1. Introduction
The provision of safe drinking water is not only an essential global health priority but also a major component of Sustainable Development Goal 6 of the United Nations. Although awareness of safe drinking water increased globally, many people still rely on unsafe water sources for consumption and daily use. As of 2022, it is estimated that approximately 1.7 billion people are using drinking water contaminated with feces, leading to horrible health consequences. Consumption of microbially contaminated water can lead to waterborne diseases such as diarrhea, cholera, typhoid, and hepatitis A. These diseases cause a huge number of deaths in the low-income world, with hundreds of preventable deaths each year [
1]. The impact of this disease is especially high for children under five years of age. Thus, the availability of safe drinking water and its sustainable management are not only a public health need, but also a matter of social and economic concern.
It is vital for preventing disease outbreaks and ensuring human health that the water quality parameters are tracked continuously and accurately. Traditional methods for water quality assessment include periodic laboratory analyses of physicochemical and microbiological parameters, which are time-consuming, labor-intensive, and costly. Complementarily, there has been a growing interest in computational prediction methods based on measurable water quality indicators. Machine learning (ML) techniques are potentially good candidates for classifying water potability automatically based on sensor data. Classical algorithms, such as decision trees, support vector machines (SVMs), k-nearest neighbors (KNN), and ensemble algorithms (random forest, AdaBoost, and XGBoost), have found great applications in this context. Among these, XGBoost emerged as a preferred method for handling large and heterogeneous datasets due to its capacity to manage missing values and model complex feature interactions. Empirical studies have shown that such tree-based models consistently outperform simpler classifiers such as logistic regression [
2,
3]. Nonetheless, conventional ML models often depend on manual feature engineering and may fail to capture the subtle nonlinear dependencies among water quality attributes. The above limitations are addressed by proposing deep learning as an alternative. It is a data-driven approach, where feature representations are learned automatically in an abstract manner. Nevertheless, it has been a point of contention as to whether classical multilayer perceptron’s (MLPs) can outperform ensemble techniques on tabular datasets [
4]. Thus, attempts to bridge this uncomfortable distance led to the conception of specialized neural architectures accommodating structured data. One of the most promising research directions in this context has been the exploration of attention mechanisms. For example, TabNet does sequential attention-based feature selection wherein the dynamic assignment of importance is given to the relevant features developed from each decision step to achieve high accuracy with interpretability [
5]. Correspondingly, the TabTransformer adopts the self-attention approach characteristic of transformers to encode categorical variables for tabular data, which exhibited a performance level commensurate with state-of-the-art ensemble methods [
6].
More recent transformer-based architectures, such as FTTransformer, embed each feature as a token and apply multi-head self-attention to model inter-feature relationships, thereby achieving or surpassing other deep learning approaches on structured prediction tasks [
4]. SAINT extends this capability by introducing a dual-attention mechanism that models both feature-wise and row-wise dependencies. Moreover, with appropriate contrastive self-supervised pretraining, SAINT performed much better than the widely used ensemble methods XGBoost and LightGBM across different benchmarks [
7]. Unsupervised techniques using deep autoencoder-based models are designed to learn compressed representations in suitably unlabeled time series data for performing anomaly detection under real-world low-label conditions. For instance, Amarbayasgalan et al. [
8] proposed an unsupervised anomaly detection method based on reconstruction error that has shown increased performance across 52 benchmark datasets over different domains. These methods are extremely attractive in the environmental sciences, considering the scarcity of annotated data that is quite expensive to acquire.
In spite of deep tabular learning’s advancement, its role in water quality classification, especially drinking water potability, remains a less explored area. Most of the literature concentrated on conventional ML methods. Very few studies involve comparative analyses of contemporary attention-based deep learning architectures within this area. For these reasons, this study aims to present the following objectives to fill this gap and further drive the current body of knowledge:
Comparative evaluation: We conduct a systematic comparison of four transformer attention-based models, namely an upgraded version of TabTransformer, FTTransformer, SAINT, and a newly formed autoencoder-augmented model that we named TAPE.
Real application scenarios in datasets: Models are trained on and evaluated against an available physicochemical water quality dataset, which resonates with real-life situations in drinking water monitoring.
