1. Introduction
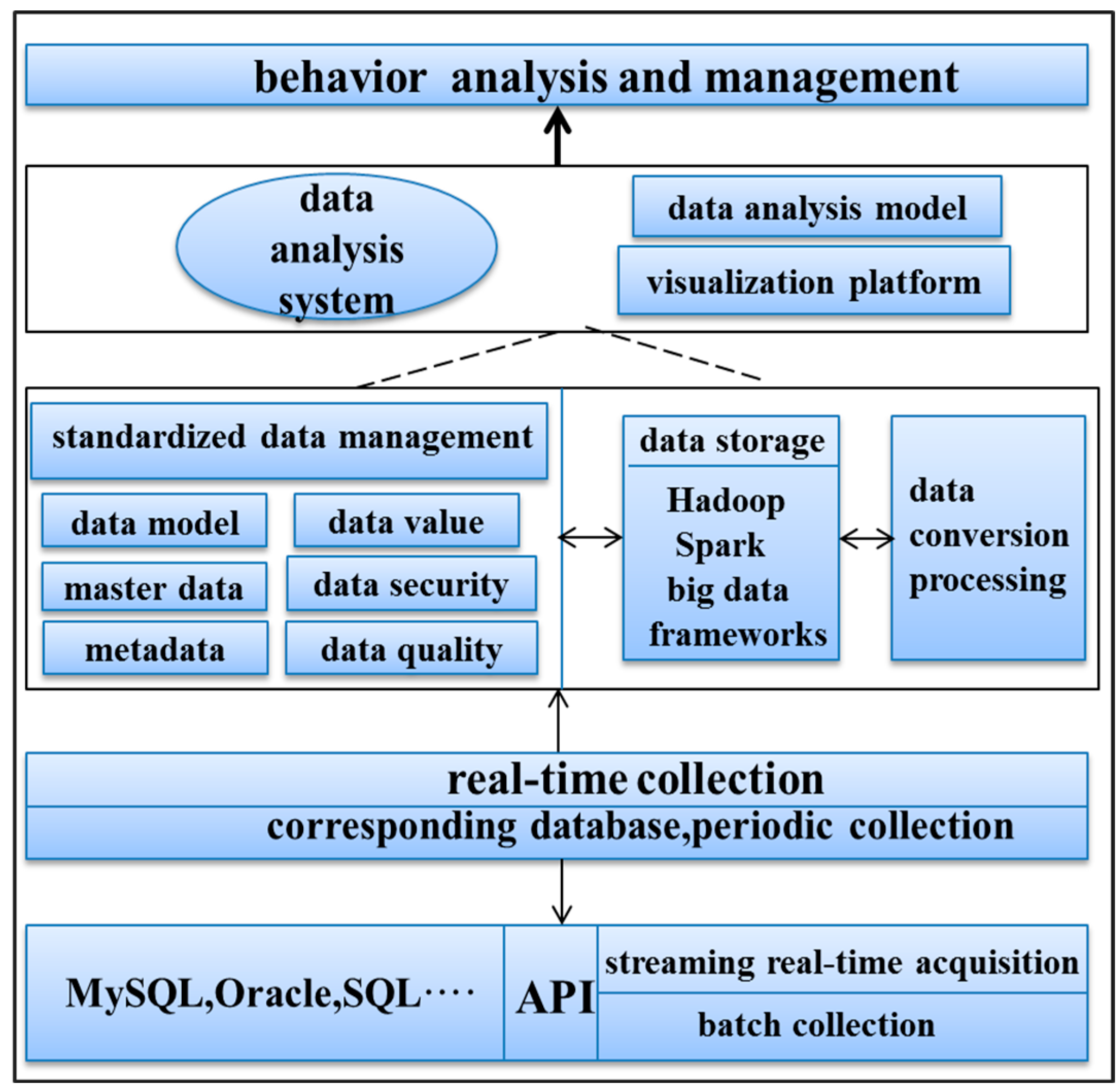
With the development of information technology, many higher education institutions have established information management and monitoring systems [
1]. Therefore, timely and effective mining of students’ behavioral characteristics has become particularly important. Student consumption data constitutes a vital component of university student datasets. As a branch of behavioral research in higher education, the analysis of student consumption behavior not only explores students’ dietary patterns and consumption levels but also provides references for evaluating financial aid. However, traditional campus management concepts and data analysis methods can no longer meet the growing demand for data processing. How to effectively manage and share campus data, optimize student management using data mining approaches, and provide students with clearer and more detailed data services has become challenges facing today’s campus service systems.
There have been preliminary studies on student consumption utilizing data mining technology both domestically and internationally. S. Fan employed the k-means clustering algorithm to analyze student consumption data based on two indicators: total consumption amount and average consumption amount. This study also explored the association between student behavior and academic performance [
2]. Jiang T. disaggregated the data, mined student consumption patterns, and analyzed the current status of canteen operations [
3]. J. A. Cook conducted behavioral profiling of college students using various data from universities, providing a comprehensive description of college students’ information from multiple dimensions. Through data mining techniques, a cluster analysis of these behavioral profiles was performed to uncover potential patterns in students’ academic and social lives [
4]. Chai Zheng analyzed students’ “One Card” consumption records to assess their spending levels, subsequently employing neural network-based data mining methods to identify at-risk students [
5]. X. Jiang utilized the forward and backward sequential pattern mining algorithm, “NegI-NSP,” to analyze students’ consumption data, establishing a correlation between consumption patterns and academic performance to examine their relationship [
6]. Yang. C. Y. proposed an early warning system for college student behavior using the Hadoop open-source platform [
7]. Traditional clustering analysis, specifically the k-means algorithm, has been used to mine large datasets on campus, studying students’ behavioral characteristics and patterns [
8,
9,
10,
11].
