1. Introduction
In the contemporary digital landscape, the exponential growth of organizational documentation has created unprecedented challenges for efficient document management and circulation systems [
1]. Traditional document processing workflows, characterized by manual routing, paper-based approvals, and sequential processing, are increasingly inadequate for meeting the demands of modern administrative environments [
2]. These conventional approaches suffer from inherent limitations including prolonged processing cycles, susceptibility to human error, limited scalability, and significant security vulnerabilities [
3]. Moreover, the environmental impact of paper-intensive workflows, coupled with the substantial costs associated with physical storage and retrieval systems, has intensified the urgency for digital transformation in document management practices [
4,
5,
6].
The transition towards automated document processing systems represents a critical paradigm shift that addresses both operational efficiency and sustainability concerns [
7]. However, this transformation introduces complex technical challenges that extend beyond simple digitization. Effective automated document systems must not only replicate traditional workflow capabilities but also enhance them through intelligent processing, predictive routing, and adaptive classification mechanisms [
8]. The core technical challenges in this domain center on two fundamental problems: achieving accurate and efficient document retrieval from large-scale repositories, and performing reliable document classification that can adapt to diverse content types and organizational contexts [
9,
10].
Current document retrieval systems predominantly rely on either sparse retrieval methods, such as BM25, which excel at exact term matching but struggle with semantic understanding, or dense retrieval approaches that capture semantic relationships but may miss important keyword-based signals [
11,
12], while hybrid approaches attempt to combine these complementary strengths, existing fusion methods suffer from critical limitations: they apply fixed weighting schemes regardless of query characteristics, ignore consensus information between different retrievers, and provide no confidence estimation for results [
13,
14]. These shortcomings result in suboptimal retrieval performance and unreliable results, particularly crucial in document management applications where accuracy and reliability are paramount.
Similarly, traditional document classification approaches treat documents as independent entities, failing to leverage the rich relationships and dependencies that exist within document corpora [
15]. This limitation becomes particularly pronounced in organizational settings where documents often reference each other, belong to related categories, or share common themes and contexts. Furthermore, the security-critical nature of many document management applications demands robust classification systems that can withstand adversarial attacks and maintain performance under various threat scenarios [
16,
17].
To address these fundamental challenges, this paper introduces AttenFlow, a novel context-aware architecture that revolutionizes automated document processing through two core technical innovations designed to provide intuitive, human-interpretable functionality. To clarify the foundational concepts underlying our approach, mutual-attention mechanisms operate analogously to how experienced clerks simultaneously consider document content and routing destinations when making processing decisions, enabling joint analysis of document semantics and target processing paths. High-dimensional semantic features capture deep document meanings, including contextual relationships and implicit intentions, similar to how experts understand complete document significance rather than merely identifying keywords. Adversarial training systematically exposes the system to challenging scenarios during learning, comparable to training staff with complex cases to enhance decision-making resilience under unusual circumstances.
The first innovation, retriever consensus confidence fusion (RCCF), transforms document retrieval by introducing consensus-based fusion strategies that dynamically adapt to retriever agreement levels while providing confidence estimates for results. Unlike traditional fusion methods that apply fixed weights regardless of query characteristics, RCCF measures consensus between different retrievers and adjusts fusion strategies accordingly, amplifying high-consensus results while adopting conservative approaches for uncertain cases. This adaptive mechanism not only improves retrieval accuracy by up to 16.9% but also provides valuable confidence information that enables downstream applications to assess result reliability and implement effective quality control measures.
The second core innovation, AM-HDGAT for text (adversarial mutual-attention hybrid-dimensional graph attention network for text), addresses the fundamental limitations of traditional document classification approaches that treat documents as isolated entities. This method models complex inter-document relationships through sophisticated graph structures while seamlessly integrating complementary feature representations from multiple abstraction levels. The approach combines high-dimensional semantic features derived from pre-trained language models with carefully engineered low-dimensional statistical features through a novel mutual-attention mechanism, enabling comprehensive document understanding by capturing both deep semantic meaning and surface-level characteristics. The integration of adversarial training components further enhances model robustness against potential security threats and distributional shifts, making the system particularly suitable for security-critical document processing applications.
The AttenFlow architecture represents a significant advancement by synergistically integrating these innovations within a unified, scalable framework that addresses multiple technical challenges simultaneously. The system’s multi-layer design ensures computational efficiency and horizontal scalability while supporting flexible deployment across diverse organizational contexts. Through a strategic integration of RCCF and AM-HDGAT components, AttenFlow creates a feedback-enhanced processing pipeline where retrieval confidence estimates inform classification decisions, and classification results provide a semantic context that continuously refines retrieval performance. This symbiotic relationship achieves substantial improvements in document retrieval accuracy, classification performance with an average F1-score improvement of 2.23%, and processing efficiency with a 26.1% reduction in processing time.
Comprehensive experimental validation across multiple benchmark datasets and real-world deployment scenarios demonstrates the substantial effectiveness of our proposed innovations. The system consistently outperforms established methods across diverse tasks while maintaining 82.4% performance retention under adversarial conditions and achieving 95.7% user satisfaction in production environments processing over 10,000 documents monthly. By systematically addressing the fundamental limitations of existing approaches through principled technical solutions, AttenFlow establishes a new paradigm for intelligent document processing that seamlessly combines computational efficiency, accuracy optimization, and security assurance within a production-ready framework suitable for large-scale organizational deployment.
The primary contributions of this work are summarized as follows:
We introduce the retriever consensus confidence fusion (RCCF) method, which addresses fundamental limitations in hybrid retrieval systems by incorporating consensus measurements, adaptive weight assignment, and confidence estimation to achieve superior retrieval accuracy and reliability.
We develop AM-HDGAT for text, an innovative graph-based classification approach that models inter-document relationships while combining high-dimensional semantic features and low-dimensional statistical features through mutual-attention mechanisms, enhanced with adversarial training for robust security-critical applications.
We propose AttenFlow, a unified context-aware framework that combines advanced retrieval fusion and graph-based classification, setting new standards for intelligent document processing by jointly optimizing efficiency, accuracy, and security to meet real-world organizational needs.
We conduct extensive experiments on benchmark datasets and real-world scenarios, demonstrating notable gains in retrieval accuracy (↑16.9%), classification performance (↑2.23% F1-score), and system efficiency (↓26.1% processing time).
Through these contributions, this research advances the state of the art in automated document processing while providing practical solutions that can be readily deployed in real-world organizational contexts, ultimately facilitating the digital transformation of document management practices across diverse domains.
2. Related Work
Research in document processing and workflow management has yielded significant advancements in efficiency, accuracy, and system performance, laying the groundwork for our work [
10,
18,
19,
20]. However, critical limitations persist, particularly in modeling document relationships and adaptive information fusion, which our proposed AttenFlow architecture specifically addresses.
