Small Language Models for Speech Emotion Recognition in Text and Audio Modalities

 ,
,  , ,
, ,  and
and 
Abstract
1. Introduction
- The performance of popular fine-tuned SLMs for speaker-independent SER is evaluated on a public benchmark dataset.
- The effect of incorporating contextual information (previous utterance) on model performance is investigated.
- Ensemble architectures for unimodal and bimodal SER are developed and tested.
2. Related Work
2.1. Architectures of SLMs
2.1.1. Encoder-Only Models
- RoBERTa [27]: Uses an optimized BERT training procedure by adjusting the hyperparameters, eliminating the next sentence prediction task, and using mini-batches and higher learning rates during training.
- ERNIE 2.0 [28]: Improves language understanding by integrating external knowledge sources during training and using knowledge masking to improve semantic understanding.
- ALBERT v2 [29]: Splits the embedding matrix into two smaller matrices and uses repeated layers split into groups to reduce the number of trainable parameters and increase training speed.
- DeBERTaV3 [30]: Uses disentangled attention, an improved mask decoder, and ELECTRA-style pre-training with gradient disentangled embedding sharing for improved performance over BERT and RoBERTa.
2.1.2. Decoder-Only Models
- GPT-2 [34]: Second version of OpenAI’s GPT model. The model’s architecture is built by stacking multiple transformer decoder blocks composed of self-attention and linear layers.
- GPT Neo [35]: Trained on a larger dataset, it uses a similar architecture to GPT-2, but differs by using local attention in a different layer with a window size of 256 tokens.
- Pythia [36]: Uses a similar architecture to the previous ones, optimized for scalability. This model features changes from GPT-2, such as the use of rotary embeddings instead of positional embeddings.
- OPT [37]: Uses an architecture similar to GPT, but optimized for efficiency. Some versions of this model achieve accuracy comparable to GPT-3 on various NLP tasks, with a substantially lower carbon footprint during training.
- XLNet [38]: Introduces a permutation approach to an auto-regressive model, allowing it to learn bidirectional context without the need to mask tokens during training, as is done in BERT-like models.
