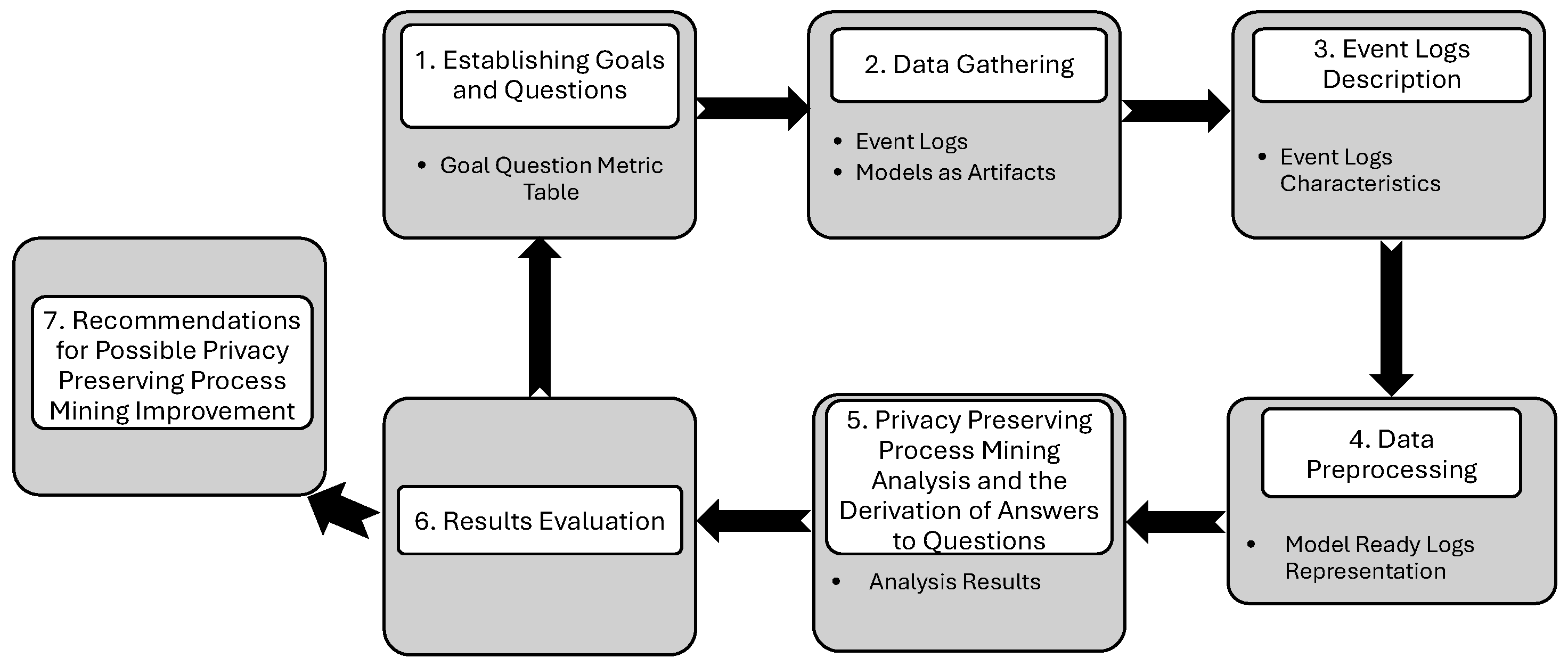
By following the seven steps of the proposed methodology, the case study is implemented and conducted by using different Python tools and libraries. Especially for the main PM analysis, such as event logs description statistics, process discovery, and conformance checking, the PM4Py tool was utilized.
4.2. Data Gathering
After the GQM table is constructed, four real-life event log datasets are extracted from the public 4TU ResearchData repository (4TU ResearchData:
https://data.4tu.nl/). Given the algorithmic variations among PPPM models, it is essential to ensure an equitable and methodologically rigorous comparison. Therefore, we utilize the event logs with diverse structural configurations and conduct a comprehensive analysis across a wide range of privacy budget parameters, including
epsilon and
sigma. The Sepsis log provides a detailed representation of hospital procedures administered to sepsis patients and encompasses a substantial number of infrequent process traces [
28]. The events recorded in the BPIC13 log are associated with the VINST system, which is designed for incident and problem management [
29]. CoSeLog is an event log originating from an actual customer support setting, systematically documenting detailed sequences of interactions and activities to support research in process mining and behavioral analysis [
30]. The Road Traffic Fines event log documents authentic administrative procedures concerning the management of traffic fines by an Italian municipality, functioning as a benchmark dataset for research in process mining, compliance analysis, and the optimization of public sector workflows [
31].
To gather privacy-preserving models, we used the respective publicly shared Python-based available code repositories in our own benchmark implementation. For the group-based privacy-preserving models, we selected AnonyPy (AnonyPy:
https://github.com/glassonion1/anonypy) [
32]. AnonyPy is a Python-based framework developed for the anonymization of datasets through group-based methodologies, incorporating privacy-preserving techniques such as
k-anonymity,
l-diversity, and
t-closeness to safeguard sensitive information. It provides researchers with the capability to anonymize tabular data through the generalization or suppression of quasi-identifiers, while supporting customizable hierarchical structures and grouping methodologies. For DP-based privacy machine learning models, we employed IBM DiffPrivLib (IBM Differential Privacy Library. Available at
https://github.com/IBM/differential-privacy-library) [
33]. Developed atop widely used scientific Python libraries such as scikit-learn (scikit-learn: machine learning in Python. Available at
https://scikit-learn.org) [
34], DiffPrivLib provides DP privacy-preserving implementations of fundamental data transformation techniques, statistical functions, and machine learning algorithms. For all the other more advanced PPPM models, their own proposed code repositories were employed with recommended configurations. While
SaCoFa and
Laplacian-DP were integrated within the
PRIPEL framework,
TraVaS operates independently, maintaining its own distinct framework.
For the process mining analysis component, the
PM4Py (PM4Py: Process Mining for Python. Available at
https://github.com/process-intelligence-solutions/pm4py) process mining tool was employed to derive process control-flow representations in the form of Petri nets using the InductiveMiner algorithm [
35]. Subsequently, conformance checking is conducted based on three distinct metrics as follows [
36]:
Fitness: A log trace is deemed to exhibit perfect conformity with the model if it can be precisely replayed within the model and corresponds fully to a complete trace of the model.
Precision: It concerns a model’s ability to accurately represent observed behavior while effectively preventing the inclusion of unobserved behavior, thereby mitigating the risk of underfitting.
Generalization: It concerns a model’s ability to incorporate previously unobserved behavior while mitigating the risk of overfitting.
To assess the performance of privacy-preserving machine learning algorithms, both accuracy and computational time metrics from the scikit-learn Python library were utilized, offering a comprehensive evaluation of model utility and efficiency. The accuracy metric measures the fraction of correct predictions generated by the model when applied to a labeled test dataset, serving as a fundamental criterion for assessing the performance of classification models within the constraints of differential privacy. For unsupervised learning tasks, specifically clustering, the inertia metric was employed to quantify the sum of squared distances between data points and their respective cluster centroids, serving as a measure of clustering cohesion. This metric quantifies cluster compactness and serves as an indirect measure of clustering quality, facilitating the assessment of how privacy-preserving transformations influence the structural integrity and coherence of the data. Furthermore, the time metric (in seconds), computed based on execution time measurements, provides valuable insights into the computational overhead imposed by privacy mechanisms, which is essential for evaluating the practicality of implementing such models in real-world scenarios.
All experimental procedures were executed on a personal desktop computer equipped with an Intel Core i7-13700K CPU and 32 GB of DDR5 RAM. An execution timeout of 30 min was established for each anonymization task, defined as the application of an algorithm, configured with specific parameters, on an individual event log.
