AuxDepthNet: Real-Time Monocular 3D Object Detection with Depth-Sensitive Features

 ,
,  , , ,
, , ,
Abstract
1. Introduction

- (1)
- We propose AuxDepthNet, a novel framework for efficient, real-time monocular 3D object detection that eliminates reliance on external depth maps or estimators.
- (2)
- We design the Auxiliary Depth Feature Module (ADF) and Depth Position Mapping Module (DPM) to implicitly learn depth-sensitive features and encode depth positional cues into the detection process.
- (3)
- We provide a plug-and-play architecture that can be seamlessly integrated into other image-based detection frameworks to enhance their 3D reasoning capabilities.
2. Related Work
2.1. Monocular 3D Object Detection Methods
2.2. Transformer in Monocular 3D Object Detection
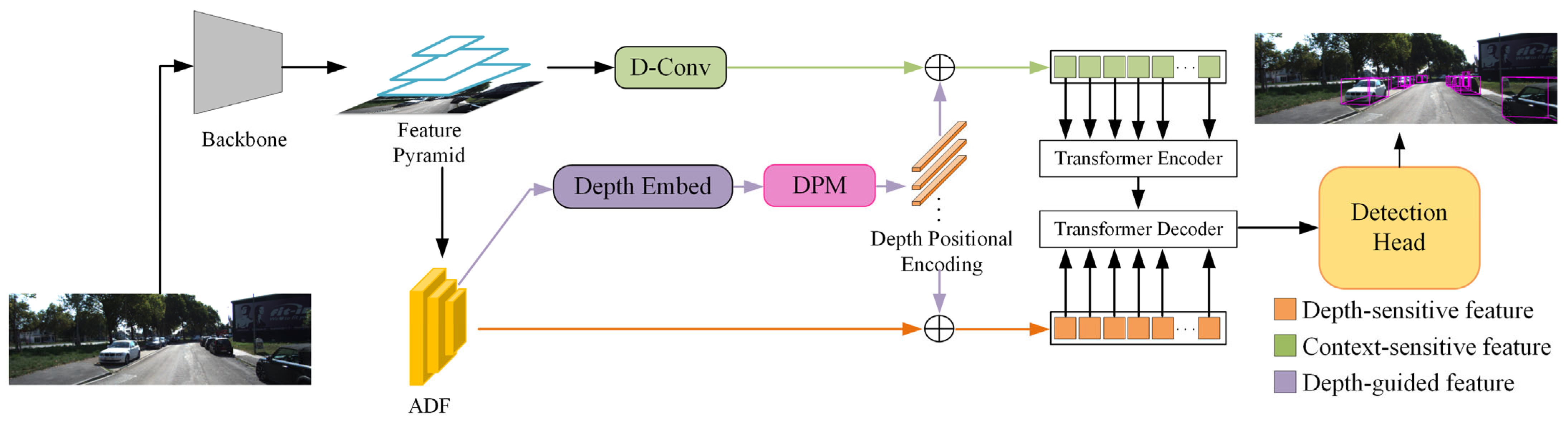
3. Proposed Method
3.1. Overview
3.2. Depth-Sensitive Feature Enhancement
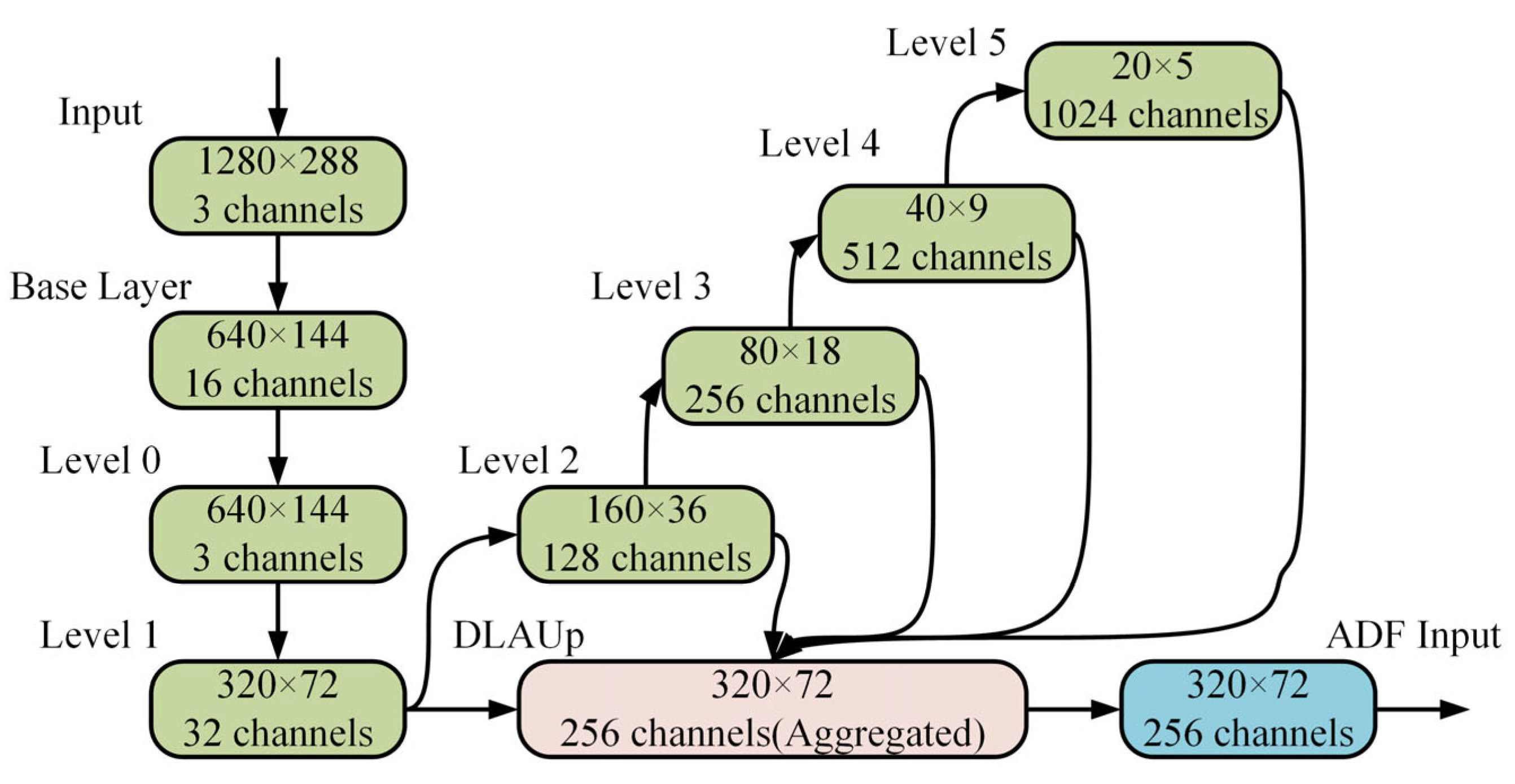
3.2.1. Backbone Network Architecture and Multi-Scale Feature Extraction
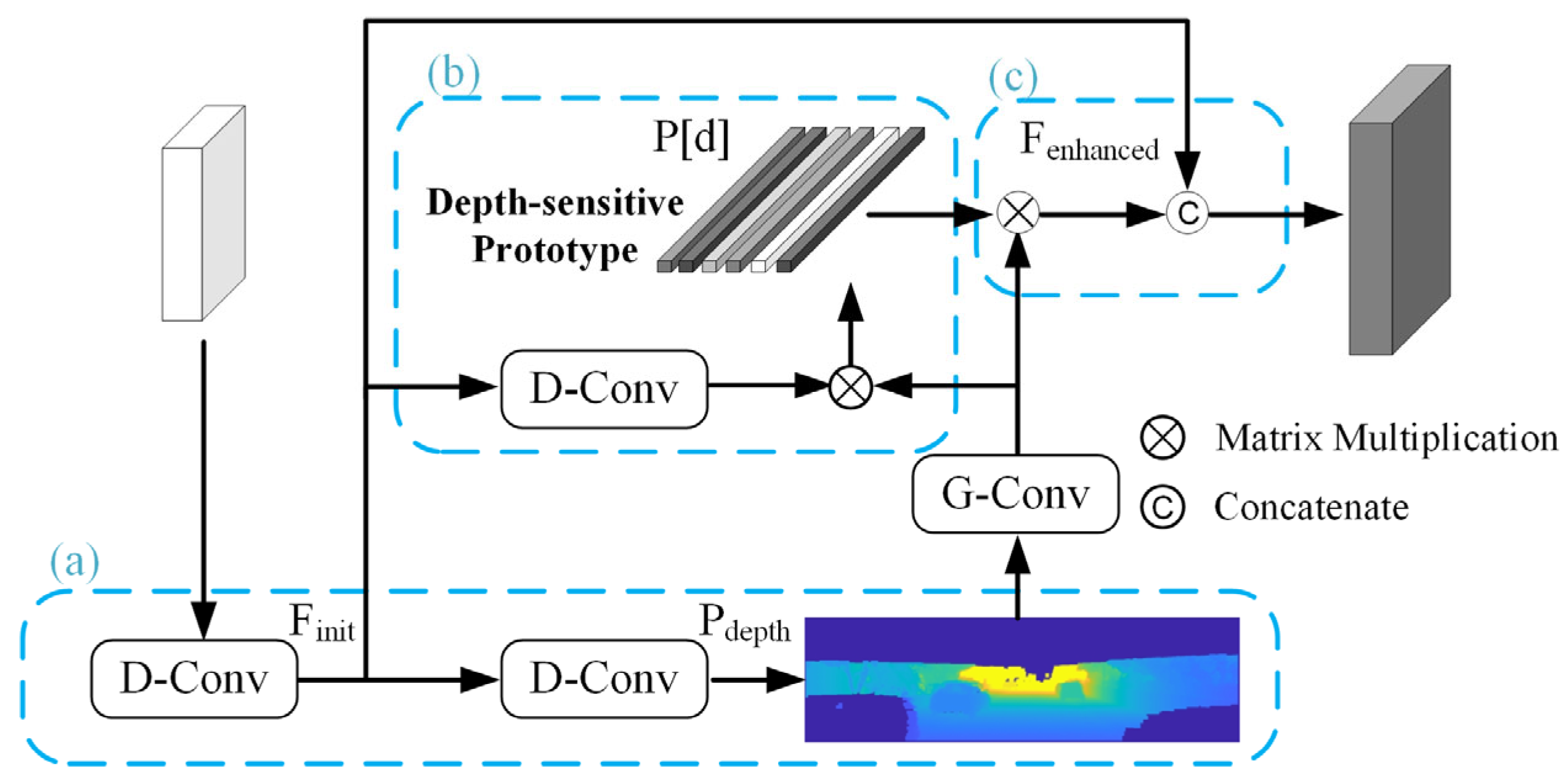
3.2.2. Extracting Foundational Depth-Sensitive Features
3.2.3. Depth-Sensitive Prototype Representation Module
3.2.4. Feature Enhancement with Depth Prototype
3.3. Depth Position Mapping and Transformer Integration
3.3.1. Transformer Encoder
3.3.2. Transformer Decoder
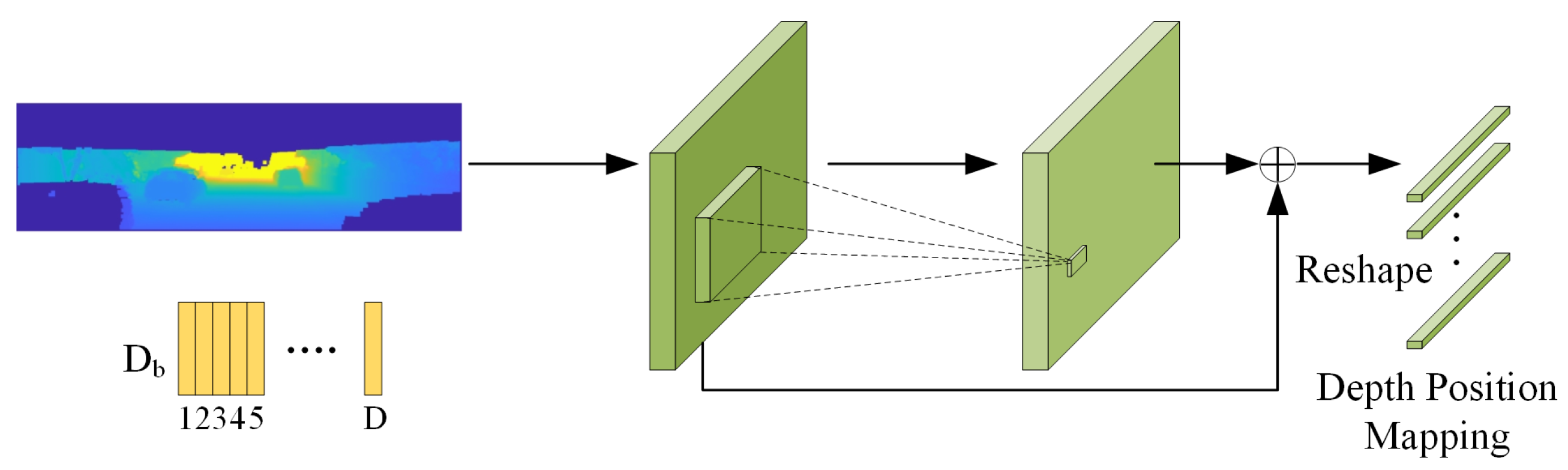
3.3.3. Depth Position Mapping (DPM) Module
3.4. Loss Function
4. Experiment and Analysis
4.1. Dataset
4.2. Valuation Metrics
4.3. Implementation Details
4.4. Comparison with State-of-the-Art Methods
4.5. Ablation Studies and Analysis
4.5.1. Effectiveness of Each Proposed Components
4.5.2. The Impact of Different Backbones