2.1.3. Encoder-Decoder Models
2.2. SLMs for SER
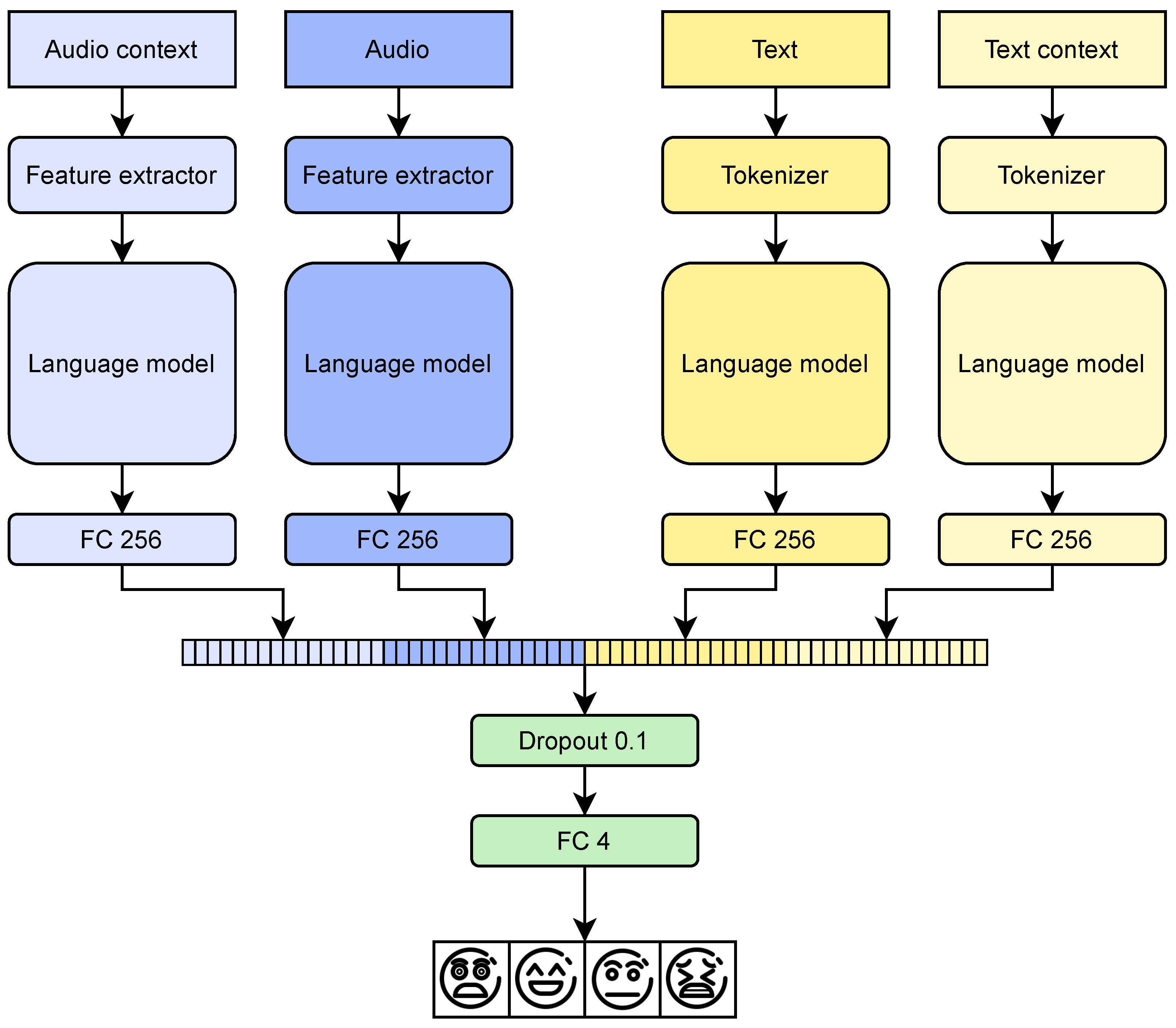
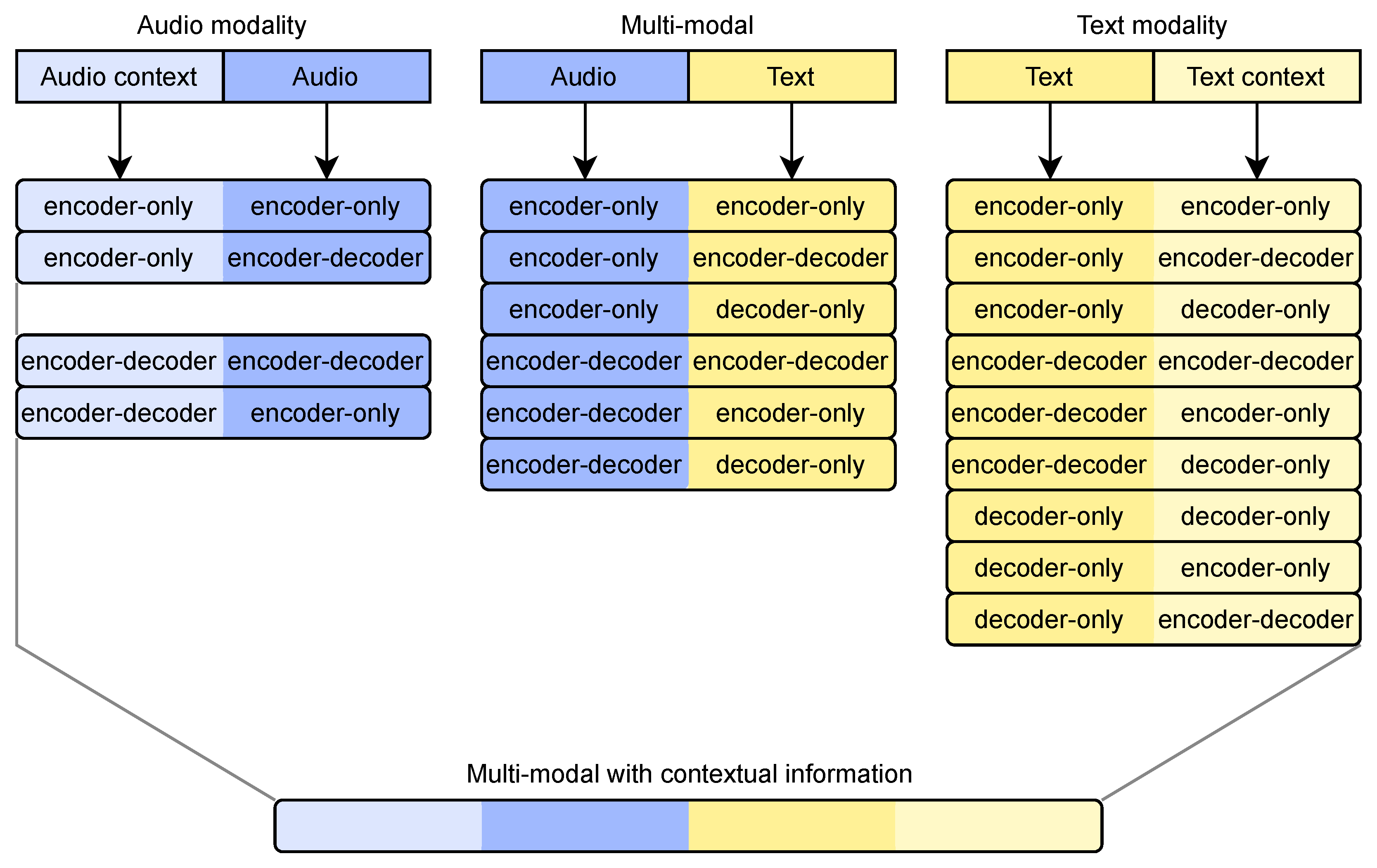
3. Materials and Methods
3.1. Dataset
3.2. Language Models
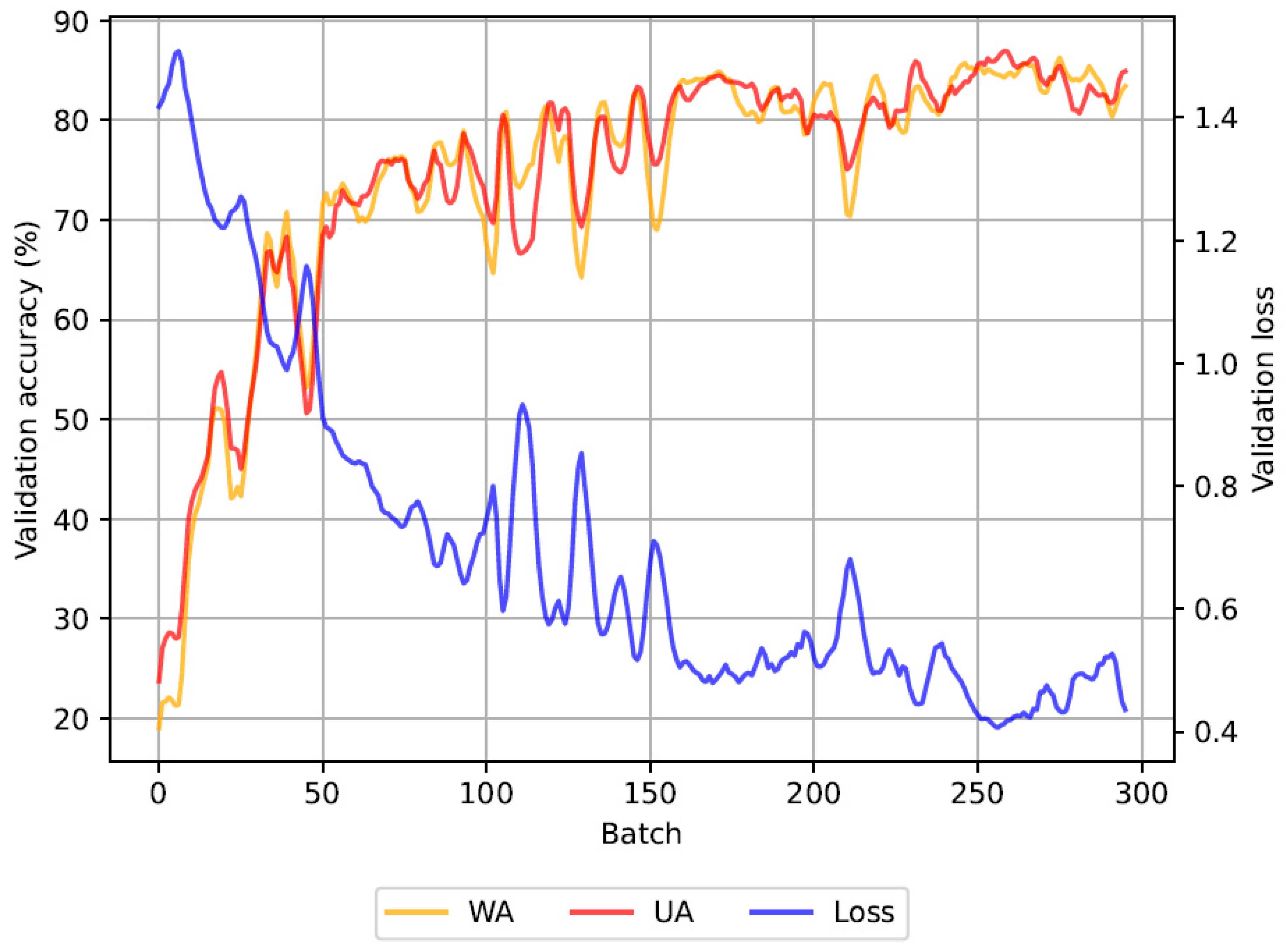
3.3. Experimental Setup
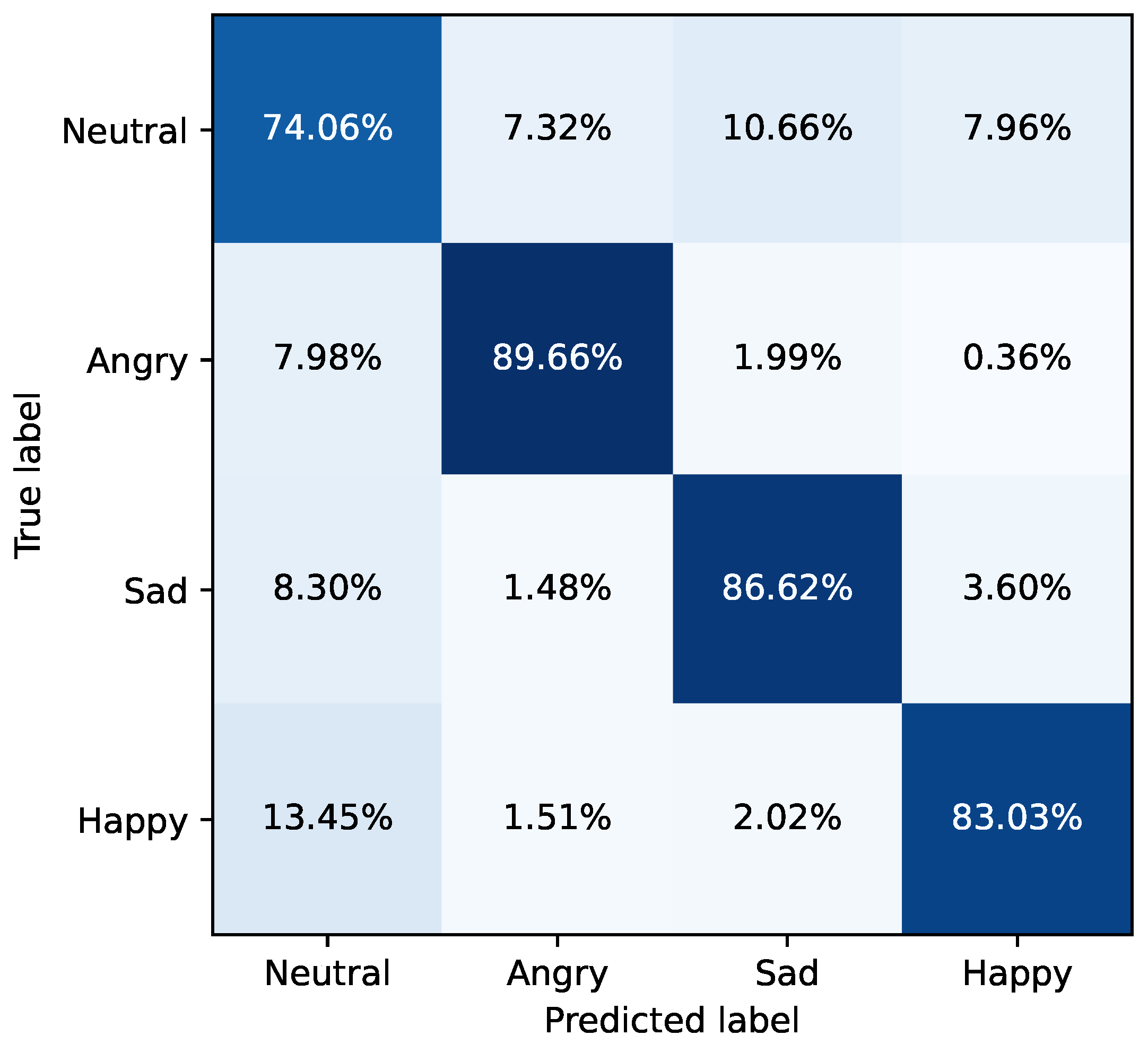
4. Results
4.1. Baseline Architectures
4.2. Ensemble Models
4.3. Comparison with Previous Works
5. Discussion
Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Majkowski, A.; Kołodziej, M. Emotion Recognition from Speech in a Subject-Independent Approach. Appl. Sci. 2025, 15, 6958. [Google Scholar] [CrossRef]
- Thiripurasundari, D.; Bhangale, K.; Aashritha, V.; Mondreti, S.; Kothandaraman, M. Speech emotion recognition for human–computer interaction. Int. J. Speech Technol. 2024, 27, 817–830. [Google Scholar] [CrossRef]
- Grágeda, N.; Busso, C.; Alvarado, E.; García, R.; Mahu, R.; Huenupan, F.; Yoma, N.B. Speech emotion recognition in real static and dynamic human-robot interaction scenarios. Comput. Speech Lang. 2025, 89, 101666. [Google Scholar] [CrossRef]
- Sigona, F.; Radicioni, D.P.; Gili Fivela, B.; Colla, D.; Delsanto, M.; Mensa, E.; Bolioli, A.; Vigorelli, P. A computational analysis of transcribed speech of people living with dementia: The Anchise 2022 Corpus. Comput. Speech Lang. 2025, 89, 101691. [Google Scholar] [CrossRef]
- Wang, Y.; Pan, K.; Shao, Y.; Ma, J.; Li, X. Applying a Convolutional Vision Transformer for Emotion Recognition in Children with Autism: Fusion of Facial Expressions and Speech Features. Appl. Sci. 2025, 15, 3083. [Google Scholar] [CrossRef]
- Xie, Y.; Yang, L.; Zhang, M.; Chen, S.; Li, J. A Review of Multimodal Interaction in Remote Education: Technologies, Applications, and Challenges. Appl. Sci. 2025, 15, 3937. [Google Scholar] [CrossRef]
- Vyakaranam, A.; Maul, T.; Ramayah, B. A review on speech emotion recognition for late deafened educators in online education. Int. J. Speech Technol. 2024, 27, 29–52. [Google Scholar] [CrossRef]
- Ülgen Sönmez, Y.; Varol, A. In-depth investigation of speech emotion recognition studies from past to present –The importance of emotion recognition from speech signal for AI–. Intell. Syst. Appl. 2024, 22, 200351. [Google Scholar] [CrossRef]
