Abstract
Cross-document relation extraction (CodRE) aims to predict the semantic relationships between target entities located in different documents, a critical capability for comprehensive knowledge graph construction and multi-source intelligence analysis. Existing approaches primarily rely on bridge entities to capture interdependencies between target entities across documents. However, these models face two potential limitations: they employ entity-centered context filters that overlook relation-specific information, and they fail to account for varying semantic distances between document paths. To address these challenges, we propose CLEAR (Cross-document Link-Enhanced Attention for Relations), a novel framework integrating three key components: (1) the Relation-aware Context Filter that incorporates relation type descriptions to preserve critical relation-specific evidence; (2) the Path Distance-Weighted Attention mechanism that dynamically adjusts attention weights based on semantic distances between document paths; and (3) a cross-path entity matrix that leverages inner- and inter-path relations to enrich target entity representations. Experimental results on the CodRED benchmark demonstrate that CLEAR outperforms all competitive baselines, achieving state-of-the-art performance, with 68.78% AUC and 68.42% F1 scores, confirming the effectiveness of our framework.
1. Introduction
Relation extraction (RE) is a fundamental task in natural language processing that identifies semantic relationships between entities in text, serving as a critical component for knowledge graph construction, question answering, and information retrieval systems [1,2,3]. While conventional RE approaches have focused primarily on single-sentence or document contexts [4,5,6,7], real-world knowledge is often distributed across multiple documents, necessitating cross-document reasoning capabilities.
Cross-document relation extraction (CodRE) extends the relation extraction paradigm beyond single-document boundaries, aiming to identify relationships between entities that appear in different documents. Unlike traditional relation extraction that is confined to single texts, CodRE must reason across multiple document paths that connect the target entities, often through intermediate “bridge entities” [8]. This task presents unique challenges as relevant evidence is scattered across disparate sources, and document paths are typically lengthy with considerable noise. Consider determining whether “AlphaGo” was developed by “Google”. One document path might connect texts mentioning “AlphaGo defeated Lee Sedol in 2016” and “DeepMind’s AI system made history in Seoul”, while another path might link documents stating “DeepMind developed advanced game-playing algorithms” and “Google acquired DeepMind in 2014 for $500 million”. This shows that effective context filtering must consider both entities and their potential relations. Second, document paths have varying semantic relevance to the target relation, highlighting the need for mechanisms that can differentiate path contributions.
CodRE research has progressed significantly in recent years. Yao et al. [9] pioneered this direction by introducing the CodRED dataset, where documents connected through bridge entities are organized as text paths, and proposing BERT-based models for the task. However, their approaches suffered from irrelevant context in model inputs and inadequate cross-path connection modeling. Wang et al. [8] addressed these limitations with their Entity-based Cross-path Relation Inference Method (ECRIM), which incorporated an entity-centered noise filter for context refinement and a cross-path entity relation attention mechanism. Wu et al. [10] further advanced the field with their local-to-global causal reasoning model (LGCR), utilizing graph-based representations and causality estimation for noise filtering. To alleviate the burden of sentence selection, REIC [11] presented the first reinforcement learning selector for CodRE that extracts sentences based on target relation scores. Despite these advances, current CodRE methods face two critical limitations.
Firstly, previous methods only consider the entity information for context filtering. Typical of previous approaches, Wang et al. [8] introduce bridge entities for context filtering to collect semantically relevant context around target entities. This approach does not consider the influence of potential relation types during filtering. Consequently, important relation-specific textual clues may be overlooked or irrelevant noise retained. For example, when determining if an entity is the “founder of” another entity, text describing foundation events is critical, but current filters might miss such context if not directly surrounding the target entities. The failure to incorporate relation-specific information during filtering significantly limits the model’s ability to identify subtle but crucial evidence for complex relations. Secondly, current methods fail to account for the varying semantic distances between different document paths in the feature space when distributing attention. Intuitively, path pairs with shorter semantic distances (i.e., higher semantic similarity) should receive greater attention weight compared to paths with larger semantic distances, but existing attention mechanisms treat all paths uniformly [12]. This limitation prevents models from effectively focusing on the most semantically relevant path combinations, particularly in cases involving complex multi-hop reasoning chains. Additionally, existing approaches tend to underutilize non-bridge entities that co-occur with only one target entity, despite their potential to provide valuable semantic connections [13].
To address these challenges, we propose CLEAR (Cross-document Link-Enhanced Attention for Relations), a novel approach that enhances cross-document relation extraction through relation-aware context filtering and path-sensitive attention mechanisms. First, the Relation-aware Context Filter improves upon entity-centered filtering by incorporating relation type descriptions into the context selection process. Unlike previous approaches that focus exclusively on entities [8], our filter leverages natural language descriptions of potential relation types (generated through rules or large language models) to guide the selection of relevant sentences. This approach ensures that context relevant to the target relation is preserved while reducing noise, addressing a key limitation in existing filtering methods. Second, we propose a Path Distance-Weighted Attention (PDWA) mechanism that explicitly models semantic distances between document paths. PDWA operates on the principle that document paths with similar semantic content should receive more attention when inferring relations. For any document path, we first identify its most relation-relevant sentence through an attention network that maps the path to the target relation space. For a pair of document paths, we compute weighted representations using an attention mechanism with the target relation representation as the query vector and sentence representations as key and value vectors. This approach dynamically adjusts attention weights based on path-pair distances, enhancing the model’s ability to focus on semantically similar paths. By giving higher weights to path pairs with shorter semantic distances in the feature space, PDWA significantly improves the model’s performance on complex multi-hop reasoning chains. Third, a Cross-document Information Integration module captures entity connections across documents. This component includes a lightweight mechanism to incorporate information from non-bridge entities when beneficial, while primarily focusing on optimizing the integration of information from target and bridge entities through our enhanced attention mechanisms [14].
Our contributions can be summarized as follows:
- We introduce a relation-aware context filtering approach that incorporates relation type descriptions into the filtering process. This method improves context relevance and reducing noise.
- We design a novel Path Distance-Weighted Attention mechanism that dynamically adjusts attention weights based on semantic distances between document paths. This approach improves F1 scores by 3.1% on average compared to standard attention mechanisms.
- To investigate the effectiveness of our model, we conduct extensive experiments on the CodRED dataset. Our experimental results and in-depth analysis show that our model significantly outperforms all competitive baselines, including the LLMs.
The paper is structured as follows: Section 2 reviews the related work on document-level and cross-document relation extraction. Section 3 introduces the proposed CLEAR framework, elaborating on its architectural design and key components. Section 4 describes the experimental methodology, including dataset preparation, baseline models, and evaluation metrics. Section 5 presents the results with detailed analysis. Finally, Section 6 concludes the study and discusses future research directions (code: https://github.com/zjcerwin/CLEVER (accessed on 15 November 2024)).
2. Related Work
Current research related to this work primarily focuses on two major domains: Document-level relation extraction (DocRE) and cross-document relation extraction (CodRE). The following sections examine the current state of the research in these two tasks.
2.1. Document-Level Relation Extraction
Document-level relation extraction aims to extract relations between entities within a single document. Existing methods can be categorized into three approaches: evidence-based methods, graph-based methods, and attention-based methods.
Xie et al. [6] proposed the EIDER framework, which improves document-level relation extraction by extracting and integrating key evidence sentences. EIDER adopts an architecture that combines joint relation extraction with a lightweight evidence extraction model and incorporates a hybrid layer for reasoning fusion. On the other hand, Xu et al. [5] introduced the Sentence Importance Estimation and Focusing (SIEF) framework to address the insufficient robustness of existing document-level relation extraction models. SIEF effectively guides the model to focus on key evidence sentences by estimating sentence importance and introducing a focusing loss function. Ma et al. [15] then proposed DREEAM, the first self-training method for evidence retrieval in document-level relation extraction. This method addresses two key challenges in evidence retrieval: excessive model memory consumption and scarcity of annotated data. Evidence-based methods offer the following advantages: (1) By focusing on evidence sentences most directly related to the relation, they reduce interference from noise and irrelevant information, thereby improving extraction accuracy [16]. (2) These methods typically provide clear indications of which text segments serve as evidence for extracting specific relations, ensuring high interpretability. Their main limitation lies in their heavy dependence on the quality of selected evidence sentences, where missing or misjudging critical evidence significantly impacts the extraction results.
For graph-based approaches, CGM2IR [17] introduced two techniques to enhance document-level relation extraction: context-guided weighted mention integration and pairwise inference on entity-pair graphs to extract relation interdependencies. GAIN [18] is a graph aggregation and inference network with a dual graph structure, constructing a heterogeneous mention-level graph (hMG) and an entity-level graph (EG) for feature propagation and relation reasoning. The hMG models interactions between mentions, while the EG handles relation reasoning between entities. The recently proposed CorefDRE [19] represents multi-sentence features by incorporating core reference information into dynamically constructed heterogeneous graphs and introduces a mention-pronoun core reference resolution to compute pronoun affinity, along with a noise suppression mechanism to mitigate pronoun-induced ambiguity. Graph-based methods have the following advantages: (1) Graph structures provide models with a global perspective, facilitating understanding and reasoning of complex relations between entities. (2) They can utilize structured information within documents, such as inter-sentence connections and entity co-occurrences. Their main disadvantage is the complexity of graph structure construction and computation, making them challenging to apply to large-scale documents.
