
High-Quality Text-to-Image Generation Using High-Detail Feature-Preserving Network


Abstract
1. Introduction
- The novel HDFpNet is proposed to be able to fully exploit a contextual representation of text and image fusion to generate high-quality, high-detail, and feature-preserving images efficiently in the use and application of optical devices.
- A novel FESFE module is proposed to preserve the contextual representation of text and image fusion through CE and CS blocks to avoid information loss before feature extraction, enabling the FFE block to extract features quickly without information loss.
- The experimental results indicate that the proposed HDFpNet achieves better performance and visual representation on the CUB-Bird and MS-COCO datasets than comparable state-of-the-art algorithms. The generated images are closer to the real ones and faithful to the text description, especially in terms of high image detail and feature preservation, making this method suitable for the use and application of optical devices.
2. Related Work
2.1. GANs
2.2. Text-to-Image Generation Networks
3. Method
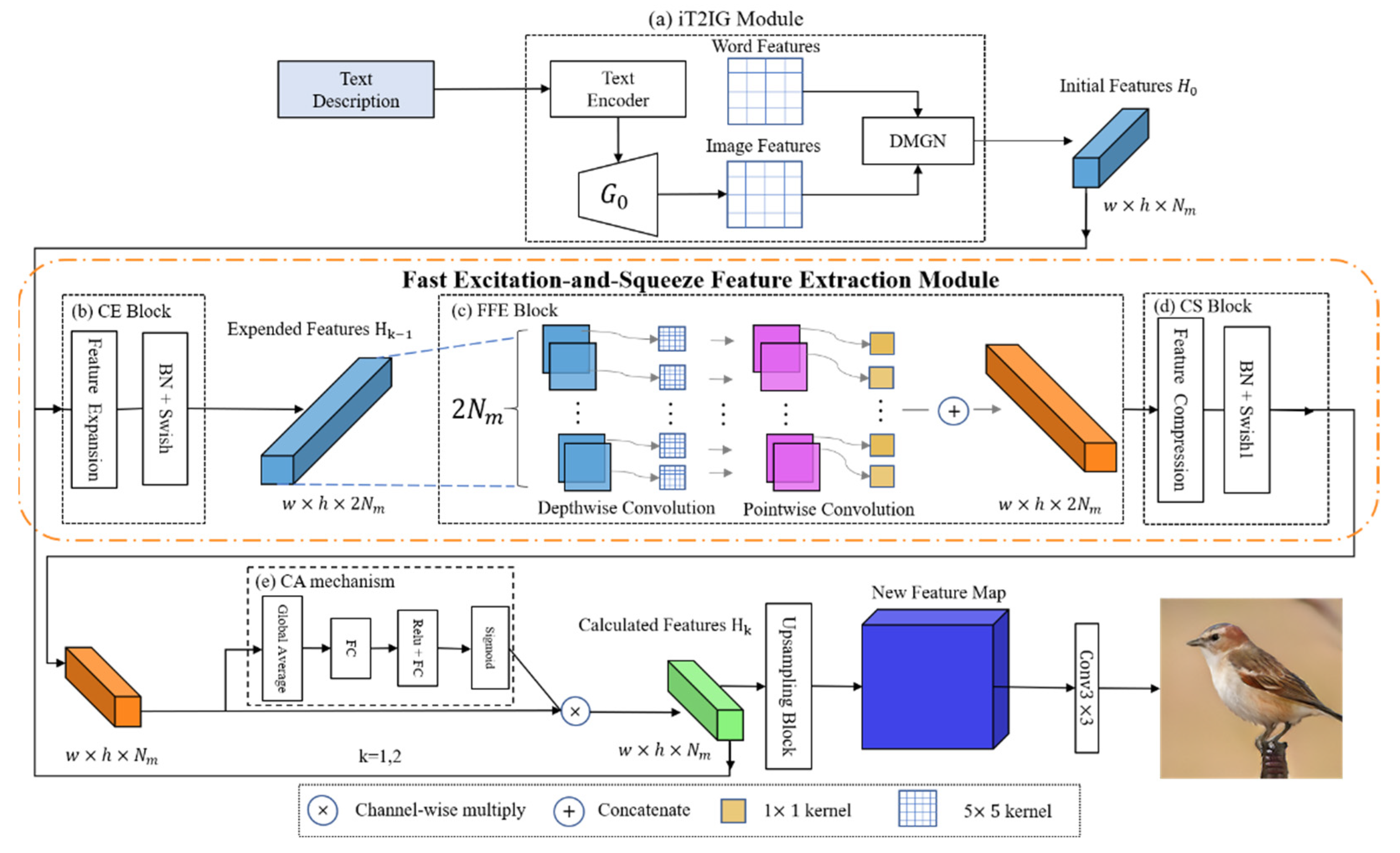
3.1. iT2IG Module
- Initial Image Generator G0: The conditioning augmentation proposed in [4] is used to optimize sentence features. Next, G0 is used to generate the initial image and image features ,
- 3.
