1. Introduction
Cloud computing is emerging as a key enabler in the digital transformation of organizations and governments, significantly contributing to increased productivity, cost reduction, and improved efficiency [
1,
2,
3]. Through cloud services, organizations such as local governments can focus on their strategies, as the scalability and reliability of their systems are enhanced [
4]. Strategies that incorporate multi-scale feature extraction and dual attention mechanisms effectively capture informative patterns at different levels of detail, enhancing decision-making and system responsiveness [
5]. The cloud is now a foundation of digital transformation and is closely linked to service-oriented architecture. It integrates storage, applications, and business processes into a dynamic, reusable environment. In Digital Open Government (DOG), the use of multi-layered cloud structures reduces infrastructure needs and software costs [
6]. Despite the benefits, cloud adoption is not uniform internationally. Factors such as the quality of the legal framework and broadband penetration influence its adoption. In particular, countries dependent on export-oriented businesses find it difficult to move to the cloud due to past investments in traditional technologies [
7].
Cloud readiness, therefore, is not only about technological infrastructure but also about developing unique skills and knowledge. Multinational companies that have strategically invested in the cloud have recorded benefits in terms of operations and competitiveness, strengthening their sustainable development and external networks [
8]. Additionally, the adoption of the cloud is also associated with quantifiable economic benefits, according to new empirical data, particularly when paired with enabling infrastructure like high-speed broadband. Nonetheless, the effects continue to vary among industries and nations, indicating the necessity of designing policies according to the circumstances [
9].
Prior research has mostly concentrated on firm-level cloud computing adoption, with little investigation into the macro-level factors that influence cloud computing adoption [
7,
10,
11,
12]. Senyo et al. [
13] state (in their review of the cloud computing literature) that research on cloud computing at the macro level (national level) will create more awareness and support towards favorable policies for cloud computing. The European Commission aims to increase the access of European businesses and public authorities to cloud infrastructures and services in order to achieve the objective of the EUs Digital Decade, where 75% of European businesses should use cloud-edge technologies for their activities by 2030.
Driven by this critical gap in the literature and its growing policy relevance, this study investigates the macro-structural determinants of cloud computing adoption across 27 EU countries. Existing research predominantly emphasizes firm- or sector-level factors, often using traditional econometric models constrained by linearity and limited interaction handling. In contrast, national-level adoption dynamics likely reflect more intricate, nonlinear relationships involving digital infrastructure, human capital, and socioeconomic context.
To capture this complexity, we propose an integrated methodology that combines interpretable machine learning (XAI) with panel econometric validation. Using harmonized Eurostat indicators, we build a dual-panel dataset covering 2014–2021 and 2014–2024. Random Forests [
14], XGBoost [
15], and Support Vector Machines are deployed to model adoption outcomes, while SHAP and ICE visualizations enable transparent interpretation of predictor influence [
16]. This flexible architecture overcomes the functional limitations of fixed-effects and linear models [
17,
18], capturing both cross-country heterogeneity and temporal evolution.
Furthermore, we estimate a dynamic panel system GMM model to benchmark causal inferences, reinforcing the centrality of digital skills while highlighting methodological complementarity. Hierarchical clustering then segments EU countries into distinct digital maturity profiles, providing actionable input for differentiated policy design.
Together, these contributions offer a data-driven, policy-relevant framework aligned with the EUs Digital Decade priorities, advancing both explanatory insight and strategic guidance for accelerating cloud adoption across member states.
The most significant determinants of cloud adoption, according to empirical findings, are ICT professionals and broadband infrastructure, confirming the critical roles that connectivity and digital skills play. Different national profiles of digital maturity are also shown by clustering analysis, which has obvious ramifications for differentiating policy formulation throughout the EU.
The remainder of the paper is structured as follows.
Section 2 reviews the relevant literature on cloud adoption and digital readiness. The data sources, variable definitions, and methodological approach, which includes clustering techniques and machine learning models, are presented in
Section 3. The primary empirical findings, such as model performance, variable relevance, and country clustering, are presented in
Section 4. The findings are addressed in
Section 5, which also places the results in the larger framework of EU digital strategy.
Section 6 concludes with limitations and directions for future research.
3. Materials and Methods
3.1. Data Preparation
3.1.1. Data Sources
This study utilizes several datasets collecting macroeconomic, educational, technological, and digital infrastructure indicators for European Union (EU) countries. Three crucial aspects of national capacity—human capital; economic development; and digital infrastructure—are reflected in the variables chosen; which are based on the literature on cloud readiness and digital transformation [
9,
35,
36].
The dependent variable, cloud computing adoption, is a direct proxy for digital transformation uptake by firms, particularly those with more than ten employees [
37]. It serves as an outcome indicator of strategic ICT integration [
38].
The independent variables were chosen to reflect enabling factors that are well acknowledged in both theoretical and empirical research on the diffusion of technology. The working-age population’s educational attainment and digital literacy are reflected in higher education levels, and these factors support the ability to absorb sophisticated digital tools like cloud platforms [
39]. Prior research has confirmed a strong correlation between GDP per capita and national digital maturity, which is a measure of economic capacity and investment potential [
40]. Higher unemployment rates can stifle both public and private investments in digital infrastructure and innovation, making them a structural restriction [
41]. The implementation and upkeep of cloud services in both the public and private sectors depend heavily on the specialized digital workforce capability that ICT specialists represent [
42]. For cloud computing and digital services in general to be technically feasible, broadband access is necessary. Even digitally savvy companies could find it difficult to fully utilize cloud capabilities without strong infrastructure [
43].
All datasets are retrieved from Eurostat, ensuring international comparability and temporal consistency. The panel covers the 27 EU member states, excluding aggregates such as EU27 or EA19. Specifically, the sample includes Austria, Belgium, Bulgaria, Croatia, Cyprus, the Czech Republic, Denmark, Estonia, Finland, France, Germany, Greece, Hungary, Ireland, Italy, Latvia, Lithuania, Luxembourg, Malta, the Netherlands, Poland, Portugal, Romania, Slovakia, Slovenia, Spain, and Sweden.
In order to handle the availability of broadband data, two analytical panels were built such that (i) broadband access is a predictor in Panel A (2014–2021). (ii) Panel B (2014–2024) permits longer longitudinal analysis but does not include broadband.
This dual-panel approach allows for robustness checks across longer time horizons as well as the evaluation of short-term consequences of digital infrastructure.
3.1.2. Variable Construction and Data Processing
Each variable was extracted, filtered, and transformed to ensure conceptual alignment, statistical consistency, and comparability across EU countries and years. All data originate from Eurostat and follow standard EU statistical codes and classifications.
Table 1 summarizes their definitions, measurement units, and sources.
All variables are available annually from 2014 to 2024, except for Broadband Access, which is limited to the period until 2021. Due to this data limitation, two separate analytical panels must be created: Panel A, which covers the period from 2014 to 2021 and includes internet infrastructure as a significant predictor, and Panel B, which covers the period from 2014 to 2024 but excludes broadband access. In addition to providing a thorough analysis of the temporal dynamics underlying cloud adoption, this dual-panel approach also acts as a robustness check, enabling an evaluation of the effects of including or excluding digital infrastructure on model estimates and the reliability of the conclusions reached. It is important to note that no automated feature selection techniques were applied, as all variables were deliberately chosen based on theoretical relevance and empirical support from the existing literature.
Data from each Eurostat data file are cleaned, filtered, and merged at the country-year level. Additionally, the two datasets are harmonized by converting all time indicators to integers and filtering for the specified EU countries, whereas missing data are dealt with through listwise deletion (complete-case analysis), ensuring that only observations with complete records across all selected predictors were retained for modeling. Finally, each variable is standardized using Z-score normalization as per Equation (1):
where
and
denote the mean and standard deviation of
, respectively. This guarantees the required numerical stability for training and interpretation by forcing all predictors to be centered around zero and carry a unit standard deviation.
3.2. Modeling
The relationship between cloud adoption and the stated socio-economic and technological aspects is examined in this study using artificial intelligence (AI) techniques. In particular, the dependent variable is modeled using supervised learning methods such as random forests, support vector machines, elastic net regression, and gradient boosting machines.
By taking into account non-linearities and intricate relationships that conventional linear models could miss, the models assess cloud adoption levels based on independent variables. The relative influence of each predictor is inferred using partial dependence graphs and variable significance metrics.
Cross-validation techniques are used for confirming the models once they have been trained on the two core periods (2014–2021 and 2014–2024, respectively).
To ensure model reliability and avoid overfitting, all machine learning models were trained and evaluated using rigorous out-of-sample validation procedures. Data were randomly split into training (80%) and testing (20%) subsets, with stratification by country where appropriate to preserve representativeness. All parameter tuning, including model hyperparameters (such as the number of trees and mtry for Random Forest, learning rate and tree count for XGBoost, and regularization constants for Elastic Net and SVM), was conducted using 10-fold cross-validation on the training set, with performance assessed by RMSE and MAE. The final model evaluation was always performed on the separate, unseen test set to provide an unbiased measure of generalization performance.
For Random Forest models, we systematically varied the number of predictors sampled at each split (mtry) from 2 to 10, and explored up to 500 trees in the ensemble. XGBoost models were tuned over nrounds (50–300), max_depth (2–6), and eta (0.1–0.4). SVM models were assessed across a range of regularization constants (C). For each algorithm, the optimal configuration was chosen based on the lowest cross-validated RMSE. Dummy variables were generated prior to standardization, and both steps were embedded within the cross-validation folds to prevent data leakage.