Most of the aforementioned studies have focused on analyzing student consumption behavior through clustering techniques [
12,
13,
14]. Clustering algorithms are a crucial aspect of data mining [
15]. The goal of clustering is to group objects in such a way that those within the same class exhibit greater similarity, while objects in different classes show greater dissimilarity. Common clustering methods include density-based [
16], model-based [
17], hierarchical [
18], and partitioning clustering [
19]. These algorithms have applications across various fields. For instance, evolutionary clustering algorithms like iECA* have proven effective for grouping medical diseases [
20]. To demonstrate how rider expertise affects postural coordination, Iman proposed a framework for automatically analyzing athlete behavior using cluster analysis [
21]. Hussain introduced a centrality-clustering method called UICPC, enhancing its effectiveness in identifying cellular groupings [
22]. Kamal developed a new version of spectral clustering named text-associated DeepWalk-Spectral Clustering (TADW-SC) for attributed networks, ensuring structural cohesiveness and attribute homogeneity among identified protein complexes [
23]. Chen proposed a novel method for predicting and classifying ventricular arrhythmias (VA), particularly fatal VA, before they occur [
24]. Some of the studies referenced above utilized supervised machine learning methods. However, since the number of student types is often unknown beforehand, unsupervised machine learning methods are necessary for clustering.
Among the various clustering algorithms, the k-means algorithm [
25,
26,
27] is widely used for analyzing student consumption behavior due to its speed, ease of understanding, and efficiency [
28]. However, traditional k-means has limitations, including a lack of flexibility with fixed weights, dependency on initial cluster centers, and the requirement for a pre-specified number of clusters (K). These limitations restrict the algorithm’s applicability. In recent years, various meta-heuristic algorithms have been proposed to optimize clustering algorithms, overcoming the shortcomings of k-means and achieving better results. Some of these meta-heuristics include the monarch butterfly optimization (MBO) algorithm [
29], the slime mold algorithm (SMA) based on the feeding behavior of slime molds [
30], the moth swarm algorithm (MSA) inspired by moth navigation toward moonlight [
31,
32], and the Harris hawks optimization (HHO) algorithm that simulates predatory behavior [
33]. The firefly algorithm, as a meta-heuristic clustering intelligence algorithm [
34], has garnered increasing attention from researchers since its inception. It boasts advantages such as a simple principle, clear process, and ease of implementation, and has been successfully applied in fields like image processing, computer networks, and engineering design [
35,
36,
37]. Lin proposed a fuzzy clustering method based on the firefly algorithm to enhance clustering accuracy [
38]. Zhou applied the firefly algorithm to determine the insulation levels of DC transmission lines, improving the insulation of UHV DC lines [
39]. Wang developed a traffic signal timing optimization method based on the firefly algorithm, effectively reducing emissions at intersections [
40]. However, the firefly algorithm typically relies on previous memory during its search process. To address the issue of local optima, the introduction of fractional-order memory—based on the properties of memory and genetic processes—has been suggested. This paper employs a fractional-order firefly-optimized k-means clustering algorithm to enhance clustering performance effectively.
The main contributions and innovations of this paper are as follows:
(1) The proposed methodology involves the utilization of a clustering algorithm for the analysis of students’ spending patterns. In comparison with the conventional statistical behavior analysis model, this clustering-based approach has the capacity to reduce the impact of human factors and thereby facilitate the more objective identification of students in need of financial aid.
