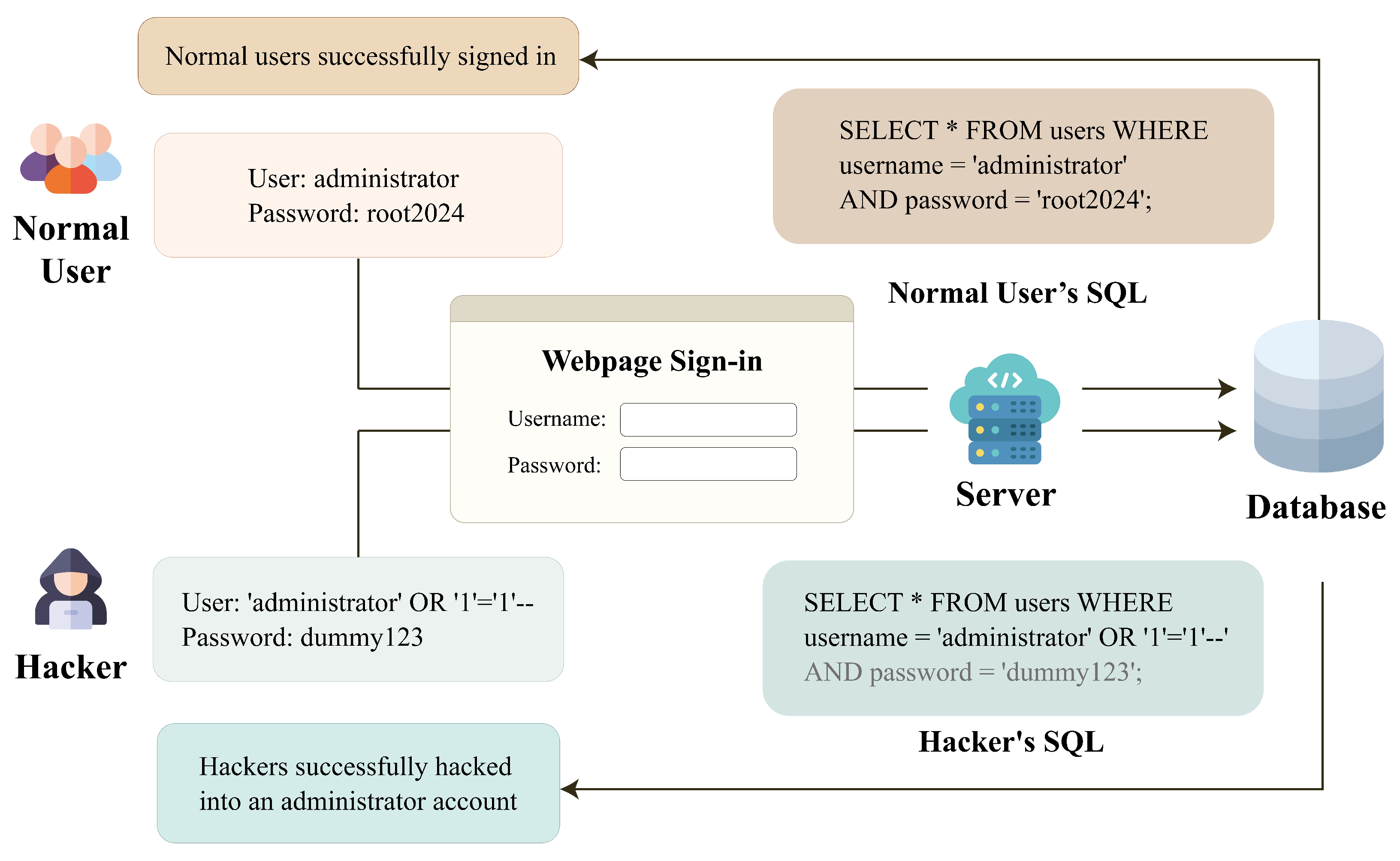
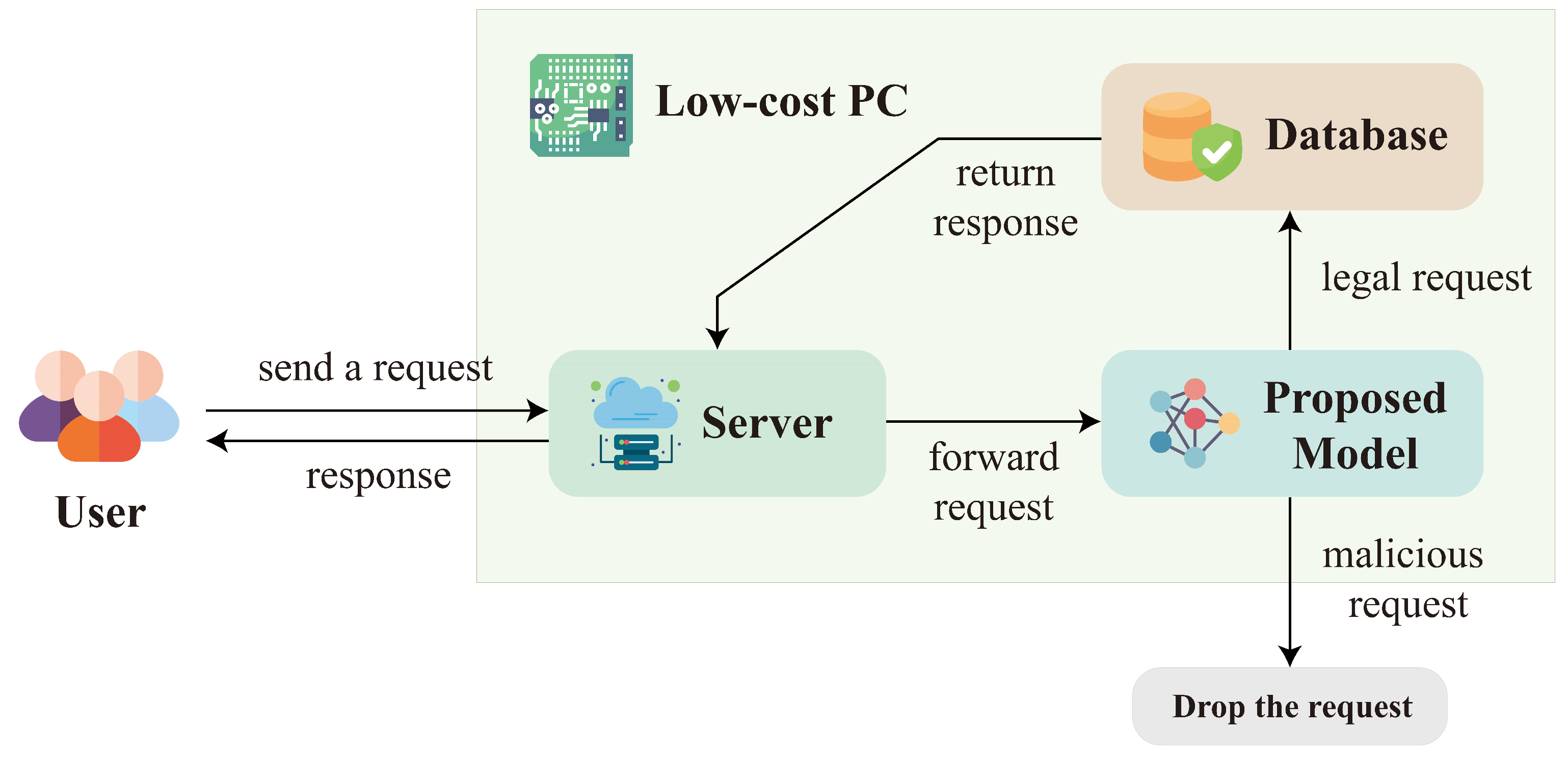
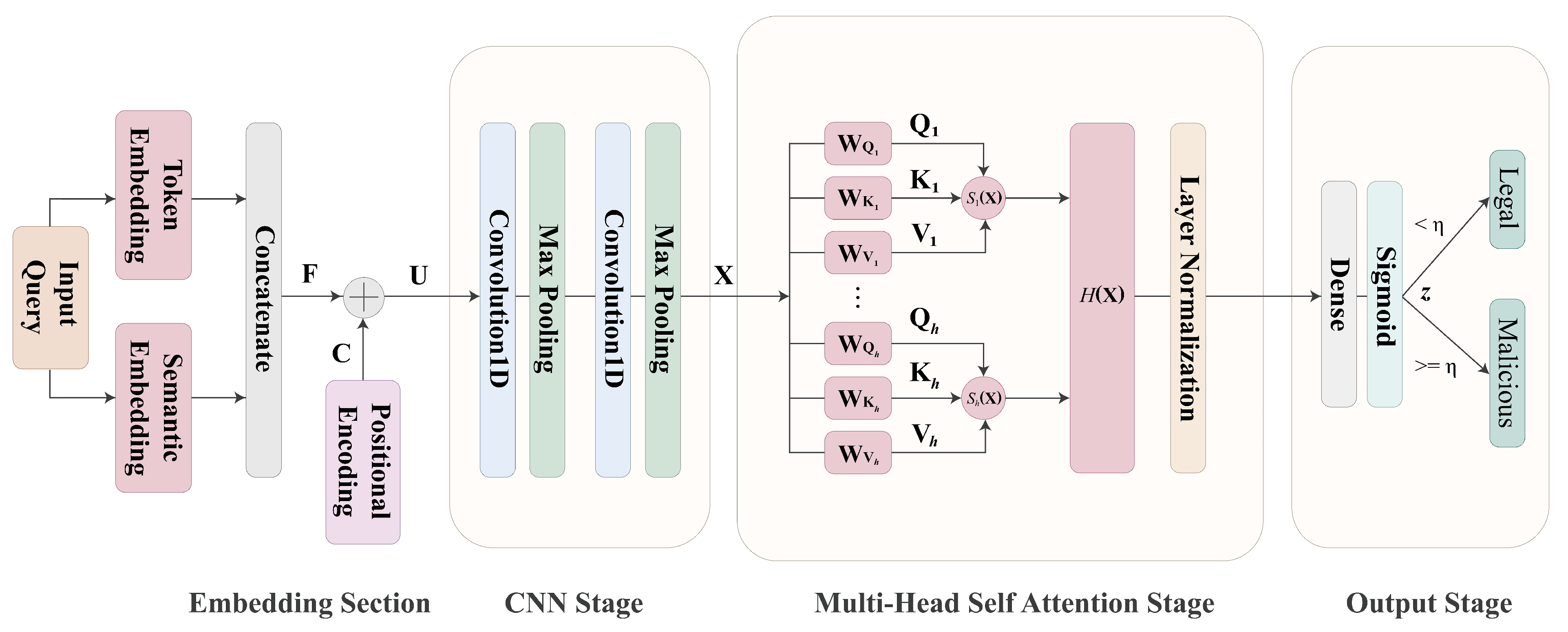
The evaluations of the proposed model for SQL injection detection are provided in this section. The setup of the experiments is presented first. We then define the performance metrics for the model. Based on the metrices, the numerical evaluations and comparisons among the proposed model and other existing techniques are included.
4.1. Experimental Setup
The databases considered in the experiments are the MySQL, PostgreSQL, Oracle, and Microsoft SQL servers. The training set
and two test sets
and
of the experiments can be found in the Kaggle platform [
30]. There are 98,275 SQL queries (i.e.,
) in the training set
. Among the queries for training, there are 55,915 malicious queries and 42,360 legal queries. The test set
contains 24,707 queries. The number of malicious and legal queries in the test set are 11,573 and 13,134, respectively. The test set
consists of queries with length exceeding 1000 characters. There are 500 queries in the test set
, where 100 queries are legal, and the others are malicious. The queries in the test set
and
are different from the ones in the training set
