
Sensitivity Estimation for Differentially Private Query Processing


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- We present a sampling-based sensitivity estimation method called Sampling-SE for differentially private join query processing, which improves the efficiency of calculating residual sensitivity while remaining comparable in terms of accuracy;
- We also present a sketch-based method called Sketch-SE using sketching sensitivity, which improves the utility of elastic sensitivity while remaining highly efficient;
- Experimental results on real-world and benchmark datasets show that our proposed methods obtain better performance than the traditional implementation of RS and ES.
2. Related Works
3. Preliminaries
3.1. Differential Privacy
3.2. Sensitivity
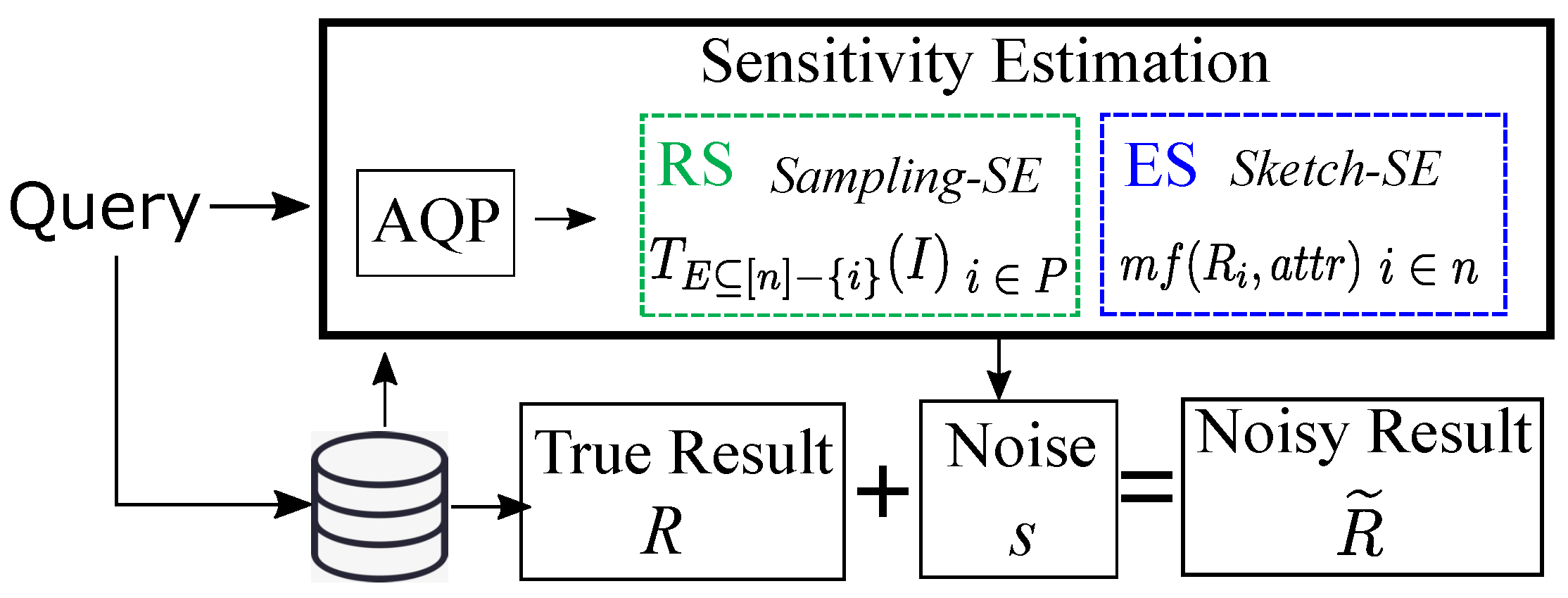
4. Sensitivity Estimation for Join Queries
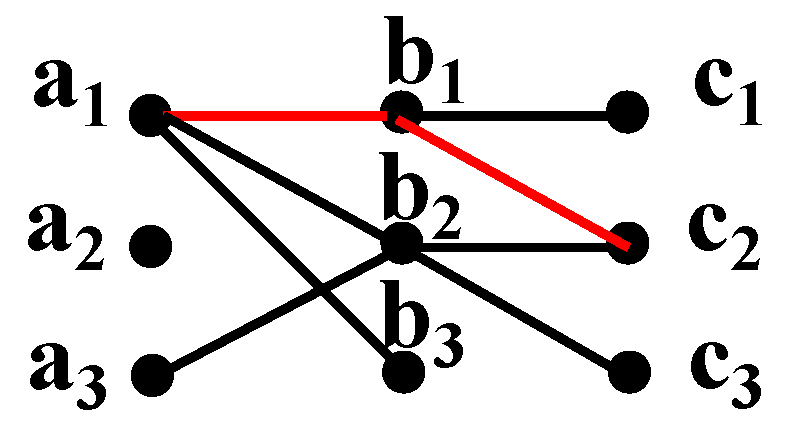
4.1. Limitation of Existing Sensitivity Measures
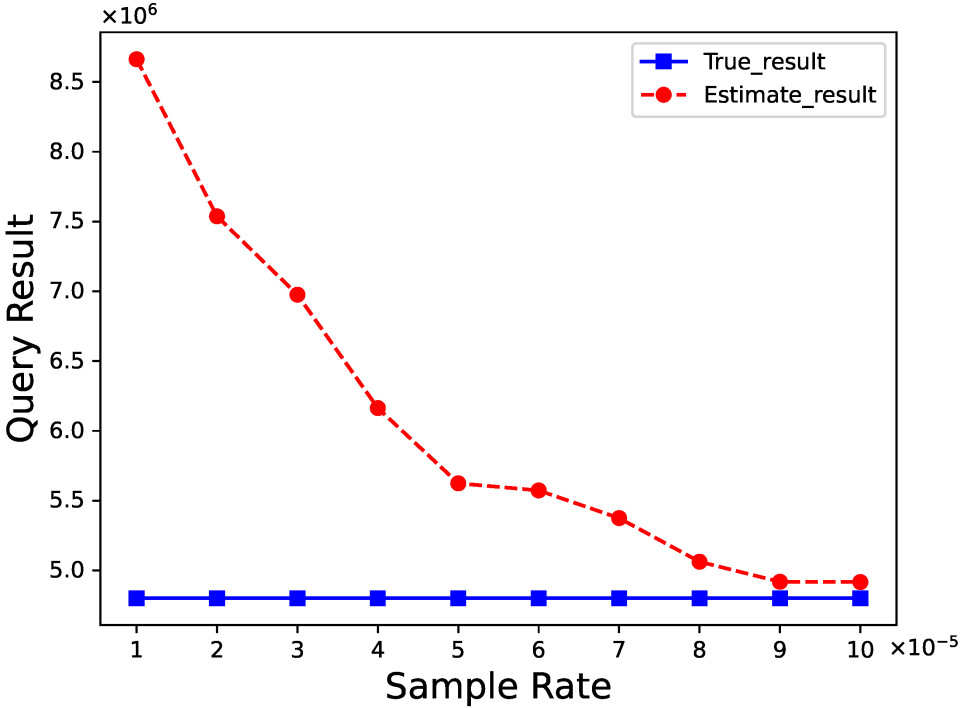
4.2. Sampling-Based Sensitivity Estimation
4.2.1. Estimation for One Residual Query
| Algorithm 1 Sampling-SE |