To further evaluate the risk of overfitting, we compared training and test set metrics, reporting out-of-bag (OOB) error for Random Forests and all relevant test set metrics (RMSE, MAE, R2) for all models.
These validation practices, along with transparent reporting of parameter ranges and results, ensure the methodological soundness and reproducibility of our findings.
3.2.1. Random Forest Modeling
Given the complex, potentially nonlinear relationships among the variables influencing cloud adoption, this study employs advanced machine learning algorithms to model these associations robustly. Building on prior research [
44,
45], ensemble-based algorithms, particularly Random Forest regressors, are selected for their capacity to handle high-dimensional datasets, accommodate missing values, and capture intricate interaction effects. These characteristics render them especially suitable for modeling the multifaceted dynamics of digital transformation across countries and over time.
A Random Forest (RF) model estimates the relationship:
where
is an unknown, potentially nonlinear function mapping the predictors to the dependent variable (cloud adoption), and
accounts for unobserved random noise.
Specifically, for the first dataset, the RF will model
whereas it will omit the last predictor for the second one.
The RF constructs an ensemble of decision trees
, each trained on bootstrap samples of the original data. Predictions are obtained as the average across all trees:
The models were trained on two distinct datasets reflecting different temporal domains, corresponding to the availability of the broadband variable. For the period 2014–2021, data include broadband access as a predictor; for 2014–2024, this variable is omitted, thus enabling a robustness check of the model’s stability and the influence of digital infrastructure.
The dataset was randomly split into training (80%) and testing (20%) subsets to evaluate out-of-sample predictive accuracy, with all splits fixed via a set seed to ensure reproducibility. To improve the forecasting trustworthiness, a linear trend analysis was performed on the historical data before modeling, and the results were then incorporated into the projections.
Approximately 10-fold cross-validation was used to enhance hyperparameter tuning, such as the number of trees (m), maximum tree depth (d), and minimum samples per split (s). This method reduces the mean squared error, or MSE:
Parallel to RF, alternative ensemble methods Extreme Gradient Boosting (XGBoost), Elastic Net regression, and Support Vector Machines (SVM with a linear kernel) were also implemented to benchmark predictive performance and assess model stability across different algorithms under identical validation schemes.
To evaluate model performance across different machine learning algorithms, we used 10-fold cross-validation, assessing each model
based on the Root Mean Squared Error (RMSE):
where
is the predicted value for observation i using model
, and n is the number of observations in the validation fold.
Additionally, a weighted ensemble model was defined as
where
denotes the weight assigned to each base model, and weights were optimized to minimize RMSE on the validation set. The ensemble was constructed using the caretEnsemble package, which optimizes model weights to minimize cross-validated RMSE. Although SVM received zero weight in the final ensemble, it was fully trained and included in the optimization process. Model training times were recorded to benchmark efficiency.
Of note, all continuous predictors were standardized (mean zero, unit variance) prior to model training, ensuring comparability across models. For models incorporating country fixed effects, the categorical country variable (geo) was first converted into binary indicators (one-hot dummies) and then included in the feature matrix subject to the same standardization procedure. This unified preprocessing pipeline was embedded within the cross-validation framework applied to the training set, effectively preventing data leakage.
Model hyperparameters were tuned using five-fold cross-validation conducted strictly within the training data. For Random Forests, mtry (the number of predictors sampled at each split) was optimized; for XGBoost, tuning covered nrounds, max_depth, and eta; for SVM with a linear kernel, only the regularization parameter C was tuned. Elastic Net models were optimized over alpha and lambda using the glmnet framework. At no point was the holdout test set used in parameter tuning. This separation between training and evaluation ensures robust generalization and mitigates overfitting, in line with best practices in applied machine learning [
18,
46].
All models were implemented in R 4.3.1 using caret and caretEnsemble and trained on a MacBook Air (Apple M3 chip) with RStudio 2024.12.1.
3.2.2. Country Segmentation via Hierarchical Clustering
We used Ward’s linkage approach in conjunction with an agglomerative hierarchical clustering algorithm to find latent groupings of EU nations based on their socioeconomic and digital characteristics [
47,
48]. The Euclidean distance was used to determine how different countries
i and
j were from one another:
where
denotes the standardized value of predictor k for country
i, and
p is the total number of predictors.
A dendrogram that graphically depicts the hierarchical structure of nation similarity was produced by the algorithm’s iterative minimization of the within-cluster variance.
3.3. Result Interpretation
3.3.1. Explainability and Model Interpretation
In keeping with Tudor et al. [
49], this study uses explainable AI (XAI) strategies to solve interpretability issues that arise in complicated, nonlinear models. Specifically, the model’s output was broken down into the contribution of each predictor for individual predictions using SHapley Additive exPlanations (SHAP) values [
50,
51]:
where
f(
S) is the prediction based solely on features in subset
S. By providing detailed policy insights and helping stakeholders comprehend the factors driving cloud adoption, these values provide for a thorough knowledge of changeable importance at both the local and global levels.
Individual Conditional Expectation (ICE) curves were calculated to evaluate variability in predictor effects at the observation level in order to supplement SHAP studies [
52]. For each observation
and predictor
the ICE curve is defined as
where
holds all other predictors fixed at their actual values for observation i, and f(⋅) represents the fitted machine learning model.
These ICE curves provide a disaggregated view of predictor influence, highlighting variation across different countries and years.
3.3.2. Partial Dependence and Interaction Effects
Partial dependence plots (PDPs) were created in order to further elucidate the impact of each predictor and how they interact. Keeping other variables at their average, these charts show the marginal impact of each predictor
on the target variable:
where
represents all predictors except
fixed at the observed values for each data point
. PDPs offer insights into nature, i.e., linear, nonlinear, or threshold effects, of each predictor’s relationship with cloud adoption, without imposing strict parametric assumptions.
We next measured and ranked factors according to their total interaction strength to further the interaction analysis, and the pair with the strongest joint effect was ICT specialists and broadband access. An intuitive understanding of the nonlinear and multiplicative dynamics of cloud adoption was then made possible by the contour plot visualization of this interaction study.
Figure 1 includes a flowchart of the implemented method.
4. Results
4.1. Exploratory Data Analysis
The descriptive statistics of the standardized variables, which are shown in
Table 2, are covered in this subsection. In order to facilitate comparability and interpretation within the random forest model, all variables were standardized to have a mean of zero and a standard deviation of one, as previously specified.
While cloud adoption shows a moderate range of 4.11, the unemployment rate (6.14), which shows significant fluctuation among EU nations and years, has the widest range. Notably, the sampled countries’ economic differences are reflected in the range of 5.46 for GDP per capita.
Asymmetry and tail behavior are emphasized by skewness and kurtosis. The majority of the variables indicate moderate skewness, but the cloud adoption rate (0.84) and unemployment rate (1.64) show a noticeable right skew, suggesting a longer upper tail.
On the other hand, GDP per capita (−0.30) and internet availability (−0.59) exhibit a slight left skew. In contrast to broadband access (0.00) and higher education (−1.03), which have relatively flat distributions when compared to a normal curve, the unemployment rate is notable for its high kurtosis (3.80), which indicates a distribution with heavy tails and possible outliers.
These descriptive insights highlight the differences among EU member states, especially with regard to digital infrastructure and labor market conditions, which are anticipated to affect cloud adoption trends in the ensuing modeling.
To illustrate the bivariate correlations between all variables, a correlation matrix (
Appendix A.1) was created in addition to descriptive information. While the unemployment rate shows lower, negative associations, the figure shows large positive relationships between cloud adoption, broadband access, and ICT specialists.
Furthermore, to ensure the reliability of predictor effects, we assessed potential multicollinearity among core variables using Variance Inflation Factors (VIFs). The results indicated low multicollinearity: VIF values were 2.89 for ICT specialists, 2.77 for broadband access, and 1.91 for higher education. All variables fell well below conventional thresholds (VIF < 5), suggesting that multicollinearity is not a concern in our setting. Moreover, as our primary models are tree-based ensemble methods (e.g., Random Forest and XGBoost), which are inherently robust to moderate collinearity, no additional regularization or dimensionality reduction was required. The stability of feature importance across different algorithms and cross-validation folds further supports this robustness.
4.2. Model Performance and Variable Importance
The predictive performance of the Random Forest (RF) model was evaluated using the Root Mean Squared Error (RMSE) on the test dataset. Given the variation in cloud adoption rates among EU member states, the default RF model’s RMSE of 0.456 suggests an acceptable fit.
Using 10-fold cross-validation, we conducted hyperparameter tuning of the random forest model by exploring mtry values ranging from 2 to 10. The model’s predictive performance was relatively stable across this range, with the best configuration observed at mtry = 2, yielding an RMSE of 0.5639, R
2 of 0.6887, and MAE of 0.4158 (see
Table 3). Performance differences among adjacent mtry values were minor, suggesting that the model was not highly sensitive to this hyperparameter in the absence of country and year fixed effects.
