1. Introduction
As cultural diversity continues to grow in modern society, understanding the identity of each culture has become increasingly important. In particular, language not only functions as a means of communication but also reflects cultural identity and historical context. In Korean society, Hanja (Chinese characters) and four-character idioms (Sajaseongeo, 四字成語, idioms strictly composed of four characters) serve as representative cultural elements that embody symbolic meaning. Over a long historical period, they have acquired distinct meanings within Korea. In fact, Hanja accounts for approximately 70% of Korean vocabulary and over 90% of technical terms, demonstrating its substantial influence on the Korean language [
1,
2,
3]
Chinese character idioms, a subset of Sino-Korean vocabulary, effectively encapsulate complex meanings or expressions in a concise form by leveraging the logographic nature of Hanja [
4]. These idioms encompass both Gosaseongeo (故事成語, idioms derived from classical stories) and Sajaseongeo. Among them, Sajaseongeo are idiomatic expressions consisting of exactly four characters that convey the meaning of long sentences within a compact structure. This study focuses specifically on Sajaseongeo.
Hanja has its roots in China but has been adopted and developed differently across various Asian countries, including Korea, Japan, and Vietnam [
5]. Chinese characters were first introduced to the Korean Peninsula during the late Gojoseon period, primarily in the Pyeongan region. In the regions of the Four Commanderies of Han, it is presumed that people were exposed to a relatively well-developed form of Classical Chinese [
6,
7,
8]. By the Three Kingdoms period (4th–7th centuries), Goguryeo, Baekje, and Silla actively adopted and utilized Chinese characters [
9,
10]. By the Unified Silla period (7th–9th century), the Idu script, a writing system that borrows the pronunciation and meaning of Chinese characters to represent the Korean language, emerged. This development marked the beginning of Korean adaptations of Hanja, where native Korean words were either written phonetically using Chinese characters or combined with borrowed Chinese vocabulary to create new words [
11]. During the Goryeo and Joseon dynasties, Hanja evolved beyond a mere writing system to become a central component of bureaucratic governance. In particular, Confucian classics formed the foundation of state education in the Joseon period, solidifying the use of Hanja vocabulary and four-character idioms as the common linguistic framework among scholars and officials. However, with the advent of modern times and the implementation of the Hangul exclusive policy, the use of Hanja gradually declined [
12].
Throughout this historical transformation, certain Sino-Korean expressions have developed unique meanings and usage patterns within the Korean cultural context [
13,
14]. In particular, Korean four-character idioms have evolved in various ways, such as being derived from classical Korean texts, as seen in Gyeonmunbalgeom (見蚊拔劍, reacting with excessive anger over a trivial matter) and Myoduhyeollyeong (猫頭懸鈴, a futile discussion that cannot be put into practice), or by recombining and condensing existing Chinese idioms to create uniquely Korean expressions [
15].
For instance, the idiom Hongikingan (弘益人間, “to benefit all of humanity”), originates from Samguk Yusa (Memorabilia of the Three Kingdoms), which documents the founding myth of Gojoseon. Another example is Hamheungchasa (咸興差使), a metaphor for a situation in which no news returns after sending a message or errand. In this case, Hamheung refers to a city in present-day North Korea. Additionally, Sino-Korean synonyms, antonyms, and homophones, despite their roots in the Chinese writing system, have frequently been transformed and redefined under the influence of Korean culture [
16]. These examples illustrate that both Hanja and four-character idioms serve as linguistic features that require not only linguistic knowledge but also cultural understanding and contextual interpretation. Thus, they present unique challenges for evaluating the cultural contextual comprehension of large language models (LLMs).
Modern LLMs have predominantly been developed and trained on Western languages and cultural frameworks, while non-Western linguistic and cultural contexts remain underrepresented [
17,
18]. This limitation suggests that LLMs may struggle to fully grasp the contextual nuances presented by diverse cultures. In response, this study proposes a benchmark for evaluating the natural language processing capability and cultural comprehension of LLMs using Hanja and Sajaseongeo, which are core cultural elements in Korea. The following sections will review the relevant literature, present experimental design and methodology, describe the experimental setup and results, and conclude with limitations and directions for future research.