Input: Multi-Join query q Output: The sensitivity of q
|
| Algorithm 2 RQE |
Input: Residual query , Error bound Output: The estimation
|
| Algorithm 3 Estimate (p, q, m, C) |
|
4.2.2. Improved Sampling-Based Sensitivity Estimation
| Algorithm 4 Improved-RQE |
Input: Multi-way Query q, Residual queries , Terminal error bound Output: The estimations
|
4.3. Sketch-Based Sensitivity Estimation
4.3.1. Sketch-Based Multi-Join Size Estimation
4.3.2. Sketching Sensitivity for Multi-Join Queries
4.4. Discussion
5. Experiments
5.1. Experimental Setup
5.1.1. Hardware and Library
5.1.2. Datasets
5.1.3. Queries
5.1.4. Competitors
5.1.5. Error Metric
5.1.6. Parameters
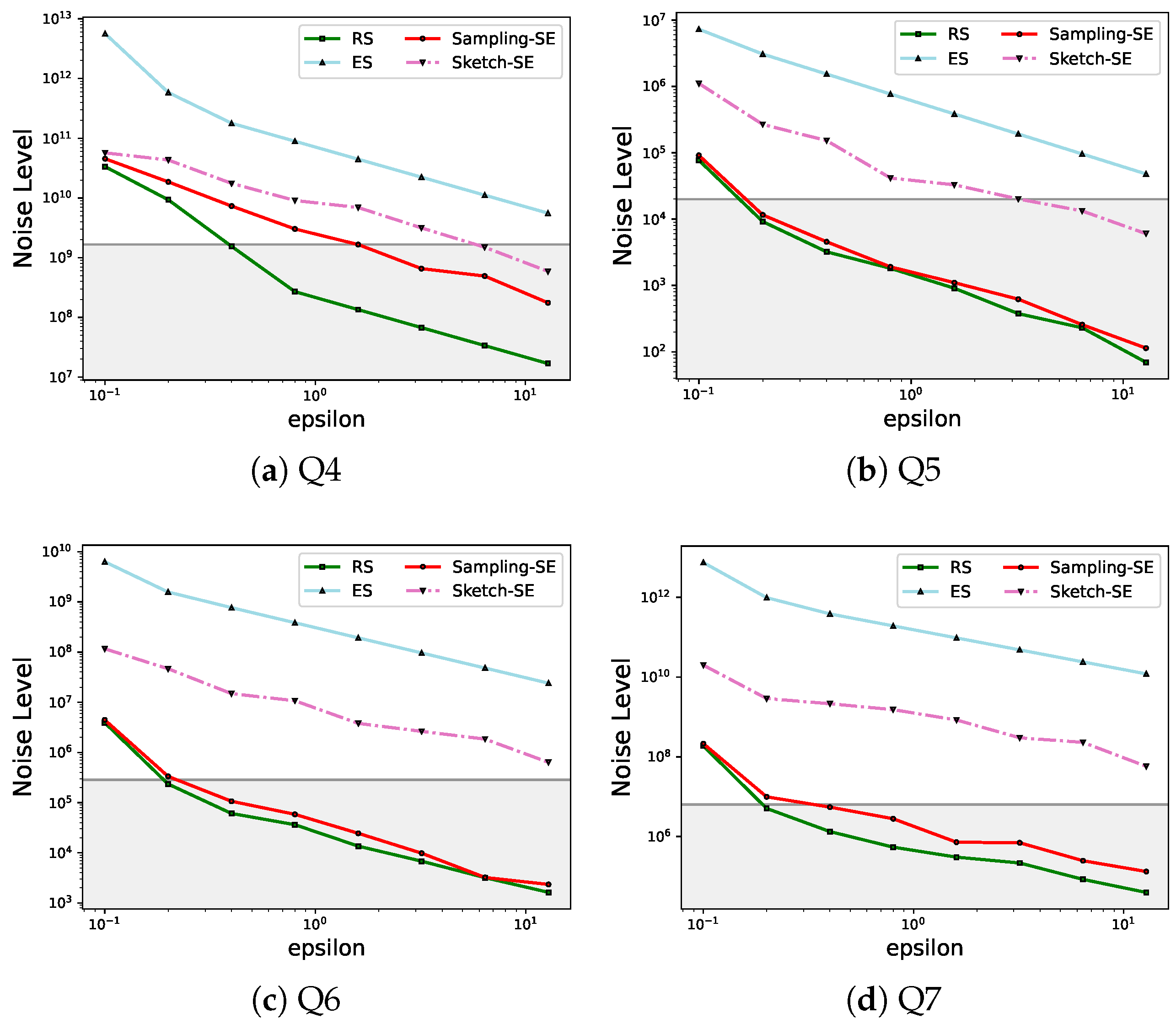
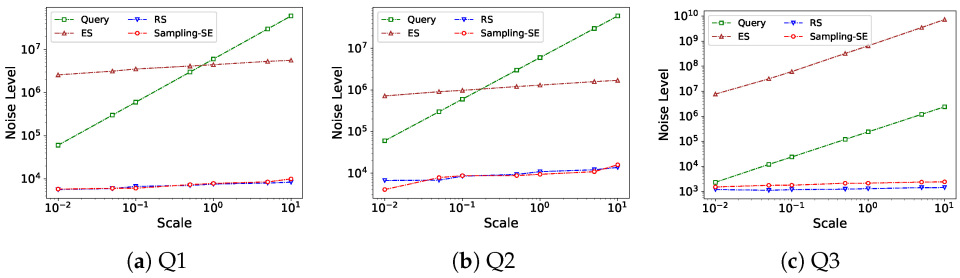
5.2. Accuracy
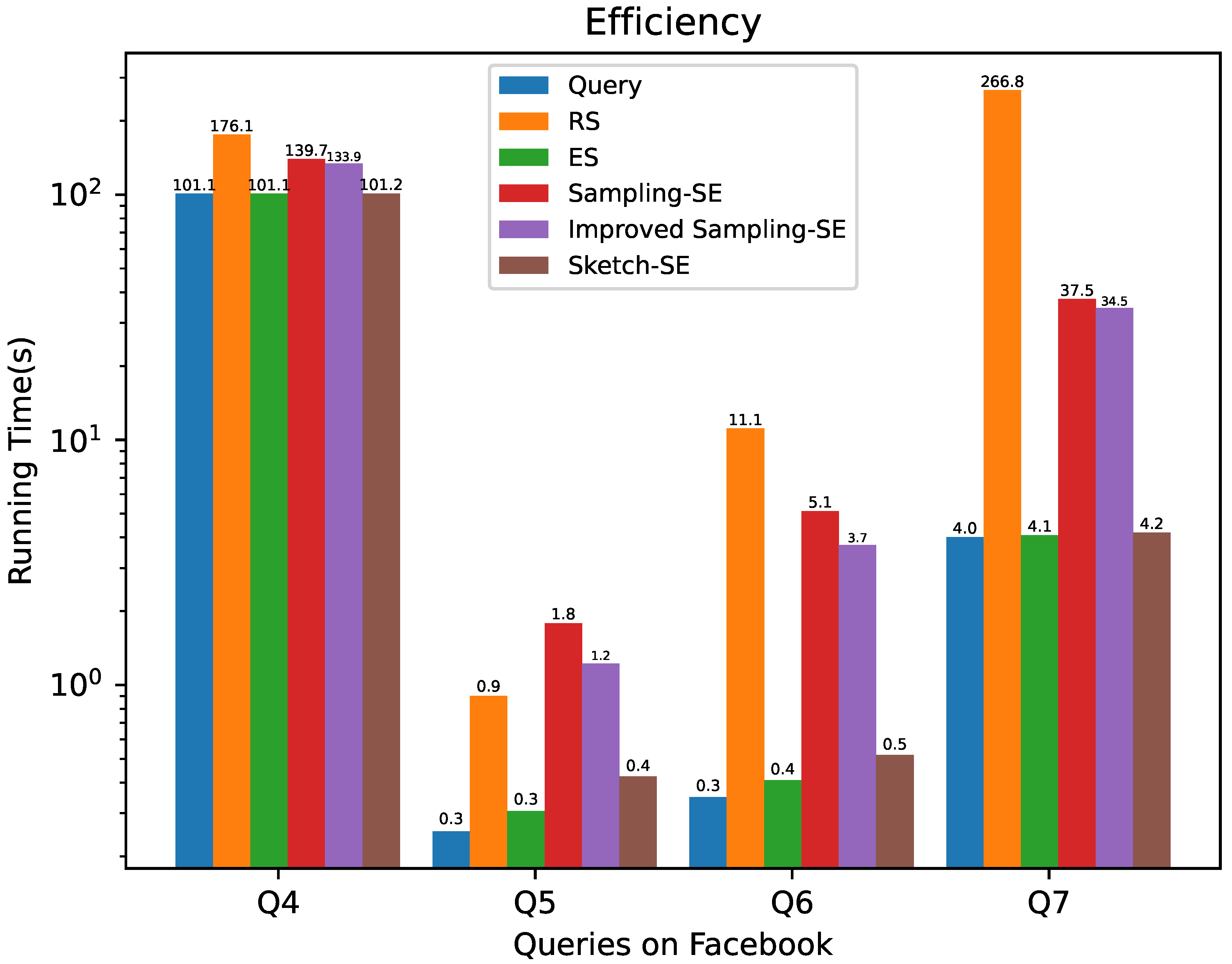
5.3. Efficiency
5.4. Impact of Parameters
5.5. Summary for Experimental Results
- •
- Sampling-SE and Sketch-SE both have higher efficiency than residual sensitivity for join queries with large-scale datasets;
- •
- With an appropriate sample rate, Sampling-SE has an equal level of accuracy to residual sensitivity while keeping a lower time overhead.
