

Multi-Modal Excavator Activity Recognition Using Two-Stream CNN-LSTM with RGB and Point Cloud Inputs



Abstract
1. Introduction
- A novel multi-stream input data-based methodology for excavators’ activity recognition using a two-stream CNN-LSTM DL algorithm.
- Improvement of activity recognition through a two-stream CNN-LSTM algorithm by effectively combining spatial (RGB frames) and temporal (optical flow) data from RGB camera and Lidar streams under occlusion.
- A distinct dataset has been developed with two different input sources for excavator activities during the earthmoving process at various site conditions. A database containing 495,000 video frames of RGB external camera images and point cloud images from various construction sites with different conditions has been developed.
- A standard data labelling format is proposed for labelling the data gathered based on the excavator activities at a specific timestamp.
- Comprehensive performance evaluation of CNN-LSTM for the single-stream and two-stream CNN-LSTM for multi-stream activity recognition of the excavator.
2. Literature Review
2.1. Vision-Based Methods for Construction Equipment Monitoring
2.2. Vision-Based Earthmoving Activity Detection
2.3. Problem Statement and Objective
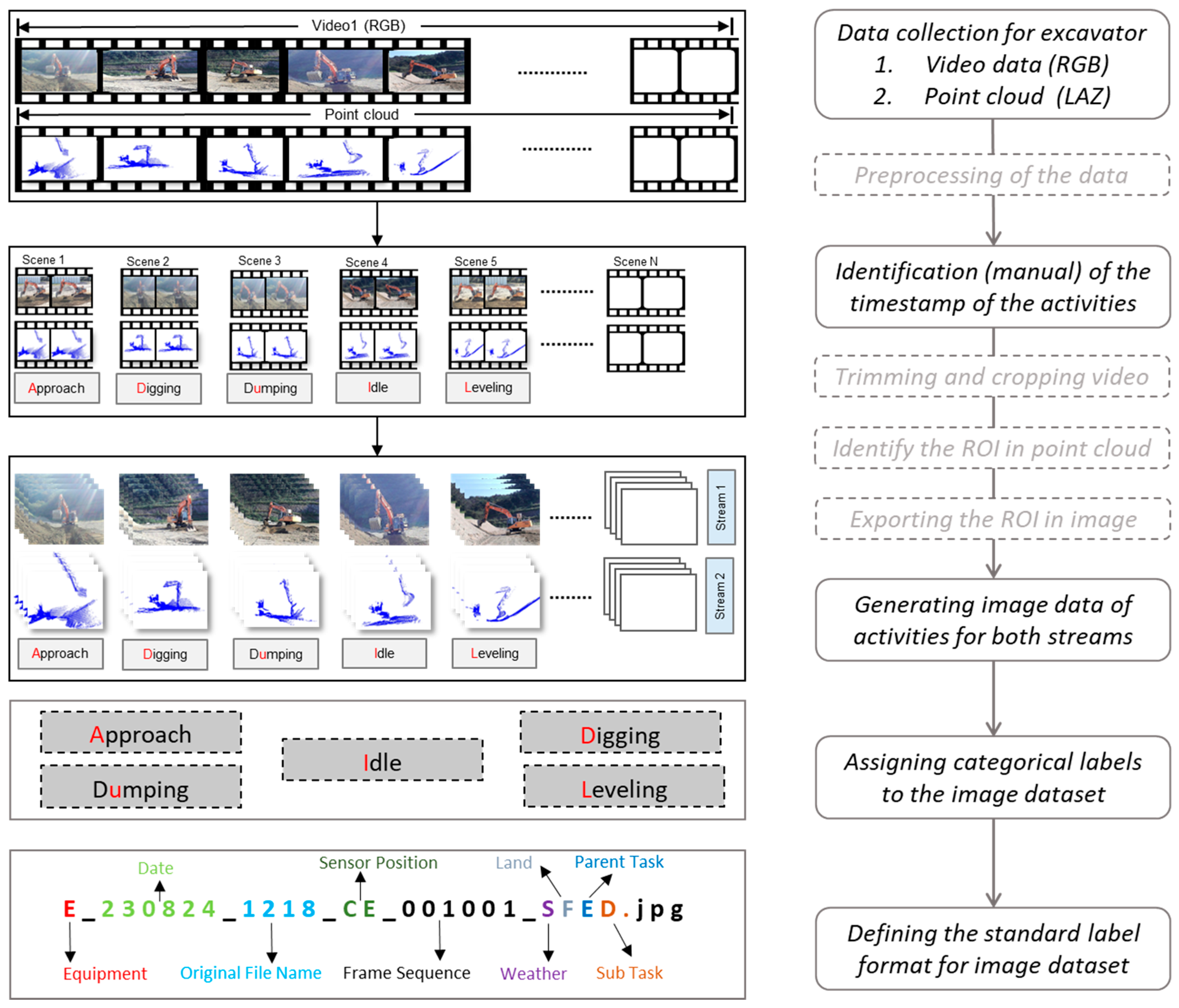
3. Methodology
3.1. Overview
3.2. Data Collection and Work Type Definition
3.3. Data Cleaning and Labeling Process
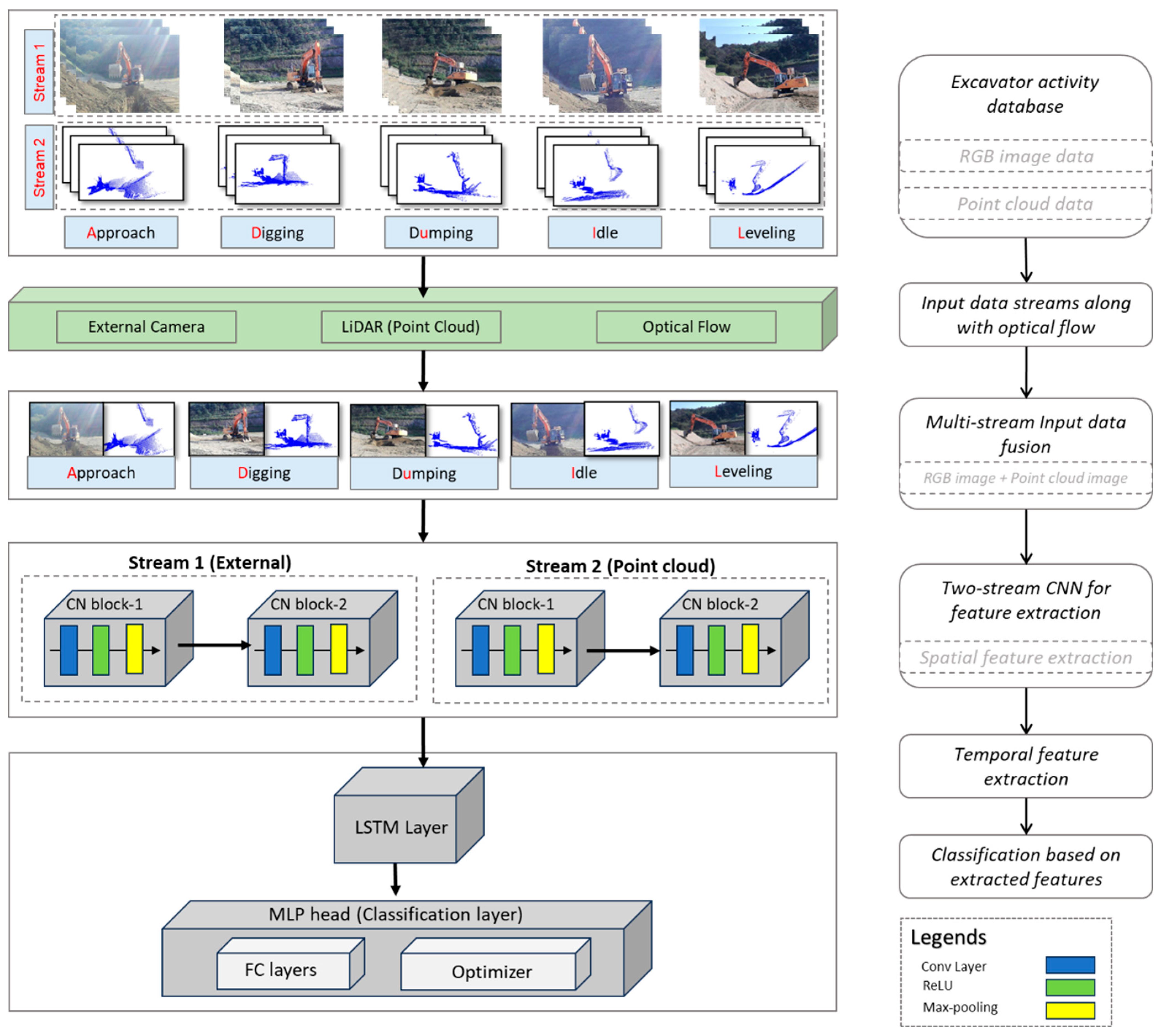
3.4. Data Fusion
3.5. CNN Network for Activity Recognition Through Optical Flow
3.6. Performance Metrics
4. Experimental Implementation and Results
4.1. Datasets
4.2. Classification Model Training and Testing Process
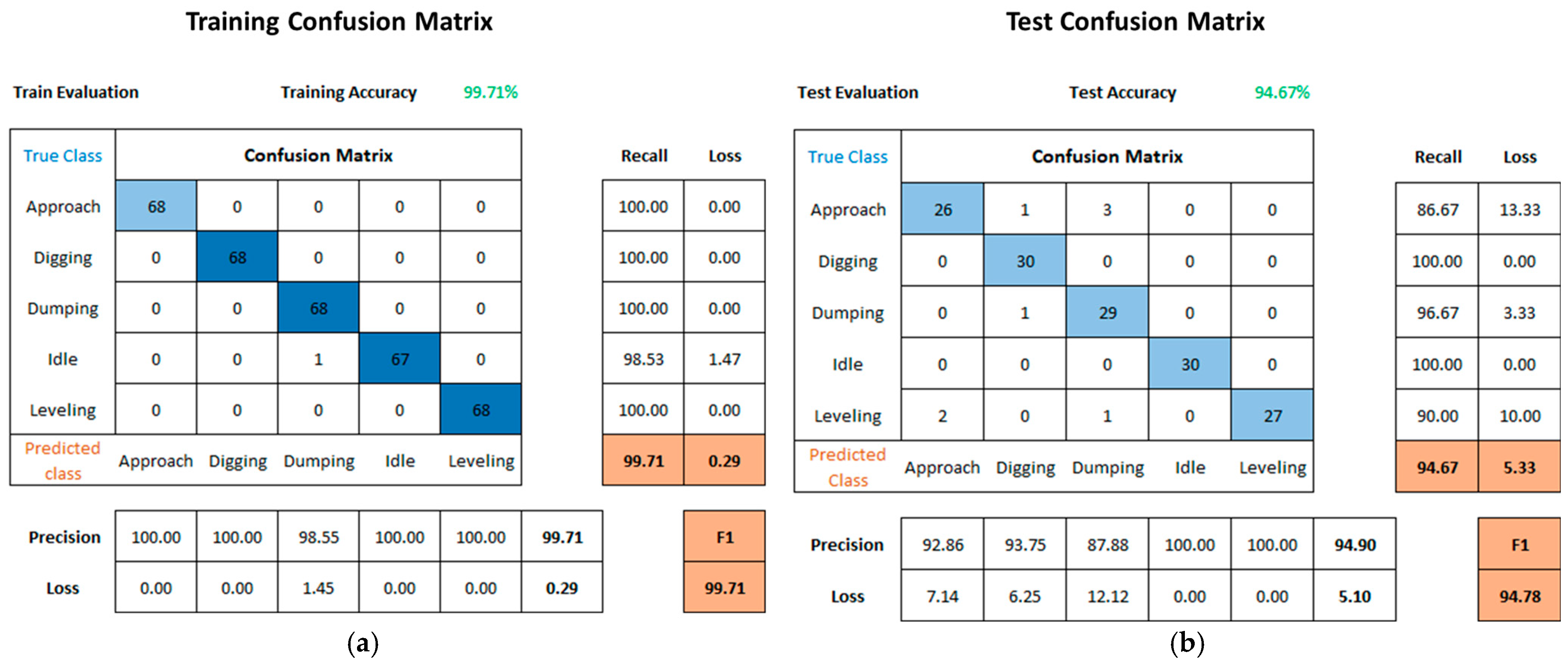
4.3. Results
4.4. Sensitivity Analysis of Hyperparameters
5. Evaluation and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AVI | Audio Video Interleave (video format) |
| CE | Camera External |
| CNN | Convolutional Neural Network |
| CV | Computer Vision |
| DL | Deep Learning |
| DIGER | Deep Information Guided Excavator Recognition |
| DT | Decision Tree |
| FC | Fully Connected (layer) |
