
Aggregatable Subvector Commitment with Efficient Updates

Abstract
1. Introduction
1.1. Our Contributions
- This paper proposes a novel aggregatable subvector commitment scheme based on Newton interpolation. When appending a value to the vector, it eliminates the need to fully recompute the original commitment value and proofs. Instead, the client incrementally updates the commitment and proofs for each position, significantly reducing computational overhead.
- The Karatsuba algorithm can efficiently perform large-integer multiplication, which can reduce the computational overhead from to for the multiplication of two n-digit numbers. By leveraging this algorithm, our scheme improves the efficiency of both aggregation and verification operations.
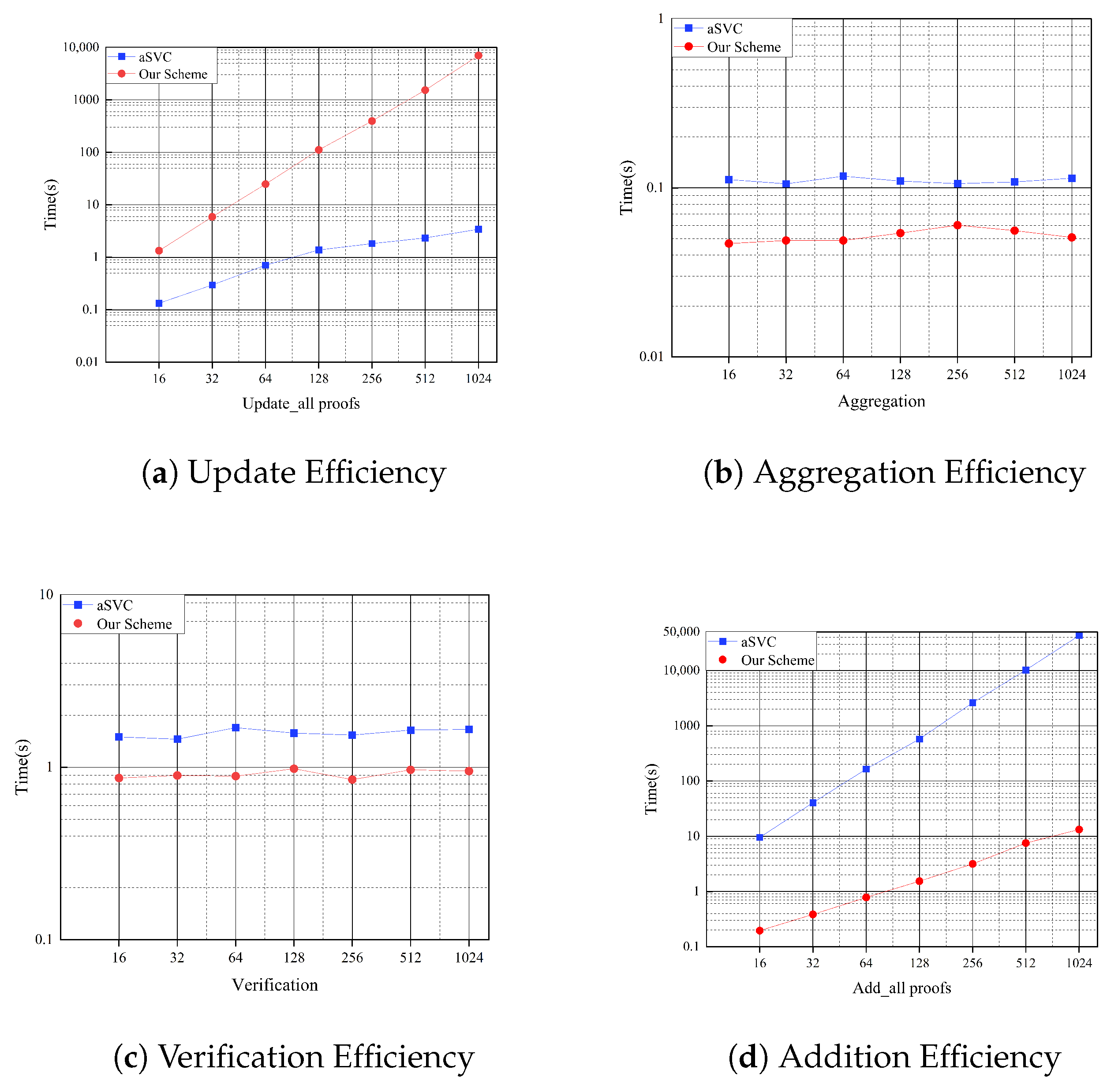
- We present a formal security analysis to prove that our scheme can achieve the security of position binding. Furthermore, we provide a thorough implementation, and the experiment results demonstrate that our scheme is more efficient at aggregation and verification, and at updating the proofs when appending a new value. Specifically, compared with aSVC, the proposed scheme achieves a 48× speedup when adding an element to a 16-length vector, as well as 2.13× and 1.73× speedups for aggregating eight proofs and performing verification, respectively.
