
CLEAR: Cross-Document Link-Enhanced Attention for Relation Extraction with Relation-Aware Context Filtering


Abstract
1. Introduction
- We introduce a relation-aware context filtering approach that incorporates relation type descriptions into the filtering process. This method improves context relevance and reducing noise.
- We design a novel Path Distance-Weighted Attention mechanism that dynamically adjusts attention weights based on semantic distances between document paths. This approach improves F1 scores by 3.1% on average compared to standard attention mechanisms.
- To investigate the effectiveness of our model, we conduct extensive experiments on the CodRED dataset. Our experimental results and in-depth analysis show that our model significantly outperforms all competitive baselines, including the LLMs.
2. Related Work
2.1. Document-Level Relation Extraction
2.2. Cross-Document Relation Extraction
3. Framework
3.1. Task Description
3.2. Overall Model Architecture
- 1.
- Relation-aware input constructor: Processes document paths through dual-stage filtering that dynamically weights sentences based on entity co-occurrence patterns and semantic relevance to potential relations. This generates compressed, relation-focused sequences (Section 3.3).
- 2.
- Contextual encoder: Transforms filtered inputs into deep semantic representations using pre-trained language models (RoBERTa). This component extracts target and bridge entity embeddings critical for cross-document reasoning (Section 3.4).
- 3.
- Cross-path integration core: The framework’s nexus features our novel Path Distance-Weighted Attention (PDWA) mechanism. This computes pairwise semantic distances between document paths and dynamically adjusts attention weights to prioritize information from semantically aligned paths while suppressing noisy connections (Section 3.5).
- 4.
- Relation prediction module: Aggregates refined path representations, applies multi-instance pooling, and generates final predictions through adaptive threshold classification (Section 3.6).
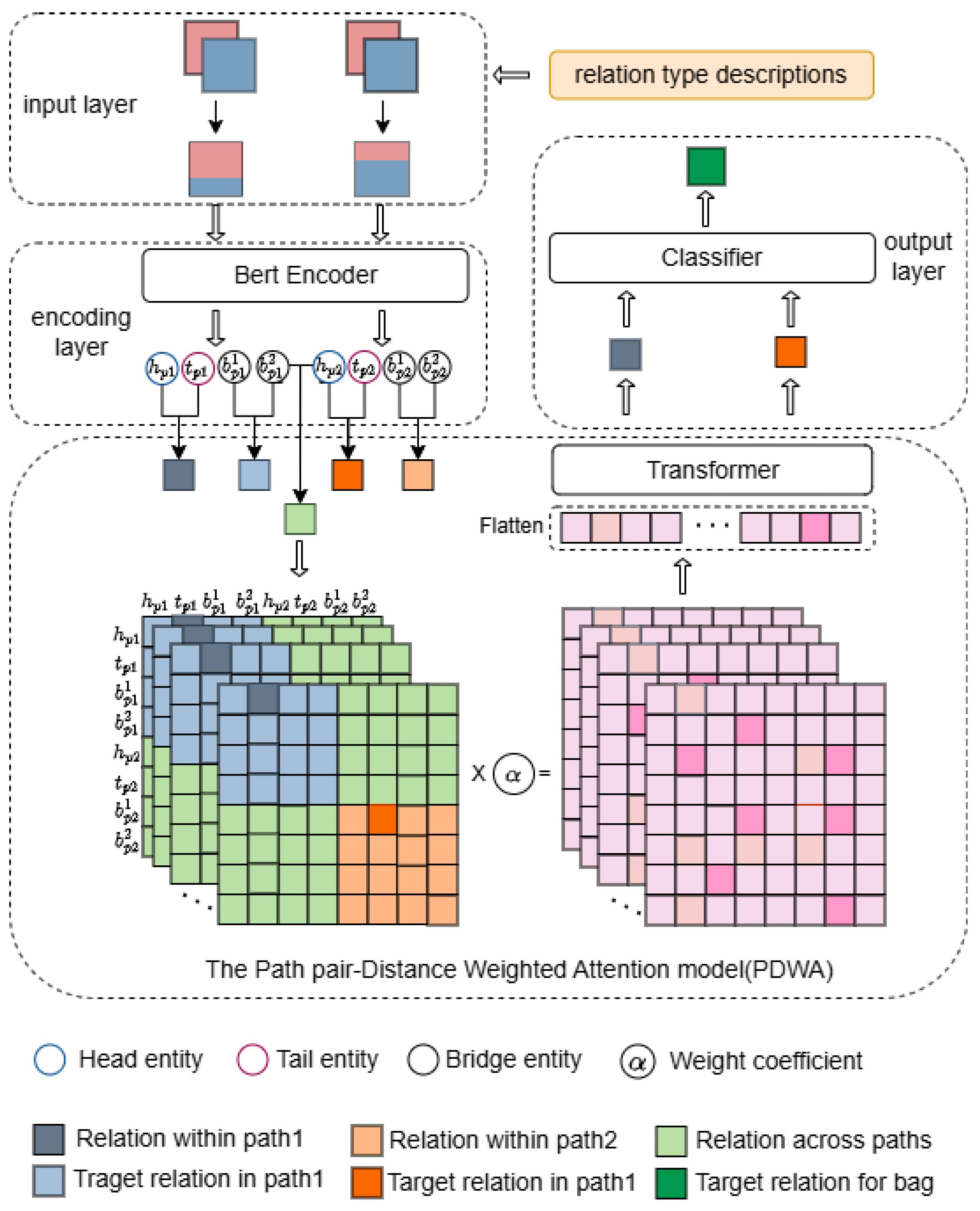
3.3. Relation-Aware Document-Context Filter
3.3.1. Stage I: Important-Sentence Filtering
- -
- if co-occurs with in sentences;
- -
- is an indicator function (1 if satisfies , else 0).
- -
- is the set of sentences containing bridge entity ;
- -
- is a set of candidate relation descriptions;
- -
- measures the semantic similarity between sentence s and relation description r.
3.3.2. Stage II: Semantic Relevance Reorganization
3.3.3. Mathematical Expressions and Parameters
