


On Explainability of Reinforcement Learning-Based Machine Learning Agents Trained with Proximal Policy Optimization That Utilizes Visual Sensor Data



Abstract
1. Introduction
1.1. State of the Art
- model distillation (indirect inference): training of a simpler model (e.g., a decision tree) [46] whose task is to mimic the performance of a more complex RL agent on the assumption that a simpler model is more straightforward to interpret and can provide more comprehensible information about the agent’s decisions.
1.2. Novelty of This Paper
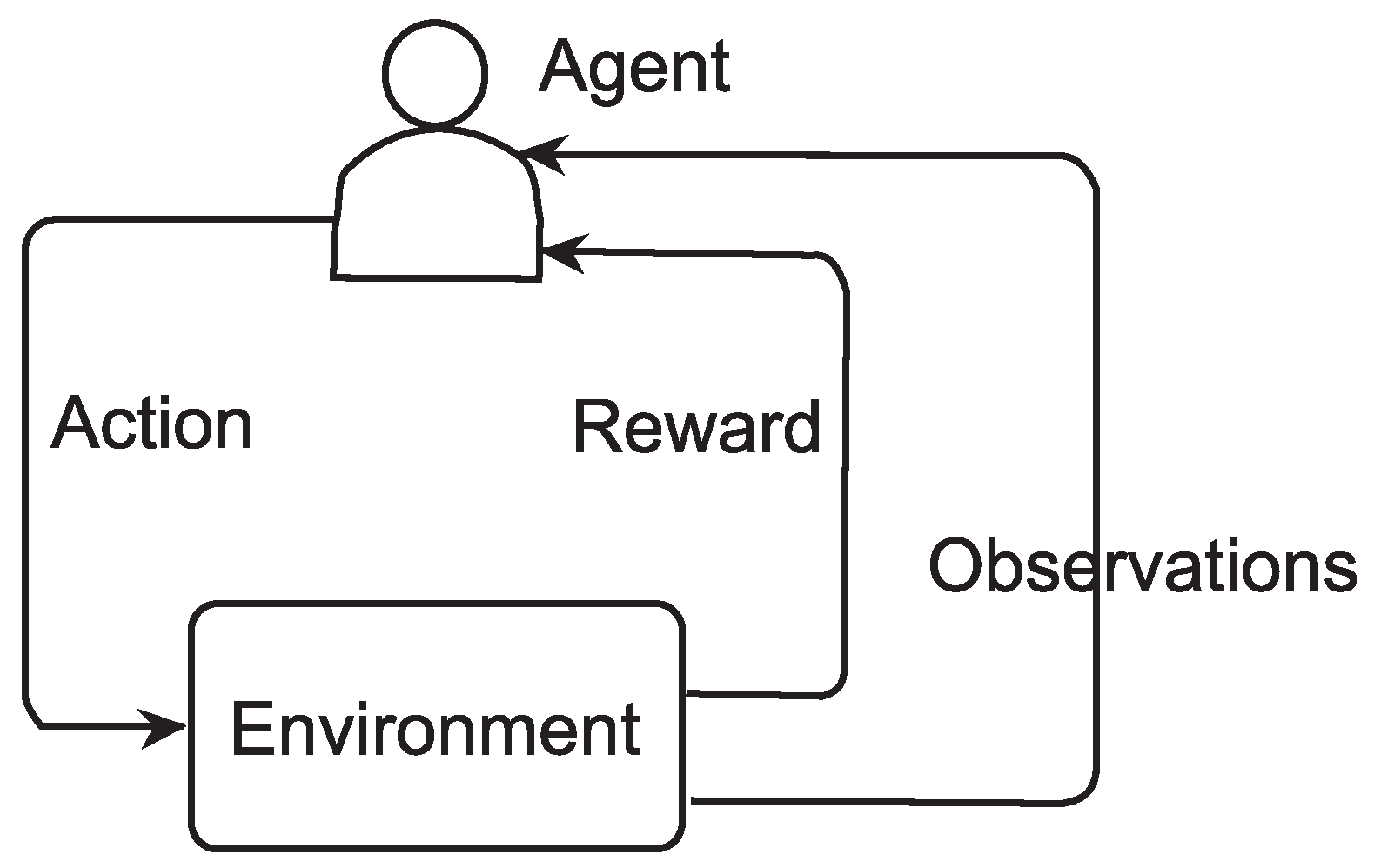
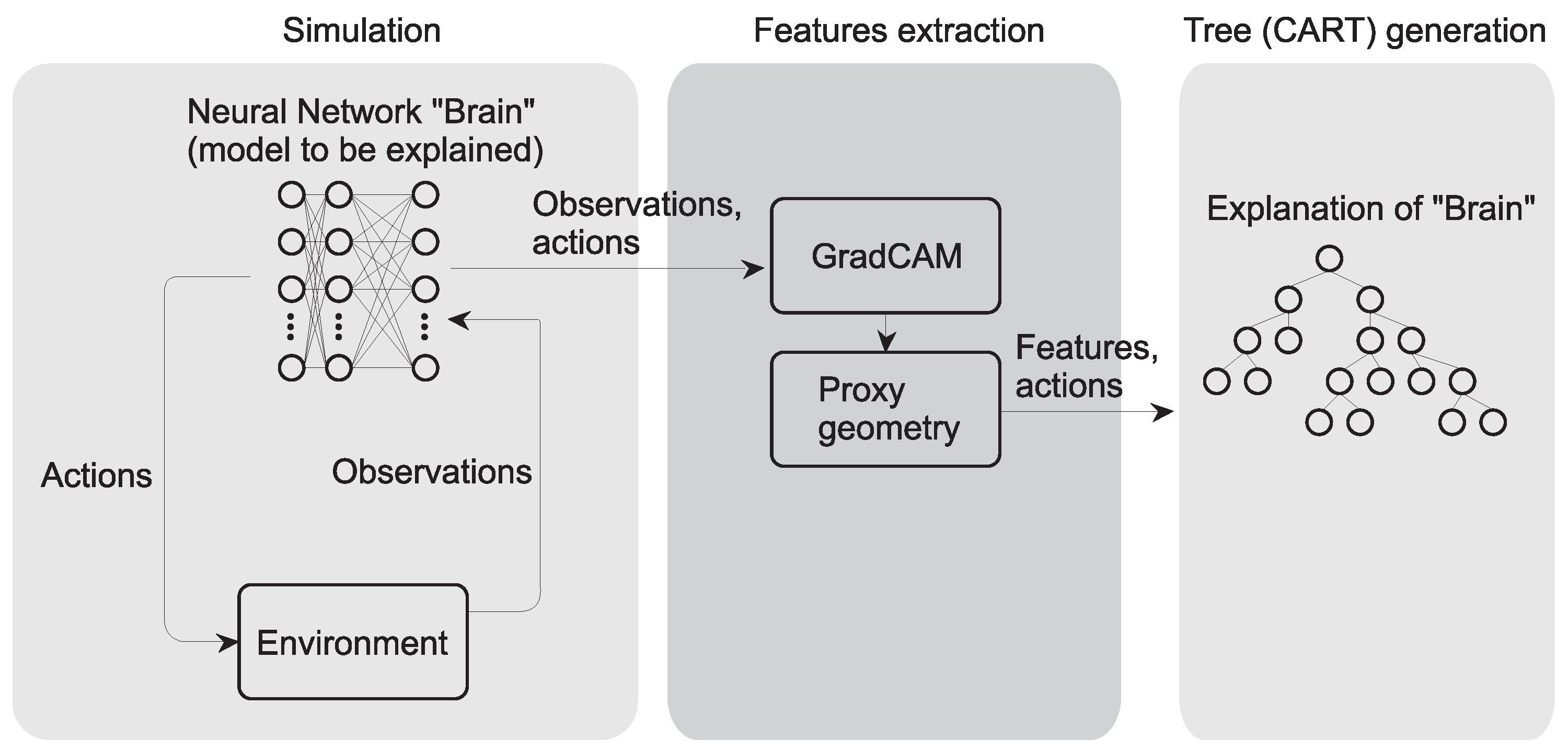
2. Materials and Methods
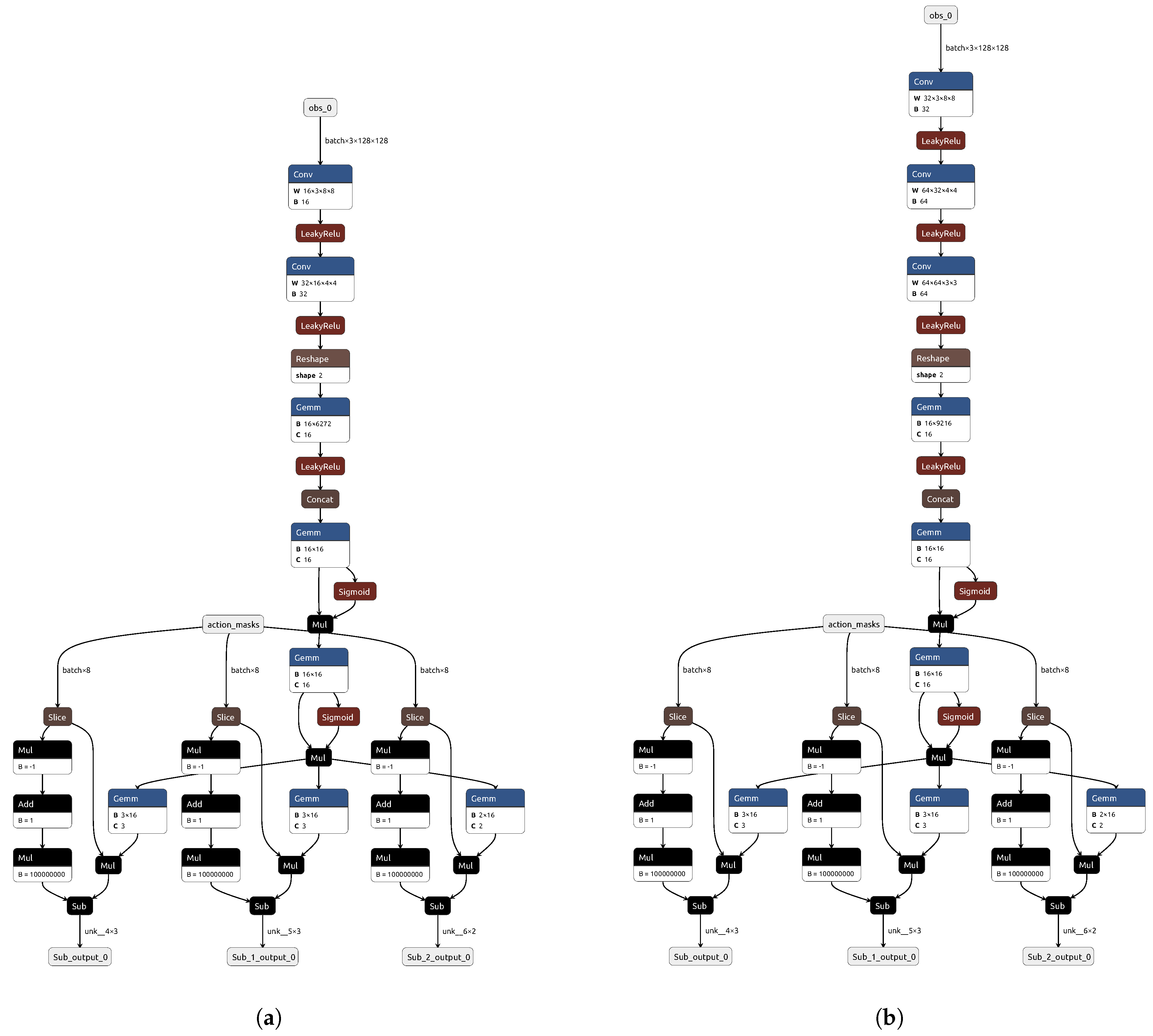
2.1. The Neural Network of an Agent Trained with Proximal Policy Optimization with Visual (Image) Input
2.2. GradCAM for Image Processing Layer Explanation
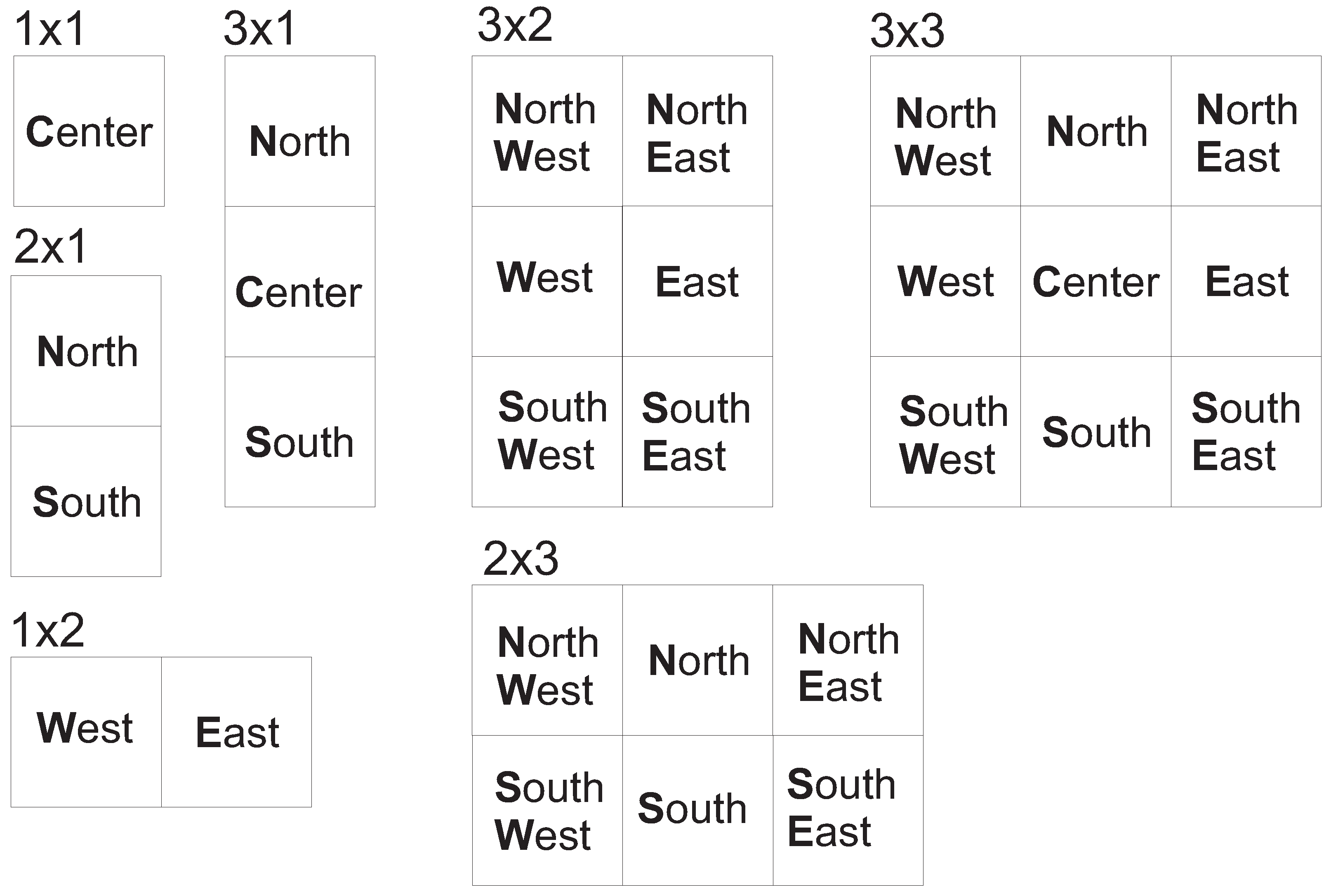
2.3. Decision Trees, Proxy Geometry and Semantic Scene Segmentation
- Input image to the model, even if it is not high-resolution, for example, pixels, contains 2304 features. This is far too many to build an explanation of the model.
