Deep-Learning Integration of CNN–Transformer and U-Net for Bi-Temporal SAR Flash-Flood Detection


Abstract
1. Introduction
- The model combines a U-Net convolutional path for precise spatial and contextual feature extraction with a Transformer branch employing a CCT tokenizer to grasp sequential long-range dependencies and global context.
- The model minimizes parameter needs and enhances generalization on small datasets commonly associated with flood detection by employing the CCT tokenizer instead of traditional Vision Transformer tokenization.
- This innovative method merges global features derived from the convolutional decoder and the Transformer feature space, resulting in a thorough representation that enhances classification.
2. Study Area and Flood Detection Datasets
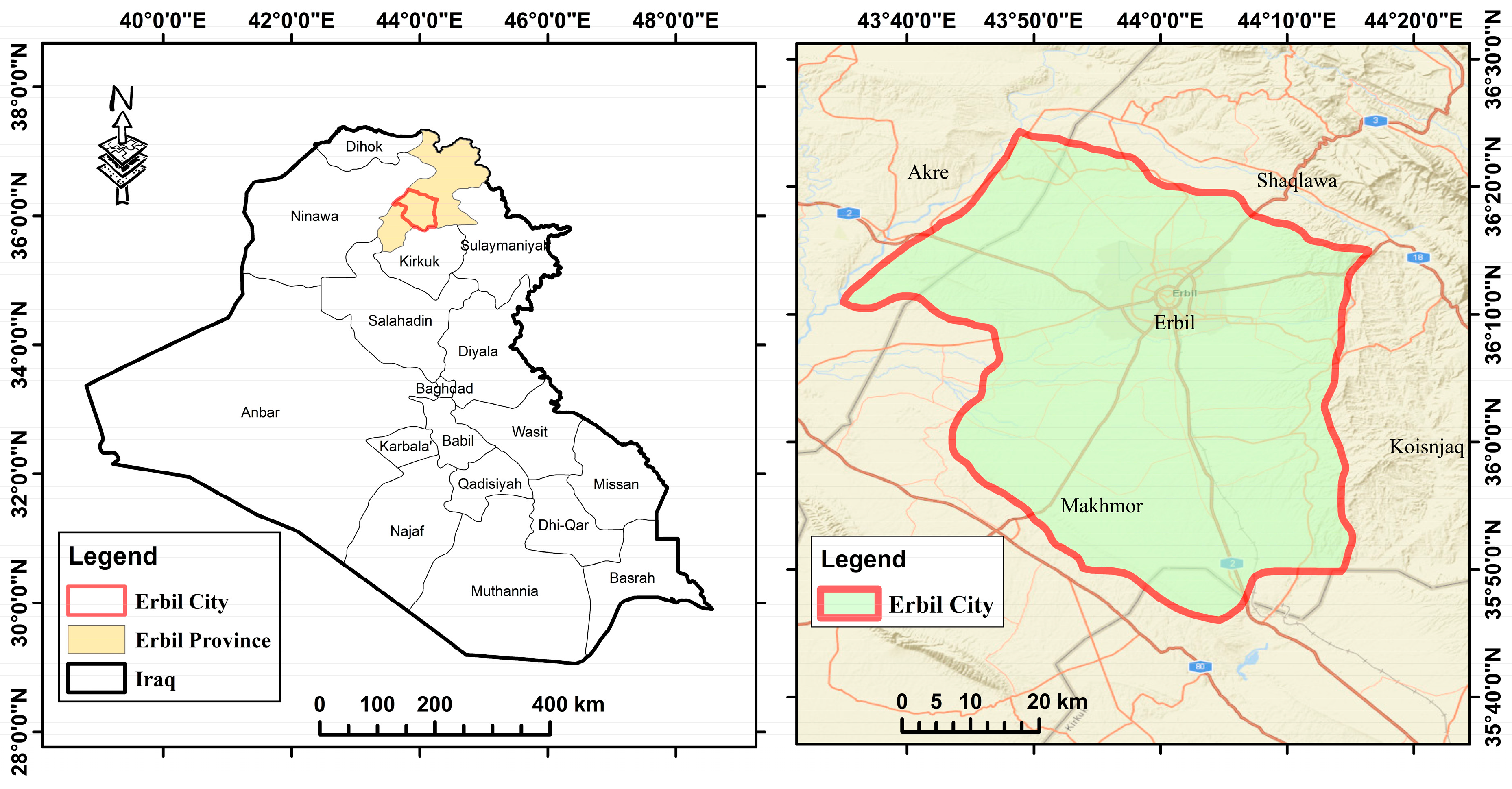
2.1. Description of the Study Area
2.2. Flood Detection Datasets
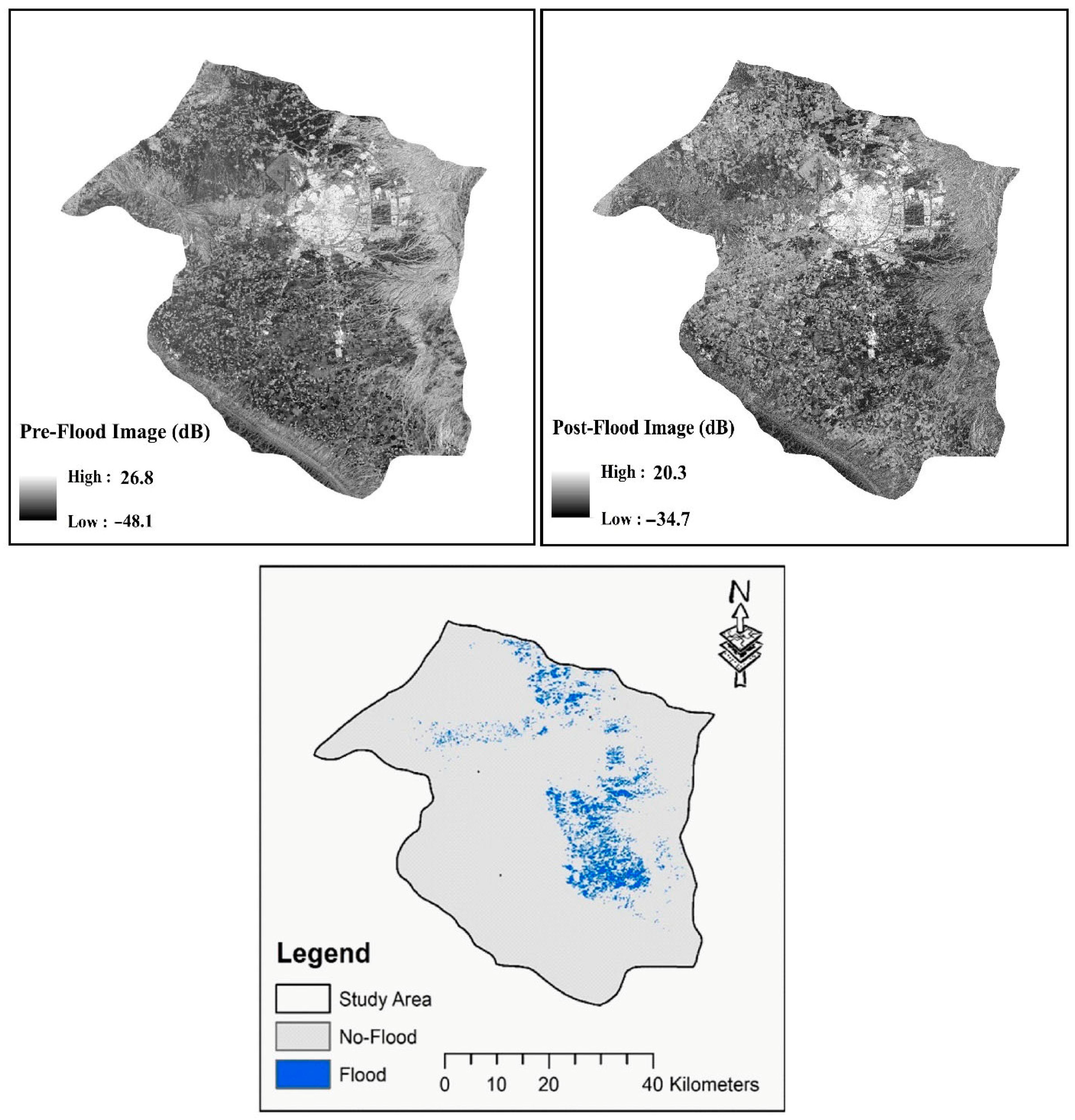
2.2.1. Erbil Flood Dataset
2.2.2. S1GFloods Dataset
3. Methodology
3.1. Network Architecture Overview
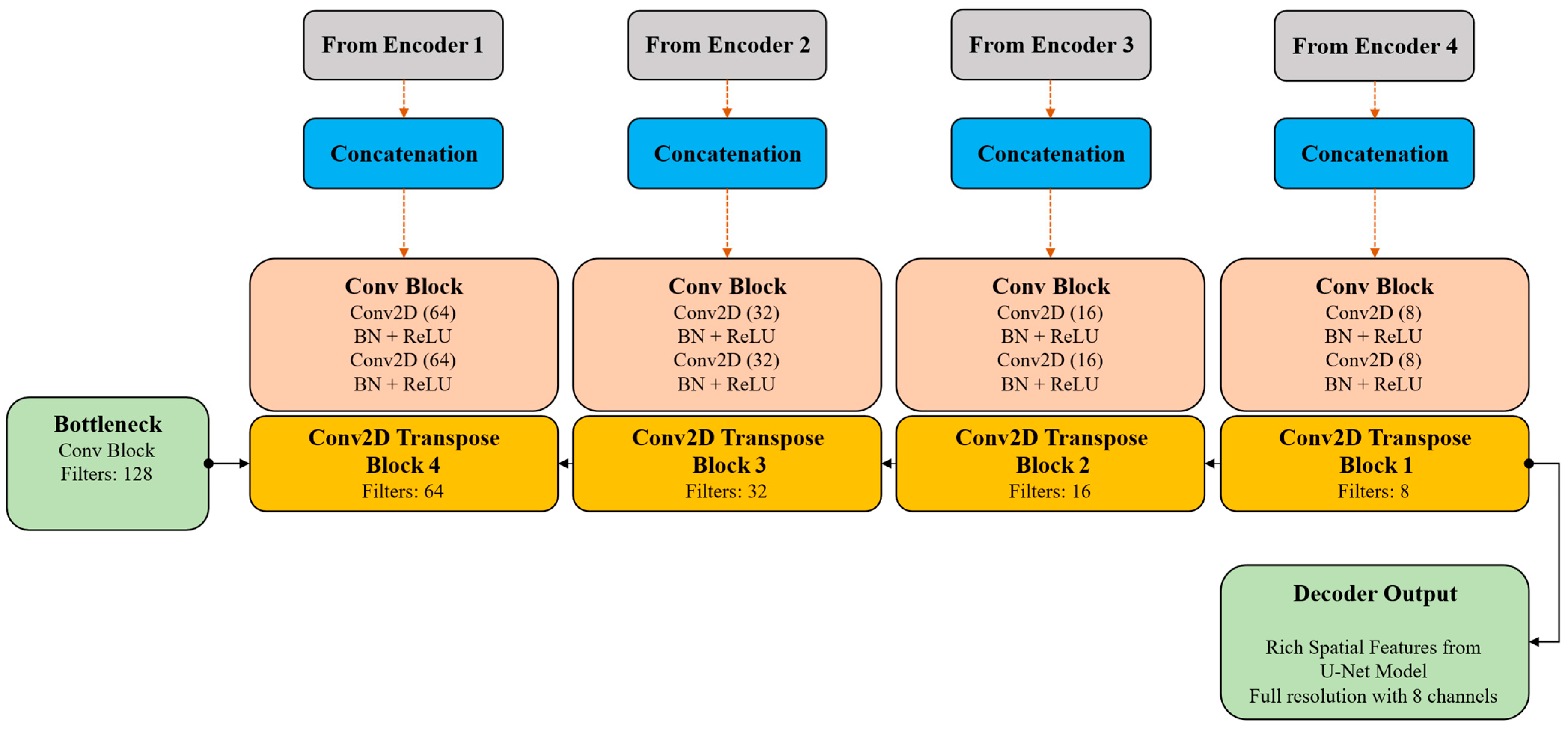
3.2. U-Net Architecture
3.2.1. U-Net Encoder with Hierarchical Convolutional Blocks
3.2.2. U-Net Decoder with Transposed Convolutions and Skip Connections
3.3. CNN-Based Tokenizer for Transformer Input (CCTTokenizer)
3.4. Transformer Blocks
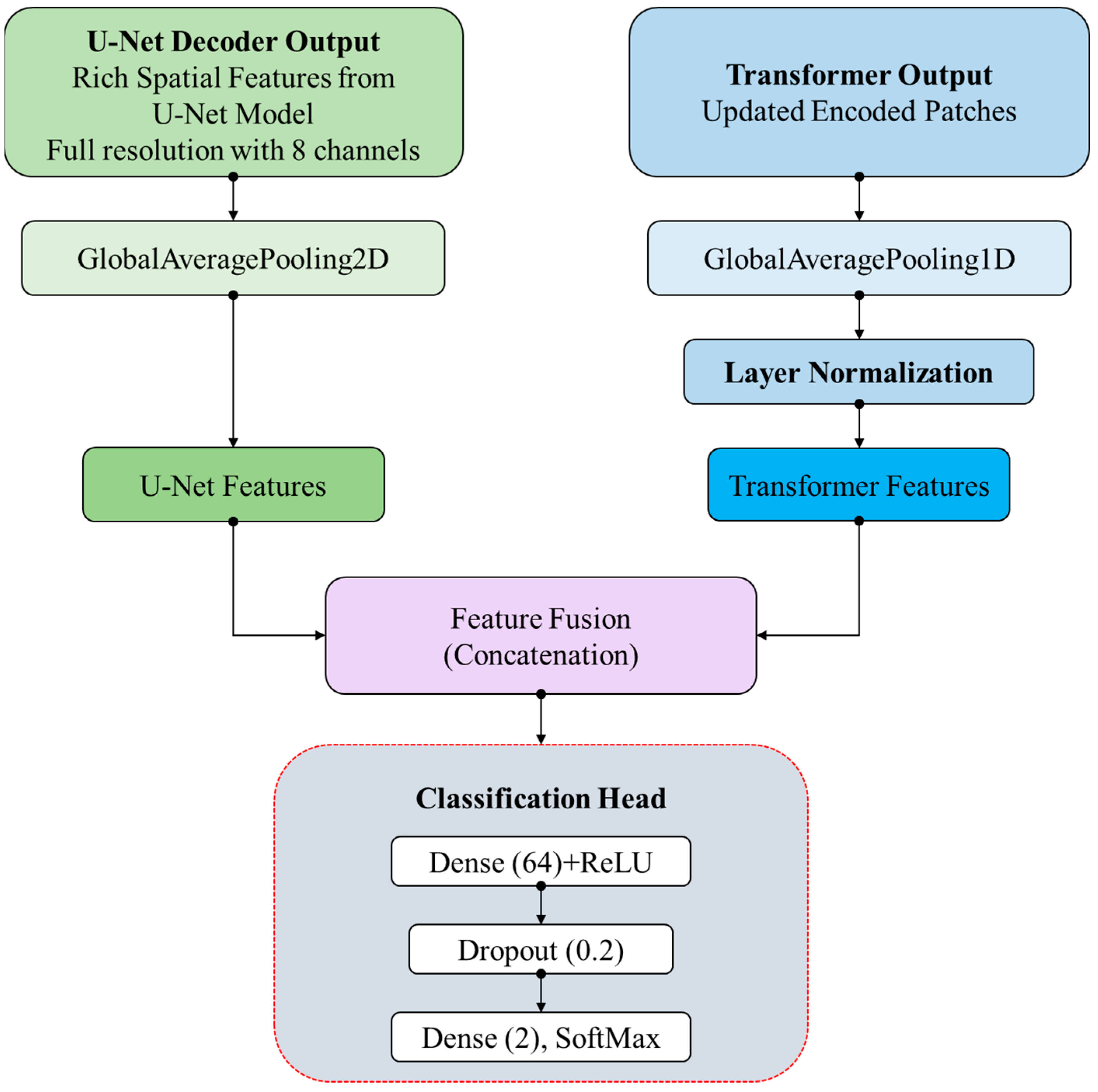
3.5. Feature Fusion and Classification Head
3.6. Benchmark Models
3.6.1. CNN 2D-1 Layer [21]
3.6.2. CNN 2D-2 Layers [21]
3.6.3. CNN 3D-1 Layer [65]
3.6.4. CNN 3D-2 Layers [22]
3.6.5. Hybrid CNN [66]
3.6.6. U-Net [67]
3.6.7. Vision Transformer (ViT) [43]
3.6.8. CNN–Transformer [68]
3.7. Performance Metrics
- TP = True Positives (correctly detected flood pixels)
- TN = True Negatives (correctly detected non-flood pixels)
- FP = False Positives (non-flood pixels classified as flood)
- FN = False Negatives (flood pixels classified as non-flood)
- = Observed agreement (the actual accuracy of the model)
- = Expected agreement by chance (the agreement expected if the model were to classify randomly)
- Precision is the proportion of detected flood pixels that are correctly classified as flood
- Recall is the proportion of actual flood pixels that are correctly detected
4. Results and Discussions
4.1. Experimental Setup and Parameter Settings
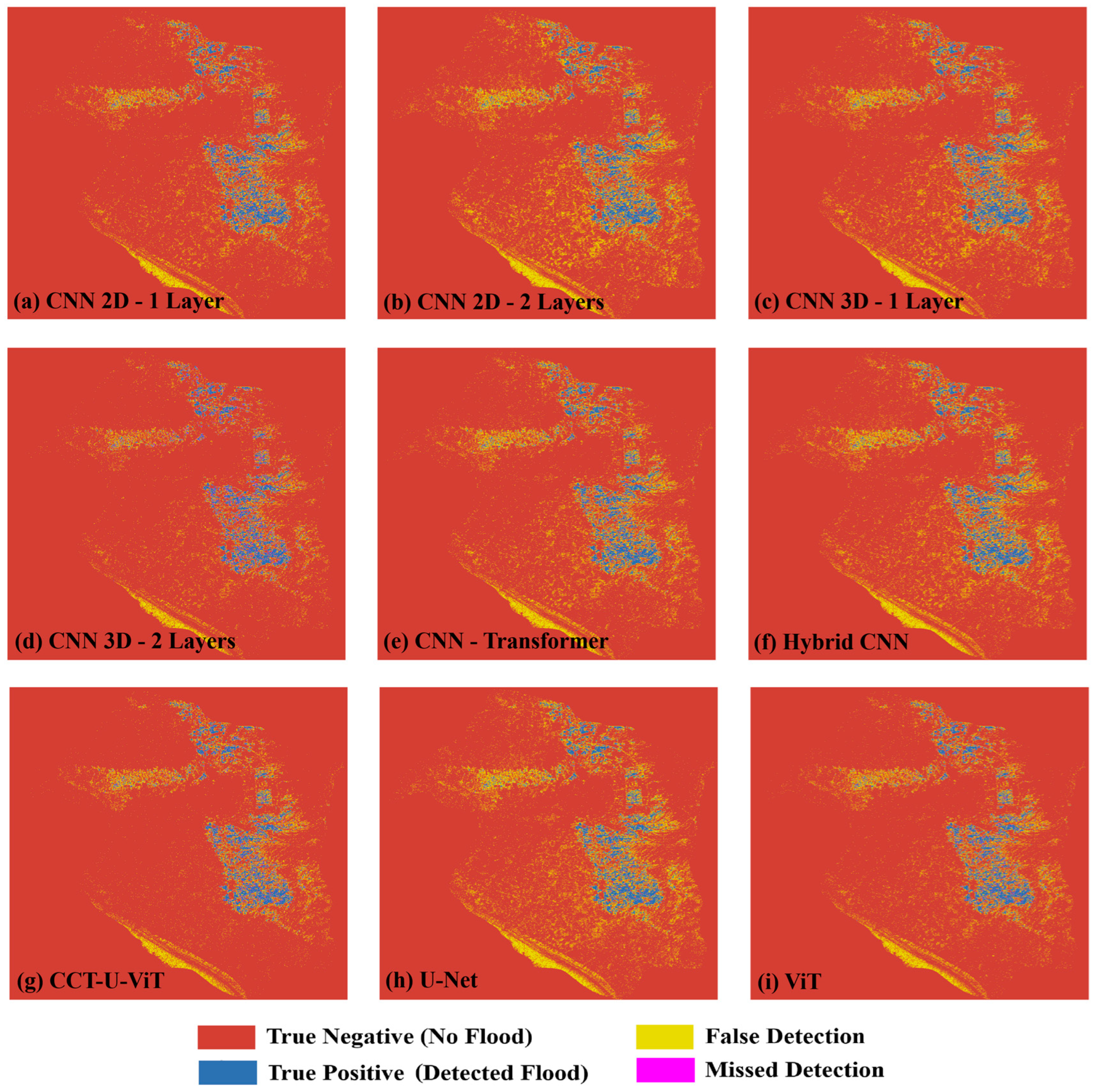
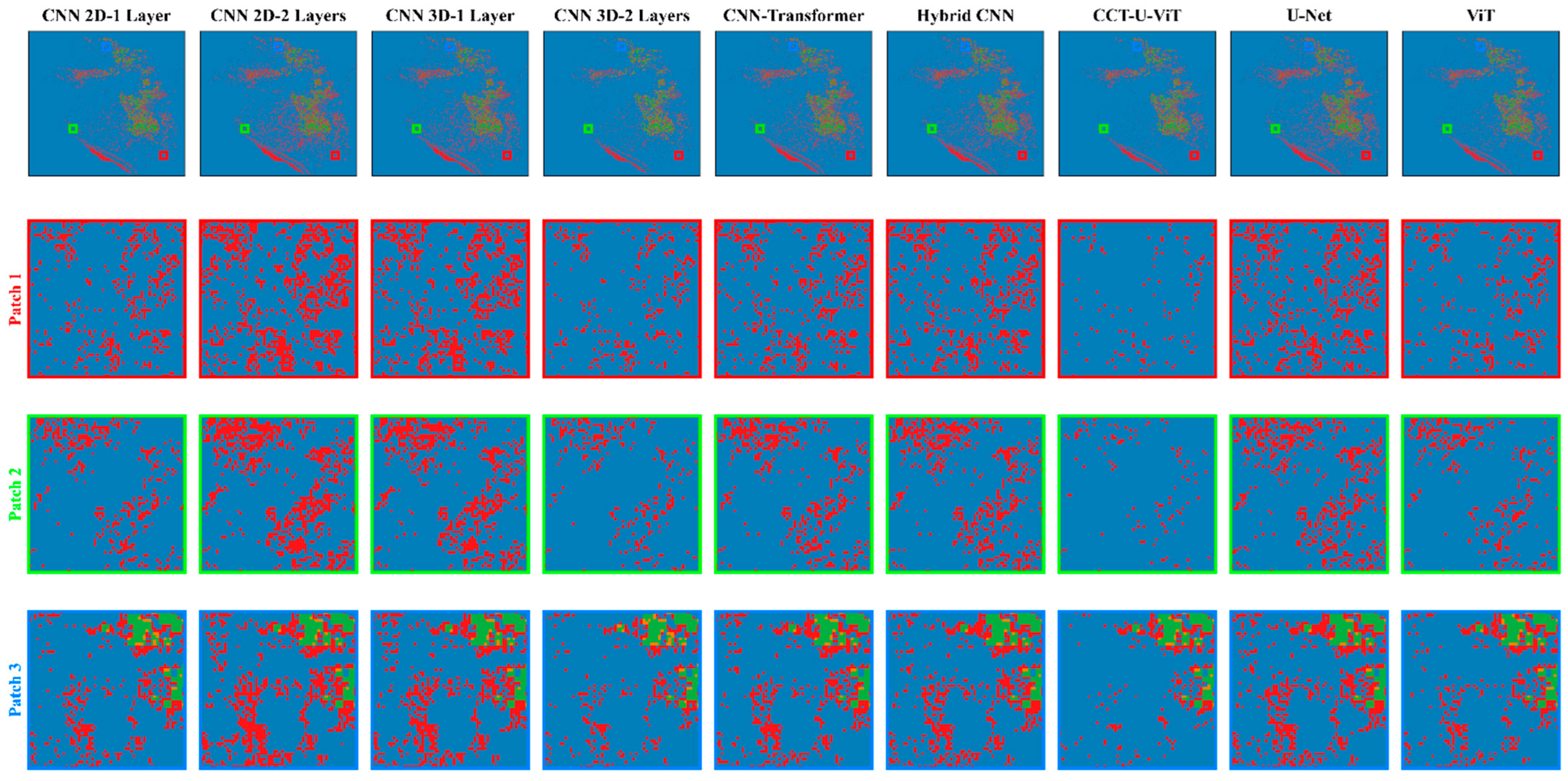
4.2. Results of Erbil Flood Detection
4.3. Experimental Results on the S1GFloods Dataset
