


Intelligent System Using Data to Support Decision-Making


Abstract
1. Introduction
Related Work
2. Materials and Methods
- Modeling preferences among criteria—that is, determining the importance (weight) that individual criteria hold for the user.
- Modeling preferences among alternatives with respect to individual criteria and aggregating them to express the overall preference.
- the ranking method,
- the scoring method,
- the pairwise comparison method of criteria,
- the quantitative pairwise comparison method of criteria (Saaty’s method).
- 1—criteria and are of equal importance,
- 3—criterion is slightly preferred over ,
- 5—criterion is strongly preferred over ,
- 7—criterion is very strongly preferred over ,
- 9—criterion is absolutely preferred over
- the maximum utility method,
- the method of minimizing the distance to the ideal alternative (Technique for Order Preference by Similarity to Ideal Solution—TOPSIS),
- the method of evaluating alternatives based on a preference relation.
- if there are n alternatives, the top-ranked receives n − 1 point,
- the second n − 2, etc.,
- with the last receiving 0 points.
- Accuracy—using this metric, we will evaluate whether individual models are suitable, functional, and achieve high-quality accuracy [42].
- Identity—this metric can help us to make sure that there are two identical cases that exist in the data, and if so, they must have identical interpretations [43]. This means that for every two cases in the test dataset, if the distance between them is equal to zero, that is, identical, then the distance between their interpretations should also be equal to zero.
- Separability—the metric states that if there are two distinct cases, they must also have distinct interpretations. The metric assumes that the model has no degrees of freedom, that is, all features used in the model are relevant for prediction. If we want to measure the separability metric, we choose a subset S from the test dataset that does not contain duplicate values and then obtain their interpretations. Then, for each instance of s in S, we compare its interpretation with all other interpretations of instances in S, and if such an interpretation does not have a duplicate, then we can say that it satisfies the separability metric. Using this metric, we will reveal how well the model explanations are separated between different classes. Higher values indicate a better ability of the model to distinguish between classes based on the explained attributes.
- Stability—this metric states that instances belonging to the same class must have comparable interpretations. The authors first grouped the interpretations of all instances in test dataset using the K-means algorithm, so that the number of clusters is equal to the number of labels in the data. For each instance in the test dataset, they compared the cluster label assigned to its interpretations after clustering with the predicted class label of the instance; if they match, the interpretation satisfies the stability metric. This metric could help us evaluate the consistency of model explanations across training datasets. The higher the stability, the more consistent and reliable the explanations.
- Understandability—helps us evaluate whether the explanations are easy for doctors to understand. It is related to the ease with which an observer understands the explanation. This metric is crucial, because no matter how accurate an explanation may be, it is useless if it is not understandable. It is related to how well people understand the explanations [44]. According to Joyce et al. [45], understandability is understood as the confidence that a domain expert can understand the behavior of algorithms and their inputs, based on their everyday professional knowledge. The doctor assigns a value from 1 to 5 based on the Likert scale, with 1 being the lowest and 5 being the highest.
- User experience—evaluates how well the model explanations fit into the overall user interface and interaction between individual system functionalities. A good user experience improves user engagement and trust. This metric was created based on an understanding of how usability is evaluated using the ISO/IEC 25002 [46] quality assessment metrics. The doctor assigns a value from 1 to 5 based on the Likert scale.
- Response time (Effectiveness)—assesses how quickly and effectively the model generates explanations. Higher efficiency reduces the time needed to explain the model. Doctors will evaluate this metric based on a Likert scale from 1 to 5, where
- ○
- If the explanation generation time is up to 30 s, the doctor will assign a value of 5.
- ○
- If the explanation generation time is between 30 and 60 s, the doctor assigns a value of 4.
- ○
- If the explanation generation time is more than 60 s, the doctor assigns a value 3.
- ○
- If the explanation generation time is between 2 and 5 min, the doctor assigns a value 2.
- ○
- If the explanation generation time is more than 5 min, the doctor assigns a value 1.
