1. Introduction
Many different healthcare and entertainment applications have been created, adapting human activity recognition in smartphones with embedded sensors. Activity recognition is especially relevant for fitness, running, and other sports. A lot of smartphone users track their activity and how long they are active, count their steps, calculate burnt calories, detect falls or posture, and much more. Various apps have been created for such purposes. Initially, several wearable sensors were used to identify various physical activities for the aforementioned applications. However, because smartphones contain a variety of sensors, research has moved to these types of devices in recent years [
1,
2,
3,
4,
5,
6,
7]. Smartphones are useful for human activity recognition because they come with a combination of sensors, including accelerometers and magnetic field sensors, gyroscopes, magnetometers, GPSs, and so on. Recently, many researchers started using smartphones to explore human activity recognition and algorithms used for learning various human activities [
8].
For example, experiments with human activity recognition using cell phone accelerometers were performed in ref. [
3]. In the paper, the extracted features from accelerometers were used with the following classification techniques: Multilayer Perceptron, Simple Logistic, Random Forest, LMT, SVM, and LogitBoost. These techniques showed good recognition accuracy in relation to walking, jogging, standing, and sitting, whereas climbing upstairs and downstairs were poorly recognized. A survey in ref. [
9] analyzed activity recognition with smartphone sensors such as an accelerometer, ambient temperature sensor, light sensor, magnetometer, proximity sensor, barometer, humidity sensor, gyroscope, etc. Several categories of activities were analyzed, including simple activities like walking, jogging, standing or sitting; more complex activities like taking buses, shopping, and driving a car; and other categories of activities such as living, working, and health-related activities. The authors listed the major, common challenges for activity recognition using mobile sensors: subject sensitivity, location sensitivity, activity complexity, energy and resource constraints, and insufficient training sets.
The secure client–server architecture proposed in ref. [
10] allowed for the creation of a real-time human activity recognition system. A K-nearest neighbors (KNN) algorithm was used for activity recognition. Up to 100% of recognition accuracy for running and walking activities was achieved. Also, the overall accuracy of the model reached up to 95%. Deep learning is also used in various studies of activity recognition, such as ref. [
11]. Deep learning models require a lot of available data and computing resources, which are not available for wearable devices. Moreover, these models are often trained offline, which cannot be executed in real-time.
A survey of using Hidden Markov models (HMMs) in human activity recognition was performed in ref. [
12]. A continuous HMM and discrete HMM were proposed as a hierarchical probabilistic model to recognize a user’s activities in smartphones. A separate HMM was used to model a single activity. In ref. [
13], the authors proposed a user adaptation technique to improve a human activity recognition system based on an HMM. Several different physical activities (walking, walking upstairs, walking downstairs, sitting, standing, and lying down) were modeled. As reported, the experimental results showed a significant error rate reduction.
Various recognition algorithms can be divided into three parts by the nature of learning patterns in data. The first type is offline algorithms, with the classifiers trained solely before starting to use them. The second type is adaptive learning (also referred as online) algorithms, which are trained in real-time with incoming data as they are being used [
14,
15]. The third type is semi-online algorithms, which are initially trained in a supervised manner and then used in simultaneous real-time self-supervised learning and classification. Such algorithms can be autonomous as they perform all calculations independently from other systems.
