1. Introduction
Code smells propose weak design and execution choices, which could prevent code comprehension while increasing change and error proneness [
1]. A code smell (CS) is a distinctive feature in the source code of a program that indicates the presence of a more significant issue. Code smells manifest when the coding process lacks adherence to ethical principles [
2]. Software developers encounter a challenging endeavor when it comes to identifying code smells.
Unlike Java, Python features dynamic typing, indentation-based scoping, and a more compact syntax. These language-specific characteristics affect how code smells manifest and challenge traditional detection techniques. Thus, machine-learning (ML)-based detection approaches validated on Java code may not directly translate to Python environments, underscoring the need for a dedicated study.
Software development may encounter technical hurdles and design obstacles as it strives to meet deadlines and adapt to changing requirements [
3]. According to Zazworka et al. [
4], technical issues may be described as the act of compromising one development criterion in favor of another, such as software quality, in order to fulfill a certain deadline. The presence of code smells may have a significant negative influence on the overall quality of a program. Güzel and Aktas [
5] define code smells as instances of suboptimal code design or implementation, characterized by the presence of intricate or extensive classes. Examples of code smells include a class that has an excessive number of responsibilities (Large Class) or a function with an excessive number of arguments (Long Method). Code smells may occur at several levels, including the class, method, and statement levels. However, code smells affect the system’s quality rather than its functioning. Thus, the early detection of code smells improves the quality of code and system efficiency [
6,
7].
Code smells can be found either automatically or manually in system designs or source code. Three primary methods for detecting code smells are rule-based, ML-based, and metrics-based. A rule-based method involves software engineers optimizing a rule to describe each code smell. However, this process of defining rules needs to be standardized and occasionally performed by hand, which can lead to inconsistencies and arbitrary interpretations [
8]. Metrics-based detection involves code metrics such as lines of code or cyclomatic complexity but lacks standard thresholds, reducing accuracy [
9,
10,
11]. ML-based techniques, especially ensemble models, have proven effective in automating code smell detection by capturing complex patterns in source code [
12]. However, most existing research focuses on Java-based, object-oriented systems, leaving dynamically typed languages like Python relatively underexplored. Given Python’s growing popularity and its unique language characteristics, such as dynamic typing and indentation-based scoping, there is a clear need for further research in this area [
13]. To address this gap, the present study proposes a Python-specific ensemble-based detection framework that incorporates SMOTE (Synthetic Minority Oversampling Technique) for class balancing, Chi-square Feature Selection Technique (FST) for dimensionality reduction, and five ensemble classifiers. While some of these methods were applied in our previous Java-based research [
14], this study adapts and evaluates them in the Python context, introducing new empirical insights into their cross-language generalizability.
Unlike the Java-centric datasets used previously, this study utilizes two Python-specific code smell datasets, Large Class (LC) and Long Method (LM), collected from real-world open-source Python repositories. We investigate the performance of multiple ensemble models in this new context and assess whether established techniques retain their effectiveness. Challenges such as imbalanced datasets, noisy or irrelevant features, and overfitting are further exacerbated in Python due to limited tooling and benchmark datasets. Our proposed ensemble framework aims to address these challenges, improving robustness and generalizability.
Despite the success of ML models in detecting Java code smells, many still struggle with complex smells requiring deeper semantic understanding (e.g., Feature Envy, Data Class). Moreover, adapting such techniques to dynamically typed languages like Python has not been systematically studied. This research presents a novel contribution by rigorously evaluating the transferability and adaptation of ensemble learning, Chi-square FST, and SMOTE in the Python context. Given the fundamental differences between Java and Python in terms of syntax, type system, and code structure, this research provides new empirical insights into the behavior and generalizability of ML-based code smell detectors across programming languages. To the best of our knowledge, this is among the first comprehensive efforts to benchmark these techniques on Python datasets, contributing valuable insights for cross-language ML model transferability.
The primary goal of the proposed research is to identify code smells from the Python code smell dataset using ensemble learning approaches with an applied Chi-square FST and SMOTE methods. This research is significant as it aims to enhance the understanding of code smells in Python, a crucial step toward improving software quality and system efficiency.
1.1. Motivation
Sandouka et al. [
3] used six ML techniques as reference benchmarks to assess their effectiveness in identifying Python code smells. They examined the baseline results using the Matthews correlation coefficient (MCC) and accuracy criteria. However, their work did not consider ensemble learning or the impact of preprocessing techniques like feature selection and class balancing.
This work aims to enhance the results using five ensemble learning approaches, including the FST on the Python code smell dataset. Ensemble learning techniques enable the amalgamation of predictions generated by numerous ML models, possibly producing more precise and resilient outcomes. Six performance measurements were conducted, and the issue of class imbalance was resolved by using the SMOTE class balancing approach. Subsequently, a comparison was made between the performance of the system with and without FST and SMOTE.
1.2. Research Queries
The following research questions (RQ) will be investigated to attain the study purpose:
RQ.1: Which ensemble algorithms perform best for detecting Python-specific code smells, considering structural and syntactic differences from Java?
Motivation: This study investigates two method-level Python code smell datasets, LC and LM, originally introduced by Sandouka et al. [
3]. While their work applied six individual ML models, it did not explore the potential of ensemble learning techniques, which are known for improving generalization and robustness. Furthermore, Python’s dynamic typing, lack of explicit access modifiers, and indentation-sensitive syntax present unique detection challenges not encountered in statically typed languages like Java. To address this gap, our study evaluates five ensemble classifiers, aiming to enhance predictive performance and provide a more robust benchmark for Python code smell detection.
RQ.2: Does chi-square-FST improve model performance in Python code smell detection, given Python’s unique metric distribution influenced by dynamic typing and indentation-based structure?
Motivation: Prior research by Sandouka et al. [
3] demonstrated improved classification accuracy on Python code smells through Gain ratio-based feature selection. However, the effectiveness of other filter-based FSTs, such as the widely used chi-square technique, remains unexplored in this context. Python code metrics differ significantly in structure and distribution from those in Java due to the language’s dynamic characteristics. This study investigates the impact of chi-square FST on ensemble models across the LC and LM datasets. It compares results with and without FST to determine its contribution to detection accuracy.
RQ.3: How does class imbalance in Python smell datasets influence model accuracy, and does SMOTE remain effective compared to its performance on Java datasets?
Motivation: Both the LC and LM datasets used in this study are highly imbalanced, containing 1000 instances each, with only 200 labeled as smelly and 800 as non-smelly. Class imbalance can significantly hinder classifier performance, especially in minority class detection. While the SMOTE method has shown effectiveness in prior Java-based code smell studies, its impact on Python datasets remains to be evaluated. This study applies SMOTE to the Python smell datasets and empirically assesses whether it improves model performance under these skewed distributions.
1.3. Contributions
The key contributions of this study are as follows:
A domain-adapted ensemble learning framework tailored for Python-based code smell detection;
Empirical evaluation of SMOTE and chi-square FST effectiveness on Python-specific datasets;
Comparative analysis of ensemble classifiers for detecting Python code smells;
A discussion of how domain-specific factors influence model behavior and generalizability.
Our findings demonstrate that the adaptation of known techniques to Python is non-trivial and reveals significant variation in performance, supporting the case for language-specific model tuning and evaluation.
The remaining sections are arranged as follows: The ‘Related Work’ section highlights related work on constructing code smell datasets and research that employed ML to identify code smells. The ‘Research Framework’ section describes a step-by-step research framework. The study’s results are presented in the section ‘Results Analysis’, which provides a comprehensive analysis of the findings. The section ‘Discussion’ compares the obtained results with other relevant studies and highlights possible threats to validity, and the ‘Conclusion’ section summarizes this study and discusses future work.
