1. Introduction
Deep Learning (DL) [
1] has enabled significant and rapid progress in signal analysis and applications such as speech recognition [
2], natural language processing [
3], and diagnostic support [
4,
5]. However, building a deep learning model is increasingly becoming an expensive process that requires (i) large amounts of data; (ii) substantial computational resources (such as GPUs); (iii) expertise from DL specialists to carefully define the network topology and correctly set training hyperparameters (such as learning rate, batch size, weight decay, etc.); and (iv) domain experts with specialized knowledge (sometimes, these experts are very rare, as in the medical field). Consequently, the illegal copying and redistribution of such models represents a significant financial loss for their creators.
Watermarking has been proposed to protect the ownership of deep learning models. It consists of inserting a message (a watermark) into a host document by imperceptibly modifying some of its characteristics. For example, image watermarking [
6,
7,
8,
9,
10,
11] is based on slight modifications (or modulations) of pixel values to encode the message. This message can then help verify the origin/destination of the document it protects in the context of copyright protection or data leak prevention [
12,
13]. DL model watermarking relies on the same principles while taking into account the specific features and operating constraints of neural networks. A DL model differs from a multimedia document in many fundamental ways.
Problem definition: Designing an effective and efficient DNN watermarking scheme must meet the following six key criteria [
14,
15,
16,
17,
18]:
Fidelity—the performance of the model should be well preserved after watermarking;
Integrity—the watermarking scheme’s ability to produce minimal false alarms and ensure that the watermarked model can be uniquely identified using the appropriate watermarking key;
Robustness—the watermark cannot be easily removed when the model is attacked;
Security—the watermark cannot be easily detected by malicious attackers;
Capacity—the scheme’s ability to effectively embed an amount of data (payload—size of the watermark) into the protected model;
Efficiency—the computation cost of watermark embedding and extraction must be kept reasonably low.
In practice, most existing schemes achieve only a partial compromise between these criteria. For instance, while the watermark should not degrade the model performance, it must simultaneously resist to attacks aimed at detecting or removing it. Among these attacks, the most common are the following:
The pruning attack (PA), where model weights whose absolute values are below a threshold are set to zero;
The fine-tuning attack (FTA), which retrains and updates the model without decreasing its accuracy;
The overwriting attack (OWA), where the attacker embeds their own watermark to suppress the original one;
The Wang and Kerschbaum attack (WKA), which analyzes the weight distribution of the watermarked model to detect watermark presence;
The Property Inference Attack (PIA), which trains a discriminator capable of differentiating watermarked from non-watermarked models by analyzing their statistical properties.
Note that removal attacks are considered effective and efficient only if the watermark is completely removed while maintaining high test accuracy and requiring significantly fewer computational resources than retraining a model from scratch. Currently, the literature lacks both a formal unified definition of white-box watermarking schemes and a watermarking method that simultaneously satisfies all the requirements mentioned above. To address these gaps, we first present a formal unified framework for white-box watermarking algorithms. We then propose DICTION, a novel, dynamic white-box algorithm that overcomes the limitations of existing methods. In particular, we propose using a neural network following a generative adversarial-based strategy to map activation maps of the target model to the watermark space, rather than using a static projection matrix, as in DeepSigns.
To embed a watermark
b in a target model, DICTION first considers the initial portion of the target model up to layer
l as a generative adversarial network (GAN) generator [
19] and then trains a projection neural network (acting as a GAN discriminator) concurrently with the generator model. This joint training ensures that the trigger set activation maps of the watermarked model are mapped to the desired watermark
b, while those of the non-watermarked model (i.e., the original/initial one) are mapped to random watermarks. To detect the watermark, it is sufficient to use the trigger set samples as model input and verify that the projection neural network outputs the watermark from the corresponding activation maps.
Using a neural network for mapping activation-maps-to-watermarking space, significantly expands the ability to embed robust watermarks while increasing the capacity. Additionally, our projection neural network can be trained either while embedding the watermark into a pretrained model or during initial training, whereas DeepSigns requires a trained target model. Another key innovation of our proposal is the use of a trigger set composed of samples from a latent space defined by its mean and standard deviation. DICTION can insert watermarks into the activation maps of a single layer or a combination of multiple layers. The concatenation of these activation maps forms a tensor where each channel represents the output from a hidden layer of the model. This strategy propagates the watermark across all model layers, better preserving model accuracy and avoiding potential misclassification of real images, as observed in DeepSigns.