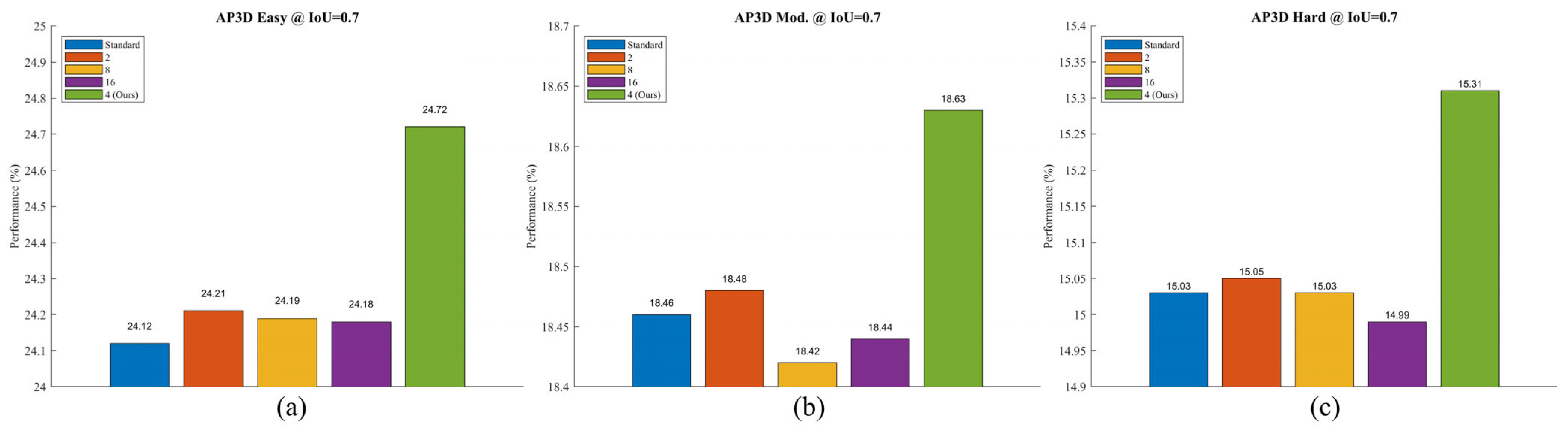
4.5.3. The Impact of Different Dilation Rates in the ADF Module
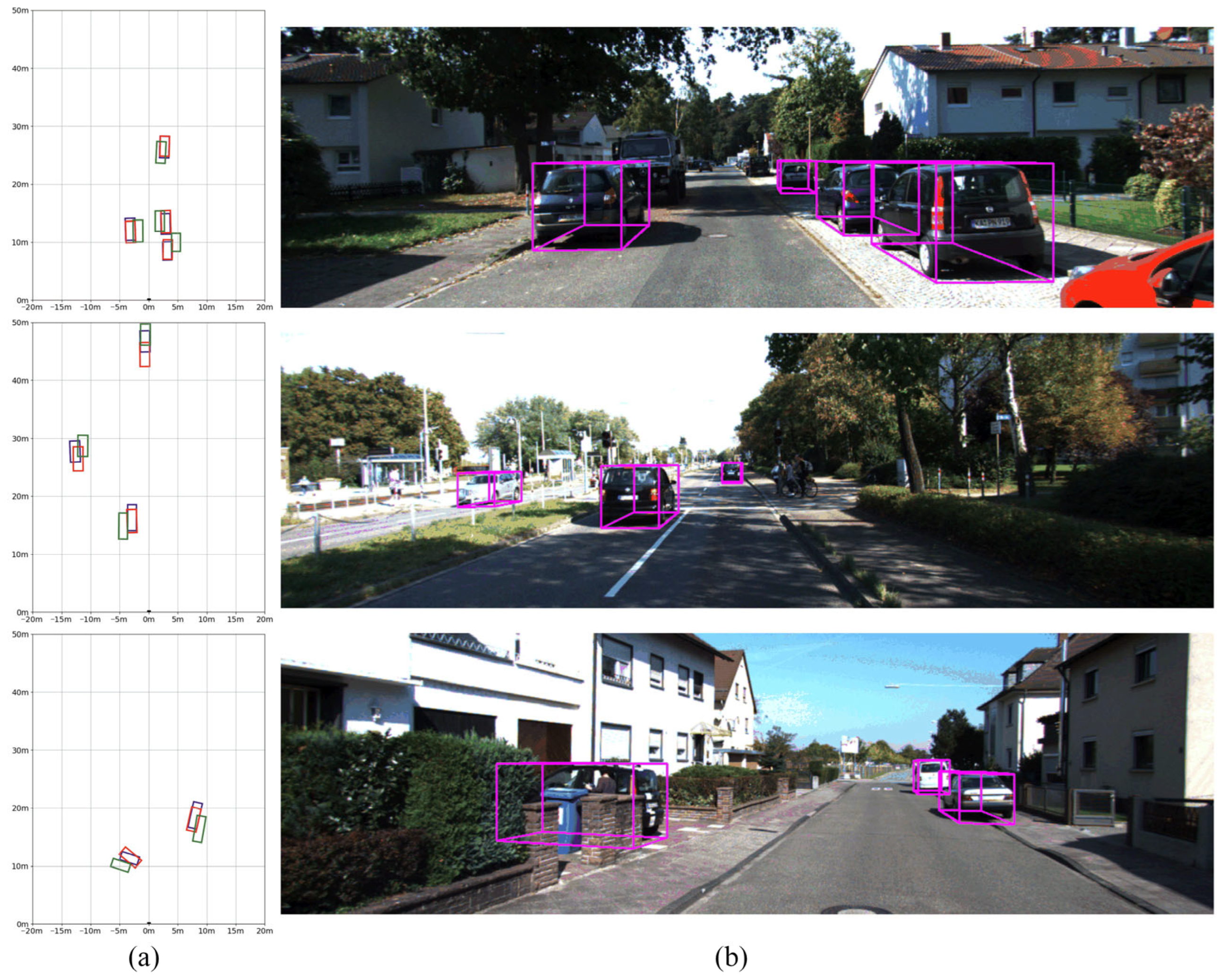
5. Visualization
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, C.; Zeng, H.; Huang, J.; Hua, X.-S.; Zhang, L. Structure aware single-stage 3d object detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11873–11882. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Li, P.; Chen, X.; Shen, S. Stereo r-cnn based 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7644–7652. [Google Scholar]
- Wang, Y.; Chao, W.-L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8445–8453. [Google Scholar]
- Brazil, G.; Pons-Moll, G.; Liu, X.; Schiele, B. Kinematic 3d object detection in monocular video. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XXIII 16; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 135–152. [Google Scholar]
- Chen, Y.; Tai, L.; Sun, K.; Li, M. Monopair: Monocular 3d object detection using pairwise spatial relationships. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12093–12102. [Google Scholar]
- Ku, J.; Pon, A.D.; Waslander, S.L. Monocular 3d object detection leveraging accurate proposals and shape reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11867–11876. [Google Scholar]
- Shen, F.; Xie, Y.; Zhu, J.; Zhu, X.; Zeng, H. Git: Graph interactive transformer for vehicle re-identification. IEEE Trans. Image Process. 2023, 32, 1039–1051. [Google Scholar] [CrossRef] [PubMed]
- Shen, F.; Shu, X.; Du, X.; Tang, J. Pedestrian-specific bipartite-aware similarity learning for text-based person retrieval. In Proceedings of the 31st ACM International Conference on Multimedia, New York, NY, USA, 27 October 2023; pp. 8922–8931. [Google Scholar]
