generalization capability of the YOLOv8 detection model in complex tasks.
- (3)
- A classification prediction network is designed, where a Swin Transformer-based classification network works in collaboration with a cosine similarity-based feature matching network. This approach enhances classification accuracy while effectively addressing the classification issues of new categories.
- (4)
- Ablation experiments and experimental results demonstrate the effectiveness of the proposed method, which can be applied to both indoor and outdoor fruit recognition and ripeness assessment.
2. Materials and Methods
2.1. Data Preparation
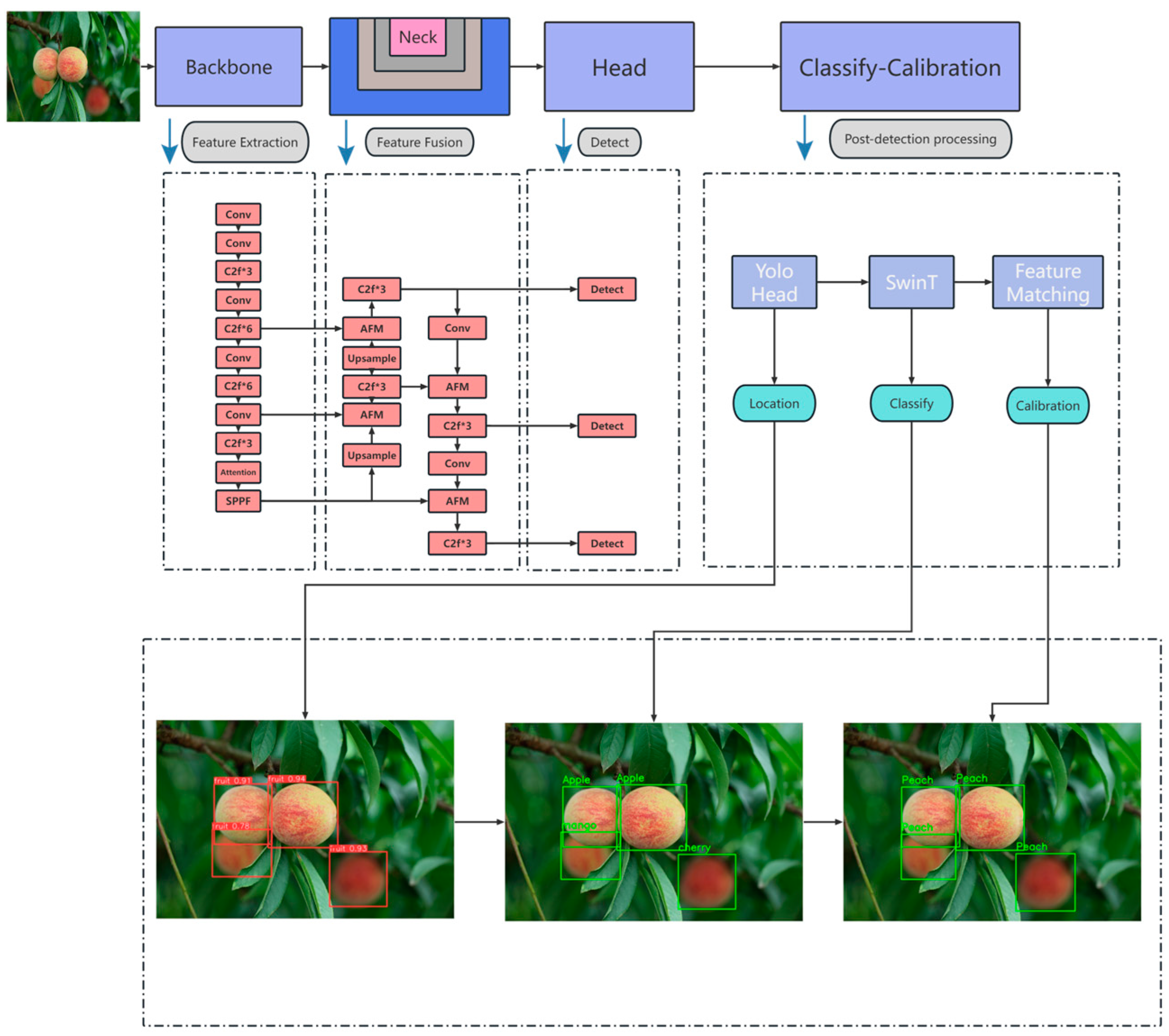
2.2. Proposed Method
2.2.1. Detection Model Based on Improved YOLOv8
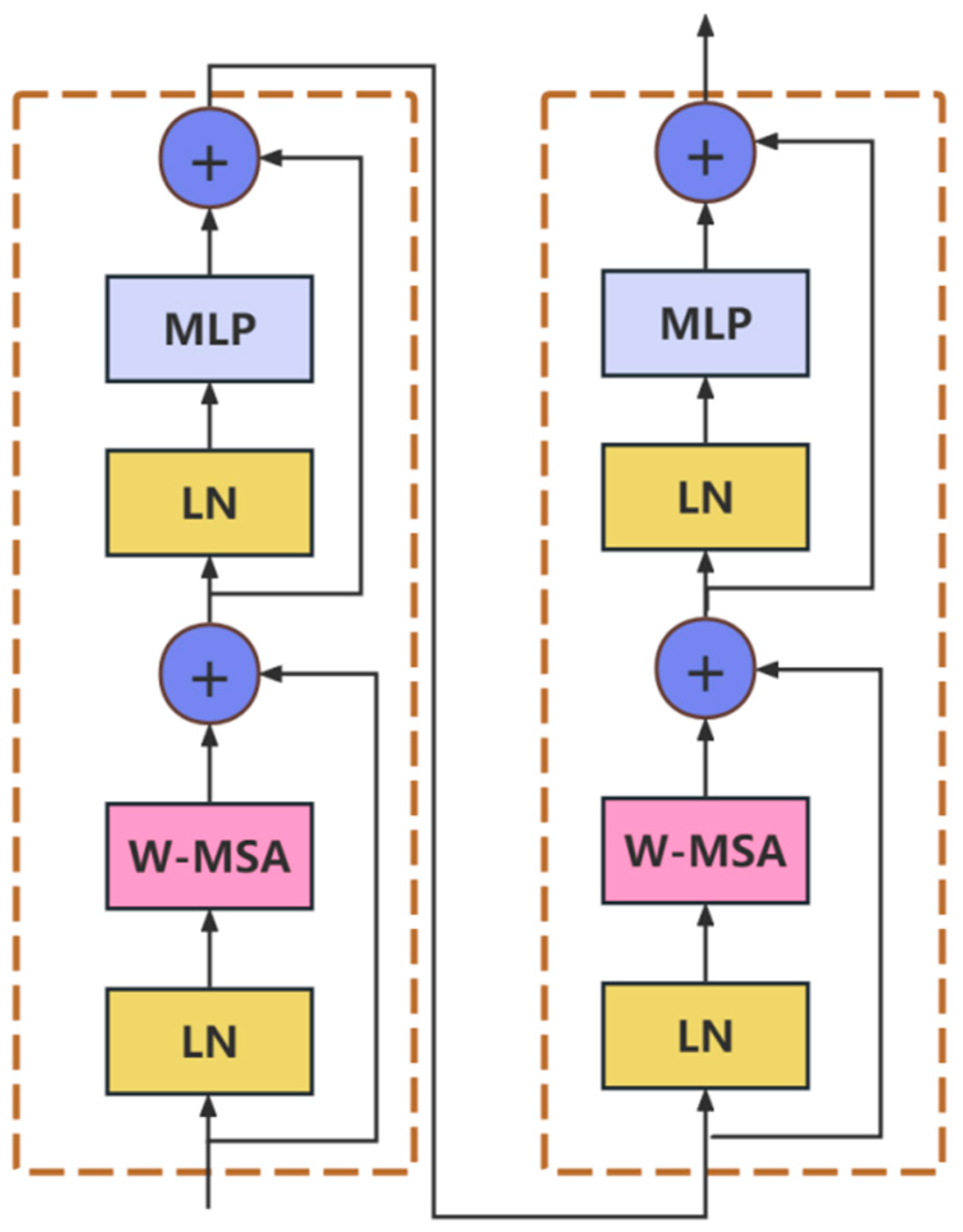
2.2.2. Classification Model with Swin Transformer
2.2.3. Cosine Similarity-Based Feature Matching Network
3. Experiments and Results
3.1. Experimental Environment and Training Parameter Settings
3.2. Evaluation Index
3.2.1. Evaluation Index of YOLOv8 Detection Model
3.2.2. Evaluation Metrics for Swin Transformer Classification Models