4.4. Comparison of Computational Efficiency
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tanoue, M.; Taguchi, R.; Nakata, S.; Watanabe, S.; Fujimori, S.; Hirabayashi, Y. Estimation of Direct and Indirect Economic Losses Caused by a Flood With Long-Lasting Inundation: Application to the 2011 Thailand Flood. Water Resour. Res. 2020, 56, e2019WR026092. [Google Scholar] [CrossRef]
- Merz, B.; Blöschl, G.; Vorogushyn, S.; Dottori, F.; Aerts, J.; Bates, P.; Bertola, M.; Kemter, M.; Kreibich, H.; Lall, U.; et al. Causes, Impacts and Patterns of Disastrous River Floods. Nat. Rev. Earth Environ. 2021, 2, 592–609. [Google Scholar] [CrossRef]
- Puttinaovarat, S.; Horkaew, P. Internetworking Flood Disaster Mitigation System Based on Remote Sensing and Mobile GIS. Geomat. Nat. Hazards Risk 2020, 11, 1886–1911. [Google Scholar] [CrossRef]
- Ziboon, A.R.T.; Alwan, I.A.; Khalaf, A.G. Utilization of Remote Sensing Data and GIS Applications for Determination of the Land Cover Change in Karbala Governorate. Eng. Technol. J. 2013, 31, 2773–2787. [Google Scholar] [CrossRef]
- Ziboon, A.R.T. Monitoring of Agricultural Drought in the Middle Euphrates Area, Iraq Using Landsat Dataset. Eng. Technol. J. 2019, 37. [Google Scholar]
- Shihab, T.H.; Al-hameedawi, A.N. Desertification Hazard Zonation in Central Iraq Using Multi-Criteria Evaluation and GIS. J. Indian Soc. Remote Sens. 2020, 48, 397–409. [Google Scholar] [CrossRef]
- Noori, A.M.; Ziboon, A.R.T.; AL-Hameedawi, A.N. Assessment of Flash Flood Detection in Erbil City Using Change Detection Indices for SAR Images. Eng. Technol. J. 2024, 42, 1378–1386. [Google Scholar] [CrossRef]
- Chini, M.; Pelich, R.; Li, Y.; Hostache, R.; Zhao, J.; Mauro, C.; Matgen, P. Sar-Based Flood Mapping, Where We Are and Future Challenges. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 884–886. [Google Scholar] [CrossRef]
- Tsokas, A.; Rysz, M.; Pardalos, P.M.; Dipple, K. SAR Data Applications in Earth Observation: An Overview. Expert Syst. Appl. 2022, 205, 117342. [Google Scholar] [CrossRef]
- Li, Y.; Martinis, S.; Wieland, M.; Schlaffer, S.; Natsuaki, R. Urban Flood Mapping Using SAR Intensity and Interferometric Coherence via Bayesian Network Fusion. Remote Sens. 2019, 11, 2231. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Wang, L.; Plaza, A. Integration of Remote Sensing and Crowdsourced Data for Fine-Grained Urban Flood Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 13523–13532. [Google Scholar] [CrossRef]