- Hazmoune, S.; Bougamouza, F. Using transformers for multimodal emotion recognition: Taxonomies and state of the art review. Eng. Appl. Artif. Intell. 2024, 133, 108339. [Google Scholar] [CrossRef]
- Mares, A.; Diaz-Arango, G.; Perez-Jacome-Friscione, J.; Vazquez-Leal, H.; Hernandez-Martinez, L.; Huerta-Chua, J.; Jaramillo-Alvarado, A.F.; Dominguez-Chavez, A. Advancing Spanish Speech Emotion Recognition: A Comprehensive Benchmark of Pre-Trained Models. Appl. Sci. 2025, 15, 4340. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 15 December 2024).
- Raiaan, M.A.K.; Mukta, M.S.H.; Fatema, K.; Fahad, N.M.; Sakib, S.; Mim, M.M.J.; Ahmad, J.; Ali, M.E.; Azam, S. A Review on Large Language Models: Architectures, Applications, Taxonomies, Open Issues and Challenges. IEEE Access 2024, 12, 26839–26874. [Google Scholar] [CrossRef]
- Zhu, X.; Li, J.; Liu, Y.; Ma, C.; Wang, W. Distilling mathematical reasoning capabilities into Small Language Models. Neural Netw. 2024, 179, 106594. [Google Scholar] [CrossRef]
- Roh, J.; Kim, M.; Bae, K. Towards a small language model powered chain-of-reasoning for open-domain question answering. ETRI J. 2024, 46, 11–21. [Google Scholar] [CrossRef]
- Jovanović, M.; Campbell, M. Compacting AI: In Search of the Small Language Model. Computer 2024, 57, 96–100. [Google Scholar] [CrossRef]
- Oralbekova, D.; Mamyrbayev, O.; Othman, M.; Kassymova, D.; Mukhsina, K. Contemporary Approaches in Evolving Language Models. Appl. Sci. 2023, 13, 12901. [Google Scholar] [CrossRef]
- Zafrir, O.; Boudoukh, G.; Izsak, P.; Wasserblat, M. Q8BERT: Quantized 8Bit BERT. In Proceedings of the Fifth Workshop on Energy Efficient Machine and Cognitive Computing-NeurIPS Edition (EMC2-NIPS), Vancouver, BC, Canada, 13 December 2019; pp. 36–39. [Google Scholar] [CrossRef]
- Goswami, J.; Prajapati, K.K.; Saha, A.; Saha, A.K. Parameter-efficient fine-tuning large language model approach for hospital discharge paper summarization. Appl. Soft Comput. 2024, 157, 111531. [Google Scholar] [CrossRef]
- Pan, B.; Hirota, K.; Jia, Z.; Dai, Y. A review of multimodal emotion recognition from datasets, preprocessing, features, and fusion methods. Neurocomputing 2023, 561, 126866. [Google Scholar] [CrossRef]