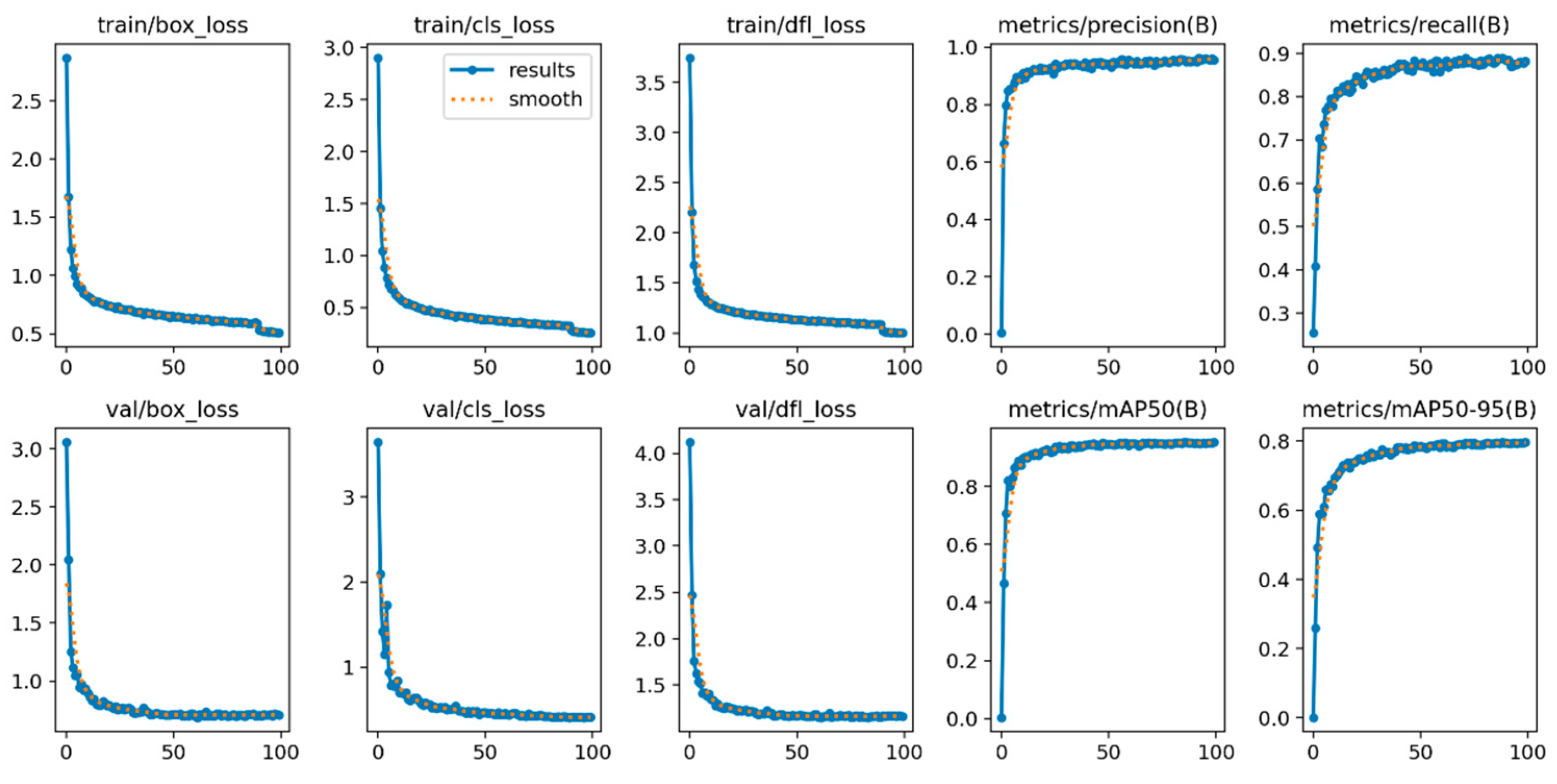
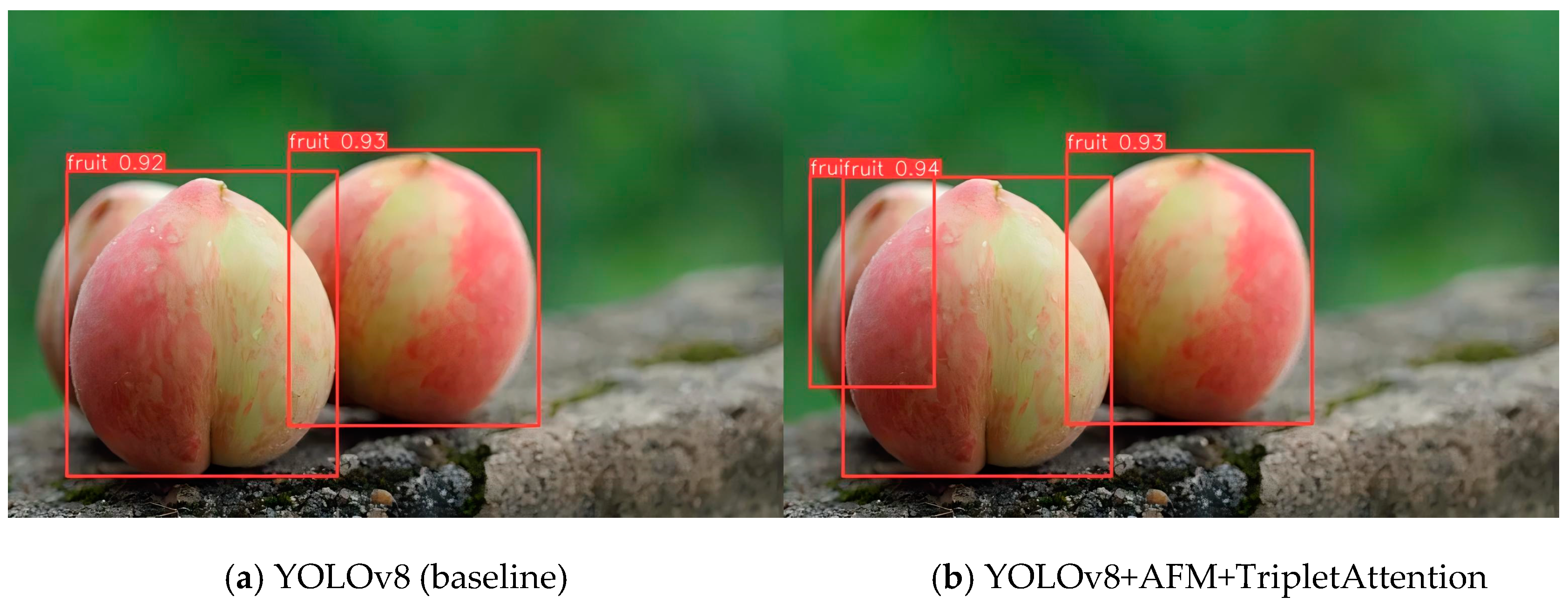
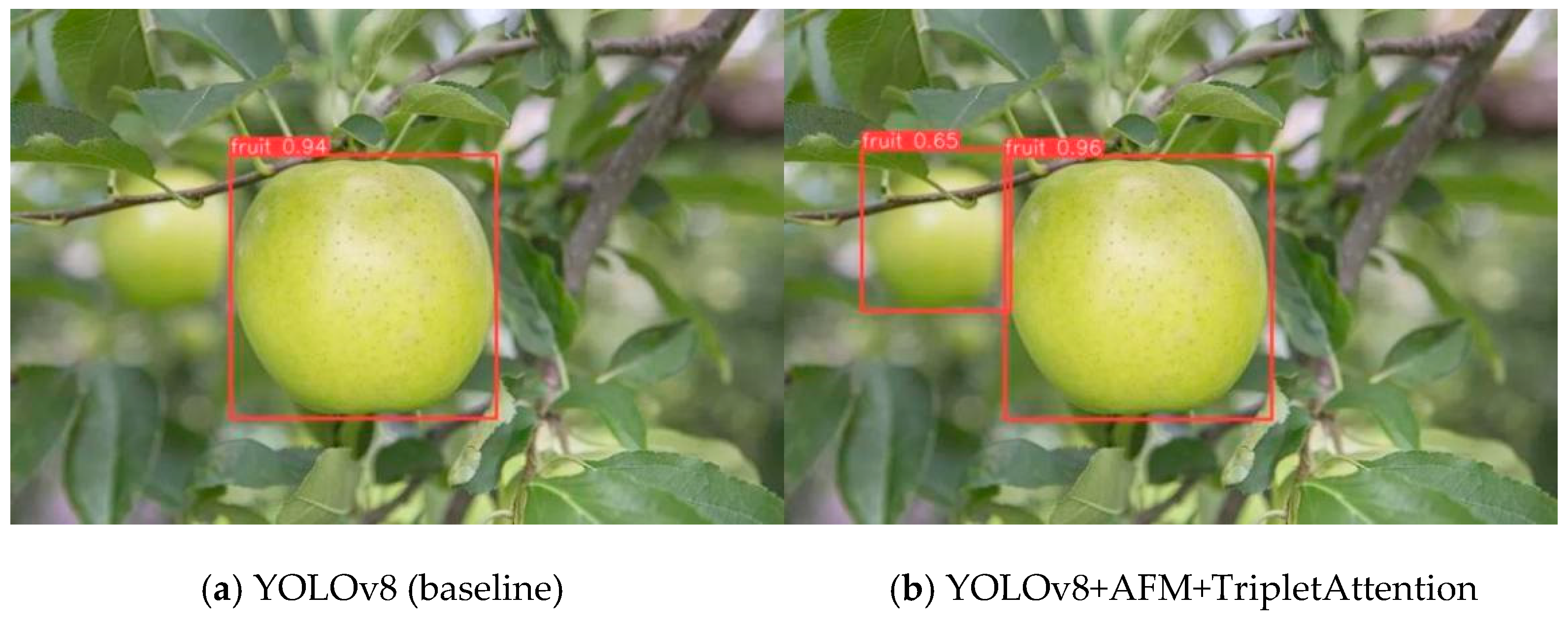
3.3. Ablation Experiment of Improved YOLOv8 Detection Model
3.4. Training the Swin Transformer Classification Model
3.5. Result and Analysis
3.5.1. Experiment on Detecting Untrained Fruit Categories
3.5.2. Experiment on Classifying Untrained Fruit Categories
3.5.3. Fruit Evaluation Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goel, N.; Sehgal, P. Fuzzy classification of pre-harvest tomatoes for ripeness estimation—An approach based on automatic rule learning using decision tree. Appl. Soft Comput. 2015, 36, 45–56. [Google Scholar] [CrossRef]
- Yu, L.; Xiong, J.; Fang, X.; Yang, Z.; Chen, Y.; Lin, X.; Chen, S. A litchi fruit recognition method in a natural environment using RGB-D images. Biosyst. Eng. 2021, 204, 50–63. [Google Scholar] [CrossRef]
- Lu, J.; Lee, W.S.; Gan, H.; Hu, X. Immature citrus fruit detection based on local binary pattern feature and hierarchical contour analysis. Biosyst. Eng. 2018, 171, 78–90. [Google Scholar] [CrossRef]