- Mason, D.; Speck, R.; Devereux, B.; Schumann, G.; Neal, J.; Bates, P. Flood Detection in Urban Areas Using TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2010, 48, 882–894. [Google Scholar] [CrossRef]
- Tanguy, M.; Chokmani, K.; Bernier, M.; Poulin, J.; Raymond, S. River Flood Mapping in Urban Areas Combining Radarsat-2 Data and Flood Return Period Data. Remote Sens. Environ. 2017, 198, 442–459. [Google Scholar] [CrossRef]
- Schlaffer, S.; Matgen, P.; Hollaus, M.; Wagner, W. Flood Detection from Multi-Temporal SAR Data Using Harmonic Analysis and Change Detection. Int. J. Appl. Earth Obs. Geoinf. 2015, 38, 15–24. [Google Scholar] [CrossRef]
- Huang, M.; Jin, S. Backscatter Characteristics Analysis for Flood Mapping Using Multi-Temporal Sentinel-1 Images. Remote. Sens. 2022, 14, 3838. [Google Scholar] [CrossRef]
- Saleh, T.; Holail, S.; Xiao, X.; Xia, G. High-Precision Flood Detection and Mapping via Multi-Temporal SAR Change Analysis with Semantic Token-Based Transformer. Int. J. Appl. Earth Obs. Geoinf. 2024, 131, 103991. [Google Scholar] [CrossRef]
- Li, J.; Meng, Y.; Li, Y.; Cui, Q.; Yang, X.; Tao, C.; Wang, Z.; Li, L.; Zhang, W. Accurate Water Extraction Using Remote Sensing Imagery Based on Normalized Difference Water Index and Unsupervised Deep Learning. J. Hydrol. 2022, 612, 128202. [Google Scholar] [CrossRef]
- Noori, A.M.; Ziboon, A.R.T.; Al-Hameedawi, A.N. An Overview and Trends of Flood Detection, Hazard, Vulnerability and Risk Assessment. In AIP Conference Proceedings, Proceedings of the 5th International Conference on Building, Construction and Environmental Engineering, Amman, Jordan, 21–23 November 2024; AIP Publishing: Amman, Jordan, 2024; Volume 3219. [Google Scholar]
- Wang, D.; Chen, X.; Jiang, M.; Du, S.; Xu, B.; Wang, J. ADS-Net: An Attention-Based Deeply Supervised Network for Remote Sensing Image Change Detection. Int. J. Appl. Earth Obs. Geoinf. 2021, 101, 102348. [Google Scholar]
- Eftekhari, A.; Samadzadegan, F.; Javan, F.D. Building Change Detection Using the Parallel Spatial-Channel Attention Block and Edge-Guided Deep Network. Int. J. Appl. Earth Obs. Geoinf. 2023, 117, 103180. [Google Scholar] [CrossRef]
- Aparna, A.; Sudha, N. SAR-FloodNet: A Patch-Based Convolutional Neural Network for Flood Detection on SAR Images. In Proceedings of the 2022 International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 9–11 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 195–200. [Google Scholar]
