
Evaluating Skin Tone Fairness in Convolutional Neural Networks for the Classification of Diabetic Foot Ulcers

 ,
,  , ,
, ,
Abstract
1. Introduction
1.1. Background
1.2. Problem
1.3. Objectives
1.4. Related Studies
2. Materials and Methods
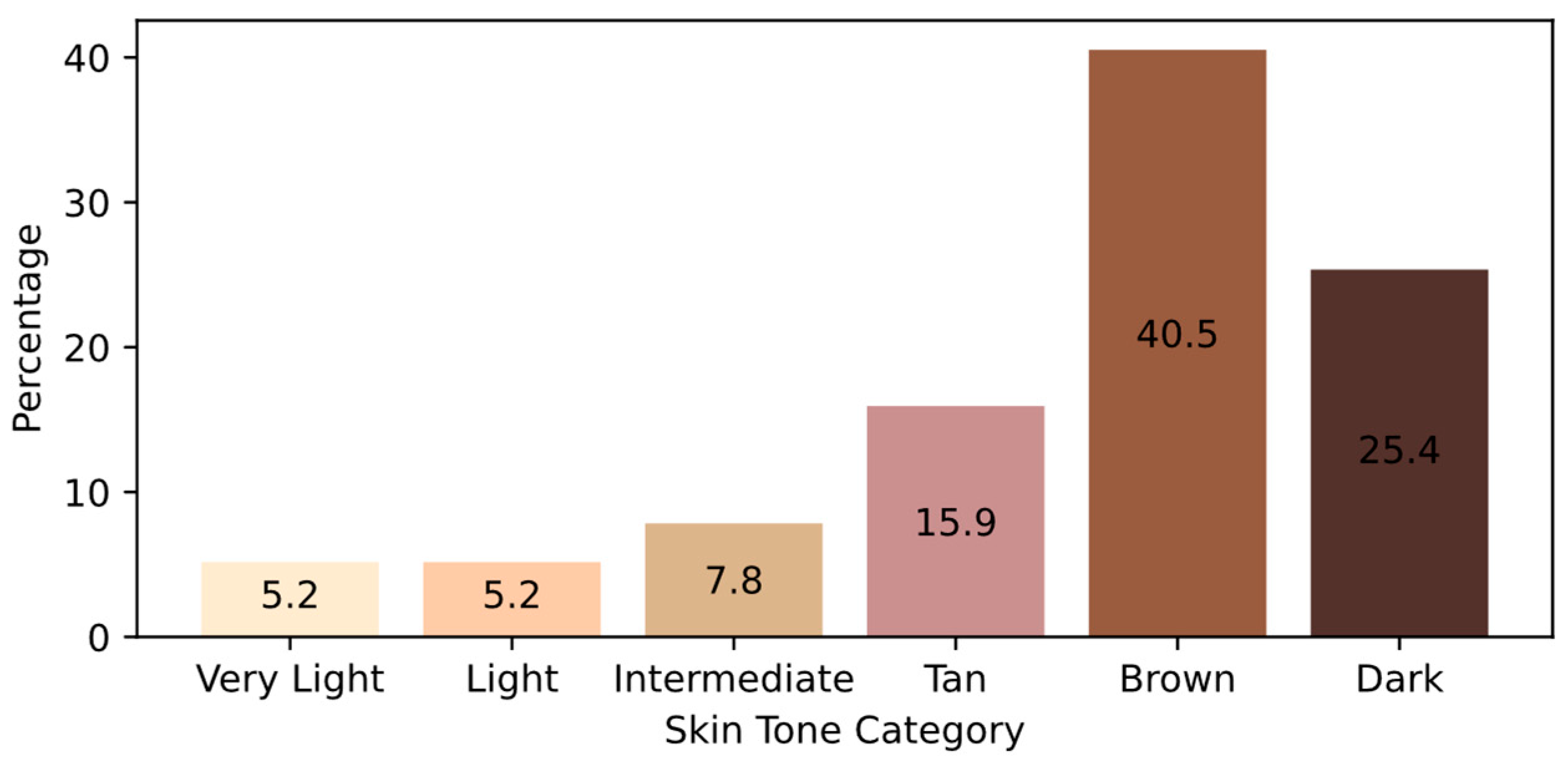
2.1. Datasets
2.2. Tools
2.3. Methods
2.3.1. Data Preparation and Pre-Processing
- Geometric Transformations
- ○
- Image rotation or Flipping: varying rotation angles by up to 30° or applying a vertical or horizontal flip, which helps the model recognise ulcers regardless of image orientation.
