1. Introduction
Data and information collected from the human body are becoming increasingly rich and varied because of recent technological advancements in data collection and storage. Research studies have been conducted in various fields, including healthcare, virtual environments, and the clothing industry, to collect data on the human body using the Internet of Things (IoT) and to measure the human body using artificial intelligence (AI) technologies such as machine learning and deep learning [
1,
2,
3,
4]. Therein, the human body is measured to extract body data and information such as height, weight, body shape, and posture, which are used primarily for medical, safety, and aesthetic purposes [
5,
6,
7,
8]. For example, in the healthcare industry, the analysis of such information as height, weight, and body shape through body estimation is used in research on obesity management [
9,
10]. In sectors such as personal healthcare and virtual clothing try-on, photos and videos of the user’s body are used to provide personalized services. In recent years, research on the human body has also been conducted vigorously in industries associated with the Fourth Industrial Revolution. In autonomous transportation, pedestrians are detected using cameras installed on autonomous vehicles or CCTV images installed in road infrastructure, and pedestrian intentions (i.e., whether the pedestrian stops or crosses the road) are analyzed [
11]. The analyzed pedestrian intentions are applied to route planning and secure operation of autonomous vehicles [
12]. In virtual reality, body shape information is extracted from human images and used to create the user’s avatar on the metaverse [
13].
Height, weight, morphology, and posture are frequently obtained from the human body for use in studies on the human body. Body shape data can be gathered using both direct and indirect methods. Direct measurement is performed via the manual collection of information, such as height, weight, and torso circumference, using a tape measure, scale, etc. [
14]. On the other hand, indirect measurements collect such information as posture and body shape through the use of computational technology [
15,
16].
Early research on the human body relied predominantly on direct measurement techniques to gather body data [
17,
18,
19]. However, using direct measurement methods to acquire data can be time-consuming and, depending on the measurement tool, inaccurate. Therefore, as computational technology advanced, research on the human body has relied primarily on indirect measurement techniques [
20,
21,
22]. Examples include image processing algorithms and deep learning to capture data from images of the human body [
15,
16]. However, indirect measurement methods can be extremely inaccurate because the data collected are affected by the clothes worn on the body, necessitating that subjects wear minimal or skin-tight clothing [
23,
24]. These requirements have led to problems such as invasion of privacy and resistance to measurement.
Accordingly, this study aimed to design a body shape inference method that performs well even when the subject wears loose or occlusive garments. Our goal was to develop a robust and practical solution that enables indirect measurement while addressing privacy and usability concerns. Various studies have been conducted to infer body regions covered by clothes and determine body shapes. However, previous research studies had limitations, such as low accuracies of body shape measurement owing to the shape of clothing [
25,
26,
27] and high computation times for the parametric generation model [
28,
29,
30,
31]. Recently, some studies have attempted to overcome these limitations by addressing the problem of 3D human body reconstruction under clothing. For example, [
32] proposed a method that generates realistic clothing deformation based on SMPL body meshes and 3D supervision. However, this approach requires high-resolution 3D ground-truth data obtained through detailed full-body scans, which are typically available only in synthetic datasets or in strictly controlled laboratory environments.
Unlike prior works that relied on texture-based cues or required skin-tight garments, our model explicitly integrates joint-based spatial structure and surface geometry to improve reconstruction accuracy under occlusions.
Therefore, this study sought to reduce training time by developing an algorithm that could estimate the human body while the body is covered by various garments. To determine the characteristics of a body wearing clothes, we used the Human Body Estimator. Body features can be identified based on derivations of the coordinates of the major joints of the body [
33], which can be used to identify body information, such as regarding the arms, legs, shoulders, and pelvis, that is unique to each individual. In this study, we aimed to generate body shapes with no missing areas by including position information for unstructured body elements, such as body angles and positions, when deriving body features.
Building on this motivation, we propose Pix2Body, a pose-guided conditional generative adversarial network (GAN) that reconstructs full 3D human body shapes from a single RGB image of a clothed person. A conditional generative adversarial network (cGAN) is a variant of a GAN in which both the generator and the discriminator are conditioned on additional inputs such as pose, semantic maps, or other structural priors. This allows the network to generate context-aware outputs and is particularly useful for structured prediction tasks. By leveraging 2D joint coordinates and both front-view and back-view normal maps as auxiliary inputs, our method achieves accurate and realistic reconstruction even in occluded regions, such as folded arms or skirt-covered legs.
Unlike conventional approaches such as Pix2Pix that rely solely on texture mappings, Pix2Body incorporates spatial priors derived from pose and surface cues, enabling improved structural reasoning. Furthermore, unlike recent state-of-the-art models such as PIFuHD, ICON, or ROMP that often require multi-view images, dense supervision, or parametric mesh fitting, Pix2Body is designed to operate with only single-view RGB images and lightweight annotations. This makes our method highly practical and scalable for real-world applications, especially in scenarios with limited data or real-time processing constraints. This hybrid design enhances both reconstruction accuracy and surface detail quality, even under clothing-induced occlusion.
We validated the effectiveness of our framework through experiments on a custom dataset of 190 clothed individuals with diverse body types and poses. The results show that Pix2Body delivers superior performance in both quantitative metrics (e.g., SSIM) and qualitative realism, providing a practical and efficient solution for non-invasive, indirect body measurement.
While previous pose-guided or SMPL-based frameworks often required 3D mesh supervision or optimization-based inference, Pix2Body introduces a lightweight approach that combines pose estimation and normal maps within a conditional GAN framework. This combination has been relatively underexplored in prior research, and our work aimed to implement it in a practical and application-oriented manner.
The main contributions of this study are summarized as follows:
We propose Pix2Body, a pose-guided conditional GAN that reconstructs full-body 3D shapes from clothed RGB images.
Our model integrates 2D joint coordinates and front/back normal maps to enhance performance in occluded areas.
The method supports non-invasive body modeling without requiring skin-tight clothing.
We constructed a dataset of 190 individuals with diverse poses and garments for robust evaluation.
The experimental results confirm the model’s capability to infer realistic body shapes even in challenging conditions.
The remainder of this paper is structured as follows.
Section 2 reviews related works on human body shape estimation and generative models.
Section 3 presents the proposed method, including data preprocessing, network design, and loss functions.
Section 4 describes the experimental setup and evaluation results.
Section 5 discusses the findings and limitations. Finally,
Section 6 concludes the paper and outlines directions for future work.
2. Related Works
2.1. Research on Body Shape Inference
Based on the type of data they use, body shape inference methods can be divided into four categories: three-dimensional (3D) sequences, single 3D scans, single RGB images, and multi-view RGB images. Methodologies that use depth cameras, 3D scanners, etc., to infer the shape of the naked body use 3D sequences and single 3D images, whereas the remaining types use data acquired using regular cameras.