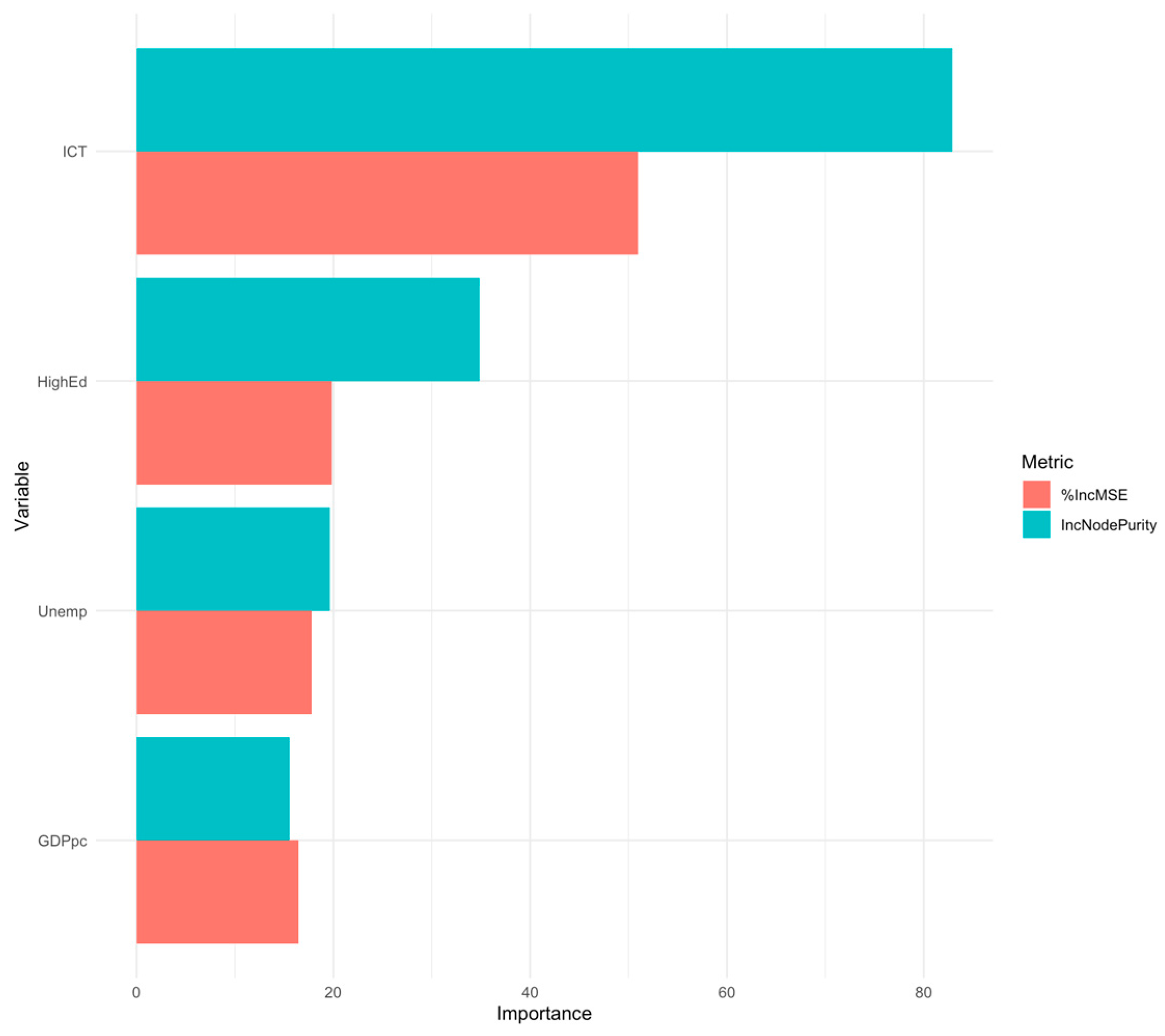
Variable importance was evaluated using the percentage increase in mean squared error (%IncMSE), a standard measure in random forest models that reflects how much worse the model performs when a given predictor is permuted. As per
Table 4, in the tuned model, ICT specialists and broadband access are the most influential predictors, with importance scores of 29.16% and 21.23%, respectively. This affirms the central role of both digital skills and infrastructure in shaping cloud adoption outcomes across EU member states.
Economic and educational indicators played secondary but meaningful roles: GDP per capita (14.26%) and higher education (10.82%) were moderately important. In contrast, the unemployment rate continued to contribute the least (9.67%). These results are consistent with the hypothesis that digital capacity, not just socioeconomic status, is a primary driver of cloud uptake.
Figure 2 illustrates the relative importance of each variable visually, reinforcing the dominant influence of ICT-related factors on model predictions. The emphasis on digital enablers highlights key areas for targeted policy intervention.
These findings underscore that while economic and educational variables contribute meaningfully, it is digital infrastructure and workforce readiness that most strongly predict cloud adoption. The results further support policy strategies focused on broadband expansion and ICT skill development as levers for accelerating digital transformation across the EU.
4.3. Robustness Check
4.3.1. Random Forest with Country Fixed Effects
To account for unobserved structural differences between EU member states, we extended the random forest model by introducing country fixed effects using one-hot encoding of the geo variable. In addition, we retained year as a continuous numeric predictor to capture temporal trends in cloud adoption over the study period. This enhanced specification allowed the model to jointly estimate the impact of structural geographic variation and the progression of digital transformation over time.
The inclusion of country identifiers resulted in a clear improvement in predictive performance. On the test set, the model achieved a root mean squared error (RMSE) of 0.421, a mean absolute error (MAE) of 0.321, and an R2 of 0.864, outperforming the tuned model without fixed effects, which had an RMSE of 0.437, MAE of 0.327, and R2 of 0.853. This improvement demonstrates that incorporating country-specific heterogeneity via dummy variables, along with a continuous temporal trend, enhances the model’s ability to generalize and capture complex variation in cloud adoption across EU member states.
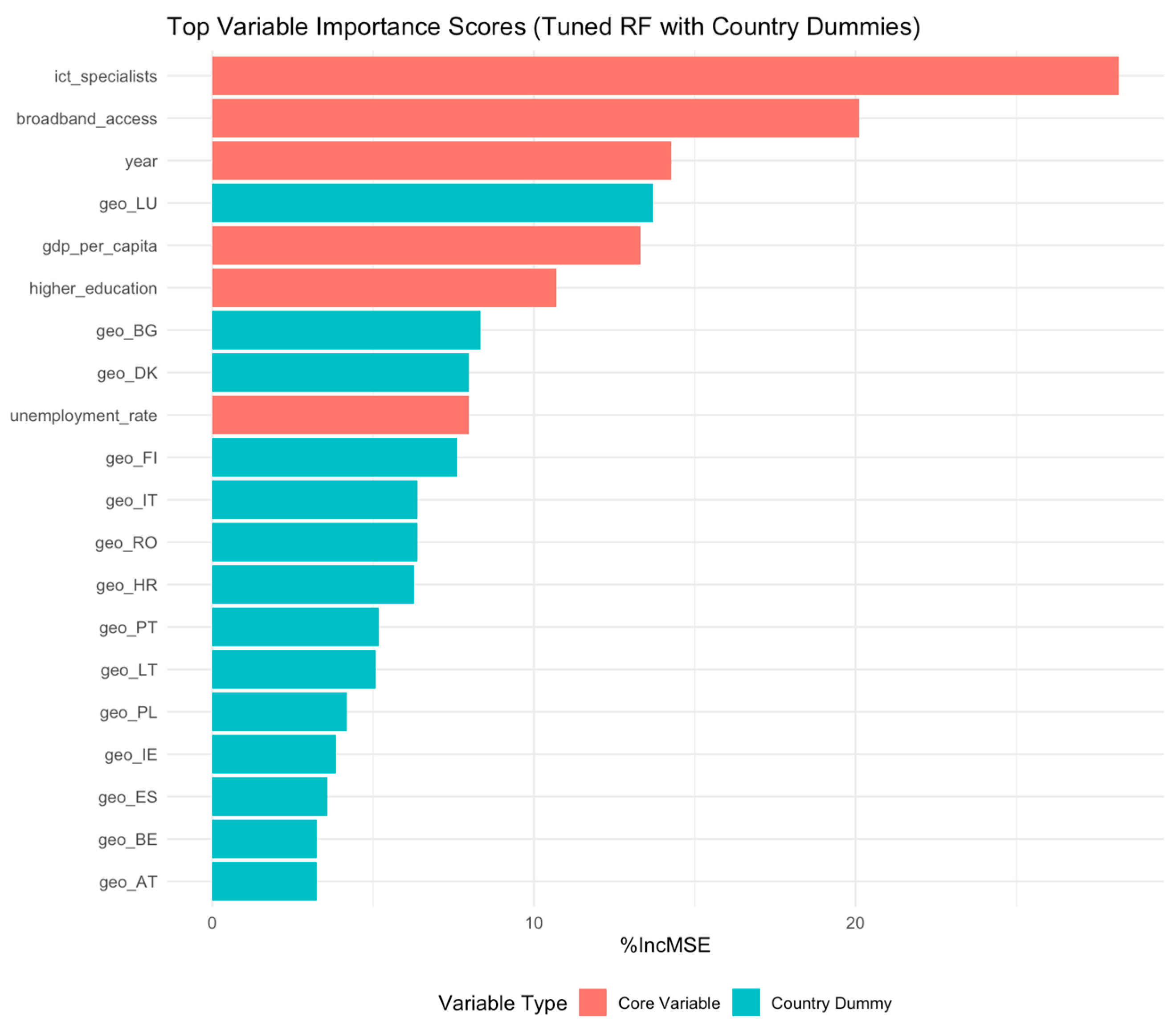
The updated variable importance scores are shown in
Table 5. Consistent with previous models, ICT specialists and broadband access remained the most influential predictors, with %IncMSE values of 28.18% and 20.12%, respectively. The year variable also emerged as highly predictive (14.27%), indicating a clear upward trend in cloud adoption over time. In addition, several country dummies, i.e., most notably Luxembourg (geo_LU) and Bulgaria (geo_BG), ranked among the top predictors, each contributing over 8–13% to model accuracy. This highlights the significance of national context, beyond economic or digital infrastructure measures alone.