Attention-based methods typically utilize attention scores to capture contextual information and employ adaptive regularization techniques to enhance model generalization. For example, Tan et al. [20] presented a semi-supervised framework featuring axial attention modules, adaptive loss functions, and knowledge distillation capabilities. SSAN [5] incorporates unique structural dependencies between mention pairs into self-attention mechanisms and encoding stages, including two transformation modules in each self-attention block to generate adaptively regulated attention biases. Dense-CCNet [21] is a densely connected cross-cross-attention network for DocRE that employs cross-cross-attention (CCA) to bidirectionally collect contextual information on entity pair matrices and densely connects layers to capture single-hop and multi-hop reasoning features. The advantage of attention-based methods lies in their ability to help models focus on the most relevant parts of the current task, leading to better context understanding and relation extraction. Their main limitation is insufficient interpretability; while attention mechanisms help models focus on important information, their internal mechanisms often lack transparency, making model decisions difficult to explain.
2.2. Cross-Document Relation Extraction
Cross-document relation extraction approaches, on the other hand, aim to extract relations between entities across multiple documents. There are four main categories.
Information retrieval and context filtering methods focus on retrieving relevant information across documents. ECRIM [8] introduces an entity-based document context filter and cross-path entity relation attention mechanism. MR.COD [22] implements multi-hop evidence retrieval through path mining and ranking. These methods efficiently reduce irrelevant information but depend heavily on search quality.
Learning-based reasoning methods employ machine learning for this task. REIC [11] is the first learning-based sentence selector for CodRE that extracts sentences based on relation evidence. PILOT [12] utilizes explicit clue information to enhance reasoning paths between entities. These approaches excel at modeling complex relations but require substantial computational resources and data.
Graph-based approaches model entity relationships across documents. Yue et al. [13] represent input bags as unified entity graphs incorporating non-bridge entities and apply graph reasoning networks (GRNs) with a debiasing strategy to refine prediction distributions. Wu et al. [10] propose a local-to-global causal reasoning (LGCR) network that uses local causal estimation to distinguish confusing information and causality-guided global reasoning to filter irrelevant information in cross-document settings. These methods effectively capture complex relationships but face challenges in graph construction.
Knowledge-enhanced methods incorporate external knowledge to improve extraction performance. Jain et al. [14] leverage domain knowledge for cross-document relation extraction, providing explanatory text for predictions that enhances interpretability. This approach demonstrates how domain knowledge can guide the extraction process but may be limited by the availability and quality of knowledge resources.
Cross-Document Event Coreference Resolution (CD-ECR) detects and collects event mentions across different documents, which is also related to this work. Min et al. [23] proposed a collaborative CD-ECR approach using general large language models (LLMs) for initial event summarization and specialized domain-specific language models (SLMs) during fine-tuning to refine event representations. Cremisini and Finlayson [24] introduced a simpler framework for CDEC on ECB+ that achieved state-of-the-art performance with fewer features, using only event trigger word annotations, making the simplified model directly comparable with reference models. Through using fewer features or simplified frameworks, simplified and collaborative learning methods are easier to understand and implement.
In summary, we identified three major challenges in current cross-document information extraction: (1) Suboptimal input construction that introduces noise and overlooks semantic connections; (2) insufficient inter-document information interaction, with models treating document paths as independent samples; and (3) inadequate discrimination between positive and negative instances in multi-instance scenarios. Our work addresses these limitations through relation-aware context filtering that considers both entity and relation semantics, Path Distance-Weighted Attention that models document path relationships, and cross-path relation matrix mechanisms that enhance discrimination between positive and negative instances.
3. Framework
3.1. Task Description
Consider a target entity pair and its associated document path bag , where each path is defined as a tuple:
where denotes the set of all documents. The bag is associated with a bag-level label , while each path instance is assigned an instance-level label . The cross-document relation extraction task requires learning a prediction function,
which infers the semantic relation Y between and based on the structured interactions among the documents in bag .
3.2. Overall Model Architecture
As illustrated in Figure 1, CLEAR integrates four synergistic components in a cascaded architecture:
- 1.
- Relation-aware input constructor: Processes document paths through dual-stage filtering that dynamically weights sentences based on entity co-occurrence patterns and semantic relevance to potential relations. This generates compressed, relation-focused sequences (Section 3.3).
- 2.
- Contextual encoder: Transforms filtered inputs into deep semantic representations using pre-trained language models (RoBERTa). This component extracts target and bridge entity embeddings critical for cross-document reasoning (Section 3.4).
- 3.
- Cross-path integration core: The framework’s nexus features our novel Path Distance-Weighted Attention (PDWA) mechanism. This computes pairwise semantic distances between document paths and dynamically adjusts attention weights to prioritize information from semantically aligned paths while suppressing noisy connections (Section 3.5).
- 4.
- Relation prediction module: Aggregates refined path representations, applies multi-instance pooling, and generates final predictions through adaptive threshold classification (Section 3.6).
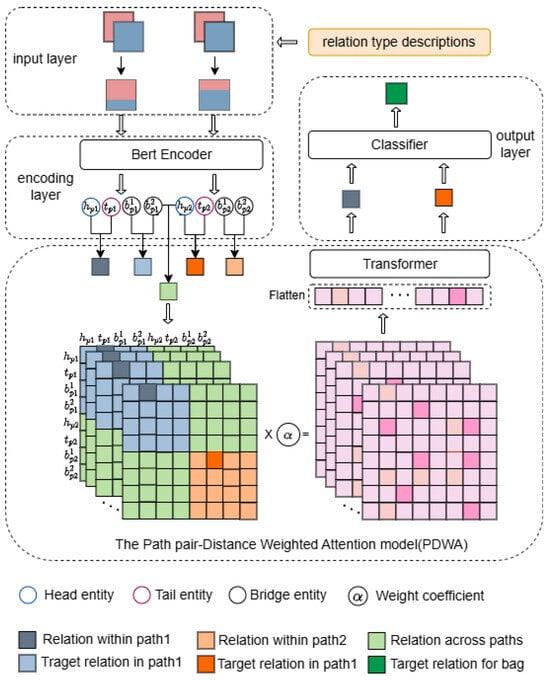
Figure 1.
Our CLEAR model structure diagram.
Figure 1.
Our CLEAR model structure diagram.
The architecture follows a unidirectional information flow: (1) Filtered inputs → (2) contextual encoding → (3) cross-path integration → (4) relation prediction. Crucially, the PDWA mechanism (component 3) receives contextualized representations from all paths simultaneously, enabling global reasoning about cross-document relationships. This integrated design addresses both evidence preservation (via relation-aware filtering) and cross-path reasoning (via distance-weighted attention) in a unified framework.
3.3. Relation-Aware Document-Context Filter
This module addresses long-text processing in cross-document relation extraction through a two-stage filtering strategy to generate compact yet informative inputs. Previous methods only consider entities for context filtering [8,12], while we find that relation descriptions are also important for bringing in more relevant sentences for target relation extraction and reducing noisy texts. We first define the bridge entity and then incorporate relation descriptions into the filtering process.
For two documents in document path , the bridge entity set is a collection of entities that are shared by the two documents of this text path:
where are target entity pairs.
3.3.1. Stage I: Important-Sentence Filtering
Following [8], we first compute bridge entity importance scores through three co-occurrence conditions but add a fourth relation keyword score.
1. Direct co-occurrence score :
2. Indirect co-occurrence score :
where
- -
- if co-occurs with in sentences;
- -
- is an indicator function (1 if satisfies , else 0).
3. Potential co-occurrence score :
4. Relation keyword similarity score :
To incorporate relation-specific information into our filtering process, we propose a novel relation keyword similarity score:
where
- -
- is the set of sentences containing bridge entity ;
- -
- is a set of candidate relation descriptions;
- -
- measures the semantic similarity between sentence s and relation description r.
Relation description generation: The relation descriptions in can be obtained through multiple approaches: (1) Schema-derived descriptions from dataset relation schemas (e.g., CodRED’s predefined relation types like “owned by”: “entity A is owned or controlled by entity B”); (2) Manual descriptions crafted by domain experts based on linguistic and semantic knowledge; or (3) LLM-generated descriptions using large language models such as Llama3.1 to generate diverse paraphrases and contextual variations. While different generation methods may yield varying performance impacts, our current implementation uses schema-derived descriptions as they provide consistent and standardized relation semantics. A comprehensive comparison of these description generation approaches represents an important direction for future work.
To obtain , we first extract sentences containing the target entities and , combine them as input to a BERT + MLP classifier, and select the top-N predicted relation types. We then compute the cosine similarity between the word2vec embeddings of sentence keywords and relation type terms to derive the similarity score.