- Jia, W.; Tian, Y.; Luo, R.; Zhang, Z.; Lian, J.; Zheng, Y. Detection and segmentation of overlapped fruits based on optimized mask R-CNN application in apple harvesting robot. Comput. Electron. Agric. 2020, 172, 105380. [Google Scholar] [CrossRef]
- Zhang, C.; Kang, F.; Wang, Y. An Improved Apple Object Detection Method Based on Lightweight YOLOv4 in Complex Backgrounds. Remote Sens. 2022, 14, 4150. [Google Scholar] [CrossRef]
- Gu, Z.; He, D.; Huang, J.; Chen, J.; Wu, X.; Huang, B.; Dong, T.; Yang, Q.; Li, H. Simultaneous detection of fruits and fruiting stems in mango using improved YOLOv8 model deployed by edge device. Comput. Electron. Agric. 2024, 227, 109512. [Google Scholar] [CrossRef]
- Lu, S.; Chen, W.; Zhang, X.; Karkee, M. Canopy-attention-YOLOv4-based immature/mature apple fruit detection on dense-foliage tree architectures for early crop load estimation. Comput. Electron. Agric. 2022, 193, 106696. [Google Scholar] [CrossRef]
- Ananthanarayana, T.; Ptucha, R.; Kelly, S.C. Deep Learning based Fruit Freshness Classification and Detection with CMOS Image sensors and Edge processors. Electron. Imaging 2020, 32, 2352. [Google Scholar] [CrossRef]
