


Application of Deep Neural Networks in Recognition of Selected Types of Objects in Digital Images


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Results of Research
2.1. Description of Selected Convolutional Network Structures
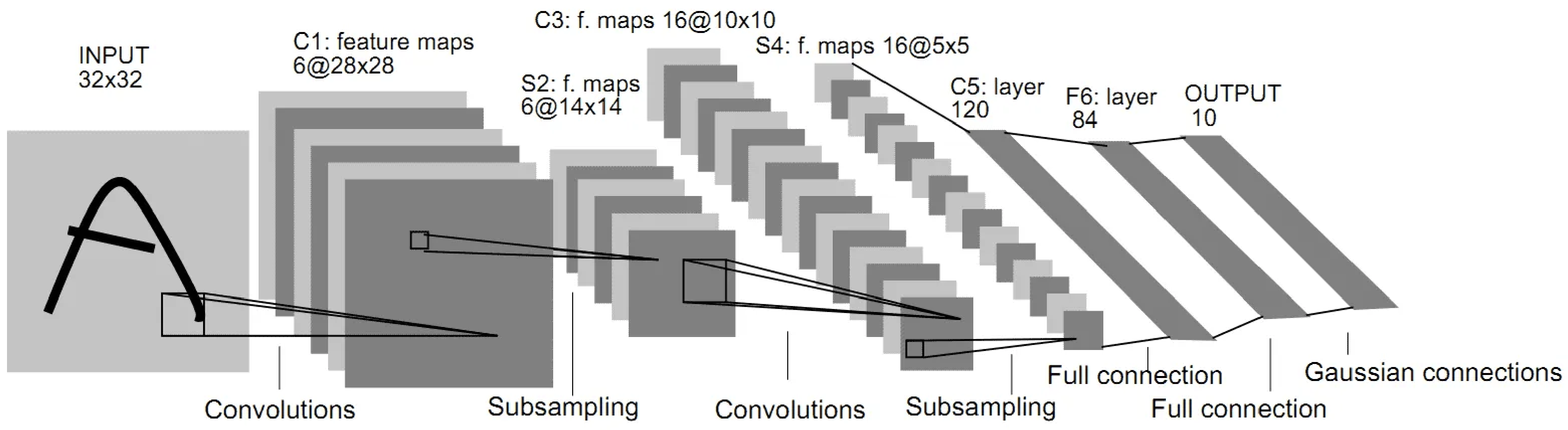
- Two convolutional layers: the first one processes the input image of 32 × 32 pixels, using 6 filters of size 5 × 5 pixels. The second convolutional layer uses 16 filters.
- Two subsampling layers: they reduce the resolution of feature maps using max-pooling operations.
- Three fully connected layers: these layers function similarly to the classical multilayer perceptron layers and are used for final classification [27].
- Five convolutional layers: the first convolutional layer processes the input image of 227 × 227 pixels (some sources use 224 × 224 pixels), using 96 filters of 11 × 11 pixels. The next convolutional layers apply smaller filters, 5 × 5 and 3 × 3, respectively, with different numbers of filters (256, 384, 384, 256).
- Three max-pooling layers: these layers reduce the resolution of the feature maps using max-pooling operations, which reduces the amount of data to be processed and introduces some robustness to image shifts.
- Three fully-connected layers: the first two fully-connected layers have 4096 neurons each and function similarly to classical multilayer perceptron layers, and the third fully-connected layer contains 1000 neurons and is used for final classification using the softmax function [29].
- Initial layers: The architecture starts with convolutional layers, which are used to extract features from the input image. Given a 224 × 224 × 3 input, the following operations are applied:
- –
- 7 × 7 convolutional layer with 64 filters, stride 2, ReLU activation function;
- –
- MaxPooling2D layer with 3 × 3 filter size and stride 2;
- –
