

MPVT: An Efficient Multi-Modal Prompt Vision Tracker for Visual Target Tracking
 , ,
, ,
Abstract
1. Introduction
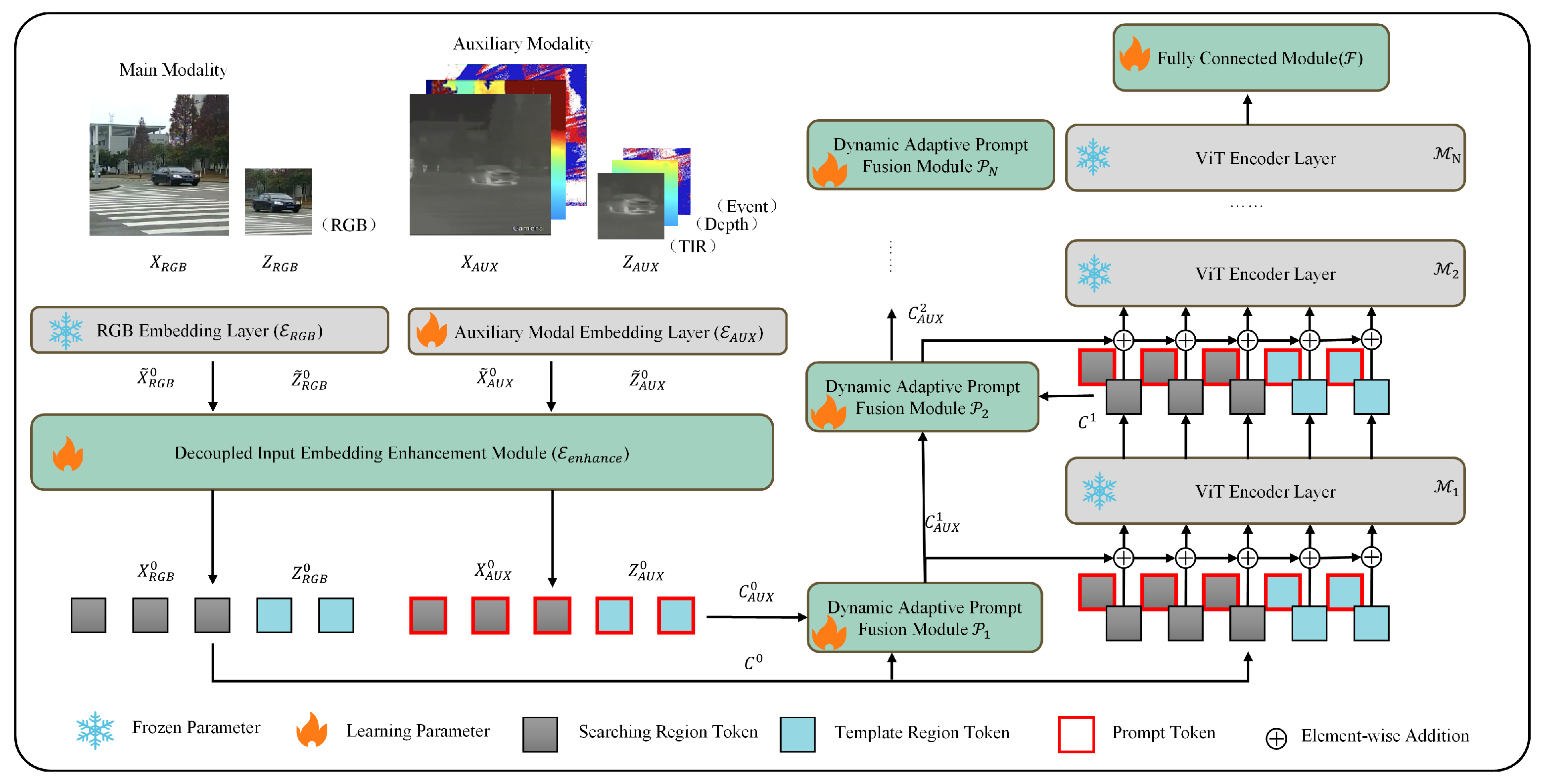
2. Materials and Methods
2.1. Decoupled Input Embedding Enhancement Module
2.2. Dynamic Adaptive Prompt Fusion Module
- (1)
- Dynamic Channel Scaling Convolution
- (2)
- Low-Rank Cross-Modal Attention
- (3)
- Grouped Linear Mapping
2.3. Fully Connected Head Network Module
3. Experimental Results and Discussion
3.1. Datasets
3.2. Evaluation Indices
3.3. Model Parameter Settings
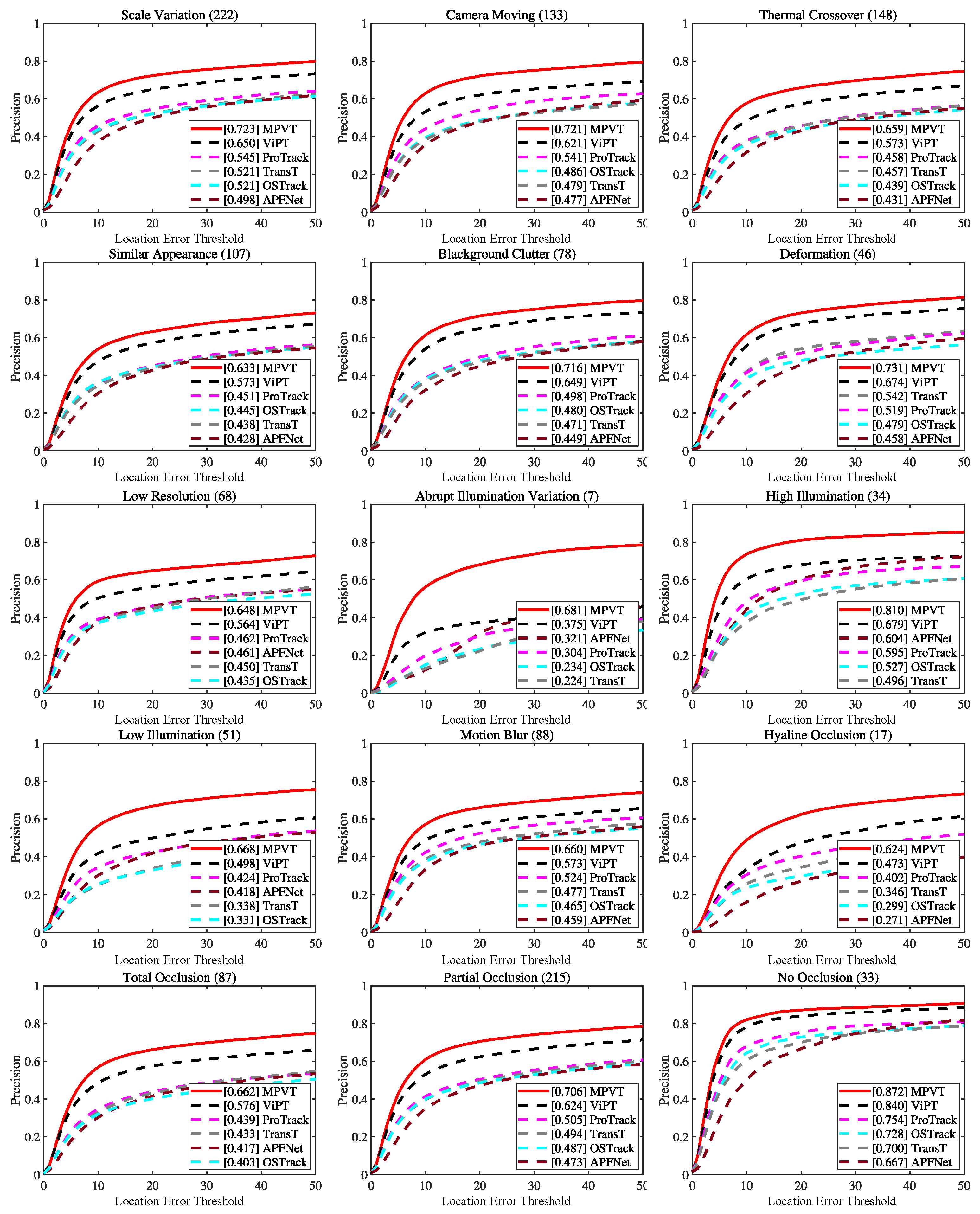
3.4. Main Results
3.5. Ablation Study
3.6. Model Analysis
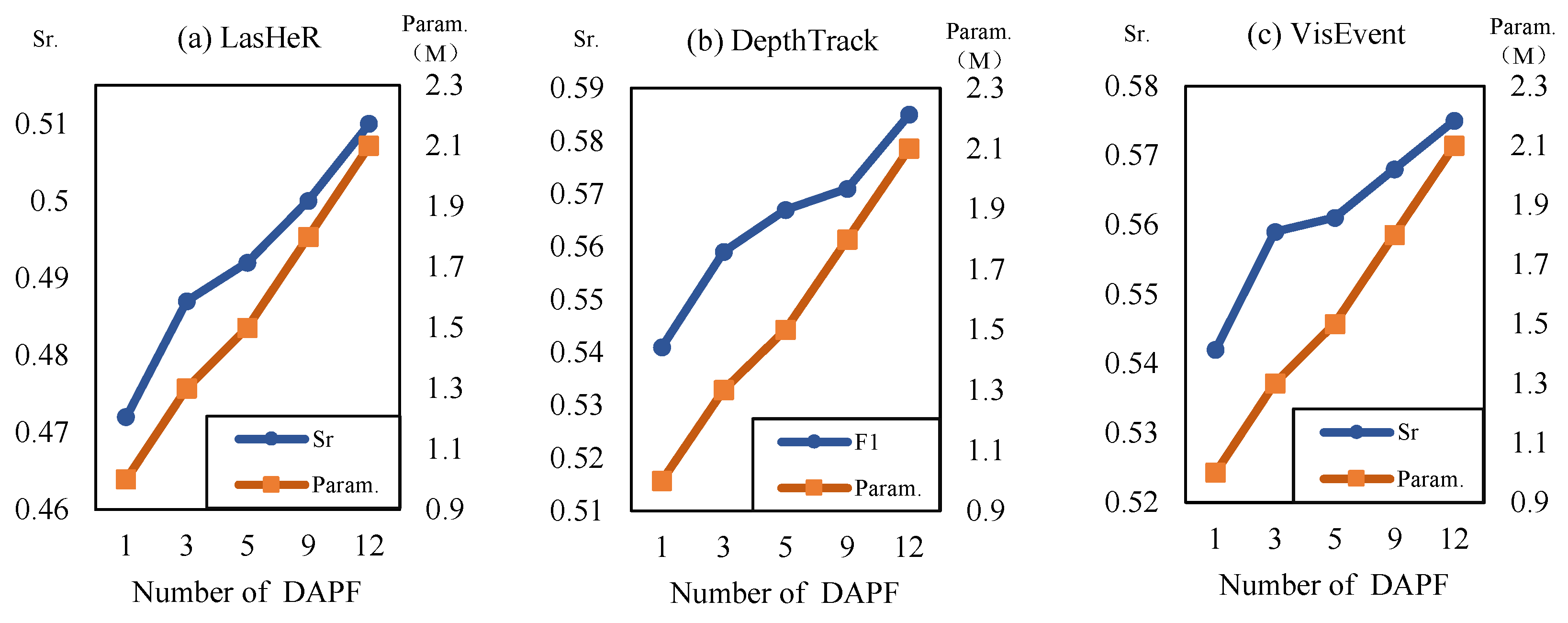
3.6.1. Sensitivity Analysis of Prompt Depth
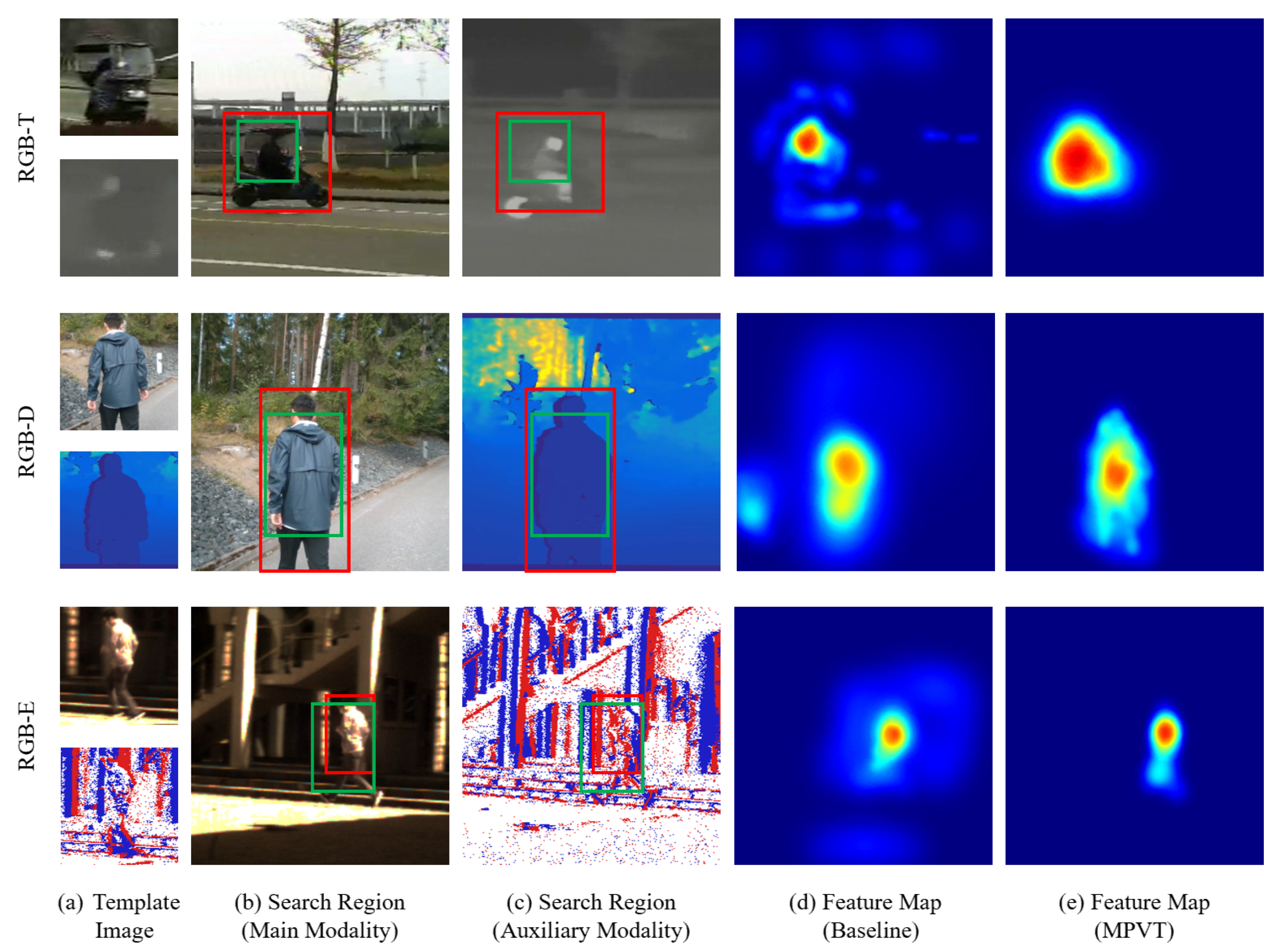
3.6.2. Feature Visualization
3.6.3. Model Efficiency
3.6.4. Differences Between MPVT and Vision–Language Prompting
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cui, Y.; Jiang, C.; Wang, L.; Wu, G. MixFormer: End-to-End Tracking with Iterative Mixed Attention. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 13598–13608. [Google Scholar] [CrossRef]
- Zhang, Z.; Peng, H. Deeper and Wider Siamese Networks for Real-Time Visual Tracking. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4586–4595. [Google Scholar] [CrossRef]
- Chen, X.; Peng, H.; Wang, D.; Lu, H.; Hu, H. SeqTrack: Sequence to sequence learning for visual object tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 14572–14581. [Google Scholar] [CrossRef]
- Hui, T.; Xun, Z.; Peng, F.; Huang, J.; Wei, X.; Wei, X.; Dai, J.; Han, J.; Liu, S. Bridging search region interaction with template for RGB-T tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 13630–13639. [Google Scholar] [CrossRef]