Practical relevance and interpretability: Assessing each architecture on practical feasibility and interpretability in environmental monitoring use, including its benefits and drawbacks.
Newness: This is the most comprehensive study to date that benchmarks various transformer-inspired deep models primarily for the specific application of predicting potable drinking water.
2. Related Work
Previous studies used conventional machine learning (ML) techniques extensively to predict the potability of drinking water from the different physicochemical properties. Simple models such as logistic regression and decision trees make basic baselines because of their interpretability and computational efficiency [
9]. Such is the case with Jijo and Abdulazeez (2021) [
9], who found that decision trees are appropriate classifiers for classification tasks on water quality. According to Uddin et al. (2023) [
10], several machine learning models have been evaluated for classifying water quality, and they found that support vector machines (SVMs) demonstrated strong performance across all metrics. However, the XGBoost model achieved the highest overall performance with respect to accuracy, with 100% precision and an F1-score of 0.99 and specificity of 1.0, rendering it far better in predicting water quality index in this study. As the demand for greater predictive performance increased, ensemble-based algorithms such as random forest and XGBoost gained prominence due to their robustness and ability to capture intricate feature interactions. Random forest handles high-dimensional data effectively by averaging multiple decision trees, which also enhances its interpretability [
11]. XGBoost, as developed by Chen and Guestrin (2016) [
12], went a step further by employing the aspect of regularization and efficient handling of sparse data. Several studies highlight XGBoost’s superiority over traditional models, such as logistic regression and SVM, for predicting water potability [
13,
14]. Patel et al. (2023) [
2], for example, demonstrated the model’s strong performance even on complex, high-dimensional, and imbalanced datasets. However, tree-based approaches depend heavily on manual feature engineering and often perform poorly when dealing with multi-modal data or dynamic changes in water quality patterns over time. Chen et al. (2024) [
15] specified these limitations, adding that such traditional ensemble models, such as gradient-boosted decision trees (GBDTs), were unable to match hybrid attention-based architectures. In contrast, new evidence by Grinsztajn et al. (2022) [
16] argues that tree-based models may still outperform deep learning models in many tabular data settings owing to their aforementioned strong inductive biases, stability under low data regimes, and lower sensitivity to hyperparameter tuning.
All these constraints incited a lot of empathy for deep learning models, with a primary focus on those trained in a structurally data-sensitive environment. For example, conventional neural networks experience some restrictions in tabular environments, such as the weakness of inter-feature dependence and the issue of space structure. Thus, specialized architectures with an inductive bias for tabular learning have been created by researchers. Among these, for example, is TabNet, introduced by Arik and Pfister (2021) [
5], which features a sequential attention-based mechanism wherein at every decision step, it dynamically chooses the most relevant features, in turn improving the accuracy and interpretability of the model. This was followed by TabTransformer by Huang et al. (2020) [
6]; this extended the transformer encoder format by embedding the categorical features to perform multi-head self-attention, modeling contextual relationships among the ‘n’ inputs. Gorishniy et al. (2021) [
4] presented the FTTransformer. It is a much cleaner design; hence, each tabular feature is a token that can be processed by transformer layers successfully, adopting NLP mechanisms to structured data tasks. Having accomplished all this, we cannot forget that they have shown good results compared to gradient-boosting algorithms under different types of noise and incomplete conditions. Going further, Somepalli et al. (2021) [
7] presented a SAINT that incorporates intra-row and inter-row attentions. Instead of an approach that considers only sample dependencies, SAINT models the dependencies across different instances within a batch by which the network learns across patterns dataset wide. Therefore, such complementary training is with contrastive pretraining and advanced embedding strategies, enabling it to consistently surpass baseline models across a variety of structured datasets.
Accompanying architectural advances is another important research direction aimed at boosting generalization through unsupervised and self-supervised learning. Bengio et al. (2013) [
17] joined Erhan et al. (2010) [
18] in emphasizing that an unsupervised objective should allow pretraining of the deep neural networks—traditionally using objectives such as autoencoders or restricted Boltzmann machines—to learn an underlying structure of the data well within the time frame of supervised training. This line of development catalyzed recent transformer-based models such as TAPE, where autoencoder-style pretraining is performed together with attention-based encoders to develop robust feature representations from unlabeled data. The hybrid methods prove particularly useful, for example, in water quality assessment, where the availability of labeled datasets is limited or expensive.
