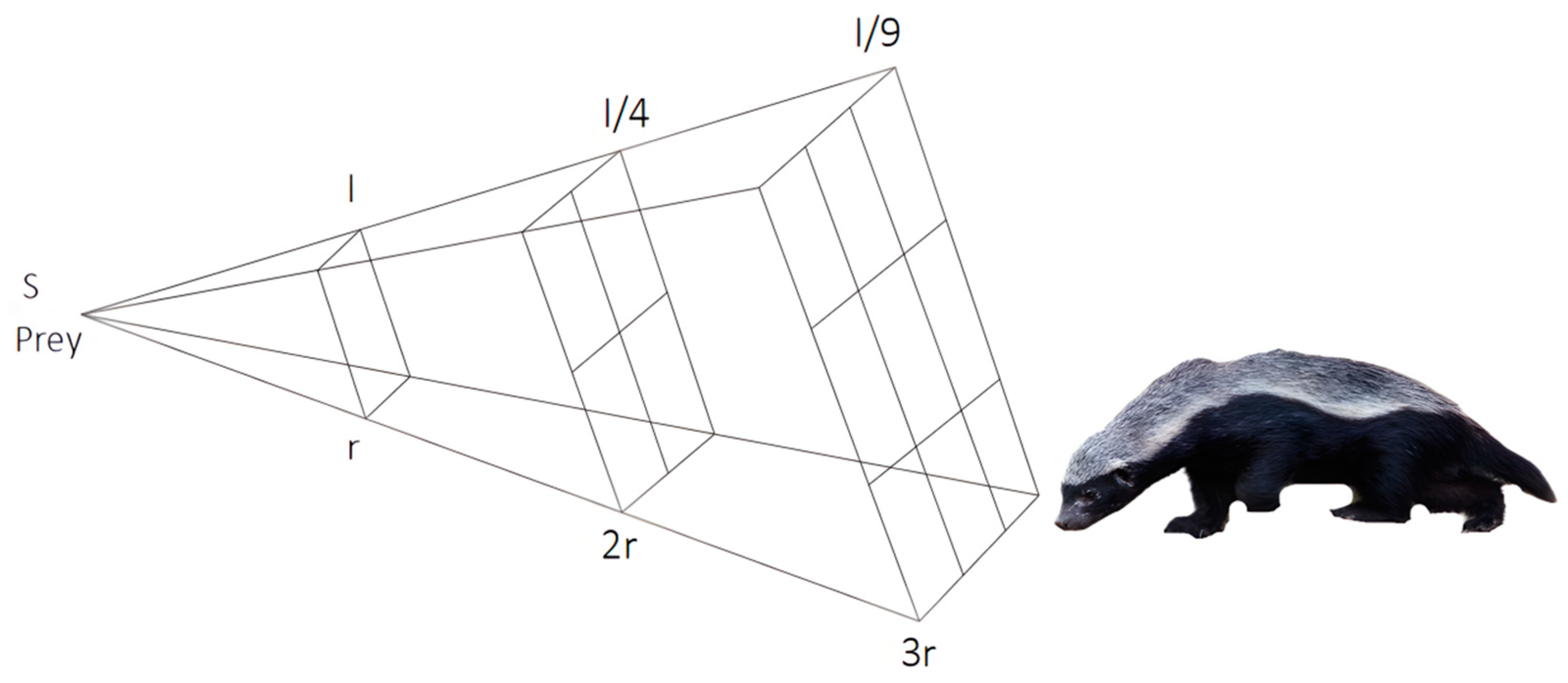
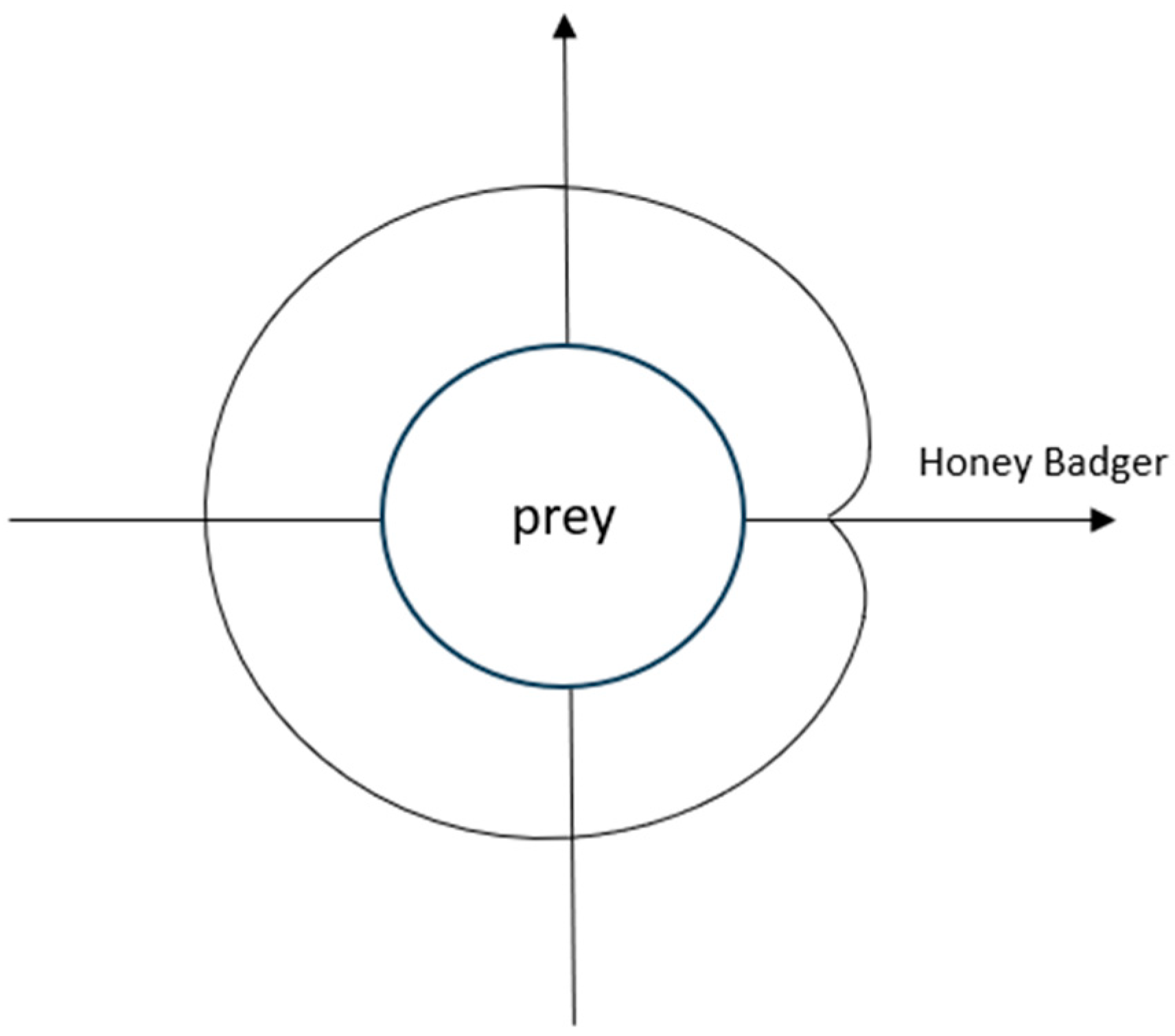
The initial experiment aimed to evaluate the efficacy of the Particle Swarm Optimization (PSO) [
36], Whale Optimization Algorithm (WOA) [
37], Artificial Rabbit Optimization (ARO) [
38], Spider Wasp Optimization (SWO) [
39], HBA, and IHBA on the benchmark function, and then to conduct a detailed comparative analysis based on the results. Specific parameter settings are shown in
Table 1. The second set of experiments applied IHBA to the K-means clustering task. This was compared with HBA and the standard K-means algorithm to evaluate the advantages of IHBA in clustering performance.
5.2. Experimental Comparative Analysis of Improved Honey Badger Algorithm
The IHBA and the comparison algorithm were tested at
= 30 and
= 200, respectively, and the test results are shown in
Table 5,
Table 6 and
Table 7. In the comparison of single-peak test functions, the IHBA showed remarkable advantages, especially in solving accuracy and stability, among the F1–F5 functions. The accuracy of the IHBA average was far ahead compared to other algorithms, indicating the effectiveness of the improvement measures in this paper. The standard deviation of IHBA was 0 for each run, indicating that its stability was better than that of other algorithms in multiple runs. IHBA was closest to the optimal solution in F6. In the F7 to F9 functions, IHBA continued to maintain its advantages, especially in the performance of F7; the average value and optimal solution of IHBA were much lower than other algorithms, showing efficiency and stability in the case of problems. When
= 200, the dimensionality increased, leading to a corresponding rise in the complexity of the algorithm. The performance of comparison algorithms was diminished in terms of solving accuracy, standard deviation, and other metrics. In contrast, IHBA continued to outperform other comparative algorithms; it achieved theoretical optimal values for solving accuracy on F1–F9 while maintaining a standard deviation of 0. This indicates that IHBA exhibited strong robustness. In summary, IHBA showed strong solving ability and stability on multiple single-peak test functions, significantly superior to ATR, PSO, WOA, ARO, SWO, and other algorithms.