- Xiao, Y.; Yang, M.; Li, C.; Liu, L.; Tang, J. Attribute-based progressive fusion network for RGBT tracking. Proc. AAAI Conf. Artif. Intell. 2022, 36, 2831–2838. [Google Scholar] [CrossRef]
- Feng, M.; Su, J. Learning reliable modal weight with transformer for robust RGBT tracking. Knowl.-Based Syst. 2022, 249, 108945. [Google Scholar] [CrossRef]
- Yan, S.; Yang, J.; Käpylä, J.; Zheng, F.; Leonardis, A.; Kämäräinen, J.K. DepthTrack: Unveiling the power of RGBD tracking. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10705–10713. [Google Scholar] [CrossRef]
- Qian, Y.; Yan, S.; Lukežič, A.; Kristan, M.; Kämäräinen, J.K.; Matas, J. DAL: A deep depth-aware long-term tracker. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 7825–7832. [Google Scholar] [CrossRef]
- Wang, X.; Li, J.; Zhu, L.; Zhang, Z.; Chen, Z.; Li, X.; Wang, Y.; Tian, Y.; Wu, F. VisEvent: Reliable object tracking via collaboration of frame and event flows. IEEE Trans. Cybern. 2024, 54, 1997–2010. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wang, Y.; Liu, W.; Li, M.; Bai, J.; Yin, B.; Yang, X. Frame-event alignment and fusion network for high frame rate tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 9781–9790. [Google Scholar] [CrossRef]
- Zhu, Z.; Hou, J.; Wu, D.O. Cross-modal orthogonal high-rank augmentation for RGB-event transformer-trackers. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 22045–22055. [Google Scholar]
- Li, C.; Liu, L.; Lu, A.; Ji, Q.; Tang, J. Challenge-aware RGBT tracking. In Computer Vision—ECCV 2020; Lecture Notes in Computer Science; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12367, pp. 222–237. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, D.; Lu, H.; Yang, X. Learning adaptive attribute-driven representation for real-time RGB-T tracking. Int. J. Comput. Vis. 2021, 129, 2714–2729. [Google Scholar] [CrossRef]