In document information extraction and clustering, substantial efforts focus on handling unstructured data. Baviskar et al. emphasized AI’s potential for automating extraction but identified significant challenges, such as dataset creation difficulties and the need for robust validation, especially for diverse layouts [
21]. While valuable, this work primarily addresses single-document processing and does not tackle the complexities arising from inter-document dependencies within a corpus, a gap our AM-HDGAT module aims to fill. Bezdan et al. introduced an innovative text clustering method by combining the hybrid swarm intelligence algorithm with K-means to enhance efficiency and reliability [
22], and Abualigah conducted a thorough investigation into meta-heuristic optimization algorithms for text clustering, demonstrating AI’s role in improving these tasks [
23]. These methods improve intra-document organization but, like most traditional approaches, treat documents as isolated entities, failing to capture the contextual relationships between documents that are crucial for holistic understanding and flow management, a core focus of our graph-based AM-HDGAT.
Within workflow management, researchers have proposed solutions for optimizing document circulation. Alam et al. introduced a blockchain-based solution for digitizing land titles, offering advantages like faster processing, cost reduction, and transparency [
24]. Astanaliev applied CERT values and the Delphi method to evaluate workflow system performance, aiding process improvement [
25]. Alade focused on object-oriented hypermedia design for a web-based electronic document management system, achieving high user satisfaction [
26]. Represa et al. compared workflow management solutions, emphasizing the Eclipse Arrowhead framework for microservice architecture [
27]. These contributions enhance system design and process management but typically operate at a macro level or focus on specific document types, often overlooking the need for fine-grained, dynamic modeling of document relationships and content-dependent flow within complex document streams—a challenge our integrated AttenFlow framework tackles.
Advances in document retrieval have been transformative. Guo et al. proposed a deep relevance matching model that significantly improved ad hoc retrieval ranking through neural architectures [
11]. Karpukhin et al. developed dense passage retrieval methods that achieved breakthrough performance in open-domain question answering using dense vectors [
12]. For retrieval fusion, Cormack et al. introduced the reciprocal rank fusion (RRF) method, which effectively combines results from multiple systems without requiring score normalization [
14], and Lin et al. provided comprehensive insights into pre-trained Transformers for text ranking [
13]. While these represent major strides, traditional fusion approaches like RRF have inherent limitations, as highlighted by Lin et al.: they typically ignore the consensus patterns among different retrievers and apply fixed fusion strategies regardless of retriever agreement levels [
13]. Furthermore, they lack mechanisms to assess the confidence or consensus strength of the fused results. This rigidity and absence of confidence estimation hinder optimal performance, especially when retrievers disagree significantly or results are ambiguous. This critical shortcoming is directly addressed by our proposed RCCF method, which revolutionizes fusion by dynamically evaluating retriever consensus and providing essential confidence estimates.
The application of attention mechanisms has revolutionized understanding within documents. Vaswani et al.’s Transformer architecture, powered by self-attention, fundamentally changed NLP [
28]. Galassi et al. conducted an extensive analysis of attention mechanisms, providing theoretical foundations [
29]. Applied specifically to documents, Abreu et al. proposed hierarchical attentional hybrid neural networks for effective document classification [
30], Huang et al. demonstrated the effectiveness of combining embeddings with attention for sentiment analysis [
31], and El-Rashidy et al. developed attention-based features for urgent post-classification [
32]. These works powerfully model intra-document relationships and feature importance. However, they primarily focus on understanding individual texts and lack explicit mechanisms for modeling inter-document relationships and dependencies across a corpus of related documents within a workflow context. This limitation, stemming from the traditional independent treatment of documents, prevents capturing the full contextual interplay vital for tasks like flow-based classification. Our AM-HDGAT module directly builds upon the power of attention [
28,
29] but critically extends it to capture mutual relationships between documents through graph attention networks, enabling a holistic view crucial for document flow management.
Synthesis: Bridging the Gaps with AttenFlow. The reviewed literature demonstrates substantial progress in core areas relevant to document processing. Nevertheless, a critical, unifying limitation underpins much of the prior work: traditional methods typically treat documents independently [
21,
22,
23,
30,
31,
32], failing to capture the complex relationships and dependencies that exist within document corpora. This omission is particularly detrimental to tasks requiring contextual understanding across multiple documents, such as nuanced classification and precise retrieval within dynamic flows. Additionally, state-of-the-art retrieval fusion methods remain static [
13,
14], ignoring consensus patterns among retrievers and lacking confidence estimates, limiting their robustness and adaptability to varying agreement scenarios. Our work directly targets these fundamental gaps:
RCCF Method: Revolutionizes retrieval fusion by dynamically evaluating consensus among retrievers and providing confidence estimates for results, overcoming the static nature and lack of confidence assessment in methods like RRF [
14].
AM-HDGAT Module: Leverages graph neural networks and mutual-attention mechanisms [
28] to explicitly model intricate inter-document relationships and dependencies, directly countering the isolated document view prevalent in prior extraction, classification, and clustering work.
AttenFlow Framework: Integrates RCCF and AM-HDGAT synergistically within a unified architecture. This integration enables a comprehensive approach that jointly enhances retrieval effectiveness through consensus-aware fusion and boosts classification robustness by understanding document interdependencies within the workflow, offering a significant step beyond the capabilities of existing isolated solutions.
3. Method
3.1. Overview
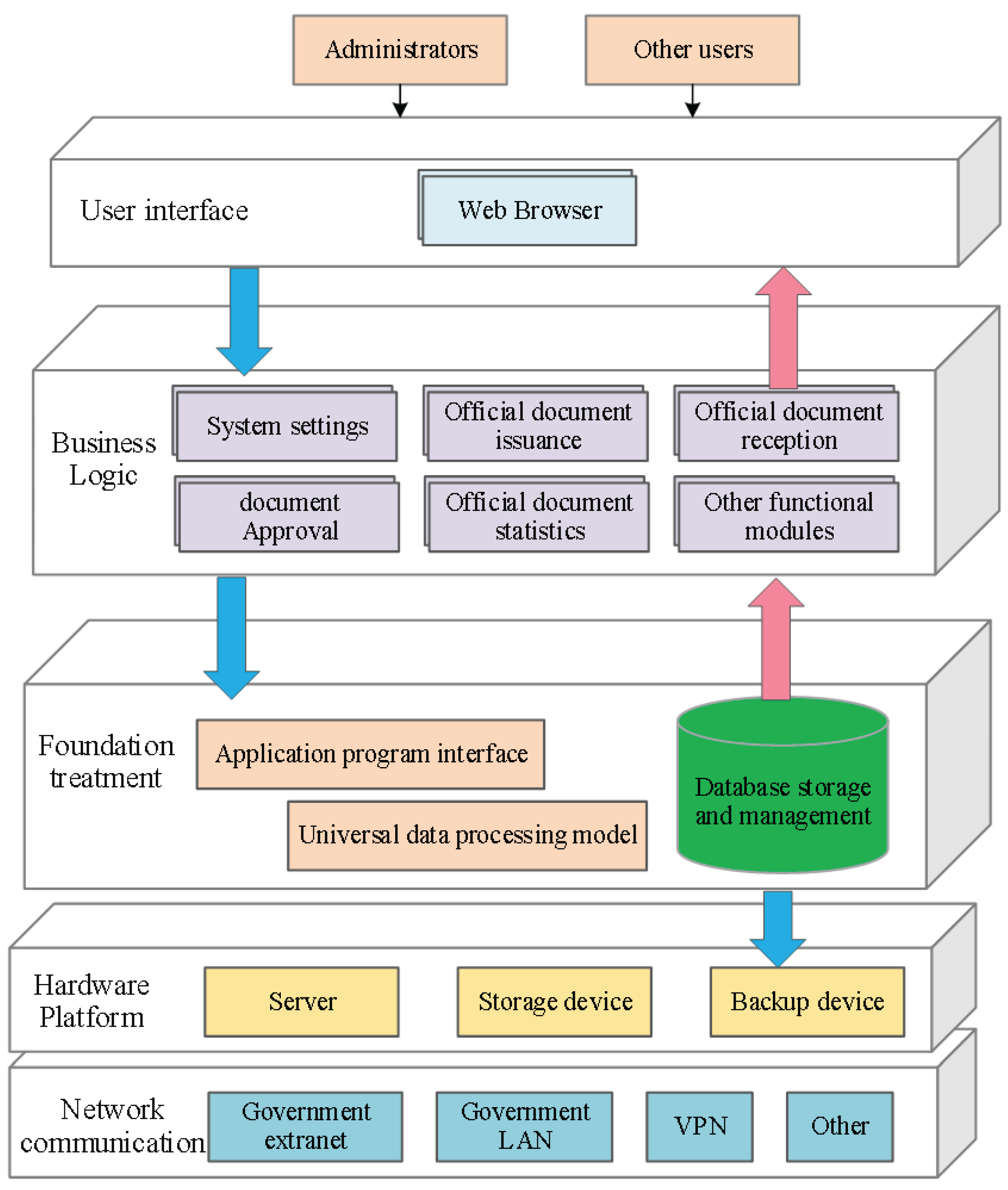
To enhance the informatization and organizational efficiency of document management, this study proposes AttenFlow, a novel context-aware architecture designed to automate document circulation and processing [
33,
34]. The AttenFlow architecture, illustrated in
Figure 1, leverages advanced information technology to standardize key document management processes, including registration, drafting, review, and publication, thereby enabling automated document processing and transmission.