3. Methodology
3.1. Benchmark Construction
The benchmark dataset for this study was constructed based on the question types used in the Korean Hanja Proficiency Test (
https://www.hanja.re.kr/ (accessed on 14 May 2025)), a state-certified examination conducted in South Korea to assess proficiency in Hanja. Among the six official testing institutions recognized by the Ministry of Education of South Korea, we referred to the Korean Language Society’s Korean Hanja Proficiency Test. This test is structured into proficiency levels ranging from Grade 8 (beginner) to Grade 1 (advanced), with additional higher-tier classifications such as “Special Grade” and “Semi-Special Grade” for expert-level assessment.
For this study, we focused on Grade 1 to Grade 6, as these levels are widely taken by test candidates and cover the common-use Hanja shared across multiple testing institutions. The Special Grade and Semi-Special Grade levels were excluded since they assess expert-level proficiency and follow different question formats compared to other levels.
Among the common question types in Grades 1 to 6, we selected four primary question types for evaluation: four-character idioms, synonyms, antonyms, and homophones. The Hanja Proficiency Test includes different question types depending on the level, and it primarily focuses on assessing individual Hanja characters. However, questions involving four-character idioms, synonyms, antonyms, and homophones appear across Grades 1 to 6. These four types were selected for this study because they assess not individual characters but word-level expressions that often involve figurative meanings. Moreover, actual questions from each of these types in the official test were used as prompts in the experiment.
The dataset was constructed as follows:
Question Type 1 (four-character idioms): Each entry consists of a four-character idiom, its constituent Chinese characters, and the Korean definition.
Question Type 2 (synonyms) and Question Type 4 (homophones): Each entry includes a two-syllable Sino-Korean word presented as the question, its corresponding Hanja representation, and its Korean definition.
Question Type 3 (antonyms): Each entry consists of a two-syllable Sino-Korean word as the base term, its opposing two-syllable Sino-Korean word, and the Korean definition of the antonym.