Numerous studies conducted in this field have analyzed sensor data gathered for offline activity recognition. They often use various software suites, such as MATLAB and WEKA, containing machine learning algorithms [
3,
15]. Smartphones are now capable of running recognition systems themselves as available resources like CPUs, memory, and batteries grow increasingly powerful. Therefore, activity recognition systems can now be implemented on these more powerful smartphones in a fully online learning mode [
16,
17]. Several studies have examined offline activity recognition in depth [
18,
19,
20]. Another common issue increasingly faced in offline learning, which would be dealt with using adaptive learning algorithms, is insufficient data [
9]. Training data may not match data collected by device sensors in a real environment. Insufficient data increases the variability of model prediction for a given data point or a value that tells us how the data is spread. This means that the model will fit the training data perfectly, but will stop working as soon as new data are fed into it. Adaptive learning algorithms can solve this problem by continuously using new data in training and prediction. Thus, it is relevant to develop self-learning algorithms that would autonomously adapt HAR recognition for each individual device using data received from the sensors of the trained device. It is natural to use incremental algorithms that only recalculate the parameters necessary for recognizing activities at each step, using only the information of the current step, and consuming limited computer resources, i.e., the complexity of the incremental algorithm becomes linear in terms of the sample size and the computer time consumed. However, incremental algorithms, created on the basis of most well-known machine learning algorithms, are not autonomous; their operation is related to training and exchanging data in the cloud [
21,
22,
23,
24]. It is necessary to emphasize that HAR recognition tools, devoted to massive implementation on smart mobile devices, should also meet the requirements of algorithmic simplicity and computational economy. In this paper, we propose to apply maximum likelihood methods to achieve the above goals, since they provide optimal, asymptotically unbiased, consistent, and normally distributed estimates, ensuring the highest entropy and minimum recognition error, obtained using simple statistics in the form of weighted sample means or covariances. A special computational technique is used, allowing us to adapt direct maximum likelihood algorithms into incremental ones. In this way, the recursive hidden Markov model (RHMM) is created as an adaptive learning method for activity recognition using data from smartphone sensors. The application of this algorithm allows for gathering new data from sensors and using them to adjust the model parameters in real-time. The recognition of a number of physical activities where motion sensors are used in the recognition process was analyzed.
2. Adaptive Activity Recognition
The proposed system for human activity recognition consists of the following components, representing data processing stages: data gathering, preprocessing, feature extraction, and training or classification [
25,
26]:
In the activity recognition process, classification is an essential part. Over the last few years, different types of classification algorithms have been implemented on smartphones such as support vector machines (SVMs), decision trees, K-nearest neighbors (KNN), fuzzy classification, and neural networks [
11,
30]. As previously mentioned, supervised learning can be used to train activity recognition models for smartphones in either an online or offline mode. In an online mode, the classifiers are trained on smartphones in real-time, whereas in an offline mode, the classifiers are trained beforehand, typically on a computer.
Likewise, there are two alternatives for using the trained model to perform classification—locally on the device (offline and real-time) or in the cloud (online). These options have a significant effect on speed, power, privacy, and cost [
15]. For example, if the cloud is used to make a prediction, the application must be connected to the internet, whereas if the predictions are performed locally on the device, some hardware constraints must be met. In this case, a smartphone might not be able to perform any type of machine learning due to RAM and CPU limitations.
Performing classification directly on the device (in an offline mode) might be useful in cases where an application cannot rely on network connectivity. In this case, speed and reliability are the main advantages because all sensor data are processed and used in real-time predictions locally on the smartphone, without sending requests to the cloud online. However, in the case of a static offline trained model, it is challenging to update the training model once it is being used to make predictions. The model might become out-of-date over time and stop working exactly as expected. Subsequently, it must be re-trained with more or newer data and updated with the application which contains it. On the other hand, in the cloud, the model can be continuously updated. Thus, it will be unnecessary to update the application of human activity recognition. And in the case of re-training, the updated model will be available to all users [
31].
The offline approach where only the classification is implemented on smartphones while the training is performed on desktop computers has been used in the majority of studies. The key reason is the reduced computational cost of training. Only a few studies used online training, in which classifiers could be trained in real-time on smartphones. However, the real-time classification occurs without subsequent real-time model adaptation.
Further, we propose a model for online human activity recognition.
2.1. Proposed System Architecture
Let us propose the system architecture based on the machine learning algorithm to classify activities using features extracted from gathered sensor data. Note, the inertial signals are recorded from sensors, such as an accelerometer (ACC), gyroscope (GYR), and magnetometer (MAG), extracting the required features from these signals. Lastly, the machine learning module (classifier) estimates model parameters from feature vectors sent to this module and identifies which class (state) the given signal belongs to.
Parts of this proposed architecture are discussed further in detail.
2.1.1. Sensor Data Gathering
Depending on the smartphone, various sensors provide the data for training and classification. An accelerometer, gyroscope, and magnetometer can be used to gather data [
25].
2.1.2. Feature Extraction
After gathering the data, they need to be transformed so as to extract the features that would provide all of the necessary information to the machine learning algorithm.