- DM-GN: The DM-GN [14] is used to generate feature maps because its effective image enhancement method dynamically adjusts word weights to achieve images with more word-level detail. As presented in Figure 2a, the inputs of the DM-GN are the initial image features Hi and the word features W to the DM-GN:
3.2. FESFE Module
- CE Block: Based on previous studies on deep residual networks [35,42,43], the present study introduces a receptive field to improve the relevance of the prediction models and increase the number of extracted image details. Previous studies have used 3 × 3 filters without dilation to extract features [10,14]. The proposed CE block optimizes and excites existing channels to increase the effectiveness of subsequent feature extraction (Figure 2b). The purpose of the CE block is to create a channel excitation effect that increases the number of channels, enabling a subsequent feature extraction process without feature loss. Batch normalization (BN) [37] is also implemented in the excitation process to optimize the overall network; . Each iteration of BN might result in a small shift, which causes considerable changes to the network output. Therefore, a swish activation function [37], , is added to improve the BN process. The proposed method enables the extraction of more image details than in existing methods, thereby generating images that more closely resemble the target images. Mathematically, the process can be described as follows:
- 2.
- FFE Block: Extending the dimensions of the CE block (Figure 2b) increases the computational cost. To accelerate the feature extraction process without reducing the model’s effectiveness, an FFE block (Figure 2c) is incorporated into the proposed model based on previous research [42,43]. The FFE block performs convolutions on the spatial and depth dimensions (i.e., channel dimensions) to reduce the computations and quickly extract features. The block includes both depth-wise convolution and point-wise convolution calculations.
- 3.
- CS Block: After a new feature map is obtained, the CS block performs a channel squeeze process to accelerate the data propagation speed (Figure 2d) and reduce the number of channels to its original value, namely that obtained after the iT2IG module calculation.
3.3. CA Mechanism
3.4. Loss Functions
4. Experiments
4.1. Experimental Settings
- Implementation Details: To generate an initial feature map, text processing was performed using a bidirectional LSTM text encoder as proposed in [10]. This encoder transformed each textual description into two hidden states representing the forward and backward sentences. Each word also had two corresponding hidden states. These two hidden states for each sentence were concatenated and then input into the initial image generator to create the initial image features. Three image generation stages were conducted to produce images with resolutions of 64 × 64, 128 × 128, and 256 × 256 in sequence. Subsequently, the dynamic network generator proposed in [14] was employed to integrate the hidden states of each word with the initial image features. By employing the training method described in [14], the CUB-Bird dataset parameters were configured as and = 5, while the MS-COCO dataset parameters were configured as and = 50. After generating the initial text–image feature map, 1 × 1 filters doubled the number of feature map channels. Then, depth-wise and point-wise convolution were performed using 5 × 5 and 1 × 1 filters, respectively. Finally, 1 × 1 filters were employed to reduce the number of feature map channels to its original value (= 128). All networks were trained using the Adam optimizer [39] with a batch size of 16 and a learning rate of 0.0002. The CUB-Bird and MS-COCO datasets were used to train the HDFpNet model for 600 and 200 epochs, respectively. The model training process was conducted using an NVIDIA RTX A5000 card.
- Dataset: Two public datasets were utilized in this study—the CUB-Bird dataset and the MS-COCO dataset. The CUB-Bird dataset comprises 11,788 images of 200 bird species, with each image being accompanied by ten descriptive sentences. The MS-COCO dataset contains 80,000 training images and 40,000 test images, with each image being associated with five textual annotations.