- Li, C.L.; Lu, A.; Zheng, A.H.; Tu, Z.; Tang, J. Multi-adapter RGBT tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 2262–2270. [Google Scholar] [CrossRef]
- Lu, A.; Li, C.; Yan, Y.; Tang, J.; Luo, B. RGBT tracking via multi-adapter network with hierarchical divergence loss. IEEE Trans. Image Process. 2021, 30, 5613–5625. [Google Scholar] [CrossRef] [PubMed]
- Lu, A.; Qian, C.; Li, C.; Tang, J.; Wang, L. Duality-gated mutual condition network for RGBT tracking. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 4118–4131. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Li, C.; Tang, J.; Luo, B. Quality-aware feature aggregation network for robust RGBT tracking. IEEE Trans. Intell. Veh. 2021, 6, 121–130. [Google Scholar] [CrossRef]
- Wang, C.; Xu, C.; Cui, Z.; Zhou, L.; Zhang, T.; Zhang, X.; Yang, J. Cross-modal pattern-propagation for RGB-T tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7062–7071. [Google Scholar] [CrossRef]
- Zhu, Y.; Guo, R.; Wang, Y.; Lu, W. ViPT: Visual prompt multi-modal tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12234–12243. [Google Scholar]
- Hou, R.; Xu, B.; Ren, T.; Wu, G. MTNet: Learning modality-aware representation with transformer for RGBT tracking. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; pp. 1163–1168. [Google Scholar] [CrossRef]
- Xue, Y.; Zhang, J.; Lin, Z.; Li, C.; Huo, B.; Zhang, Y. SiamCAF: Complementary attention fusion-based siamese network for RGBT tracking. Remote Sens. 2023, 15, 3252. [Google Scholar] [CrossRef]
- Wang, H.; Xu, T.; Tang, Z.; Wu, X.J.; Kittler, J. Multi-modal adapter for RGB-T tracking. Inf. Fusion 2025, 118, 102940. [Google Scholar] [CrossRef]
- Hannuna, S.; Camplani, M.; Hall, J.; Mirmehdi, M.; Damen, D.; Burghardt, T.; Paiement, A.; Tao, L. DS-KCF: A real-time tracker for RGB-D data. J. Real-Time Image Process. 2019, 16, 1439–1458. [Google Scholar] [CrossRef]