- Individual pixels are not a semantic interpretation of what is in the image. What is interpretable is their position relative to each other. The convolution layer, acting as a multi-cascade image filter, analyzes the textures and mutual position of graphic primitives in the image.
| Algorithm 1: Generate proxy geometry |
 |
| Algorithm 2: Generate image features using proxy geometry |
 |
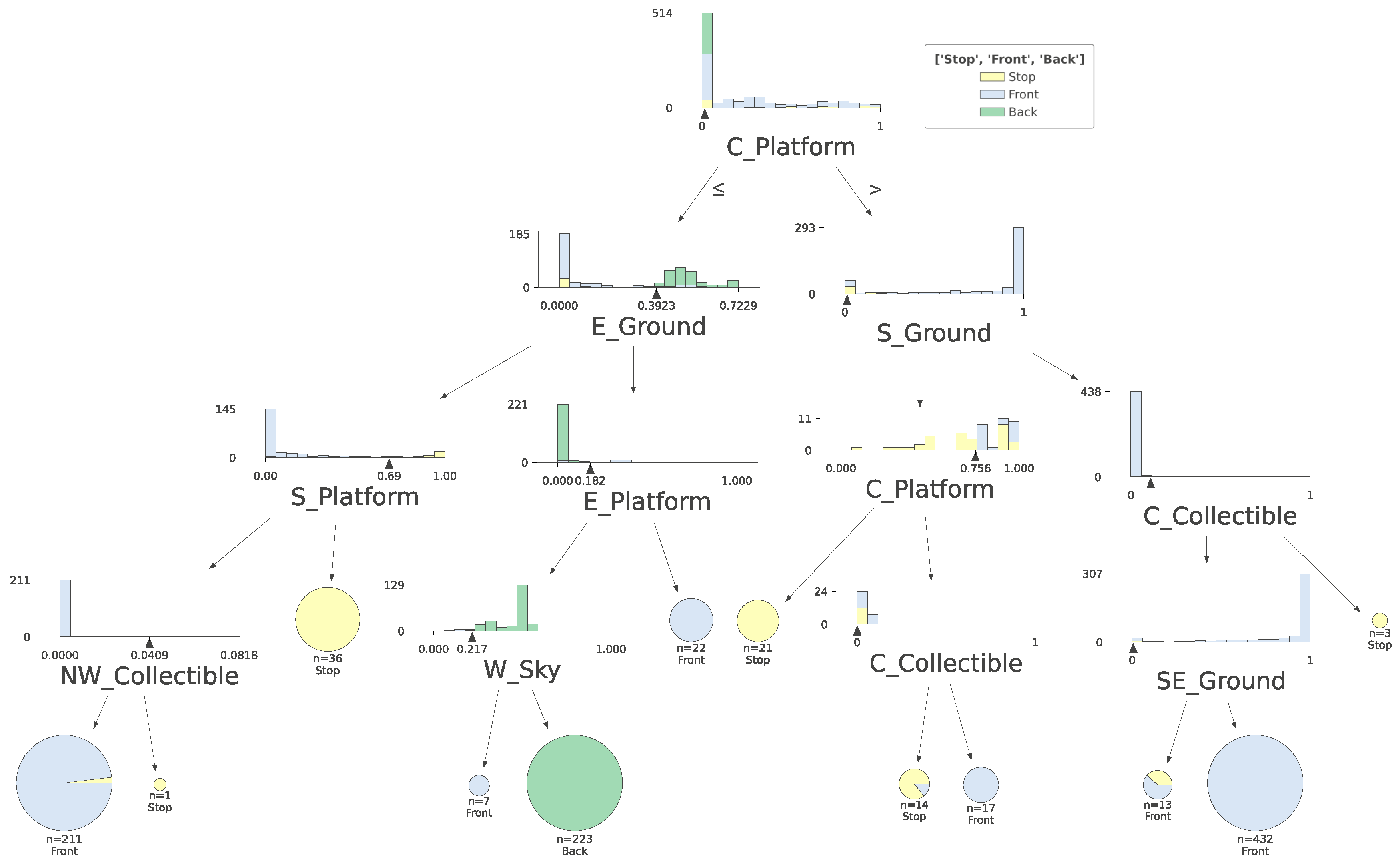
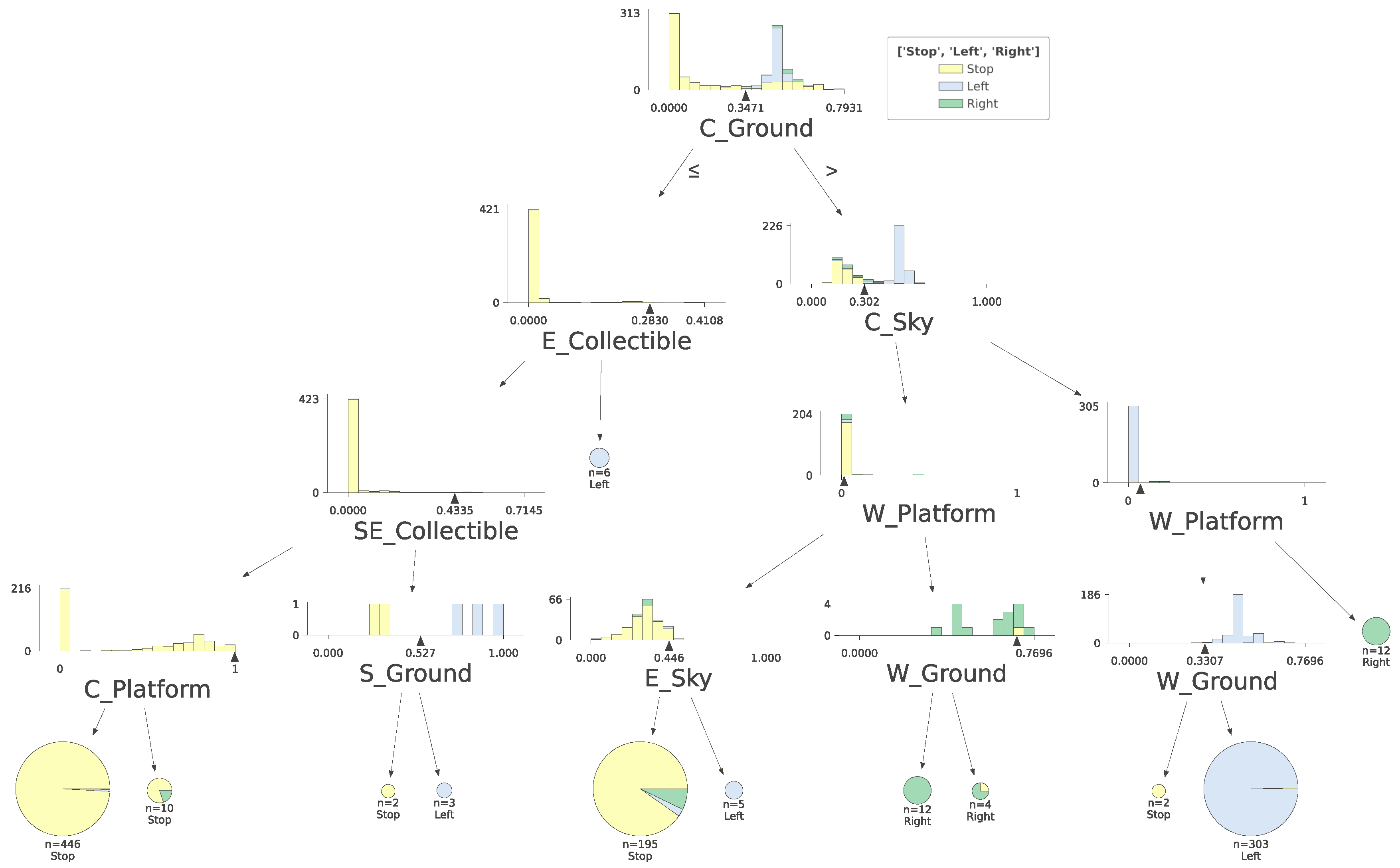
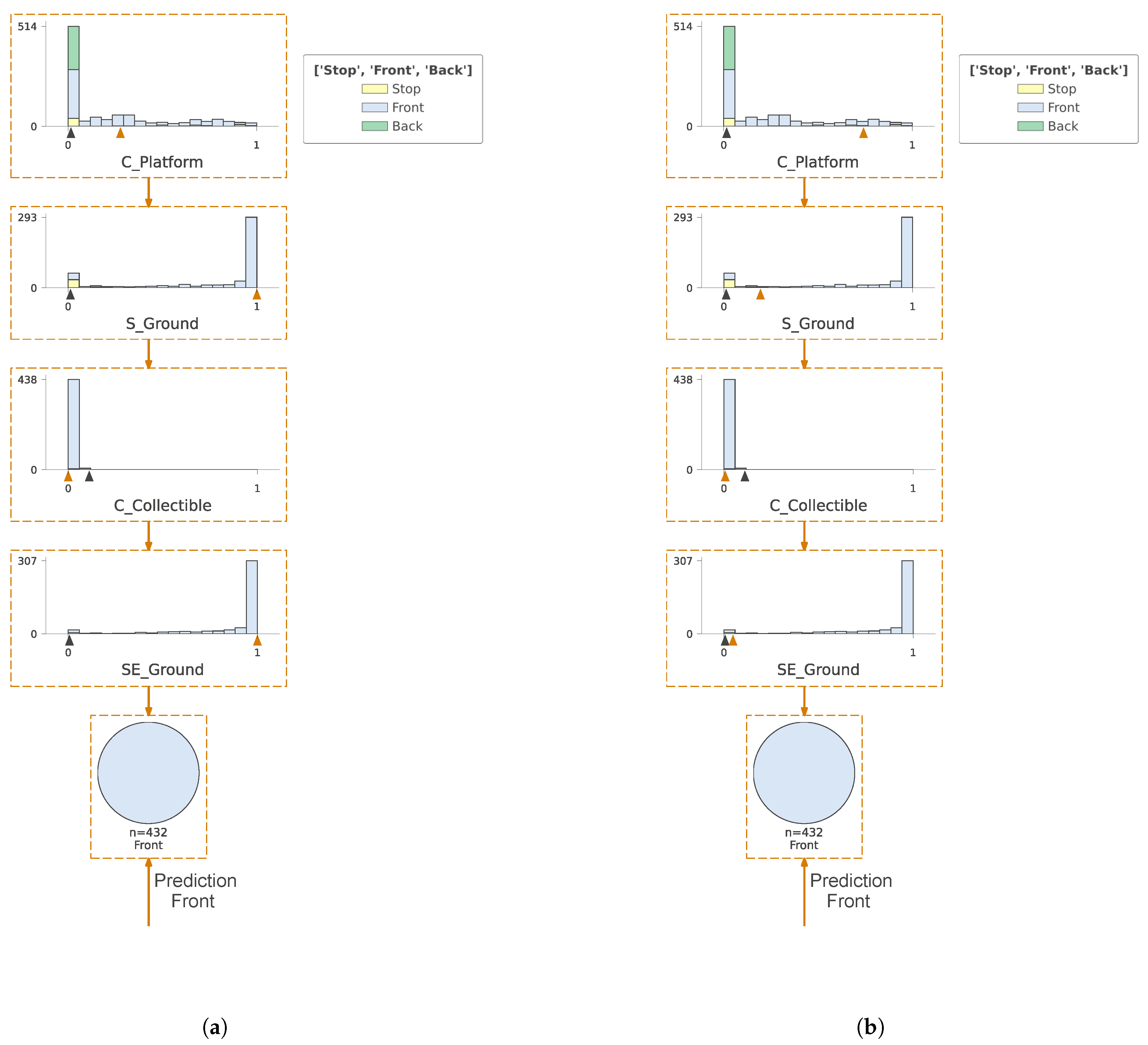
2.4. PPO Model Approximation with Decision Tree-Based Naive Method and with GradCam Weights
2.5. Computational Complexity and Comparison with Other Methods
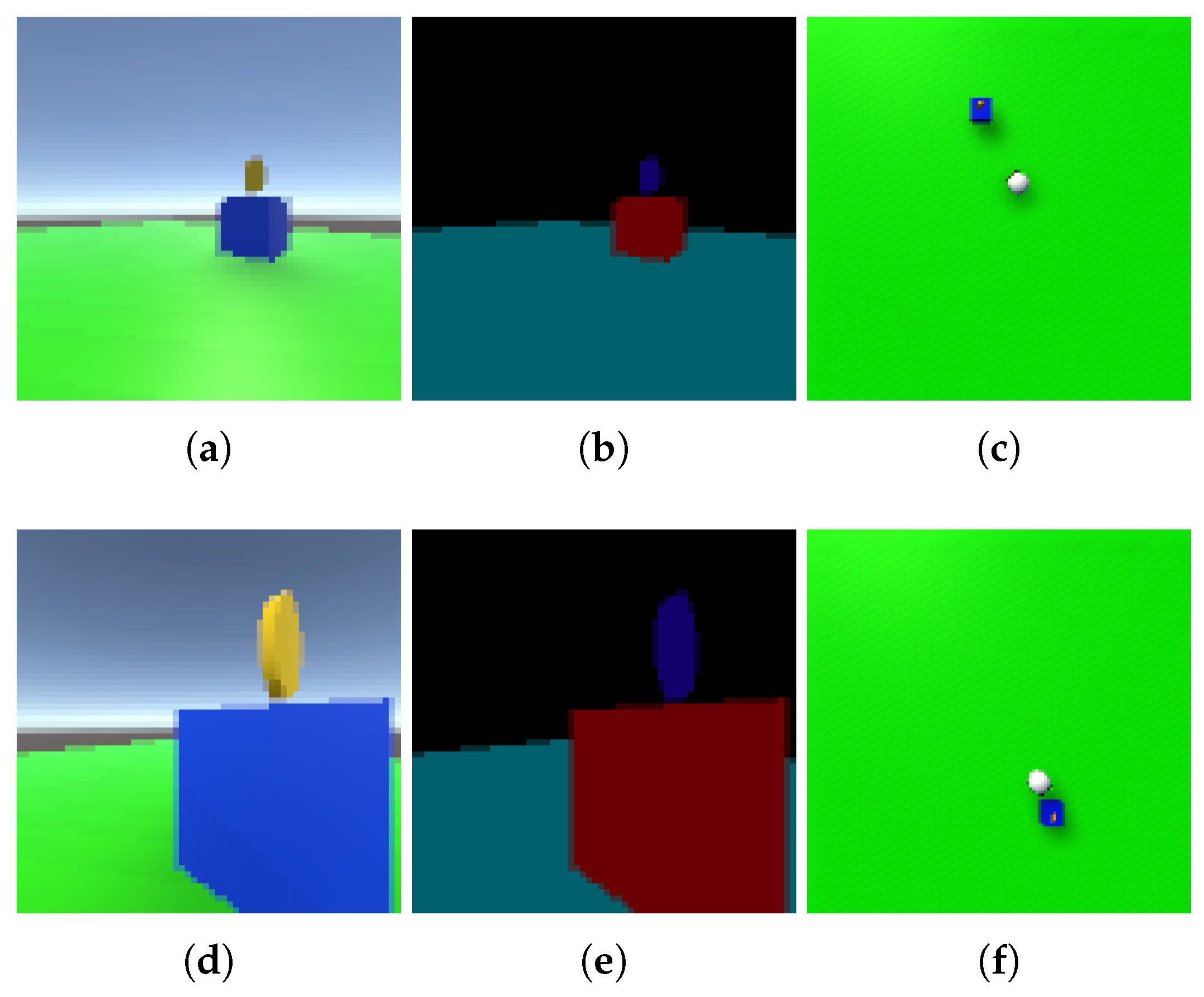
2.6. Experiment Setting
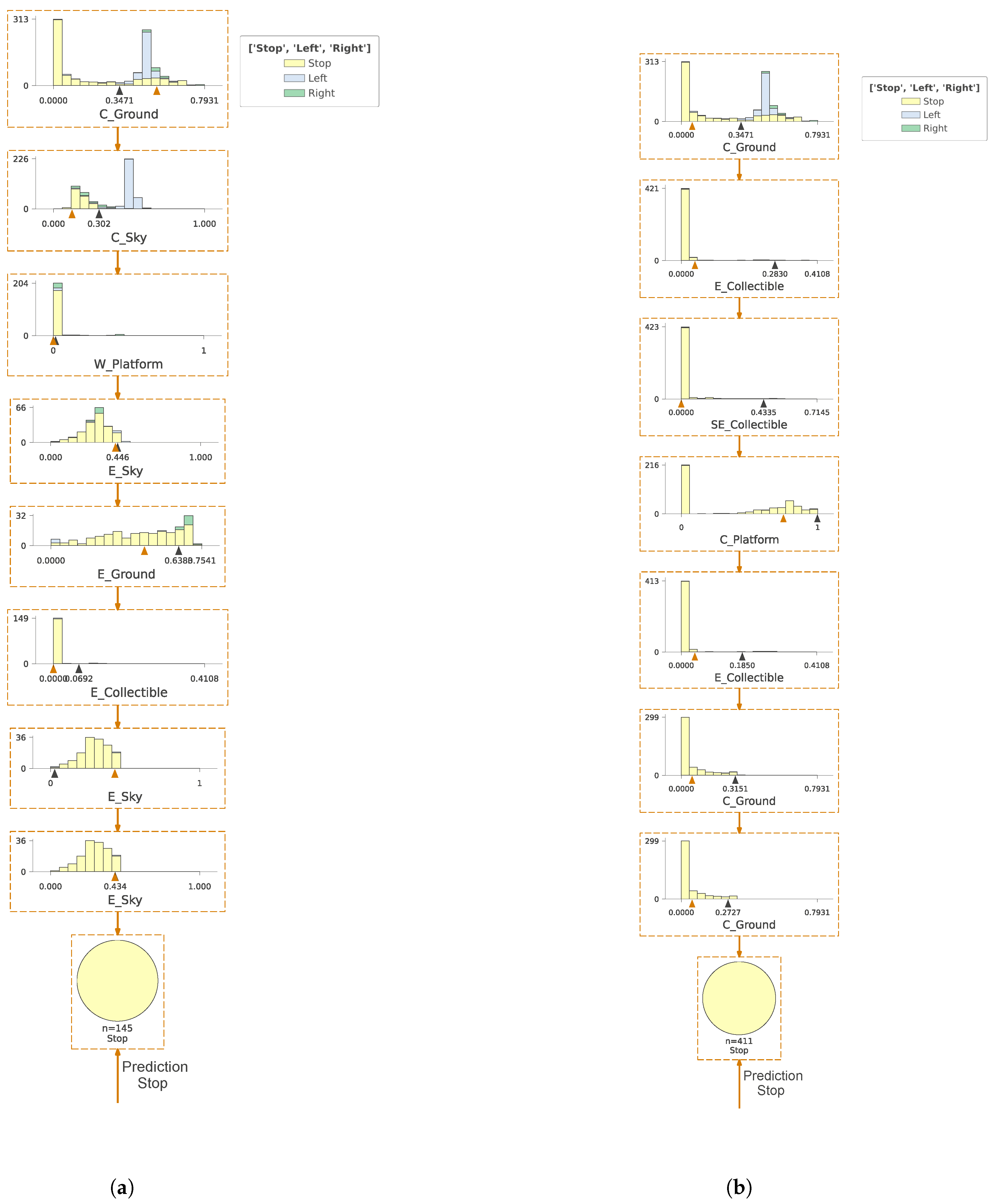
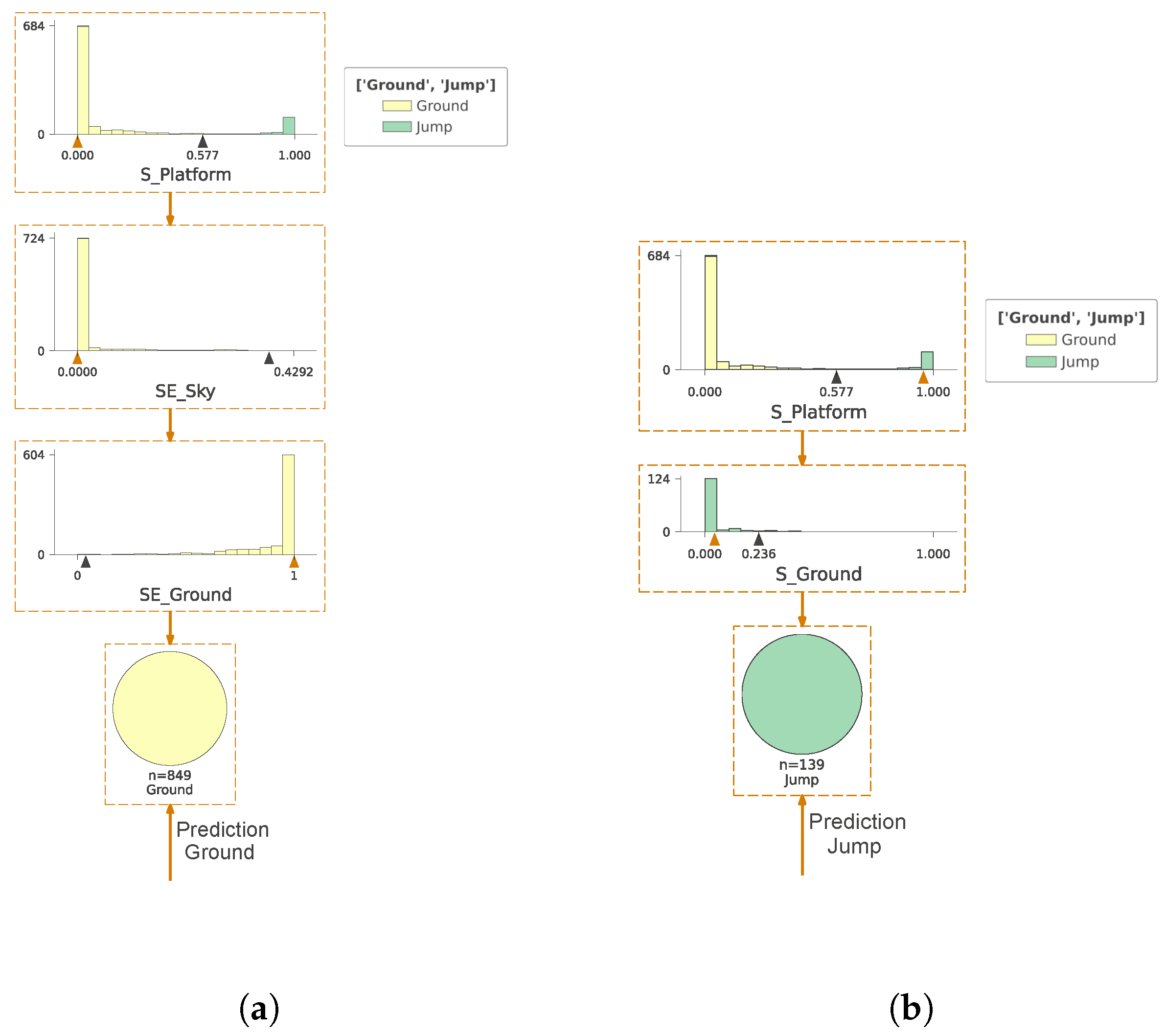
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ding, W.; Abdel-Basset, M.; Hawash, H.; Ali, A.M. Explainability of artificial intelligence methods, applications and challenges: A comprehensive survey. Inf. Sci. 2022, 615, 238–292. [Google Scholar] [CrossRef]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar]
- Holzinger, A.; Saranti, A.; Molnar, C.; Biecek, P.; Samek, W. Explainable AI methods—A brief overview. In Proceedings of the International Workshop on Extending Explainable AI Beyond Deep Models and Classifiers; Springer: Berlin/Heidelberg, Germany, 2022; pp. 13–38. [Google Scholar]
- Lin, Y.S.; Lee, W.C.; Celik, Z.B. What do you see? Evaluation of explainable artificial intelligence (XAI) interpretability through neural backdoors. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 1027–1035. [Google Scholar]
- Rong, Y.; Leemann, T.; Nguyen, T.T.; Fiedler, L.; Qian, P.; Unhelkar, V.; Seidel, T.; Kasneci, G.; Kasneci, E. Towards human-centered explainable ai: A survey of user studies for model explanations. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 2104–2122. [Google Scholar] [CrossRef] [PubMed]
- McDermid, J.A.; Jia, Y.; Porter, Z.; Habli, I. Artificial intelligence explainability: The technical and ethical dimensions. Philos. Trans. R. Soc. A 2021, 379, 20200363. [Google Scholar] [CrossRef] [PubMed]
- Spartalis, C.N.; Semertzidis, T.; Daras, P. Balancing XAI with Privacy and Security Considerations. In Proceedings of the European Symposium on Research in Computer Security, The Hague, The Netherlands, 25–29 September 2023; pp. 111–124. [Google Scholar]
- Akhtar, M.A.K.; Kumar, M.; Nayyar, A. Privacy and Security Considerations in Explainable AI. In Towards Ethical and Socially Responsible Explainable AI: Challenges and Opportunities; Springer: Berlin/Heidelberg, Germany, 2024; pp. 193–226. [Google Scholar]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A review of machine learning interpretability methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef]
