1. Introduction
Traditional optimization methods have established precise mathematical models for addressing diverse real-world problems, including linear programming, quadratic programming, nonlinear programming, penalty function methods, and Newton’s method. However, when dealing with large-scale non-convex optimization problems, these conventional approaches not only demand substantial computational resources but also tend to converge to local optima [
1]. In contrast to traditional optimization algorithms, heuristic algorithms leverage historical information while incorporating stochastic elements for exploration. This approach not only reduces computational burden but also enhances the ability to escape the local optimum, making it particularly suitable for solving complex problems where exact solutions are difficult to obtain, notably NP-hard issues [
2]. Heuristic algorithms have been widely used to solve different problems, such as portfolio optimization [
3], path planning [
4], electrical system control [
5], industrial internet of things service request [
6], water resources management [
7], urban planning [
8], wireless sensor point coverage [
9], etc.
Most existing heuristic algorithms can be classified by their inspiration sources into four categories: evolutionary algorithms (EA), physics-based methods (PM), human behavior models (HM), and swarm intelligence (SI).
(1) Evolutionary algorithms.Evolutionary algorithms draw their inspiration from the theory of biological evolution, and their most notable feature is the simulation of biological inheritance and variation to produce new individuals. Genetic Algorithm (GA) [
10] algorithm explores the solution space by cross-combining the genetic information of parents. It also uses mutation to explore areas not covered by crossover in the early stage and to refine the search solution in the later stage. In addition to GA, other algorithms in the EA category include the Differential Evolution (DE) algorithm [
11], which is different from GA’s mutation strategy in difference. It multiplies the difference between two randomly selected individuals by the difference term to indicate the distance of mutation, so that the current individual changes at the corresponding distance and then enters the crossover stage. Each dimension in the intersection determines whether to replace it with the differentiated dimension value according to the user-defined intersection probability. It is helpful to keep excellent dimension values and combine excellent genetic characteristics into new individuals. Genetic Programming (GP) algorithm [
12] has the same algorithm flow as GA, but the individual objects operated by GP are usually programs in the form of a tree structure, and its main purpose is to generate or optimize computer programs. Some other evolutionary-based algorithms include Evolutionary Programming (EP) algorithm [
13], Evolution Strategy (ES) [
14], Biogeography-Based Optimizer (BBO) [
15].
(2) Physics-based methods. The physical phenomenon is used to simulate the change of the function solution space, and physical principles are used to balance the exploration and exploitation in the process of solving a function. For example, the Gravity Search Algorithm (GSA) [
16] uses the fitness value of the particle to represent its quality, and the velocity of the particle related to the particle position update is calculated by Newton’s law of universal gravitation and Newton’s second law of motion. The Simulated Annealing algorithm (SA) [
17] imitates the annealing process in physics and helps the material to achieve a more stable structure by controlling the rate of temperature drop. In the application of optimization, the exploration and development of the balanced algorithm are controlled by controlling the diversity of the solutions of the offspring. Big-Bang Big-Crunch (BB-BC) optimization [
18] optimizes the algorithm by simulating the expansion and contraction of the universe, that is, controlling the distance between particles. Specifically, in the big bang stage, the global search is carried out by increasing the distance between particles, and in the big collision stage, the local search is carried out by reducing the distance between particles. The electromagnetic algorithm [
19] transforms the solution search space by simulating the attraction and repulsion between charged particles and specifically updates the position of the particle solution by using the fitness value to represent the charge intensity and introducing Coulomb’s law, Newton’s second law, and related formulas of kinematics equations. There are Quantum-Inspired metaheuristic algorithms (QI) [
20], Central Force Optimization (CFO) [
21], Charged System Search algorithm (CSS) [
22], Ray Optimization (RO) algorithm [
23], and so on.
(3) Human behavior models. In the Teaching-Learning-Based Optimization algorithm (TLBO) [
24], each particle represents a student, and the particle position is updated by simulating two stages of teaching and learning. In the teaching stage, each particle learns the optimal value and average value in the population. In the learning stage, particles learn from each other, and particles with higher fitness value guide particles with lower fitness value. In the Imperialist Competitive Algorithm (ICA) [
25], each particle represents a country, and these particles are divided into imperialist countries and colonies according to the fitness value. The imperial competition process is used to determine the possibility of being occupied by other empires, and the colonial parties update their solutions according to the position of imperialist countries in the assimilation process. In the Educational Competition Optimization (ECO) algorithm [
26], schools represent the evolution of the population, and students represent the particles in the population. The algorithm is divided into three stages: primary school represents the average position of the population, middle school represents the average and optimal position of the population, and students choose their nearby schools as their moving direction. In high school, schools represent the average, optimal, and worst positions in the population, while students choose the optimal position as their moving direction. In the Human Learning Optimization (HLO) algorithm [
27], each latitude value of each particle is selected from three learnable operators according to probability, and the random learning operator uses random number generation to simulate extensive human learning. Individual learning operators store and use the best experience of individual history to generate solutions, while social learning operators generate new values through population knowledge sharing. HM categories include Driving Training-Based Optimization (DTBO) [
28], Supply–Demand-Based Optimization (SDO) [
29], Student Psychology Based Optimization (SPBO) algorithm [
30], Poor and Rich Optimization (PRO) algorithm [
31], Fans Optimization (FO) [
32], Political Optimizer (PO) [
33], and so on.
(4) Swarm intelligence. The most commonly used algorithm is the Particle Swarm Optimization algorithm [
34]. In PSO, each bird represents the position of a solution, and the individual position is updated and optimized by simulating the foraging behavior of birds and recording the historical optimal position found by each bird and the whole flock. The Moth-Flame Optimization algorithm (MFO) [
35] uses the behavior of the moth fireworm to find and approach the light source at night to simulate the process of function optimization. The Whale Optimization Algorithm (WOA) [
36] compares each candidate solution to a humpback whale and updates the position of the candidate solution through the random search, encirclement, and rotation of the humpback whale when hunting. In the Harris Hawks optimization algorithm (HHO) [
37], each eagle represents a potential solution, and the position of the candidate solution is updated by simulating the siege, scattered search, and direct attack of eagles during hunting. In the Coati Optimization Algorithm (COA) [
38], each raccoon represents a candidate solution and effectively searches the solution space by simulating raccoon hunting and escaping from predators. The Tunicate Swarm Algorithm (TSA) [
39] uses cystic worms to represent candidate solutions, and the position updating strategy in the search process draws lessons from the jet propulsion and group cooperation behavior of the cystic swarm in navigation and foraging activities. In the Reptile Search Algorithm (RSA) [
40], each reptile represents the position of a solution, and the optimization idea of the algorithm draws lessons from the two stages of reptile hunting to carry out global and local search. SI categories include the American Zebra Optimization Algorithm (ZOA) [
41], Artificial Bee Colony (ABC) algorithm [
42], Spotted Hyena Optimizer (SHO) [
43], Hermit Crab Optimization Algorithm (HCOA) [
44], Grasshopper Optimization Algorithm (GOA), [
45] and so on.
However, the existing heuristic algorithms determine the optimization mechanism through the source of inspiration, rather than establishing the optimization paradigm from the optimization mechanism, which does not have strong explanatory power or stability of the algorithm. They also do not make good use of the information on historical stagnation and the distribution of the particle itself, which makes the algorithm prone to missing the opportunity to evolve towards excellent dimension values and difficult to converge to the global optimal value.
Based on the above problems, we establish a paradigm that balances exploration and exploitation. Instead of directly interacting with particle groups and historical solutions by adjusting step sizes, we aim to make the most of historical information. We first create a template based on particle characteristics and population history information, and then the template is used to guide the particle optimization. During the whole algorithm, there are no user-defined parameters.
The main contributions of this paper are as follows:
We propose a PTG algorithm based on an optimization principle. In the template generation stage, a personalized template containing key exploration areas is generated. In the template guidance stage, the particle exploits key areas under the guidance of the template. By gradually narrowing and locking the optimal value area, this paradigm solves the difficult problems of setting the search step size and defining parameters.
We find that historical stagnation information can enhance the exploitation ability of the particle. So we extract this information as the history-retrace template’s base points. Historical stagnation information refers to the population particle information when the optimal value of the population is unchanged. The timely use of this information can guide particles to mine in the historical optimal solution area and avoid missing the global optimal value.
