1. Introduction
Bearings are critical mechanical components that significantly influence the reliability, performance, and efficiency of various industrial systems, such as automotive engines, aerospace equipment, and wind turbines [
1]. These bearings typically operate in environments characterized by high rotational speeds, heavy loads, elevated temperatures, and constant vibration, collectively defined as demanding operational conditions [
2]. Such conditions significantly accelerate the wear and deterioration of bearings, increasing their susceptibility to faults. Numerous studies have consistently indicated that bearing faults account for over half of all mechanical system failures, leading to substantial economic losses due to unplanned downtime, costly repairs, and decreased productivity [
3,
4]. Consequently, the development of accurate and efficient real-time fault detection and diagnosis methodologies is crucial for enhancing system reliability and operational safety.
Traditionally, bearing fault diagnosis approaches typically involve manual extraction of discriminative features from vibration signals and classic machine learning algorithms [
5]. While these techniques can be effective, they heavily rely on expert domain knowledge and are highly sensitive to noise and varying operating conditions. To overcome these limitations, researchers have increasingly adopted deep-learning-based methods, benefiting from their automated feature extraction capabilities and robust performance in noisy environments. In particular, convolutional neural networks (CNNs), renowned for their effectiveness in image processing tasks, have demonstrated significant success in bearing fault diagnosis applications [
6,
7]. However, bearing vibration signals inherently possess temporal characteristics that CNN architectures alone may inadequately capture. This shortcoming has motivated further exploration into sequence-based models, such as recurrent neural networks (RNNs) [
8,
9] and transformer architectures [
10,
11], both of which have shown improved capability in modeling temporal dependencies.
Despite the demonstrated performance improvements, deploying conventional deep learning architectures in practical, real-time industrial scenarios remains challenging. These deep networks usually feature a large number of parameters and complex computations, resulting in significant memory usage and computational costs [
12,
13,
14,
15]. Such characteristics limit their suitability for real-time monitoring, especially in resource-constrained edge computing environments where power consumption and inference speed are critical considerations. Edge computing devices facilitate early fault detection and immediate response actions, significantly reducing the risk of minor faults escalating into severe breakdowns [
16]. Additionally, processing data locally on edge devices reduces the communication burden on centralized systems, supports autonomous operation in remote or inaccessible installations, and enhances overall system efficiency through reduced energy consumption. These advantages become increasingly important for real-time monitoring in large-scale or remotely situated industrial systems.
In response to these challenges, spiking neural networks (SNNs) [
17] have emerged as a compelling alternative. SNNs process information using discrete binary spike signals and operate based on an event-driven computing paradigm, substantially reducing energy consumption compared to traditional neural networks. Specifically, the SNN architecture replaces computationally intensive multiply-and-accumulate (MAC) operations with simpler accumulate (AC) operations, exploiting their inherent sparsity and asynchronous processing nature [
18]. Their asynchronous, event-driven nature keeps the network largely inactive until meaningful input spikes arrive, thereby further lowering power requirements. This advantage is especially suitable for real-time industrial monitoring scenarios, where memory and computational resources are limited but inference speed is critical. Nevertheless, spike-driven SNNs commonly exhibit lower performance accuracy compared to conventional deep neural networks, primarily due to the sparsity and limited information representation of spike signals [
19].
To mitigate this performance degradation, hybrid neural network architectures combining SNNs and artificial neural networks (ANNs) have been proposed [
20]. These approaches typically integrate SNNs with ANN-based modules to enhance accuracy. However, they inevitably reintroduce MAC operations, undermining the computational and energy-efficiency benefits of purely spike-driven systems. As a result, research has increasingly shifted toward improving performance within fully spike-driven architectures that preserve the energy efficiency of SNNs.
A key challenge in this pursuit is converting continuous-valued input signals into spike trains. Among the various encoding techniques explored—such as rate coding [
21] and temporal coding [
22]—direct encoding has shown notable advantages. By mapping continuous values directly into spike magnitudes at each timestep, direct encoding effectively retains informative content with fewer timesteps, thereby reducing latency and memory requirements [
23,
24]. In parallel, the inherent non-differentiability of spike signals has been addressed using surrogate gradient learning methods, which approximate gradients and enable efficient backpropagation training in spike-based networks [
25].
Building upon these foundational advancements, attention-based SNN models—such as SEW-ResNet—have emerged, demonstrating that spike-driven architectures can achieve performance comparable to ANN counterparts while maintaining significantly lower energy consumption [
18,
26,
27,
28]. These innovations have made it possible to build SNN models that perform well while still using much less energy and computing power. Despite recent advances in SNNs, existing approaches for bearing fault diagnosis have yet to simultaneously achieve ANN-level accuracy and genuine event-driven efficiency. Furthermore, previous SNN methods have not effectively incorporated attention mechanisms to dynamically weight spatial-temporal features and adequately extend receptive fields, which is crucial for processing long-sequence vibration signals commonly encountered in bearing fault diagnosis.
Motivated by these developments, we propose the spike convolutional attention network (SpikeCAN), a fully spike-driven architecture explicitly tailored for energy-efficient, real-time bearing fault diagnosis. SpikeCAN incorporates two novel modules: the spike attention module and the multi-dilated receptive field (MDRF) convolutional module. The spike attention module dynamically emphasizes critical spatial-temporal features, whereas the MDRF module efficiently captures extensive temporal dependencies through dilated convolutions and multi-scale kernels. Additionally, SpikeCAN employs carefully designed residual connections to alleviate spike-vanishing issues, thereby ensuring robust training and enhanced accuracy.
