
A Hybrid Framework for Metal Artifact Suppression in CT Imaging of Metal Lattice Structures via Radon Transform and Attention-Based Super-Resolution Reconstruction



Abstract
1. Introduction
- A lightweight Radon-domain MAR framework that achieves high-quality CT reconstruction with minimal processing overhead by fusing deep learning and physical modeling.
- A specially designed EDSR-Tiny network for sinogram restoration that has a single residual layer and a Radon-consistent loss function.
2. Methodology
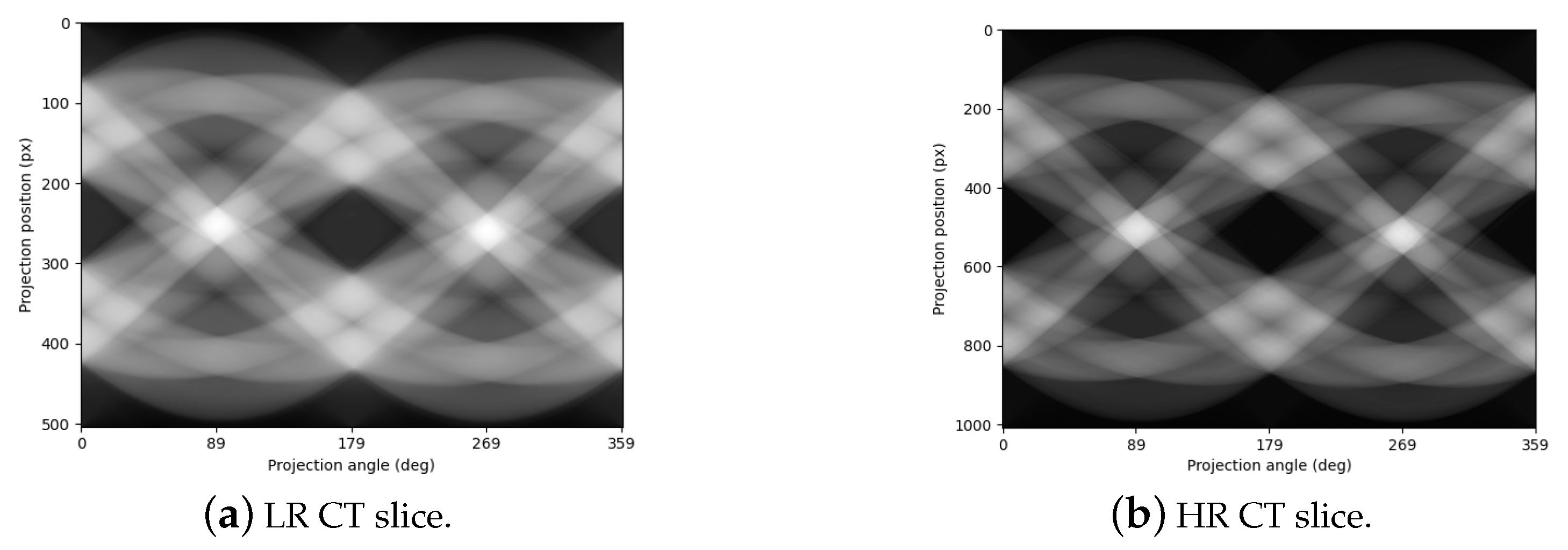
2.1. Image Interpolation Enhancement: Bicubic Interpolation
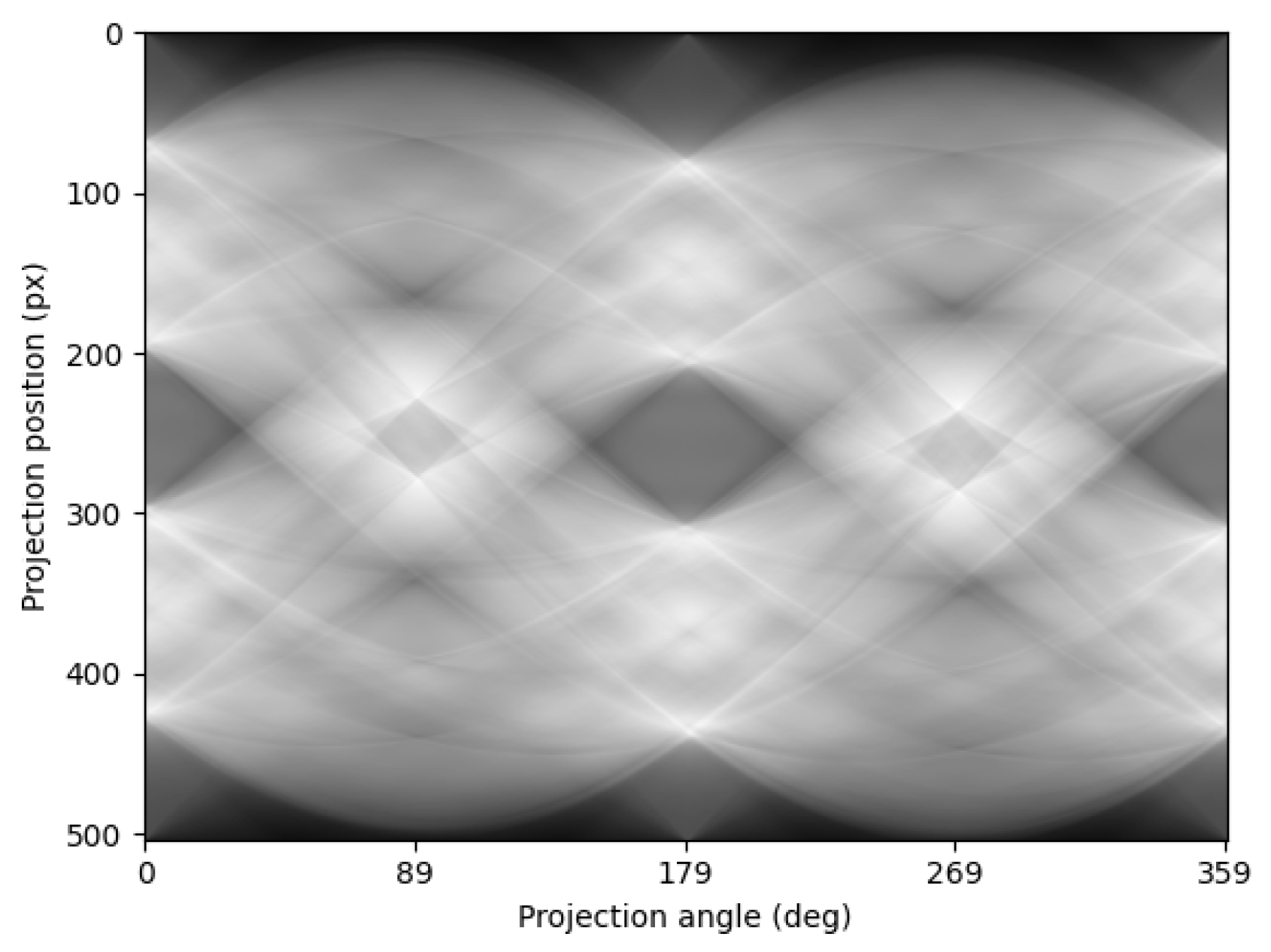
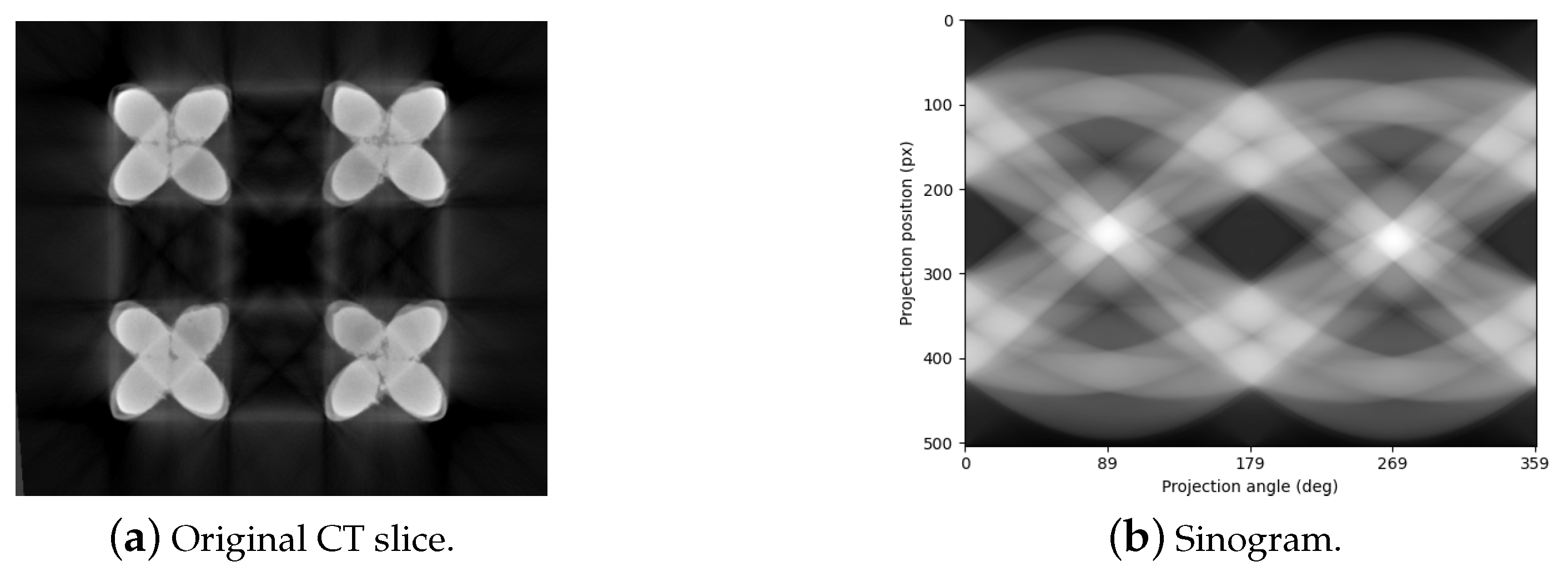
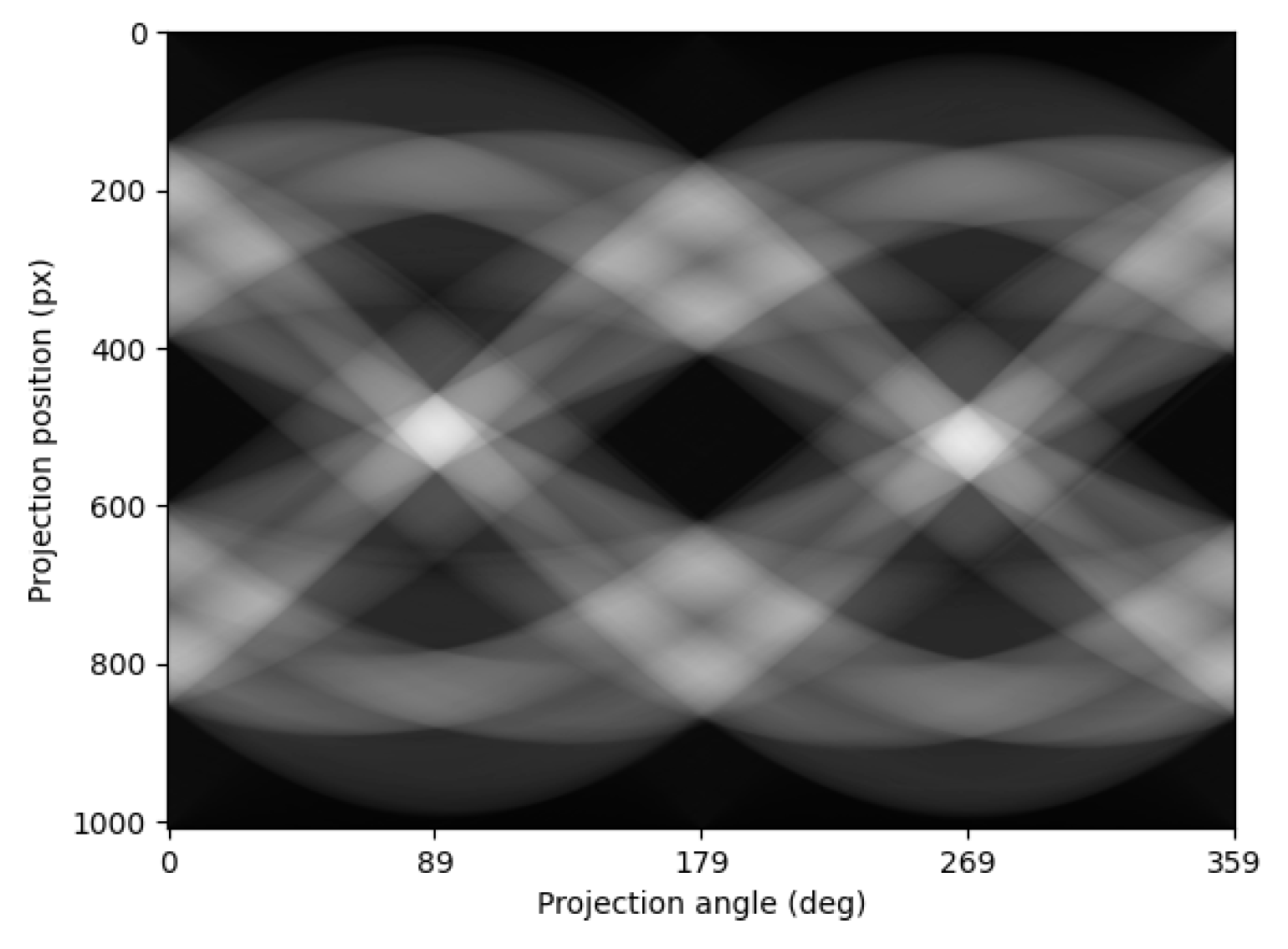
2.2. Radon Transform and Sinogram Generation
2.3. Differential Removal of Metal Artifacts
2.4. Lightweight Super-Resolution Network Optimization Based on Channel Attention Mechanism
2.4.1. Edsr-Tiny Network
2.4.2. Channel Attention Layer (CALayer)
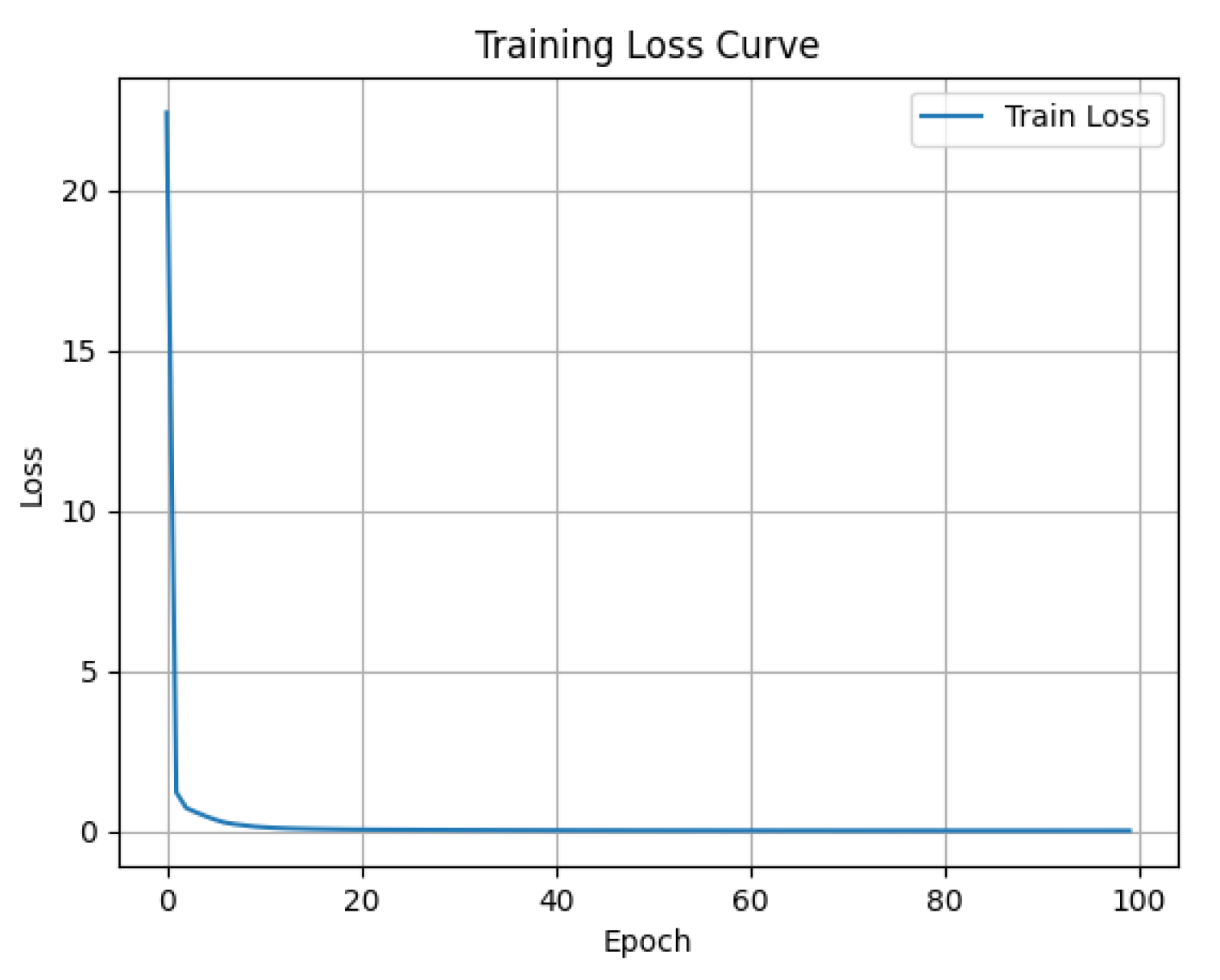
2.4.3. Loss Function
2.5. Inverse Radon Transformation and Reconstruction
2.6. Evaluation Metrics
3. The Experimental Results
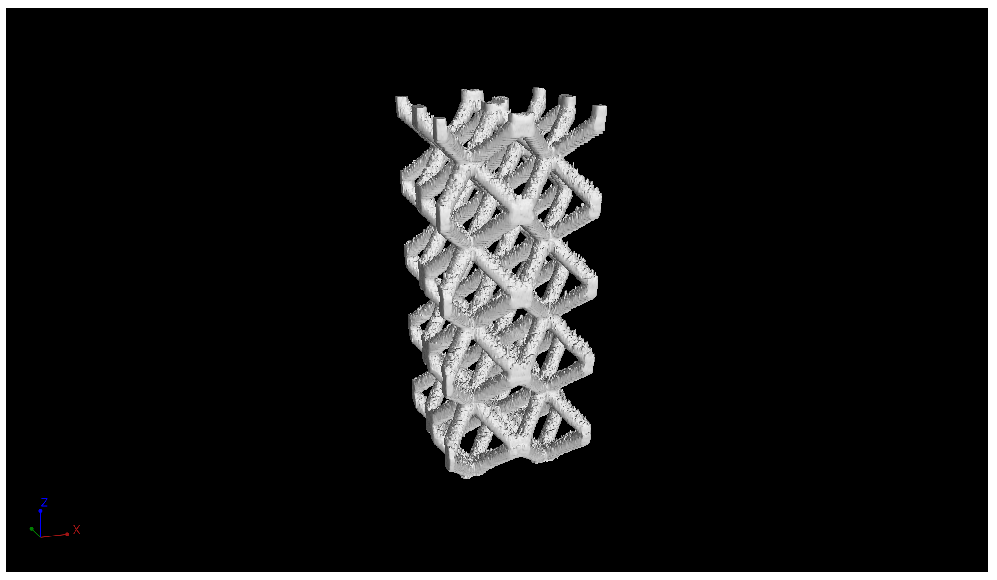