In recent times, innovations have become variegated concerning their adequacy for the assessment of water potability. For example, Akhlaq et al. (2024) [
19] compared multiple ML algorithms, including decision tree, KNN, MLP, SVM, and random forest, showing that environmental monitoring tasks require interpretability, predictive performances, and reliable models, with random forest providing the best accuracy and F1 scores during their investigations. In Wang et al.’s work (2024) [
20], a hybrid deep learning model for water quality prediction in normal plain watershed environments was proposed, which combined LSTM, GRU, and Bayesian optimization. By improving the predictive performance of the algorithm, the framework proved to be promising by bringing down RMSE by 32.1% and enhancing R
2 over multiple targets, thus demonstrating its utility in heterogeneous water sources. The Sekarlangit et al. (2024) [
21] study is a comparative exercise between ANN and LSTM models for dissolved oxygen (DO) prediction in river waters. Their study established that although LSTM attained a lower MSE, superior results were seen in the case of the ANN model with respect to lower RMSE (0.00436) and MAPE (1.85%), indicating better overall accuracy in DO predictions. Classical neural architectures prove particularly effective in specific contexts that utilize well-calibrated model parameters and configurations tailored to domain-specific characteristics. As highlighted in his water quality assessments, Gan et al. (2021) [
22] presented evidence that the LightGBM model can effectively predict estuarine water levels in the Columbia River by considering upstream river discharges and tidal input. The model achieved a correlation coefficient ranging from 0.975 to 0.987 and RMSE values as low as 0.14 m, outperforming traditional physics-based models in both accuracy and skill score. The opposite development was carried out by Li and Gu (2023) [
23], who built a hybrid model based on CNN, BiLSTM, and the attention mechanism to obtain sequential dependencies in diverse water quality parameters. All these efforts thus manifest a considerable shift toward hybrid, interpretable, and context-aware models, addressing real-world problems along with their associated complexities in the estimation of water potability.
A comprehensive tabular summary of the most recent scientific studies published between 2021 and 2024 on the estimation of drinking water potential using ML and deep learning (DL) techniques is presented in
Table 1. The studies are arranged in reverse chronological order and provide a broad perspective in terms of the variety of algorithms used, types of datasets, and modeling approaches applied. This review presents current trends and methodological developments in the field of water quality assessment.
In summary, the reviewed literature suggests two main approaches to improve deep learning performance on tabular water quality data: (1) the use of attention-based architectures capable of modeling complex relationships between features, e.g., transformer models, TabNet, and SAINT; and (2) the application of unsupervised or semi-supervised pre-learning methods to extract robust feature representations from unlabeled data. Accordingly, this paper presents a unified evaluation framework that includes attention mechanism-based models (FTTransformer and SAINT) together with a newly developed model, the transformer autoencoder potability estimator (TAPE), and proposes specially optimized solutions for drinking water classification problems.
3. Materials and Methods
3.1. Data Acquisition and Preprocessing
The dataset comprises 3276 water samples with nine physicochemical attributes: pH (unitless, range 0–14), hardness (mg/L CaCO3), total dissolved solids (mg/L), chloramines (mg/L), sulfate (mg/L), conductivity (µS/cm), organic carbon (mg/L), trihalomethanes (µg/L), and turbidity (NTU). Approximately 10% of entries contained missing values due to sensor limitations, addressed via median imputation. Attribute distributions were analyzed using kernel density estimation to confirm suitability for classification tasks.
This investigation employed a comprehensive water potability dataset encompassing multiple physicochemical parameters to develop a binary classification framework distinguishing between potable (drinkable) and non-potable water samples. The dataset incorporates various water quality metrics, including, but not limited to, pH, hardness, solids content, chloramines, sulfates, conductivity, organic carbon, trihalomethanes, and turbidity parameters established by international drinking water standards organizations as critical determinants of water safety.
