1. Introduction
Tool wear is an inevitable phenomenon in machining processes [
1,
2]. Intelligent manufacturing systems require accurate tool wear predictions to optimize production parameters, schedule maintenance activities, and ensure consistent product quality [
3]. The phenomenon critically influences product quality, manufacturing efficiency, and operational costs [
4,
5], with direct economic implications for industry. Unplanned tool failure may lead to increased manufacturing downtime, whereas accurate wear prediction enables just-in-time maintenance strategies that reduce tool replacement costs.
Traditional approaches to tool wear analysis have primarily employed empirical or physics-based models, such as the Usui Adhesion Wear Model and Taylor’s extended formula, which correlate tool life with cutting parameters. Although these classical formulations provide interpretable relationships, their effectiveness is limited by oversimplified assumptions [
6]. These limitations reduce their applicability in modern machining scenarios, where dynamic interactions between tools, materials, and processes require more sophisticated modeling frameworks [
7]. It is particularly evident in high-mix, low-volume production environments, where tool wear patterns vary significantly across different workpiece materials and cutting conditions. Consequently, traditional models often prove inadequate for real-time adaptive control.
In recent years, machine learning has emerged as a promising alternative for tool wear prediction [
8,
9,
10]. Methods such as neural networks and support vector regression demonstrate superior capability in capturing nonlinear patterns from operational data. Nevertheless, their “black-box” nature presents significant barriers to practical adoption [
11]. The lack of interpretability in machine learning models hinders the identification of root causes underlying wear progression [
12,
13]. Furthermore, these models typically require extensive datasets and computational resources while remaining susceptible to overfitting [
14,
15]. This situation creates a critical gap between academic research and industrial implementation. Although deep learning models achieve high accuracy in controlled experiments, their deployment in factory settings is frequently impeded by the need for continuous recalibration and the inability to explain decision-making processes to plant engineers.
Unlike conventional machine learning models, Kolmogorov–Arnold Networks (KANs) are a novel class of interpretable neural networks grounded in the Kolmogorov–Arnold representation theorem (KART) [
16]. It inherently adopts a “white-box” structure with network layers that are designed as learnable univariate functions [
17]. In essence, KANs approximate multivariate functions using an architecture based on KART, bridging the gap between interpretability and accuracy. This dual advantage addresses two major challenges in industrial AI adoption: the need for explainable models in tool condition monitoring and the ability to generalize across different machining scenarios without extensive retraining.
Driven by the need for more interpretable and efficient neural networks, researchers have proposed some KAN variants and tested their effectiveness across diverse problems. For instance, Wang et al. [
18] introduced Convolutional Kolmogorov–Arnold Networks (CKANs), combining the foundational principles of KANs with convolutional mechanisms to achieve enhanced interpretability in intrusion detection. Similarly, Aghaei [
19] developed the Fractional Kolmogorov–Arnold Network (fKAN), demonstrating the versatility of KANs through the use of adaptive fractional–orthogonal Jacobi functions as basis functions. Reinhardt et al. [
20] proposed SineKAN, which substitutes the commonly used B-spline activation functions with re-weighted sinusoidal functions.
The significance of KANs is further evident in computational physics applications. Wang et al. [
21] proposed the Kolmogorov–Arnold-Informed Neural Network (KINN) as an alternative to Multi-Layer Perceptrons (MLPs) for solving partial differential equations (PDEs). Similarly, Shuai and Li [
22] introduced physics-informed KANs (PIKANs) tailored for power system applications. Additionally, KANs have demonstrated promising results in time-series forecasting. Livieris [
23] developed a model known as the C-KAN, which integrates convolutional layers with the KAN architecture to improve multi-step forecasting accuracy.
In image processing, KANs have also garnered attention. Firsov et al. [
24] explored KAN-based networks for hyperspectral image classification. Jiang et al. [
25] presented the KansNet for detecting pulmonary nodules in CT images. For load forecasting, Danish and Grolinger [
26] developed the Kolmogorov–Arnold Recurrent Network (KARN), which integrates KANs with a recurrent neural network (RNN) to improve the modeling of nonlinear relationships in load data. This approach surpasses traditional RNNs in accuracy.
For fault diagnosis, Tang et al. [
27] introduced the MCR-KAResNet-TLDAF method, which combines image fusion techniques with KANs to enhance the extraction and recognition of bearing fault features. Likewise, Cabral et al. [
28] proposed a KAN-based approach, KAN
Diag, for fault diagnosis in power transformers using dissolved gas analysis. Peng et al. [
29] established a method for predicting the pressure and flow rate of flexible electrohydrodynamic pumps using KANs, replacing fixed activation functions with learnable spline-based functions.
In structural analysis, KANs have proven to be a valuable tool. Wang et al. [
30] demonstrated KANs’ capability to accurately predict the Poisson’s ratio of a hexagonal lattice elastic network, showing how this ratio transitions with changes in geometric configuration. In environmental science, Saravani et al. [
31] evaluated KANs’ performance in predicting chlorophyll-a concentrations in lakes, confirming their robustness in handling nonlinearity and long-term dependencies.
In quantum computing applications, Kundu et al. [
32] demonstrated that KANs significantly outperformed MLP-based approaches, achieving higher success probabilities in quantum state preparation. In finance, Liu et al. [
33] investigated KAN integration within Finance-Informed Neural Networks (FINNs) to improve financial modeling and regulatory decision-making. For magnetic positioning systems, Gao and Kong [
34] developed a KAN-based algorithm, incorporating learnable activation functions through spline functions. Multiple spline curves and strategic thresholds were used to enhance accuracy.
Despite the importance of tool wear in manufacturing processes, research on KANs in this field remains limited. Only two studies had been published by the completion of this work. Bao et al. [
35] proposed a novel approach utilizing KANs to map sensor features to real-time maximum flank wear (VBmax), with a Transformer model predicting future wear sequences. Kupczyk et al. [
36] employed KANs to predict tool life in gear production from carburizing alloy steels, demonstrating accurate predictions based on cutting speed, coating thickness, and feed rate.
The unique advantages of KANs for tool wear modeling include the following: (1) a mathematical foundation that enables rigorous error bound analysis, ensuring prediction reliability for safety-critical manufacturing operations; (2) an adaptive basis function selection mechanism that reduces model complexity compared to conventional neural networks, facilitating deployment on resource-constrained edge devices; and (3) interpretable mathematical expressions generated by KANs that provide actionable insights for process optimization.