- Ma, X.; Wang, Z.; Li, H.; Zhang, P.; Ouyang, W.; Fan, X. Accurate monocular 3d object detection via color-embedded 3d reconstruction for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 6851–6860. [Google Scholar]
- Weng, X.; Kitani, K. Monocular 3d object detection with pseudo-lidar point cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Ding, M.; Huo, Y.; Yi, H.; Wang, Z.; Shi, J.; Lu, Z.; Luo, P. Learning depth-guided convolutions for monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 1000–1001. [Google Scholar]
- Ouyang, E.; Zhang, L.; Chen, M.; Arnab, A.; Fu, Y. Dynamic depth fusion and transformation for monocular 3d object detection. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Kim, B.; Lee, J.; Kang, J.; Kim, E.-S.; Kim, H.J. Hotr: End-to-end human-object interaction detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 74–83. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Wang, L.; Du, L.; Ye, X.; Fu, Y.; Guo, G.; Xue, X.; Feng, J.; Zhang, L. Depth-conditioned dynamic message propagation for monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 454–463. [Google Scholar]
- Xu, B.; Chen, Z. Multi-level fusion based 3d object detection from monocular images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2345–2353. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Reading, C.; Harakeh, A.; Chae, J.; Waslander, S.L. Categorical depth distribution network for monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8555–8564. [Google Scholar]