A visual summary of these scores is provided in
Figure 3, which reinforces the dominant role of digital infrastructure and skills while also illustrating the added explanatory power of temporal and geographic indicators. The inclusion of fixed effects did not displace core digital predictors but rather enriched the model’s context awareness.
4.3.2. Econometric Benchmark: System GMM Estimation
To complement our machine learning analysis and address potential endogeneity in cloud adoption dynamics, we estimated a system GMM model [
53,
54] as a conventional econometric benchmark. This approach accounts for unobserved heterogeneity, autocorrelation, and potential reverse causality, offering a robustness check on our primary results.
The model includes lagged cloud adoption, ICT specialists, higher education, GDP per capita, broadband access, and unemployment rate as regressors. Lagged cloud adoption and ICT specialists are instrumented using their own lags in levels and differences, while the remaining predictors are treated as exogenous.
Key results show a strong and statistically significant persistence effect in cloud adoption (lag coefficient = 0.825, p < 0.001), alongside a positive and significant impact of ICT specialists (p = 0.023). Other variables—including education; income; and broadband access—do not achieve conventional significance levels in this linear specification.
These findings reinforce the results obtained from the random forest models: ICT workforce availability emerges as the most consistent and influential driver of cloud uptake across estimation strategies. Furthermore, all diagnostic tests (Sargan, AR(2)) indicate the validity of the instrument set and absence of higher-order autocorrelation.
However, the machine learning framework captures nonlinearities and complex interactions not fully accommodated by linear panel methods [
55,
56].
The system GMM full estimation output is reported in
Appendix A.2, which also includes the Sargan and Arellano–Bond tests in detail.
4.3.3. Alternative Machine Learning Models and Ensemble Learning
To validate the robustness of our modeling approach, we developed and assessed a range of alternative machine learning models, including Extreme Gradient Boosting (XGBoost), Support Vector Machines (SVM) with a linear kernel, and Elastic Net regression, alongside our primary Random Forest (RF) model. All models were tuned via 10-fold cross-validation, and their predictive performance was compared using RMSE, MAE, and R2.
Among the individual learners, Elastic Net achieved the best average performance (MAE = 0.224, RMSE = 0.297, R2 = 0.907), followed closely by SVM and XGBoost. The Random Forest model, while slightly behind in overall prediction accuracy (MAE = 0.354, RMSE = 0.455, R2 = 0.765), consistently demonstrated robust performance and stability across resamples.
We further combined all models into an ensemble using a greedy error-minimizing strategy. The resulting ensemble achieved the best overall MAE (0.214), assigning dominant weight to Elastic Net (75.5%) and XGBoost (22.0%), while RF contributed only marginally (2.5%). This reflects the ensemble’s bias toward models with minimal error variance in cross-validation.
However, while ensemble blending improved raw accuracy slightly, its complexity and lack of interpretability limit its practical value in policy settings. In contrast, the Random Forest model provides direct access to variable importance metrics and compatibility with SHAP explanations, making it especially useful for identifying key drivers of cloud adoption.
Crucially, across all models, ICT specialists emerged as one of the top three predictors, reaffirming the central role of digital workforce capacity (
Table 6). Both XGBoost and RF ranked ICT specialists and broadband access as their top two predictors, while Elastic Net identified year and ICT specialists as the most influential variables.
These findings underscore that while alternative models may offer slight gains in predictive accuracy, Random Forest remains the most appropriate tool for this analysis due to its explanatory power, transparency, and alignment with policy needs.
To ensure transparency and reproducibility, we report the training time required for each model under standardized settings in
Table 7. All models were trained on a MacBook Air 13” (Apple M3 chip) using RStudio Version 2024.12.1 and R 4.3.1, with 10-fold cross-validation for internal tuning. The computations were performed using the caret and caretEnsemble libraries.
Although the ensemble required the longest runtime, all models completed training in under 15 s, illustrating the feasibility of our approach even on lightweight consumer hardware. These timing benchmarks confirm that the proposed methods are not only statistically sound but also computationally efficient.
4.4. Explainable AI (XAI) Analysis
SHapley Additive exPlanations (SHAP) were used to better interpret the Random Forest (RF) model, providing detailed information on the ways in which each predictor influences cloud adoption. SHAP is a crucial tool for model transparency and policy interpretation since it helps quantify the average influence of each feature as well as the variability of its contribution across various projections.
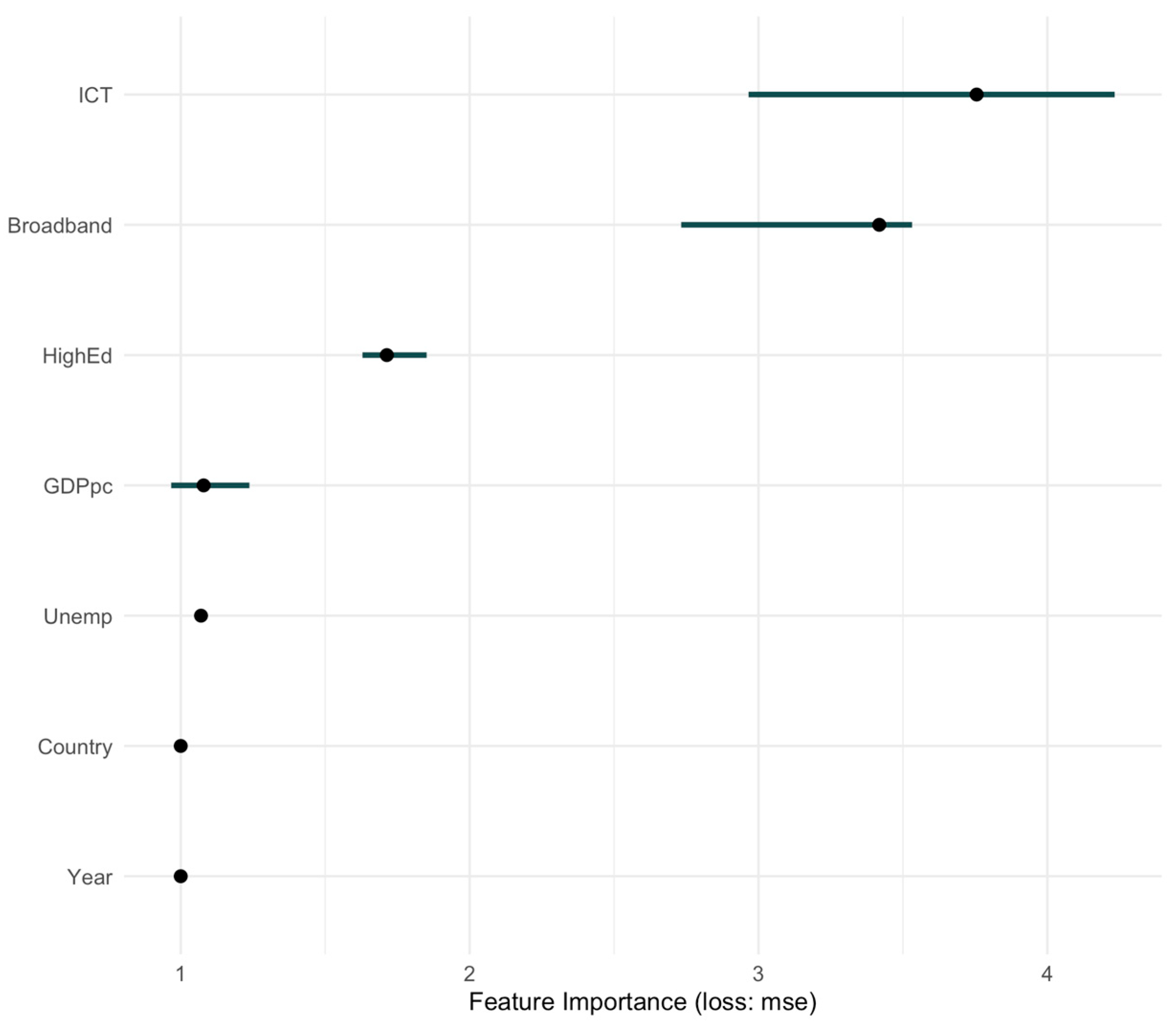
The SHAP-based feature importance plot for Panel A (2014–2021), derived from the tuned Random Forest model (mtry = 10, ntree = 500), trained on the standardized dataset without country fixed effects, is shown in
Figure 4. Of note, SHAP values were calculated using the iml package in R [
57,
58], which implements model-agnostic feature attribution based on the concept of marginal contributions from cooperative game theory [
59]. Specifically, we used the FeatureImp class, which approximates permutation-based Shapley values by quantifying each feature’s marginal impact on model error (measured as increased MSE) when its values are permuted. This approach captures global importance while preserving consistency and local accuracy. The visualized SHAP plot is derived from the tuned Random Forest model trained on standardized data without fixed effects and reflects feature contributions aggregated over all test observations. The predictor object was instantiated using the actual trained randomForest model and the test dataset held out during training.
