
Large Language Models’ Trustworthiness in the Light of the EU AI Act—A Systematic Mapping Study

 and
and
Abstract
1. Introduction
- A systematic assessment of LLMs, examining both the current state and the most studied trustworthiness aspects across various high-impact domains in the light of the EU AI Act’s trustworthiness dimensions;
- An exploration of emerging trends in the domain-specific LLM applications, highlighting existing gaps and underexplored areas in the development of trustworthy LLMs;
- A systematic review of the applied methods and techniques to identify the type of research contributions presented in studies on LLM trustworthiness.
2. Related Works
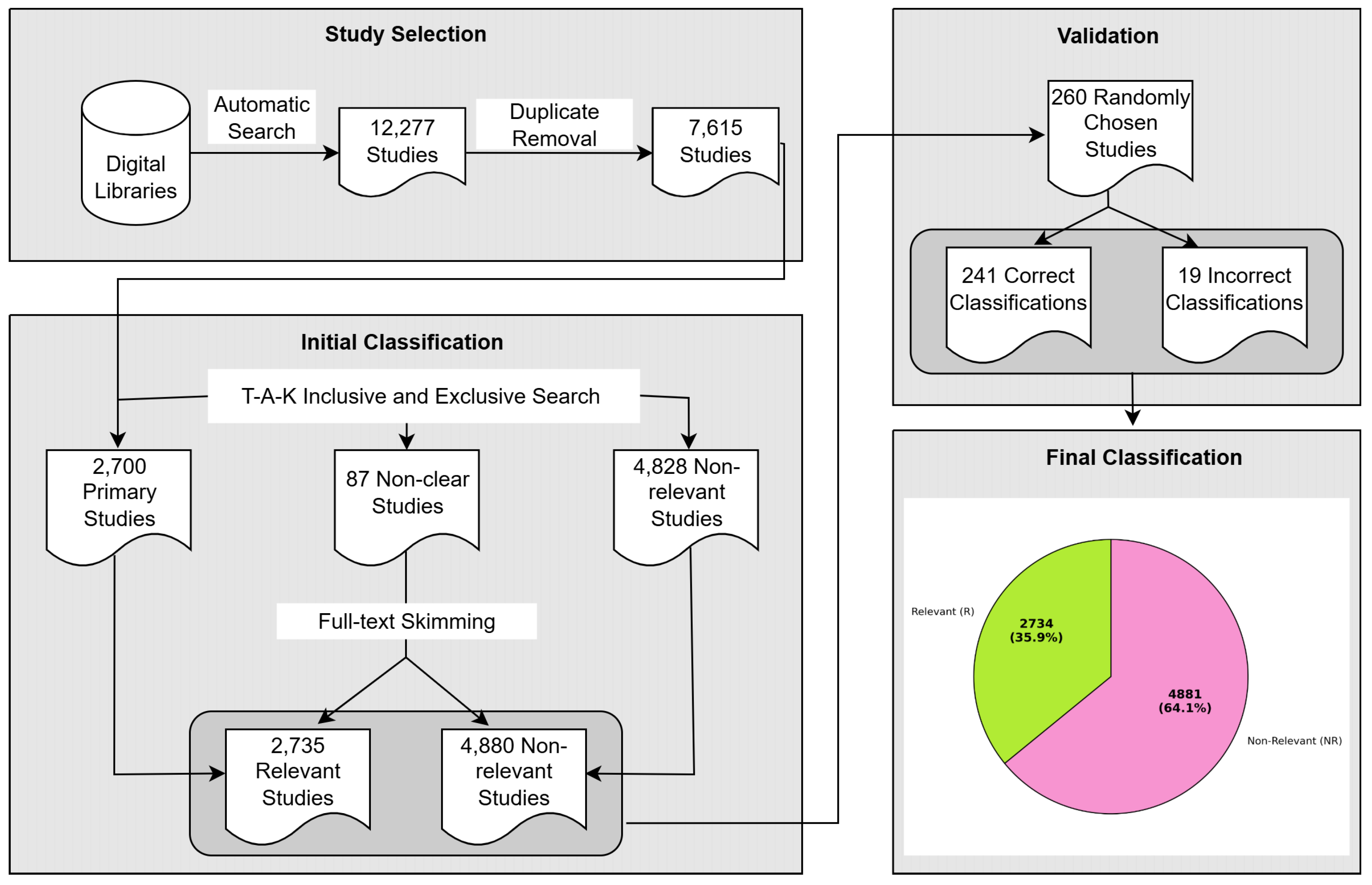
3. Study Method
- (1)
- Planning
- 1.
- Justify the need to conduct a mapping study on the trustworthiness aspects of the LLM algorithms.
- 2.
- Establish the key research questions.
- 3.
- Develop the search string and identify the scientific online digital libraries for carrying out the systematic mapping study.
- (2)
- Conducting
- 1.
- Study retrieval: The finalized search string is applied to the selected academic search databases. This process produces a comprehensive list of all potential studies found in digital libraries.
- 2.
- Study selection: Duplicate entries are removed from the list of candidate studies. The remaining entries are then filtered on the basis of inclusion and exclusion criteria, followed by applying the Title–Abstract–Keywords (T-A-K) criteria to finalize a list of relevant studies for further analysis [20,33].
- 3.
- Classification scheme definition: The next step involves determining how the relevant studies will be categorized. The classification scheme is designed to collect data necessary to answer the research questions defined in the planning phase.
- 4.
- Data extraction: Each selected study is reviewed, and relevant information is extracted. A data extraction form is used to organize and record this information for analysis in the next step.
- 5.
- Data analysis: This final step of the conducting phase involves a thorough analysis of the extracted data, which is represented through various maps, such as radial bar charts, histogram charts, pie charts, and line graphs.
- (3)
- Documentation
- 1.
- A comprehensive analysis of the information gathered in the prior phase.
- 2.
- Detailed explanations of the results.
- 3.
- An evaluation of potential threats to validity.
3.1. Planning
3.1.1. Definition of Research Questions
- RQ1: What is the current state of trustworthiness in LLMs?
- –
- Objective: Identify the current state of the trustworthines in LLMs.
- RQ1a: Which LLMs are most studied for trustworthiness?
- –
- Objective: Identify specific LLMs that have been researched with a focus on trustworthiness.
- RQ1b: Which aspects of trustworthiness are explored in LLMs?
- –
- Objective: Explore specific dimensions of trustworthiness (e.g., based on EU Trustworthy AI guidelines) that researchers focus on within the LLM domain.
- RQ2: What are the current research gaps in the study of LLM trustworthiness in popular application domains?
- –
- Objective: Identify areas in LLM trustworthiness research that need further exploration, especially within high-impact application domains.
- RQ3: What are the emerging trends and developments in addressing trustworthiness in LLMs?
- –
- Objective: Track trends over time, identifying shifts in focus or methodology regarding LLM trustworthiness.
- RQ4: What types of research contributions are primarily presented in studies on LLM trustworthiness?
- –
- Objective: Classify the nature of contributions, such as frameworks, methodologies, tools, or empirical studies, made by researchers in this area.
- RQ5: Which research methodologies are employed in the studies on LLM trustworthiness?
- –
- Objective: Understand the research approaches and methodologies that are commonly used to investigate LLM trustworthiness.
- RQ6: What is the distribution of publications in terms of academic and industrial affiliation concerning LLM trustworthiness?
- –
- Objective: Assess the level of interest and involvement from academic institutions and industry players in LLM trustworthiness.
3.1.2. Search String and Source Selection
3.1.3. Search String Formulation
- Population: Refers to the category, application domain, or specific role that encompasses the scope of this systematic mapping study.
- Intervention: Represents the methodology, tool, or technology applied within the study’s context.
- Comparison: Identifies the methodology, tool, or technology used for comparative analysis in the study.
- Outcome: Denotes the expected results or findings of the study.
3.1.4. PICO Definition for This Study
- Population: Types of LLM.
- Intervention: Trustworthiness aspect.
- Comparison: No empirical comparison is made, therefore not applicable.
- Outcome: A classification of the primary studies, indicating the trustworthiness aspect of LLM.
3.1.5. Keyword Analysis and Synonym Sets
- Set 1: Terms related to the LLM field.
- Human oversight;
- Record-keeping;
- Data and data governance;
- Transparency;
- Accuracy;
- Robustness;
- Cybersecurity;
- Trustworthy.
- Record-keeping: It is covered under traceability.
- Accuracy: It is a commonly used metric for evaluating AI models beyond just LLMs. To prevent a significant increase in the number of retrieved papers, we covered it under faithfulness which refers to how accurately an explanation represents a model’s reasoning process.
- Data and data governance: It is addressed as part of ethics and bias.
- Cybersecurity: It is covered under safety and resilience against unauthorized third parties.
3.1.6. Source Selection and the Scope of This Study
3.2. Conducting
3.2.1. Study Retrieval
3.2.2. Study Selection
Criteria for Study Selection
Evaluation of Study Relevance
- A study is marked as relevant (R) if it meets all the inclusion criteria and none of the exclusion criteria.
- A study is marked as not-relevant (NR) if it does not fulfill one of the inclusion criteria or meets at least one of the exclusion criteria.
- A study is marked as not-clear (NC) if there are uncertainties from the T–A–K analysis.
Snowballing
3.2.3. Classification Schemes Definition
- Reading: The abstracts and keywords of the selected relevant studies were reviewed again, focusing on identifying a set of keywords representing the application domains, cellular and non-cellular communication types, the trustwothiness aspect, and the LLMs that are studied for trustworthiness.
- Clustering: The obtained keywords were grouped into clusters, resulting in a set of representative keyword clusters, which were then used for classifying the studies.
3.2.4. Data Extraction
3.2.5. Data Analysis
4. Classification Scheme
4.1. LLM Classification
- ALPACA: A lightweight, instruction-following model by Stanford for task-oriented AI interactions [41].
- BARD: Google’s conversational AI optimized for creative content and open-ended user queries [42].
- BART: Facebook’s transformer model for text generation and transformation tasks like summarization [43].
- BERT: Google’s transformer-based model, excels in understanding context for tasks like sentiment analysis and question answering [7].
- BingAI: Microsoft’s integration of AI with Bing search for real-time web-based responses [44].
- BLOOM: Open-source multilingual text generation model designed for cross-lingual applications [45].
- ChatGLM: General-purpose conversational AI optimized for natural, coherent dialogues [46].
- CLAUDE: Anthropic’s ethical AI focused on safe, unbiased conversational interactions [47].
- Cohere: AI model for text generation and summarization, widely used for content creation [48].
- Copilot: OpenAI and GitHub’s CLI 1.0 code assistant that provides real-time code suggestions and completions [49]
- CodeGen: Model designed specifically for generating functional code across multiple programming languages [50].
- DALL-E: OpenAI’s image generation model that creates images from textual descriptions [51].
- ERNIE: Baidu’s model that enhances language understanding by integrating knowledge graphs [52].
- FALCON: AI model focused on generating coherent, context-aware dialogues in real-time [53].
- FLAN: Google’s fine-tuned T5 variant optimized for specific NLP tasks like summarization and question answering [54].
- GEMINI: A versatile AI model by Google for scalable and multi-purpose NLP tasks [55].
- GEMMA: Multilingual AI model for text generation and translation, supporting diverse languages [56].
- GPT: OpenAI’s general-purpose language model excelling in generating text and language understanding [57].
- LAMDA: Google’s conversational AI for maintaining fluid and natural open-ended conversations [58].
- LLaMa: Meta’s efficient and open-source language model optimized for natural language understanding [59].
- LLM: A broad class of large language models designed for various NLP tasks like text generation [3].
- T5: Google’s unified model for handling diverse NLP tasks by framing them as text-to-text problems [4].
- MISTRAL: A multi-modal model combining language and vision capabilities for complex tasks [60].
- MT5: A multilingual extension of T5, designed to handle text-to-text tasks across multiple languages [5].
- MPT: Memory-augmented AI model focused on improving learning efficiency and long-term retention [61].
- ORCA: Conversational AI optimized for generating coherent, context-aware dialogues [62].
- PaLM: Google’s Pathways Language Model designed for complex reasoning and large-scale NLP tasks [63].
- Phi: AI model focusing on ethical decision-making and reducing biases in responses [64].
- StableLM: A robust language model designed for stable and predictable AI-generated text [65].
- StartCoder: AI model designed specifically for coding assistance and code generation tasks [66].
- Vicuna: A safe, high-quality conversational AI model focused on ethical interactions [67].
- XLNet: An autoregressive model built to capture flexible contextual dependencies in language understanding [68].
- Zephyr: Lightweight AI model designed for efficient performance in resource-constrained environments [69].
4.2. Trustworthiness Aspects
- Human Oversight: The system shall be designed with appropriate human–machine interface tools to ensure adequate oversight. It must aim to prevent or minimize risks to health, safety, and fundamental rights. The level of oversight shall be commensurate with the system’s autonomy, risks, and context of use. Additionally, the system must be verified and confirmed by at least two qualified natural persons with the necessary competence, training, and authority. Risk management measures should also address potential biases, including those originating from users’ cognitive biases, automation bias, and algorithmic bias.
- Record-Keeping: To ensure traceability and accountability, the system shall have logging capabilities to record relevant events. These logs should be sufficient for the intended purpose of the system, facilitating proper tracking of system functionality and decisions.
- Data and Data Governance: The datasets used for training, validation, and testing must be carefully chosen and reflect the relevant design choices and data collection processes. The origin of data, data-preparation operations, and the formulation of assumptions should be clearly documented. A comprehensive assessment of the data’s availability, quantity, suitability, and potential biases should be conducted, especially considering potential risks to health and safety, fundamental rights, or discrimination as outlined under applicable laws (e.g., Union law).
- Transparency: The system shall be transparent enough to allow deployers and users to interpret its outputs (explainability) and use them effectively. This includes providing clear, concise, and accurate instructions for use, available in a digital format or otherwise. These instructions should be comprehensive, correct, and easily understood by the system’s users.
- Trustworthy: The paper did not mention any specific aspects related to trustworthiness, but the general requirement is that the system’s design and operation must adhere to best practices for ethical AI use, ensuring it meets the aforementioned criteria.
- Accuracy: The system must be developed to achieve an appropriate level of accuracy, maintaining consistent performance throughout its lifecycle. The expected levels of accuracy, along with relevant accuracy metrics, should be clearly declared in the accompanying instructions for use.
- Robustness: The system must be designed to be robust, capable of maintaining consistent performance even in the presence of errors, faults, or inconsistencies. Robustness can be achieved through technical redundancy solutions, including backup systems or fail-safe mechanisms, ensuring that the system can continue functioning reliably in adverse conditions.