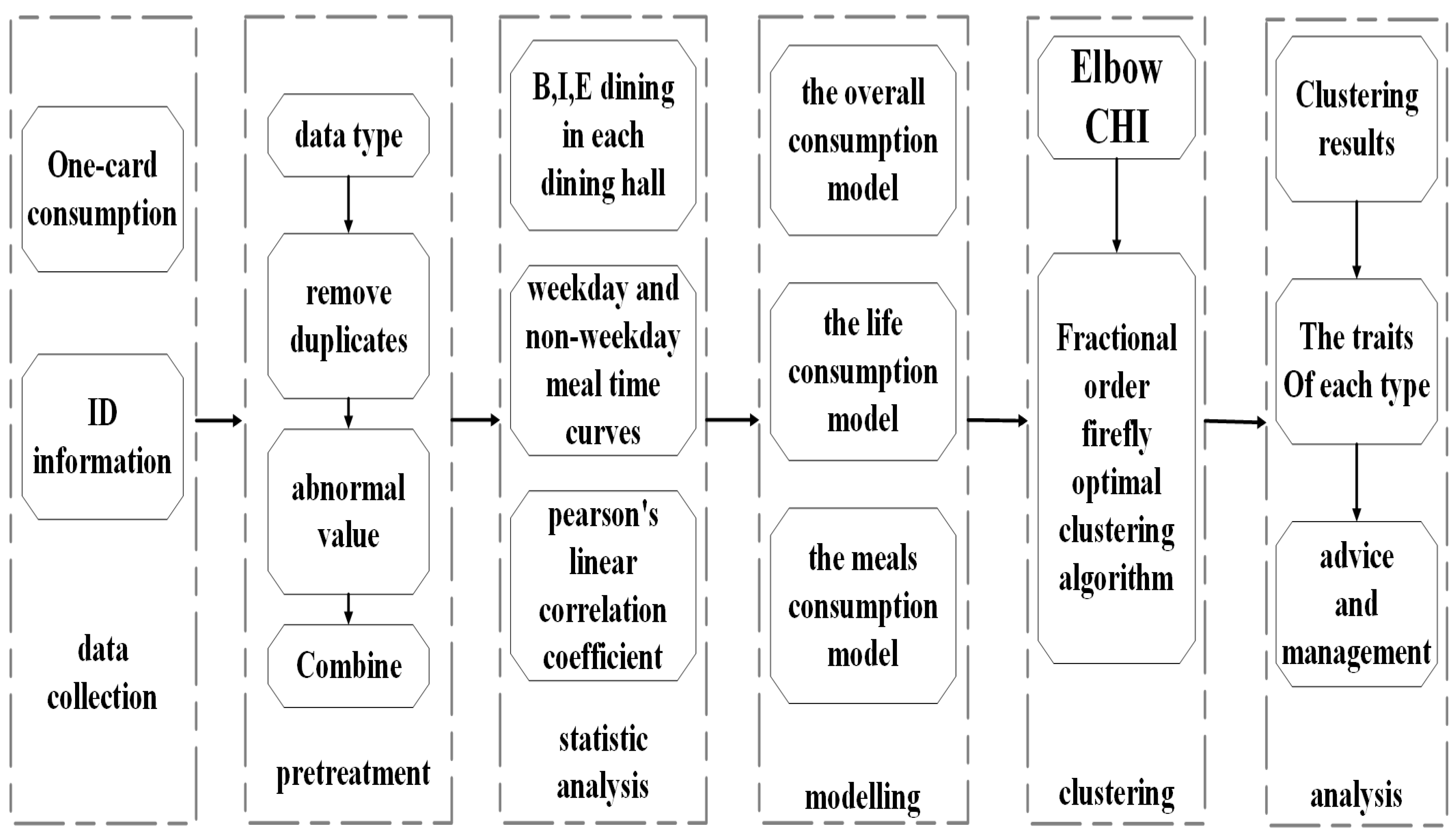
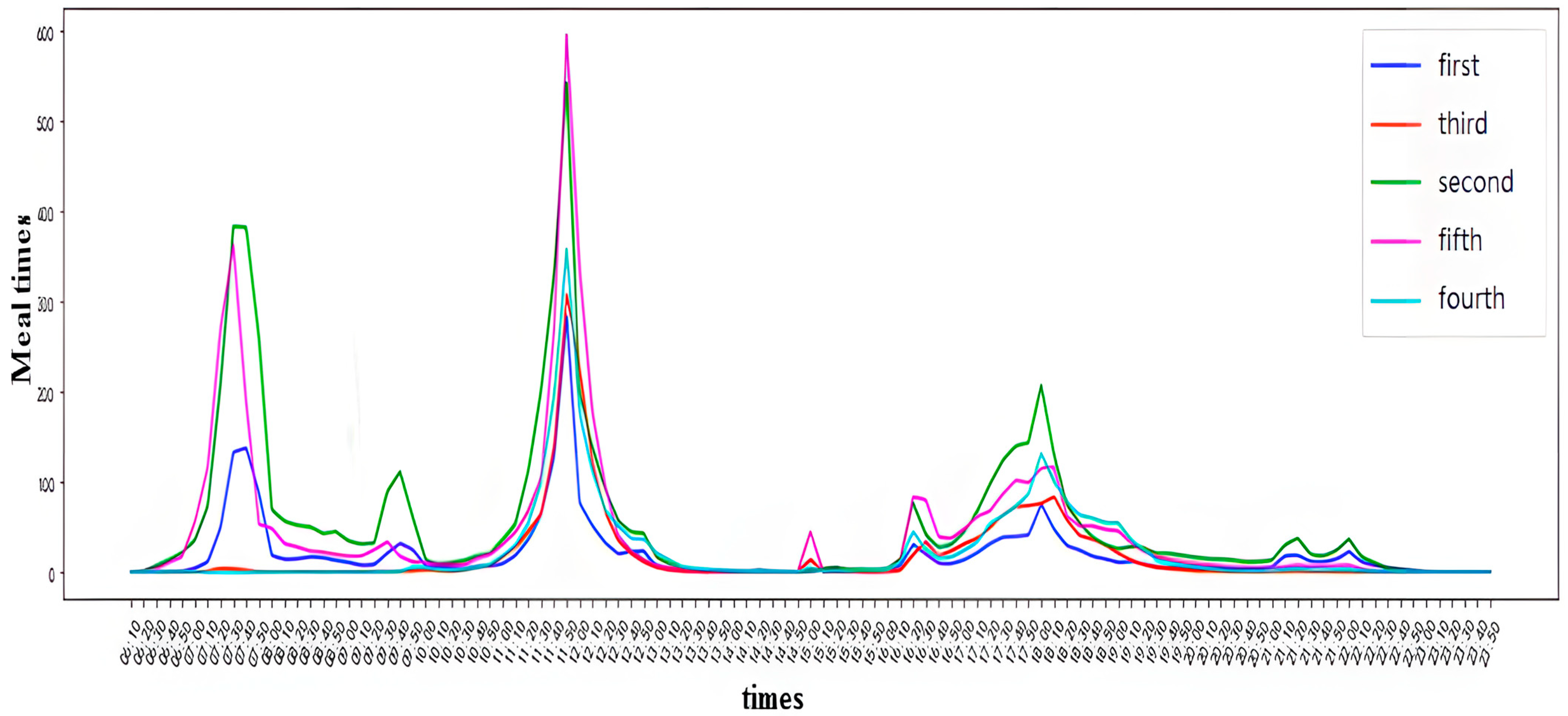
(2) We proposed three models: the overall consumption model, the living diet model, and the average consumption model for morning, lunch, and dinner. These models seek to evaluate students’ consumption levels by leveraging data from the university’s digital system, thereby offering a more comprehensive representation of their consumption patterns.