With the biggest average contributions to lowering model error (as determined by mean squared error, or MSE), the ICT specialists (ICT) and broadband access (Broadband) variables emerged as the dominating predictors. These findings demonstrate the critical role that labor competencies and digital infrastructure play in propelling cloud adoption throughout the EU.
Economic and educational metrics, such as GDP per capita (GDPpc) and higher education (HighEd), showed moderate importance, while the unemployment rate (Unemp) had the least average influence.
Notably, the plot also illustrates variability (horizontal bars), indicating how consistently each feature influences predictions. ICT and broadband access show both high average importance and wide variability, suggesting their impact fluctuates across different country-year contexts, likely reflecting disparities in both workforce skills and digital infrastructure maturity. In contrast, higher education and GDP per capita demonstrate smaller average importance and lower variability, underscoring their stable but less dominant roles.
These SHAP results reinforce and deepen the earlier random forest importance findings, confirming that broadband connectivity and ICT workforce capacity are critical drivers of cloud adoption. The combination of high mean importance and substantial variability for ICT and broadband access suggests that policy interventions to boost human resource skills and digital infrastructure can have transformative effects, particularly in lagging regions.
4.5. Nonlinear and Interaction Effects
Partial Dependence Plots (PDPs) were created for broadband access, ICT specialists, and GDP per capita in addition to a 2D interaction plot for broadband and ICT specialists in order to better understand how key variables affect cloud adoption. Nonlinear linkages and interaction effects that are not immediately visible from normal variable significance measures are revealed by these visualizations.
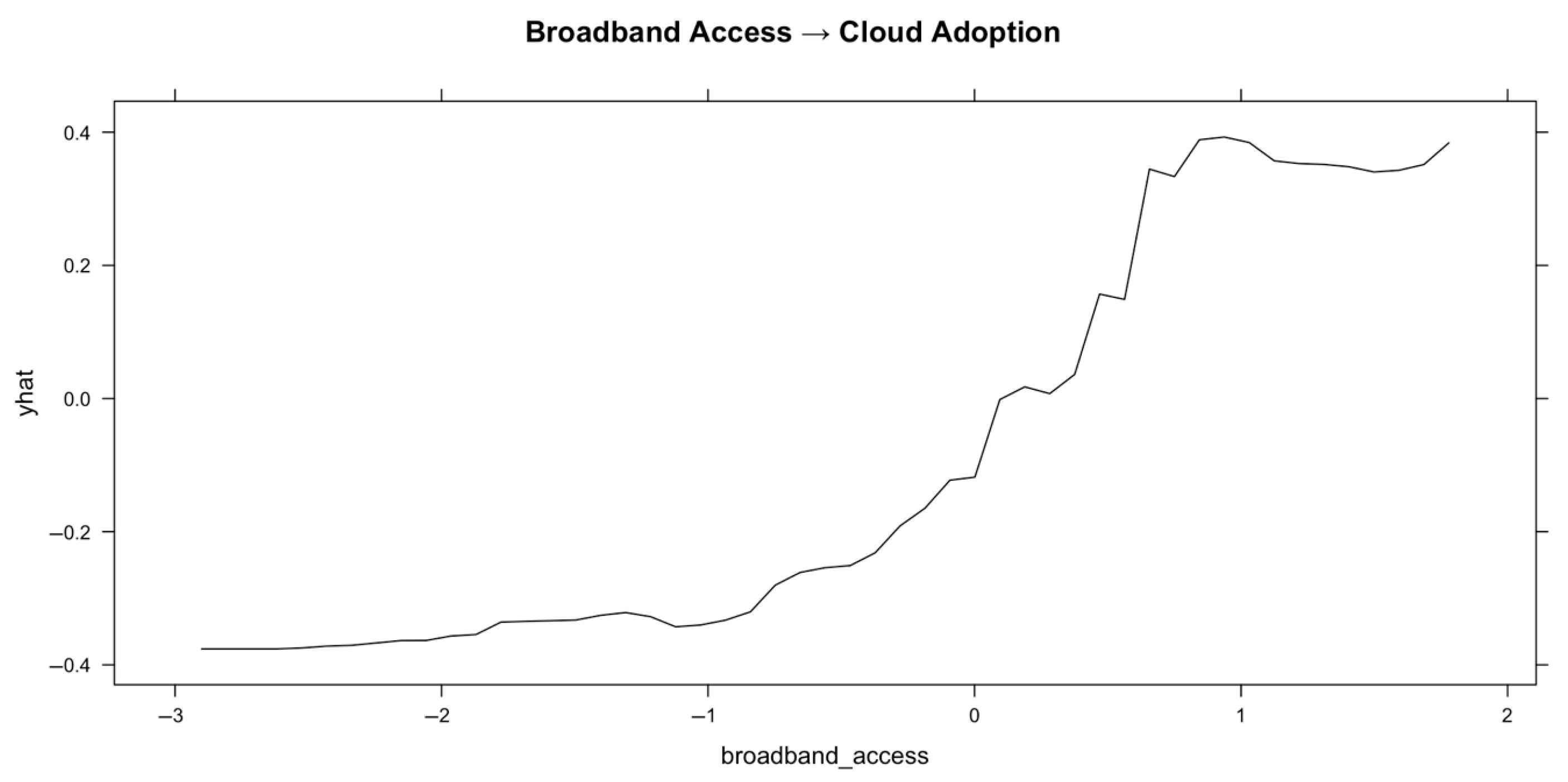
Figure 5 illustrates the substantial positive correlation between cloud use and broadband access. The PDP reveals a nonlinear trend: cloud adoption is still muted at very low broadband connection levels (standardized values below −1). The anticipated cloud adoption rate, however, rises dramatically as internet availability gets closer to average (about 0), plateauing at higher broadband levels. This implies that increasing broadband infrastructure above a particular point accelerates the adoption of cloud computing.
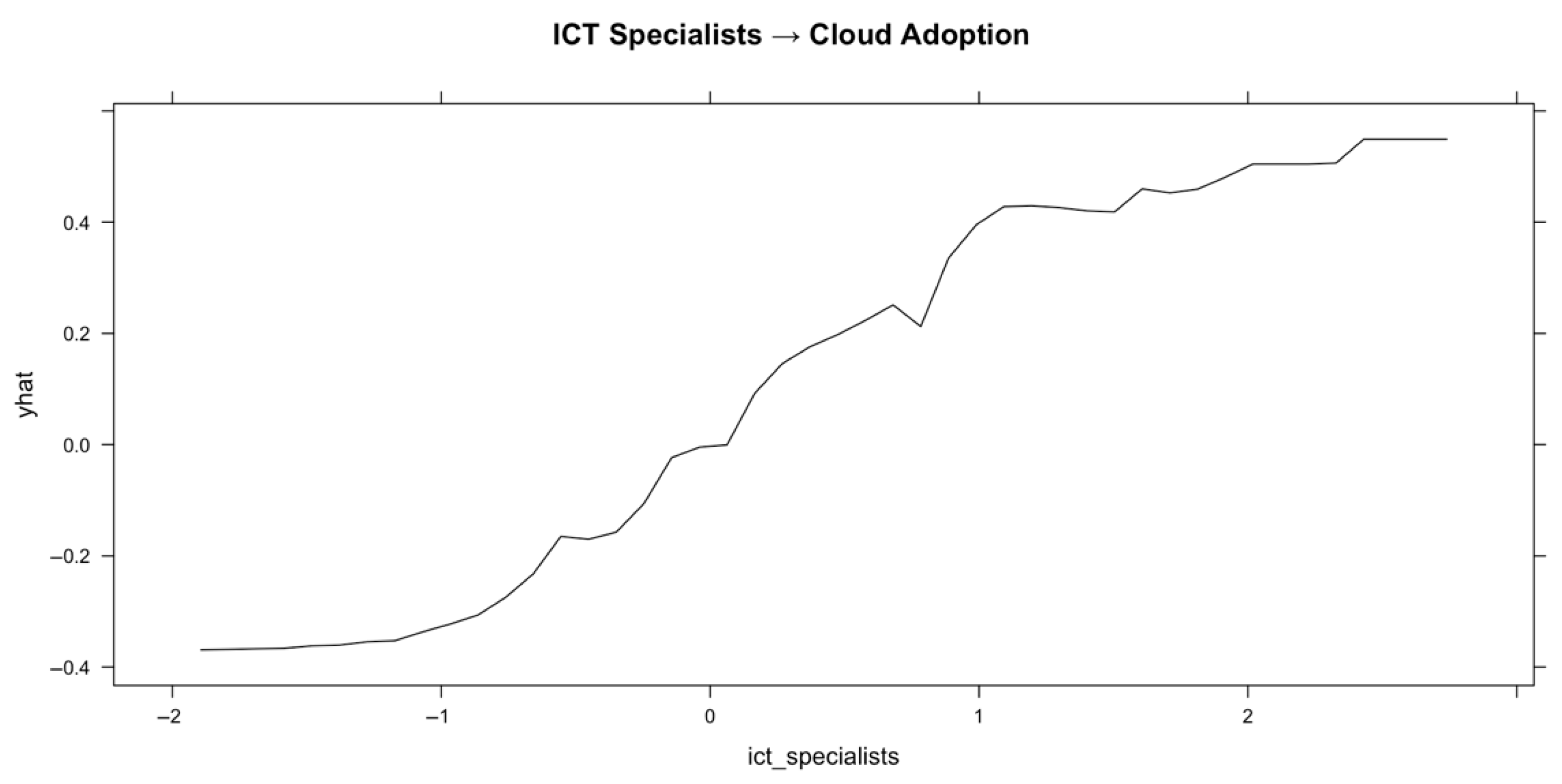
Figure 6 illustrates the relationship between ICT specialists and cloud adoption. The PDP reveals a strong, consistently positive relationship: as the share of ICT specialists increases, the predicted cloud adoption rate rises steadily, with no evident plateau. This trend underscores the critical role of digital workforce skills in facilitating cloud transformation across EU countries.