2. Related Work
The various literature has successfully applied machine learning, deep learning, and ensemble learning to detect code smells. These techniques, along with different FST and parameter optimization methods, have proven to be effective. A. Nandini et al. [
15] proposed a systematic literature review of various tools and techniques, further reinforcing the success of these methods. Other tools and techniques used in the different literature are summarized below:
N. Vatanapakorn et al. [
16] used eight ML models employing logistic regression, forward stepwise selection, and correlation-based FSTs for detecting code smells within a Python dataset. Their approach achieved a maximum accuracy of 99.72% for identifying LM and Long Base Class List code smells. However, such high scores may be inflated due to limited dataset diversity or overfitting to specific characteristics of the dataset, raising questions about model robustness when applied to different projects or languages. T. Sharma et al. [
17] proposed deep learning-based detection methods utilizing convolutional and recurrent neural networks. The results of their studies demonstrate that transfer learning can be implemented for implementation purposes and achieves performance close to direct learning. In a separate replication study, H.G. Nunes et al. [
18] examined the effects of dataset imbalance on model performance. The results revealed that predictive accuracy decreased as the degree of imbalance increased. However, their study also found that under-sampling proved to be a highly effective strategy for highly imbalanced datasets, providing reassurance about the reliability of the models. Oversampling, on the other hand, provides better results for datasets with less pronounced imbalances. Additionally, the incorporation of polynomial features did not produce a statistically significant improvement in prediction performance. Thus, the findings underscore the need for appropriate class balancing techniques such as SMOTE to mitigate skewed predictions and false negatives in minority classes. Fontana et al. [
19] investigated various ML approaches such as binary classifiers, ordinal classification, multinomial classification, and regression. According to Spearman’s p, their analysis showed an interaction between the expected and actual severity, with an 88–96% accuracy. In a separate study, Abdou et al. [
20] employed various ML models, such as multinomial, ordinal, and regression classifiers, to classify code smell severity. The PART method was utilized to assess feature effectiveness, while the LIME technique was applied to interpret model predictions and decision rules. Accuracy, measured via Spearman correlation, reached between 92% and 97%. Both Fontana et al. [
19] and Abdou et al. [
20] reported accuracy between 88% and 97%. However, the interpretability and generalizability of such models across languages remain uncertain, particularly since the majority of these studies rely on Java datasets and code structures.
Using six distinct datasets, Alazba et al. [
21] evaluated fourteen ML algorithms alongside stacking ensemble methods for code smell detection. Among these, the Stack-SVM algorithm produced the highest performance, attaining an accuracy of 99.24% on the LM dataset. While this suggests that ensemble methods can outperform single classifiers, their study did not evaluate transferability across programming languages or consider feature selection’s impact on performance and interpretability.
Amorim L. et al. [
22] used four medium-sized open-source projects using twelve distinct code smells to validate the decision tree method’s efficacy. On the other hand, Tian Y. et al. [
23] used SVM to find instances of the Swiss Army Knife, Functional Decomposition, God Class (GC), and Spaghetti Code. Yadav P.S. et al. [
24] used the decision tree ML model to detect Data Class (DC) and Blob class code smells and obtained 97.62% best accuracy using the decision tree model. Kheria I. et al. [
25] proposed a semi-supervised learning method to identify code smells using both widely used labeled and manually collected unlabeled data. They demonstrated this method through a clustering-based approach for class-level and a label propagation-based approach for method-level code smell detection. They observed that the semi-supervised learning method resulted in an accuracy increase of up to 8.4% for class-level and method-level code smells. Kim et al. [
26] used six code smells using the MLP method and obtained a 99.25% accuracy score. Bayesian Belief Networks were suggested by Khomh et al. [
27] and Vaucher et al. [
28] as a means of detecting the GC. Similarly, Wang et al. [
29] applied these models to find duplicate code smells.
With Chi-square FST and SMOTE, Dewangan et al. [
14] achieved 100% accuracy for the LM dataset via ensemble and deep learning. U. Mansoor et al. [
30] proposed multi-objective genetic programming (MOGP) to find the best combination of metrics that maximizes the detection of code smell examples and minimizes the detection of well-designed code examples. They evaluated proposals on seven large open-source systems and found that, on average, most of the three different Code smell types were detected with an average of 86% precision and 91% recall. A. Nızam et al. [
31] proposed the system’s effectiveness with widely used BERT, CodeBERT, and GraphCodeBERT pre-trained models to create code embedding for the code classification task of code smell detection. They observed that the proposed system may offer improvements in accuracy, an average of 8% and a maximum of 13% for models. In their study, Dewangan et al. [
32] used five ML techniques with principal component analysis (PCA) FST to identify the severity of Code smell across four datasets. The Decision Tree and Random Forest approaches achieved an accuracy score of 0.99 for the LM dataset. A. Yavuz et al. [
33] proposed different ML methods for code smell detection in C++ projects. The hyperparameter optimization was used to determine the optimal parameters for each model. The KNN model found an accuracy of 93.902% and a F1 score of 82.758%. Pushpalatha et al. [
34] explored ensemble methods incorporating both supervised and unsupervised classification techniques combined with information gain and chi-square FST. The reported accuracy for the Pits C dataset ranged from 79.85% to 89.80%. Their study focused on bug severity reporting in closed-source datasets. P. S. Yadav et al. [
35] proposed a multi-label approach for classifying and detecting method-level code smells. A rule-based technique was developed for multi-label code smell detection, achieving a maximum accuracy of 99.54% using the Decision Tree model.
Ray B. et al. [
36] studied the different types of programming languages and their code qualities, further enriching the knowledge base of software engineering.
Rehef KK et al. [
37] built the two models based upon stacked autoencoders, employing a hybrid architecture that combines bidirectional long short-term memory and convolutional neural network components for code smell detection.
The research conducted by Khleel N.A.A. et al. [
38] introduces a Deep Convolutional Neural Network (D-CNN) model integrated with SMOTE for the identification of bad code smells within a set of Java projects. For the evaluation, four code smell datasets were used. The results demonstrate that the proposed model, when applied with oversampling techniques, enhances performance in code smell detection.
Sandouka et al. [
3] introduced a Python code smell dataset containing instances of Long Methods and Large Classes for smell detection. Six ML methods were applied in this study. The MCC and accuracy percentage were computed, with the DT model achieving the best MCC rate of 0.89 and accuracy of up to 96%. Their study lacked ensemble methods, did not address class imbalance, and offered limited insight into feature importance or selection. This highlights a critical gap in the literature for Python-based code smell detection: the absence of robust ensemble frameworks that incorporate both feature selection and data balancing strategies.
Other Python-focused works, such as Gupta et al. [
9] and Chen et al. [
39], explored severity detection and rule-based tools, respectively, but similarly lacked rigorous ensemble-based evaluations with cross-validation and statistical testing.
The reviewed literature demonstrates that ML, ensemble learning, and deep learning techniques have been extensively applied to Java-based code smell datasets. However, the application of these methods to other programming languages, particularly Python, remains underexplored. Sandouka et al. [
3] demonstrated the feasibility of using ML models for detecting code smells in Python, marking an important step toward expanding beyond Java-centric approaches. Nonetheless, comprehensive investigations assessing the effectiveness of ensemble learning techniques, feature interpretability, and class balancing remain unaddressed on Python code smell datasets.
A primary challenge is the lack of diverse, language-specific datasets, especially those tailored to Python, which hampers the generalization and applicability of existing methods. Most existing studies are tightly coupled to the structural and semantic features of Java, and few attempt to examine the cross-language generalizability of their methods. This leaves a critical gap in our understanding of how programming language paradigms influence the design and effectiveness of ML-based code smell detection approaches. This study addresses these gaps by employing a comprehensive ensemble-based framework using five ensemble methods (Bagging, Gradient Boost, Max Voting, AdaBoost, and XGBoost) on two Python-specific code smell datasets, LC and LM, combined with chi-square FST to retain only the most informative metrics, and SMOTE to correct class imbalance. This combination not only enhances model robustness and interpretability but also directly addresses the shortcomings of prior Python-based studies, particularly the reliance on individual classifiers and unbalanced datasets. Moreover, by evaluating the approach using 10-fold cross-validation and multiple performance metrics, including MCC and Cohen’s Kappa, we aim to ensure balanced and reproducible outcomes.