- ○
- Translation: small positional variations of up to 20% of the image dimensions were applied to simulate different ulcer locations and improve the model’s robustness to spatial displacement.
- ○
- Scaling/Zoom: applied with a range of up to 50%, allowing the model to focus on both smaller details and broader aspects of the images.
- ○
- Shear: introducing small geometric distortions, which forces the model to learn more complex variations in ulcer shapes.
- Colour and Photometric Transformations
- ○
- Brightness Adjustment: The brightness of the images has been adjusted in a range of 20% up or down, which simulates different lighting conditions and makes the model more robust to these variations. The operation alters luminance but does not significantly shift colour balance (chrominance).
- ○
- Gamma adjustment: Very small adjustments to mid-tone brightness can be useful to mimic different camera sensors. It keeps relative colour ratios mostly intact.
2.3.2. Model Architecture Configuration
2.3.3. Training and Validation
- Early Stopping: used to stop training when the validation metric has not improved after a certain number of epochs, known as patience. This ensures that the model does not continue to train unnecessarily after reaching its best performance. It was configured with a patience of 10 epochs for both models;
- Reduce Learning Rate on Plateau: reduces the learning rate when the validation metric stops improving, allowing the model to make finer adjustments as it approaches convergence;
- Model Checkpoint: saves the model during training whenever the validation metric (in this case, loss) improves. This ensures that the best version of the model is saved.
2.3.4. Analysis with Grad-CAM
2.3.5. Evaluation Metrics
- True Positive (TP): images showing ulcers that the model classifies as ‘abnormal’.
- False Negative (FN): samples with ulcers that were incorrectly classified as ‘normal’, representing a missed diagnosis.
- False Positive (FP): samples without ulcers that were incorrectly classified as ‘abnormal’.
- True Negative (TN): samples without ulcers that were correctly classified.
3. Results
4. Discussion
4.1. Impact of Image Augmentation Techniques
4.2. Performance Metrics Analysis
4.3. Grad-CAM Analysis
5. Conclusions
5.1. Main Contributions
5.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Casarin, D.E.; Donadel, G.; Dalmagro, M.; de Oliveira, P.C.; de Cássia Faglioni Boleta-Ceranto, D.; Zardeto, G. Diabetes Mellitus: Causas, Tratamento e Prevenção/Diabetes Mellitus: Causes, Treatment and Prevention. Braz. J. Dev. 2022, 8, 10062–10075. [Google Scholar] [CrossRef]
- Banday, M.Z.; Sameer, A.S.; Nissar, S. Pathophysiology of Diabetes: An Overview. Avicenna J. Med. 2020, 10, 174–188. [Google Scholar] [CrossRef]
- Atkinson, M.A.; Eisenbarth, G.S.; Michels, A.W. Type 1 Diabetes. Lancet 2014, 383, 69–82. [Google Scholar] [CrossRef]
- Perego, C.; Da Dalt, L.; Pirillo, A.; Galli, A.; Catapano, A.L.; Norata, G.D. Cholesterol Metabolism, Pancreatic β-Cell Function and Diabetes. Biochim. Biophys. Acta (BBA)–Mol. Basis Dis. 2019, 1865, 2149–2156. [Google Scholar] [CrossRef]
- Cole, J.B.; Florez, J.C. Genetics of Diabetes Mellitus and Diabetes Complications. Nat. Rev. Nephrol. 2020, 16, 377–390. [Google Scholar] [CrossRef]
- Boulton, A.J.M.; Armstrong, D.G.; Hardman, M.J.; Malone, M.; Embil, J.M.; Attinger, C.E.; Lipsky, B.A.; Aragón-Sánchez, J.; Li, H.K.; Schultz, G.; et al. Diagnosis and Management of Diabetic Foot Infections; ADA Clinical Compendia Series; American Diabetes Association: Arlington, VA, USA, 2020. [Google Scholar]
- Castro-Martins, P.; Marques, A.; Coelho, L.; Vaz, M.; Costa, J.T. Plantar Pressure Thresholds as a Strategy to Prevent Diabetic Foot Ulcers: A Systematic Review. Heliyon 2024, 10, e26161. [Google Scholar] [CrossRef]
- In-Shoe Plantar Pressure Measurement Technologies for the Diabetic Foot: A Systematic Review: Heliyon. Available online: https://www.cell.com/heliyon/fulltext/S2405-8440(24)05703-7 (accessed on 22 June 2025).