3. Results
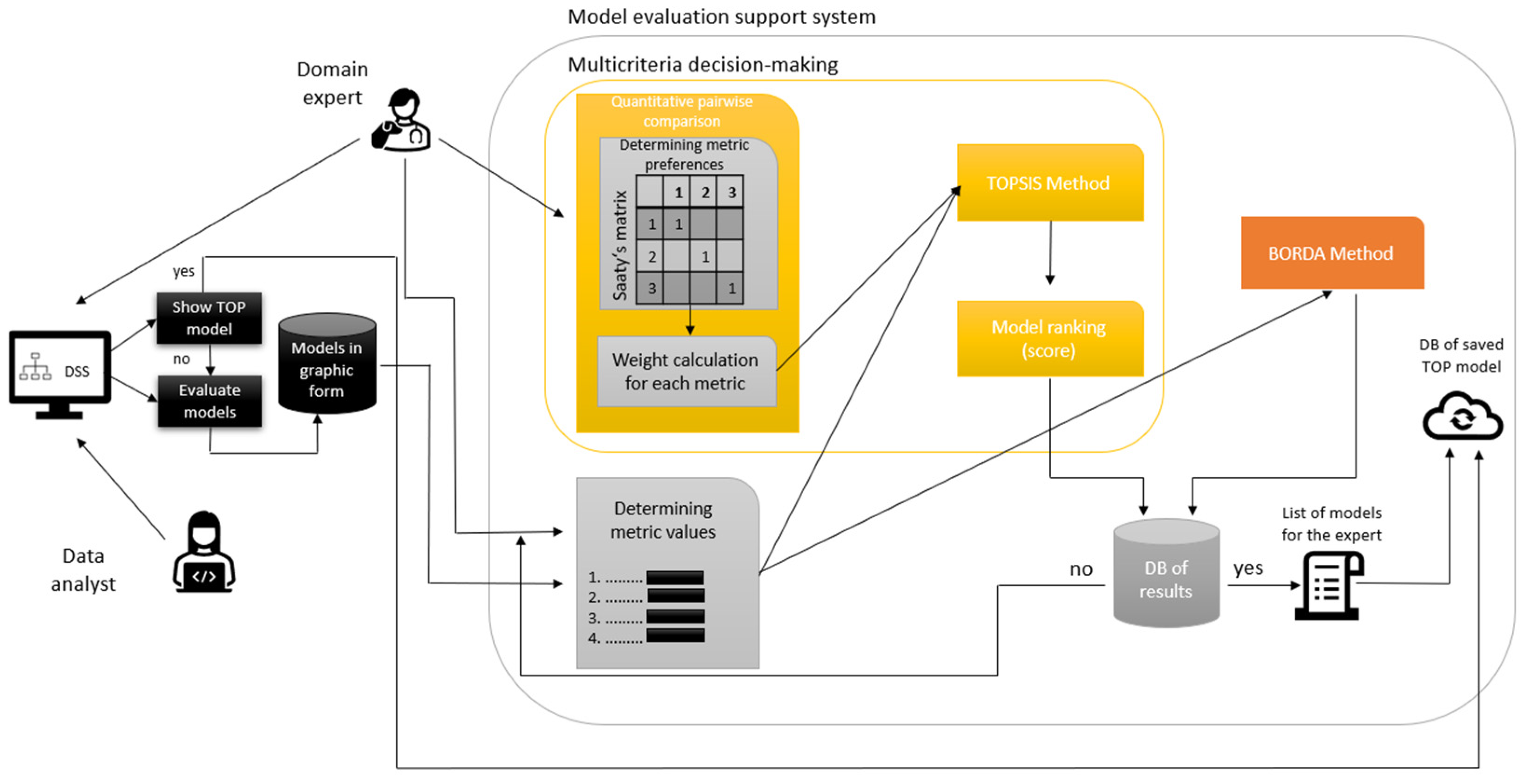
3.1. Proposed Approach
- The user shall show the best model selected and rated by a doctor with many years of clinical experience or generate explainable representations of models in the graphical form in the implemented clinical DSS.
- Subsequently, whether similar models are already stored in the database is checked (DB of saved TOP model).
- If the best model is not stored yet, a domain expert (in our case, a doctor) enters the process.
- The doctor will determine the values of the metrics.
- In the MCDM process, the doctor then determines the metrics preferences of which metric is more important to the other.
- a.
- The doctor chooses preferences between each metric. The values use a scale from 1 to 9, where 1 represents equal importance and 9 represents extreme importance.
- The calculation is performed, the Saaty matrix is filled in, and the weights for each metric are calculated using the normalized geometric diameter of this matrix. The higher the weight, the more critical the metric.
- The values of metrics and metric weights shall be used for calculations performed in the TOPSIS and Borda methods.
