
SE-TransUNet-Based Semantic Segmentation for Water Leakage Detection in Tunnel Secondary Linings Amid Complex Visual Backgrounds


Abstract
1. Introduction
2. SE-TransUNet Water Seepage Detection Model
2.1. Overall Model Architecture of Water Seepage Recognition
2.2. SE Channel Attention Mechanism
- (1)
- Transformation
- (2)
- Squeeze Operation
- (3)
- Excitation Operation
- (4)
- Scale Operation
2.3. Encoder of Water Seepage Recognition Model
- (1)
- ResNet50 Submodule Analysis
- (2)
- ViT Module Analysis
2.4. Decoder of Water Seepage Recognition Model
3. Construction of Tunnel Water Seepage Dataset
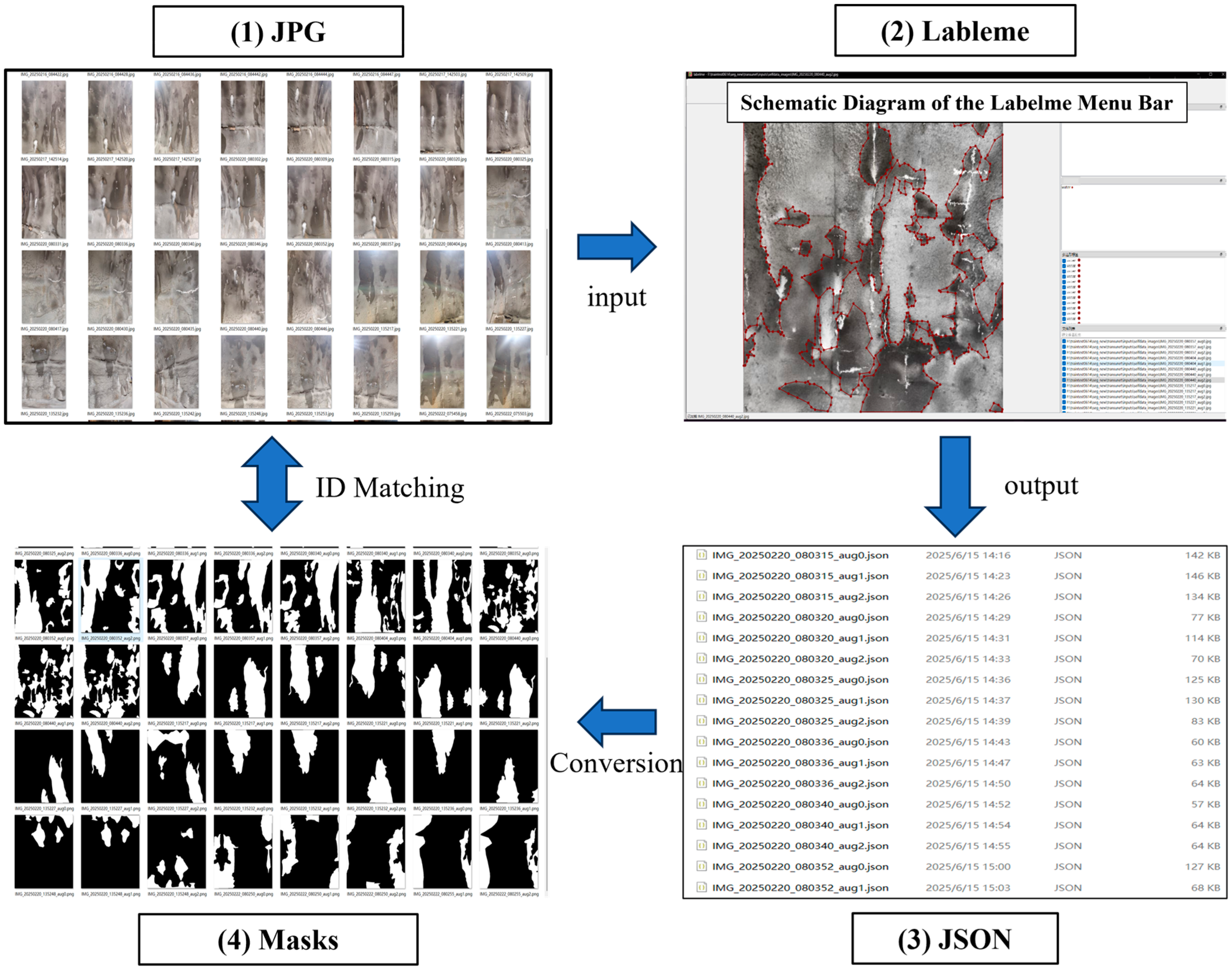
3.1. Collection of Tunnel Water Seepage Images
3.2. Data Enhancement Method
3.3. Image Annotation
4. Model Training
4.1. Training Environment
4.2. k-Fold Cross-Validation Setup
4.3. BCE-Dice Loss Function
4.4. Evaluation Indicators
5. Analysis of Training Results
5.1. Performance Analysis of the SE-TransUnet Model
- (1)
- loss function
- (2)
- Analysis of k-fold cross-validation results
5.2. Comparison of Results of Various Models on the Test Set
5.3. Analysis of Visual Segmentation Results
6. Ablation Experiments
6.1. Analysis of Ablation Experiment Results
6.2. Analysis of Heatmaps from Ablation Experiments
- (1)
- Heatmap Analysis of Image 1: Area-Type Leakage
- (2)
- Heatmap Analysis of Image 2: Spot-Type Leakage
- (3)
- Heatmap Analysis of Image 3: Linear Leakage
- (4)
- Heatmap Analysis of Image 4: Mixed-Type Leakage
7. Limitations
7.1. Limitations of the Dataset and Annotations
7.2. Limitations in Computational Resources and Real-Time Performance
7.3. Gaps in Interpretability and Engineering Applicability
7.4. Limitations in Experimental Design
8. Conclusions
- (1)
- Based on the SE channel attention mechanism, an SE-TransUNet model was proposed for tunnel lining leakage detection. Trained on a constructed hybrid leakage dataset, the model achieved average values of 0.8318 (IoU), 0.8304 (Dice), 0.9394 (Recall), 0.8480 (Precision), 0.9733 (AUC), 0.8562 (MCC), 0.9218 (F1-score), and 6.53 FPS. The model demonstrated strong generalization and robustness under challenging conditions, including shadowed indentations on the lining surface, surface contamination such as white spots and stains, shallow leakage marks with low contrast against the background, and partial occlusions.
- (2)
- Ablation experiments were conducted by progressively removing the SE-Block and ViT modules from the SE-TransUNet model. All evaluation metrics declined to varying extents. The variant with all SE-Blocks and the ViT module removed showed a substantial performance gap from SE-TransUNet, with an IoU difference of up to 7.04%.
- (3)
- Score-CAM heatmap analysis across different leakage patterns revealed that SE-TransUNet performed consistently well in detecting area-type, linear, spot-type, and mixed-form tunnel leakage. Compared with ablation variants, its heatmaps provided more complete coverage of the leakage regions, with high-activation areas more closely aligned with the true leakage boundaries and exhibiting stronger spatial continuity, thereby enabling more accurate characterization of leakage spatial distributions across diverse forms.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, L.; Guan, C.; Wu, Y.; Feng, C. Impact Analysis and Optimization of Key Material Parameters of Embedded Water-Stop in Tunnels. Appl. Sci. 2023, 13, 8468. [Google Scholar] [CrossRef]