- Ansari, P.; Akther, S.; Khan, J.T.; Islam, S.S.; Masud, M.S.R.; Rahman, A.; Seidel, V.; Abdel-Wahab, Y.H.A. Hyperglycaemia-Linked Diabetic Foot Complications and Their Management Using Conventional and Alternative Therapies. Appl. Sci. 2022, 12, 11777. [Google Scholar] [CrossRef]
- Castro-Martins, P.; Marques, A.; Pinto-Coelho, L.; Fonseca, P.; Vaz, M. A Portable Insole System for Actively Controlled Offloading of Plantar Pressure for Diabetic Foot Care. Sensors 2025, 25, 3820. [Google Scholar] [CrossRef]
- World Health Organization Diabetes Fact Sheet. Available online: https://www.who.int/news-room/fact-sheets/detail/diabetes (accessed on 22 December 2021).
- Monteiro-Soares, M.; Boyko, E.J.; Jeffcoate, W.; Mills, J.L.; Russell, D.; Morbach, S.; Game, F. Diabetic Foot Ulcer Classifications: A Critical Review. Diabetes/Metab. Res. Rev. 2020, 36, e3272. [Google Scholar] [CrossRef]
- Castro-Martins, P.; Pinto-Coelho, L.; Campilho, R.D.S.G. Calibration and Modeling of the Semmes–Weinstein Monofilament for Diabetic Foot Management. Bioengineering 2024, 11, 886. [Google Scholar] [CrossRef]
- Iraj, B.; Khorvash, F.; Ebneshahidi, A.; Askari, G. Prevention of Diabetic Foot Ulcer. Int. J. Prev. Med. 2013, 4, 373–376. [Google Scholar]
- Costa, T.; Coelho, L.; Silva, M.F. Automatic Segmentation of Monofilament Testing Sites in Plantar Images for Diabetic Foot Management. Bioengineering 2022, 9, 86. [Google Scholar] [CrossRef]
- Armstrong, D.G.; Swerdlow, M.A.; Armstrong, A.A.; Conte, M.S.; Padula, W.V.; Bus, S.A. Five Year Mortality and Direct Costs of Care for People with Diabetic Foot Complications Are Comparable to Cancer. J. Foot Ankle Res. 2020, 13, 16. [Google Scholar] [CrossRef]
- Pinto-Coelho, L. How Artificial Intelligence Is Shaping Medical Imaging Technology: A Survey of Innovations and Applications. Bioengineering 2023, 10, 1435. [Google Scholar] [CrossRef]
- Das, S.K.; Roy, P.; Singh, P.; Diwakar, M.; Singh, V.; Maurya, A.; Kumar, S.; Kadry, S.; Kim, J. Diabetic Foot Ulcer Identification: A Review. Diagnostics 2023, 13, 1998. [Google Scholar] [CrossRef]
- Zhao, X.; Liu, Z.; Agu, E.; Wagh, A.; Jain, S.; Lindsay, C.; Tulu, B.; Strong, D.; Kan, J. Fine-Grained Diabetic Wound Depth and Granulation Tissue Amount Assessment Using Bilinear Convolutional Neural Network. IEEE Access 2019, 7, 179151–179162. [Google Scholar] [CrossRef]
- Wang, C.; Yu, Z.; Long, Z.; Zhao, H.; Wang, Z. A Few-Shot Diabetes Foot Ulcer Image Classification Method Based on Deep ResNet and Transfer Learning. Sci. Rep. 2024, 14, 29877. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Fadhel, M.A.; Oleiwi, S.R.; Al-Shamma, O.; Zhang, J. DFU_QUTNet: Diabetic Foot Ulcer Classification Using Novel Deep Convolutional Neural Network. Multimed. Tools Appl. 2020, 79, 15655–15677. [Google Scholar] [CrossRef]
- Yap, M.H.; Cassidy, B.; Pappachan, J.M.; O’Shea, C.; Gillespie, D.; Reeves, N.D. Analysis Towards Classification of Infection and Ischaemia of Diabetic Foot Ulcers. In Proceedings of the 2021 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI), Athens, Greece, 27–30 July 2021. [Google Scholar]