- Ghosh, A.; Kandasamy, D. Interpretable artificial intelligence: Why and when. Am. J. Roentgenol. 2020, 214, 1137–1138. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Marcinkevičs, R.; Vogt, J.E. Interpretable and explainable machine learning: A methods-centric overview with concrete examples. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2023, 13, e1493. [Google Scholar] [CrossRef]
- Rawal, A.; McCoy, J.; Rawat, D.B.; Sadler, B.M.; Amant, R.S. Recent advances in trustworthy explainable artificial intelligence: Status, challenges, and perspectives. IEEE Trans. Artif. Intell. 2021, 3, 852–866. [Google Scholar] [CrossRef]
- Minh, D.; Wang, H.X.; Li, Y.F.; Nguyen, T.N. Explainable artificial intelligence: A comprehensive review. In Artificial Intelligence Review; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–66. [Google Scholar]
- Speith, T. A review of taxonomies of explainable artificial intelligence (XAI) methods. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 2239–2250. [Google Scholar]
- Dwivedi, R.; Dave, D.; Naik, H.; Singhal, S.; Omer, R.; Patel, P.; Qian, B.; Wen, Z.; Shah, T.; Morgan, G.; et al. Explainable AI (XAI): Core ideas, techniques, and solutions. ACM Comput. Surv. 2023, 55, 1–33. [Google Scholar] [CrossRef]
- Gianfagna, L.; Di Cecco, A. Model-agnostic methods for XAI. In Explainable AI with Python; Springer: Berlin/Heidelberg, Germany, 2021; pp. 81–113. [Google Scholar]
- Darias, J.M.; Díaz-Agudo, B.; Recio-Garcia, J.A. A Systematic Review on Model-agnostic XAI Libraries. In Proceedings of the ICCBR Workshops, Salamanca, Spain, 13–16 September 2021; pp. 28–39. [Google Scholar]
- Saeed, W.; Omlin, C. Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. Knowl.-Based Syst. 2023, 263, 110273. [Google Scholar] [CrossRef]
- Abusitta, A.; Li, M.Q.; Fung, B.C. Survey on explainable ai: Techniques, challenges and open issues. Expert Syst. Appl. 2024, 255, 124710. [Google Scholar] [CrossRef]
- Le, T.T.H.; Prihatno, A.T.; Oktian, Y.E.; Kang, H.; Kim, H. Exploring local explanation of practical industrial AI applications: A systematic literature review. Appl. Sci. 2023, 13, 5809. [Google Scholar] [CrossRef]
- Aechtner, J.; Cabrera, L.; Katwal, D.; Onghena, P.; Valenzuela, D.P.; Wilbik, A. Comparing user perception of explanations developed with XAI methods. In Proceedings of the 2022 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Padua, Italy, 18–23 July 2022; pp. 1–7. [Google Scholar]
