1. Introduction
With the continuous development of Artificial Intelligence (AI), research in many fields has been significantly optimized by leveraging this technology [
1,
2,
3]. For example, AI can be employed to analyze real-time sensor data, such as temperature, humidity, and gas concentration, to assess air quality and predict weather changes [
4,
5,
6]. Furthermore, AI has the ability to predict environmental trends based on long-term data [
7,
8]. Many inefficient and unstable monitoring systems have been replaced by AI-based automation systems, improving the efficiency and accuracy of monitoring or forecasting, which is critical for applications such as disaster management and pollution control [
9,
10]. In smart transportation planning, AI analyzes urban traffic conditions to dynamically allocate road resources, thus alleviating traffic congestion [
11,
12]. Similarly, in wireless sensor networks, AI evaluates the status and access requirements of communication nodes, enabling the dynamic adjustment of resource allocation to minimize power consumption. Additionally, neural networks are adept at analyzing object image data, thereby completing tasks such as predictive maintenance and anomaly detection [
13,
14]. For example, in the application of chest X-ray images, neural networks can effectively improve diagnostic efficiency [
15,
16].
These advantages in efficiency and stability also demonstrate AI’s potential in enabling smarter, more adaptable systems across various industries.
However, the environments in which sensors acquire and analyze images in real time are often less than ideal [
17,
18]. For instance, underwater monitoring systems lack sufficient lighting, resulting in reduced clarity of images captured by sensors. Even under consistent lighting conditions, factors such as depth and suspended particles can attenuate the light reflected from an object’s surface to the sensor [
19,
20]. Moreover, water flow can induce object motion or microbial adhesion, further leading to blurred or distorted images. Under these conditions, real-time monitoring systems become unstable, failing to meet the demands for accurate detection and recognition. These limitations not only reduce the clarity of the collected data but also hinder the backpropagation process in neural networks during training. Therefore, developing more robust solutions is crucial.
To address these challenges, many improvements have been made in both hardware and software. From a hardware perspective, low-light cameras, specialized underwater imaging sensors, and enhanced lighting conditions can improve image acquisition [
21,
22]. On the software side, techniques such as noise reduction, image enhancement, and illumination compensation can significantly improve image clarity. However, while these methods meet practical requirements, they are often unable to adapt to specific tasks or perform effectively in more general scenarios [
23,
24]. For example, optimization methods may fail when devices operate in highly dynamic environments. At the same time, neural network-based algorithms for feature extraction and detailed classification have become the mainstream approach in image processing [
25,
26]. Convolutional Neural Networks (CNNs), such as AlexNet, were among the earliest methods proposed for handling image-related tasks [
27]. AlexNet pioneered the extraction of image features from the lowest layers of the network, enabling higher-level layers to monitor targets from a global perspective. However, the rigid structure of AlexNet hinders adaptation to task-specific requirements, and issues such as shallow network depth and susceptibility to overfitting remain. These limitations have exceeded the capabilities of existing system architectures, highlighting the need to develop more advanced neural networks to meet the requirements of a broader range of applications.
In pursuit of optimal CNN structures, researchers developed the EfficientNet network, which effectively addresses the issues of overfitting and high data requirements inherent in traditional CNNs [
28]. Additionally, the adjustable architecture of EfficientNet enables it to accommodate diverse task requirements. Despite these advantages, the number of parameters generated in the EfficientNet network is higher than that of most CNNs, requiring substantial computational resources. This limitation restricts EfficientNet’s learning ability and scalability in real-time applications involving small tasks or datasets, failing to adequately balance computational efficiency and high accuracy. Moreover, on large datasets, EfficientNet often suffers from the drawback of forgetting earlier objectives. To further enhance neural network performance, researchers adapted the Transformer model, originally designed for natural language processing (NLP), to image processing tasks [
29,
30]. The core of the Transformer lies in the self-attention mechanism, which identifies key features by calculating relationships among input data. However, Vision Transformer (ViT) requires significant computational resources and time to train on large datasets [
31,
32]. To alleviate the computational burden of Transformers in image-related tasks, researchers proposed the Swin Transformer (Swin) [
33]. By dividing images into smaller regions and processing them in parallel, Swin achieves a substantial reduction in the number of parameters and computational costs while maintaining high accuracy [
34]. These advancements indicate a shift in neural networks towards modular and hierarchical approaches, facilitating more efficient processing pipelines while maintaining high levels of accuracy.
Despite the continuous optimization of image processing methods, the performance of networks in real-world applications is often suboptimal due to insufficient actual data. To address the challenges posed by limited training data, we propose a novel method named concatenated attention (CA), which enhances networks by augmenting input data from a computational perspective. Specifically, we introduce a split-and-concatenate approach based on the matrix computation methodology of the self-attention mechanism. This method not only leverages existing feature extraction mechanisms but also enriches the diversity of input data while computing intermediate variables, thereby improving the model’s learning capacity. In detail, the core matrices generated from input data retain identical feature information but are designed to strengthen the learning ability of the neural network when training data is insufficient. In the CA method, the Query and Key matrices are split into two equal-sized submatrices along the same dimension. These submatrices undergo pairwise multiplication, yielding two result matrices of the same size as the original computation. Subsequently, these matrices are combined through a weighted computation to produce a new result matrix. Ultimately, this method enhances the network’s learning process by adjusting the weights of the intermediate variables. Furthermore, since the implementation of the method does not introduce additional trainable parameters, the overall computational demand of the neural network remains unchanged.
