Research on a Multi-Type Barcode Defect Detection Model Based on Machine Vision

Abstract
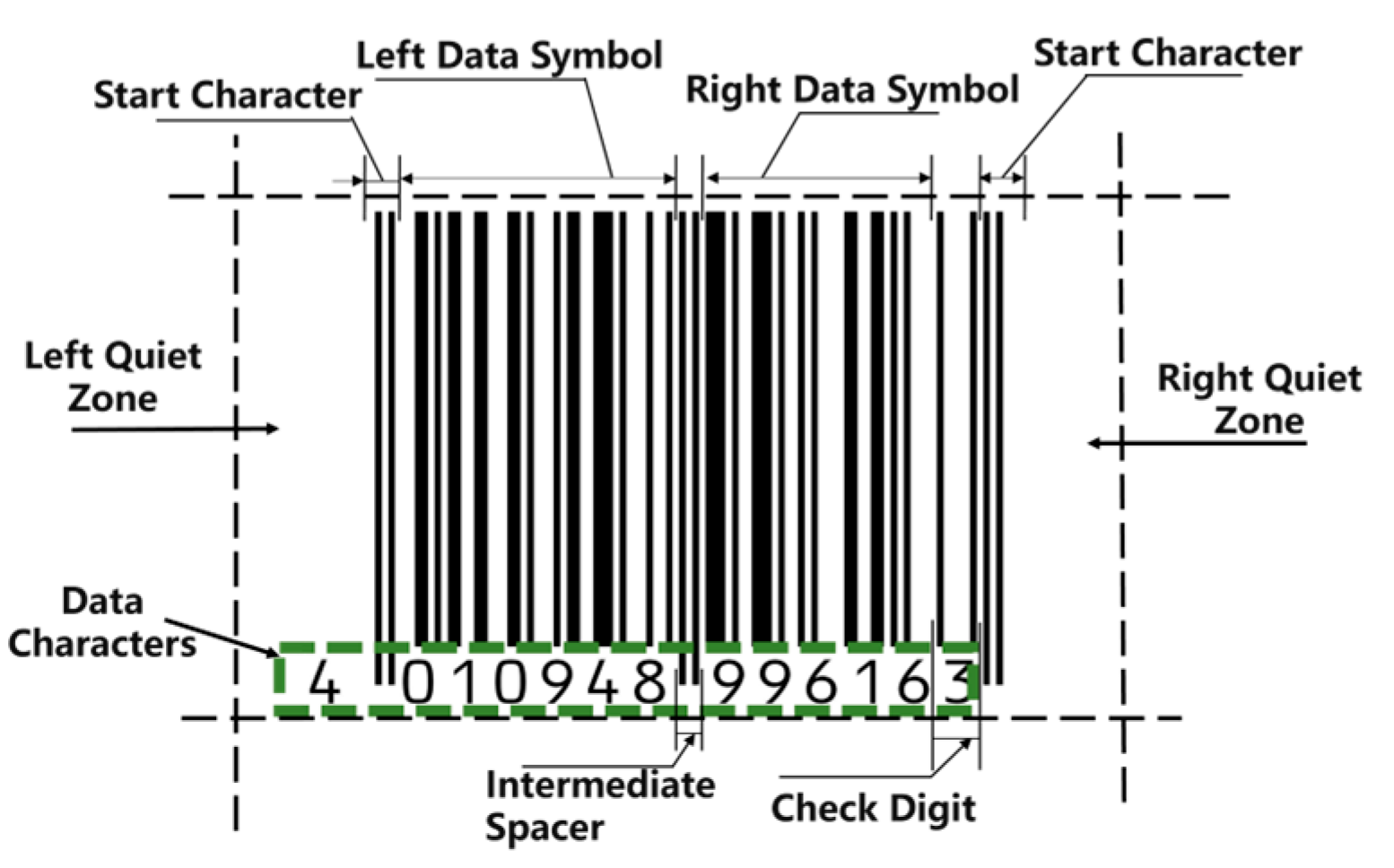
1. Introduction
2. Background Literature
3. Model Construction
3.1. Barcode Localization Submodule-YOLOv8n
3.2. Feature Representation Submodule-ResNet50
3.3. Global Semantic Submodule-ViT-B/16
3.4. Lightweight Two-Stage Fusion Model-Y8-LiBAR Net
4. Experiment and Results Analysis
4.1. Dataset Introduction
4.2. Object Detection Experiment
- (1)
- Detection Curve Analysis
- (2)
- Confusion Matrix Analysis
4.3. Defect Detection Experiment
4.4. Failure Case Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Weng, D.; Yang, L. Design and implementation of barcode management information system. In Proceedings of the Information Engineering and Applications: International Conference on Information Engineering and Applications, Chongqing, China, 26–28 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1200–1207. [Google Scholar]
- Sanchez, N.C. Impacting Patient Identification Barcode Medication Scanning in Ambulatory Care. Ph.D. Theses, Aspen University, Denver, CO, USA, 2025. [Google Scholar]
- Kubánová, J.; Kubasáková, I.; Culik, K.; Stitik, L. Implementation of barcode technology to logistics processes of a company. Sustainability 2022, 14, 790. [Google Scholar] [CrossRef]
- Taveerad, N.; Vongpradhip, S. Development of color QR code for increasing capacity. In Proceedings of the 2015 11th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Bangkok, Thailand, 27 November 2015; pp. 645–648. [Google Scholar]
- Duan, G.; Zhang, S.; Shang, Y.; Kong, W. Research on X-ray Diagnosis Model of Musculoskeletal Diseases Based on Deep Learning. Appl. Sci. 2024, 14, 3451. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, S. Automatic recognition and inspection method of 128 bar code. Coal Technol. 2011, 30, 162–164. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8 (Version 8.0.0) [Computer Software]. Ultralytics. Available online: https://github.com/ultralytics/ultralytics (accessed on 23 October 2024).
- Wudhikarn, R.; Charoenkwan, P.; Malang, K. Deep learning in barcode recognition: A systematic literature review. IEEE Access 2022, 10, 8049–8072. [Google Scholar] [CrossRef]
- Vezzali, E.; Bolelli, F.; Santi, S.; Grana, C. Barber: A barcode benchmarking repository. In Proceedings of the International Conference on Pattern Recognition, Kolkata, India, 1–5 December 2024; Springer: Cham, Switzerland, 2025; pp. 187–203. [Google Scholar]
- Wei, S. Application of bar code verifier in testing bar code quality. China Meas. Test 2011, 37, 38–40. [Google Scholar]
- Dong, X. Study on semiconductor surface defect detection based on machine vision. Metrol. Meas. Technol. 2014, 34, 4. [Google Scholar] [CrossRef]