3.1. Dataset Preparation
3.2. The Result of Removing Metal Artifacts
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Boas, F.E.; Fleischmann, D. CT artifacts: Causes and reduction techniques. Imaging Med. 2012, 4, 229–240. [Google Scholar] [CrossRef]
- Wellenberg, R.; Hakvoort, E.; Slump, C.; Boomsma, M.; Maas, M.; Streekstra, G. Metal artifact reduction techniques in musculoskeletal CT-imaging. Eur. J. Radiol. 2018, 107, 60–69. [Google Scholar] [CrossRef]
- Gjesteby, L.; De Man, B.; Jin, Y.; Paganetti, H.; Verburg, J.; Giantsoudi, D.; Wang, G. Metal artifact reduction in CT: Where are we after four decades? IEEE Access 2016, 4, 5826–5849. [Google Scholar] [CrossRef]
- Selles, M.; van Osch, J.A.; Maas, M.; Boomsma, M.F.; Wellenberg, R.H. Advances in metal artifact reduction in CT images: A review of traditional and novel metal artifact reduction techniques. Eur. J. Radiol. 2024, 170, 111276. [Google Scholar] [CrossRef]
- Kalender, W.A.; Hebel, R.; Ebersberger, J. Reduction of CT artifacts caused by metallic implants. Radiology 1987, 164, 576–577. [Google Scholar] [CrossRef]