- Zhai, J.; Wang, Q.; Wang, H.; Xie, X.; Zhou, M.; Yuan, D.; Zhang, W. Highway Tunnel Defect Detection Based on Mobile GPR Scanning. Appl. Sci. 2022, 12, 3148. [Google Scholar] [CrossRef]
- Jin, Y.; Yang, S.; Guo, H.; Han, L.; Su, S.; Shan, H.; Zhao, J.; Wang, G. A Novel Visual System for Conducting Safety Evaluations of Operational Tunnel Linings. Appl. Sci. 2024, 14, 8414. [Google Scholar] [CrossRef]
- Lin, C.; Wang, X.; Li, Y.; Zhang, F.; Xu, Z.; Du, Y. Forward Modelling and GPR Imaging in Leakage Detection and Grouting Evaluation in Tunnel Lining. KSCE J. Civ. Eng. 2020, 24, 278–294. [Google Scholar] [CrossRef]
- Gong, C.; Wang, Y.; Ding, W.; Lei, M.; Shi, C. Waterproof Performance of Sealing Gasket in Shield Tunnel: A Review. Appl. Sci. 2022, 12, 4556. [Google Scholar] [CrossRef]
- Feng, Z.; Li, D.; Wang, F.; Zhang, L.; Wang, S. Field Test and Numerical Simulation Study on Water Pressure Distribution and Lining Deformation Law in Water-Rich Tunnel Crossing Fault Zones. Appl. Sci. 2024, 14, 7110. [Google Scholar] [CrossRef]
- Dohyun, P. Numerical Investigation on the Effect of Water Leakage on the Ground Surface Settlement and Tunnel Stability. Tunn. Undergr. Space Technol. 2024, 146, 105656. [Google Scholar] [CrossRef]
- Panthi, K.K.; Nilsen, B. Uncertainty Analysis for Assessing Leakage Through Water Tunnels: A Case from Nepal Himalaya. Rock Mech. Rock Eng. 2010, 43, 629–639. [Google Scholar] [CrossRef]
- Türkmen, S. Water leakage from the power tunnel of Gezende Dam, southern Turkey: A case study. Environ. Earth Sci. 2010, 61, 419–427. [Google Scholar] [CrossRef]
- Lin, C.; Wang, X.; Nie, L.; Sun, H.; Xu, Z.; Du, Y.; Liu, L. Comprehensive Geophysical Investigation and Analysis of Lining Leakage for Water-Rich Rock Tunnels: A Case Study of Kaiyuan Tunnel, Jinan, China. Geotech. Geol. Eng. 2020, 38, 3449–3468. [Google Scholar] [CrossRef]
- Liu, X.; Hong, Z.; Shi, W.; Guo, X. Image-Processing-Based Subway Tunnel Crack Detection System. Sensors 2023, 23, 6070. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Xu, Q.; Song, Z.; Meng, S.; Liu, S. Dynamic wave tunnel lining GPR images multi-disease detection method based on deep learning. NDT E Int. 2024, 144, 103087. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, H.; Zhou, S.; Yan, L.; Yang, H. A deep learning-based algorithm for fast identification of multiple defects in tunnels. Eng. Appl. Artif. Intell. 2025, 145, 110035. [Google Scholar] [CrossRef]
- Xiong, L.; Zhang, D.; Zhang, Y. Water leakage image recognition of shield tunnel via learning deep feature representation. J. Vis. Commun. Image Represent. 2020, 71, 102708. [Google Scholar] [CrossRef]