- 1 × 1 convolutional layer with 64 filters, ReLU activation function;
- –
- 3 × 3 convolutional layer with 192 filters, ReLU activation function;
- –
- MaxPooling2D layer with 3 × 3 filter size and stride 2.
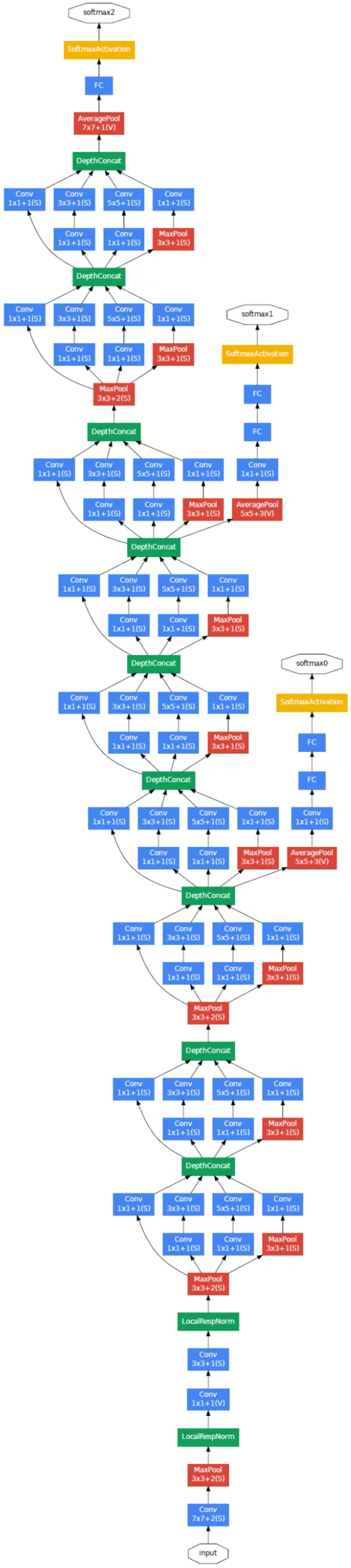
- Nine inception modules (red boxes): Inception modules are the key element of the architecture, using multiple convolution branches with different filter sizes to efficiently extract features from images.
- Two softmax auxiliary layers (green boxes): These layers play a key role in the network training and regularization process. Their presence is intended to speed up the learning process by guiding the network towards the goal and ensuring that the intermediate functions generated by the network are good enough.
- Global Average Pooling: Instead of a fully connected layer, global averaging is used, which makes it easier to adjust and improve the network.
- An averaging layer with a filter size of 5 × 5 and stride 3, giving an output of size 4 × 4 × 512 for the first auxiliary layer softmax0 and 4 × 4 × 528 for the second auxiliary layer softmax1;
- A 1 × 1 convolutional layer with 128 filters, with a ReLU function after each of them;
- A fully connected layer with 1024 neurons and a ReLU activation function;
- A dropout layer with a value of 70%;
- A linear layer with 1000 classes and a softmax function.
2.2. Research Methodology
- -
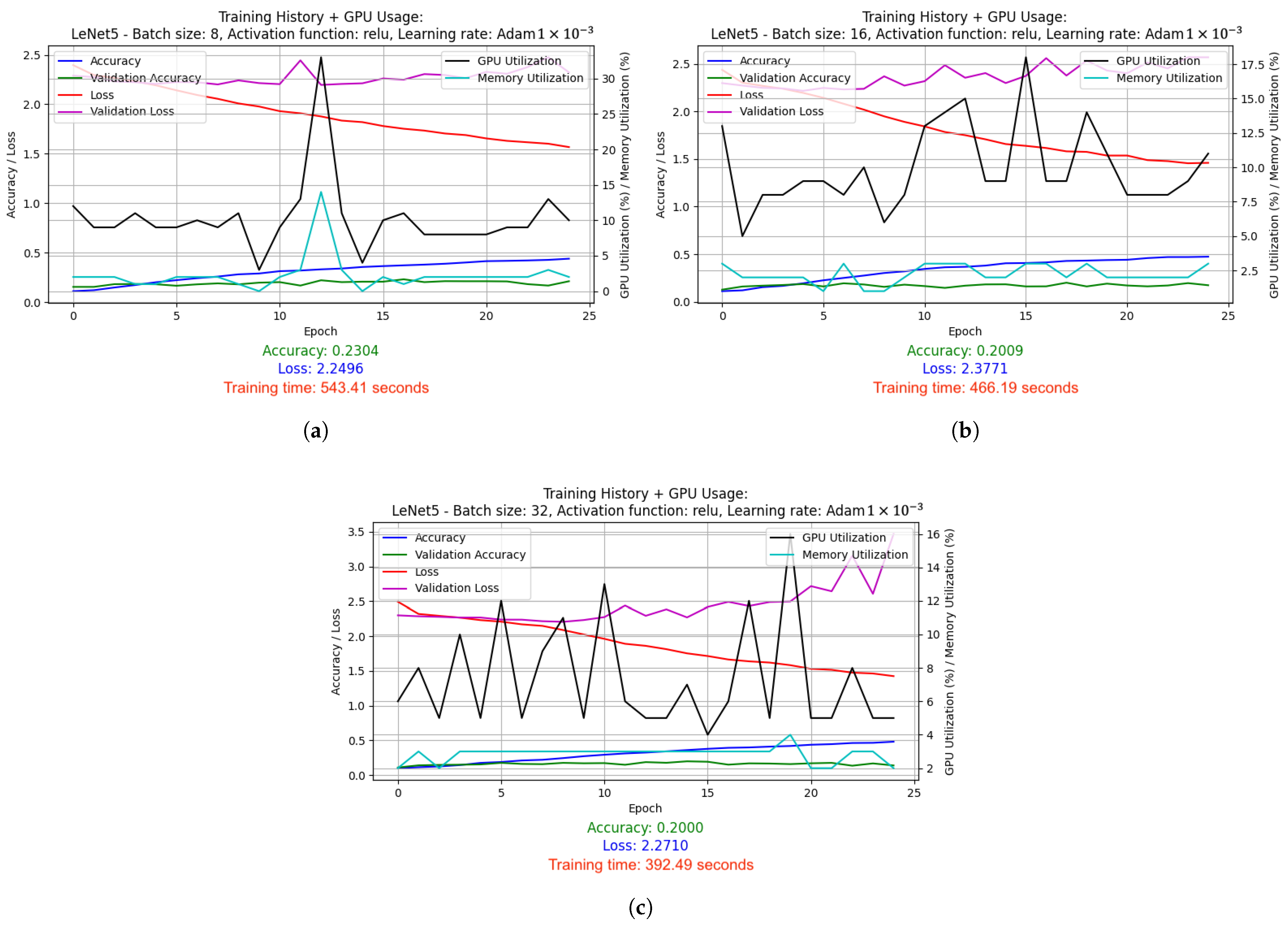
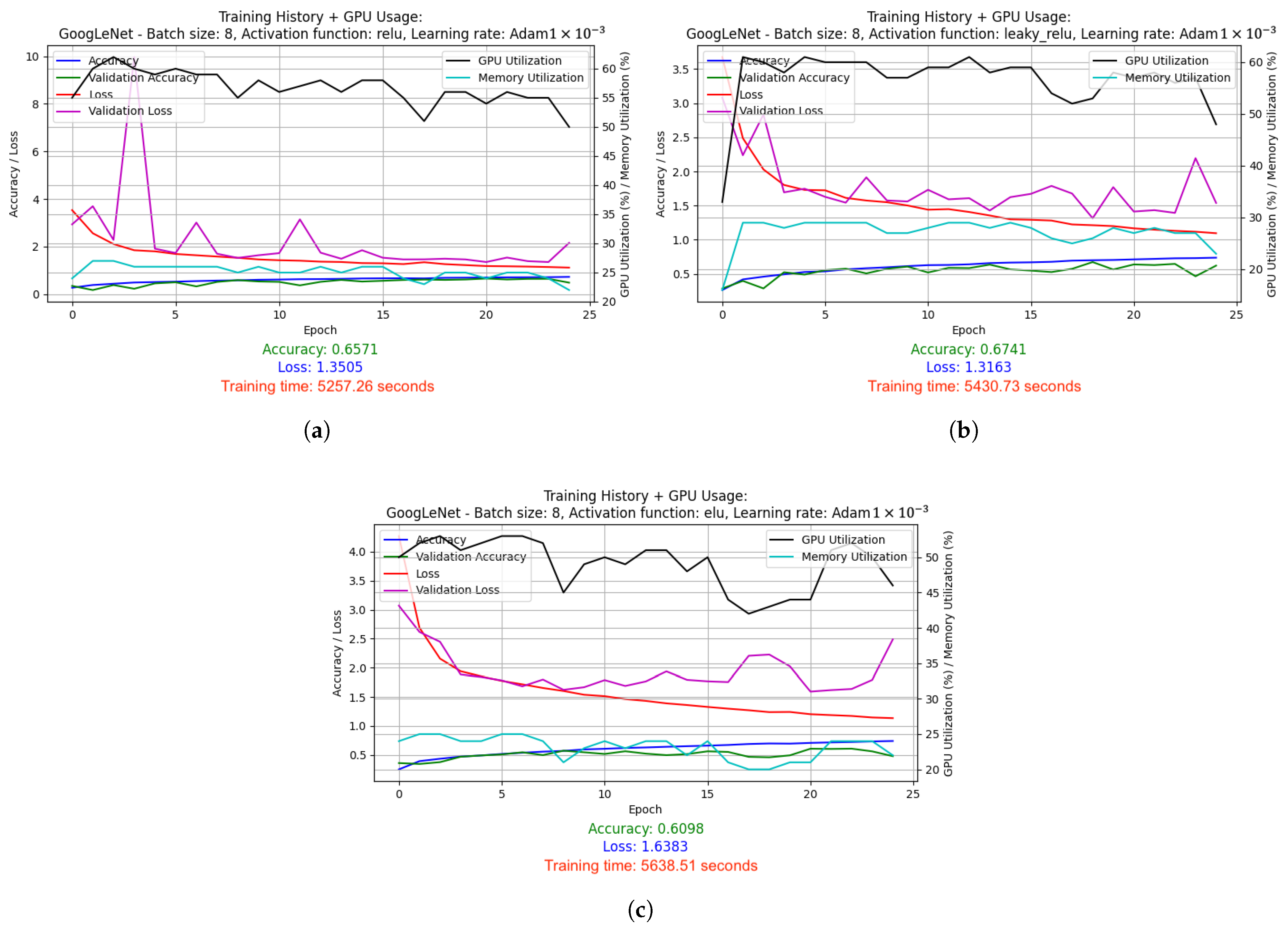
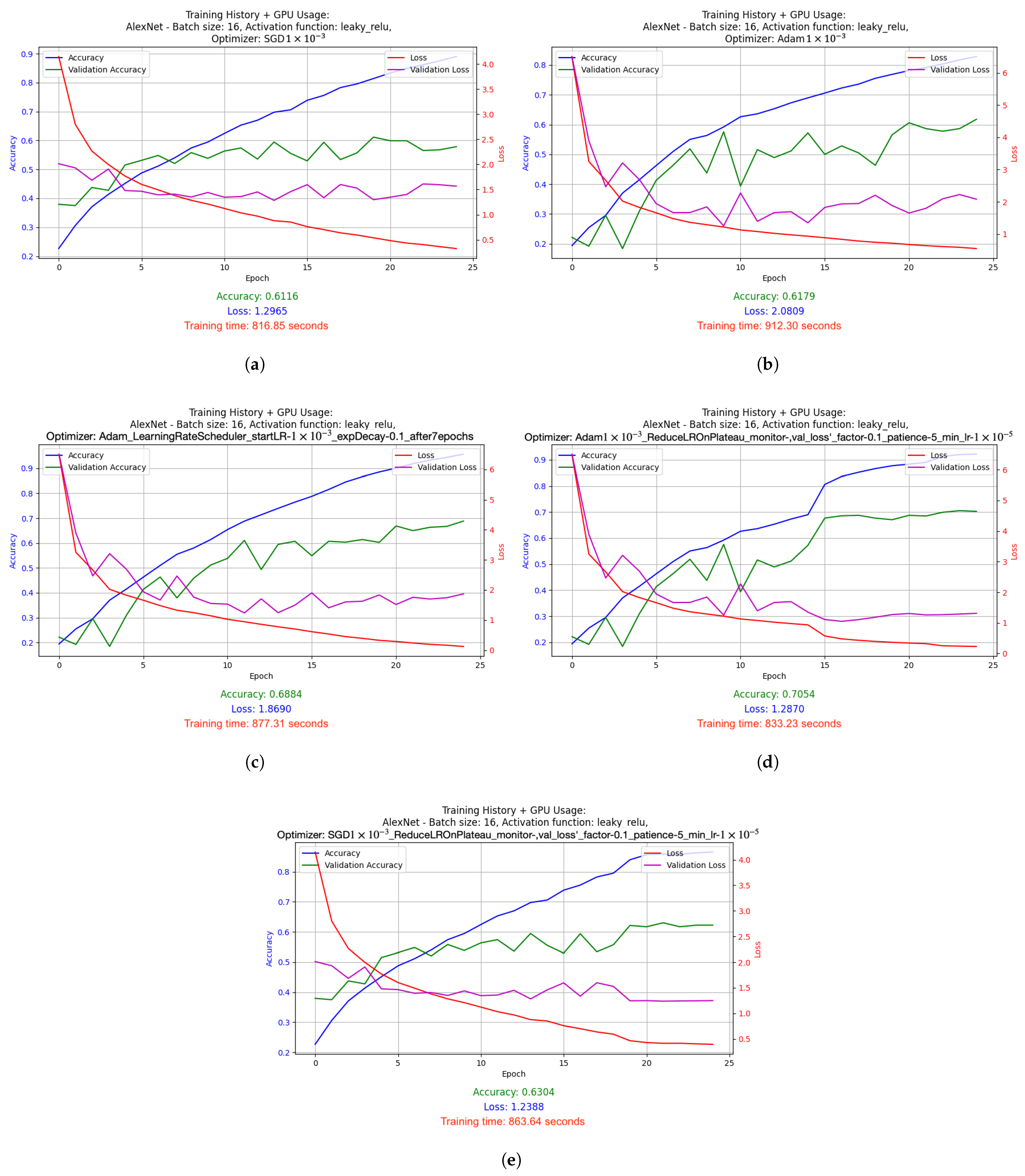
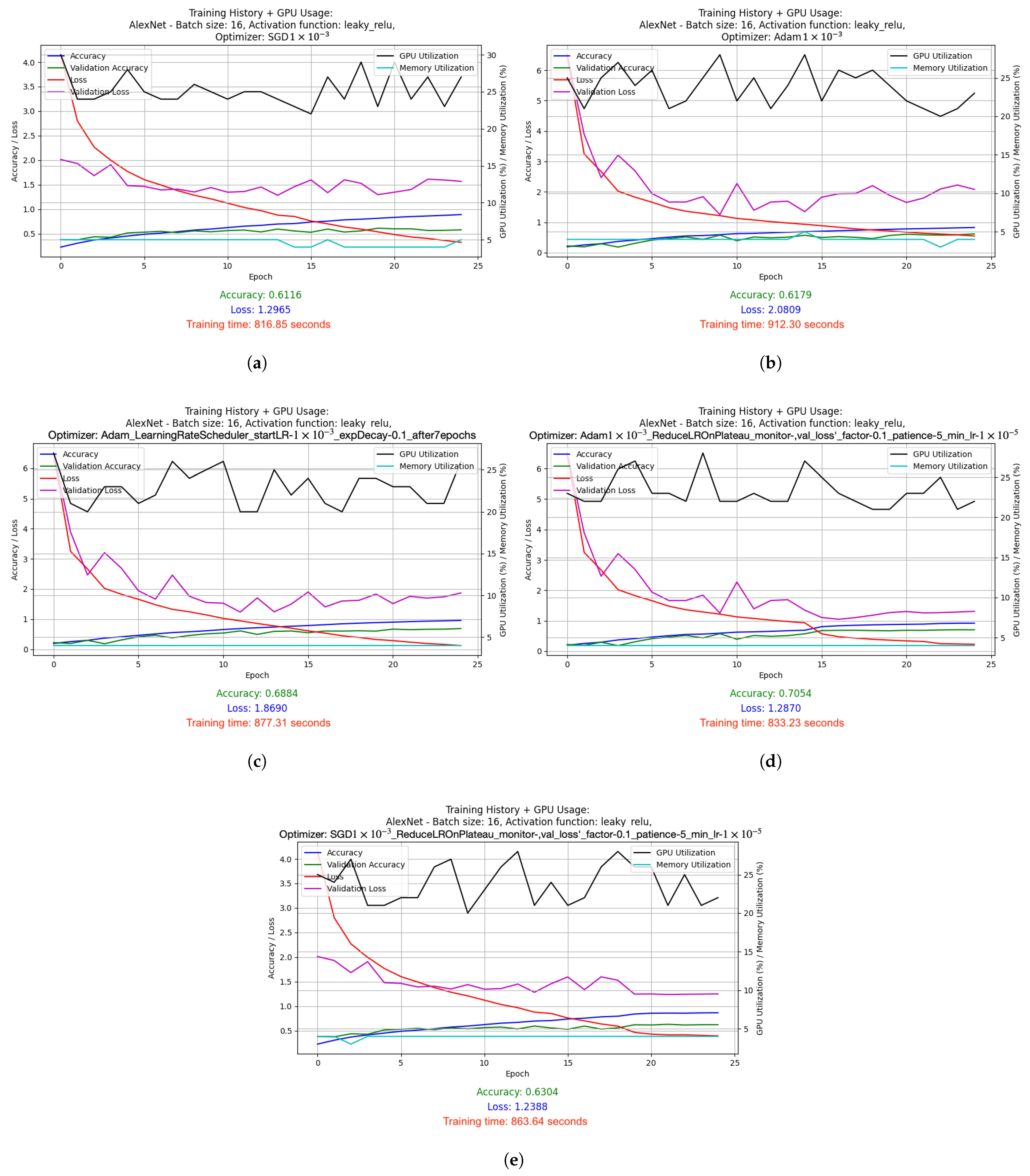
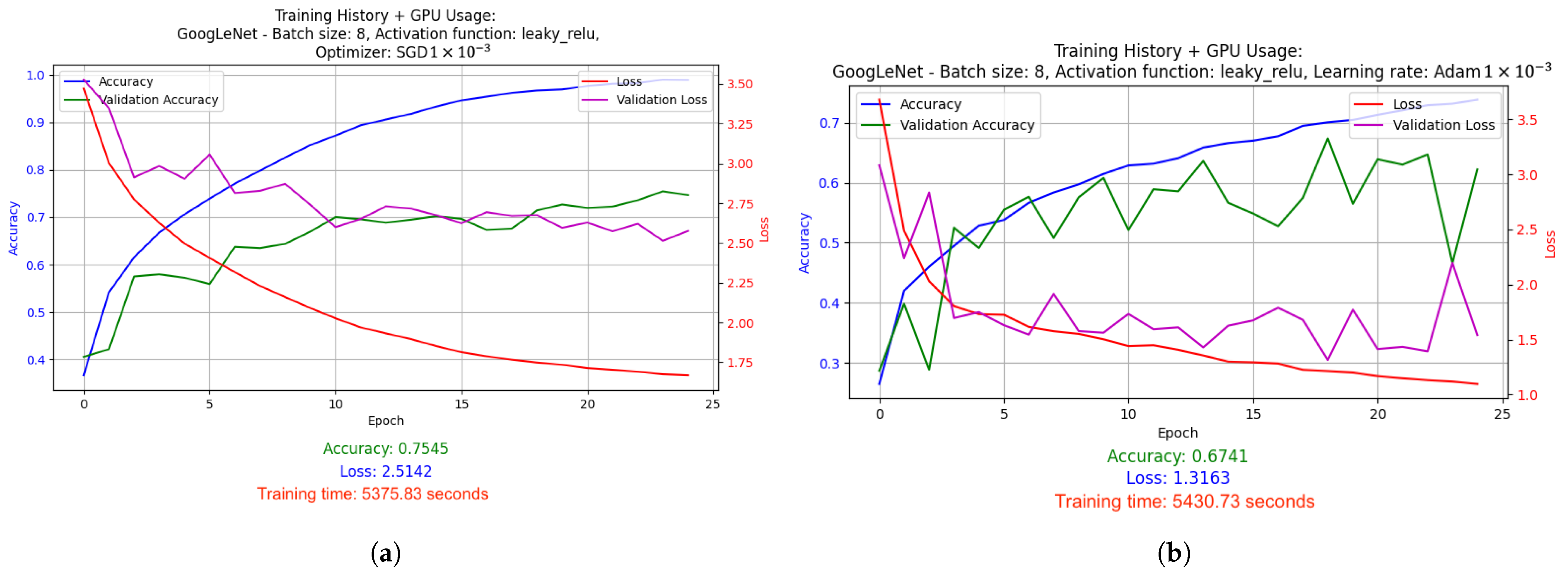
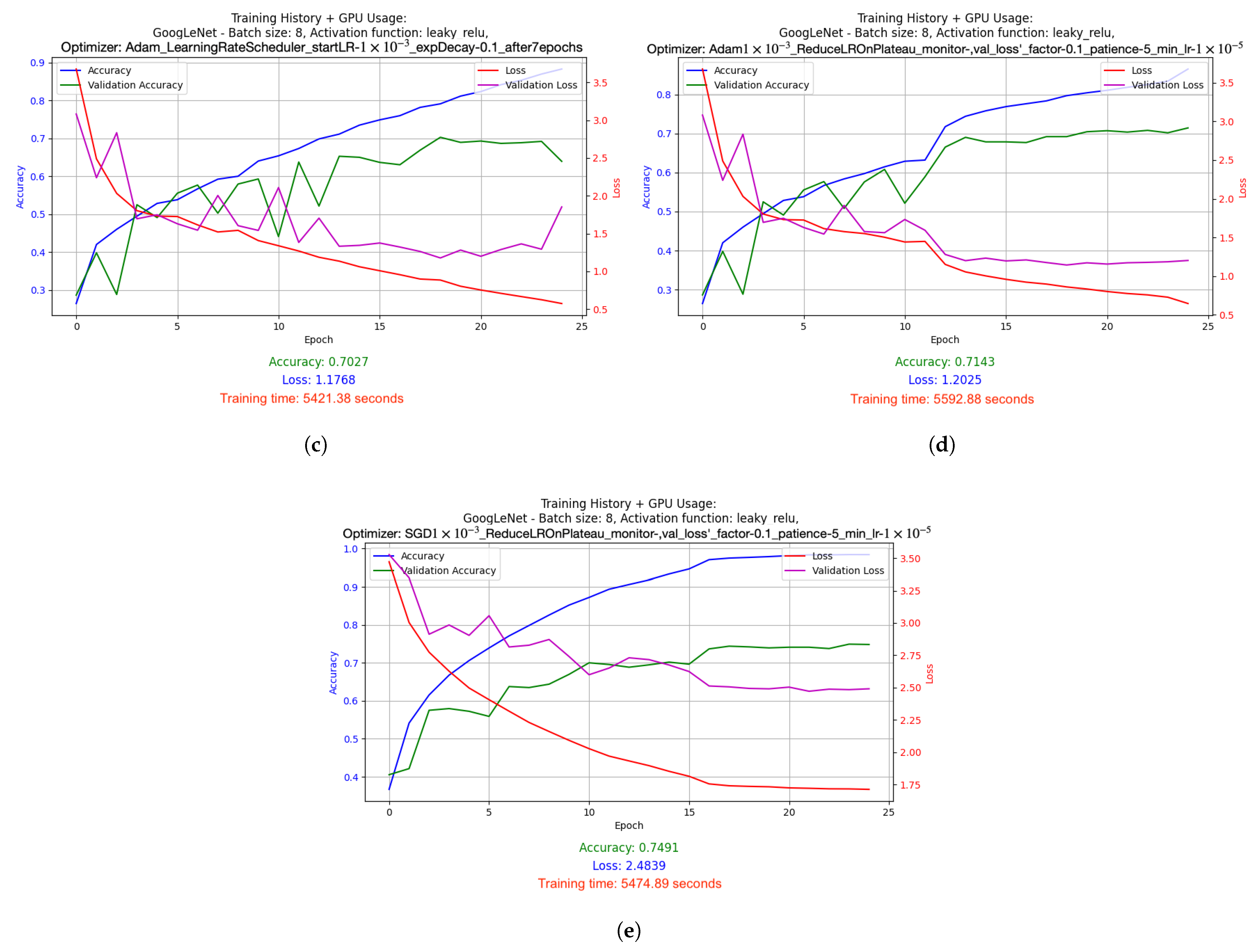
- Graphs depicting the results of the conducted experiments. Two graphs were created for each experiment: a basic one, which included information such as accuracy, validation accuracy, loss and validation loss, and an extended version, which additionally showed GPU and memory usage.
