1. Introduction
The proliferation of Internet of Things (IoT) devices and the increasing demand for real-time applications are driving the need for efficient object recognition capabilities at the network edge [
1,
2]. Traditional cloud-based approaches face challenges in meeting the latency, bandwidth, and privacy requirements of these applications. Edge computing, which brings computation and data storage closer to the data sources, offers a promising solution by enabling local processing and reducing reliance on the cloud [
3]. The proximity of edge computing can support scalability and privacy-policy enforcement for the IoT, highly responsive cloud services for mobile computing, and the capacity to conceal temporary cloud outages [
4].
Integrating artificial intelligence (AI), particularly deep learning techniques, with edge computing architectures is transforming object recognition capabilities across various domains [
5]. This powerful combination, known as edge AI or edge intelligence, allows for real-time object detection, tracking, and classification on resource-constrained edge devices, opening up new possibilities for intelligent systems. From smart surveillance systems that can identify suspicious activities to autonomous vehicles that can navigate complex environments, edge AI is crucial in enhancing safety, efficiency, and automation [
1,
6]. The emergence of edge AI is motivated by rapid improvement in edge devices and single-board computer technology. Some edge devices with high-performance hardware accelerators are on the market, such as NVIDIA Jetson, Google Coral, FPGA, mobile device, and drone platform [
7]. This emergence of edge devices is also accompanied by the emergence of special deep learning frameworks for edge devices, such as TensorflowLite [
8], TensorRT [
9], ONNX [
10], OpenCL [
11], and VitisAI [
12].
Despite their potential, deploying and optimizing deep neural networks for object recognition on edge devices presents unique challenges related to the edge device, object recognition, security and performance evaluation aspects. Edge devices often have limited processing power, memory, and battery life, making it essential to design and implement AI models that are lightweight, efficient, and adaptable to these constraints [
13]. Techniques like model compression, network pruning, and hardware-aware neural architecture search are crucial for tailoring deep learning models to the specific requirements of edge hardware [
14]. Furthermore, strategies for task offloading, model partitioning, and distributed inference are essential for optimizing resource utilization and achieving real-time performance [
15]. In terms of object recognition, there are several well-known challenges. For examples, in terms of aerial object detection using drones, there are challenges related to the object detection in challenging weather conditions [
16], small object detection [
17], and object detection with varying orientations [
18].
In terms of security, some problems have been raised about privacy policy enforcement. Edge computing offers the opportunity to preserve privacy by not uploading all sensitive data to cloud infrastructure. The federated learning approach is one enabler which encourages the training process to be performed on the edge device, with only training weight being uploaded to cloud platform to update the global model [
19]. On the other hand, there are also concerns about the reliability of edge AI systems against some well-known attacks, such as adversarial attacks and overload attacks, which can reduce the accuracy and latency performance of the systems [
20,
21]. In terms of evaluation performance, edge AI is different to traditional AI, which is only evaluated based on detection accuracy performance. An excellent edge AI solution needs to balance between detection accuracy, real-time performance, energy consumption, security, and reliability, depending on the application [
22,
23,
24].
This article provides a comprehensive exploration of AI in edge computing for object recognition applications, covering the fundamentals, challenges, and emerging trends in this rapidly evolving field. It examines the benefits, challenges, and deployment strategies for effectively integrating AI algorithms with edge computing infrastructure. Through practical examples and case studies, readers will gain insights into designing and implementing AI-powered edge solutions for various object recognition use cases, including smart surveillance, autonomous vehicles, and industrial automation. This article also addresses emerging trends, such as federated learning and hardware accelerators, which are set to further enhance the capabilities and efficiency of AI in edge computing for object recognition. The contributions of this paper are summarized as follows
Key considerations of object recognition in edge computing based on literature study and our research experience in this field.
Case study of object recognition in real-time power line inspection with edge computing. In this part, a new evaluation metric, such as the edge–AI deployment score (EADS), is also proposed.
Future research suggestions for object recognition in edge computing.
This paper is organized as follows. In
Section 2, a system overview of the edge computing architecture is discussed.
Section 3 discusses the key considerations of object recognition on edge computing platforms.
Section 4 discusses a case study of power line transmission using edge computing platforms.
Section 5 discusses the future research direction. Finally, the conclusion is presented in
Section 6.