- Xiao, J.; Stolkin, R.; Gao, Y.; Leonardis, A. Robust fusion of color and depth data for RGB-D target tracking using adaptive range-invariant depth models and spatio-temporal consistency constraints. IEEE Trans. Cybern. 2018, 48, 2485–2499. [Google Scholar] [CrossRef] [PubMed]
- Jiang, M.; Deng, C.; Shan, J.; Wang, Y.; Jia, Y.; Sun, X. Hierarchical multi-modal fusion FCN with attention model for RGB-D tracking. Inf. Fusion 2019, 50, 1–8. [Google Scholar] [CrossRef]
- Kart, U.; Lukežič, A.; Kristan, M.; Kämäräinen, J.K.; Matas, J. Object tracking by reconstruction with view-specific discriminative correlation filters. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1339–1348. [Google Scholar] [CrossRef]
- Gao, L.; Ke, Y.; Zhao, W.; Zhang, Y.; Jiang, Y.; He, G.; Li, Y. RGB-D visual object tracking with transformer-based multi-modal feature fusion. Knowl.-Based Syst. 2025, 322, 113531. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, X.; Fu, Y.; Wei, X.; Yin, B.; Dong, B. Object tracking by jointly exploiting frame and event domain. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 13023–13032. [Google Scholar] [CrossRef]
- Yang, J.; Li, Z.; Zheng, F.; Leonardis, A.; Song, J. Prompting for multi-modal tracking. In Proceedings of the MM ’22: 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 3492–3500. [Google Scholar] [CrossRef]
- Hong, L.; Yan, S.; Zhang, R.; Li, W.; Zhou, X.; Guo, P.; Jiang, K.; Chen, Y.; Li, J.; Chen, Z.; et al. OneTracker: Unifying visual object tracking with foundation models and efficient tuning. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 19079–19091. [Google Scholar] [CrossRef]
- Shi, L.; Zhong, B.; Liang, Q.; Li, N.; Zhang, S.; Li, X. Explicit visual prompts for visual object tracking. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI’24), Vancouver, BC, Canada, 20–27 February 2024; AAAI Press: Cambridge, MA, USA, 2024; Volume 38, pp. 4838–4846. [Google Scholar] [CrossRef]