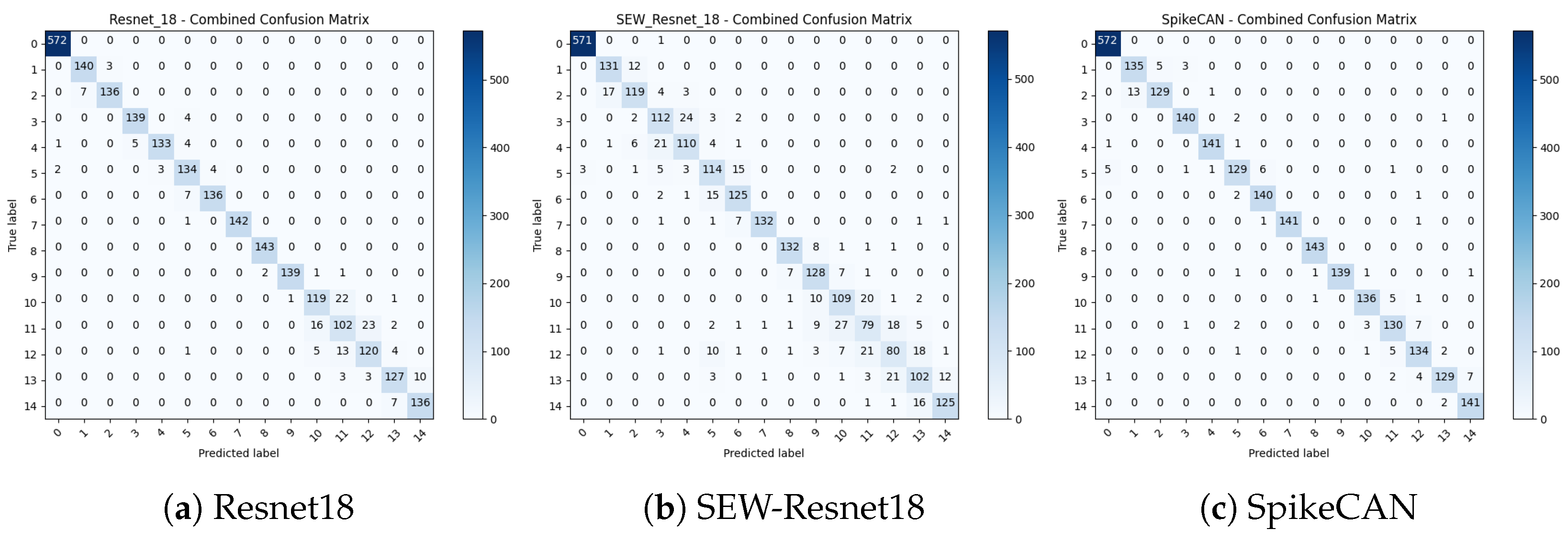
We comprehensively evaluate the proposed SpikeCAN model using two prominent benchmark datasets in the bearing fault diagnosis domain: the Case Western Reserve University (CWRU) dataset [
29] and the Society for Machinery Failure Prevention Technology (MFPT) dataset [
30]. Our results demonstrate outstanding accuracy, with SpikeCAN achieving 99.86% accuracy on the four-class classification task of the CWRU dataset using five-fold cross-validation and 99.88% accuracy under a conventional 70:30 train–test split averaged over five random seeds. Additionally, SpikeCAN achieves a notable 96.31% accuracy on the challenging fifteen-class MFPT dataset, surpassing existing spike-driven approaches and establishing a new state-of-the-art benchmark. Overall, our findings underscore the potential of SpikeCAN to significantly advance energy-efficient, real-time bearing fault diagnosis, highlighting its practical applicability in industrial settings.
The remainder of this paper is structured as follows.
Section 2 provides a review of related work and discusses the motivation behind the proposed approach.
Section 3 introduces the SpikeCAN model, detailing its architecture and key mechanisms. In
Section 4, we describe the experimental setup and datasets used in this study.
Section 5 presents the evaluation methods along with comprehensive results and analyses.
Section 6 outlines the methodology employed to calculate energy consumption.
Section 7 reports on detailed ablation studies to validate the effectiveness of individual components and the model’s robustness to variations in training sample size. Finally,
Section 8 provides conclusions and discussions along with potential future research directions.
3. Method
In this study, we propose SpikeCAN, a spike-driven SNN architecture for bearing fault diagnosis. SpikeCAN supports end-to-end learning from raw input signals without requiring any handcrafted feature extraction or signal preprocessing. Designed entirely within the spike domain, the model is optimized for low energy consumption and is well-suited for deployment on edge devices with constrained computational resources.