- Liu, Z.; John, J.; Agu, E. Diabetic Foot Ulcer Ischemia and Infection Classification Using EfficientNet Deep Learning Models. IEEE Open J. Eng. Med. Biol. 2022, 3, 189–201. [Google Scholar] [CrossRef]
- Anisuzzaman, D.M.; Patel, Y.; Rostami, B.; Niezgoda, J.; Gopalakrishnan, S.; Yu, Z. Multi-Modal Wound Classification Using Wound Image and Location by Deep Neural Network. Sci. Rep. 2022, 12, 20057. [Google Scholar] [CrossRef]
- Alqahtani, A.; Alsubai, S.; Rahamathulla, M.P.; Gumaei, A.; Sha, M.; Zhang, Y.-D.; Khan, M.A. Empowering Foot Health: Harnessing the Adaptive Weighted Sub-Gradient Convolutional Neural Network for Diabetic Foot Ulcer Classification. Diagnostics 2023, 13, 2831. [Google Scholar] [CrossRef]
- Sathya Preiya, V.; Kumar, V.D.A. Deep Learning-Based Classification and Feature Extraction for Predicting Pathogenesis of Foot Ulcers in Patients with Diabetes. Diagnostics 2023, 13, 1983. [Google Scholar] [CrossRef]
- Fadhel, M.A.; Alzubaidi, L.; Gu, Y.; Santamaría, J.; Duan, Y. Real-Time Diabetic Foot Ulcer Classification Based on Deep Learning & Parallel Hardware Computational Tools. Multimed. Tools Appl. 2024, 83, 70369–70394. [Google Scholar] [CrossRef]
- Gudivaka, R.K.; Gudivaka, R.L.; Gudivaka, B.R.; Basani, D.K.R.; Grandhi, S.H.; Khan, F. Diabetic Foot Ulcer Classification Assessment Employing an Improved Machine Learning Algorithm. Technol. Heal. Care 2025, 33, 1645–1660. [Google Scholar] [CrossRef]
- Johnson, J.; Johnson, A.R.; Andersen, C.A.; Kelso, M.R.; Oropallo, A.R.; Serena, T.E. Skin Pigmentation Impacts the Clinical Diagnosis of Wound Infection: Imaging of Bacterial Burden to Overcome Diagnostic Limitations. J. Racial Ethn. Heal. Disparities 2024, 11, 1045–1055. [Google Scholar] [CrossRef]
- Avsar, P.; Moore, Z.; Patton, D.; O’Connor, T.; Skoubo Bertelsen, L.; Tobin, D.J.; Brunetti, G.; Carville, K.; Iyer, V.; Wilson, H. Exploring Physiological Differences in Injury Response by Skin Tone: A Scoping Review. J. Tissue Viability 2025, 34, 100871. [Google Scholar] [CrossRef]
- Cassidy, B.; Reeves, N.D.; Pappachan, J.M.; Gillespie, D.; O’Shea, C.; Rajbhandari, S.; Maiya, A.G.; Frank, E.; Boulton, A.J.; Armstrong, D.G.; et al. The DFUC 2020 Dataset: Analysis Towards Diabetic Foot Ulcer Detection. touchREV Endocrinol. 2021, 17, 5–11. [Google Scholar] [CrossRef]
- Pictures of Wounds and Surgical Wound Dressings. Available online: https://www.medetec.co.uk/files/medetec-image-databases.html (accessed on 16 July 2025).
- Alzubaidi, L.; Fadhel, M.A.; Al-Shamma, O.; Zhang, J.; Santamaria, J.; Duan, Y. Robust Application of New Deep Learning Tools: An Experimental Study in Medical Imaging. Multimed. Tools Appl. 2022, 81, 13289–13317. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Fadhel, M.A.; Al-Shamma, O.; Zhang, J.; Santamaría, J.; Duan, Y.; Oleiwi, S.R. Towards a Better Understanding of Transfer Learning for Medical Imaging: A Case Study. Appl. Sci. 2020, 10, 4523. [Google Scholar] [CrossRef]
- Schwartz, R.; Vassilev, A.; Greene, K.K.; Perine, L.; Burt, A.; Hall, P. Towards a Standard for Identifying and Managing Bias in Artificial Intelligence; NIST: Gaithersburg, MD, USA, 2022.
