
LSANet: Lightweight Super Resolution via Large Separable Kernel Attention for Edge Remote Sensing

Abstract
1. Introduction
- Breaking through module design bottlenecks: The large separable kernel attention mechanism (LSKA) is innovatively introduced into the feature distillation network, and the residual feature distillation module (RLSKFDM) is proposed. By constructing a large-receptive-field attention mechanism, the modeling of complex textures and edge information in remote sensing images is strengthened, breaking through the limitation of insufficient representation ability of shallow residual blocks and providing a more effective feature processing path for the detail restoration of remote sensing images;
- Innovation in multi-dimensional feature enhancement: A residual feature enhancement module (RFEM) that fuses multiple attention mechanisms is designed. It integrates the contrast-aware channel attention (CCA) and the large separable kernel attention (LSKA) and combines with a multi-level skip connection structure. It accurately strengthens local feature expression and multi-scale information fusion, realizes the efficient coupling of shallow details and deep semantics, and meets the interpretation requirements of multi-dimensional features of remote sensing images;
- Synergistic optimization of lightness and performance: While improving the reconstruction performance, through the design of lightweight modules and the optimization of the feature flow mechanism, LSANet can greatly reduce the number of parameters and computational overhead while maintaining a competitive restoration effect. An efficient model suitable for edge computing and low-resource remote sensing scenarios is created, solving the “performance - cost” imbalance problem of lightweight networks in the actual application of remote sensing;
- Verification for remote sensing scenarios: Systematic experiments are carried out on two representative remote sensing image datasets, NWPU-RESISC45 and UC Merced Land Use. The advantages of LSANet in image reconstruction quality, model efficiency, and visual performance are fully verified. Covering typical application data scenarios of remote sensing, it fully demonstrates the generality and practical value of the model and provides strong technical support for the implementation of remote sensing super resolution.
2. Related Works