In the comparison of multi-modal test functions, IHBA showed a strong search ability; its performance was particularly outstanding, especially in the F12, F14, and F16 functions. When the dimension was set to 30, the average value of IHBA reached 0 in F12, which showed a lower value than other algorithms, indicating that it was more efficient in finding the optimal solution. In F14, the average value, standard deviation, and optimal value of IHBA were all 0, which far exceeded the performance of other algorithms, reflecting its powerful ability to deal with complex functions. In F16, IHBA also obtained the optimal value and revealed a gap with the results of other algorithms. This suggests that it possesses a greater capacity to circumvent the local optimal solution. For F10, IHBA was slightly less stable, and SWO was better. When = 200, the efficacy of the comparative algorithms across all three metrics diminished; however, IHBA continued to maintain a superior position over its counterparts throughout the solution process. In F12, the accuracy and stability of other comparison algorithms decreased to varying degrees. ARO decreased by six orders of magnitude compared with the average value of = 30, and the optimal value in 30 runs decreased by nine orders of magnitude. Compared with = 30, the performance of HBA in this test function also decreased, and the average value decreased by 20 orders of magnitude, while IHBA still reached the theoretical optimal value of 0 in the three indexes. In F10 and F15, the IHBA results decreased relative to the mean and standard deviation at = 30. This shows that the change in dimension had a certain influence on IHBA, which affected the accuracy and stability of the algorithm. In general, although IHBA showed a certain optimization ability and excellent stability on multi-modal test functions, demonstrating its wide applicability in complex optimization problems, it still needs to be further improved.
In the evaluation of fixed-dimension functions, IHBA demonstrated strong performance for functions F17 and F19–F22, achieving both optimal mean values and optimal standard deviations. In function F18, all six algorithms found the optimal value, but IHBA reached the optimal standard deviation, indicating the stability of IBHA on F18. In the F23, ARO demonstrated the highest