- •
- Sketch-SE has the same level of efficiency as elastic sensitivity but results in a relatively lower value of sensitivity, which leads to higher accuracy.
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Notation | Meaning |
| Privacy budget. | |
| The probability that pure differential privacy fails to hold. | |
| Local sensitivity of q on a database at distance k from I. | |
| The upper bound of computed by ES. | |
| The upper bound of computed by RS. | |
| The frequency of the most frequent value of attribute A. | |
| The maximum boundary of a residual query . | |
| A residual query on a subset E of a multi-join query q. | |
| The sample size for the ith group of residual query . | |
| Half-width of the confidence interval for the ith group of . | |
| g | The number of groups of a residual query. |
| J | Join size. |
| The probability that the confidence interval fails to hold. | |
| The AGMS sketch of a relation R. |
References
- Tabassum, S.; Pereira, F.S.; Fernandes, S.; Gama, J. Social network analysis: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1256. [Google Scholar] [CrossRef]
- Singh, S.S.; Muhuri, S.; Mishra, S.; Srivastava, D.; Shakya, H.K.; Kumar, N. Social network analysis: A survey on process, tools, and application. ACM Comput. Surv. 2024, 56, 1–39. [Google Scholar] [CrossRef]
- Chen, C.M.; Agrawal, H.; Cochinwala, M.; Rosenbluth, D. Stream query processing for healthcare bio-sensor applications. In Proceedings of the IEEE 20th International Conference on Data Engineering, Boston, MA, USA, 30 March–2 April 2004; pp. 791–794. [Google Scholar]
- Soni, K.; Sachdeva, S.; Minj, A. Querying Healthcare Data in Knowledge-Based Systems. In Proceedings of the International Conference on Big Data Analytics, Sorrento, Italy, 15–18 December 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 59–77. [Google Scholar]
- Bell, R.M.; Koren, Y. Lessons from the Netflix prize challenge. ACM Sigkdd Explor. Newsl. 2007, 9, 75–79. [Google Scholar] [CrossRef]
- Barbaro, M.; Zeller, T.; Hansell, S. A face is exposed for AOL searcher no. 4417749. New York Times 2006, 9, 8. [Google Scholar]
- Dwork, C. Differential Privacy. In Proceedings of the Encyclopedia of Cryptography and Security; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A.D. Calibrating Noise to Sensitivity in Private Data Analysis. In Proceedings of the Theory of Cryptography Conference, New York, NY, USA, 4–7 March 2006. [Google Scholar]
- Nissim, K.; Raskhodnikova, S.; Smith, A.D. Smooth sensitivity and sampling in private data analysis. In Proceedings of the Symposium on the Theory of Computing, San Diego, CA, USA, 11–13 June 2007. [Google Scholar]
- Johnson, N.M.; Near, J.P.; Song, D.X. Towards Practical Differential Privacy for SQL Queries. Proc. VLDB Endow. 2017, 11, 526–539. [Google Scholar] [CrossRef]
- Dong, W.; Yi, K. Residual Sensitivity for Differentially Private Multi-Way Joins. In Proceedings of the 2021 International Conference on Management of Data, Xi’an, China, 20–25 June 2021. [Google Scholar]
- Dobra, A.; Garofalakis, M.N.; Gehrke, J.; Rastogi, R. Processing complex aggregate queries over data streams. In Proceedings of the Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data, Madison, WI, USA, 3–6 June 2002; Franklin, M.J., Moon, B., Ailamaki, A., Eds.; ACM: New York, NY, USA, 2002; pp. 61–72. [Google Scholar] [CrossRef]