- Ye, B.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Joint feature learning and relation modeling for tracking: A one-stream framework. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer: Cham, Switzerland, 2022; pp. 341–357. [Google Scholar] [CrossRef]
- Li, C.; Xue, W.; Jia, Y.; Qu, Z.; Luo, B.; Tang, J.; Sun, D. LasHeR: A large-scale high-diversity benchmark for RGBT tracking. IEEE Trans. Image Process. 2022, 31, 392–404. [Google Scholar] [CrossRef] [PubMed]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. arXiv 2017. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Chia Laguna Resort, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar] [CrossRef]
- Danelljan, M.; Van Gool, L.; Timofte, R. Probabilistic regression for visual tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7181–7190. [Google Scholar] [CrossRef]
- Dai, K.; Zhang, Y.; Wang, D.; Li, J.; Lu, H.; Yang, X. High-performance long-term tracking with meta-updater. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6297–6306. [Google Scholar] [CrossRef]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8122–8131. [Google Scholar] [CrossRef]
- Wang, H.; Liu, X.; Li, Y.; Sun, M.; Yuan, D.; Liu, J. Temporal adaptive RGBT tracking with modality prompt. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; AAAI Press: Cambridge, MA, USA, 2024; Volume 38, pp. 5436–5444. [Google Scholar] [CrossRef]
- Ying, G.; Zhang, D.; Ou, Z.; Wang, X.; Zheng, Z. Temporal adaptive bidirectional bridging for RGB-D tracking. Pattern Recognit. 2025, 158, 111053. [Google Scholar] [CrossRef]