- Sudiana, D.; Riyanto, I.; Rizkinia, M.; Arief, R.; Prabuwono, A.S.; Sumantyo, J.T.S.; Wikantika, K. Performance Evaluation of 3-Dimensional Convolutional Neural Network for Multi-Temporal Flood Classification Framework with Synthetic Aperture Radar Image Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 18, 3198–3207. [Google Scholar] [CrossRef]
- Sherrah, J. Fully Convolutional Networks for Dense Semantic Labelling of High-Resolution Aerial Imagery. arXiv 2016, arXiv:1606.02585. [Google Scholar]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed]
- Zagoruyko, S.; Komodakis, N. Learning to Compare Image Patches via Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Doan, T.-N.; Le-Thi, D.-N. A Novel Deep Learning Model for Flood Detection from Synthetic Aperture Radar Images. J. Adv. Inf. Technol. 2025, 16, 57–70. [Google Scholar] [CrossRef]
- Huang, B.; Li, P.; Lu, H.; Yin, J.; Li, Z.; Wang, H. WaterDetectionNet: A New Deep Learning Method for Flood Mapping with SAR Image Convolutional Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 14471–14485. [Google Scholar] [CrossRef]
- Tahermanesh, S.; Mohammadzadeha, A.; Mohsenifar, A.; Moghimi, A. SISCNet: A Novel Siamese Inception-Based Network with Spatial and Channel Attention for Flood Detection in Sentinel-1 Imagery. Remote Sens. Appl. Soc. Environ. 2025, 38, 101571. [Google Scholar] [CrossRef]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. Ce-Net: Context Encoder Network for 2d Medical Image Segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef]
- Hu, Y.; Guo, Y.; Wang, Y.; Yu, J.; Li, J.; Zhou, S.; Chang, C. Automatic Tumor Segmentation in Breast Ultrasound Images Using a Dilated Fully Convolutional Network Combined with an Active Contour Model. Med. Phys. 2019, 46, 215–228. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-Aware Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Bai, Y.; Wu, W.; Yang, Z.; Yu, J.; Zhao, B.; Liu, X.; Yang, H.; Mas, E.; Koshimura, S. Enhancement of Detecting Permanent Water and Temporary Water in Flood Disasters by Fusing Sentinel-1 and Sentinel-2 Imagery Using Deep Learning Algorithms: Demonstration of Sen1floods11 Benchmark Datasets. Remote Sens. 2021, 13, 2220. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A Nested u-Net Architecture for Medical Image Segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Ghosh, B.; Garg, S.; Motagh, M.; Martinis, S. Automatic Flood Detection from Sentinel-1 Data Using a Nested UNet Model and a NASA Benchmark Dataset. PFG–J. Photogramm. Remote Sens. Geoinf. Sci. 2024, 92, 1–18. [Google Scholar] [CrossRef]