- Meyer, E.; Raupach, R.; Lell, M.; Schmidt, B.; Kachelrieß, M. Normalized metal artifact reduction (NMAR) in computed tomography. Med. Phys. 2010, 37, 5482–5493. [Google Scholar] [CrossRef]
- Meyer, E.; Raupach, R.; Lell, M.; Schmidt, B.; Kachelrieß, M. Frequency split metal artifact reduction (FSMAR) in computed tomography. Med. Phys. 2012, 39, 1904–1916. [Google Scholar] [CrossRef]
- Scardigno, R.M.; Brunetti, A.; Marvulli, P.M.; Carli, R.; Dotoli, M.; Bevilacqua, V.; Buongiorno, D. CALIMAR-GAN: An unpaired mask-guided attention network for metal artifact reduction in CT scans. Comput. Med. Imaging Graph. 2025, 123, 102565. [Google Scholar] [CrossRef]
- Yu, L.; Zhang, Z.; Li, X.; Ren, H.; Zhao, W.; Xing, L. Metal artifact reduction in 2D CT images with self-supervised cross-domain learning. Phys. Med. Biol. 2021, 66, 175003. [Google Scholar] [CrossRef]
- Zhu, L.; Han, Y.; Xi, X.; Li, L.; Yan, B. Completion of metal-damaged traces based on deep learning in sinogram domain for metal artifacts reduction in CT images. Sensors 2021, 21, 8164. [Google Scholar] [CrossRef]
- Peng, C.; Li, B.; Li, M.; Wang, H.; Zhao, Z.; Qiu, B.; Chen, D.Z. An irregular metal trace inpainting network for x-ray CT metal artifact reduction. Med. Phys. 2020, 47, 4087–4100. [Google Scholar] [CrossRef]