- Atmaja, B.T.; Sasou, A.; Akagi, M. Survey on bimodal speech emotion recognition from acoustic and linguistic information fusion. Speech Commun. 2022, 140, 11–28. [Google Scholar] [CrossRef]
- Gan, C.; Zheng, J.; Zhu, Q.; Cao, Y.; Zhu, Y. A survey of dialogic emotion analysis: Developments, approaches and perspectives. Pattern Recognit. 2024, 156, 110794. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv 2020, arXiv:2006.11477. [Google Scholar] [CrossRef]
- Qian, T.; Xie, A.; Bruckmann, C. Sensitivity Analysis on Transferred Neural Architectures of BERT and GPT-2 for Financial Sentiment Analysis. arXiv 2022, arXiv:2207.03037. [Google Scholar] [CrossRef]
- Dhiman, P.; Kaur, A.; Gupta, D.; Juneja, S.; Nauman, A.; Muhammad, G. GBERT: A hybrid deep learning model based on GPT-BERT for fake news detection. Heliyon 2024, 10, e35865. [Google Scholar] [CrossRef]
- Devathasan, K.; Arony, N.N.; Gama, K.; Damian, D. Deciphering Empathy in Developer Responses: A Hybrid Approach Utilizing the Perception Action Model and Automated Classification. In Proceedings of the IEEE 32nd International Requirements Engineering Conference Workshops (REW), Reykjavik, Iceland, 24–25 June 2024; pp. 88–94. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. ERNIE 2.0: A Continual Pre-training Framework for Language Understanding. arXiv 2019, arXiv:1907.12412. [Google Scholar] [CrossRef]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv 2019, arXiv:1909.11942. [Google Scholar] [CrossRef]
- He, P.; Gao, J.; Chen, W. DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing. arXiv 2021, arXiv:2111.09543. [Google Scholar] [CrossRef]
- Hsu, W.N.; Bolte, B.; Tsai, Y.H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. arXiv 2021, arXiv:2106.07447. [Google Scholar] [CrossRef]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing. arXiv 2021, arXiv:2110.13900. [Google Scholar] [CrossRef]
- Wu, F.; Kim, K.; Pan, J.; Han, K.; Weinberger, K.Q.; Artzi, Y. Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition. arXiv 2021, arXiv:2109.06870. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. 2019. Available online: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf (accessed on 15 December 2024).