2. System Overview
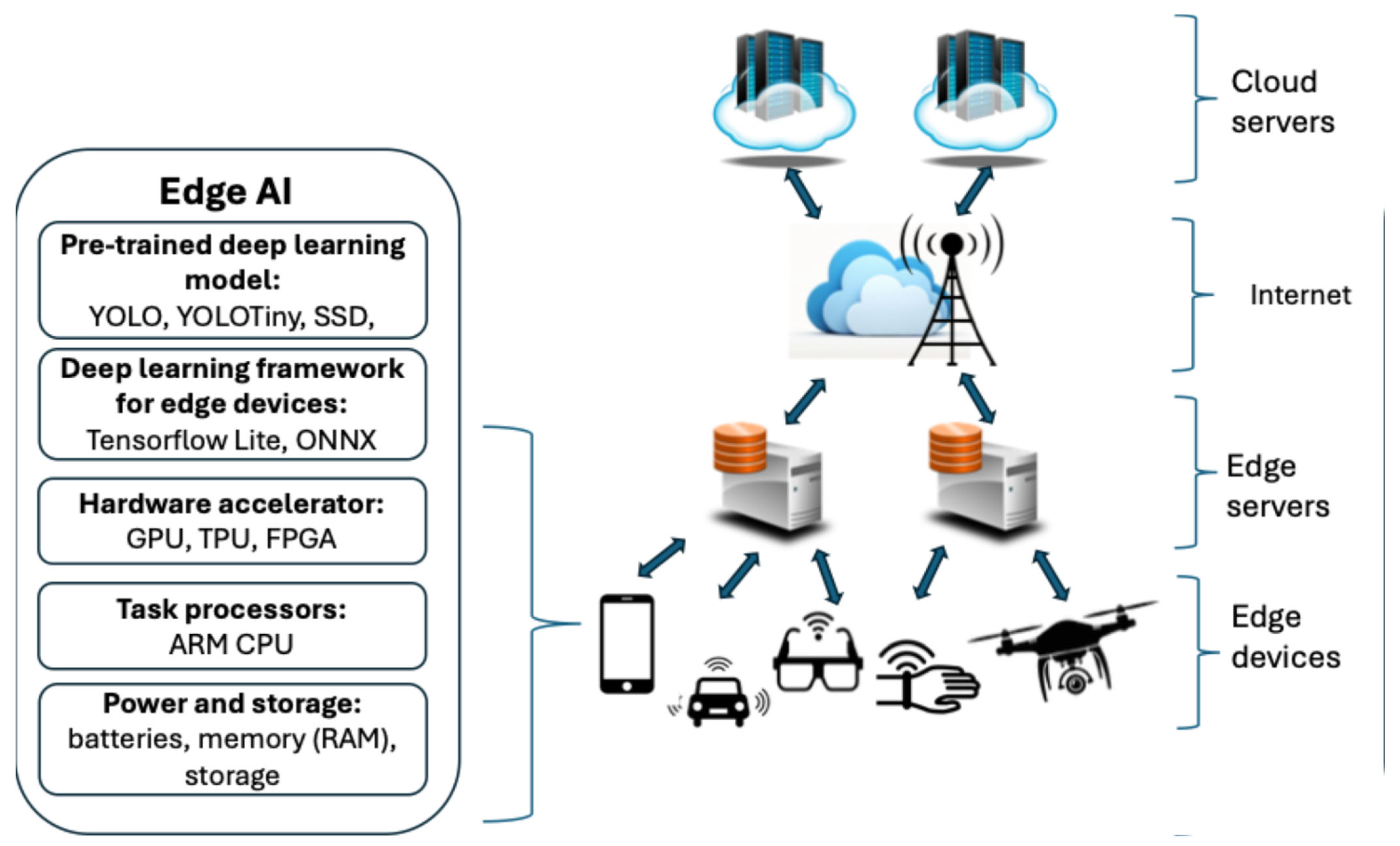
In this section, a system overview of edge AI, including the general architecture, benefits, and challenges of the systems, are discussed. Edge computing architectures are designed to bring computation closer to the data sources, reducing latency and improving the performance of AI applications. They involve a hierarchical structure that distributes processing tasks across different layers, including end devices, edge servers, and the cloud. This is shown in
Figure 1.
Edge devices: This layer comprises devices like smartphones, IoT sensors, wearable devices, drones, and surveillance cameras. These devices may have limited computational capabilities but play a crucial role in data collection and potential pre-processing. Edge devices can perform lightweight AI computations locally, reducing reliance on the cloud. Examples include smartphones running facial recognition apps or smart speakers responding to voice commands [
25]. Edge AI implementation includes several components, i.e., deep learning models, deep learning frameworks for edge devices, hardware accelerators, task processors, power, and storage. In this paper, we try to emphasize how to optimize edge AI implementation in each of these components.
Edge servers: This layer consists of more powerful computing resources located closer to end devices, such as cloudlets, fog nodes, edge servers, routers, base stations, and IoT gateways. These nodes handle more complex AI tasks that are offloaded from end devices or require the aggregation of data from multiple sources. They can perform tasks like object detection in video streams, data filtering, and local model updates [
26].
Cloud: The cloud layer acts as a central hub with substantial computational and storage resources [
27]. It is responsible for tasks that require extensive processing power or involve large datasets. These tasks may include training complex deep learning models, performing large-scale data analytics, and managing and orchestrating the overall edge computing infrastructure. The cloud can also provide backup and support for edge nodes, ensuring service continuity.
Communication between these layers is crucial for efficient data flow and task distribution. Edge computing frameworks include KubeEdge, OpenEdge, and Azure IoT [
28]. Edge computing facilitates this communication and enables the deployment and management of AI services across the edge computing ecosystem. The specific architecture and task distribution depend on the application requirements, device capabilities, and network conditions. It is important to design edge computing architectures that are scalable, flexible, and adaptive to the dynamic nature of edge environments.
There are some benefits of using edge computing for object recognition applications [
1,
5].
Reduced latency and agile service response: Edge computing reduces latency by processing data closer to the data source, leading to faster response times. This is particularly beneficial for AI applications that require real-time interactions, like autonomous driving, smart cities, and industrial automation. Edge systems serve as nearby computing platforms that process data locally and quickly. Some studies have been developed to optimize latency reduction in edge AI implementation [
29,
30]
Reduced bandwidth: Edge computing alleviates the burden on the core network by processing data locally, reducing the amount of data transmitted to the cloud. This is especially important with the explosive growth in data generated by IoT devices. It can also reduce reliance on expensive cloud computing resources. A recent study by Rouf et al. reported that the implementation of AI in edge computing can reduce bandwidth usage by 51% compared to implementation on the cloud [
31]
Enhanced privacy and security: Processing sensitive data locally on edge devices reduces the risk of data breaches during transmission to the cloud. Edge AI can analyze information locally without exposing it to humans, potentially improving data security. Some studies have reported efforts to improve the security and privacy of edge AI implementation against several threat models [
32,
33].
Improved reliability and availability: Edge computing enables AI systems to operate even with intermittent or no internet connectivity. This decentralized nature enhances the reliability and availability of critical AI applications. A recent study by Aral et al. proposed dependency- and topology-aware failure resilience (DTFR), a two-stage scheduler that minimizes failure probability while maintaining low network delay to achieve superior availability performance [
34].
Real-time data analysis: Edge AI systems can analyze data in real time, allowing for faster decision making and responses to changing conditions. This is crucial for applications like autonomous vehicles and smart homes, which require immediate actions based on sensor data. A recent study by Al Amin et al. reported an inference latency of 15 frames per second (FPS) on the FPGA platform [
35].