The dataset utilized in this study was obtained from an open-access water quality repository made publicly available via the Data. World platform [
24]. It comprises physicochemical measurements relevant to potability classification tasks, including parameters such as pH, hardness, total dissolved solids (TDS), chloramines, sulfate, conductivity, organic carbon, trihalomethanes, and turbidity. This dataset has been widely used in prior water quality modeling studies due to its balanced representation of real-world water samples and diverse feature attributes.
Before analytical implementation, a thorough examination of the dataset’s characteristics was conducted to ensure robust model development. Statistical analysis revealed several distributional properties inherent to environmental monitoring data, including the presence of missing values attributed to sensor malfunctions or field collection limitations. To address this common challenge in environmental datasets, we implemented a median-based imputation strategy. This methodological choice was predicated on the median’s robustness to outliers frequently encountered in water quality parameters, particularly in cases where contamination events may produce extreme values. We employed a median-based imputation strategy, a standard preprocessing technique known for its robustness to outliers frequently observed in water quality parameters, particularly during contamination events [
25]. The median imputation can be mathematically represented as follows:
here,
denotes the imputed value for the
-th missing entry in the
-th feature column, which is derived from the median of all observed values within that feature.
To characterize the dataset, we conducted a statistical analysis of attribute distributions using kernel density estimation, confirming their suitability for classification tasks. Frequency analysis revealed the class distribution between potable and nonpotable samples, guiding the selection of a stratified 70:15:15 train–validation–test split to maintain class balance [
26]. This split balance training data availability with robust evaluation ensures reliable performance estimates.
To ensure complete reproducibility of the computational workflow, deterministic behavior was enforced across all stochastic processes by implementing fixed seed initialization (seed value: 42) across the numerical computational framework, including all random number generators in the NumPy library (2.3.0), PyTorch tensors (2.0), and CUDA (11.8) operations when applicable. This aligns with the standard first-order Markov property, ensuring that the probability of the next state depends only on the current state [
27]. The property is expressed as follows:
This probabilistic constraint ensures that sequential executions of the analytical pipeline produce identical outcomes, a fundamental requirement for scientific reproducibility.
3.2. Deep Learning Model Architectures for Tabular Data Classification
This study implements and evaluates four advanced deep learning architectures specifically designed for tabular data classification: enhanced tab transformer, feature tokenizer transformer (FTTransformer), self-attention and inter-sample attention network (SAINT), and tabular autoencoder pretraining enhancement (TAPE). Each architecture employs distinct approaches to capture feature interactions and extract meaningful representations from water quality parameters. The model comparisons are represented in
Table 2.
3.3. Enhanced Tabular Transformer Framework
The enhanced tabular transformer architecture represents a specialized adaptation of the canonical transformer framework [
28] specifically optimized for tabular data analysis. This architecture incorporates the following:
Feature embedding layer: transforms the input features into a high-dimensional representation space through a non-linear projection:
where
represents the rectified linear unit activation function [
28], LN denotes layer normalization, and
and
are learnable parameters mapping the
-dimensional input to an
-dimensional hidden representation.
Self-attention mechanism: Enables the model to capture complex relationships between different water quality parameters through multi-head attention. This embedding is followed by a scaled dot product attention mechanism, which computes attention scores to focus on relevant features:
where
represent query, key, and value projections, respectively, and
is the dimensionality of the key vectors. These components, introduced by Vaswani et al. [
28], form the basis of the transformer encoder block used in ETT and FTTransformer.
This formulation allows the model to attend differently to various feature interactions through multiple attention heads.
where
with projection matrices
and
. Here,
represents the dimension per attention head. The feed-forward network (FFN) applies a two-layer transformation with GELU activation:
where GELU denotes the Gaussian error linear unit activation function [
29], providing smoother gradients compared to ReLU. Each sub-layer (multi-head attention or FFN) incorporates a residual connection and dropout, followed by layer normalization:
The complete encoder layer chains these sub-layers:
Multi-layer encoder structure: consists of
stacked encoder layers, allowing for hierarchical feature extraction:
Classification head: processes the encoded representation through a multi-layer perception with dimensionality reduction:
where
represents the sigmoid activation function, yielding a probability distribution over the binary classification targets.