The primary contributions of this paper are as follows:
A novel split-and-cross-multiplication method is proposed for matrices, enabling control over intermediate variables.
A weighted summation mechanism is introduced to optimize the network learning process by tuning intermediate variables.
The effectiveness of the proposed method is validated through network training on a crack dataset collected from real-world applications.
2. Methods
2.1. Split and Concatenate
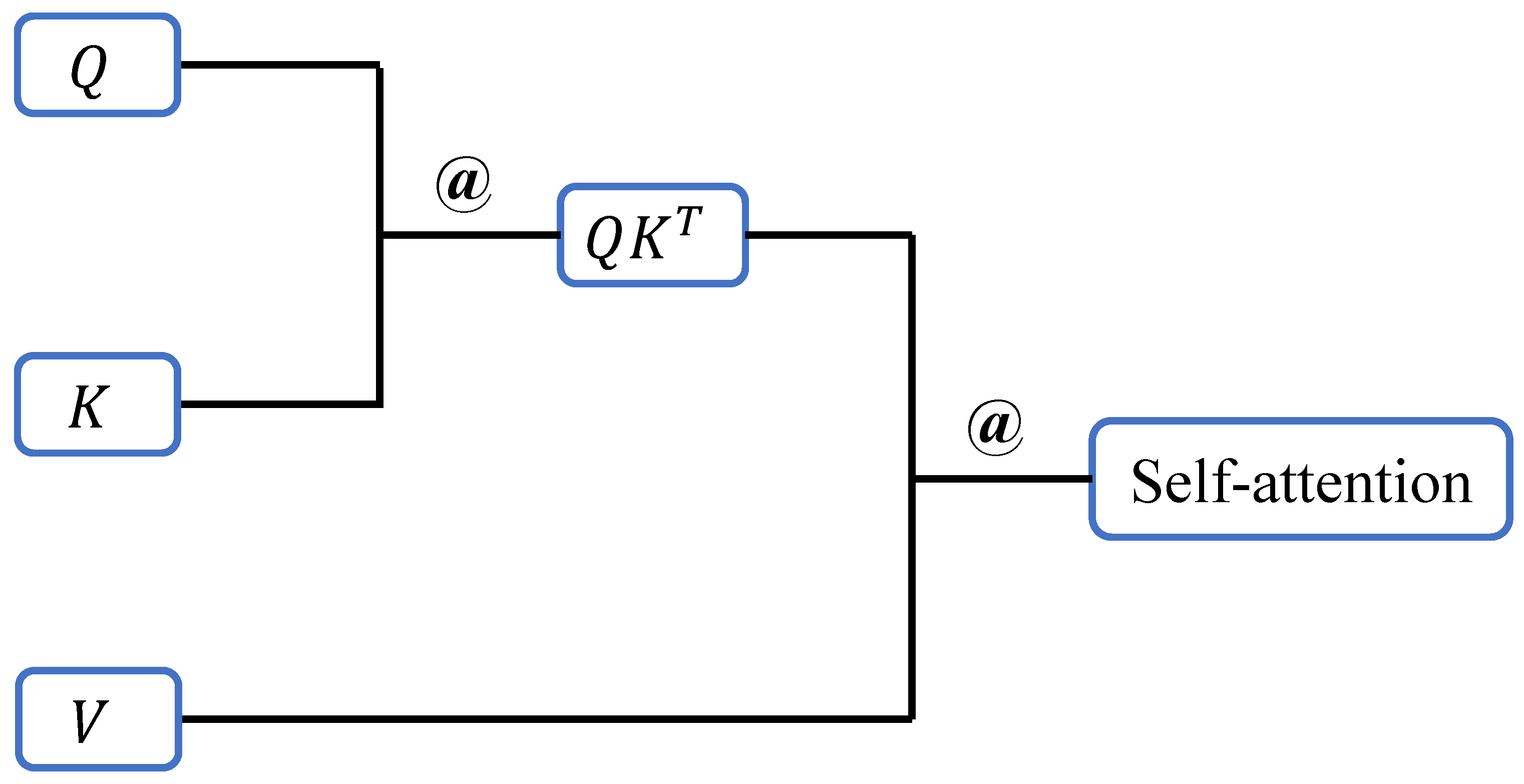
In the self-attention mechanism, the input data, after preprocessing, is transformed into three matrices of identical size, which form the core of the self-attention mechanism. These matrices—commonly referred to as the Query (
Q), Key (
K), and Value (
V) matrices—encapsulate the essential features of the input data. The results obtained from matrix multiplication and normalization represent the relationships between individual data elements, enabling the network to identify which parts of the input data are most important for the current task. The matrix computation process is illustrated in
Figure 1. Specifically, the
Q matrix is multiplied by the
K matrix to produce an intermediate matrix, which represents the association scores between units of input data. These scores, after normalization, are transformed into a probability matrix, where higher probabilities indicate a greater likelihood of selecting important information as features. This probability matrix is then applied in a matrix multiplication with the
V matrix to generate the self-attention matrix, which encodes the relationships among features. This process strengthens the network’s ability to capture long-range dependencies and contextual relevance, effectively mitigating the issue of the network forgetting initial features.