- Kang, H.; Chen, C. Fast implementation of real-time fruit detection in apple orchards using deep learning. Comput. Electron. Agric. 2020, 168, 105108. [Google Scholar]
- Xue, G.; Liu, S.; Ma, Y. A hybrid deep learning-based fruit classification using attention model and convolution autoencoder. Complex Intell. Syst. 2023, 9, 2209–2219. [Google Scholar] [CrossRef]
- Chen, S.; Xiong, J.; Jiao, J.; Xie, Z.; Huo, Z.; Hu, W. Citrus fruits maturity detection in natural environments based on convolutional neural networks and visual saliency map. Precis. Agric. 2022, 23, 1515–1531. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Category | Amount | Number | Category | Amount | Number | Category | Amount |
|---|---|---|---|---|---|---|---|---|
| 1 | Banana | 181 | 10 | Watermelon | 186 | 19 | Hami melon | 188 |
| 2 | Bayberry | 186 | 11 | Mango | 165 | 20 | Pineapple | 189 |
| 3 | Strawberry | 191 | 12 | Lemon | 148 | 21 | Durian | 184 |
| 4 | Coconut | 192 | 13 | Sugar oranges | 177 | 22 | Orange | 188 |
| 5 | Mangosteen | 178 | 14 | Green grapes | 155 | 23 | Red apples | 177 |