Energy efficiency: Edge AI can improve efficiency by processing data locally, significantly reducing the amount of data transmitted to a cloud server. It also reduces reliance on energy-intensive data centers. Finally, the deep learning model is executed on resource-constrained edge devices with a lower power consumption. For example, Xiangjie et al. proposed a deep reinforcement learning-based edge computing scheme that can reduce energy costs by more than 15% while ensuring the task can be completed on time [
36]. On the other hand, Mendula et al. proposed a novel middleware for adaptive and efficient split computing that can preserve up to 30% energy while achieving a 16% higher accuracy rate [
37].
However, there are some potential challenges in system development that require us to reconsider every approach or method that will be used in the development process, such as the following.
Development cost: There is a need to reduce development costs to produce a product with a competitive price. The cost depends on several factors, such the selection of the device, the development time, and the hiring of engineers with special skills.
The demand of the applications: Every application demands different requirements. For example, autonomous driving systems requires the real-time performance [
6], while the autonomous drones require an energy-efficient system [
38].
Human resources: There are some development approaches that requires special expertise. For example, hardware design expertise is needed for FPGA system development. This expertise comes with a steep learning curve compared to other systems’ development, which will impact the development cost.
Ever-changing systems requirements: There rapid evolution of industry standards requires the system to be adaptable to requirement changes. Some requirements include accuracy performance, hardware performance, security and privacy, and interoperability [
39].
Performance evaluation: There is a need to achieve a good balance some parameters, such as accuracy, latency, energy consumption, security, and reliability, depending on the application. Therefore, there is a need for good metrics that can represent an ideal implementation of edge AI [
40].
Thermal driven performance collapse: Mobile GPU on edge devices can be leveraged to improve the processing performance of deep neural networks (DNNs). However, this consumes a large amount of energy. After a short period of time, the mobile device may become overheated and the processors are forced to reduce the clock speed, significantly reducing the inference speed [
41].
Accuracy and latency attack on edge AI: Some studies reveal that the implementation of edge AI for objective recognition is also prone to the accuracy and latency attacks. Adversarial attacks introduce carefully crafted changes to the input data that can reduce the accuracy performance of a deep learning model [
20]. Meanwhile, overload attacks can escalate the required computing costs during the inference time, consequently leading to an extended inference time for object detection. They present a significant threat, especially to systems with limited computing resources [
21]
3. Key Considerations of Object Recognition on Edge Computing
In
Section 2, the challenges of edge AI development are discussed. In this section, the key considerations to solving the challenges are discussed. There are some key considerations for efficiently deploying and optimizing deep learning for object detection on resource-constrained edge computing devices that we defined based on a couple years of research experience in this field [
42,
43,
44,
45,
46]. In terms of computing resources, edge computing devices have limited procession capabilities compared to the cloud, making it challenging to run complex AI models for object detection, such as deep neural networks or the multistage processing pipeline [
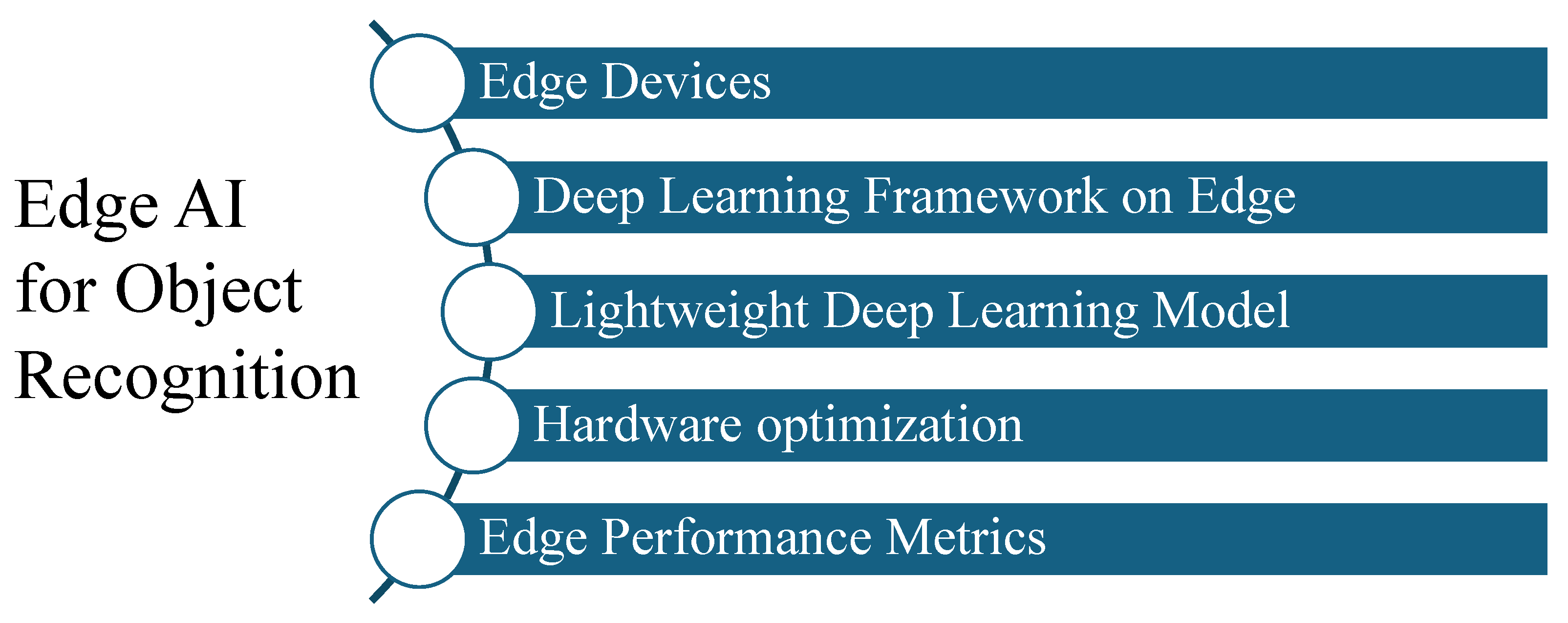
47]. Another consideration is the real-time processing requirements. Time-critical applications, such as object recognition, need low latency and high throughput, demanding efficient AI models on edge devices. As shown in
Figure 2, some points that need to be considered when deploying deep learning on edge computing devices are defined in detail in
Section 3.1,
Section 3.2,
Section 3.3,
Section 3.4 and
Section 3.5.