- The doctor chooses to evaluate explainable models using the TOPSIS method. Steps in the TOPSIS method:
- a.
- Compilation of the criterion matrix with alternatives (models) as rows and criteria (metrics) as columns. We assign a score (the resulting metric calculation) to each alternative for each criterion.
- b.
- Adjust all metrics to the same extreme type.
- c.
- Normalization of the adjusted criterion matrix.
- d.
- Creating a weighted criterion matrix by multiplying the normalized decision matrix by the weight of each criterion.
- e.
- From the weighted criterion matrix, we determine the ideal and basic models.
- f.
- Finally, we calculate the distance of the model from the ideal model and the basic model, and, using these values, we calculate the relative indicator of the distance of the model from the basic model
- The doctor chooses to evaluate explainable models using the Borda method which is calculated automatically by metaethical formula.
- The system arranges the individual models in descending order.
- The results database will store individual models, model order, values, weights, and preference metrics.
- The doctor will obtain a list of recommended models according to the Borda and TOPSIS methods.
- The doctor will decide whether to save the most understandable model according to the Borda or TOPSIS method or choose his own model that he found most understandable.
3.2. Data Preparation
3.3. CDSS-EQCM Development
3.3.1. First Version
3.3.2. Second Version
3.3.3. Classifier Training Details
- Random Forest (RF): 100 trees (n_estimators = 100), no limit on depth (max_depth = None).
- Decision Tree (DT): default Gini criterion, no pruning.
- Logistic Regression (LR): solver = lbfgs, C = 1.0, max_iter = 1000.
- k-Nearest Neighbors (k-NN): n_neighbors = 5, Euclidean distance.
- Support Vector Machine (SVM): linear kernel, C = 1.0, probability = True.
- RF: n_estimators ∈ {50, 100, 200}, max_depth ∈ {None, 10, 20}.
- DT: max_depth ∈ {None, 10, 20}, min_samples_split ∈ {2, 5}.
- LR: C ∈ {0.1, 1, 10}.
- k-NN: n_neighbors ∈ {3, 5, 7}.
- SVM: C ∈ {0.1, 1, 10}.
3.4. CDSS-EQCM Testing
- Test Scenario 1: Evaluating the Interpretability of Explainable Models Using Evaluation Methods.
- Test Scenario 2: Displaying the Best Option from the Previous Evaluation.
- Test Scenario 3: Verification of the Application’s Functionality and Transparency.
- I think that I would like to use this system frequently.
- I found the system unnecessarily complex.
- I thought the system was easy to use.
- I think that I would need the support of a technical person to be able to use this system.
- I found the various functions in this system were well-integrated.
- I thought there was too much inconsistency in this system.
- I would imagine that most people would learn to use this system very quickly.
- I found the system very cumbersome to use.
- I felt very confident using the system.
- I needed to learn a lot of things before I could get going with this system.
4. Discussion
- System Performance and Accuracy: During testing, all system responses matched the expected outputs, confirming reliability. To prevent overfitting, we held out 20% of the data as an unseen test set (stratified by class) and applied stratified five-fold cross-validation on the remaining 80% for hyperparameter tuning. For each configuration, we tracked the mean and standard deviation of the F1-score across folds (all σF1 < 0.02), retrained the best model on the full training split, and then evaluated on the test set. The gap between training and test accuracy was negligible (<0.01—for example, Random Forest achieved 0.98 on both), and precision, recall, and F1-scores aligned within 1–2%. These low-variance results demonstrate robust generalization without overtraining. Finally, integrating LIME and SHAP enabled transparent identification of key predictive features, further reinforcing confidence in model behavior on unseen data.
- Interpretability and Usability: Physicians evaluated the interpretability of the models using metrics like accuracy, separability, stability, and subjective measures (understandability, user experience, and response time). The multi-criteria decision-making framework—implemented through the TOPSIS and Borda methods—allowed for an ordered ranking of models according to the experts’ preferences. Feedback collected via a questionnaire based on a Likert scale revealed that the explanations provided by the system are clear and comprehensible. In particular, the SHAP visualizations were found to be more intuitive, which was corroborated by the Borda-based ranking.
- Data Handling and Adaptability: The system processed multiple COVID-19 data waves, addressing challenges such as missing values and inconsistent data types through two phases of rigorous preprocessing. The flexible data-handling pipeline ensures that the system can adapt to both synthetic and real patient data, making it applicable for diverse clinical environments. Real data from the UNLP Košice were successfully incorporated after additional modifications, proving the system’s adaptability.