This approach also simplifies detection, as one only needs to generate samples from the latent space to constitute the trigger set. DICTION is thus independent of selecting a set of real samples (e.g., images) as a trigger set. Moreover, very few parameters need to be stored (only the mean and standard deviation of the latent distribution). In some cases, model accuracy is even improved because our watermarking proposal acts as a regularization term. As we demonstrate, our proposal is highly resistant to all the attacks listed previously (PA, FTA, OWA, WKA, and PIA) and outperforms the DeepSigns white-box dynamic watermarking scheme in terms of both watermark robustness and watermarked model accuracy.
The rest of this paper is organized as follows.
Section 2 presents the background and related work.
Section 3 introduces our unified white-box watermarking framework that encompasses the most recent static and dynamic schemes, illustrating their advantages and weaknesses through theoretical unification.
Section 4 presents DICTION, our novel, dynamic white-box watermarking scheme that generalizes DeepSigns with significantly improved performance.
Section 5 provides the experimental results and a comparative evaluation of our scheme against state-of-the-art solutions.
Section 6 discusses the limitations and future work, while
Section 7 concludes this paper.
4. DICTION: Proposed Methodology
4.1. Architectural Overview
DICTION is a novel, dynamic white-box watermarking scheme for DNN that inserts watermarks into the activation maps of one or multiple concatenated layers of the target model. Its originality lies in two key innovations.
First, to ensure the fidelity requirement (i.e., preserving the target model’s performance while embedding the watermark), DICTION uses a trigger set from a distribution different from the training set. Our key insight is that if the trigger set is out-of-distribution from the training data, such as data from a latent space defined as a Gaussian distribution similar to GAN generators [
19] and Variational AutoEncoder (VAE) decoders [
63], we can better preserve the probability density function of the activation maps of the training samples. This approach consequently maintains the accuracy of the target model while increasing watermark robustness.
Second, to achieve an optimal trade-off between insertion capacity and watermark robustness against PA, FTA, OWA, WKA, and PIA attacks, the projection function of DICTION is defined as a DNN that learns to map the activations of the target model to a watermark b and the activations of the non-watermarked model to a random watermark using the trigger set. This projection function is analogous to the discriminator of a GAN model trained to distinguish (for samples in the latent space) the activation maps produced by a watermarked model from those of a non-watermarked model.
DICTION workflow: The workflow of DICTION is illustrated in
Figure 2. In each training round, it follows these steps to produce a watermarked model:
Latent space generation: Generate a trigger set image LS of the same size as the training set images from a latent space following a Gaussian distribution with mean and standard deviation .
Activation map extraction: Feed LS to both the original (non-watermarked) model M and the watermarked model under training to compute, for a given layer l, the activation maps and , where are the weights of and w are those of M, respectively. Note that at the first round, is initialized with the parameters of M.
Projection model training: Use
and
to train the projection model
by assigning the following labels: the watermark
b for the activation maps of
and a random watermark
for those of
M. This dual-label training prevents
from becoming a trivial function that maps any input to
b (addressing the integrity requirement described in
Section 1).
Model training: To ensure fidelity requirements, train the target model on the training set at each round. The original model M remains frozen during the watermarking process.
These steps are repeated until the bit error rate (BER) between the extracted watermark from and the embedded watermark b is equal to zero while maintaining good accuracy for the target model .
GAN-like training strategy: Our embedding process is analogous to GAN training, where the projection model acts as a discriminator that learns to classify the activation maps of the original model M as and those of the target model as b. The first l layers of the target model function as the generator, trained to produce appropriate activation maps for the discriminator while maintaining main task performance (i.e., classification). The original model M is not trained during the embedding process, and its activation maps are fed to the projection model to prevent trivial solutions. The watermarked model and the projection model are trained simultaneously to achieve fast convergence.
4.2. Formal Definition of DICTION
We formulate our scheme following the unified framework presented in
Section 3.1 for state-of-the-art white-box schemes through its embedding regularization term
. Consider a trigger set defined as a latent space from a normal distribution
with the mean
and standard deviation
. From this perspective, the feature extraction function for a given target model
M is
where
is the secret extraction key composed of the following:
l (the index of the layer to be watermarked),
Z (a permutation matrix used to secretly select a subset of features from
and order them), and LS (a sample from the latent space, i.e., an image whose pixel values follow a normal distribution).