- Cybersecurity: The system must be developed with a strong focus on cybersecurity to prevent unauthorized access or manipulation by third parties. This includes measures to safeguard against data poisoning, model poisoning, adversarial examples, and confidentiality attacks. The system should include solutions to prevent, detect, respond to, resolve, and control attacks that could compromise its integrity, including manipulating the training dataset or exploiting model vulnerabilities.
4.3. Classification of Communication Technology
- Cellular;
- Non-cellular;
- Not Mentioned.
- 4G—With significantly higher data rates, 4G enabled new applications such as IoT and industrial automation. LTE is another common term used for 4G.
- 5G—Offering low-latency communication and very high data rates, 5G broadens the range of use cases across diverse sectors.
- 6G—Expected to offer ultra-low latency, terabit-per-second data rates, and AI-driven network optimization, 6G aims to enable futuristic applications such as holographic communications, pervasive intelligence, and seamless global connectivity.
- Cellular (not-specified)—This category includes studies that do not specify which particular cellular technology is employed in the T-A-K fields.
- WiFi—Encompasses technologies based on the IEEE 802.11 standard, including vehicular ad hoc networks (VANET) and dedicated short-range communication (DSRC).
- Radio-frequency Identification (RFID)—A short-range communication method using electromagnetic fields to transmit data.
- Bluetooth—A technology designed for low power consumption, short-range communication, and low data transfer rates.
- Satellite—A long-range communication method that is sensitive to interference and relies on a clear line of sight.
- Non-cellular (not-specified)—Includes studies that do not specify the non-cellular technology used in the T-A-K fields.
4.4. Application Domain Classification
- Air Space—Ensuring that LLMs provide accurate, reliable, and unbiased information for aerospace applications, such as navigation systems and communication protocols.
- Automotive—Maintaining safety and reliability in LLM-driven automotive technologies, including autonomous driving systems and in-vehicle assistants.
- Construction—Ensuring precision and safety in LLM applications for construction project planning, risk assessments, and management.
- Cybersecurity—Enhancing security measures and threat detection systems in the cybersecurity domain using LLMs.
- Defence—Ensuring the ethical application, security, and accuracy of LLMs in defense scenarios, such as threat analysis and decision support systems.
- Education—Promoting fairness, accuracy, and bias reduction in LLM-based educational tools for personalized learning and academic assistance.
- Environment—Ensuring LLM-driven technologies support environmental monitoring and sustainability efforts.
- Finance—Ensuring transparency, bias reduction, and data protection in LLM applications for the fintech industry.
- History—Supporting transparent and reliable LLM usage in the analysis and preservation of cultural heritage.
- Human–Computer Interaction (HCI)—Enhancing interactions between humans and AI through improved dialogues, negotiations, and task delegation.
- Information Verification—Utilizing LLMs in automated fake news detection, fact-checking processes, and cross-domain analysis for verifying information credibility.
- Smart Factory—Maintaining operational integrity, reliability, and efficiency in LLM applications for automated manufacturing and production systems.
- Health Care—Ensuring privacy, accuracy, and ethical practices in LLM applications for medical diagnostics, patient care, and health data management.
- Internet of Things (IoT)—Ensuring precision, reliability, and ethical behavior in LLM-guided IoT systems across diverse applications.
- Law—Ensuring transparency, data integrity, and fairness in the use of LLMs for legal purposes.
- Linguistic—Promoting linguistic accuracy, cultural sensitivity, and reducing bias in LLM applications for translation, text generation, and language learning.
- Marine—Ensuring the safety and reliability of LLM applications in marine navigation, communication, and environmental monitoring.
- Mining—Enhancing operational safety and efficiency in LLM applications for resource extraction, site management, and predictive maintenance.
- News/Media—Leveraging LLMs for ethical reporting, fact-checking, and content creation in the media industry.
- Robotics—Ensuring the ethical behavior, precision, and reliability of LLM-powered robotic systems in both industrial and domestic settings.
- Smart System/Coding—Utilizing LLMs to improve software development processes, automate code generation, and ensure robust, efficient, and secure software systems.
- Smart Business—Harnessing LLMs to foster innovative business solutions, enhance operational efficiency, and provide data-driven insights for strategic decision-making.
- Social Scoring—Promoting fairness, transparency, and objectivity in social scoring systems by identifying and mitigating biases related to politics and social context.
- Surveillance—Ensuring the ethical use of LLMs in surveillance systems for monitoring, threat detection, and security analysis, while safeguarding privacy.
- Telecommunication—Ensuring security, reliability, and unbiased communication in LLM applications used for network management, customer service, and data analysis.
- Not Specified—This category is used for studies that do not specify the application domain.
- Other—This category includes studies working on application domains not listed here.
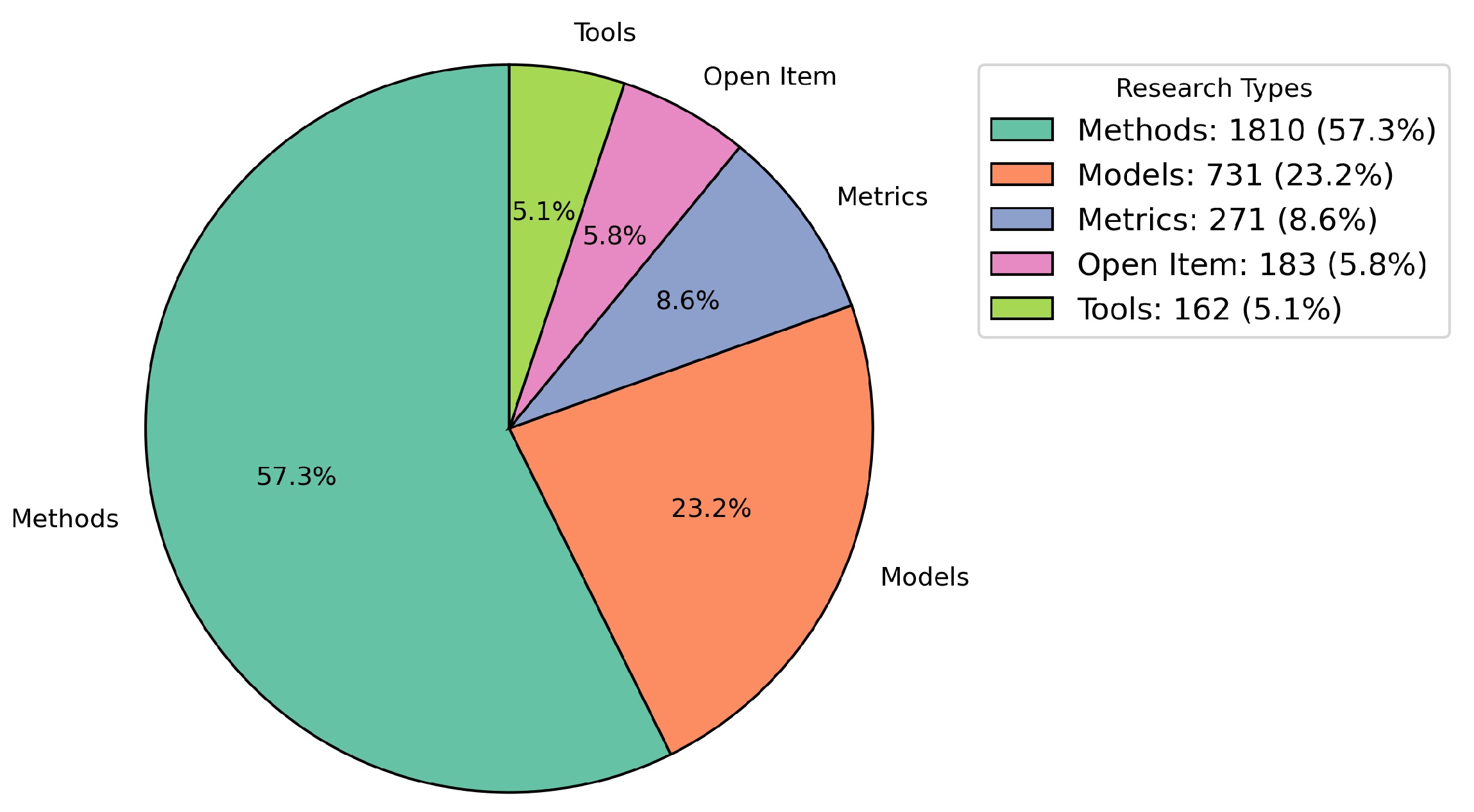
4.5. Research Contribution Classification
- Model—Represents conceptual frameworks or abstract structures addressing key principles and theoretical aspects in AI-based safety implementations. These frameworks are typically idea-focused and aim to guide and ensure trustworthiness in large language models (LLMs).
- Method—Describes procedural steps and actionable guidelines designed to tackle specific challenges in trustworthiness in large language models (LLMs). These are practical, action-oriented processes, such as steps to evaluate the accuracy of LLMs.
- Metric—Pertains to measurable indicators or quantitative criteria used to evaluate the properties and performance of large language models (LLMs) in trustworthiness aspects.
- Tool—Refers to software, prototypes, or applications that support or operationalize the models and methods discussed.
- Open Item—Includes studies that do not conform to the categories of models, methods, metrics, or tools, covering unique aspects outside the defined classifications.
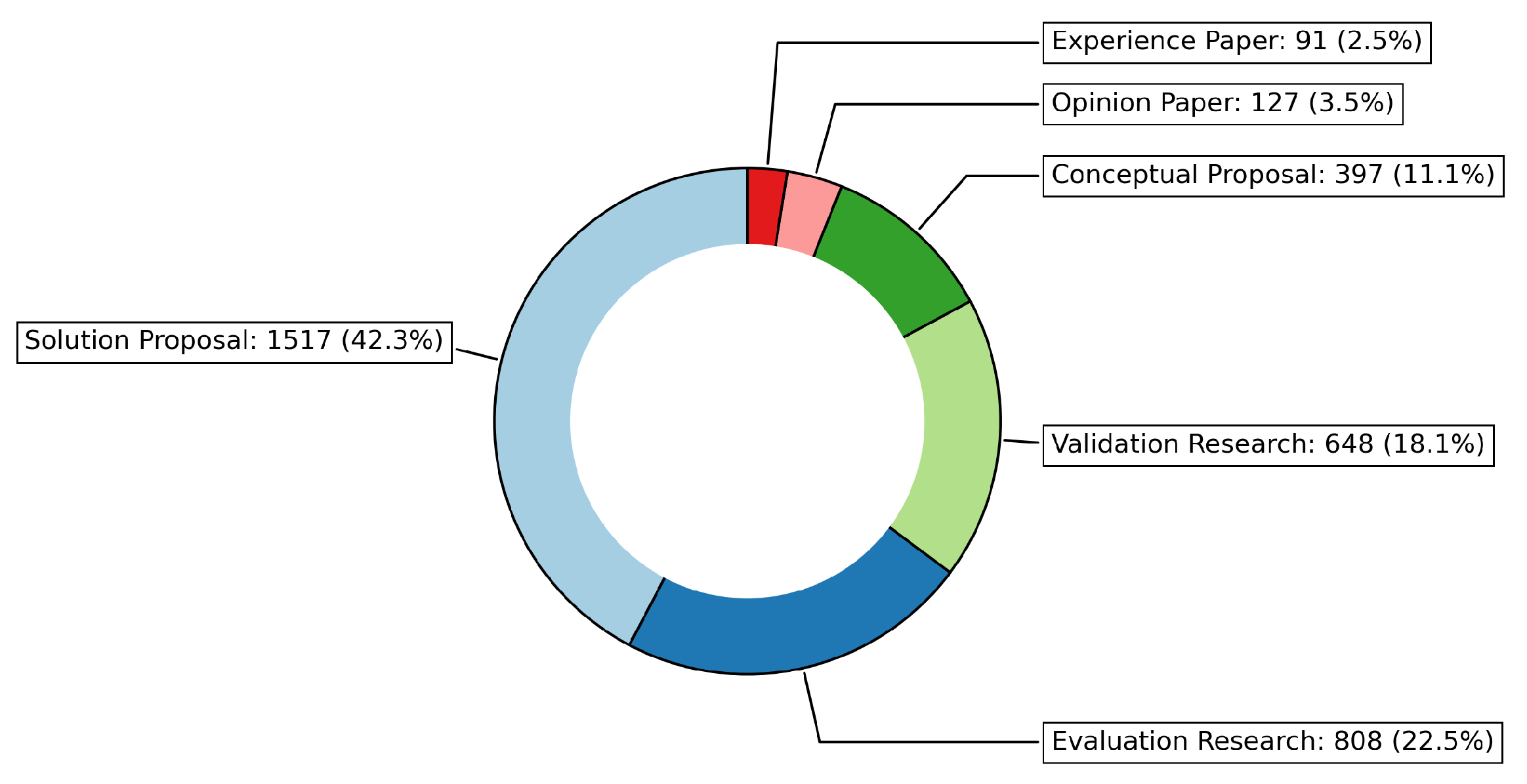
4.6. Research Types Classification
- Validation Research—Investigates new techniques that have not yet been applied in practice, typically through experiments, prototyping, and simulations.
- Evaluation Research—Assesses implemented solutions in practice, considering both the advantages and drawbacks. This includes case studies, field experiments, and similar approaches.
- Solution Proposal—Proposes a novel solution for an existing problem or a significant enhancement to an existing solution.
- Conceptual Proposal—Provides a new perspective on a topic by organizing it into a conceptual framework or taxonomy.
- Experience Paper—Shares the experiences of the authors, describing the practical application or implementation of a concept.
- Opinion Paper—Presents the personal opinions of the authors on specific methods or approaches.
5. Results and Discussion
- Each subsection addresses one or more research questions outlined in Section 3.1.1.
- Each research question is analyzed and supported with a corresponding chart to provide a comprehensive answer.