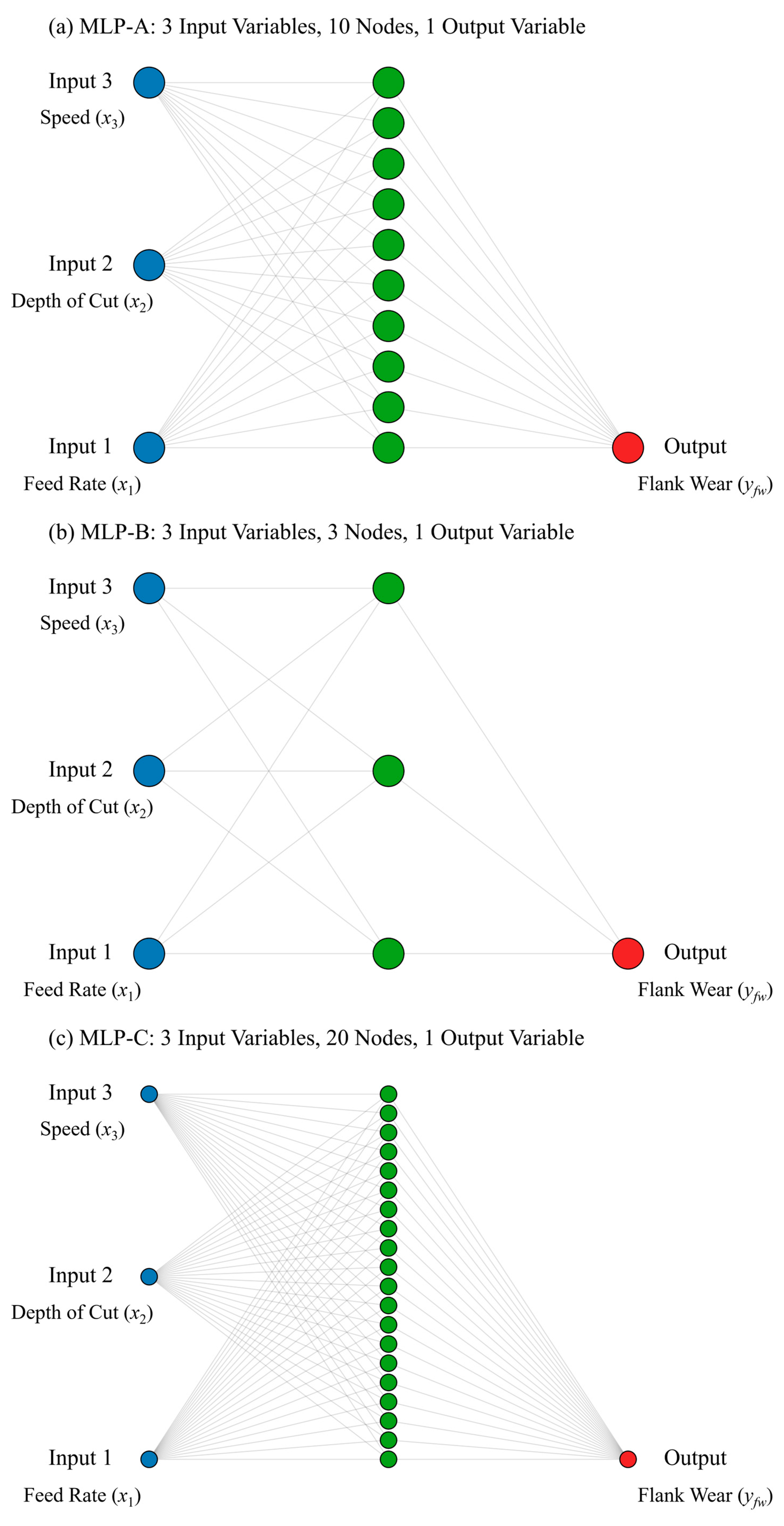
This study proposes three KAN-based models to address tool wear modeling in CNC turning processes. First, KAN-A, KAN-B, and KAN-C models with progressively increasing complexity are developed, accompanied by detailed training protocols and parameter specifications. The readily measurable cutting parameters (feed rate, depth of cut, and cutting speed) are adopted as independent variables. Mathematical expressions relating these variables to flank wear are established using the KAN-A, KAN-B, and KAN-C models, respectively. Furthermore, the physical interpretability of the derived formulas is systematically analyzed from three complementary perspectives: (1) a variable importance assessment, (2) the topological evolution of KAN architectures, and (3) the mathematical relationships between input–output variables. A comparative analysis of KAN-A, KAN-B, and KAN-C is conducted to evaluate modeling errors and identify their underlying causes. Subsequently, MLP-A, MLP-B, and MLP-C models are designed by referencing the topological structures of their KAN counterparts. A comparative study between KAN and MLP frameworks is performed to examine differences in tool wear modeling performance. Particular emphasis is placed on analyzing the effects of network depth, width, and parameter configurations, which reveals distinct sensitivities to architectural variations. The fundamental disparities in modeling capabilities are theoretically interpreted through the lens of KART and Cybenko’s Theorem. Finally, this work systematically compares classical wear equations, machine learning methods, and KAN-based approaches, highlighting their respective strengths. Simulations of turning processes are conducted using DEFORM-3D to further evaluate the wear modeling capabilities of KAN-A, KAN-B, and KAN-C. The advantages of the KAN-derived formula, along with its applicability and limitations, are thoroughly discussed.
The remaining parts of this paper are organized as follows:
Section 2 presents the fundamental principles of KANs and the architectures of the proposed models. In
Section 3, the public dataset is described, and three modeling experiments are conducted. Additionally, the mathematical expressions derived from KANs and their physical interpretations are discussed.
Section 4 introduces multiple metrics to quantify modeling errors and computational efficiency. A vertical comparison of modeling performance among KAN-A/B/C is performed, with a systematic evaluation of error analysis and performance trade-offs. In
Section 5, three MLP-based neural networks are constructed, mirroring the configurations of KAN-A/B/C, respectively. A horizontal pairwise comparison of prediction errors is presented. The underlying causes of performance disparities are analyzed through the theoretical frameworks of KART and Cybenko’s theorem.
Section 6 provides a comparative analysis of classical tool wear equations, machine learning methods, and KAN-based approaches.
Section 7 simulates turning operations and employs KAN-A/B/C for tool wear modeling, discussing both the advantages and limitations of the approach. Finally, the research findings are synthesized to form a comprehensive conclusion, and potential future research directions are outlined.
3. Public Data and Modeling Experiments
3.1. Public Data Description
Flank wear, a detrimental phenomenon in single-point cutting processes, arises from adhesion and abrasion when the cutting tool contacts the workpiece. It is measured by distinguishing geometric relationships in rake face images between new and worn tools.
Flank wear of lathe tools impacts machining quality: it degrades surface finish, increases tool replacement frequency, reduces machining efficiency, and may cause dimensional errors affecting overall precision. Tool wear is primarily influenced by the feed rate, depth of cut, and cutting speed during turning, as summarized in
Table 3. Establishing mathematical relationships between these physical variables and flank wear serves as the foundation for intelligent optimization of cutting parameters.
The dataset contains 2001 samples without missing values. However, 45 samples were incorrectly recorded as negative or excessively large values (physically meaningless for flank wear measurement) and were thus removed, leaving 1956 samples for experiments. The training and test sets were divided at a 1:1 ratio.
3.2. Modeling Experiment Based on KAN-A
First, experiments using KAN-A for training and modeling were conducted.
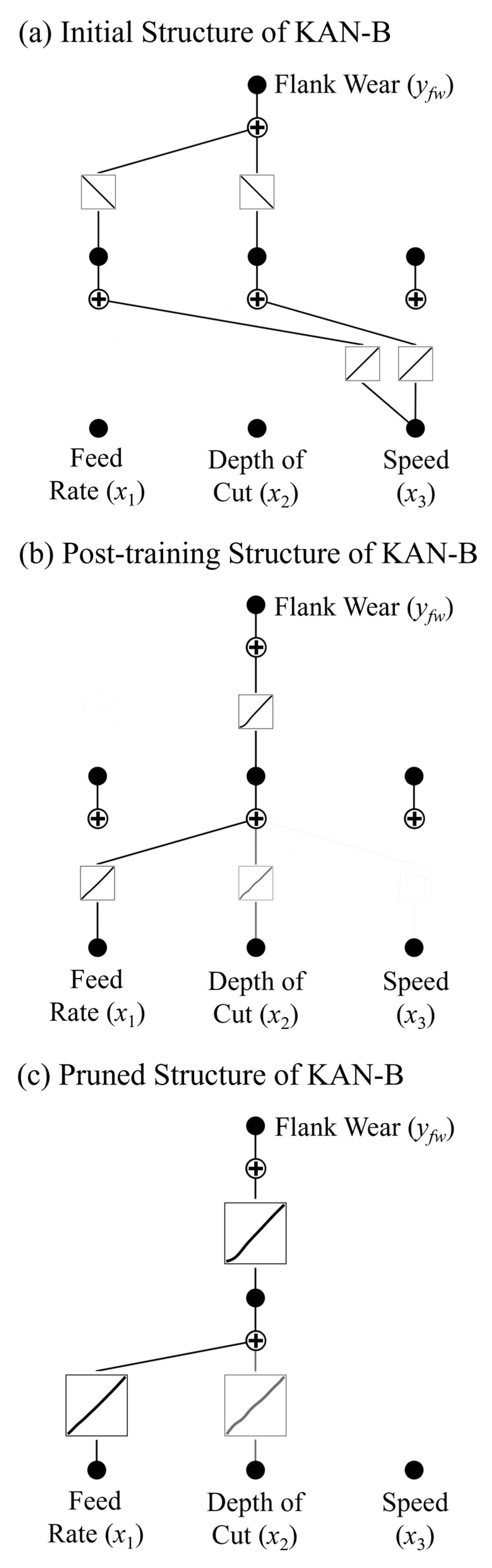
Figure 1 illustrates three structural states of KAN-A and their evolutions during training. Guided by mathematical priors from KART, simple basis functions with uniform distributions are typically used during initialization. The initial structure has dense but redundant connections. The parameters remain unadopted to data distributions. It is analogous to an “uncarved blank”.