(3) In order to address the issues inherent to the k-means algorithm, namely the challenges associated with determining the optimal number of student clusters and the random allocation of cluster centers, a methodology is proposed that utilizes the elbow rule and the Calinski–Harabasz index to determine the number of clusters. Concurrently, the fractional-order firefly algorithm is employed to select the initial cluster centers. This approach has been demonstrated to be effective in addressing the issue of the algorithm’s sensitivity to the initial value and its susceptibility to local optimization. In comparison with the conventional k-means algorithm, the proposed method facilitates more rational clustering.
(4) Based on the aforementioned models, we conduct a comprehensive analysis of students’ consumption characteristics. The experimental findings have significant practical implications, assisting college administrative personnel in enhancing their operational efficiency. Furthermore, these results provide reliable data for colleges to accurately assess students’ economic situations and inform decisions regarding grant allocations. This approach elevates the scientific rigor and precision of targeted poverty alleviation initiatives within universities, ensuring that resources are effectively distributed to those in genuine need.
The remainder of this paper is organized as follows: In
Section 2, we provide an overview of related work, outline the proposed general objectives, and present the framework and flowchart.
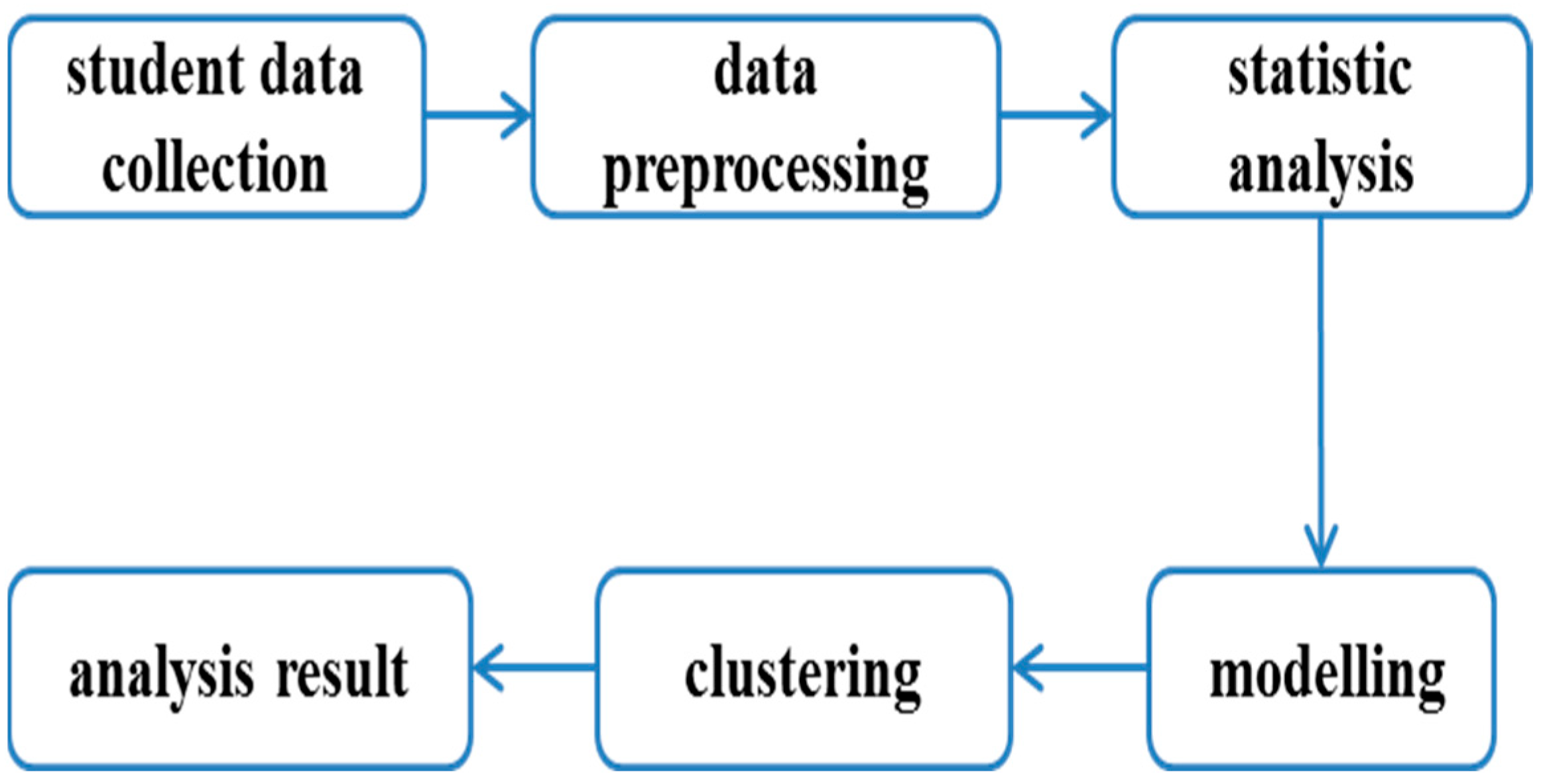
Section 3 details the specific process of analyzing students’ consumption behavior, offering step-by-step instructions for the analysis. In
Section 4, we present and discuss the experimental results, examining them from multiple perspectives. Finally, we summarize the work performed, highlight the main findings and contributions, and propose potential directions for future research.