| 6 | Pomegranate | 187 | 15 | Pitaya | 182 | 24 | Lichee | 194 |
| 7 | Tomato | 184 | 16 | Longan | 191 | 25 | Grape | 194 |
| 8 | Pear | 188 | 17 | Green apples | 188 | 26 | Grapefruit | 185 |
| 9 | Cherries | 161 | 18 | Cherry tomatoes | 191 | 27 | Kiwi | 187 |
| Configuration Name | Enviromental Parameter |
|---|---|
| CPU | 13th Gen Intel(R) Core(TM) i9-13900KF |
| GPU | NVIDIA GeForce RTX 4080, 16375MiB |
| Memory | 128 G |
| Python | 3.7.16 |
| Torch | 1.13.1 |
| CUDA | 11.6 |
| Parameter | Setting |
|---|---|
| Batch Size | 64 |
| Learning Rate | 0.002 |
| Epochs | 100 |
| Pretrained Weights | No (Training from scratch) |
| Dataset Split | 80% training, 20% test |
| Momentum | 0.9 |
| Data Caching | Yes |
| Optimizer | AdamW |
| Device | CUDA |
| Workers | 8 |
| Parameter | Setting |
|---|---|
| Batch Size | 32 |
| Learning Rate | 0.0001 |
| Epochs | 100 |
| Pretrained Weights | Yes |
| Dataset Split | 80% training, 20% test |
| Optimizer | AdamW |
| Weight Decay | 5E-2 |
| Device | CUDA |
| Workers | 8 |
| Fine-tuning Layers | Fine-tuned all layers |
| Model | Method | P | R | mAP50 | mAP50-95 | Parameters |