4.6. Results Evaluation
Our observations indicate that the implementation of privacy-preserving algorithms can yield a high degree of precision. However, elevated values for certain quality measures do not inherently indicate that the privacy-preserving algorithm maintains data utility, as its primary objective is to generate results that closely resemble the original data rather than to enhance the quality of the discovered models. At this stage, a specific instance of the GQM table is constructed based on the actual metric values, and the quantitative findings are systematically synthesized into responses addressing each question.
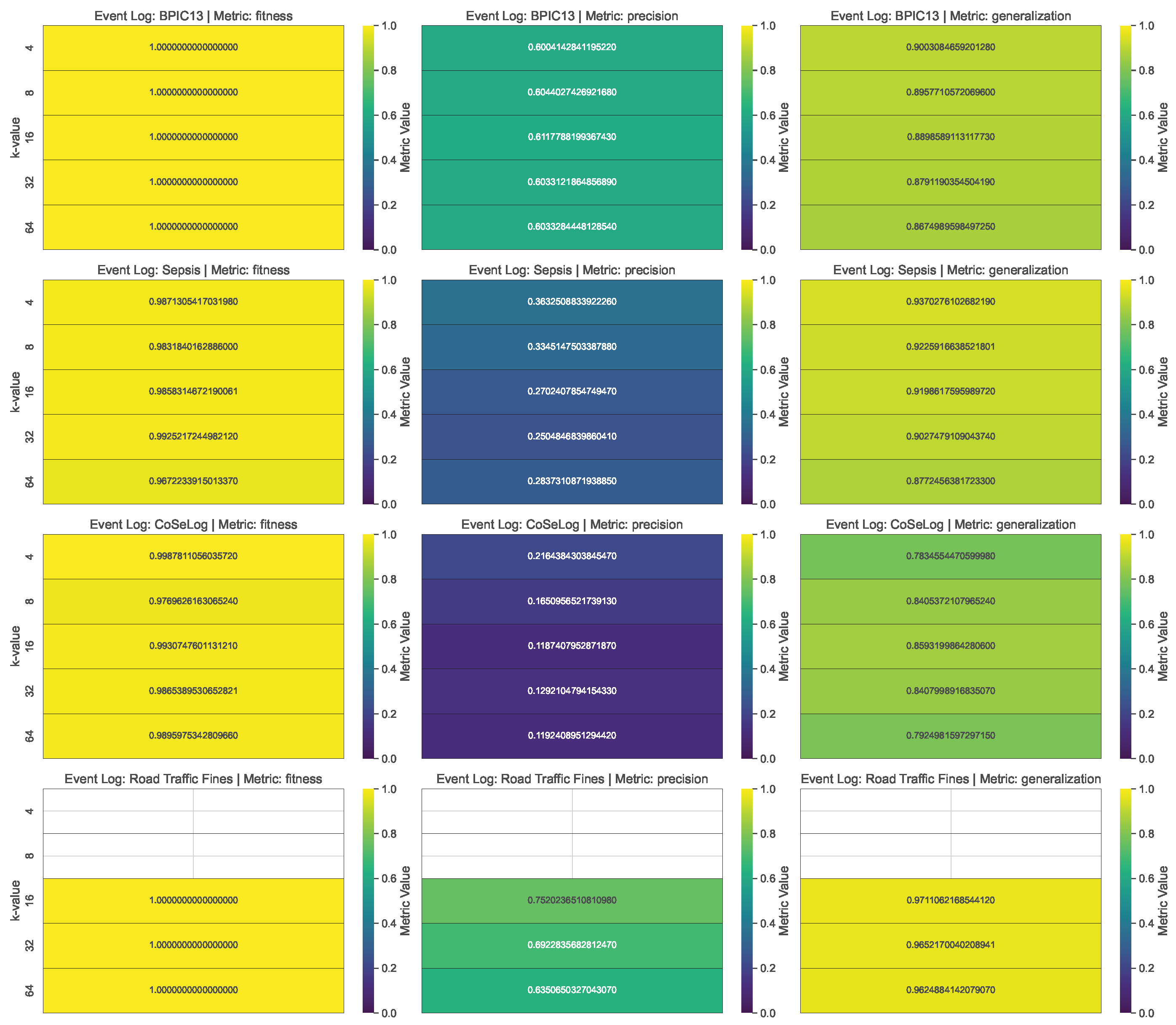
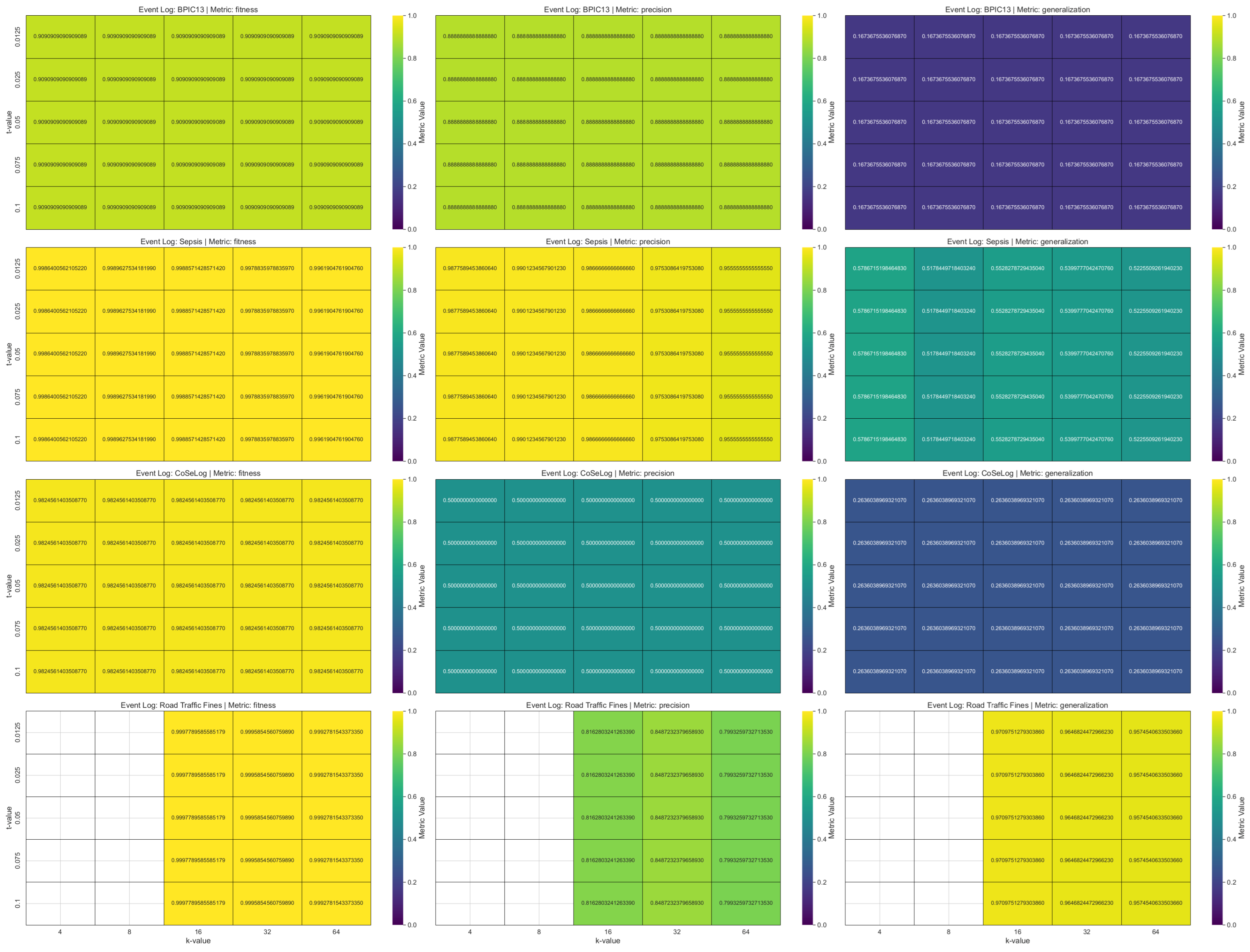
(Q1.1.1.) The findings reveal that as the value of k increases, a greater degree of generalization and suppression becomes necessary, leading to a reduction in the granularity of the trace data. Precision exhibits a more pronounced decline as the reduction in trace variety heightens the probability of the model accommodating unobserved behaviors, thereby leading to potential overgeneralization. In addition, since k-anonymity considers the contextual information, it is not scaled well for the event logs that include a higher number of instances.