1.2. Related Work
1.3. Organization
2. Preliminaries
2.1. Newton Interpolation
2.2. Bilinear Pairing
- Bilinearity: and it is .
- Non-degeneracy: .
- Computable: For all , we have an efficient algorithm to compute .
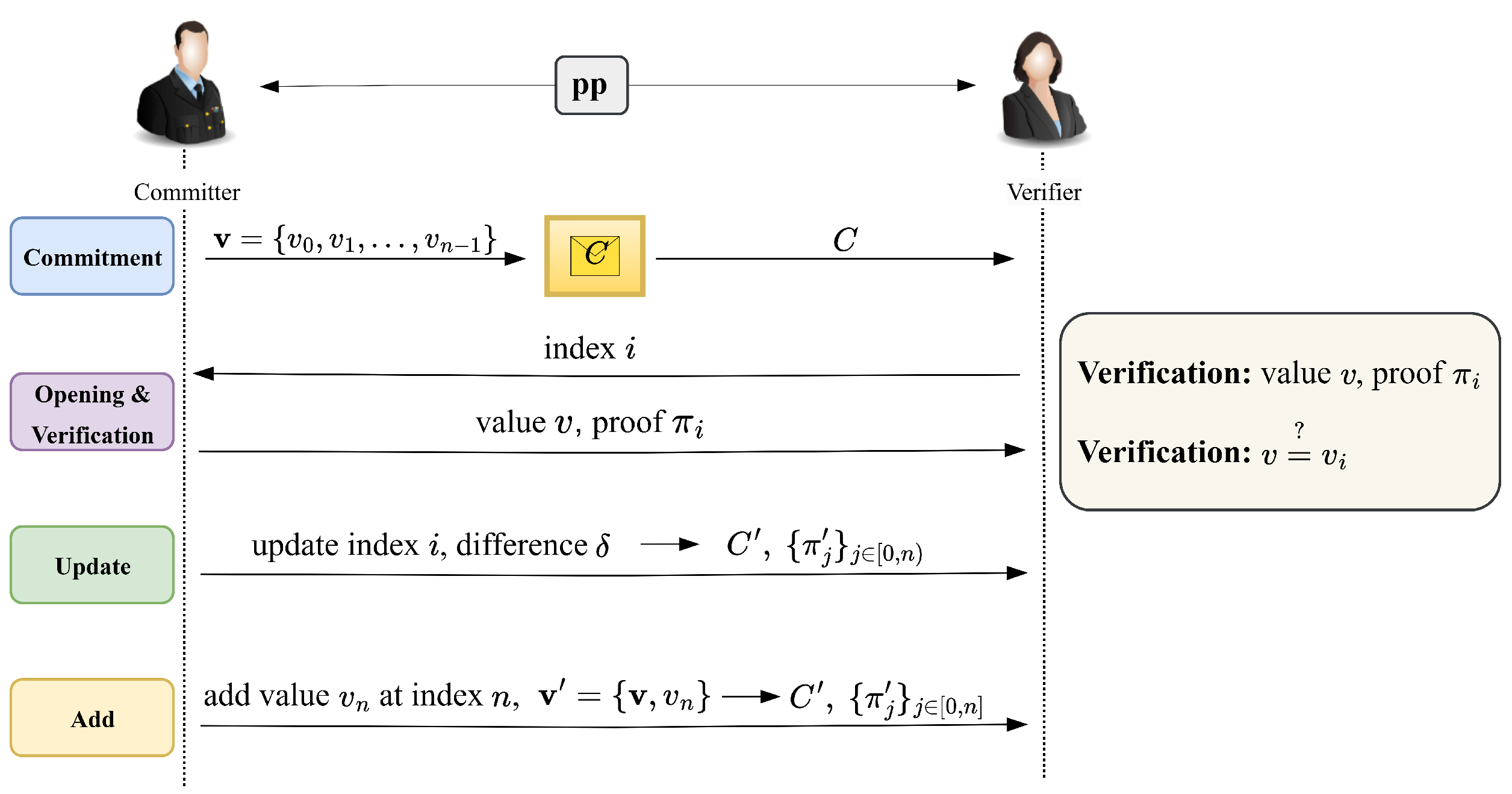
2.3. Vector Commitment
- Gen pp: Inputting vector size n and security parameter λ outputs the public parameters.