| FN | False Negative |
| FP | False Positive |
| GPS | Global Positioning System |
| GT | Ground Truth |
| HOG | Histogram of Oriented Gradients |
| HMM | Hidden Markov Model |
| IFaster R-CNN | Improved Faster Region-based CNN |
| IMU | Inertial Measurement Unit |
| JPG | Joint Photographic Experts Group (image format) |
| JSON | JavaScript Object Notation |
| KNN | K-Nearest Neighbors |
| LAZ | Compressed LAS (LiDAR data format) |
| LSTM | Long Short-Term Memory |
| MLP | Multi-Layer Perceptron |
| MS-TCN | Multi-Stage Temporal Convolutional Network |
| PC | Point Cloud |
| RGB | Red Green Blue |
| RNN | Recurrent Neural Network |
| ReLU | Rectified Linear Unit |
| RPN | Region Proposal Network |
| SVM | Support Vector Machine |
| TN | True Negative |
| TP | True Positive |
| YOLO | You Only Look Once |
| YOWO | You Only Watch Once |
References
- Latif, K.; Sharafat, A.; Seo, J. Digital Twin-Driven Framework for TBM Performance Prediction, Visualization, and Monitoring through Machine Learning. Appl. Sci. 2023, 13, 11435. [Google Scholar] [CrossRef]
- Yang, J.; Park, M.-W.; Vela, P.A.; Golparvar-Fard, M. Construction Performance Monitoring via Still Images, Time-Lapse Photos, and Video Streams: Now, Tomorrow, and the Future. Adv. Eng. Inform. 2015, 29, 211–224. [Google Scholar] [CrossRef]
- Parente, M.; Gomes Correia, A.; Cortez, P. Artificial Neural Networks Applied to an Earthwork Construction Database. In Proceedings of the Second International Conference on Information Technology in Geo-Engineering, Durham, UK, 21–22 July 2014; pp. 200–205. [Google Scholar]
- Li, B.; Hou, B.; Yu, W.; Lu, X.; Yang, C. Applications of Artificial Intelligence in Intelligent Manufacturing: A Review. Front. Inf. Technol. Electron. Eng. 2017, 18, 86–96. [Google Scholar] [CrossRef]
- Aziz, R.F.; Hafez, S.M.; Abuel-Magd, Y.R. Smart Optimization for Mega Construction Projects Using Artificial Intelligence. Alex. Eng. J. 2014, 53, 591–606. [Google Scholar] [CrossRef]
- Sharafat, A.; Tanoli, W.A.; Zubair, M.U.; Mazher, K.M. Digital Twin-Driven Stability Optimization Framework for Large Underground Caverns. Appl. Sci. 2025, 15, 4481. [Google Scholar] [CrossRef]