- Guo, C.; Szemenyei, M.; Yi, Y.; Wang, W.; Chen, B.; Fan, C. Sa-Unet: Spatial Attention u-Net for Retinal Vessel Segmentation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1236–1242. [Google Scholar]
- Wang, F.; Feng, X. Flood Change Detection Model Based on an Improved U-Net Network and Multi-Head Attention Mechanism. Sci. Rep. 2025, 15, 3295. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Tavus, B.; Can, R.; Kocaman, S. A CNN-Based Flood Mapping Approach Using Sentinel-1 Data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 3, 549–556. [Google Scholar] [CrossRef]
- Zhou, L.; Zhou, X.; Feng, H.; Liu, W.; Liu, H. Transformer-Based Semantic Segmentation for Flood Region Recognition in SAR Images. IEEE J. Miniaturization Air Sp. Syst. 2025. [Google Scholar] [CrossRef]
- Park, S.; Kim, G.; Oh, Y.; Seo, J.B.; Lee, S.M.; Kim, J.H.; Moon, S.; Lim, J.-K.; Ye, J.C. Vision Transformer for Covid-19 Cxr Diagnosis Using Chest x-Ray Feature Corpus. arXiv 2021, arXiv:2103.07055. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training Data-Efficient Image Transformers & Distillation through Attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR: New York, NY, USA, 2021; pp. 10347–10357. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Chamatidis, I.; Istrati, D.; Lagaros, N.D. Vision Transformer for Flood Detection Using Satellite Images from Sentinel-1 and Sentinel-2. Water 2024, 16, 1670. [Google Scholar] [CrossRef]
- Sharma, N.; Saharia, M. Mapping Floods from SAR Data Using CNNs and Vision Transformers. In Proceedings of the AGU Fall Meeting Abstracts, Washington, DC, USA, 9–13 December 2024; Volume 2024, p. H53M–1271. [Google Scholar]
- Liu, X.; Gao, P.; Yu, T.; Wang, F.; Yuan, R.-Y. CSWin-UNet: Transformer UNet with Cross-Shaped Windows for Medical Image Segmentation. Inf. Fusion 2025, 113, 102634. [Google Scholar] [CrossRef]
- Qiu, P.; Yang, J.; Kumar, S.; Ghosh, S.S.; Sotiras, A. AgileFormer: Spatially Agile Transformer UNet for Medical Image Segmentation. arXiv 2024, arXiv:2404.00122. [Google Scholar]
- Fan, C.-M.; Liu, T.-J.; Liu, K.-H. SUNet: Swin Transformer UNet for Image Denoising. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2333–2337. [Google Scholar]