For each question type, the dataset includes 200 samples, ensuring a balanced distribution across all categories. In addition, a supplementary dataset comprising 3829 individual Hanja entries was constructed for the purpose of generating answer choices. This dataset includes information on each character’s Hanja form, Korean meaning, and pronunciation. The dataset is publicly available at
https://github.com/es133lolo/Knowing-the-Words-Missing-the-Meaning (accessed on 14 May 2025).
3.2. Evaluation Method
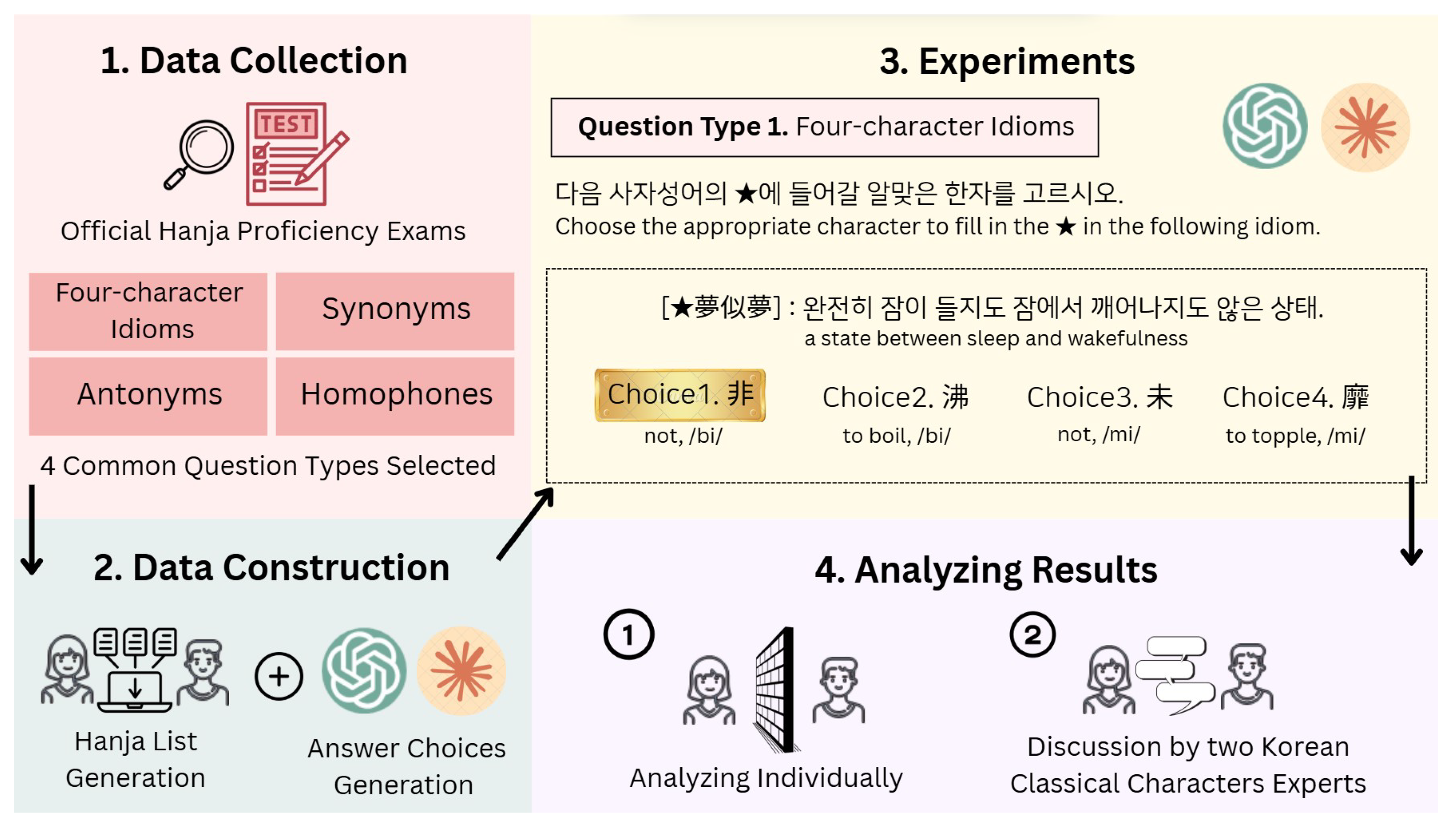
This study followed the procedure illustrated in
Figure 1. First, four common question types from the official Hanja Proficiency Test, which are shared across Levels 1 through 6, were selected. Prompt templates and answer choice generation rules were then established for each question type. Subsequently, datasets specific to each question type and individual Hanja character data necessary for generating answer choices were constructed. Using the ChatGPT API, experiments were conducted based on this standardized dataset. The GPT-4o model was employed for the experiments.
Following the prompt instructions, the GPT model was tasked with generating four choices, selecting the correct answer, and providing an explanation for its choice. All responses and explanations generated by GPT were recorded. The correctness of the selected answers and the accuracy of the explanations were reviewed by graduate students specializing in Classical Chinese. Lastly, the selection rate of each answer choice and the accuracy of the model-generated explanations were analyzed.
This study evaluated the GPT model based on three metrics: the accuracy of the selected answers, the accuracy of the explanations, and the consistency in answer selection across different engines. For each GPT engine, the accuracy of explanations corresponding to both the generated and selected choices was assessed by question type. In all four question types, the correct answer was consistently set as choice 1, and choices 2, 3, and 4 were regarded as distractors. However, even if the model selected choice 1, the item was treated as containing an explanatory error if the accompanying explanation included inaccurate information.