- Xu, L.; Zeng, X.; Li, W.; Zheng, B. MFGAN: Multi-modal feature-fusion for CT metal artifact reduction using GANs. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–17. [Google Scholar] [CrossRef]
- Wang, H.; Li, Y.; He, N.; Ma, K.; Meng, D.; Zheng, Y. DICDNet: Deep interpretable convolutional dictionary network for metal artifact reduction in CT images. IEEE Trans. Med. Imaging 2021, 41, 869–880. [Google Scholar] [CrossRef]
- Shi, Z.; Wang, N.; Kong, F.; Cao, H.; Cao, Q. A semi-supervised learning method of latent features based on convolutional neural networks for CT metal artifact reduction. Med. Phys. 2022, 49, 3845–3859. [Google Scholar] [CrossRef]
- Kim, S.; Ahn, J.; Kim, B.; Kim, C.; Baek, J. Convolutional neural network–based metal and streak artifacts reduction in dental CT images with sparse-view sampling scheme. Med. Phys. 2022, 49, 6253–6277. [Google Scholar] [CrossRef]
- Ikuta, M.; Zhang, J. A deep recurrent neural network with FISTA optimization for CT metal artifact reduction. IEEE Trans. Comput. Imaging 2022, 8, 961–971. [Google Scholar] [CrossRef]