- Black, S.; Gao, L.; Wang, P.; Leahy, C.; Biderman, S. GPT-Neo: Large Scale Autoregressive Language Modeling with Meshtensorflow; Version v1.1.1; Zenodo: Geneva, Switzerland, 2021. [Google Scholar] [CrossRef]
- Biderman, S.; Schoelkopf, H.; Anthony, Q.; Bradley, H.; O’Brien, K.; Hallahan, E.; Khan, M.A.; Purohit, S.; Prashanth, U.S.; Raff, E.; et al. Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling. arXiv 2023, arXiv:2304.01373. [Google Scholar] [CrossRef]
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X.V.; et al. OPT: Open Pre-trained Transformer Language Models. arXiv 2022, arXiv:2205.01068. [Google Scholar] [CrossRef]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar] [CrossRef]
- Ghadimi, A.; Beigy, H. Hybrid multi-document summarization using pre-trained language models. Expert Syst. Appl. 2022, 192, 116292. [Google Scholar] [CrossRef]
- Dharrao, D.; Mishra, M.; Kazi, A.; Pangavhane, M.; Pise, P.; Bongale, A.M. Summarizing Business News: Evaluating BART, T5, and PEGASUS for Effective Information Extraction. Rev. Intell. Artif. 2024, 38, 847–855. [Google Scholar] [CrossRef]
- Rahman, A.B.S.; Ta, H.T.; Najjar, L.; Azadmanesh, A.; Gönul, A.S. DepressionEmo: A novel dataset for multilabel classification of depression emotions. J. Affect. Disord. 2024, 366, 445–458. [Google Scholar] [CrossRef]
- Ao, J.; Wang, R.; Zhou, L.; Wang, C.; Ren, S.; Wu, Y.; Liu, S.; Ko, T.; Li, Q.; Zhang, Y.; et al. SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing. arXiv 2021, arXiv:2110.07205. [Google Scholar] [CrossRef]
- Wang, C.; Tang, Y.; Ma, X.; Wu, A.; Popuri, S.; Okhonko, D.; Pino, J. fairseq S2T: Fast Speech-to-Text Modeling with fairseq. arXiv 2020, arXiv:2010.05171. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv 2022, arXiv:2212.04356. [Google Scholar] [CrossRef]
- Zou, S.; Huang, X.; Shen, X.; Liu, H. Improving multimodal fusion with Main Modal Transformer for emotion recognition in conversation. Knowl.-Based Syst. 2022, 258, 109978. [Google Scholar] [CrossRef]
- Ho, N.H.; Yang, H.J.; Kim, S.H.; Lee, G. Multimodal Approach of Speech Emotion Recognition Using Multi-Level Multi-Head Fusion Attention-Based Recurrent Neural Network. IEEE Access 2020, 8, 61672–61686. [Google Scholar] [CrossRef]
- Pepino, L.; Riera, P.; Ferrer, L.; Gravano, A. Fusion Approaches for Emotion Recognition from Speech Using Acoustic and Text-Based Features. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6484–6488. [Google Scholar] [CrossRef]
- Kumar, P.; Kaushik, V.; Raman, B. Towards the Explainability of Multimodal Speech Emotion Recognition. In Proceedings of the 22nd Annual Conference of the International Speech Communication Association, Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 1748–1752. [Google Scholar] [CrossRef]
- Setyono, J.C.; Zahra, A. Data augmentation and enhancement for multimodal speech emotion recognition. Bul. Electr. Eng. Inform. 2023, 12, 3008–3015. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, G.; Okada, S.; Wang, L.; Zhao, B.; Dang, J. MBCFNet: A Multimodal Brain–Computer Fusion Network for human intention recognition. Knowl.-Based Syst. 2024, 296, 111826. [Google Scholar] [CrossRef]
- Furutani, J.; Kang, X.; Kiuchi, K.; Nishimura, R.; Sasayama, M.; Matsumoto, K. Learning a Bimodal Emotion Recognition System Based on Small Amount of Speech Data. In Proceedings of the 8th International Conference on Systems and Informatics (ICSAI), Kunming, China, 10–12 December 2022; Volume E602, pp. 1–5. [Google Scholar] [CrossRef]
- Triantafyllopoulos, A.; Reichel, U.; Liu, S.; Huber, S.; Eyben, F.; Schuller, B.W. Multistage linguistic conditioning of convolutional layers for speech emotion recognition. Front. Comput. Sci. 2023, 5, 107247. [Google Scholar] [CrossRef]
- Tan, L.; Yu, K.; Lin, L.; Cheng, X.; Srivastava, G.; Lin, J.C.W.; Wei, W. Speech Emotion Recognition Enhanced Traffic Efficiency Solution for Autonomous Vehicles in a 5G-Enabled Space–Air–Ground Integrated Intelligent Transportation System. IEEE Trans. Intell. Transp. Syst. 2022, 23, 2830–2842. [Google Scholar] [CrossRef]
- Asiya, U.A.; Kiran, V.K. A Novel Multimodal Speech Emotion Recognition System. In Proceedings of the Third International Conference on Intelligent Computing Instrumentation and Control Technologies (ICICICT), Kannur, India, 11–12 August 2022; pp. 327–332. [Google Scholar] [CrossRef]
- Braunschweiler, N.; Doddipatla, R.; Keizer, S.; Stoyanchev, S. Factors in Emotion Recognition With Deep Learning Models Using Speech and Text on Multiple Corpora. IEEE Signal Process. Lett. 2022, 29, 722–726. [Google Scholar] [CrossRef]