- Xu, H.; Liu, X. Printing quality inspection method based on multi-object matching and fusion character features. Packag. Eng. 2019, 40, 188–193. [Google Scholar]
- Wang, J.; Xu, G.; Yan, F.; Wang, J.; Wang, Z. Defect transformer: An efficient hybrid transformer architecture for surface defect detection. Measurement 2023, 211, 112614. [Google Scholar] [CrossRef]
- Wang, X.; Gao, S.; Zou, Y.; Guo, J.; Wang, C. IH-ViT: Vision Transformer-based Integrated Circuit Appear-ance Defect Detection. arXiv 2023, arXiv:2302.04521. [Google Scholar]
- Jeong, M.; Yang, M.; Jeong, J. Hybrid-DC: A Hybrid Framework Using ResNet50 and Vision Transformer for Steel Surface Defect Classification in the Rolling Process. Electronics 2024, 13, 4467. [Google Scholar] [CrossRef]
- Zhao, L.; Liu, J.; Ren, Y.; Lin, C.; Liu, J.; Abbas, Z.; Islam, S.; Xiao, G. YOLOv8-QR: An improved YOLOv8 model via attention mechanism for object detection of QR code defects. Comput. Electr. Eng. 2024, 118, 109376. [Google Scholar] [CrossRef]
- Qi, W.; Liu, J.; Li, Y.; Liu, J. Research on defect detection in printing barcode area based on machine learning. In Proceedings of the 2024 20th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Zhongshan, China, 27–29 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–7. [Google Scholar]
- Do, T.; Kim, D. Quick browser: A unified model to detect and read simple objects in real-time. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Virtual Conference, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Hansen, D.K.; Nasrollahi, B.; Moeslund, T.B. Real-time barcode detection and classification using deep learning. In Proceedings of the 9th International Joint Conference Computational Intelligence, Funchal, Portugal, 1–3 November 2017; pp. 321–327. [Google Scholar]
- Kamnardsiri, T.; Charoenkwan, P.; Malang, C.; Wudhikarn, R. 1D barcode detection: Novel benchmark datasets and comprehensive comparison of deep convolutional neural network approaches. Sensors 2022, 22, 8788. [Google Scholar] [CrossRef] [PubMed]
- Zharkov, A.; Zagaynov, I. Universal barcode detector via semantic segmentation. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 837–843. [Google Scholar]
- Jia, J.; Zhai, G.; Zhang, J. EMBDN: An efficient multiclass barcode detection network for complicated environments. IEEE Internet Things J. 2019, 6, 9919–9933. [Google Scholar] [CrossRef]
- Zhang, Z.; Min, X.; Wang, J. Fine localization and distortion resistant detection of multi-class barcode in complex environments. Multimed. Tools Appl. 2020, 80, 16153–16172. [Google Scholar] [CrossRef]
- Zhang, D.; Hao, X.; Wang, D.; Qin, C.; Zhao, B.; Liang, L.; Liu, W. An efficient lightweight convolutional neural network for industrial surface defect detection. Artif. Intell. Rev. 2023, 56, 10651–10677. [Google Scholar] [CrossRef]