As illustrated in
Figure 2, our projection function
is a DNN that takes as input the extracted features
and outputs the watermark
b. The input and output dimensions are equal to the size of the extracted features
and the watermark size
, respectively. To embed
b in the secretly selected layer
l of the target model, our watermarking regularization term is defined as
where
is the watermarked version of
M,
is a random watermark, and
is a watermark distance measure. The random watermark
ensures that
projects the desired watermark
b only for
. Note that
depends on the watermark type: for binary sequences, cross-entropy is appropriate, while for images, pixel mean squared error is more relevant. Our global embedding loss is
where
adjusts the trade-off between the original target model loss term
and the watermarking regularization term
, and
is the training set. Importantly,
depends only on the trigger set, not on
.
Parameter updates: The parameters of
are updated according to the following regularization term from
E:
This ensures that the parameters of are updated to maintain the accuracy of the original target model while minimizing the distance between the projection of the activation maps and the watermark b.
Note that the projection model
serves as a discriminator that associates the projection of the trigger set activation maps of
to
b and those of
M to
. The shared term
in Equations (
19) and (
20) allows for an optimal compromise between the parameters
and
, ensuring that the activation maps projection is close to
b without impacting accuracy and remains unique for
. In practice,
and
are trained simultaneously for fast convergence. The parameters of
are updated based on
Watermark detection: The watermark detection process works as follows. Given a suspicious model
, and using the feature extraction key
, the projection key
, and the latent space
, the watermark extraction is given as
where HT is the Hard Thresholding operator at 0.5. In contrast to DeepSigns, which uses a fixed subset of the training set (see Equation (
14)), DICTION extraction can sample an unlimited number of latent space images. This approach makes the watermarked model and projection function extremely resistant to attacks, such as fine-tuning, pruning, and overwriting, because they overfit to the latent space rather than a few specific images.
Advantages of latent space triggers: The use of latent space triggers provides several benefits:
Storage efficiency: Reduces storage complexity, as only latent space parameters (mean and standard deviation) need to be recorded, rather than storing trigger images;
Distribution preservation: Preserves the distribution of the weights and activation maps of the watermarked model.
Computational simplicity: Avoid the need for additional DNN like in the RIGA scheme, which requires complex hyperparameter tuning and increased computational complexity.
4.3. Projection Model Design
The projection function
is a DNN with an input dimension
and an output dimension
(watermark size). In this work, we employ a two-layer, fully-connected network:
where
is the sigmoid function for binary watermark output,
are weight matrices, and
are bias vectors.
Architecture Details:
Hidden layer: A total of 256 neurons with ReLU activation, and a dropout rate of 0.3;
Learning rates: A total of for and for ;
Alternative architectures: ResNet-style or CNN-based architectures can be used for applications requiring higher capacity.
Joint training strategy: The projection model and watermarked model are trained jointly through alternating optimization:
This alternating optimization ensures that both the projection function learns to discriminate correctly between watermarked and non-watermarked activation maps, while the watermarked model maintains its primary task performance and embeds the watermark effectively.
5. Experimental Results
We evaluated DICTION in terms of its (1) impact on model performance (fidelity); (2) robustness against three watermark removal techniques (overwriting, fine-tuning, and weight pruning); and (3) resilience to watermark detection attacks (security). For all attacks, we considered the most challenging threat model, assuming that the attacker has access to or knowledge of the training data and the watermarked layer.
5.1. Datasets and Models
Our experiments were conducted on two well-known public benchmark image datasets for image classification: CIFAR-10 [
64] and MNIST [
22]. We utilized four distinct DNN architectures as target models: three previously experimented on with DeepSigns [
51] (MLP, CNN, and ResNet-18) and one with RIGA [
57] (LeNet).
Table 2 summarizes their topologies, training epochs, and corresponding baseline accuracies.
Throughout the experimental section, we use the following abbreviations for our four benchmark configurations:
BM1: MLP architecture on the MNIST dataset,
BM2: CNN architecture on the CIFAR-10 dataset,
BM3: ResNet-18 architecture on the CIFAR-10 dataset, and
BM4: LeNet architecture on the MNIST dataset. The implementations of DeepSigns [
51], ResEncrypt [
55], and DICTION, along with their configurations, are publicly available at
https://github.com/Bellafqira/DICTION, accessed on 15 June 2025.