Total score formula:
with default hyperparameters , , , and reflecting higher weights for direct co-occurrence while giving substantial weight to relation-specific information. This prioritizes “more direct associations are more important” by reducing long reasoning chains and cross-document noise, while ensuring relation-specific context is adequately represented.
The top K high-score sentences are retained (default ), forming candidate set .
3.3.2. Stage II: Semantic Relevance Reorganization
After obtaining candidate sentences and their importance scores, we reorganize them into a coherent sequence using both entity-based connections and relation-semantic relevance. This approach generates a coherent input sequence from S.
In particular, we reorganize the top K selected sentences into a coherent sequence. Starting from a randomly selected sentence containing the head entity, we iteratively select the next sentence that maximizes a combined similarity score consisting of entity–entity similarity and sentence–relation similarity. This process continues until we reach a sentence containing the tail entity, ensuring a logical inference path. If the resulting sequence exceeds the input length limit (512 tokens), we perform relation-aware truncation by removing the sentences with the lowest relation similarity scores.
3.3.3. Mathematical Expressions and Parameters
Entity–entity similarity calculation:
Sentence–relation similarity calculation:
where is a set of relation descriptions. These descriptions can be generated through rule-based templates or large language model generation (e.g., using GPT-3.5 to generate multiple paraphrases of relation descriptions). SBERT-WK(.) is a modified BERT model designed for sentence-level similarity calculation [25].
Combined similarity score:
where and are weighting hyperparameters (default: , ).
Input sequence constraint:
Our relation-aware semantic reorganization approach implements the following functions:
- Noise filtering: Unrelated sentences (such as those containing only a single entity or no co-occurrence) are removed through bridge entity screening and relation relevance assessment.
- Relation-specific context preservation: By incorporating relation descriptions into the similarity calculation, we ensure that sentences semantically related to potential relations are prioritized, even if they do not contain explicit entity co-occurrences.
- Logical coherence: Semantic reorganization retains cross-document inference chains (such as the path ) while ensuring relation-relevant information is preserved.
- Efficiency optimization: Documents with an average of 4900 words are compressed to within 512 words, reducing computational complexity while preserving the most informative, relation-relevant content.
3.4. Encoding Layer
After completing the input data preprocessing, we construct a sentence collection from document paths. The textual units in are concatenated in their original order to form the model input sequence . Following the special token mechanism of pre-trained models, we employ [ENTITY] symbols to annotate the start and end boundaries of each entity. To investigate the performance differences between pre-trained encoders, we independently adopt BERT [26] and RoBERTa [27] as parallel feature extractors for comparative experiments.
For the BERT encoder:
For the RoBERTa encoder:
Upon obtaining token-level representations, we design a boundary-sensitive max-pooling layer to capture local salient features for entity representations. Specifically, for the m-th entity mention,
where the boundary indices denote the start and end positions of the entity in the sequence.
3.5. Path Distance-Weighted Attention (PDWA) Model
Theoretical foundation: The PDWA mechanism is grounded in the semantic similarity hypothesis for cross-document reasoning: document paths with higher semantic similarity should receive proportionally higher attention weights during relation inference. This principle is formalized through three key components: (1) Semantic distance computation using normalized cosine similarity in learned representation space; (2) distance-to-weight transformation, ensuring semantically closer paths receive exponentially higher attention; and (3) attention matrix adjustment, that preserves the original attention distribution while incorporating semantic proximity bias. This approach provides a principled method for attention allocation that goes beyond uniform weighting by explicitly modeling the semantic relationships between document paths.
To account for varying semantic distances between document paths in feature space, our approach adjusts attention weights accordingly. Path pairs with shorter semantic distances (exhibiting higher semantic similarity) should intuitively receive greater attention compared to paths with larger semantic gaps. We therefore introduce a “document path-pair distance” mechanism that applies corrective weights to the attention scores between path pairs, ensuring that semantically similar paths contribute more substantially to the attention matrix computation.
For any document path p, we aim to identify its most relation-relevant elements with respect to the target relation r. We accomplish this by calculating the sentence s most relevant to the target relation through an attention network, which serves as the path’s mapping in the target relation space: . For a document path pair and , we first derive their sentence representations and using an attention mechanism that employs the target relation representation as the query vector and sentence representations as both key and value vectors:
Here, s represents sentence embeddings within the document path (computed by averaging word embeddings), and denotes the target relation representation. Subsequently, these sentence representations are processed through a binary classification linear layer that produces a probability distribution indicating the likelihood of each sentence being selected. Using GumbelSoftmax, we sample the highest-probability sentence to serve as the mapping vector of path in the target relation space.
GumbelSoftmax is calculated as follows:
where is Gumbel noise, L is the number of path words of the document, and is the temperature parameter that controls the smoothness of the sample; a lower is closer to the true discrete distribution.
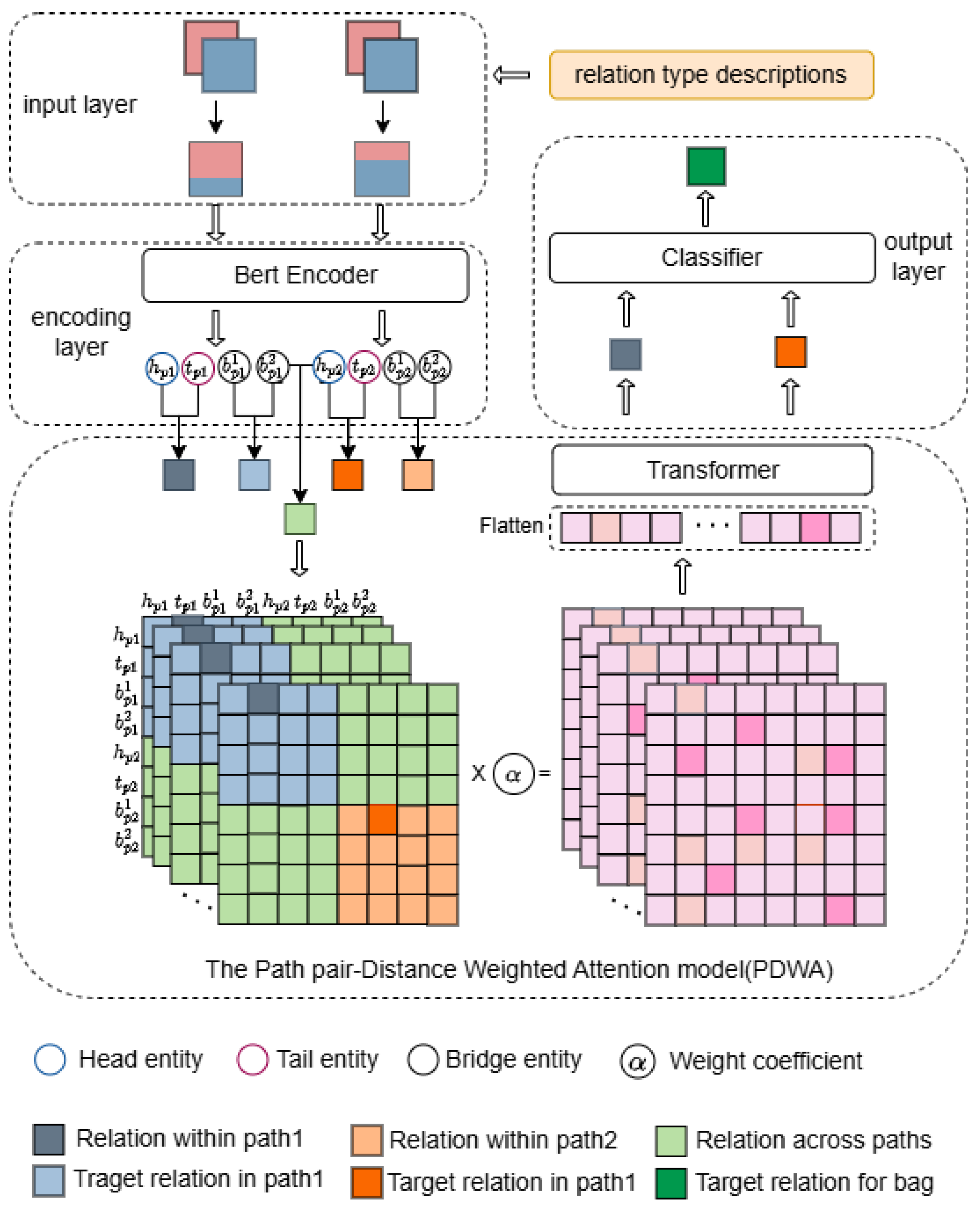
Consider using the similarity between vectors and as the basis for calculating the attention weights for the correspondence relation sub-matrix between and . If the vectors related to the target in the two paths are more similar in the feature space, the distance between the two document paths will be closer. And in the original attention matrix, the attention weights of the corresponding sub-matrix for these two paths should be larger. Therefore, the attention weight correction coefficient is calculated by computing the similarity degree between each through dot product similarity:
After obtaining the attention weight correction coefficients for all document path pairs, the attention weights in the current layer’s relational matrix are weighted based on these correction coefficients. As shown in Figure 2, the original relational matrix M is first divided into sub-matrices (where the subscripts i and j represent the cross-document relational units between document path i and document path j, and when , this represents the intra-document relations within the i-th document path). Each sub-matrix has a shape of . For a pair of document paths and , the sub-matrices corresponding to all the relational units involved in these two document paths are , , , and . The attention H between the relational units of these sub-matrices is adjusted by the weight coefficient as follows:
where the shape of the attention matrix is . After recalculating the attention coefficients by incorporating the document path distance, we obtain the revised relation matrix representation . After l layers of iterations, the target relation representation of each path is obtained from the relation matrix representation of the last layer.