- Workflow Integration and Deployment: Developed using Python and Streamlit, the CDSS-EQCM features a user-friendly interface that facilitates seamless data uploading and preprocessing; interactive model evaluation, including individualized interpretations for selected patients; automatic model ranking and selection based on expert ratings; and the option to use a pre-evaluated “best model” directly, thereby reducing the diagnostic time and effort required from the clinicians. The clear organization of test scenarios and the resultant documentation (supported by figures and tabulated results) demonstrate that the system’s functionalities align well with the clinical decision-making process. This ensures that it can be effectively integrated into current clinical workflows with minimal adjustments.
- Practical Impact and Future Enhancements: The combined objective and subjective evaluations indicate that the system not only supports accurate predictions but also enhances the interpretability and transparency of the results. This builds trust among physicians, enabling them to make informed decisions quickly. As the system saves valuable time by offering the single, most comprehensible model after evaluation, it paves the way for improved patient management and streamlined clinical operations. Based on clinician comments, we identify three key focus areas for future versions to increase the SUS score: streamlining the model-selection workflow, reducing data-loading times for large datasets, expanding inline tooltips and contextual help. Based on SUS sub-scores and qualitative feedback, we pinpoint “ease of operation” (simpler navigation) and “interpretability guidance” (built-in tutorials) as top priorities to boost usability. Future enhancements, informed by ongoing feedback from the clinical community, aim to further tailor the system to specific clinical contexts, extend its functionalities, and ensure robustness in diverse healthcare scenarios.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Osheroff, J.; Teich, J.; Levick, D.; Saldana, L.; Velasco, F.; Sittig, D.; Rogers, K.; Jenders, R. Improving Outcomes with Clinical Decision Support: An Implementer’s Guide; Routledge: London, UK, 2012; p. 323. [Google Scholar]
- Sim, I.; Gorman, P.; Greenes, R.A.; Haynes, R.B.; Kaplan, B.; Lehmann, H.; Tang, P.C. Clinical Decision Support Systems for the Practice of Evidence-based Medicine. J. Am. Med. Inform. Assoc. 2001, 8, 527–534. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4766–4775. [Google Scholar]
- Holzinger, A.; Carrington, A.; Müller, H. Measuring the Quality of Explanations: The System Causability Scale (SCS): Comparing Human and Machine Explanations. Kunstl. Intell. 2020, 34, 193–198. [Google Scholar] [CrossRef]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Lee, E.H. eXplainable DEA approach for evaluating performance of public transport origin-destination pairs. Res. Transp. Econ. 2024, 108, 101491. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards A Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608v2. [Google Scholar]
- Molnar, C. Interpretable Machine Learning. A Guide for Making Black Box Models Explainable; Lulu Publishing: Morrisville, NC, USA, 2019; p. 247. Available online: https://christophm.github.io/interpretable-ml-book (accessed on 16 May 2025).