5.2. Experimental Configuration
In all experiments, we embedded a 256-bit watermark
b in the second-to-last layer of the target model, following the approach used in DeepSigns. This watermark could represent, for example, the hash of the model owner’s identifier generated using the SHA-256 hash function. We used the bit error rate (BER) to measure the discrepancy between the original and extracted watermarks:
where
is the extracted watermark,
I is the indicator function returning 1 if the condition is true and 0 otherwise, and
l is the watermark size (
). A BER close to 0 indicates identical watermarks, while a BER close to 0.5 indicates uncorrelated watermarks.
DICTION configuration: We used a simple two-layer fully connected neural network as the architecture for the DICTION projection function
in our experiments. The normal distribution
serves as a latent space to embed the watermark, and the selection matrix
Z serves as the identity. We used the Adam optimizer with a learning rate of
, a batch size of 100, and a weight decay of
to train the DICTION projection function. We set
in Equation (
18). We used 10 epochs for each benchmark to embed the watermark.
Baseline method configurations: Regarding the implementation of DeepSigns, we used the second-to-last layer for embedding, as in its original version. and were set to 0.01 to obtain a BER equal to zero. The number of watermarked classes s equals 2, N was 128 (i.e., a watermark of 256 bits), and the watermark projection matrix A was generated based on the standard normal distribution . The trigger set corresponds to 1% of the training data.
For ResEncrypt, we used two-layer, fully connected neural networks as the architecture for MappingNet. We recall that the role of MappingNet is to expand the size of the selected weights to the watermark. In our implementation, we used an expansion factor equal to 2 for LeNet and 1 for the other benchmarks.
5.3. Fidelity Analysis
By definition, watermarked model accuracy should not be degraded compared to the target model.
Table 3 presents the accuracy of watermarked models after embedding a 256-bit watermark. The results show that the watermarked model accuracies are very close to those of the non-watermarked models for all three methods (DeepSigns, ResEncrypt, and DICTION), indicating successful optimization of both model accuracy and watermark embedding (minimizing the watermark loss term
, as discussed in
Section 4). In particular, DICTION achieves the best accuracy preservation across all benchmarks.
5.4. Robustness Evaluation
We evaluated our scheme’s robustness against the three contemporary removal attacks discussed in
Section 1.
Pruning attack: We employed the pruning approach proposed by Han et al. [
66] to compress watermarked models. For each layer, this method sets the
of the weights with the lowest absolute values to zero.
Figure 3 illustrates the impact of pruning on watermark extraction/detection and model accuracy for different values of