- Aydöre, S.; Brown, W.; Kearns, M.; Kenthapadi, K.; Melis, L.; Roth, A.; Siva, A. Differentially Private Query Release Through Adaptive Projection. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Wang, T.; Chen, J.Q.; Zhang, Z.; Su, D.; Cheng, Y.; Li, Z.; Li, N.; Jha, S. Continuous Release of Data Streams under both Centralized and Local Differential Privacy. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, Republic of Korea, 15–19 November 2021. [Google Scholar]
- Maruseac, M.; Ghinita, G. Precision-Enhanced Differentially-Private Mining of High-Confidence Association Rules. IEEE Trans. Dependable Secur. Comput. 2020, 17, 1297–1309. [Google Scholar] [CrossRef]
- Wang, T.; Li, N.; Jha, S. Locally Differentially Private Frequent Itemset Mining. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–23 May 2018; pp. 127–143. [Google Scholar]
- Triastcyn, A.; Faltings, B. Bayesian Differential Privacy for Machine Learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Zheng, H.; Ye, Q.; Hu, H.; Fang, C.; Shi, J. Protecting Decision Boundary of Machine Learning Model With Differentially Private Perturbation. IEEE Trans. Dependable Secur. Comput. 2020, 19, 2007–2022. [Google Scholar] [CrossRef]
- Jiang, H.; Pei, J.; Yu, D.; Yu, J.; Gong, B.; Cheng, X. Applications of Differential Privacy in Social Network Analysis: A Survey. IEEE Trans. Knowl. Data Eng. 2023, 35, 108–127. [Google Scholar] [CrossRef]
- Erlingsson, Ú.; Pihur, V.; Korolova, A. Rappor: Randomized aggregatable privacy-preserving ordinal response. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 1054–1067. [Google Scholar]
- Ding, B.; Kulkarni, J.; Yekhanin, S. Collecting telemetry data privately. Adv. Neural Inf. Process. Syst. 2017, 30, 3571–3580. [Google Scholar]
- McSherry, F. Privacy integrated queries: An extensible platform for privacy-preserving data analysis. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, Providence, RI, USA, 29 June–2 July 2009. [Google Scholar]
- Proserpio, D.; Goldberg, S.; McSherry, F. Calibrating Data to Sensitivity in Private Data Analysis. Proc. VLDB Endow. 2012, 7, 637–648. [Google Scholar] [CrossRef]
- Chaudhuri, S.; Ding, B.; Kandula, S. Approximate Query Processing: No Silver Bullet. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017. [Google Scholar]
- Ganguly, S.; Gibbons, P.B.; Matias, Y.; Silberschatz, A. Bifocal sampling for skew-resistant join size estimation. In Proceedings of the 1996 ACM SIGMOD International Conference on Management of Data, Montreal, QC, Canada, 4–6 June 1996; pp. 271–281. [Google Scholar]
- Estan, C.; Naughton, J.F. End-biased samples for join cardinality estimation. In Proceedings of the IEEE 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006; p. 20. [Google Scholar]
- Haas, P.J.; Hellerstein, J.M. Ripple joins for online aggregation. In Proceedings of the ACM SIGMOD Conference, Philadelphia, PA, USA, 1–3 June 1999. [Google Scholar]
- Li, F.; Wu, B.; Yi, K.; Zhao, Z. Wander Join: Online Aggregation via Random Walks. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Zhao, Z.; Christensen, R.; Li, F.; Hu, X.; Yi, K. Random Sampling over Joins Revisited. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018. [Google Scholar]