3.1. Edge Devices
An appropriate edge device with the necessary processing power, memory, and connectivity is crucial for efficient AI deployment. Edge AI usually contains a hardware accelerator, which is hardware that is designed to perform specific tasks more efficiently compared to the general-purpose processor. There are three well-known hardware accelerators for edge AI, which are a graphics processing unit (GPU), tensor processing unit (TPU), and field programmable gate array (FPGA) [
48]. The GPU was initially designed to render graphics and perform parallel processing tasks. The main advantage of the GPU is its highly parallel architecture, which is ideal for matrix computations in deep learning [
49]. The high performance of the GPU makes it excellent for training and inference tasks. However, it consumes significant power, making it less ideal for resource-constrained applications and typically more expensive than TPUs and FPGAs.
On the other hand, a TPU is a specialized hardware developed by Google for accelerating tensor-based operations, specifically for machine learning workloads [
50]. It is highly optimized for matrix multiplications and tensor operations used in neural networks. It is also more energy efficient than a GPU. The limitation of the TPUs is its low flexibility, which means it is not well suited for general-purpose computations or tasks outside AI. It also has limited support for frameworks other than TensorFlow.
Finally, FPGA is a reconfigurable hardware that can be programmed to execute specific tasks efficiently. It is highly customizable for specific workloads, including AI and non-AI tasks [
51]. It is also excellent for real-time applications and energy efficient for tailored AI inference tasks. However, developing an FPGA-based solution requires hardware design expertise with a steep learning curve compared to GPUs and TPUs. The development cycle is usually more prolonged due to the need for custom configuration. A comparison of the GPU, TPU, and FPGA is presented in
Table 1.
The actual edge AI devices are presented in
Table 2. NVIDIA Jetson Nano (Santa Clara, CA, USA) [
52] and Jetson Orin Nano (Santa Clara, CA, USA) [
53] are devices empowered by GPU. Google Coral Dev board [
54] and Xilinx Kria KV 260 are empowered by TPU and FPGA, respectively. Raspberry Pi 4 (Cambridge, UK) is a device with no specific hardware accelerator but it is sometimes also used for edge AI applications [
43]. Some end devices contain the embedded CPU and hardware accelerator, for example, the unmanned aerial vehicle (UAV) platform and mobile phones. Flight RB5 5G is a UAV platform produced by Qualcomm, with an embedded CPU and GPU [
38]. In this platform, developers can easily implement TensorFlow, ONNX, or PyTorch-trained deep learning models by using the Qualcomm neural processing SDK for AI. On the other hand, the Samsung Galaxy S24 ultra is one of the mobile devices empowered by Qualcomm Snapdragon octa-core and Adreno. The deep learning model can be implemented on the mobile device using Qualcomm Neural Processing SDK or TensorFlow Lite. This capability can be used for various applications such as real-time object and scene recognition or portrait/background segmentation.
The selection of edge devices depends on the system requirement, such as the required system performance, development cost, and development time. For example, NVIDIA Jetson Orin Nano might produce a significant improvement in performance because it is equipped with a high-specs GPU from NVIDIA. It might also be easier to develop due to a wealth of resources and a well-developed community [
53]. However, the cost of the device is the highest among all devices presented in
Table 2. On the other, Raspberry Pi 4 might present the cheapest solution among all of them, but the performance is limited, especially for high-complexity and time-constrained applications [
22].
3.2. Deep Learning Frameworks for Edge Implementation
Deep learning frameworks play a significant role in enabling edge AI for object recognition applications. These frameworks are designed to optimize the deployment of deep learning models in resource-constrained edge devices, ensuring real-time inference and efficient implementation on resource-constrained edge devices.
One of the well-known deep learning frameworks on edge devices is TensorFlow Lite. It supports model quantization for efficient deployment that can convert the model to lower-precision formats, such as floating point 16 bits (FP16) or integer 8 bits (INT8), to reduce memory usage and speed up inference [
58]. Two types of quantization methods can be supported by TensorFlow Lite, which are post-training quantization and quantization-aware training (QAT) [
59]. Post-quantization is a model optimization technique applied after training, where model weights and activations are reduced in precision (e.g., from FP32 to INT8) to improve inference efficiency; it is more straightforward but may lead to slight accuracy degradation. On the other hand, QAT simulates quantization during training by incorporating quantization effects into the loss function, resulting in a model that is more robust to precision reduction and retains higher accuracy after quantization.
For hardware acceleration, TensorFlow Lite can support layer fusion, fusing operations, e.g., convolution, activation, and batch normalization, into single kernels to minimize memory transfers and computation overhead. It also has the capability to offload computations to hardware accelerators, such as GPU or TPU, for real-time inference. TensorFlow Lite is ideal for TensorFlow-trained models and specific edge platforms, such as Google Coral and mobile devices. TensorRT from NVIDIA is also another framework that can support model quantization and layer fusion [
9].
Some of the well-known deep learning frameworks are vendor-specific frameworks, such as TensorRT (NVIDIA), OpenVINO (Intel) [
60], and VitisAI (Xilinx) [
12]. If the flexibility in development or cross-compatibility to several hardware becomes a concern, then an ONNX framework can provide a solution. It provides cross-platform compatibility by acting as an open standard for representing deep learning models. This compatibility enables the seamless deployment and interoperability of models across various deep learning frameworks and hardware platforms [
23]. For example, ONNX defines a standardized format (.onnx) for representing deep learning models, independent of the framework in which they were trained. Models from popular frameworks such as TensorFlow, PyTorch, and Keras can be converted to ONNX format. ONNX Runtime also supports various execution providers, which enable hardware-specific optimizations while maintaining compatibility; for example, CUDA execution provides optimized inference on NVIDIA GPUS, and OpenVINO execution provides model optimization in Intel-based edge devices.