- Noise filtering: Unrelated sentences (such as those containing only a single entity or no co-occurrence) are removed through bridge entity screening and relation relevance assessment.
- Relation-specific context preservation: By incorporating relation descriptions into the similarity calculation, we ensure that sentences semantically related to potential relations are prioritized, even if they do not contain explicit entity co-occurrences.
- Logical coherence: Semantic reorganization retains cross-document inference chains (such as the path ) while ensuring relation-relevant information is preserved.
- Efficiency optimization: Documents with an average of 4900 words are compressed to within 512 words, reducing computational complexity while preserving the most informative, relation-relevant content.
3.4. Encoding Layer
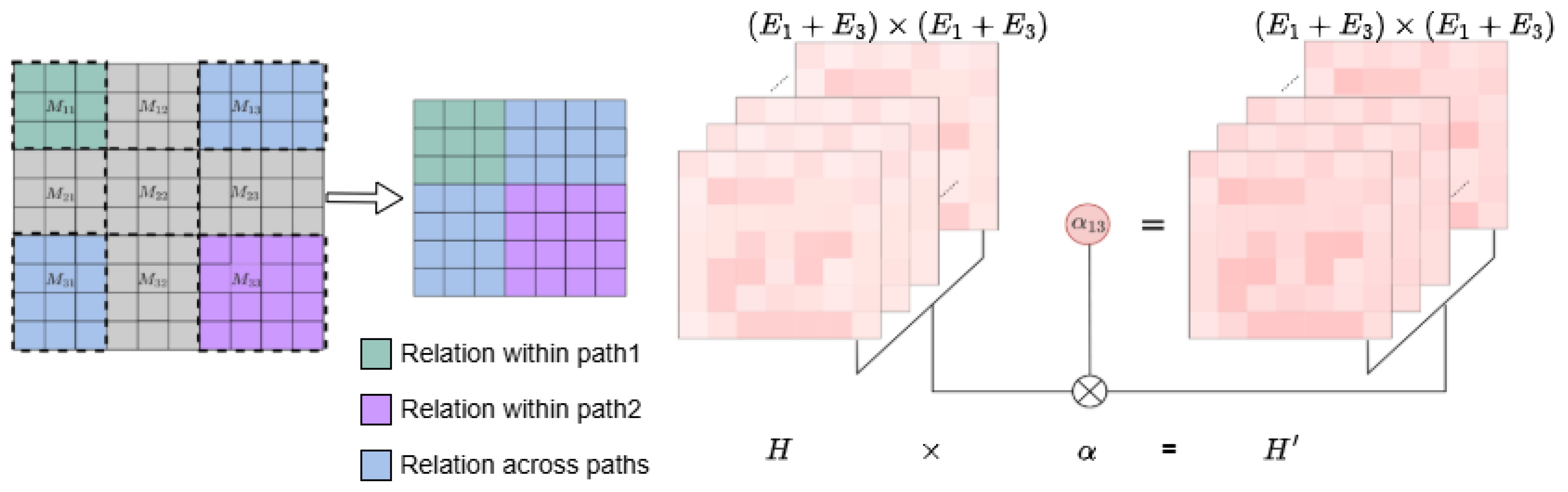
3.5. Path Distance-Weighted Attention (PDWA) Model
3.5.1. Cross-Path Entity Matrix Construction
| Algorithm 1 Path Distance-Weighted Attention (PDWA). |
Require: Document paths , target relation , entity representations E Ensure: Enhanced relation representations
|
3.5.2. PDWA Construction Steps
3.6. Output Layer
3.7. Auxiliary Training Task
3.8. Model Training
3.9. Model Reliability and Robustness
4. Experimental Settings
4.1. Experimental Data
4.2. Experimental Parameters
4.3. Baseline Model
- The pipeline model [9] is a multi-stage process, where each stage builds upon the previous one, consisting of the following steps: (1) First, extracting relational graphs within individual documents using a BERT-based model; (2) then, reasoning over potential connected entities to predict relations across documents based on the extracted graphs; and (3) finally, aggregating relation scores from head and tail entity representations to determine the final relation.
- The end-to-end model introduced by Yao et al. [9] offers a unified approach that processes text directly and predicts relations simultaneously, mitigating error propagation risks. This approach employs a four-stage architecture: (1) Encoding text with BERT to identify intra-document relations through distant supervision; (2) concatenating and tokenizing documents with entity markers to obtain contextualized representations; (3) applying selective attention mechanisms to synthesize information-rich paths and derive aggregated entity pair representations; and (4) feeding these representations into a neural network to predict relation distributions between entity pairs.