2.1. Attention Mechanism
2.2. Single Image Super Resolution
3. Method
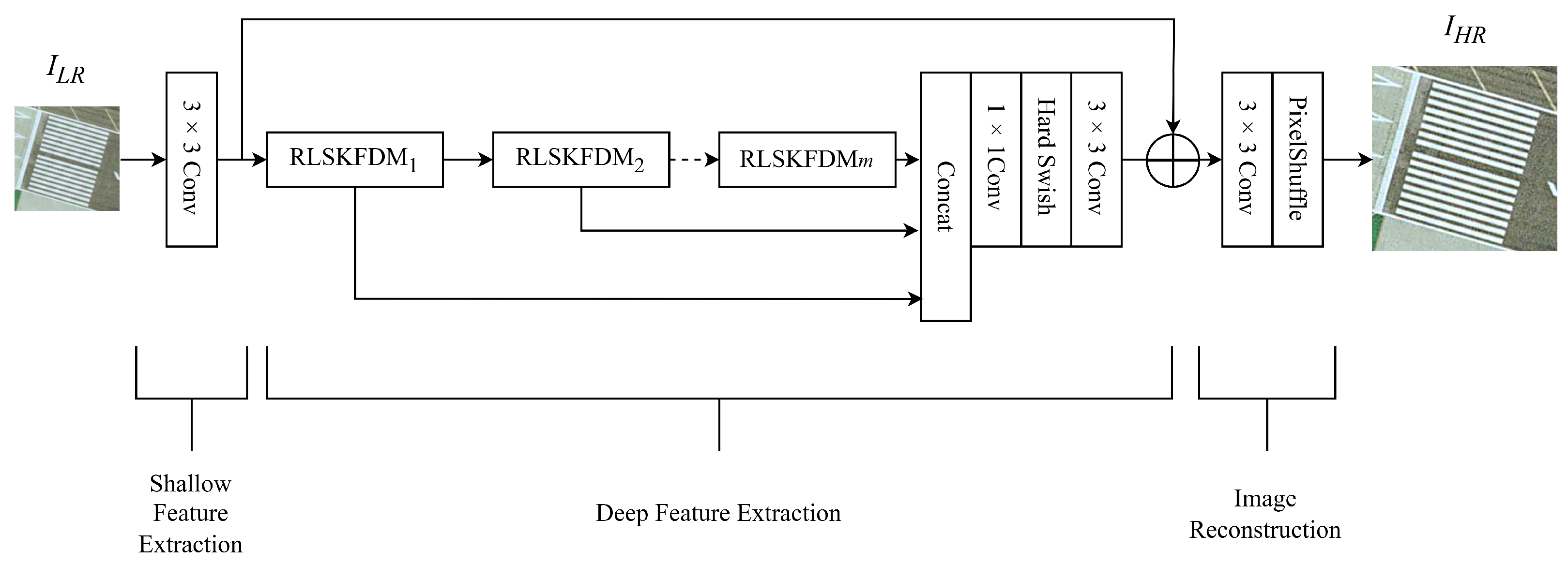
3.1. Network Architecture
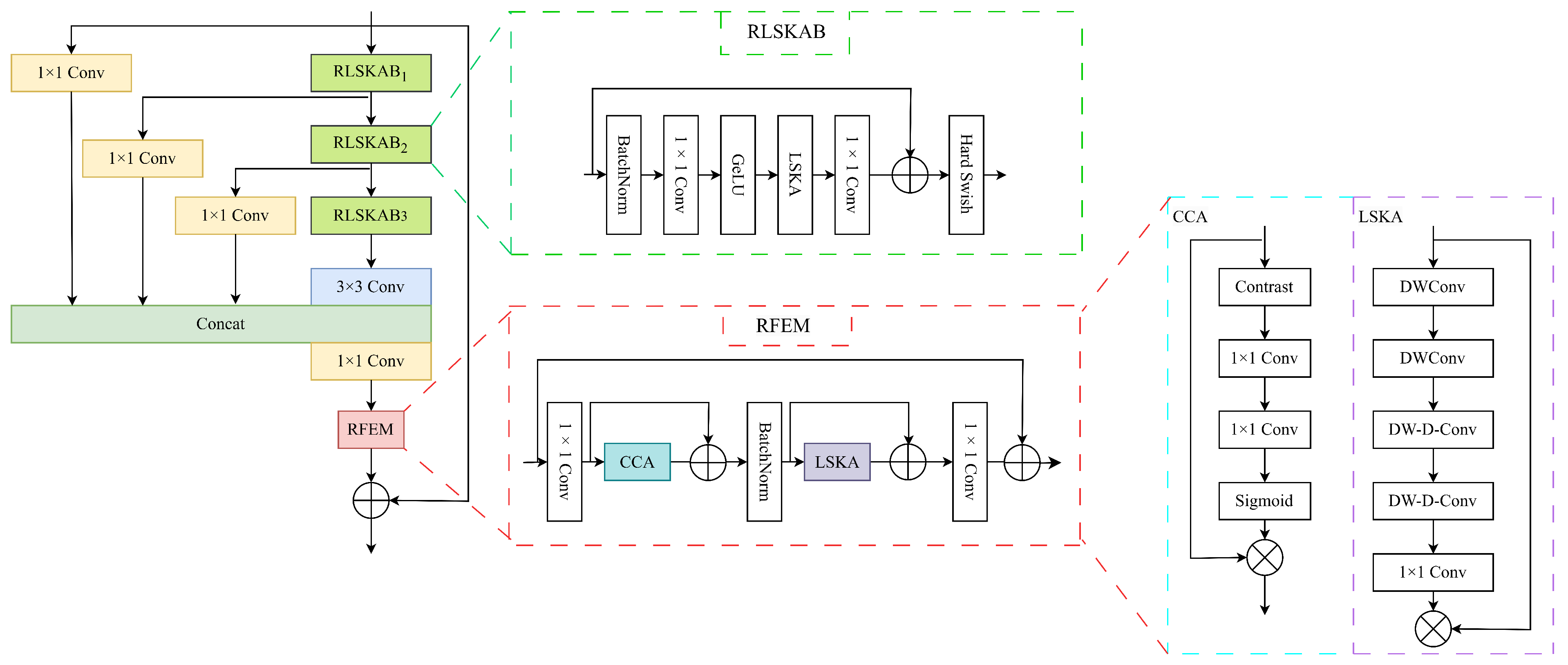
3.2. Residual Large Kernel Separable Feature Distillation Module (RLSKFDM)
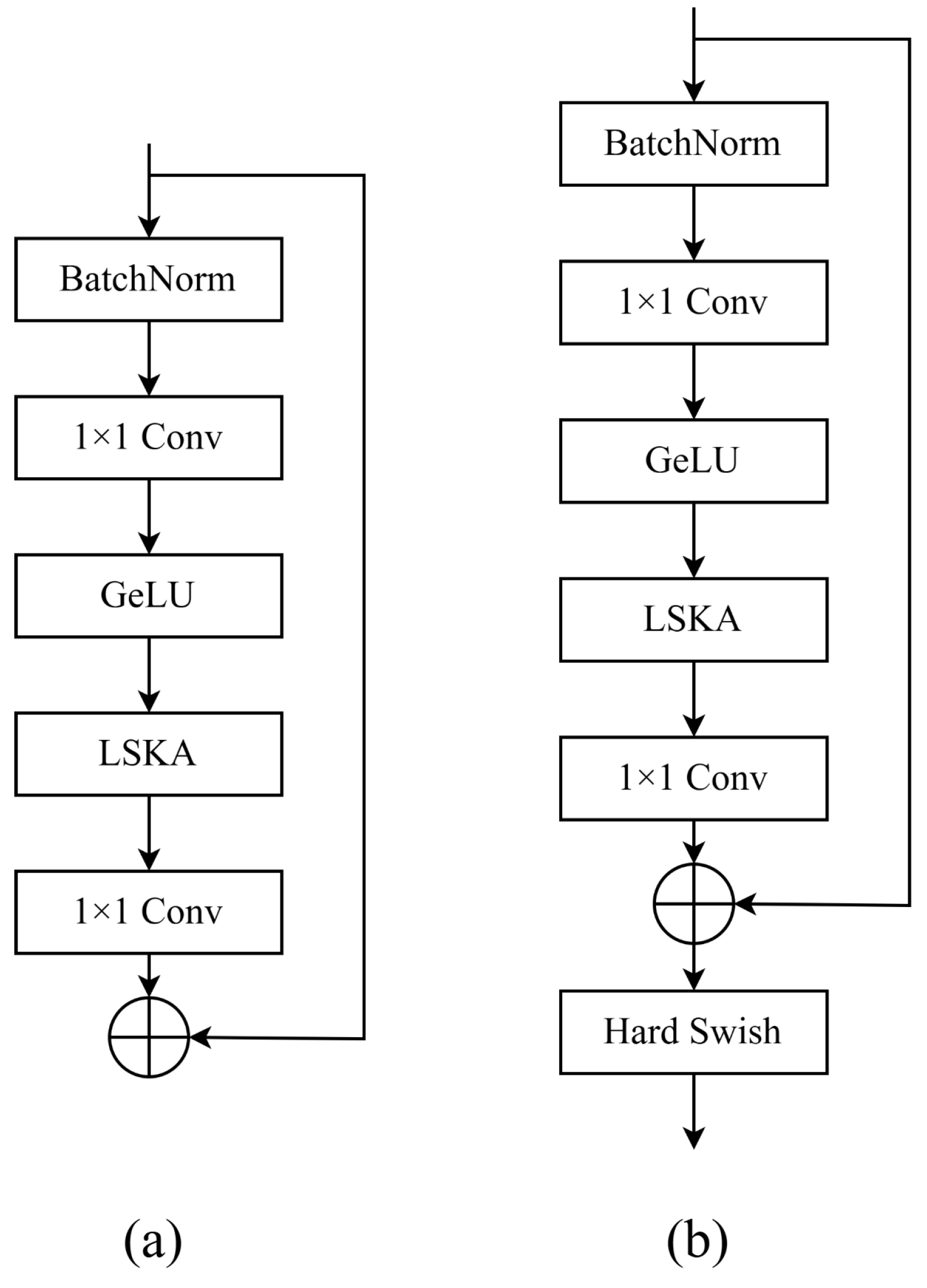
3.3. Residual Large Kernel Separable Attention Block (RLSKAB)
3.4. Residual Feature Enhancement Module (RFEM)
4. Implementation Details
4.1. Experimental Configuration
4.2. Dataset
4.3. Quantitative Experimental Results
4.3.1. Quantitative Results Obtained on the UC Merced Land Use Dataset
4.3.2. Quantitative Results Obtained on the NWPU-RESISC45 Dataset
4.4. Ablation Study
4.4.1. Effectiveness of Feature Extraction Module
4.4.2. Effectiveness of the Feature Processing Part of the Module
4.4.3. Effectiveness of Hard Swish Activation Function
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SRCNN | Super-resolution convolutional neural network |
| VDSR | Very deep super resolution |
| GoogLeNet | Google Inception net |
| EDSR | Enhanced deep residual networks |
| RDN | Residual dense network |
| RCAN | Very deep residual channel attention network |
| CARN | Cascading residual network |
| IMDN | Information multi-distillation network |
| RFDN | Residual feature distillation network |
| MAFFSRN | Multi-attentive feature fusion super-resolution network |
| RepLKNet | Reparameterized large kernel network |
| LKA | Large kernel attention |
| SE | squeeze-and-excitation network |
| CBAM | Convolutional block attention module |
| SAN | Storage area network |
| SwinIR | Swin Transformer for image restoration |
| CAS-ViT | Convolutional additive self-attention vision Transformers |
| RFANet | Residual feature aggregation network |
| SRDenseNet | Image super-resolution using dense skip connections network |
| DRCN | Deep recursive convolutional network |
| DRRN | Deep recursive residual network |
| LapSRN | Laplacian Pyramid super-resolution network |
| LSANet | Large separable kernel attention network |
| CCA | Contrast-aware channel attention |
| LSKA | Large separable kernel attention |
| VAN | Visual attention network |
| RLSKFDM | Residual large separable kernel feature distillation module |
| RLSKAB | Residual large kernel separable attention block |
| RFEM | Residual feature enhancement module |
| PSNR | Peak signal-to-noise ratio |