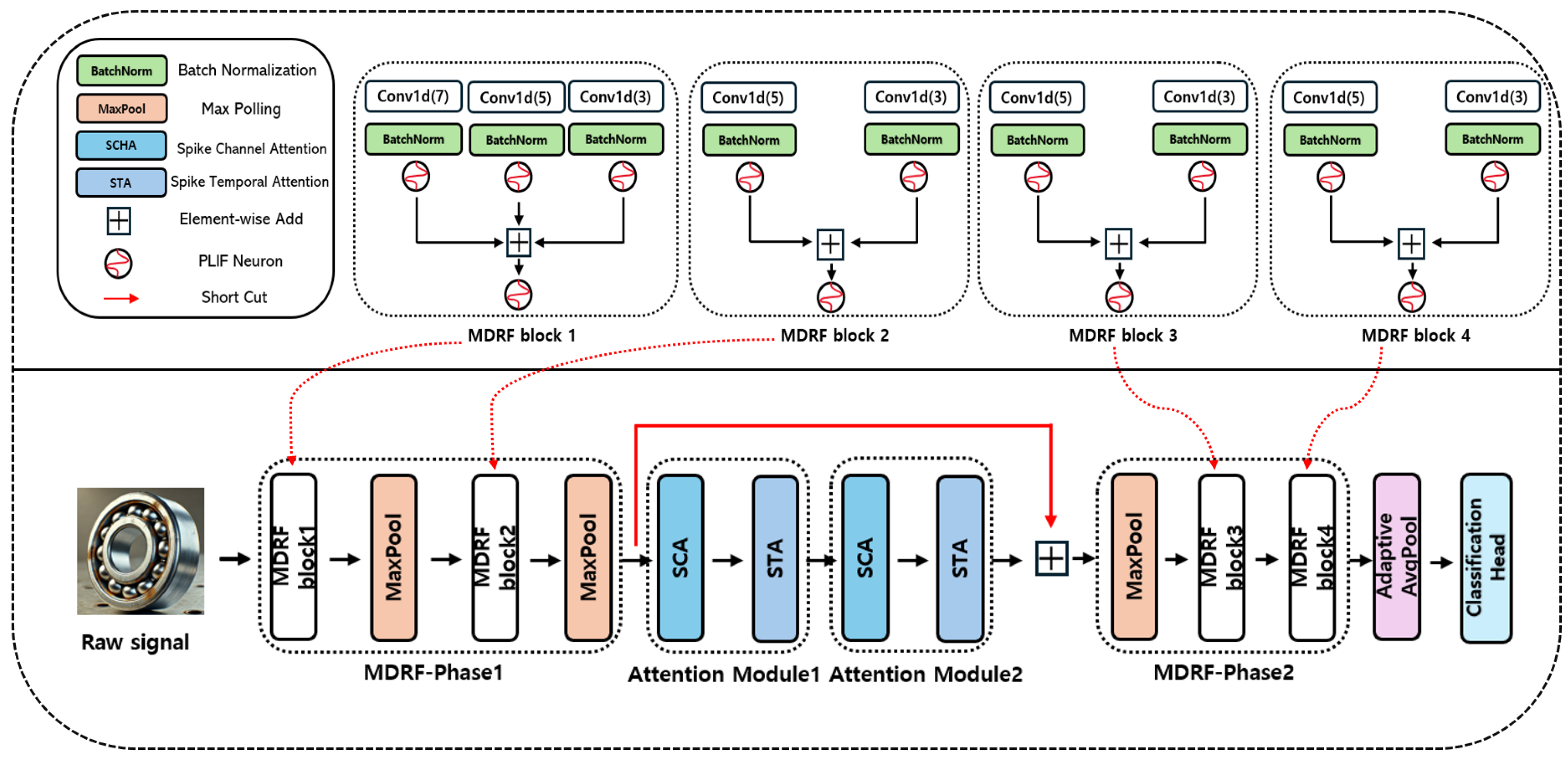
SpikeCAN is composed of three main components: the MDRF block, SCA block, and STA block. The overall architecture of the proposed model is illustrated in
Figure 1. The hyperparameters employed in the model were systematically determined through a grid search over several candidate values based on commonly adopted configurations from established literature [
36]. The model processes input data in three sequential stages. First, the input signal is passed through MDRF-Phase 1, which extracts global temporal features using multi-scale convolutional processing. Next, the output is refined using two consecutive attention modules, each composed of an SCA block followed by an STA block, enabling the model to adaptively focus on relevant features. Finally, the resulting spike-based features are processed by MDRF-Phase 2 to extract localized patterns, followed by adaptive average pooling and a classification head to produce the final prediction.
3.1. MDRF-Phase 1
MDRF-Phase 1 serves as the initial feature extraction stage. It takes the raw input spike train and processes it through two sequential MDRF blocks, each followed by a MaxPooling operation. This stage is designed to capture global and long-range temporal dependencies in the input signal by leveraging wide receptive fields enabled by dilated convolutions.
Formally, given input
, the operations in this phase can be described as:
Each MDRF block applies multiple 1D convolutions in parallel using different kernel sizes and dilation rates to extract multi-scale temporal features. The resulting spike maps are fused using spike-domain operations and passed through a PLIF neuron to generate spike outputs.
3.2. Attention Module 1 and 2
After the initial feature extraction, the feature
is further refined through two attention modules, each composed of an SCA block followed by an STA block. These modules allow the network to adaptively highlight discriminative features along both the channel and temporal dimensions. The flow of computation through the attention modules is as follows:
where the final attention output of the attention stage, denoted as
, is computed by applying spike-element-wise addition between the output of the second STA block (
) and the input of the first attention module (
). This residual connection helps preserve the original feature information while integrating refined attention-enhanced features.
3.3. MDRF-Phase 2
MDRF-Phase 2 aims to capture more fine-grained local features using smaller kernels and reduced dilation. This phase begins with a MaxPooling operation to reduce the temporal resolution, followed by two additional MDRF blocks (MDRF-block 3 and MDRF-block 4), which further refine the feature representation learned in the earlier stages. The processing flow is defined as:
This stage completes the hierarchical feature extraction process, preparing the spike-based feature map for the final classification stage.
3.4. MDRF Block
Bearing fault diagnosis typically involves time-series signals that require capturing both short- and long-range temporal dependencies. Although Transformer-based models have proven effective for this purpose, their high computational cost often limits their deployment in real-time or edge computing scenarios. To address these limitations, we propose a convolution-based MDRF block that enables efficient temporal modeling while maintaining low computational complexity.