From the perspective of historical distribution information, the template interval expansion strategy is proposed to extract the distribution change knowledge of population offspring, expand the particle exploration space, and enhance the particle’s exploration ability. We find that the particle’s own dimension distribution attribute can provide effective information to speed up particle optimization, so we propose the personalized template generation strategy based on particle dimensional distribution to generate a personalized template for each particle.
The following part of this paper is organized as follows. In
Section 1, the existing heuristic algorithms are introduced. In
Section 2, we introduce the proposed PTG algorithm. In
Section 3, we conduct experiments and analysis of results. In
Section 4, we summarize the content of this paper. In order to cover and vividly represent the newly generated individuals, population individuals, and populations. This paper draws on the expression of the PSO algorithm and describes individuals as particles. However, the method proposed in this paper has nothing to do with the PSO algorithm.
2. Methods
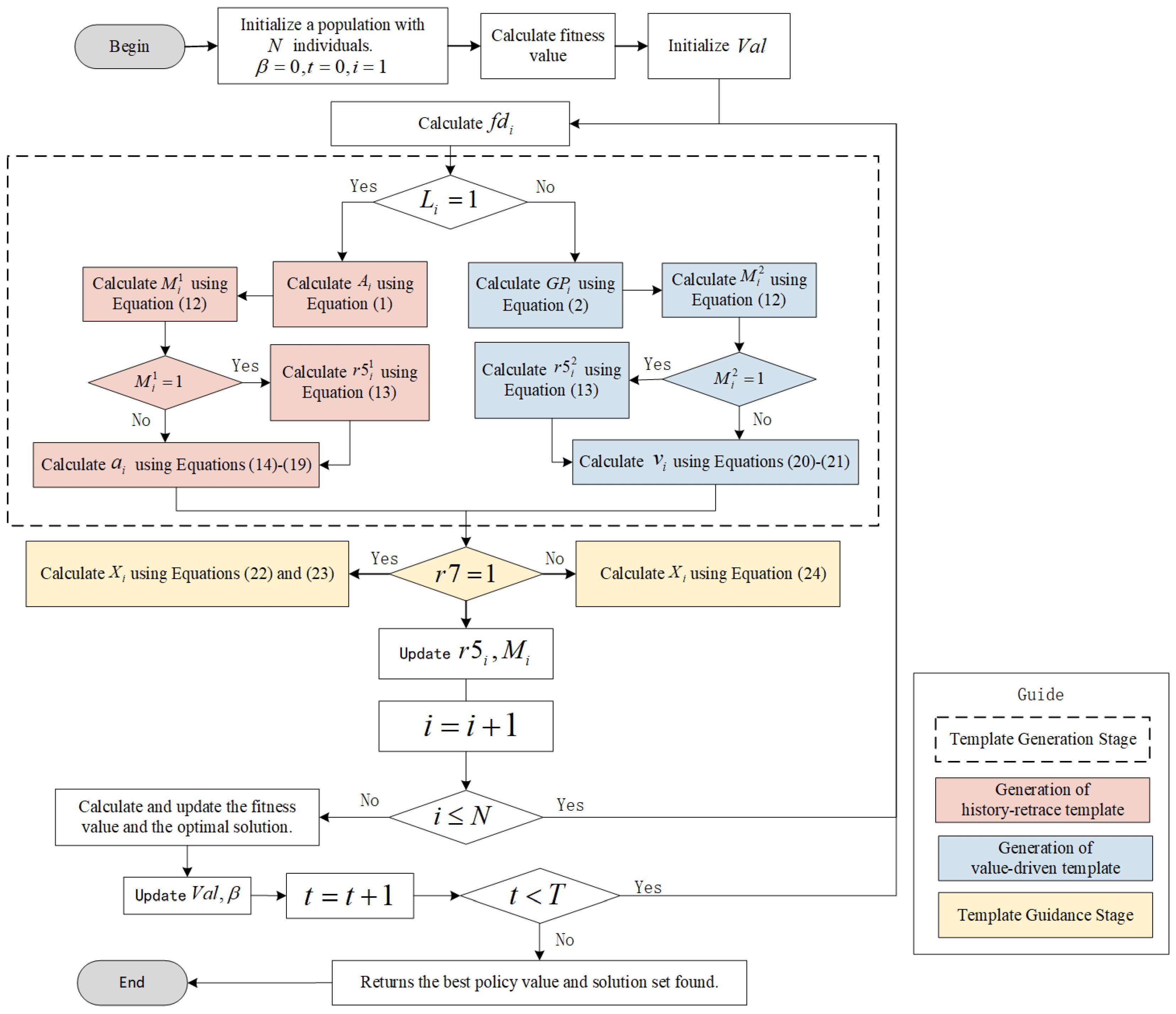
A personalized-template-guided intelligent evolutionary algorithm includes the template generation stage and the template guidance stage. The purpose of the template generation stage is to generate a guiding particle for the current particle, that is, a personalized template. Firstly, each particle randomly selects whether to generate a value-driven template or a history-retrace template to increase the diversity of exploration. Then the selection strategy of the template base point set is applied to determine the base point set of the template. Then, based on the template interval expansion strategy, the template interval surrounded by basic points is expanded. Finally, the personalized template generation strategy based on particle dimensional distribution is adopted to generate a personalized template in the corresponding interval dimension. In the template guidance stage, the template-guided knowledge transfer strategy is used to update the position of the particle. See Algorithm 1 for the specific process.
The detailed flowchart of the algorithm is shown in
Figure 1. First, initialize the population and parameter values, and calculate the fitness value. Use the template interval expansion strategy to get the value
, and then enter the loop. Calculate the
value of the
i-th particle, and decide whether to generate the history-retrace template or the value-driven template according to the value of the random integer
L. When
, enter the left half of the process to generate a history-retrace template, and use the selection strategy of the template base point set to calculate the base point
of the history-retrace template by Equation (
1). Then, the template generation strategy is adopted, and the
is calculated by Equation (
12), which determines whether to use the personalized template generation strategy based on particle dimensional distribution. When
, the dimension to be learned is obtained by Equation (
13), and then the history-retrace template
is generated by Equations (
14)–(
19) in combination with the interval extension value
. When
, only the template generation strategy is used, and the history-retrace template
is generated by Equations (
14)–(
19) in combination with the interval extension value
. When
, enter the right half of the process to generate a value-driven template. Calculate the base point
of the value-driven template by Equation (
2), and calculate the
value by Equation (
12). When
, the dimension to be learned is obtained by Equation (
13), and then the value-driven template
is generated by combining the interval spacing value with Equations (
20) and (
21). When
,
is directly generated by combining the interval spacing value with Equations (
20) and (
21). After the template is generated, the algorithm enters the template guidance stage. First, a value of the random number
is calculated. When
, a new solution
is obtained by Equations (
22) and (
23), and when
, a new solution
is obtained by Equation (
24). Update the
M and
of the
i-th particle. After
N new solutions are generated by the above steps for
N particles, the fitness value of the population is calculated, and the values of
and
are updated. When
, continue the above cycle. Otherwise, jump out of the loop, return to the optimal solution value and its position, and end the algorithm.
| Algorithm 1: Pseudocode of PTG |
- Input:
popultion size N, number of iterations T - Output:
the best solution of the objective function - 1:
- 2:
Calculate based on Equation ( 7) - 3:
Calculate the population fitness value, sort and record the optimal value - 4:
while
do - 5:
for to N do - 6:
Calculate based on Equations ( 8)–( 11) - 7:
- 8:
- 9:
for to D do - 10:
if then - 11:
Calculate based on Equation ( 1) - 12:
Calculate based on Equation ( 12) - 13:
if then - 14:
Calculate based on Equation ( 13) - 15:
end if - 16:
Generate based on Equations ( 14)–( 19) - 17:
end if - 18:
if then - 19:
Calculate based on Equation ( 2) - 20:
Calculate based on Equation ( 12) - 21:
if then - 22:
Calculate based on Equation ( 13) - 23:
end if - 24:
Generate based on Equations ( 20) and ( 21) - 25:
end if - 26:
if then - 27:
Generate a new particle based on Equations ( 22) and ( 23) - 28:
end if - 29:
if then - 30:
Generate a new particle based on Equation ( 24) - 31:
end if - 32:
end for - 33:
Record , - 34:
end for - 35:
Calculate and rank population fitness values - 36:
Update the spacing value based on Equations ( 3)–( 7) - 37:
Update - 38:
end while
|
2.1. Template Generation Stage
Firstly, an example is given to illustrate the brief process of template generation. Suppose there is a particle that has two dimensions.