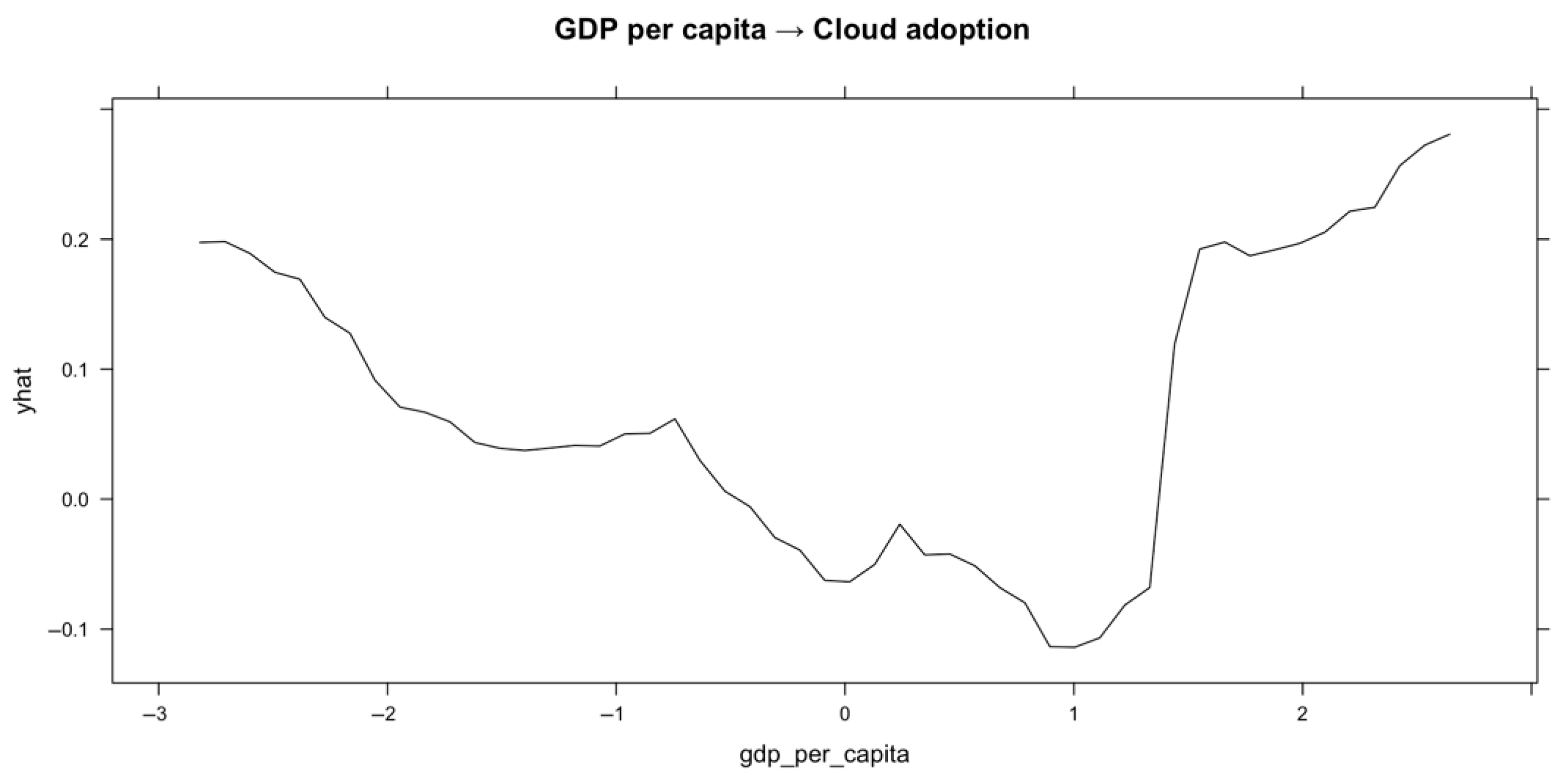
There is a complicated, nonlinear link between GDP per capita and PDP (
Figure 7). Initially, cloud adoption decreases significantly as GDP per capita rises from low levels (below 0); this seems contradictory and may indicate that cloud adoption is initially influenced more by digital readiness than by economic circumstance alone. Cloud use, however, starts to rise quickly as GDP per capita surpasses average levels (about 1), indicating that wealthier economies undergo a stronger push toward digital transformation provided specific baseline criteria are satisfied.
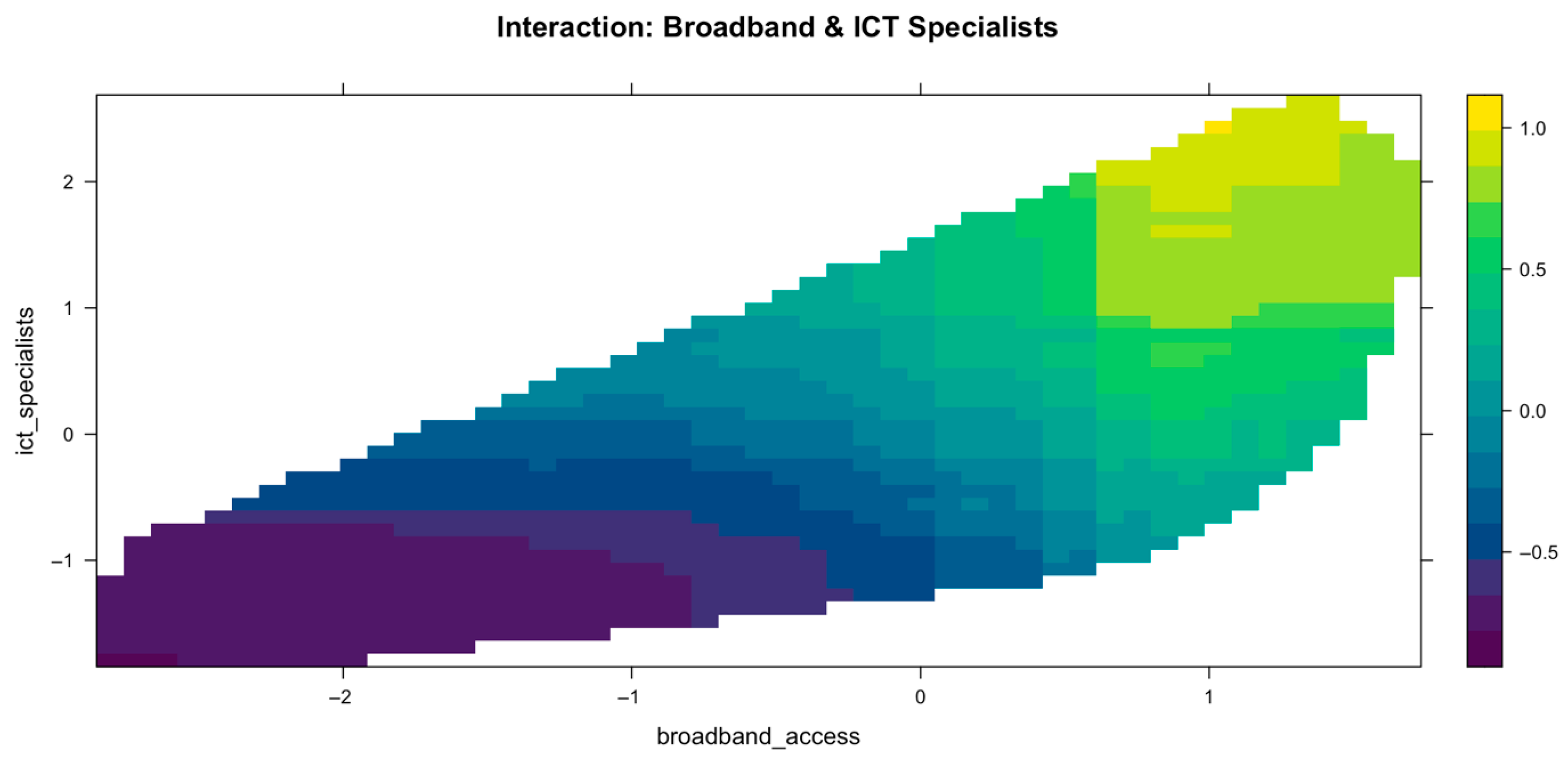
The interaction between broadband access and ICT specialists is visualized in
Figure 8. The contour plot reveals that cloud adoption is highest when both broadband access and ICT specialist density are high (top-right corner of the plot). On the other hand, the lowest anticipated cloud adoption is seen in regions with low internet and ICT levels (bottom-left). It is interesting to note that the relationship is nonlinear and synergistic: while increases in either component result in modest gains, increasing both broadband access and ICT capacity has a far greater overall impact, indicating that digital infrastructure and digital skills complement each other.