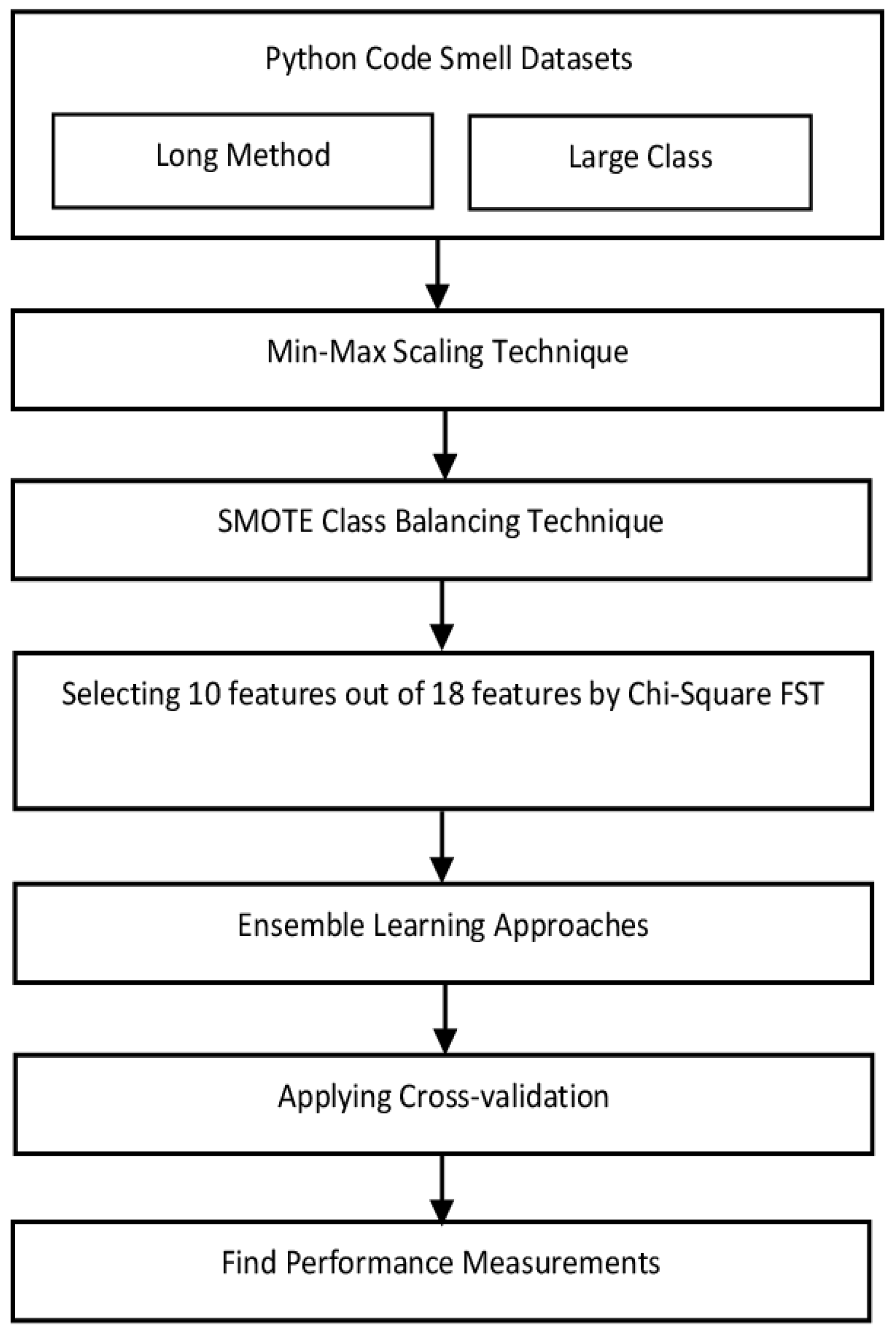
3. Proposed Research Framework
This section proposes a structured framework for detecting code smells in Python using ensemble learning techniques. As illustrated in
Figure 1, the process begins with the utilization of two Python code smell datasets introduced by Sandouka et al. [
3], followed by min–max normalization of feature values. To address the class imbalance, the SMOTE technique is applied. The most relevant ten features from each dataset are then selected using the chi-square FST. Five ensemble classifiers, Bagging, Gradient Boost, Max Voting, AdaBoost, and XGBoost, are employed to build predictive models. A 10-fold cross-validation is conducted to ensure reliability, and performance is assessed using accuracy, precision, recall, F-measure, Cohen’s Kappa, and MCC. The detailed steps are presented in the subsequent subsections.
3.1. Data Selection
This study used two Python datasets (LM and LC) from Sandouka et al. [
3], accessible at
https://doi.org/10.5281/zenodo.7512516. The datasets were constructed using four widely adopted open-source Python libraries: Scipy-V0.16.0b2, Matplotlib-V1.4.3, Django-V1.8.2, and Numpy-V1.9.2. These libraries were chosen for their widespread use in the Python community and their relevance to the code smell detection problem.
The selection of Python code was based on a number of factors, including its Python writing language, open-source status, and the PySmell dataset’s assessment of its smelliness or non-smelliness. The data collection process involved a rigorous sampling strategy. In the LC dataset, 1000 samples were randomly chosen from a total of 10,000, while in the LM dataset, 1000 samples were randomly selected from a pool of 40,000. Each sample that was chosen was categorized as “smelly” or “non-smelly” according to predetermined code smell detection standards using well-known tools (like PySmell).
Although we utilized PySmell to categorize “smelly” and “non-smelly” labels, it is important to recognize that automated labeling tools may introduce bias. Mislabeling can occur if the tool inaccurately interprets ambiguous or context-dependent code constructs, potentially impacting the quality of the ground truth.
Among the selected samples, only 200 samples in the LC and approximately 900 samples in the LM were found to meet the criteria for classification as ‘smelly,’ resulting in a class imbalance (roughly 20% smelly to 80% non-smelly). To address this, we applied SMOTE to augment the minority class while preserving the dataset’s statistical integrity. This step was crucial to mitigate the inherent skewness typical in code smell detection problems [
40].
While the datasets are relatively small, each was specifically designed to identify two common and well-known classes of code smells in Python. These two types are critical indicators of poor code quality, rendering them appropriate for our analysis. Working with these two categories enables us to concentrate on resolving essential issues in code smell detection, including class imbalance and feature selection. Moreover, analysis indicates that despite the limited dataset, we attained superior performance across various ensemble models (e.g., Max Voting and Gradient Boost), highlighting the efficacy of the proposed methods in identifying code smells.
Nonetheless, we acknowledge that the scope and size of the datasets may limit the generalizability of our findings. Future work will explore the extension of this framework to larger and more diverse datasets to validate its effectiveness across a broader range of Python code smells.
The choice to focus on two specific code smells, LC and LM, was based on their practical significance and frequent manifestation in actual software projects. Although broadening the scope to encompass additional categories of code smells is essential, concentrating on these two establishes a robust basis for subsequent research in Python code smell detection. This emphasis assures that the methodologies and techniques employed are tailored to these particular issues, providing a comprehensive understanding of the challenges associated with identifying these code smells in Python.
3.1.1. Feature Extraction
Eighteen distinct characteristics were extracted for every code smell to construct the Python code smell dataset. Code metrics, such as lines of code, comments, and defects, measure the software’s properties and are included in the extracted features. Two categories can be used to categorize the extracted code metrics. The first kind of metrics is called raw metrics, and it measures general metrics like the number of code lines that do not require complicated computations. Halstead complexity is the second kind of metric developed by the late Maurice Halstead to quantitatively determine the complexity of code by analyzing its operators and operands [
41].
The Radon tool was utilized to extract metrics from the source code. This popular Python tool is known for its reliability in extracting several code metrics, such as raw metrics, cyclomatic complexity, maintainability metrics, and Halstead metrics, from the code and providing accurate results.
3.1.2. Dataset Validation
For the Python code smell dataset, Sandouka et al. [
3] conducted a thorough validation process to ensure its quality. This process involved examining the dataset from various aspects, including the distribution of features and labels and the relevance of the extracted metrics to code smell detection. A certified feature extraction tool, Radon, was employed to ensure the reliability of the code metrics. The Pysmell dataset was examined by professionals in order to extract labels from a Python code smell dataset that has been confirmed and released.
3.1.3. Feature Distribution of the Python Dataset
A complete dataset consisting of 1000 cases was built for each code smell, namely the LC and LM, by painstaking labelling of class and method instances. The Python code smells dataset, which has been carefully produced, is given in
Table 1.
The datasets are defined below:
LC: A class that has become too big, including several lines, is a complicated entity referred to as an LC. This is a code smell at the class level that requires care.
LM: It describes a lengthy, complex, and multi-line procedure that poses a significant challenge in understanding and emphasizes immediate action.
3.1.4. Preprocessing Technique
It is a preprocessing technique that seeks to equalize each feature’s contribution to normalizing the range of data characteristics between 0 and 1. Before creating ML models, feature scaling is a popular preprocessing technique. Several research works on binary classification issues in various domains have shown that it may improve the quality of data and ML model performance [
42]. The min–max normalization approach was used in this study to scale the features. The min–max formula, as represented by Equation (1), is used to compute the normalized value (X′) based on the original value (X). The feature’s minimum value (Xmin) is set to “0,” while its maximum value (Xmax) is set to “1.” All other values are in relation, scaled as decimals in the range of 0 to 1.