- Lee, S.; Sharafat, A.; Kim, I.S.; Seo, J. Development and Assessment of an Intelligent Compaction System for Compaction Quality Monitoring, Assurance, and Management. Appl. Sci. 2022, 12, 6855. [Google Scholar] [CrossRef]
- Xiao, B.; Kang, S.-C. Development of an Image Data Set of Construction Machines for Deep Learning Object Detection. J. Comput. Civ. Eng. 2021, 35. [Google Scholar] [CrossRef]
- Liu, G.; Wang, Q.; Wang, T.; Li, B.; Xi, X. Vision-Based Excavator Pose Estimation for Automatic Control. Autom. Constr. 2024, 157, 105162. [Google Scholar] [CrossRef]
- Lu, Y.; You, K.; Zhou, C.; Chen, J.; Wu, Z.; Jiang, Y.; Huang, C. Video Surveillance-Based Multi-Task Learning with Swin Transformer for Earthwork Activity Classification. Eng. Appl. Artif. Intell. 2024, 131, 107814. [Google Scholar] [CrossRef]
- Kim, J.; Chi, S. Multi-Camera Vision-Based Productivity Monitoring of Earthmoving Operations. Autom. Constr. 2020, 112, 103121. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, C.R.; Engelhaupt, D.; Lee, S. Application of Dynamic Time Warping to the Recognition of Mixed Equipment Activities in Cycle Time Measurement. Autom. Constr. 2018, 87, 225–234. [Google Scholar] [CrossRef]
- Ahn, C.R.; Lee, S.; Peña-Mora, F. Application of Low-Cost Accelerometers for Measuring the Operational Efficiency of a Construction Equipment Fleet. J. Comput. Civ. Eng. 2013, 29. [Google Scholar] [CrossRef]
- Akhavian, R.; Behzadan, A.H. Smartphone-Based Construction Workers’ Activity Recognition and Classification. Autom. Constr. 2016, 71, 198–209. [Google Scholar] [CrossRef]
- Teizer, J. Status Quo and Open Challenges in Vision-Based Sensing and Tracking of Temporary Resources on Infrastructure Construction Sites. Adv. Eng. Inform. 2015, 29, 225–238. [Google Scholar] [CrossRef]
- Yang, J.; Vela, P.; Teizer, J.; Shi, Z. Vision-Based Tower Crane Tracking for Understanding Construction Activity. J. Comput. Civ. Eng. 2014, 28, 103–112. [Google Scholar] [CrossRef]