Figure 2 shows a brief process of generating a personalized template for this particle, and the same applies to the other particles. For specific details, please refer to the following content of this section. The pink part on the left of the figure represents the generation process of the history-retrace template, while the part on the right shows the generation process of the value-driven template. The length of the yellow square is the interval expansion value
obtained through the interval expansion strategy. The two small dots on the left and right of the black line segment in the figure represent the upper and lower bounds of the particle dimension value.
j represents the dimension of the particle.
a refers to the generated history-retrace template, and
v represents the generated value-driven template.
If the particle chooses to generate a historical backtracking template, there are two possible cases for the selection of template base points. When , there is only one template base point. When , there are two template base points. In the case of , the selection strategy of the template base point set for the history-retrace template is given. According to this strategy, two basic points are obtained in each dimension of the particle. Next, if , the personalized template generation strategy based on particle dimensional distribution is implemented. Suppose the learning object selected by the particle is dimension 2; then, on the basis of the template base point , the interval range is expanded with the , and the value obtained within the dashed box range is used as the value of the personalized template dimensions 1 and 2. If , the template generation strategy is executed. Based on the base points of particle dimensions 1 and 2, add to expand the interval range, and then generate new values within their respective ranges as the generated templates.
If the particle selects to generate a value-driven template, there is only one basis point for its template. In the template-based point selection strategy, one base point is obtained on each of the two dimensions of the particle. The following demonstrations are consistent with the historical backtracking template, but it should be noted that the specific principles and formulas of the two are different. For details, please refer to the following content of this section.
2.1.1. Selection Strategy of Template Base Point Set
The choice of base point set is very important because it determines what area the template guides the particle to explore. In particular, this algorithm stores a random particle in the merged population when the merit of each generation is unchanged, which helps the algorithm to review the previous solutions and extract historical stagnation information from them. In the specific algorithm steps, each particle randomly chooses to generate a history-retrace template or a value-driven template, which increases the diversity of exploration. In order to balance exploration and exploitation, the corresponding template base point set selection strategy is adopted under the guidance of the optimal value signal . This strategy realizes the collaborative exploration of the population; some particles review the previous limited historical area, and some particles exploit near the optimal value.
Specifically, when the signal is the change of the previous generation’s merit, the base point of the history-retrace template is the random particles in the merged population when the merit stored in the last two generations is unchanged, while the value-driven template randomly selects one of the top three elite particles of the parent as the base point, thus realizing the collaborative exploration of the population. Some particles review the local points when they were unchanged before, and some particles are developed near the merit to jointly promote the further optimization of the solution. When the signal is the unchanged merit of the previous generation, the history-retrace template’s base point is selected from historical particles, and the value-driven template’s base point is a random particle of the parent. So as to expand the exploration scope of particles, help particles jump out of local optimization, and explore new fields.
where
is the base point set of the history-retrace template of the
i-th particle. In each iteration, randomly select one of the top
N elite individuals in the merged population and store it in
C.
t is the current iteration number,
, and
T is the total iteration number. Where
and
are random integers of
.
represents the
individual in
C. When the optimal value of the t-iteration population remains unchanged, a random individual of the
t-iteration merged population will be stored in
Q.
h is the number of individuals stored in Q.
N is the number of individuals in the population.
is the location of the optimal solution of the population.
is the optimal value signal; when the optimal value of the population changes,
is 1, otherwise it is 0.
where
is the value-driven template’s base point set of the
i-th particle,
P is the parent population, and
is a random integer of
.
is a random integer of
.
2.1.2. Template Interval Expansion Strategy
The selection strategy of the template base point set is only based on historical information. If the particles are guided to explore the template interval surrounded by the basic points they choose, the algorithm will easily fall into local optimization, especially in the late convergence stage. In order to solve this problem, we use Equations (
3)–(
7) to calculate the interval value
.
When the optimal value of the population changes, the offspring population, the parent population, and the merged population all contain valid information about the distribution of optimal values. It should be noted that is the spacing of the optimal particle population after the elite selection strategy, which lacks diversity compared with . Therefore, we set the parameter to balance the diversity and convergence of interval values. In the early stage, when the optimal value area is uncertain, the weight of decreases gradually, while increases gradually, which makes the randomness of the template interval expansion value increase gradually with iteration to help the particles jump out of the local optimization. After the midterm iteration, the weight of gradually decreases, and the weight of gradually increases, which makes the randomness of the template interval expansion value gradually decrease to help the particles gradually converge.
When the optimal value of the population is constant, the combined population may contain new distribution knowledge, because some particles in the offspring may be better than some particles in the parent. For this reason, we set the interval expansion range as the absolute difference between two random particles in the combined population to help the particle jump out of the local optimum.
where
is the interval value in the
j-th dimension of the current iteration,
, and
D is the maximum dimension value.
is the
j-th dimension value of the
i-th individual in the offspring population.
is the
j-th dimension value of the
i-th individual of the parent population.
is the mean difference between the offspring population and the parent population in the
j-th dimension.
is the collection of the top
N outstanding individuals in the contemporary merged population.
is the difference between the average of the top 50% of individuals and the average of the bottom 50% of individuals in
.
is the adjustment parameter.
is the absolute value of the difference between random individuals in
in the
j-th dimension.
is a random integer of
.
is a random integer of
. And
is not equal to
.
2.1.3. Personalized Template Generation Strategy Based on Particle Dimensional Distribution
There are three kinds of dimensional distribution of a particle: the first is concentrated distribution, the second is similar to normal distribution, and the third is random distribution. In the first two cases, just finding the mean point of the dimensional distribution can help the particle converge quickly. Therefore, we put forward the particle dimensional concentration degree to judge the particle dimensional distribution. For the particle that meets one of the first two conditions, all dimension values of the personalized template are the same, so as to guide the particle to mine near this dimension value, and then get the mean point of particle dimension distribution through the elite selection strategy.
We use the parameter
to regulate the value of
. At the initial stage of optimization, the particle dimension distribution is not stable, so
should be small. With the progress of iteration, under the elite selection strategy, the dimension distribution of particles will gradually stabilize. At this time, the personalized guidance template can be made for the particle according to its dimensional distribution to help mine their potential knowledge. At the later stage, the dimension distribution of the particle itself has been particularly stable. At this time, each dimension should be optimized and converged separately, so the value of
should be reduced.
where
is the particle dimension concentration,
is the
i-th particle,
is the concentration control parameter, and
is a new particle obtained by disrupting the dimension order in
.
When
is large, it is more likely to generate templates with the same dimension values. In addition, the dimension value the template chooses for knowledge guidance is the selection of the
i-th particle of the parent in the corresponding template block with a certain probability. If the historical particle selection value is empty, it will be generated randomly. See Equations (
12) and (
13) below for the specific dimension value selection.
where
represents the dimension learning mode selected when the
i-th particle generates the template
L. If
, a template with the same dimension value is generated. We set judgment condition 2 in our expression to be superior to condition 1. Where
r is a random number between 0 and 1.
represents the mode of dimension learning selected when the
i-th parent particle generates the template
L.
L is a random integer of 1 or 2. The history-retrace template is selected when
, and the value-driven template is selected when
.
where
represents the dimension selected by the
i-th particle when generating the
L-type template.
represents the dimension selected by the
i-th parent particle when generating the
L-type template.
is a random integer from 1 to
D.
- ①
Generate a history-retrace template
When
, Equations (
14)–(
16) are used to generate the history-retrace template, where
is the history-retrace template generated for the
i-th particle,
is the interval lower bound, and
is the interval upper bound.
represents the first value in
, and
represents the second value in
.
When
, the history-retrace template is generated by calculating Equations (
17)–(
19), where
is the lower bound of the interval, and
is the upper bound of the interval.
- ②
Generate a value-driven template
When the optimal value changes, the change value of the particle dimension value of the optimal value of the previous generation and the current generation contains certain particle optimization trend information, and following this change rule may help the particle find the optimal value.
The particle selects the optimal value template generation method through a random number . When , the optimal value template generation method follows the changing law of the optimal value, and when , the optimal value template is generated randomly. is used to randomly select whether the template value is increased or decreased.
Where
and
are both random integers of 1 or 2. When the random number
, and in the corresponding selected dimension
, or the random number
and
, the following Equation (
20) is used to generate the value-driven template.
When
and
or
and
, the following Equation (
21) is used to generate the value-driven template.
where
is the value-driven template generated for the
i-th individual in the
j-th dimension.