The post-training structure exhibits substantial differences from the initial structure: the waveform of the activation function (B-spline) adjusts its shape after one training cycle, becoming either more peaked or smoother depending on data characteristics and training parameters. Concurrently, these dynamic adjustments optimize the positions and coefficients of the B-spline control points. Some connection weights are significantly strengthened, while others approach zero. It is a data-driven feature selection process.
Pruning endows KANs with a more compact topology by retaining task-sensitive B-spline functions and removing less relevant ones. The pruned structure, free of redundant nodes and edges, serves as the basis for symbolic computation of KANs. Notably, in the initial structure, the third input variable was connected to all nodes. The first two input variables had no connections. This was due to dimensional discrepancies between the variables. During initialization, the first two variables exhibited lower gradient magnitudes, leading to misjudgments of their importance. However, after training and pruning, their importance was significantly enhanced. It indicates that the KAN’s initial structure does not necessarily reflect true feature significance. Instead, the training process involves learning the importance of input variables. Thus, it can be inferred that KANs have the ability to automatically select core features.
Mathematical relationships between the input variables (feed rate, depth of cut, and speed) and the output variable (flank wear) were derived via the KAN. Formulas with coefficients retained to 1, 2, and 4 decimal places are provided, as follows:
A higher coefficient precision can enhance modeling accuracy, but it might also bring in noise due to the retention of some negligible terms. Lower-precision formulas facilitate clearer interpretation of mathematical connections between inputs and outputs. Taking Formula (3) as an example, the effects of the feed rate (x1), depth of cut (x2), and speed (x3) on flank wear (yfw) are discussed.
The physical meaning of is that when , the relationship between the feed rate and flank wear undergoes a sudden change. At lower feed rates, flank wear decreases linearly with an increasing feed rate, possibly due to insufficient cutting force prolonging tool–material friction time, where frictional effects dominate tool wear. Conversely, at higher feed rates, flank wear increases linearly with the feed rate. Sharp increases in cutting force elevate mechanical stress and thermal load on the tool. Consequently, the tool wear is accelerated.
Unlike the feed rate (x1), the second term in the formula indicates that flank wear fluctuates periodically with the depth of cut. It may arise from periodic changes in tool force distribution caused by varying cutting depths. Due to the phase shift of the sine function, as the depth of cut increases, flank wear first decreases and then increases overall. It is hypothesized that specific cutting depths may correspond to the tool’s resonance frequency, exacerbating wear; at other depths, stress dispersion or non-resonant conditions lead to less severe wear.
Speed (x3) does not explicitly appear in the formula for two reasons: firstly, KANs’ pruning process removed the speed-related connections deemed insignificant to the output. Secondly, terms with x3 as the coefficients were too small to contribute to the flank wear modeling, and were thus eliminated when retaining 1-digit decimal precision.
Compared with machine learning and deep learning approaches, KAN-based symbolic modeling not only clarifies mathematical relationships between variables (as a white-box model) but also provides precise guidance for machining process optimization. For example, to minimize flank wear, the feed rate (x1) and depth of cut (x2) can be configured based on and , while the speed (x3) can be determined according to roughing or finishing requirements.
This advantage is generalizable: the established mathematical relationships adapt to different datasets. For researchers, changes in physical relationships become focal points of discussion. For engineers, mathematical connections between variables under diverse machining demands and conditions can be obtained to optimize processes toward specific goals. It transcends reliance on empirical intuition.
3.3. Modeling Experiment Based on KAN-B
KANs’ learning capability does not correlate positively with the number of network nodes or layers. KART states that any multivariate continuous function can be decomposed into a combination of finite univariate functions.
KANs can directly learn to approximate these functions efficiently. This reduces dependence on network depth. Therefore, KAN-B was designed as a KAN with an extremely simple structure. Its purpose was to investigate KAN characteristics through analysis of its test results. We aimed to analyze the similarities and differences between the mathematical relationships of KAN-B and those of KAN-A.
Most parameters of KAN-B are consistent with KAN-A, with modified parameters listed in
Table 4.
The initial, post-training, and pruned structures of KAN-B are shown in
Figure 2. After first loading the training data, KAN-B identified speed (
x3) as the most important variable, again influenced by data dimensionality. After training, the increased weights of the feed rate (
x1) and depth of cut (
x2) demonstrate that the sparse connections from the input layer to the first hidden layer prioritize these two features. After pruning, the nodes and edges of low modeling importance were removed, which makes the relationship between input vectors and output targets intuitive.
Mathematical relationships between the input variables (feed rate, depth of cut, and speed) and the output variable (flank wear) were derived based on KAN-B. The formulas with coefficients retained to 1, 2, and 4 decimal places are provided, as follows:
Formula (6) highlights a core term: . The absolute value describes wear asymmetry: wear accelerates when the linear combination exceeds the threshold, while the wear rate remains lower below the threshold. The coefficient 0.1 before the absolute value acts as a scaling factor. The linear terms and indicate that the feed rate (x1) contributes more to wear than the depth of cut (x2).
Speed (x3) does not appear in the formula, suggesting that within the experimental parameter range, its impact on flank wear is insignificant. The constant term −6.0 represents a critical threshold: when , the wear begins to increase. This constant may relate to turning conditions or material properties.
Formula (6) shares similarities with Formula (3): both reflect a threshold effect in wear, where wear increases notably when variables exceed specific limits, and neither includes terms for speed (x3). However, Formula (3) contains a sine term, which better describes wear fluctuations. The more complex structure of KAN-A, with a larger number of nodes, facilitates fitting more intricate mathematical relationships.
3.4. Modeling Experiment Based on KAN-C
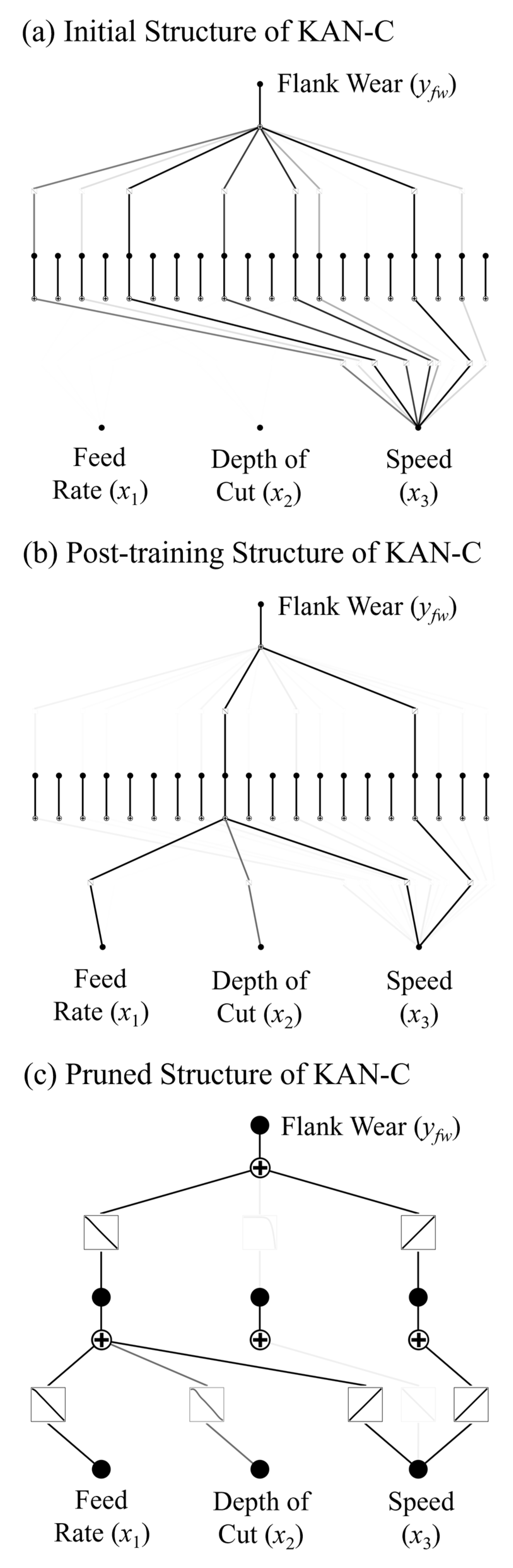
KAN-C, featuring the largest number of neural nodes, offers greater degrees of freedom in modeling input–output relationships compared to KAN-A and KAN-B.