- Chen, J.; Mei, J.; Li, X.; Lu, Y.; Yu, Q.; Wei, Q.; Luo, X.; Xie, Y.; Adeli, E.; Wang, Y. TransUNet: Rethinking the U-Net Architecture Design for Medical Image Segmentation through the Lens of Transformers. Med. Image Anal. 2024, 97, 103280. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 205–218. [Google Scholar]
- Wang, R.; Cai, M.; Xia, Z.; Zhou, Z. Remote Sensing Image Road Segmentation Method Integrating CNN-Transformer and UNet. IEEE Access 2023, 11, 144446–144455. [Google Scholar] [CrossRef]
- Yang, L.; Wang, H.; Meng, W.; Pan, H. CvT-UNet: A Weld Pool Segmentation Method Integrating a CNN and a Transformer. Heliyon 2024, 10, 1–17. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, L. Detection of Pavement Cracks by Deep Learning Models of Transformer and UNet. IEEE Trans. Intell. Transp. Syst. 2024, 25, 15791–15808. [Google Scholar] [CrossRef]
- Zhang, H.; Lian, J.; Ma, Y. FET-UNet: Merging CNN and Transformer Architectures for Superior Breast Ultrasound Image Segmentation. Phys. Medica 2025, 133, 104969. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like Transformer for Efficient Semantic Segmentation of Remote Sensing Urban Scene Imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Sha, Y.; Zhang, Y.; Ji, X.; Hu, L. Transformer-Unet: Raw Image Processing with Unet. arXiv 2021, arXiv:2109.08417. [Google Scholar]
- Zhou, N.; Xu, M.; Shen, B.; Hou, K.; Liu, S.; Sheng, H.; Liu, Y.; Wan, J. ViT-UNet: A Vision Transformer Based UNet Model for Coastal Wetland Classification Based on High Spatial Resolution Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 19575–19587. [Google Scholar] [CrossRef]
- Al-Hameedawi, A.; Buchroithner, M. Object-Oriented Classifications for Land Use/Land Cover Using Cosmo-SkyMed and LandSat 7 Satellite Data: An Example of Erbil/Iraq. In Proceedings of the EUSAR 2014—10th European Conference on Synthetic Aperture Radar, Berlin, Germany, 3–5 June 2014; VDE: Taipei, China, 2014; pp. 1–4. [Google Scholar]
- Aziz, S.Q.; Saleh, S.M.; Muhammad, S.H.; Ismael, S.O.; Ahmed, B.M. Flood Disaster in Erbil City: Problems and Solutions. Environ. Prot. Res. 2023, 3, 303–318. [Google Scholar]
- Ali, B.A.; Mawlood, D.K. Applying the SWMM Software Model for the High Potential Flood-Risk Zone for Limited Catchments in Erbil City Governorate. Zanco J. Pure Appl. Sci. 2023, 35, 41–50. [Google Scholar]