The MDRF block employs parallel 1D convolutions with different kernel sizes and dilation rates to construct a multi-scale receptive field. This design captures temporal features at various scales, reducing information loss that might occur in single-scale architectures. Structurally, four MDRF blocks—MDRF-block 1 through MDRF-block 4—are incorporated into SpikeCAN. Specifically, MDRF-block 1 uses three parallel 1D convolution (Conv1d) layers with kernel sizes
and dilation factors
applied to the batch-normalized input. The outputs are summed element-wise and passed through a PLIF neuron to generate spike activations:
In contrast, MDRF-blocks 2, 3, and 4 are designed to be lighter in computational cost. Each of these blocks utilizes two convolution branches with kernel sizes of 3 and 5 and corresponding dilation factors of 1 and 2. For each block, the outputs are batch-normalized, fused via element-wise addition, and passed through a PLIF neuron to produce spike-based outputs. This structure allows efficient local feature extraction while preserving compatibility with event-driven SNN processing.
Additionally, each of these blocks is followed by a MaxPooling operation to reduce the temporal resolution, helping to lower the computational load and mitigate feature redundancy. Formally, for each input
, the computation proceeds as:
In this manner, MDRF-block 1 extracts richer temporal representations using three convolution branches, while MDRF-blocks 2 through 4 offer computationally efficient alternatives optimized for real-time applications.
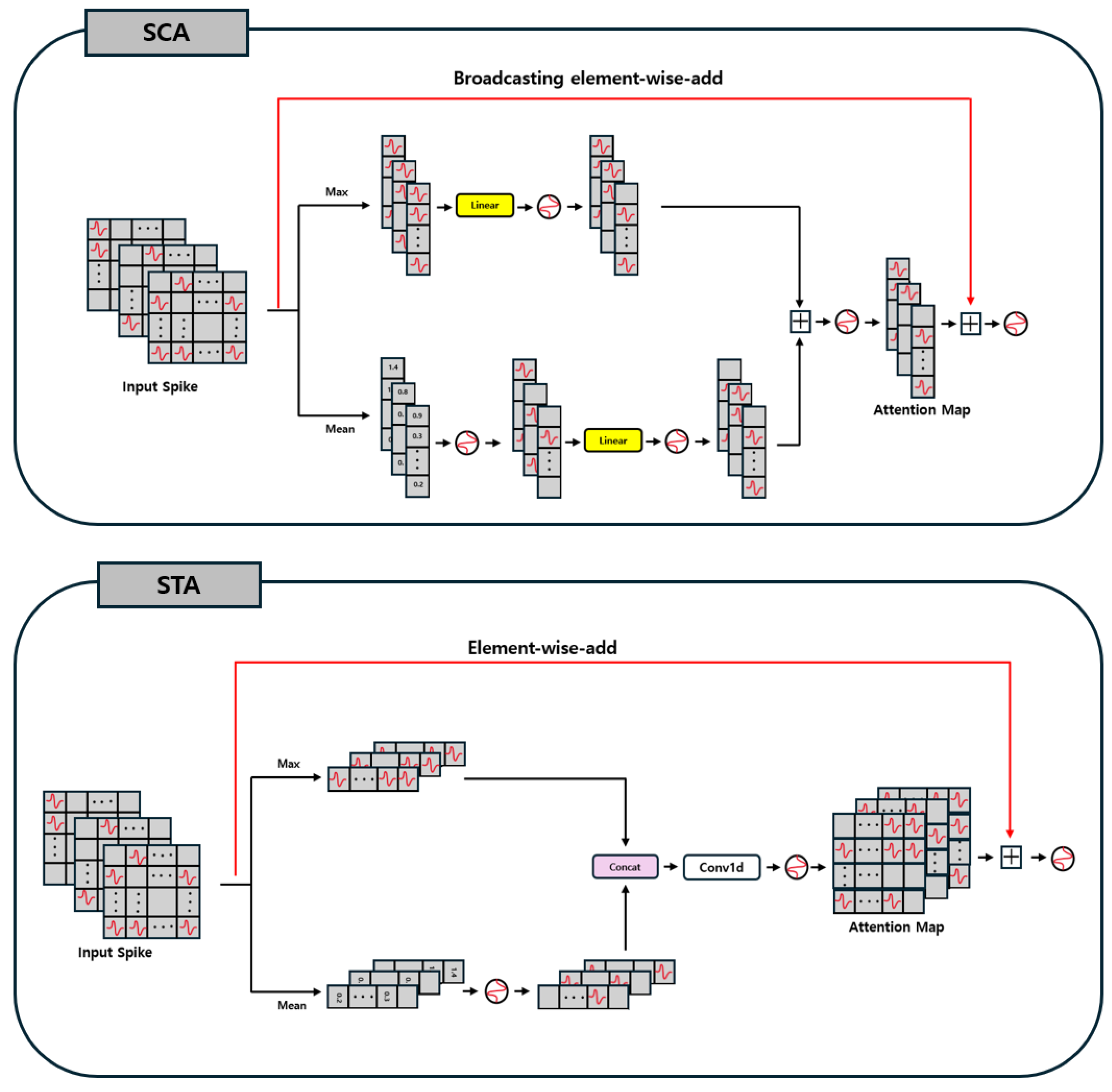
3.5. Spike Convolutional Attention
We introduce two convolution-based attention blocks, SCA and STA, specifically designed for spike-driven SNNs. These methods effectively adapt conventional ANN-based convolutional attention mechanisms for spike-based processing, enabling SNNs to achieve maximal performance improvements while fully maintaining spike-driven computations. The overall architecture of SCA and STA is shown in
Figure 2.