- Saleem, R.; Yuan, B.; Kurugollu, F.; Anjum, A.; Liu, L. Explaining deep neural networks: A survey on the global interpretation methods. Neurocomputing 2022, 513, 165–180. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “ Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-precision model-agnostic explanations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Goldstein, A.; Kapelner, A.; Bleich, J.; Pitkin, E. Peeking inside the black box: Visualizing statistical learning with plots of individual conditional expectation. J. Comput. Graph. Stat. 2015, 24, 44–65. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Freedman, D.A. Statistical Models: Theory and Practice; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harv. JL Tech. 2017, 31, 841. [Google Scholar] [CrossRef]
- Simonyan, K. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations From Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Sutton, R.S. Reinforcement learning: An introduction. In A Bradford Book; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Tesauro, G. Td-gammon: A self-teaching backgammon program. In Applications of Neural Networks; Springer: Berlin/Heidelberg, Germany, 1995; pp. 267–285. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 1999, 12, 1057–1063. [Google Scholar]
- Shah, H.; Gopal, M. Fuzzy decision tree function approximation in reinforcement learning. Int. J. Artif. Intell. Soft Comput. 2010, 2, 26–45. [Google Scholar] [CrossRef]
- Silva, A.; Gombolay, M.; Killian, T.; Jimenez, I.; Son, S.H. Optimization methods for interpretable differentiable decision trees applied to reinforcement learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Online, 26–28 August 2020; pp. 1855–1865. [Google Scholar]
- Wang, C.; Aouf, N. Explainable Deep Adversarial Reinforcement Learning Approach for Robust Autonomous Driving. IEEE Trans. Intell. Veh. 2024, 1–13. [Google Scholar] [CrossRef]
- Shukla, I.; Dozier, H.R.; Henslee, A.C. Learning behavior of offline reinforcement learning agents. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications VI, National Harbor, MD, USA, 22–26 April 2024; Volume 13051, pp. 188–194. [Google Scholar]
- He, L.; Nabil, A.; Song, B. Explainable deep reinforcement learning for UAV autonomous navigation. arXiv 2020, arXiv:2009.14551. [Google Scholar]
- Sarkar, S.; Babu, A.R.; Mousavi, S.; Ghorbanpour, S.; Gundecha, V.; Guillen, A.; Luna, R.; Naug, A. Rl-cam: Visual explanations for convolutional networks using reinforcement learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 3861–3869. [Google Scholar]