(Q1.1.2.) The results show that precision diminishes as trace merging renders the discovered model more permissive, enabling the incorporation of behaviors that were not originally recorded in the log. However, for some event logs, generalization is adversely affected, as the suppression of low-frequency patterns diminishes the model’s capacity to accommodate previously unseen yet plausible behaviors. In addition, since the l-diversity model considers the contextual information, it is not scaled well for the event logs that include a higher number of instances.
(Q1.1.2.) Our findings suggest that as the parameter t decreases, privacy is enhanced; however, the richness of trace-level behavioral patterns deteriorates, thereby adversely impacting the quality and expressiveness of the model’s results. Generalization further declines as the omission of lower-frequency, nuanced behaviors diminishes the model’s capacity to extend its applicability to previously unseen yet valid behavioral patterns. Also, for this model, the time performance did not scale well with respect to the number of instances.
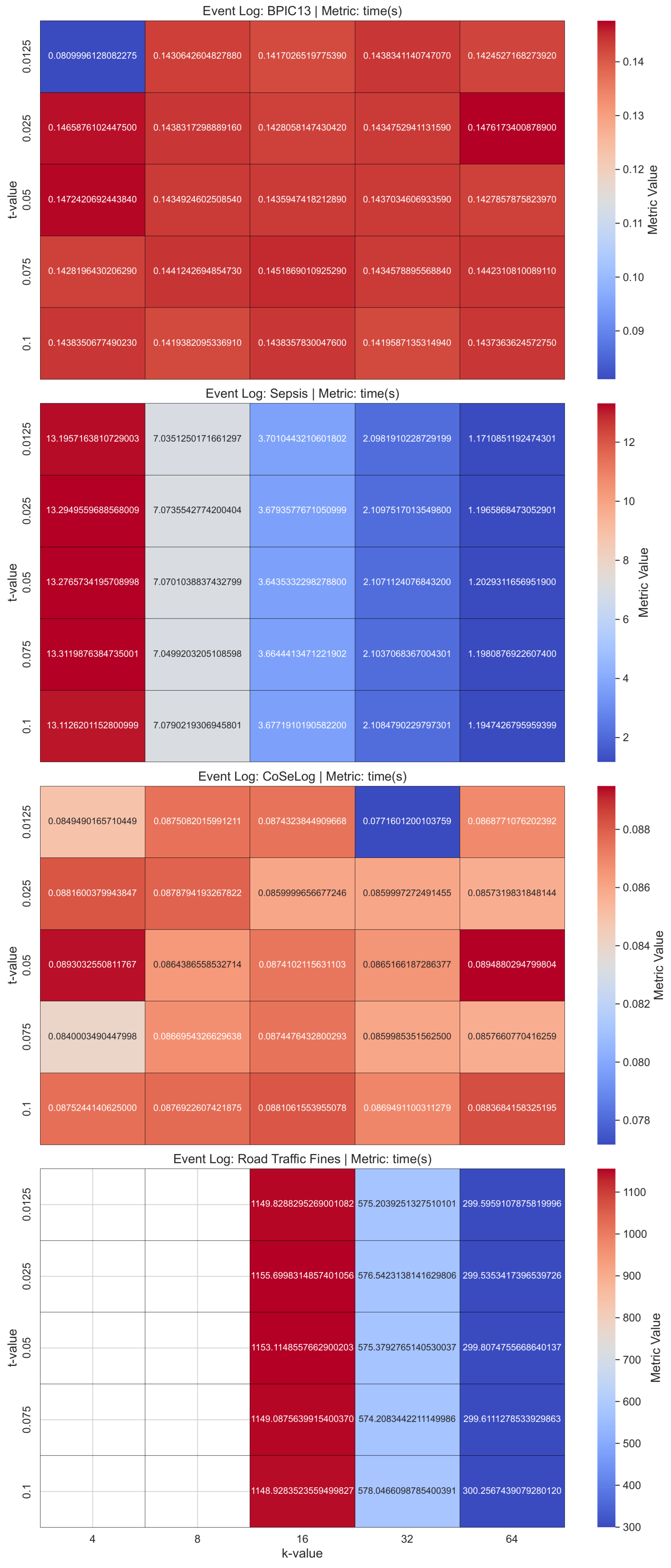
(Q1.2.1.) As validated with the PRETSA PPPM model quality results, precision decreases over time, especially when the k parameter goes high. Thus, the more privacy is gained, the more utility decreases. In order to achieve higher k-values, the event log data are often generalized more. As the generalization increases, the data become less detailed, leading to a loss in precision. If the event log data have the maximum trace uniqueness percentage, PRETSA may be the right choice for privacy-utility trade-off. However, it did not show time performance efficiency for large event logs.