- -
- Saved models after training, which can be used in the future for prediction or further testing.
- -
- Log files from TensorBoard and TensorFlow Profiler, which included training metrics such as accuracy and loss, as well as data on operation performance and resource consumption such as GPU and memory.
2.3. Data Analysis Methods
2.4. Tools and Software
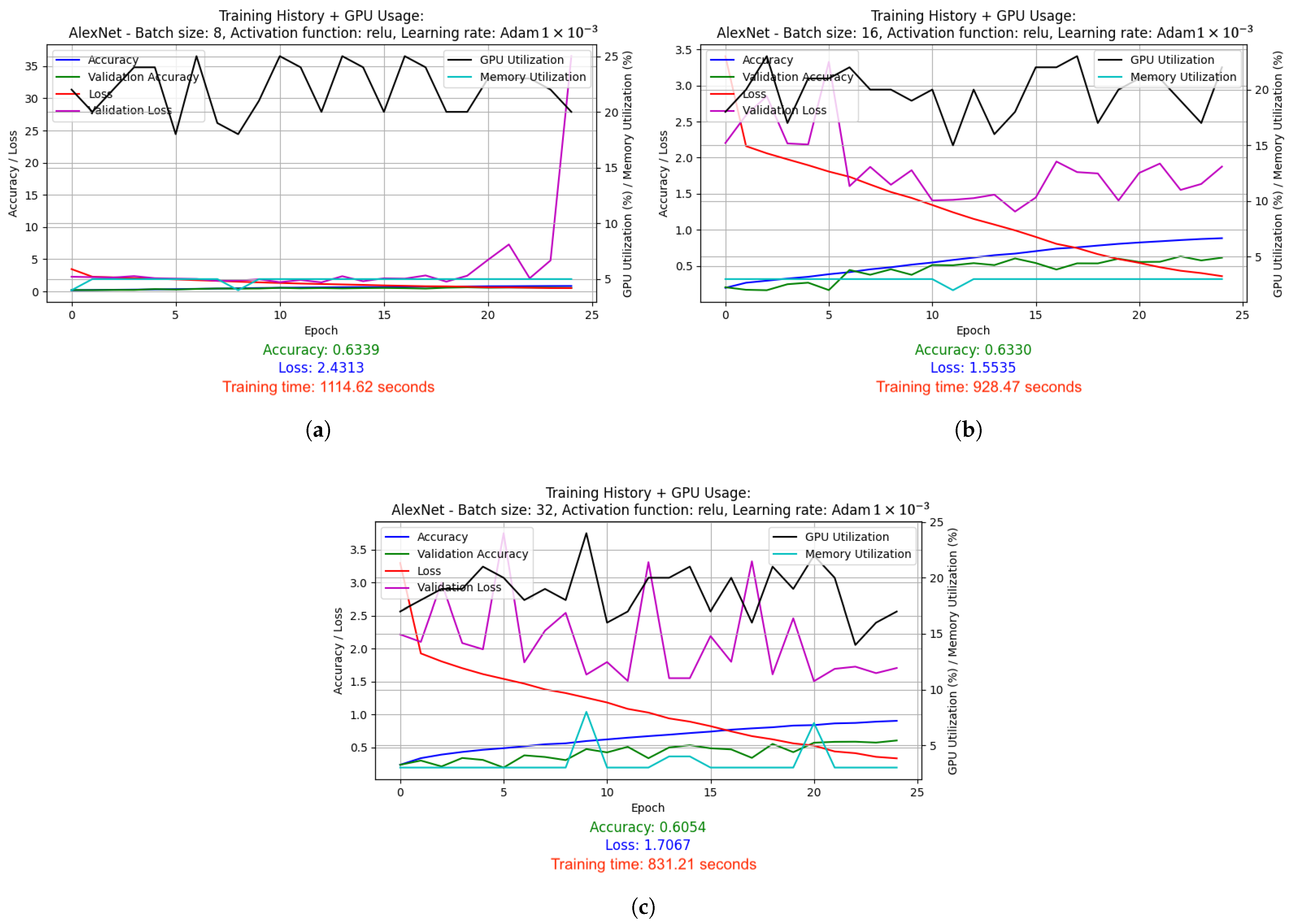
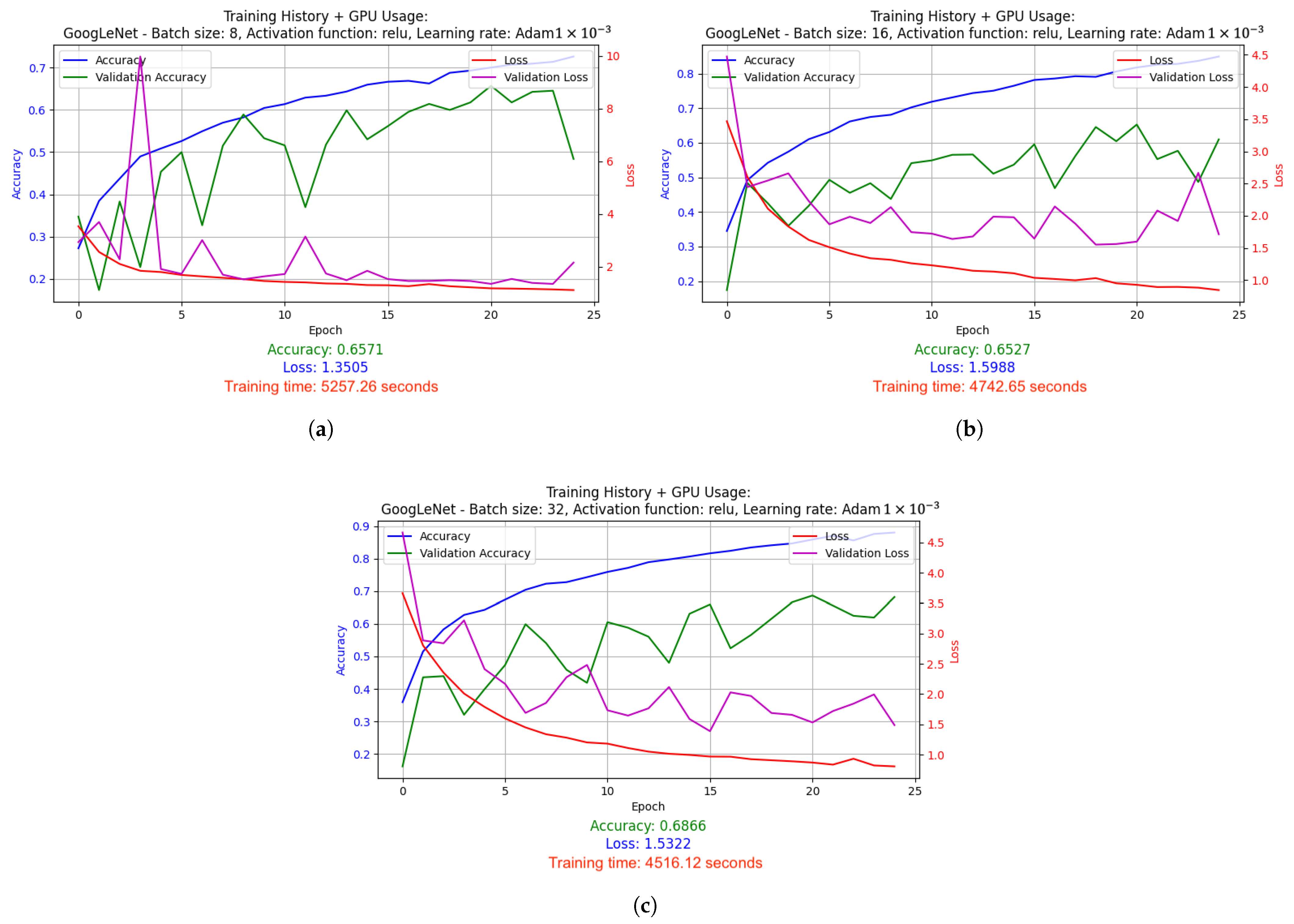
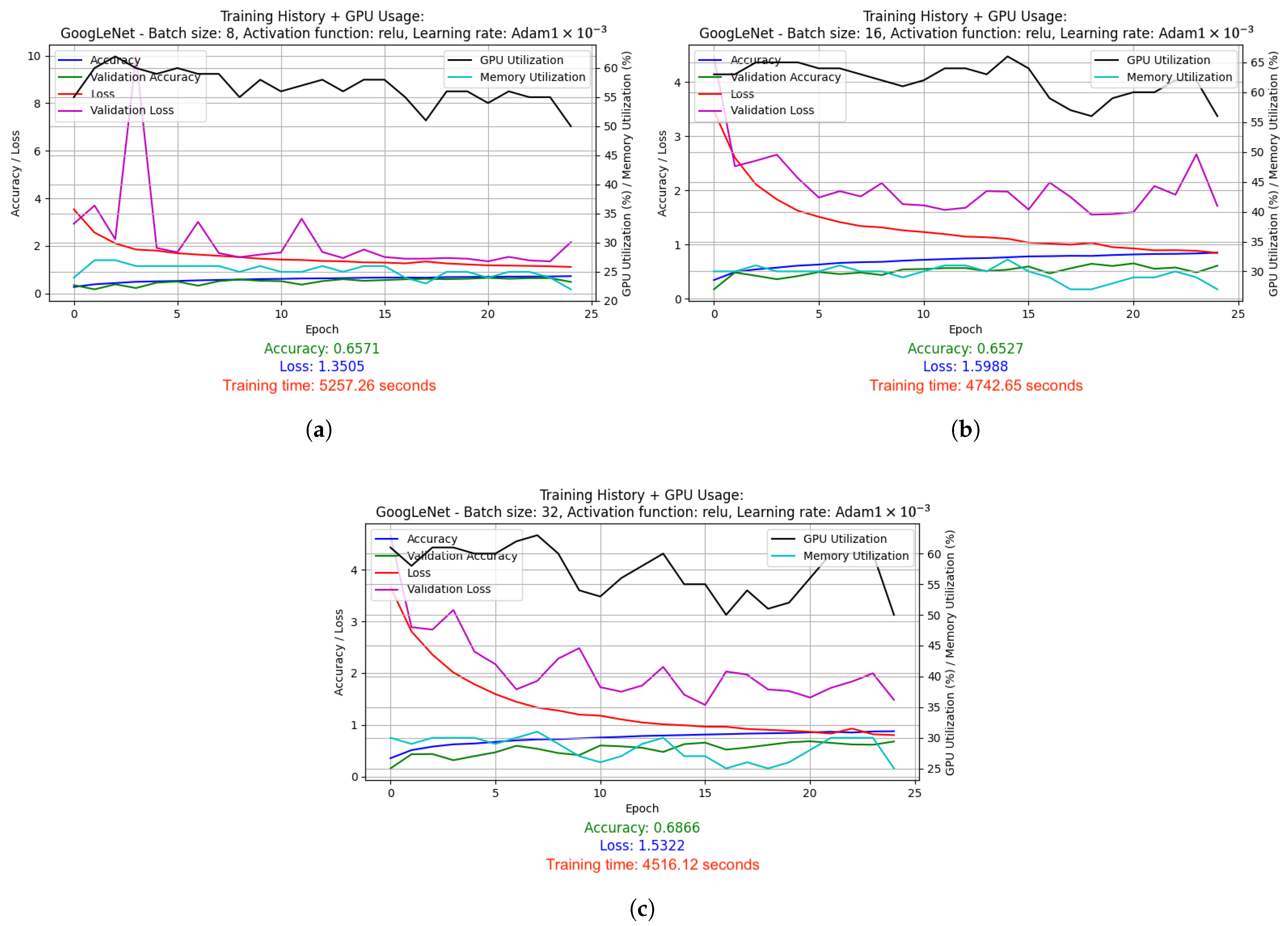
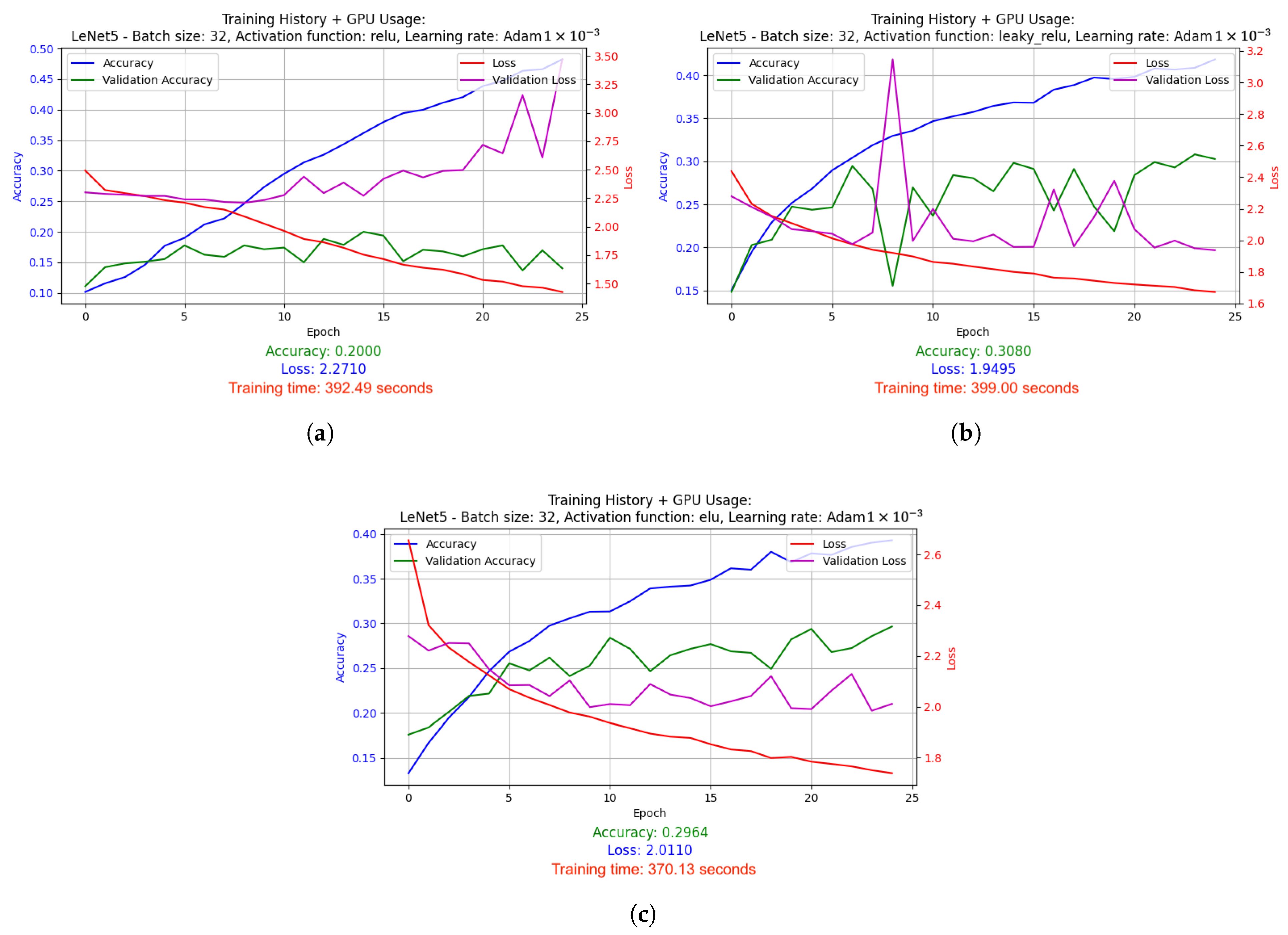
2.5. Test Results
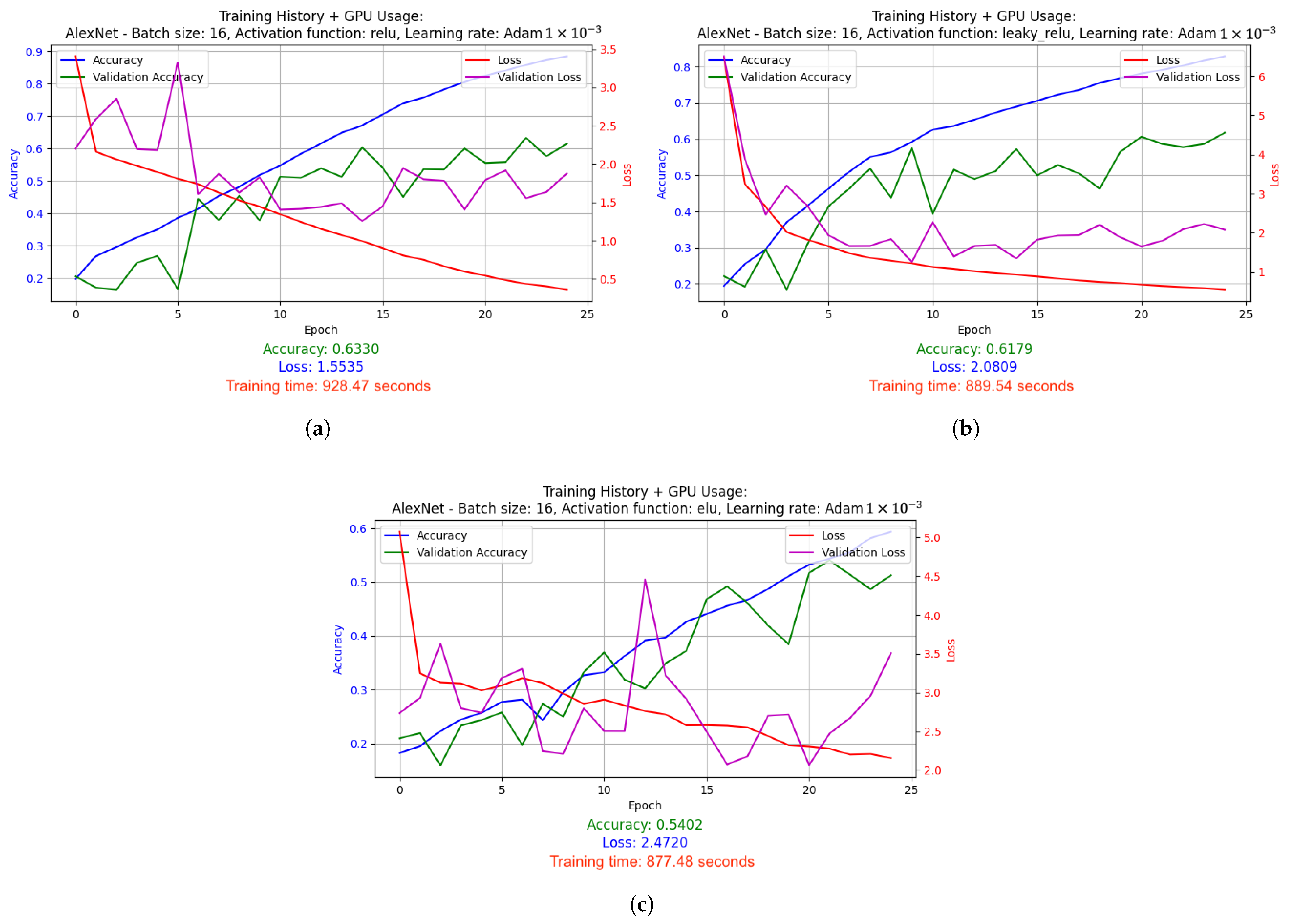
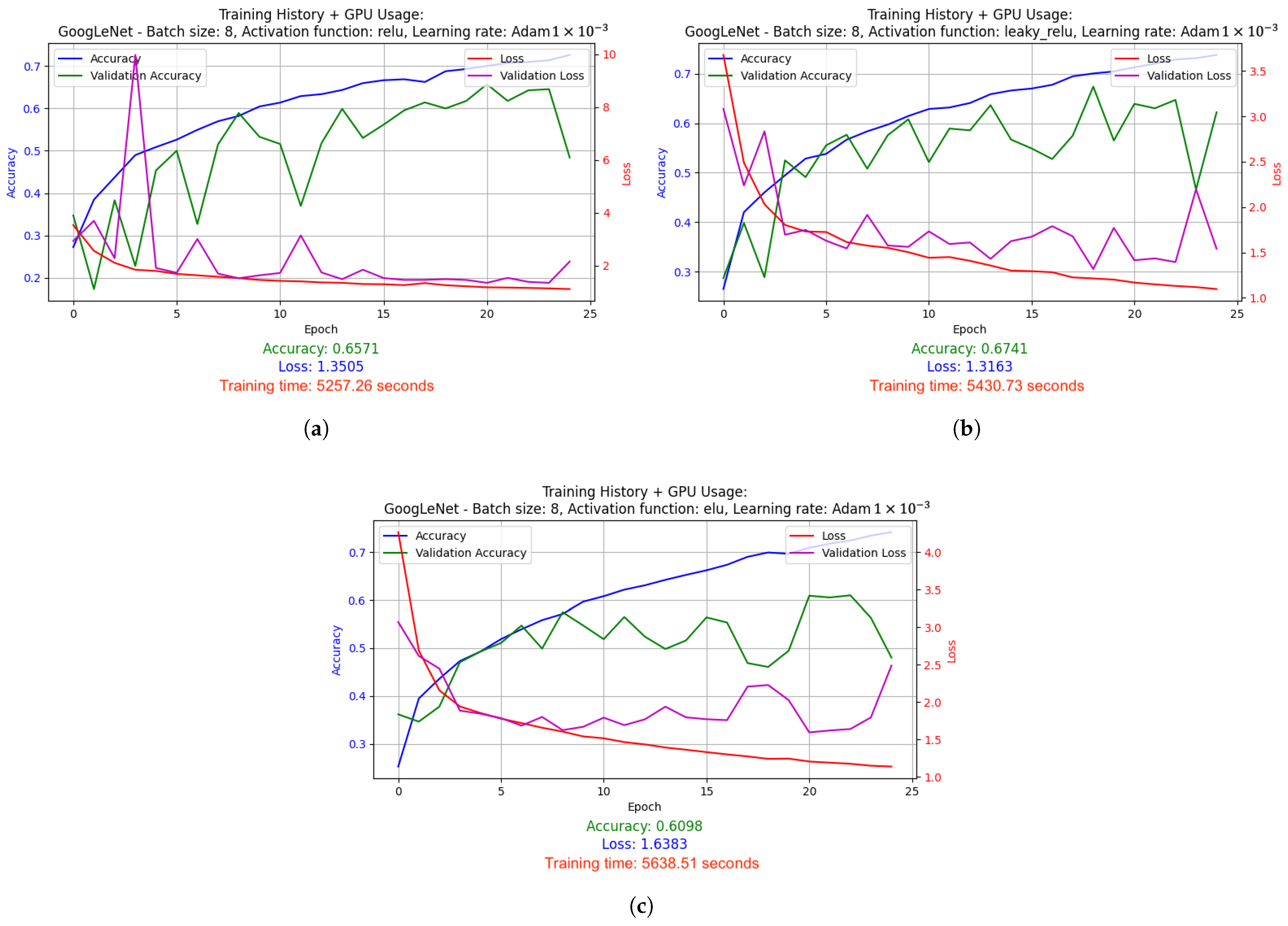
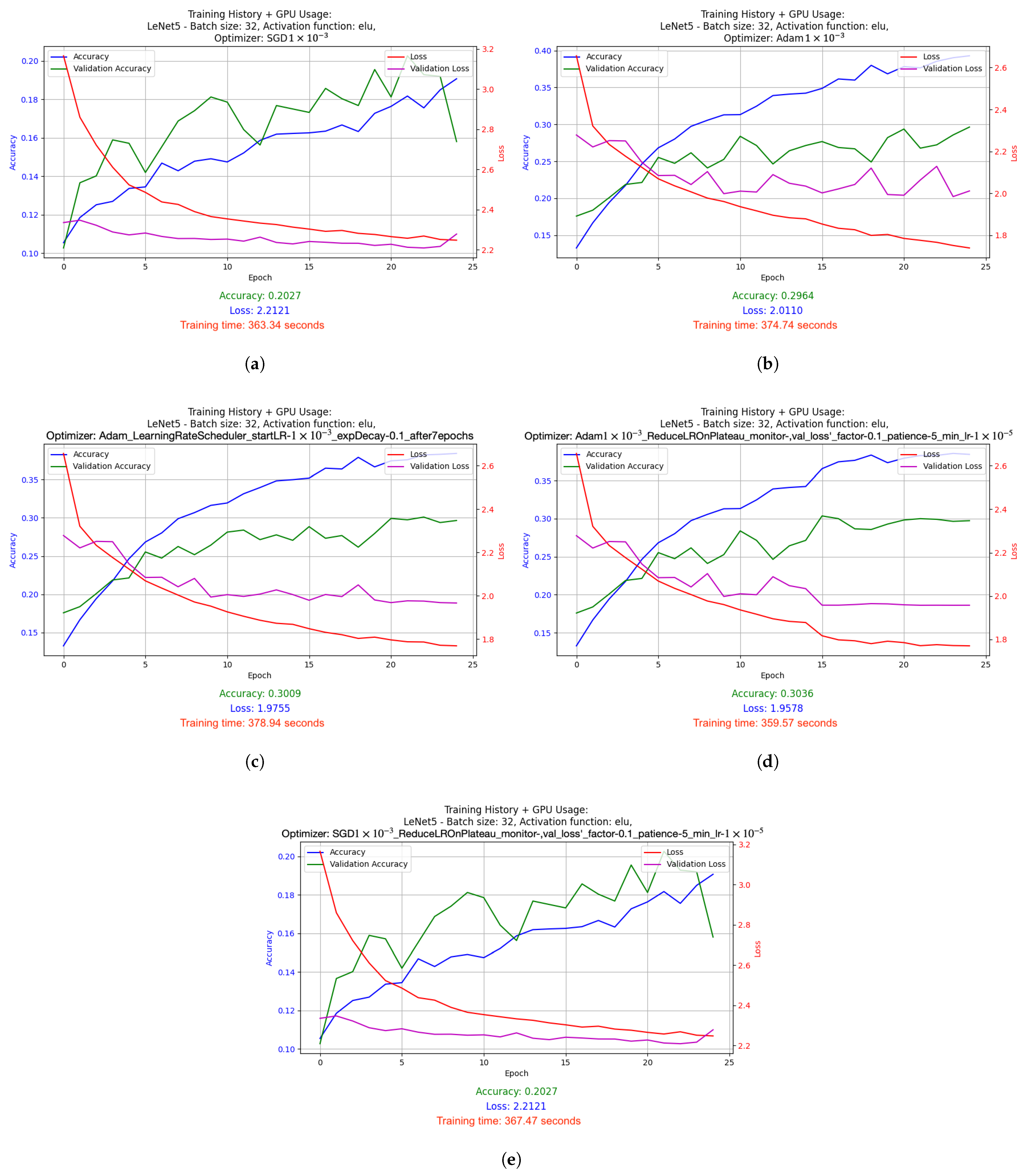
2.5.1. Results of Hyperparameter Optimization Experiments for Supervised Learning Technique
- -
- is accuracy—the accuracy of the model, measured as the proportion of correct predictions to the total number of predictions (a value between 0 and 1). It has been recognized as a key indicator of model quality, hence its importance in the evaluation.
- -
- is loss—the loss of the model, a measure of the deviation of the prediction from the actual values. A low loss value indicates a better fit of the model to the training data.
- -
- is training time—the time it takes to fully overtrain the model, expressed in seconds. The shorter the training time while maintaining high accuracy, the more effective the model.
- -
- is average GPU usage—the average use of GPU resources during training, expressed as a percentage. It is included to evaluate the load on the computing hardware.
- -
- is average memory consumption—the average memory consumption of the model during training, also expressed as a percentage. It is crucial for evaluating the model’s effectiveness in terms of memory management.