First, both SCA and STA perform their internal operations using spike signals composed of . As a result, most of MAC operations in conventional convolutional attention can be replaced with AC operations, thereby reducing computational cost. Moreover, due to the nature of spike signals, which never produce negative values during computation, non-linear operations such as the sigmoid and exponential functions become unnecessary, further decreasing the overall calculation overhead.
Additionally, we introduce a spike-compatible attention integration method termed spike addition, which leverages the binary nature of spike signals. Because spike signals consist of , the attention maps in SCA and STA are also represented by . When added to the original spike features, the resulting values become . Here, 0 denotes unimportant information, 1 indicates that a spike occurred in either the attention map or the original feature alone, and 2 indicates that spikes occurred in both simultaneously. By employing this spike addition method, the attention map can be applied to the original features effectively while minimizing any loss of spike information.
3.5.1. SCA Block
The SCA block is a convolution-based attention mechanism designed to emphasize channel-specific information in the input. Its operation proceeds as follows: first, the mean and maximum values are computed along the temporal axis. The mean value captures the overall distribution of the data, while the maximum value highlights salient regions. Given the spiking nature of the model, the mean value is processed by a PLIF neuron to be converted back into a spike signal.
Then, each value is passed through its own linear layer for training and is subsequently transformed into a spike signal via another PLIF neuron. These two spike signals are combined using a spike-element-wise addition. The resulting feature map is again fed into a PLIF neuron to generate the final spike channel attention map, which is subsequently added to the original input through a spike-element-wise addition to perform the channel attention mechanism.
The computation steps of SCA are given by:
3.5.2. STA Block
The STA block is a convolution-based attention mechanism specifically designed to emphasize temporal features in the data. First, STA computes both mean and maximum values along the channel axis, capturing overall trends and salient information. The mean output is then passed through a PLIF neuron to be converted into a spike signal. Next, this spike-based mean output is concatenated with the max output, and the combined tensor is fed into a Conv1d layer for further training. Finally, the resulting feature map is processed by another PLIF neuron, yielding a spike feature map that is integrated with the original input via spike-element-wise addition, thus completing the attention operation.