| SSIM | Structural similarity index |
| LGCNet | Lightweight global context network |
| DCM | Dual channel module |
| HSENet | Hybrid spectral enhancement network |
References
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision And pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5791–5800. [Google Scholar]
- Chen, G.; Wang, H.; Chen, K.; Li, Z.; Song, Z.; Liu, Y. A survey of the four pillars for small object detection: Multiscale representation, contextual information, super-resolution, and region proposal. IEEE Trans. Syst. Man Cybern. Syst. 2020, 52, 1–18. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part IV 13. pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Liu, J.; Tang, J.; Wu, G. Residual feature distillation network for lightweight image super-resolution. In Proceedings of the Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Part III 16. pp. 41–55. [Google Scholar]
- Hu, Z.; Sun, W.; Chen, Z. Lightweight image super-resolution with sliding Proxy Attention Network. Signal Process. 2025, 227, 109704. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31×31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Huang, W.; Ju, M.; Yin, J.; Sun, L.; Wu, Z.; Xu, Y. Multiscale Feature Enhancement Network Based on Large Kernel Attention Mechanism for Pansharpening; SSRN: Rochester, NY, USA, 2022. [Google Scholar]
- Cai, X.; Lai, Q.; Wang, Y.; Wang, W.; Sun, Z.; Yao, Y. Poly Kernel Inception Network for Remote Sensing Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Lai, S.J.; Cheung, T.H.; Fung, K.C.; Xue, K.W.; Lam, K.M. HAAT: Hybrid attention aggregation transformer for image super-resolution. arXiv 2025, arXiv:2411.18003. [Google Scholar]
- Jie, H.; Li, S.; Gang, S.; Albanie, S.; Wu, E. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Xing, N.; Wang, J.; Wang, Y.; Ning, K.; Chen, F. Point Cloud Completion Based on Nonlocal Neural Networks with Adaptive Sampling. Inf. Technol. Control 2024, 53, 160–170. [Google Scholar] [CrossRef]
- Lyn, J.; Yan, S. Non-local second-order attention network for single image super resolution. In Proceedings of the Machine Learning and Knowledge Extraction: 4th IFIP TC 5, TC 12, WG 8.4, WG 8.9, WG 12.9 International Cross-Domain Conference, CD-MAKE 2020, Dublin, Ireland, 25–28 August 2020; Proceedings 4. pp. 267–279. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Zhang, T.; Li, L.; Zhou, Y.; Liu, W.; Qian, C.; Hwang, J.N.; Ji, X. Cas-vit: Convolutional additive self-attention vision transformers for efficient mobile applications. arXiv 2024, arXiv:2408.03703. [Google Scholar]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual feature aggregation network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2359–2368. [Google Scholar]
- Xu, Y.; Guo, T.; Wang, C. A remote sensing image super-resolution reconstruction model combining multiple attention mechanisms. Sensors 2024, 24, 4492. [Google Scholar] [CrossRef]
- Zhu, Y.; Gei, C.; So, E. Image super-resolution with dense-sampling residual channel-spatial attention networks for multi-temporal remote sensing image classification. Int. J. Appl. Earth Obs. Geoinf. 2021, 104, 102543. [Google Scholar] [CrossRef]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient long-range attention network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 649–667. [Google Scholar]
- Zeng, H.; Wu, Q.; Zhang, J.; Xia, H. Lightweight subpixel sampling network for image super-resolution. Vis. Comput. 2024, 40, 3781–3793. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, L.; Zhang, Z.; Wang, X.; Liu, W.; Xia, B.; Ding, H.; Zhang, J.; Xu, S.; Wang, X. Dual-path aggregation transformer network for super-resolution with images occlusions and variability. Eng. Appl. Artif. Intell. 2025, 139, 109535. [Google Scholar] [CrossRef]
- Liu, B.; Ning, X.; Ma, S.; Yang, Y. Multi-scale dense spatially-adaptive residual distillation network for lightweight underwater image super-resolution. Front. Mar. Sci. 2024, 10, 1328436. [Google Scholar] [CrossRef]
- Fan, S.; Song, T.; Li, P.; Jin, J.; Jin, G.; Zhu, Z. Dense-gated network for image super-resolution. Neural Process. Lett. 2023, 55, 11845–11861. [Google Scholar] [CrossRef]
- Fang, J.; Chen, X.; Zhao, J.; Zeng, K. A scalable attention network for lightweight image super-resolution. J. King Saud. Univ. Comput. Inf. Sci. 2024, 36, 102185. [Google Scholar] [CrossRef]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Zhang, Y.; Gao, F.; Zhou, K. Efficient Energy Disaggregation via Residual Learning-Based Depthwise Separable Convolutions and Segmented Inference. IEEE Trans. Ind. Inform. 2025, 21, 2224–2233. [Google Scholar] [CrossRef]
- Yasir, M.; Ullah, I.; Choi, C. Depthwise channel attention network (DWCAN): An efficient and lightweight model for single image super-resolution and metaverse gaming. Expert Syst. 2024, 41, e13516. [Google Scholar] [CrossRef]