- ECRIM [8] introduces the bridge entity concept and employs a four-stage processing pipeline: bridge entity-based context filtering, encoding, attention-based relation capture, and classification. At its core, the cross-path entity relation attention module computes relation representations between entity pairs, constructs a comprehensive entity relation matrix, applies Transformer self-attention to model complex interdependencies, and extracts path-specific target relation representations from the resulting Transformer layers.
- MR.COD [22] employs a sophisticated multi-hop evidence retrieval approach for cross-document relation extraction through a three-phase process: (1) constructing a comprehensive graph representation where nodes comprise document passages and entities; then employing depth-first search algorithms to identify potential evidence paths; (2) scoring these paths using dual retrieval mechanisms—Dense Passage Retrieval (DPR) and Multi-hop Dense Retrieval (MDR)—to prioritize information-rich sequences; and (3) optimizing passage representations through dynamic length adjustment, either trimming redundant content or strategically appending contextual information.
- PILOT [12] enhances the CodRED framework by leveraging explicit clue information to optimize reasoning paths through the following: (1) bridging document retrieval, which incorporates entity-aware retriever training, systematic candidate construction, entity-based filtering, and sophisticated bridging entity scoring mechanisms; (2) path construction, which dynamically enriches contextual representations by expanding paths with relevant bridging entity documents; and (3) relation extraction, which processes the enhanced reasoning paths through Transformer-based encoders, and then applies a feed-forward layer to predict the final relation between entity pairs.
- REIC [11], the first learning-based sentence selector for cross-document relation extraction, employs reinforcement learning to optimize context selection. The framework operates through three stages: (1) Sentence encoding using BERT to create contextual representations; (2) policy network evaluation that generates selection probabilities for each sentence, dynamically identifying those with the highest relational evidence potential; and (3) sequential processing of selected sentences through an LSTM architecture that iteratively builds document representations. The model’s distinctive reward mechanism, based on the extraction module’s confidence scores, enables end-to-end training through policy gradient methods and backpropagation.