The computation steps of STA are given by:
3.6. Classification Head
After the final MDRF block, the output spike feature map is passed through an adaptive average pooling layer, followed by a linear projection and batch normalization. This classification head maps the features to class logits used for the final prediction:
6. Energy Consumption Calculation
To estimate the energy cost of SpikeCAN, we follow the methodology commonly adopted in recent spiking neural network studies. In conventional ANNs, most operations rely on MAC computations, which are energy-intensive. In contrast, SNNs primarily use AC operations in their internal layers, requiring MAC operations only in the first layer for input encoding.
In SNNs, the effective number of floating-point operations (FLOPs) depends not only on the layer dimensions but also on the spike firing rate (SFR) and the number of simulation time steps (T), since spike-based operations are event-driven and occur only when spikes are present. Following the formulation in prior work [
27], the computational cost of SNNs is split as:
To convert FLOPs into energy consumption, we use standard energy coefficients:
pJ per MAC operation and
pJ per AC operation. Using these values, the total energy consumption of SpikeCAN can be estimated as:
where
L represents the total number of layers and
indicates the average spike firing rate in the
i-th layer. Since spiking activity is sparse, the effective energy usage in deeper layers is typically much lower than in the first layer.
This formula allows us to approximate the total energy usage of our model under a realistic SNN execution paradigm. All spike firing rates and FLOPs values are empirically computed based on simulation logs during evaluation.
7. Ablation Study
7.1. Impact of Spike Convolutional Attention on Performance
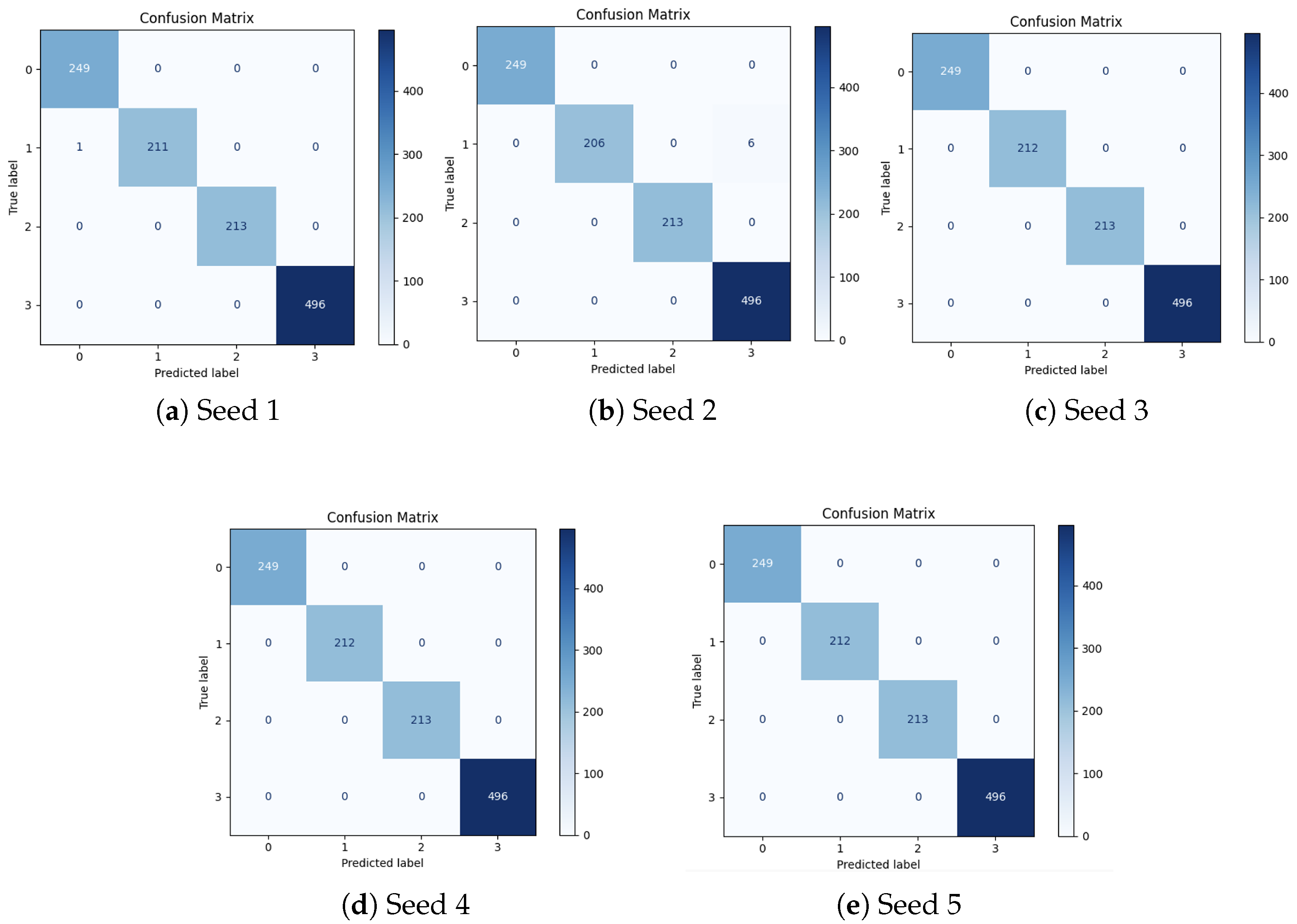
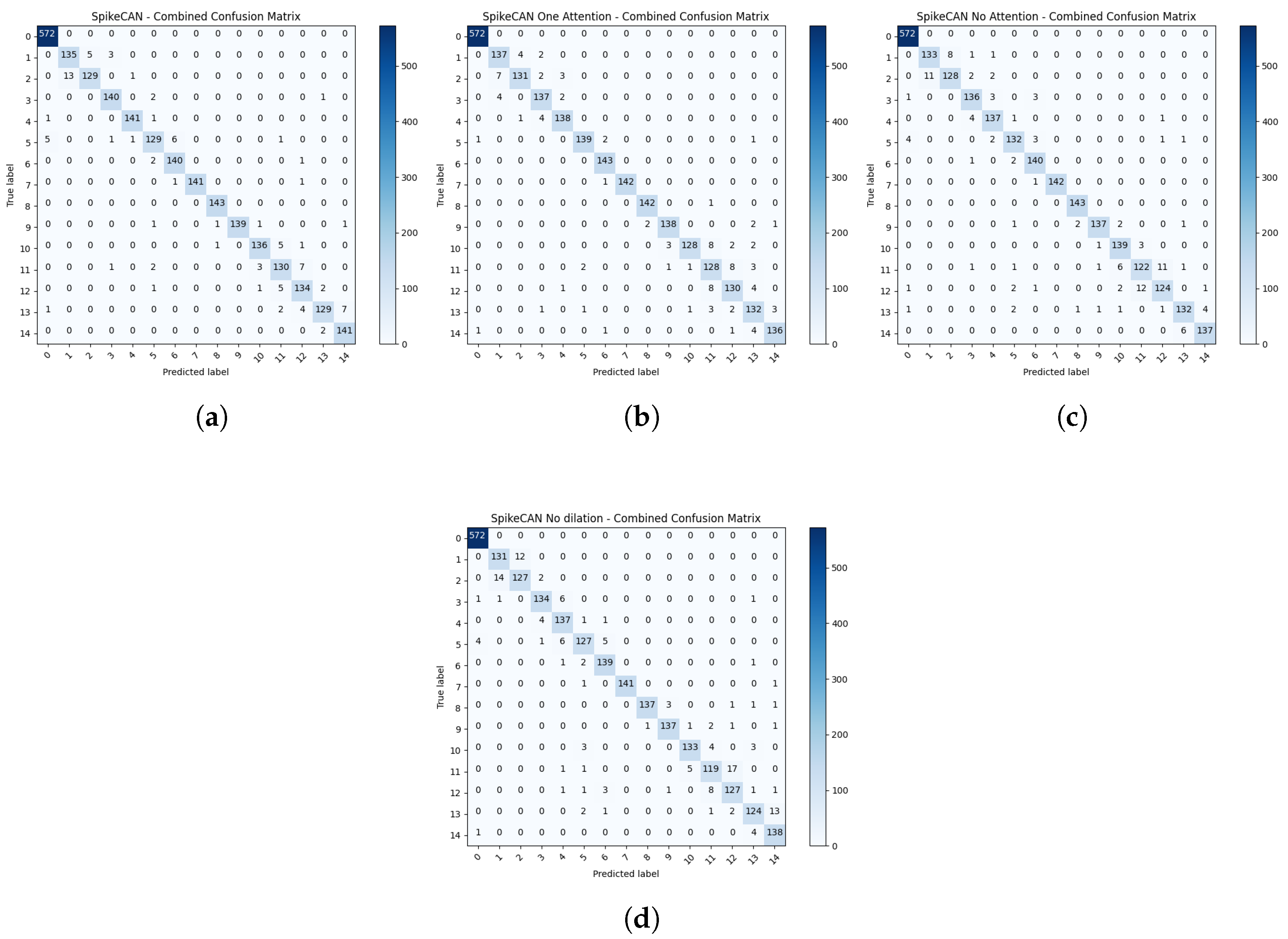
To assess the contribution of each core component in SpikeCAN, we conducted a series of ablation experiments by systematically removing or modifying individual modules. These experiments were performed on the MFPT dataset using five-fold cross-validation for the 15-class classification task, ensuring statistical robustness across evaluations.