(Q1.2.2.) The TLKC PPPM model needed higher trace uniqueness to produce optimum results due to the model’s nature. Notably, despite the enforcement of stringent TLKC constraints, certain anonymized event logs produced process models characterized by high precision. This phenomenon can be ascribed to the limited behavioral diversity present in the original log, as well as to the targeted influence of TLKC on attribute-level generalization rather than on control-flow structures. In these cases, the prevailing trace variants are preserved, enabling the model to constrain behavior in a manner closely corresponding to the original log.
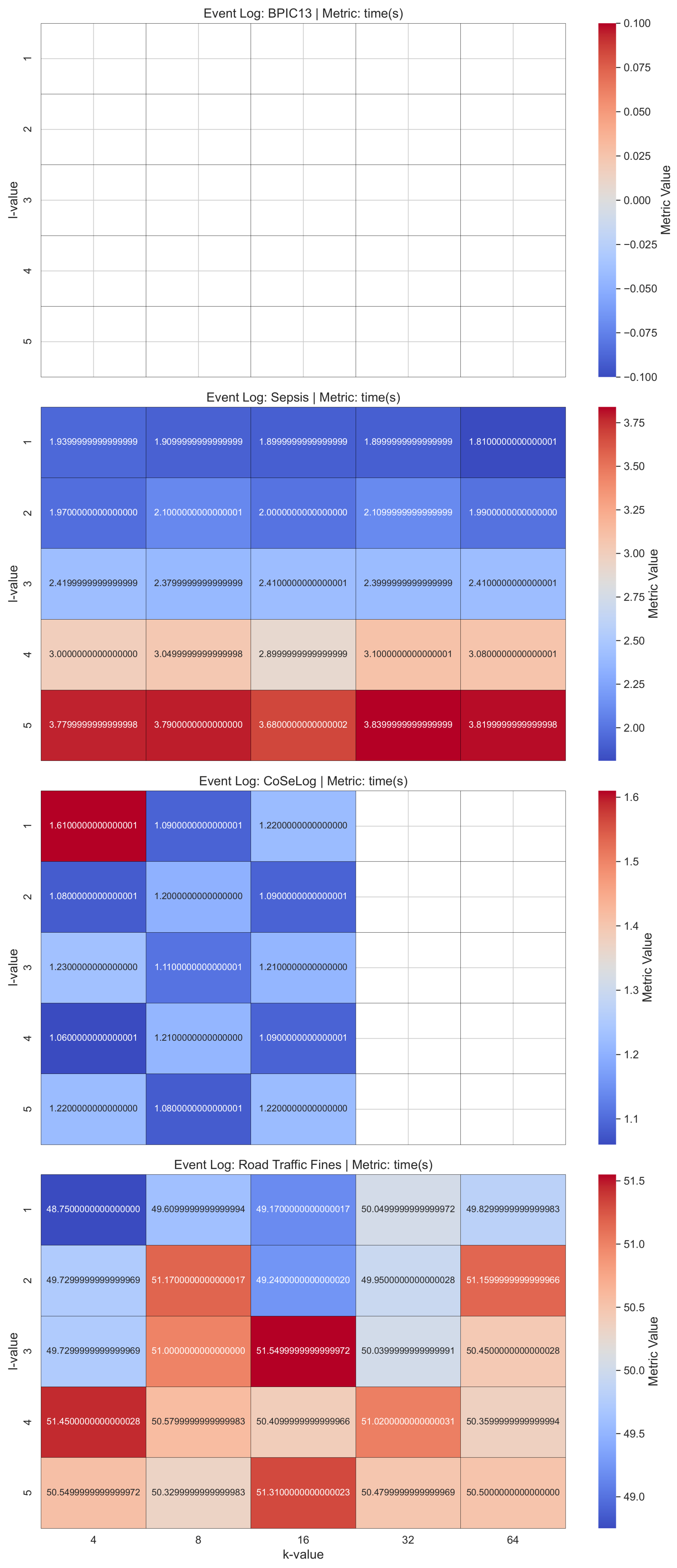
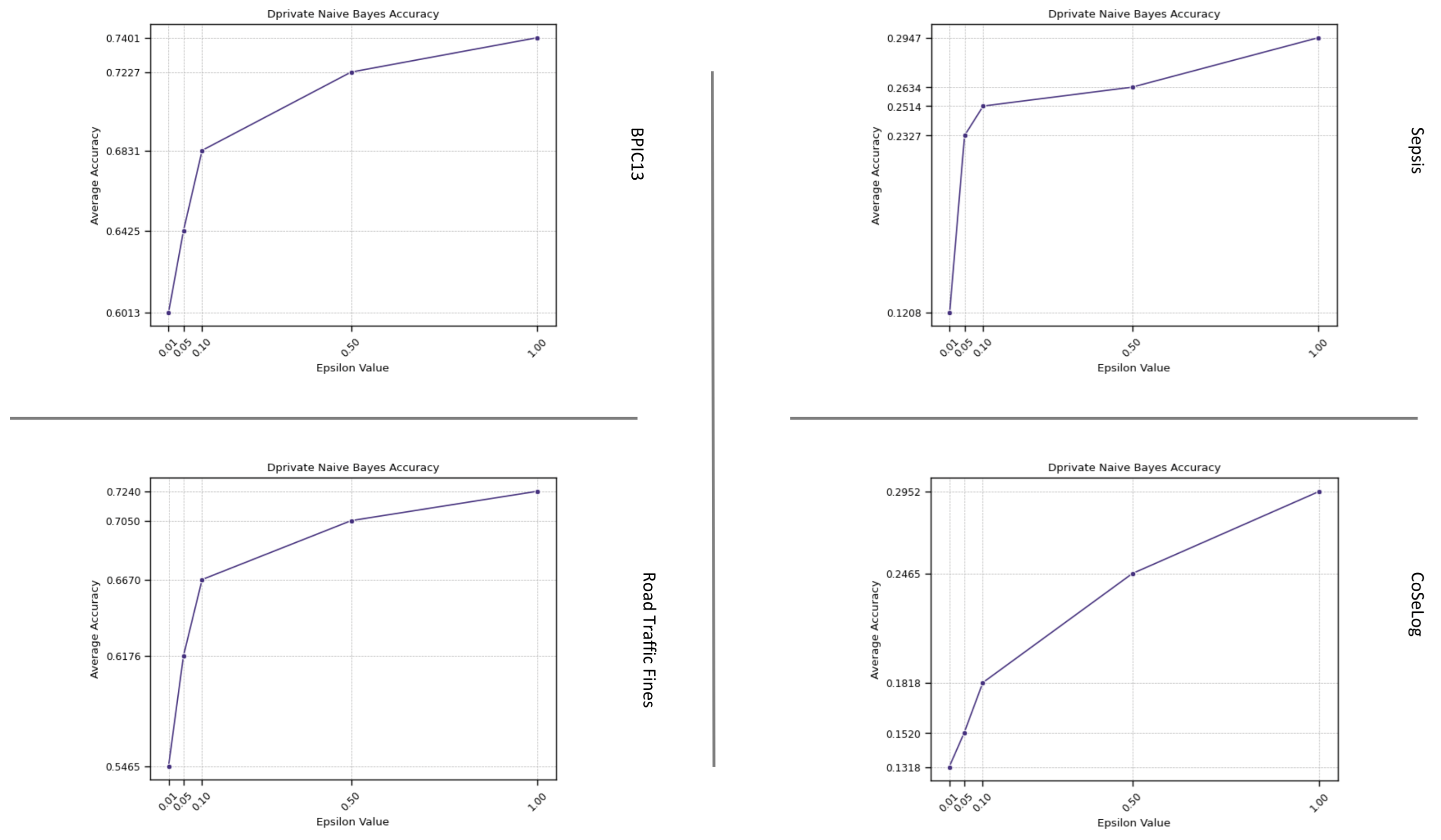
(Q2.1.1.) DP-Naive Bayes offers a viable approach to privacy-preserving classification, characterized by the following key attributes: effective for moderate values and not ideal for strict privacy settings. On the other hand, due to exhibiting high computational efficiency, this model is particularly well suited for the rapid and cost-effective deployment of anonymized models.
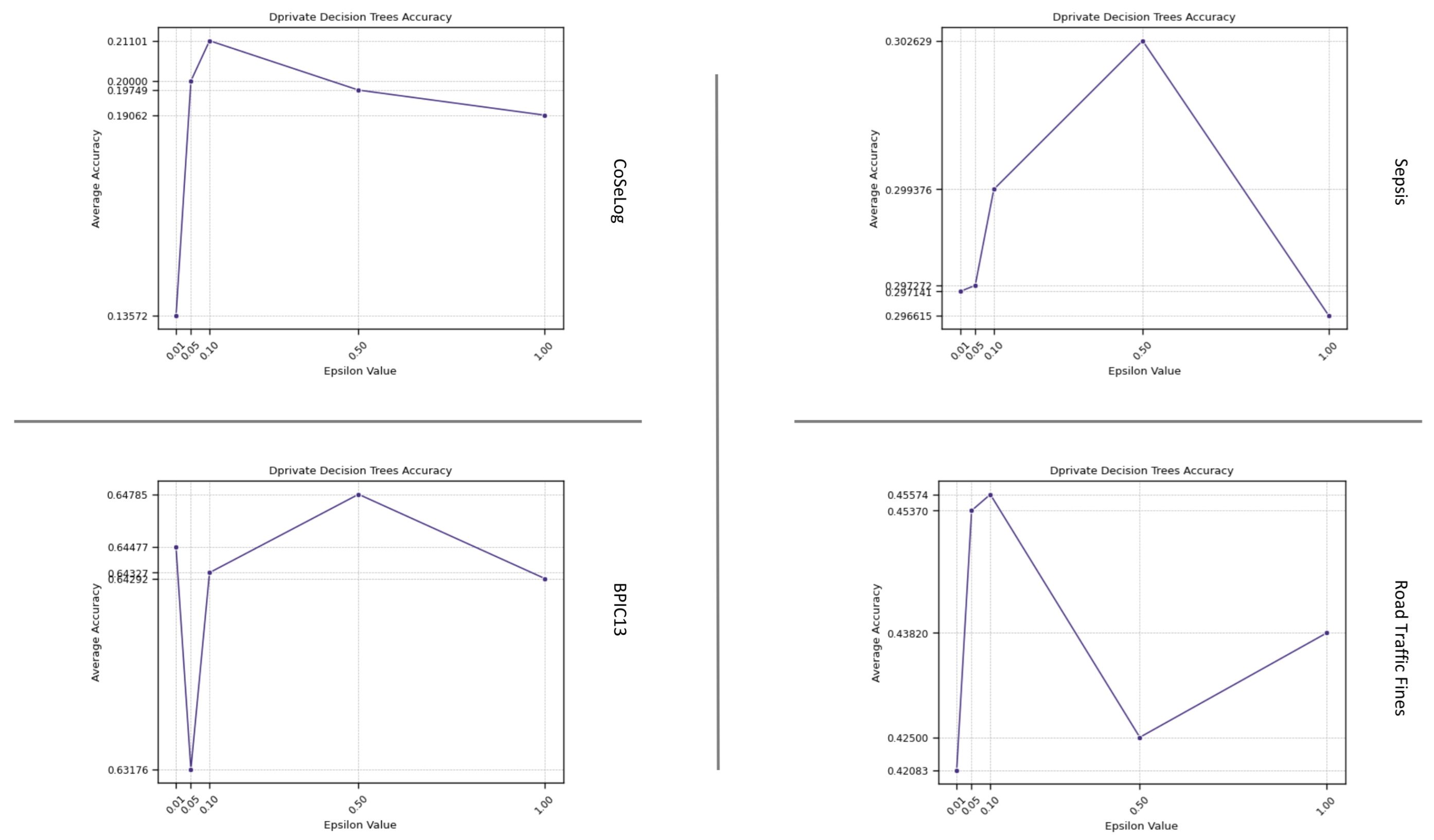
(Q2.1.2.) As seen from the results, DP-Decision Trees provide an effective trade-off among interpretability, privacy preservation, and computational efficiency. However, under stringent privacy constraints, performance declines as a result of imprecise split decisions introduced by noise. Training maintains a high level of computational efficiency, even when operating at lower values. The behavior of the model also exemplifies the bias–variance trade-off within the framework of differential privacy, necessitating careful management during parameter selection to optimize performance.