5.1. Results of RQ1(a–b)
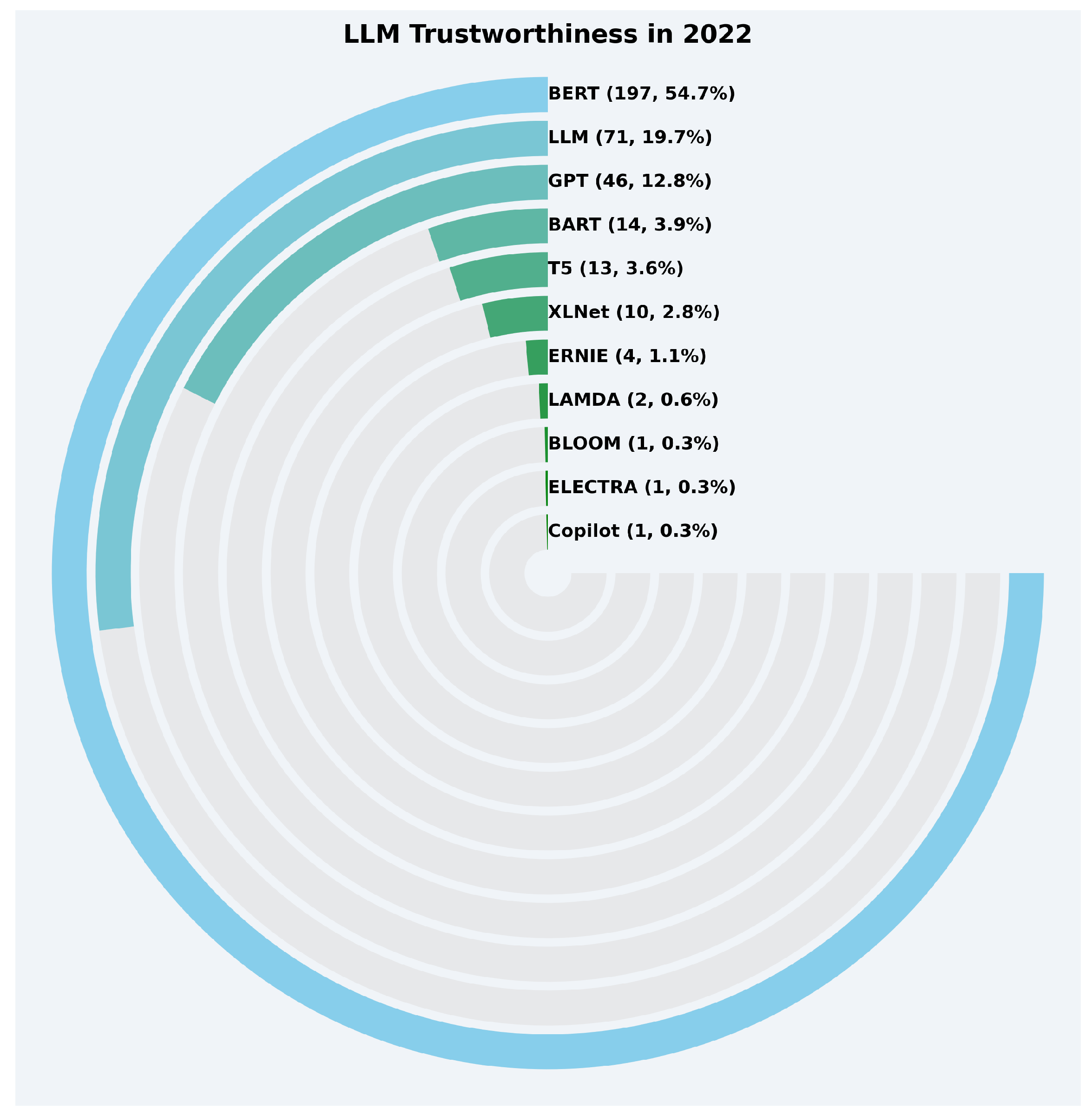
5.1.1. RQ1a: Which LLMs Are Most Studied for Trustworthiness?
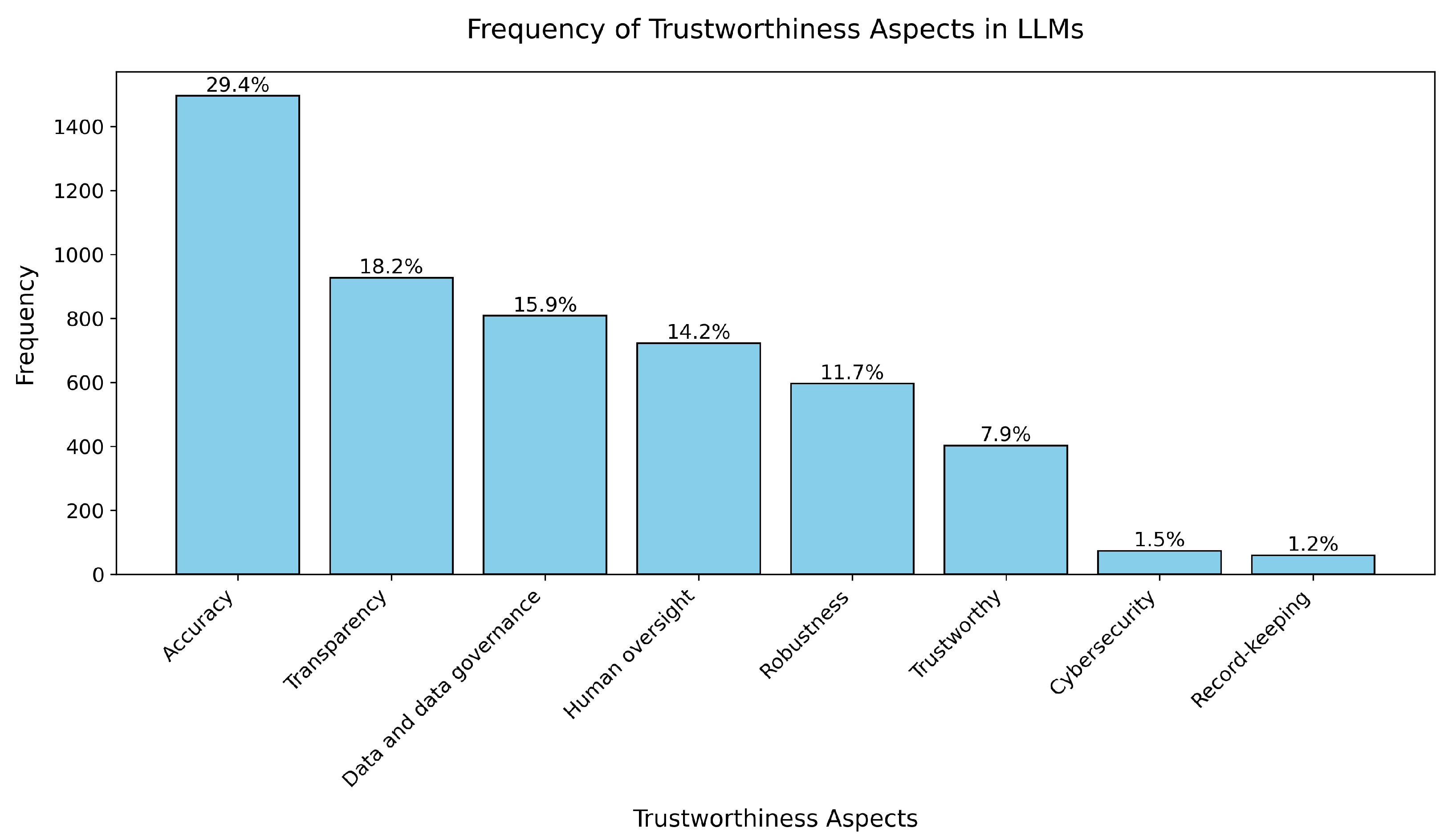
5.1.2. RQ1b: Which Aspects of Trustworthiness Are Explored in LLMs?
5.2. Results of RQ2
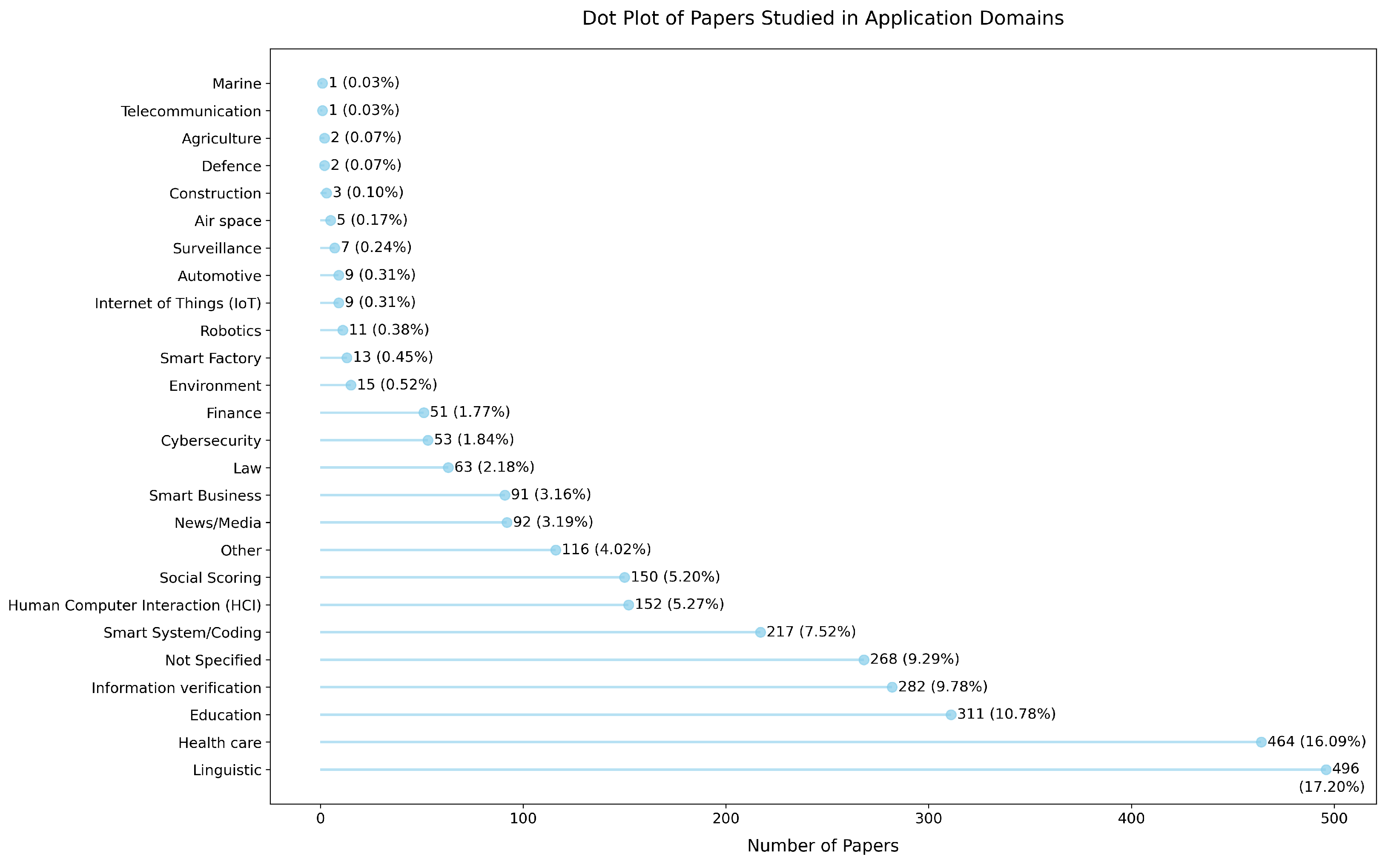
Analysis and Results
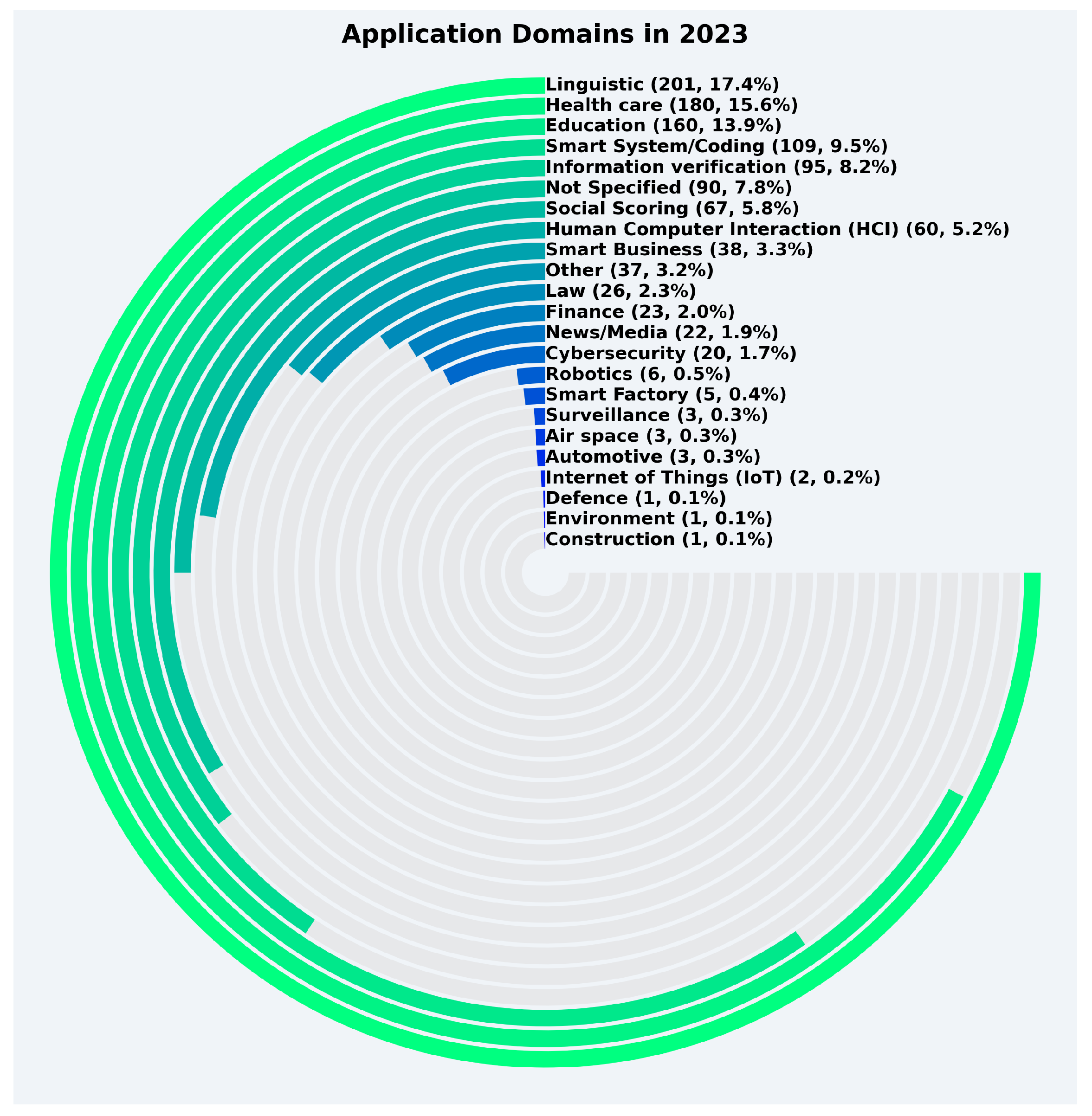
- Linguistic Applications: This domain accounts for the largest share of studies, with 496 papers (17.20%). This reflects the significant interest in improving language comprehension, generation, and translation tasks in LLMs. However, the focus on linguistic applications may overshadow trustworthiness considerations in other high-impact domains.