|---|---|---|---|---|---|---|
| a | YOLOv8 (baseline) | 0.945 | 0.878 | 0.947 | 0.789 | 3,005,843 |
| b | YOLOv8+TripletAttention | 0.966 | 0.883 | 0.956 | 0.804 | 3,006,143 |
| c | YOLOv8+AFM | 0.957 | 0.884 | 0.956 | 0.800 | 3,110,019 |
| d | YOLOv8+AFM+TripletAttention | 0.969 | 0.899 | 0.957 | 0.802 | 3,110,319 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, M.; Chen, D.; Feng, D. The Fruit Recognition and Evaluation Method Based on Multi-Model Collaboration. Appl. Sci. 2025, 15, 994. https://doi.org/10.3390/app15020994
Huang M, Chen D, Feng D. The Fruit Recognition and Evaluation Method Based on Multi-Model Collaboration. Applied Sciences. 2025; 15(2):994. https://doi.org/10.3390/app15020994
Chicago/Turabian StyleHuang, Mingzheng, Dejin Chen, and Dewang Feng. 2025. "The Fruit Recognition and Evaluation Method Based on Multi-Model Collaboration" Applied Sciences 15, no. 2: 994. https://doi.org/10.3390/app15020994
APA StyleHuang, M., Chen, D., & Feng, D. (2025). The Fruit Recognition and Evaluation Method Based on Multi-Model Collaboration. Applied Sciences, 15(2), 994. https://doi.org/10.3390/app15020994