- Zhang, R.; Qiu, H.; Wang, T.; Guo, Z.; Cui, Z.; Qiao, Y.; Li, H.; Gao, P. Monodetr: Depth-guided transformer for monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 9155–9166. [Google Scholar]
- Yang, F.; He, X.; Chen, W.; Zhou, P.; Li, Z. MonoPSTR: Monocular 3D Object Detection with Dynamic Position & Scale-aware Transformer. IEEE Trans. Instrum. Meas. 2024, 73, 5028313. [Google Scholar]
- Shen, F.; Ye, H.; Zhang, J.; Wang, C.; Han, X.; Yang, W. Advancing pose-guided image synthesis with progressive conditional diffusion models. arXiv 2023, arXiv:2310.06313. [Google Scholar]
- Shen, F.; Ye, H.; Liu, S.; Zhang, J.; Wang, C.; Han, X.; Yang, W. Boosting consistency in story visualization with rich-contextual conditional diffusion models. In Proceedings of the AAAI Conference on Artificial Intelligence, Madrid, Spain, 20–22 October 2025; Volume 39, pp. 6785–6794. [Google Scholar]
- Shen, F.; Jiang, X.; He, X.; Ye, H.; Wang, C.; Du, X.; Li, Z.; Tang, J. Imagdressing-v1: Customizable virtual dressing. In Proceedings of the AAAI Conference on Artificial Intelligence, Madrid, Spain, 20–22 October 2025; Volume 39, pp. 6795–6804. [Google Scholar]
- Shen, F.; Tang, J. Imagpose: A unified conditional framework for pose-guided person generation. Adv. Neural Inf. Process. Syst. 2024, 37, 6246–6266. [Google Scholar]
- Zou, C.; Wang, B.; Hu, Y.; Liu, J.; Wu, Q.; Zhao, Y.; Li, B.; Zhang, C.; Zhang, C.; Wei, Y.; et al. End-to-end human object interaction detection with hoi transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11825–11834. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 20750–20762. [Google Scholar]
- Ross, T.Y.; Dollár, G. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wei, L.; Zheng, C.; Hu, Y. Oriented object detection in aerial images based on the scaled smooth L1 loss function. Remote Sens. 2023, 15, 1350. [Google Scholar] [CrossRef]