- Chen, Y.; Wan, L.; Li, S.; Liao, L. AMF-SparseInst: Attention-guided Multi-Scale Feature Fusion Network Based on SparseInst. Inf. Technol. Control 2024, 53, 675–694. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Bian, J.; Liu, Y.; Chen, J. Lightweight Super-Resolution Reconstruction Vision Transformers of Remote Sensing Image Based on Structural Re-Parameterization. Appl. Sci. 2024, 14, 917. [Google Scholar] [CrossRef]
- Peng, G.; Xie, M.; Fang, L. Context-Aware Lightweight Remote-Sensing Image Super-Resolution Network. Front. Neurorobot. 2023, 17, 1220166. [Google Scholar] [CrossRef]
- Lau, K.W.; Po, L.M.; Rehman, Y.A.U. Large separable kernel attention: Rethinking the large kernel attention design in cnn. Expert Syst. Appl. 2023, 236, 121352. [Google Scholar] [CrossRef]
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. Visual attention network. Comput. Vis. Media 2023, 9, 733–752. [Google Scholar] [CrossRef]
- Ponomarenko, N.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Carli, M. Modified image visual quality metrics for contrast change and mean shift accounting. In Proceedings of the 2011 11th International Conference: The Experience of Designing and Application of CAD Systems in Microelectronics (CADSM), Polyana, Ukraine, 23–25 February 2011; pp. 305–311. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Wang, Z.; Li, L.; Xue, Y.; Jiang, C.; Wang, J.; Sun, K.; Ma, H. FeNet: Feature enhancement network for lightweight remote-sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z.; Zou, Z. Super-resolution for remote sensing images via local–global combined network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Haut, J.M.; Paoletti, M.E.; Fernández-Beltran, R.; Plaza, J.; Plaza, A.; Li, J. Remote sensing single-image superresolution based on a deep compendium model. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1432–1436. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z. Hybrid-scale self-similarity exploitation for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–10. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Scale | Params/K | M-Adds/G | PSNR | SSIM |
|---|---|---|---|---|---|
| SRCNN | ×2 | 8 | 4.5 | 32.89 | 0.8975 |
| CARN | ×2 | 16 | 0.3 | 33.18 | 0.9196 |