level of integration, while the IHBA exhibited a slightly lower performance in comparison to the ARO. In summary, IHBA performed well on multiple test functions and demonstrated superiority over the comparison algorithm regarding solution quality and robustness.
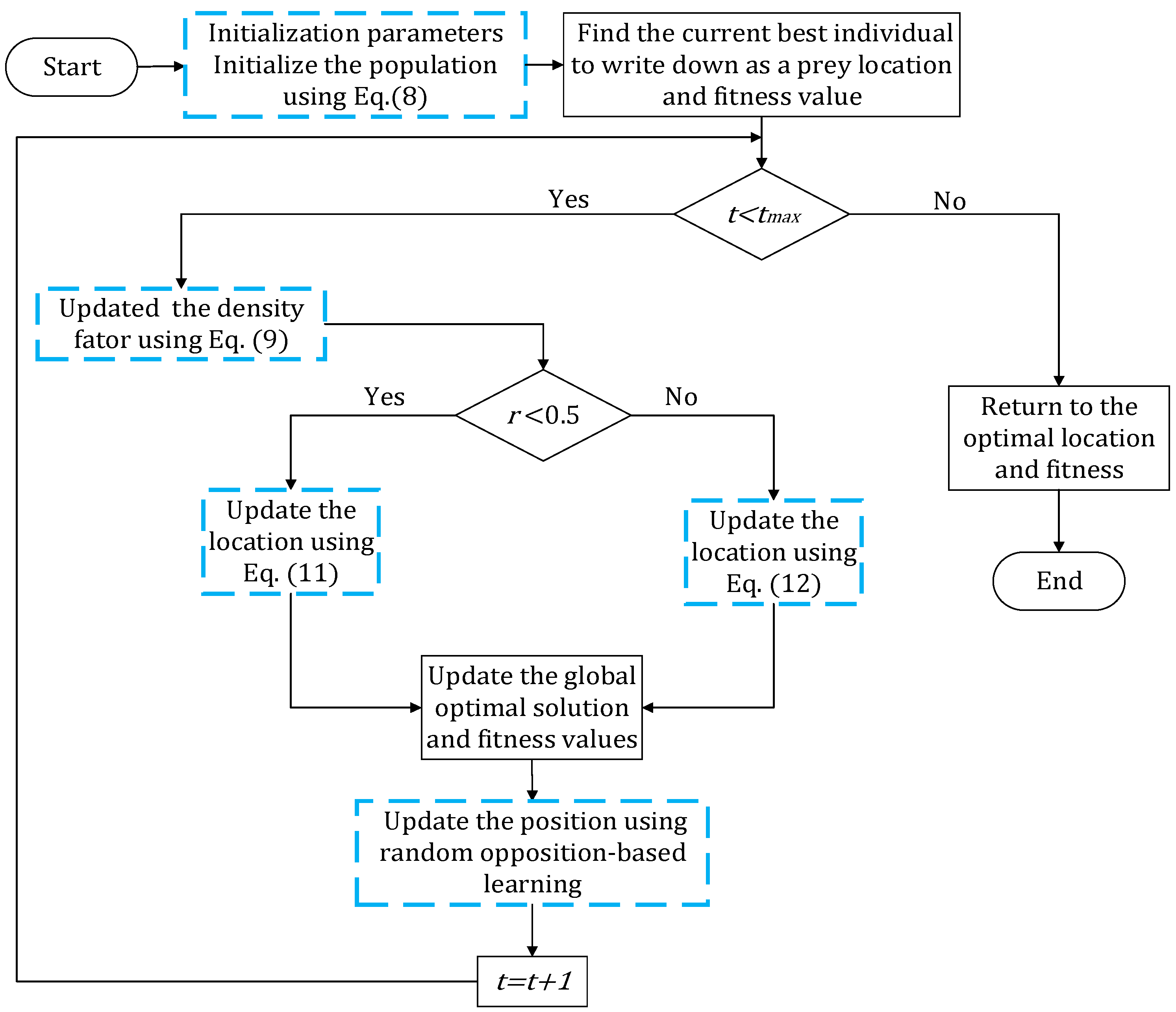
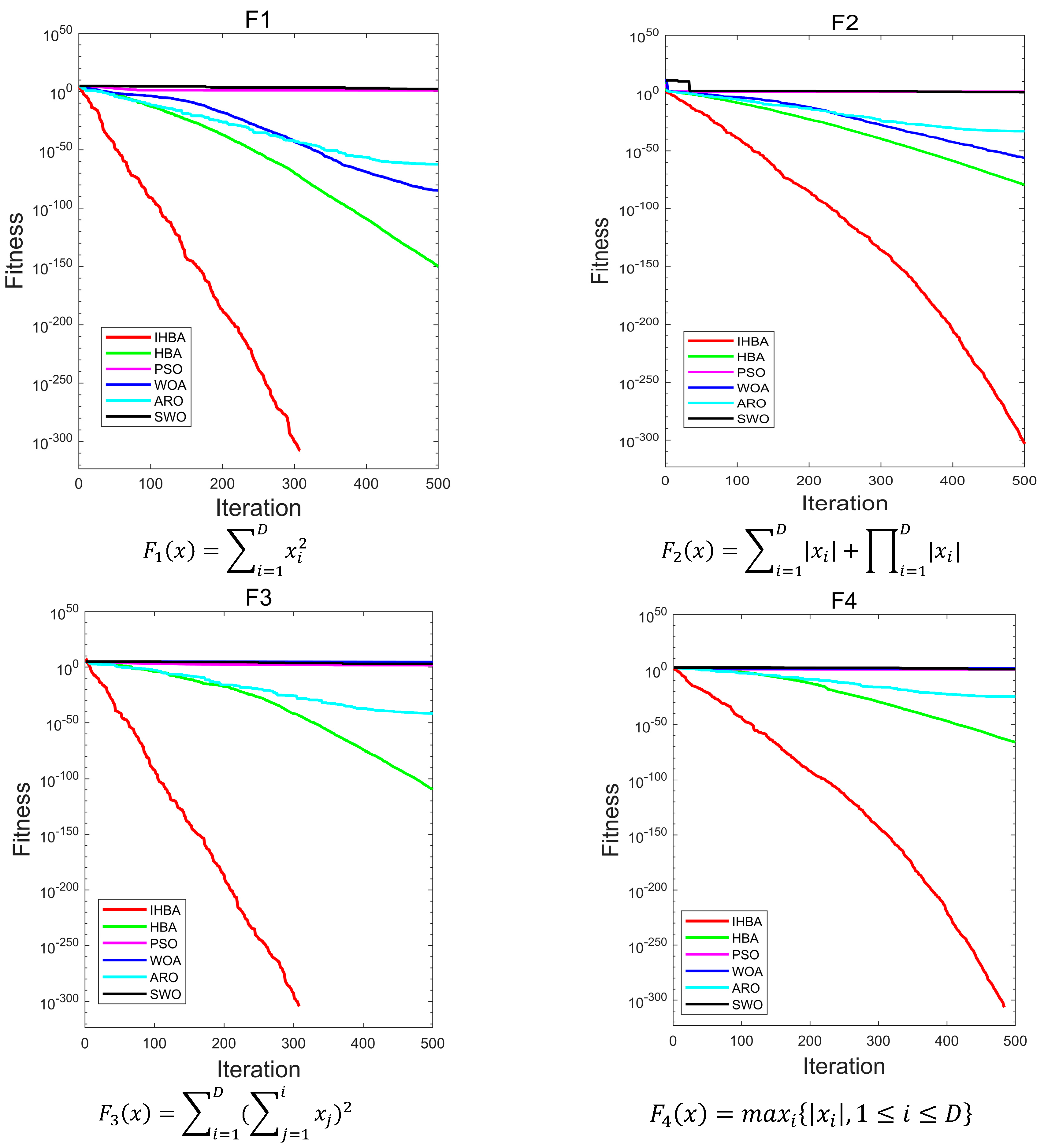
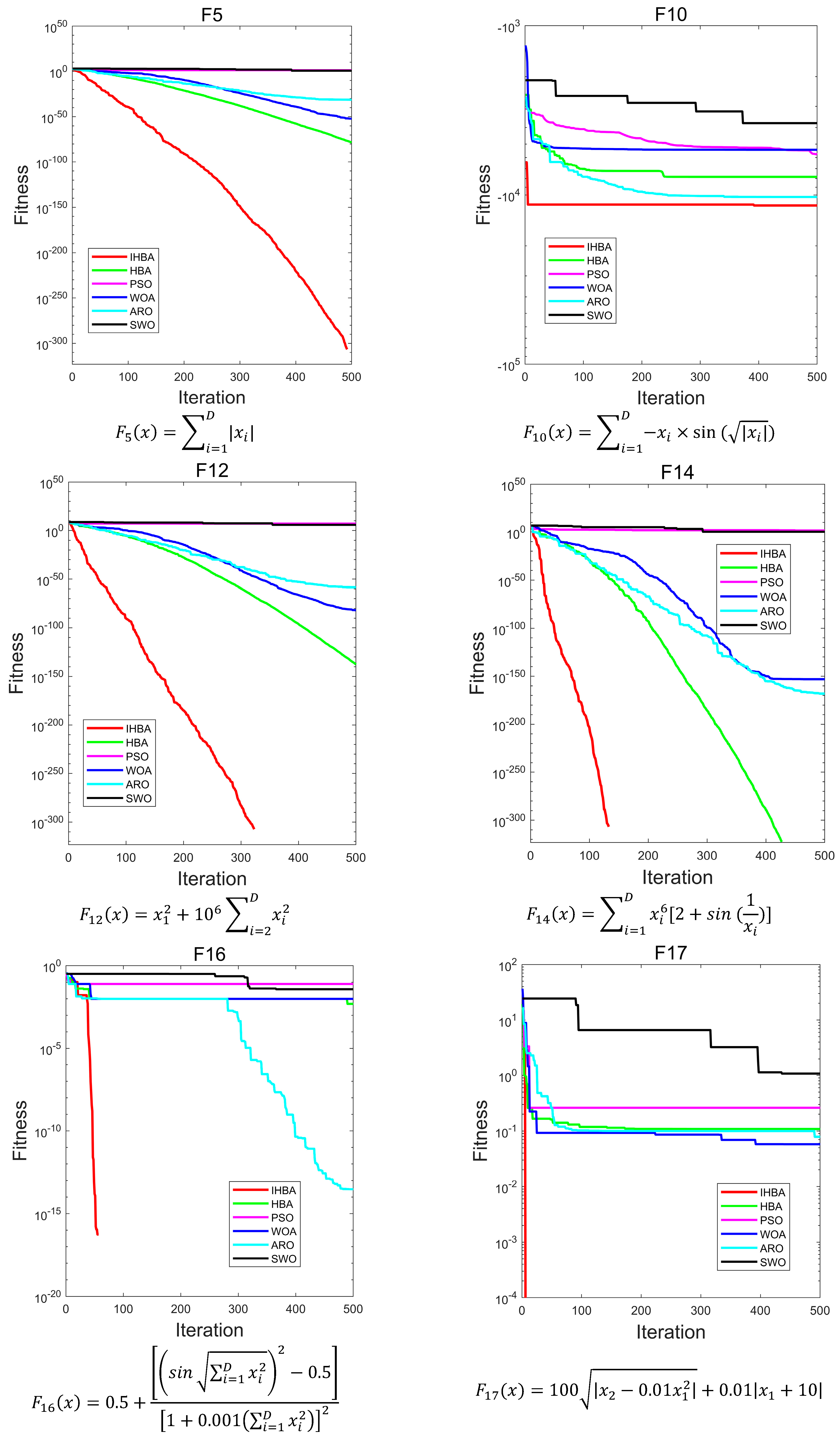
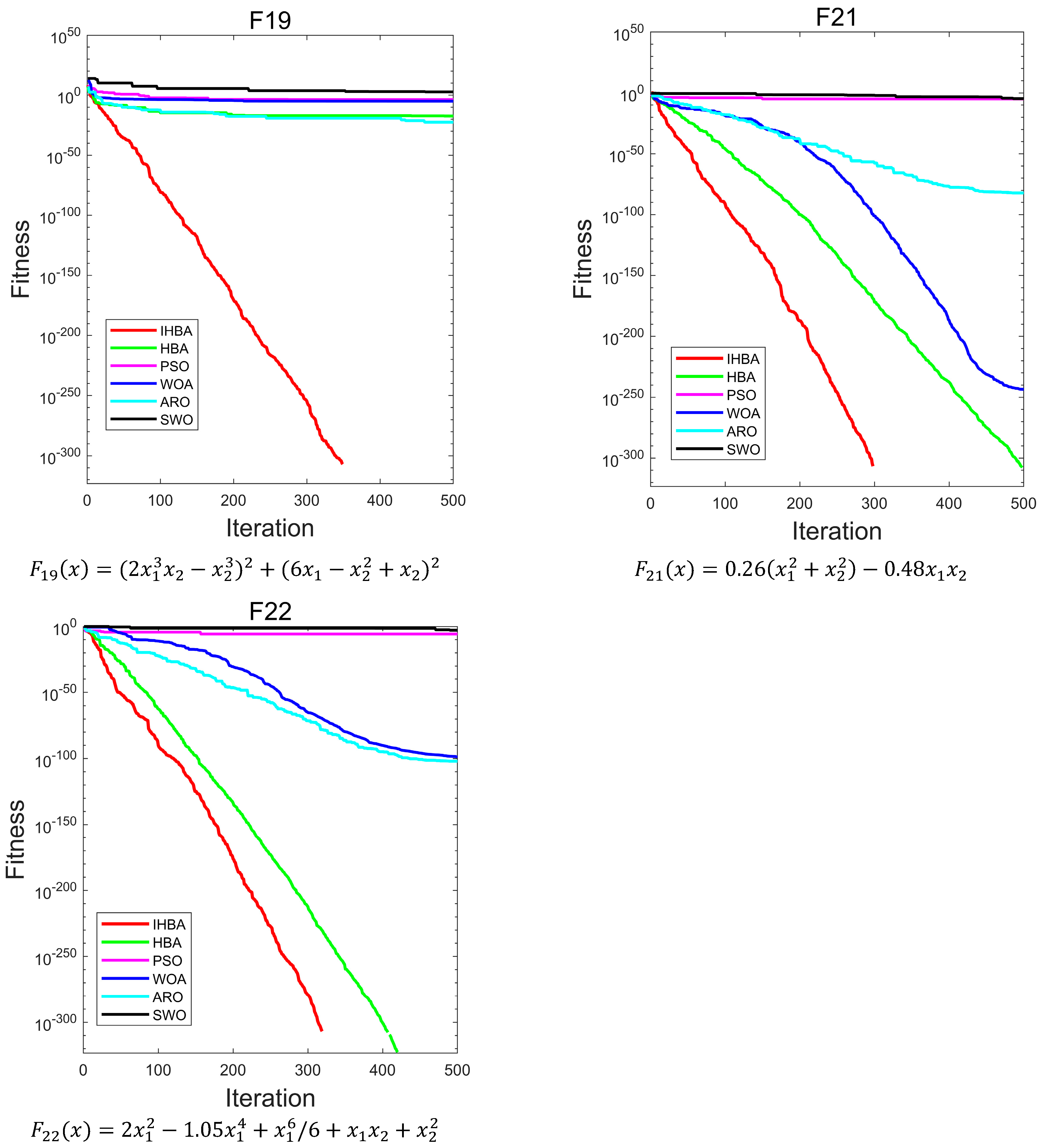
Figure 6 is a convergence diagram of the IHBA on the benchmark function. To ensure fairness, a population
= 50, a maximum number of iterations
= 500, and a dimension
= 30 was set in the experiment. Each algorithm was run independently 30 times. Due to the limited space, this paper selected some test functions for convergence analysis and comparison. F1–F5 in single-peak test function; F10, F12, F14, and F16 in multi-peak test function; and F17, F19, F21, and F22 in constant-dimension test function were selected, respectively.
As illustrated in
Figure 6, for the unimodal test functions, IHBA demonstrated the fastest convergence speed among the five algorithms. Additionally, IHBA achieved the highest search accuracy throughout the iterative process. In contrast, other algorithms converge slowly and have low convergence accuracy. In the multimodal test function, IHBA also converged quickly and achieved the highest search accuracy among the six algorithms, especially F14. Both IHBA and HBA found the optimal value of 0 in 500 iterations. However, by observing the convergence curve, IHBA converged more quickly than HBA, finding the optimal value first. This demonstrates the good performance of IHBA. In the fixed-dimension test function, IHBA performed well on F17, F19, F21, and F22. It was obviously better than the other comparison algorithms, and also performed well on F21. In general, IHBA showed a better performance.
5.3. Simulation Analysis of K-Means for Improved Honey Badger Algorithm
To further validate the practicality of IHBA, this study selected K-means, IHBA-KM, and K-means algorithm based on Honey Badger Algorithm (HBA-KM) for a clustering experiment comparison. This experiment selected three data sets from the UCI database. For details, see
Table 8.
In this paper, the error sum of squares (SSE), accuracy, and F-score were employed as metrics for evaluating clustering results.