- Commit(pp,) → (C,aux): Inputting vector outputs commitment C and auxiliary information .
- Open(pp, i,, aux) : Inputting the position index i, the vectors and outputs proof at index i.
- OpenAll(pp, ) : Inputting vector outputs proofs at all positions .
- Agg(pp,: For the aggregate set , inputting the proofs and the values outputs , which is an aggregated proof of constant size.
- Verify(pp, C, : Inputting values , commitment C and aggregate proof outputs either 0 or 1.
- UpdateCom(pp, C, : Inputting update index i, update value δ and commitment C outputs the update commitment after changing δ at position i.
- UpdateProof(pp,: Inputting update index i, update value δ, index j and proof outputs updated proof after changing δ at position i.
- UpdateAllProofs(pp, ) : Inputting update index i, update value δ, all proofs and auxiliary information outputs all updated proofs and updated auxiliary information after changing δ at position i.
2.4. Karatsuba Algorithm
2.4.1. Ordinary Calculation: Degree-t Polynomials
2.4.2. Recursive KA: Polynomials of Arbitrary Degree
| Algorithm 1 KA |
|
3. The Proposed Scheme
- Gen pp: It takes as input the size of the vector n and security parameter , and outputs the public parameter pp. First, it computes two groups and of order prime p for which there exists a symmetric bilinear pairing . Then, the generators and are chosen at random and generate an -tuple . Additionally, a mapping is defined to map an integer to a prime, such that . Finally, it outputs
- Commit(pp: It takes as input a vector , and generates the number of n primes by invoking for . Given n interpolation points , it computes the Newton interpolating polynomial such that . We represent . The commitment for is
- Open(pp: Upon inputting position index i, vector , it outputs proof . In particular, it calculates the following polynomial:and then the proof is . That is, for the value at the i-th position of the vector is the commitment to the polynomial .
- OpenAll(pp: Upon inputting the vector , we can call the Open algorithm to output all proofs in sequence.
- Agg(pp: Upon inputting the index set at which the proofs are to be aggregated, the set of messages corresponding with proofs , it aggregates multiple proofs into a proof of constant size for the set I. Specifically, is a commitment to the following polynomial:where satisfies for , , and is calculated as shown in Algorithm 2.
Algorithm 2 MultiplyAll - Input:
- Output:
- 1:
- if then
- 2:
- Output:
- 3:
- else
- 4:
- mid =
- 5:
- left_result = MultiplyAll (mid
- 6:
- right_result = MultiplyAll (mid
- 7:
- end if
- 8:
- return = KA(left_result, right_result) =
Similar to aSVC [3], the specific form of iswhere the derivative of can be expressed as . Let ; then, our aggregate proof , and the polynomial can be computed with the help of KA in time complexity , while its derivative has computational complexity . Therefore, it is possible to obtain all in .
- Verify(pp: Upon inputting the index set I at which the proofs are to be aggregated, the set of messages , the batch proof and commitment value C, it outputs 1 iff:where , and satisfies for . When and , we can verify that passes the following equation:
- UpdateCom(pp: Upon inputting the original commitment value C, the updated index i, and the difference at the updated index, it calculates the new interpolation polynomial , where is the interpolation polynomial coefficient, and outputs the new commitment value .
- UpdateAllProofs(pp: Upon inputting the index i at the update and difference between message update , it can calculate the updated Newton interpolation polynomial, and output all proofs by calling it OpenAll.
- UpdateProof(pp: Upon inputting the index i of the update location, the message update difference , the index j and the proof , calculate the updated Newton interpolation polynomial, call the algorithm Open, and output the updated proof to reflect the message at position i changing by .
- AddCom(pp: Input the original commitment value C and the vector after adding the node, where l represents the number of nodes we want to add. Call Gen to obtain the new public parameter .where . Compute the new difference quotient values , and we can obtain a new polynomial . Output
- AddProof: Whenever we add a new vector node, the original proof changes. Entering the index i of the newly added node and adding the difference quotient value requires updating the proof . Add a new node and the interpolating polynomial changes as follows:At this point, the quotient polynomial of our computational proofs changes as follows: ifStore in the public parameter as the update parameter, then . Otherwise, we need to call the algorithm the Open( algorithm to calculate the proof at position .