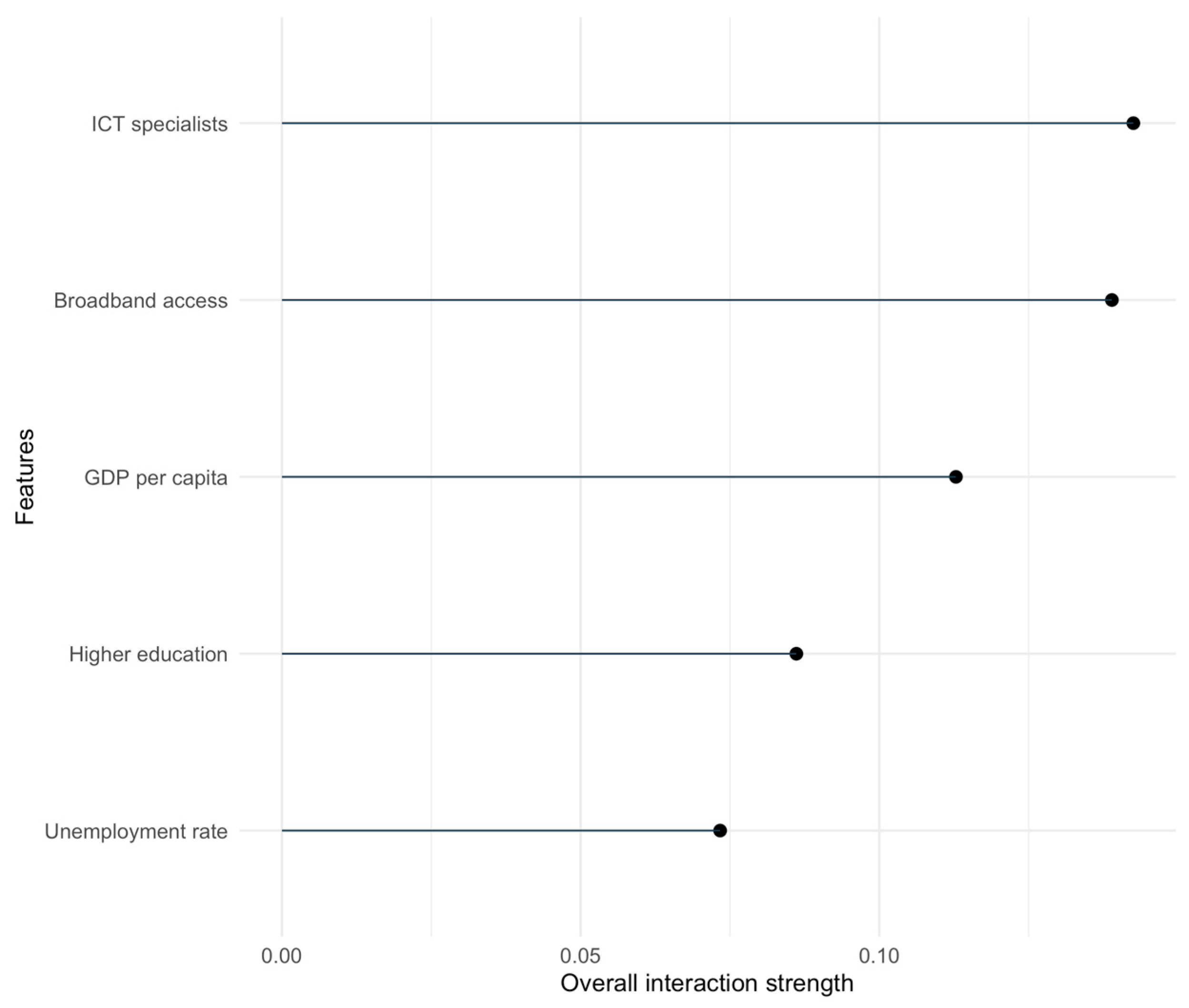
To further support the presence of nonlinear dependencies and conditional effects, we computed global feature interaction strengths using Friedman’s H-statistic, implemented via the Interaction$new() method in the iml package. This diagnostic quantifies how strongly each variable’s effect on the outcome depends on interactions with other features.
As shown in
Figure 9, ICT specialists and broadband access exhibit the highest interaction strengths, indicating their predictive effects are not purely additive but conditional on other structural features. Other predictors such as GDP per capita and higher education also demonstrate notable interaction behavior. These findings reinforce earlier SHAP and PDP visualizations, emphasizing that cloud adoption in the EU arises from nonlinear, complementary relationships between human capital and digital infrastructure.
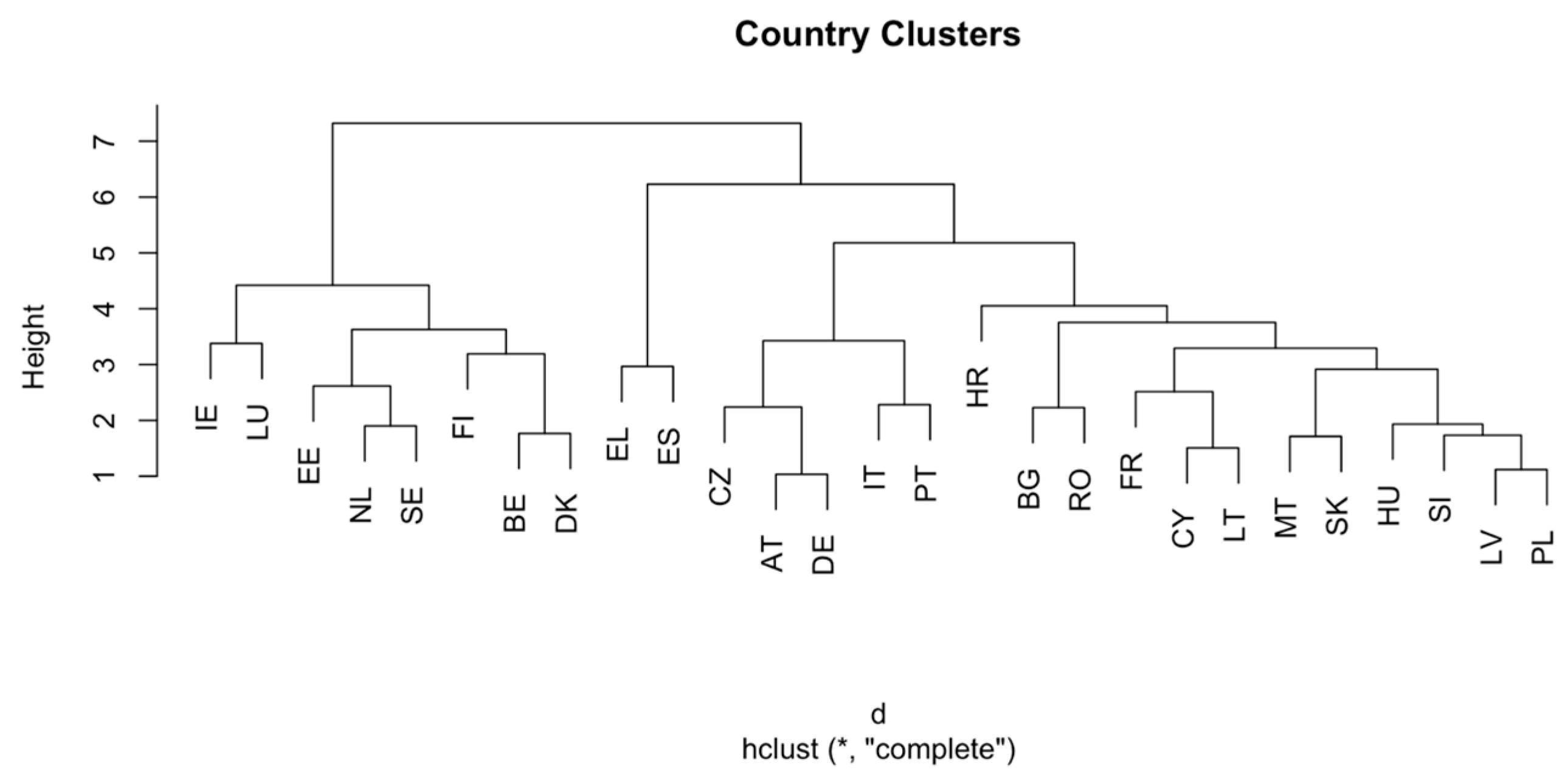
4.6. Country Clustering
We used standardized predictor variables to conduct a hierarchical clustering analysis of EU countries in order to investigate trends of digital and socioeconomic similarity. Three main clusters are identified by the resulting dendrogram (
Figure 10):
- (i)
Austria, Germany, Portugal, Italy, and the Czech Republic are examples of mid-tier countries with balanced but moderate levels of digital infrastructure and human capital;
- (ii)
a cluster of digitally lagging economies, such as Bulgaria, Romania, Slovakia, Latvia, and Hungary, which are characterized by lower digital maturity and broader socio-economic challenges; and
- (iii)
a group of digitally advanced countries, such as Luxembourg, Ireland, the Netherlands, Sweden, and Finland, which exhibit strong digital infrastructure, high ICT specialist density, and favorable socio-economic indicators.