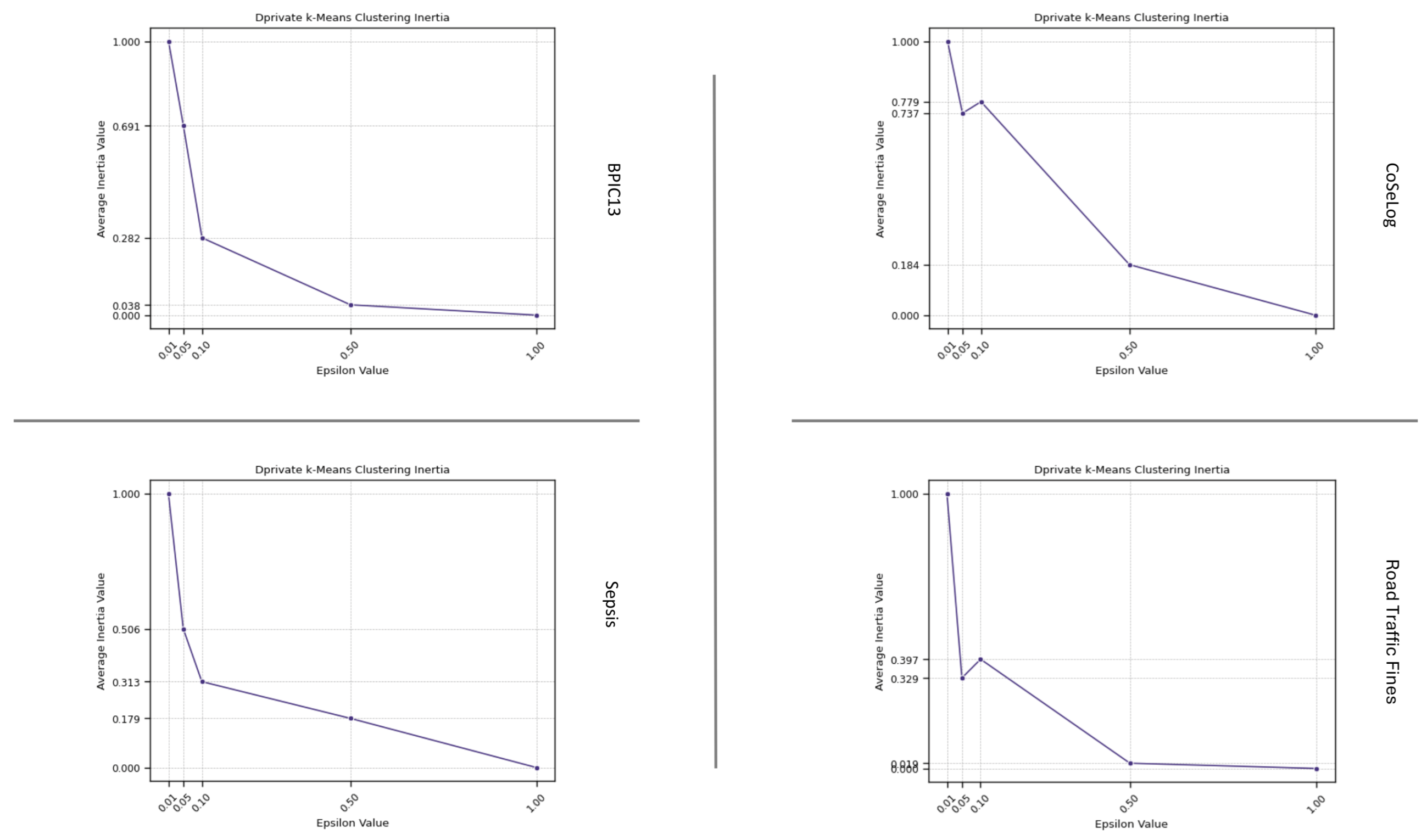
(Q2.1.3.) We have visualized the inertia values with respect to the epsilon parameter in the DP-k-Means model results. A lower inertia value indicated that the event log instances were closer to their respective cluster centroids, suggesting more compact and well-defined clusters. That is desirable as it means the clusters are tight and compact. On the other hand, the results indicated that a higher degree of trace uniqueness within the event logs is associated with a more pronounced decline in the model runtime performance.