Responses and explanations were classified into the following five categories for systematic assessment:
Both the answer and explanation were correct.
The answer was correct, but the explanation was incorrect.
The answer was incorrect, but the explanation was correct.
Both the answer and explanation were incorrect.
No explanation was provided, despite being prompted.
By applying these detailed evaluation criteria, the response quality of GPT models was assessed systematically. For items with inaccurate or flawed explanations, the two experts engaged in discussion to reach a final evaluation. To assess inter-annotator agreement, the IAA was calculated using Cohen’s Kappa coefficient. The resulting score, denoted by
, was 0.607, indicating a substantial level of agreement between the two expert annotators.
5. Results and Analysis
5.1. Metrics
5.1.1. Accuracy
In this study, we evaluated the accuracy of different GPT engine models in solving the primary question types from the Korean Hanja Proficiency Test, including four-character idioms, synonyms, antonyms, and homonyms. Accuracy is defined as follows:
C (choice) refers to Choice 1 (the correct answer), and E (explanation) denotes the explanation generated by the large language model. represents the number of questions for which the GPT model correctly selected the answer and provided an accurate explanation, and denotes the total number of questions evaluated for each question type. (In this study, each question type consisted of 200 questions, making the total dataset size 800 questions across all types.).
5.1.2. Partial Accuracy
Partial Accuracy () is composed of two categories:
It is defined as follows:
where
is the number of cases where the model selected the correct answer but provided an incorrect explanation, and
is the number of cases where the model selected an incorrect answer but provided a correct explanation.
5.1.3. Error Rate
The Error Rate (
) measures the proportion of cases where both the answer and the explanation were incorrect, calculated as follows:
where
represents the number of completely incorrect responses (i.e., cases where the model provided both an incorrect answer and an incorrect explanation). Since the total number of questions in the experiment is 200 per question type, the total dataset size is 800 questions across all question types.
5.1.4. No Explanation Provided Rate
The No Explanation Provided (
) rate refers to the proportion of cases where the model did not generate an explanation, despite being prompted to do so. This is calculated as follows:
where
is the number of questions for which the model provided a correct answer but failed to generate an explanation.
5.1.5. Mean Scores for Comparative Performance Analysis Across Models
To compare the performance of different models, we computed the mean scores by averaging the accuracy across the four question types:
where
represents the accuracy score for each of the four question types.
5.2. Overall Performance Evaluation
Table 2 presents the evaluation results of GPT-4o’s understanding of questions related to four-character idioms and Sino-Korean words, based on the metrics outlined in
Section 5.1. GPT-4o demonstrated consistently high accuracy across all question types. In particular, it achieved 97.0% accuracy for Question Type 2 and 97.5% for Question Type 4. Even in Question Type 1 and Question Type 3, the model recorded accuracies of 88.0% and 97.0%, respectively, maintaining a performance level above 88% across all types.
An analysis of the incorrect responses revealed that GPT-4o rarely selected incorrect answer choices. Notably, in Question Types 2 and 4, the error rate remained below 3%, suggesting that the model is highly capable of distinguishing the most semantically appropriate choice among distractors. Furthermore, the near-zero rate of unanswered questions across all types indicates that GPT-4o generated responses with a high level of confidence when presented with questions involving four-character idioms and Hanja.
The highest accuracy was observed for Question Type 4 (97.5%), demonstrating GPT-4o’s ability to identify the most semantically suitable Hanja character among those with identical pronunciations. In contrast, the lowest accuracy was found for Question Type 1. Within this category, the model most frequently selected choice 3, which corresponds to a Hanja expression with the same meaning as the correct answer. This suggests that GPT-4o may encounter difficulties in contextually distinguishing between semantically equivalent Hanja expressions when selecting the most contextually appropriate form.