4. Experiment Result and Analysis
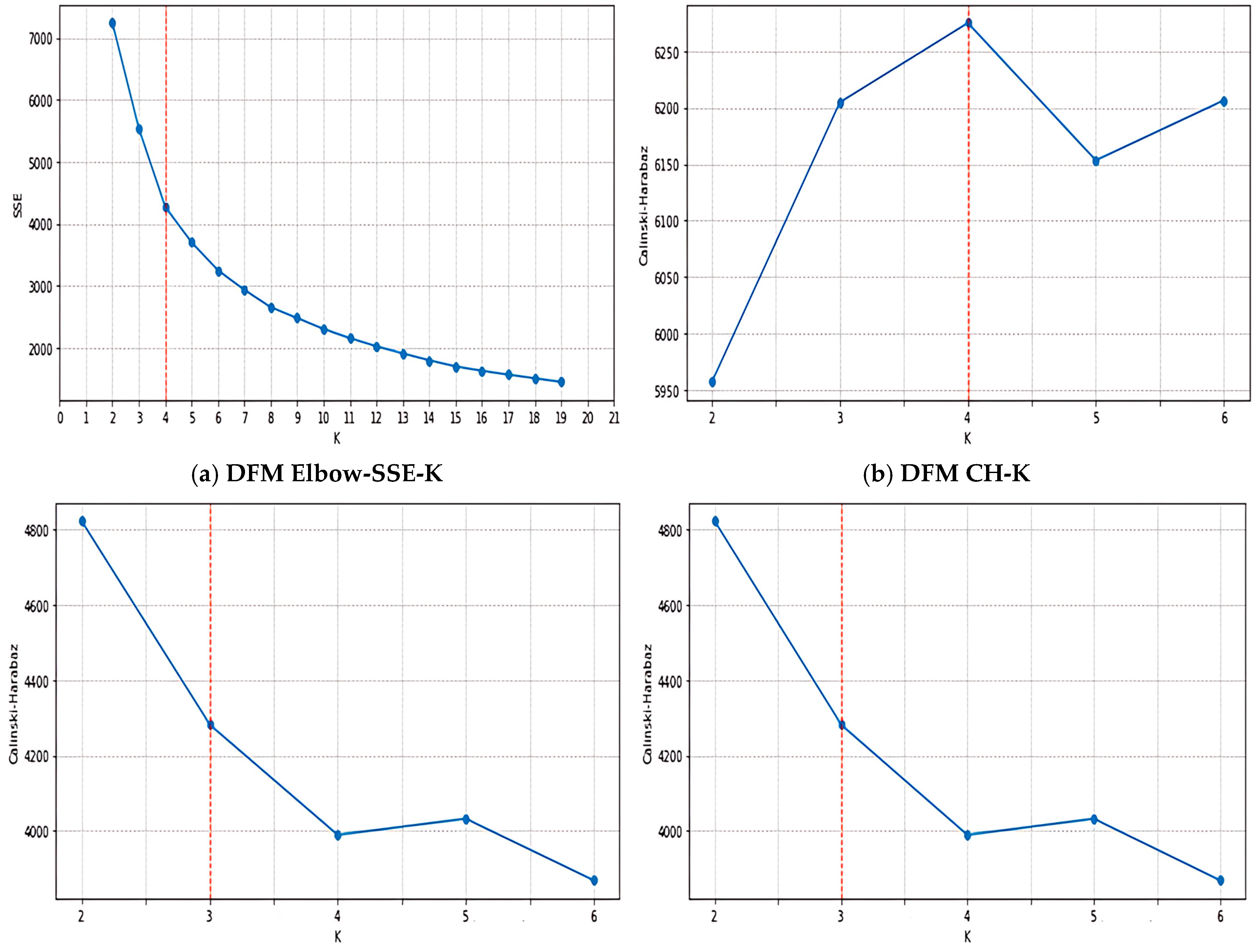
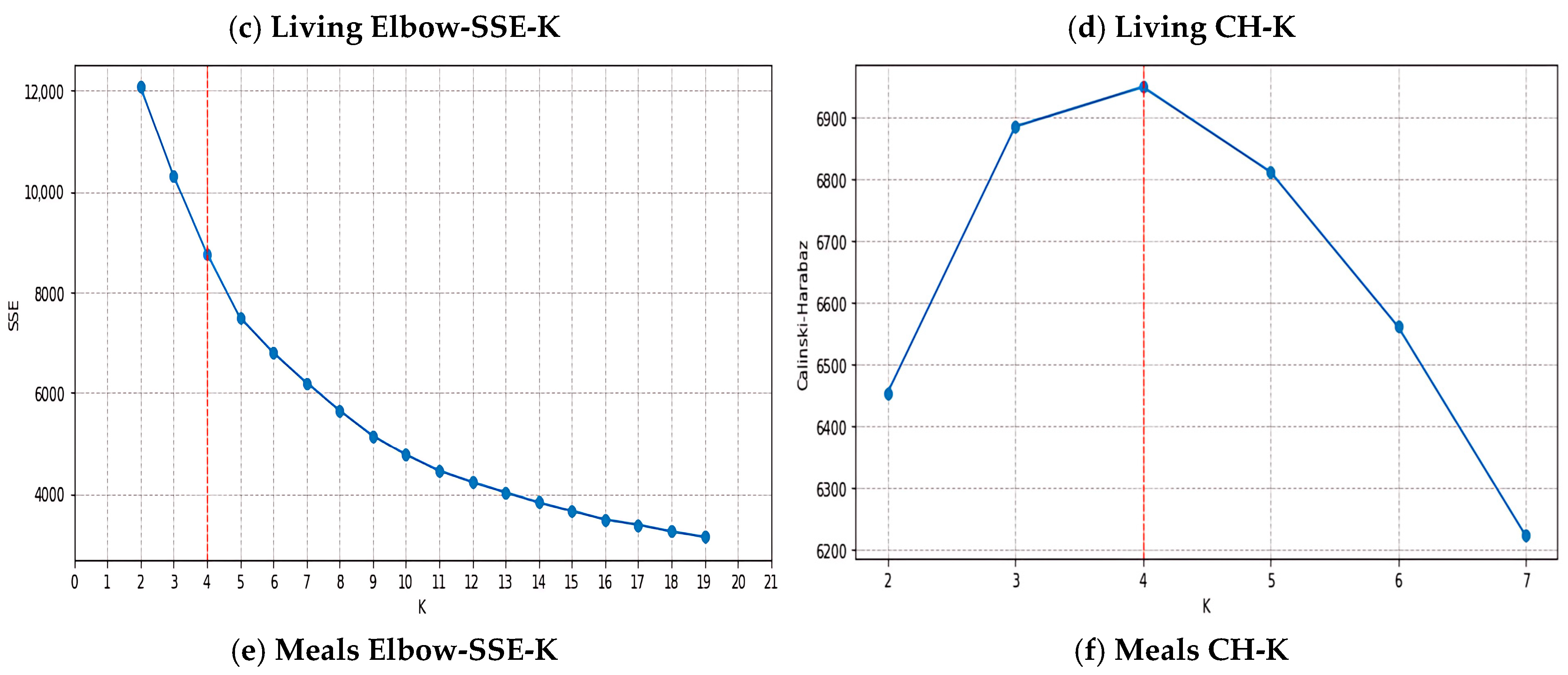
4.1. Optimal Number of Clusters
The number of student types for the overall consumption model, living diet model, and average consumption model for breakfast, lunch, and dinner was determined to be 4, 3, and 3, respectively, using the Elbow Method and Calinski–Harabasz indices, as shown in
Figure 8.
Figure 8a,c,e depict the process of determining the K value using the Sum of Squared Errors (SSE), the most critical metric in the Elbow Method. In contrast,
Figure 8b,d,f illustrate the procedure for identifying the k value based on the Calinski–Harabasz Index. In these figures, the corresponding metric values are highlighted by red vertical lines.