It is necessary to transform the gathered data in order to extract features that include all the information needed by the machine learning algorithm. First, the sequences of inertial signal samples are divided into frames with overlapping and fixed-width sliding windows, calculating for each frame a feature vector, which is required in learning the internal characteristics of the inertial signals. These features are well-known statistics, namely, the mean, correlation, signal magnitude area (SMA), autoregression coefficients, and some more complex ones. These features, together with time domain signals, are selected according to prior work and importance analysis [
25,
28,
32,
33].
The time domain signals are as follows [
33]:
Three accelerometer signals (XYZ axis).
Three jerk signals given by the accelerometer signal data.
One magnitude signal index computed as the vector-length of the three previous original accelerometer signals.
The jerk magnitude index computed as the vector-length of these jerk signals.
The features estimated from the time domain signals are as follows:
Mean value, computed usually as the average of readings per axis, where N is the number of readings for each sensor: .
Median absolute deviation to evaluate the variation around the mean value, computed as (for each axis) .
Standard deviation, quantifying the variation of readings from the mean value: .
Average Resultant Acceleration, computed as the average of vector-lengths of each reading: .
Minimum and maximum in a frame.
Inter-quartile range to measure the variability in a dataset.
Energy measure computed as the average of squared samples in a frame.
Signal magnitude area (SMA) computed through the normalized integral.
Frequency domain signals are as follows [
33]:
Three Fast Fourier transforms (FFTs) computed from three original accelerometer signals.
Three FFTs computed from three jerk accelerometer signals.
One FFT computed from a magnitude signal.
One FFT computed from a jerk magnitude signal.
The features estimated from frequency domain signals (including similar features to those from the time domain) are as follows:
Frequency component index with the largest magnitude.
Weighted average of the frequency components.
Skewness and Kurtosis of the frequency domain signal.
Histogram, which is constructed in a standard manner, dividing the range of minimum–maximum values of each axis into a specified number of equal-sized intervals, equipped with frequencies of hitting to these intervals: .
2.1.3. Algorithm for Classification
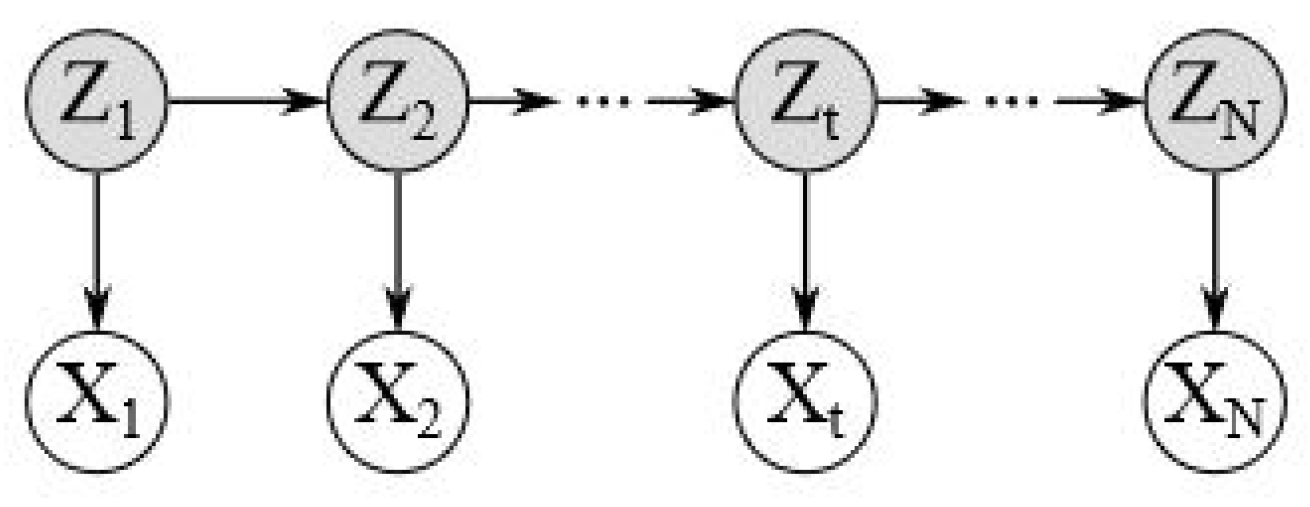
The recognition of human activities in a real-life setting is an important engineering and scientific problem. Several probability-based methods have been developed to build models to study it. HMM is a highly popular modeling technique for the analysis of stochastic processes by representing probability distributions over samples of observation, connected via Markov chains (
Figure 1). In this model, an observation
at time
t is produced by a stochastic process in a certain state, although the state is considered as hidden. Thus, this hidden process is assumed to satisfy the Markov property, namely, state
at time
t depends only on the previous state,
at time
. Hidden Markov model parameters that are estimated with observations are used in further analysis.