- Nakao, M.; Imanishi, K.; Ueda, N.; Imai, Y.; Kirita, T.; Matsuda, T. Regularized three-dimensional generative adversarial nets for unsupervised metal artifact reduction in head and neck CT images. IEEE Access 2020, 8, 109453–109465. [Google Scholar] [CrossRef]
- Koike, Y.; Anetai, Y.; Takegawa, H.; Ohira, S.; Nakamura, S.; Tanigawa, N. Deep learning-based metal artifact reduction using cycle-consistent adversarial network for intensity-modulated head and neck radiation therapy treatment planning. Phys. Med. 2020, 78, 8–14. [Google Scholar] [CrossRef]
- Liao, H.; Lin, W.A.; Zhou, S.K.; Luo, J. ADN: Artifact disentanglement network for unsupervised metal artifact reduction. IEEE Trans. Med Imaging 2019, 39, 634–643. [Google Scholar] [CrossRef]
- Ketcha, M.D.; Marrama, M.; Souza, A.; Uneri, A.; Wu, P.; Zhang, X.; Helm, P.A.; Siewerdsen, J.H. Sinogram+ image domain neural network approach for metal artifact reduction in low-dose cone-beam computed tomography. J. Med Imaging 2021, 8, 052103. [Google Scholar] [CrossRef]
- Lee, D.; Park, C.; Lim, Y.; Cho, H. A metal artifact reduction method using a fully convolutional network in the sinogram and image domains for dental computed tomography. J. Digit. Imaging 2020, 33, 538–546. [Google Scholar] [CrossRef]