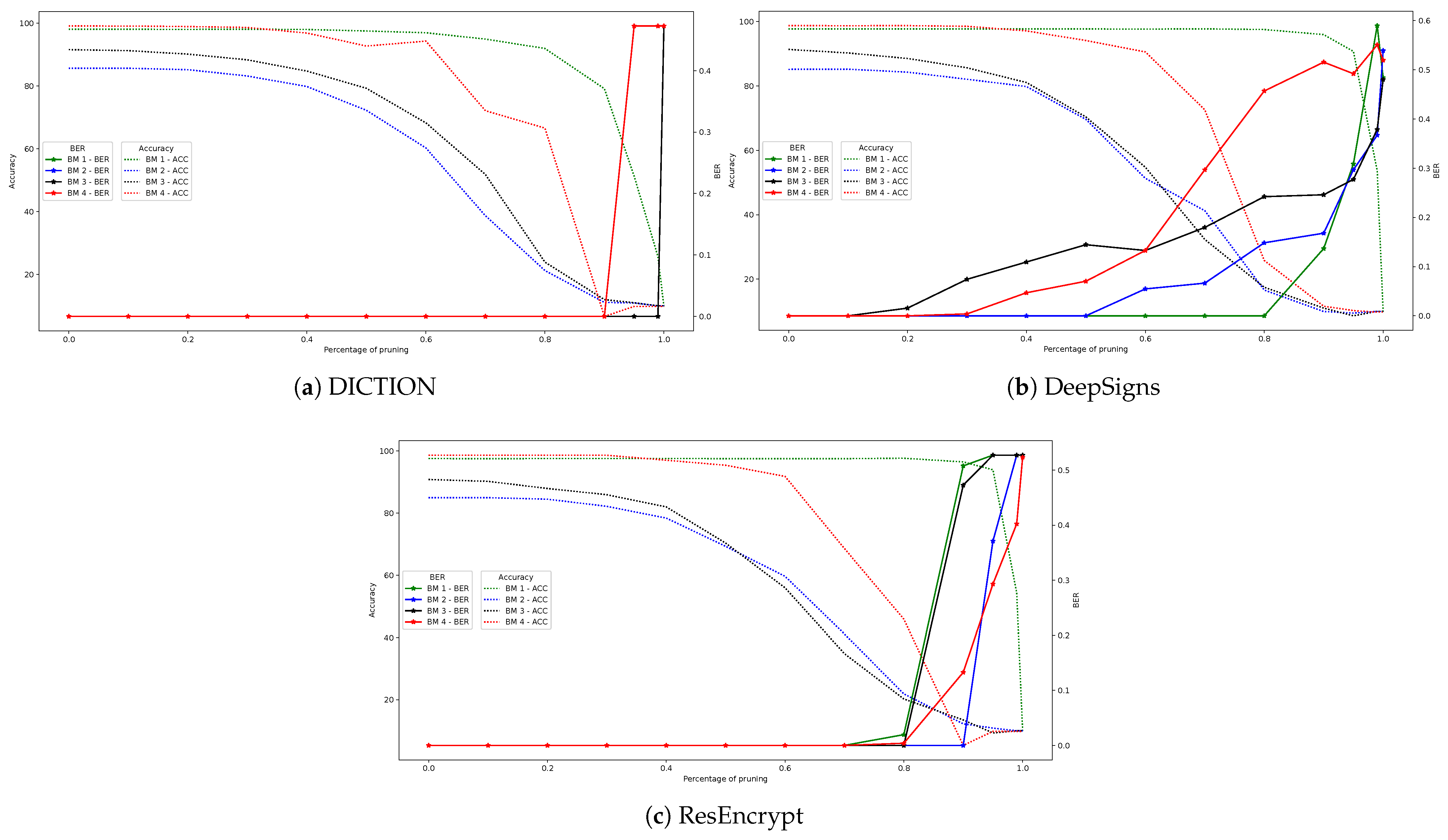
. DICTION demonstrates superior robustness, tolerating up to 90-95% pruning across all benchmark networks, compared to 80% for ResEncrypt. DeepSigns shows increased vulnerability when a 256-bit watermark is inserted. Importantly, when pruning achieves substantial BER values, the attacked watermarked model suffers significant accuracy loss compared to the baseline, indicating that watermark removal comes at the cost of model performance degradation.
Fine-tuning attack: Fine-tuning represents another transformation attack that adversaries might use to remove watermarks. In its most effective implementation, the watermarked model is fine-tuned using original training data and the target model’s loss function (conventional cross-entropy in our case), without exploiting watermarking loss functions . Fine-tuning deep learning models causes convergence to different local minima that may not be equivalent to the original in terms of prediction accuracy.
Our fine-tuning attack protocol multiplies the last training learning rate by a factor of 10, then divides it by 10 after 20 epochs, allowing the model to explore new local minima.
Table 4 summarizes the impact of fine-tuning on watermark detection rates (expressed as BER) for all benchmark models. DICTION successfully detects watermarks even after extensive fine-tuning, unlike DeepSigns or ResEncrypt. The poor performance of ResEncrypt on BM4 can be attributed to the small number of parameters in the watermarked layer, while the limited capacity of DeepSigns makes 256-bit watermark insertion vulnerable to fine-tuning attacks.
Overwriting attack: Assuming that the attacker knows the watermarking technique, they may attempt to damage the original watermark by embedding a new watermark in the watermarked model. In practice, attackers lack knowledge about watermarked layer locations. However, considering the worst-case scenario, we assume that the attacker knows the watermark location but not the original watermark or projection function. To perform the overwriting attack, the attacker follows the protocol described in
Section 4 to embed a new watermark of the same size (256 bits) or larger size (512 bits) using different or identical latent spaces.
Table 5 presents the results against this attack for all four benchmarks. DICTION demonstrates robustness against overwriting attacks and successfully detects the original embedded watermark in overwritten models, while the DeepSigns and ResEncrypt watermarks are perturbed and sometimes completely erased (achieving a BER close to 50%), especially with shallower models such as BM1 and BM4.
5.5. Security Analysis (Watermark Detection Attacks)
We tested all schemes against the attack proposed by Wang et al. [
56] and Property Inference Attack (PIA). Watermark embedding should not leave noticeable changes in the probability distribution of the watermarked model.