Three-dimensional image data are collected largely using Microsoft’s Kinect cameras. To infer the disrobed body and the corresponding parametric model, the collected data are translated into a 3D sequence [
34,
35]. However, these technologies are hampered by the high cost of depth cameras used to capture 3D images. They also necessitate creating algorithms that transform 3D images into a series and algorithms that ideally match the parameters of the parametric model with the resulting 3D image sequence, both of which tend to be complicated. Even if the 3D image sequence is converted, and parametric model matching is utilized to infer the unclothed body, matching the ideal parametric model requires a long time. Furthermore, to acquire 3D images, participants must wear skin-tight clothing, which can lead to difficulties such as invasion of privacy and refusal to participate.
To address these problems, efforts have been made to develop methods of deducing the body shape of an unclothed person from a single 3D image [
26,
27]. For example, some of these methods infer the body shape from a single 3D image and weight based on the sizes of the clothes. However, there are problems with these techniques, such as setting weights for various clothing sizes and the accuracy of the body shape generated based on the selection of the range of clothing, and the drawback of utilizing a parametric model. As indicated earlier, this model requires a long computation time. Even recent studies focusing on 3D optical imagery have aimed to improve accuracy by applying deep 3D convolutional networks and non-linear regression, acknowledging the limitations of previous linear algorithms [
36].
To lower the cost of 3D image acquisition, RGB images have recently been utilized to infer unclothed body shapes [
28,
29,
30,
31]. Image processing algorithms, deep learning methodologies, and other techniques have been used in these research studies to extract body silhouettes and body joint points from photos and match them with parametric models to construct body shapes. However, there are drawbacks, such as limited postures for acquiring body silhouettes and joint points from test subjects, and the low accuracy of body shapes generated by image processing algorithms and deep learning approaches. To overcome these challenges, recent research has introduced more sophisticated approaches. For instance, SHAPY tackles the scarcity of paired image and 3D scan data by training a network with easily obtainable anthropometric measurements and linguistic shape attributes, thereby improving 3D body shape regression from a single image [
37]. Similarly, the GenHMR framework reformulates the problem by explicitly modeling uncertainties in the 2D-to-3D mapping, which improves the estimation of 3D pose and shape, especially in cases with occlusions [
38].
2.2. Research on Body Shape Generation Models
In general, parametric models are used to generate unclothed body shapes from 2D images. Well-known parametric models employed in research studies include Shape Completion and Animation of PEople (SCAPE) and Skinned Multi-Person Linear (SMPL) model body parameters [
39,
40].
The SCAPE model estimates a naked body shape by matching the pose of a person in a single RGB image to a SCAPE model [
25]. However, studies using the SCAPE model suffer from the limited pose range of the model, which requires the subject to assume a precise pose in their photos. Furthermore, the generated body shape may be excessively smooth. To solve these challenges, researchers created body shapes using SMPL, a body joint point parameter model [
28,
30,
41]. Deep learning approaches are used by SMPL researchers to extract body joint locations from photos. To generate a body shape, the extracted body joint points are matched with the optimal SMPL parameters, and a pre-trained body shape template is output. This process of personalizing body models continues to be an active area of research, with recent studies exploring advanced mesh morphing techniques to generate personalized human body models from baseline templates such as VIVA+ by using statistical models such as SMPL and OSSO [
42]. However, these approaches are disadvantaged by the computing time required to optimize and recreate the SMPL parameters.
Past research studies on unclothed body shape generation and body shape creation suffered from high camera costs for data collection, poor accuracy due to different clothing shapes, and extensive computational times of optimization with parametric models [
43]. In this study, we propose a low-cost method for inferring the unclothed body shape from a single 2D image, where the method is not hampered by the shape of the clothing [
44,
45].
3. Materials and Methods
3.1. Materials
The dataset employed in this study is the Synthetic Human Avatars under wiDE gaRment (SHADER) dataset.
Figure 1 shows samples from the SHADER dataset, which is a synthetic dataset of avatars in the SMPL model with diverse body shapes, postures, clothes, and skin tones [
26]. The dataset is available at
https://github.com/YCL92/SHADER (accessed on 5 July 2023). A dataset of paired clothed and unclothed images is required to infer body shapes from photos of people wearing clothes, which is the objective of this study. Therefore, we chose SHADER for this study, as it provides paired clothed and unclothed images and a wide variety of clothing styles. The dataset contains 22,493 training pairs and 6548 test pairs, all scaled to 256 × 256 pixels. The training settings include a batch size of 16, a learning rate of 0.0002, the Adam optimizer, and 200 training epochs.
3.2. Development and Implementation of the Pix2Body Algorithm
3.2.1. Pose Estimation—BlazePose
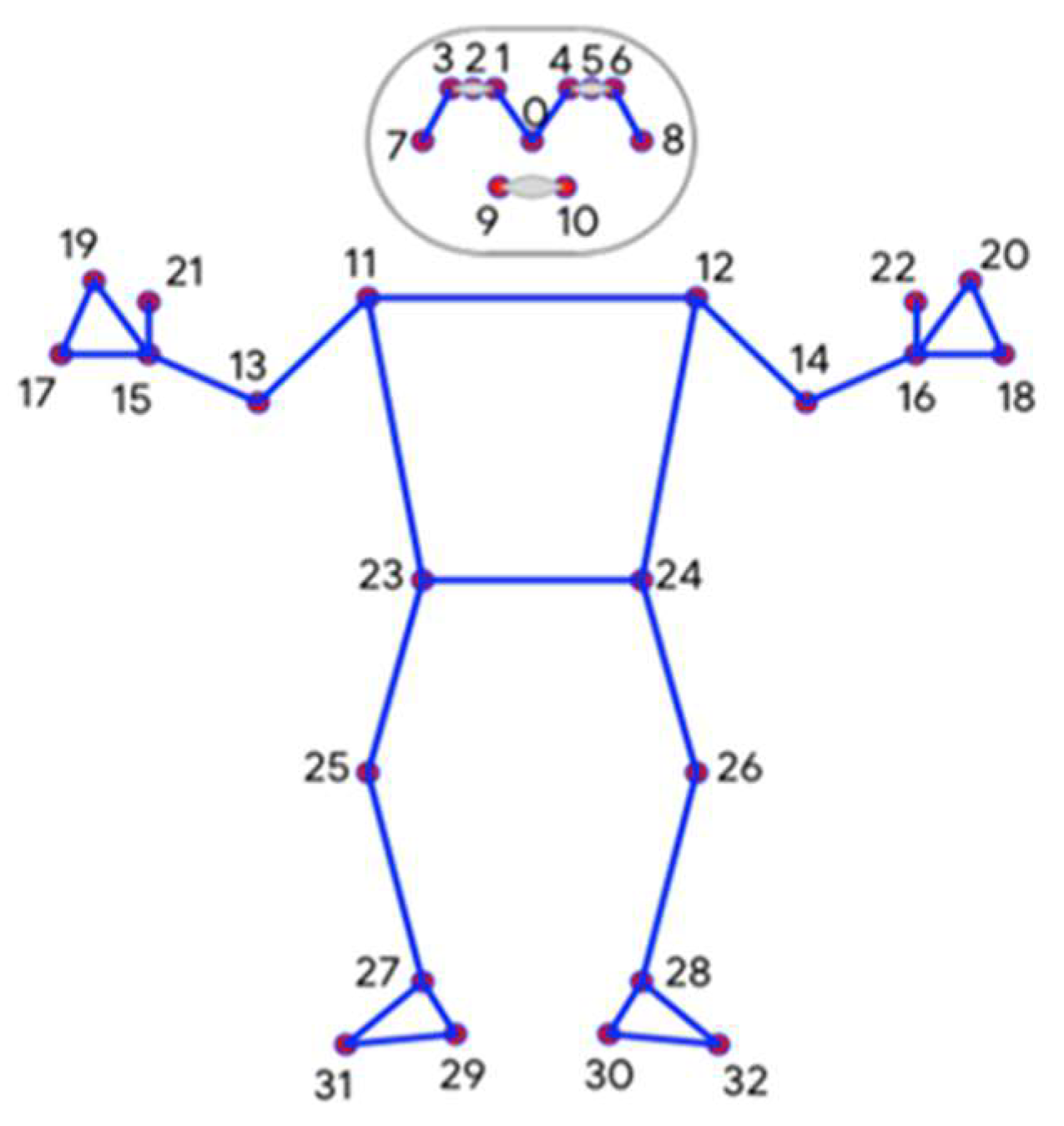
Pose estimation recognizes and estimates human posture based on the x- and y-coordinates of body joints in an image. Because of recent advances in deep learning, posture estimation has become more accurate, and its applications have expanded to posture correction, behavior recognition, and abnormal behavior detection. In this study, BlazePose is used to calculate the body joint points. First, unlike other models, BlazePose can infer the orientation of the feet and hands, estimate the size of the upper body, and use facial features to distinguish between the front and the back.