3.4. Feature Tokenized Transformer Architecture
The feature tokenizer transformer [
4] introduces an innovative approach to tabular data processing by treating each numerical feature as a distinct token requiring specialized embedding.
Feature-specific tokenization: each feature undergoes individualized transformation through dedicated embedding networks:
where each feature
is independently embedded through a dedicated transformation
, followed by the incorporation of learned positional embeddings
that enable the architecture to maintain feature ordering information.
Feature interaction modeling through multi-head attention:
where
represents a masking matrix enabling control over allowed feature interactions. For this implementation, full attention was permitted (
).
Multi-layer transformer encoding: .
Where represents the -th transformer layer, and denotes the total number of layers.
Final classification pathway via dimensionality reduction:
The flattening operation concatenates the embedded representations across all features to form a comprehensive representational vector. The FTTransformer architecture is particularly effective for capturing intricate relationships between water quality parameters through its specialized feature tokenization approach.
3.5. Self-Attention and Inter-Sample Attention Network (SAINT)
The self-attention and inter-sample attention network (SAINT) model, introduced by Somepalli et al. [
7], is designed for tabular data classification by integrating feature-level and inter-sample attention mechanisms. This dual-attention approach enables SAINT to capture both intra-sample feature relationships and inter-sample contextual patterns, making it particularly effective for datasets such as the water potability dataset used in this study. SAINT [
7] implements a dual-attention mechanism that simultaneously captures both feature interactions and sample-to-sample interactions.
This embedding aligns with the preprocessing steps applied to the dataset’s attributes (e.g., pH, hardness, and total dissolved solids). The embedded features are then processed through feature-level attention, which models relationships within each sample’s features using multi-head attention:
For
where
represents the
-th transformer encoder layer, and
denotes the total number of feature attention layers. To capture contextual patterns across samples in a batch, SAINT employs inter-sample attention:
The dual-attention structure in Equations (17)–(19) is directly inspired by the SAINT model, which integrates feature-level and sample-level attention for tabular data modeling [
7].
where
represents the batch size, and the inter-sample attention enables the model to leverage contextual information from other samples in the batch, potentially capturing population-level patterns in water quality data.
Integrated classification pathway:
The SAINT architecture offers a unique advantage in capturing both featured interactions within individual water samples and patterns across different samples, potentially identifying subtle quality relationships that affect potability.
3.6. Tabular Autoencoder Pretraining Enhancement (TAPE) Architecture
We introduce a novel method, TAPE, which leverages unsupervised representation learning through an autoencoder framework to capture intrinsic data structures before fine-tuning for classification:
Multi-layer encoder network: transforms input features into a compressed latent representation through multiple non-linear transformations:
where
denotes the number of encoding layers, and
represents the ReLU activation function.
Symmetric decoder network for reconstruction (used during pretraining):
With reconstruction loss [
17] defined as follows:
.
Classification module leveraging learned representations for supervised classification:
This two-phase training approach [
18] enables the model to first learn general data structures from all available samples (including those with missing target values) before specializing in the classification task. While autoencoders are commonly applied to image and text data [
7], their use for tabular data has gained attention in recent years. The TAPE architecture’s focus on tabular data aligns with emerging research in this area. The TAPE approach offers the advantage of utilizing unlabeled water quality data for representation learning, potentially capturing intrinsic patterns before fine-tuning for potability classification.
3.7. Feature Importance Quantification Methodologies
For a comprehensive interpretation of model decisions, feature importance metrics were calculated for each architecture to elucidate the contribution of individual water quality parameters to potability classification.
For the enhanced tabular transformer architecture, feature importance was derived from the weights of the initial linear transformation layer:
where
represents weights from the first fully connected layer following the transformer encoder, and
denotes the hidden dimensionality. This approach leverages the absolute values of the weights to quantify how much each input feature contributes to the latent representation [
30]. This method is consistent with interpretability techniques used in neural networks, where layer weights are analyzed to understand feature contributions.