2.2. Template Guidance Stage
Particle optimization needs to explore the right spatial range at the right time node. After the template generation stage, we obtained the space that needs to be explored emphatically. Therefore, in the template guidance stage, we adopt the template-guided knowledge transfer strategy. The strategy, aimed at improving the optimization efficiency of particles, further controls the step size of particles based on the current iteration’s time node, guiding them to search for key optimal points within the focused exploration space.
is a random integer of 1 or 2. In order to increase randomness, the particle uses
to randomly select particle-led knowledge transfer or template-led knowledge transfer. When
, all dimensions use the same random number. In order to balance the ability to optimize exploration and development, it is not necessary to constrain step size and direction through time when the optimal value changes.
When
, the above Equations (
22) and (
23) generate new particles
through knowledge transfer.
is the regulatory parameter, and
is the template selected by the
i-th individual. When
,
, and when
,
.
When the figure of merit is constant, the knowledge transfer strategy with the template as the main learning object will gradually move closer to the particle direction with iteration, and the step size will gradually increase.
When
, Equation (
24) generates new particles
through knowledge transfer.
is a random number in the range
.
When the figure of merit is constant, the direction of the knowledge transfer strategy with the particle itself as the core is random, and with the iteration, the step size of the particle to the template gradually decreases.
2.3. Computation Complexity
This section analyzes the time complexity and algorithm running time of PTG. Suppose the population size is N, the number of iterations is T, and the problem dimension is D. The main loop of the algorithm executes T iterations, and in each iteration, the algorithm needs to generate particles through the template generation stage and the