- Luo, H.; Xiong, C.; Fang, W.; Love, P.E.D.; Zhang, B.; Ouyang, X. Convolutional Neural Networks: Computer Vision-Based Workforce Activity Assessment in Construction. Autom. Constr. 2018, 94, 282–289. [Google Scholar] [CrossRef]
- Deng, T.; Sharafat, A.; Lee, S.; Seo, J. Automatic Vision-Based Dump Truck Productivity Measurement Based on Deep-Learning Illumination Enhancement for Low-Visibility Harsh Construction Environment. J. Constr. Eng. Manag. 2024, 150. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, Z.; Hammad, A. Automated Excavators Activity Recognition and Productivity Analysis from Construction Site Surveillance Videos. Autom. Constr. 2020, 110, 103045. [Google Scholar] [CrossRef]
- Cheng, M.-Y.; Cao, M.-T.; Nuralim, C.K. Computer Vision-Based Deep Learning for Supervising Excavator Operations and Measuring Real-Time Earthwork Productivity. J. Supercomput. 2022, 79, 4468–4492. [Google Scholar] [CrossRef]
- Gong, J.; Caldas, C.H.; Gordon, C. Learning and Classifying Actions of Construction Workers and Equipment Using Bag-of-Video-Feature-Words and Bayesian Network Models. Adv. Eng. Inform. 2011, 25, 771–782. [Google Scholar] [CrossRef]
- Fang, Q.; Li, H.; Luo, X.; Ding, L.; Luo, H.; Rose, T.M.; An, W. Detecting Non-Hardhat-Use by a Deep Learning Method from Far-Field Surveillance Videos. Autom. Constr. 2018, 85, 1–9. [Google Scholar] [CrossRef]
- Kim, J.; Chi, S. Action Recognition of Earthmoving Excavators Based on Sequential Pattern Analysis of Visual Features and Operation Cycles. Autom. Constr. 2019, 104, 255–264. [Google Scholar] [CrossRef]
- Kim, I.-S.; Latif, K.; Kim, J.; Sharafat, A.; Lee, D.-E.; Seo, J. Vision-Based Activity Classification of Excavators by Bidirectional LSTM. Appl. Sci. 2022, 13, 272. [Google Scholar] [CrossRef]
- Latif, K.; Sharafat, A.; Tao, D.; Park, S.; Seo, J. Digital Twin for Excavator-Dump Optimization Based on Two-Stream CNN-LSTM and DES. In Proceedings of the KSCE Convention Conference and Civil Expo, Jeju, Republic of Korea, 16–18 October 2024; pp. 17–18. Available online: https://www.dbpia.co.kr/Journal/articleDetail?nodeId=NODE12088514 (accessed on 25 July 2025).