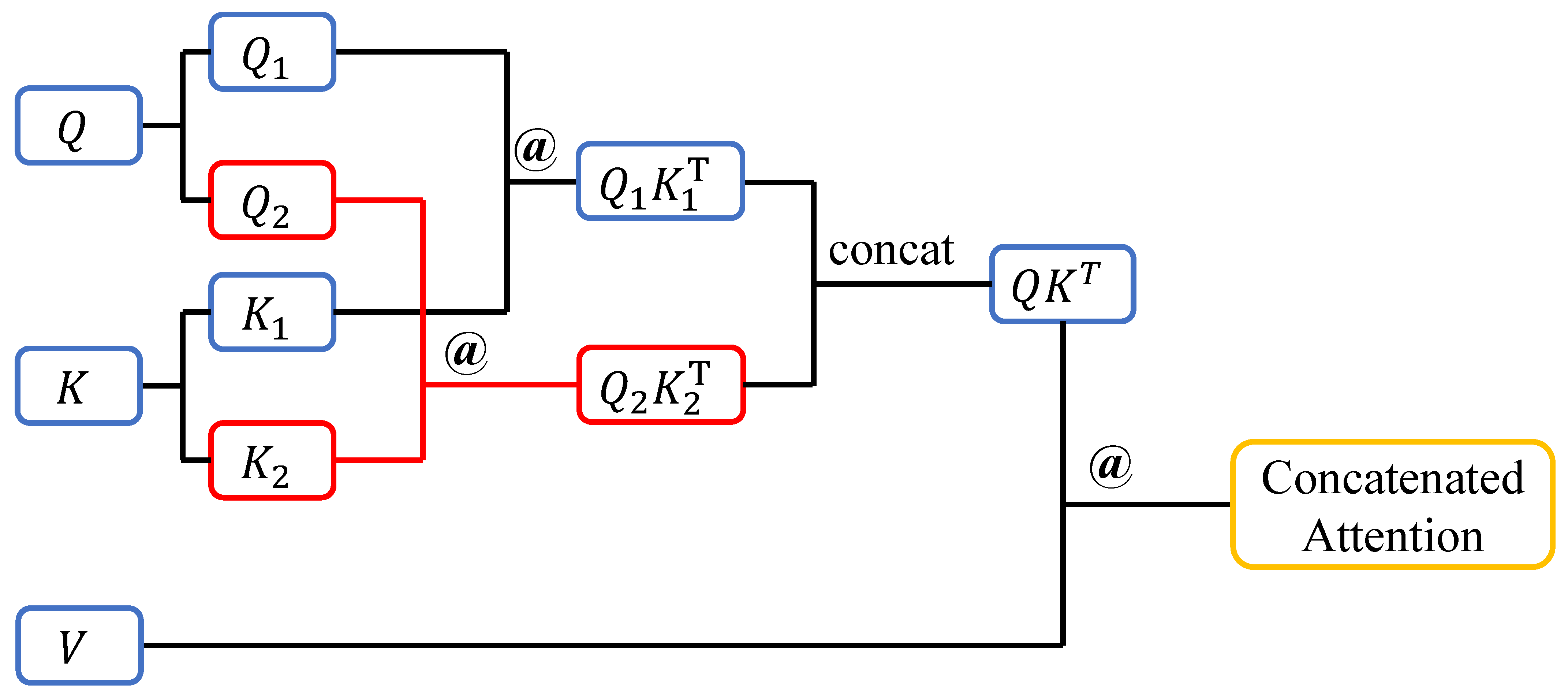
To enhance the diversity of input data features, we propose optimizing the neural network’s feature perception through a split-and-concatenate method. This approach increases the informational richness of the self-attention mechanism by introducing additional flexibility and granularity in the representation of intermediate variables. The detailed process of the proposed CA method is shown in
Figure 2. After generating the three core matrices
Q,
K, and
V, the
Q and
K matrices are first equally split along the same dimension, ensuring that the resulting submatrices are of equal size. This guarantees that the dimensions of the subsequent result matrices will also remain consistent. This splitting operation introduces variability into the computation process, as the submatrices not only focus on different parts of the data’s feature space but also enable fine-tuning when computing
.
Next, the resulting submatrices are multiplied pairwise along the split dimension, producing two intermediate matrices of the same size as the original result. Compared to traditional methods, these intermediate matrices capture finer-grained relationships between data elements, allowing the network to better differentiate subtle variations in input features. The two matrices are then concatenated and subsequently multiplied by the V matrix to generate the final matrix. This concatenation step reintroduces the feature diversity captured by the intermediate matrices, ensuring that the final result reflects a richer and more comprehensive representation of the input data.