- -
- is average RAM consumption—the average RAM consumption of the system during training, in percent. This parameter affects the ability to process large datasets simultaneously.
- -
- is average CPU consumption—the average use of CPU resources by the model during training, in percent.
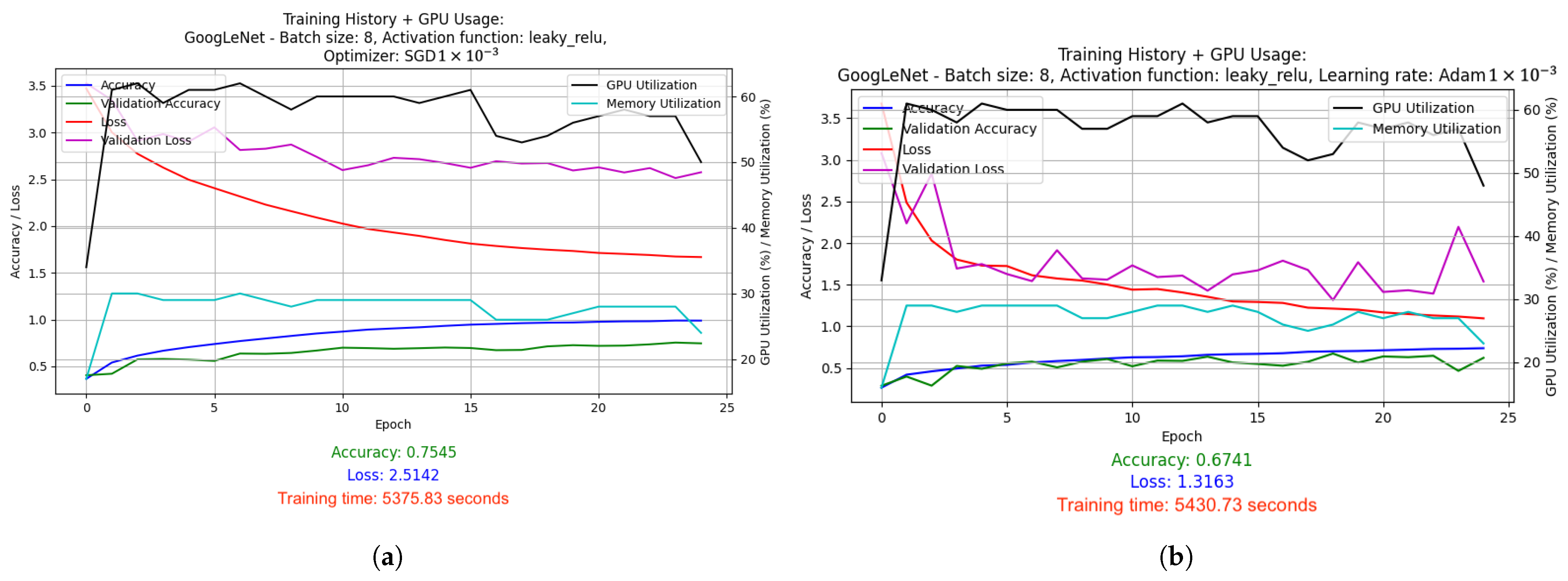
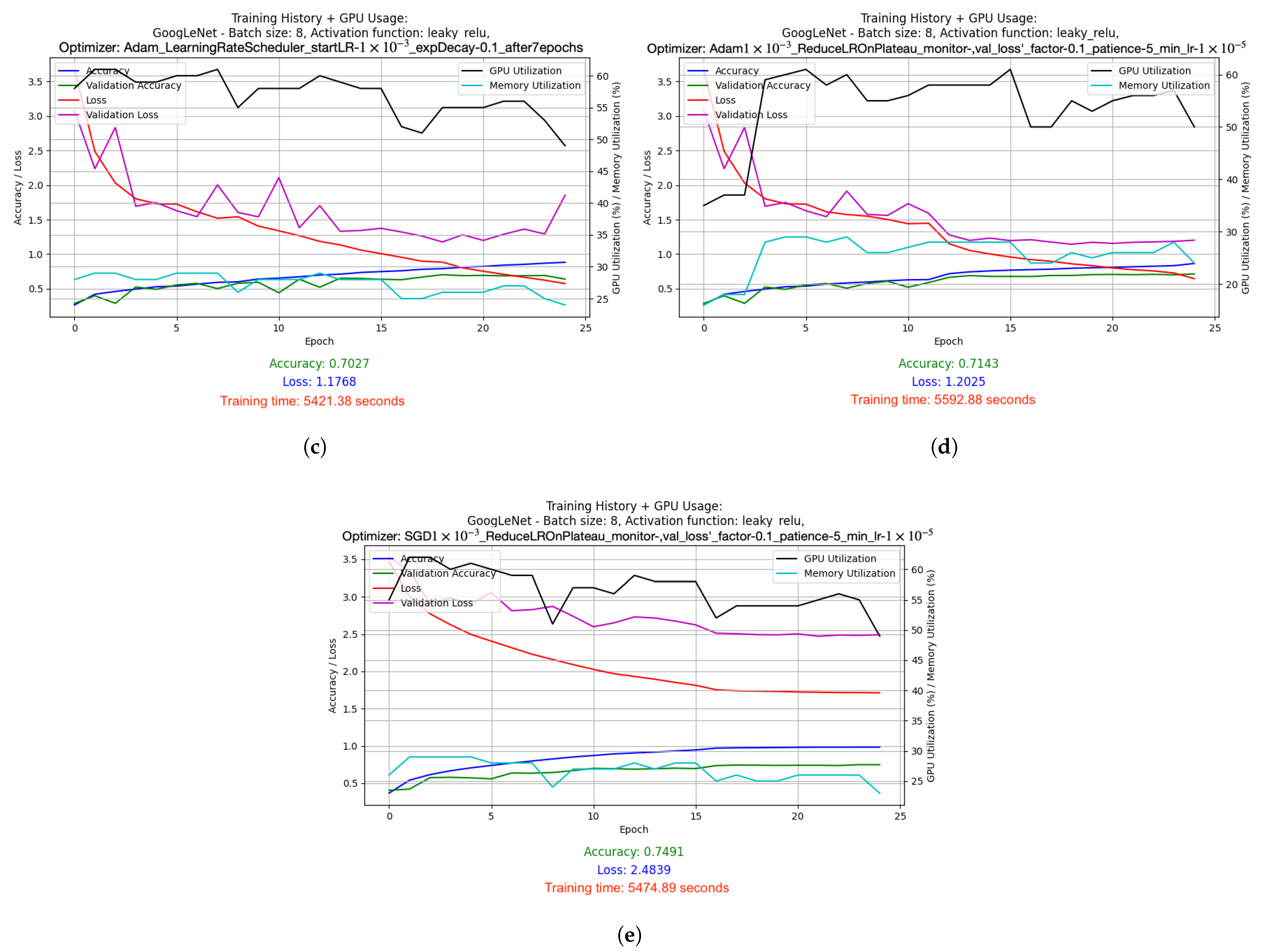
- SGD with LR = 1 × 10−3: Stochastic Gradient Descent (SGD) optimizer with a fixed, constant learning rate of 0.001. SGD is one of the simplest optimizers that updates the model weights based on the average gradient calculated for each batch (batch). The fixed learning rate causes the model to learns at a steady pace throughout the training.
- Adam with LR = 1 × 10−3: Adam optimizer, which is a more advanced version of the optimizer that combines the advantages of RMSprop and SGD with momentum. With a fixed learning rate of 0.001, Adam dynamically adjusts the weight update steps, which usually leads to faster and more stable convergence compared to classic SGD.
- Adam with dynamically adjusted LR using LearningRateScheduler: This setup used a starting learning rate of 0.001, which was dynamically reduced by a factor of 0.1 after 7 epochs of training. This mechanism allows for faster learning at the beginning, and then stabilizes the process as the model approaches the minimum of the cost function.
- Adam with LR reduced on Plateau: In this version, the learning factor was automatically reduced when it was noticed that the improvement in the value of the cost function stopped (i.e., when the value of val_loss stopped decreasing). The learning rate was reduced by a factor of 0.1 from its initial level of 0.001, and the minimum possible learning rate was set at 0.00001. This method allows the model to tune itself more accurately when it begins to reach the limits of its optimization capabilities.
- SGD with LR reduced on Plateau: Similar to Adam’s, here, the learning rate reduction mechanism was also used on Plateau, but in combination with the SGD optimizer. This allows better use of the simple mechanism for SGD to update the weights, especially in the later phases of training, where model accuracy requires finer adjustments.
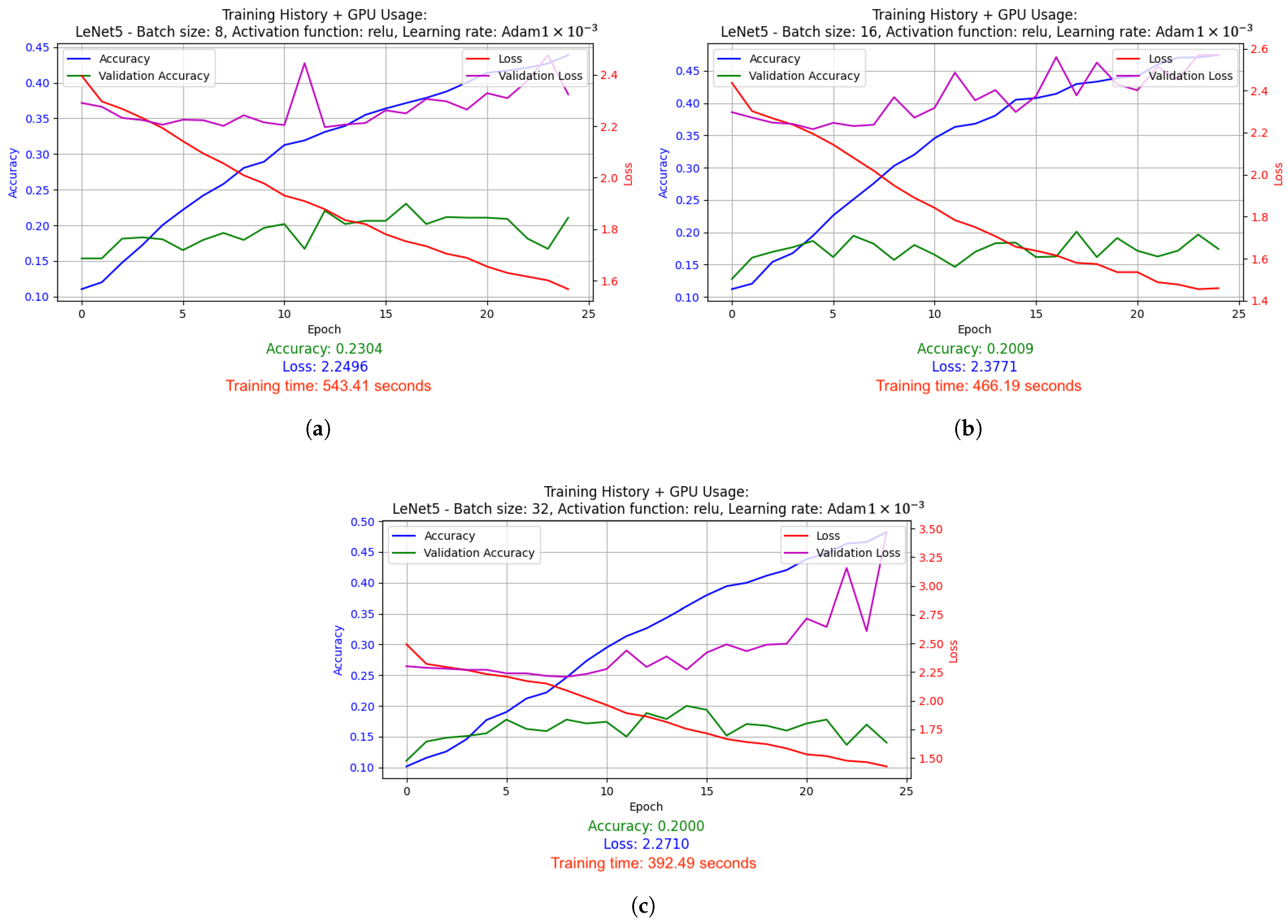
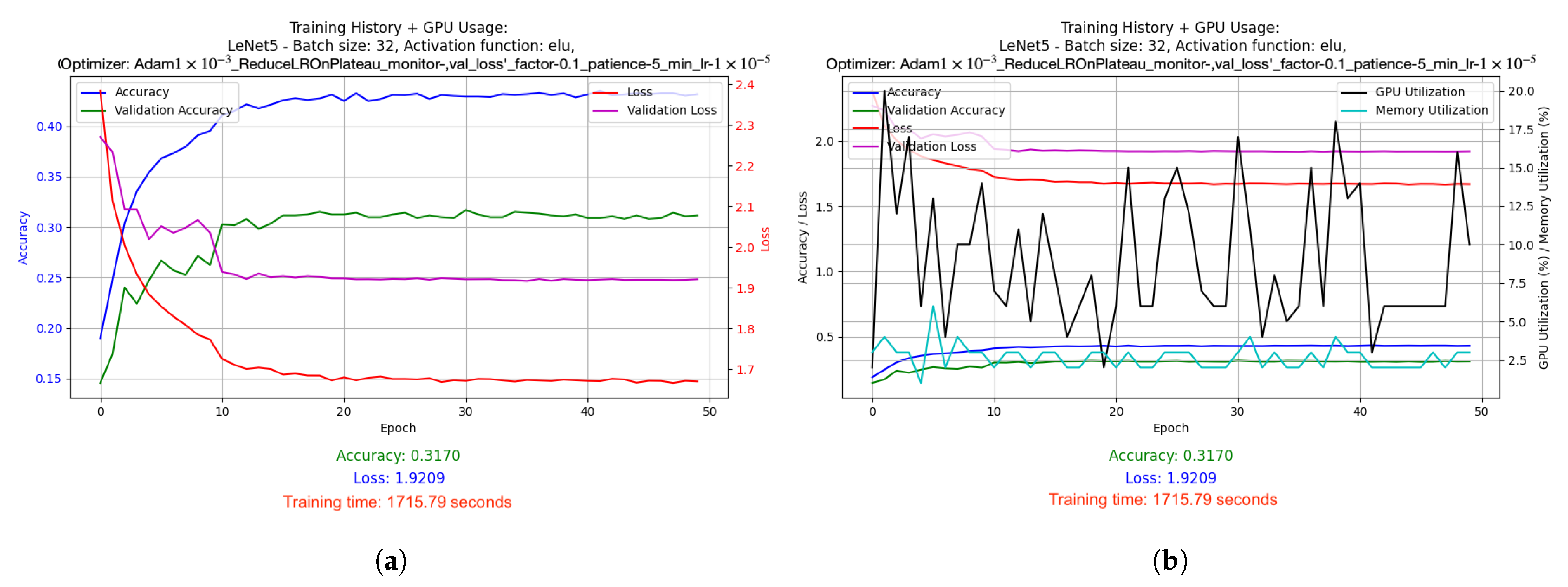
- LeNet-5 used batch size 32 and ELU activation function. It was optimized using the Adam algorithm (learning rate: 1 × 10−3) and the LR reduced on Plateau method. Results: accuracy 0.3170, loss 1.9209, average GPU usage 9.02%, average RAM usage 51.52%, training time 1715.79 s.