Figure 3 illustrates its three network structures.
The initial structure displays the neurons and connections in KAN-C. The post-training structure shows dynamic parameter adjustments, such as reduced weights (observed as lighter colors) for some neurons and connections and strengthened weights for frequently activated neurons (observed as darker colors). Despite its complex initial structure, numerous nodes and edges were pruned away in the final pruned structure.
Similar to KAN-A and KAN-B, KAN-C retains KANs’ common characteristics: upon data loading, input features with larger numerical values were deemed more important. After training and pruning, information transmission in KAN-C shifted to prioritize the feed rate (x1) and depth of cut (x2) as primary features.
Mathematical relationships between the input variables (feed rate, depth of cut, and speed) and the output variable (flank wear) were established using KAN-C. Formulas with coefficients retained to 1, 2, and 4 decimal places are provided, as follows:
The piecewise linear structure of Formula (9) aligns well with the general physical characteristics of tool wear, where wear rates often exhibit abrupt changes as process parameters exceed critical thresholds in practical machining. First, focusing on its linear term: indicates a positive correlation between the depth of cut (x2) and flank wear (yfw), with the coefficient 0.3 quantifying the intensity of this effect.
The nonlinear term reveals a critical effect of the feed rate (x1). The turning point occurs when 6.9x1 = 2.2, where the impact of the feed rate on wear is minimized. The presence of the absolute value function validates KANs’ capability to automatically identify nonlinear features. Speed (x3) does not appear in the formula, indicating its contribution is lower than other features in this dataset. An alternative possibility is that x3 implicitly influences other parameters, thereby affecting flank wear (yfw).
Furthermore, Formula (9) contains both linear and absolute value terms, showing similarities with Formulas (3) and (6). KAN-A, KAN-B, and KAN-C exhibit commonalities in structure, training processes, and modeling results. This demonstrates that KANs’ modeling of physical processes is less susceptible to network design and possesses generalizability.
4. Modeling Errors of KANs and Discussion
4.1. Error Metrics
Multiple error metrics were selected, including the Mean Squared Error (MSE), Mean Absolute Error (MAE), Symmetric Mean Absolute Percentage Error (sMAPE), MaxAE (Maximum Absolute Error), Coefficient of Determination (R
2), and Adjusted R
2. Their mathematical formulas are defined as:
where
is the actual observed value,
is the predicted value,
n is the total number of samples,
represents the sum of the Squared Residuals,
represents the total Sum of Squares, and
p is the number of independent variables.
The MSE is sensitive to outliers due to squared errors, penalizing large deviations strongly. The MAE offers robustness against outliers and reflects overall performance on training and test sets. Unlike the MAPE, the sMAPE stabilizes near-zero values with a fixed range (0–200%), enabling better model comparability. The MaxAE captures the worst-case performance, while R2 and Adjusted R2 jointly prevent overfitting misjudgment by accounting for variable quantity.
4.2. Modeling Errors of KAN-A
Table 5 presents the experimental results for KAN-A. KAN-A’s test set errors (MSE, MAE, and sMAPE) were marginally lower than the training set values, validating the regularization strategy’s effectiveness and demonstrating generalization. The MaxAE decreased from 0.7555 (training) to 0.3350 (test), which suggests improved prediction of extreme cases.
Both R2 and Adjusted R2 approached 1, confirming that KAN-A explained most variance between the inputs and outputs. The model not only learned data patterns but also generalized them effectively.
The total runtime for KAN-A was 614.5063 s. This duration is substantial but justified by its symbolic output. Once validated with low errors, the derived mathematical relationships will directly guide research and engineering efforts. There is no need for retraining, which makes it cost-efficient in the long term.
4.3. Modeling Errors of KAN-B
The results of KAN-B appear in
Table 6. KAN-B exhibited minimal discrepancies between training and test errors, indicating no overfitting/underfitting. The sMAPE values demonstrated tight control over relative errors. The MaxAE values (0.4950 training, 0.4736 test) showed robust fitting of challenging samples. With a runtime of ~300 s (half of KAN-A), its simple structure delivered computational efficiency.
R2 and Adjusted R2 remained near 1, confirming that KAN-B fully explained target variance and statistically input contributions. This implies that KAN-B learned universal underlying patterns in the data. The derived mathematical expressions are valid and trustworthy.
4.4. Modeling Errors of KAN-C
The experimental results of KAN-C are shown in
Table 7. Its R
2 and Adjusted R
2 on the training set both reach 0.9986, which indicates excellent fitting performance for the training data. Although slightly lower, the R
2 and Adjusted R
2 of the test set remain close to 0.9950, demonstrating good generalization capability.
The MaxAE of the test set is roughly double that of the training set, indicating larger maximum prediction errors in testing. The gap explains why KAN-C performs better on training data than on test data. The MSE and MAE metrics follow this pattern consistently.
However, the test set’s sMAPE (3.7965) is smaller than the training set’s (4.0589). This may be attributed to the larger overall magnitude of flank wear in the test set: according to the sMAPE formula, relative errors are diluted when actual values increase, leading to a numerically smaller sMAPE.