- Metz, Y.; Bykovets, E.; Joos, L.; Keim, D.; El-Assady, M. Visitor: Visual interactive state sequence exploration for reinforcement learning. In Proceedings of the Computer Graphics Forum, Los Angeles, CA, USA, 6–10 August 2023; Wiley Online Library: Hoboken, NJ, USA, 2023; Volume 42, pp. 397–408. [Google Scholar]
- Hatano, T.; Tsuneda, T.; Suzuki, Y.; Imade, K.; Shesimo, K.; Yamane, S. GBDT modeling of deep reinforcement learning agents using distillation. In Proceedings of the 2021 IEEE International Conference on Mechatronics (ICM), Kashiwa, Japan, 7–9 March 2021; pp. 1–6. [Google Scholar]
- Hickling, T.; Zenati, A.; Aouf, N.; Spencer, P. Explainability in deep reinforcement learning: A review into current methods and applications. ACM Comput. Surv. 2023, 56, 1–35. [Google Scholar] [CrossRef]
- Puiutta, E.; Veith, E.M. Explainable reinforcement learning: A survey. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Dublin, Ireland, 25–28 August 2020; pp. 77–95. [Google Scholar]
- Wells, L.; Bednarz, T. Explainable ai and reinforcement learning—A systematic review of current approaches and trends. Front. Artif. Intell. 2021, 4, 550030. [Google Scholar] [CrossRef]
- Milani, S.; Topin, N.; Veloso, M.; Fang, F. Explainable reinforcement learning: A survey and comparative review. ACM Comput. Surv. 2024, 56, 1–36. [Google Scholar] [CrossRef]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Feng, Q.; Xiao, G.; Liang, Y.; Zhang, H.; Yan, L.; Yi, X. Proximal Policy Optimization for Explainable Recommended Systems. In Proceedings of the 2022 4th International Conference on Data-driven Optimization of Complex Systems (DOCS), Chengdu, China, 28–30 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Blanco-Justicia, A.; Domingo-Ferrer, J. Machine Learning Explainability Through Comprehensible Decision Trees. In Proceedings of the Machine Learning and Knowledge Extraction, Canterbury, UK, 26–29 August 2019; Holzinger, A., Kieseberg, P., Tjoa, A.M., Weippl, E., Eds.; ACM: Cham, Switzerland, 2019; pp. 15–26. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Niu, Y.-F.; Gao, Y.; Zhang, Y.-T.; Xue, C.-Q.; Yang, L.-X. Improving eye–computer interaction interface design: Ergonomic investigations of the optimum target size and gaze-triggering dwell time. J. Eye Mov. Res. 2019, 12. [Google Scholar] [CrossRef]
- Asgari Taghanaki, S.; Abhishek, K.; Cohen, J.P.; Cohen-Adad, J.; Hamarneh, G. Deep semantic segmentation of natural and medical images: A review. Artif. Intell. Rev. 2021, 54, 137–178. [Google Scholar] [CrossRef]
- Liu, X.; Deng, Z.; Yang, Y. Recent progress in semantic image segmentation. Artif. Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef]
- Khan, M.Z.; Gajendran, M.K.; Lee, Y.; Khan, M.A. Deep neural architectures for medical image semantic segmentation. IEEE Access 2021, 9, 83002–83024. [Google Scholar] [CrossRef]