4.4. Evaluation Metrics
4.4.1. F1 Index
4.4.2. AUC Index
4.4.3. P@N
5. Results and Analyses
5.1. Main Results
5.1.1. Interpretation and Significance of Performance Metrics
5.1.2. Comparison with Large Language Models
5.2. Experimental Analyses
5.2.1. Ablation Experiments
- (1)
- Input construction (-IC): The input construction module was replaced with the baseline model’s input method to assess the importance of the proposed input encoding strategy.
- (2)
- Bridge entity removal (-BR): Bridge entities were removed from the relation matrix construction process to evaluate their role in cross-document reasoning.
- (3)
- Cross-path interaction removal (-CP): Cross-document path relation interactions were eliminated, retaining only intra-document path interactions, to examine the necessity of inter-path information exchange.
- (4)
- Threshold loss replacement (-TL): The global threshold loss was replaced with cross-entropy loss to investigate the effectiveness of adaptive threshold learning.
- (5)
- Uniform attention (-UA): The distance-based weighting mechanism in PDWA (Path Distance-Weighted Attention) was removed, and uniform attention was assigned to all document path instances to analyze the significance of distance-aware attention allocation.
- (6)
- Relation-aware context filtering removal (-RF): The relation-aware filtering component was replaced with traditional entity-only filtering, eliminating the use of relation type descriptions during context selection. This ablation evaluates our claim that incorporating relation-specific information during filtering significantly enhances the model’s ability to identify subtle but crucial evidence for complex relations.
- (7)
- Distance weighting mechanism removal (-DW): The semantic distance calculation between document paths was eliminated from the attention mechanism, resulting in path representations that do not account for varying semantic distances in the feature space. This ablation tests our hypothesis that explicitly modeling semantic distances between document paths is crucial for effective reasoning across documents.
- (1)
- -IC: Replacing the proposed input construction module with the baseline method led to a performance decline of 1.46 percentage points in F1 and 1.56 in AUC. This underscores the importance of selectively integrating bridge entity-related information during input encoding for effective relation extraction.
- (2)
- -BR: The exclusion of bridge entities from the relation matrix construction process resulted in the most significant performance degradation (3.11 decrease in F1 score and 3.10 decrease in AUC). This highlights their critical role in facilitating cross-document relation reasoning by connecting disparate pieces of information.
- (3)
- -CP: Eliminating cross-document path interactions while retaining intra-document path relations caused a substantial drop in performance (2.09 reduction in F1 score and 2.17 reduction in AUC). This demonstrates the necessity of modeling interactions across different document paths to capture complex relational dependencies.
- (4)
- -TL: Substituting the global threshold loss with cross-entropy loss led to a marginal but consistent performance decline (0.75 decrases in F1 score and 0.87 decrease in AUC). This suggests that adaptive threshold learning provides a more nuanced optimization objective for cross-document relation extraction compared to traditional loss functions.
- (5)
- -UA: Removing the distance-weighted attention mechanism in PDWA and assigning uniform attention to all path instances resulted in a significant performance drop (1.67 decreases in F1 score and 2.04 decrease in AUC). This confirms that differentially modeling path-pair distances is essential for effective attention allocation and relation reasoning.
- (6)
- -RF: Eliminating relation-aware context filtering and reverting to entity-only filtering caused a substantial performance decline (2.40 decrases in F1 score and 2.78 decrease in AUC). This validates our approach of incorporating relation type descriptions during context selection, demonstrating its effectiveness in preserving crucial relation-specific textual evidence that might otherwise be overlooked.
- (7)
- -DW: Removing the semantic distance calculation mechanism between document paths led to one of the largest performance drops (2.96 decrease in F1 score and 2.85 decrease in AUC). This strongly supports our hypothesis that explicitly modeling semantic distances between document paths is crucial for effective cross-document reasoning, particularly for complex multi-hop reasoning chains.
5.2.2. Attention Mechanism Comparison
- Uniform Attention: Equal weights assigned to all path pairs.
- Graph attention network (GAT): Using graph-based attention on entity–document graphs.
- Metric learning attention: Learning distance metrics through contrastive learning.
- Standard multi-head attention: Transformer-style attention without distance weighting.