- Liu, C.; Yu, S.; Yu, M.; Wei, B.; Li, B.; Li, G.; Huang, W. Adaptive smooth L1 loss: A better way to regress scene texts with extreme aspect ratios. In Proceedings of the 2021 IEEE Symposium on Computers and Communications (ISCC), IEEE, Athens, Greece, 5–8 September 2021; pp. 1–7. [Google Scholar]
- Chen, X.; Kundu, K.; Zhu, Y.; Ma, H.; Fidler, S.; Urtasun, R. 3d object proposals using stereo imagery for accurate object class detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1259–1272. [Google Scholar] [CrossRef] [PubMed]
- Zou, Z.; Ye, X.; Du, L.; Cheng, X.; Tan, X.; Zhang, L.; Feng, J.; Xue, X.; Ding, E. The devil is in the task: Exploiting reciprocal appearance-localization features for monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2713–2722. [Google Scholar]
- Zhou, Y.; He, Y.; Zhu, H.; Wang, C.; Li, H.; Jiang, Q. Monocular 3d object detection: An extrinsic parameter free approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7556–7566. [Google Scholar]
- Zhang, Y.; Lu, J.; Zhou, J. Objects are different: Flexible monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3289–3298. [Google Scholar]
- Lu, Y.; Ma, X.; Yang, L.; Zhang, T.; Liu, Y.; Chu, Q.; Yan, J.; Ouyang, W. Geometry uncertainty projection network for monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3111–3121. [Google Scholar]
- Huang, K.-C.; Wu, T.-H.; Su, H.-T.; Hsu, W.H. Monodtr: Monocular 3d object detection with depth-aware transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4012–4021. [Google Scholar]