Finally, for FPGA implementation, there are several well-known frameworks, such as Vitis AI, OpenCL [
61], and FINN, that enable the efficient deployment of AI models on FPGA platforms by leveraging hardware-specific optimizations and parallel processing capabilities. Vitis AI, developed by Xilinx, offers pre-built tools and libraries for deploying optimized models on Xilinx FPGAs, supporting frameworks like TensorFlow and PyTorch while providing model pruning, quantization, and real-time performance [
62]. OpenCL provides a standardized programming interface for creating portable FPGA implementations, allowing developers to write high-level, parallel code that is compiled into FPGA-compatible logic, making it versatile for custom AI applications [
11]. FINN, a framework from Xilinx, focuses on ultra-low-latency, quantized neural networks, generating FPGA-optimized designs tailored for resource-constrained tasks like edge computing [
63]. These frameworks make FPGAs accessible for deep learning, offering high energy efficiency, real-time processing, and customizable solutions for AI workloads in applications like autonomous systems, healthcare, and robotics. A summary of deep learning frameworks for edge implementation is shown by
Table 3.
3.3. Lightweight Deep Learning Model
Lightweight deep learning models, as shown by
Table 4, are specifically designed for efficient object recognition on resource-constrained edge devices. MobileNet uses depthwise separable convolutions, which factorize a standard convolution into a depthwise convolution and a 1 × 1 pointwise convolution to reduce computational complexity while maintaining significantly good accuracy, making it ideal for mobile and embedded systems [
64]. MobileNet V2 [
65] adds inverted residual blocks and linear bottlenecks, enhancing performance and memory efficiency while improving representational power for tasks like object detection and segmentation. MobileNet V3 [
66] combined neural architecture search (NAS) and advances like SE (Squeeze-and-Excitation) blocks to optimize accuracy, latency, and energy consumption, providing both small (MobileNetV3-Small) and large (MobileNetV3-Large) variants for different use cases. The common characteristic across all versions of MobileNet is its focus on efficiency and scalability for mobile and edge devices, enabling high-performance deep learning with minimal computational and memory requirements.
Tiny YOLO, a smaller variant of the YOLO architecture, prioritizes real-time detection with reduced model complexity [
67]. There are some commonly used Tiny YOLO model versions. Tiny YOLO v3 is the reduced version of the YOLOv3. YOLOv3 was developed based on a robust Darknet-53 framework employing 53 convolution layers [
68] to improve performance. YOLOv3-tiny introduced much-reduced network depth, seven convolution layers, and six max-pooling layers, significantly reducing the processing time [
69]. Tiny YOLO v7 [
70] is part of the YOLOv7 series [
71]. The main idea of YOLOv7 is to introduce trainable auxiliary architectures and optimize the network for real-time object detection. The modifications to create YOLOv7-tiny involved reducing the model size and using a simplified architecture. This significantly reduced the number of parameters to 6.2 million, compared to 36.9 million in YOLOv7. It also uses a leaky rectified linear unit (RELU), which has less complexity than the sigmoid linear unit (SILU) used in YOLOV7. Throughout their development, Tiny YOLO models have consistently aimed to balance speed, accuracy, and computational efficiency for surveillance, robotics, and IoT applications.
There are also some well-known lightweight deep learning models other than MobileNet and Tiny YOLO. EfficientNet-Lite [
72], a streamlined version of EfficientNet [
73], employs compound scaling to balance model size, accuracy, and speed, offering excellent performance for classification and detection tasks on edge platforms. NASNet-Mobile [
74], developed through neural architecture search (NAS) techniques, provides high accuracy with an optimized structure for mobile devices, though it is slightly more resource-intensive than other models. SqueezeNet and ShuffleNet focus on extreme compactness; SqueezeNet [
75] achieves high efficiency through 1 × 1 convolutions and parameter reduction, while ShuffleNet [
76] leverages grouped convolutions and channel shuffling for fast and lightweight inference. These models are highly optimized for edge environments, enabling real-time and power-efficient object recognition in applications like IoT, autonomous systems, and AR/VR.
Table 4.
Lightweight deep learning model.
Table 4.
Lightweight deep learning model.
| Model | Key Features | Advantages | Limitations | Common Use Cases |
|---|
MobileNet [64]
MobileNetV2 [65] MobileNetV3 [66] | Designed for mobile and edge devices, focusing on efficiency. | Low computational cost; supports quantization | Slightly lower accuracy compared to larger models for complex tasks | Real-time image classification; object detection |
| TinyYOLO [69] | Simplified YOLO model with fewer layers and parameters. | High inference speed; supports smaller devices | Accuracy trade-off for speed | Real-time surveillance; autonomous driving |
| EfficientNetLite [73] | Optimized version of EfficientNet for edge devices with compound scaling. | Excellent trade-off between accuracy and efficiency | Requires specific tuning for edge deployment | Image classification; object detection demanding high accuracy |
| NASNetMobile [74] | AutoML-designed lightweight architecture for mobile devices. | High accuracy; optimized structure | More resource-intensive than MobileNet | Mobile classification and detection tasks |
| SqueezeNet [75] | Compact architecture using 1 × 1 convolutions to reduce parameters. | Very small model size; low latency. | Lower accuracy than modern architectures | Resource-constrained applications; resource constraint hardware like FPGA |
| ShuffleNet [76] | Uses pointwise group convolution and channel shuffle for efficiency. | High speed; low computational cost | Slightly lower accuracy compared to MobileNet, may require specialized hardware for optimal performance | Embedded systems, AR/VR applications |
Another technique to building a lightweight deep learning model is using model compression techniques. Model compression techniques are essential for deploying efficient object recognition models on edge AI devices, where resources like memory, storage, and processing power are limited [
77]. There are five well-known model compression techniques, as listed in
Table 5. Model quantization reduces parameter precision from floating-point (e.g., floating points (FPs) 32 bits) to lower-bit formats (e.g., integer (INT) 8 bits), significantly shrinking memory usage and accelerating inference on constrained edge devices [
78]. On the other hand, model pruning and sparsity techniques focus on removing redundant weights, channels, or layers to compress the network structure, thus reducing storage and computational resource usage [
79]. Knowledge distillation transfers knowledge from a larger, complex model (the teacher) to a smaller, more efficient model (the student), allowing the student model to achieve similar performance while using significantly fewer parameters [
80]. Additionally, low-rank factorization breaks large-weight matrices into products of smaller matrices, lowering the total parameter count and decreasing the required number of multiply-accumulate operations [
81]. Finally, layer fusion can combine multiple layers into one to reduce computational overheads and improve efficiency [
82]. Model optimization techniques can be applied individually or in combination to achieve the best balance between accuracy and resource consumption for specific edge devices.