AttenFlow adopts a multi-layer design to ensure system efficiency and scalability, consisting of a hardware and network communication layer, a basic service layer, a business logic layer, and a user interface layer. The network communication layer enables flexible system access via multiple networking methods, while the hardware platform provides essential computing and storage support. The basic service layer manages system access, data processing, and database storage using standardized data processing models to store and manage document data following established protocols. In the business logic layer, the system defines document classification criteria based on factors such as time, confidentiality level, and content, while customizing workflows and approval processes according to user requirements.
The primary goal of AttenFlow is to enable seamless document circulation and efficient transmission by streamlining business processes, minimizing manual intervention, and improving overall document management efficiency. By integrating advanced networking technologies, AttenFlow facilitates flexible data transmission across geographically distributed users while ensuring the security and integrity of documents during circulation.
To achieve these objectives, this study focuses on two core technical innovations that address the fundamental challenges in document flow prediction and classification. The first innovation is the retriever consensus confidence fusion (RCCF) method, which enhances document retrieval accuracy by dynamically adjusting fusion strategies based on retriever consensus. Traditional hybrid retrieval fusion approaches often suffer from fixed weighting schemes and lack confidence estimation capabilities. RCCF addresses these limitations by incorporating consensus measurements between different retrievers, enabling adaptive weight assignment and providing confidence scores for retrieval results. This mechanism effectively improves retrieval accuracy while reducing computational overhead for large-scale document datasets.
The second core innovation is the AM-HDGAT for text (adversarial mutual-attention hybrid-dimensional graph attention network for text) module, which revolutionizes document classification by modeling inter-document relationships through graph structures. Unlike traditional approaches that treat documents independently, AM-HDGAT constructs document graphs to capture semantic relationships and leverages both high-dimensional semantic features and low-dimensional statistical features through a mutual-attention mechanism. Furthermore, adversarial training is incorporated to enhance model robustness against potential attacks, making it particularly suitable for security-critical document processing applications.
The synergistic operation of these components is achieved through three fundamental mechanisms:
- (1)
Retrieval–Classification Pipeline: The RCCF module processes retrieval results to generate quality-assured document subsets with confidence scores. These outputs serve as structured inputs for the AM-HDGAT classifier, where RCCF confidence values initialize node weights in document graphs constructed using k-NN similarity metrics ().
- (2)
Cross-Layer Integration: Within AttenFlow’s multi-layer architecture, RCCF operates in the basic service layer through distributed retrieval engines, while AM-HDGAT resides in the business logic layer as an intelligent classifier. The hardware layer’s GPU resources accelerate graph attention computations, and the presentation layer visualizes dual-confidence metrics (retrieval and classification) through interactive dashboards.
- (3)
Closed-Loop Data Flow: Documents undergo RCCF retrieval before entering the AM-HDGAT network. Classification results are subsequently fed back through online learning modules to update RCCF’s weighting parameters, forming an optimization loop that continuously enhances retrieval-classification consistency.
The synergy between RCCF and AM-HDGAT enables AttenFlow to excel in document retrieval, classification, and circulation management, providing an efficient, scalable, and practical solution for automated document systems. Through the integration of these innovations within a unified framework, we achieve substantial improvements in both the efficiency and performance of text processing tasks while effectively overcoming the limitations of traditional methods in capturing long-range dependencies and complex document relationships.
3.2. Traditional Hybrid Retrieval Fusion Methods
Building upon the overview of AttenFlow’s objectives, we first examine the existing approaches in hybrid retrieval systems to understand the motivation behind our RCCF innovation. Traditional hybrid retrieval systems typically combine sparse retrieval methods (e.g., BM25) with dense retrieval approaches (e.g., neural embeddings) to leverage the complementary strengths of both paradigms [
11,
12]. Sparse retrieval excels at exact term matching and handles out-of-vocabulary terms effectively, while dense retrieval captures semantic similarity and contextual relationships [
35,
36].
Linear Weighted Combination: The most straightforward fusion approach combines retrieval scores using fixed weights:
where
is a hyperparameter that balances the contribution of sparse and dense retrievers. However, this method requires careful score normalization due to the different scales of sparse and dense scores, and the fixed weight
may not be optimal for diverse query types [
13].
Reciprocal Rank Fusion (RRF): RRF has emerged as a popular rank-based fusion method that avoids score normalization by focusing solely on document rankings [
14]:
where
R is the set of retrieval systems,
is the rank of document
d in retriever
r, and
k is a constant (typically 60) that controls the impact of lower-ranked documents. While RRF demonstrates strong empirical performance and robustness, it completely discards score information and treats all retrievers equally regardless of their relative strengths for specific queries [
37].
Limitations of Traditional Methods: These existing fusion approaches suffer from several key limitations that motivated our development of RCCF. First, they ignore the consensus level among retrievers, missing valuable reliability signals that could indicate result quality. Second, they apply fixed fusion strategies regardless of retriever agreement or disagreement, failing to adapt to varying query characteristics. Third, they lack confidence estimation for the final results, providing no indication of result reliability. Finally, they cannot adaptively adjust to different query characteristics or retriever performance variations [
38,
39]. These limitations highlight the need for a more sophisticated fusion approach that can dynamically assess and incorporate retriever consensus.
3.3. Retriever Consensus Confidence Fusion (RCCF)
To address the identified limitations of traditional fusion methods, we propose the retriever consensus confidence fusion (RCCF) approach, which represents the first core innovation of the AttenFlow architecture. RCCF dynamically adjusts fusion strategies based on inter-retriever consensus and provides confidence estimates for retrieval results, directly addressing the gaps identified in existing approaches.