- Lian, Q.; Li, P.; Chen, X. Monojsg: Joint semantic and geometric cost volume for monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1070–1079. [Google Scholar]
- Kumar, A.; Brazil, G.; Corona, E.; Parchami, A.; Liu, X. Deviant: Depth equivariant network for monocular 3d object detection. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 664–683. [Google Scholar]
- Li, Y.; Chen, Y.; He, J.; Zhang, Z. Densely constrained depth estimator for monocular 3d object detection. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 718–734. [Google Scholar]
- Peng, L.; Wu, X.; Yang, Z.; Liu, H.; Cai, D. Did-m3d: Decoupling instance depth for monocular 3d object detection. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 71–88. [Google Scholar]
- Brazil, G.; Kumar, A.; Straub, J.; Ravi, N.; Johnson, J.; Gkioxari, G. Omni3d: A large benchmark and model for 3d object detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13154–13164. [Google Scholar]
- Jinrang, J.; Li, Z.; Shi, Y. Monouni: A unified vehicle and infrastructure-side monocular 3d object detection network with sufficient depth clues. Adv. Neural Inf. Process. Syst. 2023, 36, 11703–11715. [Google Scholar]
- Zhou, Y.; Zhu, H.; Liu, Q.; Chang, S.; Guo, M. Monoatt: Online monocular 3d object detection with adaptive token transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17493–17503. [Google Scholar]
- Zhang, J.; Li, J.; Lin, X.; Zhang, W.; Tan, X.; Han, J.; Ding, E.; Wang, J.; Li, G. Decoupled Pseudo-Labeling for Semi-Supervised Monocular 3D Object Detection. arXiv 2024. [Google Scholar] [CrossRef]