- Yu, L.; Zhang, Z.; Li, X.; Xing, L. Deep sinogram completion with image prior for metal artifact reduction in CT images. IEEE Trans. Med. Imaging 2020, 40, 228–238. [Google Scholar] [CrossRef]
- Wang, T.; Xia, W.; Huang, Y.; Sun, H.; Liu, Y.; Chen, H.; Zhou, J.; Zhang, Y. DAN-Net: Dual-domain adaptive-scaling non-local network for CT metal artifact reduction. Phys. Med. Biol. 2021, 66, 155009. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Voltage | 145 kV | Current | 220 μA |
|---|---|---|---|
| Exposure time | 1000 ms | Frames | 1440 |
| Reconstruction matrix | 2048 × 2048 | pixel size | 0.07 mm × 0.07 mm × 0.1 mm |
| Method | Average SNR | Average PSNR | The Variance of PSNR |
|---|---|---|---|
| Original | 14.27 dB | - | - |
| Bicubic interpolation method | 20.13 dB | 30.25 dB | - |
| CycleGAN | 21.63 dB | 32.53 dB | 2.21 dB |
| pix2pix | 26.26 dB | 37.13 dB | 0.82 dB |
| Reconstruction using EDSR-Tiny | 29.75 dB | 40.39 dB | 2.56 dB |
| Without | CALayer | Without CALayer | SNR | PSNR | |
|---|---|---|---|---|---|
| √ | √ | 22.13 dB | 33.25 dB | ||
| √ | √ | +3.15 dB | +2.12 dB | ||
| √ | √ | +3.45 dB | +3.56 dB | ||