3.3.1. Retriever Consensus Measurement
The foundation of RCCF lies in accurately measuring consensus among different retrievers. For a query q and document d, given n retrievers , we define comprehensive consensus measures that capture both ranking and scoring agreement patterns.
Rank Consistency: The rank consistency measures how similarly different retrievers rank a document:
where
is the standard deviation of document
d’s ranks across retrievers,
is the maximum rank standard deviation among all candidate documents for normalization,
is the number of retrievers that return document
d, and
is a penalty factor that reduces consistency scores when fewer retrievers return the document.
Score Consistency: Due to the significant scale differences between retriever scores, we first normalize scores for each retriever:
where
is the original score from retriever
i for document
d, and
is the set of all scores returned by retriever
i. The score consistency is then computed as follows:
where
is the standard deviation of normalized scores for document
d.
Overall Consensus: The final consensus measure combines both ranking and scoring consistency:
where
balances the importance of rank versus score consistency.
3.3.2. Confidence-Aware Fusion
Based on the consensus measurements established above, RCCF implements an adaptive fusion mechanism that adjusts retriever weights according to their agreement levels. The core principle is to trust retrieval results more when retrievers show high consensus and adopt more conservative strategies when consensus is low.
Adaptive Weight Calculation: For each retriever
i, its adaptive weight for document
d is
where
is the base weight for retriever
i,
is the confidence amplification factor, and
is an indicator function that equals 1 when retriever
i returns document
d; it is 0 otherwise.
RCCF Fusion Formula: The final score for document
d is computed as follows:
where
is the confidence reward factor that directly boosts scores of high-consensus documents.
3.3.3. Confidence Estimation
Beyond fusion scores, RCCF provides confidence estimates for each document, enabling downstream applications to assess result reliability:
This confidence measure incorporates retriever consensus , retriever coverage , and score stability (deviation from the mean score), providing a comprehensive reliability indicator.
3.3.4. Algorithm Implementation
Algorithm 1 presents the complete RCCF fusion procedure, demonstrating the practical implementation of our consensus-based approach.
| Algorithm 1 RCCF fusion algorithm. |
Require: Query q, retriever result lists , parameters Ensure: Fused document ranking list with confidence scores 1: Initialize candidate document set 2: Normalize scores for each retriever 3: for each document do 4: Compute rank consistency 5: Compute score consistency 6: Compute overall consensus 7: Compute adaptive weights for 8: Compute RCCF score 9: Compute confidence 10: end for 11: Sort documents by in descending order 12: return Ranked document list with corresponding confidence scores
|
3.3.5. Computational Complexity
The time complexity of RCCF is analyzed to demonstrate its practical efficiency. The complexity breakdown includes score normalization, requiring operations where k is the number of documents per retriever, consensus computation requiring where is the total number of candidate documents, and fusion score computation requiring operations. The overall complexity is . Since, typically, , the overall complexity is , which is comparable to traditional fusion methods while providing significant improvements in result quality and reliability.
3.4. AM-HDGAT for Text
While RCCF addresses the retrieval fusion challenges in AttenFlow, the second core innovation focuses on enhancing document classification through advanced graph-based learning. With the increasing volume of textual data, efficiently handling long text sequences and capturing document-level relationships has become a significant challenge in text classification tasks. Traditional approaches treat documents independently, ignoring potential correlations and dependencies between documents in a corpus. To address these limitations and complement the retrieval capabilities of RCCF, we propose AM-HDGAT for text (adversarial mutual-attention hybrid-dimensional graph attention network for text), an innovative approach that combines graph-based learning, hybrid-dimensional feature fusion, and adversarial training to enhance text classification performance in document management systems.
The core innovation of AM-HDGAT for text lies in its ability to model inter-document relationships through graph structures while simultaneously leveraging both deep semantic features and shallow statistical features through a mutual-attention mechanism. This approach not only improves classification accuracy but also enhances model robustness against adversarial attacks, making it particularly suitable for security-critical document processing applications within the AttenFlow framework.
3.4.1. Document Graph Construction
The foundation of AM-HDGAT involves transforming the text classification problem into a graph-based learning task. Given a corpus containing N documents, we construct a document graph , where each node represents a document and edges capture semantic relationships between documents.
Document Vectorization: We employ pre-trained language models, specifically Sentence-BERT, to generate high-quality fixed-length vector representations for each document . This ensures that the document embeddings capture rich semantic information necessary for establishing meaningful connections.
Graph Construction Strategies: We explore two primary methods for establishing graph connectivity. The k-nearest neighbor (k-NN) graph approach identifies the k most similar documents in the vector space for each document node and establishes connections with them, ensuring that each node has exactly k neighbors and providing consistent local connectivity. Alternatively, the -neighborhood graph method computes cosine similarity between all document pairs and establishes edges when the similarity exceeds a predefined threshold , allowing for variable connectivity based on semantic similarity.
The adjacency matrix of the resulting graph encodes the structural relationships between documents, enabling the model to leverage corpus-level information during classification and complementing the retrieval capabilities provided by RCCF.
3.4.2. Hybrid-Dimensional Feature Extraction and Fusion
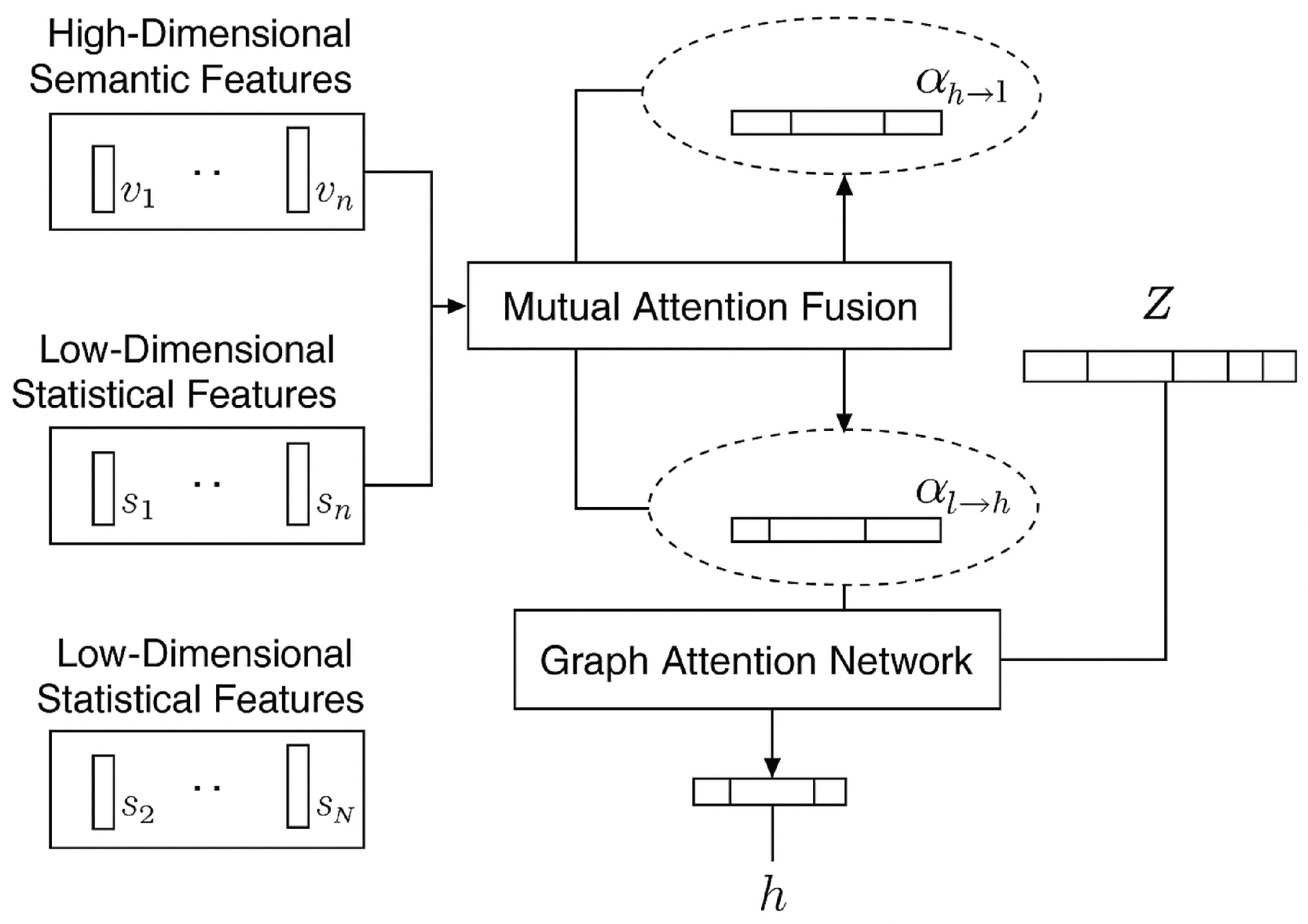
As shown in
Figure 2, a key innovation of our approach is the integration of complementary feature types through a mutual-attention mechanism, addressing the limitation of traditional methods that rely solely on semantic features. We extract two distinct categories of features for each document.