Figure 2 illustrates the key points used in BlazePose. Second, the ability to estimate body joints hidden by clothing is essential for inferring body shape. BlazePose’s visibility classifier features can be used to determine body joints that are obscured by clothes. Third, to be applicable in diverse industries, the developed algorithm should also be able to perform real-time inference on CPUs. For these reasons, the BlazePose model is used to derive body information in this study.
3.2.2. Pix2Pix
The baseline model for the algorithm developed in this study is Pix2Pix [
44], an image-to-image translation algorithm. Image-to-image translation is a subfield of computer vision that attempts to match an input image to an output image. The conventional generative adversarial network (GAN) model is composed of generator and discriminator models, with the generator producing a random image from the noise z. However, the discriminator evaluates whether a generated image is real or fake, rather than generating an image itself. By contrast, Pix2Pix’s generator takes one image as input and creates an image as an auto-encoder. Because Pix2Pix’s generator has a U-net structure, it reduces the information loss in the input image by connecting features in the encoder’s down-sampling layer to the up-sampling layer. This enables Pix2Pix to generate output images that are associated with the input image rather than generate random images, which is consistent with the objective of this study of generating unclothed body shapes from clothed body shapes. However, Pix2Pix alone relies solely on texture-level supervision and lacks the ability to handle spatial structure under occlusions. Therefore, we propose Pix2Body, a novel extension that incorporates pose-derived joint coordinates and surface geometry to more accurately reconstruct body shapes even under loose or occlusive garments. Our proposed framework is built upon a conditional generative adversarial network (cGAN) architecture. In this structure, the generator creates human body shapes conditioned on 2D joint coordinates and front/back normal maps, while the discriminator evaluates the realism of the generated outputs under the same conditions. Unlike standard GANs that generate outputs from random noise, cGANs enable structurally consistent generation aligned with the given inputs, making them highly suitable for tasks such as body shape reconstruction under occlusion. This architectural decision reflects the limitations of conventional CNN or YOLO-style networks in spatially constrained image generation and enhances Pix2Body’s ability to infer anatomically plausible body structures.
We propose the Pix2Body algorithm as a baseline model by integrating pose estimation with the Pix2Pix algorithm. The proposed Pix2Body algorithm is divided into two steps. The first step is to extract body shape information via pose estimation, and the second step is to generate a human body using the body information retrieved via the generator. The input and output data for each step are shown in
Table 1.
3.2.3. Body Key Point Estimator
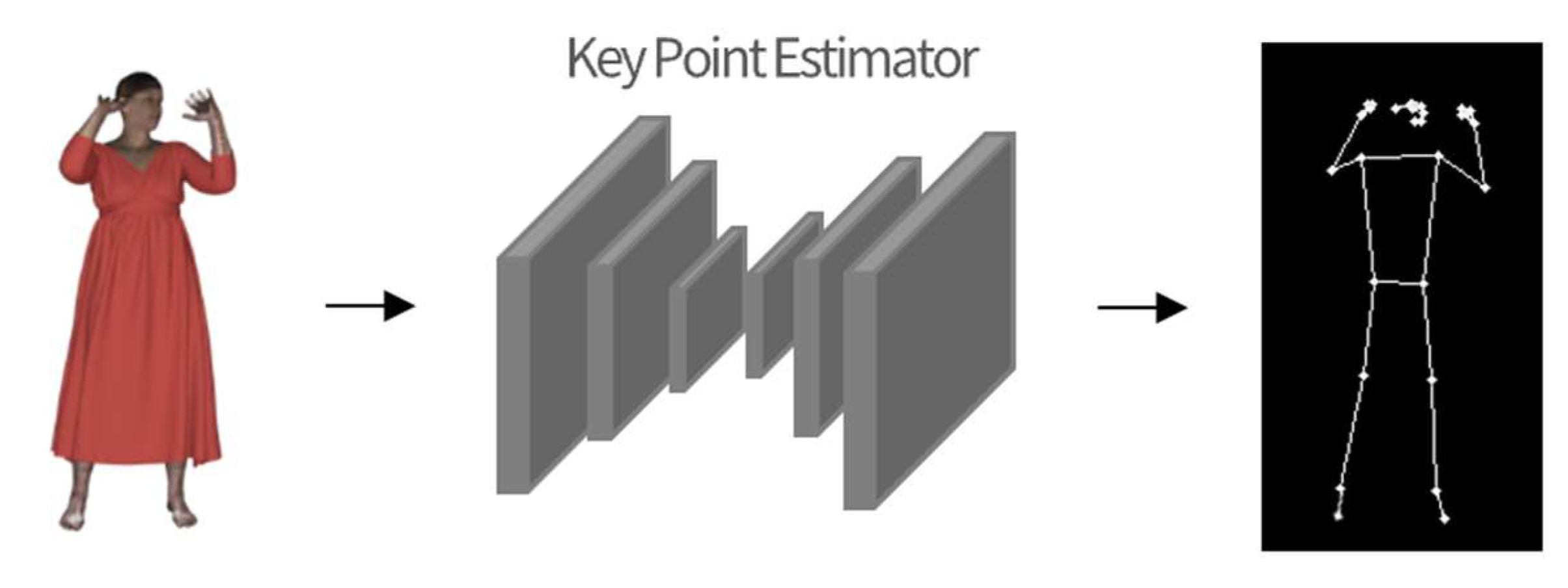
The Body Key Point Estimator attempts to extract information about body shape from a normalized full-body image of a clothed subject.
Figure 3 depicts the process of extracting body features.