4.5. Vertical (Intra-Method) Comparisons of Modeling Results Among KAN-A/B/C
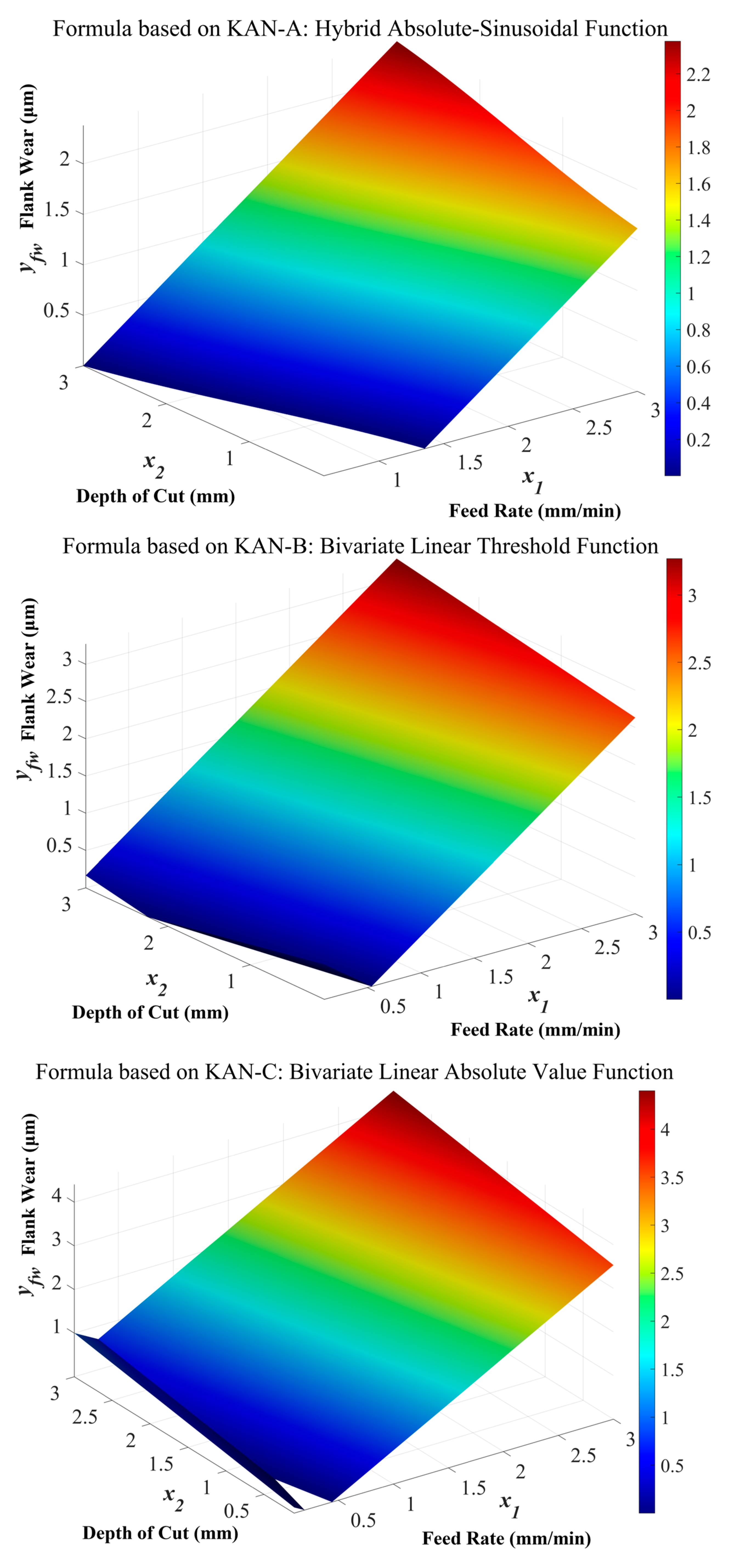
Three-dimensional plots of Formulas (3), (6), and (9) are presented in
Figure 4. Flank wear physically cannot be negative. When
x1 and
x2 take small values, both KAN-A and KAN-B predict negative flank wear, while KAN-C only exhibits a small region of negative predictions.
This indicates that KANs’ symbolic conversion process lacks the constraints of physical knowledge. In other words, it currently cannot interpret variable meanings or relationships, and instead only obtains “white-box” mathematical expressions between the input features and the output targets through fitting with minimized errors and pruning. Nevertheless, KANs represent an advancement in artificial intelligence interpretability compared to numerous “black-box” models.
Comparisons among the three plots also reveal an insight: KANs’ learning process and symbolic formulas are constrained by data characteristics. The final expression forms depend on the dataset scale, dimensionality, and value ranges. Although KAN-A/B/C have distinct architectures in this study, their functional forms exhibit substantial commonalities due to using the same dataset.
The effective application range of mathematical formulas derived by KANs is also dataset-dependent. For example, if an input variable’s sample range during training is [0.5, 20], the formula’s validity most likely remains within [0.5, 20]. KANs cannot guarantee the accurate description of input–output relationships outside the range.
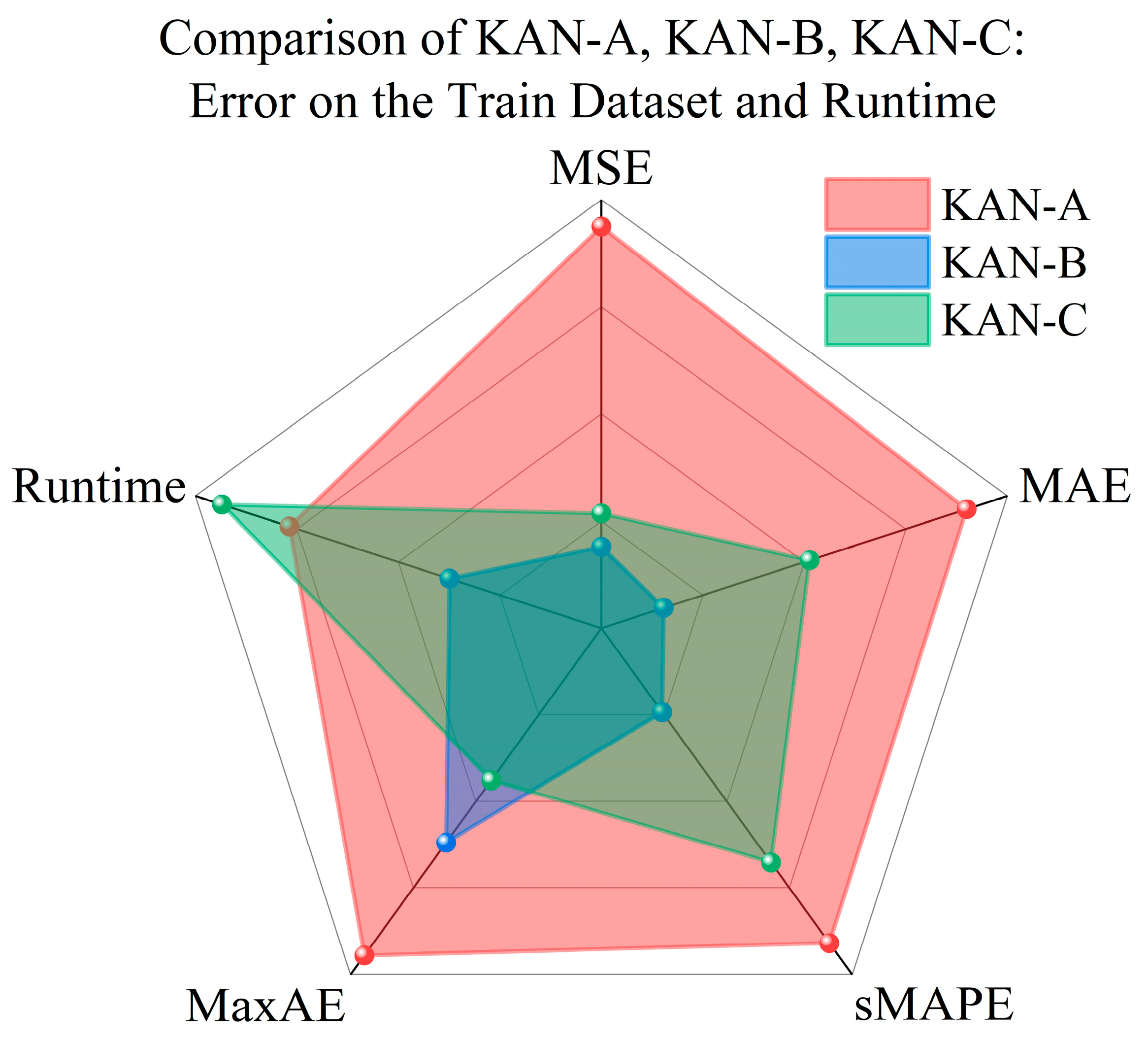
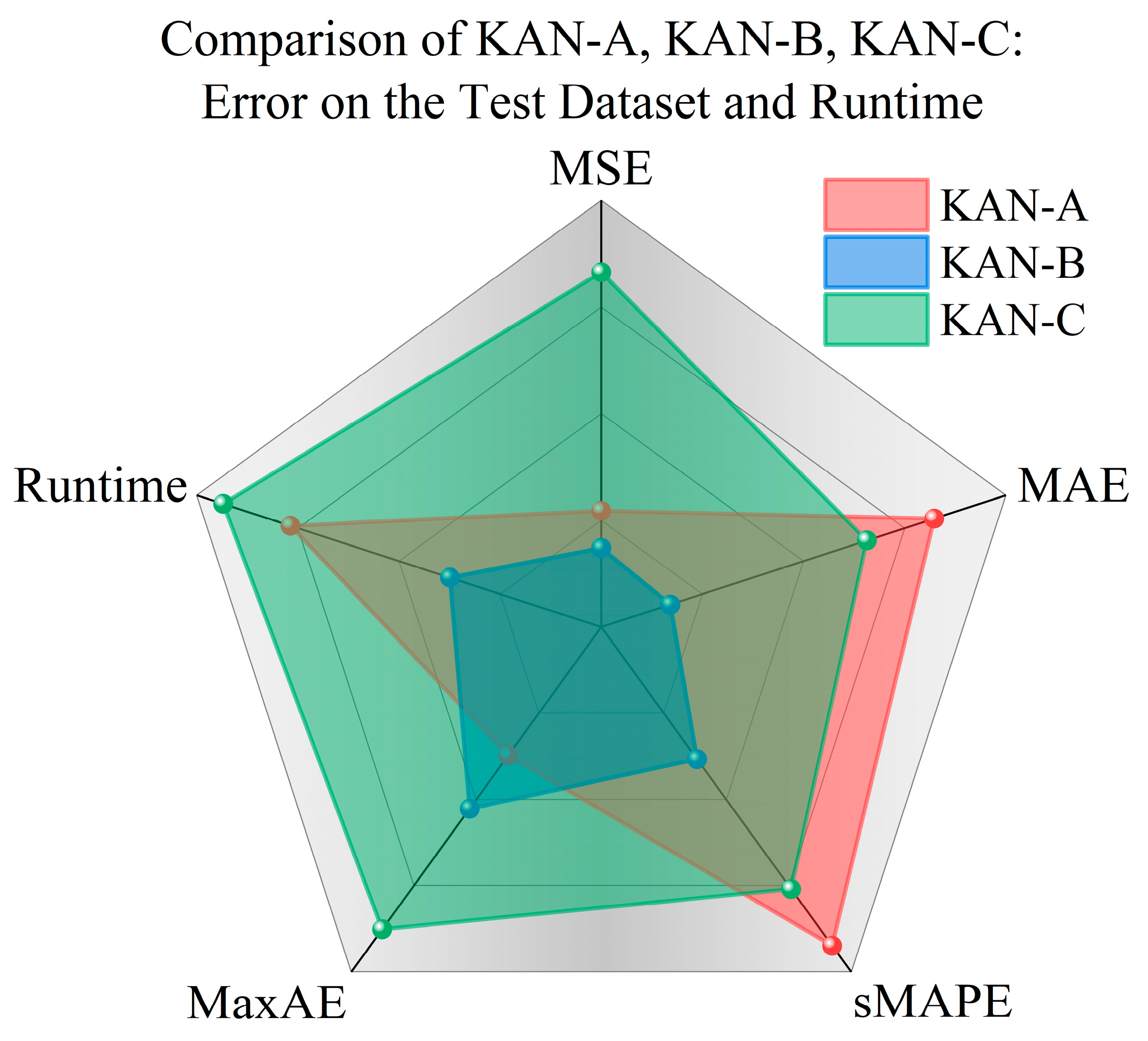
Radar charts plotting the total runtime and error metrics of KAN-A/B/C on training and test sets are shown in
Figure 5 and
Figure 6. Each endpoint of the radar chart represents an error metric or runtime. The models with higher prediction accuracy and computational efficiency occupy smaller areas.
KAN-B demonstrates the best overall performance on both training and test sets. While KAN-A performs worst on the training set, its MSE and MaxAE on the test set are lower than those of KAN-C. KAN-B’s MaxAE consistently lies between the two, with all other error and runtime metrics being optimal.
KAN-B has the simplest structure and fewest nodes. It contrasts with typical MLP training experiences. Usually, more complex architectures with more nodes are assumed to have stronger learning capabilities.
This phenomenon is explained by KART, which states that any multivariate continuous function can be decomposed into a finite combination of univariate functions. Theoretically, KANs approximate complex functions with fewer nodes by adjusting learnable activation functions on edges, whereas MLPs rely on increasing layers and nodes to enhance fitting ability. The fundamental difference accounts for their distinct dependencies on node quantity.
KAN-A/B/C all use B-spline functions as learnable activation functions, in contrast to MLPs’ fixed functions like ReLU or Sigmoid. When fitting relationships between features and target variables, MLPs require coordinating numerous parameters to modify global weight matrices, while KANs complete learning through adjustments to B-spline functions, reducing redundant parameters. Node and edge pruning in KANs further amplify the advantage.
Beyond the above benefits, KAN-B’s simple structure acts as a natural regularization. This inherently reduces overfitting risk and stabilizes training performance. These results and discussions infer that model architecture design should prioritize alignment with the problem essence over blindly increasing the complexity.