- Ladjailia, A.; Bouchrika, I.; Merouani, H.F.; Harrati, N.; Mahfouf, Z. Human Activity Recognition via Optical Flow: Decomposing Activities into Basic Actions. Neural Comput. Appl. 2020, 32, 16387–16400. [Google Scholar] [CrossRef]
- Allam, J.P.; Sahoo, S.P.; Ari, S. Multi-Stream Bi-GRU Network to Extract a Comprehensive Feature Set for ECG Signal Classification. Biomed Signal Process Control 2024, 92, 106097. [Google Scholar] [CrossRef]
- Semwal, A.; Londhe, N.D. A Multi-Stream Spatio-Temporal Network Based Behavioural Multiparametric Pain Assessment System. Biomed Signal Process Control 2024, 90, 105820. [Google Scholar] [CrossRef]
- Chowdhury, M.H.; Chowdhury, M.E.H.; Alqahtani, A. MMG-Net: Multi Modal Approach to Estimate Blood Glucose Using Multi-Stream and Cross Modality Attention. Biomed Signal Process Control 2024, 92, 105975. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. In Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Montreal, QC, Canada, 2014; Volume 27. [Google Scholar]
- Kuenzel, R.; Teizer, J.; Mueller, M.; Blickle, A. SmartSite: Intelligent and Autonomous Environments, Machinery, and Processes to Realize Smart Road Construction Projects. Autom. Constr. 2016, 71, 21–33. [Google Scholar] [CrossRef]
- Sharafat, A.; Kim, J.; Park, S.; Seo, J. Accuracy and Error Analysis of 3D Mapping Using Unmanned Aerial Vehicle (UAV) for Earthwork Project. In Proceedings of the KSCE 2019 Convention Conference and Civil Expo, KSCE, Pyeongchang, Republic of Korea, 16–18 October 2019; pp. 385–386. Available online: https://www.dbpia.co.kr/Journal/articleDetail?nodeId=NODE09328115 (accessed on 25 July 2025).
- Kim, J.; Lee, S.S.; Seo, J.; Kamat, V.R. Modular Data Communication Methods for a Robotic Excavator. Autom. Constr. 2018, 90, 166–177. [Google Scholar] [CrossRef]
- Golparvar-Fard, M.; Peña-Mora, F.; Arboleda, C.A.; Lee, S. Visualization of Construction Progress Monitoring with 4D Simulation Model Overlaid on Time-Lapsed Photographs. J. Comput. Civ. Eng. 2009, 23, 391–404. [Google Scholar] [CrossRef]
- Chen, C.; Xiao, B.; Zhang, Y.; Zhu, Z. Automatic Vision-Based Calculation of Excavator Earthmoving Productivity Using Zero-Shot Learning Activity Recognition. Autom. Constr. 2023, 146, 104702. [Google Scholar] [CrossRef]
- Deng, T.; Sharafat, A.; Wie, Y.M.; Lee, K.G.; Lee, E.; Lee, K.H. A Geospatial Analysis-Based Method for Railway Route Selection in Marine Glaciers: A Case Study of the Sichuan-Tibet Railway Network. Remote Sens. 2023, 15, 4175. [Google Scholar] [CrossRef]
- Fang, W.; Ding, L.; Love, P.E.D.; Luo, H.; Li, H.; Peña-Mora, F.; Zhong, B.; Zhou, C. Computer Vision Applications in Construction Safety Assurance. Autom. Constr. 2020, 110, 103013. [Google Scholar] [CrossRef]
- Alawad, H.; Kaewunruen, S.; An, M. Learning from Accidents: Machine Learning for Safety at Railway Stations. IEEE Access 2019, 8, 633–648. [Google Scholar] [CrossRef]
- Choi, H.; Seo, J. Safety Assessment Using Imprecise Reliability for Corrosion-damaged Structures. Comput.-Aided Civ. Infrastruct. Eng. 2009, 24, 293–301. [Google Scholar] [CrossRef]
- Molaei, A.; Kolu, A.; Lahtinen, K.; Geimer, M. Automatic Estimation of Excavator Actual and Relative Cycle Times in Loading Operations. Autom. Constr. 2023, 156, 105080. [Google Scholar] [CrossRef]
- Sabillon, C.; Rashidi, A.; Samanta, B.; Davenport, M.A.; Anderson, D.V. Audio-Based Bayesian Model for Productivity Estimation of Cyclic Construction Activities. J. Comput. Civ. Eng. 2020, 34. [Google Scholar] [CrossRef]
- Sherafat, B.; Rashidi, A.; Asgari, S. Sound-Based Multiple-Equipment Activity Recognition Using Convolutional Neural Networks. Autom. Constr. 2022, 135, 104104. [Google Scholar] [CrossRef]
- Rashid, K.M.; Louis, J. Times-Series Data Augmentation and Deep Learning for Construction Equipment Activity Recognition. Adv. Eng. Inform. 2019, 42, 100944. [Google Scholar] [CrossRef]
- Latif, K.; Sharafat, A.; Park, S.; Seo, J. Digital Twin-Based Hybrid Approach to Visualize the Performance of TBM. In Proceedings of the KSCE, Yeosu, Republic of Korea, 19–21 October 2022; pp. 3–4. Available online: https://www.dbpia.co.kr/pdf/pdfView.do?nodeId=NODE11223304 (accessed on 25 July 2025).