- Shi, P.; Dong, X.; Ge, R.; Liu, Z.; Yang, A. Dp-M3D: Monocular 3D object detection algorithm with depth perception capability. Knowl. Based Syst. 2025, 318, 113539. [Google Scholar] [CrossRef]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Images | Car Instances | Pedestrian Instances | Cyclist Instances |
|---|---|---|---|---|
| Training | 3712 | 14,357 | 2207 | 734 |
| Validation | 3769 | 14,385 | 2280 | 893 |
| Method | AP3D@IoU = 0.7 | APBEV@IoU = 0.7 | ||||
|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | |
| DDMP-3D [18] | 19.71 | 12.78 | 9.80 | 28.08 | 17.89 | 13.44 |
| CaDDN [21] | 19.17 | 13.41 | 11.46 | 27.94 | 18.91 | 17.19 |
| DFRNet [35] | 19.40 | 13.63 | 10.35 | 28.17 | 19.17 | 14.84 |
| MonoEF [36] | 21.29 | 13.87 | 11.71 | 29.03 | 19.70 | 17.26 |
| MonoFlex [37] | 19.94 | 13.89 | 12.07 | 28.23 | 19.75 | 16.89 |
| GUPNet [38] | 20.11 | 14.20 | 11.77 | - | - | - |
| MonoDTR [39] | 21.99 | 15.39 | 12.73 | 28.59 | 20.38 | 17.14 |
| MonoJSG [40] | 24.69 | 16.14 | 13.64 | 32.59 | 21.26 | 18.18 |
| DEVIANT [41] | 21.88 | 14.46 | 11.89 | 29.65 | 20.44 | 17.43 |
| DCD [42] | 23.94 | 17.38 | 15.32 | 32.55 | 21.50 | 18.25 |
| DID-M3D [43] | 24.40 | 16.29 | 13.75 | 32.95 | 22.76 | 19.83 |
| Cube R-CNN [44] | 23.59 | 15.01 | 12.56 | 31.70 | 21.20 | 18.43 |
| MonoUNI [45] | 24.75 | 16.73 | 13.49 | 33.28 | 23.05 | 19.39 |
| MonoATT [46] | 24.72 | 17.37 | 15.00 | 36.87 | 24.42 | 21.88 |
| DPL [47] | 24.19 | 16.67 | 13.83 | 33.16 | 22.12 | 18.74 |
| DPM3D [48] | 23.41 | 13.65 | 12.91 | 32.23 | 20.13 | 17.14 |
| AuxDepthNet (Ours) | 24.72 | 18.63 | 15.31 | 34.11 | 25.18 | 21.90 |
| Index | Ablation | AP3D@IoU = 0.7 | ||
|---|---|---|---|---|
| Easy | Mod. | Hard | ||
| (a) | Baseline | 19.50 | 15.51 | 12.66 |
| (b) | w/o depth prototype enhancement | 23.91 | 18.27 | 15.21 |