6. Comparison Between KANs and Classical Models
6.1. KAN-B vs. Usui Model
The classical flank wear model is the Usui Adhesion Wear Model (hereinafter “Usui Model”), which describes tool wear under high-temperature/pressure-turning conditions, based on the adhesion wear mechanism between tool and workpiece materials:
where
is the wear rate;
a,
b are material constants that depend on the tool and workpiece materials;
is the normal stress at the contact surface;
V is the sliding velocity of the chip relative to the tool; and
T is the interfacial temperature at the contact surface.
The Usui Model is a physics-based approach that can also be used with finite element simulations. However, precise material constants a and b must be determined experimentally. Moreover, adhesive wear is not the dominant mechanism under all cutting conditions. Mechanisms such as abrasive wear, diffusion wear, and chemical wear are not considered.
Taking Formula (6), , as an example, its differences from the Usui Model are discussed as follows. The mathematical formula derived by KAN-B suggests that the effect of speed (x3) is either indirectly reflected through other variables or insignificant for flank wear under the given cutting conditions. The feed rate (x1) and depth of cut (x2) are modeled via a combination of linear terms and absolute values. In contrast, the Usui Model explicitly incorporates speed (V), temperature (T), and stress () through terms like the exponential , which quantifies the temperature effect on wear.
The formula obtained by KAN-B reflects the mathematical relationships between the physical variables specific to the current dataset. Although it does not rely on prior physical knowledge or laws, it provides a white-box interpretable expression. It offers a key insight: researchers can conduct modeling studies for diverse specific machining conditions.
For instance, in high-speed milling of titanium alloys, a KAN model might reveal the asymmetric effect of axial cutting depth on wear. When the tool overhang is large, negative coefficient terms in the model could reflect critical chatter effects caused by reduced system stiffness. If KANs generate an absolute value function involving a “stiffness threshold,” the stable operating domain of the process system can be mathematically determined.
The iterative research paradigm of “phenomenological modeling–physical mechanism tracing” provides a new pathway for unraveling the mechanisms of complex manufacturing processes.
6.2. Classical Formulas, Machine Learning, and KANs
The Usui Model represents a class of classical cutting models that express relationships between machining variables. These models share key similarities. They are intuitive, interpretable, and static. Meanwhile, their forms do not evolve with the data.
Crucially, they ignore the operational data generated by CNC machines, tool systems, and materials during runtime. For example, the same formula is applied to new vs. aged machines of the same model for identical tasks, despite differences in wear states and system dynamics.
Recent machine learning and deep learning approaches have proven effective for machining process modeling, but their black-box nature remains an inescapable drawback. Even with cutting-edge methods and satisfactory test results, humans struggle to derive new knowledge from these opaque relationships. Technical innovation and engineering applicability alone cannot substitute for the discovery of fundamental insights.