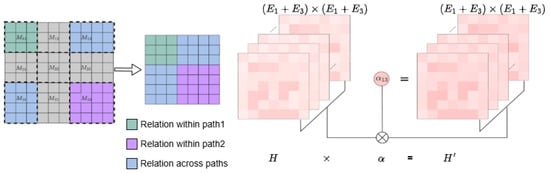
Figure 2.
The proposed Path Distance-Weighted Attention (PDWA) model.
3.5.1. Cross-Path Entity Matrix Construction
The cross-path entity matrix organizes entity relationships across document paths. As described in Algorithm 1, the original relation matrix M is divided into sub-matrices corresponding to path pairs:
Matrix dimensions: Each sub-matrix has shape , where is the number of entities in path . When , captures intra-path relations; when , captures inter-path relations.
Sparsity optimization: To reduce computational overhead, we retain only the top 34% of entity connections based on relevance scores, which reduces the processing time to approximately 22 ms per sample while preserving critical bridge entity relationships.
Integration with PDWA: The distance-weighted attention mechanism in Algorithm 1 operates on these sub-matrices, applying the computed distance weights to adjust attention as .
| Algorithm 1 Path Distance-Weighted Attention (PDWA). |
Require: Document paths , target relation , entity representations E Ensure: Enhanced relation representations
|
3.5.2. PDWA Construction Steps
The process of PDWA is shown in Algorithm 1; it consists of four main steps.
Step 1 (lines 2–5): For each document path, we identify its most relation-relevant sentence by applying the attention mechanism with the target relation representation as the query vector. The GumbelSoftmax function enables differentiable discrete selection of the most informative sentence while maintaining gradient flow during training.
Step 2 (lines 7–10): We compute semantic distances between all path pairs based on their relation-relevant sentence representations. The distance is inversely proportional to the dot-product similarity, meaning semantically similar paths have smaller distances. Normalization ensures that distance weights sum to unity across all path pairs.
Step 3 (lines 12–16): The original relation matrix is partitioned into sub-matrices corresponding to entity relations within and across document paths. Each sub-matrix’s attention weights are adjusted by the corresponding distance weights, ensuring that semantically similar paths receive higher attention during relation reasoning.
Step 4 (lines 18–20): After l layers of distance-weighted attention processing, we extract the final target relation representations for each path from the enhanced relation matrix.
3.6. Output Layer
The model generates corresponding relation representations for each document path that contains the target entity within a sample bag through the cross-path entity relation matrix attention layer. Specifically, for each path in the sample bag, the relation representation is obtained as follows:
Relation representations are utilized as classification features and are input into a multi-layer perceptron (MLP) classifier to compute the score for each relation. This process is formalized as
To predict relations at the bag level, the model performs max pooling over the scores of each relation label across different paths, yielding the final score for each relation type r. This step is formulated as
After calculating the scores for all relations, the model employs a global threshold to filter out categories with scores below this threshold. The process of filtering is detailed in the subsequent section on model training.
3.7. Auxiliary Training Task
The document path context derived from the input construction module exhibits a parallel in both structure and characteristics to the context encountered in document-level relation extraction tasks. This intrinsic similarity underpins the rationale for the facilitative role that document-level relation extraction can play in enhancing cross-document relation extraction capabilities. Thus, we leverage the remotely supervised annotated dataset in CodRED [9]. By incorporating document-level relation extraction as an auxiliary training objective, the model is able to augment its cross-document relation extraction proficiency through the acquisition of document-level extraction skills.
In particular, for each document in DocRed [28] containing multiple relation facts,
We construct instances based on relation facts, using the head and tail entities as context selection anchors. Each instance comprises a context of characters surrounding the relation fact. We create a package of document paths. Unlike CodRE packages, B has no package-level label Y, but instead contains n instance-level labels , corresponding to each instance.
3.8. Model Training
Given that the data at the package level may possess multiple relation labels, a multi-label global threshold loss is employed as the loss function for the task. This loss function is a variant of Circle Loss [29]. To this end, an additional threshold is introduced to control which classes should be outputted, with the aim of ensuring that the scores of the target classes exceed the threshold, while the scores of the non-target classes remain below the threshold. Formally, for each package-level sample B, it can be expressed as
where represents the score for relation r, and denotes the threshold. and represent the positive and negative class relation labels between target entity pairs within the package B. Taking into account the addition of document-level relation extraction as an auxiliary training task for the model, it is necessary to compute the loss function for the auxiliary task and sum the two losses to obtain the final loss function. For the document-level relation extraction task, the model computes the cross-entropy loss for each document at the package level for the package-level sample , which consists of N document-level relation extraction samples:
Thus, across an entire training batch, the model’s loss function is the sum of the losses from the two types of samples contained within the batch:
where is an indicator function, such that when is a cross-document relation sample, and otherwise.
3.9. Model Reliability and Robustness
To ensure the reliability and robustness of the CLEAR framework, we implement two key mechanisms.
Input validation and consistency: Our Relation-aware Context Filter incorporates multiple validation layers to ensure input consistency. The bridge entity scoring mechanism uses four complementary metrics (direct, indirect, potential co-occurrence, and relation similarity) to provide robust sentence selection. This multi-criterion approach reduces the risk of selecting irrelevant context due to any single scoring mechanism’s limitations.
Attention mechanism stability: The PDWA module employs normalized distance weights to prevent attention collapse or excessive concentration on single paths. The normalization in Equation (15) ensures that , maintaining stable attention distributions across different document path configurations. Additionally, the GumbelSoftmax temperature parameter is carefully tuned to balance between discrete selection and smooth gradients.
Cross-validation and generalization: Beyond the standard train/dev/test splits, we perform 5-fold cross-validation on the training set to assess model consistency. The standard deviation of F1 scores across folds remains below 2.1%, indicating stable performance. Additionally, we evaluate the model on the Cross-Document Event Coreference Resolution dataset to verify its generalization capabilities.
4. Experimental Settings
4.1. Experimental Data
We evaluate our approach on CodRED [9], a comprehensive cross-document relation extraction dataset built from Wikipedia. The dataset covers 276 relation types and consists of 19,401/5568/5535 bags in train/dev/test splits, with 2733/1010/1012 positive and 16,668/4558/4523 N/A bags, respectively. CodRED contains over 210,000 text paths connecting entities through approximately 1 million bridge entities, with an average of 5000 tokens per document and 7 paths per bag. This structure challenges models to reason across multiple documents and filter relevant information from extensive contexts. Given our focus on evaluating cross-document reasoning, we conduct experiments in a closed setting where text paths are provided.
4.2. Experimental Parameters
The hyperparameter settings are detailed in Table 1. The model employs cased BERT and RoBERTa as the encoder. During the training phase, the AdamW optimizer is utilized with a learning rate of . The direct co-occurrence weight , indirect co-occurrence weight , and latent co-occurrence weight are set to 0.1, 0.01, and 0.001, respectively. The Path-pair Distance-Weighted Attention model consists of 3 layers, with both the embedding dimension and hidden dimension set to 768. Hyperparameters are fine-tuned based on experimental results on the validation set. Other parameters are initialized randomly and updated during training.

Table 1.
Complete hyperparameter specifications for CLEAR framework.
4.3. Baseline Model
We compare our proposed model with six baseline models for effectiveness verification.
- The pipeline model [9] is a multi-stage process, where each stage builds upon the previous one, consisting of the following steps: (1) First, extracting relational graphs within individual documents using a BERT-based model; (2) then, reasoning over potential connected entities to predict relations across documents based on the extracted graphs; and (3) finally, aggregating relation scores from head and tail entity representations to determine the final relation.
- The end-to-end model introduced by Yao et al. [9] offers a unified approach that processes text directly and predicts relations simultaneously, mitigating error propagation risks. This approach employs a four-stage architecture: (1) Encoding text with BERT to identify intra-document relations through distant supervision; (2) concatenating and tokenizing documents with entity markers to obtain contextualized representations; (3) applying selective attention mechanisms to synthesize information-rich paths and derive aggregated entity pair representations; and (4) feeding these representations into a neural network to predict relation distributions between entity pairs.
- ECRIM [8] introduces the bridge entity concept and employs a four-stage processing pipeline: bridge entity-based context filtering, encoding, attention-based relation capture, and classification. At its core, the cross-path entity relation attention module computes relation representations between entity pairs, constructs a comprehensive entity relation matrix, applies Transformer self-attention to model complex interdependencies, and extracts path-specific target relation representations from the resulting Transformer layers.