- AddAllProof: Input the index i of the added node and the value of the added difference quotient. If , call the algorithm Open(, where . If , return .
4. Security Analysis
4.1. Assumptions
4.2. Security Proof
5. Experimental Evaluations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kate, A.; Zaverucha, G.M.; Goldberg, I. Constant-size commitments to polynomials and their applications. In Proceedings of the Advances in Cryptology-ASIACRYPT 2010: 16th International Conference on the Theory and Application of Cryptology and Information Security, Singapore, 5–9 December 2010; Proceedings 16. Springer: Berlin/Heidelberg, Germany, 2010; pp. 177–194. [Google Scholar]
- Catalano, D.; Fiore, D. Vector commitments and their applications. In Proceedings of the Public-Key Cryptography–PKC 2013: 16th International Conference on Practice and Theory in Public-Key Cryptography, Nara, Japan, 26 February–1 March 2013; Proceedings 16. Springer: Berlin/Heidelberg, Germany, 2013; pp. 55–72. [Google Scholar]
- Tomescu, A.; Abraham, I.; Buterin, V.; Drake, J.; Feist, D.; Khovratovich, D. Aggregatable subvector commitments for stateless cryptocurrencies. In Proceedings of the International Conference on Security and Cryptography for Networks; Springer: Berlin/Heidelberg, Germany, 2020; pp. 45–64. [Google Scholar]
- Gorbunov, S.; Reyzin, L.; Wee, H.; Zhang, Z. Pointproofs: Aggregating proofs for multiple vector commitments. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 9–13 November 2020; pp. 2007–2023. [Google Scholar]
- Srinivasan, S.; Chepurnoy, A.; Papamanthou, C.; Tomescu, A.; Zhang, Y. Hyperproofs: Aggregating and maintaining proofs in vector commitments. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022; pp. 3001–3018. [Google Scholar]
- Wang, W.; Ulichney, A.; Papamanthou, C. {BalanceProofs}: Maintainable vector commitments with fast aggregation. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 4409–4426. [Google Scholar]
- Liu, J.; Zhang, L.F. Matproofs: Maintainable matrix commitment with efficient aggregation. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, Los Angeles, CA, USA, 7–11 November 2022; pp. 2041–2054. [Google Scholar]
- Lai, R.W.; Malavolta, G. Subvector commitments with application to succinct arguments. In Proceedings of the Advances in Cryptology–CRYPTO 2019: 39th Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2019; Proceedings, Part I 39. Springer: Berlin/Heidelberg, Germany, 2019; pp. 530–560. [Google Scholar]
- Campanelli, M.; Fiore, D.; Greco, N.; Kolonelos, D.; Nizzardo, L. Incrementally aggregatable vector commitments and applications to verifiable decentralized storage. In Proceedings of the Advances in Cryptology–ASIACRYPT 2020: 26th International Conference on the Theory and Application of Cryptology and Information Security, Daejeon, Republic of Korea, 7–11 December 2020; Proceedings, Part II 26. Springer: Berlin/Heidelberg, Germany, 2020; pp. 3–35. [Google Scholar]
- Boneh, D.; Bünz, B.; Fisch, B. Batching techniques for accumulators with applications to IOPs and stateless blockchains. In Proceedings of the Advances in Cryptology–CRYPTO 2019: 39th Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2019; Proceedings, Part I 39. Springer: Berlin/Heidelberg, Germany, 2019; pp. 561–586. [Google Scholar]
- Kate, A.; Zaverucha, G.M.; Goldberg, I. Polynomial Commitments. Technical Report 2010. Available online: https://www.researchgate.net/publication/228888344_Polynomial_Commitments (accessed on 5 January 2025).