4.2. Comparison
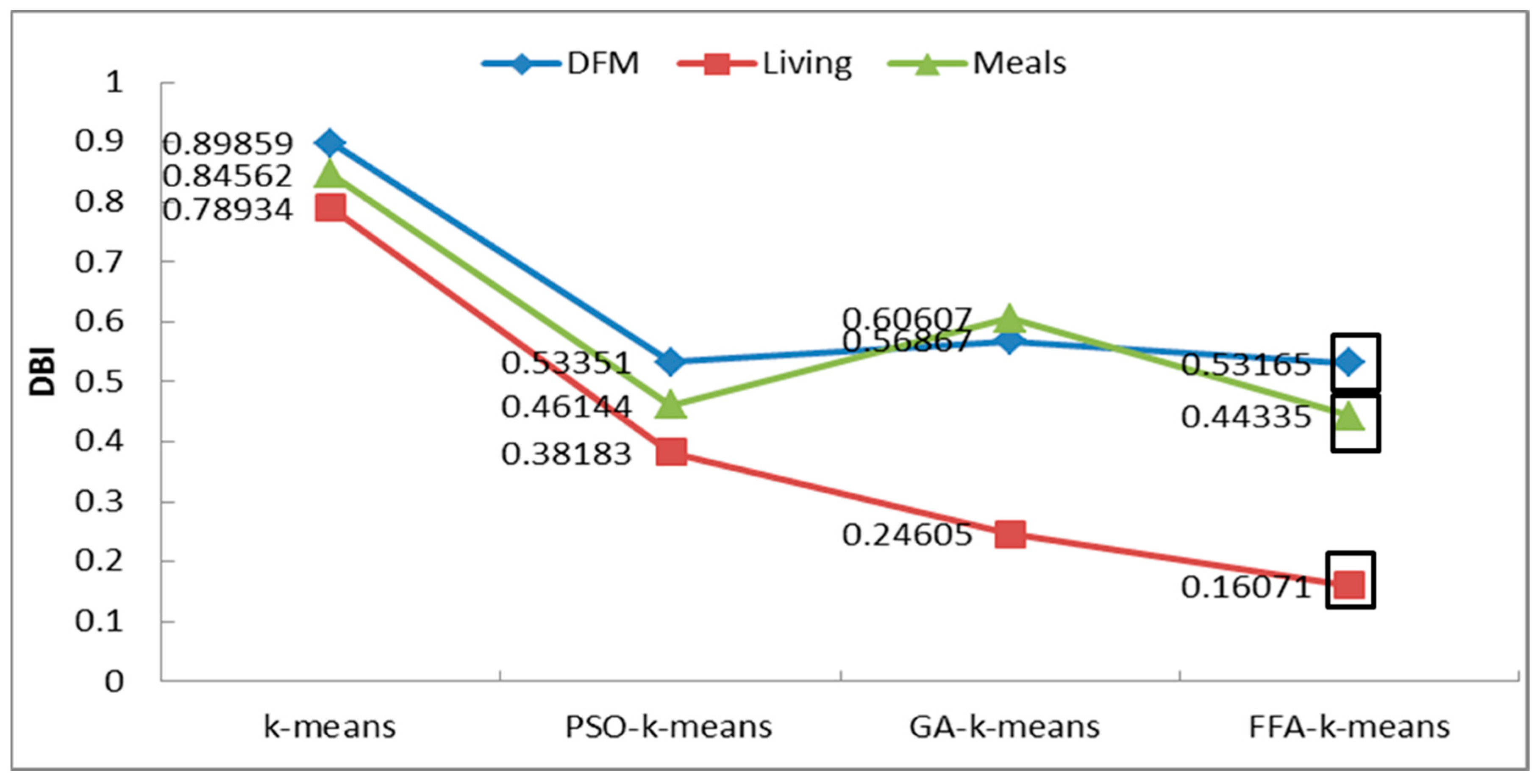
The three models were subjected to clustering analysis using a k-means algorithm optimized by a fractional-order firefly algorithm. The Davies–Bouldin Index (DBI) was employed to evaluate the clustering performance. Combining the previously established optimal k-values, this study compared the traditional k-means algorithm with PSO-k-means, GA-k-means, and FFA-k-means algorithms. The results of the experimental analysis are presented in
Table 7 and
Figure 9.
The findings indicate that the FFA-k-means algorithm demonstrates a lower DBI score and superior clustering performance, proving more effective in identifying latent groups of college students exhibiting similar patterns.
4.3. Analysis of Clustering Results
Based on the improved k-means clustering algorithm outlined in this paper, a clustering analysis was performed on the overall consumption model, with the clustering centers displayed in
Table 8.
The analysis reveals distinct consumption patterns associated with each category of students:
(1) Type 1: This group is relatively small and may represent an extreme consumption cohort.
(2) Type 2: Characterized by a high average monthly balance, total consumption, and consumption frequency, this group engages in numerous campus activities.
(3) Type 3: These individuals show a concentrated distribution with three notable characteristics: a low average monthly balance, minimal total consumption, and infrequent consumption patterns, indicating limited engagement in campus activities.
(4) Type 4: This group is more dispersed, with consumption levels that fall within an intermediate range.
Table 9 presents the results of the clustering centers for the living diet model derived from the improved k-means clustering algorithm.
(1) Type 1 students tend to have lower living and other consumption levels. They usually prefer to dine outside of college, particularly for food.
For such students, University administrators should prioritize food safety and personal health for vulnerable students. One recommended approach is for universities to collaborate with off-campus food regulatory authorities to create a “whitelist for off-campus dining.” This initiative would involve auditing the hygiene standards of nearby restaurants and disseminating safety guidelines for off-campus dining to students, thereby reducing food safety risks.
(2) Type 2 students are characterized by the highest living consumption but low other consumption and minimal card surplus, indicating a lower overall consumption level. These students often eat on campus, and their consumption patterns are stable, suggesting that their families face economic challenges and practice frugality.
For this situation, universities should provide extra support and resources for students from low-income backgrounds and pay closer attention to their living conditions. For instance, universities could establish “dedicated service windows for economically disadvantaged students” in campus dining facilities, offering low-cost, nutritious meal packages. Consumption data from campus cards can be utilized to automatically identify these students for non-symptomatic subsidies. Meanwhile, universities can collaborate with enterprises to donate daily necessities, which are distributed through a point-based redemption system to avoid the psychological pressure caused by direct financial assistance.