5.2.3. Case Study
5.2.4. Comparative Discussion and Complexity Analysis
- Input compression: Relation-aware filtering reduces the average input length from 4900 to 512 tokens (89% reduction), decreasing encoder computation by 7.8×.
- Sparse interaction: The cross-path entity matrix activates only 34% of possible path-pair connections on average.
- Parallelization: Distance calculations are batch-processed on a GPU, adding only 22 ms latency per sample.
5.3. Error Analysis
5.4. Cross-Domain Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yu, H.; Li, H.; Mao, D.; Cai, Q. A relationship extraction method for domain knowledge graph construction. World Wide Web 2020, 23, 735–753. [Google Scholar] [CrossRef]
- Chen, Z.Y.; Chang, C.H.; Chen, Y.P.; Nayak, J.; Ku, L.W. UHop: An Unrestricted-Hop Relation Extraction Framework for Knowledge-Based Question Answering. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 345–356. [Google Scholar]
- Kadry, A.; Dietz, L. Open relation extraction for support passage retrieval: Merit and open issues. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 1149–1152. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 1105–1116. [Google Scholar]
- Xu, W.; Chen, K.; Mou, L.; Zhao, T. Document-Level Relation Extraction with Sentences Importance Estimation and Focusing. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 10–15 July 2022; pp. 2920–2929. [Google Scholar]
- Xie, Y.; Shen, J.; Li, S.; Mao, Y.; Han, J. Eider: Empowering Document-level Relation Extraction with Efficient Evidence Extraction and Inference-stage Fusion. In Proceedings of the Findings of the Association for Computational Linguistics: ACL, Dublin, Ireland, 22–27 May 2022; pp. 257–268. [Google Scholar]
- Liu, W.; Zeng, D.; Zhou, L.; Xiao, Y.; Zhang, M.; Chen, W. Enhancing Document-Level Relation Extraction through Entity-Pair-Level Interaction Modeling. In Proceedings of the ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hyderabad, India, 6–11 April 2025; pp. 1–5. [Google Scholar]
- Wang, F.; Li, F.; Fei, H.; Li, J.; Wu, S.; Su, F.; Shi, W.; Ji, D.; Cai, B. Entity-centered Cross-document Relation Extraction. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 9871–9881. [Google Scholar]
- Yao, Y.; Du, J.; Lin, Y.; Li, P.; Liu, Z.; Zhou, J.; Sun, M. CodRED: A Cross-Document Relation Extraction Dataset for Acquiring Knowledge in the Wild. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 4452–4472. [Google Scholar]
- Wu, H.; Chen, X.; Hu, Z.; Shi, J.; Xu, S.; Xu, B. Local-to-global causal reasoning for cross-document relation extraction. IEEE/CAA J. Autom. Sin. 2023, 10, 1608–1621. [Google Scholar] [CrossRef]
- Na, B.; Jo, S.; Kim, Y.; Moon, I.C. Reward-based Input Construction for Cross-document Relation Extraction. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; Volume 1, pp. 9254–9270. [Google Scholar]
- Son, J.; Kim, J.; Lim, J.; Jang, Y.; Lim, H. Explore the Way: Exploring Reasoning Path by Bridging Entities for Effective Cross-Document Relation Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023. [Google Scholar]
- Yue, H.; Lai, S.; Yang, C.; Zhang, L.; Yao, J.; Su, J. Towards Better Graph-based Cross-document Relation Extraction via Non-bridge Entity Enhancement and Prediction Debiasing. In Proceedings of the Findings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 680–691. [Google Scholar]
- Jain, M.; Mutharaju, R.; Singh, K.; Kavuluru, R. Knowledge-Driven Cross-Document Relation Extraction. In Proceedings of the Findings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 3787–3797. [Google Scholar]