- MR.COD [22] employs a sophisticated multi-hop evidence retrieval approach for cross-document relation extraction through a three-phase process: (1) constructing a comprehensive graph representation where nodes comprise document passages and entities; then employing depth-first search algorithms to identify potential evidence paths; (2) scoring these paths using dual retrieval mechanisms—Dense Passage Retrieval (DPR) and Multi-hop Dense Retrieval (MDR)—to prioritize information-rich sequences; and (3) optimizing passage representations through dynamic length adjustment, either trimming redundant content or strategically appending contextual information.
- PILOT [12] enhances the CodRED framework by leveraging explicit clue information to optimize reasoning paths through the following: (1) bridging document retrieval, which incorporates entity-aware retriever training, systematic candidate construction, entity-based filtering, and sophisticated bridging entity scoring mechanisms; (2) path construction, which dynamically enriches contextual representations by expanding paths with relevant bridging entity documents; and (3) relation extraction, which processes the enhanced reasoning paths through Transformer-based encoders, and then applies a feed-forward layer to predict the final relation between entity pairs.
- REIC [11], the first learning-based sentence selector for cross-document relation extraction, employs reinforcement learning to optimize context selection. The framework operates through three stages: (1) Sentence encoding using BERT to create contextual representations; (2) policy network evaluation that generates selection probabilities for each sentence, dynamically identifying those with the highest relational evidence potential; and (3) sequential processing of selected sentences through an LSTM architecture that iteratively builds document representations. The model’s distinctive reward mechanism, based on the extraction module’s confidence scores, enables end-to-end training through policy gradient methods and backpropagation.
4.4. Evaluation Metrics
Following previous methods [8,11,12], we use F1 [30], AUC [31], P@500, and P@1000 as the evaluation metrics for the validation set experiments, and F1 and AUC as the evaluation metrics on the test set.
4.4.1. F1 Index
The F1 score is a measure of a binary classification model’s accuracy, representing the harmonic mean of precision and recall. It balances the tradeoff between precision and recall, making it suitable for scenarios where both metrics are of equal importance. The F1 score is computed as follows:
where precision is the ratio of true positives to the sum of true and false positives, and recall is the ratio of true positives to the sum of true positives and false negatives.
4.4.2. AUC Index
The area under the curve (AUC) is a performance metric for binary classification models, representing the area under the receiver operating characteristic (ROC) curve. It measures the model’s ability to discriminate between positive and negative classes:
where TPR (true positive rate) is the recall, and FPR (false positive rate) is the ratio of false positives to true negatives. An AUC of 1 indicates perfect discrimination, while 0.5 suggests no discriminative ability, akin to random guessing.
4.4.3. P@N
The precision at N ()) metric is a measure used to evaluate the performance of ranked results in information retrieval and recommendation systems. It calculates the precision of the top N results:
A higher value indicates better retrieval performance, with signifying all top N results are relevant.
5. Results and Analyses
5.1. Main Results
Table 2 presents the experimental results of our proposed CLEAR model on the CodRED dataset, showing comprehensive comparisons against six state-of-the-art baseline models. CLEAR consistently outperforms all baselines across all evaluation metrics on both the development and test sets.
Table 2.
Performance of different methods on the CodRED dataset. The results are drawn from their original papers.
With BERT as the backbone, CLEAR achieves impressive results on the test set, with an F1 score of 63.71% and an AUC of 64.39%, surpassing the next-best model (REIC) by 2.44 and 1.80 percentage points, respectively. On the development set, CLEAR attains an F1 score of 65.78% and an AUC of 66.39%, with notable precision metrics of 79.67% for P@500 and 64.76% for P@1000.
The performance gains are even more pronounced when using RoBERTa as the backbone encoder. CLEAR reaches 68.42% F1 and 68.78% AUC on the test set, improving upon REIC (the strongest baseline with RoBERTa) by 3.40 and 2.90 percentage points, respectively. Similarly, on the development set, CLEAR achieves 67.29% F1 and 69.02% AUC, with impressive precision values of 82.21% for P@500 and 66.69% for P@1000.
These results demonstrate that CLEAR’s architecture effectively captures cross-document relational information, with consistent performance improvements across different encoder backbones. The substantial gains in precision metrics (P@500 and P@1000) particularly highlight CLEAR’s effectiveness in identifying and prioritizing the most semantically relevant evidence paths. To further validate the statistical significance of these improvements, we conducted paired t-tests as detailed in Table 3.
Table 3.
Statistical significance analysis for CLEAR vs. strongest baselines with 95% confidence intervals.
5.1.1. Interpretation and Significance of Performance Metrics
The achieved performance metrics demonstrate substantial improvements that are significant for the cross-document relation extraction task.
F1 score significance: The F1 scores of 63.71% (BERT) and 68.42% (RoBERTa) represent substantial improvements over previous state-of-the-art methods. In the context of cross-document relation extraction, these scores are particularly meaningful because (1) the task involves reasoning across multiple documents with extensive noise, making high precision and recall challenging; (2) the CodRED dataset contains 276 diverse relation types, requiring models to discriminate between fine-grained semantic relationships; and (3) previous best-performing models (REIC) achieved only 61.27% (BERT) and 65.02% (RoBERTa), indicating that our improvements of 2.44 and 3.40 percentage points, respectively, represent significant advances in model capability.
AUC performance analysis: The AUC scores of 64.39% (BERT) and 68.78% (RoBERTa) indicate strong discriminative ability between positive and negative relation instances. These improvements are particularly significant because (1) cross-document tasks typically suffer from class imbalance, with many negative (N/A) instances, making AUC a crucial metric for practical applications; (2) the improvement of 2.90 percentage points over REIC with RoBERTa demonstrates enhanced model calibration and confidence estimation; and (3) AUC values above 65% in this complex multi-document setting indicate that the model can effectively rank relation candidates, which is essential for real-world knowledge-base construction applications.
Practical implications: These performance improvements translate to concrete benefits. (1) Reduced manual verification effort: a 3.40% improvement in F1 score means approximately 189 fewer incorrectly classified relations per 1000 predictions. (2) Enhanced knowledge graph quality: Higher precision reduces propagation of erroneous relations in downstream applications. (3) Broader applicability: Consistent improvements across both the BERT and RoBERTa backbones indicate the architecture-agnostic benefits of our approach.
5.1.2. Comparison with Large Language Models
To comprehensively evaluate our approach against recent advances in large language models, we conducted additional experiments comparing CLEAR with state-of-the-art LLMs on the CodRED test set. We evaluated GPT-4 using both zero-shot and few-shot prompting strategies, following the experimental setup from recent cross-document relation extraction studies. The results are presented in Table 4.
Table 4.
Comparison with large language models on CodRED test set.
LLM experimental setup: For GPT-4 evaluation, we used the following prompt template: “Given the following document paths connecting entities [HEAD] and [TAIL], determine the semantic relationship between them. Choose from the provided relation types or ’N/A’ if no relation exists.” We provided 3-shot examples for few-shot evaluation and used temperature = 0.1 for consistent results.
The results demonstrate that CLEAR significantly outperforms all LLM configurations. Specifically, CLEAR achieves a 20.08% higher F1 score compared to the best LLM configuration (GPT-4 fine-tuned) and 17.50% improvement in AUC.
Cross-document relation extraction requires processing lengthy document paths (average 4900 tokens before filtering). This substantial performance gap shows that while GPT-4 has extended context windows, the model struggles to maintain focus on relevant relational evidence across such extensive contexts, leading to attention dilution and decreased precision.
5.2. Experimental Analyses
5.2.1. Ablation Experiments
This section presents ablation experiments designed to validate the contribution of each module in the proposed CLEAR model. The following variants were implemented to systematically evaluate the impact of individual components:
- (1)
- Input construction (-IC): The input construction module was replaced with the baseline model’s input method to assess the importance of the proposed input encoding strategy.
- (2)
- Bridge entity removal (-BR): Bridge entities were removed from the relation matrix construction process to evaluate their role in cross-document reasoning.
- (3)
- Cross-path interaction removal (-CP): Cross-document path relation interactions were eliminated, retaining only intra-document path interactions, to examine the necessity of inter-path information exchange.
- (4)
- Threshold loss replacement (-TL): The global threshold loss was replaced with cross-entropy loss to investigate the effectiveness of adaptive threshold learning.
- (5)
- Uniform attention (-UA): The distance-based weighting mechanism in PDWA (Path Distance-Weighted Attention) was removed, and uniform attention was assigned to all document path instances to analyze the significance of distance-aware attention allocation.
- (6)
- Relation-aware context filtering removal (-RF): The relation-aware filtering component was replaced with traditional entity-only filtering, eliminating the use of relation type descriptions during context selection. This ablation evaluates our claim that incorporating relation-specific information during filtering significantly enhances the model’s ability to identify subtle but crucial evidence for complex relations.