- Evaluation: The performance of the HDFpNet model was evaluated through a series of experiments. Initially, the effectiveness of each block within the model was assessed. Subsequently, the performance of the model was compared with that of other state-of-the-art text-to-image generation models. For a task involving the generation of 30,000 images from textual descriptions recorded in a dataset that had not been used for testing other models, the Fréchet inception distance (FID) [42] and R-precision indicators were employed to evaluate the model’s performance as direct comparisons were not possible. The FID is based on features extracted from the Inception v3 network [44] and is used to calculate the Fréchet distance between generated and real-world images. A low FID value indicates that a generated image closely resembles a real-world image. R-precision evaluates the extent to which a generated image matches the conditions specified in a textual description. Specifically, it employs a query mechanism to determine the relevance of documents retrieved by a system. This study implemented R-precision following the procedures described in [10]. The cosine distance between the global image vector and 100 candidate sentence vectors was calculated. The candidate documents described R real images and 100 randomly selected unmatched samples. In each query, if r results obtained from the first R retrieved documents are relevant, then the R-precision equals r/R. In this study, R was set to 1. The generated images were divided into 10 leaflets for the performance of queries. The obtained scores are presented as means with standard deviations.
4.2. Comparisons with the State-of-the-Art Algorithms
4.3. Ablation Study
- (1)
- Effectiveness of FESFE Module and CA Mechanism: The proposed HDFpNet model comprises the iT2IG module, which is based on DM-GAN [14]; the FESFE module; and the CA mechanism. An ablation experiment was conducted to evaluate the effectiveness of the CE block and CS block, the FFE block in the FESFE module, and the CA mechanism. The results are presented in Table 3. The feature extraction capability of the proposed model was significantly improved by increasing the number of channels, while including the CA mechanism optimized the overall network structure. The results demonstrate that the combined use of these blocks enabled the outstanding performance of the proposed model for text-to-image generation, thereby verifying the effectiveness of the FESFE module and CA mechanism. Notably, the +CE +FFE +CA +CS sample in the fourth row of Table 3 was created by extracting features through the FFE block before they were processed by the CA mechanism and then by the CS block. This sample was created to verify the effectiveness of the CA mechanism in the HDFpNet model. The results confirm that initiating the CA mechanism while the FFE block was still extracting features reduced the model’s performance. In contrast, initiating the CA mechanism after feature extraction by the FFE block had been completed yielded optimal model performance.
- (2)
- Study of : The hyperparameter was employed to improve the performance of the HDFpNet model. An experiment was conducted using two values: 0.1 and 1. The larger value (i.e., = 1) was found to have a negative impact on the model performance (Table 4). As a result, = 0.1 was used for subsequent analyses. Evaluations based on the FID and R-precision indicators also confirmed that this value yielded the optimal results.
- (3)
- Study of : An experiment was conducted to determine the optimal number of iterations required to generate the best feature map. Between one and five iterations were performed. It was found that lower iteration numbers (i.e., ≤3) resulted in higher performance, with the optimal performance being achieved at three iterations (Table 5). In contrast, iteration numbers > 3 reduced the model performance. As a result, the iteration number was set to three to obtain optimal results in the subsequent analyses. This configuration was verified to yield outstanding image generation and quality results.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Systems. 2014, 27, 2672–2680. [Google Scholar]
- Xia, W.; Zhang, Y.; Yang, Y.; Xue, J.-H.; Zhou, B.; Yang, M.-H. GAN Inversion: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3121–3138. [Google Scholar] [CrossRef]
- Li, J.; Li, B.; Jiang, Y.; Tian, L.; Cai, W. MrFDDGAN: Multireceptive Field Feature Transfer and Dual Discriminator-Driven Generative Adversarial Network for Infrared and Color Visible Image Fusion. IEEE Trans. Instrum. Meas. 2023, 72, 5006228. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, J.; Zhang, Y.; Shan, H. DU-GAN: Generative adversarial networks with dual-domain U-Net-based discriminators for low-dose CT denoising. IEEE Trans. Instrum. Meas. 2021, 71, 4500512. [Google Scholar] [CrossRef]
- Hsu, W.-Y.; Chang, W.-C. Wavelet Approximation-Aware Residual Network for Single Image Deraining. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15979–15995. [Google Scholar] [CrossRef]
- Duman, B. A Real-Time Green and Lightweight Model for Detection of Liquefied Petroleum Gas Cylinder Surface Defects Based on YOLOv5. Appl. Sci. 2025, 15, 458. [Google Scholar] [CrossRef]
- Hsu, W.-Y.; Yang, P.-Y. Pedestrian Detection Using Multi-Scale Structure-Enhanced Super-Resolution. IEEE Trans. Intell. Transp. Syst. 2023, 24, 12312–12322. [Google Scholar] [CrossRef]
- Hsu, W.-Y.; Chung, C.-J. A Novel Eye Center Localization Method for Head Poses With Large Rotations. IEEE Trans. Image Process. 2020, 30, 1369–1381. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 27–29 October 2017; pp. 5907–5915. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1316–1324. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1947–1962. [Google Scholar] [CrossRef]
- Tan, H.; Liu, X.; Liu, M.; Yin, B.; Li, X. KT-GAN: Knowledge-transfer generative adversarial network for text-to-image synthesis. IEEE Trans. Image Process. 2020, 30, 1275–1290. [Google Scholar] [CrossRef]
- Qiao, T.; Zhang, J.; Xu, D.; Tao, D. Mirrorgan: Learning text-to-image generation by redescription. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1505–1514. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. Dm-gan: Dynamic memory generative adversarial networks for text-to-image synthesis. In Proceedings of the 019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5802–5810. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The caltech-ucsd birds-200-2011 dataset. 2011. Available online: https://authors.library.caltech.edu/records/cvm3y-5hh21 (accessed on 2 January 2025).