5.3. Evaluation of LLMs’ Cultural Understanding
To evaluate the cultural understanding of large language models, the accuracy of explanations generated by the GPT engine was also adopted as a key evaluation metric. This is because accuracy alone does not clearly indicate whether the model relied solely on the meanings of individual Hanja characters or correctly understood the semantic and cultural context of the given four-character idiom or Sino-Korean word. Therefore, higher accuracy in explanation was interpreted as indicative of stronger cultural comprehension by the model.
As shown in
Table 3, GPT-4o demonstrated high explanation accuracy across all question types. The proportion of responses in which both the selected answer and the corresponding explanation were correct reached 88.0% for four-character idioms, 84.0% for synonyms, 86.5% for antonyms, and 90.5% for homophones, maintaining an overall accuracy of over 84%. These results suggest that GPT-4o not only selects correct answers but also possesses the ability to appropriately interpret the cultural and semantic context underlying those answers.
In the case of Question Type 4, GPT-4o achieved both a 97.5% accuracy rate and a 90.5% explanation accuracy, indicating a highly stable performance in distinguishing between identically pronounced Hanja characters and in providing meaning-based interpretations. In contrast, Question Types 2 and 3 showed relatively higher explanation error rates of 13.0% and 10.5%, respectively. This suggests that the model may have relative weaknesses in the contextual reasoning required to explain fine-grained semantic differences between closely related concepts.
5.4. Comparative Evaluation Across Models
To compare the overall performance of each model, average scores were calculated. A random sample of 100 questions was drawn from the experimental items used in
Section 5.2 and
Section 5.3. The additional comparative evaluation included three GPT-based engines—GPT-3.5-turbo, GPT-4-turbo, and GPT-4o—as well as a non-GPT model, Claude 3 Opus.
As shown in
Table 4, GPT-4o exhibited the highest performance in terms of cultural understanding. The model achieved accuracy rates of 89%, 84%, 86%, and 93% for Question Types 1 through 4, respectively, maintaining stable performance above 84% across all categories. Notably, its overall average score of 88.0 was the highest among the evaluated models, suggesting that GPT-4o demonstrated the strongest ability to interpret cultural context, even when compared with the other GPT-based models.
In contrast, GPT-3.5-turbo recorded the lowest overall average score at 48.75. Its performance was particularly weak on antonyms and homophones, with accuracy rates of 24% and 7%, respectively. Although the model was prompted to provide explanations, it responded only with the selected choice number, omitting the requested justifications.
GPT-4-turbo yielded a mid-range performance, with an overall average of 78.0. However, it showed comparatively lower performance on the synonym task, with an accuracy rate of 75%.
Claude 3 Opus, the only non-GPT model included in the comparison, achieved the highest score of 97% on the homophone task. However, it demonstrated lower accuracy on synonyms (55%) and antonyms (45%). A notable issue with Claude was the frequency of incorrect explanations: Out of 100 questions, 35 explanations were incorrect for synonyms and 48 for antonyms, despite the model selecting the correct answer choices. Furthermore, during the antonym evaluation, Claude occasionally generated and answered additional questions beyond those specified in the prompt. All responses referring to these unauthorized "The Second Question" items were evaluated as incorrect. Claude autonomously generated 21 additional questions. Excluding those, it produced correct explanations for 18 questions from the original prompt.
Taken together, GPT-4o demonstrated consistently high and reliable accuracy across all four types of culturally grounded Hanja questions. These results suggest that GPT-4o is the most culturally adept model among those tested, exhibiting the most refined reasoning abilities in the context of Hanja literacy evaluation.
5.5. Limitations
This study limited its scope to four question types from the Korean Hanja Proficiency Test that emphasize the evaluation of Sino-Korean words and four-character idioms with broader semantic meanings, rather than focusing on the meanings of individual Hanja characters. Accordingly, the dataset used for the study was curated to align with these four question types, and the experiments were conducted using approximately 200 items per type. This constraint inherently limits the scale and diversity of the dataset.