| √ | √ | +7.62 dB | +7.14 dB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, B.; Zhang, Z.; Li, H.; Wu, R. A Hybrid Framework for Metal Artifact Suppression in CT Imaging of Metal Lattice Structures via Radon Transform and Attention-Based Super-Resolution Reconstruction. Appl. Sci. 2025, 15, 7819. https://doi.org/10.3390/app15147819
Wang B, Zhang Z, Li H, Wu R. A Hybrid Framework for Metal Artifact Suppression in CT Imaging of Metal Lattice Structures via Radon Transform and Attention-Based Super-Resolution Reconstruction. Applied Sciences. 2025; 15(14):7819. https://doi.org/10.3390/app15147819
Chicago/Turabian StyleWang, Bingyang, Zhiwei Zhang, Heng Li, and Ronghai Wu. 2025. "A Hybrid Framework for Metal Artifact Suppression in CT Imaging of Metal Lattice Structures via Radon Transform and Attention-Based Super-Resolution Reconstruction" Applied Sciences 15, no. 14: 7819. https://doi.org/10.3390/app15147819
APA StyleWang, B., Zhang, Z., Li, H., & Wu, R. (2025). A Hybrid Framework for Metal Artifact Suppression in CT Imaging of Metal Lattice Structures via Radon Transform and Attention-Based Super-Resolution Reconstruction. Applied Sciences, 15(14), 7819. https://doi.org/10.3390/app15147819