.
Note that the length of queries in sets
and
are below 1000 characters. However, for the NLP techniques based on self-attentions, it may be necessary to find relationship among tokens far apart in an input query. Therefore, the inclusion of the test set
containing lengthy queries is beneficial for the observation of the effectiveness of self attention operations. In this way, the robustness of neural network models to the attacks with lengthy queries can be evaluated. A summary of the datasets considered in the experiments can be found in
Table 1.
For the proposed model, the vocabulary size (i.e., the size of the set
of vocabularies) for the SQL-specific tokenizer is 158. There are three semantic labels for the vocabularies: command, expression, and symbol. The number of vocabularies having semantic labels as command, expression, and symbol are 139, 14, and 5, respectively. The maximum number of tokens from an input query was set to be
. The dimensions of numerical vectors produced by mappings
and
are
and
, respectively. Therefore,
. The dimension of the encoded representation matrix
in (
2) is then
. The number of heads for the self attention operations is
. The threshold value
was set to be
for determining whether the query is malicious. All the training operations were carried out by an NVIDIA GPU Geforce RTX 3080 Ti with a memory size of 64 GB. Furthermore, the software platform used for the training operations is TensorFlow 2.15.
4.3. Numerical Evaluations
Table 2 shows the weight size of the proposed model. We broke down the total weight size of the model into the ones for embedding section and detection section, respectively. Furthermore, the weight size for detection section was divided into the ones for the CNN, self-attention, and output stages, respectively. It can be observed from
Table 2 that the weight size of the proposed model came out to only 69,269. Therefore, the proposed model can be easily deployed in the devices with only limited storage size. We can also see from
Table 2 that there are only 1404 weights in the embedding section in the proposed model. This is because the proposed tokenizer is SQL-specific. That is, only pre-defined keywords and symbols in SQL codes are considered as vocabularies. In fact, there are only 158 vocabularies in the tokenizer. Simple networks may then suffice for the embedding operations.