- Healthcare: With 464 papers (16.09%), healthcare is the second-most explored domain, demonstrating the growing reliance on LLMs in medical decision-making, diagnostics, and patient interaction. Despite this focus, challenges in data governance, robustness, and transparency remain underexplored.
- Education: Trustworthiness in educational applications has been explored in 311 papers (10.78%). The increasing use of LLMs in personalized learning and content creation raises concerns about accuracy, bias, and human oversight.
- Information Verification: This domain has 282 papers (9.78%), reflecting the growing importance of LLMs in verifying information, particularly in the context of news, media, and social media content. Despite its relevance, further research into transparency and robustness in this area is necessary.
- Smart System/Coding: This domain has 217 papers (7.52%), showcasing the role of LLMs in software development and automation. Trustworthiness in coding tasks requires ensuring reliability, security, and the ability to handle ambiguous situations.
- Underexplored Domains: Several critical domains such as cybersecurity (53 papers, 1.84%), finance (51 papers, 1.77%), and environment (15 papers, 0.52%) have received limited attention. These domains involve high stakes, where trustworthy AI is essential, highlighting a significant research gap.
- Emerging and Niche Domains: Application areas such as smart factory (13 papers, 0.45%), robotics (11 papers, 0.38%), Internet of Things (IoT) (9 papers, 0.31%), automotive (9 papers, 0.31%), surveillance (7 papers, 0.24%), air space (5 papers, 0.17%), construction (3 papers, 0.10%), defense (2 papers, 0.07%), agriculture (2 papers, 0.07%), telecommunication (1 paper, 0.03%), and marine (1 paper, 0.03%) remain largely unexplored. These domains demand robust and transparent LLMs due to their direct impact on safety, security, and privacy.
- General Observations: A significant portion of studies (268 papers, 9.29%) did not specify a domain, indicating a lack of targeted research. Furthermore, domains like smart business (91 papers, 3.16%) and social scoring (150 papers, 5.20%) also demonstrate a notable gap in research focused on trustworthiness.
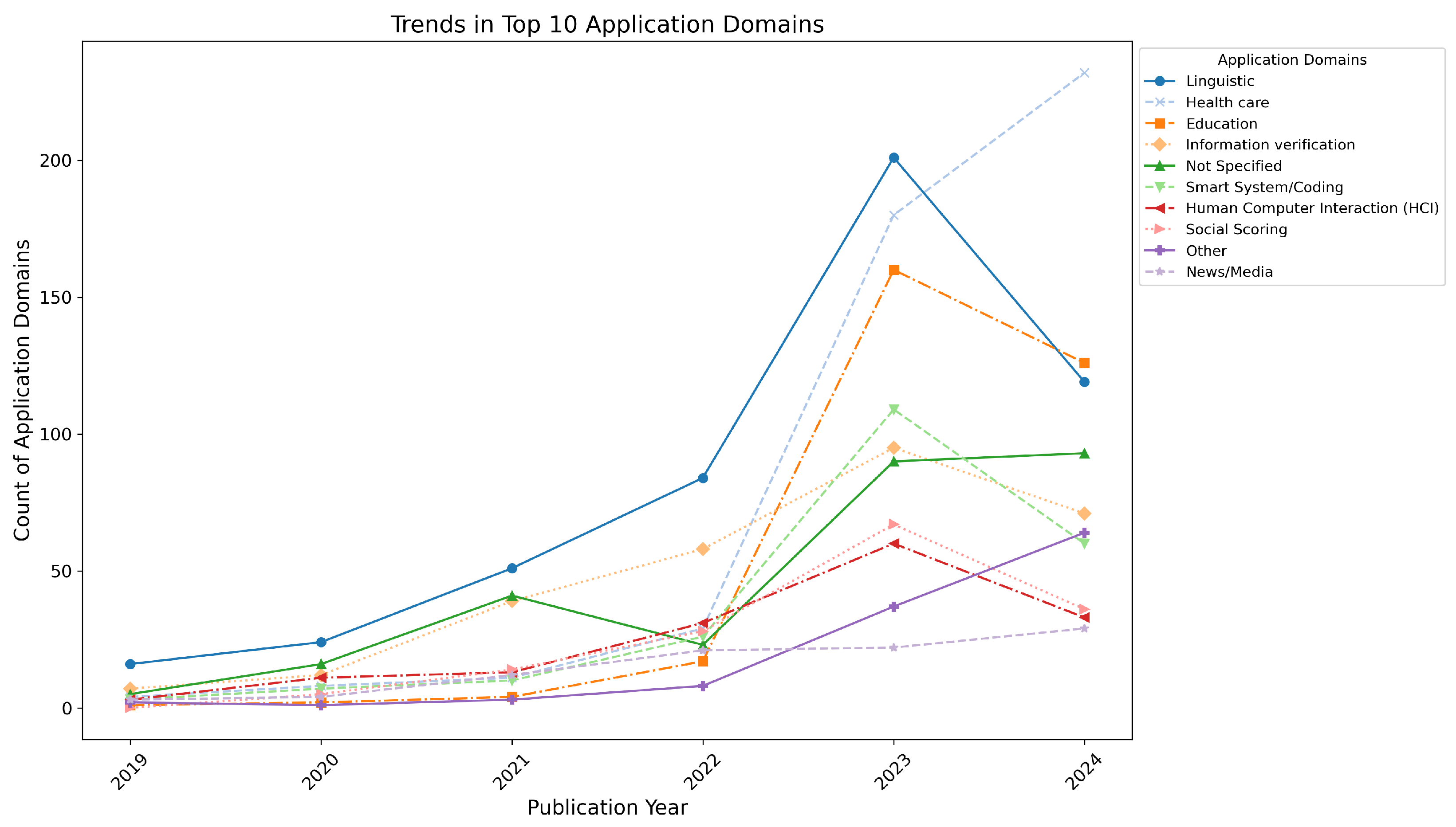
- Linguistic applications started with 16 papers in 2019 and experienced steady growth, peaking at 201 papers in 2023 before slightly declining to 119 papers in 2024. The sharp increase from 2020 to 2023 highlights the growing attention to linguistic trustworthiness.
- Healthcare exhibited the most remarkable growth, starting with 4 papers in 2019 and skyrocketing to 232 papers in 2024, with a sharp increase observed between 2022 and 2024.
- Education grew steadily from 1 paper in 2019 to 126 papers in 2024, with a dramatic surge in 2023 (160 papers).
- Information verification saw consistent growth, rising from 7 papers in 2019 to 71 papers in 2024, with a peak of 95 papers in 2023.
- Not specified domain-related papers fluctuated across the years, starting with 5 papers in 2019, peaking at 90 papers in 2023, and stabilizing at 93 papers in 2024.
- Smart system/coding applications increased significantly, starting with 3 papers in 2019 and peaking at 109 papers in 2023 before declining to 60 papers in 2024.
- Human–computer interaction (HCI) grew from 3 papers in 2019 to 33 papers in 2024, with notable peaks in 2022 (31 papers) and 2023 (60 papers).
- Social scoring saw rapid growth from 5 papers in 2020 to 67 papers in 2023, followed by a decline to 36 papers in 2024.
- Other applications started with 2 papers in 2019 and grew significantly to 64 papers in 2024, with substantial increases in 2023 and 2024.
- News/Media applications steadily increased from 3 papers in 2019 to 29 papers in 2024, showing moderate growth from 2023 onwards.
- Other Application Domains
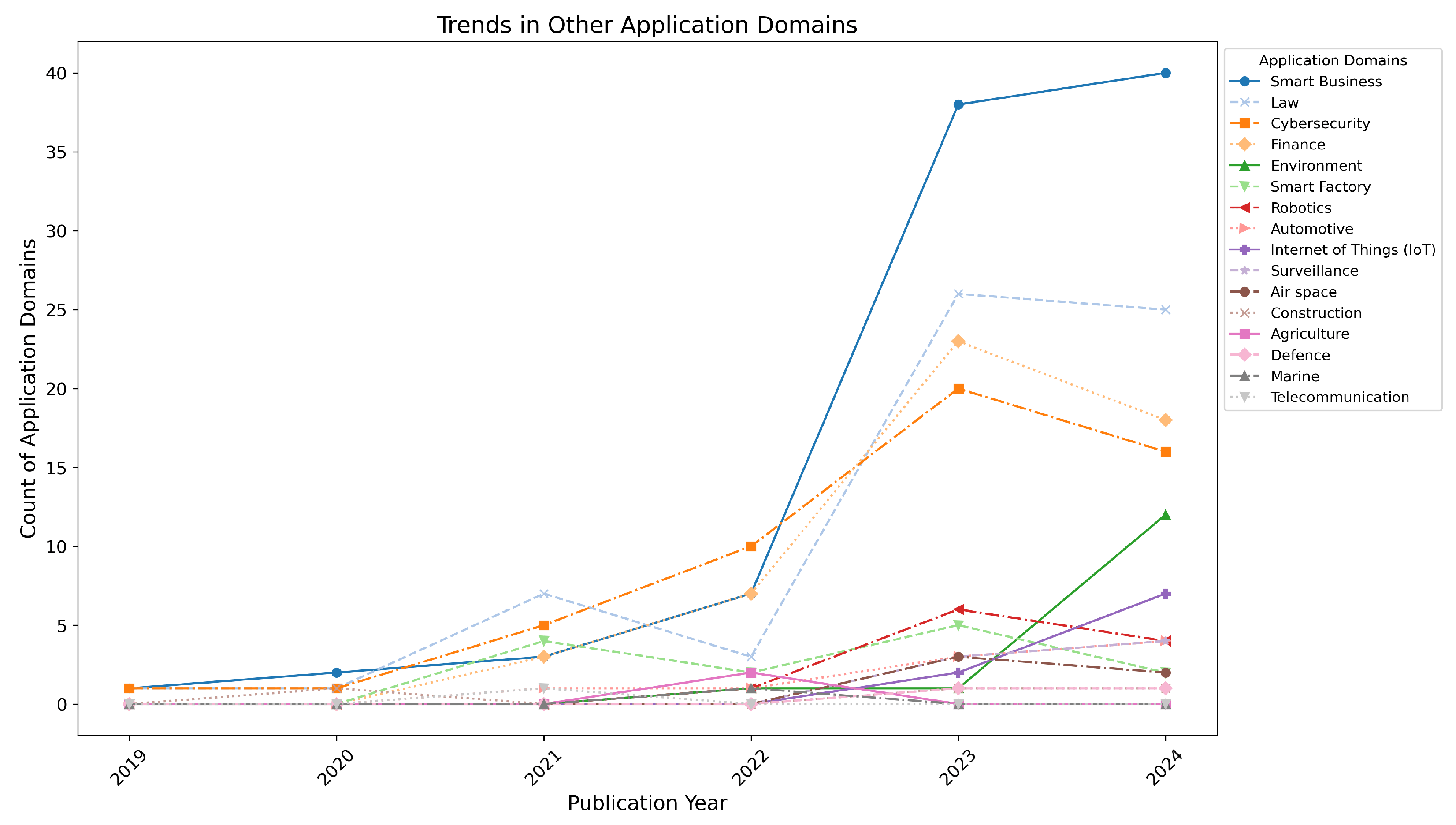
- Smart business started with 1 paper in 2019 and grew significantly, reaching 40 papers in 2024, with a sharp rise in 2023 (38 papers).
- Law grew from 1 paper in 2019 to 25 papers in 2024, with a peak of 26 papers in 2023.
- Cybersecurity started with 1 paper in 2019 and grew steadily to 16 papers in 2024, peaking at 20 papers in 2023.
- Finance grew from 3 papers in 2021 to 18 papers in 2024, with a peak of 23 papers in 2023.
- Environment emerged as a focus area in 2022 with 1 paper, growing to 12 papers in 2024.
- Smart factory showed modest growth, peaking at five papers in 2023 and declining to two papers in 2024.
- Robotics emerged in 2022 with one paper, growing to six papers in 2023 and stabilizing at four papers in 2024.
- Automotive remained minor, with one paper in 2021 and 2022, increasing slightly to four papers in 2024.
- Internet of Things (IoT) saw an increase from two papers in 2023 to seven papers in 2024.
- Surveillance grew from three papers in 2023 to four papers in 2024.
- Air space declined slightly, from three papers in 2023 to two papers in 2024.
- Domains such as construction, agriculture, defense, marine, and telecommunication maintained a minimal presence over the years, with little to no growth. For instance, construction had one paper annually in 2020, 2023, and 2024; agriculture emerged in 2022 with two papers; and defense, marine, and telecommunication exhibited sporadic publications with only one paper per year in specific instances.
5.3. Results of RQ3
Analysis and Results
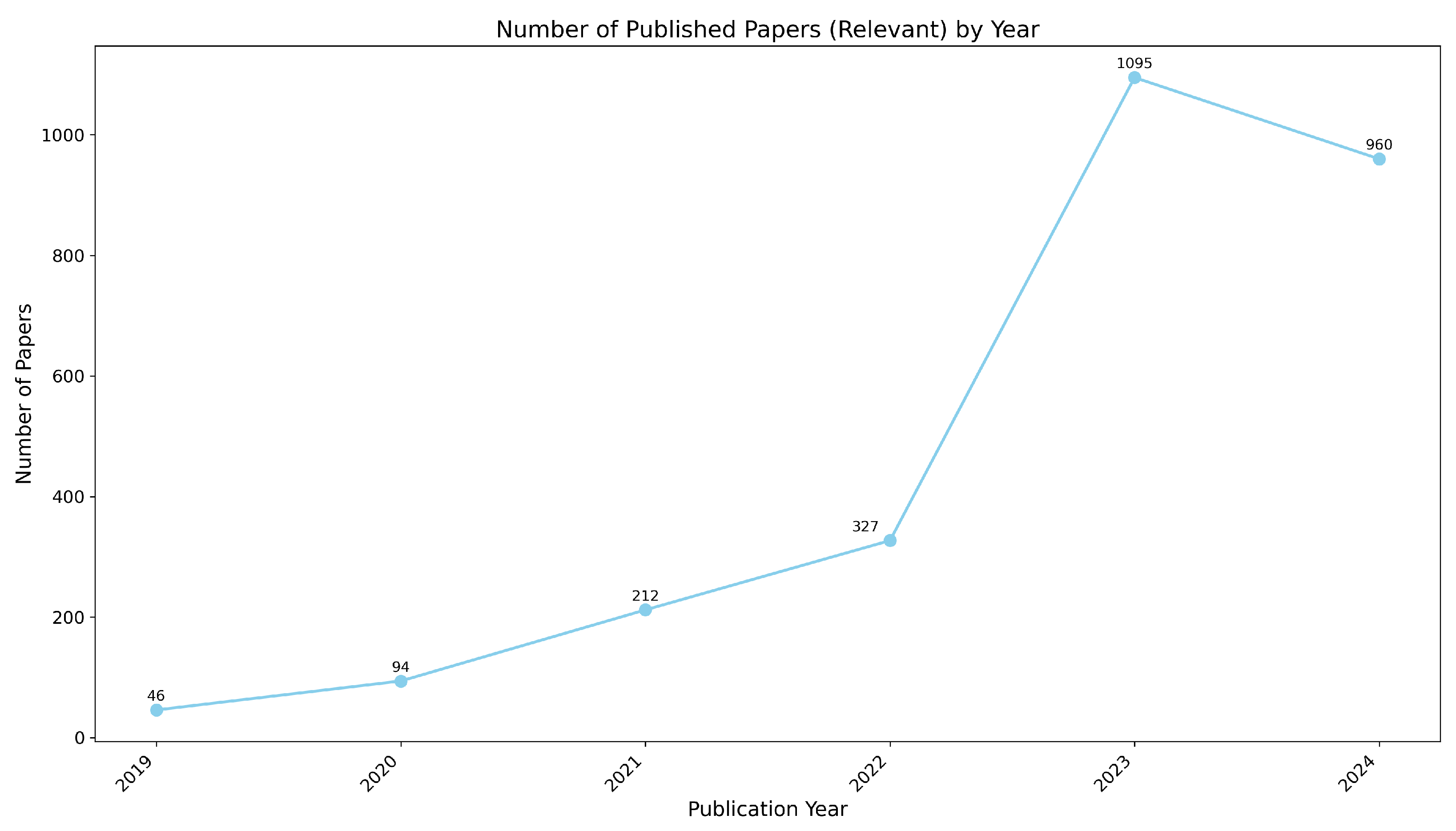
- In 2019, there were 46 papers, indicating early research interest in LLM trustworthiness.