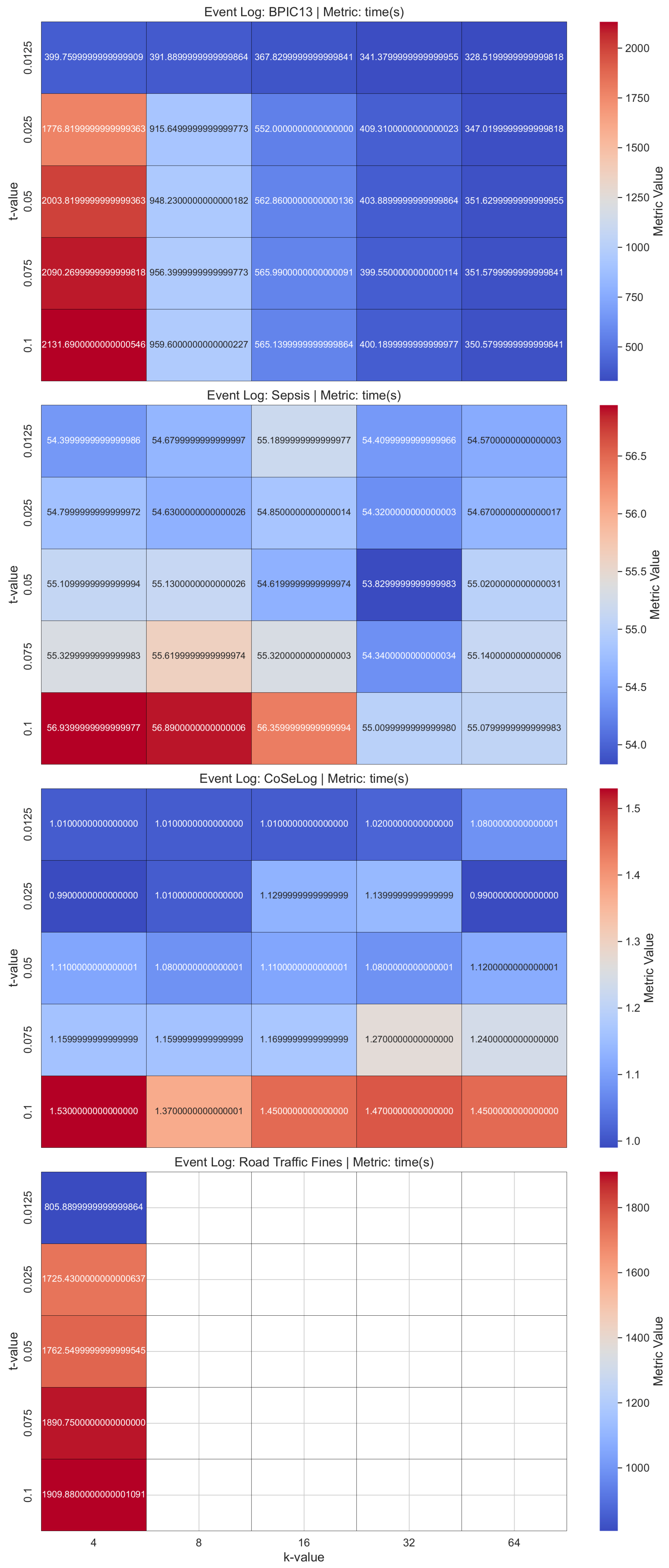
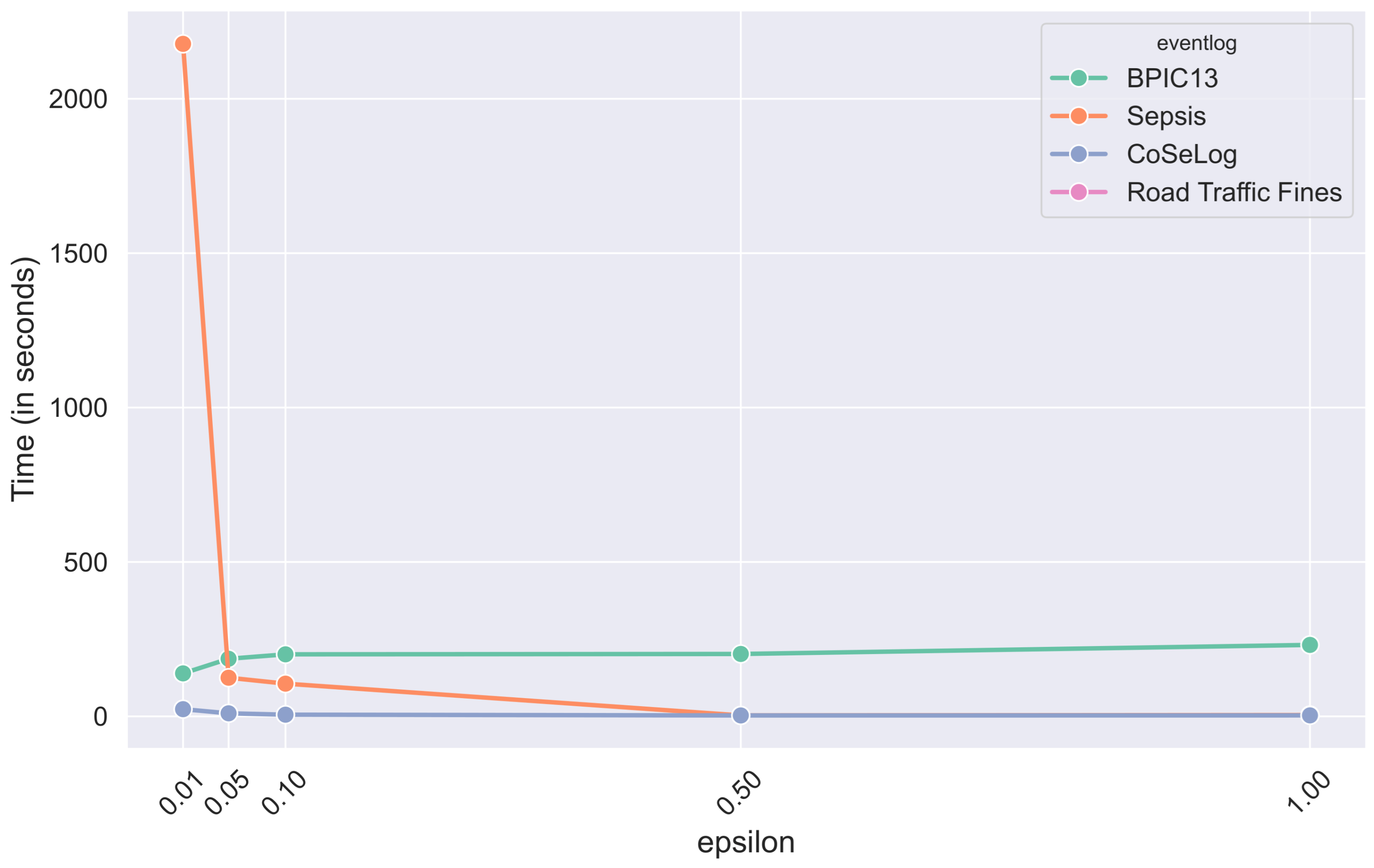
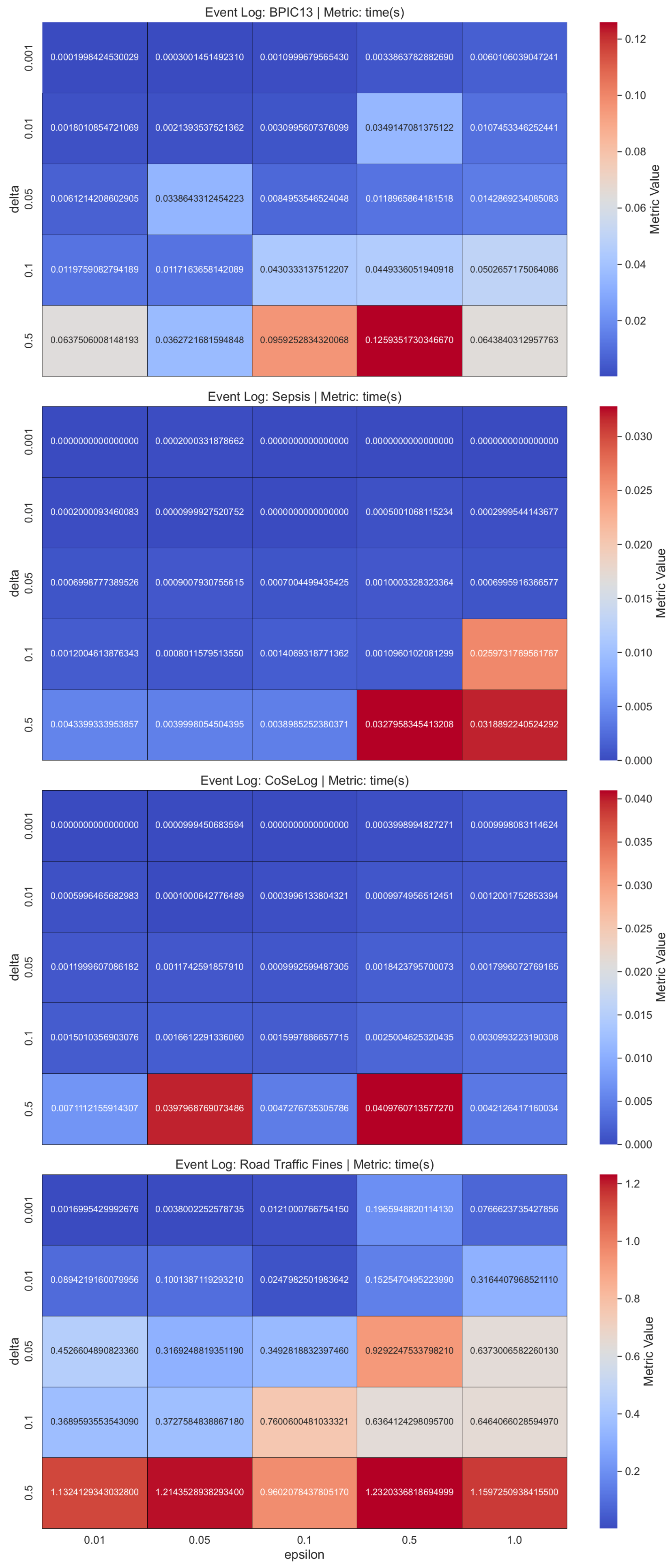
(
Q2.2.1.) Our
LaplacianDP findings revealed that different hyperparameter configurations with the data characteristics had different effects on algorithm behavior. Especially for the Road Traffic Fine event log data, the parameter configurations from the original publication had unfeasible runtimes within the
PRIPEL framework. Since the smaller
parameter introduces more privacy, precision reduces due to this fact. It indicates that the discovered model started capturing noisy events so overfitting occurred. Generalization also decreased in parallel. In addition to these, for the runtime performances, increasing the
parameter reduces the runtime in inverse proportion. In the
PRIPEL original publication [
25], the authors considered only the Sepsis event log for their experiments.