KAN-based machining variable modeling bridges the strengths of both approaches: it treats machine runtime data as dependent variables and targets physical variables of interest, which enables researchers to establish quantifiable input–target relationships, while deriving interpretable mathematical formulas. It also represents dynamic modeling that evolves with the data. In other words, machine operational and degradation processes (e.g., tool wear and spindle drift) are directly encoded into the derived formulas.
By embedding system dynamics into interpretable equations, KANs transcend static classical formulas and opaque machine learning models. They offer a dual-purpose framework for both academic discovery and industrial innovation.
7. KAN-Based Tool Wear Modeling Using Simulated Turning Test Data
7.1. Design of Simulated Turning Tests Using DEFORM-3D
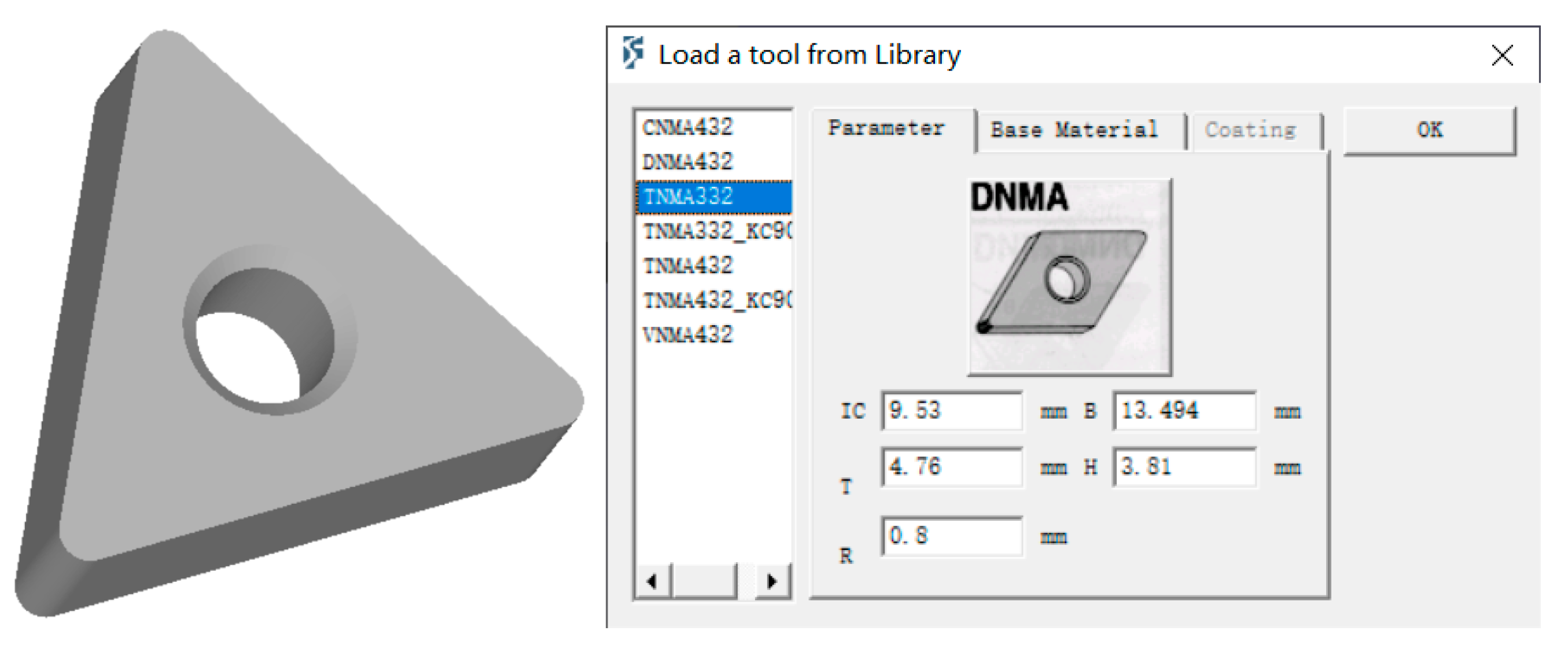
To further investigate the modeling capabilities of KAN-A/B/C on tool wear, we conducted additional simulation turning tests using DEFORM-3D software (version 11.0). Compared with ABAQUS and ANSYS (
https://www.ansys.com/), DEFORM-3D offers distinct advantages, including a comprehensive material library, rational mesh generation, and efficient data acquisition. The turning simulation was performed using TNMA332 tools with key parameters configured, as shown in
Figure 8.
AISI-1045 steel was selected as the workpiece material due to its excellent machinability, weldability, and broad applicability across mechanical manufacturing, automotive, and aerospace industries. Its physical and mechanical properties are presented in
Table 10.
The cutting parameters were set as follows: a cutting speed of 250 mm/s and a depth of cut of 0.5 mm along the lathe’s Y-axis. The Johnson–Cook constitutive model was employed to characterize the workpiece material’s dynamic behavior, while the normalized C&L fracture criterion served as the separation criterion. A shear friction model with a coefficient of 0.45 was applied to the tool–workpiece interface.
During simulation, DEFORM-3D performed dozens to hundreds of adaptive remeshing operations to accommodate severe material deformation. The computational efficiency was optimized by: (1) implementing local mesh refinement exclusively in the cutting zone, (2) adopting absolute meshing for the workpiece, with the minimum element size set at 40% of the feed rate, and (3) maintaining a ratio of 7.
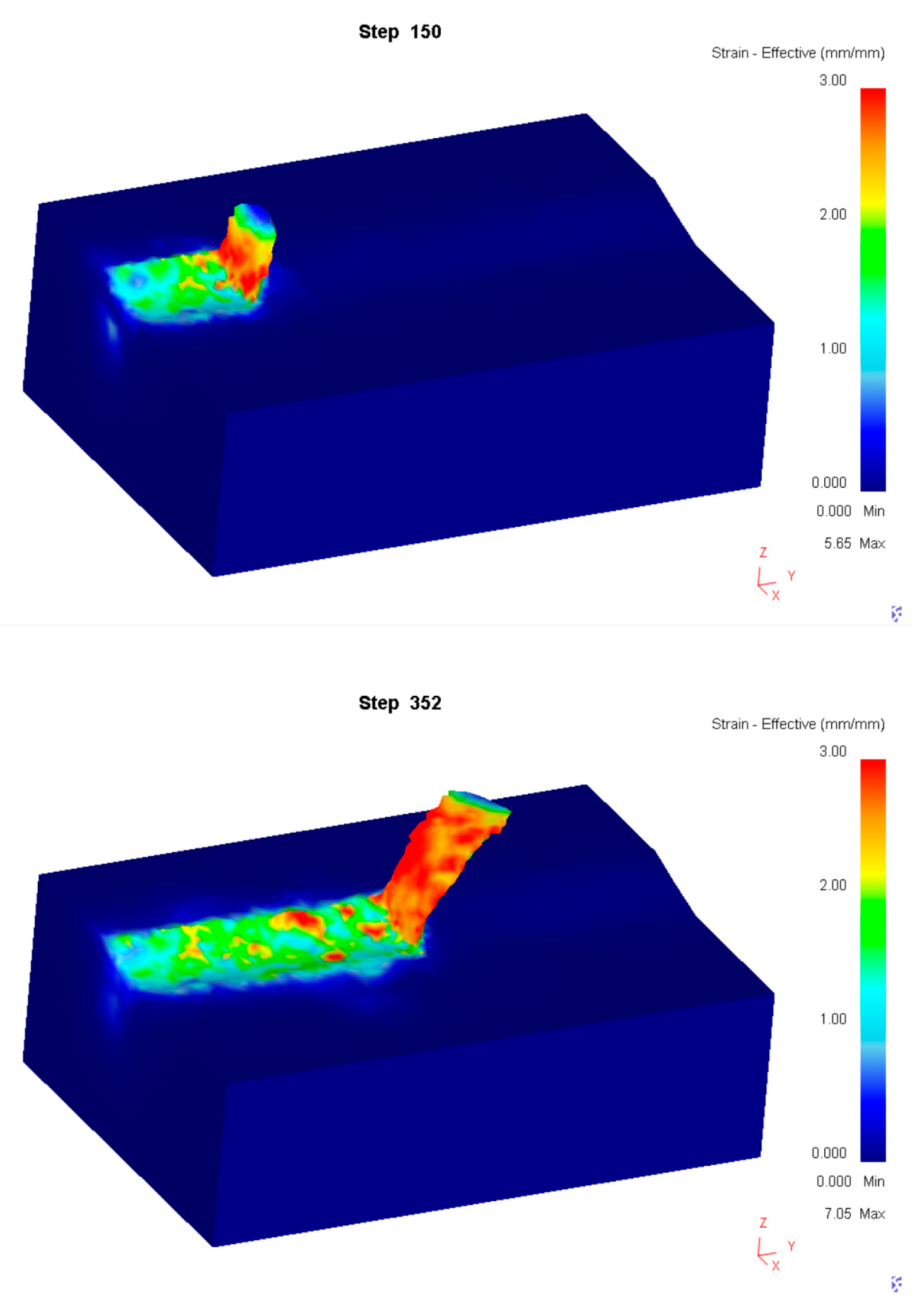
During the turning process, the relative positional relationship between the tool and workpiece is illustrated in
Figure 9. The mesh deformation of the workpiece is shown in
Figure 10. The temperature variation in the contact zone between the workpiece and cutting tool is presented in
Figure 11.