3.1.5. Class Balancing Technique
Table 1 indicates that the dataset [
3] consists of two distinct classes: smelly and non-smelly. The characteristics of the Python dataset are outlined in
Table 1. Upon examining the distribution of classes within the dataset, a notable imbalance in the number of samples across the different categories (Smelly and Non-smelly) was identified, classifying it as an imbalanced dataset. The dataset exhibits a notable imbalance in class distribution. Standard metrics were employed to measure this imbalance, including the class imbalance ratio, which represents the ratio of the majority class to the minority class. In
Table 1, there are 200 classes categorized as smelly, in contrast to 800 classes that are classified as non-smelly. A different method employed to assess the impact of class imbalance on performance accuracy involved calculating the confusion matrix for each dataset.
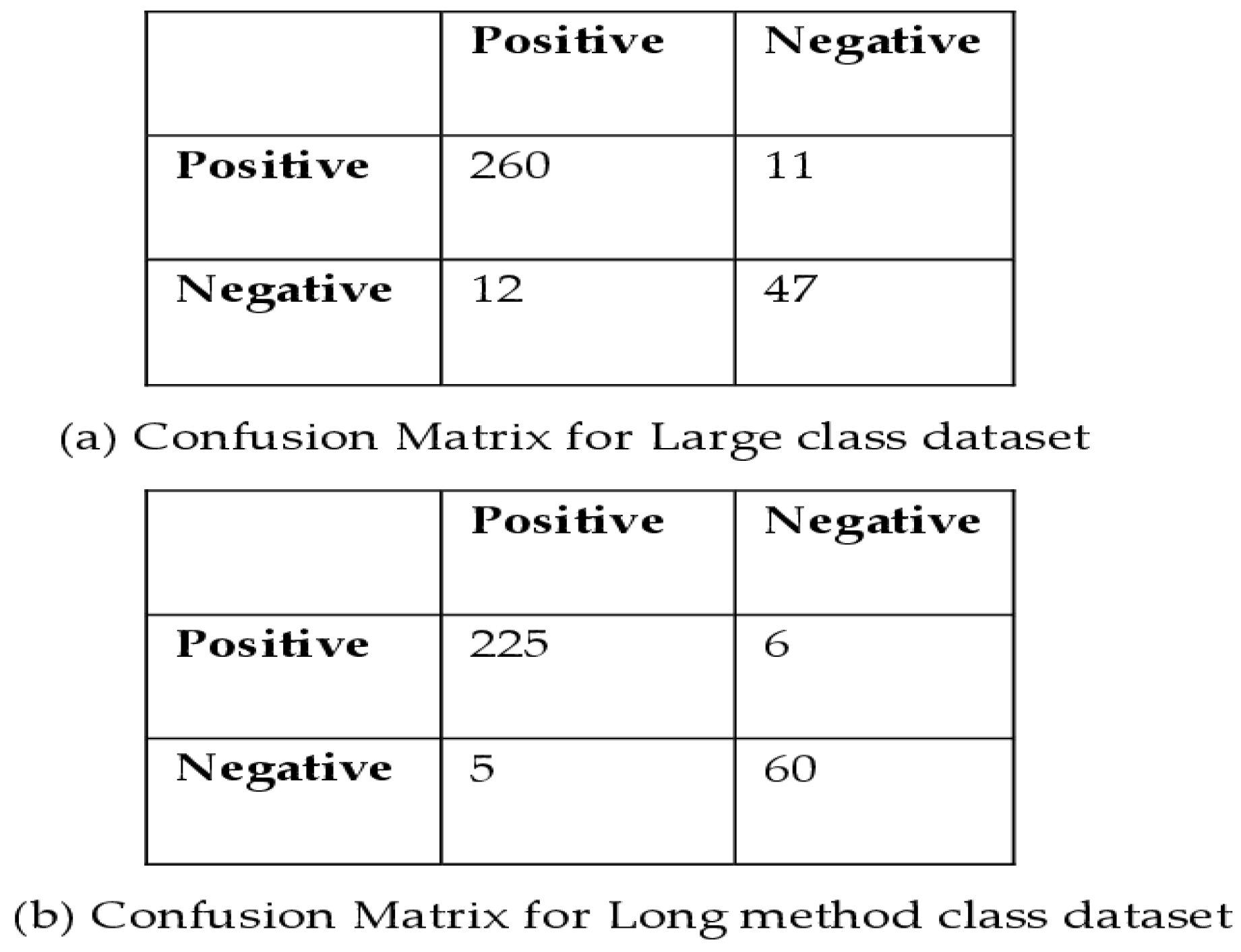
Figure 2 presents the confusion matrices for the LC and LM datasets, detailing four distinct values: True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN). In the LC dataset (
Figure 2a), the TPs amount to 260, FPs are 11, FNs total 12, and TNs stand at 47. In the LM dataset (
Figure 2b), the TPs amount to 225, FPs are 6, FNs total 5, and TNs stand at 60. To address this imbalance, the SMOTE class balancing method was employed, a widely recognized oversampling approach designed to enhance random oversampling [
43]. This method plays a crucial role in ensuring a more robust and accurate analysis.
3.1.6. Feature Selection Technique
In this study, an FST was applied to select the best features from both datasets. In many studies, different types of FST (such as Recursive Feature Elimination (RFE) or Principal Component Analysis (PCA)) have been used. However, the chi-square technique was employed in this study. The characteristics and requirements of the dataset determined the choice to utilize chi-square FST. Chi-square is well-suited for categorical data and measures the independence between features and the target variable [
14]. This is significant in this context because the features used to detect code smells, such as lines of code, comments, and complexity metrics, are treated as categorical in the feature selection process. Although these features are numerical in their raw form, they are discretized into categorical bins (e.g., low, medium, high) to facilitate the application of the chi-square test, which is most effective for categorical data. The Python code smell dataset comprises binary labels (smelly and non-smelly), rendering chi-square a logical and efficient selection. Generally, chi-square is more effective for small datasets, while the RFE is computationally intensive as it involves iteratively training models and ranking features. Given the dataset size and the need for computational efficiency, chi-square was a more practical choice. PCA focuses on dimensionality reduction by transforming features, which might reduce interpretability, as the transformed components are linear combinations of original features [
32]. The chi-square FST maintains original feature names and structures, thereby ensuring interpretability, which is essential for identifying actionable insights in code smell detection [
14]. To address potential bias, SMOTE was employed to balance the dataset, thereby ensuring robust and unbiased outcomes in feature selection.
The chi-square FST used in this study is pivotal in enhancing the validity and performance of ensemble learning models. This FST strategy eliminates unnecessary features, retaining only the most significant ones. Chi-square FST is particularly effective in categorical datasets, as it includes relationships to aid in identifying the most valuable features [
14]. Equation (2) demonstrates the chi-squared formula, a cornerstone of the feature selection process.
The observed frequency and expected frequency for the response and independent variables may be computed. The chi-square test determines how these two values differ from each other. Higher deviations lead to higher responses, indicating that the independent variables are interdependent.
Our analysis has identified the ten most precise features from each dataset.
Table 2 displays these features, retrieved using the chi-square FST. The first feature has a high score, while the last has the lowest. The best 10 features out of 18 are selected with a keen eye on balancing model performance and simplicity. Focusing on these top 10 features reduces dimensionality, improves computational efficiency, and potentially enhances the model’s generalization ability while retaining the most informative variables, contributing significantly to the predictive power. For a detailed understanding of these measures, please refer to
Appendix A Table A1.
Appendix A includes full descriptions of all selected measures.
3.1.7. Ensemble Methods
Ensemble learning is an ML technique that combines many algorithms to create a more precise prediction than a single algorithm. It trains multiple algorithms on the same data and then combines their predictions to improve the overall performance [
14]. Ensemble learning is effective because it reduces overfitting and improves generalization. The underlying principle is that different algorithms will make uncorrelated errors, which cancel each other out when aggregated.
Deep learning methods typically necessitate substantial datasets and significant computational resources. Due to the limited size of the dataset, comprising 1000 samples for both the LC and LM, ensemble learning methods are more suitable and effective in this context.
Some common ensemble learning algorithms used in this study are Bagging, Gradient Boosting, Max Voting, AdaBoost, and XGBoost.
Bagging: Alternatively referred to as Bootstrap aggregation, Bagging is an ensemble learning technique that helps to increase ML accuracy and performance. The use of bias-variance trade-offs in agreement serves to reduce the inaccuracy of a prediction model. The technique of Bagging is used in regression and classification models as a means to mitigate the risk of overfitting [
14].