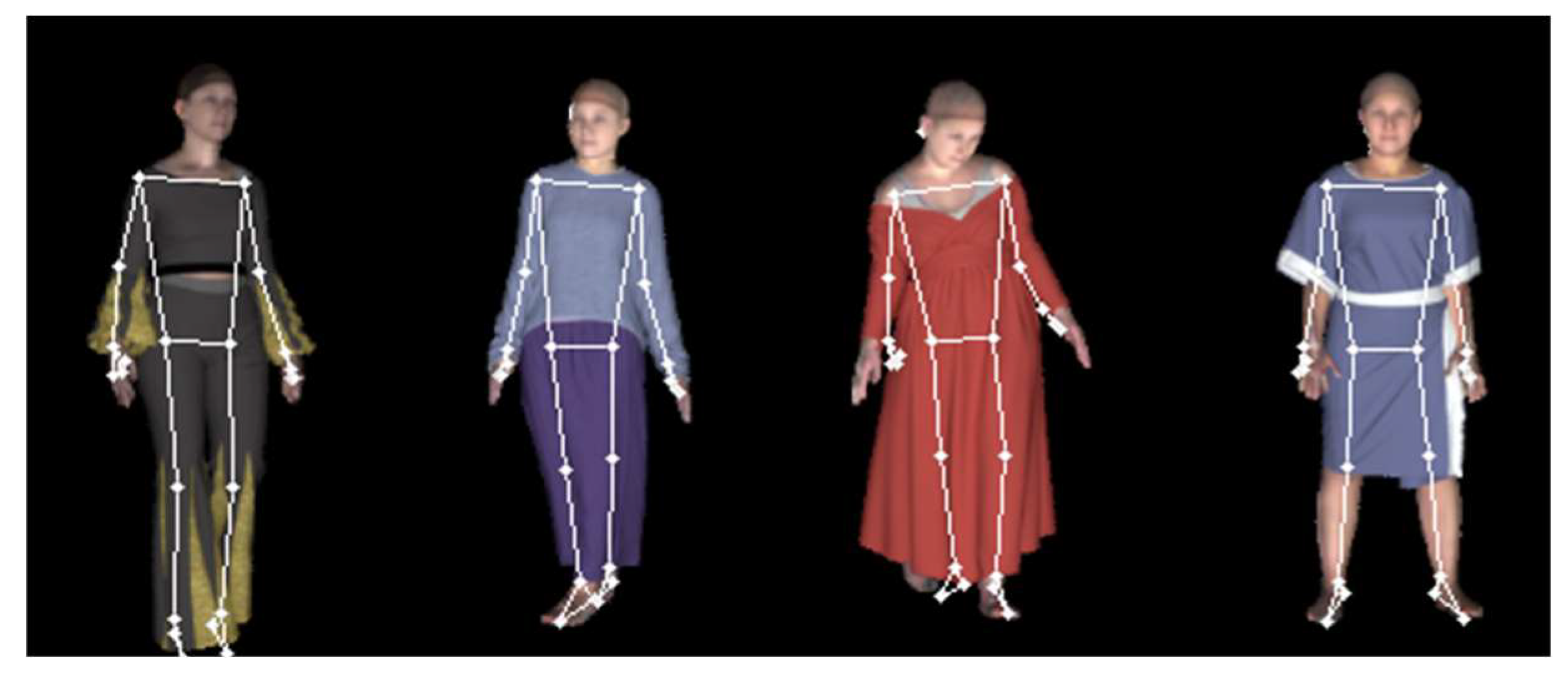
Long skirts, clothes that are larger than the actual body shape, dresses, or pants with wide legs, as illustrated in
Figure 4, make it difficult to evaluate body shape because it is difficult to distinguish between the clothes and the body. As a result, this study sought to extract body features that represent body parts that are obscured by clothes. Body key points are used in this study for two reasons: to generate body shapes without missing obscured body parts and to provide additional information to determine the exact location of the body when creating unclothed body shapes.
Figure 5 shows the outcome of extracting important points on the body using BlazePose. The body key points extracted by the Body Key Point Estimator, combined with a generalized full body shot, are used as additional information on the body shape as input for the next step of the generator.
3.2.4. Body Shape Generator
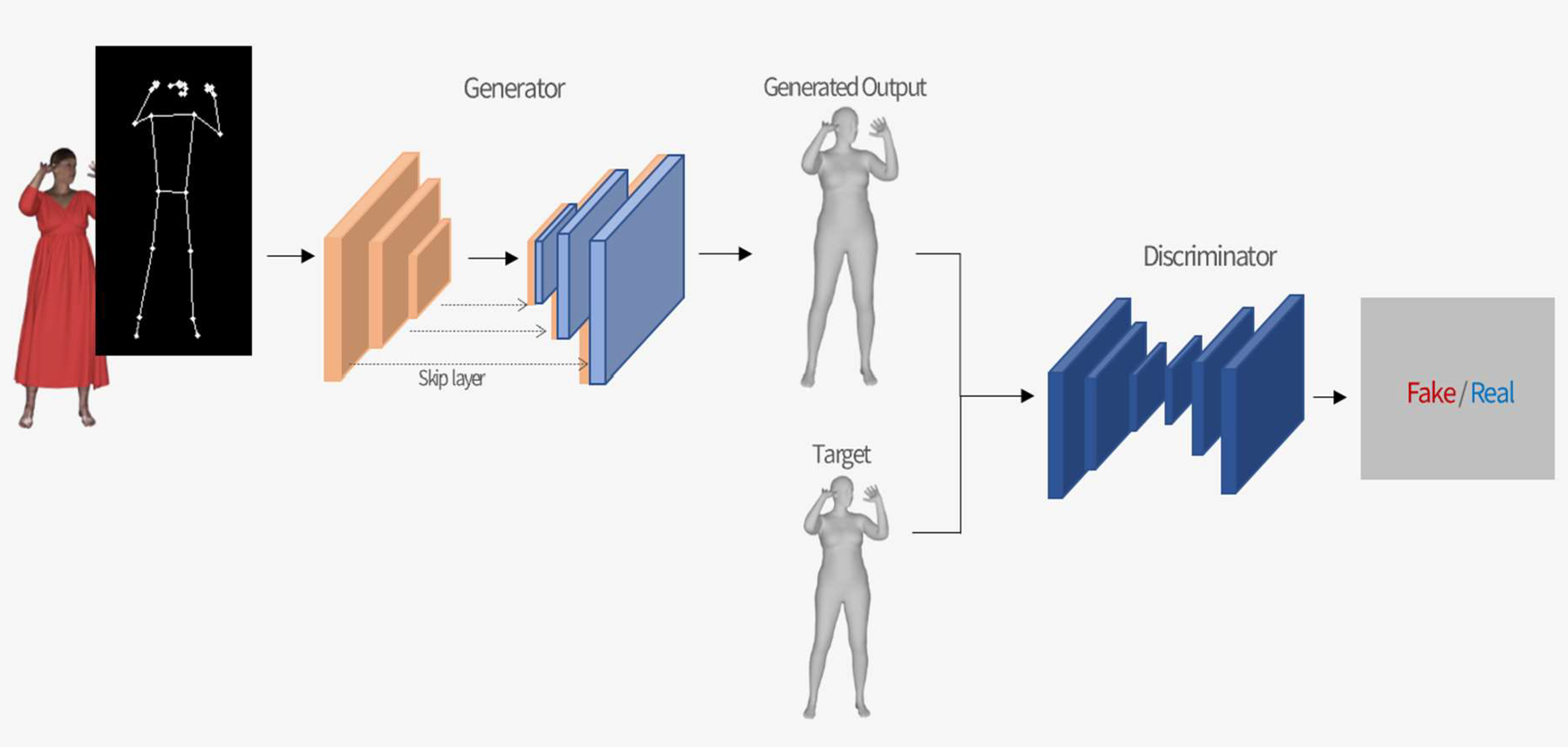
The proposed Pix2Body algorithm consists of two main stages: (1) body key point estimation and (2) body shape generation.