This approach modifies only the computation order and direction while preserving the original size of the matrices. Consequently, it does not introduce additional computational overhead or increase the number of parameters, making it a computationally efficient solution. Furthermore, the method is fully compatible with existing self-attention mechanisms and can be seamlessly integrated into a wide range of neural network architectures. By enriching the representation of intermediate variables, the proposed method enhances the network’s capacity to learn meaningful features from input data, particularly in scenarios with limited training samples or complex environmental conditions.
2.2. Weighted Calculation
To more precisely adjust the significance of individual data units in the input, we incorporated a weighted computation method into the CA calculation process. After obtaining two intermediate matrices by multiplying
with
and
with
, two distinct scalar weights are applied to these matrices. These weights enable the neural network to more directly prioritize important features, allowing for dynamic adjustments when handling different subtasks or datasets of varying sizes. This approach ensures that the network can effectively identify the most critical features without compromising final accuracy. The weighted computation can be expressed as follows:
where
a and
b are real-valued weights assigned to the two matrices. For robustness and computational efficiency, the weights are constrained by the condition
. This constraint not only ensures the simplicity of the optimization process but also maintains a balance in feature selection between the
and
matrices during their combination, thereby avoiding excessive emphasis on a single intermediate matrix.
Assuming and are one-dimensional variables, this computation represents all points on the line segment connecting these two variables. In such optimization problems, the weighted sum serves as a linear interpolation mechanism, ensuring smooth transitions between the two variables. As the weight a transitions from 0 to 1, the output gradually shifts from to . This optimization approach provides the neural network with a highly interpretable mechanism for feature selection and interaction, as it can adjust the output to emphasize features from either or based on task requirements.
Moreover, this mechanism allows the network to dynamically adjust the features derived from different parts of the input data, ensuring flexibility and applicability across diverse scenarios. This adaptability proves particularly powerful in complex, dynamic, or noisy data environments, where certain features may shift from being irrelevant to relevant under specific conditions. At the same time, the application of scalar weights preserves computational stability and simplicity, ensuring that the method can be efficiently integrated into existing architectures without introducing significant complexity or additional overhead.
2.3. Neural Network with CA Method
In underwater real-time monitoring, short time intervals between data acquisitions typically result in a large volume of data being generated within a short period. This high data throughput places significant demands on processing systems, making the computational efficiency of the neural network a critical consideration. Among the various neural networks that incorporate self-attention mechanisms, the Swin Transformer stands out for its ability to achieve high training accuracy while maintaining low computational resource consumption. By leveraging a hierarchical design and localized attention, the Swin Transformer effectively balances accuracy and efficiency, making it highly suitable for real-time monitoring of underwater target objects.
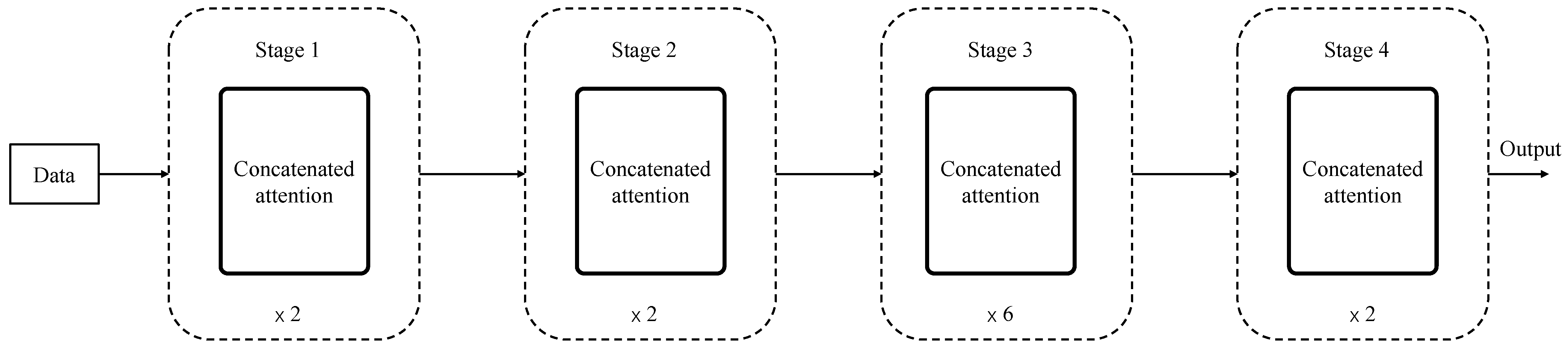
The modified neural network architecture incorporates the proposed CA method, as shown in
Figure 3. The network consists of four stages, each containing a specific number of layers required for training. The layers in each stage are trained repeatedly, with repetition counts of 2, 2, 6, and 2, as indicated below the figure. The structures of different stages vary to accommodate the diversity and complexity of features at different levels. The design of repetition within the same stage balances the number of parameters trained and the final accuracy. Additionally, the consistency within each stage simplifies parameter sharing and reduces redundancy, thereby improving computational efficiency. Similarly, the size of the core matrices applied in the CA method varies across stages, dynamically adjusting to the resolution and complexity of the input data at each level.