- Chauhan, K.; Sharma, K.K.; Varma, T. Multimodal Emotion Recognition Using Contextualized Audio Information and Ground Transcripts on Multiple Datasets. Arab. J. Sci. Eng. 2023, 49, 11871–11881. [Google Scholar] [CrossRef]
- Han, T.; Zhang, Z.; Ren, M.; Dong, C.; Jiang, X.; Zhuang, Q. Text Emotion Recognition Based on XLNet-BiGRU-Att. Electronics 2023, 12, 2704. [Google Scholar] [CrossRef]
- Li, Z.; Lin, T.E.; Wu, Y.; Liu, M.; Tang, F.; Zhao, M.; Li, Y. UniSA: Unified Generative Framework for Sentiment Analysis. In Proceedings of the MM ’23: 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; Volume 30, pp. 6132–6142. [Google Scholar] [CrossRef]
- Xie, B.; Sidulova, M.; Park, C.H. Robust Multimodal Emotion Recognition from Conversation with Transformer-Based Crossmodality Fusion. Sensors 2021, 21, 4913. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Zhang, T.; Ananiadou, S. Disentangled Variational Autoencoder for Emotion Recognition in Conversations. IEEE Trans. Affect. Comput. 2024, 15, 508–518. [Google Scholar] [CrossRef]
- Sun, C.; Zhou, Y.; Huang, X.; Yang, J.; Hou, X. Combining wav2vec 2.0 Fine-Tuning and ConLearnNet for Speech Emotion Recognition. Electronics 2024, 13, 1103. [Google Scholar] [CrossRef]
- Jo, J.; Kim, S.K.; Yoon, Y.-c. Text and Sound-Based Feature Extraction and Speech Emotion Classification for Korean. Int. J. Adv. Sci. Eng. Inf. Technol. 2024, 14, 873–879. [Google Scholar] [CrossRef]
- Pastor, M.A.; Ribas, D.; Ortega, A.; Miguel, A.; Lleida, E. Cross-Corpus Training Strategy for Speech Emotion Recognition Using Self-Supervised Representations. Appl. Sci. 2023, 13, 9062. [Google Scholar] [CrossRef]
- Naderi, N.; Nasersharif, B. Cross Corpus Speech Emotion Recognition using transfer learning and attention-based fusion of Wav2Vec2 and prosody features. Knowl.-Based Syst. 2023, 277, 110814. [Google Scholar] [CrossRef]
- Bautista, J.L.; Shin, H.S. Speech Emotion Recognition Model Based on Joint Modeling of Discrete and Dimensional Emotion Representation. Appl. Sci 2025, 15, 623. [Google Scholar] [CrossRef]
- Gladys A., A.; Vetriselvi, V. Sentiment analysis on a low-resource language dataset using multimodal representation learning and cross-lingual transfer learning. Appl. Soft Comput. 2024, 157, 111553. [Google Scholar] [CrossRef]
- O’Shaughnessy, D. Review of Automatic Estimation of Emotions in Speech. Appl. Sci. 2025, 15, 5731. [Google Scholar] [CrossRef]
- Yi, M.H.; Kwak, K.C.; Shin, J.H. HyFusER: Hybrid Multimodal Transformer for Emotion Recognition Using Dual Cross Modal Attention. Appl. Sci. 2025, 15, 1053. [Google Scholar] [CrossRef]
- Mustafa, H.H.; Darwish, N.R.; Hefny, H.A. Automatic Speech Emotion Recognition: A Systematic Literature Review. Int. J. Speech Technol. 2024, 27, 267–285. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Facebook AI Research. Fvcore Library. Available online: https://github.com/facebookresearch/fvcore/ (accessed on 2 February 2025).
- Kuncheva, L.I.; Whitaker, C.J. Measures of Diversity in Classifier Ensembles and Their Relationship with the Ensemble Accuracy. Mach. Learn. 2003, 51, 181–207. [Google Scholar] [CrossRef]
- Yan, Y.; Shen, X. Research on Speech Emotion Recognition Based on AA-CBGRU Network. Electronics 2022, 11, 1409. [Google Scholar] [CrossRef]
- Wen, G.; Liao, H.; Li, H.; Wen, P.; Zhang, T.; Gao, S.; Wang, B. Self-labeling with feature transfer for speech emotion recognition. Knowl.-Based Syst. 2022, 254, 109589. [Google Scholar] [CrossRef]
- Xu, X.; Li, D.; Zhou, Y.; Wang, Z. Multi-type features separating fusion learning for Speech Emotion Recognition. Appl. Soft Comput. 2022, 130, 109648. [Google Scholar] [CrossRef]
- Lu, C.; Zheng, W.; Lian, H.; Zong, Y.; Tang, C.; Li, S.; Zhao, Y. Speech Emotion Recognition via an Attentive Time–Frequency Neural Network. IEEE Trans. Comput. Soc. Syst. 2023, 10, 3159–3168. [Google Scholar] [CrossRef]
- Tellai, M.; Gao, L.; Mao, Q.; Abdelaziz, M. A novel conversational hierarchical attention network for speech emotion recognition in dyadic conversation. Multimed. Tools Appl. 2023, 83, 59699–59723. [Google Scholar] [CrossRef]
- Adel, O.; Fathalla, K.M.; Abo ElFarag, A. MM-EMOR: Multi-Modal Emotion Recognition of Social Media Using Concatenated Deep Learning Networks. Big Data Cogn. Comput. 2023, 7, 164. [Google Scholar] [CrossRef]
- Sun, D.; He, Y.; Han, J. Using Auxiliary Tasks In Multimodal Fusion of Wav2vec 2.0 And Bert for Multimodal Emotion Recognition. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; Volume 30, pp. 1–5. [Google Scholar] [CrossRef]
- Tellai, M.; Mao, Q. CCTG-NET: Contextualized Convolutional Transformer-GRU Network for speech emotion recognition. Int. J. Speech Technol. 2023, 26, 1099–1116. [Google Scholar] [CrossRef]