- Zhang, D.; Hao, X.; Liang, L.; Liu, W.; Qin, C. A novel deep convolutional neural network algorithm for surface defect detection. Comput. Des. Eng. 2022, 9, 1616–1632. [Google Scholar] [CrossRef]
- Shen, H.; Wang, Z.; Zhang, J.; Zhang, L. L-Net: A lightweight convolutional neural network for devices with low computing power. Inf. Sci. 2024, 660, 120131. [Google Scholar] [CrossRef]
- Zamberletti, A.; Gallo, I.; Carullo, M.; Binaghi, E. Neural image restoration for decoding 1-D barcodes using common camera phones. In Proceedings of the VISAPP (1), Angers, France, 17–21 May 2010; pp. 5–11. [Google Scholar]
- Zamberletti, A.; Gallo, I.; Albertini, S. Robust angle invariant 1D barcode detection. In Proceedings of the 2013 2nd IAPR Asian Conference. Pattern Recognit (ACPR), Washington, DC, USA, 5–8 November 2013; pp. 160–164. [Google Scholar]
- Yun, I.; Kim, J. Vision-based 1D barcode localization method for scale and rotation invariant. In Proceedings of the TENCON-IEEE 2017 Conference, Penang, Malaysia, 5–8 November 2017; pp. 2204–2208. [Google Scholar]
- Wachenfeld, S.; Terlunen, S.; Jiang, X. Robust recognition of 1-D barcodes using camera phones. In Proceedings of the 19th International Conference on Pattern Recognition (ICPR), Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Szentandrási, I.; Herout, A.; Dubská, M. Fast detection and recognition of QR codes in high-resolution images. In Proceedings of the 28th Spring Conference. Computer. Graphics (SCCG), New York, NY, USA, 2–4 May 2012; pp. 129–136. [Google Scholar]
- Dubská, M.; Herout, A.; Havel, J. Real-time precise detection of regular grids and matrix codes. J. Real-Time Image Process. 2016, 11, 193–200. [Google Scholar] [CrossRef]
- Bodnár, P.; Grósz, T.; Nyúl, L.G. Efficient visual code localization with neural networks. Pattern Anal. Appl. 2018, 21, 249–260. [Google Scholar] [CrossRef]
- Generate a Large Labelled Dataset of Barcodes from Open Food Facts Data. 2018. Available online: https://github.com/openfoodfacts/openfoodfacts-ai/issues/15 (accessed on 11 October 2024).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Proessing Systems 28, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q. DETRs beat YOLOs on real-time object detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Images | Resolution (Min → Max) | Total Annotations | Barcode Types Included |
|---|---|---|---|---|
| BarBeR | 8748 | 200 × 141 → 5984 × 3376 | 9818 | 1D and 2D |
| DEAL KAIST Lab | 3308 | 141 × 200 → 3480 × 4640 | 3454 | 1D and 2D |
| Dubská QR | 810 | 402 × 604 → 2560 × 1440 | 806 | 1D |
| InventBar | 527 | 480 × 640 | 563 | 1D and 2D |