3.4. Hardware Optimization
Hardware optimization is crucial for implementing edge AI, given the resource constraints of edge devices. There are some well-known hardware optimization techniques, as defined in
Table 6.
Table 6 also cites the references and highlights the achievements in the research. Pipeline design divides tasks into sequential stages that can execute concurrently, maximizing throughput and reducing latency for real-time inference [
83]. Parallel processing leverages multiple hardware resources to perform operations simultaneously, significantly improving inference speed but requiring careful synchronization [
84]. Dataflow optimization focuses on minimizing data transfer delays by optimizing memory access patterns, which enhances processing efficiency, particularly in data-heavy tasks [
85]. Winograd convolution accelerates convolutional layers by reducing the number of multiplications, making it ideal for optimizing CNN-based object recognition models [
86]. Memory hierarchy optimization customizes on-chip memory usage to minimize reliance on slower off-chip memory, improving data locality and reducing access latency [
87]. Approximate computing minorly sacrifices accuracy for faster, lower-power operations by reducing computation precision or complexity, making it suitable for energy-constrained devices like drones and IoT cameras [
88,
89]. These techniques, when combined, enable real-time, scalable AI deployment on edge devices with limited resources. For example, Tatar et al. [
83]. and Rezk et al. [
84] achieved a throughput of 24,715 GOP and 3458 Gbps for a proposing pipeline and parallel processing techniques, respectively. In another work, Shubham et al. achieved an average reduction of 49% in energy consumption for their proposed tunable compressor, and an average reduction of 36% in energy consumption for the proposed multiply and accumulate (MAC) unit [
89]. However, each optimization requires careful tuning to balance accuracy, speed, and hardware constraints.
Another approach in hardware design for edge AI is hardware–software (HW-SW) co-design and co-optimization [
90]. HW-SW co-design and co-optimization is a development approach that integrates both hardware and software optimizations to create efficient edge AI solutions for object recognition on FPGAs. This approach optimizes the AI model and algorithms alongside the hardware design to maximize performance, resource utilization, and power efficiency. Software optimizations involve model compression techniques such as quantization, pruning, and layer fusion, which reduce the computational load and memory usage for efficient inference. On the hardware side, some hardware optimization techniques mentioned in
Table 6 can be utilized [
91]. Additionally, on the hardware side, some ready-made FPGA-specific accelerators like the Deep Learning Processing Unit (DPU) can also be used to optimize tasks such as convolutions, activations, and data movement, enabling parallelism and pipelining.
Frameworks like Vitis AI simplify the co-design process by allowing pre-trained models to be compiled and deployed on FPGA hardware while providing hardware-specific optimizations. Additionally, developers can create custom accelerators using High-Level Synthesis (HLS) to tailor the hardware for specific AI workloads. The integration of both hardware and software improvements ensures low-latency, real-time object recognition, making this co-design approach ideal for applications like autonomous vehicles, surveillance, and industrial automation. By aligning hardware capabilities with model requirements, edge AI systems achieve both high performance and scalability in resource-constrained environments.
Another term that is also used is cross-layer optimization [
92]. It involves optimizing multiple layers of the system stack, which are the application layer, the model layer, the framework/runtime layer, firmware, and the hardware layer [
93]. They are all optimized jointly rather than in isolation. This ensures efficiency, low latency, and reduced power consumption. Cross-layer optimization is essential in edge AI because it aligns AI models, hardware, and software to work together efficiently. Instead of optimizing each layer separately, collaborative optimization across layers leads to better power efficiency, lower latency, and improved overall system performance.
The smart surveillance system serves as a use case example for cross-layer optimization. In the application layer, we can simplify the detection operations to detect only suspicious human movements to remove unnecessary computations. In the model layer, we can utilize a lightweight deep learning model (
Table 4) and model compression technique (
Table 5) to achieve real-time inference. In the framework/runtime layer, the framework, such as VitisAI or TensorRT, can optimize data flow and fuse layers to accelerate processing. Finally, in the hardware layer, we can use hardware optimization techniques (
Table 6) or a custom-made hardware accelerator such as DPU or GPU to process the deep neural network operations efficiently. As a result of joint optimization, we obtain the low-power and real-time object recognition with minimal latency.
3.5. Edge Performance Metrics
It is essential to evaluate the development of edge AI solutions on metrics beyond just accuracy, including processing time, hardware utilization model size, and power consumption. There are several categories of metric performance, which are AI model performance (
Table 7), hardware performance (
Table 8), communication and network performance (
Table 9), security and reliability (
Table 10). Inference accuracy denotes the percentage of correctly classified or detected objects, which ensures reliable recognition results [
94]. Some commonly used accuracy metrics are accuracy, F1-score, precision, and recall [
95]. Processing time measures the real-time performance of the proposed solutions. It is critical for real-time applications, such as self-driving vehicles, industrial automation, and precision farming. The processing time can be represented by some metrics, such as inference time or latency [
96]. Other than processing time, the compute efficiency can also be evaluated using the ratio of floating-point operations per second (FLOPs) and multiply-accumulate operations (MACs) [
23]. Lower FLOPs/MACs indicates better efficiency on edge devices. Finally, the model size metrics confirm if the deep learning model is deployable on devices with limited storage [
97]. A summary of AI model performance metrics is shown in
Table 7.