SSE is a widely used metric for assessing the quality of clustering, referred to as fitness. It evaluates the sum of the squared distances between each data point and the center of its corresponding cluster. A lower fitness value signifies that a data point’s proximity to the clustering center correlates with improved clustering quality. The specific calculation formula is shown in Equation (16).
k denotes the number of clusters; represents all data points within the kth class; refers to the data points in the kth cluster; and signifies the center of that cluster.
Accuracy refers to the ratio of correctly clustered elements to the total number of elements, as expressed by the following equation. A higher accuracy indicates superior clustering results:
represents the number of samples assigned to the correct cluster, and represents the number of samples.
The
F-score is a widely used metric for evaluating clustering results, with a value range from 0 to 1. It reflects the degree of similarity between the clustering outcomes and the true classifications. A higher
F-score, closer to 1, indicates a more effective clustering performance. Given the issue of class imbalance present in the data set utilized in this study, we employed the weighted
F-score as a metric to evaluate the clustering outcomes. The specific formula is as follows.
where
TP is a true-false example,
FP is a false-positive example, and
FN is a negative-false example.
when the data set is a class-unbalanced data set, which focuses more on small class recall, and
when the data set is a class-balanced data set, which is the traditional
F-score.
To ensure fairness, the parameters were kept consistent across all experiments: The number of populations was established at
, with a maximum iteration limit set to
= 100. Each algorithm was executed independently a total of 30 times. The best, worst, and average values, along with the standard deviation, were recorded for each run. Experimental results are summarized in
Table 9,
Table 10 and
Table 11, while the convergence plots are shown in
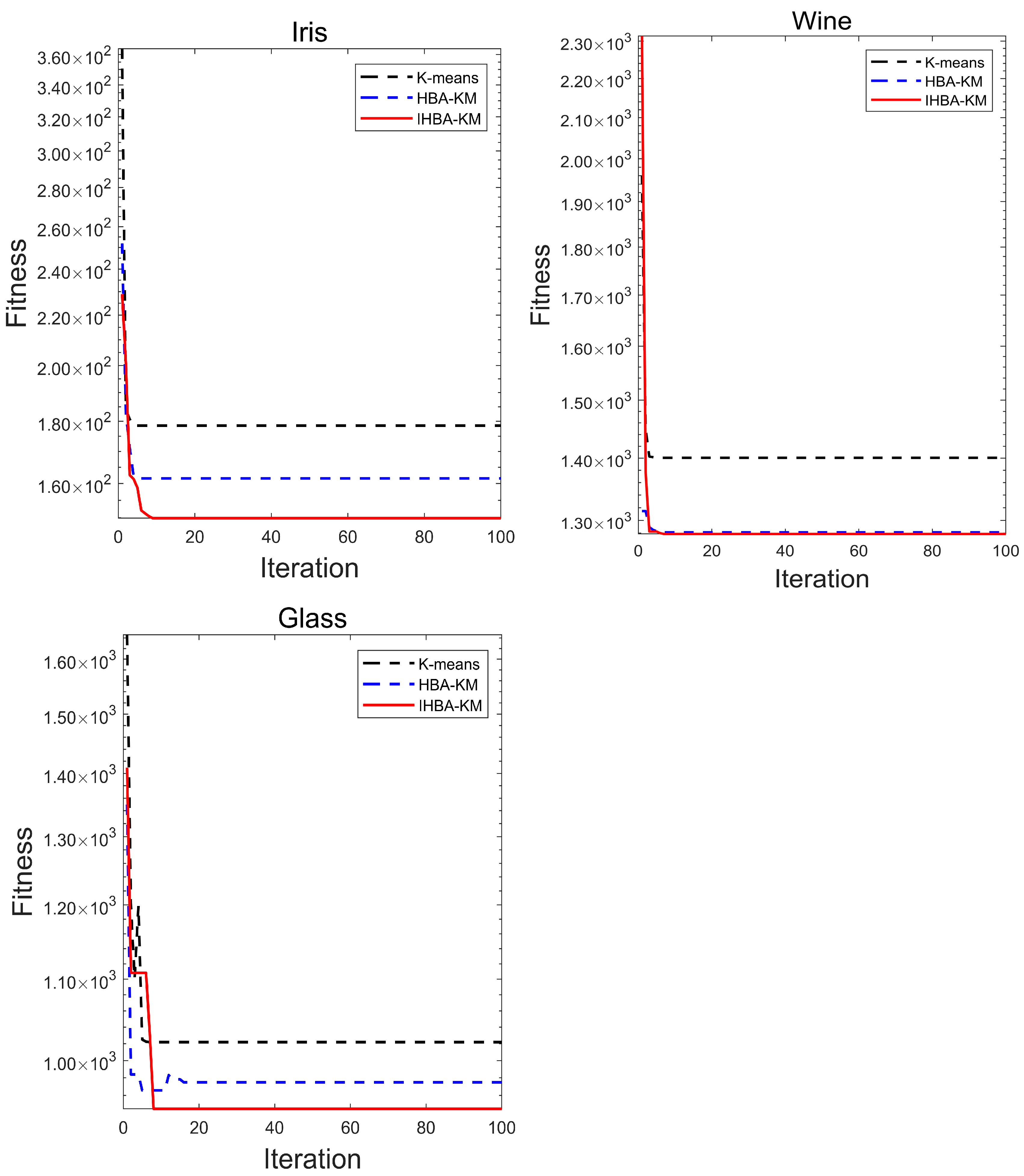
Figure 7.