The application of the CA method, combined with the staged design strategy, ensures scalability and adaptability, enabling the network to handle different computational requirements effectively. Early stages focus on extracting localized and fine-grained features, while later stages progressively integrate the information into high-level representations. This hierarchical approach not only enhances the model’s ability to capture contextual relationships but also optimizes computational efficiency by allocating resources to where they are most needed. Furthermore, the integration of the CA method within the framework adds flexibility, allowing the network to enrich feature representations without increasing computational overhead. This makes the modified architecture particularly suitable for underwater monitoring, where the ability to process large volumes of data quickly and accurately is crucial.
4. Discussion
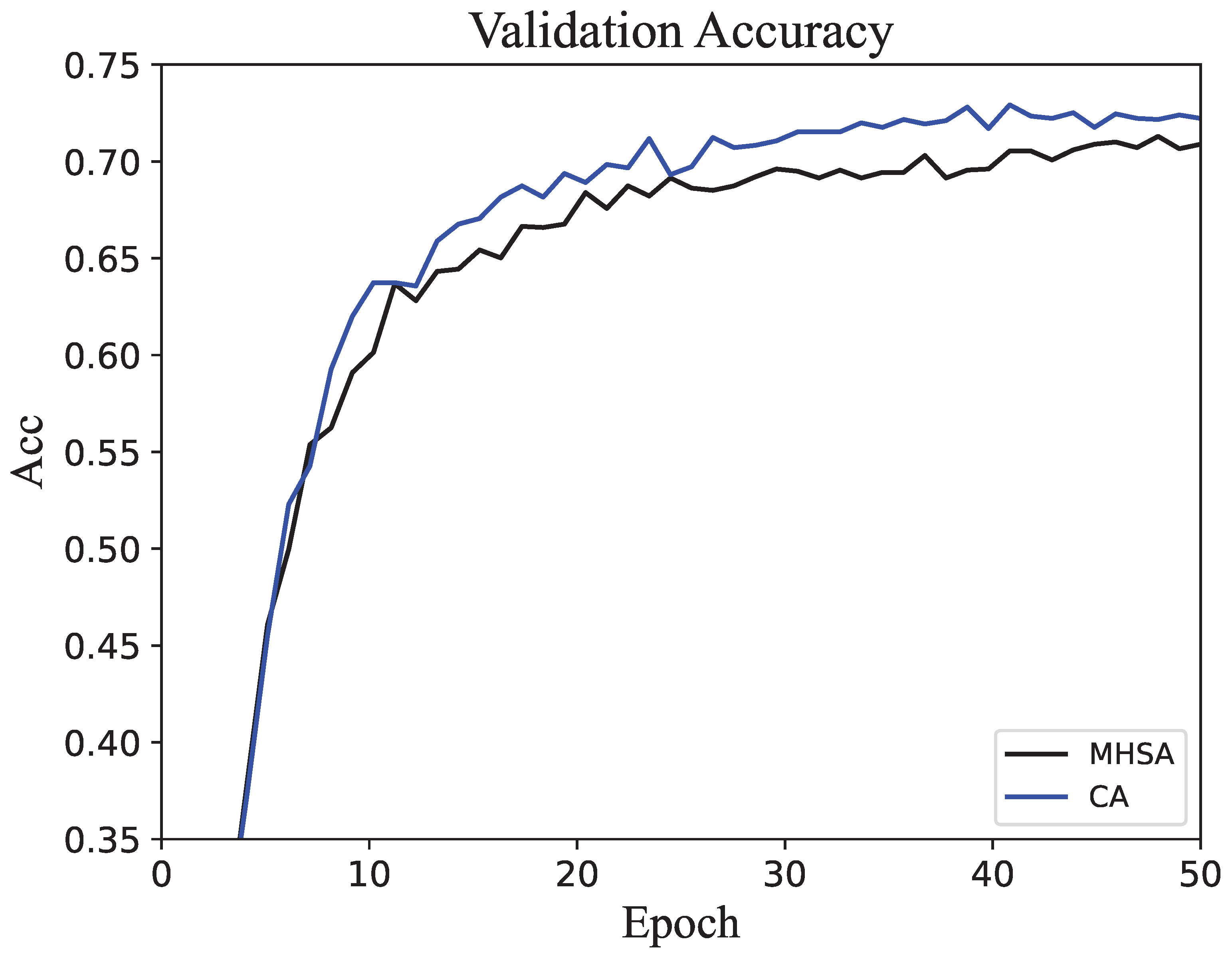
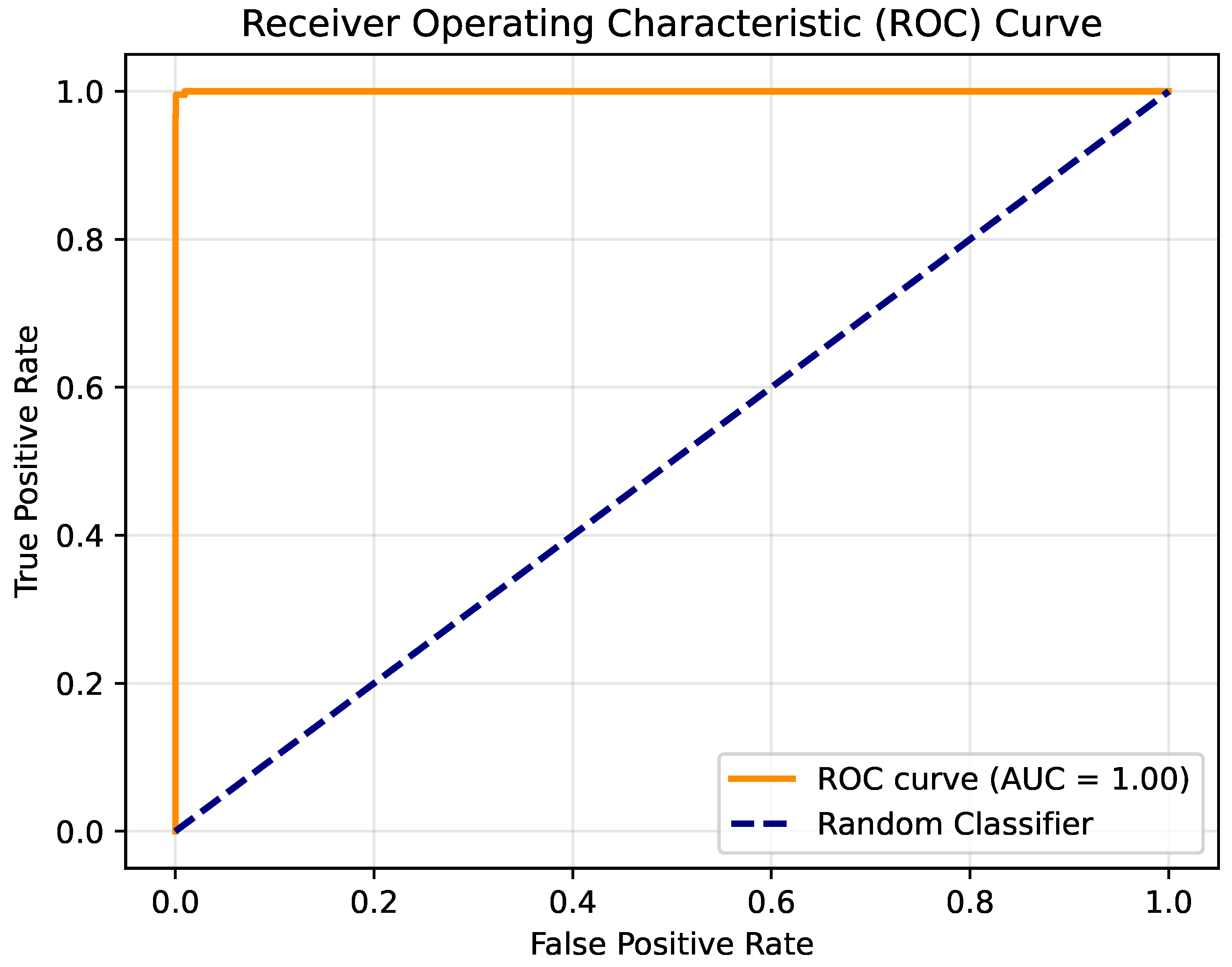
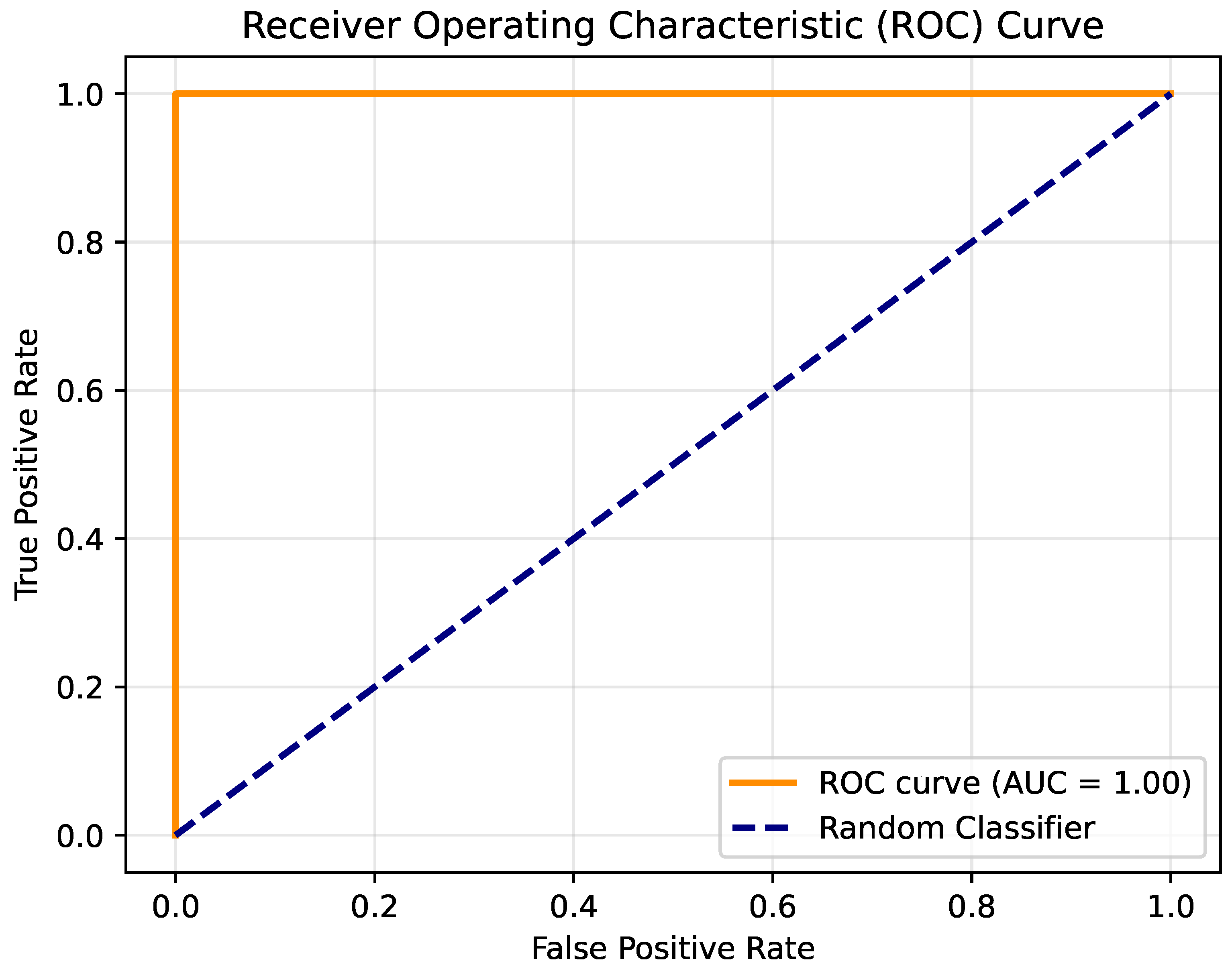
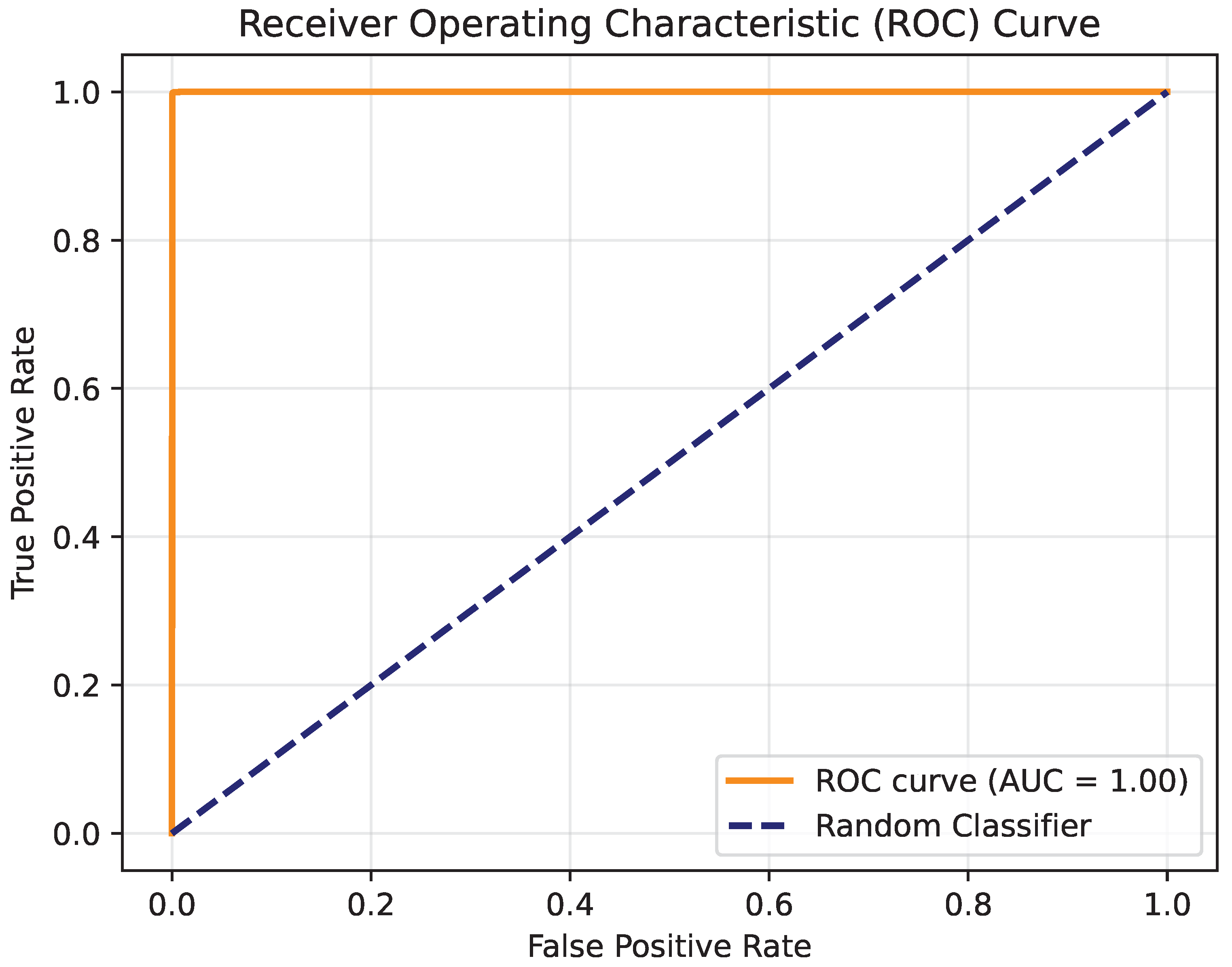
The experimental results validate the effectiveness and generalizability of the proposed method across multiple datasets. Compared to the original MHSA method, the proposed approach achieved higher average accuracy. The improvement is consistent across diverse datasets, ranging from general-purpose image classification benchmarks to specialized datasets captured under challenging conditions, underscoring the versatility of the proposed approach. This demonstrates that the processes of splitting, weighted summation, and recombination within the self-attention mechanism can