(3) Type 3 students exhibit the highest other living expenses and have the largest card surpluses, along with elevated living and dining costs. This indicates that they belong to a high-consumption group. Universities should facilitate students’ understanding of the detriments of irrational consumption and provide systematic guidance for rational consumption behaviors.
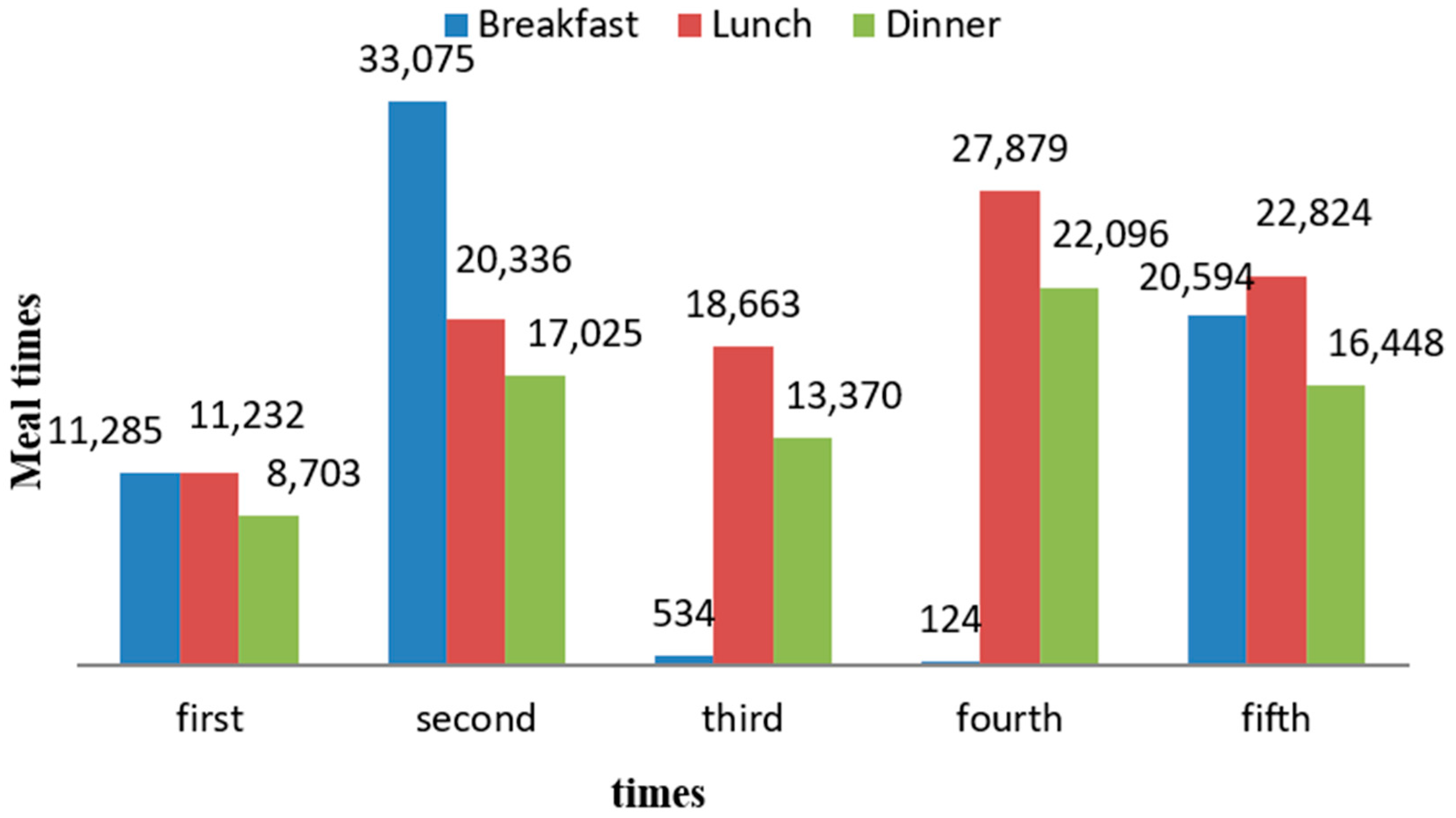
Based on the improved k--means clustering algorithm in this dissertation, the students were classified into three categories after the average consumption patterns of morning, midday, and evening were clustered and analyzed. According to the information presented in
Table 10, the characteristics of students in each category are as follows:
(1) Students classified as Type 1 and Type 2 exhibit infrequent dining habits on campus. Type 1 students display a significantly elevated average consumption per meal during lunch, while Type 2 students report the highest average consumption per meal during dinner. It is recommended to set up special food windows in the campus canteen and update the menu regularly to attract students to dine on campus.
(2) Type 3 students demonstrate lower average expenditure per meal for breakfast, lunch, and dinner while maintaining a higher monthly dining frequency. This suggests that they tend to spend less on individual meals but dine on campus more often, reflecting frugality that may indicate economic pressures on their families. Therefore, when allocating resources for economically disadvantaged students, prioritizing this group is advised. In addition to regular scholarships, recommendations for on-campus work-study positions can be provided to ease their financial burdens effectively.
(3) Type 4 students maintain relatively stable average consumption per meal for breakfast, lunch, and dinner, as well as consistent meal frequency.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}