- Ma, Y.; Wang, A.; Okazaki, N. DREEAM: Guiding Attention with Evidence for Improving Document-Level Relation Extraction. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 2–4 May 2023; pp. 1971–1983. [Google Scholar]
- Jeong, M.; Suh, H.; Lee, H.; Lee, J.H. A named entity and relationship extraction method from trouble-shooting documents in korean. Appl. Sci. 2022, 12, 11971. [Google Scholar] [CrossRef]
- Zeng, D.; Zhao, C.; Jiang, C.; Zhu, J.; Dai, J. Document-level relation extraction with context guided mention integration and inter-pair reasoning. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 3659–3666. [Google Scholar] [CrossRef]
- Zeng, S.; Xu, R.; Chang, B.; Li, L. Double Graph Based Reasoning for Document-level Relation Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1630–1640. [Google Scholar]
- Xue, Z.; Li, R.; Dai, Q.; Jiang, Z. Corefdre: Document-level relation extraction with coreference resolution. arXiv 2022, arXiv:2202.10744. [Google Scholar]
- Tan, Q.; He, R.; Bing, L.; Ng, H.T. Document-Level Relation Extraction with Adaptive Focal Loss and Knowledge Distillation. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 1672–1681. [Google Scholar]
- Zhang, L.; Cheng, Y. A Densely Connected Criss-Cross Attention Network for Document-level Relation Extraction. arXiv 2022, arXiv:2203.13953. [Google Scholar]
- Lu, K.; Hsu, I.H.; Zhou, W.; Ma, M.D.; Chen, M. Multi-hop Evidence Retrieval for Cross-document Relation Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 10336–10351. [Google Scholar]
- Min, Q.; Guo, Q.; Hu, X.; Huang, S.; Zhang, Z.; Zhang, Y. Synergetic Event Understanding: A Collaborative Approach to Cross-Document Event Coreference Resolution with Large Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; Volume 1, pp. 2985–3002. [Google Scholar]
- Cremisini, A.; Finlayson, M. New Insights into Cross-Document Event Coreference: Systematic Comparison and a Simplified Approach. In Proceedings of the First Joint Workshop on Narrative Understanding, Storylines, and Events, Online, 9 July 2020; pp. 1–10. [Google Scholar]
- Wang, B.; Kuo, C.C.J. Sbert-wk: A sentence embedding method by dissecting bert-based word models. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2146–2157. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yao, Y.; Ye, D.; Li, P.; Han, X.; Lin, Y.; Liu, Z.; Liu, Z.; Huang, L.; Zhou, J.; Sun, M. DocRED: A Large-Scale Document-Level Relation Extraction Dataset. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 764–777. [Google Scholar]
- Sun, Y.; Cheng, C.; Zhang, Y.; Zhang, C.; Zheng, L.; Wang, Z.; Wei, Y. Circle Loss: A Unified Perspective of Pair Similarity Optimization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 6397–6406. [Google Scholar]
- Rijsbergen, C.J.V. Information Retrieval, 2nd ed.; University of Glasgow: Glasgow, UK, 1979. [Google Scholar]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Ahmed, S.R.; Nath, A.; Martin, J.H.; Krishnaswamy, N. 2* n is better than n2: Decomposing Event Coreference Resolution into Two Tractable Problems. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 1569–1583. [Google Scholar]
- Ling, C.; Zhao, X.; Zhang, X.; Liu, Y.; Cheng, W.; Wang, H.; Chen, Z.; Oishi, M.; Osaki, T.; Matsuda, K.; et al. Improving Open Information Extraction with Large Language Models: A Study on Demonstration Uncertainty. In Proceedings of the ICLR 2024 Workshop on Reliable and Responsible Foundation Models, Vienna, Austria, 10 May 2024. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| General Training | Model Architecture | PDWA Mechanism | |||