(Q2.2.2.) In the SaCoFa model experiments, various hyperparameter configurations, in conjunction with the underlying data characteristics, exerted distinct influences on algorithmic behavior. Especially for the Road Traffic Fines event log data, the parameter configurations (from original publication) had unfeasible runtimes within the PRIPEL framework, so we discarded it from our experiments. Thus, the data instance count is the main issue to consider for this model’s contextual information-carrying nature. We concluded that the PRIPEL framework is unfeasible to use with event logs that have a high count of events.
(Q2.2.3.) As validated with the TraVaS PPPM model quality results, the effectiveness of this model is considerably influenced by the privacy parameters. It may struggle with event logs that contain many infrequent trace variants. While TraVaS had runtimes that are efficient for event logs that have a high count of instances, its quality is affected by the high trace uniqueness characteristics.
In order to extend and support our fine-grained analysis results, we validated and discussed the result and time utility qualities of each PPPM model under their respective categories by using different statistical analysis techniques. To align with our subgoals, we applied statistical tests for each model within its category to gain a further comprehensive and competitive perspective.
To evaluate the practical equivalence of alternative models relative to a predefined baseline, we employed the Two One-Sided Tests (TOST) procedure, a statistical framework specifically designed to formally assess equivalence within a defined tolerance margin [
37]. In contrast to conventional hypothesis testing, which seeks to identify statistically significant differences, the TOST procedure explicitly evaluates whether a model’s performance is statistically equivalent to that of a baseline, within a user-specified range of practical relevance known as the equivalence margin (△). This consideration is particularly critical when the objective is not to establish superiority, but rather to demonstrate that a model performs comparably to a reference system within the bounds of operational constraints.
Since PPPM models have a heterogeneous nature of their kind, to determine the equivalence margins for each model’s categories, we conducted a sensitivity analysis by following a 70%-equivalence-count rule that, after a grid of candidate margins was defined, computed the empirical equivalence count to specify the margin satisfying our threshold. This rule balances two imperatives in privacy model comparison: utility retention and privacy prioritization. By stipulating that a substantial proportion (70%) of utility losses must fall within a predefined margin, we ensure that the privacy-preserving approach maintains acceptable performance in the majority of cases. Conversely, by selecting the minimal margin that satisfies the condition , we adopt a sufficiently permissive criterion that allows for the recognition of stronger privacy guarantees, even in cases where utility loss occasionally exceeds the specified threshold.
For each PPPM model, we conducted a one-sample TOST comparing the distribution of the model result quality metrics to their fixed baseline metric scores. For some models with absent metric results, we employed a single imputation technique by replacing the missing value with the mean of its group values to ensure statistical significance.
Table A1 presents the one-sample TOST results for the discovered process model quality metrics as a result of applying group-based privacy models on our event logs. All group-based anonymization models showed statistically equivalent fitness because they allow sufficient behavior to replay the logs. For
k-anonymity, only the precision metric for the Road Traffic Fines event log is not statistically equivalent as it slightly increases on average. It showed an overgeneralization trend over variability for low trace uniqueness event logs due to removal of rare behaviors; the model becomes more deterministic. For
l-diversity, although the precision for Road Traffic Fines is not statistically equivalent, the precision and generalization metrics for BPIC13 also had no equivalence. However, while
l-diversity showed a similar trend with
k-anonymity for the BPIC13 event log, it had reduced precision and generalization metrics on average, so overfitting the rare, non-representative behaviors. This phenomenon was most prominent in logs with high trace variability, indicating that such logs require careful preprocessing or more robust PPPM approaches. For
t-closeness, only the fitness values are statistically equivalent to their baselines for all the event logs in addition to slightly lowering, except that the generalization metric for the Road Traffic Fines is also equivalent apart from this. For all the event logs, we observed a pattern of low fitness, high precision, and low generalization trend. This indicates
t-closeness that is overly restrictive; it accepts only a narrow slice of the behavior seen in the event log, rejecting many valid traces as the model fails to abstract over variations. For
PRETSA, all the metrics are statistically equivalent for the Sepsis event log and for BPIC13 only the generalization metric is not equivalent in a negligible amount. Thus, it is the most promising model for the event logs that have high trace uniqueness. For CoseLog, only the fitness is equivalent but a cumulative increasing trend is shown for this event log that has the lowest instance count. This situation may be attributed to the log’s structured nature and the algorithm’s ability to abstract meaningful control-flow patterns while anonymizing. For Road Traffic Fines, only the precision metric is not equivalent as the model also included behavior that was not present in the log. This trade-off may be desirable in this domain where future flexibility is important. For
TLKC, only the precision metric had no equivalence for all the available event logs (no result for BPIC13 due to algorithmic behavior). However, it struck a strong balance between specificity and generality for Sepsis; it fits the log, avoids unnecessary behavior, and generalizes well. Thus, this model is specifically addressed for this event log due to its algorithmic nature.
Table A2 shows the one-sample TOST results for the discovered process model quality metrics as a result of applying a differential privacy model on the event log data by fitting learning algorithms. For the ml-based DP PPPM models result qualities, their metrics have different interpretations. For the DP-Naïve Bayes and DP-Decision Trees supervised models, only the accuracy metric for BPIC13 had statistical equivalence for their respective margins. However, for the DP-k-Means unsupervised model, all the metric values were equivalent except for the BPIC13 event log for its given margin. This suggest that for supervised models, DP-Naïve Bayes has a more preferable approach in more privacy need domains due to its lower margin and utility loss especially for high instance count event logs like Road Traffic Fines and BPIC13. On the other hand, DP-k-Means showed optimum clustering behavior when compared to baseline since all the event logs had already naturally been built grouped into a cases structure.
Table A3 includes the one-sample TOST results for the discovered process model quality metrics as a result of applying a more advanced differential privacy model on the event log data. In advanced DP PPPM models, for
LaplacianDP, BPIC13 had optimal equivalence for all three metrics due to its moderate amount of trace uniqueness and instance count characteristics. For the other event logs, only precision had no equivalence to their baseline. The fitness metrics showed a likely decreasing trend since noise injection with DP mechanism changes activity sequences or inserts spurious events. We also observed a small but consistent increase in both precision and generalization. This trade-off aligns with the goals of PPPM, where some reduction in replayability is acceptable in exchange for better abstraction and protection of sensitive behaviors. Also for
SaCoFa, only the precision values were not equivalent to their baselines for all event logs (for Road Traffic Fines, no results are available for either
LaplacianDP or
SaCoFa algorithms). They had non-inferior precision performance due their
p-values. However, high trace uniqueness, as in the Sepsis event log data, causes a slight reduction in the generalization metric so that the
SaCoFa’s algorithmic design may not introduce a semantically filtered noise that smooths the trace-variant distribution for that. For
TraVaS, BPIC13 had equivalence for all metrics. Sepsis was not equivalent to its baseline for the generalization metric only. In other words, mean generalization dropped while mean precision increased a little. This trade-off points to a form of overfitting, where the model overly emphasizes dominant behaviors at the cost of completeness and flexibility. CoSeLog had equivalence only for the fitness metric. Road Traffic Fines was not equivalent for precision only. It had considerably reduced mean precision and showed nonsuperior performance due to its
p-values. For this event log, we observed a simultaneous drop in fitness, precision, and generalization. Such outcomes may result from a poor match between the privacy algorithm and the log characteristics, excessive noise, or overly aggressive filtering that removes meaningful structure. These findings reveal that even if the
TraVaS model had successful metric results for all event logs, its result quality is highly sensitive to event log data characteristics like trace uniqueness. This highlights the importance of carefully selecting privacy techniques and preprocessing steps based on log complexity and domain needs.