- Gong, Y.; Liu, G.; Xue, Y.; Li, R.; Meng, L. A Survey on Dataset Quality in Machine Learning. Inf. Softw. Technol. 2023, 162, 107268. [Google Scholar] [CrossRef]
- Fitzpatrick, T.B. The Validity and Practicality of Sun-Reactive Skin Types I through VI. Arch. Dermatol. 1988, 124, 869–871. [Google Scholar] [CrossRef]
- Chardon, A.; Cretois, I.; Hourseau, C. Skin Colour Typology and Suntanning Pathways. Int. J. Cosmet. Sci. 1991, 13, 191–208. [Google Scholar] [CrossRef]
- Osto, M.; Hamzavi, I.; Lim, H.; Kohli, I. Individual Typology Angle and Fitzpatrick Skin Phototypes Are Not Equivalent in Photodermatology. Photochem. Photobiol. 2021, 98, 127–129. [Google Scholar] [CrossRef]
- Fijałkowska, M.; Koziej, M.; Żądzińska, E.; Antoszewski, B.; Sitek, A. Assessment of the Predictive Value of Spectrophotometric Skin Color Parameters and Environmental and Behavioral Factors in Estimating the Risk of Skin Cancer: A Case–Control Study. J. Clin. Med. 2022, 11, 2969. [Google Scholar] [CrossRef]
- Groh, M.; Harris, C.; Soenksen, L.; Lau, F.; Han, R.; Kim, A.; Koochek, A.; Badri, O. Evaluating Deep Neural Networks Trained on Clinical Images in Dermatology with the Fitzpatrick 17k Dataset. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- İsmail Mendi, B.; Kose, K.; Fleshner, L.; Adam, R.; Safai, B.; Farabi, B.; Atak, M.F. Artificial Intelligence in the Non-Invasive Detection of Melanoma. Life 2024, 14, 1602. [Google Scholar] [CrossRef]
- Rathore, P.S.; Kumar, A.; Nandal, A.; Dhaka, A.; Sharma, A.K. A Feature Explainability-Based Deep Learning Technique for Diabetic Foot Ulcer Identification. Sci. Rep. 2025, 15, 6758. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks 2019. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chassagnon, G.; Vakalopolou, M.; Paragios, N.; Revel, M.-P. Deep Learning: Definition and Perspectives for Thoracic Imaging. Eur. Radiol. 2020, 30, 2021–2030. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Bach, F., Blei, D., Eds.; PMLR: New York, NY, USA, 2015; Volume 37, pp. 448–456. [Google Scholar]
- Liu, Y.; Agarwal, S.; Venkataraman, S. Autofreeze: Automatically Freezing Model Blocks to Accelerate Fine-Tuning. arXiv 2021, arXiv:2102.01386. [Google Scholar]
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- Nikbakhtsarvestani, F.; Ebrahimi, M.; Rahnamayan, S. Multi-Objective ADAM Optimizer (MAdam). In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Maui, HI, USA, 1–4 October 2023; pp. 3860–3867. [Google Scholar]
- Tian, J.; Li, H.; Qi, Y.; Wang, X.; Feng, Y. Intelligent Medical Detection and Diagnosis Assisted by Deep Learning. Appl. Comput. Eng. 2024, 64, 121–126. [Google Scholar] [CrossRef]
- Zhang, H.; Ogasawara, K. Grad-CAM-Based Explainable Artificial Intelligence Related to Medical Text Processing. Bioengineering 2023, 10, 1070. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Methodology | # Images | Performance (%) |
|---|---|---|---|
| Zhao et al. (2019) [19] | VGG16 | 1639 | Accuracy: 83.36 |
| Wang et al. (2020) [20] | MobileNetv2, VGG16 | 1109 | F1-score: 94.05 |
| Alzubaidi et al. (2020) [21] | DFU-QUTNet, SVM, KNN | 754 | Precision: 95.40 |
| Yap et al. (2021) [22] | VGG16, ResNet, EfficientNet | 15,683 | Precision: 57.3; F1-score: 55.2 |
| Liu et al. (2022) [23] | EfficientNet | 58,200 | Accuracy Ischaemia: 99.39 Accuracy Infection: 97.92 |
| Anisuzzaman et al. (2022) [24] | VGG16, VGG19 | 1088 | Precision: 100 |
| Alqahtani et al. (2023) [25] | AWSg CNN | 493 | Accuracy, F1-score, AUC: 99 |
| Preiya et al. (2023) [26] | DRNN, PFCNN | 15,683 | Accuracy: 99.32 |