- Tas, E.N.; Boneh, D. Vector Commitments with Efficient Updates. arXiv 2024, arXiv:2307.04085. [Google Scholar]
- Acharya, O.; Baldimtsi, F.; Gordon, S.D.; McVicker, D.; Yadav, A. Universal Vector Commitments; Springer: Berlin/Heidelberg, Germany, 2024; pp. 161–181. [Google Scholar]
- Libert, B. Vector Commitments with Proofs of Smallness: Short Range Proofs and More. In Proceedings of the IACR International Conference on Public-Key Cryptography, Sydney, Australia, 15–17 April 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 36–67. [Google Scholar]
- Libert, B.; Yung, M. Concise mercurial vector commitments and independent zero-knowledge sets with short proofs. In Proceedings of the Theory of Cryptography Conference; Springer: Berlin/Heidelberg, Germany, 2010; pp. 499–517. [Google Scholar]
- Catalano, D.; Fiore, D.; Messina, M. Zero-knowledge sets with short proofs. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 2008; pp. 433–450. [Google Scholar]
- Wang, Q.; Zhou, F.; Xu, J.; Xu, Z. A (Zero-Knowledge) Vector Commitment with Sum Binding and its Applications. Comput. J. 2020, 63, 633–647. [Google Scholar] [CrossRef]
- Merkle, R.C. A digital signature based on a conventional encryption function. In Proceedings of the Conference on the Theory and Application of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 1987; pp. 369–378. [Google Scholar]
- Bünz, B.; Maller, M.; Mishra, P.; Tyagi, N.; Vesely, P. Proofs for inner pairing products and applications. In Proceedings of the Advances in Cryptology–ASIACRYPT 2021: 27th International Conference on the Theory and Application of Cryptology and Information Security, Singapore, 6–10 December 2021; Proceedings, Part III 27. Springer: Berlin/Heidelberg, Germany, 2021; pp. 65–97. [Google Scholar]
- Von zur Gathen, J.; Gerhard, J. Fast multiplication. In Modern Computer Algebra; Cambridge University Press: Cambridge, UK, 2013; pp. 221–254. [Google Scholar]
- Newton Polynomial. Available online: https://encyclopedia.thefreedictionary.com/Newton+polynomial (accessed on 5 January 2025).
- Joux, A. A one round protocol for tripartite Diffie–Hellman. In Proceedings of the International Algorithmic Number Theory Symposium; Springer: Berlin/Heidelberg, Germany, 2000; pp. 385–393. [Google Scholar]
- Menezes, A.; Vanstone, S.; Okamoto, T. Reducing elliptic curve logarithms to logarithms in a finite field. In Proceedings of the Twenty-Third Annual ACM Symposium on Theory of Computing, New Orleans, LA, USA, 6–8 May 1991; pp. 80–89. [Google Scholar]
- Enge, A. Bilinear pairings on elliptic curves. arXiv 2014, arXiv:1301.5520v2. [Google Scholar] [CrossRef]
- Meert, D. Bilinear Pairings in Cryptography; Radboud Universiteit Nijmegen: Nijmegen, The Netherlands, 2009; pp. 22–82. [Google Scholar]
- Weimerskirch, A.; Paar, C. Generalizations of the Karatsuba algorithm for efficient implementations. Cryptol. ePrint Arch. 2006, 2006, 224. [Google Scholar]
- Karatsuba, A.A. The complexity of computations. Proc. Steklov Inst. Math.-Interperiodica Transl. 1995, 211, 169–183. [Google Scholar]
- Karatsuba, A. Multiplication of multidigit numbers on automata. In Proceedings of the Soviet Physics Doklady; American Institute of Physics: College Park, MD, USA, 1963; Volume 7, pp. 595–596. [Google Scholar]
- Boneh, D.; Boyen, X. Short signatures without random oracles. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 2004; pp. 56–73. [Google Scholar]
- Papamanthou, C.; Shi, E.; Tamassia, R. Signatures of correct computation. In Proceedings of the Theory of Cryptography Conference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 222–242. [Google Scholar]
- Guo, F.; Mu, Y.; Chen, Z. Identity-based encryption: How to decrypt multiple ciphertexts using a single decryption key. In Proceedings of the International Conference on Pairing-Based Cryptography; Springer: Berlin/Heidelberg, Germany, 2007; pp. 392–406. [Google Scholar]

{kind=link}
{kind=link}
| Scheme | Aggregate | Verify | Verify | UpdateAllProofs | AddAllProofs | ||
|---|---|---|---|---|---|---|---|
| aSVC | 1 | ||||||
| Our Scheme | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Q.; Gao, C.; Wang, Y. Aggregatable Subvector Commitment with Efficient Updates. Appl. Sci. 2025, 15, 554. https://doi.org/10.3390/app15020554
Xu Q, Gao C, Wang Y. Aggregatable Subvector Commitment with Efficient Updates. Applied Sciences. 2025; 15(2):554. https://doi.org/10.3390/app15020554
Chicago/Turabian StyleXu, Qing, Chenyang Gao, and Yunling Wang. 2025. "Aggregatable Subvector Commitment with Efficient Updates" Applied Sciences 15, no. 2: 554. https://doi.org/10.3390/app15020554
APA StyleXu, Q., Gao, C., & Wang, Y. (2025). Aggregatable Subvector Commitment with Efficient Updates. Applied Sciences, 15(2), 554. https://doi.org/10.3390/app15020554