Gradient Boosting (GB): This methodology is the most effective Ensemble ML method. The most prevalent forms of ML faults are bias error and variance error. The GB method is a boosting technique that may be used to enhance the bias accuracy of the approach. The GB method employs statistical techniques such as regression and classifiers to manipulate constant and categorical target variables. The cost function used in regression is the mean square error, whereas in classification, it is the log loss [
14].
Max Voting: It generates outcomes by selecting the class with the highest probability from a set of ensemble models. The Voting Classifier aggregates the outcomes of each classifier and predicts the class with the highest number of votes. In general, a unified predictive model is developed that incorporates many models and uses the aggregate number of votes for each output class to forecast output, as opposed to generating distinct individual models and assessing their performance [
14].
AdaBoost: It was the first boosting algorithm extensively used for binary classification and was developed by Yoav Freund and Robert Schapire. The boosting approach merges several “weak classifiers” into one “strong classifier” [
14].
XGBoost: The Extreme Gradient Boosting approach (XGBoost) is a tree-based ML model with better performance and speed. Tianqi Chen designed it, and the Distributed ML Community organization manages it. XGBoost has gained significant relevance in the field. It has proven its worth by consistently producing good results in structured and tabular data sets, making it a valuable tool for data scientists and ML practitioners.
3.1.8. Cross Validation
A 10-fold cross-validation (CV) is an iterative process that plays a crucial role in validating ML baselines. This process, performed ten times (ten splits and ten repetitions), involves randomly partitioning a dataset into ten equal subgroups. This method is then built using nine folds and tested on the remaining fold. Each fold is swapped with one of the training folds for a single testing dataset. This technique, used ten times, combines the outcomes to determine the outcome. Repeated cross-validation, which involves repeating the CV process multiple times, can further enhance the precision and trustworthiness of the results by addressing overfitting with low variance [
44].
3.1.9. Performance Measures
This paper examines Python code smell detection as a binary classification issue. The proposed ML models play a crucial role in distinguishing between smelly and non-smelly code occurrences. These models were rigorously assessed using six performance parameters: accuracy, precision, recall, F-measure, Cohen_kappa, and MCC. These metrics collectively capture various aspects of model performance, such as correctness, sensitivity to minority classes, and overall agreement between predictions and ground truth. MCC and Cohen’s Kappa are particularly useful in imbalanced classification settings, as they provide a more balanced evaluation compared to accuracy alone.
Accuracy: Measures the overall correctness of the classifier.
Precision: Reflects the proportion of correctly predicted positive instances among all predicted positives.
Recall: Indicates the proportion of correctly predicted positive instances among all actual positives.
F-measure: The harmonic mean of precision and recall, balancing both.
Cohen_kappa: Evaluates the agreement between predicted and actual classifications, adjusted for chance.
MCC: A balanced metric that considers true and false positives and negatives, especially useful for imbalanced datasets.
4. Result Analysis
To address the research questions, five ensemble ML models (Bagging, Gradient Boost, Max Voting, AdaBoost, and XGBoost) were evaluated on two Python code smell datasets (LC and LM) using six metrics: accuracy, precision, recall, F-measure, Cohen’s Kappa, and MCC. The impact of chi-square FST and SMOTE was assessed to examine improvements in model robustness and balance. The experimental code is available at
https://github.com/seemadewangan/Long-Method-Python-dataset-with-gradient-boost-ensemble-method/blob/main/Large%20class%20python%20dataset%20with%20AdaBoost%20Model.txt (accessed on 26 June 2025).
4.1. Results for the LC Dataset
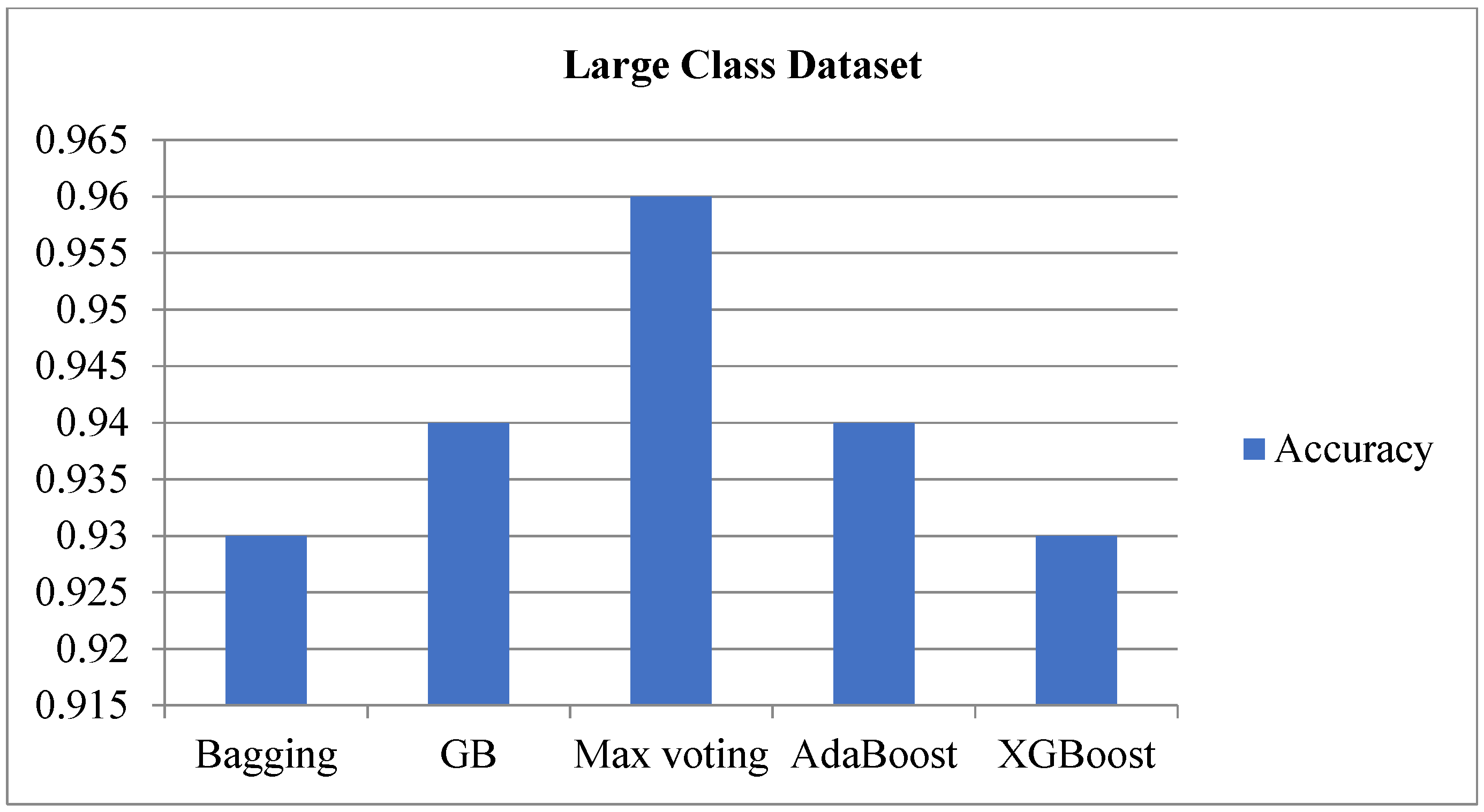
Table 3 presents the Python code smell detection results, showcasing the six performance measurements using five ensemble learning methods with applied chi-square FST and SMOTE. Notably, the max voting method emerged as the frontrunner, attaining an impressive 0.96 accuracy and F-measure scores and an MCC score of 0.85. This achievement underscores the effectiveness of the proposed approach or the combination of techniques used in the max voting method. This high accuracy, F-measure, and MCC score highlight the method’s strong predictive power and balanced performance in terms of precision and recall, especially for the LC dataset. By concentrating on the most pertinent features and reducing class imbalance, the improvement in the MCC score indicates that using FST and SMOTE improves classification. In contrast, the Bagging and XGBoost models recorded the lowest accuracy and F-measure scores of 0.93. The lowest scores indicate that these are less effective for this dataset compared to the max voting method. Additionally,
Figure 3 visually compares the results among the five Ensemble methods for the LC datasets.