Hardware performance metrics measure the computing speed and hardware utilization efficiency. Compute throughput measures the number of inferences per second that hardware can perform. Hardware utilization (such as GPU, TPU, CPU, and RAM utilization) and power consumption (consumed power frame and battery life) are standard metrics that can measure the resource-efficient implementation of edge AI solutions. Thermal efficiency is also an important metric to ensure that the designed hardware operates without overheating. A summary of the key performance metrics is shown in
Table 8. Other than the two categories already discussed above, two other metric categories can also be evaluated depending on the implementation case. The communication and network metrics, as shown in
Table 9, can be considered for hybrid edge–cloud implementation, especially for remote IoT applications. Meanwhile, the security and reliability metrics, as shown in
Table 10, are significant for applications that contains sensitive data, for example, the digital health applications.
Table 11 summarizes existing related research and the performance metrics used in the evaluation [
23,
44,
45,
107,
108,
109,
110,
111]. Listed research in
Table 11 is conducted on different hardware platforms, i.e., Jetson platform [
23,
107,
109,
110,
111], Raspberry Pi [
108], and FPGA [
44]. mAP and F1-score are the most common accuracy parameters used. While a few studies also evaluated accuracy, precision, recall, for processing time performance, most studies in
Table 11 evaluated inference time (ms), FPS, Giga FLOPS (FLOPS), and throughput in giga operations per seconds (GOPSs). Meanwhile, for hardware utilization, most of the studies in
Table 11 evaluated energy consumption (Watt hour (WH)), RAM/CPU/GPU utilization for studies conducted on the Jetson platform, and block random access memory (BRAM), digital signal processing (DSP) elements, look-up table (LUT), and flip-flop (FF) utilizations for studies conducted on FPGA.
4. Case Study: Real-Time Power Line Inspection
In
Section 3, the key considerations in object recognition development on edge computing devices have been discussed. In order to understand the real-implementation of the concepts and issues presented in previous sections, an example of an application in power transmission line inspection is presented in this section. This case study was selected by considering the need for real-time object recognition to be conducted on the edge devices that are installed on the drone [
112,
113,
114]. The power transmission line should be regularly inspected to promptly identify and fix any damage to guarantee the effective and dependable transmission of high-voltage electricity. The traditional method, i.e., line crawling, is not safe because the possibility of the engineers falling from the wire or getting electrocuted is very high. Some other methods have been developed, such as using telescopes to observe the lines from the ground, power transmission line inspection robots (PTLIRs) [
115], helicopter-assisted inspection, and automated helicopter-assisted inspection [
116]. However, these methods mainly depend on human observation, are less effective, and present high risk [
55].
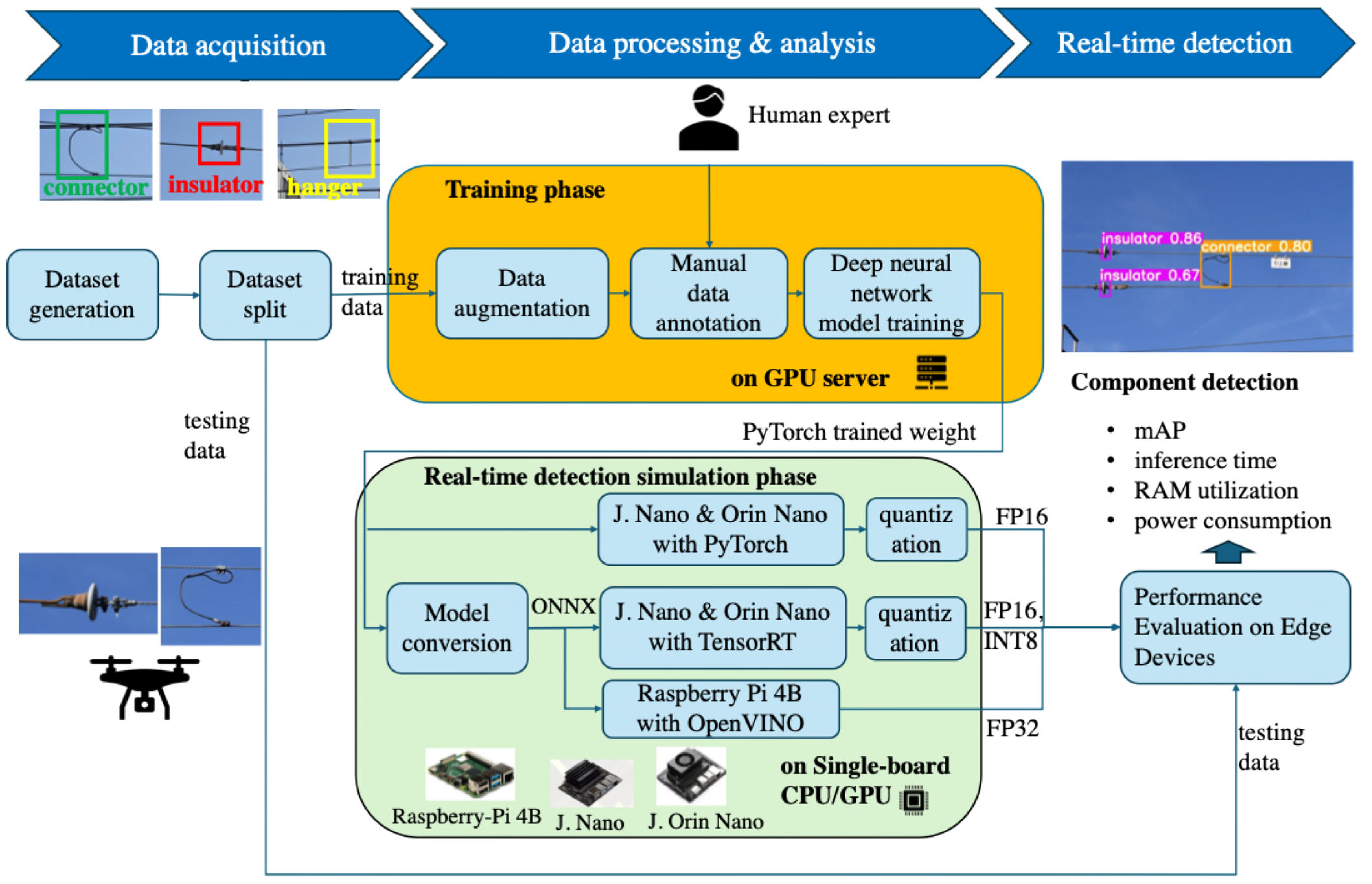
In our study, we develop a power transmission line inspection system using edge computing platforms [
22]. The developed deep learning framework for this research is shown in
Figure 3. It primarily consists of two stages, which are the training phase and the real-time detection phase. In the training phase, the data generation, data annotation, and training are conducted. In this study, YOLOv7 and Tiny YOLOv7 are trained. Both are state-of-the-art methods for the object detection task. In the real-time detection phase, the trained model is evaluated on edge computing devices, which are Raspberry Pi 4B, Jetson Nano, and Jetson Orin Nano. The specification of each device is defined in
Table 12. Some deep learning frameworks are also evaluated in this research, i.e., OpenVINO 2023.1.0, PyTorch 2.1.2, and TensorRT 8.2.1. The model quantization to FP16 and INT8 are also evaluated in this research. Finally, the final evaluation results are the mAP, inference time, RAM utilization, and power consumption.