- This number grew to 94 papers in 2020, showing increased attention to the topic.
- In 2021, the publications sharply rose to 212 papers, and by 2022, this number further increased to 327 papers.
- The trend peaked in 2023 with 1095 papers, reflecting a significant surge in research on LLM trustworthiness.
- In 2024, the number slightly decreased to 960 papers, but still remains high. This decrease can be attributed to the fact that we considered data only up to June 2024, which explains the slightly lower number compared to the peak of 2023. Despite this, the data shows a promising, massive increase in the number of papers, indicating strong and ongoing interest in the area.
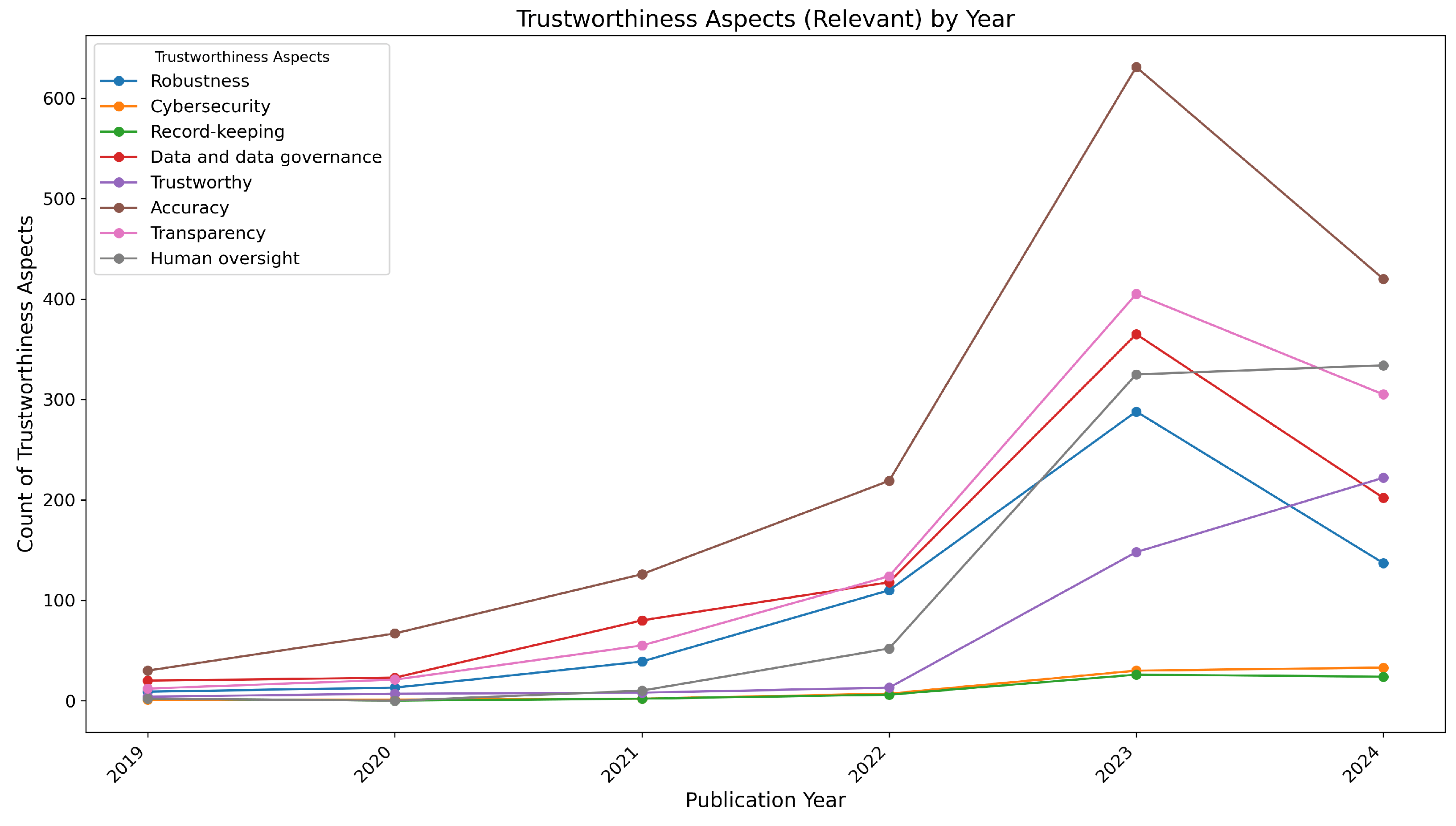
- In 2019, the focus was on accuracy with 30 papers, followed by data and data governance (20 papers) and transparency (12 papers).
- In 2020, accuracy rose to 67 papers, and transparency increased to 21 papers, reflecting growing interest in these areas.
- In 2021, accuracy saw a significant jump to 126 papers, with robustness reaching 39 papers, highlighting the growing emphasis on these aspects.
- The trend continued in 2022, with accuracy at 219 papers and transparency reaching 124 papers, alongside a notable increase in human oversight (52 papers).
- In 2023, accuracy surged to 631 papers, robustness to 288 papers, and transparency to 405 papers, marking the highest level of research attention.
- In 2024, we only considered papers up to June, where accuracy remained at 420 papers, and robustness decreased to 137 papers. However, there was still a strong focus on human oversight (334 papers) and data governance (202 papers).
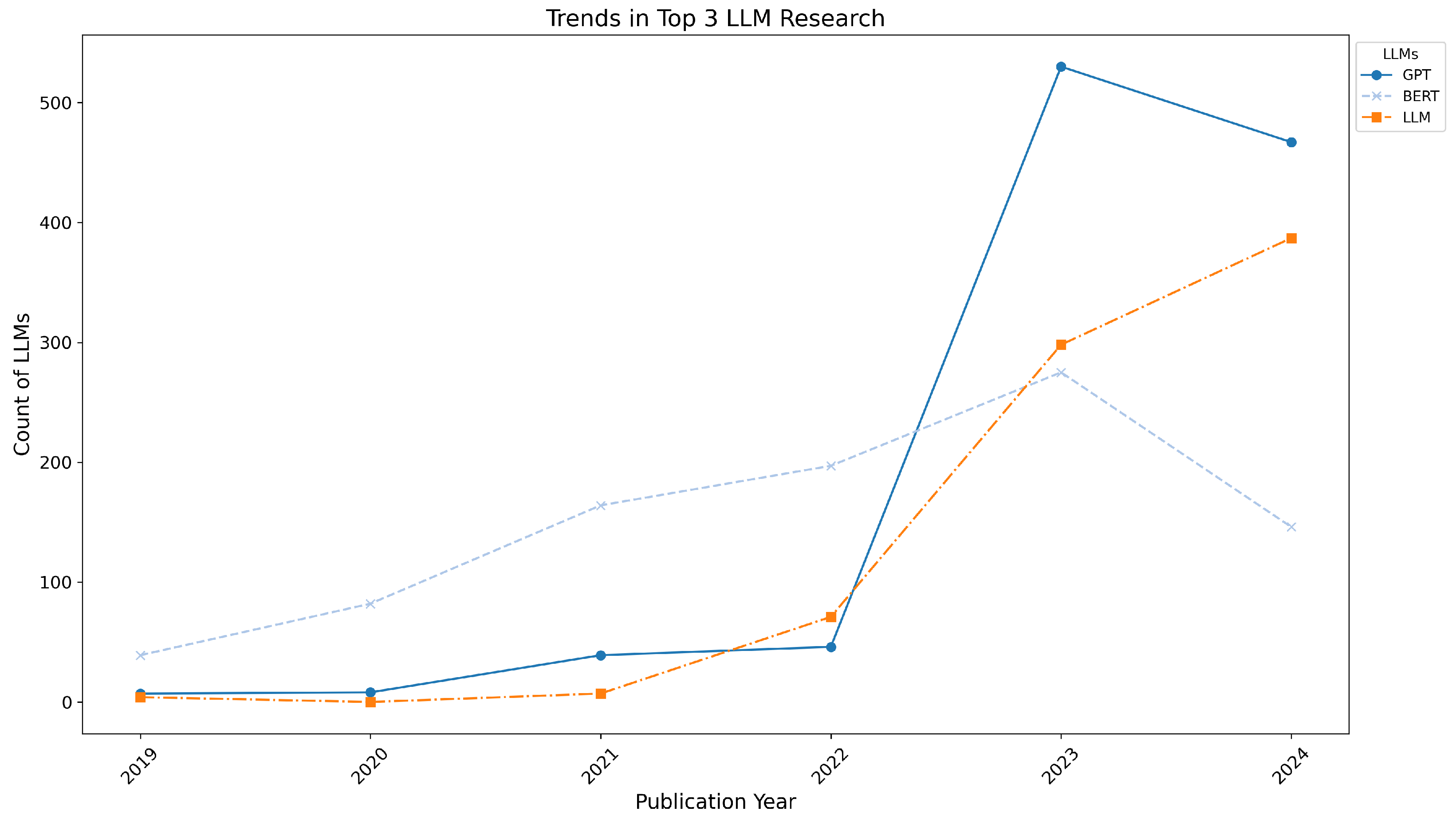
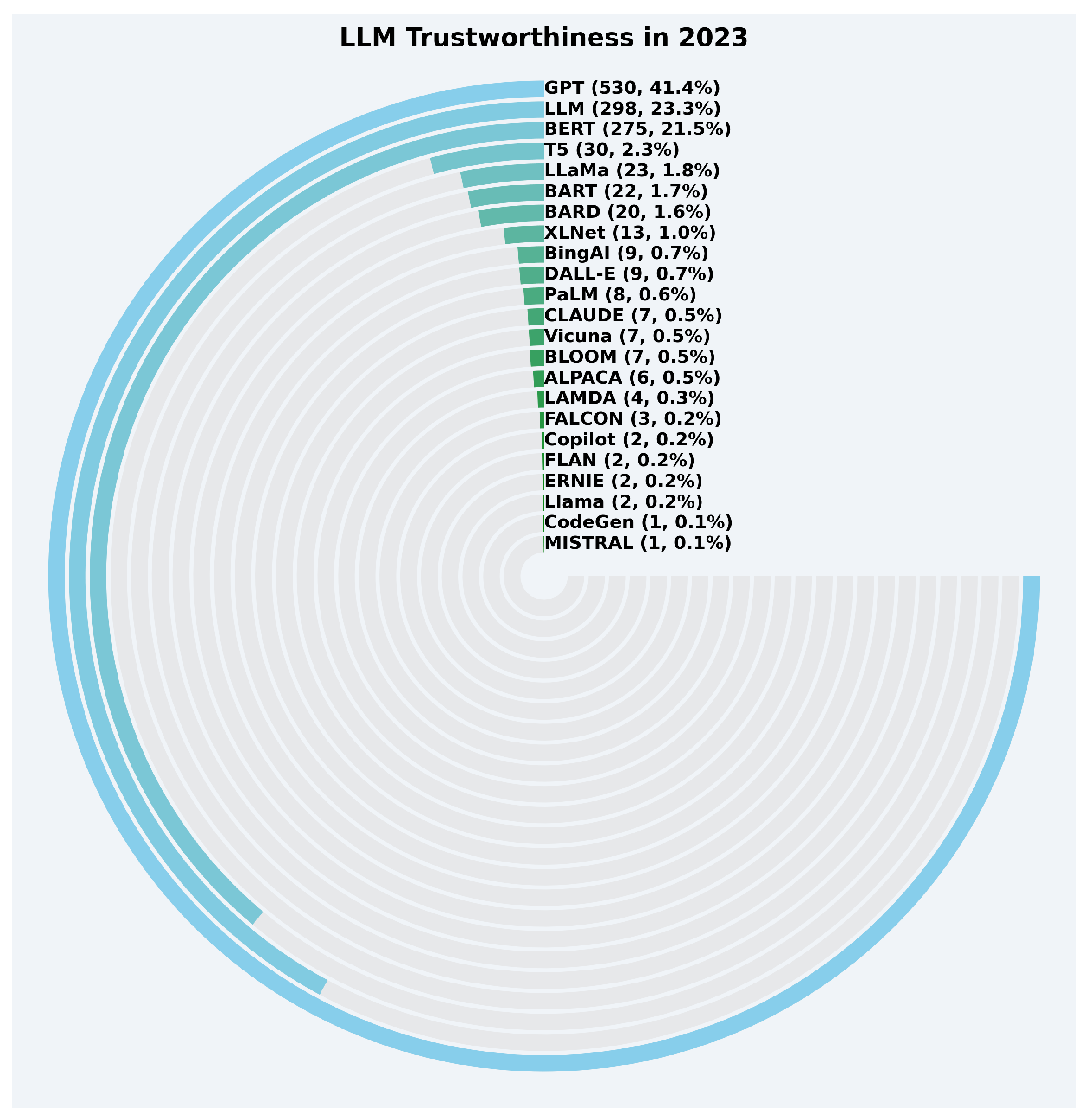
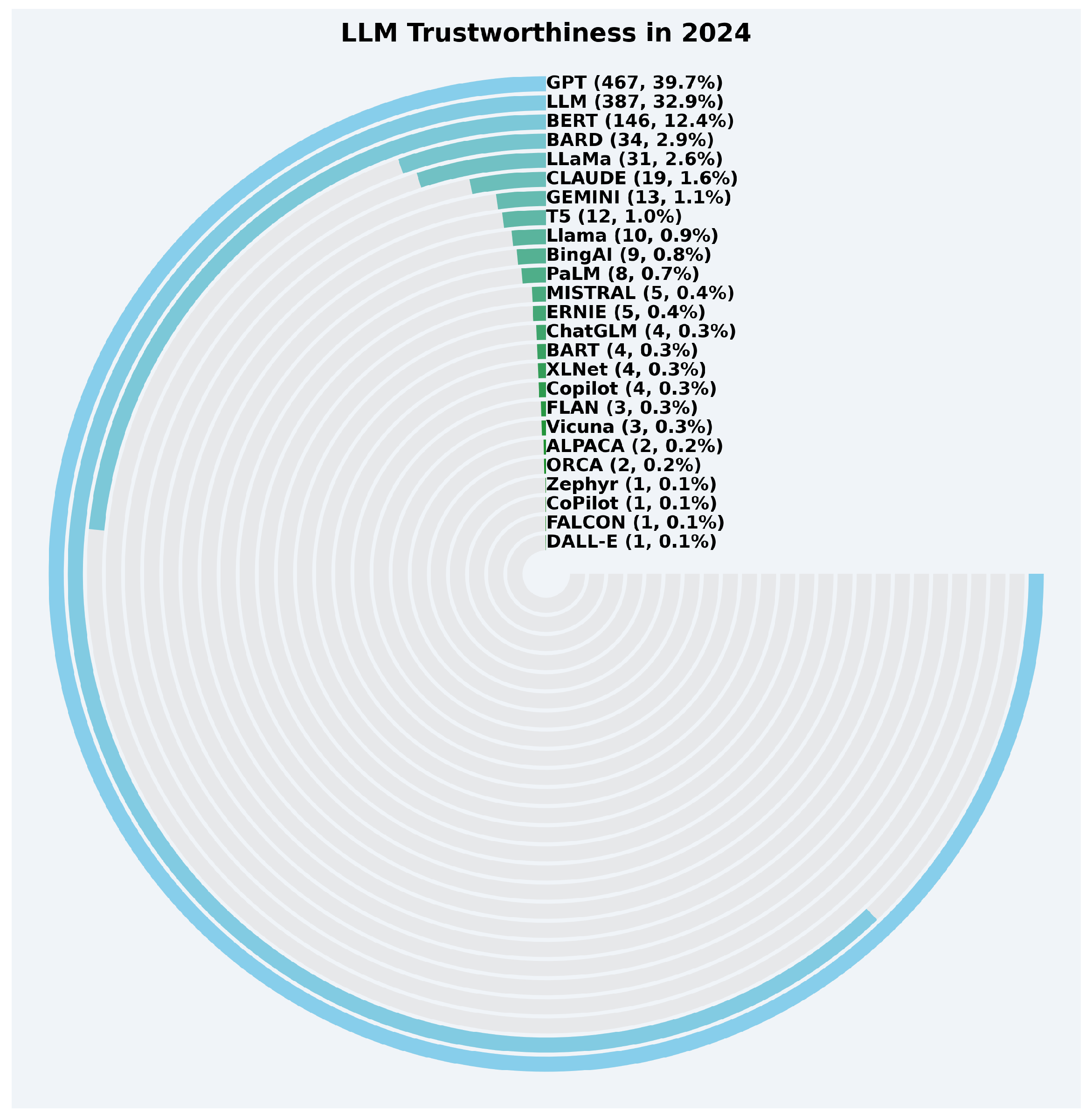
- GPT: Research on GPT’s trustworthiness has grown significantly, starting with 7 papers in 2019 and gradually increasing to 530 papers in 2023, before a slight decline to 467 papers in 2024.