- Stiglic, G.; Kocbek, P.; Fijacko, N.; Zitnik, M.; Verbert, K.; Cilar, L. Interpretability of machine learning-based prediction models in healthcare. WIREs Data Min. Knowl. Discov. 2020, 10, 1–13. [Google Scholar] [CrossRef]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2018; pp. 80–89. [Google Scholar]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine learning interpretability: A survey on methods and metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Yasodhara, A.; Asgarian, A.; Huang, D.; Sobhani, P. On the Trustworthiness of Tree Ensemble Explainability Methods. In Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2021; Volume 12844, pp. 293–308. [Google Scholar] [CrossRef]
- Luna, D.R.; Rizzato Lede, D.A.; Otero, C.M.; Risk, M.R.; González Bernaldo de Quirós, F. User-centered design improves the usability of drug-drug interaction alerts: Experimental comparison of interfaces. J. Biomed. Inform. 2017, 66, 204–213. [Google Scholar] [CrossRef]
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and explainability of artificial intelligence in medicine. WIREs Data Min. Knowl. Discov. 2019, 9, 1312. [Google Scholar] [CrossRef] [PubMed]
- Itani, S.; Rossignol, M.; Lecron, F.; Fortemps, P.; Stoean, R. Towards interpretable machine learning models for diagnosis aid: A case study on attention deficit/hyperactivity disorder. PLoS ONE 2019, 14, e0215720. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Ruan, W.; Wang, J.; Zheng, D.; Liu, B.; Geng, Y.; Chai, X.; Chen, J.; Li, K.; Li, S.; et al. Interpretable machine learning for COVID-19: An empirical study on severity prediction task. IEEE Trans. Artif. Intell. 2021, 4, 764–777. [Google Scholar] [CrossRef]
- Barr Kumarakulasinghe, N.; Blomberg, T.; Liu, J.; Saraiva Leao, A.; Papapetrou, P. Evaluating Local Interpretable Model-Agnostic Explanations on Clinical Machine Learning Classification Models. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2020; pp. 7–12. [Google Scholar] [CrossRef]
- Thimoteo, L.M.; Vellasco, M.M.; do Amaral, J.M.; Figueiredo, K.; Lie Yokoyama, C.; Marques, E. Interpretable Machine Learning for COVID-19 Diagnosis Through Clinical Variables. Interpretable Machine Learning for COVID-19 Diagnosis Through Clinical Variables. In Proceedings of the Congresso Brasileiro de Automática-CBA, Online, 23–26 October 2020. [Google Scholar] [CrossRef]
- Nesaragi, N.; Patidar, S. An explainable machine learning model for early prediction of sepsis using ICU data. In Infections and Sepsis Development; IntechOpen: London, UK, 2021. [Google Scholar]
- Prinzi, F.; Militello, C.; Scichilone, N.; Gaglio, S.; Vitabile, S. Explainable Machine-Learning Models for COVID-19 Prognosis Prediction Using Clinical, Laboratory and Radiomic Features. IEEE Access 2023, 11, 121492–121510. [Google Scholar] [CrossRef]
- Gabbay, F.; Bar-Lev, S.; Montano, O.; Hadad, N. A LIME-Based Explainable Machine Learning Model for Predicting the Severity Level of COVID-19 Diagnosed Patients. Appl. Sci. 2021, 11, 10417. [Google Scholar] [CrossRef]
- ElShawi, R.; Sherif, Y.; Al-Mallah, M.; Sakr, S. Interpretability in healthcare: A comparative study of local machine learning interpretability techniques. Comput. Intell. 2021, 37, 1633–1650. [Google Scholar] [CrossRef]
- Stasko, J.; Zhang, E. Focus + Context Display and Navigation Techniques for Enhancing Radial, Space-Filling Hierarchy Visualizations. In Proceedings of the IEEE Symposium on Information Vizualization, Salt Lake City, UT, USA, 9–10 October 2000; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2000; pp. 57–65. [Google Scholar] [CrossRef]