Figure 6 illustrates the complete end-to-end pipeline of Pix2Body, which integrates both stages. First, the Body Key Point Estimator extracts pose information from the clothed input image. These key points are aligned with the input image size and concatenated with the original image to serve as input for the generator.
This figure illustrates the full pipeline from key point estimation to body shape generation and discrimination. The clothed image and extracted key points are jointly used as input for the generator, which synthesizes an unclothed body image. The discriminator then distinguishes between the real and generated body shapes.
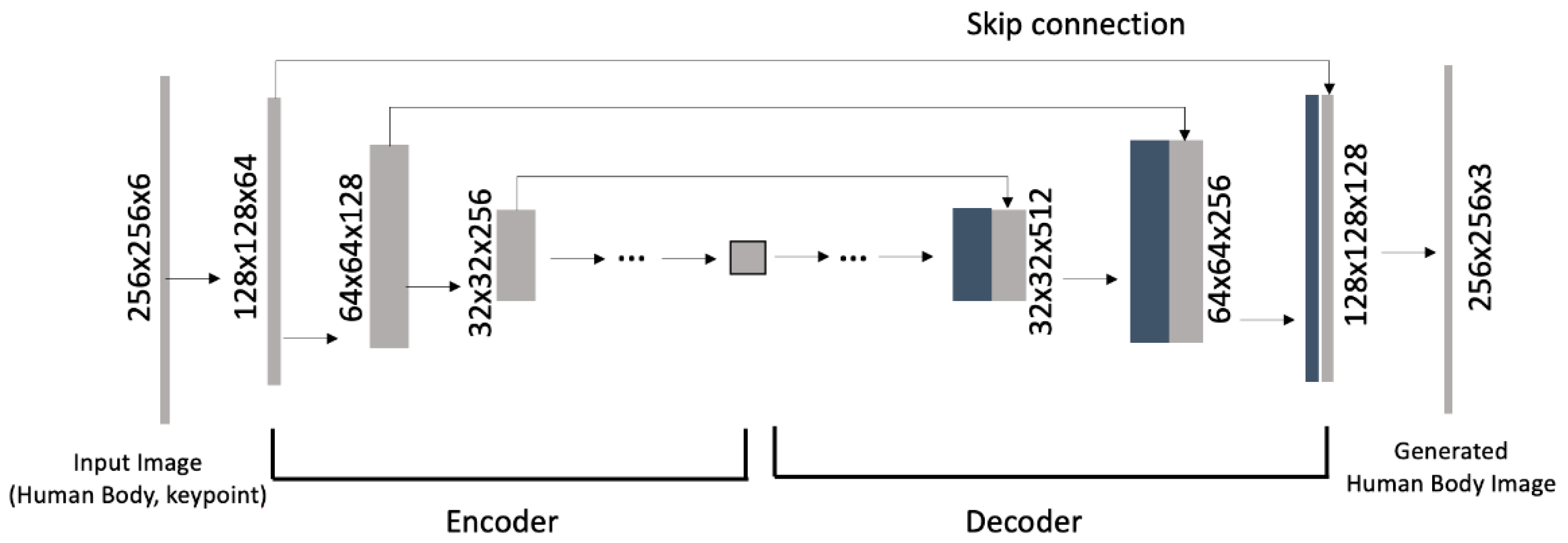
The generator is designed based on a U-net structure to minimize the loss of input information and produce a photo-realistic estimation of the human body beneath clothing. Unlike the original Pix2Pix model, which performs image-to-image translation using only RGB textures, the proposed generator incorporates both the RGB image and the structural pose information to enhance the accuracy of body shape reconstruction, particularly in occluded areas such as folded arms or wide garments.
While Pix2Pix performs a 1:1 mapping between input and output, Pix2Body extends this by performing n:1 mapping, where pose information acts as additional guidance. This helps preserve body proportions even when large parts are concealed.
Figure 7 shows the architecture of the Pix2Body generator.
3.2.5. Body Shape Discriminator
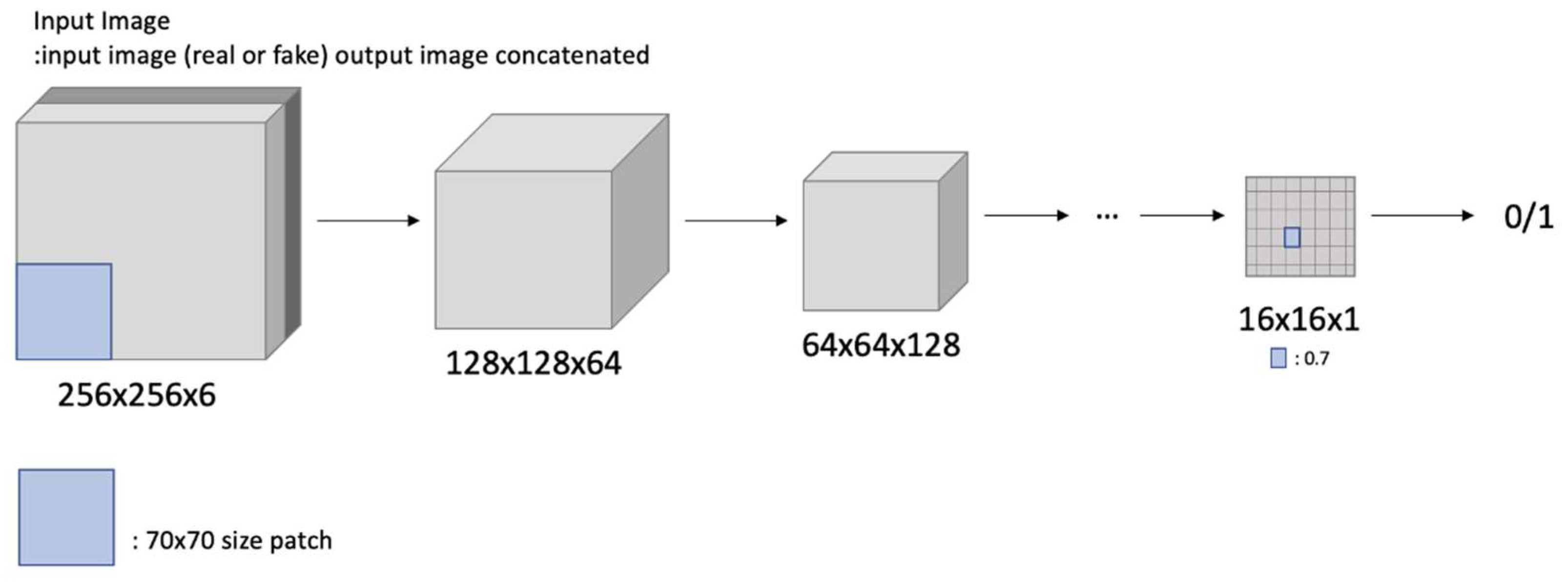
The discriminator assesses whether the input image, the generated image, and the correct image are paired. Instead of looking at the complete image, the patch GAN in the discriminator reads information by detecting areas of a given size in patches [
28]. It is faster and can determine the authenticity of the image formed by the generator with more details by executing operations in small image patches.