- Ioannidis, Y.E.; Christodoulakis, S. Optimal histograms for limiting worst-case error propagation in the size of join results. ACM Trans. Database Syst. (TODS) 1993, 18, 709–748. [Google Scholar] [CrossRef]
- Ioannidis, Y.E.; Poosala, V. Balancing histogram optimality and practicality for query result size estimation. ACM Sigmod Rec. 1995, 24, 233–244. [Google Scholar] [CrossRef]
- Bater, J.; Park, Y.; He, X.; Wang, X.; Rogers, J. Saqe: Practical privacy-preserving approximate query processing for data federations. Proc. VLDB Endow. 2020, 13, 2691–2705. [Google Scholar] [CrossRef]
- Ock, J.; Lee, T.; Kim, S. Privacy-preserving approximate query processing with differentially private generative models. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; pp. 6242–6244. [Google Scholar]
- Alon, N.; Gibbons, P.B.; Matias, Y.; Szegedy, M. Tracking join and self-join sizes in limited storage. In Proceedings of the Eighteenth ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Philadelphia, PA, USA, 31 May–2 June 1999; pp. 10–20. [Google Scholar]
- Charikar, M.; Chen, K.; Farach-Colton, M. Finding frequent items in data streams. In Proceedings of the International Colloquium on Automata, Languages, and Programming, Malaga, Spain, 8–13 July 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 693–703. [Google Scholar]
- Cormode, G.; Muthukrishnan, S. An improved data stream summary: The count-min sketch and its applications. J. Algorithms 2005, 55, 58–75. [Google Scholar] [CrossRef]
- Vengerov, D.; Menck, A.C.; Zaït, M.; Chakkappen, S. Join Size Estimation Subject to Filter Conditions. Proc. VLDB Endow. 2015, 8, 1530–1541. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, X.; Yin, L. Sketches-based join size estimation under local differential privacy. In Proceedings of the 2024 IEEE 40th International Conference on Data Engineering (ICDE), Utrecht, The Netherlands, 13–16 May 2024; pp. 1726–1738. [Google Scholar]
- Cormode, G.; Garofalakis, M. Sketching streams through the net: Distributed approximate query tracking. In Proceedings of the 31st International Conference on Very Large Data Bases, Trondheim, Norway, 30 August–2 September 2005; pp. 13–24. [Google Scholar]
- Kim, A.; Blais, E.; Parameswaran, A.G.; Indyk, P.; Madden, S.; Rubinfeld, R. Rapid Sampling for Visualizations with Ordering Guarantees. Proc. VLDB Endow. 2015, 8, 521–532. [Google Scholar] [CrossRef] [PubMed]
- Hoeffding, W. Probability Inequalities for Sums of Bounded Random Variables. J. Am. Stat. Assoc. 1963, 58, 13. [Google Scholar] [CrossRef]
- Rusu, F.; Dobra, A. Sketches for size of join estimation. ACM Trans. Database Syst. (TODS) 2008, 33, 1–46. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Liu, X.; Yin, L. Sensitivity Estimation for Differentially Private Query Processing. Appl. Sci. 2025, 15, 7667. https://doi.org/10.3390/app15147667
Zhang M, Liu X, Yin L. Sensitivity Estimation for Differentially Private Query Processing. Applied Sciences. 2025; 15(14):7667. https://doi.org/10.3390/app15147667
Chicago/Turabian StyleZhang, Meifan, Xin Liu, and Lihua Yin. 2025. "Sensitivity Estimation for Differentially Private Query Processing" Applied Sciences 15, no. 14: 7667. https://doi.org/10.3390/app15147667
APA StyleZhang, M., Liu, X., & Yin, L. (2025). Sensitivity Estimation for Differentially Private Query Processing. Applied Sciences, 15(14), 7667. https://doi.org/10.3390/app15147667