|---|---|---|---|---|---|
| Batch size | 4 | Transformer layers | 3 | GumbelSoftmax temp () | 0.5 |
| Learning rate | 3 × | Embedding dimension | 768 | Distance normalization | L2 |
| Weight decay | 1 × | Hidden dimension | 768 | PDWA layers | 2 |
| Epochs | 30 | Attention heads | 12 | Path attention heads | 8 |
| Warmup steps | 1000 | Dropout rate | 0.1 | Distance threshold | 0.8 |
| Gradient clipping | 1.0 | ||||
| Context Filter | Auxiliary Training | Selection Parameters | |||
| Direct co-occurrence | 0.1 | Auxiliary weight () | 0.3 | Top k sentences | 20 |
| Indirect co-occurrence | 0.01 | Auxiliary learning rate | 1 × | Max path length | 3 |
| Potential co-occurrence | 0.001 | Entity type emb dim | 128 | Min entity distance | 2 |
| Backbone | Model | Dev | Test | ||||
|---|---|---|---|---|---|---|---|
| AUC | F1 | P@500 | P@1000 | AUC | F1 | ||
| BERT | Pipeline | 17.45 | 30.54 | 30.60 | 26.70 | 18.94 | 32.29 |
| End-to-end | 47.94 | 51.26 | 62.80 | 51.00 | 47.46 | 51.02 | |
| ECRIM | 62.96 | 61.43 | 78.40 | 61.80 | 62.17 | 60.80 | |
| Mr. COD | 59.22 | 61.20 | - | - | 61.68 | 62.53 | |
| PILOT | 63.31 | 62.53 | 78.54 | 62.24 | 62.19 | 61.75 | |
| REIC | 64.50 | 63.77 | 78.60 | 63.80 | 62.59 | 61.27 | |
| CLEAR | 66.39 | 65.78 | 79.67 | 64.76 | 64.39 | 63.71 | |
| RoBERTa | Pipeline | - | - | - | - | - | - |
| End-to-end | 56.47 | 57.49 | 72.60 | 57.10 | 56.32 | 56.05 | |
| ECRIM | 59.36 | 61.81 | 79.60 | 61.90 | 62.12 | 63.06 | |
| Mr. COD | - | - | - | - | - | - | |
| PILOT | - | - | - | - | - | - | |
| REIC | 66.41 | 63.47 | 80.20 | 63.50 | 65.88 | 65.02 | |
| CLEAR | 69.02 | 67.29 | 82.21 | 66.69 | 68.78 | 68.42 | |
| Method | F1 Score (%) | AUC Score (%) | p-Value |
|---|---|---|---|
| BERT Backbone | |||
| REIC | 61.27 ± 1.82 | 62.59 ± 1.95 | - |
| CLEAR | 63.71 ± 1.74 | 64.39 ± 1.88 | <0.001 |
| Improvement | +2.44 [1.23, 3.65] | +1.80 [0.89, 2.71] | t = 3.91 |
| RoBERTa Backbone | |||
| REIC | 65.02 ± 1.97 | 65.88 ± 2.03 | - |
| CLEAR | 68.42 ± 1.89 | 68.78 ± 1.96 | <0.001 |
| Improvement | +3.40 [2.18, 4.62] | +2.90 [1.94, 3.86] | t = 4.23 |
| Method | F1 (%) | AUC (%) |
|---|---|---|
| GPT-3.5-turbo | 28.05 | 31.24 |
| GPT-4 (zero-shot) | 42.18 | 44.67 |
| GPT-4 (few-shot) | 48.34 | 51.28 |
| InstructUIE [13] | 51.23 | 53.89 |
| CLEAR (RoBERTa) | 68.42 | 68.78 |
| Model | F1 | AUC | P@500 | P@1000 |
|---|---|---|---|---|
| CLEAR (our model) | 67.29 | 69.02 | 82.21 | 66.69 |
| -IC | 65.83 | 67.46 | 80.75 | 64.98 |
| -BR | 64.18 | 65.92 | 79.37 | 63.52 |
| -CP | 65.20 | 66.85 | 80.14 | 64.23 |
| -TL | 66.54 | 68.15 | 81.43 | 65.87 |
| -UA | 65.62 | 66.98 | 80.42 | 64.78 |
| -RF | 64.89 | 66.24 | 79.88 | 64.05 |
| -DW | 64.33 | 66.17 | 79.65 | 63.92 |
| Attention Method | F1 | AUC |
|---|---|---|
| Uniform Attention | 64.12 | 65.43 |
| Graph Attention (GAT) | 66.12 | 67.21 |
| Metric Learning Attention | 66.62 | 67.98 |
| Multi-Head Attention | 65.89 | 66.87 |
| PDWA (ours) | 68.42 | 68.78 |
| Head entity: DE 9 Truck | ||||
| Tail entity: Delaware Department of Transportation (DelDOT) | ||||
| Relational tag: owned by; maintained by | ||||
| REIC model prediction relation: n/a | ||||
| CLEAR model prediction relation: owned by; maintained by | ||||
| Path 1 | Path 2 | Path 3 | Path 4 | |