For the feature-tokenized transformer, feature importance was calculated by aggregating the absolute values of the weights across feature tokenizers:
where
represents the weight connecting the
-th feature’s
-th token to the
-th dimension of the embedding space. This approach reflects the contribution of each feature across its tokenized embeddings [
28]. The aggregation captures both local and global importance within the embedding space.
For the SAINT architecture, feature importance was derived from the weights of the initial linear transformation layer:
where
denotes the weight matrix of the initial feature embedding layer. This method emphasizes the role of embedding weight in capturing feature relevance, aligning with the attention mechanism’s focus on feature interactions [
7].
The TAPE architecture combines weights from both the encoder and decoder layers to capture bidirectional importance:
, representing the product of absolute weights in the first encoder layer and first decoder layer, capturing both the feature’s importance for representation learning and reconstruction [
12].
3.8. Experimental Protocol and Computational Implementation
The models were trained using PyTorch (version 2.5.1+cu12) on a system equipped with an NVIDIA GeForce RTX 4090 GPU (24 GB VRAM), a 13th Gen Intel(R) Core (TM) i9-13900KF CPU 3.00 GHz, 128 GB RAM, and running Windows 11 Pro. The environment utilized CUDA compilation tools version 12.6 (V12.6.77) and CUDA runtime version 12.1.
The training pipeline employed binary cross-entropy (BCE) as the loss function and the Adam optimizer. Training data were processed in batches of 128 and shuffled at each epoch to improve generalization. Early stopping was implemented based on validation loss, with the model corresponding to the lowest validation loss across 100 epochs being saved to prevent overfitting. To ensure reproducibility, a fixed random seed (42) was set for NumPy, PyTorch, and CUDA, enabling deterministic weight initialization and data shuffling.
The following hyperparameters were applied across the transformer-based models used in the study. For the enhanced tab transformer, a hidden dimensionality of 128 was selected, with 8 attention heads to enable diverse feature representations through multi-head self-attention. The architecture consisted of 3 layers, incorporated a dropout rate of 0.2 to mitigate overfitting, and was trained with a learning rate of 0.001. The FTTransformer employed an embedding dimensionality of 32, specifically designed for feature-specific tokenization to model attribute interactions. Similar to the enhanced tab transformer, it utilized 8 attention heads, 3 layers, a dropout rate of 0.2, and a learning rate of 0.001. For the SAINT model, the configuration included a hidden dimensionality of 128, 8 attention heads, and 3 layers, with a dropout rate of 0.2 and a learning rate of 0.001. Lastly, the TAPE model used a hidden dimensionality of 128 with 3 layers, a dropout rate of 0.2, and was trained using a learning rate of 0.001.
The 70:15:15 split was chosen to balance sufficient training data for deep learning models, which require substantial samples to learn complex feature interactions, with adequate validation and test sets for hyperparameter tuning and unbiased performance estimation. Five-fold cross-validation was not implemented in the training pipeline due to the computational cost of training deep models on a moderately sized dataset and the sufficiency of the stratified split for robust evaluation. The single split, combined with stratified sampling and a fixed seed, ensures representative subsets and reproducible results. Model optimization employed the binary cross-entropy loss function, mathematically expressed as follows:
where
represents the true potability label and
denotes the model’s predicted probability of potability.
Parameter optimization utilized the Adam optimizer with the following configuration:
Initial learning rate: ,
Exponential decay rates: ,
Weight decay coefficient: .
Models were trained using mini-batch gradient descent with a batch size of 64. To prevent overfitting, we implemented early stopping based on validation loss with a patience of 500 epochs, monitoring validation loss with a minimum improvement threshold of
3.9. Evaluation Metrics and Statistical Analysis
Model performance was comprehensively evaluated using a multi-metric approach to address various aspects of classification quality:
Accuracy: The proportion of correctly classified instances: .
Precision: The proportion of true positive predictions among all positive predictions: .
Recall (sensitivity): The proportion of true positives identified among all actual positives: .
F1-scor: The harmonic means of precision and recall: .