- Hachaj, T.; Piekarczyk, M. High-Level Hessian-Based Image Processing with the Frangi Neuron. Electronics 2023, 12, 4159. [Google Scholar] [CrossRef]
- Sankar, K.; Pooransingh, A.; Ramroop, S. Synthetic Data Generation: An Evaluation of the Saving Images Pipeline in Unity. In Proceedings of the 2023 Congress in Computer Science, Computer Engineering, & Applied Computing (CSCE), Las Vegas, NV, USA, 24–27 July 2023; pp. 2009–2013. [Google Scholar] [CrossRef]
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 969–977. [Google Scholar]
- Breiman, L. Classification and Regression Trees; Routledge: Oxfordshire, UK, 2017. [Google Scholar] [CrossRef]
- Le, N.; Rathour, V.S.; Yamazaki, K.; Luu, K.; Savvides, M. Deep reinforcement learning in computer vision: A comprehensive survey. Artif. Intell. Rev. 2022, 59, 2733–2819. [Google Scholar] [CrossRef]
- Ranaweera, M.; Mahmoud, Q.H. Virtual to Real-World Transfer Learning: A Systematic Review. Electronics 2021, 10, 1491. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Naive | 0.945 | 0.961 | 0.963 | 0.962 | 0.967 | 0.932 |
| = 1; t = 0 | 0.959 | 0.977 | 0.976 | 0.968 | 0.962 | 0.941 |
| = 1; t = 0.1 | 0.953 | 0.982 | 0.976 | 0.969 | 0.968 | 0.944 |
| = 1; t = 0.2 | 0.955 | 0.984 | 0.976 | 0.967 | 0.970 | 0.943 |
| = 1; t = 0.3 | 0.949 | 0.982 | 0.982 | 0.961 | 0.955 | 0.93 |
| = 1; t = 0.4 | 0.942 | 0.981 | 0.976 | 0.959 | 0.948 | 0.93 |
| = 1; t = 0.5 | 0.944 | 0.977 | 0.976 | 0.966 | 0.946 | 0.935 |
| = 2; t = 0 | 0.944 | 0.978 | 0.976 | 0.967 | 0.966 | 0.945 |
| = 2; t = 0.1 | 0.946 | 0.98 | 0.976 | 0.964 | 0.958 | 0.941 |
| = 2; t = 0.2 | 0.952 | 0.982 | 0.974 | 0.96 | 0.937 | 0.938 |
| = 2; t = 0.3 | 0.944 | 0.969 | 0.977 | 0.954 | 0.935 | 0.929 |
| = 2; t = 0.4 | 0.931 | 0.965 | 0.972 | 0.941 | 0.943 | 0.919 |
| = 2; t = 0.5 | 0.937 | 0.971 | 0.962 | 0.942 | 0.928 | 0.918 |
| = 3; t = 0 | 0.947 | 0.975 | 0.974 | 0.973 | 0.96 | 0.945 |
| = 3; t = 0.1 | 0.953 | 0.984 | 0.973 | 0.961 | 0.945 | 0.931 |
| = 3; t = 0.2 | 0.941 | 0.968 | 0.972 | 0.95 | 0.941 | 0.929 |
| = 3; t = 0.3 | 0.935 | 0.968 | 0.968 | 0.936 | 0.936 | 0.913 |
| = 3; t = 0.4 | 0.934 | 0.97 | 0.955 | 0.938 | 0.922 | 0.917 |
| = 3; t = 0.5 | 0.927 | 0.97 | 0.935 | 0.911 | 0.918 | 0.901 |
| = 5; t = 0 | 0.953 | 0.971 | 0.973 | 0.968 | 0.951 | 0.944 |
| = 5; t = 0.1 | 0.934 | 0.968 | 0.97 | 0.941 | 0.94 | 0.922 |
| = 5; t = 0.2 | 0.934 | 0.971 | 0.96 | 0.935 | 0.928 | 0.917 |
| = 5; t = 0.3 | 0.929 | 0.968 | 0.948 | 0.916 | 0.922 | 0.901 |
| = 5; t = 0.4 | 0.914 | 0.966 | 0.928 | 0.9 | 0.911 | 0.9 |
| = 5; t = 0.5 | 0.896 | 0.959 | 0.901 | 0.846 | 0.913 | 0.891 |