In our ablation study, we evaluated three modified versions of the original SpikeCAN model. The first variant, referred to as SpikeCAN with one attention module, retains only the first attention module while removing the second, allowing us to examine the marginal benefit of the second attention stage. The second variant, called SpikeCAN without attention modules, completely eliminates both SCA and STA blocks from the architecture. Finally, in the third variant, SpikeCAN without dilation, all dilated convolutions in the MDRF blocks are replaced with standard convolutions to assess the role of dilation in expanding temporal receptive fields.
The accuracies and F1 Scores for these ablation experiments are provided in
Table 5, and the corresponding confusion matrices are shown in
Figure 6. The results clearly show that the full SpikeCAN model, with all modules intact, consistently achieves superior performance across all evaluation metrics. Notably, the confusion matrices reveal that the complete model maintains stable accuracy across all classes, including challenging cases such as Class 11 and Class 12. In contrast, the ablated variants exhibit increased misclassification in these classes, highlighting the effectiveness of the removed components.
Statistical analysis revealed that removing dilation from the SpikeCAN model resulted in a significant decrease in performance, with the accuracy reduced by approximately 2.22% (t = , ) and the F1 Score decreased by about 0.0272 (t = , ), highlighting the critical role of dilation in feature extraction. When examining the impact of removing attention modules, eliminating one attention module caused a slight performance drop compared to the original model, but this decrease was not statistically significant. However, removing both attention modules led to a marginally significant decrease in accuracy (t-statistic = , p = ) and a statistically significant reduction in F1 Score (t-statistic = , p = ), demonstrating the important contribution of attention mechanisms to the model’s performance.
These findings underscore the importance of both the attention mechanism and the dilated convolutional design in achieving high classification performance. The attention modules help focus on discriminative temporal and channel-wise features, while the use of dilation expands the receptive field without increasing computational cost. Together, they enable SpikeCAN to achieve robust and accurate diagnosis in complex fault scenarios.
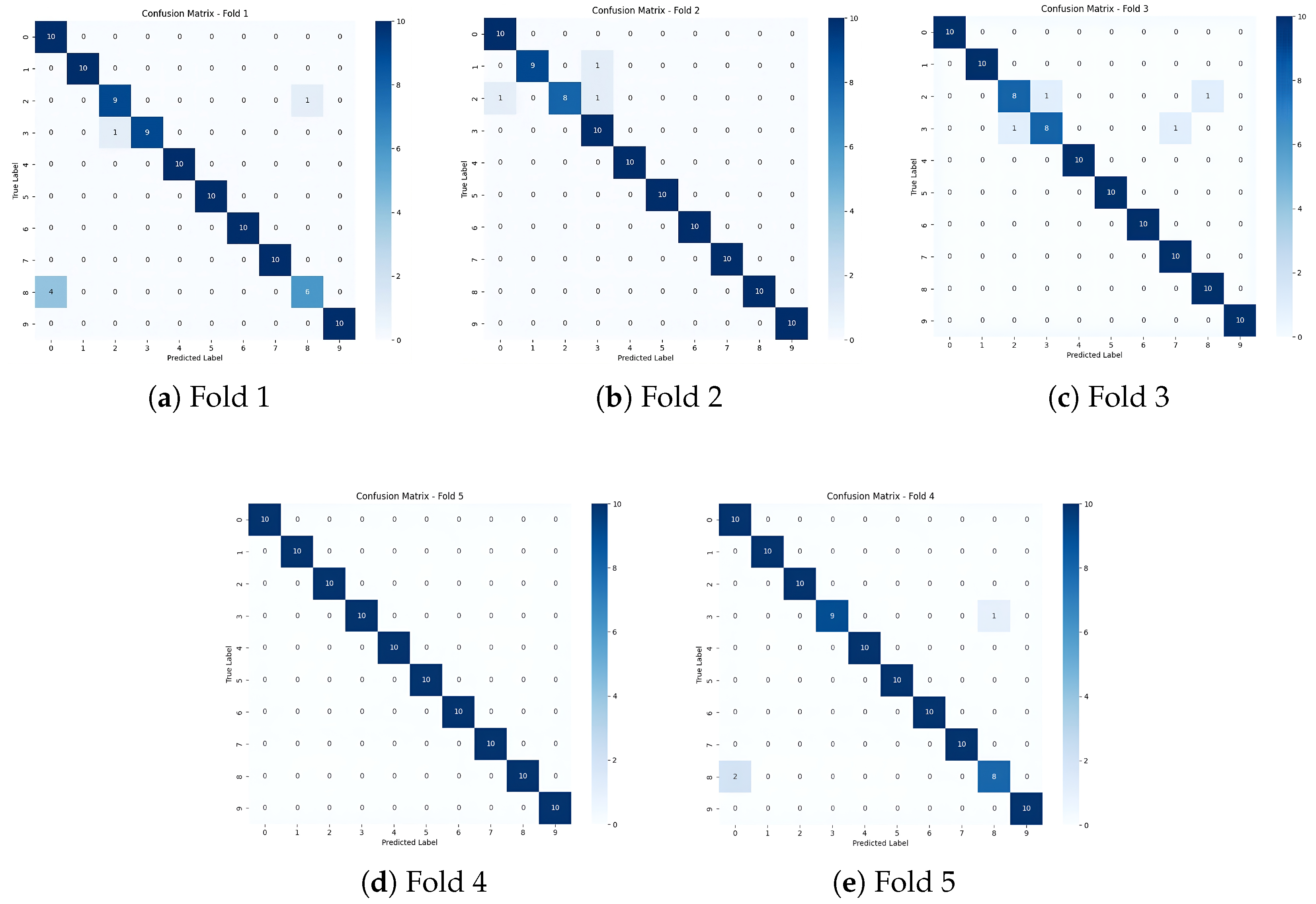
7.2. Robustness Analysis Under Varying Training Sample Sizes
To assess the robustness of our SpikeCAN model with respect to the number of training samples per class presented in [
47], we conducted experiments on the CWRU 10-class classification dataset. We systematically reduced the number of samples per class to 50, 40, and 30, and evaluated the model’s performance under each condition using five-fold cross-validation, summarized in
Table 6.