- HU, S.; WANG, Y.; YANG, L.; YI, L.; NIAN, Y. Primary Non-Hodgkin’s Lymphoma of the Prostate with Intractable Hematuria: A Case Report and Review of the Literature. Oncol. Lett. 2015, 9, 1187–1190. [Google Scholar] [CrossRef]
- Teizer, J.; Venugopal, M.; Walia, A. Ultrawideband for Automated Real-Time Three-Dimensional Location Sensing for Workforce, Equipment, and Material Positioning and Tracking. Transp. Res. Rec. J. Transp. Res. Board 2008, 2081, 56–64. [Google Scholar] [CrossRef]
- Shi, Y.; Xia, Y.; Luo, L.; Xiong, Z.; Wang, C.; Lin, L. Working Stage Identification of Excavators Based on Control Signals of Operating Handles. Autom. Constr. 2021, 130, 103873. [Google Scholar] [CrossRef]
- Langroodi, A.K.; Vahdatikhaki, F.; Doree, A. Activity Recognition of Construction Equipment Using Fractional Random Forest. Autom. Constr. 2021, 122, 103465. [Google Scholar] [CrossRef]
- Pradhananga, N.; Teizer, J. Automatic Spatio-Temporal Analysis of Construction Site Equipment Operations Using GPS Data. Autom. Constr. 2013, 29, 107–122. [Google Scholar] [CrossRef]
- Sresakoolchai, J.; Kaewunruen, S. Railway Infrastructure Maintenance Efficiency Improvement Using Deep Reinforcement Learning Integrated with Digital Twin Based on Track Geometry and Component Defects. Sci. Rep. 2023, 13, 2439. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuen, K. Crack Detection Using Fusion Features-based Broad Learning System and Image Processing. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 1568–1584. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, L. Dual Attention Deep Learning Network for Automatic Steel Surface Defect Segmentation. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 1468–1487. [Google Scholar] [CrossRef]
- Golparvar-Fard, M.; Heydarian, A.; Niebles, J.C. Vision-Based Action Recognition of Earthmoving Equipment Using Spatio-Temporal Features and Support Vector Machine Classifiers. Adv. Eng. Inform. 2013, 27, 652–663. [Google Scholar] [CrossRef]
- Kaewunruen, S.; Adesope, A.A.; Huang, J.; You, R.; Li, D. AI-Based Technology to Prognose and Diagnose Complex Crack Characteristics of Railway Concrete Sleepers. Discov. Appl. Sci. 2024, 6, 217. [Google Scholar] [CrossRef]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded Pyramid Network for Multi-Person Pose Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar] [CrossRef]
- Rezazadeh Azar, E.; McCabe, B. Part Based Model and Spatial-Temporal Reasoning to Recognize Hydraulic Excavators in Construction Images and Videos. Autom. Constr. 2012, 24, 194–202. [Google Scholar] [CrossRef]
- Assadzadeh, A.; Arashpour, M.; Li, H.; Hosseini, R.; Elghaish, F.; Baduge, S. Excavator 3D Pose Estimation Using Deep Learning and Hybrid Datasets. Adv. Eng. Inform. 2023, 55, 101875. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Zhao, Y.; Xiong, Y.; Lin, D. Recognize Actions by Disentangling Components of Dynamics. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6566–6575. [Google Scholar]
- Roberts, D.; Golparvar-Fard, M. End-to-End Vision-Based Detection, Tracking and Activity Analysis of Earthmoving Equipment Filmed at Ground Level. Autom. Constr. 2019, 105, 102811. [Google Scholar] [CrossRef]
- Torres Calderon, W.; Roberts, D.; Golparvar-Fard, M. Synthesizing Pose Sequences from 3D Assets for Vision-Based Activity Analysis. J. Comput. Civ. Eng. 2021, 35. [Google Scholar] [CrossRef]
- Zhang, B.; Wang, L.; Wang, Z.; Qiao, Y.; Wang, H. Real-Time Action Recognition with Enhanced Motion Vector CNNs. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2718–2726. Available online: https://openaccess.thecvf.com/content_cvpr_2016/html/Zhang_Real-Time_Action_Recognition_CVPR_2016_paper.html (accessed on 25 July 2025).