- Hyeon, J.; Oh, Y.H.; Lee, Y.J.; Choi, H.J. Improving speech emotion recognition by fusing self-supervised learning and spectral features via mixture of experts. Data Knowl. Eng. 2024, 150, 102262. [Google Scholar] [CrossRef]
- Qu, L.; Li, T.; Weber, C.; Pekarek-Rosin, T.; Ren, F.; Wermter, S. Disentangling Prosody Representations With Unsupervised Speech Reconstruction. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 39–54. [Google Scholar] [CrossRef]
- Chen, W.; Xing, X.; Chen, P.; Xu, X. Vesper: A Compact and Effective Pretrained Model for Speech Emotion Recognition. IEEE Trans. Affect. Comput. 2024, 15, 1711–1724. [Google Scholar] [CrossRef]
- Zhang, S.; Feng, Y.; Ren, Y.; Guo, Z.; Yu, R.; Li, R.; Xing, P. Multi-Modal Emotion Recognition Based on Wavelet Transform and BERT-RoBERTa: An Innovative Approach Combining Enhanced BiLSTM and Focus Loss Function. Electronics 2024, 13, 3262. [Google Scholar] [CrossRef]
- Liu, K.; Wei, J.; Zou, J.; Wang, P.; Yang, Y.; Shen, H.T. Improving Pre-trained Model-based Speech Emotion Recognition from a Low-level Speech Feature Perspective. IEEE Trans. Multimed. 2024, 26, 10623–10636. [Google Scholar] [CrossRef]
- Lei, J.; Wang, J.; Wang, Y. Multi-level attention fusion network assisted by relative entropy alignment for multimodal speech emotion recognition. Appl. Intell. 2024, 54, 8478–8490. [Google Scholar] [CrossRef]
- Khan, M.; Gueaieb, W.; El Saddik, A.; Kwon, S. MSER: Multimodal speech emotion recognition using cross-attention with deep fusion. Expert Syst. Appl. 2024, 245, 122946. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, S.; Li, P. Improvement of Multimodal Emotion Recognition Based on Temporal-Aware Bi-Direction Multi-Scale Network and Multi-Head Attention Mechanisms. Appl. Sci. 2024, 14, 3276. [Google Scholar] [CrossRef]
- Song, Y.; Zhou, Q. Bi-Modal Bi-Task Emotion Recognition Based on Transformer Architecture. Appl. Artif. Intell. 2024, 38, 2356992. [Google Scholar] [CrossRef]
- Saleem, N.; Elmannai, H.; Bourouis, S.; Trigui, A. Squeeze-and-excitation 3D convolutional attention recurrent network for end-to-end speech emotion recognition. Appl. Soft Comput. 2024, 161, 111735. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Song, Y.; Li, Y.; Wang, S.; Yuan, W.; Li, Y.; Zhao, Z. Discriminative feature learning based on multi-view attention network with diffusion joint loss for speech emotion recognition. Eng. Appl. Artif. Intell. 2024, 137, 109219. [Google Scholar] [CrossRef]
- Lian, H.; Lu, C.; Chang, H.; Zhao, Y.; Li, S.; Li, Y.; Zong, Y. AMGCN: An adaptive multi-graph convolutional network for speech emotion recognition. Speech Commun. 2025, 168, 103184. [Google Scholar] [CrossRef]
- Qi, X.; Song, Q.; Chen, G.; Zhang, P.; Fu, Y. Acoustic Feature Excitation-and-Aggregation Network Based on Multi-Task Learning for Speech Emotion Recognition. Electronics 2025, 14, 844. [Google Scholar] [CrossRef]
- Jin, G.; Xu, Y.; Kang, H.; Wang, J.; Miao, B. DSTM: A transformer-based model with dynamic-static feature fusion in speech emotion recognition. Comput. Speech Lang. 2025, 90, 101733. [Google Scholar] [CrossRef]
- Khan, M.; Tran, P.N.; Pham, N.T.; El Saddik, A.; Othmani, A. MemoCMT: Multimodal emotion recognition using cross-modal transformer-based feature fusion. Sci. Rep. 2025, 15, 5473. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, C.; Wang, Z.; Zhao, C.; Lin, M.; Zheng, Q. MTLSER: Multi-task learning enhanced speech emotion recognition with pre-trained acoustic model. Expert Syst. Appl. 2025, 273, 126855. [Google Scholar] [CrossRef]
- Gómez-Sirvent, J.L.; López de la Rosa, F.; López, M.T.; Fernández-Caballero, A. Facial Expression Recognition in the Wild for Low-Resolution Images Using Voting Residual Network. Electronics 2023, 12, 3837. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Version | Modality | # Parameters | GFLOPs |
|---|---|---|---|---|
| ALBERT | v2-base | text | 11.69 | 8.70 |
| BERT | base | text | 109.49 | 8.50 |
| DeBERTa | v3-base | text | 184.43 | 16.88 |
| ERNIE | v2-base | text | 109.49 | 8.69 |
| RoBERTa | base | text | 124.65 | 8.69 |
| BART | base | text | 140.01 | 9.92 |
| T5 | base (encoder-only) | text | 109.63 | 17.72 |
| GPT-2 | 124m | text | 124.44 | 8.50 |
| GPT-Neo | 125m | text | 125.20 | 8.69 |
| OPT | 125m | text | 125.24 | 8.69 |
| Pythia | 160m | text | 123.69 | 8.50 |
| XLNet | base | text | 117.31 | 10.29 |
| HuBERT | base | audio | 94.37 | 69.61 |
| SEW | small | audio | 89.62 | 25.26 |
| WavLM | base | audio | 94.39 | 69.64 |
| Wav2Vec2 | base | audio | 94.37 | 69.61 |
| S2T | ASR-large (encoder-only) | audio | 156.81 | 40.83 |