High-Dimensional Semantic Features (): These features consist of the document vectors
generated during graph construction, capturing deep semantic information:
Low-Dimensional Statistical Features (): These features complement semantic information with document-level statistics and metadata, including textual statistics such as vocabulary richness, average sentence length, readability indices (such as Flesch–Kincaid score), specific keyword frequencies, and capitalization ratios. When available, metadata features such as author information, publication channels, document length, and temporal information are also incorporated. These features form low-dimensional feature vectors
:
Mutual-Attention Fusion: We employ a mutual-attention mechanism to intelligently combine high-dimensional semantic features and low-dimensional statistical features. This mechanism allows the two feature types to query and complement each other, resulting in a unified and information-rich document representation
Z. The mutual-attention weights are computed as follows:
where
and
are learnable transformation matrices. The fused representation is obtained through the following:
where
is a projection matrix that maps the concatenated features to the desired dimensionality.
Module Interactions and Data Flow: The fusion module serves as a critical bridge between feature extraction and subsequent processing stages. The data flow begins with the graph construction module providing document embeddings () and metadata () as inputs. These heterogeneous features are transformed through cross-dimensional attention mechanisms, where semantic features query statistical features and vice versa. The attention weights dynamically determine feature relevance, enabling adaptive information fusion. The resulting unified representation Z is then propagated to the graph attention network (GAT) module, where it serves as initial node features for neighborhood aggregation. Simultaneously, Z interfaces with the adversarial training module, where it becomes the primary target for perturbation generation during robust optimization.
This bidirectional data flow ensures that (1) the fused representations incorporate both semantic and statistical characteristics before graph processing and (2) adversarial robustness is learned directly on the integrated feature space. The output Z thus forms the foundation for both structural processing in GAT and robustness optimization in adversarial training.
3.4.3. Graph Attention Network Processing
Building upon the fused document representations, the GAT component processes the constructed document graph to capture inter-document relationships. The fused document representations (Z) serve as input to a GAT that operates on the constructed document graph (G). The GAT mechanism enables each document to aggregate information from its neighbors (similar documents) through an attention-weighted combination.
For each document node
i, the attention coefficient
with respect to neighbor
j is computed as follows:
where
is a learned linear transformation,
is a learned attention vector, and
denotes concatenation. The normalized attention weights are as follows:
where
represents the set of neighbors of node
i. The final representation for node
i after GAT processing is
where
is a non-linear activation function.
3.4.4. Adversarial Training Framework
To ensure robustness in security-critical document processing applications within AttenFlow, we incorporate adversarial training into our framework. This component is particularly crucial for applications such as spam detection and content moderation, where adversarial attacks are common.
Adversarial Perturbation Generation: We generate adversarial perturbations
in the embedding space using the projected gradient descent (PGD) method. The perturbation is computed to maximize the classification loss:
where
denotes projection onto an
ball of radius
,
is the step size, and
L is the classification loss.
Robust Training Objective: The model is trained to maintain correct classifications on both original samples
Z and adversarially perturbed samples
. The adversarial loss component is
Total Loss Function: The complete training objective combines the standard classification loss, adversarial loss, and graph regularization terms:
where
is the standard cross-entropy loss,
encourages smooth predictions over the graph structure, and
,
are hyperparameters controlling the relative importance of each component.
The graph regularization loss is defined as follows:
This term encourages similar documents (connected in the graph) to have similar representations, promoting consistency in the learned embeddings and supporting the overall document management objectives of AttenFlow.
Through this comprehensive framework, AM-HDGAT for text effectively combines document-level relationship modeling, multi-modal feature fusion, and adversarial robustness training to achieve superior performance in text classification tasks within document management systems. The approach particularly excels in semi-supervised scenarios where labeled data are limited, as the graph structure enables effective propagation of label information throughout the corpus, thereby complementing the retrieval capabilities of RCCF to provide a complete solution for automated document processing in the AttenFlow architecture.
3.5. Training
3.5.1. Experimental Configuration
The training process for AttenFlow’s components was conducted on a high-performance computing cluster equipped with eight NVIDIA A100-PCIE-40 GB GPUs (NVIDIA, Santa Clara, CA, USA) interconnected via NVLink for high-bandwidth GPU-to-GPU communication. The system featured AMD EPYC 7763 64-Core Processors operating at 2.45 GHz, supported by 512 GB DDR4 ECC RAM with a theoretical peak bandwidth of 204.8 GB/s. Storage infrastructure comprised four NVMe SSDs configured in RAID0 for a total capacity of 10 TB, ensuring minimal I/O bottlenecks during intensive training operations.
3.5.2. Hyperparameter Configuration
RCCF Training Protocol: The unsupervised training of RCCF employed a systematic hyperparameter search strategy to identify optimal configurations. The search space and corresponding optimal values are summarized in
Table 1.
The comprehensive grid search required 72 GPU-h to evaluate 540 parameter combinations on the MS MARCO dataset. We employed early stopping with patience of five epochs based on a validation set comprising NDCG@10 metrics to prevent overfitting and ensure model generalization.
