2.1. Q-Learning Algorithm
Q-learning, introduced in [
2], is a foundational algorithm in RL. It enables agents to learn optimal action-selection policies within Markov Decision Processes (MDPs) without requiring an environment model.
In an MDP, the agent interacts with an environment composed of states, actions, transition probabilities, and rewards. At each timestep, the agent observes the current state, selects an action, and transitions to a new state according to the environment dynamics. The agent receives a reward based on this transition and aims to learn a policy that maximizes cumulative rewards over time.
An MDP is formally defined by a tuple , where
S is the set of states, with representing a particular state;
A is the set of actions, with representing a particular action;
is the transition probability function, which gives the probability of transitioning from state s to state after taking action a;
is the reward function, which gives the immediate reward obtained after transitioning from state s to state due to taking action a;
is the discount factor, which determines the importance of future rewards relative to immediate rewards—it is a value between 0 and 1.
The objective in an MDP is typically to find a policy
, which is a mapping from states to actions, that maximizes the expected cumulative reward over time. This is often formulated as finding the policy that maximizes the expected value of the sum of discounted rewards:
where
is the value function, representing the expected cumulative reward starting from state
s and following policy
, and
is the expected immediate reward obtained after taking action
a in state
s and following policy
.
The optimal value function represents the maximum expected cumulative reward achievable from each state, and the optimal policy is the policy that achieves this maximum expected cumulative reward.
Q-learning maintains an estimate of the value of taking action a in state s, denoted as , which represents the expected cumulative reward the agent will receive if it starts in state s, takes action a, and follows an optimal policy thereafter.
The Q-learning algorithm iteratively updates the Q-values based on the Bellman equation:
where
is the learning rate, controlling the extent to which new information overrides old information, and
is the state reached after taking action
a in state
s.
The agent interacts with the environment by selecting actions according to an exploration–exploitation strategy, such as -greedy or softmax, to balance between exploring new actions and exploiting the current best-known actions. Over time, as the agent interacts with the environment and receives feedback, Q-learning updates its Q-values to converge toward the optimal action-selection policy, maximizing the cumulative rewards obtained over the agent’s lifetime.
2.2. Similarity-Based Approaches
The ability to use similarity as a means of transferring knowledge is widely recognized in the scientific literature. The use of similarity allows for knowledge generalization, enhances learning efficiency, reduces uncertainty, and promotes cognitive flexibility.
For example, in [
9,
10], researchers found that humans tend to generalize knowledge learned in specific situations to similar situations, facilitating adaptation to new circumstances. This ability to generalize knowledge is fundamental to human learning and adaptive behavior.
Furthermore, the efficiency of learning through recognizing similarities between past and new situations has been documented in various fields. For instance, in [
11], it was highlighted how recognizing similarities enables individuals to quickly grasp and adapt to new situations, resulting in more efficient learning.
The reduction in uncertainty through identifying similarities between situations has also been a subject of research. In [
12], it was demonstrated that by identifying similarities, individuals can make informed predictions about future events, allowing them to make decisions with greater confidence and reduce uncertainty associated with the unknown.
Moreover, cognitive flexibility facilitated by the ability to recognize similarities has been extensively studied [
13]. This ability enables individuals to easily adapt strategies and approaches used in the past to new circumstances, thereby increasing their ability to solve problems effectively.
This principle is not confined to cognitive sciences but also extends to computational fields such as data mining and supervised learning, where similarity measures play a fundamental role in uncovering hidden patterns [
14], clustering [
15], classification [
16], and handling mixed data [
17].
Recent research in RL has also highlighted the significance of similarity in knowledge transfer and adaptation, allowing accelerated learning and improved decision-making in new and unseen environments. RL algorithms, inspired by principles of human learning, utilize similarity to generalize experiences across different states or contexts.
Works like [
18,
19,
20] propose identifying states with similar sub-policies (what could be described by the Principle of Optimality) using homomorphism. These approaches use the history of states, actions, and rewards in a tree-like structure to identify similar sub-policies based on the number of shared items among these sequences, in a model-free fashion. However, these structures and homomorphisms are quite restrictive and computationally expensive [
21].