The Expectation–Maximization algorithm can be used to learn HMM parameters (emission probabilities B and transition probabilities), given the observation sequence and the set of the possible states in the HMM. The EM algorithm allows for iterative learning of HMM parameters. It computes the initial estimate of the parameters, and then uses these estimates to compute an improved estimate of the parameters. The EM algorithm is performed in the following steps: calculation of the logarithmic likelihood function and maximization of the conditional mean of the likelihood function. It is well known that the maximum likelihood estimate for an HMM is a consistent and asymptotically normal estimator, and it converges to a stationary point of the sample likelihood.
Various human activities can be modeled accurately as Markov chains [
21,
22,
23,
24,
34,
35]. Observing signals stemming from complex or unfamiliar activities can be utilized to indirectly build an HMM of the activity. There are two main ways an activity can be modeled with an HMM. The first one is to model one activity as a separate HMM. If it is denoted that one activity (for example, running) has a start, middle, and end, then this activity can be modeled with a minimum three-state HMM. The second one is to model several activities as one HMM. For example, if it is denoted that three activities (walking, running, and standing) are interconnected, and there are various possibilities to transition from one activity to another, then these activities can be modeled with one HMM. In this case, one state in HMM will represent one particular activity.
Similar to the above-mentioned classification, HMM parameters can be estimated in batch or online mode as well, where the online estimation algorithm allows for real-time sequential and re-evaluative parameter estimation. The model parameters are re-estimated on feed and processing with each new observation vector, without preserving previous observations data.
In this paper, an RHMM parameter estimation algorithm is proposed for HAR using the likelihood maximization and maximum likelihood estimates with sequential refinement of HMM parameters in an online setting [
36].
Let us consider an HMM of
N states with a sequence of observations of length
T. Assume the HMM is stationary, i.e., its probabilistic properties do not change over time. Thus, denote the HMM state probability
N-dimensional vector as
; the state transition probability matrix as
Q; and the density function of the probability distribution of observation
o, generated from state
s, as
which is assumed to be normal with
M-dimensional mean
and covariance matrix
and
.
The logarithmic likelihood function, which describes the observation in a state
s, is as follows:
Let us calculate
derivatives according to
,
, and
using the Lagrange multiplier method regarding the constraint
:
where
, and
is the Lagrange multiplier.
The equations with derivatives
,
, and
are solved with respect to
,
and
as follows:
The derived Formulas (
7) and (
8) can be used in offline MLE estimation, given a fixed data sample. The complexity of such calculations is linear. However, if applied for online estimation, their complexity becomes of second order because the calculations must be carried out over the entire dataset at each appearance of new data (i.e., each re-estimation of parameters). Therefore, in order to enable online estimation, recursive formulas for re-estimating the HMM parameters are needed.
It is not difficult to observe that the estimates obtained by Formulas (
7) and (
8) at
and
t satisfy the following recursive relations:
where the state probabilities
are calculated as
There are two parts of the RHMM parameter estimation algorithm.
The first part uses Equations (
10)–(
12) to estimate initial parameters given a small fixed-size observation set. During the initial training process,
and
represent fixed parameter values used in estimation. The algorithm’s stability is ensured by initial training. However, usually, it is not difficult to have a large enough dataset to initialize parameter values that correctly identify and classify the observations. This crucial size is about 100–200; moreover, the proposed online algorithm is easily adapted for offline estimation. The second part uses Equations (
10)–(
12) to re-estimate parameters based on classified observations. The values of the previous steps
and
are denoted by
and
in the re-estimation process. A Bayes classifier is used to classify the observations into groups.