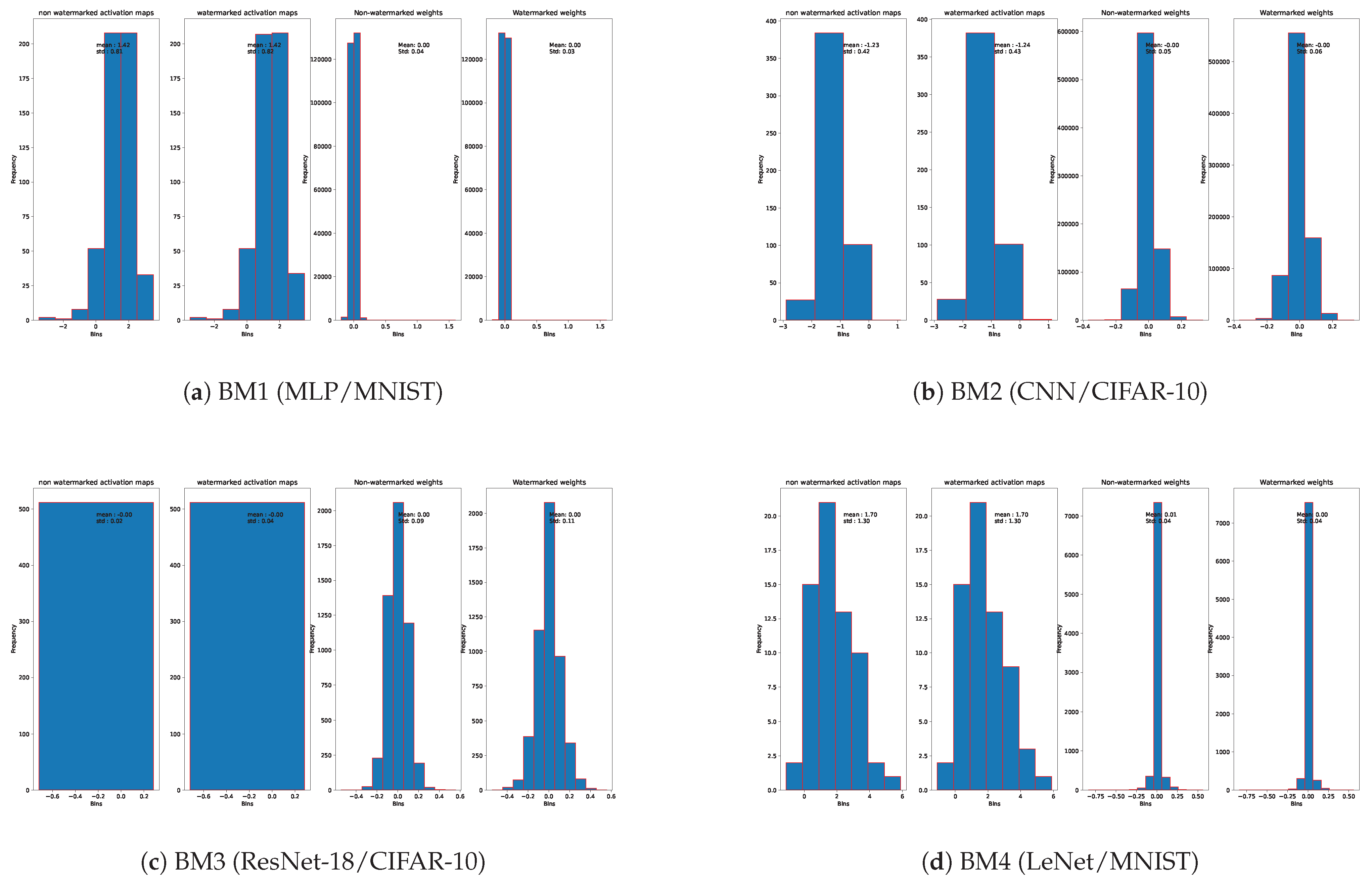
Figure 4 illustrates histograms of activation maps from watermarked and non-watermarked models. DICTION preserves the model’s distribution while robustly embedding the watermark. The range of activation maps is not deterministic across different models and cannot be used by malicious users to detect watermark existence.
Table 6 provides the mean and standard deviation of the parameter distributions and activation maps of the watermarked layer for all watermarking schemes. DICTION minimally disturbs the distribution of model parameters across all four benchmarks, demonstrating superior security properties.