| IMDN | ×2 | 694 | 21.3 | 32.19 | 0.8996 |
| RFDN | ×2 | 534 | 26.4 | 33.55 | 0.9032 |
| DCM | ×2 | 1842 | 30.2 | 33.52 | 0.9166 |
| LGCNet | ×2 | 193 | 12.7 | 33.65 | 0.9285 |
| CTN | ×2 | 349 | 4.2 | 33.50 | 0.9242 |
| FeNet | ×2 | 423 | 67.8 | 33.65 | 0.9278 |
| HSENet | ×2 | 5286 | 66.8 | 34.23 | 0.9332 |
| LSANet | ×2 | 527 | 19.5 | 34.33 | 0.9328 |
| SRCNN | ×3 | 8 | 4.5 | 28.66 | 0.8038 |
| CARN | ×3 | 17 | 0.8 | 29.09 | 0.8167 |
| IMDN | ×3 | 706 | 22.1 | 29.19 | 0.8367 |
| RFDN | ×3 | 584 | 28.7 | 29.47 | 0.8392 |
| DCM | ×3 | 2258 | 16.3 | 29.52 | 0.8396 |
| LGCNet | ×3 | 193 | 12.7 | 29.65 | 0.8239 |
| CTN | ×3 | 349 | 2.6 | 29.44 | 0.8319 |
| FeNet | ×3 | 430 | 69.2 | 29.85 | 0.8405 |
| HSENet | ×3 | 5370 | 70.8 | 29.98 | 0.8416 |
| LSANet | ×3 | 539 | 15.8 | 30.08 | 0.8446 |
| SRCNN | ×4 | 8 | 4.5 | 26.78 | 0.7219 |
| CARN | ×4 | 20 | 1.1 | 26.93 | 0.7267 |
| IMDN | ×4 | 721 | 22.5 | 27.10 | 0.7413 |
| RFDN | ×4 | 598 | 30.8 | 27.28 | 0.7505 |
| DCM | ×4 | 2175 | 13.0 | 27.22 | 0.7528 |
| LGCNet | ×4 | 193 | 12.7 | 27.02 | 0.7333 |
| CTN | ×4 | 360 | 2.6 | 27.41 | 0.7512 |
| FeNet | ×4 | 438 | 71.5 | 27.65 | 0.7596 |
| HSENet | ×4 | 5433 | 81.2 | 27.73 | 0.7623 |
| LSANet | ×4 | 558 | 13.6 | 27.79 | 0.7635 |
| Method | Scale | Params/K | M-Adds/G | PSNR | SSIM |
|---|---|---|---|---|---|
| SRCNN | ×2 | 57 | 0.52 | 30.21 | 0.8722 |
| CARN | ×2 | 1592 | 222.6 | 33.93 | 0.9203 |
| IMDN | ×2 | 694 | 141.2 | 33.72 | 0.9181 |
| RFDN | ×2 | 534 | 94.1 | 34.15 | 0.9215 |
| DCM | ×2 | 2341 | 387.2 | 33.54 | 0.9176 |
| LGCNet | ×2 | 193 | 12.7 | 33.82 | 0.9197 |
| CTN | ×2 | 1128 | 178.3 | 34.06 | 0.9224 |
| FeNet | ×2 | 423 | 67.8 | 33.32 | 0.9156 |
| HSENet | ×2 | 312 | 48.6 | 33.63 | 0.9187 |
| LSANet | ×2 | 602 | 22.1 | 35.02 | 0.9305 |
| SRCNN | ×3 | 57.2 | 0.53 | 27.84 | 0.8123 |
| CARN | ×3 | 1602 | 225.3 | 30.74 | 0.8681 |
| IMDN | ×3 | 702 | 143.7 | 30.57 | 0.8656 |
| RFDN | ×3 | 541 | 94.1 | 30.99 | 0.8714 |
| DCM | ×3 | 2355 | 390.6 | 30.49 | 0.8635 |
| LGCNet | ×3 | 193 | 12.7 | 30.62 | 0.8698 |
| CTN | ×3 | 1135 | 180.1 | 30.84 | 0.8721 |
| FeNet | ×3 | 430 | 69.2 | 30.22 | 0.8608 |
| HSENet | ×3 | 318 | 49.8 | 30.57 | 0.8668 |
| LSANet | ×3 | 605 | 22.3 | 31.24 | 0.8799 |
| SRCNN | ×4 | 57.3 | 0.54 | 26.13 | 0.7633 |
| CARN | ×4 | 1618 | 228.9 | 28.87 | 0.8275 |
| IMDN | ×4 | 715 | 28.65 | 28.74 | 0.7413 |
| RFDN | ×4 | 550 | 96.8 | 29.05 | 0.8317 |