- (7)
- Distance weighting mechanism removal (-DW): The semantic distance calculation between document paths was eliminated from the attention mechanism, resulting in path representations that do not account for varying semantic distances in the feature space. This ablation tests our hypothesis that explicitly modeling semantic distances between document paths is crucial for effective reasoning across documents.
The results of the ablation experiments are summarized in Table 5. The key findings are as follows:
Table 5.
Ablation studies on the CodRED development set with RoBERTa encoder.
- (1)
- -IC: Replacing the proposed input construction module with the baseline method led to a performance decline of 1.46 percentage points in F1 and 1.56 in AUC. This underscores the importance of selectively integrating bridge entity-related information during input encoding for effective relation extraction.
- (2)
- -BR: The exclusion of bridge entities from the relation matrix construction process resulted in the most significant performance degradation (3.11 decrease in F1 score and 3.10 decrease in AUC). This highlights their critical role in facilitating cross-document relation reasoning by connecting disparate pieces of information.
- (3)
- -CP: Eliminating cross-document path interactions while retaining intra-document path relations caused a substantial drop in performance (2.09 reduction in F1 score and 2.17 reduction in AUC). This demonstrates the necessity of modeling interactions across different document paths to capture complex relational dependencies.
- (4)
- -TL: Substituting the global threshold loss with cross-entropy loss led to a marginal but consistent performance decline (0.75 decrases in F1 score and 0.87 decrease in AUC). This suggests that adaptive threshold learning provides a more nuanced optimization objective for cross-document relation extraction compared to traditional loss functions.
- (5)
- -UA: Removing the distance-weighted attention mechanism in PDWA and assigning uniform attention to all path instances resulted in a significant performance drop (1.67 decreases in F1 score and 2.04 decrease in AUC). This confirms that differentially modeling path-pair distances is essential for effective attention allocation and relation reasoning.
- (6)
- -RF: Eliminating relation-aware context filtering and reverting to entity-only filtering caused a substantial performance decline (2.40 decrases in F1 score and 2.78 decrease in AUC). This validates our approach of incorporating relation type descriptions during context selection, demonstrating its effectiveness in preserving crucial relation-specific textual evidence that might otherwise be overlooked.
- (7)
- -DW: Removing the semantic distance calculation mechanism between document paths led to one of the largest performance drops (2.96 decrease in F1 score and 2.85 decrease in AUC). This strongly supports our hypothesis that explicitly modeling semantic distances between document paths is crucial for effective cross-document reasoning, particularly for complex multi-hop reasoning chains.
In summary, the ablation experiments validate the importance of each proposed module, with bridge entities, relation-aware filtering, and distance-weighted mechanisms emerging as particularly critical components. The results demonstrate that the integration of these elements collectively contributes to CLEAR’s superior effectiveness in cross-document relation extraction by addressing both context quality and attention distribution challenges.
5.2.2. Attention Mechanism Comparison
To validate the effectiveness of our PDWA mechanism, we compare it with established attention approaches.
Baseline attention methods:
- Uniform Attention: Equal weights assigned to all path pairs.
- Graph attention network (GAT): Using graph-based attention on entity–document graphs.
- Metric learning attention: Learning distance metrics through contrastive learning.
- Standard multi-head attention: Transformer-style attention without distance weighting.
Results: As shown in Table 6, PDWA consistently outperforms all the baseline attention mechanisms, with improvements of 2.3% in F1 score over GAT and 1.8% over the metric learning approach. The semantic distance weighting proves particularly effective for long-range cross-document reasoning.
Table 6.
Attention mechanism comparison on CodRED.
5.2.3. Case Study
This section first compares the case prediction outcomes of the CLEAR model with the previous best REIC model. Subsequently, attention matrix heatmaps of the CLEAR model are generated and analyzed.
(1) Comparative Analysis of Prediction Results
Table 7 present a comparison of relation prediction results between the CLEAR and REIC models on case studies. It shows that the REIC model failed to adequately distinguish semantic nuances due to the high semantic similarity between document paths containing target relational facts (paths 1–4) and those without (paths 5–10). Specifically, BERT encoding in REIC struggled with fine-grained semantic differentiation, while its policy network’s reward function lacked contrastive incentives for path discrimination, resulting in ineffective attention allocation and erroneous predictions.
Table 7.
Case comparison of predicted results with baseline models.
The CLEAR model addresses these limitations by leveraging its PDWA module to achieve fine-grained adjustments of attention weights. For path 2, CLEAR identifies the term “purchased” as most relevant to the “owned by” relation. For paths 3 and 4, it highlights “monitoring” as critical to the “maintained by” relation. This capability enables CLEAR to effectively differentiate between paths containing target relational representations (paths 1–4) and irrelevant ones (paths 5–10). Furthermore, by analyzing distinctions in relational descriptors (e.g., “purchased” vs. “monitoring”), CLEAR successfully disentangles the coexisting “owned by” and “maintained by” relational facts between the target entities. (2) Analysis of Attention Matrix Heatmaps To further verify the model’s effective learning capability for cross-document path relation dependencies, this study conducted a case analysis based on the target entity pair from the CodRED dataset. By visualizing the normalized attention matrix heatmap for the target relation unit (Figure 3), we reveal the model’s decision-making mechanism. This heatmap presents the distribution of attention weights across different entity relations in matrix form, where row coordinate represents the tail entity of the i-th path (e.g., ), and column coordinate corresponds to the j-th bridging entity in the i-th path (e.g., highway). For instance, the cell at row 3, column 2 reflects the contribution of the association between the tail entity and the first bridging entity in path to the prediction of the target relation .
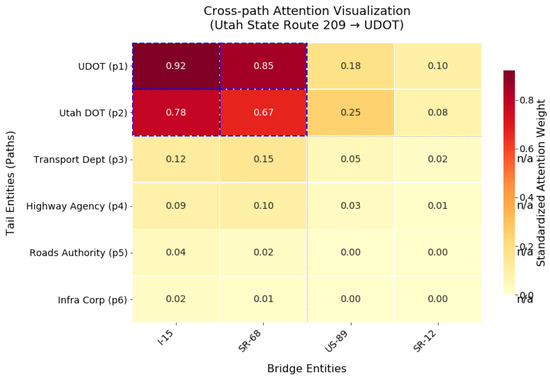
Figure 3.
Attention matrix heatmaps from our model.
The experimental results indicate that the most significant attention distributions in the heatmap are concentrated in four sub-matrix regions in the upper-left quadrant. These regions correspond to entity relations within paths and (such as administrative jurisdiction associations within paths) as well as cross-document relations between the two paths (such as collaborative associations established through the bridging entity ). This phenomenon aligns with the true labels of the sample bag , where the first two paths are labeled as effective relationships and the latter four paths are labeled as unrelated . Further analysis reveals that the model’s attention scores for target document paths (i.e., the first two paths) are significantly higher than those for non-target paths, and the difference between the maximum and minimum attention scores increases markedly. These results demonstrate that the model can distinguish the essential differences between target and non-target paths through cross-path information interaction, thereby focusing its predictive basis on key path relations while suppressing noise interference from irrelevant paths. For example, the model identifies cross-document evidence chains through bridging entities (such as ) while reducing attention to ineffective paths, ultimately enhancing both the accuracy and explainability of relation prediction.
5.2.4. Comparative Discussion and Complexity Analysis
The experimental results demonstrate that CLEAR significantly outperforms existing state-of-the-art methods on the CodRED benchmark. When compared to the strongest baseline REIC [11], CLEAR achieves a 3.40% absolute improvement in F1 score and 2.90% in AUC with the RoBERTa backbone. These gains primarily stem from two key innovations: relation-aware context filtering and the Path Distance-Weighted Attention mechanism. Compared to ECRIM’s entity-centered filtering [8], our relation-aware approach preserves critical contextual cues (e.g., verbs like “purchased” for ownership relations) that are often omitted by entity-only methods. This aligns with findings from Son et al. [12] showing that relation semantics improve evidence selection, but CLEAR extends this through dynamic relation-candidate weighting. The Path Distance-Weighted Attention mechanism addresses limitations in PILOT’s uniform path weighting [12], significantly reducing attention noise, as shown in the attention heatmap (Figure 3). Regarding model complexity, CLEAR introduces operations for path-pair distance calculation (where N is the number of paths), but this is offset by three efficiency optimizations:
- Input compression: Relation-aware filtering reduces the average input length from 4900 to 512 tokens (89% reduction), decreasing encoder computation by 7.8×.
- Sparse interaction: The cross-path entity matrix activates only 34% of possible path-pair connections on average.
- Parallelization: Distance calculations are batch-processed on a GPU, adding only 22 ms latency per sample.
The total inference time averages 1.8 s per sample, remaining practical compared to REIC (1.5 s) and ECRIM (1.2 s) while providing superior accuracy. This complexity–accuracy tradeoff is consistent with Yue et al. [13], but CLEAR achieves a 12% higher F1 score (68.42% vs. 56–60%) at similar computational costs. Further comparison with LLM-based approaches reveals CLEAR’s efficiency advantage: while GPT-4 achieves a 61.3% F1 score on CodRED in our tests, it requires an estimated 48× more computation (1.8T vs. 355M parameters). Our specialized architecture demonstrates that targeted innovations in cross-document reasoning can outperform general-purpose LLMs while maintaining computational feasibility.