| SpeechT5 | ASR (encoder-only) | audio | 94.40 | 76.49 |
| Whisper | small (encoder-only) | audio | 87.01 | 43.58 |
| Model | Architecture | Modality | WA (%) | UA (%) |
|---|---|---|---|---|
| ALBERT | encoder-only | text | 64.65 | 64.79 |
| BERT | encoder-only | text | 69.61 | 70.64 |
| DeBERTa | encoder-only | text | 69.80 | 70.60 |
| ERNIE | encoder-only | text | 68.11 | 69.67 |
| RoBERTa | encoder-only | text | 68.62 | 70.55 |
| BART | encoder-decoder | text | 69.16 | 70.23 |
| T5 | encoder-decoder | text | 66.20 | 67.52 |
| GPT-2 | decoder-only | text | 66.43 | 67.38 |
| GPT-Neo | decoder-only | text | 63.73 | 64.27 |
| OPT | decoder-only | text | 68.49 | 69.73 |
| Pythia | decoder-only | text | 64.31 | 65.97 |
| XLNet | decoder-only | text | 67.34 | 68.17 |
| HuBERT | encoder-only | audio | 68.85 | 66.99 |
| SEW | encoder-only | audio | 67.81 | 64.35 |
| WavLM | encoder-only | audio | 69.13 | 66.81 |
| Wav2Vec2 | encoder-only | audio | 71.56 | 68.73 |
| S2T | encoder-decoder | audio | 65.30 | 63.34 |
| SpeechT5 | encoder-decoder | audio | 67.83 | 68.07 |
| Whisper | encoder-decoder | audio | 72.95 | 72.82 |
| Utterance | Context | Modality | WA (%) | UA (%) |
|---|---|---|---|---|
| BERT | BERT | text | 75.83 | 78.38 |
| BERT | BART | text | 77.25 | 78.42 |
| BERT | OPT | text | 75.48 | 78.13 |
| BART | BART | text | 76.84 | 79.07 |
| BART | BERT | text | 75.47 | 78.32 |
| BART | OPT | text | 75.29 | 77.38 |
| OPT | OPT | text | 77.70 | 79.15 |
| OPT | BERT | text | 76.22 | 77.85 |
| OPT | BART | text | 76.92 | 78.68 |
| Wav2Vec2 | Wav2Vec2 | audio | 71.72 | 70.84 |
| Wav2Vec2 | Whisper | audio | 72.28 | 71.60 |
| Whisper | Whisper | audio | 76.86 | 76.31 |
| Whisper | Wav2Vec2 | audio | 75.73 | 75.17 |
| Audio Model | Text Model | WA (%) | UA (%) |
|---|---|---|---|
| Wav2Vec2 | BERT | 76.93 | 76.92 |
| Wav2Vec2 | BART | 75.36 | 75.99 |
| Wav2Vec2 | OPT | 76.11 | 75.79 |
| Whisper | BERT | 76.33 | 75.48 |
| Whisper | BART | 76.42 | 74.62 |
| Whisper | OPT | 79.06 | 78.05 |
| Audio | Text | WA (%) | UA (%) | ||
|---|---|---|---|---|---|
| Utterance | Context | Utterance | Context | ||
| ✓ | ✓ | ✓ | ✓ | 82.12 | 83.34 |
| ✓ | — | ✓ | ✓ | 81.84 | 82.76 |
| ✓ | ✓ | ✓ | — | 80.66 | 81.11 |
| ✓ | ✓ | — | — | 76.86 | 76.31 |
| — | — | ✓ | ✓ | 77.70 | 79.15 |
| ✓ | — | ✓ | – | 79.06 | 78.05 |
| Method | Year | WA (%) | UA (%) |
|---|---|---|---|
| AA-CBGRU [75] | 2022 | 72.8 | 67.8 |
| TFCNN + SL + Vggish [76] | 2022 | 73.0 | — |
| HD-MFM [77] | 2022 | 72.0 | 73.4 |
| ATFNN [78] | 2023 | 73.8 | 64.5 |
| Wav2Vec2 and prosody [66] | 2023 | 74.2 | 75.6 |
| CHAN [79] | 2023 | 75.0 | 75.9 |
| MM-EMOR [80] | 2023 | 77.9 | 77.1 |
| BERT + Wav2Vec2 + CA Aux [81] | 2023 | 78.3 | 79.6 |
| CCTG-NET [82] | 2023 | 88.4 | 89.1 |
| SSL-SF-MoE [83] | 2024 | 73.9 | 72.3 |
| Prosody2Vec + HuBERT Large [84] | 2024 | 72.4 | 73.3 |
| Vesper (Shiftformer) [85] | 2024 | 73.7 | 74.3 |
| BERT-RoBERTa BiLSTM [86] | 2024 | 74.0 | 74.3 |
| TsPCA [87] | 2024 | 74.0 | 74.6 |
| MAF network [88] | 2024 | 75.7 | 75.5 |
| MSER [89] | 2024 | 77.2 | 76.6 |
| Mul-TAB [90] | 2024 | 83.9 | 81.9 |
| Bi-modal Bi-task ERM [91] | 2024 | 82.3 | 83.0 |
| SE3D-CARN [92] | 2024 | 84.0 | 83.0 |
| MVAN [93] | 2024 | 86.9 | 86.6 |
| AMGCN [94] | 2025 | 74.3 | 65.1 |
| AFEA-Net [95] | 2025 | 75.1 | 75.3 |
| DSTM [96] | 2025 | 76.3 | 77.4 |
| MemoCMT [97] | 2025 | 81.9 | 81.3 |
| MTLSER [98] | 2025 | 82.6 | 82.2 |
| Whisper + OPT with context (Ours) | 2025 | 82.1 | 83.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gómez-Sirvent, J.L.; López de la Rosa, F.; Sánchez-Reolid, D.; Sánchez-Reolid, R.; Fernández-Caballero, A. Small Language Models for Speech Emotion Recognition in Text and Audio Modalities. Appl. Sci. 2025, 15, 7730. https://doi.org/10.3390/app15147730
Gómez-Sirvent JL, López de la Rosa F, Sánchez-Reolid D, Sánchez-Reolid R, Fernández-Caballero A. Small Language Models for Speech Emotion Recognition in Text and Audio Modalities. Applied Sciences. 2025; 15(14):7730. https://doi.org/10.3390/app15147730
Chicago/Turabian StyleGómez-Sirvent, José L., Francisco López de la Rosa, Daniel Sánchez-Reolid, Roberto Sánchez-Reolid, and Antonio Fernández-Caballero. 2025. "Small Language Models for Speech Emotion Recognition in Text and Audio Modalities" Applied Sciences 15, no. 14: 7730. https://doi.org/10.3390/app15147730
APA StyleGómez-Sirvent, J. L., López de la Rosa, F., Sánchez-Reolid, D., Sánchez-Reolid, R., & Fernández-Caballero, A. (2025). Small Language Models for Speech Emotion Recognition in Text and Audio Modalities. Applied Sciences, 15(14), 7730. https://doi.org/10.3390/app15147730