| DCM | ×4 | 2378 | 395.1 | 28.54 | 0.8223 |
| LGCNet | ×4 | 193 | 12.7 | 28.74 | 0.8286 |
| CTN | ×4 | 1147 | 1.8 | 28.93 | 0.8332 |
| FeNet | ×4 | 438 | 71.5 | 28.35 | 0.8189 |
| HSENet | ×4 | 325 | 51.3 | 28.69 | 0.8242 |
| LSANet | ×4 | 609 | 22.7 | 29.29 | 0.8405 |
| Number | SRB | RLSKAB | LSKA Size | Params/K | FLOPS/G | PSNR | SSIM | Times/s |
|---|---|---|---|---|---|---|---|---|
| (a) | ✓ | – | 550 | 26.3 | 25.99 | 1.29 | – | |
| (b) | ✓ | (3, 5) | 334 | 15.4 | 26.19 | 0.7866 | 0.80 | |
| (c) | ✓ | (5, 5) | 346 | 16.1 | 26.22 | 0.7875 | 0.86 | |
| (d) | ✓ | (5, 7) | 365 | 17.1 | 26.25 | 0.7884 | 0.91 | |
| (e) | ✓ | (7, 7) | 387 | 18.2 | 26.21 | 0.7871 | 0.94 | |
| (f) | ✓ | (7, 9) | 396 | 19.3 | 26.23 | 0.7890 | 0.99 |
| Number | CCA | CCA+LSKA | RFEM | Inp. Dim. | Params/K | FLOPS/G | PSNR | Times/s |
|---|---|---|---|---|---|---|---|---|
| (d) | ✓ | 48 | 365 | 17.1 | 26.25 | 0.74 | ||
| (g) | ✓ | 48 | 414 | 19.2 | 26.28 | 0.82 | ||
| (h) | ✓ | 48 | 414 | 19.2 | 26.33 | 0.85 | ||
| (i) | ✓ | 52 | 463 | 21.4 | 26.39 | 0.90 | ||
| (j) | ✓ | 56 | 506 | 24.8 | 26.42 | 0.96 | ||
| (k) | ✓ | 60 | 594 | 29.6 | 26.47 | 1.02 |
| Number | Activation Function | Params/K | FLOPS/G | PSNR | SSIM |
|---|---|---|---|---|---|
| (l) | Hard Swish | 558 | 13.6 | 27.79 | 0.7635 |
| (m) | – | 556 | 13.4 | 26.25 | 0.7584 |
| (n) | ReLU | 557 | 13.5 | 26.38 | 0.7599 |
| (o) | Sigmoid | 560 | 13.7 | 26.40 | 0.7611 |
| (p) | ELU | 557 | 13.5 | 26.47 | 0.7602 |
| (q) | Tanh | 561 | 13.9 | 27.40 | 0.7622 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yong, T.; Liu, X. LSANet: Lightweight Super Resolution via Large Separable Kernel Attention for Edge Remote Sensing. Appl. Sci. 2025, 15, 7497. https://doi.org/10.3390/app15137497
Yong T, Liu X. LSANet: Lightweight Super Resolution via Large Separable Kernel Attention for Edge Remote Sensing. Applied Sciences. 2025; 15(13):7497. https://doi.org/10.3390/app15137497
Chicago/Turabian StyleYong, Tingting, and Xiaofang Liu. 2025. "LSANet: Lightweight Super Resolution via Large Separable Kernel Attention for Edge Remote Sensing" Applied Sciences 15, no. 13: 7497. https://doi.org/10.3390/app15137497
APA StyleYong, T., & Liu, X. (2025). LSANet: Lightweight Super Resolution via Large Separable Kernel Attention for Edge Remote Sensing. Applied Sciences, 15(13), 7497. https://doi.org/10.3390/app15137497