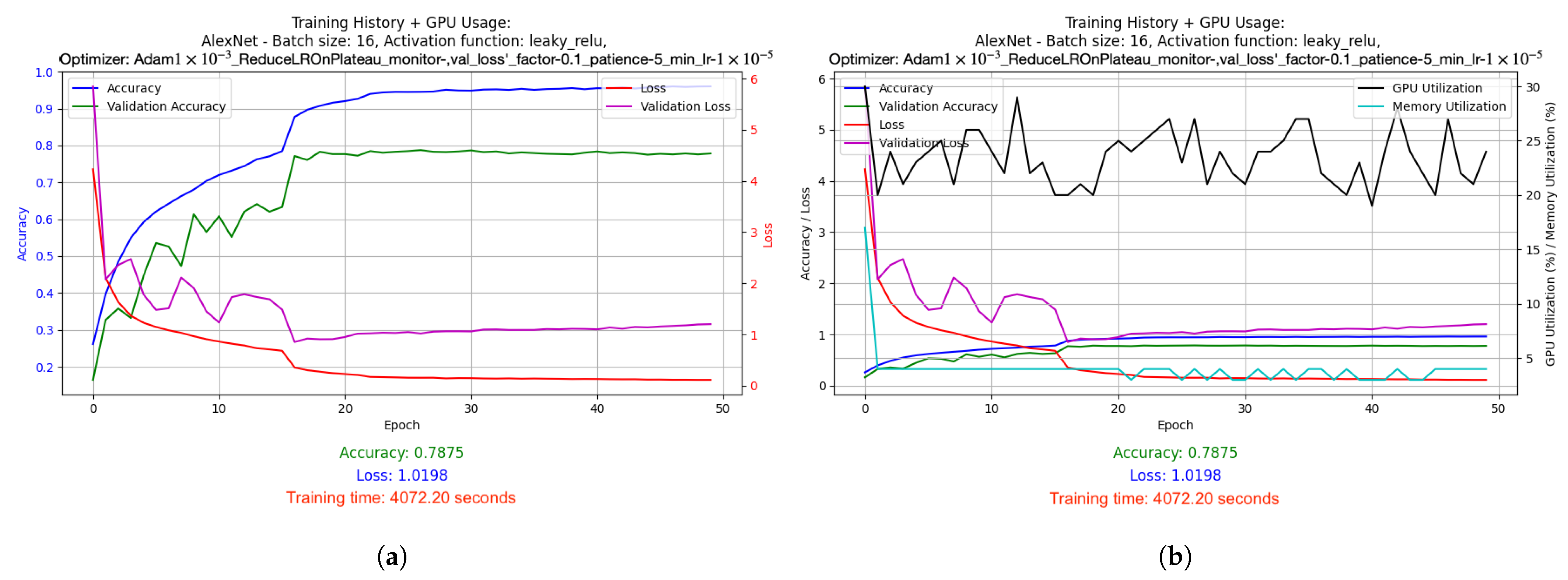
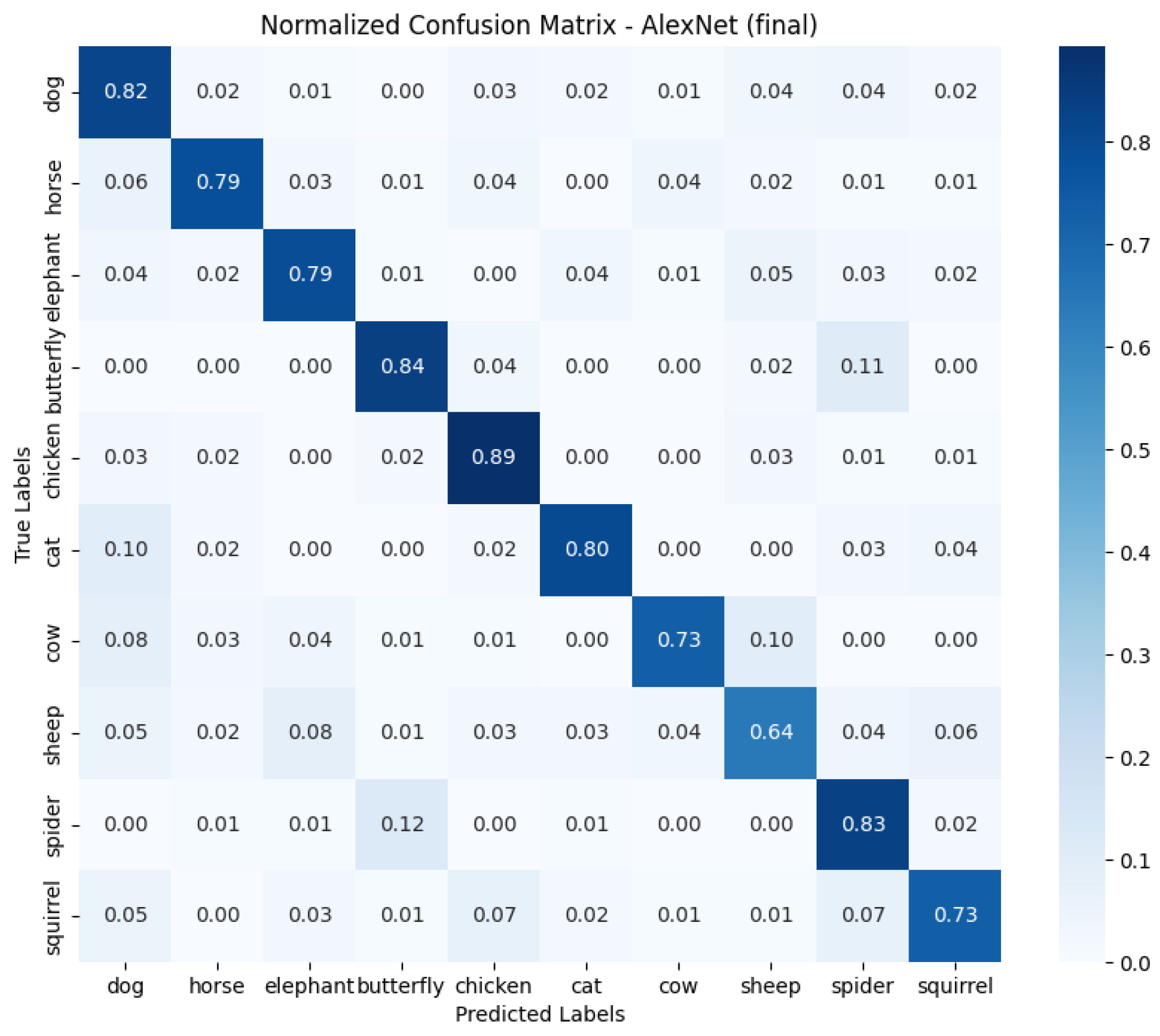
- AlexNet was trained with batch size 16 and Leaky ReLU activation function. Adam algorithm was used (learning rate: 1 × 10−3). Results: accuracy 0.7875, loss 1.0198, average GPU usage 23.48%, average RAM usage 50.55%, training time 4072.20 s.
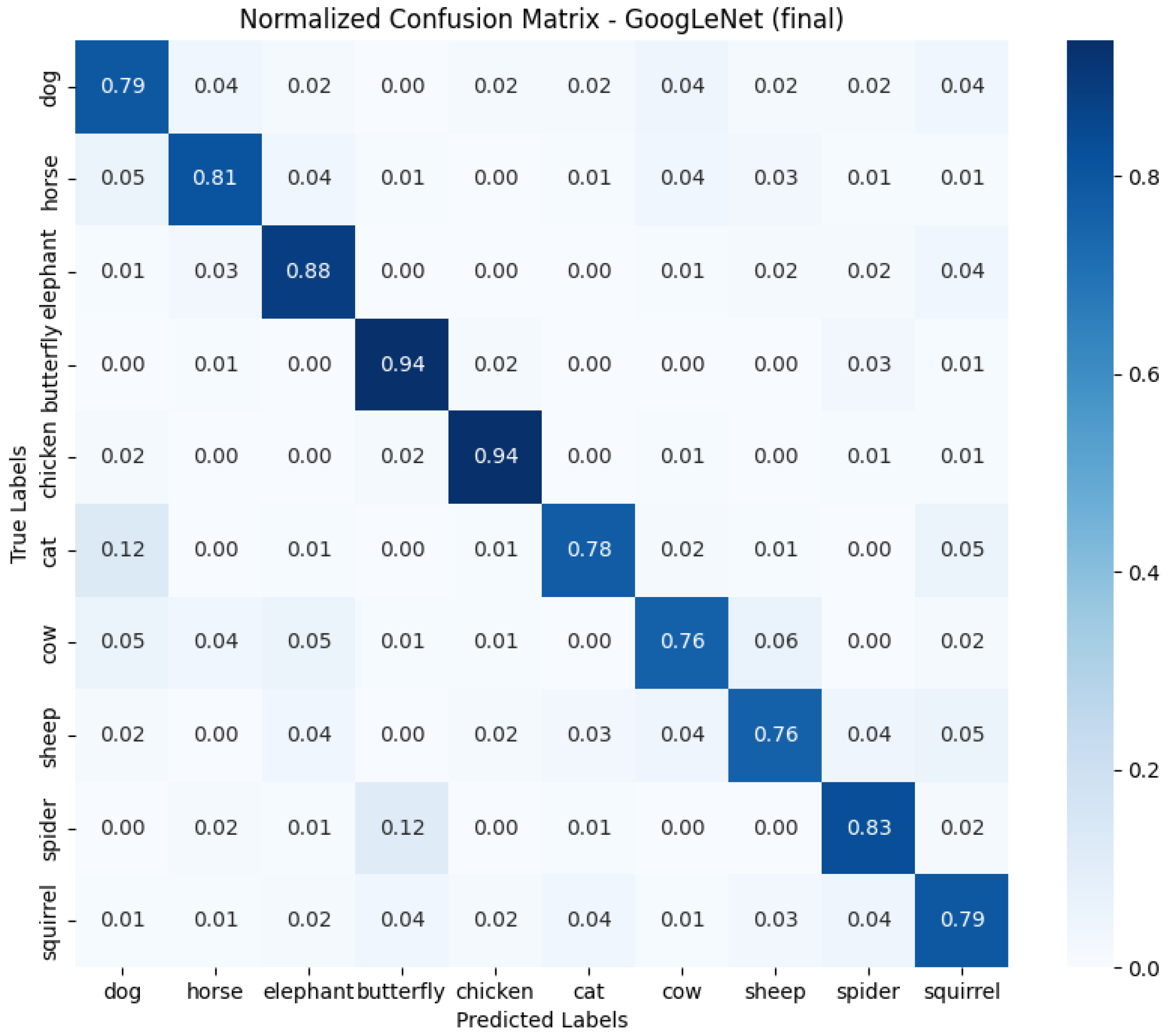
- GoogLeNet used batch size 8 and the Leaky ReLU activation function. Optimized with the Adam algorithm with a learning rate change schedule (learning rate: 1 × 10−3). Results: accuracy 0.8286, loss 1.0534, average GPU usage 58.62%, average RAM usage 52.12%, training time 25,251.97 s.