- Liu, C.; Wang, P. A Sunburst-based hierarchical information visualization method and its application in public opinion analysis. In Proceedings of the 2015 8th International Conference on Biomedical Engineering and Informatics (BMEI), Shenyang, China, 14–16 October 2015; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2015; pp. 832–836. [Google Scholar] [CrossRef]
- Rouwendal, D.; Stolpe, A.; Hannay, J. Using Block-Based Programming and Sunburst Branching to Plan and Generate Crisis Training Simulations; Springer: Cham, Switzerland, 2020; pp. 463–471. [Google Scholar]
- Oceliková, E. Multikriteriálne Rozhodovanie; Elfa: Malmö, Sweden, 2004. [Google Scholar]
- Maňas, M.; Jablonský, J. Vícekriteriální Rozhodování, 1st ed.; Vysoká škola ekonomická v Praze: Praha, Czech Republic, 1994. [Google Scholar]
- Fiala, P. Modely a Metody Rozhodování, 3rd ed.; Oeconomica: Praha, Czech Republic, 2013. [Google Scholar]
- Behnke, J. Bordas Text „Mémoire sur les Élections au Scrutin “von 1784: Einige einführende Bemerkungen. In Jahrbuch für Handlungs-und Entscheidungstheorie; Springer: Cham, Switzerland, 2004; pp. 155–177. [Google Scholar]
- Paralič, J. Objavovanie Znalost v Databázach; Technická Univerzita v Košiciach: Košiciach, Slovakia, 2003. [Google Scholar]
- Maimon, O.; Rokach, L. Data Mining and Knowledge Discovery Handbook; Springer: New York, NY, USA, 2010. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Vogels, M.; Zoeckler, R.; Stasiw, D.M.; Cerny, L.C. P. F. Verhulst’s “notice sur la loi que la populations suit dans son accroissement” from correspondence mathematique et physique. Ghent, vol. X, 1838. J. Biol. Phys. 1975, 3, 183–192. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2013. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Fix, E. Discriminatory Analysis: Nonparametric Discrimination, Consistency Properties; USAF School of Aviation Medicine: Dayton, OH, USA, 1985; Volume 1. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Thomson, W.; Roth, A.E. The Shapley Value: Essays in Honor of Lloyd S. Shapley; Cambridge University Press: Cambridge, UK, 1991; Volume 58. [Google Scholar]
- Velmurugan, M.; Ouyang, C.; Moreira, C.; Sindhgatta, R. Evaluating Fidelity of Explainable Methods for Predictive Process Analytics. In Intelligent Information Systems; Springer: Cham, Switzerland, 2021; pp. 64–72. [Google Scholar]
- Honegger, M. Shedding light on black box machine learning algorithms: Development of an axiomatic framework to assess the quality of methods that explain individual predictions. arXiv 2018, arXiv:1808.05054. [Google Scholar]
- Oviedo, F.; Ferres, J.L.; Buonassisi, T.; Butler, K.T. Interpretable and Explainable Machine Learning for Materials Science and Chemistry. Acc. Mater. Res. 2022, 3, 597–607. [Google Scholar] [CrossRef]
- Joyce, D.W.; Kormilitzin, A.; Smith, K.A.; Cipriani, A. Explainable artificial intelligence for mental health through transparency and interpretability for understandability. npj Digit. Med. 2023, 6, 6. [Google Scholar] [CrossRef] [PubMed]
- ISO/IEC 25002:2024; Systems and Software Engineering—Systems and Software Quality Requirements and Evaluation (SQuaRE)—Quality Model Overview and Usage. International Organization for Standardization: Geneva, Switzerland, 2024. Available online: https://www.iso.org/standard/78175.html (accessed on 16 May 2025).
- Brooke, J. SUS: A ’quick and dirty’ usability scale. Usabil. Eval. Ind. 1996, 189, 189–194. [Google Scholar]

{kind=link}
| ML Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| RF | 0.98 | 0.97 | 0.96 | 0.965 |
| DT | 0.97 | 0.95 | 0.94 | 0.945 |
| LR | 0.95 | 0.94 | 0.94 | 0.935 |
| k-NN | 0.88 | 0.85 | 0.88 | 0.845 |
| SVM | 0.95 | 0.95 | 0.96 | 0.950 |
| Random Forest Confusion Matrix | |||
|
Real
classes | Predicted classes | ||
| 0 | 508 | 0 | |
| 1 | 12 | 67 | |
| Decision Tree Confusion Matrix | |||