3.10. Additional Information on Dataset and Assessment Protocol
This section provides additional information on the structure of the dataset used and the model assessment process. The dataset used in the study consists of a total of 2011 water samples defined by nine basic physicochemical parameters. Missing values were found for pH (2.7%), sulfate (2.1%), and trihalomethanes (4.5%) variables, and these missing values were filled with the median imputation method, as it is robust to outliers.
The dataset was split into 70% training, 15% validation, and the remaining 15% for testing in order to obtain a reliable result when evaluating model performance. Rational considerations were made to apply stratified five-fold cross-validation on the training set to further keep class imbalance based on class distribution percentage: 61% non-drinkable and 39% drinkable. This procedure provides a trade-off between computational expense and statistical reliability. Thus, the validation set will be used as the stopping criterion, while the test set will be used for final evaluation only.
For further reproducibility, random seeds were set with a fixed value (seed = 42) and a deterministic environment was thus constructed for every step of computation for all randomization sources, including NumPy, PyTorch, CUDA, etc.
4. Results and Discussion
The performances of four transformer-based deep learning architectures (EnhancedTabTransformer, TAPE, SAINT, and FTTransformer) were thoroughly evaluated using multiple classification metrics to assess their efficacy in water potability prediction. The experimental results reveal significant insights into both algorithmic performance and the relative importance of specific water quality parameters in determining potability.
4.1. Comprehensive Performance Analysis
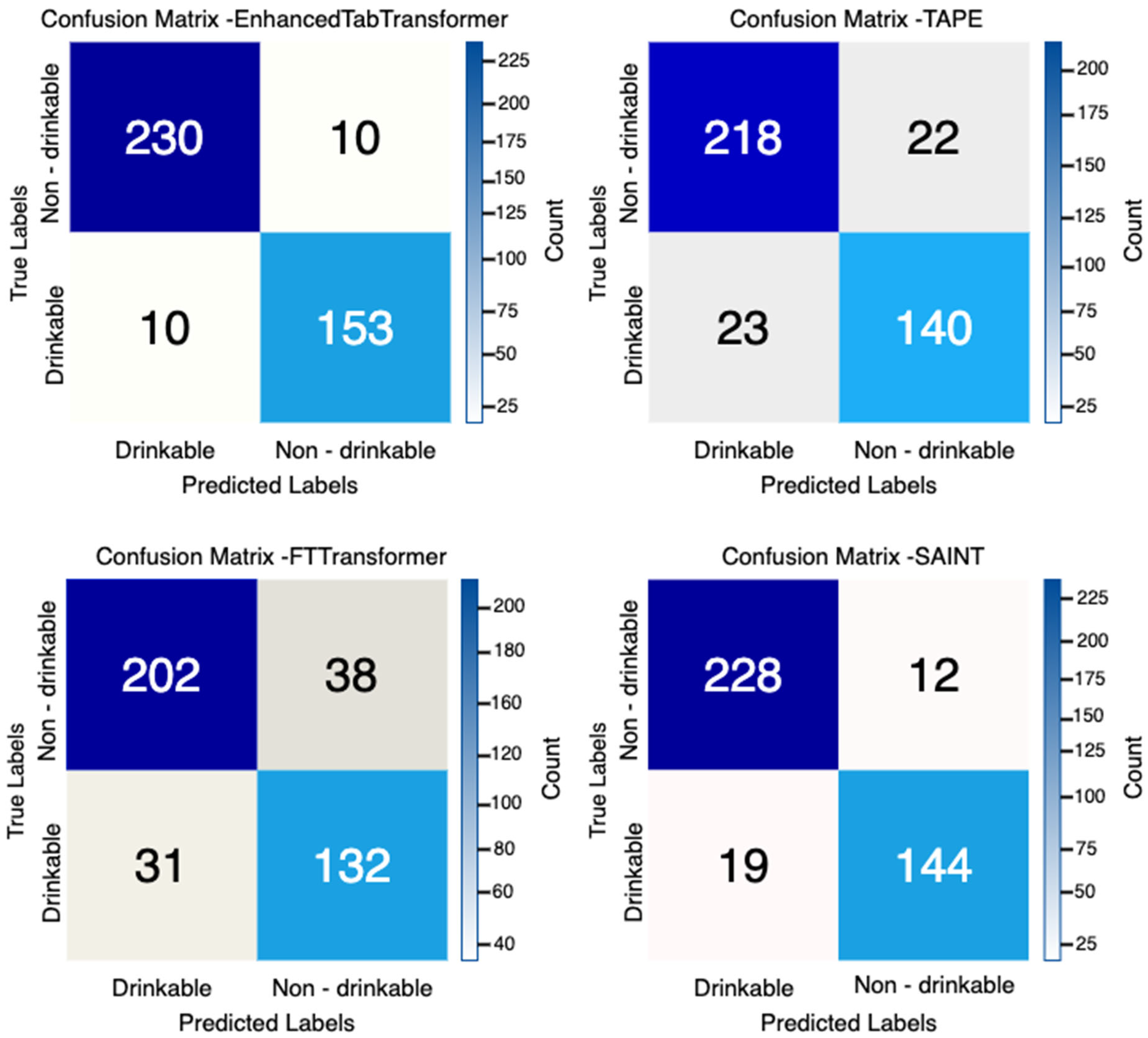
Figure 1 presents the confusion matrices for each of the four implemented models, visually demonstrating their classification performance in distinguishing between drinkable and non-drinkable water samples. The confusion matrices reveal that the EnhancedTabTransformer achieved the most balanced performance across both classes, with minimal misclassification in either category.
As detailed in
Table 3, the EnhancedTabTransformer demonstrated superior performance with an accuracy of 95.04% and an F1 score of 93.87%, establishing it as the most effective architecture for water potability classification among the evaluated models. ETT’s exceptional performance can be attributed to its sophisticated architecture, which leverages multi-head self-attention and hierarchical encoder layers to model complex, high-order interactions among physicochemical parameters. This aligns with the theoretical underpinnings of transformer models, which excel at capturing contextual dependencies through attention mechanisms [