| Arte-Lab Medium 1D | 430 | 1152 × 864 → 2976 × 2232 | 437 | 1D and 2D |
| Bodnár-Huawei QR | 98 | 1600 × 1200 | 98 | 2D |
| Barcode Detection Annotated Datasets | 708 | 1280 × 720 | – | 1D |
| Muenster BarcodeDB | 1055 | 640 × 480 → 2592 × 1944 | – | 1D |
| InventBar | 527 | 4032 × 3024 | 527 | 1D |
| ParcelBar | 844 | 1478 × 1108 | 844 | 1D |
| Dubská QR Datasets #1 | 410 | 1440 × 2560 → 2 560 × 1 440 | – | 2D |
| Dubská QR Datasets #2 | 400 | 402 ×604 → 604 × 402 | – | 2D |
| Barcode dataset | 2741 | 416 × 416 | 2741 | 1D and 2D |
| Detection Method | Precision | Recall | F1 Score |
|---|---|---|---|
| Zharkov et al. [21] | 0.715 | 0.940 | 0.812 |
| Faster R-CNN [35] | 0.979 | 0.990 | 0.984 |
| RetinaNet [36] | 0.984 | 0.986 | 0.985 |
| YOLO Nano [7] | 0.985 | 0.988 | 0.986 |
| YOLO Medium [7] | 0.982 | 0.989 | 0.985 |
| RT-DETR [37] | 0.986 | 0.993 | 0.989 |
| Y8-LiBAR-1D | 0.978 | 0.994 | 0.986 |
| Detection Method | Precision | Recall | F1 Score |
|---|---|---|---|
| Y8-LiBAR-2D | 0.955 | 0.919 | 0.937 |
| Faster R-CNN | 0.952 | 0.921 | 0.936 |
| YOLO Nano | 0.952 | 0.917 | 0.934 |
| RetinaNe | 0.954 | 0.918 | 0.936 |
| YOLO Medium | 0.948 | 0.922 | 0.935 |
| RT-DETR | 0.946 | 0.916 | 0.931 |
| Model Variant | Accuracy | Precision | Recall | F1 Score | |
|---|---|---|---|---|---|
| Y8-LiBAR Net | 0.9250 | 0.9185 | 0.9250 | 0.9187 | 0.7667 |
| w/o ViT branch | 0.8821 | 0.8673 | 0.8795 | 0.8721 | 0.5912 |
| w/o ResNet branch | 0.8634 | 0.8419 | 0.8562 | 0.8473 | 0.5238 |
| w/o Shared Encoder | 0.9073 | 0.8962 | 0.9028 | 0.8987 | 0.6984 |
| w/o Orthogonal Regularization | 0.9167 | 0.9081 | 0.9142 | 0.9103 | 0.7246 |
| Detection Method | Precision | Recall | F1 score |
|---|---|---|---|
| Y8-LiBAR Net | 0.9185 | 0.925 | 0.9217 |
| SVM-RBF | 0.872 | 0.88 | 0.876 |
| DenseNet-121 | 0.895 | 0.905 | 0.9 |
| ViT-B/16 | 0.905 | 0.915 | 0.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, G.; Zhang, S.; Shang, Y.; Shao, Y.; Han, Y. Research on a Multi-Type Barcode Defect Detection Model Based on Machine Vision. Appl. Sci. 2025, 15, 8176. https://doi.org/10.3390/app15158176
Duan G, Zhang S, Shang Y, Shao Y, Han Y. Research on a Multi-Type Barcode Defect Detection Model Based on Machine Vision. Applied Sciences. 2025; 15(15):8176. https://doi.org/10.3390/app15158176
Chicago/Turabian StyleDuan, Ganglong, Shaoyang Zhang, Yanying Shang, Yongcheng Shao, and Yuqi Han. 2025. "Research on a Multi-Type Barcode Defect Detection Model Based on Machine Vision" Applied Sciences 15, no. 15: 8176. https://doi.org/10.3390/app15158176
APA StyleDuan, G., Zhang, S., Shang, Y., Shao, Y., & Han, Y. (2025). Research on a Multi-Type Barcode Defect Detection Model Based on Machine Vision. Applied Sciences, 15(15), 8176. https://doi.org/10.3390/app15158176