- Wu, Z.; Zheng, J.; Ren, X.; Vasluianu, F.A.; Ma, C.; Paudel, D.P.; Van Gool, L.; Timofte, R. Single-model and any-modality for video object tracking. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 19156–19166. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. arXiv 2021. [Google Scholar] [CrossRef]
- Cheng, Z.; Chen, Q.; Zhang, J.; Fei, H.; Feng, X.; Che, W.; Li, M.; Qin, L. CoMT: A Novel Benchmark for Chain of Multi-modal Thought on Large Vision-Language Models. Proc. AAAI Conf. Artif. Intell. 2025, 39, 23678–23686. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Value |
|---|---|
| Layers (N) | 40 |
| Hidden dimensions (d) | 1536 |
| Size of searching image () | 378 |
| Size of template image () | 196 |
| Feature size of searching region | 27 |
| Feature size of template region | 14 |
| Epochs | 60 |
| Batch size | 16 |
| Learning rate | Maximal rate was ; minimal rate was |
| Method | * | LasHeR | DepthTrack | VisEvent | ||||
|---|---|---|---|---|---|---|---|---|
| (↑) | (↑) | 1 (↑) | (↑) | (↑) | (↑) | (↑) | ||
| TBSI [4] | 100% | 0.506 | 0.638 | - | - | - | - | - |
| APFNet [5] | 100% | 0.362 | 0.500 | - | - | - | - | - |
| FANet [17] | 100% | 0.309 | 0.441 | - | - | - | - | - |
| CAT [12] | 100% | 0.314 | 0.450 | - | - | - | - | - |
| MDNet [36] | 100% | - | - | - | - | - | 0.426 | 0.661 |
| PrDIMP50 [37] | 100% | - | - | - | - | - | 0.453 | 0.644 |
| LTMU [38] | 100% | - | - | 0.460 | 0.417 | 0.512 | 0.459 | 0.655 |
| OSTrack [32] | 100% | 0.412 | 0.515 | 0.529 | 0.522 | 0.536 | 0.534 | 0.695 |
| TransT [39] | 100% | 0.394 | 0.524 | - | - | - | 0.474 | 0.650 |
| DAL [8] | 100% | - | - | 0.429 | 0.369 | 0.512 | - | - |
| TATrack [40] | 100% | 0.559 | 0.702 | - | - | - | - | - |
| TABBTrack [41] | 100% | - | - | 0.618 | 0.615 | 0.622 | - | - |
| ProTrack [29] | <1% | 0.420 | 0.538 | 0.578 | 0.573 | 0.583 | 0.471 | 0.632 |
| ViPT [19] | 0.4% | 0.525 | 0.651 | 0.594 | 0.596 | 0.592 | 0.592 | 0.758 |