- BERT: Interest in BERT began earlier, with 39 papers in 2019, and reached its peak in 2023 with 275 papers, followed by a decline to 146 papers in 2024.
- LLM: Research on the general LLM category had a slow start with 4 papers in 2019, but experienced rapid growth from 71 papers in 2022 to 298 papers in 2023, and further rising to 387 papers in 2024.
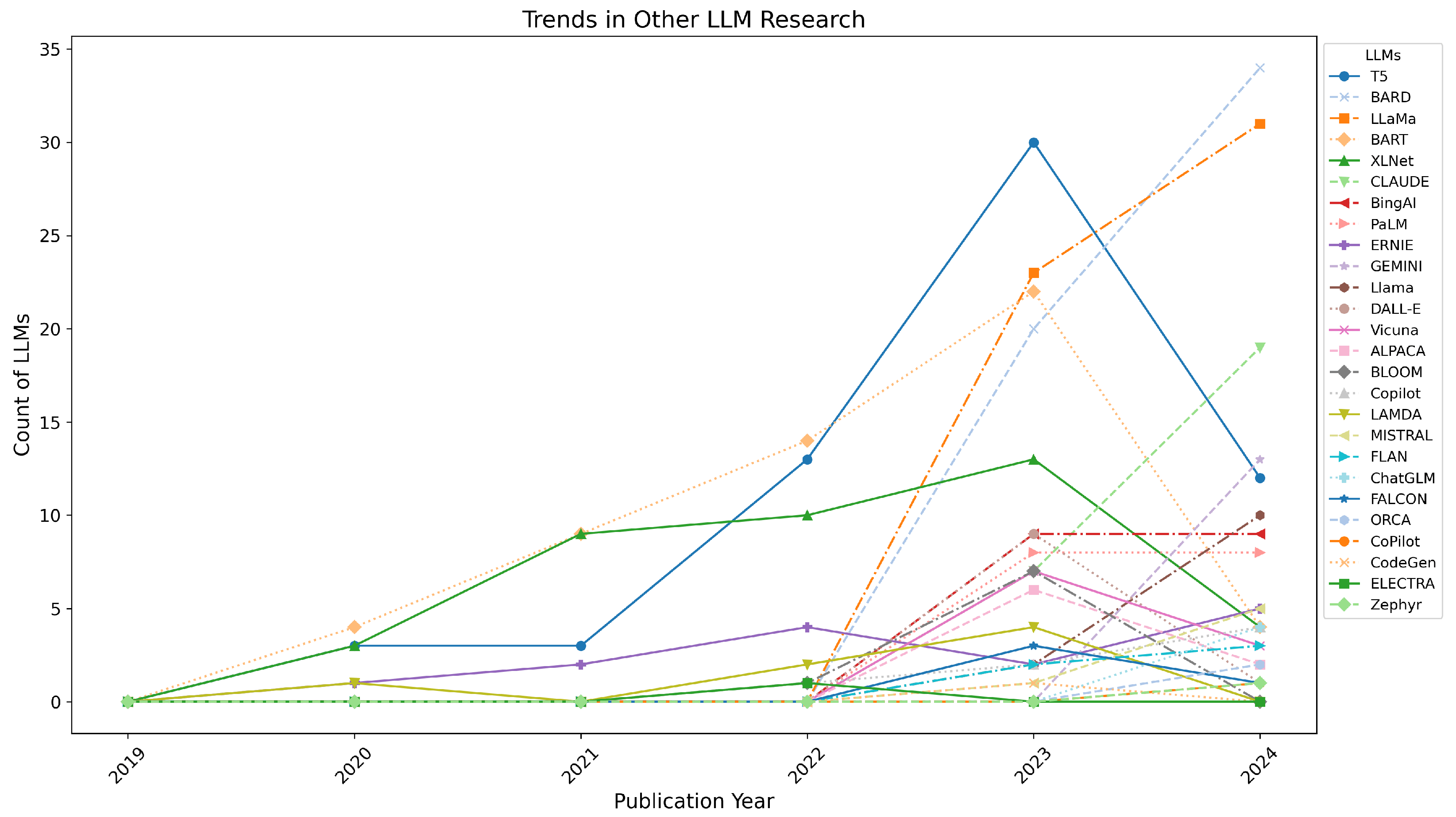
- T5: Research on T5 started in 2020 with 3 papers and peaked at 30 papers in 2023, but saw a decline to 12 papers in 2024.
- BARD: Research on BARD began only in 2023 with 20 papers, increasing to 34 papers in 2024, reflecting growing interest.
- LLaMa: LLaMa-related trustworthiness research commenced in 2023 with 23 papers, rising to 31 papers in 2024.
- Other LLMs:
- –
- BART: From 4 papers in 2020 to 22 papers in 2023, followed by a sharp drop to 4 papers in 2024.
- –
- XLNet: Showed moderate growth, with 3 papers in 2020, peaking at 13 papers in 2023, and dropping to 4 papers in 2024.
- –
- CLAUDE: Research began in 2023 with 7 papers, rising to 19 papers in 2024.
- –
- BingAI and PaLM: Both had consistent yet modest interest, with nine and eight papers, respectively, in 2023 and 2024.
- –
- Emerging Models: Models like GEMINI and Llama saw limited but increasing interest in 2024, e.g., GEMINI with 13 papers and Llama with 10 papers.
5.4. Results of RQ4
Analysis and Results
- Solution Proposal: The largest share of research types falls under solution proposals, with 1517 papers (42.3%). This indicates a strong focus on proposing new solutions and approaches for enhancing the trustworthiness of LLMs.
- Evaluation Research: Research on evaluation constitutes 808 papers (22.5%), highlighting a significant interest in assessing and evaluating the effectiveness of LLMs in ensuring their trustworthiness.
- Validation Research: Research focused on validation account for 648 papers (18.1%), emphasizing the importance of validating the methods, models, and solutions used to evaluate LLM trustworthiness.
- Conceptual Proposal: A total of 397 papers (11.1%) were categorized under conceptual proposals, suggesting that there is ongoing work to define new concepts and frameworks related to LLM trustworthiness.
- Opinion Paper: There were 127 papers (3.5%) related to opinion papers, indicating a smaller focus on providing subjective viewpoints or discussions related to LLM trustworthiness.
- Experience Paper: Experience papers constituted 91 papers (2.5%), reflecting a relatively smaller body of work focused on sharing practical experiences related to LLM trustworthiness.
5.5. Results of RQ5
Analysis and Results
- Solution Proposal: The largest share of research methodologies is in the form of solution proposals, with 1520 papers (42.3%). This indicates a predominant focus on presenting novel solutions or frameworks aimed at enhancing the trustworthiness of LLMs.
- Evaluation Research: Evaluation research accounts for 810 papers (22.5%), highlighting the importance of assessing the effectiveness and trustworthiness of proposed models, tools, or methods.
- Validation Research: With 649 papers (18.0%), validation research plays a crucial role in confirming the reliability and robustness of LLMs within specific application contexts.
- Conceptual Proposal: 400 papers (11.1%) are categorized as conceptual proposals, which involve theoretical contributions aimed at advancing the understanding of LLM trustworthiness.
- Opinion Paper: Opinion papers make up 127 contributions (3.5%), representing subjective perspectives or expert views on LLM trustworthiness.
- Experience Paper: Experience papers, accounting for 91 contributions (2.5%), focus on practical experiences, lessons learned, or case studies related to LLM trustworthiness.
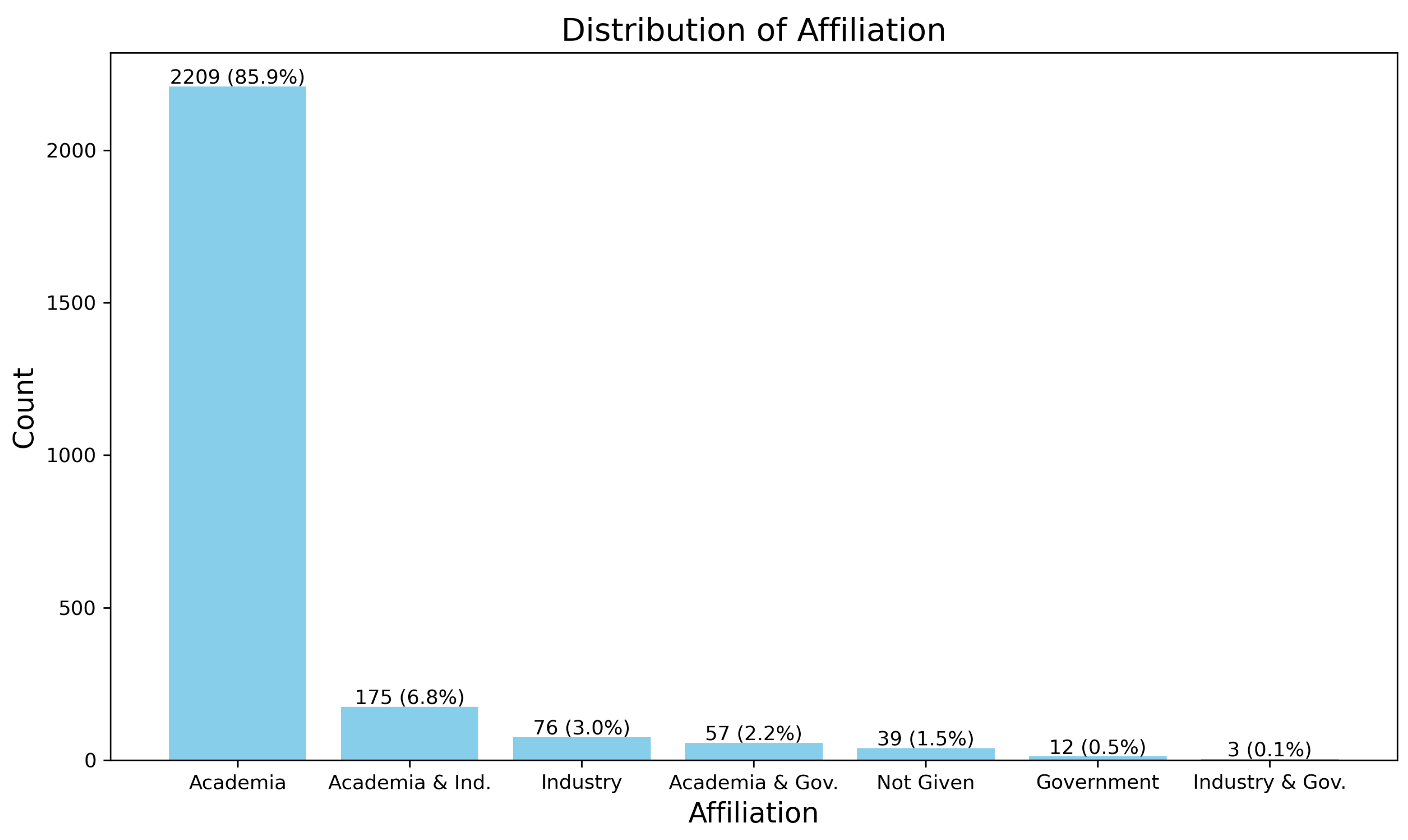
5.6. Results of RQ6
Analysis and Results
- Academia: The overwhelming majority of publications come from academic institutions, with 2209 papers (85.9%). This indicates that academic research is the primary driver of studies on LLM trustworthiness.