- Wang, B.; He, N.; Xu, F.; Du, Y.; Xu, H. Visual detection method of tunnel water leakage diseases based on feature enhancement learning. Tunn. Undergr. Space Technol. 2024, 153, 106009. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, J.; Gong, C. Hybrid semantic segmentation for tunnel lining cracks based on Swin Transformer and convolutional neural network. Comput.-Aided Civ. Infrastruct. Eng. 2023, 38, 2491–2510. [Google Scholar] [CrossRef]
- Zhou, H.; Xiao, X.; Li, H.; Liu, X.; Liang, P. Hybrid Shunted Transformer embedding UNet for remote sensing image semantic segmentation. Neural Comput. Appl. 2024, 36, 15705–15720. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Bas, R.S.; Jürgen, S. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef]
- Xue, Y.; Cai, X.; Shadabfar, M.; Shao, H.; Zhang, S. Deep learning-based automatic recognition of water leakage area in shield tunnel lining. Tunn. Undergr. Space Technol. 2020, 104, 103524. [Google Scholar] [CrossRef]
- Yan, T.; Shen, S.L.; Zhou, A.N.; Chen, X. Prediction of Geological Characteristics from Shield Operational Parameters by Integrating Grid Search and k-Fold Cross Validation into Stacking Classification Algorithm. J. Rock Mech. Geotech. Eng. 2022, 14, 1292–1303. [Google Scholar] [CrossRef]
- Chen, J.; Mei, J.; Li, X.; Lu, Y.; Yu, Q.; Wei, Q.; Luo, X.; Xie, Y.; Adeli, E.; Wang, Y.; et al. TransUNet: Rethinking the U-Net architecture design for medical image segmentation through the lens of transformers. Med. Image Anal. 2024, 97, 103208. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; MICCAI 2015, Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9351. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision—ECCV 2018, 5th European Conference, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; ECCV 2018. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11211. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Jha, D.; Riegler, M.A.; Johansen, D.; Halvorsen, P.; Johansen, H.D. DoubleU-Net: A Deep Convolutional Neural Network for Medical Image Segmentation. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; pp. 558–564. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Stoyanov, D., Taylor, Z., Carneiro, G., Syeda-Mahmood, T., Martel, A., Maier-Hein, L., Tavares, J.M.R.S., Bradley, A., Papa, J.P., Belagiannis, V., et al., Eds.; DLMIA ML-CDS 2018 2018. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11045. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. In Proceedings of the European Conference on Computer Vision Workshops, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; ECCVW 2022. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13673. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Z.; Du, M.; Yang, F.; Zhang, Z.; Ding, S. Score-CAM: Score-Weighted Visual Explanations for Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 111–119. [Google Scholar] [CrossRef]
- Huang, G.; Zheng, Z.; Li, J.; Zhang, M.; Liu, J.; Zhang, L. Dual Attention Equivariant Network for Weakly Supervised Semantic Segmentation. Appl. Sci. 2025, 15, 6474. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module Name | Input Size | Output Size | Number of Channels | Feature Type |