|
Real
classes | Predicted classes | ||
| 0 | 506 | 2 | |
| 1 | 14 | 65 | |
| Logistics Regression Confusion Matrix | |||
|
Real
classes | Predicted classes | ||
| 0 | 503 | 5 | |
| 1 | 25 | 54 | |
| k-NN Confusion Matrix | |||
|
Real
classes | Predicted classes | ||
| 0 | 493 | 15 | |
| 1 | 58 | 21 | |
| SVM Confusion Matrix | |||
|
Real
classes | Predicted classes | ||
| 0 | 497 | 11 | |
| 1 | 17 | 62 | |
| ML Method | Response Time | Understandability | User Experience | Separability | Stability | Accuracy |
|---|---|---|---|---|---|---|
| RF LIME | 1.00 | 0.80 | 1.00 | 1.00 | 0.76 | 0.98 |
| RF SHAP | 1.00 | 1.00 | 1.00 | 1.00 | 0.92 | 0.98 |
| DT LIME | 1.00 | 0.80 | 0.80 | 1.00 | 0.65 | 0.97 |
| DT SHAP | 1.00 | 1.00 | 1.00 | 1.00 | 0.90 | 0.97 |
| LR LIME | 0.80 | 1.00 | 0.80 | 1.00 | 0.75 | 0.95 |
| LR SHAP | 0.80 | 1.00 | 1.00 | 1.00 | 0.92 | 0.95 |
| k-NN LIME | 0.60 | 0.80 | 0.60 | 1.00 | 0.84 | 0.88 |
| k-NN SHAP | 1.00 | 1.00 | 1.00 | 1.00 | 0.95 | 0.88 |
| SVM LIME | 0.80 | 0.80 | 0.60 | 1.00 | 0.55 | 0.95 |
| SVM SHAP | 1.00 | 1.00 | 1.00 | 1.00 | 0.94 | 0.95 |
| Separability | Stability | Accuracy | Response Time | Understandability | User Experience | |
|---|---|---|---|---|---|---|
| Separability | 1.00 | 0.20 | 0.14 | 0.20 | 0.14 | 0.14 |
| Stability | 5.00 | 1.00 | 0.14 | 0.11 | 0.11 | 0.14 |
| Accuracy | 7.00 | 7.00 | 1.00 | 3.00 | 0.33 | 3.00 |
| Response time | 5.00 | 9.00 | 0.33 | 1.00 | 3.00 | 5.00 |
| Understandability | 7.00 | 9.00 | 3.00 | 0.33 | 1.00 | 5.00 |
| User experience | 7.00 | 7.00 | 0.33 | 0.20 | 0.20 | 1.00 |
| Metric | Weights |
|---|---|
| Separability | 0.0250 |
| Stability | 0.0371 |
| Accuracy | 0.2595 |
| Response time | 0.2786 |
| Understandability | 0.2946 |
| User experience | 0.1052 |
| TOPSIS Method | Borda Count | |||
|---|---|---|---|---|
| Classification Model | Pi Score | Classification Model | Borda Score | |
| 1 | SVM SHAP | 0.9686 | RF SHAP | 48 |
| 2 | RF SHAP | 0.9525 | RF LIME | 41 |
| 3 | k-NN SHAP | 0.9413 | DT SHAP | 38 |
| 4 | LR SHAP | 0.9308 | LR SHAP | 28 |
| 5 | DT SHAP | 0.9115 | DT LIME | 27 |
| 6 | RF LIME | 0.6660 | k-NN SHAP | 27 |
| 7 | LR LIME | 0.4980 | SVM SHAP | 25 |
| 8 | k-NN LIME | 0.4544 | LR LIME | 21 |
| 9 | DT LIME | 0.3696 | k-NN LIME | 9 |
| 10 | SVM LIME | 0.0516 | SVM LIME | 6 |
| Doctor1 | Doctor2 | Doctor3 | Doctor4 | Doctor5 | |
|---|---|---|---|---|---|
| 1 | 5 | 5 | 4 | 4 | 4 |
| 2 | 2 | 2 | 2 | 2 | 2 |
| 3 | 4 | 4 | 4 | 4 | 5 |
| 4 | 2 | 3 | 4 | 4 | 2 |
| 5 | 5 | 5 | 4 | 3 | 5 |
| 6 | 1 | 2 | 2 | 2 | 2 |
| 7 | 4 | 4 | 4 | 5 | 4 |
| 8 | 2 | 1 | 1 | 2 | 2 |
| 9 | 4 | 4 | 3 | 4 | 4 |
| 10 | 2 | 2 | 2 | 2 | 5 |
| Doctor1 | Doctor2 | Doctor3 | Doctor4 | Doctor5 | Average SUS Score | |
|---|---|---|---|---|---|---|
| Odd-numbered | 17 | 17 | 14 | 15 | 17 | |
| Even numbered | 16 | 15 | 14 | 13 | 12 | |
| SUS score | 82.5 | 80 | 70 | 70 | 72.5 | 75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anderková, V.; Babič, F.; Paraličová, Z.; Javorská, D. Intelligent System Using Data to Support Decision-Making. Appl. Sci. 2025, 15, 7724. https://doi.org/10.3390/app15147724
Anderková V, Babič F, Paraličová Z, Javorská D. Intelligent System Using Data to Support Decision-Making. Applied Sciences. 2025; 15(14):7724. https://doi.org/10.3390/app15147724
Chicago/Turabian StyleAnderková, Viera, František Babič, Zuzana Paraličová, and Daniela Javorská. 2025. "Intelligent System Using Data to Support Decision-Making" Applied Sciences 15, no. 14: 7724. https://doi.org/10.3390/app15147724
APA StyleAnderková, V., Babič, F., Paraličová, Z., & Javorská, D. (2025). Intelligent System Using Data to Support Decision-Making. Applied Sciences, 15(14), 7724. https://doi.org/10.3390/app15147724