Although generic tokenizers can be adopted in the proposed model, the resulting network size may be significantly increased. To show this fact, we included the weight size of the proposed model combined with generic SentencePiece tokenizer in
Table 2. To facilitate the deployment of SentencePiece, the tokenizer used by ALBERT was adopted, which contains 30,000 vocabularies. The weight size of the tokenizer is 60,000. To accommodate the SentencePiece tokenizer [
31], the weight size of the CNN and self attention stages were also enlarged. The total weight size came out to 749,537. The proposed model with SQL-specific tokenizer requires only 9.24% of the weight size of the proposed model with SentencePiece tokenizer (i.e., 69,269 vs. 749,537).
In addition to weight sizes, the precision rate, recall rate, F1 score, and accuracy of the proposed model were also considered, as shown in
Table 3. To achieve meaningful comparisons, all the models in
Table 3 were trained by the same training set
and were evaluated by the same test set
. With a significantly lower weight size, we can see from
Table 3 that the proposed model with SQL-specific tokenizer yielded accuracy, precision rate, recall rate, and F1 score values comparable to that of the proposed model with the SentencePiece tokenizer. These results justify the employment of the SQL-specific tokenizer for the malicious detection.
To further demonstrate the effectiveness of the proposed model, we compared the precision rate, recall rate, accuracy, F1 score, and weight size of the proposed model with existing studies, as shown in
Table 4. In the experiment, the proposed model and the model in [
22] were trained by the same training set
. The models ALBERT [
24], DistilBERT [
25], and ELECTRA [
27] in
Table 4 are the lightweight BERT models. These models have been pre-trained and can be directly used for SQL injection detection. However, in this study, they were subsequently fine-tuned by the training set
to further optimize their detection performance.
The evaluations of all the models in
Table 4 are based on the same test set
with 24,707 queries. It can be observed from
Table 4 that the proposed model has lowest weight size compared to the existing models. In particular, its weight size is only 0.1% of that of the DistilBERT [
25] (i.e., 69,269 versus 66,966,010). In addition, it has comparable precision rate, recall rate, F1 score and accuracy values to those of ALBERT [
24], DistilBERT [
25], and ELECTRA [
27]. The proposed model also has superior precision rate, recall rate, and accuracy values over those of Multi-Model [
22]. We can conclude from the results that the proposed model is able to provide accurate SQL injection detection even with a small set of weights.
A special type of attacks in the test set
was also considered in this study, where the length of each query in
exceeded 1000 characters. Note that the training set
consists of only the SQL queries with short lengths. Therefore, the evaluations of the models on the test set
reveal the robustness of the models on the individual attacks with long lengths.
Table 5 reveals the corresponding results. We can see from the table that the proposed model and models in [
24,
25,
27] were able to maintain high accuracy, precision rate, recall rate and F1 score values for the test set
. Compared to the models in [
24,
25,
27], the proposed model is still advantageous because it requires a significantly lower memory size for storing weights. Although the proposed model and the model in [
22] have similar weight sizes, the proposed model has higher accuracy, precision rate, recall rate and F1 score values. The proposed model has the superior performance because its self-attention operations are based on the skeleton queries after removing noisy information. That is, the proposed model is able to abstract only the useful information for subsequent detection. It could then be a cost-effective solution for the SQL injection detection applications.
To further elaborate the effectiveness of the proposed model,
Table 6 shows the average inference time of different models on various edge devices over the test set
. In the experiments, the average inference time was measured as the average CPU time required to produce detection result per SQL query in the test set
. The table also includes the standard deviation for each model in each edge device. There were two edge devices considered in the experiments: Up Board and PC. The Up Board uses an Intel Atom X5 Z8350 CPU and 4 GB of main memory. In the PC, the CPU is an Intel Core I9 9900K, and size of its main memory is 64 GB. The PC is also equipped with an NVIDIA GPU RX 3080 Ti.
We can see from
Table 6 that the average inference time of the proposed model is lower than existing models for each edge device. The proposed model has lower computation complexities for inference because of its small weight size. As a result, it can be accommodated in the Up Board for realtime inference operations. By contrast, although ALBERT [
24], DistilBERT [
25], and ELECTRA [
27] are lightweight BERT models, their weight sizes still exceed the memory capacity of Up Board. Therefore, they can only be deployed in the PC with sufficient memory size for online inference. This limits the flexibility of the existing lightweight BERT models for SQL injection detection applications. All these facts demonstrate the effectiveness of the proposed model.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}