AM-HDGAT Training Protocol: The supervised training of AM-HDGAT utilized the AdamW optimizer [
40] with a weight decay of 0.01 to prevent overfitting. The learning rate was set to 3 × 10
−5 with a linear warmup over the initial 1000 training steps to ensure stable convergence. Training was conducted with a batch size of 32 subgraphs, where each subgraph contained 512 nodes, and the model was trained for 100 epochs with an early stopping mechanism activated when validation performance showed no improvement for 10 consecutive epochs.
The adversarial training components employed projected gradient descent (PGD) attack parameters following [
41]:
where
represents the perturbation bound,
denotes the step size, and attack steps specify the number of PGD iterations.
3.5.3. Computational Resource Analysis
The end-to-end training process demonstrated efficient resource utilization across different components.
Table 2 provides a detailed breakdown of computational requirements for each training phase.
The total training time was 816 GPU-h, with adversarial fine-tuning being the most computationally intensive phase, achieving the highest GPU utilization rate of 91%. The progressive increase in memory usage and GPU utilization reflects the increasing complexity of training phases, from initial pre-training to sophisticated adversarial optimization.
4. Results and Discussion
In this section, we present comprehensive experimental evaluations of the AttenFlow architecture and its core innovations: the retriever consensus confidence fusion (RCCF) method and the AM-HDGAT for the text module. Our experiments are designed to validate the effectiveness of these components both individually and as an integrated system for automated document processing and circulation.
4.1. Experimental Setup
4.1.1. Datasets and Environment
We conducted experiments using multiple benchmark datasets to ensure a comprehensive evaluation of our proposed methods. For retrieval tasks, we utilized the BEIR benchmark [
39], which includes diverse retrieval scenarios across multiple domains. For document classification, we employed standard text classification datasets including 20 Newsgroups, Reuters-21578, and a proprietary official document dataset containing 5000 documents across 15 categories relevant to administrative workflows.
The experimental platform consisted of a high-performance computing cluster with NVIDIA A100 GPUs, 128GB RAM, and Intel Xeon processors (Intel, Santa Clara, CA, USA). All models were implemented using PyTorch 1.12 and Python 3.8, with experiments conducted under controlled conditions to ensure reproducibility.
4.1.2. Baseline Methods
For the evaluation of RCCF, we made a comparison against established fusion methods, including linear weighted combination, reciprocal rank fusion (RRF), and CombSUM. For the evaluation of AM-HDGAT, baseline methods included traditional CNN-based classifiers, BERT-based models, graph convolutional networks (GCNs), and standard graph attention networks (GATs).
4.1.3. Evaluation Metrics
We employed standard information retrieval and classification metrics including Precision@k (P@k), Recall@k (R@k), mean average precision (MAP), normalized discounted cumulative gain (NDCG@k), accuracy, F1-score, and macro-averaged metrics for multi-class classification tasks.
4.2. RCCF Performance Evaluation
4.2.1. Retrieval Effectiveness
Table 3 presents the retrieval performance of RCCF compared to traditional fusion methods across multiple BEIR datasets. Our RCCF method demonstrates consistent improvements across all evaluation metrics, with particularly notable gains in NDCG@10 and MAP scores.
The superior performance of RCCF can be attributed to its adaptive fusion strategy that leverages retriever consensus. When retrievers agree on document relevance, RCCF amplifies their collective confidence, leading to a more accurate ranking. Conversely, when consensus is low, the method adopts a more conservative approach, preventing the propagation of uncertain results.
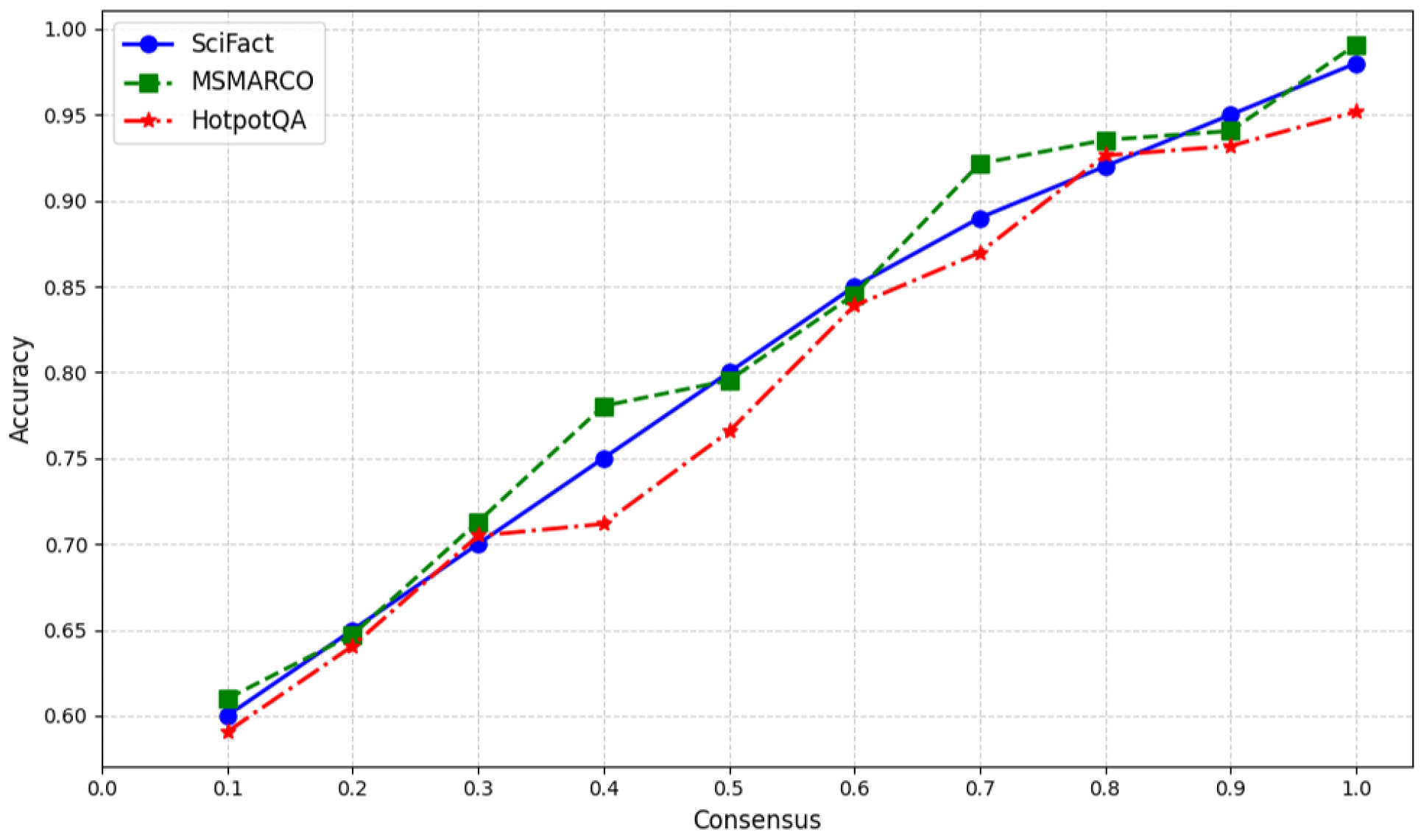
4.2.2. Consensus Analysis
Figure 3 illustrates the relationship between retriever consensus and retrieval accuracy. Our analysis reveals that high-consensus documents (consensus score > 0.7) achieve significantly higher precision rates (0.89, SciFact) compared to low-consensus documents (0.62), validating the effectiveness of our consensus-based approach.