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, L. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014, Proceedings, Part V 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Hsu, W.-Y.; Wu, C.-H. Wavelet structure-texture-aware super-resolution for pedestrian detection. Inf. Sci. 2025, 691, 121612. [Google Scholar] [CrossRef]
- Hsu, W.-Y.; Hsu, Y.-Y. Multi-Scale and Multi-Layer Lattice Transformer for Underwater Image Enhancement. ACM Trans. Multimedia Comput. Commun. Appl. 2024, 20, 354. [Google Scholar] [CrossRef]
- Padovano, D.; Martinez-Rodrigo, A.; Pastor, J.M.; Rieta, J.J.; Alcaraz, R. Deep Learning and Recurrence Information Analysis for the Automatic Detection of Obstructive Sleep Apnea. Appl. Sci. 2025, 15, 433. [Google Scholar] [CrossRef]
- Hsu, W.Y.; Lin, H.W. Context-Detail-Aware United Network for Single Image Deraining. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 1–18. [Google Scholar] [CrossRef]
- Hsu, W.Y.; Jian, P.W. Wavelet Pyramid Recurrent Structure-Preserving Attention Network for Single Image Super-Resolution. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 15772–15786. [Google Scholar] [CrossRef] [PubMed]
- Hsu, W.-Y.; Lin, W.-Y. Ratio-and-Scale-Aware YOLO for Pedestrian Detection. IEEE Trans. Image Process. 2020, 30, 934–947. [Google Scholar] [CrossRef] [PubMed]
- Hsu, W.-Y.; Jian, P.-W. Recurrent Multi-scale Approximation-Guided Network for Single Image Super-Resolution. ACM Trans. Multimedia Comput. Commun. Appl. 2023, 19, 1–21. [Google Scholar] [CrossRef]
- Hsu, W.-Y.; Chang, W.-C. Recurrent wavelet structure-preserving residual network for single image deraining. Pattern Recognit. 2023, 137, 109294. [Google Scholar] [CrossRef]
- Mouri Zadeh Khaki, A.; Choi, A. Optimizing Deep Learning Acceleration on FPGA for Real-Time and Resource-Efficient Image Classification. Appl. Sci. 2025, 15, 422. [Google Scholar] [CrossRef]
- Pico, N.; Montero, E.; Vanegas, M.; Erazo Ayon, J.M.; Auh, E.; Shin, J.; Doh, M.; Park, S.-H.; Moon, H. Integrating Radar-Based Obstacle Detection with Deep Reinforcement Learning for Robust Autonomous Navigation. Appl. Sci. 2024, 15, 295. [Google Scholar] [CrossRef]
- Hsu, W.-Y.; Chung, C.-J. A novel eye center localization method for multiview faces. Pattern Recognit. 2021, 119, 108078. [Google Scholar] [CrossRef]
- Ding, M.; Yang, Z.; Hong, W.; Zheng, W.; Zhou, C.; Yin, D.; Lin, J.; Zou, X.; Shao, Z.; Yang, H.; et al. Cogview: Mastering text-to-image generation via transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 19822–19835. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the in International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR. pp. 8821–8831. [Google Scholar]
- Tan, H.; Liu, X.; Yin, B.; Li, X. Cross-Modal Semantic Matching Generative Adversarial Networks for Text-to-Image Synthesis. IEEE Trans. Multimed. 2022, 24, 832–845. [Google Scholar] [CrossRef]
- Tan, H.; Liu, X.; Yin, B.; Li, X. DR-GAN: Distribution Regularization for Text-to-Image Generation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 10309–10323. [Google Scholar] [CrossRef] [PubMed]