Table 4 shows the result without applying chi-square FST and SMOTE. The Bagging method, a clear standout, obtained the highest 0.95 accuracy and F-measure scores and an MCC score of 0.8272, instilling confidence in the method’s performance. This indicates that Bagging is particularly effective for this dataset, providing strong predictive power and balanced performance in terms of both precision and recall. In contrast, the Gradient Boost and XGBoost models obtained the lowest accuracy and F-measure score, 0.92. This indicates that while they are still performing well, they are not as optimal as Bagging for the LC dataset.
Chi-square FST and SMOTE have significantly enhanced classification accuracy. This improvement underscores the progress achieved in the field of ensemble learning models.
When FST and SMOTE are used, the max voting model obtains better results than other ensemble models (
Table 3) because it combines several individual ML models to make predictions and produce the optimum outcomes.
The difference in performance between
Table 3 and
Table 4 highlights the significance of preprocessing, especially for models that are otherwise sensitive to data imbalance.
SMOTE prevents the classifier from being biased toward the majority class, which helps to address the class imbalance. Chi-square FST improves model efficiency by reducing irrelevant features, leading to enhanced generalization.
4.2. Results for LM Dataset
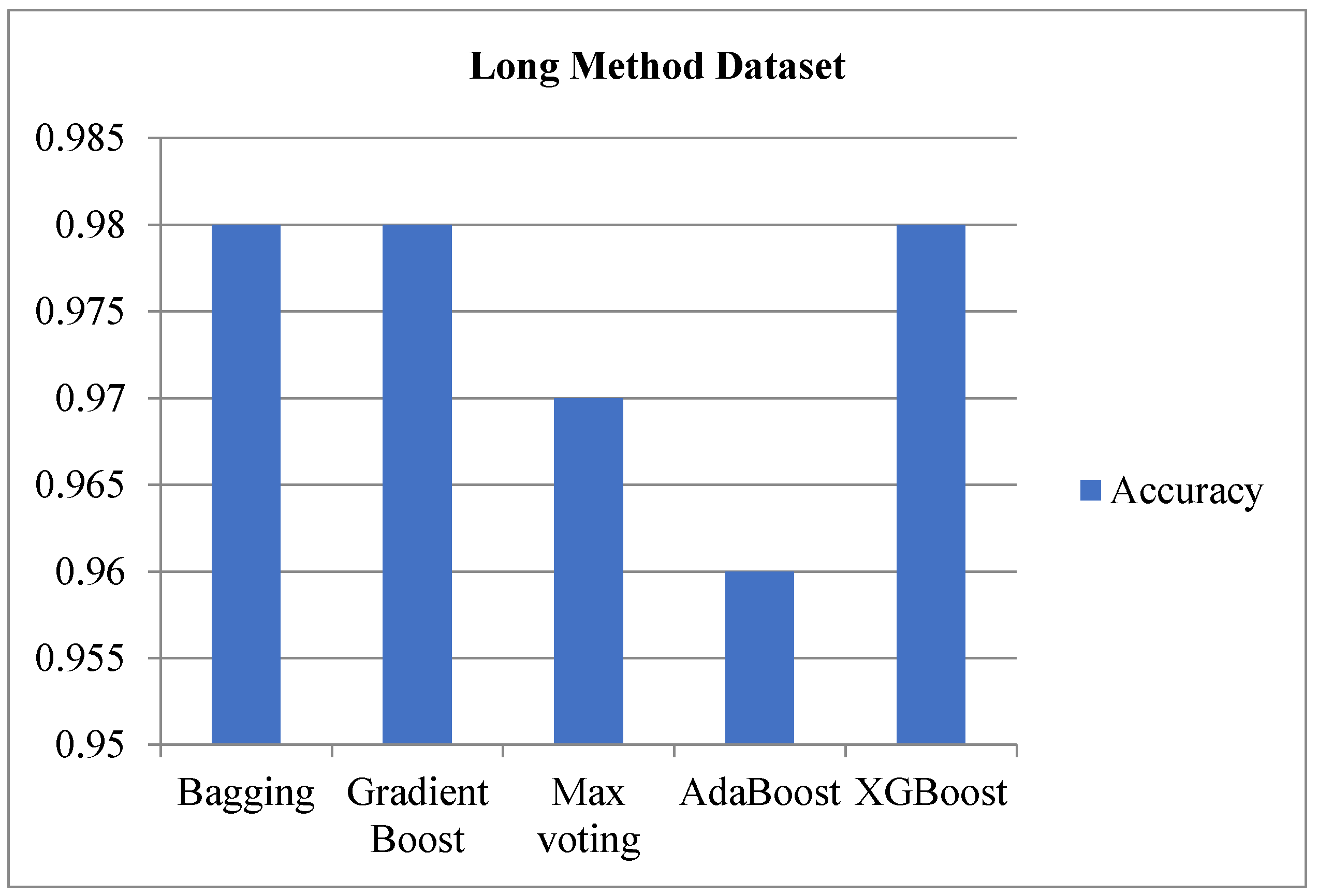
Table 5 presents the results obtained from applying chi-square FST and SMOTE. The gradient Boost method attained the highest accuracy score of 0.9845, an F-measure score of 0.98, and an MCC score of 0.94, underscoring its effectiveness. These scores reflect Gradient Boost’s ability to accurately classify data with a strong balance between precision and recall (as indicated by the high F-measure), making it a highly reliable and efficient choice for the LM dataset. Conversely, while still effective, the AdaBoost model acquired the lowest accuracy and F-measure score of 0.96. Although 0.96 is a good performance, the fact that it is described as the lowest suggests that AdaBoost is comparatively less effective than Gradient Boost, but it remains a strong model overall.
Figure 4 visually compares these methods for an LM dataset.
Table 6 reveals the results without applying chi-square FST and SMOTE. The Bagging method proved the most effective, achieving a high accuracy score, an F-measure score of 0.98, and an MCC score of 0.9187. While the performance remains high, the slight drop in MCC score compared to
Table 5 indicates that feature selection and SMOTE contribute to improved classification stability and minority class detection.
For the LM dataset, the Gradient Boost model obtained better results with FST and SMOTE, making it the most suitable model among other ensemble models (
Table 5) because it merges the predictions of several weak learners to build a single, more accurate, strong learner. On the other hand, in the absence of FST and SMOTE, the Bagging model proves its adaptability and works well. However, it is important to note that feature selection and class balancing can further improve the model’s overall consistency and dependability.
The effectiveness of FST in enhancing ensemble model accuracy is evident in the comparative improvements across most methods. SMOTE improves recall and MCC and ensures a more balanced detection of smelly and non-smelly code instances.
RQ.1 Answer: To answer RQ1, it was observed that the Max Voting performed best for the LC dataset, while Gradient Boost excelled on the LM dataset. These results suggest that no single ensemble model is universally optimal; instead, model effectiveness varies with dataset characteristics. Compared to earlier Java-based studies, the adapted ensemble methods retained strong performance, validating their transferability.
4.3. Effect of FST on Outcomes
In this study, accuracies were calculated for the LC and LM datasets.
Table 7 compares the accuracy score with and without the applied FST for the LC and LM. Gradient Boost, Max voting, AdaBoost, and XGBoost obtained better accuracy with FST than without FST for the LC datasets. Similarly, all models (except Max Voting) obtained better accuracy scores for the LM dataset. This indicates that chi-square FST helps these models by selecting the most relevant features, thereby improving their performance. Feature selection is essential for metric-based datasets, especially in dynamically typed languages like Python.
RQ.2 Answer: To answer RQ.2, it was observed that applying FST significantly improved accuracy performance across most Ensemble methods for both the LC and LM datasets. This underscores the crucial role of FST in improving detection performance by filtering irrelevant metrics. The results confirm that effective feature selection is critical in Python’s metric-rich and less standardized coding environment.
4.4. Effect of SMOTE on Outcomes
Table 8 compares accuracy across models with and without using SMOTE for the LC and LM datasets. The results indicate that most models had improved accuracy scores when SMOTE was applied to both datasets. This implies that SMOTE effectively addresses class imbalance issues and suggests that the technique is generally effective in enhancing model performance, regardless of the specific dataset. In this research, using the SMOTE approach is beneficial in enhancing performance. SMOTE enhances classifier sensitivity to minority classes (smelly code), improving recall and MCC. Gradient Boost and XGBoost benefited the most from SMOTE, especially in the more imbalanced LC dataset. The performance trend aligns with prior Java-based results, affirming SMOTE’s cross-language applicability.
RQ.3 Answer: To answer RQ.3, it was observed that SMOTE improved classification performance across both datasets, especially enhancing recall and MCC. These results are consistent with findings in Java-based detection studies, demonstrating that SMOTE remains effective for handling imbalances in Python datasets as well.