The proposed algorithm will be applied to human activity recognition. In this scenario, data from sensors are used to train and initialize the HMM model. Then, the trained model will be used for continuous activity recognition and real-time model parameter updating.
3. Results and Discussion
3.1. Dataset
The Activity Recognition System Dataset [
37], which contains various measurements extracted from the sensors—accelerometers, gyroscopes, and magnetometers—have been used in our experiments:
The acceleration in the X, Y, and Z axes measured by the sensor;
The angular velocity in the X, Y, and Z axes measured by the sensor;
The magnetic field in the X, Y, and Z axes measured by the sensor;
The time extracted from the sensor in seconds.
The HAR System dataset, annotated manually by an observer, was compiled from data collected from 6 female and 10 male subjects aged between 23 and 50 [
37]. One Inertial Measurement Unit (IMU), which provides data on the acceleration, magnetic field, and the turn rates in three dimensions, were mounted on the belt of the user. In total, it contains about 4.5 h of annotated activities: walking, walking upstairs, walking downstairs, running, standing, sitting, lying on the floor, falling, jumping forward, jumping backward, and jumping vertically [
37].
3.2. Experimental Setup
In this section, we validate the performance of the RHMM parameter estimation algorithm using the Activity Recognition System Dataset. Firstly, feature extraction was performed (no other additional preprocessing was conducted on the data). Observation vectors of 28 dimensions were extracted for the experiments from the dataset using a window size of 30 milliseconds with a 50% overlap. The features extracted from the dataset for each activity were
A mean value of accelerometer signals XYZ;
Root mean square XYZ of accelerometer signals XYZ;
Standard deviation XYZ of accelerometer signals XYZ;
Signal vector magnitude of accelerometer signals;
Signal magnitude area (FFT calculated from magnitude signal).
The following activities—modeled with a separate HMM state—were chosen for modeling and recognition: walking, walking upstairs, walking downstairs, running, standing, lying on the floor, sitting, and falling.
The online algorithm, using a fixed-size set of training observations, was implemented for initial HMM parameter evaluation, starting with randomly chosen initial parameters of mean and covariance.
The accuracy of the algorithm was explored using ten-fold cross-validation. In this procedure, the data were randomly sorted and divided into 10 folds and 10 rounds of cross-validation were run. In each round, one of the folds for validation was used, and the remaining folds were used for training. After training the model, its accuracy on the validation data was measured, and a final cross-validation accuracy was computed by obtaining the average accuracy over the 10 rounds.
3.3. Computational Details
The RHMM algorithm was implemented in Matlab. The performance of the algorithm was evaluated using accuracy, precision, recall, and F1-score because these metrics help us to notice and evaluate many recognition effects.
Accuracy, defined in Equation (
13), presents itself simply as a ratio of correctly predicted observation to the total observations. This ratio is the most intuitive measure and tells us how often we can expect our machine learning model will correctly predict an outcome out of the total number of times it made predictions.
where TP, FP, TN, and FN represent the number of true positives, false positives, true negatives, and false negatives, respectively.
Recall, precision, and F1-score metrics were chosen in addition to the accuracy metric because they are useful measures of the success of prediction when the classes are imbalanced.
Recall, defined in Equation (
14), enables us to indicate the model’s ability to correctly predict positive outcomes from true positive outcomes and is a good measure of successful prediction when classes are highly unbalanced.
Precision, defined in Equation (
15), is also a useful measure of successful prediction when classes are unbalanced.
F1-score, defined in Equation (
16), gives us equal weight to both precision and recall models when evaluating performance in terms of accuracy. In this way, it can be the alternative for accuracy metrics without knowing the total number of observations.
3.4. Experiments
The first experiment was performed by modeling activities with separate HMMs consisting of varying amounts of states. The online algorithm was implemented as described above. Several cases of HMM modeling capabilities with different state amounts were analyzed. Five different models were trained with the proposed algorithm—three-state, four-state, five-state, six-state, and seven-state HMM models. Recognition accuracy was calculated during the continuous model parameter re-estimation and recognition.
In the first case of the three-state HMM, the accuracy of the model was 89%. Increasing the number of HMM states to four increased the accuracy to 91%. The accuracy stayed at 91% when the number of states was set to five. In the case of a six-state HMM, the accuracy reached 92%, whereas in the case of a seven-state HMM, it was 92%.