Property Inference Attack (PIA): We evaluated PIA with a watermark detector trained on multiple watermarked and non-watermarked models. We assumed the worst-case scenario where the attacker knows the training data, the exact model architecture of , and the feature extraction key. While this threat model is overly strong, we use it to demonstrate our watermark scheme’s effectiveness.
For the PIA evaluation, we trained 700 watermarked and 700 non-watermarked LeNet models on MNIST with different keys, plus 100 models of each type as test sets. We tested PIA only on LeNet due to the attack’s high complexity, requiring the training and watermarking of 800 models. The detector was trained on watermarking features labeled according to the model’s watermarking status. All generated models achieved good accuracy with correctly embedded watermarks. The detector achieved only 60% accuracy on training data and around 50% on testing after 50 epochs, equivalent to random guessing. This demonstrates the resistance of DICTION to property inference attacks.
5.6. Integrity and Efficiency Analysis
Integrity: The integrity requirement refers to the watermarking scheme’s ability to minimize false alarms. DICTION achieves this through its generative adversarial network (GAN) strategy. We trained the projection model to map the activation maps of the watermarked target model to the intended watermark and those of the original model M to a random watermark . This approach enables DICTION to effectively meet integrity requirements.
Computational efficiency: We analyzed the overhead incurred by the watermark-embedding process in terms of computational and communication complexities. DICTION introduces no communication overhead for watermark embedding since the process is conducted locally by the model owner. The additional computational cost depends on the target model topology , projection model , and the number of epochs required for watermark embedding while maintaining high accuracy.
Our experiments show that 30 epochs are sufficient for
convergence with satisfactory target model accuracy. The projection model topology is modest compared to the target model, enabling efficient watermark embedding.
Table 7 provides computation times for the model training and watermarking processes. DICTION incurs reasonable overhead, with a maximum of 30 epochs for all benchmarks, suggesting high efficiency.
Complexity comparison: Our embedding complexity remains higher than the Uchida [
45] and DeepSigns [
51] methods because their projection functions are based solely on secret matrix multiplication. However, our method has similar complexity to ResEncrypt [
55], as both train an additional model (
and MappingNet, respectively), which is less expensive than RIGA [
57] since we do not require a third model to preserve weight distribution.
6. Discussion and Limitations
In this section, we discuss the properties, strengths, and limitations of DICTION, providing a comprehensive analysis of our proposed methodology.
6.1. DICTION Parameterization and Flexibility
The DICTION scheme depends on several key parameters, particularly the layers selected for calculating activation maps and the architecture of the
projection function. In
Table 8, we varied all these parameters for BM3 (ResNet-18/CIFAR-10), which contains both convolutional and fully connected layers. The results demonstrate that regardless of the watermarked layer or the architecture of the
model, our watermark resists all evaluated attacks, achieving zero BER across fine-tuning, overwriting, and pruning scenarios. This flexibility makes DICTION adaptable to various network architectures and deployment requirements.
6.2. Trigger Set Generation Strategies
While trigger sets are predominantly used in black-box watermarking where verifiers lack access to model parameters. Various methods have been proposed for trigger set generation in the literature, particularly for out-of-distribution scenarios and could be used in this work as well:
Random database selection: Images chosen randomly from public databases or images with added patterns [
30,
67,
68] (e.g., company logo).
Diffusion-based generation: As demonstrated in [
69] for image watermarking, where trigger images begin as noise (similar to DICTION) with patterns added to their Fourier transform domain.
Cryptographic primitives: Methods like [
70] that generate random images and labels serving as seeds for trigger set generation using a customized hash function.
The latent space approach of DICTION eliminates the need for storing specific trigger images while providing unlimited trigger generation capability, representing a significant advancement over traditional methods.
6.3. Watermark Generation and Encoding
Watermarks in DICTION can be either randomly generated or derived from meaningful messages (e.g., model owner and receiver identifiers). When the identifier’s encoding space does not match the watermark space, cryptographic hashing, such as HMAC [
10], serves as an effective solution. An interesting enhancement involves including a frozen part of the original model in the hash calculation, creating a watermark that attests to both the user’s identifier and the link between the original and watermarked models, and providing additional authenticity verification.
6.4. Multi-Layer Activation Map Processing
DICTION supports concatenating activation maps from multiple layers to create comprehensive tensors containing information from selected layers, which are then processed by
. This strategy captures information encoded across all model layers but increases the computational complexity of
.