The evaluation results are shown in
Table 13. It shows that the detection processing time in Raspberry Pi 4B is significantly longer compared to other platforms, and is 16.4 seconds (s). From this result, we can understand that the YOLOv7 is not suitable for real-time detection as works on the Raspberry Pi 4B platform. However, some approaches can be taken to improve the performance, for example, by using the different edge devices such as Jetson Nano and Jetson Orin Nano. Our results show that YOLOv7 can achieve 0.33 s inference time using the FP16 quantized model on Jetson Nano with the TensorRT framework. Meanwhile, it can achieve 0.02 s inference time using the INT8 quantized model on Jetson Orin Nano with the TensorRT framework.
On the other hand, using YOLOv7-tiny on Raspberry Pi4B can reduce the inference time to 2.74 s. YOLOv7-tiny can achieve 0.06 s inference time using the FP16 quantized model on Jetson Nano with the TensorRT framework, and it can achieve a 0.008 s inference time using the INT8 quantized model on Jetson Orin Nano with the TensorRT framework. In terms of accuracy, the usage of YOLOv7-tiny and model quantization technique does not reduce the mAP significantly. YOLOv7-Tiny INT8 model implementation on Jetson Orin Nano with TensorRT It can still achieve 0.936 mAP. Finally, in terms of RAM utilization and power consumption, the implementation with Raspberry Pi4B achieves the lowest RAM utilization and power consumption.
From this result, we can also understand the impact of deep learning framework selection, for example, in Jetson Nano implementation. The implementation with TensorRT can reduce the inference time for every implementation case compared to PyTorch. For example, it can reduce the inference time for quantized YOLOv7 from 1.24 s to 0.33 s. For quantized YOLOv7-tiny, it can reduce the inference time from 0.23 s. to 0.06 s. This result can be obtained due to the hardware-specific optimization performed by TensortRT for NVIDIA GPUs, including those in Jetson devices [
9].
In some previous work, researchers defined the metrics that define the balance between accuracy and complexity for practical usage. Canziani et al. defines an information density metric that evaluates the practical usage of an AI model by considering its accuracy and number of parameters [
117]. On the other hand, Wong proposed the NetScore metric, which asses the performance of a deep neural network in practical usage by considering the accuracy of the network, number of parameters in the network, and the number of multiply-accumulate operation during network inference. Inspired by these works, we propose the edge-AI deployment score (EADS) (denoted by
) metric, which asses the performance of edge AI deployment by considering the edge implementation accuracy (mAP), inference time, RAM utilization, and power consumption. The proposed EADS can be defined as follows:
where
is the accuracy of the network,
is the inference time,
is edge resource utilization (e.g., RAM, CPU), and
is power consumption. On the other hand,
are coefficients that control the influences of accuracy, inference time, resource utilization, and power consumption, respectively. Finaly,
is the scaled-value of EADS that ensures the final results are scaled from 0 to 1.
Table 13 shows the EADS results. Quantized YOLOv7-Tiny (INT8) implementation on Jetson Orin Nano shows the best score, 1.000, due to acceptable accuracy result and outstanding inference time results, while YOLO-v7 (FP-32) implementation shows the lowest score, 0.000, due to the very large value of inference time.
Although the implementation on Jetson Orin Nano achieves the lowest inference time, the cost the device is, however, much more expensive than Jetson Nano and Raspberry Pi. Therefore, further optimization of Raspberry Pi and Jetson Nano is required to achieve the best solution for object recognition on edge computing devices at a lower cost.
6. Conclusions
In this paper, we present artificial intelligence for object recognition applications. The benefits, challenges, and deployment considerations are discussed. In this paper, we consider the key considerations in employing deep learning on edge computing devices, such as selecting edge devices, deep learning frameworks, lightweight deep learning models, hardware optimization, and performance metrics. The available techniques for all aspects are also discussed in this paper. A potential application for real-time power line inspection is presented in order to give a better understanding of a real implementation of the issues discussed. The evaluation results in several edge computing platforms show that the selections of a lightweight method, model compression method, deep learning framework, and appropriate edge hardware are significant in achieving the real-time requirement. A new metric, EADS, is also proposed in the paper. This metric asses the performance of edge AI deployment by considering the edge implementation accuracy, inference time, resource utilization, and power consumption. Finally, some recommendations are made for future research in this area.




{kind=link}
{kind=link}
{kind=link}