The clustering emphasizes significant variation among EU member states and demonstrates how technological capability, human capital, and economic development interact to drive preparedness for digital transformation. Interestingly, despite national context variations, Romania and Bulgaria are immediately clustered inside the same sub-cluster, indicating their strong resemblance in digital infrastructure and socioeconomic indices. Within this cluster, their closeness to Slovakia and Latvia emphasizes the structural difficulties that are shared by regions of Eastern and Southeastern Europe.
This segmentation highlights the need for customized solutions to close gaps in digital maturity throughout the EU landscape and provides a data-driven foundation for addressing distinct policy approaches to digital transformation.
4.7. Further Robustness Analysis: Estimations on Panel B (Excluding Broadband Access)
We conducted a complementary analysis using Panel B, which spans the extended period 2014–2024 but excludes broadband availability as a predictor, to assess the robustness of our findings over time and to examine the implications of infrastructure data loss. The tuned Random Forest (RF) model trained on this temporally broader dataset achieved a Root Mean Squared Error (RMSE) of 0.515, a Mean Absolute Error (MAE) of 0.358, and an R2 of 0.737 on the test set. While this represents a moderate decline in predictive accuracy compared to Panel A (RMSE = 0.436, R2 = 0.854), it still indicates strong generalization and confirms the relevance of key predictors even in the absence of broadband metrics.
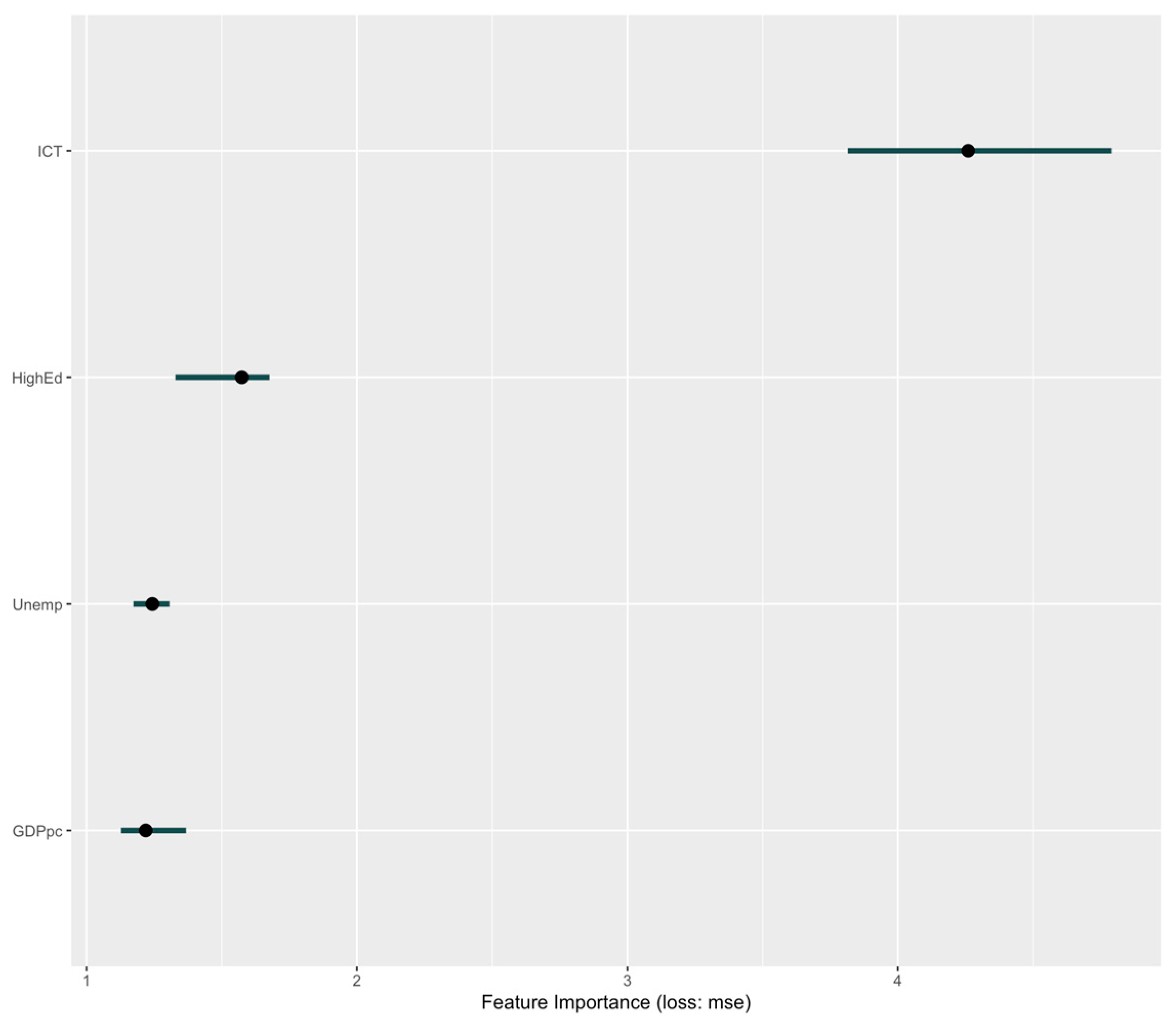
As shown in
Figure 11, ICT specialists remained the most influential factor (%IncMSE = 50.9), further emphasizing the pivotal role of digital workforce capacity in driving cloud adoption. Higher education (19.8%), unemployment rate (17.8%), and GDP per capita (16.4%) followed in importance, with a notable increase in the role of human capital variables. The exclusion of broadband slightly reshaped the relative contribution of remaining features, highlighting how digital infrastructure and skill development can act as partial substitutes in explaining adoption variation.
To enhance interpretability,
Figure 12 presents a SHAP-based feature importance visualization for Panel B. The SHAP values reinforce the dominance of ICT specialists and higher education, with ICT contributing over four times more than any other predictor to the model’s predictive loss reduction. The tight confidence intervals across features suggest stable contributions across observations and support the robustness of the identified drivers.
Taken together, the Panel B results confirm the resilience of human capital indicators in the predictive framework and further demonstrate that, even in the absence of broadband data, structural readiness remains explainable through education, labor force, and economic indicators. However, the mild performance degradation confirms the added explanatory value of infrastructure variables, underscoring the necessity of including both human and physical capital in policy design.
6. Conclusions
This study set out to examine the key macro-level determinants of cloud adoption across 27 EU member states by integrating socio-economic, educational, and technological variables into a machine learning framework. Using two harmonized panels (2014–2021 and 2014–2024), we trained and validated several models, including Random Forest, XGBoost, and SVM, to predict national cloud uptake rates. The models were further interpreted using explainable AI techniques such as SHAP values, ICE curves, and clustering analysis, yielding both predictive insights and actionable interpretations.
The findings consistently highlight the dominant role of digital human capital and infrastructure in enabling cloud transformation. Specifically, the presence of ICT specialists and broadband access emerged as the most influential predictors of cloud adoption. Higher levels of tertiary education and GDP per capita also contributed positively, albeit with a more moderate effect. Conversely, higher unemployment rates were negatively associated with cloud readiness, likely reflecting reduced capacity for investment and innovation. Partial dependence and interaction plots revealed important nonlinearities and synergies, especially between digital skills and broadband infrastructure, while hierarchical clustering uncovered clear groupings of digitally advanced, mid-tier, and lagging countries.
These insights carry strong policy relevance. First, they suggest that strengthening digital skills through vocational and higher education, particularly in ICT-related fields, remains a critical priority at the EU level. Second, investment in broadband infrastructure, especially in rural and underserved regions, is essential to unlock the full potential of cloud-based services. Third, the clustering analysis underscores the need for differentiated strategies across EU member states. For digitally lagging countries, simultaneous investment in infrastructure and human capital is vital, whereas mid-tier nations may benefit from targeted innovation policies and harmonized digital regulation. In contrast, advanced economies should focus on consolidating digital leadership and addressing institutional bottlenecks that may hinder further cloud scaling. Countries such as Romania and Bulgaria, despite strong technical indicators, may require broader socio-economic interventions to translate digital capacity into adoption outcomes.
Nevertheless, this study is not without limitations. The absence of broadband data beyond 2021 constrained full-panel modeling, limiting the temporal horizon of some analyses. While machine learning models and explainability tools offer rich insights, they remain correlational in nature; causal inference would benefit from complementary approaches such as natural experiments or instrumental variable designs. Moreover, national-level analyses cannot capture the heterogeneity that exists within countries. Thus, future studies could incorporate firm-level or regional microdata to assess intra-country disparities. Finally, while our model captures cross-sectional temporal variation, future research could benefit from explicitly incorporating dynamic modeling frameworks to account for delayed policy impacts and feedback effects over time. Moreover, future research could extend the comparative scope beyond the EU27 by including EFTA countries or adjacent regions. Such a comparison would help assess divergence in structural readiness, regulatory environments, and digital policy implementation. Also, future studies could explore how national progress toward Digital Decade targets interacts with cloud adoption over time, potentially leveraging dynamic policy indicators or national digital investment scores.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}