|---|---|---|---|---|
| encoder1 | 512 × 512 × 3 | 256 × 256 × 64 | 64 | Edges, Textures (Low-Level Features) |
| encoder2 | 256 × 256 × 64 | 128 × 128 × 256 | 256 | Textures, Simple Shapes (Mid-Low-Level Features) |
| encoder3 | 128 × 128 × 256 | 64 × 64 × 512 | 512 | Object Parts (Mid-Level Features) |
| encoder4 | 64 × 64 × 512 | 32 × 32 × 1024 | 1024 | Holistic Semantics (High-Level Features) |
| ViT | 32 × 32 × 1024 | 16 × 16 × 1024 | 1024 | Global Semantic Enhanced Features |
| Process Number | Process Function | Process Explanation |
|---|---|---|
| 1 | Input Feature Map | The output feature size of ResNet needs to match the input feature size of ViT. If they do not match, additional upsampling is required |
| 2 | Patch Partitioning | Each patch has a size of 8 × 8. If the output feature map of encoder4 is 32 × 32, then 16 patches are partitioned |
| 3 | Global Semantic Enhancement | Based on the self-attention mechanism of Transformer, long-range dependencies among 16 patches are captured |
| 4 | Resolution Adaptation | Transform the feature size to reduce the resolution difference with the shallow features in the decoder, facilitating subsequent splicing and fusion |
| Process Number | Process Function | Process Explanation |
|---|---|---|
| 1 | Input Feature and Attention Enhancement | The decoder first applies SENet attention to each feature layer. |
| 2 | Layer 1 Decoding | Upsample xvit, and splice and fuse the upsampled xvit with x3 through VGGBlock. |
| 3 | Layer 2 Decoding | Upsample the output of the first layer decoding, and splice and fuse it with x2 through VGGBlock. |
| 4 | Layer 3 Decoding | Upsample the output of the second layer decoding, and splice and fuse it with x1 through VGGBlock. |
| 5 | Final Upsampling and Output | After upsampling and convolution processing by VGGBlock; the output is performed by the segmentation head |
| Leakage Type | Number of Images | Proportion (%) |
|---|---|---|
| Spot-Type Leakage | 326 | 21.45 |
| Linear Leakage | 345 | 22.70 |
| Area-Type Leakage | 296 | 19.47 |
| Mixed-type Leakage | 553 | 36.38 |
| Total | 1520 | 100 |
| Experiment Round | IoU | Dice | Recall | Precision | AUC | MCC | F1-Score | FPS |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.8425 | 0.8425 | 0.9641 | 0.8674 | 0.9828 | 0.8728 | 0.9382 | 6.45 |
| 2 | 0.8542 | 0.8483 | 0.9626 | 0.8701 | 0.9840 | 0.8833 | 0.9493 | 6.50 |
| 3 | 0.8025 | 0.8114 | 0.9203 | 0.8456 | 0.9753 | 0.8381 | 0.9035 | 6.56 |
| 4 | 0.8462 | 0.8293 | 0.9288 | 0.8308 | 0.9867 | 0.8544 | 0.9166 | 6.59 |
| 5 | 0.8139 | 0.8106 | 0.9212 | 0.8263 | 0.9375 | 0.8326 | 0.9013 | 6.57 |
| Mean | 0.8318 | 0.8304 | 0.9394 | 0.8480 | 0.9733 | 0.8562 | 0.9218 | 6.53 |
| Standard Deviation | 0.0224 | 0.0204 | 0.0221 | 0.0202 | 0.0204 | 0.0218 | 0.0213 | 0.057 |
| Model Name | IoU | Dice | Recall | Precision | AUC | MCC | F1-Score | FPS | Parameter Count (M) |
|---|---|---|---|---|---|---|---|---|---|
| SE-TransUNet | 0.8318 | 0.8304 | 0.9394 | 0.8480 | 0.9733 | 0.8562 | 0.9218 | 6.53 | 223 |