Likewise, there are works such as [
22,
23,
24] that aim to reduce the observation space using an approximation function to represent similitude between states, effectively creating state prototypes. Each prototype contains the most representative features for each subset of similar states. These feature extraction methods are proposed with some adaptation, but they could lead to both good and bad states following the same prototype due to the use of general heuristics and the potential coarseness of the prototype space.
Meanwhile, others [
7,
8,
25] introduce human knowledge directly to abstract the problem’s domain to aid an agent in generalizing its interactions with the environment, decreasing the number of interactions needed to learn. This is achieved by designing a similarity function as a map of states, actions, or state–action pairs to real values between zero and one. These approaches allow the algorithms to obtain ad hoc knowledge for a task, but they also lead to the introduction of biases and other assumptions that the designers may make.
Alternatively, in [
25], three categories are defined to help human designers identify similarity in real problems: (1) representational, (2) symmetry, and (3) transition. Representational similarity refers to the generalization of the state–action feature space. Symmetry similarity aims to reduce redundancies for those pairs that are eventually equal given an axis. Transition similarity compares the relative effects of taking an action given a state and where the environment transitions to.
The Q-learning algorithm was upgraded through the integration of representational similarity between elements of the MDP’s two spaces—
S for states and
A for actions—as proposed by [
7]. They state that similarity in these sets could be measured by a norm (though noting this would not always be true or useful in every environment, as [
8] remarks). These norms allow some measurement of similarity that is used to select items as "most-likely similar" with a threshold
or
. The observed information in Q-learning (the temporal-difference error) is then integrated into these states or actions that are considered similar, as shown in Equation (
1), in addition to the normal algorithm behavior. These approaches are denominated as QL-Smooth Observation and QL-Smooth Action, respectively.
Meanwhile, the authors of [
8] used a similarity function between states, enabling transitional similarity, denominated as SSAS, with custom similarity functions
for all
. They also modified the Q-learning algorithm by integrating this
value, as shown in Equation (
2), for each pair whose similarity value is above zero. This algorithm is denominated as QSLearning.
Both proposals add a mechanism that uses similarity and performs extra off-policy updates for the same Q-object. QL-smooth uses a norm operation and a threshold to determine which states or actions to update additionally, with a fixed smooth rate
. The norm measures distance and then chooses a threshold that may disconnect the concept of similarity for some environments and their state–action pairs, while QSLearning updates all pairs available in the MDP where
, meaning that any positive amount of similarity between state–action pairs is considered sufficient. This could be wasteful and destructive, as the size of
could potentially be large, and allowing
for any value to modify the Q-table with Equation (
2) with any value of
equates to an excessive number of updates with excessive data.
Nevertheless, these methods have shown good results in their respective applications. Ref. [
7] has shown significant speed-up in grid-world tasks and classic control even after a single training episode. And the authors of [
8] demonstrated that their algorithm can outperform Q-learning with different designs for
in their corresponding tasks.
At this point, it is relevant to emphasize that the choice of a similarity function is a crucial aspect that must be carefully designed according to the problem domain. Although the effectiveness of similarity-based approaches heavily depends on this measure—since, in the worst case, a poorly chosen metric can compromise results—this characteristic is also one of their key strengths. Their flexible framework allows for an adaptation to diverse problems by leveraging existing similarity measures that naturally fit the context.
In continuous spaces, kernel-based similarities or cosine similarity can be used. For discrete spaces, measures such as exact match or the Jaccard index may be suitable. In geometric problems, position-based metrics are often appropriate. For mixed-data types, integrated functions can combine different approaches: kernel-based similarities (e.g., Gaussian) for continuous features, exact match or set similarity for categorical variables, and embedding-based cosine similarity for textual or image data. An example of this would be a function like , where weights and adjust the relative contribution of each component.
Furthermore, when domain-specific knowledge is available, custom similarity functions can be designed. For instance, in robotics, one might combine joint configuration similarity with expected reward metrics. In natural language processing (NLP) tasks, semantic similarity could be integrated with syntactic features to refine outcomes.
2.3. Current Limitations
Despite their demonstrated advantages, existing similarity-based Q-learning approaches exhibit several fundamental limitations that constrain their practical application.