| doc-h | DE 9 is a state highway that connects DE 1 at the Dover Air Force Base in Kent County to DE 2 in the city of Wilmington in New Castle County. It has a truck route, [H]DE 9 Truck[\H]…Dover north to [B1]US 13[\B1]in Smyrna, following its current alignment to Leipsic and Smyrna - Leipsic Road to Smyrna… | …is a state highway that connects [B2]DE 1[\B2] at the Dover Air Force Base in Kent County to DE 2 in the city of Wilmington in New Castle County.[B1] DE 9[\B1] leaves the industrial area upon crossing… and with [H]DE 9 Truck [\H]… The portion of [B1] DE 9[\B1] between DE 141/ DE 273 and East 6th Street in… | [H]DE 9 Truck[\H] heading northwest on Hamburg Road. At this point…Much of DE 9 is designated as part of the [B2] Delaware Byways system[\B2]. From the southern terminus north to New Castle, [B1]DE 9 [\B1] is designated as part of the [B3]Delaware’s Bayshore Byway[\B3], a road that is noted for following the Delaware River and… | DE 9 comes to an intersection with the southern terminus of DE 141 and the eastern terminus of [B1]DE 273[\B1], point [H] DE 9 Truck[\H]… pass through wooded areas with some homes before continuing into industrial areas and crossing a railroad spur…of [B2]DE 2[\B2] before coming to its… |
| doc-t | [T]DelDOT[\T] had purchased land at US 40 east of Glasgow for an inter change along this freeway progressed slowly, with priority given to…AASHO of U.S. approved realign… State Road and then run to the east of [B1]US 13[\B1] in the New Castle area… [T]DelDOT[\T] sought a federal loan to pay for a third of the costs… | I-95 continues through residential areas to the west of downtown Wilmington, passing over [B1]DE 9[\B1]. The widening project was completed in November 2008. Traffic congestion at the cloverleaf interchange with[B2] DE 1[\B2]/ DE 7 in Christiana led to [T]Del- DOT[\T] to improve interchange.[T] DelDOT[\T] plans to completely rebuild I-95 from… | [B2]The Delaware Byways systel\B2] consists of roads in the U.S.…The [B3] Dela ware’s Bayshore Byway[\B3] runs along the Delaware Bay and Delaware River from Lew es… [T]DelDOT[\T] has been monitoring traffic levels on the former surface alignment of US 301 and DE 896 annually to determine when the spur road will be needed… | In 2013, the [T] Delaware Department of Transportation DelDOT[\T] proposed the renumbering of routes in and around Newark. The plan called for [B2]DE 2 [\B2] to start at [B1]DE 273[\B1] (Main Street) east of Newark instead of at the Maryland state line as well as the removal of the [B2]DE 2[\B2]Bus… |
| Method | MUC | B3 | ||||
|---|---|---|---|---|---|---|
| R | P | F1 | R | P | F1 | |
| GPT-4 | 79.8 | 78.0 | 78.9 | 76.3 | 78.1 | 77.2 |
| Ahmed et al. (2023) [32] | 80.0 | 87.3 | 83.5 | 79.6 | 85.4 | 82.4 |
| Our method (CLEAR) | 86.4 | 84.1 | 85.2 | 87.1 | 84.5 | 82.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
She, Y.; Tian, T.; Zhang, J. CLEAR: Cross-Document Link-Enhanced Attention for Relation Extraction with Relation-Aware Context Filtering. Appl. Sci. 2025, 15, 7435. https://doi.org/10.3390/app15137435
She Y, Tian T, Zhang J. CLEAR: Cross-Document Link-Enhanced Attention for Relation Extraction with Relation-Aware Context Filtering. Applied Sciences. 2025; 15(13):7435. https://doi.org/10.3390/app15137435
Chicago/Turabian StyleShe, Yihan, Tian Tian, and Junchi Zhang. 2025. "CLEAR: Cross-Document Link-Enhanced Attention for Relation Extraction with Relation-Aware Context Filtering" Applied Sciences 15, no. 13: 7435. https://doi.org/10.3390/app15137435
APA StyleShe, Y., Tian, T., & Zhang, J. (2025). CLEAR: Cross-Document Link-Enhanced Attention for Relation Extraction with Relation-Aware Context Filtering. Applied Sciences, 15(13), 7435. https://doi.org/10.3390/app15137435