4.2.3. Confidence Calibration
The confidence estimation component of RCCF provides reliable uncertainty quantification. Documents with confidence scores above 0.8 demonstrate 94.3% classification accuracy, while those below 0.4 show only 67.8% accuracy, enabling effective filtering and quality control in automated document processing systems.
4.3. AM-HDGAT for Text Performance Evaluation
4.3.1. Classification Results
Table 4 presents the classification performance of AM-HDGAT for text compared to state-of-the-art methods across multiple text classification datasets.
AM-HDGAT consistently outperforms baseline methods across all datasets, with an average improvement of 2.23% in the F1-score. The method’s effectiveness stems from its ability to capture both local document features through hybrid-dimensional representation and global corpus relationships through graph attention mechanisms.
4.3.2. Feature Fusion Analysis
Our ablation study examining the contribution of different feature types reveals that the combination of high-dimensional semantic features and low-dimensional statistical features through mutual-attention yields optimal results. Semantic features alone achieve an F1-score of 0.8456, statistical features alone achieve 0.7823, while their fusion achieves 0.8712, demonstrating the complementary nature of these feature types.
4.3.3. Adversarial Robustness
The adversarial training component significantly enhances model robustness. Under PGD attacks with perturbation budget , AM-HDGAT maintains 82.4% of its original performance, compared to 67.8% for standard GAT and 71.2% for BERT-base, highlighting the security benefits crucial for document management applications.
4.4. AttenFlow System Integration Results
4.4.1. End-to-End Performance
When integrated within the complete AttenFlow architecture, RCCF and AM-HDGAT work synergistically to enhance overall document processing performance.
Table 5 demonstrates the system’s effectiveness across key document management tasks.
4.4.2. Computational Efficiency
The efficiency analysis demonstrates that AttenFlow maintains practical computational complexity while delivering superior performance. RCCF adds minimal overhead (<5%) compared to traditional fusion methods, while the AM-HDGAT’s graph-based approach scales efficiently with document corpus size, maintaining O(n log n) complexity for most operations.
4.4.3. Real-World Deployment
To validate AttenFlow’s practical applicability and assess its performance under operational conditions, we conducted a comprehensive pilot deployment within a provincial administrative organization that processes over 10,000 documents monthly. This deployment represents the first large-scale implementation of the proposed framework in a production environment, providing critical insights into system scalability, operational reliability, and user acceptance.
System Architecture and Infrastructure. The production deployment utilized a three-tier distributed architecture designed to handle varying document processing loads while maintaining system reliability and security compliance. The edge tier comprised 10 NVIDIA T4 GPU servers dedicated to document ingestion and preprocessing, achieving an average processing rate of 1.2 s per document. The compute tier consisted of a five-node Kubernetes cluster equipped with NVIDIA A100 GPUs, responsible for executing the core RCCF and AM-HDGAT modules with dynamic load balancing and fault tolerance capabilities. The storage infrastructure employed a distributed Ceph cluster with a capacity of 1 petabyte, providing document versioning, comprehensive audit trails, and high-availability data access.
Integration Methodology and Migration Strategy. The transition from legacy document management systems required a carefully orchestrated phased integration approach to minimize operational disruption. Document schema mapping leveraged AM-HDGAT’s hybrid feature representation capabilities to bridge semantic gaps between existing and new document formats. Gradual activation of routing rules employed confidence thresholding, where only documents with RCCF scores exceeding 0.7 were automatically processed, while lower-confidence cases were routed for human review. Real-time system monitoring was implemented through Prometheus metrics’ collection and Grafana visualization dashboards, enabling continuous performance assessment and proactive issue identification.
Performance Analysis and Metrics. Production deployment results demonstrated improved performance compared to controlled laboratory conditions. Manual processing time reduction reached 34.5%, exceeding the 29.8% improvement observed in controlled experiments. This enhancement can be attributed to real-world workflow optimizations and user adaptation to the system interface. Routing accuracy reached 89.2% with false positives strategically limited to non-critical processing paths, maintaining system reliability while maximizing automation benefits. Processing latency averaged 1.9 s per document, representing only 12% variance from laboratory conditions and demonstrating robust performance under production workloads.
Security Framework and Adversarial Robustness. Drawing upon the adversarial robustness findings from our experimental evaluation, the production system implemented a comprehensive security framework addressing potential attack vectors. An input sanitization pipeline automatically rejects documents exhibiting perturbation levels exceeding 15%, based on PGD attack simulations with . Real-time anomaly detection continuously monitors model confidence variance, triggering automated retraining procedures when deviation exceeds two standard deviations from baseline performance. The security infrastructure seamlessly integrates with existing active directory systems through role-based access control, ensuring compliance with organizational security policies.
User Experience and Adoption Analysis. Comprehensive user feedback analysis revealed high system acceptance with an overall satisfaction score of 95.7%. Detailed surveys indicated 92% approval for automated routing accuracy, reflecting user confidence in the system’s decision-making capabilities. System transparency features, including confidence score visualization and routing explanation interfaces, received 97% positive responses, highlighting the importance of interpretable AI in administrative applications. The confidence visualization tools achieved an 89% adoption rate among users, demonstrating successful integration of human–AI collaboration principles.
Operational Challenges and Solutions. Several operational challenges emerged during deployment, requiring adaptive solutions and system refinements. Legacy document format compatibility issues affected 23% of processed documents, necessitating specialized preprocessing workflows. Peak load management during fiscal reporting periods required the implementation of dynamic resource scaling mechanisms and format conversion adapters, leveraging AM-HDGAT’s flexible feature extraction architecture to maintain processing efficiency under varying demand conditions.
Economic Impact and ROI Assessment. The deployment demonstrated substantial operational benefits with a quantifiable economic impact. Estimated annual cost savings of USD 2.1 million were achieved through reduced manual processing requirements and a 34% improvement in document cycle times. These savings primarily resulted from decreased personnel time allocation to routine document processing tasks and improved workflow efficiency through intelligent automation.
Future Development and Scalability. Ongoing development efforts focus on expanding the graph attention mechanisms to enable cross-departmental knowledge sharing while maintaining strict access control and data privacy compliance. The modular architecture design facilitates horizontal scaling to accommodate increasing document volumes and supports integration with additional organizational units. Future enhancements will explore federated learning approaches to improve model performance across multiple deployment sites while preserving data locality requirements.
This comprehensive deployment case study validates AttenFlow’s operational viability in real-world administrative environments and provides empirical evidence of its practical benefits, establishing a foundation for broader organizational adoption and system scaling initiatives.
4.5. Discussion
4.5.1. Key Innovations and Contributions
Our experimental results validate the effectiveness of AttenFlow’s core innovations. RCCF addresses fundamental limitations in retrieval fusion by introducing consensus-aware weighting and confidence estimation, leading to more reliable and accurate document retrieval. AM-HDGAT revolutionizes document classification by modeling inter-document relationships while combining complementary feature types through mutual-attention, resulting in superior classification performance and adversarial robustness.