In addition, the experiments were conducted exclusively on closed large language models. Future research should consider conducting comparative evaluations using open-source large language models on the same dataset to examine potential differences in performance.
6. Discussion
All three GPT engines failed to correctly answer questions of Type 1 in which the correct choice was a Hanja character conveying negation. Hanja characters such as 不, 否, 弗, 非, 未, 無, and 莫 all represent forms of negation, typically meaning “not” or “none.” While these characters share a similar core meaning, their usage differs depending on context and the degree of negation. However, most dictionaries define them uniformly as “not” or “none,” without clarifying the nuanced distinctions or usage contexts among them. This limitation appears to have led the GPT models to misinterpret these differences. For example, the four-character idiom 無所不爲, meaning “there is nothing one cannot do” and typically associated with absolute power, was incorrectly answered by GPT-4o, which selected the character 莫, a synonym in meaning. Likewise, GPT-4-turbo selected 未 instead of 非 in the idiom 非夢似夢 (“a state between sleep and wakefulness”), and GPT-3.5-turbo replaced 不 with 未 in 不撤晝夜 (“working tirelessly day and night”).
Additional instances were also found in which the models failed to distinguish between Hanja characters with similar meanings. For example, in the four-character idiom 事必歸正 (meaning “everything eventually returns to what is right”), GPT confused 事 (“affair” or “matter”) with 業 (“task” or “profession”), both of which can signify “work” or “activity.” Similarly, in 打草驚蛇 (meaning “to startle a snake by striking the grass”), the character 打 (“to strike”) was confused with 擊 (“to hit” or “to attack”). These errors indicate that GPT has difficulty discerning the subtle semantic nuances between individual Hanja characters. Notably, even for idioms such as 無所不爲 and 事必歸正—both of which are widely used in Korean—GPT exhibited confusion among Hanja characters with similar meanings.
The Sino-Korean words 佳約, 約婚, 定婚, and 婚約 all denote “a promise to become married.” These expressions are commonly used in Korean society. When 佳約 was the correct answer, GPT failed to select it, likely due to its primary dictionary definition of “a beautiful promise.” However, in both Korean and Chinese cultural contexts, the promise of lifelong partnership through marriage is viewed as a beautiful and virtuous act. Therefore, 佳約 also implicitly conveys the meaning of a “marriage agreement.” Similarly, the idiom 一瀉千里, which literally means “a river flows a thousand li in a single rush,” figuratively refers to something progressing rapidly and without obstruction. In this idiom, the character “一” not only means “one” but can also mean “once” or “in one go.” However, Claude interpreted “一” solely as “one,” its most basic and common meaning. These examples suggest that both Claude and GPT were trained primarily on the canonical definitions of Sino-Korean words and four-character idioms widely used in Korean, and as a result, had difficulty recognizing the extended or context-specific meanings these expressions may carry.
Although four-character idioms consist of only four Hanja characters, they often convey broad and complex meanings. Many are metaphorical in nature and are rooted in ancient stories or classical literature. These characteristics make accurate interpretation difficult for models such as GPT and Claude. For instance, in the idiom 犬馬之勞 (meaning “humble service”), the term 犬馬 (“dogs and horses”) is a well-established metaphor from classical texts. However, GPT-4o did not associate the idiom with its historical or cultural background and instead focused on finding a meaning closest to the idiom’s Korean gloss by analyzing the individual Hanja components. As a result, GPT-4o selected the character 繭 (“cocoon”), likely based on its connotation of smallness, thereby failing to associate 犬馬with the metaphor of loyal yet humble laborers such as dogs and horses.