5. Discussion
This study evaluated the applicability and effectiveness of ensemble learning techniques for Python-specific code smell detection, guided by three research questions. Five ensemble models, Bagging, Gradient Boost, Max Voting, AdaBoost, and XGBoost, were evaluated on two real-world Python datasets (LC and LM) using six performance metrics. The models were further enhanced through the application of chi-square-based FST and the SMOTE technique for class balancing. The outcomes of these implementations are discussed in
Section 4.1 and
Section 4.2.
For Research Question 1, the Max Voting method achieved the highest accuracy score of 0.96 and an MCC score of 0.85 for the LC dataset, while the Gradient Boost method achieved the highest accuracy score of 0.9845 and an MCC score of 0.94 for the LM dataset. This variation demonstrates that ensemble model performance depends on the code smell type and dataset characteristics. The results affirm the adaptability of ensemble models to Python, though optimal model choice varies by context.
For Research Question 2, the chi-square FST enhances performance accuracy across most models for both datasets. This validates its effectiveness in filtering irrelevant or noisy metrics, a critical advantage in Python’s dynamically typed, metric-diverse environment. The gains were especially notable in boosting models such as Gradient Boost and AdaBoost.
For Research Question 3, SMOTE consistently improved recall and MCC without degrading precision, indicating enhanced detection of minority-class instances (i.e., smelly code) and reducing false negatives. This effect was particularly strong in the imbalanced LC dataset, mirroring success observed in Java-based studies and confirming SMOTE’s transferability.
Thus, the experiments show that applying chi-square FST improves model accuracy by reducing irrelevant features, while SMOTE boosts recall by addressing data imbalance. When used in combination, these techniques not only raise classification accuracy but also improve generalizability and robustness across both LC and LM datasets, thereby answering RQs in a more comprehensive and scientifically grounded manner. This study can be viewed as a domain transfer validation effort.
Importantly, this study can be understood as a domain transfer validation effort, evaluating whether ML-based code smell detection methods originally optimized for Java, a statically typed, strongly structured language, retain their effectiveness when applied to Python, which is dynamically typed and relies on indentation-based scoping. Given differences in type declaration, structural conventions, and metric distributions, this transfer is non-trivial.
Our findings suggest that while core techniques such as ensemble learning, FST, and SMOTE are effective across both languages, their performance and behavior vary depending on language-specific characteristics. This insight underscores the necessity of programming language-aware adaptation when designing ML-based software quality assurance tools.
By offering a comprehensive evaluation of two Python datasets and comparing results with prior Java-focused work, this study contributes empirical evidence toward the portability, limitations, and tuning needs of ML models across programming languages. Future work should extend this analysis to other languages (e.g., C++, JavaScript) and explore additional code smell types and model architectures to delineate the boundaries of cross-language model transfer further.
5.1. A Comparative Analysis of Our Approach with Other Relevant Studies
This section presents a comparative evaluation of the proposed ensemble-based framework against relevant studies in Python code smell detection. Sandouka et al. [
3] provided a foundational benchmark using traditional ML models but did not explore ensemble methods or data preprocessing techniques like feature selection and class balancing.
Our approach surpasses Sandouka et al.’s results across both datasets. For the LC dataset, Sandouka, R. et al. [
3] obtained a 0.93 accuracy score and a 0.77 MCC score using the random forest method with the gain ratio FST. In contrast, this approach demonstrated superior performance, achieving the best accuracy score of 0.96 and MCC score of 0.85 using the max voting method with applied chi-square FST and SMOTE class balancing techniques. For the LM dataset, Sandouka, R. et al. [
3] obtained a 0.96 accuracy score and a 0.90 MCC score using the decision tree method with the gain ratio FST. Once again, the proposed approach demonstrated its significance, achieving the best accuracy score of 0.98 and MCC score of 0.94 using the Gradient Boosting method with applied chi-square FST and SMOTE techniques.
This confirms the superiority of ensemble models, especially when supported by FST and SMOTE. Compared to other studies, such as those by Chen et al. [
39], which used the PySmell Tool and scored 97.7% precision but lacked robustness metrics like MCC, Z. N. Vatanapakorn et al. [
16] applied eight ML models with logistic regression, forward stepwise selection, and correlation FST to find code smells in the Python dataset. The result identified 99.72% maximum accuracy for the LM and Long base class list. However, the limited dataset diversity and lack of ensemble techniques reduce the generalizability of these findings. A. Gupta et al. [
9] used the AdaBoost method for severity detection and obtained 92.98% best accuracy but did not address class imbalance, FST, or use multiple ensembles.
Table 9 contextualizes our method’s performance against these works, showing consistent advantages in accuracy and MCC, particularly for real-world Python datasets.
Our experiments show that SMOTE improves recall, reducing false negatives without significantly degrading precision. This suggests that overfitting is not a concern in this setup. Furthermore, applying a 10-fold cross-validation ensures that synthetic instances do not bias generalization. SMOTE’s role in improving MCC scores across ensemble models confirms its effectiveness in enhancing minority class detection and classification stability.
The combination of Max Voting and Gradient Boost ensembles, shi-square FST, and SMOTE-based balancing sets this approach apart from prior studies. This robust configuration addresses known limitations, such as imbalance, noise, and overfitting that were not fully mitigated in earlier Python-based work. The significant improvement over established benchmarks supports the potential of our approach as a new baseline for future research in language-specific code smell detection.
For the LC and LM datasets, the ensemble learning methods obtained better accuracy and MCC scores than the ML models. This is because ensemble learning is a learning strategy that combines many ML models. One issue with ML is the poor performance of individual models, and sometimes their forecast accuracy is low. However, it is important to note that the proposed approach also has its limitations, such as the need for large amounts of training data and longer training times. In this context, the chi-square FST and SMOTE play a crucial role in enhancing accuracy, providing valuable tools for improving ML performance.
5.2. Statistical Analysis
To confirm the reliability of the results, a comprehensive statistical analysis was conducted using a Paired t-test, incorporating a 10-fold cross-validation and a 0.05 level of significance. The Paired t-test was used to identify any statistically significant difference between the two classifiers, enabling the selection of the superior one. This test requires the utilization of N separate test sets to produce each classifier, augmenting the dependability and accuracy of the findings.
A significant standard deviation indicates that a considerable proportion of the values within the dataset are dispersed throughout a wide spectrum. A low standard deviation indicates that a significant proportion of the outcomes within the sample are in close proximity to the mean. Consequently, selecting a framework with the minimum standard deviation is the most advantageous option. A p-value is a number describing the likelihood of obtaining the observed data under the null hypothesis of a statistical test. The p-value serves as an alternative to rejection points to provide the smallest level of significance at which the null hypothesis would be rejected. A smaller p-value means stronger evidence in favor of the alternative hypothesis. A p-value less than 0.05 is typically considered to be statistically significant, in which case the null hypothesis should be rejected. A p-value greater than 0.05 means that the deviation from the null hypothesis is not statistically significant, and the null hypothesis is not rejected.
Table 10 displays the mean accuracy, standard deviation, and
p-value for Python code smell datasets with LC and LM. The max voting model achieved the highest mean accuracy of 0.96, standard deviation of 0.01, and 0.04
p-value when applied to the LC dataset. The Bagging, Gradient Boost, and XGBoost models had the highest mean accuracy score of 0.98, standard deviation of 0.01, and
p-value of 0.04 for the LM dataset. These results confirm that the observed performance differences are statistically significant and not random variations.
5.3. Threats to Validity
This sub-section covers potential challenges to the experiment’s validity, including internal, external, and conclusion validity.
5.3.1. Internal Validity
A principal threat to the internal validity of this study originates from the dataset itself. The dataset comprises a corpus of Python code smells with variables extracted from diverse code characteristics. This dataset offers a robust foundation; however, alternative or supplementary metrics may enhance the efficacy of identifying Python code smells. The code samples were selected based on criteria such as being written in Python, being open source, and being labeled as “smelly” or “non-smelly” using the PySmell dataset. Random sampling techniques were employed for data selection. Feature selection was conducted using the chi-square method to examine the relationship between the dependent variable (smelly or not) and the independent variables (code metrics). Only features exhibiting a substantial gain ratio were incorporated in these experiments. The utilization of PySmell labels, grounded in expert assessment, may introduce subjectivity, thereby threatening validity. Furthermore, Chi-square analysis may produce erroneous results when the expected frequency of a characteristic is less than 5. A thorough analysis of the datasets verified that this condition was absent in the data utilized for this study, thus reassuring the absence of this limitation and the validity of this study’s results.