- Academia and Industry: A smaller share of 175 papers (6.8%) involve both academia and industry, reflecting some level of collaboration between the two sectors in this field.
- Industry: Industry-only contributions account for 76 papers (3.0%), suggesting that while industry is involved, it is less active in the publication of research focused on LLM trustworthiness.
- Academia and Government: Publications from academia and government combined make up 57 papers (2.2%), indicating a smaller involvement from government bodies in this research area.
- Not Given: In 39 papers (1.5%), the affiliation is not specified, leaving their academic or industrial origin unclear.
- Government: Research contributions from government institutions alone represent 12 papers (0.5%), showing a minimal role for government in this research domain.
- Industry and Government: Only three papers (0.1%) involve both industry and government, suggesting a very limited level of collaboration between these sectors in LLM trustworthiness research.
6. Threats to the Validity of the Results
- Potential Missing Studies: This study underwent a stringent screening process with well-defined inclusion and exclusion criteria. Although the decision to not use “snowball sampling” may limit this study’s credibility, the large number of primary studies (7615) ensures comprehensive coverage of the intended scope. Moreover, following T-A-K skimming Section 3.2.2, some relevant studies could have been excluded due to incomplete or misleading abstracts. Despite these factors, it is believed that, even if a few studies were missed, they are unlikely to significantly affect the overall results of our analysis.
- Limited Critical Depth: Although the use of the T-A-K method in this study effectively facilitated the identification of research trends, developments, underexplored areas, and methodological patterns in the research on LLM trustworthiness, its limitations hinder a more critical exploration of contributing factors that lead to interdisciplinary fragmentation. In particular, how certain trustworthiness dimensions intersect with domain-specific challenges or how they vary across established and emerging models.
- Single Regulatory Framework: The classification scheme for the trustworthiness aspects is based solely on the AI Act. We believe that this approach ensures proper alignment and contextual understanding, particularly when differing definitions or interpretations may arise from other AI-related legislative frameworks. Also, the classification was conducted independently by different authors, and using the AI Act as the primary reference point allowed us to achieve consistency across our analysis.
- Language and Publication Type Bias: To enhance validity, only peer-reviewed, English-language publications were considered, potentially excluding relevant non-English or non-peer-reviewed literature.
- Exclusion of Industry Patents: We consider that certain application domain works, particularly those originating from the industry, might be more appropriately presented in patents rather than academic publications. Since patents were not included within the scope of our study, this exclusion could potentially influence our results.
7. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rawat, B.; Bist, A.S.; Rahardja, U.; Aini, Q.; Sanjaya, Y.P.A. Recent deep learning based NLP techniques for chatbot development: An exhaustive survey. In Proceedings of the 10th International Conference on Cyber and IT Service Management (CITSM), Yogyakarta, Indonesia, 20–21 September 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Raiaan, M.A.K.; Mukta, M.S.H.; Fatema, K.; Fahad, N.M.; Sakib, S.; Mim, M.M.J.; Ahmad, J.; Ali, M.E.; Azam, S. A review on large language models: Architectures, applications, taxonomies, open issues and challenges. IEEE Access 2024, 12, 26839–26874. [Google Scholar] [CrossRef]
- Naveed, H.; Nadeem, M.F.; Munir, M.; Shaukat, A.; Iqbal, M.; Shafait, F.; Mian, A. A Comprehensive Overview of Large Language Models. arXiv 2023, arXiv:2307.06435. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A massively multilingual pre-trained text-to-text transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 483–498. [Google Scholar] [CrossRef]
- Huang, J.; Chang, K.C.-C. Towards reasoning in large language models: A survey. arXiv 2023, arXiv:2212.10403. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar] [CrossRef]
- Gokul, Y.; Ramalingam, M.; Chemmalar, S.G.; Supriya, Y.; Gautam, S.; Praveen, K.R.M.; Deepti, R.G.; Rutvij, H.J.; Prabadevi, B.; Weizheng, W.; et al. Generative Pre-trained Transformer: A Comprehensive Review on Enabling Technologies, Potential Applications, Emerging Challenges, and Future Directions. IEEE Access 2024, 12, 54608–54649. [Google Scholar] [CrossRef]
- Pandya, K.; Holia, M. Automating customer service using LangChain: Building custom open-source GPT chatbot for organizations. arXiv 2023, arXiv:2310.05421. [Google Scholar] [CrossRef]
- Shahzad, T.; Mazhar, T.; Tariq, M.U.; Ahmad, W.; Ouahada, K.; Hamam, H. A comprehensive review of large language models: Issues and solutions in learning environments. Discov. Sustain. 2025, 6, 27. [Google Scholar] [CrossRef]
- Hadi, M.U.; Al-Tashi, Q.; Qureshi, R.; Shah, A.; Muneer, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Hassan, S.Z.; et al. Large Language Models: A Comprehensive Survey of its Applications, Challenges, Limitations, and Future Prospects. TechRxiv, 2023. [Google Scholar] [CrossRef]
- High-Level Expert Group on AI. Ethics Guidelines for Trustworthy AI. European Commission, April 2019. Available online: https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai (accessed on 19 May 2025).
- European Parliament; Council of the European Union. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence. Official Journal of the European Union. Volume 2024/1689, 12 July 2024. Available online: http://data.europa.eu/eli/reg/2024/1689/oj (accessed on 19 May 2025).
- CEN; CENELEC. Artificial Intelligence. CEN-CENELEC. 2025. Available online: https://www.cencenelec.eu/areas-of-work/cen-cenelec-topics/artificial-intelligence/ (accessed on 19 May 2025).
- Bellogín, A.; Grau, O.; Larsson, S.; Schimpf, G.; Sengupta, B.; Solmaz, G. The EU AI Act and the Wager on Trustworthy AI. Communications of the ACM 2024. Available online: https://dl.acm.org/doi/10.1145/3665322 (accessed on 22 June 2025).
- Sun, L.; Huang, Y.; Wang, H.; Wu, S.; Zhang, Q.; Gao, C.; Huang, Y.; Lyu, W.; Zhang, Y.; Li, X.; et al. TrustLLM: Trustworthiness in Large Language Models. Proc. ICML 2024 PMLR 235 2024, 20166–20270. Available online: https://proceedings.mlr.press/v235/huang24x.html (accessed on 19 May 2025).
- Liu, Z.; Xia, C.; He, W.; Wang, C. Trustworthiness and self-awareness in large language models: An exploration through the think-solve-verify framework. Nanjing Univ. AI Res. Pap. 2024, 16855–16866. [Google Scholar]
- Ferdaus, M.M.; Abdelguerfi, M.; Ioup, E.; Niles, K.N.; Pathak, K.; Sloan, S. Towards Trustworthy AI: A Review of Ethical and Robust Large Language Models. arXiv 2024, arXiv:2407.13934. [Google Scholar] [CrossRef]
- Kowald, D.; Scher, S.; Pammer-Schindler, V.; Müllner, P.; Waxnegger, K.; Demelius, L.; Fessl, A.; Toller, M.; Mendoza Estrada, I.G.; Šimić, I.; et al. Establishing and Evaluating Trustworthy AI: Overview and Research Challenges. Front. Big Data 2024, 7, 1467222. [Google Scholar] [CrossRef]
- Petersen, K.; Vakkalanka, S.; Kuzniarz, L. Guidelines for conducting systematic mapping studies in software engineering: An update. Inf. Softw. Technol. 2015, 64, 1–18. [Google Scholar] [CrossRef]
- Patil, R.; Gudivada, V. A Review of Current Trends, Techniques, and Challenges in Large Language Models (LLMs). Appl. Sci. 2024, 14, 2074. [Google Scholar] [CrossRef]
- Matarazzo, A.; Torlone, R. A survey on large language models with some insights on their capabilities and limitations. arXiv 2025, arXiv:2501.04040. [Google Scholar] [CrossRef]
- Ling, C.; Zhao, X.; Lu, J.; Deng, C.; Zheng, C.; Wang, J.; Chowdhury, T.; Li, Y.; Cui, H.; Zhang, X.; et al. Domain specialization as the key to make large language models disruptive: A comprehensive survey. arXiv 2023, arXiv:2305.18703. [Google Scholar]
- Fan, L.; Li, L.; Ma, Z.; Lee, S.; Yu, H.; Hemphill, L. A bibliometric review of large language models research from 2017 to 2023. ACM Trans. Intell. Syst. Technol. 2024, 15, 91. [Google Scholar] [CrossRef]
- Lin, Z.; Guan, S.; Zhang, W.; Zhang, H.; Li, Y.; Zhang, H. Towards trustworthy LLMs: A review on debiasing and dehallucinating in large language models. Artif. Intell. Rev. 2024, 57, 243–266. [Google Scholar] [CrossRef]
- Hadi, M.U.; Qureshi, R.; Shah, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Wu, J.; Mirjalili, S. Large Language Models: A Comprehensive Survey of Its Applications, Challenges, Limitations, and Future Prospects. GitHub Repos 2024. Available online: https://github.com/anas-zafar/LLM-Survey (accessed on 19 May 2025).
- Hong, J.; Duan, J.; Zhang, C.; Li, Z.; Xie, C.; Lieberman, K.; Diffenderfer, J.; Bartoldson, B.; Jaiswal, A.; Xu, K.; et al. Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression. Neural Process. Syst. Conf. 2024. Available online: https://decoding-comp-trust.github.io (accessed on 19 May 2025).
- Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. A Presidential Document by the Executive Office of the President on 11/01/2023. U.S. Office of the Federal Register. Executive Order 14110 of October 30 2023. Available online: https://www.federalregister.gov/documents/2023/11/01/2023-24283/safe-secure-and-trustworthy-development-and-use-of-artificial-intelligence (accessed on 22 June 2025).
- Government of Canada. The Artificial Intelligence and Data Act (AIDA)—Companion Document, Part of Bill C-27, the Digital Charter Implementation Act, 2022. 2022. Available online: https://ised-isde.canada.ca/site/innovation-better-canada/en/artificial-intelligence-and-data-act-aida-companion-document (accessed on 22 June 2025).
- Code of Ethics, The Ethical Norms for the New Generation Artificial Intelligence, China. Ministry of Science and Technology of the People’s Republic of China. 2021. Available online: https://www.most.gov.cn/kjbgz/202109/t20210926_177063.html (accessed on 22 June 2025).
- Presidential Committee on the Fourth Industrial Revolution, South Korea, Guidebook for Trustworthy AI(Sector), National Guidelines for Artificial Intelligence (AI) Ethics. 2024. Available online: https://ai.kisdi.re.kr/eng/main/contents.do?menuNo=500014 (accessed on 22 June 2025).
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol. TIST 2024, 15, 1–45. [Google Scholar] [CrossRef]
- Inam, R.; Hata, A.Y.; Prifti, V.; Asadollah, S.A. A Comprehensive Study on Artificial Intelligence Algorithms to Implement Safety Using Communication Technologies. Wirel. Pers. Commun. J. 2021. Available online: https://arxiv.org/abs/2205.08404 (accessed on 19 May 2025).
- Petersen, K.; Feldt, R.; Mujtaba, S.; Mattsson, M. Systematic Mapping Studies in Software Engineering. In Proceedings of the 12th International Conference on Evaluation and Assessment in Software Engineering (EASE), 26–27 June 2008; British Computer Society: London, UK; pp. 68–77. Available online: https://www.scienceopen.com/hosted-document?doi=10.14236/ewic/EASE2008.8 (accessed on 22 June 2025).
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Technical Report EBSE-2007-01; Keele University and University of Durham: 2007. Available online: https://cs.ecu.edu/gudivada/research/papers/guidelines-for-se-literature-reviews-summary.pdf (accessed on 19 May 2025).
- European Parliament and the Council. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 Laying Down Harmonised Rules on Artificial Intelligence and Amending Regulations (EC) No 300/2008, (EU) No 167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 and (EU) 2019/2144 and Directives 2014/90/EU, (EU) 2016/797 and (EU) 2020/1828 (Artificial Intelligence Act). 2024. Available online: https://eur-lex.europa.eu/eli/reg/2024/1689/oj/eng (accessed on 7 July 2025).
- Brereton, P.; Kitchenham, B.A.; Budgen, D.; Turner, M.; Khalil, M. Lessons from applying the systematic literature review process within the software engineering domain. J. Syst. Softw. 2007, 80, 571–583. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Jalali, S.; Wohlin, C. Systematic literature studies: Database searches vs. backward snowballing. In Proceedings of the ESEM 2012 ACM-IEEE International Symposium on Empirical Software Engineering and Measurement, Lund, Sweden, 19–20 September 2012; Association for Computing Machinery: New York, NY, USA; pp. 29–38. [Google Scholar] [CrossRef]
- Wieringa, R.; Maiden, N.; Mead, N.; Rolland, C. Requirements engineering paper classification and evaluation criteria: A proposal and a discussion. Requir. Eng. 2006, 11, 102–107. [Google Scholar] [CrossRef]
- Taori, R.; Gulrajani, I.; Zhang, T.; Dubois, Y.; Li, X.; Guestrin, C.; Liang, P.; Hashimoto, T.B. Alpaca: A Strong, Replicable Instruction-Following Model. Stanford Alpaca 2024. Available online: https://crfm.stanford.edu/2023/03/13/alpaca.html (accessed on 7 July 2025).
- Nicholson, A.E.; Korb, K.B.; Nyberg, E.P.; Wybrow, M.; Zukerman, I.; Mascaro, S.; Thakur, S.; Alvandi, A.O.; Riley, J.; Pearson, R.; et al. BARD: A structured technique for group elicitation of Bayesian networks to support analytic reasoning. arXiv 2020, arXiv:2003.01207. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Microsoft. Microsoft New Future of Work Report 2023. 2023. Available online: https://www.microsoft.com/en-us/research/uploads/prod/2023/12/NFWReport2023_v5.pdf (accessed on 19 May 2025).