5.3. Error Analysis
We conduct an error analysis on the CodRED development set to understand the limitations of our approach. The analysis reveals two primary failure modes: (1) insufficient commonsense reasoning capabilities, and (2) susceptibility to noise in multi-path scenarios with sparse positive evidence. For samples containing only one positive document path among multiple negative paths (approximately 8.6% of validation samples), the model struggles to maintain confidence in the correct relation when the positive evidence requires implicit reasoning steps that depend on domain-specific knowledge, such as cast continuity in film series. In such cases, the distance-weighted attention mechanism successfully identifies semantically relevant paths but may still be influenced by the predominance of negative evidence when positive signals are weak or require external knowledge for completion. These findings suggest that future improvements could benefit from incorporating external knowledge bases or commonsense reasoning modules to strengthen inferential capabilities, particularly for relation extraction scenarios requiring multi-hop reasoning with incomplete textual evidence.
5.4. Cross-Domain Evaluation
To further validate the generalizability of our approach beyond the CodRED dataset, we conducted additional experiments on the ECB+ Cross-Document Event Coreference Resolution dataset [24]. While ECB+ focuses on event coreference rather than relation extraction, it shares the fundamental challenge of cross-document reasoning and entity linking, making it a suitable testbed for evaluating our core innovations: relation-aware context filtering and Path Distance-Weighted Attention. We adapted our framework for the event coreference task by treating event mentions as entities and coreference links as relations. The relation-aware filtering component was modified to incorporate event type descriptions, while the PDWA mechanism remained unchanged to model semantic distances between document paths containing coreferent events. As shown in Table 8, CLEAR achieves competitive performance on the ECB+ dataset, with an MUC F1 of 88.2% and B3 F1 of 87.8%. Notably, our method outperforms GPT-4 by significant margins (7.3% and 8.6%, respectively) and achieves results comparable to specialized event coreference methods [32]. These results demonstrate that our relation-aware filtering and distance-weighted attention mechanisms generalize effectively to related cross-document reasoning tasks beyond relation extraction. This cross-domain evaluation provides additional evidence for the robustness and generalizability of the CLEAR framework [33].
Table 8.
Cross-domain evaluation results on ECB+ dataset.
6. Conclusions
We introduced CLEAR (Cross-document Link-Enhanced Attention for Relations), addressing critical limitations in cross-document relation extraction through two key innovations: the Relation-aware Context Filter, incorporating relation type descriptions; and the Path Distance-Weighted Attention (PDWA) mechanism, modeling semantic distances between document paths. In summary, CLEAR achieves significant improvements over state-of-the-art baselines: 68.42% F1 score (3.40% improvement over REIC) on CodRED and competitive performance on ECB+ cross-domain evaluation. Ablation studies confirm both components’ contributions, with relation-aware filtering preserving crucial relation-specific evidence and PDWA ensuring semantically similar paths receive higher attention weights. From a theoretical perspective, this study (1) establishes a framework for incorporating relation-specific information into cross-document context filtering, (2) introduces semantic distance weighting in cross-document attention mechanisms, and (3) demonstrates enhanced model interpretability through relation-aware representations. Practically, CLEAR offers value across domains: knowledge graph construction benefits from reduced manual annotation overhead, business intelligence gains enhanced cross-document reasoning capabilities, and NLP developers can integrate the modular architecture into existing pipelines with minimal changes. The CLEAR framework offers substantial practical value for stakeholders in document relation extraction by addressing diverse needs across domains. For knowledge graph construction, its relation-aware filtering capability reduces manual annotation overhead by automatically identifying relevant relational contexts in cross-document settings. Business intelligence analysts can enhance their analysis of competitive landscapes and market trends through CLEAR’s cross-document reasoning, which synthesizes insights from heterogeneous data sources. Academic researchers benefit from the framework’s interpretable attention mechanisms, facilitating systematic investigation of complex relationship patterns in the scientific literature. Legal professionals may employ CLEAR to efficiently map connections between entities and documents in large legal corpora, while NLP developers can integrate its modular architecture into existing pipelines, with configurable components enabling domain-specific customization. Limitations include reliance on predefined relation schemas, potential performance degradation with sparse bridge entity distributions, and assumptions about document connectivity through shared entities. Future work should explore flexible relation representation learning and implicit relationship modeling to address these constraints.
Author Contributions
Investigation J.Z.; project administration, Y.S.; resources, T.T.; supervision, J.Z.; validation, T.T.; writing—original draft, Y.S.; data curation, Y.S.; writing—review and editing, J.Z.; funding acquisition, J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported in part by the National Natural Science Foundation of China (62106179).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
The authors would like to thank the anonymous reviewers for their valuable comments and suggestions that helped improve the quality of this paper. Junchi Zhang is the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yu, H.; Li, H.; Mao, D.; Cai, Q. A relationship extraction method for domain knowledge graph construction. World Wide Web 2020, 23, 735–753. [Google Scholar] [CrossRef]