To assess the comparative time utility performance of the PPPM models across the event logs under each respective category, we applied the non-parametric Friedman test, a robust statistical method well suited for comparing multiple algorithms across diverse datasets, without requiring the assumption of normality in performance metrics [
38]. This choice is particularly warranted given the limited sample size and the ordinal nature of the ranking data obtained from the assessment of anonymization effectiveness.
The Friedman statistic is derived from the average ranks assigned to each method across the set of event logs. These ranks provide a summary of the relative performance of each method across individual event logs, with lower ranks denoting superior performance. The test is designed to assess the null hypothesis that, on average, all models exhibit equivalent performance across the datasets.
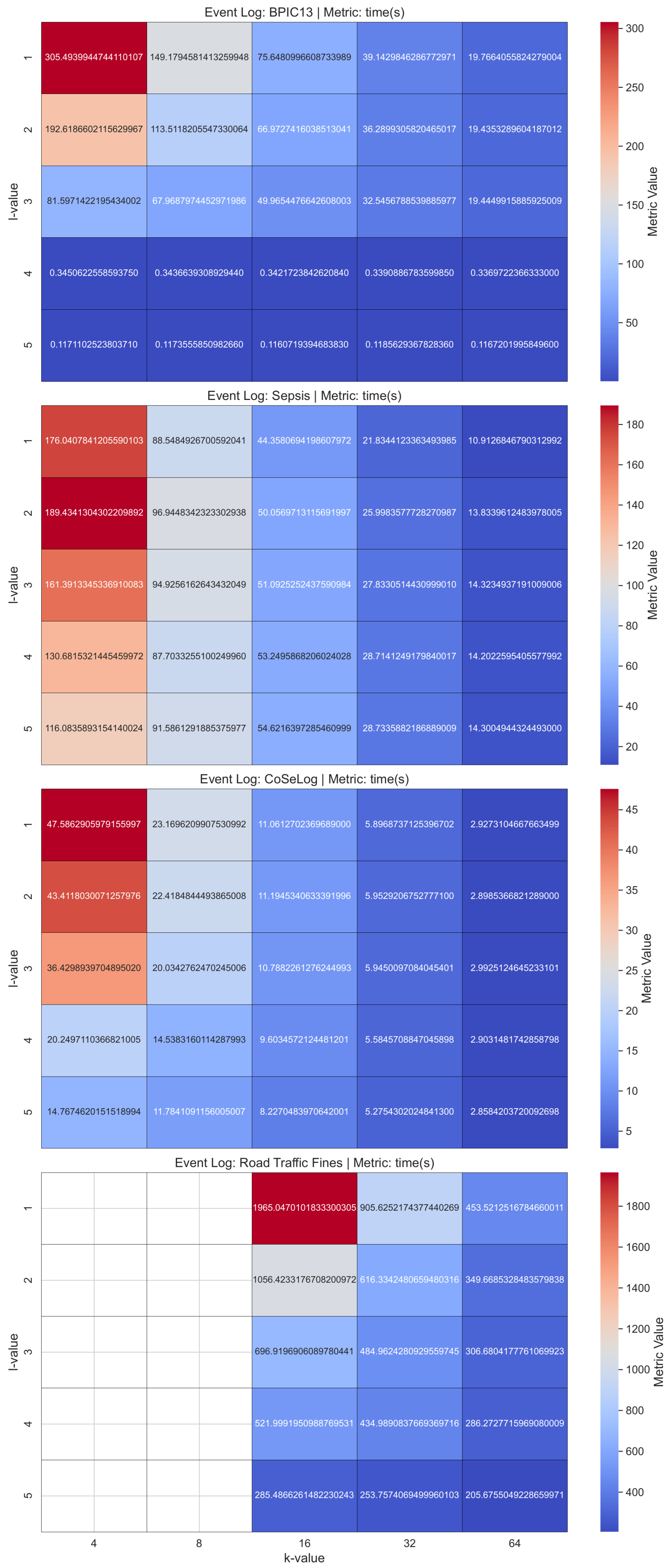
For the five group-based anonymization PPPM models across the event logs, the results of the Friedman test yielded a Friedman statistic of 8.800 with an associated p-value of 0.0663. This result suggests that there may be meaningful performance differences, albeit not statistically strong enough to declare definitive superiority using the strictest standards. However, closer inspection of the average ranks may still reveal trends or practical performance patterns among the models, even when the omnibus test is not statistically significant.
Table A4 shows the per-event log and average ranks that reveal which group-based PPPM models runtime was consistently better or worse across the event logs.
t-closeness ranks the best in most event logs. This suggests robust performance, even though the
TLKC model’s data-dependent nature can be misleading for Road Traffic Fines due to averaging the absent times with a single imputation method for statistical validity.
t-closeness typically demonstrates greater computational efficiency by employing optimized clustering heuristics alongside a single distribution-distance metric (e.g., Earth Mover’s Distance), thereby circumventing the combinatorial complexity inherent in repeated generalization or diversity evaluations. In contrast,
k-anonymity exhibits poorer runtime performance, reflecting limited generalizability and heightened sensitivity to event log characteristics, because identifying the minimal set of generalizations and suppressions required to ensure every quasi-identifier tuple appears in at least
k records constitutes an NP-hard combinatorial optimization problem, necessitating exhaustive or heuristic search strategies with repeated event log data scans.
For the three ml-based differential privacy PPPM models across the event logs, the results of the Friedman test yielded a Friedman statistic of 0.000 with an associated
p-value of 1.0000. Thus, there is also no sufficiently strong statistical evidence to declare definitive superiority using the strictest standards.
Table A5 shows the per-event log and average ranks that reveals which ml-based DP PPPM models runtimes were consistently better or worse across the event logs. All models have consistently better equal runtime performances according to their average ranks that indicate richer generalizability. However, for the supervised algorithms, DP-Decision Trees is not a good candidate for the high instance count event logs like Road Traffic Fines, so that building a full tree involves many costly randomized queries instead of simple impurity computations.
For the three more advanced differential privacy PPPM models across the event logs, the results of the Friedman test yielded a Friedman statistic of 6.500 with an associated
p-value of 0.00388. This result suggests that significant meaningful performance differences are found among the models. A post hoc Nemenyi test [
38] was also conducted to explore pairwise differences among the models. The Nemenyi post hoc procedure systematically performs pairwise comparisons among models, applies the studentized range distribution to adjust for multiple testing, and identifies which specific pairs exhibit statistically significant differences.
Table A6 includes the per-event log and average ranks that reveal which of the more advanced DP PPPM models runtimes were consistently better or worse across the event logs. The
TraVaS model’s highest runtime robustness is also statistically validated with respect to its first ranked place across all the event logs. This model would be a strong candidate for preferred adoption due to its consistent top performance. A Nemenyi post hoc analysis (
) yielded the pairwise
p-value matrix shown in
Table A7. We found that
TraVaS runs significantly faster than
SaCoFa and
LaplacianDP (all
p < 0.05) whereas no significant difference was observed between
SaCoFa and
LaplacianDP (
p = 0.759287).
TraVaS attains superior runtime efficiency by employing a direct differentially private partition-selection mechanism to release precise trace-variant frequencies in a single thresholding pass, thereby obviating the computationally intensive prefix-based variant generation and iterative noise-query procedures characteristic of other models.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}