Figure 8 shows the architecture of the Pix2Body’s discriminator patch GAN.
3.2.6. Loss Function
In this study, we used two loss functions to train the architecture. First, the GAN loss was trained using the probability value of whether the image was identical to the correct image. Equation (1) expresses the GAN loss, where x represents the input image and y represents the correct image. The discriminator expresses the relationship between the correct image and the created image using 0 and 1. Specifically, it seeks to output 0 when the image is generated by the generator and 1 when it is a proper image. The purpose of the generator is to persuade the discriminator that the created image is the proper image. Consequently, in the context of Equation (1), the generator learns to minimize, while the discriminator learns to maximize.
When designing the loss function of the generator, we added a GAN loss to show the similarity to the correct image and a reconstruction loss to ensure that the image was similar to the correct image. In this study, we used the L1 loss to quantify the similarity (distance) between the correct image and the data generated by the generator. The L1 loss is defined in Equation (2). As shown in this equation, we find the absolute value of the error between the correct image and the generated image and sum the errors.
The final loss function is expressed by Equation (3). In this study, the loss function combined the GAN loss and the L1 loss to limit the tendency of the L1 loss to create blurred results and of the GAN loss to provide results that differ from the correct value. As indicated earlier, the discriminator is trained to maximize, while the generator is trained to minimize. Furthermore, by conditioning the generation process on body key point information, we introduced a spatial prior that helped guide the generator toward anatomically coherent outputs. This integration alleviates the limitations of texture-only supervision, which often fails to preserve correct body proportions under occlusion.
4. Results
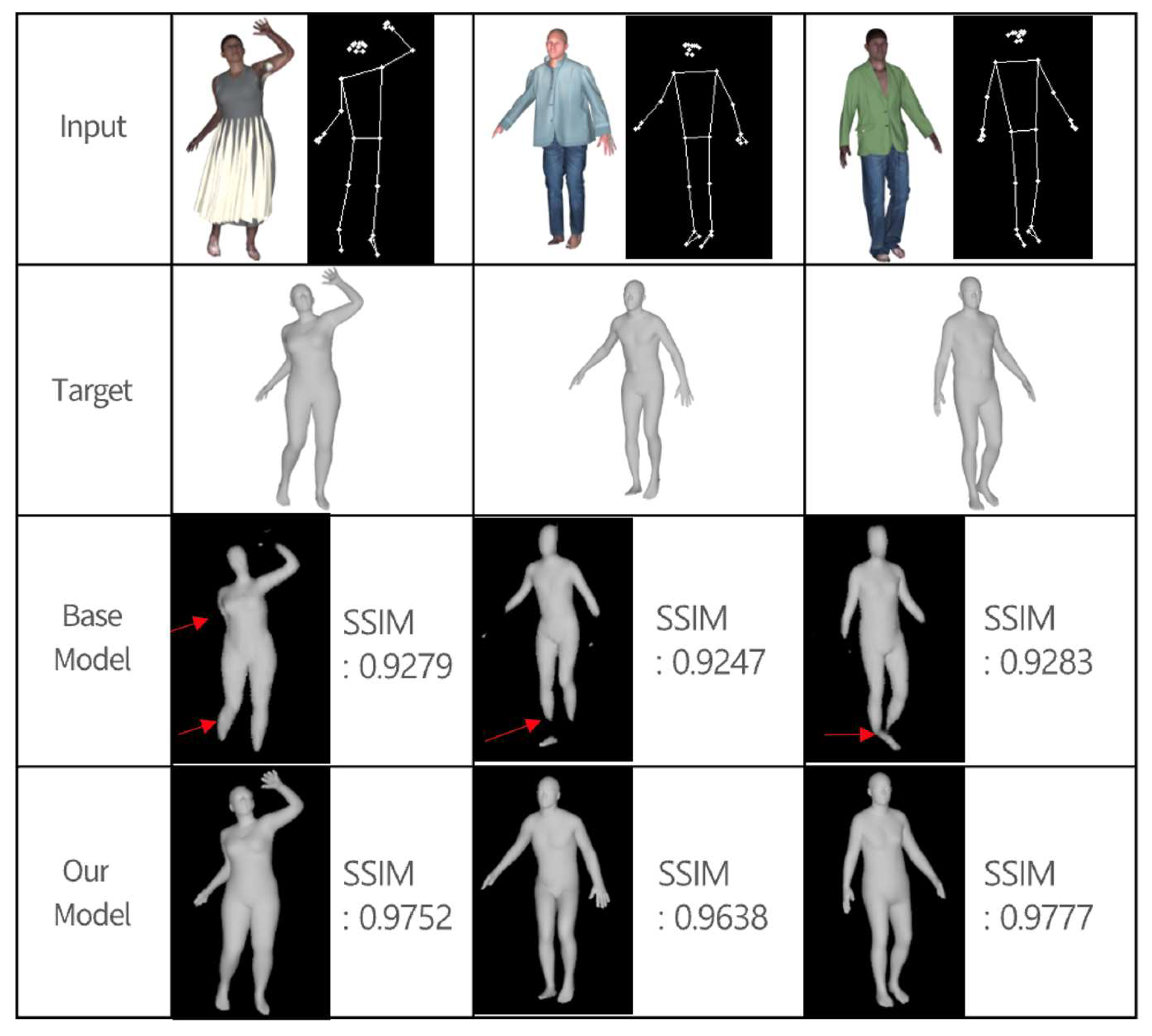
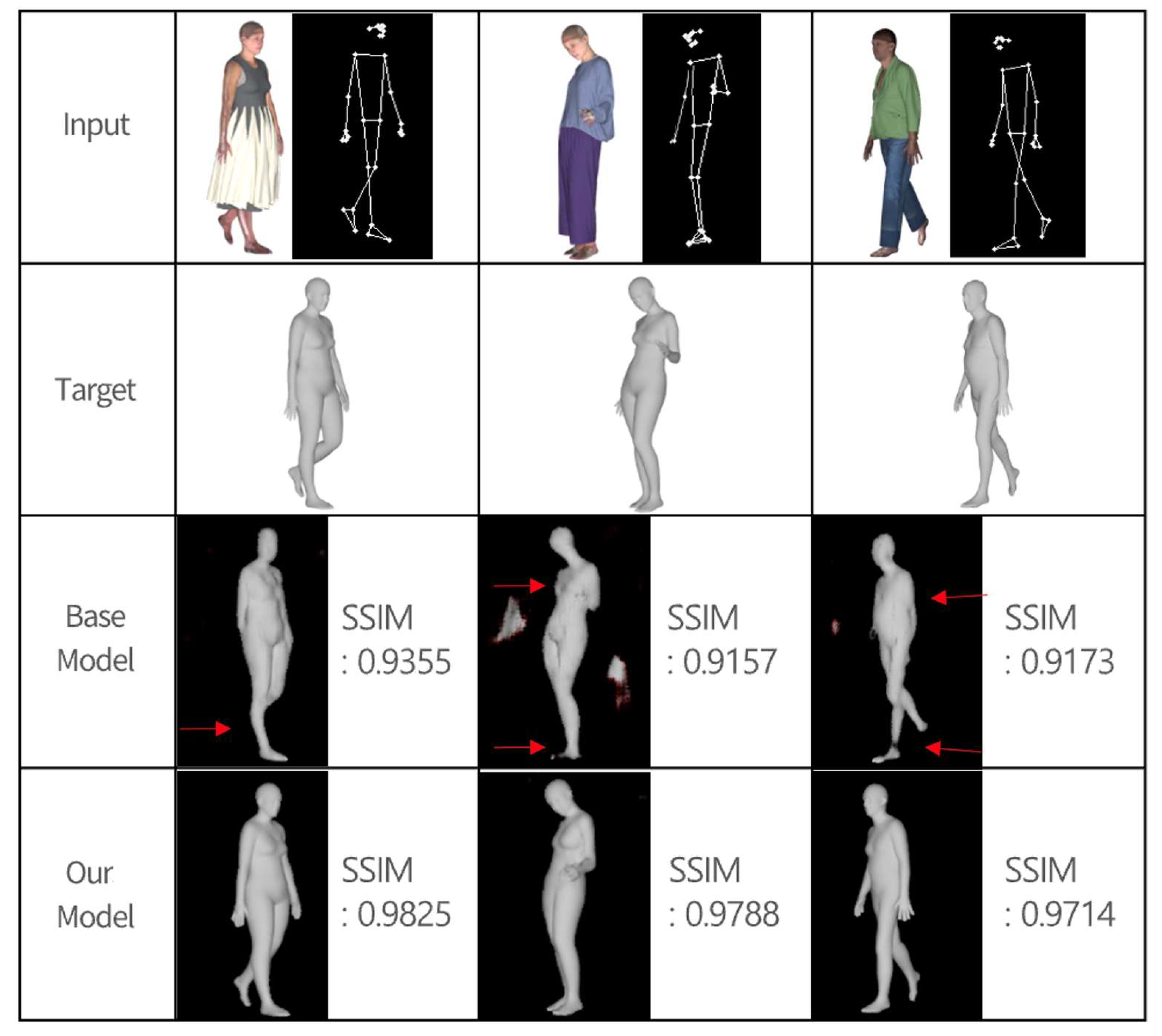
Samples of the findings of a qualitative comparison of the base and proposed models based on the front and side datasets are shown in
Figure 9 and
Figure 10. Pix2Body successfully infers body shape despite the presence of occluded parts that conceal the body shape, such as a skirt that covers the entire lower body or a shirt that is significantly larger than the upper body size, as illustrated in
Figure 9. In the case of the baseline model, the results on the side dataset, in contrast to those on the front dataset, clearly show missing regions, particularly in the arms and legs. By contrast, Pix2Body is able to reconstruct regions that are difficult to infer in both the front and side parts of the body, such as body bends and unstructured arms and legs. The model also successfully generates the body shape even in dynamic postures; this is because we included datasets for both static and dynamic postures in the training. Pix2Body significantly outperforms the baseline model (Pix2Pix).
Table 2 presents a summary of the SSIM scores and visual comparisons between the baseline and the proposed models under both front and side views. The structural similarity index measure (SSIM) quantitatively evaluates the perceptual similarity between the predicted and ground-truth images by considering luminance, contrast, and structural information. Higher SSIM scores indicate better reconstruction quality. It has also been determined that including body information, such as foot orientation and upper body size, using body joint points allows for a more accurate body shape to be generated.