- Chen, C.; Zhu, Z.; Hammad, A.; Akbarzadeh, M. Automatic Identification of Idling Reasons in Excavation Operations Based on Excavator–Truck Relationships. J. Comput. Civ. Eng. 2021, 35. [Google Scholar] [CrossRef]
- Bhokare, S.; Goyal, L.; Ren, R.; Zhang, J. Smart Construction Scheduling Monitoring Using YOLOv3-Based Activity Detection and Classification. J. Inf. Technol. Constr. 2022, 27, 240–252. [Google Scholar] [CrossRef]
- Ghelmani, A.; Hammad, A. Improving Single-stage Activity Recognition of Excavators Using Knowledge Distillation of Temporal Gradient Data. Comput.-Aided Civ. Infrastruct. Eng. 2024, 39, 2028–2053. [Google Scholar] [CrossRef]
- Chen, J.; Wang, J.; Yuan, Q.; Yang, Z. CNN-LSTM Model for Recognizing Video-Recorded Actions Performed in a Traditional Chinese Exercise. IEEE J. Transl. Eng. Health Med. 2023, 11, 351–359. [Google Scholar] [CrossRef]
- Imran, H.A.; Ikram, A.A.; Wazir, S.; Hamza, K. EdgeHARNet: An Edge-Friendly Shallow Convolutional Neural Network for Recognizing Human Activities Using Embedded Inertial Sensors of Smart-Wearables. In Proceedings of the 2023 International Conference on Communication, Computing and Digital Systems (C-CODE), Islamabad, Pakistan, 17–18 May 2023; pp. 1–6. [Google Scholar]
- Kaya, Y.; Topuz, E.K. Human Activity Recognition from Multiple Sensors Data Using Deep CNNs. Multimed. Tools Appl. 2024, 83, 10815–10838. [Google Scholar] [CrossRef]
- Li, X.; Hao, T.; Li, F.; Zhao, L.; Wang, Z. Faster R-CNN-LSTM Construction Site Unsafe Behavior Recognition Model. Appl. Sci. 2023, 13, 10700. [Google Scholar] [CrossRef]
- Younesi Heravi, M.; Jang, Y.; Jeong, I.; Sarkar, S. Deep Learning-Based Activity-Aware 3D Human Motion Trajectory Prediction in Construction. Expert. Syst. Appl. 2024, 239, 122423. [Google Scholar] [CrossRef]
- Zhu, Z.; Ren, X.; Chen, Z. Visual Tracking of Construction Jobsite Workforce and Equipment with Particle Filtering. J. Comput. Civ. Eng. 2016, 30. [Google Scholar] [CrossRef]
- Park, M.-W.; Brilakis, I. Continuous Localization of Construction Workers via Integration of Detection and Tracking. Autom. Constr. 2016, 72, 129–142. [Google Scholar] [CrossRef]
- Bilge, Y.C.; Mutlu, B.; Esin, Y.E. BusEye: A Multi-Stream Approach for Driver Behavior Analysis on Public Bus Driver Cameras. Expert. Syst. Appl. 2024, 245, 123148. [Google Scholar] [CrossRef]
- Yang, J.; Shi, Z.; Wu, Z. Vision-Based Action Recognition of Construction Workers Using Dense Trajectories. Adv. Eng. Inform. 2016, 30, 327–336. [Google Scholar] [CrossRef]
- Lee, S.; Bae, J.Y.; Sharafat, A.; Seo, J. Waste Lime Earthwork Management Using Drone and BIM Technology for Construction Projects: The Case Study of Urban Development Project. KSCE J. Civ. Eng. 2024, 28, 517–531. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Year | Source Type | No. of Stream | Input Data | Method/Classifier | Purpose/Goal |
|---|---|---|---|---|---|---|
| Golparvar-Fard et al. [53] | 2013 | External Camera | One | RGB Image | 3D HOG feature + SVM classifier | Activity recognition of excavator and status of dump truck |
| Yang et al. [75] | 2016 | External Camera | One | RGB Image | HOG, HOE, MBH features + SVM classifier | Action recognition of construction workers using dense trajectories |
| J. Kim and Chi [23] | 2019 | External Camera | One | RGB Image | CNN | Detection of Excavator |
| CNN-LSTM | Tracking of the excavator | |||||
| CNN-DLSTM | Activity recognition of excavator | |||||
| Chen et al. [19] | 2020 | External Camera | One | RGB Image | Faster R-CNN + Deep SORT tracker + 3D ResNet classifier | Detection of Excavator |
| Tracking, activity recognition of excavators | ||||||
| Ladjailia et al. [26] | 2020 | External Camera | One | RGB Image | (optical flow descriptor) KNN, DT, SVM | An optical flow descriptor to recognize human actions by considering only features derived from the motion (Weizmann and UCF101 databases) |
| Bhokare et al. [65] | 2021 | External Camera | One | RGB Image | YOLOV3 | Detection and activity classification |
| Torres Calderon et al. [62] | 2021 | External Camera | One | RGB Image | Multistage Temporal Convolutional Network (MS-TCN) | Synthesis data to improve the vision-based activity recognition of excavator |