After completing the simulated turning tests, the data on tool wear progression were obtained. Only the data samples corresponding to each observed change in tool wear were retained, as these points better represent the interaction characteristics between the tool and workpiece. For instance, during the stable wear phase, the wear amount of the cutting edge remains nearly constant, with minimal impact on part machining accuracy and surface quality.
This data processing approach helps verify whether the proposed method can effectively learn wear progression patterns. After processing, 350 samples were obtained and divided equally into training and test sets for model development.
The acquired data samples were further categorized into distinct features, with their definitions and explanations provided in
Table 11.
7.2. Modeling Results of KAN-A/B/C and Discussion of Their Physical Significance
Subsequently, KAN-A/B/C were, respectively, employed to model and predict tool wear in simulated turning operations. All formulas retained four decimal places for precision. The formulas demonstrate the following:
where
x1 (step) was identified by all three KAN architectures as a significant variable influencing tool wear. KAN-B specifically indicated that increasing
x3 (temperature) accelerates tool wear progression.
It is readily apparent that KANs’ computational approach differs from conventional physics-based analysis. In other words, physics-driven formula derivation focuses on clarifying physical meanings and analyzing physical processes, providing researchers and engineers with broad reference values.
In contrast, KAN-based modeling primarily depends on the sample data itself. It can establish explicit ‘white-box’ formulas within given sample ranges. These formulas yield accurate modeling and prediction results, though they do not guarantee physical accuracy.
Thus, KANs can be characterized as a data-driven method that produces explicit formulas with potential physical interpretability. Compared to traditional “black-box” methods, KANs offer superior physical interpretability, though their derived formulas may not always align with physical assumptions.
Tool wear is a dynamic process involving multi-physics coupling (thermal, mechanical, and material deformation effects). In the current prediction results, KANs achieve explicit modeling through univariate or bivariate functions, specifically by establishing functional relationships between the time step (‘step’) and contact zone temperature (‘temperature’). The variable ‘step’ was identified by all KAN architectures as strongly correlated with the wear amount, consistent with the cumulative nature of tool wear. The role of ‘temperature’ reflects its direct influence on the hardness and chemical stability of tool materials under elevated temperatures.
However, KANs do not account for the influence of cutting forces and cutting speeds on tool wear, which are typically critical factors in physics-based modeling. It suggests that, as a data-driven regression method, KANs may struggle to incorporate the assumptions and constraints inherent in physical principles.
On the other hand, KANs’ characteristics offer new insights for advancing tool wear research. While many traditional models are highly accurate and meaningful, they often rely heavily on empirical formulas or physics-based derivations. Such physics-based models require extensive experimental calibration of parameters. Conversely, KANs adopt a data-driven approach to directly learn the implicit relationships among machining parameters, thereby reducing manual intervention.
Consequently, KAN-based regression and derivation are more outcome-oriented. The formulas provided by KAN-A/B/C achieve minimal errors and high R
2 values during both training and prediction phases, as demonstrated in
Table 12.
Unlike conventional deep learning methods, which typically require large, labeled datasets, KANs achieve stable predictions in the experiment using only 350 samples (with a 1:1 training–test split).
Provided that machining conditions remain unchanged, the formulas derived by KANs hold significant reference value for tool wear prediction. Moreover, although the physical interpretability of KAN-A/B/C’s formulas is limited, they are explicit functions, enabling intuitive analysis of the relationship between input parameters and tool wear.
8. Conclusions
This study presented a progressively complex model system (KAN-A/B/C) based on KANs. Initially, tool wear modeling was conducted using flank wear data for turning tools obtained from Kaggle. Physically interpretable analytical expressions were proposed for tool wear prediction, establishing a foundation for real-time wear calculation under complex working conditions.
Subsequent vertical (intra-method) comparisons among KAN-A/B/C employed six error metrics and the computational time, revealing quantitative relationships between model complexity and prediction accuracy/efficiency. For horizontal comparison, isomorphic MLP benchmark models were developed, demonstrating KANs’ superiority in generalization performance and convergence stability across training, parameter, and basic principles. The comprehensive advantages of KANs in prediction accuracy and physical interpretation were further examined through comparisons with traditional empirical formulas (Usui Model) and machine learning methods.
Following this, turning simulations were implemented using DEFORM-3D, with the resultant data samples serving to validate the modeling capabilities of KAN-A/B/C. An in-depth discussion addresses the characteristics and limitations of the KAN-based “white-box” tool wear formula. KANs integrate data adaptability with mechanistic interpretability, and their reduced parameter count alongside high accuracy suggest that KANs offer a more efficient alternative. These findings underscore their uniqueness in manufacturing process modeling.
8.1. Current Limitations of KANs
The data-driven tool wear modeling based on KANs exhibits several limitations. First, while KANs can derive explicit mathematical formulas compared to black-box models, these derived results do not fully align with conventional physical principles.
Second, KAN-A/B/C primarily focuses on achieving low training and testing errors within the given dataset, with limited incorporation of physical understanding. For instance, in tests on public datasets, KANs identified cutting speed (Speed) as a non-critical parameter. It does not negate the role of cutting speed but rather reflects its relatively weak influence within the specific data range used.
Furthermore, the mathematical relationships derived from KAN-A/B/C are strictly valid only within the training data range. Due to the absence of physical constraints in the symbolic formulas, extrapolation beyond these bounds may lead to inaccurate predictions. Compared to traditional MLPs, the optimization of B-spline basis functions and edge-based activation learning increases the computational overhead in KANs.
8.2. Future Research Directions
(1) Integration of KANs with Physical Models
Construct hybrid models by combining KANs with explicit physical equations to enhance robustness. For tool wear processes, compute predictions using physical equations first, then employ KANs to compensate for discrepancies between the calculated results and the actual wear measurements. Develop a white-box model, integrating physical knowledge with KAN inference capabilities.
(2) KAN-Based Monitoring, Prediction, and Parameter Feedback
Leverage KANs’ lightweight architecture with significantly fewer parameters than traditional neural networks to develop embedded systems for real-time monitoring and predictive analysis of tool wear states. Dynamically feed predictive outputs back into CNC systems to optimize cutting parameter configurations.
(3) Multi-Material and Multi-Tool Wear Prediction
Investigate the accuracy and generalization capability of KANs in wear modeling across dissimilar materials (e.g., titanium alloys and composites) and tool geometries (e.g., coated tools and indexable inserts).





 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}