For the quantitative comparison, we used three metrics: root mean square error (RMSE), peak signal-to-noise ratio (PSNR), and structural similarity index measure (SSIM). These metrics evaluate how closely the generated images match the corresponding ground-truth images. RMSE quantifies the average pixel-wise difference between the generated and reference images. It is calculated as the square root of the mean of squared differences between pixel values. A lower RMSE indicates higher similarity and better reconstruction accuracy. PSNR measures the ratio between the maximum possible signal (pixel intensity) and the distortion caused by the reconstruction process, expressed in decibels (dB). It is based on the mean square error (MSE) and is commonly used to evaluate the fidelity of lossy image compression or generation. A higher PSNR indicates better image quality. SSIM assesses perceptual image quality by comparing luminance, contrast, and structural information between two images, mimicking human visual perception. SSIM values range from 0 to 1, where values closer to 1 indicate higher structural similarity. The mathematical formulations of these metrics are presented as follows:
Equation (4) defines RMSE as the square root of the average squared difference between each corresponding pixel of the predicted image and the ground-truth image , where denotes the total number of pixels. A lower RMSE indicates a higher similarity between the two images.
Equation (5) defines PSNR as a logarithmic measure of the ratio between the maximum possible pixel value and the mean square error (MSE) between the predicted and ground-truth images. A higher PSNR value indicates less distortion and better image quality.
Equation (6) expresses SSIM as the product of three components: luminance comparison , contrast comparison , and structural comparison . Each term measures the similarity of brightness, contrast, and structural information, respectively, between two images. SSIM ranges from 0 to 1, where a value closer to 1 indicates higher perceptual similarity. The constants used within each component help stabilize the division operations, especially when denominators are near zero.
Table 3 compares the front full-body images generated by the proposed Pix2Body model and the baseline Pix2Pix model using three evaluation metrics: RMSE, PSNR, and SSIM. As shown in
Table 3, the RMSE difference is 0.0083, the PSNR difference is 0.9659, and the SSIM difference is 0.0406, with Pix2Body outperforming the baseline across all metrics. Although the numerical differences in RMSE and SSIM appear modest, this can be attributed to the minimal luminance and contrast variation between the two models’ outputs, as illustrated in the qualitative comparison in
Figure 9 and
Figure 10. Furthermore, since the test set contains a high proportion of static poses, the baseline model was able to achieve relatively favorable results.
To validate the statistical significance of the observed improvements, we collected sample-wise RMSE, PSNR, and SSIM values across the entire test set and conducted paired t-tests comparing the performance of Pix2Pix and Pix2Body. The results revealed statistically significant differences in all three metrics: RMSE: p = 0.0032, PSNR: p = 0.0011, SSIM: p = 0.0026. These findings demonstrate that the improvements achieved by Pix2Body are not only visually and qualitatively evident but also quantitatively and statistically significant, reinforcing the effectiveness of the proposed method for reconstructing human body shapes from clothed RGB images.
Subsequently, we performed a generalization test on a typical human body rather than on synthetic data, which had already been employed for training.