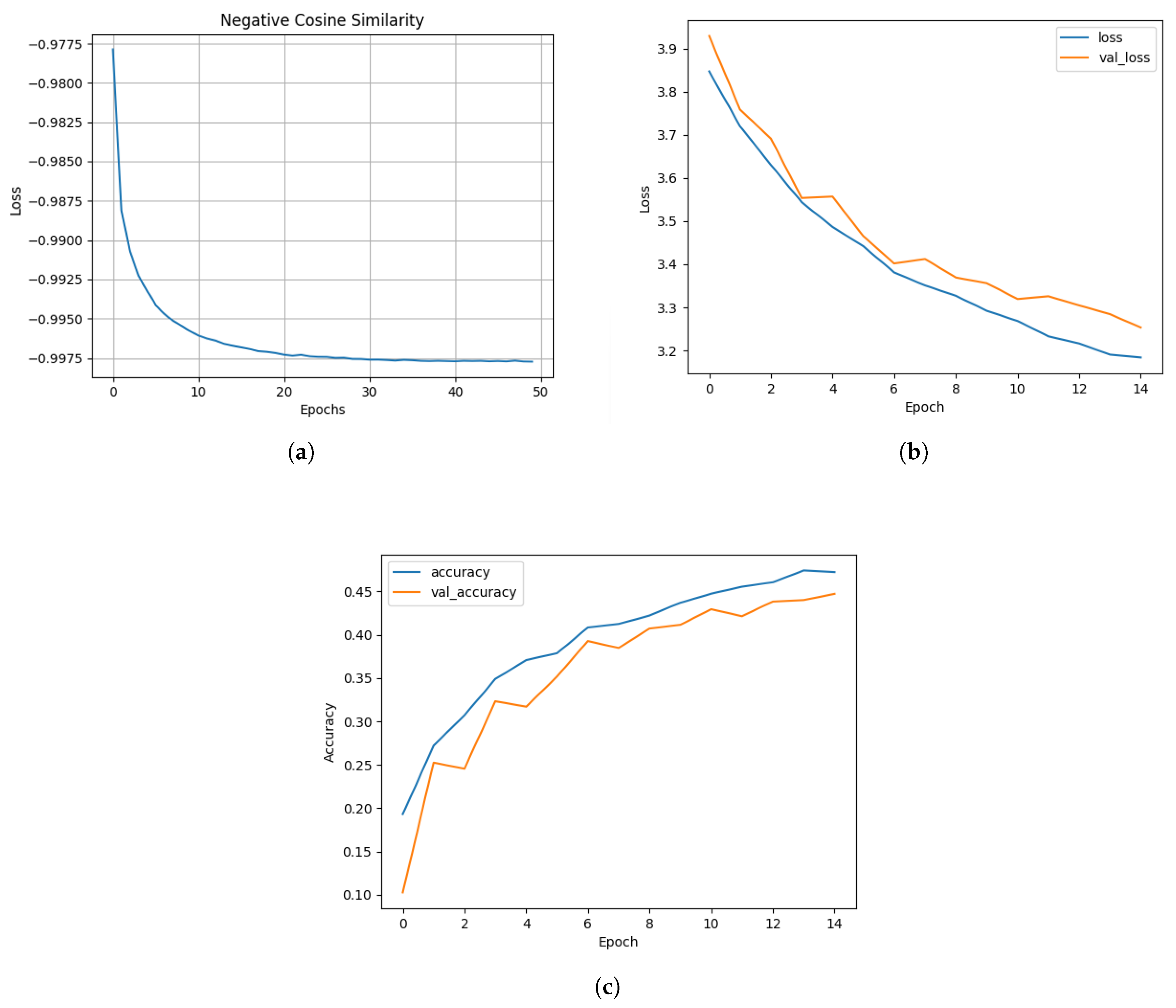
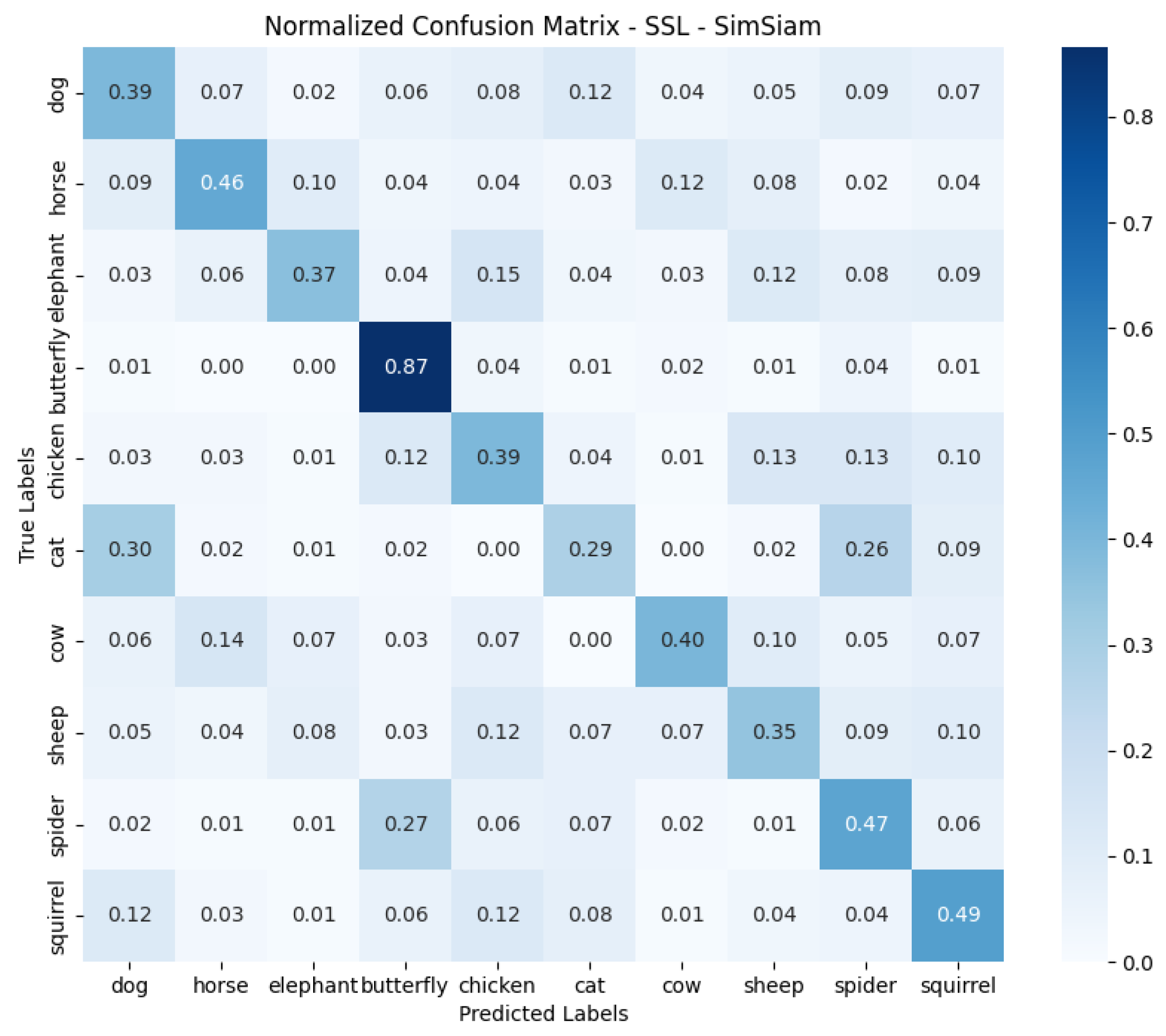
2.5.2. Experimental Results for Self-Supervised Learning Technique
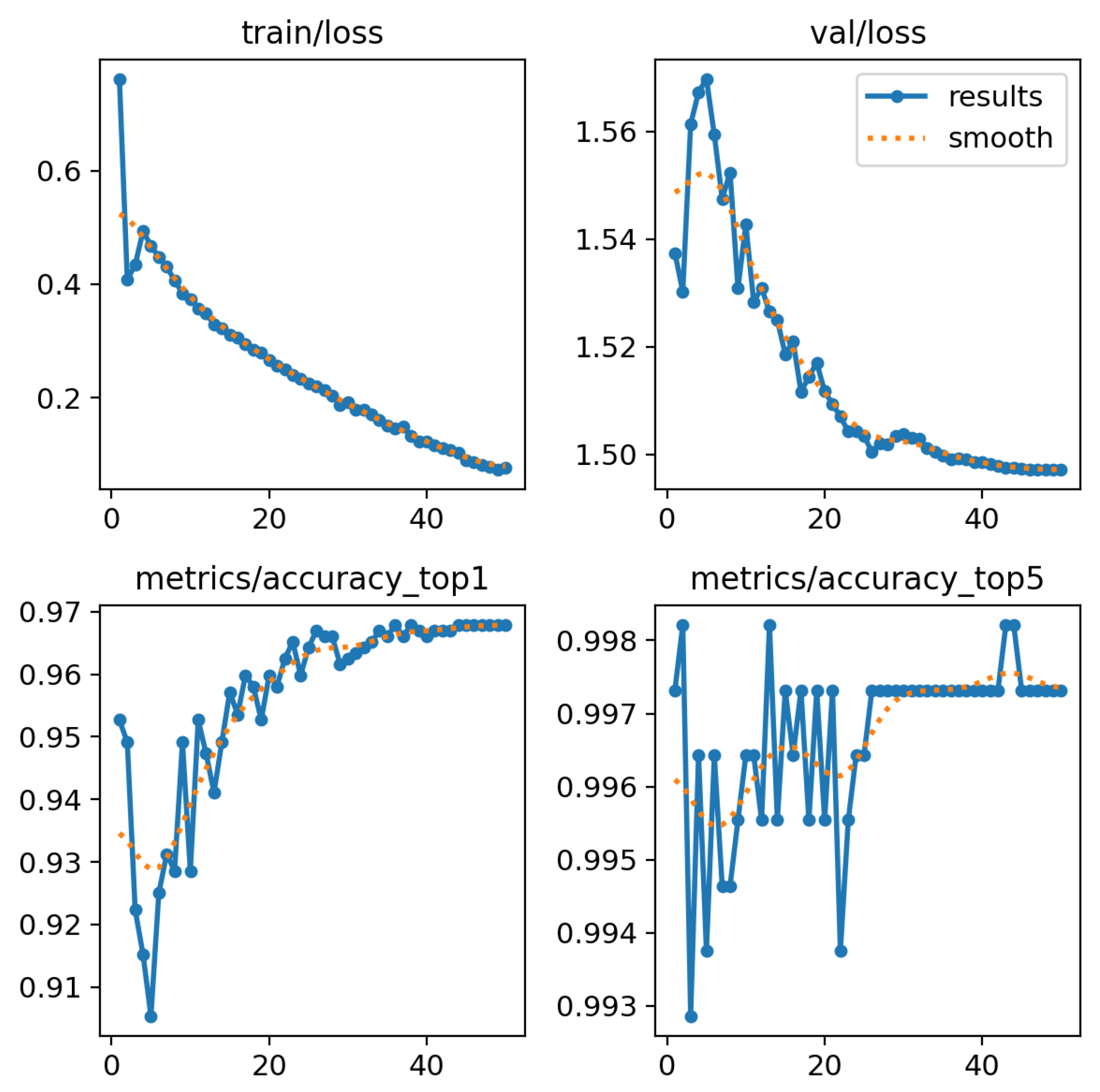
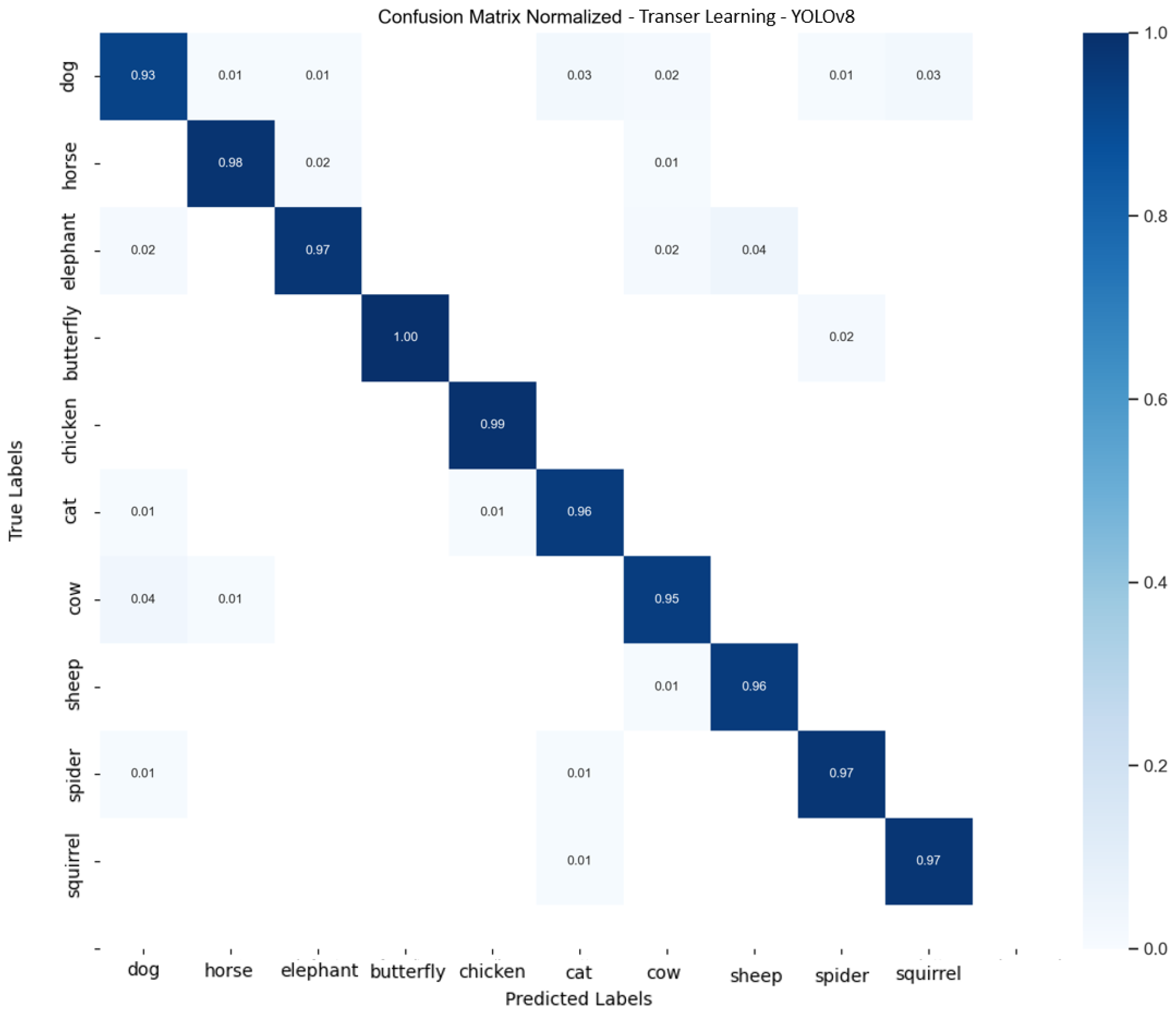
2.5.3. Experimental Results for the Transfer Learning Technique
- Training loss graph (train/loss): This graph shows that training loss decreases steadily with each successive epoch, suggesting that the model adjusts effectively to the training data.
- Validation loss chart (val/loss): Despite initial fluctuations, validation losses are also decreasing, indicating an improvement in the model’s ability to generalize on new data.
- Accuracy of top-1 and top-5 classifications:
- –
- Top-1 Accuracy: A measure that indicates how often the correct label (class) is the highest rated by the model among all possible classes. In other words, it is the percentage of cases in which the model correctly predicts the most likely class.