template guidance stage. In the template generation stage, the dimension analysis value of each particle needs to be calculated, so the time complexity is . In the template interval expansion strategy, the value of each particle is the same in the current iteration, so the computational complexity is . The time complexity of generating history-retrace templates or value-driven templates for particles is . In the template guidance stage, the time complexity of both boot modes is . Therefore, the overall time complexity of the algorithm is . Since the constant term can be ignored, it can be reduced to .
4. Conclusions
Existing heuristic algorithms are mostly based on inspiration sources, which are random and unstable. Therefore, based on the optimization principle, this paper proposes a highly stable algorithm named PTG. In particular, PTG can effectively use the knowledge of the particle’s own dimension distribution to accelerate the convergence of particle optimization and also effectively use the knowledge of population distribution to help the particle jump out of local optimization. Different from other comparison algorithms, PTG preserves and uses the random particles of the population with constant merit, which helps the algorithm trace back the previous limited points and prevents missing the merit solution.
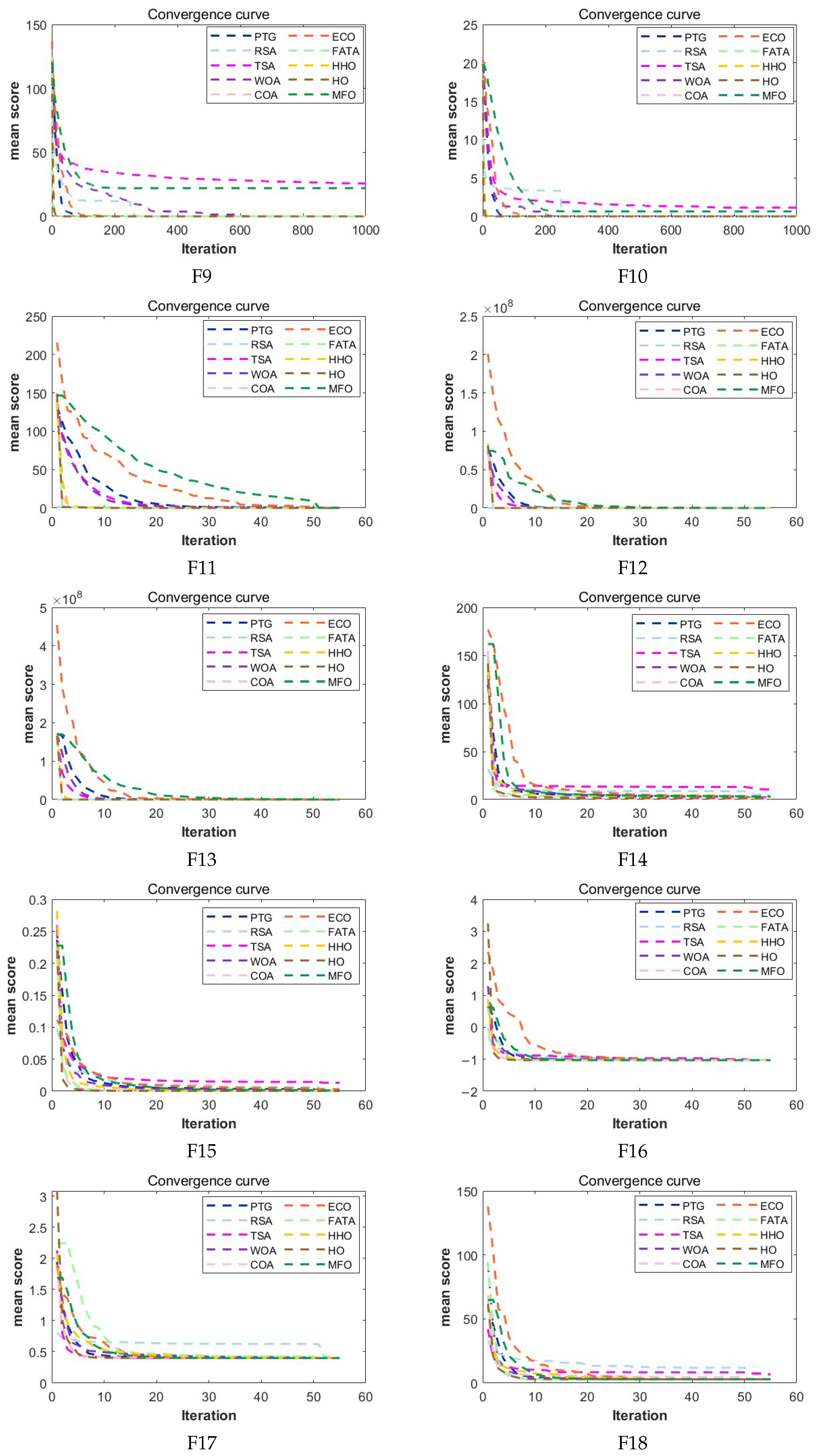
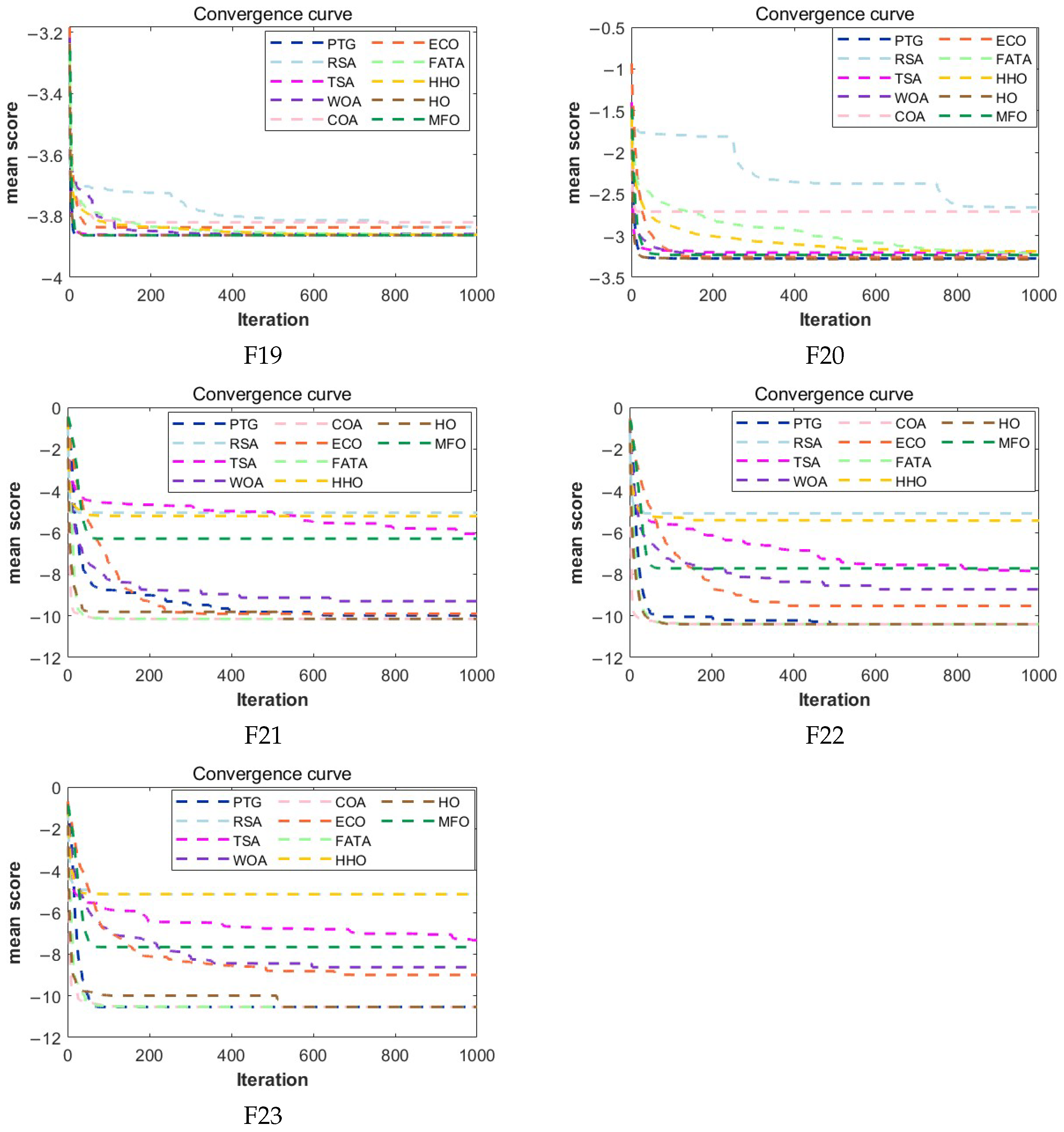
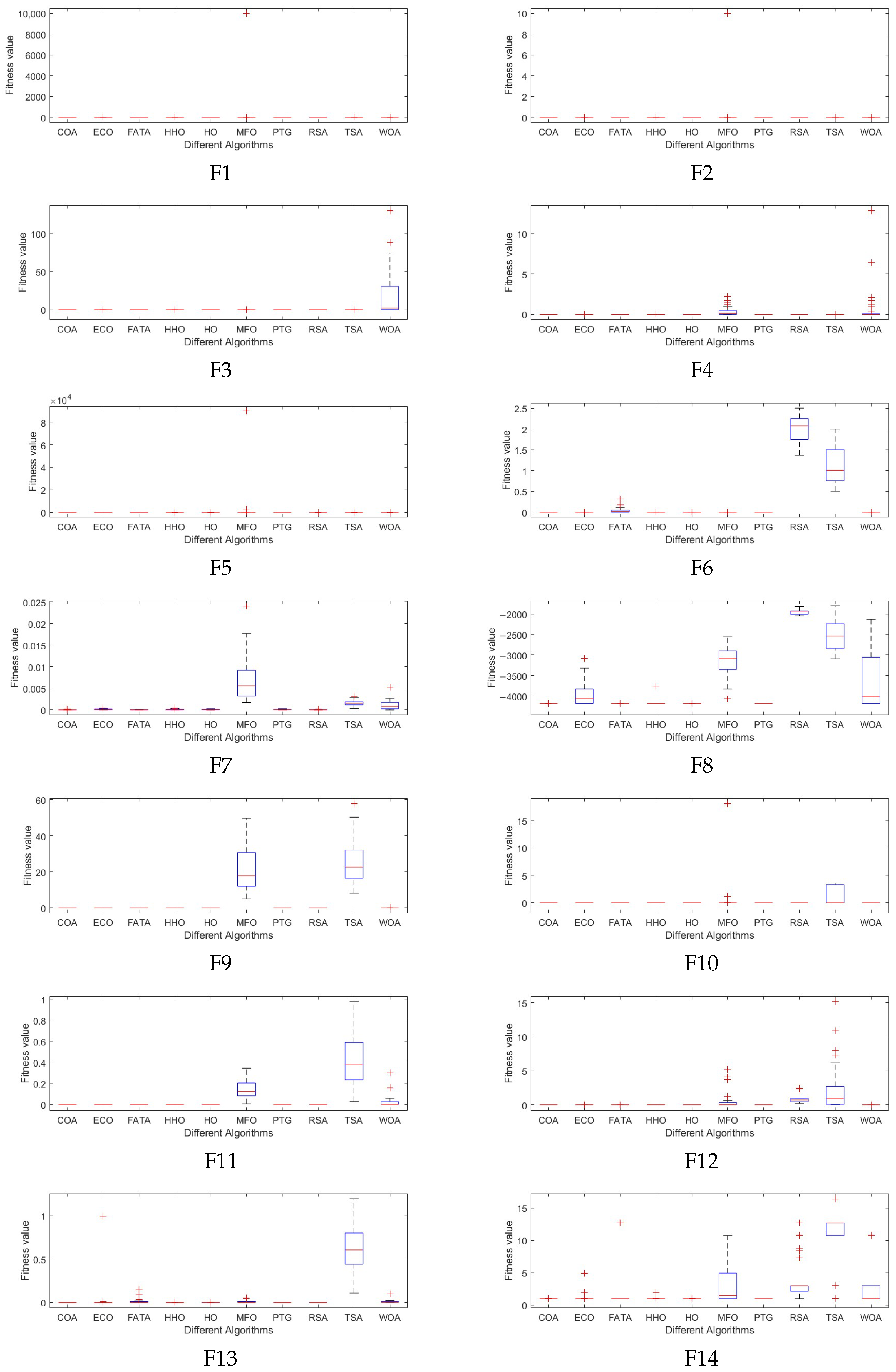
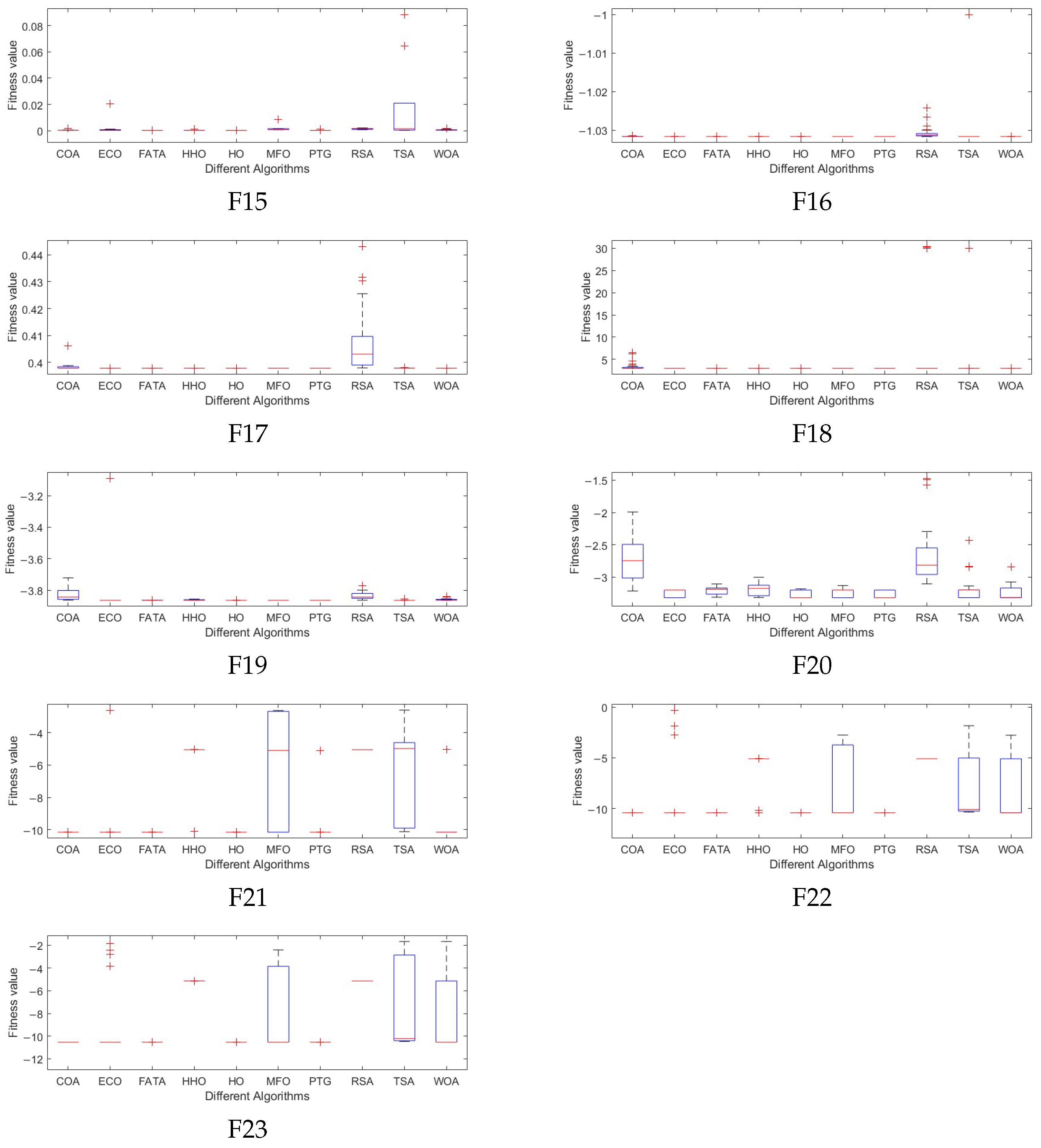
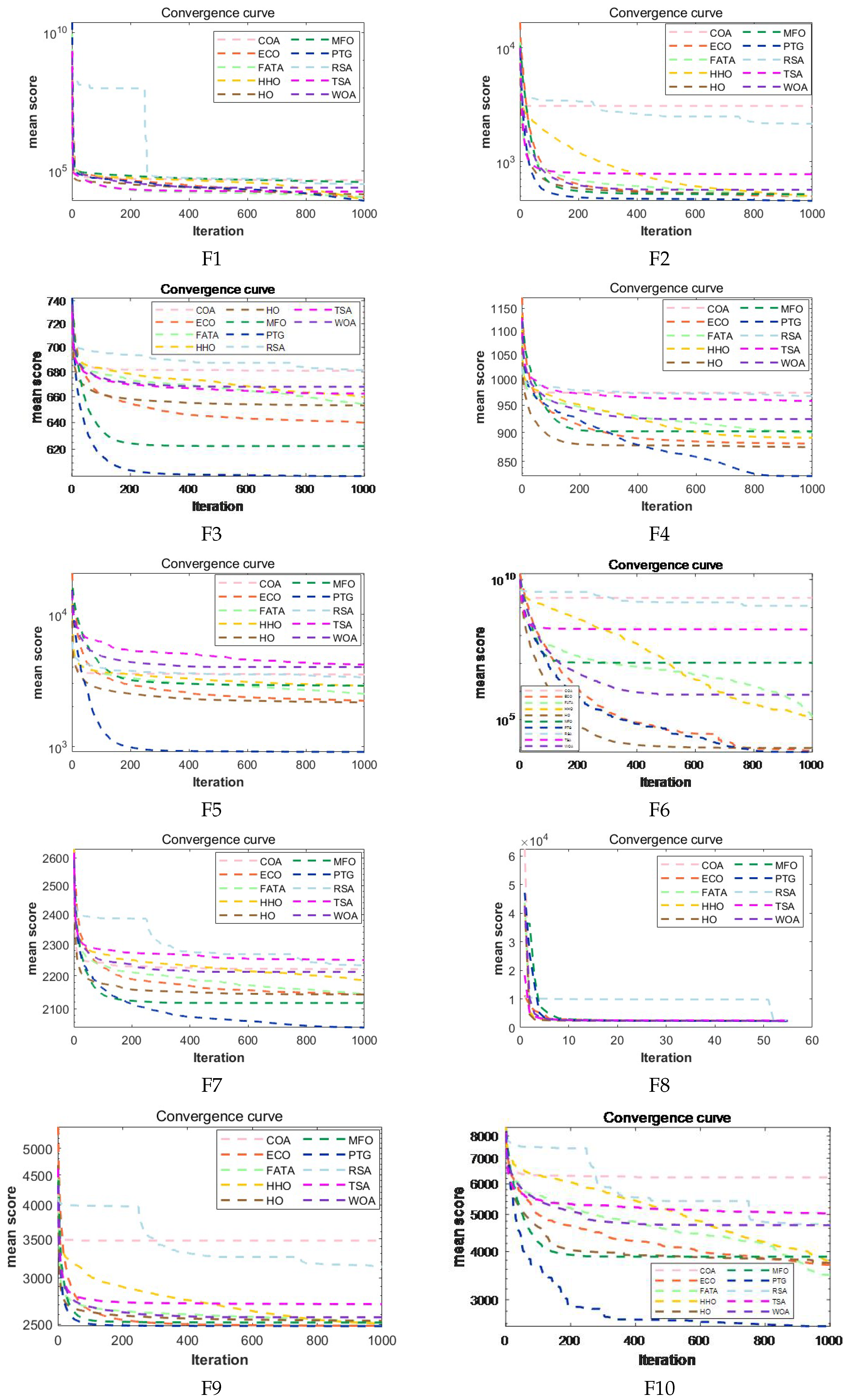
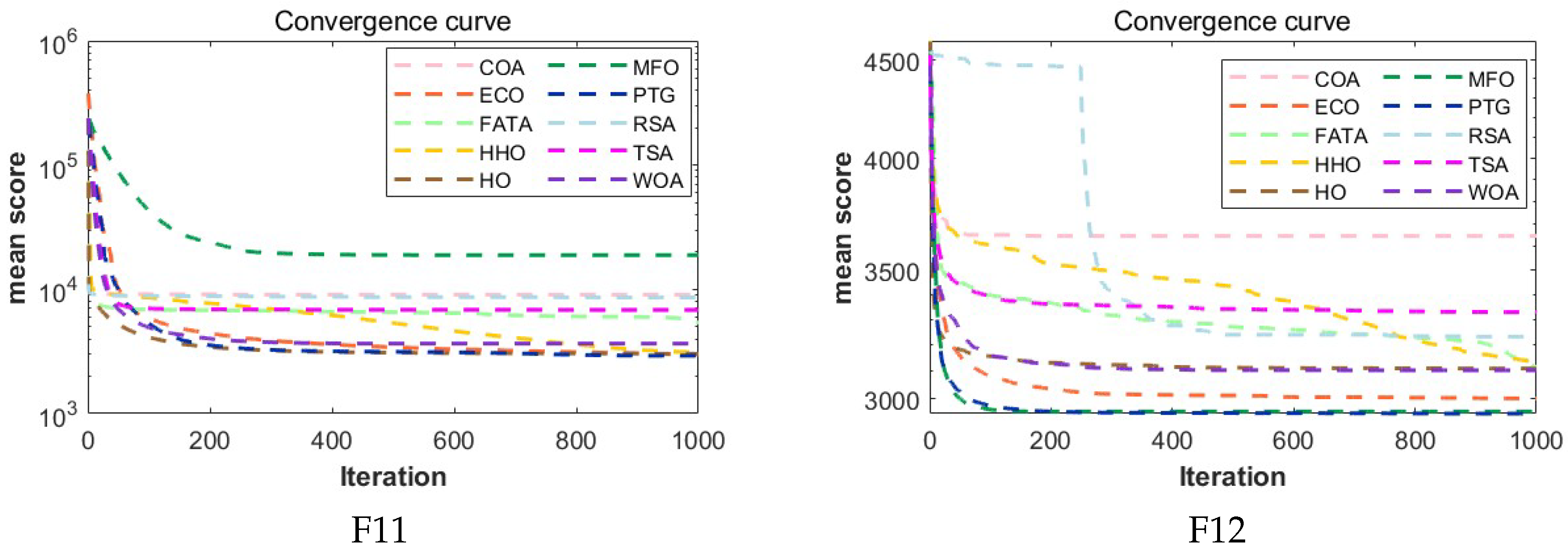
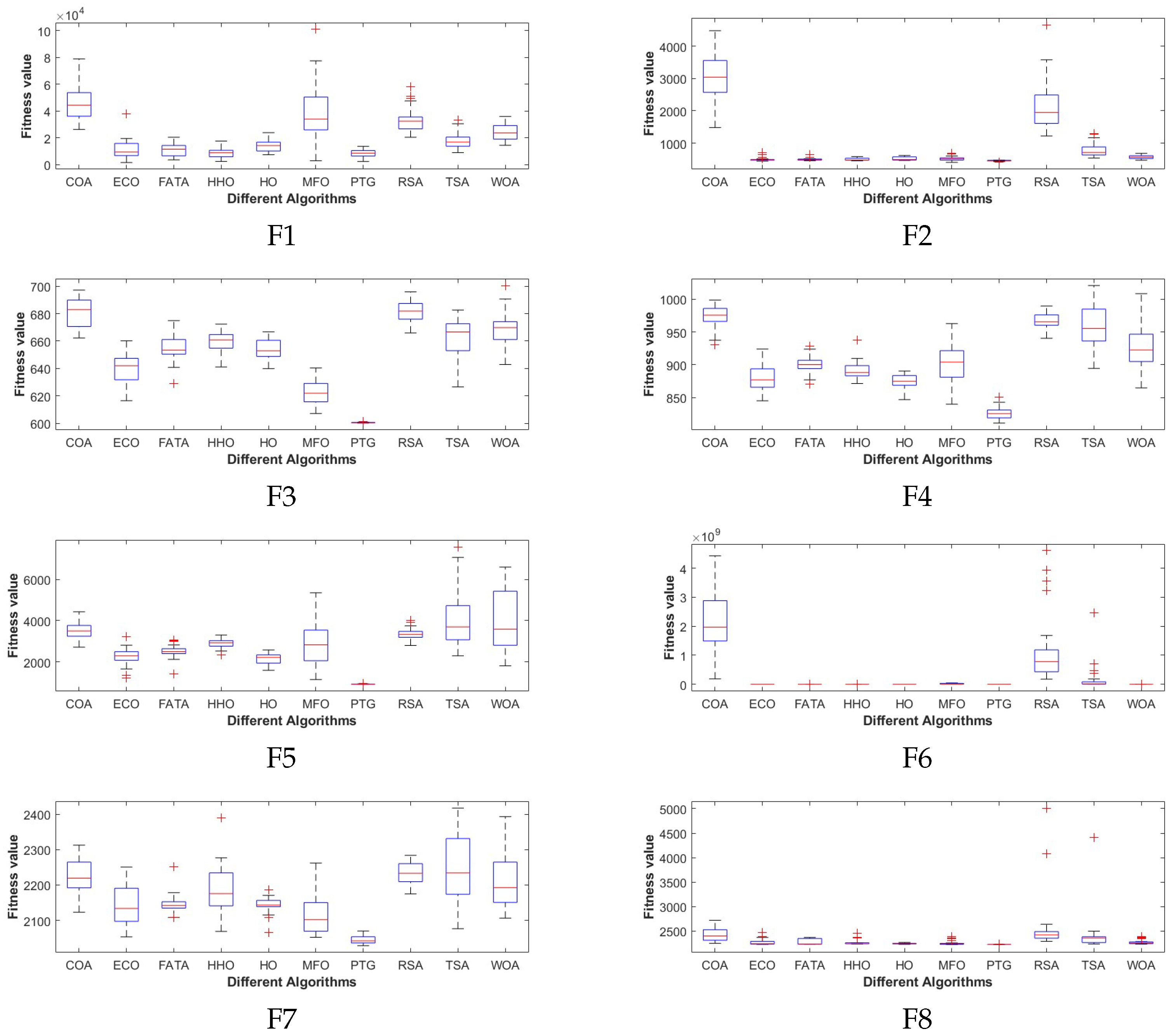
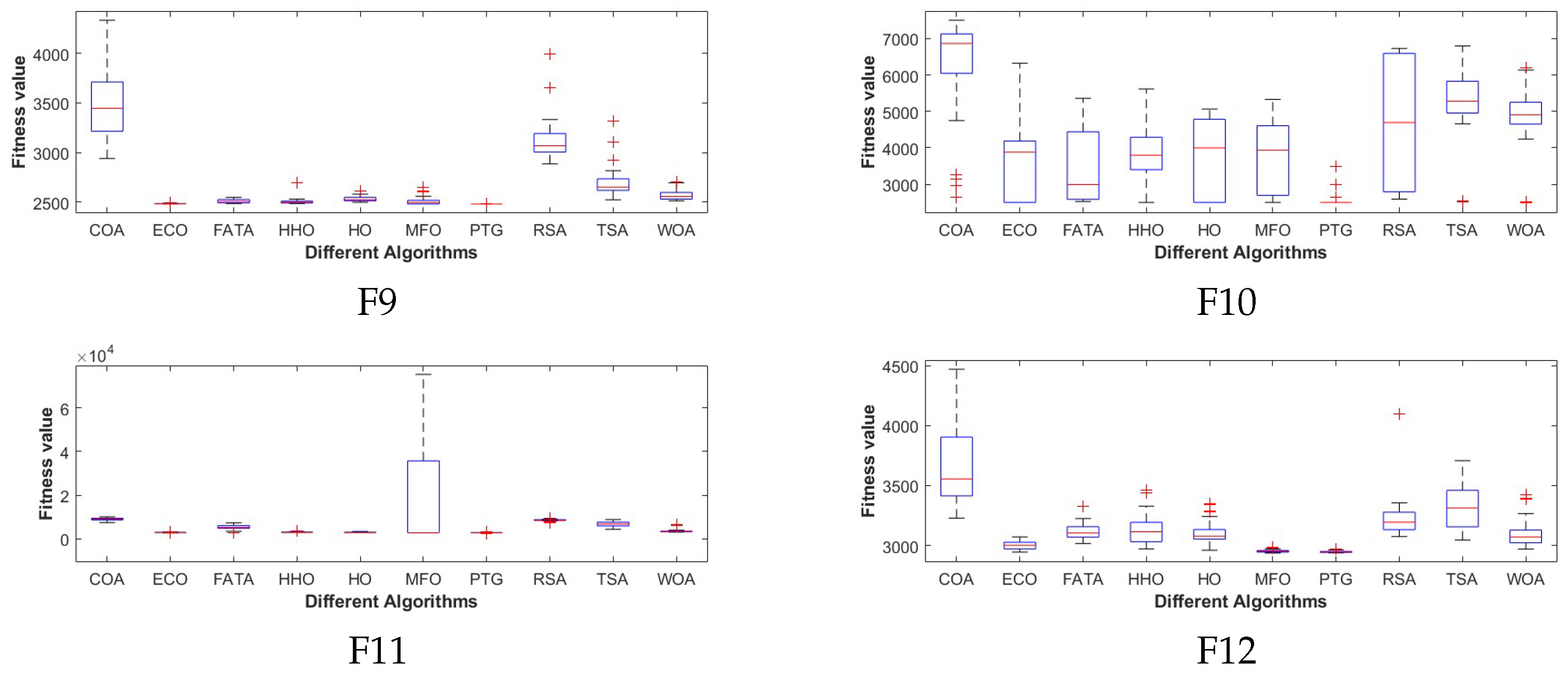
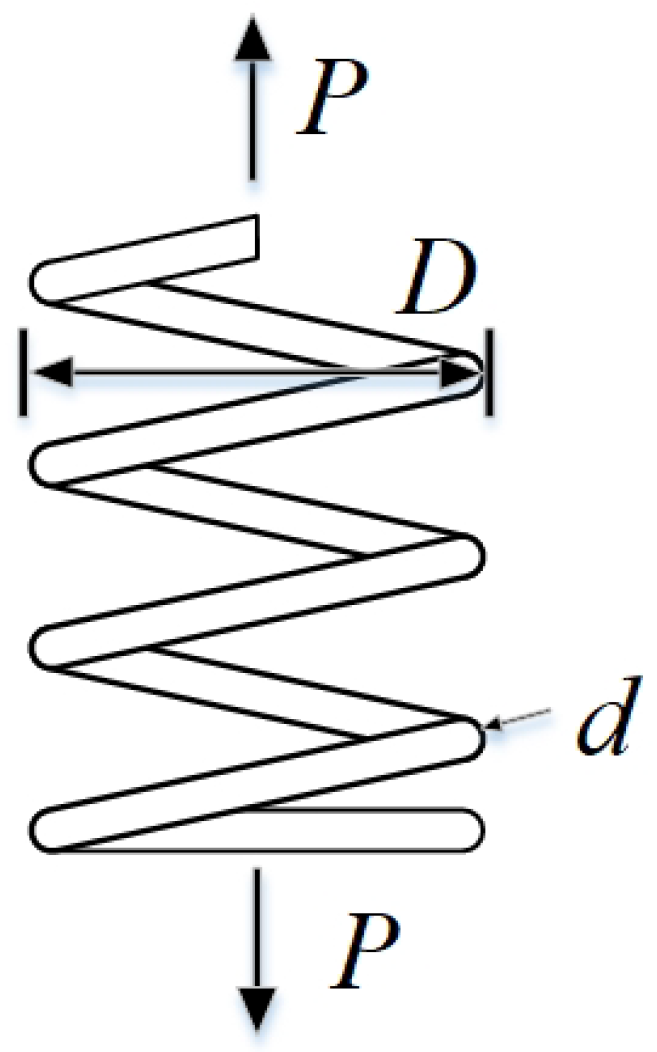
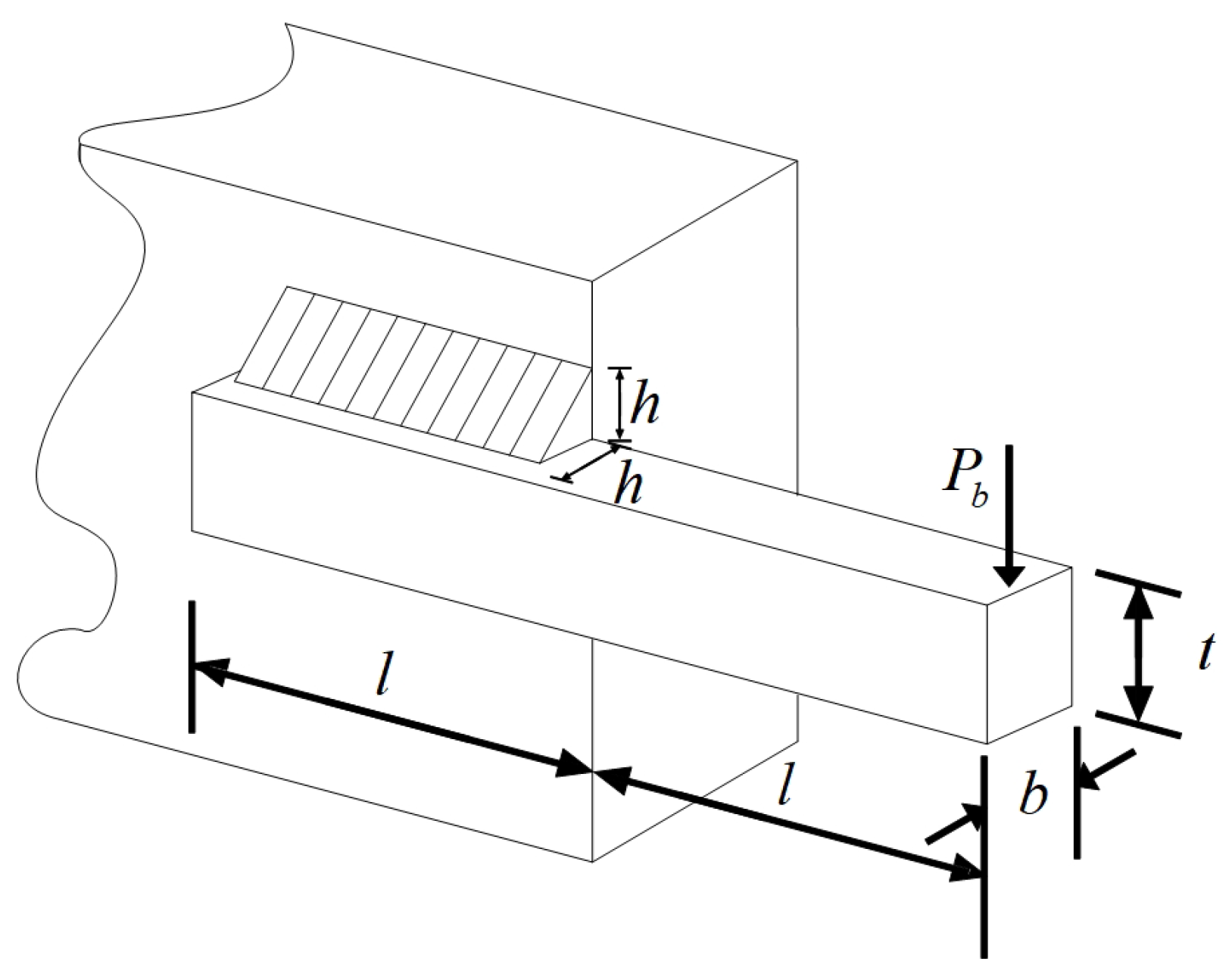
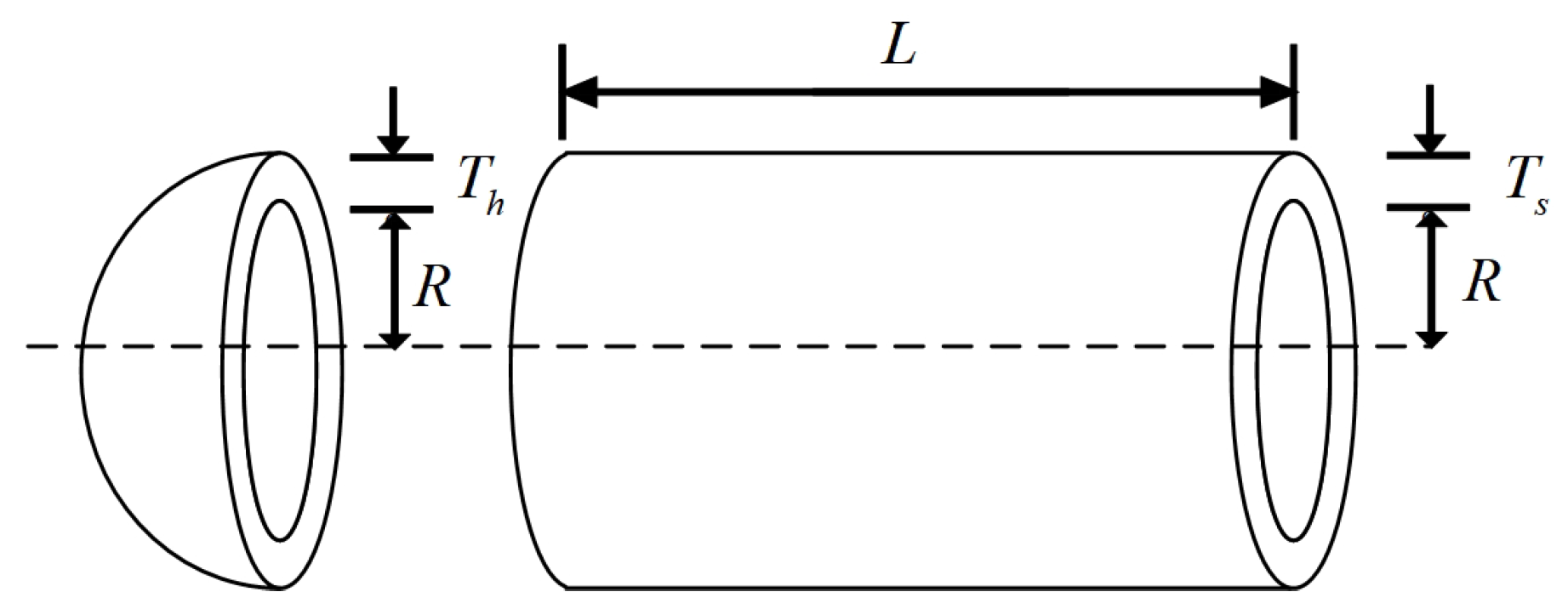
The experimental results show that compared with the other nine comparison algorithms, PTG performs best among 23 classical benchmark functions and CEC2022 benchmark functions, which shows that PTG is suitable for solving multimodal problems and unimodal benchmark functions with global convergence. In addition, PTG has solved four engineering problems, including spring compression design, welded beam structure, pressure vessel, and reducer design, which have practical application value. In addition, PTG ranks first in the Friedman test, which shows that PTG has obvious advantages in two different types of test functions. Although PTG has many advantages, there are still several limitations. Firstly, when dealing with high-dimensional data, the performance of PTG is similar to that of contrast algorithms, which indicates that the dimension distribution strategy requires a more comprehensive design to handle high-dimensional complex problems. Secondly, real-world problems are intricate and complex. For issues under complex constraints, the PTG algorithm may perform poorly, and all these need to be improved in future work. And in the future, we also plan to further expand the PTG algorithm to solve multi-objective optimization problems and use it to optimize large deep models.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}