- Noori, A.M.; Ziboon, A.R.T.; Al-Hameedawi, A.N. Flash Flood Susceptibility Mapping via Morphometric Analysis of Erbil City Basins, Iraq. In AIP Conference Proceedings, Proceedings of the 5th International Conference on Civil and Environmental Engineering Technologies, Kufa, Iraq, 24–25 April 2024; AIP Publishing: Melville, NY, USA, 2024; Volume 3249. [Google Scholar]
- Sissakian, V.K.; Al-Ansari, N.; Adamo, N.; Abdul Ahad, I.D.; Abed, S.A. Flood Hazards in Erbil City Kurdistan Region Iraq, 2021: A Case Study. Engineering 2022, 14, 591–601. [Google Scholar] [CrossRef]
- Zhou, Y.; Yang, B.; Yin, Q.; Ma, F.; Zhang, F. Improved SAR Radiometric Cross-Calibration Method Based on Scene-Driven Incidence Angle Difference Correction and Weighted Regression. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5224216. [Google Scholar] [CrossRef]
- Vijayakumar, S.; Saravanakumar, R.; Arulanandam, M.; Ilakkiya, S. Google Earth Engine: Empowering Developing Countries with Large-Scale Geospatial Data Analysis—A Comprehensive Review. Arab. J. Geosci. 2024, 17, 139. [Google Scholar] [CrossRef]
- Riyanto, I.; Rizkinia, M.; Arief, R.; Sudiana, D. Three-Dimensional Convolutional Neural Network on Multi-Temporal Synthetic Aperture Radar Images for Urban Flood Potential Mapping in Jakarta. Appl. Sci. 2022, 12, 1679. [Google Scholar] [CrossRef]
- Seydi, S.T.; Saeidi, V.; Kalantar, B.; Ueda, N.; van Genderen, J.L.; Maskouni, F.H.; Aria, F.A. Fusion of the Multisource Datasets for Flood Extent Mapping Based on Ensemble Convolutional Neural Network (CNN) Model. J. Sens. 2022, 2022, 2887502. [Google Scholar] [CrossRef]
- Emek, R.A.; Demir, N. Building Detection from Sar Images Using Unet Deep Learning Method. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 44, 215–218. [Google Scholar] [CrossRef]
- Li, Z.; Chen, G.; Zhang, T. A CNN-Transformer Hybrid Approach for Crop Classification Using Multitemporal Multisensor Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 847–858. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite | Acquisition Date | Processing Level | Polarization | Spatial Resolution (m) |
|---|---|---|---|---|
| Sentinel-1 | Pre-flood 25 September 2021 | Level 1 | Single—VH | 10 |
| Sentinel-1 | Post-flood 20 December 2021 | Level 1 | Single—VH | 10 |
| Model | Metric | |||
|---|---|---|---|---|
| OA | Kappa | F1 Score | mIoU | |
| CNN 2D-1 Layer | 0.9041 | 0.8082 | 0.9031 | 0.8234 |
| CNN 2D-2 Layers | 0.9056 | 0.8113 | 0.9044 | 0.8254 |
| CNN 3D-1 Layer | 0.8741 | 0.7482 | 0.8642 | 0.7609 |
| CNN 3D-2 Layers | 0.8892 | 0.7784 | 0.8845 | 0.7929 |