Comparing the results of the K-means algorithm, HBA-KM, and IHBA-KM, the IHBA-KM algorithm showed obvious advantages in many indexes. According to
Table 9, it can be seen that the IHBA-KM in Iris data set was much less adaptive; in terms of standard deviation, IHBA-KM was 54.87 higher than K-means and 6.6 higher than HBA-KM, which strongly proves that the clustering stability and quality of IHBA-KM algorithm are better. It is evident from
Figure 7 that the three algorithms exhibited rapid declines during the initial stages of iteration. The K-means algorithm and HBA-KM finally fell into local optimal, while IHBA-KM emerged from the trap in search of a higher-quality solution. The findings illustrate the efficacy of IHBA-KM in clustering within the data set. Especially in the Glass data set, IHBA-KM had the smallest fitness value, and it was found through the convergence curve that the comparison algorithm fell into local optimal rapid convergence, while IHBA-KM jumped out of the trap of local optimal and obtained better clustering centers. However, the standard deviation of 67.5 also indicated that the stability of IHBA was poor, suggesting that the improvement measures in this paper can enhance the clustering effect, but there is still room for improvement.
In summary, IHBA-KM is superior to the traditional K-means algorithm and HBA-KM in terms of clustering effect, stability, and consistency. The experimental results show that the IHBA in this study can alleviate the influence of the initial clustering center on the clustering results and enhance the stability and efficiency of clustering.
In order to further evaluate IHBA-KM, this study continued to explore the use of the accuracy and
F-score metrics as criteria. Detailed results can be found in
Table 10 and
Table 11.
The IHBA-KM showed significant advantages in multiple clustering tasks, especially in the accuracy index. Taking the Iris data set as an example, the average accuracy of IHBA-KM was 89.63%, higher than that of the K-means algorithm (80.73%) and HBA-KM (88.00%). In addition, the maximum accuracy of IHBA-KM was also outstanding, reaching 96.66%. The performance of this algorithm was markedly superior to those of other algorithms, suggesting that it possesses a greater capacity for achieving optimal clustering results. In the context of the Wine data set, IHBA-KM demonstrated a consistently high accuracy rate, averaging approximately 10% higher and achieving a minimum improvement of 27% compared to the K-means algorithm. This indicates its robustness and the stability in its performance. In the Glass data set, the average accuracy of IHBA was 67.62%, while the average accuracy of HBA stood at 64.11%. This represents an improvement of 3.51%, highlighting the positive impact of the enhanced strategy on classification performance. This stability and high accuracy make IHBA-KM a more reliable choice in practical applications, especially in scenarios where high-precision clustering results are required. On the whole, the IHBA-KM algorithm has obvious advantages in terms of clustering effect and accuracy.
As can be observed in
Table 11, the IHBA-KM algorithm performed well on
F-score indicators, especially on the Iris and Wine data sets. Its average
F-score was 0.83, significantly higher than K-means’ 0.73 and HBA-KM’s 0.82. This enhancement reflects the effectiveness of IHBA-KM clustering. In terms of maximum
F-score, IHBA-KM reached 0.91, surpassing the other two algorithms, indicating that it can achieve higher classification accuracy. In addition, its minimum
F-score remained at 0.77, showing consistency and stability across different data sets. This advantage means that IHBA-KM can provide a reliable performance in a diverse array of application scenarios. In high-dimensional data, feature similarity often becomes less clear, negatively impacting clustering quality. Therefore, according to the Glass data set, the average
F-scores for K-means and HBA were 0.40 and 0.42, respectively, while the average
F-score for IHBA was 0.45. Compared to the other two algorithms, the clustering performance of IHBA on this data set was marginally superior; however, the relatively low values indicate a potential limitation of IHBA when applied to high-dimensional data.
In summary, the IHBA’s advantage in accuracy and F-score is unquestionable. By incorporating the HBA, IHBA reduces the reliance of the traditional K-means on the initial cluster centers. To address the issues of the HBA, including its vulnerability to local optima and slow convergence, the IHBA introduces several improvements. These enhancements help the algorithm to avoid local optima, speed up convergence, and ultimately enhance the overall efficacy of the clustering process.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}