The results of these experiments show that increasing the state count from three to seven increases classification accuracy. For a better understanding of the performance of these models, the F1-score was calculated for each activity (see
Table 1). It gives some insight into how many states are needed to model HMM for the best recognition of each activity.
Table 1 shows that running, walking, walking downstairs, and sitting activities have the best F1-score when they are modeled with seven-state HMM. Standing has the highest F1-score (0.78) when it is modeled with the seven- or six-state HMM. Walking upstairs modeled with five- or six-state HMM has the best F1-score. Laying on the floor modeled with the three-state HMM has the best F1-score of 0.9. It is a significant difference compared to the F1-score (0.65) of seven-state HMM. Falling has the highest F1-score (0.96) when this activity is modeled with four states. This experiment showed that different activities should not be modeled with the HMM of the same number of states if we want to achieve the best recognition results.
The confusion matrix of the experiments where each activity is modeled with the seven-state HMM is given in
Table 2. It shows that running, sitting, and falling are well discriminated among other activities. However, walking, walking upstairs, and walking downstairs are often confused with each other. Other static activities such as standing and lying are confused with each other as well.
Table 3 shows the detailed algorithm performance metrics for each activity. Running, sitting, and falling reached the best precision out of all activities. The worst precision result occurred for the sitting activity. The best recall results were reached for running, standing, and fall activities. The worst recall and F1-score results occurred for walking and sitting activities.
The overall performance of the algorithm is presented in the last row of
Table 3. It shows that the percentage error rate is 8% and the percentage success rate is 92%. While the accuracy of the algorithm is relatively high, precision, recall, and F1-score reached 0.68.
Further experiments were performed with the RHMM algorithm to analyze the recognition rate of activities in a case where all activities are modeled with a single HMM, e.g., one state of HMM represents one activity. Six different activities—standing, sitting, laying, walking, walking downstairs, walking upstairs—were chosen for this experiment. Laying on the floor and falling activities were left out because of the insufficient number of observations in the dataset. The confusion matrix of the proposed method was calculated (see
Table 4).
Table 4 shows that more than 90% of standing and walking upstairs instances were correctly recognized. Walking downstairs was correctly recognized 80%. Laying and walking are above 70%, whereas sitting activity has the lowest recognition rate among all activities, at 69%. Further study showed that sitting and laying are often confused. The same applies for standing and sitting. However, activities of standing, sitting, and laying are well discriminated from walking, walking downstairs, and walking upstairs.
The computational time needed for the first and the second part of the algorithm to process one observation vector in the five-state HMM model was collected. The first part of the algorithm performs initial model training, whereas the second part performs recognition and parameter re-estimation. Experiments were conducted on Matlab with an Acer computer with Intel(R) Core(TM) i7-9750H CPU @ 2.60 GHz 2.59 GHz processor and 16.0 GB RAM. Computational time (in seconds) is given in
Table 5. It shows the computational time’s dependency on dimensions of observation. We can see that there is a small increase (around 1 millisecond) in computational time when dimensions of observation increase. Secondly, it is obvious that the second part of the algorithm is taking more time to process the observation than the first part because not only does it re-estimate the model parameters, but it also classifies the observation to one of the activities.
The proposed online activity recognition system is adaptable because it would allow users to train the system in real-time to meet their specific needs. It is important because different users may walk, run, or climb differently than others. The same behavior cannot be applied by generalizing it to all users because models trained offline are dependent on users on whom the training data were collected as well as tested. It can have an impact on how well the system can recognize human activities in real-life situations. This problem can be solved by the proposed online algorithm, which adapts to new situations.
For future research, we propose making a resource consumption analysis like CPU, memory, and battery usage, for an algorithm implemented in a smartphone. It is significant because the proposed algorithm does not merely make a classification on-the-fly but is also updating model parameters. It would be a key factor in deciding whether or not this algorithm could be implemented on smartphones.
It is apparent that confusion between some activities results in lower performance metrics. The experiments of activity modeling with four- to seven-state HMMs showed that a bigger state number resulted in a higher recognition rate. It might be useful to research modeling different activities with a different number of states because simple activities might need fewer state numbers than more complex ones.




{kind=link}