| Fadhel et al. (2024) [27] | DFU_FNet, DFU_TFNet | 493 | AlexNet: Accuracy: 89.11; F1-score: 88.1 VGG16: Accuracy: 90.37; F1- score: 90.9 GoogleNet: Accuracy: 91.93; F1-score: 92.9 DFU_FNet + SVM: Accuracy: 94.71; F1-score: 94.5 |
| Gudivaka et al. (2025) [28] | RL, CPPN, SVM, ELM, ResNet50 | 4000 | Classification accuracy: 93.75 Cluster 1 Efficiency: 71–88 Cluster 2 Efficiency: 85–97 Cluster 3 Efficiency: 90–98 Cluster 4 Efficiency: 93.5–98.2 |
| Name | Images Available | Collection Conditions | Resolution (Pixels) | Open-Acess |
|---|---|---|---|---|
| DFUC 2020 [31] | 4000 (2496 training and 2097 test) | Captured by digital camera; variations in distance, angle, orientation, lighting, focus and presence of background objects | 640 × 480 | No |
| DFUC 2021 [22] | 15,683 (3994 unidentified and 5734 for the test set) | Three cameras used: Kodak DX4530, Nikon D3300 and Nikon COOLPIX P100 | 640 × 480 | Yes |
| Nasiriyah diabetic hospital centre [18] | 754 | Used a Samsung Galaxy Note 8 and an iPad | - | No |
| Medetec Wound Database [32] | 49 (358 wounds) | Not specified | Width: from 358 to 560 Height: from 371 to 560 | Yes |
| Diabetic Foot Ulcer [33] | 2673 | Captured by digital camera | 224 × 224 | Yes |
| ITA (°) | Skin Type |
|---|---|
| >55 | Very Light |
| 41–55 | Light |
| 28–41 | Intermediate |
| 10–28 | Tan |
| 330–10 | Brown |
| <−30 | Dark |
| Model | TP | FN | FP | TN | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|
| MobileNetV2 | 769 | 270 | 169 | 1016 | 80% | 82% | 74% | 78% |
| VGG16 | 966 | 73 | 84 | 1101 | 93% | 92% | 93% | 92% |
| VGG19 | 1008 | 31 | 31 | 1154 | 97% | 97% | 97% | 97% |
| Model | Raw | Rot./Flip. | Trans. | Scaling | Shear | Bright. |
|---|---|---|---|---|---|---|
| MobileNetV2 | 67% | 72% (+5%) | 69% (+2%) | 72% (+5%) | 69% (+2%) | 71% (+4%) |
| VGG16 | 74% | 79% (+5%) | 77% (+3%) | 77% (+3%) | 78% (+4%) | 80% (+6%) |
| VGG19 | 70% | 74% (+4%) | 73% (+3%) | 74% (+4%) | 72% (+2%) | 74% (+4%) |
| Skin Tone | TP | FN | FP | TN | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|---|
| Very Light | 56 | 2 | 1 | 57 | 97% | 98% | 97% | 97% |
| Light | 48 | 7 | 11 | 50 | 84% | 81% | 87% | 84% |
| Intermediate | 88 | 8 | 7 | 70 | 91% | 93% | 92% | 92% |
| Tan | 139 | 3 | 3 | 209 | 98% | 98% | 98% | 98% |
| Brown | 417 | 8 | 7 | 469 | 98% | 98% | 98% | 98% |
| Dark | 260 | 3 | 2 | 299 | 99% | 99% | 99% | 99% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reis, S.S.; Pinto-Coelho, L.; Sousa, M.C.; Neto, M.; Silva, M.; Sequeira, M. Evaluating Skin Tone Fairness in Convolutional Neural Networks for the Classification of Diabetic Foot Ulcers. Appl. Sci. 2025, 15, 8321. https://doi.org/10.3390/app15158321
Reis SS, Pinto-Coelho L, Sousa MC, Neto M, Silva M, Sequeira M. Evaluating Skin Tone Fairness in Convolutional Neural Networks for the Classification of Diabetic Foot Ulcers. Applied Sciences. 2025; 15(15):8321. https://doi.org/10.3390/app15158321
Chicago/Turabian StyleReis, Sara Seabra, Luis Pinto-Coelho, Maria Carolina Sousa, Mariana Neto, Marta Silva, and Miguela Sequeira. 2025. "Evaluating Skin Tone Fairness in Convolutional Neural Networks for the Classification of Diabetic Foot Ulcers" Applied Sciences 15, no. 15: 8321. https://doi.org/10.3390/app15158321
APA StyleReis, S. S., Pinto-Coelho, L., Sousa, M. C., Neto, M., Silva, M., & Sequeira, M. (2025). Evaluating Skin Tone Fairness in Convolutional Neural Networks for the Classification of Diabetic Foot Ulcers. Applied Sciences, 15(15), 8321. https://doi.org/10.3390/app15158321