| Chen et al. [64] | 2021 | External Camera | One | RGB Image | YOLOv3 | Activity recognition, identification of idling reason based on excavator–truck relationships |
| M.-Y. Cheng et al. [20] | 2022 | External Camera | One | RGB Image | YOWO | Vision-based autonomous excavator productivity estimation |
| Chen et al. [35] | 2022 | External Camera | One | RGB Image | YOLO, SORT, Zero-shot learning method CLIP | Activity recognition of excavator and productivity estimation |
| I.-S. Kim et al. [24] | 2023 | External Camera | One | RGB Image | CNN-BiLSTM | Activity classification of the excavator to improve the safety, monitoring, and productivity of the earthwork site |
| Ghelmani and Hammad [66] | 2024 | External Camera | One | RGB Image | DIGER based on YOWO | simultaneous activity recognition and localization |
| Components of the Proposed Standard | File Naming Standard E_230905_0907_CE_000750_SFSD.jpg | |||||
|---|---|---|---|---|---|---|
| Equipment type | Excavator | |||||
| Acquisition date | Year month date | 230905 | ~ | 0907 | ||
| Acquisition time | Hour min | |||||
| Source sensor type | Camera External (CE) | Point Cloud (PC) | ||||
| Frame number | xxxxxx | 000000 | ~ | 999999 | ||
| Work type | Excavating and Loading | Grading (Leveling) | Foundation and Trenching | Slope Digging | ||
| Activity type | Approach | Digging | DUmping | Idle | Leveling | |
| Activity | No. of Video Clips per Stream | Training Clips (70%) | Testing Clips (30%) | Total Clips (RGB + PC) |
|---|---|---|---|---|
| Approach | 98 (RGB *) + 98 (PC **) | 68 (RGB) + 68 (PC) | 30 (RGB) + 30 (PC) | 196 |
| Digging | 98 (RGB) + 98 (PC) | 68 (RGB) + 68 (PC) | 30 (RGB) + 30 (PC) | 196 |
| Dumping | 98 (RGB) + 98 (PC) | 68 (RGB) + 68 (PC) | 30 (RGB) + 30 (PC) | 196 |
| Idle | 98 (RGB) + 98 (PC) | 68 (RGB) + 68 (PC) | 30 (RGB) + 30 (PC) | 196 |
| Leveling | 98 (RGB) + 98 (PC) | 68 (RGB) + 68 (PC) | 30 (RGB) + 30 (PC) | 196 |
| Total | 980 (RGB + PC) | 680 (RGB + PC) | 300 (RGB + PC) | 980 |
| Epochs | Learning Rate | |||
|---|---|---|---|---|
| 0.01 | 0.001 | 0.0001 | 0.00001 | |
| 20 | 27.83 | 20 | 90.43 | 84.35 |
| 25 | 38.26 | 86.96 | 93.91 | 86.09 |
| 30 | 43.48 | 22.61 | 94.67 | 86.09 |
| Parameter | Accuracy (%) | F1-Score (%) | Loss (%) | Observation | |
|---|---|---|---|---|---|
| Learning Rate | |||||
| 0.01 | 43.48 | 40.25 | 58.33 | Unstable training | |
| 0.001 | 22.61 | 21.9 | 75.14 | Divergence or slow learning | |
| 0.0001 | 94.67 | 94.78 | 5.33 | Optimal setting | |
| 0.00001 | 86.09 | 85.4 | 16.05 | Underfitting | |
| Epochs | |||||
| 20 | 90.43 | 91.12 | 9.57 | Early stopping risk | |
| 25 | 93.91 | 94.1 | 6.09 | Better generalization | |
| 30 | 94.67 | 94.78 | 5.33 | Best performance | |
| Sequence Length | |||||
| 10 | 89.32 | 89.5 | 10.68 | Temporal context insufficient | |
| 15 | 94.67 | 94.78 | 5.33 | Balanced setting | |
| 20 | 94.12 | 94.3 | 5.88 | Slight improvement, higher cost | |
| Input Data | Algorithm | Accuracy | Recall | Precision | F1 Score | Loss |
|---|---|---|---|---|---|---|
| RGB * | CNN-LSTM | 90.67 | 90.67 | 90.89 | 90.78 | 9.33 |
| PC ** | CNN-LSTM | 92.00 | 92.00 | 92.28 | 92.14 | 8.00 |
| Multi-St. *** | Two-stream CNN-LSTM | 94.67 | 94.67 | 94.90 | 94.78 | 5.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, H.S.; Latif, K.; Sharafat, A.; Seo, J. Multi-Modal Excavator Activity Recognition Using Two-Stream CNN-LSTM with RGB and Point Cloud Inputs. Appl. Sci. 2025, 15, 8505. https://doi.org/10.3390/app15158505
Cho HS, Latif K, Sharafat A, Seo J. Multi-Modal Excavator Activity Recognition Using Two-Stream CNN-LSTM with RGB and Point Cloud Inputs. Applied Sciences. 2025; 15(15):8505. https://doi.org/10.3390/app15158505
Chicago/Turabian StyleCho, Hyuk Soo, Kamran Latif, Abubakar Sharafat, and Jongwon Seo. 2025. "Multi-Modal Excavator Activity Recognition Using Two-Stream CNN-LSTM with RGB and Point Cloud Inputs" Applied Sciences 15, no. 15: 8505. https://doi.org/10.3390/app15158505
APA StyleCho, H. S., Latif, K., Sharafat, A., & Seo, J. (2025). Multi-Modal Excavator Activity Recognition Using Two-Stream CNN-LSTM with RGB and Point Cloud Inputs. Applied Sciences, 15(15), 8505. https://doi.org/10.3390/app15158505