| Naive | 0.919 | 0.953 | 0.944 | 0.911 | 0.961 | 0.956 |
| = 1; t = 0 | 0.911 | 0.963 | 0.953 | 0.921 | 0.968 | 0.967 |
| = 1; t = 0.1 | 0.917 | 0.966 | 0.961 | 0.926 | 0.965 | 0.962 |
| = 1; t = 0.2 | 0.922 | 0.97 | 0.95 | 0.919 | 0.967 | 0.966 |
| = 1; t = 0.3 | 0.914 | 0.97 | 0.953 | 0.908 | 0.964 | 0.964 |
| = 1; t = 0.4 | 0.917 | 0.972 | 0.95 | 0.893 | 0.963 | 0.961 |
| = 1; t = 0.5 | 0.915 | 0.962 | 0.956 | 0.874 | 0.957 | 0.954 |
| = 2; t = 0 | 0.911 | 0.962 | 0.949 | 0.921 | 0.968 | 0.963 |
| = 2; t = 0.1 | 0.918 | 0.973 | 0.957 | 0.912 | 0.961 | 0.963 |
| = 2; t = 0.2 | 0.913 | 0.972 | 0.955 | 0.876 | 0.959 | 0.951 |
| = 2; t = 0.3 | 0.92 | 0.965 | 0.946 | 0.874 | 0.951 | 0.954 |
| = 2; t = 0.4 | 0.912 | 0.961 | 0.939 | 0.872 | 0.955 | 0.952 |
| = 2; t = 0.5 | 0.918 | 0.934 | 0.937 | 0.863 | 0.947 | 0.949 |
| = 3; t = 0 | 0.911 | 0.963 | 0.957 | 0.915 | 0.96 | 0.966 |
| = 3; t = 0.1 | 0.911 | 0.97 | 0.953 | 0.878 | 0.959 | 0.953 |
| = 3; t = 0.2 | 0.919 | 0.963 | 0.947 | 0.874 | 0.958 | 0.952 |
| = 3; t = 0.3 | 0.917 | 0.957 | 0.937 | 0.863 | 0.948 | 0.949 |
| = 3; t = 0.4 | 0.913 | 0.907 | 0.935 | 0.858 | 0.947 | 0.95 |
| = 3; t = 0.5 | 0.913 | 0.922 | 0.933 | 0.844 | 0.939 | 0.942 |
| = 5; t = 0 | 0.911 | 0.966 | 0.947 | 0.911 | 0.961 | 0.962 |
| = 5; t = 0.1 | 0.914 | 0.964 | 0.943 | 0.869 | 0.953 | 0.948 |
| = 5; t = 0.2 | 0.917 | 0.907 | 0.937 | 0.864 | 0.945 | 0.945 |
| = 5; t = 0.3 | 0.914 | 0.921 | 0.935 | 0.847 | 0.937 | 0.947 |
| = 5; t = 0.4 | 0.91 | 0.925 | 0.928 | 0.834 | 0.938 | 0.944 |
| = 5; t = 0.5 | 0.905 | 0.926 | 0.935 | 0.819 | 0.931 | 0.935 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hachaj, T.; Piekarczyk, M. On Explainability of Reinforcement Learning-Based Machine Learning Agents Trained with Proximal Policy Optimization That Utilizes Visual Sensor Data. Appl. Sci. 2025, 15, 538. https://doi.org/10.3390/app15020538
Hachaj T, Piekarczyk M. On Explainability of Reinforcement Learning-Based Machine Learning Agents Trained with Proximal Policy Optimization That Utilizes Visual Sensor Data. Applied Sciences. 2025; 15(2):538. https://doi.org/10.3390/app15020538
Chicago/Turabian StyleHachaj, Tomasz, and Marcin Piekarczyk. 2025. "On Explainability of Reinforcement Learning-Based Machine Learning Agents Trained with Proximal Policy Optimization That Utilizes Visual Sensor Data" Applied Sciences 15, no. 2: 538. https://doi.org/10.3390/app15020538
APA StyleHachaj, T., & Piekarczyk, M. (2025). On Explainability of Reinforcement Learning-Based Machine Learning Agents Trained with Proximal Policy Optimization That Utilizes Visual Sensor Data. Applied Sciences, 15(2), 538. https://doi.org/10.3390/app15020538