Despite being a popular tool for automated code smell detection, PySmell may not be able to detect some smells precisely because of rule-based limitations or misunderstandings of intricate code structures. Biases in feature extraction may result from this, especially if the labelled dataset contains false positives or false negatives.
To address these concerns, a subset of the PySmell-labeled samples in the dataset was examined as part of an initial verification step. Although a fully manual validation process could further enhance the accuracy of the ground truth, the scalability of the dataset offers potential for future improvements in automated code analysis. The size of the dataset enables the possibility of incorporating manual validation for a larger proportion of samples. To improve dataset reliability, a hybrid strategy that combines automated detection with human validation is intended for future exploration.
5.3.2. External Validity
The ability to generalize findings across various Python code smell datasets and attain comparable classification performance influences external validity. To mitigate this issue, datasets were gathered from four separate Python libraries, with the number of examples increasing relative to existing Java code smell datasets. Nonetheless, real-world projects may display diverse structural attributes, requiring additional validation. Future research should expand this study to encompass larger and more heterogeneous datasets sourced from industrial settings, thereby improving generalizability.
5.3.3. Conclusion Validity
Several factors may undermine the validity of the conclusion. The evaluation of model performance is intricately linked to these factors. Modifications to the evaluation metrics may be necessary to assess model effectiveness accurately. This condition was evaluated using six assessment measures, which were further refined through a 10-fold cross-validation. To address the potential for overfitting, which is frequently seen with ensemble methods, a 10-fold cross-validation was utilized. Overfitting arises when a model aligns excessively with the training data, thereby diminishing its ability to generalize to new, unseen data. To maintain the integrity of performance evaluation, SMOTE was exclusively applied to the training set, ensuring that the test set remained unaffected. An examination of feature significance was performed for each dataset (LC and LM), and the leading 10 features were identified utilizing the chi-square FST, as presented in
Table 2. The paired
t-test was employed to assess the statistical significance of the differences in detection performance across the models.
5.4. Comparative Analysis of the Approach with the Authors’ Previous Studies
We acknowledge that some aspects of this research framework, such as the use of ensemble models, SMOTE, and chi-square FST, were previously explored in our Java-based code smell detection studies [
6,
14,
24,
32,
35]. However, we emphasize that this study contributes novel insights by recontextualizing these techniques for Python-based code smells, which differ markedly from Java in structure, metrics, and coding patterns.
The following
Table 11 summarizes the distinct contributions of this study relative to our previous studies [
6,
14,
24,
32,
35]:
This table compares key elements, including language characteristics, code smell types, programming language focus, models used, feature selection strategies, contributions, and the novelty of each work. For clarity, we summarize the key distinctions below:
Programming Language Focus: Our previous studies were primarily based on Java datasets (e.g., Fontana and Guggulothu datasets), while this is the first ensemble learning application of our framework to Python, a dynamically typed language with a different code structure and metric distribution than Java.
Dataset Structure and Code Smell Types: Previous works addressed multiple smells or severity levels in Java datasets, whereas the current study focuses specifically on the binary classification of two Python code smells, LC and LM, curated from open-source libraries, which reflect real-world code issues in Python rather than Java.
Methodological Shift: The previous study [
35] employed the chi-square FST for multi-label code smell detection at the method level. In contrast, while this current study also uses chi-square, it does so in a different context, Python-based datasets with ensemble learning, not multi-label learning. In [
32], the previous work used PCA-based feature selection to detect the severity of code smells, which differs both in methodological application and in problem scope, marking a methodological divergence aligned with the statistical properties of the Python datasets.
Ensemble Strategy Focus: Previous works such as [
32] focused on the severity classification of smells [
14,
35], including ensemble models, but applied them to different problem settings such as severity prediction or multi-label classification. In contrast, this study concentrates on single-label binary classification using five ensemble methods (Bagging, Gradient Boost, Max Voting, AdaBoost, XGBoost) on Python code smells, which has not been explored in our previous work and is a relatively unexplored direction in the literature.
Class Balancing and Performance Evaluation: While SMOTE was used in some earlier studies ([
32]), our present work compares the impact of SMOTE in the context of Python datasets with ensemble classifiers and chi-square FST, showing performance enhancements over baseline ML methods.
Novelty and Contribution: The proposed study demonstrates the effectiveness of ensemble learning techniques on Python code smell detection, supported by a rigorous evaluation involving chi-square FST and SMOTE for class balancing. Unlike prior publications focused on Java datasets, model comparison, or severity ranking, this study demonstrates the transferability and effectiveness of ensemble models from Java to Python, offering insights into language-specific challenges and detection patterns. This addresses a notable gap in the literature, where most code smell detection is Java-centric.
Additionally, the datasets, features, and resulting model behaviors are entirely new, as evidenced by the distinct performance outcomes and confusion matrix analyses. This validates the importance of domain-specific evaluation even when using established methods.
This study provides the first comprehensive evaluation of ensemble models for code smell detection in Python, addressing a notable gap in the quality software literature. It demonstrates that techniques previously optimized for Java (ensemble learning, Chi-square FST, and SMOTE) can be adapted for Python, though their performance varies due to language-specific characteristics. These findings suggest that future code analysis tools should account for language semantics and structure to maximize detection accuracy and generalizability.
6. Conclusions
This study proposed a Python-specific framework developed by Sandouka et al. [
3] for detecting method-level code smells, LC and LM, using five ensemble learning techniques combined with chi-square FST and SMOTE-based class balancing. Unlike most prior studies that focus on Java, this work explores the performance of ensemble classifiers in Python, a dynamically typed and indentation-structured language, posing unique analytical challenges.
This study was guided by three research questions:
RQ1: Which ensemble algorithms perform best for detecting Python-specific code smells, considering structural and syntactic differences from Java?
The results show that the Max Voting model achieved the highest performance on the LC dataset (accuracy: 0.96, MCC: 0.85), while Bagging, Gradient Boost, and XGBoost performed best on the LM dataset (accuracy: 0.98, MCC: 0.94). These outcomes affirm the applicability of ensemble learning in the Python domain while also highlighting different behaviors across classifiers compared to Java-based studies.
RQ2: Does chi-square-FST improve model performance in Python code smell detection, given Python’s unique metric distribution influenced by dynamic typing and indentation-based structure?
The application of chi-square FST led to consistent gains in performance, as it selected the most relevant structural and lexical code features. The selected features (e.g., lloc, scloc, h1, n2) reflect Python-specific code properties and contribute to more robust classification outcomes.
RQ3: How does class imbalance in Python smell datasets influence model accuracy, and does SMOTE remain effective compared to its performance on Java datasets?
The Python datasets were highly imbalanced (20:80 class ratio). Applying SMOTE significantly improved minority class detection, particularly in terms of the recall and MCC scores, validating its effectiveness in the Python context. A paired t-test analysis confirmed the statistical significance of performance gains (p-values < 0.05 for top models), affirming the robustness of the proposed framework.
A comprehensive comparison with the authors’ earlier Java-based work is presented in
Section 5.4 and
Table 11, highlighting differences in language structure, dataset design, model behavior, and performance metrics. These insights validate that adapting feature selection, balancing methods, and ensemble configurations to language-specific contexts is crucial for accurate and meaningful code smell detection.
This study provides valuable insights for both researchers and software practitioners. Accurate detection of Python code smells is fundamental to improving software quality and maintainability, reducing the risk of failure, and facilitating effective code refactoring. The ensemble learning-based methods presented here demonstrate high accuracy and robustness in identifying Python code smells. These techniques can be integrated into development workflows, such as code reviews or continuous integration pipelines, to identify and resolve code smells early, ultimately reducing technical debt. In addition to offering a practical framework for detecting Python code smells, this work emphasizes the importance of feature selection and class balancing techniques. By incorporating ensemble learning and chi-square FST, this study presents a comprehensive approach to enhancing code smell detection in Python, contributing to more efficient and reliable software development practices.
Future work will involve expanding the scope to include additional types of code smells and evaluating the proposed approach on larger and more diverse datasets. Open-source repositories (e.g., GitHub, GitLab) and various Python projects will be leveraged to improve dataset diversity. These efforts aim to further assess the robustness and scalability of the proposed methods and explore their applicability to other programming languages. Performance improvements will continue through the exploration of alternative feature selection and class balancing techniques.





{kind=link}
{kind=link}
{kind=link}
{kind=link}