Table 8 demonstrates that DICTION with a three-hidden-layer
using ReLU activation functions achieves zero BER against all attacks, confirming the method’s robustness across different architectural configurations.
The projection model architecture can be adapted to various designs, such as ResNet-50 or VGG-16, by modifying the final layer to match the size of the binary watermark. Moreover, if the watermark is an image or text, the projection function could employ a diffusion model [
69] or an NLP model, such as BERT or GPT, respectively. Nevertheless, choosing a deeper and more complex model will increase the computational complexity of the watermarking process, requiring a trade-off based on available computational resources.
6.5. Study Limitations and Computational Considerations
Two-model training requirement: The watermarking process of DICTION requires training two models (the target model and projection network), unlike methods such as those of Uchida et al. and DeepSigns, which only require single-model training. This represents the computational cost for ensuring robust watermarking properties. The impact is particularly significant for large models like GPT, but several mitigating factors exist: (i) Offline processing: Watermarking occurs in offline mode, eliminating runtime overhead for end users. (ii) One-time cost: The computational overhead is incurred only during watermarking, not during model deployment or inference. (iii) Deployment efficiency: Once watermarked and deployed, the model operates with identical performance characteristics to the original.
6.6. Future Research Directions
Building on the promising results of DICTION, we identify several key directions for future research that could significantly enhance the framework’s applicability and robustness.
Large language models and transformer architectures: Extending DICTION to transformer architectures and large language models like GPT and BERT represents a critical next step. This requires adapting the activation-based watermarking approach to attention mechanisms and token embeddings, which presents unique challenges given the fundamentally different computational structure of transformers compared to traditional neural networks. The growing importance of language models in practical applications makes this extension particularly valuable for ensuring model ownership protection in NLP domains.
Federated learning applications: The adaptation of DICTION for federated learning environments presents another promising direction. This involves addressing the unique challenges of decentralized model ownership verification while preserving watermark integrity across multiple clients. In federated settings where data privacy is paramount, the watermarking mechanism must maintain its effectiveness without compromising the privacy guarantees that make federated learning attractive. This includes developing protocols for watermark verification that do not require centralized access to client models.
Advanced attack resistance: Developing enhanced robustness against emerging attacks remains crucial for practical deployment. This includes defending against model extraction attacks, as studied by Kinakh et al. [
71], where adversaries attempt to steal model functionality through query access. Additionally, architectural modification attacks that add dummy neurons, as analyzed by Yan et al. [
72], pose unique challenges that require watermarking schemes to be invariant to such structural changes. Furthermore, gradient inversion and other privacy-focused attacks that attempt to extract training data or watermark information through gradient analysis must be considered in future defense mechanisms.
Real-world deployment and integration: Practical deployment considerations warrant a thorough investigation to transition DICTION from research prototype to a production-ready solution. This encompasses integration with existing ML pipelines and frameworks such as TensorFlow, PyTorch, and MLflow, ensuring minimal overhead on training and inference processes. Performance optimization for large-scale deployment becomes critical when dealing with models serving millions of requests. Additionally, conducting comprehensive cost–benefit analyses for industrial applications will help organizations understand the trade-offs between watermarking overhead and intellectual property protection. Finally, working toward standardization and ensuring compatibility with existing watermarking protocols will facilitate broader adoption across the machine learning community.
7. Conclusions
In this paper, we present a unified framework that encompasses all existing white-box watermarking algorithms for DNN models. This framework establishes theoretical connections between previous works on white-box watermarking for DNN models. From this framework, we derived DICTION, a novel white-box dynamic robust watermarking scheme that relies on a GAN strategy. Its main innovation lies in a watermark extraction function that is a DNN trained using latent space triggers as an adversarial network.
We subjected DICTION to a comprehensive evaluation against several watermark detection and removal attacks, and demonstrated that it is significantly more robust than existing works with superior embedding and extraction efficiency. DICTION achieves a zero bit error rate while maintaining model accuracy within 0.5% of the baseline, tolerates up to 95% weight pruning compared to 80% for existing methods, and shows complete resistance to fine-tuning and overwriting attacks where competing methods fail.
In future work, we plan to broaden the scope of our evaluation by incorporating additional machine learning applications, such as natural language processing, and learning strategies, such as federated learning.






{kind=link}
{kind=link}
{kind=link}
{kind=link}