improve network performance without increasing computational overhead. By introducing finer-grained control over intermediate variable interactions, the CA method enhances the network’s ability to capture subtle relationships in the data, leading to improved feature representation and decision making. The strength of the CA method lies in its ability to enrich the representation of intermediate variables. Furthermore, despite challenging conditions such as low-light environments and surface contaminants in real-world applications, the results on the Crack dataset confirm the robustness of the CA method. The robustness highlights its potential for deployment in environments where data quality or illumination conditions may vary significantly, such as underwater monitoring or industrial inspection systems.
The lack of statistical significance for the CA method’s improvement on the Flower-102, Pet-37, and Crack datasets can be attributed to several factors. First, the small sample size or limited number of repetitions might have led to wider confidence intervals, making it difficult to detect subtle differences. Second, the intrinsic characteristics of these datasets, such as balanced class distributions, high-quality images, or low noise levels, likely reduced the potential for significant performance gains, as the MHSA method already performed effectively in capturing key features. Additionally, on the Crack dataset, the model’s accuracy was near its upper limit, leaving little room for further improvement. Together, these factors suggest that the datasets themselves and the experimental setup may have constrained the measurable advantages of the CA method.
From the perspective of prior research, the CA method aligns with the trend of optimizing neural network architectures to improve accuracy without significantly increasing computational demands. This alignment is particularly evident in its compatibility with existing attention-based architectures, enabling seamless integration without requiring major modifications to network structures or hyperparameters. The method effectively addresses data limitations and environmental challenges, making it a practical and scalable solution for applications that demand both high precision and computational efficiency. It provides a practical solution for real-world applications such as defect detection and image classification under adverse conditions. Moreover, the CA method’s emphasis on maintaining computational efficiency while improving accuracy ensures its applicability in resource-constrained scenarios, paving the way for broader adoption in edge computing and real-time processing tasks.
However, the improvements in CA methods on some datasets, while showing improvements in accuracy, are not statistically satisfactory. This suggests that performance gains may depend on dataset characteristics, such as class balance or intrinsic task difficulty. Future work could focus on understanding and mitigating these dependencies.
5. Conclusions
This paper proposes a novel split-and-concatenate approach to enhance the performance of self-attention mechanisms in neural networks, particularly under challenging conditions such as limited training data and unfavorable environmental factors. The proposed method builds upon the core principles of self-attention by introducing greater flexibility in feature interaction modeling, making it adaptable to diverse datasets and application scenarios. By introducing the steps of splitting, weighted summation, and recombination, the method optimizes intermediate variables. These processes allow the network to better capture subtle feature relationships and reduce the risk of overfitting in data-scarce environments. It achieves improved accuracy and computational efficiency by enriching the learning process without increasing parameter counts or computational costs. This balance between performance and efficiency ensures the scalability of the proposed method in both high-resource environments and edge computing scenarios.
The contributions of this work include optimizing the self-attention mechanism to enhance feature representation and providing a computationally efficient solution for real-world image processing tasks. The method has been rigorously validated across diverse datasets, demonstrating its generalizability and robustness under varying conditions, such as low-light environments and noisy data. Future research could extend the method to object detection, temporal data analysis, and video processing tasks, which would benefit from the enriched feature representation introduced by the proposed approach. Further exploration of adaptive weighting strategies and integration with other attention-based architectures could also enhance its applicability and effectiveness, paving the way for its deployment in increasingly complex AI-driven applications such as real-time monitoring.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}