- Vahdat, A.; Kautz, J. NVAE: A deep hierarchical variational autoencoder. Adv. Neural Inf. Process. Syst. 2020, 33, 19667–19679. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the in 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR. pp. 448–456. [Google Scholar]
- Zoph, B.; Le, Q. Searching for activation functions. In Proceedings of the in 6th International Conference on Learning Representations, ICLR 2018-Workshop Track Proceedings, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–13. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the ICLR, Banff, AB, Canada, 14–16 April 2014; pp. 1–15. [Google Scholar]
- Li, B.; Qi, X.; Lukasiewicz, T.; Torr, P. Controllable text-to-image generation. Adv. Neural Inf. Process. Syst. 2019, 32, 2065–2075. [Google Scholar]
- Liu, B.; Song, K.; Zhu, Y.; de Melo, G.; Elgammal, A. Time: Text and image mutual-translation adversarial networks. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 2–9 February 2021; volume 35, pp. 2082–2090. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6629–6640. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the NIPS′16: Proceedings of the 30th International Conference on Neural Information Processing Systems; Barcelona, Spain, 5–10 December 2016, Volume 29.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | StackGAN [9] | AttnGAN [10] | ControlGAN [40] | MirrorGAN [13] | KT-GAN [12] | DM-GAN [14] | TIME [14] | Ours |
|---|---|---|---|---|---|---|---|---|
| CUB | -- | 23.98 | -- | -- | 17.32 | 16.09 | 14.3 | 13.89 |
| COCO | 74.05 | 81.59 | 35.49 | -- | 30.73 | 32.64 | 31.14 | 27.21 |
| Dataset | StackGAN [9] | AttnGAN [10] | ControlGAN [40] | MirrorGAN [13] | KT-GAN [12] | DM-GAN [14] | TIME [14] | Ours |
|---|---|---|---|---|---|---|---|---|
| CUB | 10.37 | 67.82 | 69.33 | 69.58 | -- | 72.31 | 71.57 | 84.33 |
| COCO | -- | 83.53 | 82.43 | 84.21 | -- | 91.87 | 89.57 | 92.44 |
| Architecture | FID ↓ | R-Precision ↑ |
|---|---|---|
| Baseline | 22.94 | 71.40% |
| +CE +CS | 21.45 | 79.12% |
| +CE +FFE +CS | 15.51 | 82.57% |
| +CE +FFE +CA +CS | 17.50 | 81.38% |
| +CE +FFE +CS +CA | 13.89 | 84.33% |
| FID ↓ | R-Precision ↑ | |
|---|---|---|
| 13.89 | 84.33% | |
| 15.42 | 82.91% |
| Iteration (Times) | FID ↓ | R-Precision ↑ |
|---|---|---|
| 1 | 25.75 | 81.12% |
| 2 | 14.301 | 82.72% |
| 3 | 13.89 | 84.33% |
| 4 | 14.91 | 83.15% |
| 5 | 16.1153 | 83.25% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsu, W.-Y.; Lin, J.-W. High-Quality Text-to-Image Generation Using High-Detail Feature-Preserving Network. Appl. Sci. 2025, 15, 706. https://doi.org/10.3390/app15020706
Hsu W-Y, Lin J-W. High-Quality Text-to-Image Generation Using High-Detail Feature-Preserving Network. Applied Sciences. 2025; 15(2):706. https://doi.org/10.3390/app15020706
Chicago/Turabian StyleHsu, Wei-Yen, and Jing-Wen Lin. 2025. "High-Quality Text-to-Image Generation Using High-Detail Feature-Preserving Network" Applied Sciences 15, no. 2: 706. https://doi.org/10.3390/app15020706
APA StyleHsu, W.-Y., & Lin, J.-W. (2025). High-Quality Text-to-Image Generation Using High-Detail Feature-Preserving Network. Applied Sciences, 15(2), 706. https://doi.org/10.3390/app15020706