| (c) | Depth-sensitive feature → object query | 20.25 | 16.15 | 13.89 |
| (d) | Depth-sensitive feature → DORN [49] | 24.27 | 17.15 | 13.84 |
| (e) | AuxDepthNet (full model) | 24.72 | 18.63 | 15.31 |
| Backbone | AP3D@IoU = 0.7 | APBEV@IoU = 0.7 | ||||
|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | |
| DLA-102 | 24.40 | 18.55 | 15.30 | 34.02 | 25.11 | 21.24 |
| DLA-102x2 | 24.59 | 18.56 | 15.25 | 34.01 | 25.13 | 21.32 |
| DLA-60 | 22.85 | 17.37 | 14.33 | 32.14 | 23.64 | 19.92 |
| DenseNet | 24.24 | 18.04 | 15.14 | 33.01 | 24.69 | 21.48 |
| ResNet | 24.09 | 17.98 | 15.15 | 32.97 | 24.39 | 21.33 |
| Ours | 24.72 | 18.63 | 15.31 | 34.11 | 25.18 | 21.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, R.; Choi, H.-S.; Jung, D.; Anh, P.H.N.; Jeong, S.-K.; Zhu, Z. AuxDepthNet: Real-Time Monocular 3D Object Detection with Depth-Sensitive Features. Appl. Sci. 2025, 15, 7538. https://doi.org/10.3390/app15137538
Zhang R, Choi H-S, Jung D, Anh PHN, Jeong S-K, Zhu Z. AuxDepthNet: Real-Time Monocular 3D Object Detection with Depth-Sensitive Features. Applied Sciences. 2025; 15(13):7538. https://doi.org/10.3390/app15137538
Chicago/Turabian StyleZhang, Ruochen, Hyeung-Sik Choi, Dongwook Jung, Phan Huy Nam Anh, Sang-Ki Jeong, and Zihao Zhu. 2025. "AuxDepthNet: Real-Time Monocular 3D Object Detection with Depth-Sensitive Features" Applied Sciences 15, no. 13: 7538. https://doi.org/10.3390/app15137538
APA StyleZhang, R., Choi, H.-S., Jung, D., Anh, P. H. N., Jeong, S.-K., & Zhu, Z. (2025). AuxDepthNet: Real-Time Monocular 3D Object Detection with Depth-Sensitive Features. Applied Sciences, 15(13), 7538. https://doi.org/10.3390/app15137538