Figure 11 depicts the experimental outcomes of body shape generation tests on one man and one woman. This study was approved by the Institutional Review Boards of Dongguk University (DUIRB-202202-14), and the procedures performed in the study complied with the principles of the Declaration of Helsinki. All study participants provided written informed consent for their participation and publication of their images, and the study design was approved by the ethics review board: Kyunghee Kwon, Sungju Park, Dongwook Kang, Kyucheol Lim, and Wonhee Jang.
Body joint coordinates were extracted from the normalized full-body image of a clothed subject and used as input features, following the same procedure as in the previous qualitative evaluation. The results of Pix2Body, the model proposed in this study, had fewer missing areas than those of the baseline model and a more detailed representation of body bends, as demonstrated in
Figure 11. Pix2Body correctly inferred the positions of the knees and the orientations of the arms and legs based on the positions, sizes, and orientations of the joint points of the body and organically depicted body shapes such as the torso and thighs. However, the accuracy was lower than that on the training dataset, which was a synthetic dataset.
This study provides four probable explanations for the reduced accuracy demonstrated in the generalization test compared to that on the synthetic dataset. First, the synthetic dataset has consistent subject locations and angles, whereas the real-world full-body images had inconsistent shooting angles and measuring distances, resulting in erroneous results. Second, there was a discrepancy in image quality. The image quality of the real-world images was lower than that of the training data because they were resized to 256 × 256. Furthermore, caps and shoes were present in the real-world images, which were not included in the training data, making accurate reconstruction of these areas difficult. Finally, artifacts were identified in the real-world outputs that were not present in the previous qualitative results, indicating insufficient background removal. Nonetheless, despite the low accuracy observed in the generalization test, the results demonstrate that Pix2Body is capable of generating body shapes from actual full-body photographs of clothed individuals, rather than from template-like synthetic body shapes. Moreover, if self-portraits are used, it may be possible to infer body shapes from both the front and side views, suggesting the scalability of this approach for healthcare applications such as body measurement.
Since this study predicts human body shape through 2D image translation, we evaluated performance using image-based metrics such as SSIM, PSNR, and RMSE on the synthetic SHADER dataset specifically constructed for this research. To contextualize our approach with respect to major prior works in 3D body reconstruction,
Table 4 presents a comparative summary of modeling strategies, benchmark datasets, and reported evaluation metrics. Among these, SSIM, PSNR, and normal consistency are similarity-based metrics, where higher values indicate better performance. In contrast, RMSE, MPJPE, PVE, P2S, and chamfer distance are error-based metrics, where lower values represent better accuracy. These distinctions help clarify the comparative positioning of Pix2Body relative to the existing methods.
Table 4 highlights three key structural differences that preclude direct metric-based comparison: (1) differing evaluation criteria (2D vs. 3D metrics), (2) different datasets, and (3) fundamentally distinct modeling paradigms. Given these factors, direct performance ranking based on numerical metrics is neither feasible nor academically meaningful. Rather, this comparison clarifies Pix2Body’s distinct design goals, emphasizing visual plausibility, inference efficiency, and deployment practicality within a lightweight 2D framework. This alternative is especially valuable for real-world applications requiring fast and intuitive shape estimation without reliance on full 3D supervision.
5. Discussion
In this study, we developed an algorithm that predicts naked body shapes by calculating major joint positions from two-dimensional complete clothed-body photos. The newly developed method generates body features while accounting for the diversity of human body shapes that exist among different people. Thus, the algorithm proposed in this research can be used to infer the unclothed body shape of a clothed individual without the need to implement constraints such as the removal of clothes or the wearing of clothes that stick to the body.
Conventional generation algorithms do not include body shape information, making it impossible to generate unstructured parts with inconsistent body angles and positions, or body parts that are difficult to predict because they are hidden by clothes, etc. To address these limitations, this study extracted body joint points (body key points) via pose estimation and incorporated body shape information. Body key points can be used to deduce not only body features but also body orientation and location. Unlike conventional generation methods, the developed algorithm can infer and construct disrobed body shapes with no missing parts.
Although our method demonstrates improved performance over Pix2Pix by leveraging pose information, the scope of comparative evaluation remains limited. Several notable parametric reconstruction frameworks—such as SPIN, GraphCMR, and SMPLify-X—were not included in our evaluation due to practical constraints. In addition, recent non-parametric methods such as PIFuHD, ICON, and ROMP have shown strong performance in human shape reconstruction. However, these models typically rely on multi-view inputs, dense 3D supervision, or pretrained SMPL parameters, making them less suitable for lightweight or real-time applications. In contrast, Pix2Body prioritizes ease of deployment by requiring only a single-view RGB image, 2D keypoints, and front/back normal maps. This enables practical application in uncontrolled environments without the need for expensive 3D ground-truth scans or complex rendering pipelines. While Pix2Pix can be easily implemented in modern GPU environments using recent versions of PyTorch (e.g., v1.13.1), these parametric models require legacy PyTorch versions (e.g., v0.4.1)and dependencies (e.g., Chumpy, OpenDR, SMPL-X model license) that are difficult to integrate into the current development pipelines. Moreover, SMPLify-X involves optimization-based inference, which is computationally expensive and unsuitable for our real time-oriented framework.
In future work, we aim to address these limitations by designing a unified evaluation pipeline that incorporates mesh-based and parametric representations, possibly using intermediate metrics such as PVE (per-vertex error) or chamfer distance. Additionally, we plan to include recent SOTA models such as ICON, PIFuHD, and ROMP for more comprehensive benchmarking. Expanding this evaluation will help clarify the strengths and weaknesses of Pix2Body within the broader landscape of human body reconstruction methods.
In addition to these architectural and comparative limitations, another key limitation lies in the absence of precise ground-truth body measurements (GT) obtained from real human subjects wearing tight-fitting clothing. Due to ethical concerns surrounding body exposure and practical challenges in recruiting a sufficient number of participants, direct comparison with actual physical measurements could not be conducted.
Nevertheless, the model was trained and evaluated using a custom dataset comprising RGB images, front and back normal maps, and corresponding 3D meshes from 190 individuals with diverse clothing styles and poses. Through indirect quantitative evaluation using structural similarity (SSIM) and visual inspection, the model demonstrated its capability to reconstruct body shapes accurately, even in regions occluded by clothing.
In future work, we aim to validate the practical accuracy of our algorithm by acquiring 3D scans of subjects in spandex to obtain precise body measurements (e.g., chest, waist, and hip circumferences) and comparing these with predictions generated from images of the same subjects in regular clothing. This enhanced validation protocol will strengthen the real-world applicability and reliability of the proposed method.
6. Conclusions
This proposed algorithm is a model that can be implemented using only a small amount of data. It is significant that the algorithm could be applied to many real-world industries that use mobile or web services. Furthermore, the approach of inferring the unclothed body shape can be employed not only for front images but also for side images, allowing body measurements such as waist circumference and arm and leg lengths to be measured using both front and side photographs. This algorithm is expected to provide a time- and cost-effective method of measuring body shape information to industries that rely on body shape evaluation, such as clothing, medicine, and healthcare.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}