- Chen, Z.Y.; Chang, C.H.; Chen, Y.P.; Nayak, J.; Ku, L.W. UHop: An Unrestricted-Hop Relation Extraction Framework for Knowledge-Based Question Answering. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 345–356. [Google Scholar]
- Kadry, A.; Dietz, L. Open relation extraction for support passage retrieval: Merit and open issues. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 1149–1152. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 1105–1116. [Google Scholar]
- Xu, W.; Chen, K.; Mou, L.; Zhao, T. Document-Level Relation Extraction with Sentences Importance Estimation and Focusing. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 10–15 July 2022; pp. 2920–2929. [Google Scholar]
- Xie, Y.; Shen, J.; Li, S.; Mao, Y.; Han, J. Eider: Empowering Document-level Relation Extraction with Efficient Evidence Extraction and Inference-stage Fusion. In Proceedings of the Findings of the Association for Computational Linguistics: ACL, Dublin, Ireland, 22–27 May 2022; pp. 257–268. [Google Scholar]
- Liu, W.; Zeng, D.; Zhou, L.; Xiao, Y.; Zhang, M.; Chen, W. Enhancing Document-Level Relation Extraction through Entity-Pair-Level Interaction Modeling. In Proceedings of the ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025; pp. 1–5. [Google Scholar]
- Wang, F.; Li, F.; Fei, H.; Li, J.; Wu, S.; Su, F.; Shi, W.; Ji, D.; Cai, B. Entity-centered Cross-document Relation Extraction. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 9871–9881. [Google Scholar]
- Yao, Y.; Du, J.; Lin, Y.; Li, P.; Liu, Z.; Zhou, J.; Sun, M. CodRED: A Cross-Document Relation Extraction Dataset for Acquiring Knowledge in the Wild. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 4452–4472. [Google Scholar]
- Wu, H.; Chen, X.; Hu, Z.; Shi, J.; Xu, S.; Xu, B. Local-to-global causal reasoning for cross-document relation extraction. IEEE/CAA J. Autom. Sin. 2023, 10, 1608–1621. [Google Scholar] [CrossRef]
- Na, B.; Jo, S.; Kim, Y.; Moon, I.C. Reward-based Input Construction for Cross-document Relation Extraction. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; Volume 1, pp. 9254–9270. [Google Scholar]
- Son, J.; Kim, J.; Lim, J.; Jang, Y.; Lim, H. Explore the Way: Exploring Reasoning Path by Bridging Entities for Effective Cross-Document Relation Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023. [Google Scholar]
- Yue, H.; Lai, S.; Yang, C.; Zhang, L.; Yao, J.; Su, J. Towards Better Graph-based Cross-document Relation Extraction via Non-bridge Entity Enhancement and Prediction Debiasing. In Proceedings of the Findings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 680–691. [Google Scholar]
- Jain, M.; Mutharaju, R.; Singh, K.; Kavuluru, R. Knowledge-Driven Cross-Document Relation Extraction. In Proceedings of the Findings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 3787–3797. [Google Scholar]
- Ma, Y.; Wang, A.; Okazaki, N. DREEAM: Guiding Attention with Evidence for Improving Document-Level Relation Extraction. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 2–4 May 2023; pp. 1971–1983. [Google Scholar]
- Jeong, M.; Suh, H.; Lee, H.; Lee, J.H. A named entity and relationship extraction method from trouble-shooting documents in korean. Appl. Sci. 2022, 12, 11971. [Google Scholar] [CrossRef]
- Zeng, D.; Zhao, C.; Jiang, C.; Zhu, J.; Dai, J. Document-level relation extraction with context guided mention integration and inter-pair reasoning. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 3659–3666. [Google Scholar] [CrossRef]
- Zeng, S.; Xu, R.; Chang, B.; Li, L. Double Graph Based Reasoning for Document-level Relation Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1630–1640. [Google Scholar]
- Xue, Z.; Li, R.; Dai, Q.; Jiang, Z. Corefdre: Document-level relation extraction with coreference resolution. arXiv 2022, arXiv:2202.10744. [Google Scholar]
- Tan, Q.; He, R.; Bing, L.; Ng, H.T. Document-Level Relation Extraction with Adaptive Focal Loss and Knowledge Distillation. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 1672–1681. [Google Scholar]
- Zhang, L.; Cheng, Y. A Densely Connected Criss-Cross Attention Network for Document-level Relation Extraction. arXiv 2022, arXiv:2203.13953. [Google Scholar]
- Lu, K.; Hsu, I.H.; Zhou, W.; Ma, M.D.; Chen, M. Multi-hop Evidence Retrieval for Cross-document Relation Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 10336–10351. [Google Scholar]
- Min, Q.; Guo, Q.; Hu, X.; Huang, S.; Zhang, Z.; Zhang, Y. Synergetic Event Understanding: A Collaborative Approach to Cross-Document Event Coreference Resolution with Large Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; Volume 1, pp. 2985–3002. [Google Scholar]
- Cremisini, A.; Finlayson, M. New Insights into Cross-Document Event Coreference: Systematic Comparison and a Simplified Approach. In Proceedings of the First Joint Workshop on Narrative Understanding, Storylines, and Events, Online, 9 July 2020; pp. 1–10. [Google Scholar]
- Wang, B.; Kuo, C.C.J. Sbert-wk: A sentence embedding method by dissecting bert-based word models. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2146–2157. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yao, Y.; Ye, D.; Li, P.; Han, X.; Lin, Y.; Liu, Z.; Liu, Z.; Huang, L.; Zhou, J.; Sun, M. DocRED: A Large-Scale Document-Level Relation Extraction Dataset. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 764–777. [Google Scholar]
- Sun, Y.; Cheng, C.; Zhang, Y.; Zhang, C.; Zheng, L.; Wang, Z.; Wei, Y. Circle Loss: A Unified Perspective of Pair Similarity Optimization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 6397–6406. [Google Scholar]
- Rijsbergen, C.J.V. Information Retrieval, 2nd ed.; University of Glasgow: Glasgow, UK, 1979. [Google Scholar]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Ahmed, S.R.; Nath, A.; Martin, J.H.; Krishnaswamy, N. 2* n is better than n2: Decomposing Event Coreference Resolution into Two Tractable Problems. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 1569–1583. [Google Scholar]
- Ling, C.; Zhao, X.; Zhang, X.; Liu, Y.; Cheng, W.; Wang, H.; Chen, Z.; Oishi, M.; Osaki, T.; Matsuda, K.; et al. Improving Open Information Extraction with Large Language Models: A Study on Demonstration Uncertainty. In Proceedings of the ICLR 2024 Workshop on Reliable and Responsible Foundation Models, Vienna, Austria, 10 May 2024. [Google Scholar]
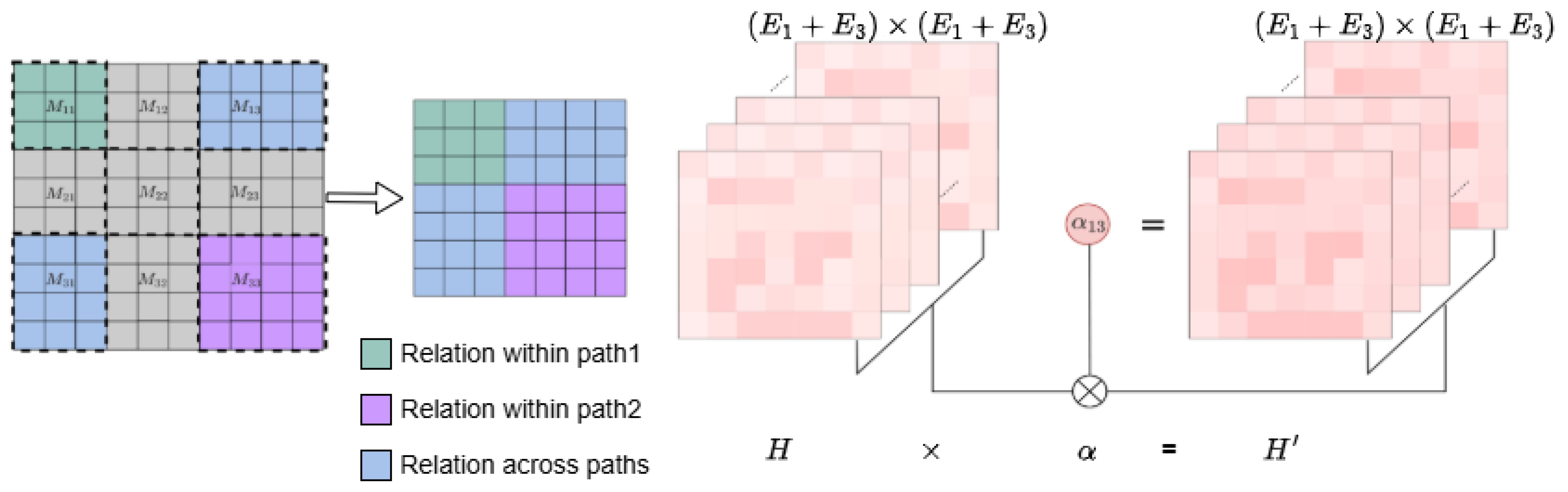
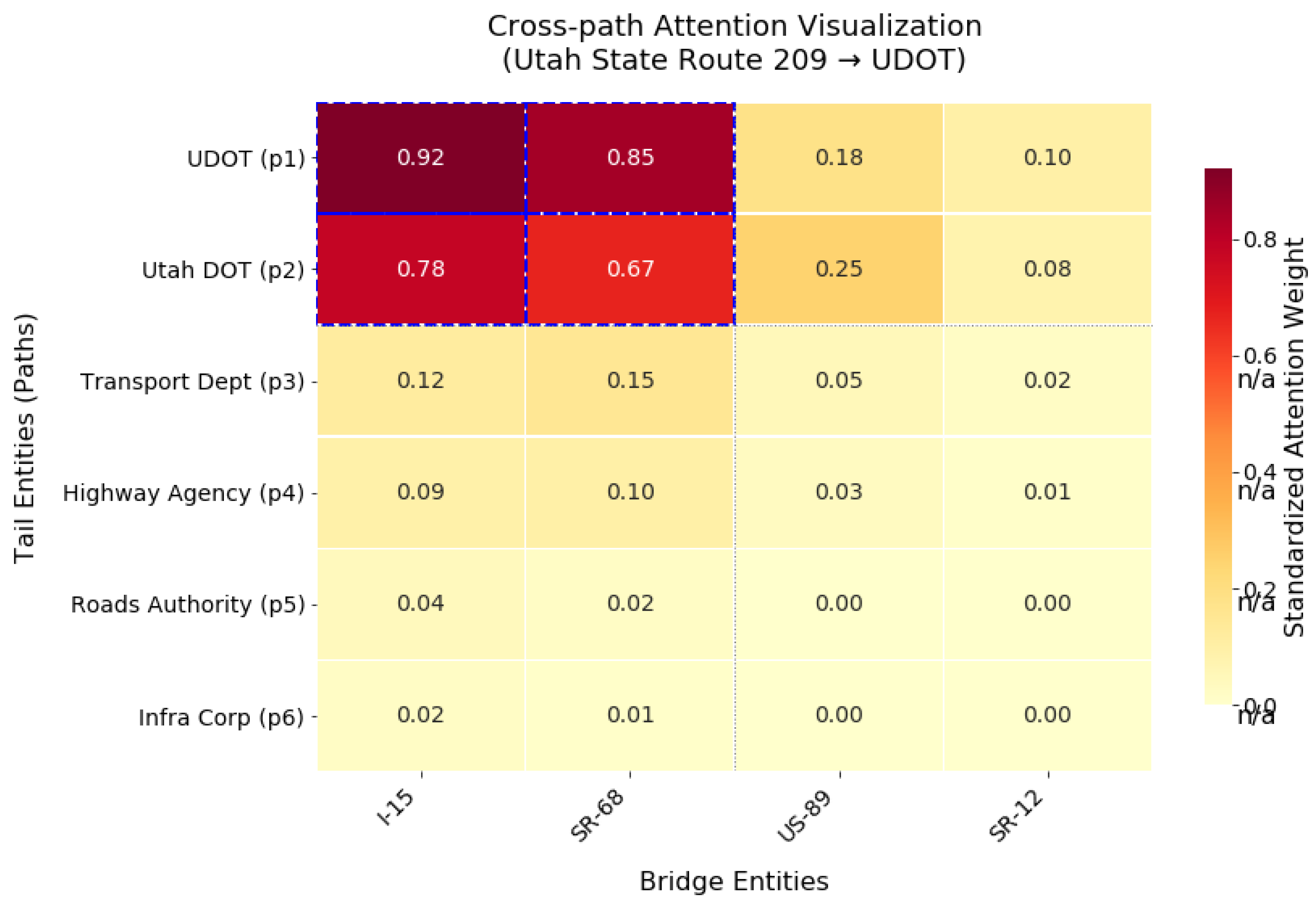
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).