| Hybrid CNN | 0.9008 | 0.8016 | 0.8985 | 0.8158 |
| U-Net | 0.8953 | 0.7907 | 0.9013 | 0.8204 |
| ViT | 0.9064 | 0.8127 | 0.9086 | 0.8326 |
| CNN–Transformer | 0.9079 | 0.8158 | 0.9076 | 0.8308 |
| CCT-U-ViT (ours) | 0.9124 | 0.8248 | 0.9121 | 0.8383 |
| Method | Kappa | OA | F1 Score | mIoU |
|---|---|---|---|---|
| CNN 2D-1 Layer | 0.872 | 0.937 | 0.911 | 0.843 |
| CNN 2D-2 Layers | 0.908 | 0.956 | 0.933 | 0.877 |
| CNN 3D-1 Layer | 0.911 | 0.959 | 0.937 | 0.882 |
| U-Net | 0.927 | 0.955 | 0.932 | 0.877 |
| CNN 3D-2 Layers | 0.930 | 0.955 | 0.932 | 0.878 |
| ViT | 0.945 | 0.961 | 0.941 | 0.896 |
| Hybrid CNN | 0.936 | 0.962 | 0.942 | 0.894 |
| CNN–Transformer | 0.958 | 0.968 | 0.952 | 0.915 |
| CCT-U-ViT (ours) | 0.969 | 0.979 | 0.966 | 0.933 |
| Model | # Layers | # Parameters | Trainable Parameters | Model Size (MB) | Inference Time (Batch 64) (s) | Batch Time (Batch 64) (s) |
|---|---|---|---|---|---|---|
| CNN 2D-1 Layer | 4 | 2386 | 2386 | 0.03 | 0.0232 | 634.62 |
| CNN 2D-2 Layers | 5 | 4754 | 4754 | 0.04 | 0.0181 | 495.86 |
| CNN 3D-1 Layer | 4 | 4306 | 4306 | 0.03 | 0.0218 | 595.25 |
| CNN 3D-2 Layers | 5 | 9618 | 9618 | 0.06 | 0.0183 | 501.54 |
| CNN–Transformer | 29 | 407,683 | 407,683 | 1.64 | 0.0231 | 632.13 |
| Hybrid CNN | 9 | 4130 | 4130 | 0.04 | 0.02 | 545.8 |
| U-Net | 69 | 237,946 | 236,474 | 1.12 | 0.0233 | 638.21 |
| CCT-U-ViT | 95 | 669,482 | 668,010 | 2.82 | 0.0258 | 705.91 |
| ViT | 47 | 372,770 | 372,770 | 1.57 | 0.0383 | 1047.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Noori, A.M.; Ziboon, A.R.T.; AL-Hameedawi, A.N. Deep-Learning Integration of CNN–Transformer and U-Net for Bi-Temporal SAR Flash-Flood Detection. Appl. Sci. 2025, 15, 7770. https://doi.org/10.3390/app15147770
Noori AM, Ziboon ART, AL-Hameedawi AN. Deep-Learning Integration of CNN–Transformer and U-Net for Bi-Temporal SAR Flash-Flood Detection. Applied Sciences. 2025; 15(14):7770. https://doi.org/10.3390/app15147770
Chicago/Turabian StyleNoori, Abbas Mohammed, Abdul Razzak T. Ziboon, and Amjed N. AL-Hameedawi. 2025. "Deep-Learning Integration of CNN–Transformer and U-Net for Bi-Temporal SAR Flash-Flood Detection" Applied Sciences 15, no. 14: 7770. https://doi.org/10.3390/app15147770
APA StyleNoori, A. M., Ziboon, A. R. T., & AL-Hameedawi, A. N. (2025). Deep-Learning Integration of CNN–Transformer and U-Net for Bi-Temporal SAR Flash-Flood Detection. Applied Sciences, 15(14), 7770. https://doi.org/10.3390/app15147770