In Question Type 2, the terms 瓜年, 瓜期, 瓜滿, 瓜時, and 破瓜 all refer to the end of a government official’s term. Additionally, 瓜年 is used to describe a woman who has reached marriageable age. Both meanings are derived metaphorically from the ripening of cucumbers. In this context, the cucumber is symbolically associated with both official duties and women, and these meanings emerged from cultural metaphors linking seasonal ripeness with life transitions. However, the GPT models focused only on the literal meaning of the character 瓜 (“cucumber”) and failed to connect it with its culturally derived metaphorical extensions. As a result, the models generated inaccurate explanations such as “the year for harvesting cucumbers” and produced incorrect answers. This case suggests that GPT engines face significant challenges in interpreting metaphorical expressions embedded in culturally specific linguistic contexts.
The origin of Hanja can be traced back to China, and the meanings of many Sino-Korean words are based on usage patterns established in Chinese contexts. However, some Sino-Korean words have diverged in meaning or usage within Korean society. For example, the term 總角 refers to an “unmarried man” in Korean, whereas in Chinese, it is interpreted as “a minor” or “a young child.” The GPT-4o model interpreted 總角 as “a child” and attempted to select the antonym “adult” as the correct answer, but was unable to do so because that option was not included among the choices. This outcome likely reflects the fact that the number of users of Chinese characters is significantly higher in China than in Korea, and that the amount of Hanja-related data available online is disproportionately skewed toward Chinese usage. In other words, GPT has been far more exposed to Chinese interpretations of Hanja, and, thus, has had insufficient training on meanings and usage cases that are specific to the Korean context.
This example underscores the need for further efforts to accurately reflect Korean language and cultural perspectives. In order for large language models to attain a deeper understanding of Korean Hanja culture, a large-scale parallel corpus of Korean and Hanja is necessary. Such a dataset must not only include surface-level meanings but also encompass culturally embedded and context-specific interpretations that are prevalent in Korean society. Moreover, to accurately infer the meanings of Sino-Korean words and four-character idioms, it is essential to shift the modeling approach away from focusing solely on the literal meanings of individual Hanja characters. Instead, the models should be informed by Korean classical literature and real-world language usage data that better capture the cultural and metaphorical dimensions of these expressions.
7. Conclusions and Future Work
This study proposes a novel benchmark for evaluating the cultural understanding and natural language processing capabilities of large language models, grounded in Hanja and four-character idioms, which are significant linguistic assets in Korean culture. Reflecting the official question types used in Korea’s Hanja Proficiency Test, the benchmark includes four question types: four-character idioms, synonyms, antonyms, and homophones. Based on this framework, the study systematically compares and analyzes the performance of both GPT-based and non-GPT-based large language models.
The experimental results indicate that GPT-4o achieved the highest accuracy and explanation quality across all four question types. This suggests the model’s potential to comprehend the nuanced meanings of Korean Sino-Korean words and four-character idioms, as well as interpret their cultural contexts. The model demonstrated particularly strong performance in antonym and homophone questions, and the four-character idiom tasks enabled an assessment of how large language models infer metaphorical expressions. However, difficulties remain in distinguishing the subtle semantic nuances of individual Hanja characters. GPT-4o often relied on the primary dictionary definitions of Hanja and tended to interpret them according to Chinese usages rather than meanings specific to Korean society.
This study reveals the current limitations in large language models’ understanding of Hanja as used in Korean contexts, underscoring the need for evaluation tools that reflect the uniquely Korean interpretations of Hanja, distinct from Chinese conventions. To develop models that accurately represent individual cultures and languages, including Korean, it is essential to build datasets that reflect the culturally embedded meanings of Korean Hanja. Moreover, collaborative frameworks that incorporate multiple tools—such as compound systems—should be actively adopted.
By constructing a benchmark based on Korean–Hanja pairs rather than a single language, this study introduces a new approach to evaluating cultural comprehension in large language models through Sino-Korean words and four-character idioms. This research contributes to advancing performance evaluation from a purely quantitative focus to a more qualitative evaluation that incorporates cultural context, bridging the fields of humanities and natural language processing. Ultimately, it aims to serve as a foundation for global benchmarking efforts that assess the linguistic and cultural competencies of large language models in non-English languages, including Korean.



{kind=link}