| TransUNet | 0.7864 | 0.8471 | 0.9142 | 0.8481 | 0.9730 | 0.8523 | 0.8714 | 14.64 | 176 |
| UNet | 0.7614 | 0.8631 | 0.8985 | 0.8213 | 0.9712 | 0.8440 | 0.8911 | 16.64 | 23 |
| Swin-Unet | 0.8159 | 0.8184 | 0.9242 | 0.8310 | 0.9483 | 0.8472 | 0.8993 | 8.33 | 134 |
| DeepLabV3plus | 0.7515 | 0.8430 | 0.8542 | 0.8420 | 0.9790 | 0.8314 | 0.8544 | 15.72 | 50 |
| SegNet | 0.6761 | 0.7918 | 0.7740 | 0.8473 | 0.9499 | 0.7346 | 0.8036 | 17.32 | 14 |
| BiSeNetV2 | 0.5791 | 0.6904 | 0.6961 | 0.7823 | 0.9149 | 0.6405 | 0.7279 | 19.13 | 8 |
| FPN | 0.7873 | 0.8738 | 0.8893 | 0.8968 | 0.9853 | 0.8540 | 0.8923 | 16.51 | 25 |
| DoubleUnet | 0.7500 | 0.8216 | 0.8206 | 0.8986 | 0.9735 | 0.8057 | 0.8543 | 14.47 | 40 |
| NestedUNet | 0.7320 | 0.8194 | 0.8749 | 0.8197 | 0.9639 | 0.7791 | 0.8409 | 15.33 | 30 |
| Metrics | SE-TransUNet (Mean ± SD) | TransUNet (Mean ± SD) | Difference (d) | t-Value | p-Value |
|---|---|---|---|---|---|
| IoU | 0.8318 ± 0.0224 | 0.7864 ± 0.0213 | 0.0454 | 3.25 | 0.031 |
| Dice | 0.8304 ± 0.0204 | 0.8471 ± 0.0202 | −0.0167 | −2.10 | 0.095 |
| Recall | 0.9394 ± 0.0221 | 0.9142 ± 0.0241 | 0.0252 | 2.87 | 0.042 |
| Precision | 0.8480 ± 0.0202 | 0.8481 ± 0.0215 | −0.0001 | −0.01 | 0.992 |
| AUC | 0.9733 ± 0.0204 | 0.9730 ± 0.0201 | 0.0003 | 0.03 | 0.977 |
| MCC | 0.8562 ± 0.0218 | 0.8523 ± 0.0221 | 0.0039 | 0.41 | 0.698 |
| F1-score | 0.9218 ± 0.0213 | 0.9218 ± 0.0211 | 0.0000 | 0.00 | 1.000 |
| FPS | 6.53 ± 0.057 | 14.64 ± 0.031 | −8.11 | −120.5 | <0.001 |
| Step Number | Ablation Module | IoU | Dice | Recall | Precision | F1-Score |
|---|---|---|---|---|---|---|
| 0 | None | 0.8318 | 0.8304 | 0.9394 | 0.8480 | 0.9218 |
| 1 | SE-Block1 | 0.8159 | 0.8385 | 0.9210 | 0.8668 | 0.8847 |
| 2 | SE-Block2 | 0.7974 | 0.8242 | 0.9117 | 0.8575 | 0.8817 |
| 3 | SE-Block3 | 0.7948 | 0.8221 | 0.9100 | 0.8423 | 0.8742 |
| 4 | SE-Block4 | 0.7864 | 0.8471 | 0.9142 | 0.8481 | 0.8714 |
| 5 | ViT | 0.7614 | 0.8631 | 0.8985 | 0.8213 | 0.8911 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, R.; Wu, Y.; Wan, L.; Shao, S.; Wu, H. SE-TransUNet-Based Semantic Segmentation for Water Leakage Detection in Tunnel Secondary Linings Amid Complex Visual Backgrounds. Appl. Sci. 2025, 15, 7872. https://doi.org/10.3390/app15147872
Song R, Wu Y, Wan L, Shao S, Wu H. SE-TransUNet-Based Semantic Segmentation for Water Leakage Detection in Tunnel Secondary Linings Amid Complex Visual Backgrounds. Applied Sciences. 2025; 15(14):7872. https://doi.org/10.3390/app15147872
Chicago/Turabian StyleSong, Renjie, Yimin Wu, Li Wan, Shuai Shao, and Haiping Wu. 2025. "SE-TransUNet-Based Semantic Segmentation for Water Leakage Detection in Tunnel Secondary Linings Amid Complex Visual Backgrounds" Applied Sciences 15, no. 14: 7872. https://doi.org/10.3390/app15147872
APA StyleSong, R., Wu, Y., Wan, L., Shao, S., & Wu, H. (2025). SE-TransUNet-Based Semantic Segmentation for Water Leakage Detection in Tunnel Secondary Linings Amid Complex Visual Backgrounds. Applied Sciences, 15(14), 7872. https://doi.org/10.3390/app15147872