| Un-Track [42] | 6.74% | 0.536 | 0.667 | - | - | - | 0.589 | 0.755 |
| MPVT | 0.9% | 0.578 | 0.724 | 0.628 | 0.626 | 0.631 | 0.624 | 0.761 |
| Method | LasHer | DepthTrack | VisEvent | |||||
|---|---|---|---|---|---|---|---|---|
| (↑) | (↑) | 1 (↑) | (↑) | (↑) | (↑) | (↑) | ||
| MPVT | 0.9% | 0.578 | 0.724 | 0.628 | 0.626 | 0.631 | 0.624 | 0.761 |
| MPVT-FC | 0.8% | 0.562 | 0.711 | 0.613 | 0.612 | 0.614 | 0.609 | 0.758 |
| MPVT-PF | 100% | 0.523 | 0.654 | 0.570 | 0.569 | 0.571 | 0.594 | 0.754 |
| MPVT-IE | 100% | 0.517 | 0.648 | 0.556 | 0.554 | 0.557 | 0.587 | 0.752 |
| Type | Training Time | GPU Memory Usage | Inference Speed |
|---|---|---|---|
| (Hours)↓ | (GB)↓ | (fps)↑ | |
| Full fine-tuning | 62.2 | 38.1 | 18 |
| (removing prompt fusion module) | |||
| Prompt learning | 23.1 | 21.4 | 17 |
| (enabling prompt fusion module) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, J.; Fu, Y.; Zhou, J.; He, T.; Wang, X.; Fang, Y.; Chen, D. MPVT: An Efficient Multi-Modal Prompt Vision Tracker for Visual Target Tracking. Appl. Sci. 2025, 15, 7967. https://doi.org/10.3390/app15147967
Xie J, Fu Y, Zhou J, He T, Wang X, Fang Y, Chen D. MPVT: An Efficient Multi-Modal Prompt Vision Tracker for Visual Target Tracking. Applied Sciences. 2025; 15(14):7967. https://doi.org/10.3390/app15147967
Chicago/Turabian StyleXie, Jianyu, Yan Fu, Junlin Zhou, Tianxiang He, Xiaopeng Wang, Yuke Fang, and Duanbing Chen. 2025. "MPVT: An Efficient Multi-Modal Prompt Vision Tracker for Visual Target Tracking" Applied Sciences 15, no. 14: 7967. https://doi.org/10.3390/app15147967
APA StyleXie, J., Fu, Y., Zhou, J., He, T., Wang, X., Fang, Y., & Chen, D. (2025). MPVT: An Efficient Multi-Modal Prompt Vision Tracker for Visual Target Tracking. Applied Sciences, 15(14), 7967. https://doi.org/10.3390/app15147967