- BigScience Workshop; Le Scao, T.; Fan, A.; Akiki, C.; Pavlick, E.; Ilić, S.; Hesslow, D.; Castagné, R.; Luccioni, A.S.; Yvon, F.; et al. BLOOM: A 176B-parameter open-access multilingual language model. arXiv 2022, arXiv:2211.05100. [Google Scholar]
- Team GLM; Zeng, A.; Xu, B.; Wang, B.; Zhang, C.; Yin, D.; Zhang, D.; Rojas, D.; Feng, G.; Zhao, H.; et al. ChatGLM: A family of large language models from GLM-130B to GLM-4 All Tools. arXiv 2024, arXiv:2406.12793. [Google Scholar] [CrossRef]
- Caruccio, L.; Cirillo, S.; Polese, G.; Solimando, G.; Sundaramurthy, S.; Tortora, G. Claude 2.0 Large Language Model: Tackling a Real-World Classification Problem with a New Iterative Prompt Engineering Approach. Intell. Syst. Appl. 2024, 21, 200336. [Google Scholar] [CrossRef]
- Aryabumi, V.; Dang, J.; Talupuru, D.; Dash, S.; Cairuz, D.; Lin, H.; Venkitesh, B.; Smith, M.; Campos, J.A.; Tan, Y.C.; et al. Aya 23: Open Weight Releases to Further Multilingual Progress. arXiv 2024, arXiv:2405.15032. [Google Scholar]
- Smit, D.; Smuts, H.; Louw, P.; Pielmeier, J.; Eidelloth, C. The Impact of GitHub Copilot on Developer Productivity from a Software Engineering Body of Knowledge Perspective. In Proceedings of the 30th Americas Conference on Information Systems (AMCIS 2024); AIS: Salt Lake City, UT, USA, 2024; p. 1528. [Google Scholar]
- Nijkamp, E.; Pang, B.; Hayashi, H.; Tu, L.; Wang, H.; Zhou, Y.; Savarese, S.; Xiong, C. CodeGen: An open large language model for code with multi-turn program synthesis. arXiv 2022, arXiv:2203.13474. [Google Scholar] [CrossRef]
- Betker, J.; Goh, G.; Jing, L.; Brooks, T.; Wang, J.; Li, L.; Ouyang, L.; Zhuang, J.; Lee, J.; Guo, Y.; et al. Improving Image Generation with Better Captions. OpenAI 2023. Available online: https://cdn.openai.com/papers/dall-e-3.pdf (accessed on 19 May 2015).
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced language representation with informative entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1441–1451. [Google Scholar] [CrossRef]
- Almazrouei, E.; Alobeidli, H.; Alshamsi, A.; Cappelli, A.; Cojocaru, R.; Debbah, M.; Goffinet, E.; Hesslow, D.; Launay, J.; Malartic, Q.; et al. The Falcon series of open language models. arXiv 2023, arXiv:2311.16867. [Google Scholar] [CrossRef]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned Language Models Are Zero-Shot Learners. In Proceedings of the 10th International Conference on Learning Representations (ICLR 2022). 2022. Available online: https://openreview.net/forum?id=gEZrGCozdqR (accessed on 19 May 2025).
- Team, G.; Anil, R.; Borgeaud, S.; Alayrac, J.B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K.; et al. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar] [CrossRef]
- Mesnard, T.; Hardin, C.; Dadashi, R.; Bhupatiraju, S.; Pathak, S.; Sifre, L.; Rivière, M.; Kale, M.S.; Love, J.; Tafti, P.; et al. Gemma: Open models based on Gemini research and technology. arXiv 2024, arXiv:2403.08295. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. OpenAI. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 19 May 2025).
- Thoppilan, R.; Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.-T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. LaMDA: Language models for dialog applications. arXiv 2022, arXiv:2201.08239. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar] [CrossRef]
- Jiang, Q.A.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot D., S.; Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B: A highly efficient and performant 7-billion-parameter language model. arXiv 2023, arXiv:2310.06825. [Google Scholar] [CrossRef]
- Mosaic AI Research. Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs. Databricks Blog. 5 May 2023. Available online: https://www.databricks.com/blog/mpt-7b (accessed on 19 May 2025).
- Mukherjee, S.; Mitra, A.; Jawahar, G.; Agarwal, S.; Palangi, H.; Awadallah, A. Orca: Progressive learning from complex explanation traces of GPT-4. arXiv 2023, arXiv:2306.02707. [Google Scholar] [CrossRef]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling language modeling with Pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar] [CrossRef]
- Abdin, M.; Aneja, J.; Awadalla, H.; Awadallah, A.; Awan, A.A.; Bach, N.; Bahree, A.; Bakhtiari, A.; Bao, J.; Behl, H.; et al. Phi-3 Technical Report: A highly capable language model locally on your phone. arXiv 2024, arXiv:2404.14219. [Google Scholar] [CrossRef]
- Bellagente, M.; Tow, J.; Mahan, D.; Phung, D.; Zhuravinskyi, M.; Adithyan, R.; Baicoianu, J.; Brooks, B.; Cooper, N.; Datta, A.; et al. Stable LM 2 1.6B Technical Report. arXiv 2024, arXiv:2402.17834. [Google Scholar] [CrossRef]
- Li, R.; Allal, L.B.; Zi, Y.; Muennighoff, N.; Kocetkov, D.; Mou, C.; Marone, M.; Akiki, C.; Li, J.; Chim, J.; et al. StarCoder: May the Source Be With You! arXiv 2023, arXiv:2305.06161. [Google Scholar] [CrossRef]
- The Vicuna Team. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality. 30 Mar 2023. Available online: https://lmsys.org/blog/2023-03-30-vicuna/ (accessed on 19 May 2025).
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar] [CrossRef]
- Tunstall, L.; Beeching, E.; Lambert, N.; Rajani, N.; Rasul, K.; Belkada, Y.; Huang, S.; von Werra, L.; Fourrier, C.; Habib, N.; et al. Zephyr: Direct Distillation of LM Alignment. arXiv 2023, arXiv:2310.16944. [Google Scholar] [CrossRef]
- Zou, H.; Zhao, Q.; Tian, Y.; Bariah, L.; Bader, F.; Lestable, T.; Debbah, M. TelecomGPT: A Framework to Build Telecom-Specific Large Language Models. arXiv 2024, arXiv:2407.09424. [Google Scholar] [CrossRef]
- Shao, J.; Tong, J.; Wu, Q.; Guo, W.; Li, Z.; Lin, Z.; Zhang, J. WirelessLLM: Empowering Large Language Models Towards Wireless Intelligence. arXiv 2024. Available online: https://arxiv.org/html/2405.17053v1 (accessed on 19 May 2025).
- Asadollah, S.A.; Sundmark, D.; Eldh, S.; Hansson, H.; Afzal, W. 10 years of research on debugging concurrent and multicore software: A systematic mapping study. Softw. Qual. J. 2017, 25, 49–82. [Google Scholar] [CrossRef]
- Wohlin, C.; Runeson, P.; Höst, M.; Ohlsson, M.C.; Regnell, B.; Wesslén, A. Experimentation in Software Engineering; Springer: Berlin/Heidelberg, Germany, 2012; ISBN 978-3-642-29044-2. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Final Search String |
|---|
| (“*Language Model*” OR “LLM” OR “ALPACA” OR “BART” OR |
| “*BERT*” OR “BLOOM” OR “ChatGLM” OR “CLAUDE” OR |
| “Cohere” OR “CodeGen” OR “ERNIE” OR “FALCON” OR “FLAN” OR |
| “GEMINI” OR “GEMMA” OR “GPT” OR “LAMDA” OR “Llama” OR |
| “T5” OR “MISTRAL” OR “MT5” OR “MPT” OR “OpenAI” OR |
| “ORCA” OR “PaLM” OR “Phi-” OR “StableLM” OR “StartCoder” OR |
| “Vicuna” OR “XLNet” OR “WebGPT” OR “Zephyr”) |
| AND |
| (“Trust*” OR “Human Oversight” OR “Safe*” OR “Reliab*” OR |
| “Robust*” OR “Resilen*” OR “Transparen*” OR “Traceab*” OR |
| “Explainab*” OR “Ethic” OR “Bias” OR “Faithful” OR |
| “Responsible” OR “Accountable”) |
| Digital Library | Description |
|---|---|
| IEEE Xplore Digital Library | The search string is performed in the “Advanced Search”. Since the number of occurrences was very large, the search was divided into three parts and applied within Document Title, Abstract, and Author Keywords, limiting the publication year to 2017. |
| ACM Digital Library | The search string is performed in the “Advanced Search”. Due to the high number of occurrences, the search was divided into three parts and applied within Title, Abstract, and Author Keywords, restricting the publication year to 2017. |
| Scopus | In “Search” of Document Search, the search string is applied. Given the large number of occurrences, the search was focused on a single part and applied within Article Title, Abstract, and Keywords. |
| Web of Science | In the text box of “Advanced Search”, the string is applied. The prefix “TS=” is added to the beginning of the string, where TS represents the Topic. |
| Digital Library | Search Results |
|---|---|
| IEEE Xplore Digital Library | 1622 |
| ACM Digital Library | 277 |
| Scopus | 6512 |
| Web of Science | 3866 |
| Total | 12,277 |
| ID | Criteria |
|---|---|
| IC 1 | Studies presented the trustworthy aspects in LLMs. |
| EC 1 | Studies that are duplicates of other studies. |
| EC 2 | Studies that are considered secondary studies to other ones. |
| EC 3 | Studies that are not peer-reviewed, short papers (4 pages or less). |
| EC 4 | Studies that are not written in English. |
| EC 5 | Studies that are not available in full-text. |
| Category | Data Item | Description | RQ |
|---|---|---|---|
| General | Study ID | Number | - |
| Title | Name of the study | - | |
| Abstract | Abstract of the study | - | |
| Keywords | Set of keywords | - | |
| Author | Set of authors | - | |
| Author affiliation | Type of affiliation | RQ6 | |
| Pages | Number | - | |
| Year of publication | Calendar year | RQ3 | |
| Specific | LLM algorithm | Type of LLM algorithm | RQ1a, RQ2, RQ3 |
| Trustworthiness aspect | Type of Trustworthiness aspect | RQ1b, RQ2, RQ3 | |
| Communication technology | Type of communication technology | RQ2, RQ3 | |
| Application domains | Type of application domain | RQ2, RQ3 | |
| Research contribution | Type of contribution | RQ4 | |
| Research type | Type of research | RQ5 |
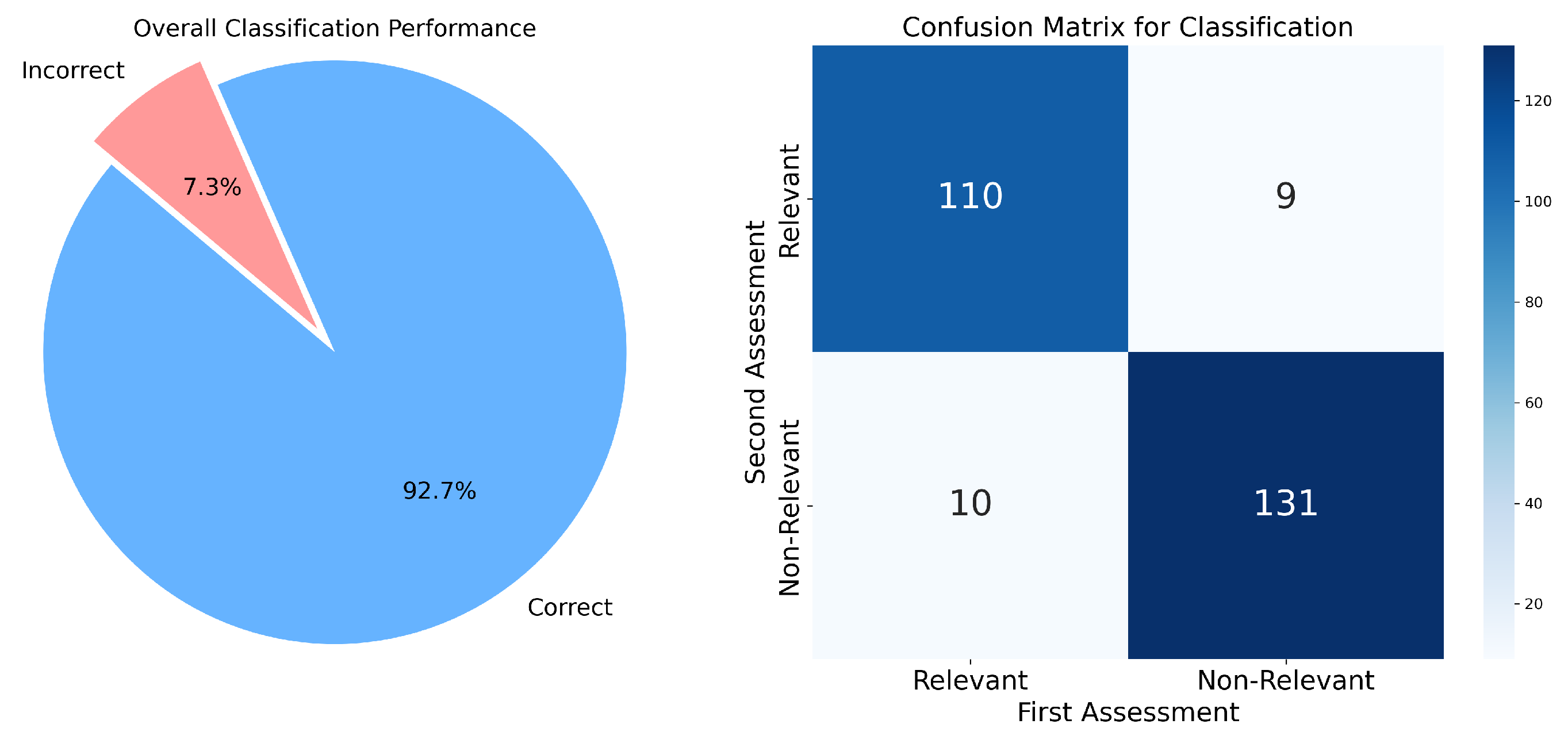
| Classification | Amount |
|---|---|
| Correct | 241 out of 260 (92.69 %) |
| Incorrect | 19 out of 260 (7.31 %) |
| Total | 260 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Billah, M.M.; Hamjaya, H.S.; Shiralizade, H.; Singh, V.; Inam, R. Large Language Models’ Trustworthiness in the Light of the EU AI Act—A Systematic Mapping Study. Appl. Sci. 2025, 15, 7640. https://doi.org/10.3390/app15147640
Billah MM, Hamjaya HS, Shiralizade H, Singh V, Inam R. Large Language Models’ Trustworthiness in the Light of the EU AI Act—A Systematic Mapping Study. Applied Sciences. 2025; 15(14):7640. https://doi.org/10.3390/app15147640
Chicago/Turabian StyleBillah, Md Masum, Harry Setiawan Hamjaya, Hakima Shiralizade, Vandita Singh, and Rafia Inam. 2025. "Large Language Models’ Trustworthiness in the Light of the EU AI Act—A Systematic Mapping Study" Applied Sciences 15, no. 14: 7640. https://doi.org/10.3390/app15147640
APA StyleBillah, M. M., Hamjaya, H. S., Shiralizade, H., Singh, V., & Inam, R. (2025). Large Language Models’ Trustworthiness in the Light of the EU AI Act—A Systematic Mapping Study. Applied Sciences, 15(14), 7640. https://doi.org/10.3390/app15147640