Our results reveal that SpikeCAN maintains robust performance, with only a moderate decline in F1 Score of approximately 0.0847 when reducing the training samples from 50 to 40 per class, although this decrease is statistically significant (t-statistic = 2.9093, ). This suggests that 40 samples per class can be a practical lower bound for reliable model training under the current experimental conditions. However, further reduction to 30 samples per class induces a pronounced degradation in performance, with an F1 Score drop of approximately 0.2119 relative to the 50-sample baseline (t-statistic = 5.9901, ). Additionally, the difference in F1 Score between 40 and 30 samples per class is about 0.1272 (t-statistic = 2.8178, ), reinforcing that the performance decline accelerates beyond the 40-sample threshold. These findings highlight an important trade-off between training data availability and diagnostic accuracy, emphasizing the necessity of sufficient sample sizes to ensure dependable fault diagnosis in practical industrial applications.
8. Discussion and Conclusions
The experimental evaluations conducted on the MFPT and CWRU datasets clearly demonstrate the substantial potential and practical utility of the proposed SpikeCAN model for industrial fault diagnosis tasks. On the MFPT dataset, SpikeCAN achieved a remarkable accuracy of 96.31% across a challenging 15-class classification scenario, while maintaining an exceptionally low theoretical energy consumption of 0.78 mJ per inference. Similarly, on the widely used CWRU dataset, SpikeCAN delivered robust classification performance, achieving 97.80% accuracy in a constrained data scenario (10-class) and 99.86% accuracy in a 4-class configuration, consuming only 3.71 mJ per inference. Furthermore, inference speed tests conducted on an RTX 4090 GPU indicate a processing time of approximately 27.49 ms per inference, underscoring SpikeCAN’s suitability for real-time monitoring tasks.
Beyond these promising quantitative results, SpikeCAN also presents important practical advantages that enhance its suitability for real-world industrial deployments. The inherent energy efficiency of its fully spike-driven architecture directly facilitates its application on resource-constrained edge devices, potentially leading to substantial reductions in operational costs and overall energy demands. Additionally, extensive experimental evaluations and comprehensive ablation studies have validated the robustness of SpikeCAN, highlighting its reliable and consistent performance across diverse fault conditions. Additional techniques, such as adaptive spike thresholding and data augmentation, could be effectively integrated to enhance robustness in real-world environments characterized by sensor noise and operational variability. SpikeCAN’s rapid inference capabilities, demonstrated empirically, also highlight its promise for timely fault detection and immediate corrective actions required in practical industrial monitoring scenarios.
Nevertheless, we acknowledge several practical limitations that must be considered when interpreting these results. Primarily, the reported energy consumption values are theoretical estimates derived from model operations, and fully realizing SpikeCAN’s low-energy advantages hinges critically upon the continued development and broader availability of specialized neuromorphic hardware designed specifically for spike-driven computation. Achieving optimal real-world performance on such hardware platforms will require substantial hardware-specific optimization of SpikeCAN, including dedicated encoding strategies for efficiently converting raw sensor data into spike signals. Additionally, practical challenges, such as dealing with data scarcity for rare fault conditions and managing noise and variability in industrial environments, must be carefully addressed in future developments and deployments.
Looking forward, several promising research opportunities emerge from this study. Extending SpikeCAN’s architecture to handle various types of industrial time-series signals beyond vibration data, including acoustic, electrical, and multi-modal sensor inputs, represents a compelling direction. Additionally, examining the interpretability of attention patterns learned by SpikeCAN, especially regarding their alignment with fault-relevant signal features, could provide valuable insights for enhanced diagnostic transparency and trustworthiness. Furthermore, integrating unsupervised or semi-supervised learning techniques could enable SpikeCAN to dynamically adapt to evolving operational conditions or previously unseen fault types without extensive labeled datasets.
In conclusion, this work introduced SpikeCAN, a fully spike-driven neural network architecture specifically designed to meet the rigorous demands of real-time and energy-efficient bearing fault diagnosis. By innovatively integrating spike-compatible channel and temporal attention mechanisms (SCA and STA) and multi-dilated receptive field convolutional structures (MDRF), SpikeCAN effectively extracts informative temporal features directly from raw sensor data with minimal computational overhead. The experimental results validate SpikeCAN’s state-of-the-art performance and significantly reduced theoretical energy requirements, highlighting its substantial potential for deployment in industrial IoT and edge computing scenarios. We anticipate that this study will stimulate further exploration into spike-driven architectures and contribute meaningfully toward the development of reliable, energy-aware, and robust real-time fault monitoring systems.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}