- –
- Top-5 Accuracy: This metric measures how often the correct label is among the five highest rated classes by the model. Top-5 accuracy is used in tasks where there are many classes to choose from and it is possible that the model will identify several classes as potentially correct. This metric is more forgiving than top-1 because it allows for some margin of error.
3. Discussion of Results
4. Summary
- One of the biggest challenges was the limitation of computing resources. For very deep and complex architectures, such as GoogLeNet and GoogLe-Net in combination with SimSiam, memory started to run out at larger batch sizes, limiting the ability to test more resource-intensive hyperparameter values.
- Training more complex models, such as GoogLeNet and GoogLeNet+ SimSiam, was also very time-consuming. The long training time affected the performance of the project and translated into significant power consumption.
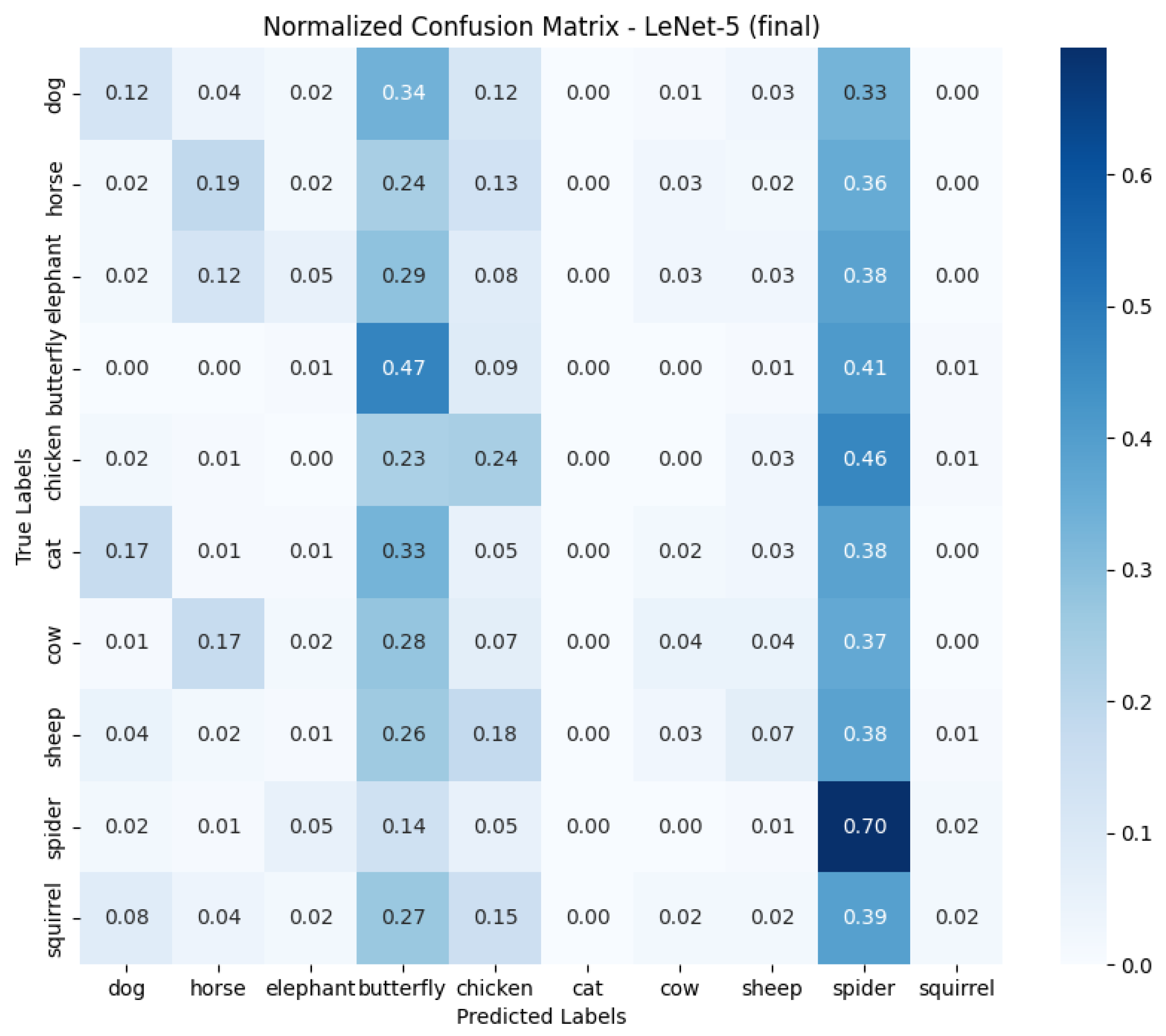
- Relatively low accuracy was obtained for the LeNet-5 model due to the architecture itself. LeNet-5 accepts small images that become pixelated during processing, leading to a significant loss of relevant information.
- Another difficulty was synchronizing versions of different tools, libraries, environments, and programming language. Compatibility issues often caused delays and required additional work to make sure all the system components worked harmoniously.
- Analyzing the results and selecting the best solution was also a challenge. Looking at the confusion matrix, different approaches did better with different classes of objects, making it difficult to clearly identify the best model. Final decisions were made based on the overall results, which may not have taken into account detailed differences in classification.
- Reliably assessing which configuration of hyperparameters was better when optimizing architectures in a supervised learning approach was also a difficulty. To cope with this problem, a proprietary training and model quality evaluation formula was created, which allowed a more precise analysis of the results. The project has opened the door to further development in several directions:
- Improving the LeNet-5 architecture: You might consider using a model that first determines the position of an object in an image and then cropping the image at that location. Reducing the image size to 32 × 32 pixels would then not cause so much pixelization, which could lead to better results while maintaining high speed.
- Optimizing the SimSiam model: The SimSiam model could be optimized for hyperparameters such as learning rate, and training time could be increased by increasing the number of epochs, which could contribute to better results.
- Confusion matrix analysis: A more thorough confusion matrix analysis could lead to improvements in the dataset for augmentation. The abundance of each data class could be equalized, especially where accuracy was weaker, which could improve the overall effectiveness of the models.
- Transfer learning: an interesting direction for further research would be to test transfer learning from the GoogLeNet model, obtained using the supervised learning method, on other data containing entirely new object classes. Comparing the results of such transfer learning with those obtained from the YOLOv8 model could provide valuable new insights into the effectiveness of these approaches in different contexts.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Budak, Ü.; Şengür, A.; Halici, U. Deep convolutional neural networks for airport detection in remote sensing images. In Proceedings of the 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Aitkenhead, M.; McDonald, A. A neural network face recognition system. Eng. Appl. Artif. Intell. 2003, 16, 167–176. [Google Scholar] [CrossRef]
- Maitra, D.S.; Bhattacharya, U.; Parui, S.K. CNN based common approach to handwritten character recognition of multiple scripts. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1021–1025. [Google Scholar] [CrossRef]
- Chahuán-Jiménez, K. Neural Network-Based Predictive Models for Stock Market Index Forecasting. J. Risk Financ. Manag. 2024, 17, 242. [Google Scholar] [CrossRef]
- Abhishek, K.; Singh, M.; Ghosh, S.; Anand, A. Weather Forecasting Model using Artificial Neural Network. Procedia Technol. 2012, 4, 311–318. [Google Scholar] [CrossRef]
- Hemanth, D.J.; Estrela, V.V. Deep Learning for Image Processing Applications; IOS Press: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Sumathi, S.; Janani, M. Neural Networks for Natural Language Processing; IGI Global: Hershey, PA, USA, 2020. [Google Scholar] [CrossRef]
- Sabharwal, N.; Agrawal, A. Neural Networks for Natural Language Processing. In Hands-On Question Answering Systems with BERT: Applications in Neural Networks and Natural Language Processing; Apress: Berkeley, CA, USA, 2021; pp. 15–39. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June2009; pp. 248–255. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Bappy, J.H.; Roy-Chowdhury, A.K. CNN based region proposals for efficient object detection. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3658–3662. [Google Scholar] [CrossRef]
- Zhao, Z.; Alzubaidi, L.; Zhang, J.; Duan, Y.; Gu, Y. A comparison review of transfer learning and self-supervised learning: Definitions, applications, advantages and limitations. Expert Syst. Appl. 2024, 242, 122807. [Google Scholar] [CrossRef]
- Michalski, B.; Plechawska-Wójcik, M. Comparison of LeNet-5, AlexNet and GoogLeNet models in handwriting recognition. J. Comput. Sci. Inst. 2022, 23, 145–151. [Google Scholar] [CrossRef]
- Iqbal, S.; Qureshi, A.N.; Ullah, A.; Li, J.; Mahmood, T. Improving the Robustness and Quality of Biomedical CNN Models through Adaptive Hyperparameter Tuning. Appl. Sci. 2022, 12, 11870. [Google Scholar] [CrossRef]
- Nugraha, G.S.; Darmawan, M.I.; Dwiyansaputra, R. Comparison of CNN’s architecture GoogleNet, AlexNet, VGG-16, Lenet-5, Resnet-50 in Arabic handwriting pattern recognition. Kinet. Game Technol. Inf. Syst. Comput. Netw. Comput. Electron. Control 2023, 8. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, G.; Wang, R.; Tang, S.; Su, H.; Cao, K. Intelligent fault diagnosis of hydraulic piston pump combining improved LeNet-5 and PSO hyperparameter optimization. Appl. Acoust. 2021, 183, 108336. [Google Scholar] [CrossRef]
- Imen, W.; Amna, M.; Fatma, B.; Ezahra, S.F.; Masmoudi, N. Fast HEVC intra-CU decision partition algorithm with modified LeNet-5 and AlexNet. SIgnal Image Video Process. 2022, 16, 1811–1819. [Google Scholar] [CrossRef]
- Ramesh Babu, P.; Srikrishna, A.; Gera, V.R. Diagnosis of tomato leaf disease using OTSU multi-threshold image segmentation-based chimp optimization algorithm and LeNet-5 classifier. J. Plant Dis. Prot. 2024, 131, 2221–2236. [Google Scholar] [CrossRef]
- Ha, K.W.; Park, S.; Chon, S.; Kim, J.K.; Jung, S. A SimSiam-based Generalized Model Training Technique for Classification of ECG from Heterogeneous Devices. In Proceedings of the 2023 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Republic of Korea, 13–16 February 2023; pp. 312–313. [Google Scholar] [CrossRef]
- Aboutorab, H.; Hussain, O.K.; Saberi, M.; Hussain, F.K.; Chang, E. A survey on the suitability of risk identification techniques in the current networked environment. J. Netw. Comput. Appl. 2021, 178, 102984. [Google Scholar] [CrossRef]
- YOLOv8 Description. Available online: https://yolov8.com/ (accessed on 30 August 2024).
- Raiaan, M.A.K.; Sakib, S.; Fahad, N.M.; Mamun, A.A.; Rahman, M.A.; Shatabda, S.; Mukta, M.S.H. A systematic review of hyperparameter optimization techniques in Convolutional Neural Networks. Decis. Anal. J. 2024, 11, 100470. [Google Scholar] [CrossRef]
- Wojciuk, M.; Swiderska-Chadaj, Z.; Siwek, K.; Gertych, A. Improving classification accuracy of fine-tuned CNN models: Impact of hyperparameter optimization. Heliyon 2024, 10, e26586. [Google Scholar] [CrossRef] [PubMed]
- Aguerchi, K.; Jabrane, Y.; Habba, M.; El Hassani, A.H. A CNN Hyperparameters Optimization Based on Particle Swarm Optimization for Mammography Breast Cancer Classification. J. Imaging 2024, 10, 30. [Google Scholar] [CrossRef] [PubMed]
- Jian, L.; Pu, Z.; Zhu, L.; Yao, T.; Liang, X. SS R-CNN: Self-Supervised Learning Improving Mask R-CNN for Ship Detection in Remote Sensing Images. Remote Sens. 2022, 14, 4383. [Google Scholar] [CrossRef]
- Hojjati, H.; Ho, T.K.K.; Armanfard, N. Self-supervised anomaly detection in computer vision and beyond: A survey and outlook. Neural Netw. 2024, 172, 106106. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Lin, F.; Xiang, Y.; Katranuschkov, P.; Scherer, R.J. Fast Crack Detection Using Convolutional Neural Network. In EG-ICE 2021 Workshop on Intelligent Computing in Engineering; Abualdenien, J., Borrmann, A., Ungureanu, L.C., Hartmann, T., Eds.; Universitätsverlag der TU Berlin: Berlin, Germany, 2021; pp. 540–549. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Poonkuntran, S.; Dhanraj, R.; Balusamy, B. Object Detection with Deep Learning Models: Principles and Applications; Taylor & Francis Limited: Abingdon, UK, 2022. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, J. PSI Analysis of Adversarial-Attacked DCNN Models. Appl. Sci. 2023, 13, 9722. [Google Scholar] [CrossRef]
- Yu, X.; Wang, S.H.; Zhang, X.; Zhang, Y.D. Detection of COVID-19 by GoogLeNet-COD. In Intelligent Computing Theories and Application; Huang, D.S., Bevilacqua, V., Hussain, A., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 499–509. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Animals-10 Dataset Description. Available online: https://www.kaggle.com/datasets/alessiocorrado99/animals10 (accessed on 30 September 2024).
- Brownlee, J. Better Deep Learning: Train Faster, Reduce Overfitting, and Make Better Predictions; Machine Learning Mastery: San Francisco, CA, USA, 2018. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Babiarz, A.; Bugaj, M. Application of Deep Neural Networks in Recognition of Selected Types of Objects in Digital Images. Appl. Sci. 2025, 15, 7931. https://doi.org/10.3390/app15147931
Babiarz A, Bugaj M. Application of Deep Neural Networks in Recognition of Selected Types of Objects in Digital Images. Applied Sciences. 2025; 15(14):7931. https://doi.org/10.3390/app15147931
Chicago/Turabian StyleBabiarz, Artur, and Michał Bugaj. 2025. "Application of Deep Neural Networks in Recognition of Selected Types of Objects in Digital Images" Applied Sciences 15, no. 14: 7931. https://doi.org/10.3390/app15147931
APA StyleBabiarz, A., & Bugaj, M. (2025). Application of Deep Neural Networks in Recognition of Selected Types of Objects in Digital Images. Applied Sciences, 15(14), 7931. https://doi.org/10.3390/app15147931