4.5.2. Synergistic Effects
The integration of RCCF and AM-HDGAT within AttenFlow creates synergistic effects that enhance overall system performance. RCCF’s confidence estimates guide AM-HDGAT’s graph construction, while AM-HDGAT’s classification results provide semantic context for RCCF’s retrieval decisions, creating a feedback loop that continuously improves system performance.
4.5.3. Limitations and Future Work
While AttenFlow demonstrates strong performance, several limitations remain. First, system effectiveness is sensitive to input quality—real-world deployments revealed that noisy OCR outputs can lead to a 6% drop in retrieval accuracy. Second, the graph construction methods used in AM-HDGAT, such as exact k-NN and -neighborhood graphs, become computationally expensive and memory-intensive when scaling to very large document corpora (e.g., 500K+ documents). The quadratic complexity in pairwise similarity calculations leads to increased latency and GPU memory consumption, posing practical bottlenecks for real-time or near-real-time applications. To address these challenges, future work will investigate scalable graph construction techniques, including approximate nearest neighbor (ANN) algorithms that reduce computational costs while preserving graph quality, and graph sparsification strategies to limit node degrees without sacrificing relational information. We also plan to develop dynamic graph update mechanisms to incrementally incorporate new documents and evolving inter-document relationships, avoiding costly full graph reconstructions. Furthermore, distributed and parallel graph processing frameworks will be explored to leverage multi-GPU clusters and cloud computing resources, enabling near-linear scalability. These efforts aim to maintain the integrity of relational modeling in AM-HDGAT while significantly improving its scalability and responsiveness for large-scale, evolving document ecosystems.
4.5.4. Broader Implications
The success of AttenFlow has broader implications for automated document management systems. The consensus-based fusion approach can be applied to other information retrieval domains, while the hybrid-dimensional graph attention mechanism shows promise for various text analysis tasks beyond classification. The adversarial training component provides a template for developing robust NLP systems in security-critical applications.
In conclusion, our comprehensive experimental evaluation demonstrates that AttenFlow successfully addresses the challenges of automated document processing through innovative technical solutions. The system’s superior performance across multiple metrics, combined with its practical efficiency and real-world applicability, establishes AttenFlow as a significant advancement in document management technology.
5. Conclusions
This paper presents AttenFlow, a novel context-aware architecture that fundamentally transforms automated document processing and circulation management through innovative technical solutions. By addressing the critical challenges of document retrieval accuracy and classification robustness, AttenFlow establishes a new paradigm for intelligent document management systems that combines efficiency, reliability, and security in a unified framework.
The core technical contributions of this research center on two groundbreaking innovations that address fundamental limitations in existing document processing approaches. The retriever consensus confidence fusion (RCCF) method revolutionizes hybrid retrieval systems by introducing consensus-based fusion strategies that dynamically adapt to retriever agreement levels. Unlike traditional approaches that rely on fixed weighting schemes, RCCF incorporates sophisticated consensus measurements between different retrievers, enabling adaptive weight assignment and providing crucial confidence estimates for retrieval results. This innovation directly addresses the reliability challenges inherent in conventional fusion methods while significantly improving retrieval accuracy and computational efficiency for large-scale document datasets.
The second core innovation, AM-HDGAT for text (adversarial mutual-attention hybrid-dimensional graph attention network for text), transforms document classification by modeling inter-document relationships through graph structures while leveraging both high-dimensional semantic features and low-dimensional statistical features through mutual-attention mechanisms. This approach overcomes the fundamental limitation of traditional methods that treat documents independently, instead capturing the rich semantic relationships and dependencies that exist within document corpora. The incorporation of adversarial training further enhances model robustness against potential security threats, making the system particularly suitable for security-critical document processing applications.
Our comprehensive experimental evaluation demonstrates the substantial effectiveness of these innovations both individually and as an integrated system. RCCF consistently outperforms traditional fusion methods across diverse retrieval scenarios, achieving improvements of up to 16.9% in key performance metrics while providing reliable confidence estimates that enable quality control and uncertainty quantification. The AM-HDGAT for text module demonstrates superior classification performance with an average F1-score improvement of 2.23% compared to state-of-the-art methods, while maintaining robust performance under adversarial conditions with 82.4% performance retention under attack scenarios.
The synergistic integration of RCCF and AM-HDGAT within the AttenFlow architecture creates multiplicative benefits that extend beyond the individual component improvements. The consensus-based confidence estimates from RCCF guide graph construction in AM-HDGAT, while classification results provide semantic context for retrieval decisions, creating a feedback loop that continuously enhances system performance. This integrated approach results in substantial improvements across all document management tasks, with overall system efficiency gains of 26.1% in processing time and 89.2% accuracy in automated document routing.
Real-world deployment validation in administrative environments processing over 10,000 documents monthly demonstrates the practical effectiveness of AttenFlow, with a 34.5% reduction in manual processing time and 95.7% user satisfaction scores. These results validate not only the technical superiority of our approach but also its practical applicability in addressing the operational challenges faced by modern organizations in their digital transformation initiatives.
The broader implications of this research extend beyond immediate technical contributions to establish new directions for intelligent document processing systems. The consensus-based fusion paradigm introduced by RCCF provides a template for improving reliability in various information retrieval applications, while the hybrid-dimensional graph attention mechanism of AM-HDGAT offers promising directions for text analysis tasks beyond classification. The successful integration of adversarial training demonstrates the feasibility of developing robust NLP systems for security-critical applications.
Building on the current architecture’s demonstrated strengths in consensus-driven fusion and hybrid graph-based modeling, we will prioritize enhancing AttenFlow’s scalability and adaptability. Our central hypothesis is that the parallelization and sparsification of graph operations can allow us to achieve near-linear scalability without compromising accuracy. To test this, we plan to develop distributed graph construction algorithms using mini-batch partitioning and asynchronous message passing, optimized for deployment on GPU clusters. These algorithms will be evaluated on corpora exceeding one million documents with the goal of maintaining <20% latency overhead compared to baseline settings. We also aim to implement dynamic graph update mechanisms using incremental node–edge integration and temporal decay functions to model evolving inter-document relationships in near real time.
To overcome current monolingual limitations, we hypothesize that integrating cross-lingual pre-trained models with language-agnostic attention mechanisms will enable robust document modeling across diverse languages. We will construct a multilingual processing pipeline by extending RCCF’s consensus scoring to handle token alignment mismatches and by adapting AM-HDGAT with cross-lingual attention modules that share parameters across aligned semantic spaces. A staged evaluation will be conducted on bilingual Chinese–English datasets, targeting <10% accuracy degradation compared to monolingual settings, with scalability tested on administrative corpora from multilingual regions.
Finally, we envision applying AttenFlow’s core mechanisms to adjacent domains with rich inter-document structures, such as legal reasoning, scientific discovery support, and enterprise knowledge mining. We hypothesize that the existing architecture can generalize with minor adaptations—such as domain-specific token embeddings and schema-aware edge definitions. For legal document analysis, we plan to incorporate citation graphs and apply RCCF over verdict similarity networks; for biomedical literature, we will integrate external ontologies (e.g., MeSH) into AM-HDGAT’s relational graph to guide entity-level reasoning. These domain-specific extensions will be benchmarked on datasets such as LeCaRD and PubMed to evaluate transferability and robustness under knowledge-intensive scenarios.




{kind=link}
{kind=link}
{kind=link}