First, computational complexity remains a significant bottleneck. Methods relying on exhaustive similarity searches [
20] face
time complexity for pairwise state comparisons, becoming prohibitive in large or high-dimensional state spaces. This overhead persists even with approximate similarity metrics, as the comparison operations themselves scale quadratically with the number of states. Moreover, these methods typically lack mechanisms to prioritize or filter updates based on their expected utility or trustworthiness, limiting their scalability.
Second, the static nature of similarity thresholds and update parameters limits adaptability. Approaches like QL-Smooth [
7] employ fixed thresholds (
,
) and smoothing factors (
) that cannot adjust to local variations in state space density or problem dynamics. This rigidity often leads to either insufficient generalization (when thresholds are too strict) or over-propagation of updates (when thresholds are too lenient). Furthermore, such parameters remain constant throughout the learning process, making it difficult to accommodate heterogeneous regions of the state space or evolving dynamics as training progresses.
Third, uncontrolled update propagation risks policy degradation. QSLearning’s [
8] strategy of updating all state–action pairs with
can introduce harmful interference, particularly when
The similarity function imperfectly captures true task-relevant similarities;
The state–action space contains regions with fundamentally different dynamics;
The learning rate remains high during later training stages.
These problems are exacerbated by the fact that existing methods do not incorporate mechanisms to scale updates based on the confidence in value estimates, nor do they adapt similarity propagation in response to learning progress.
Additionally, current methods share two subtle but important weaknesses:
Our
XSQ-Learning algorithm, detailed in
Section 3, addresses these limitations through three distinctive components: (1) adaptive similarity thresholds that evolve in response to the agent’s current performance and temporal-difference signals, (2) confidence-weighted update propagation that scales similarity-based updates based on the stability of each Q-value estimate, and (3) a local similarity clipping mechanism that limits propagation to highly reliable regions. These design choices maintain the generalization benefits of similarity-based learning while mitigating over-propagation, improving convergence stability, and enhancing scalability to more complex environments.

 ,
, 


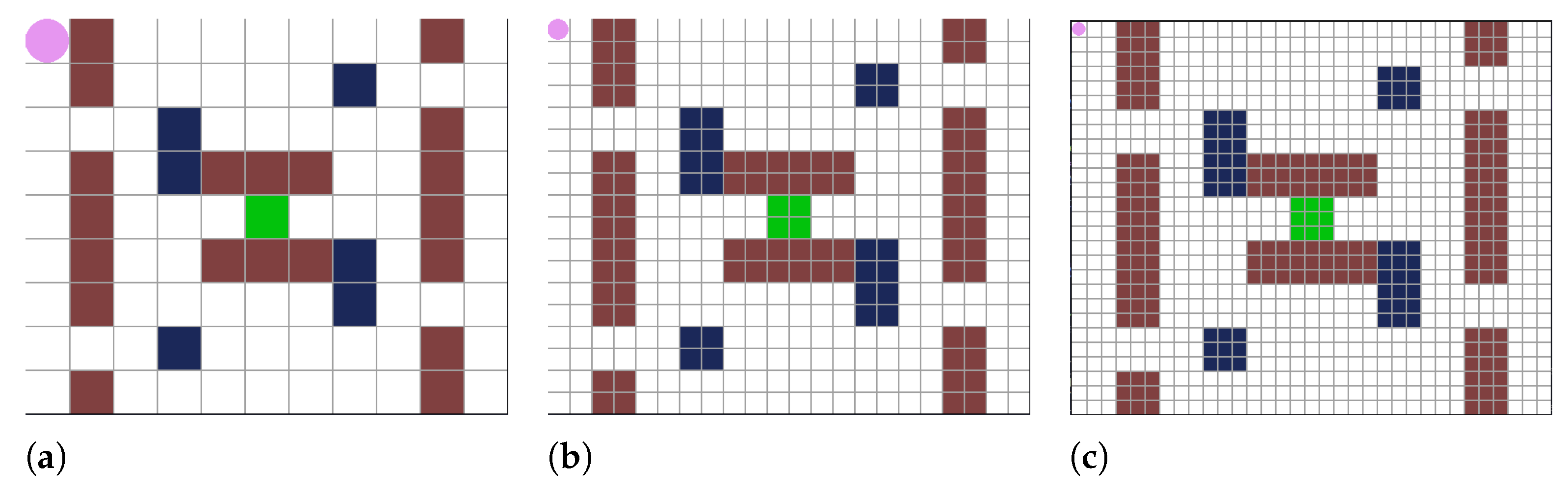
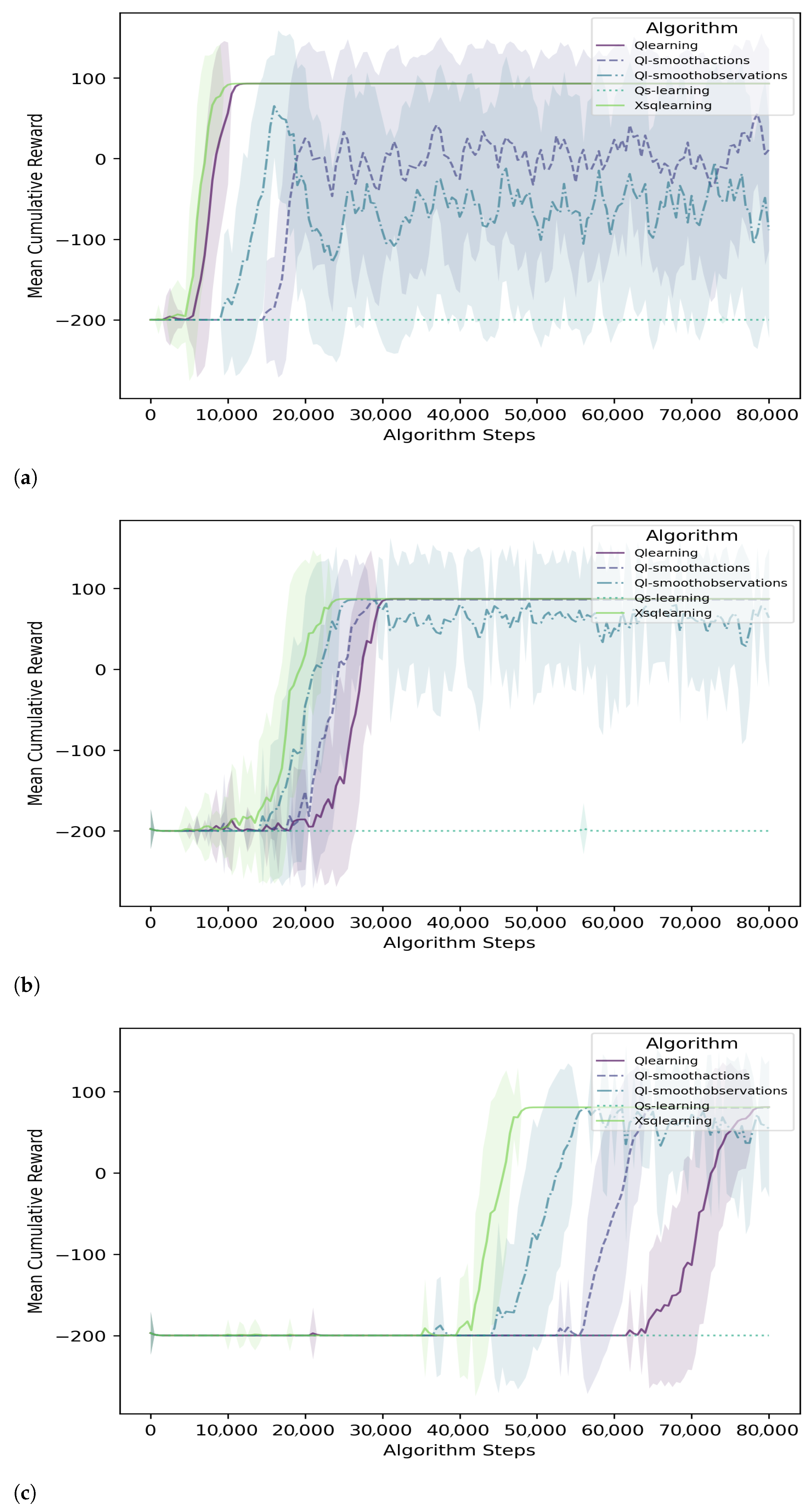

{kind=link}
{kind=link}