28].
The SAINT architecture followed closely, with an accuracy of 92.31% and an F1 score of 90.28%, demonstrating its effectiveness in capturing both intra-feature and inter-sample relationships through its dual-attention mechanism. Its slightly lower accuracy compared to ETT may be due to its inter-sample attention, which increases training time (789.18 s vs. ETT’s 540.45 s,
Table 3). This complexity, while enhancing the model’s ability to capture population-level patterns, may introduce sensitivity to batch composition, as inter-sample attention relies on contextual information from other samples in the batch [
7].
TAPE exhibited moderate performance (88.83% accuracy, 86.15% F1 score), but demonstrated remarkable computational efficiency with the shortest training time (202.90 s), making it an attractive option for resource-constrained environments. However, its lower F1 score suggests that the pretraining phase, while effective at learning generalized representations, may not fully capture the detailed feature interactions that are critical for precise potability classification. The FTTransformer, despite its innovative feature tokenization approach, exhibited the lowest performance metrics (82.89% accuracy, 79.28% F1 score) while requiring considerable computational resources (740.24 s training time).
The detailed classification report for the EnhancedTabTransformer (
Table 4) indicates highly balanced performance across both classes. The model achieved 96% precision, recall, and F1-score for the non-drinkable class and 94% for all metrics in the drinkable class.
This balanced performance across classes is particularly valuable in water quality assessment applications, where both false positives (classifying non-potable water as potable) and false negatives (classifying potable water as non-potable) carry significant consequences for public health and resource management.
4.2. Feature Importance Analysis
Feature importance analysis (
Table 5) revealed distinct patterns in how each architecture weighted the contribution of water quality parameters to potability classification. The EnhancedTabTransformer identified chloramines (0.102632) as the most significant parameter, followed by conductivity (0.075384), and trihalomethanes (0.070908). This aligns with established water quality standards, as chloramines serve as disinfection agents with strict regulatory thresholds due to their potential health impacts at elevated concentrations.
The SAINT architecture assigned the highest importance to pH (0.194173), followed by sulfate (0.188918) and TDS solids (0.172967), suggesting that this model places greater emphasis on the chemical balance aspects of water quality. The FTTransformer displayed a more uniform distribution of feature importance values (ranging from 0.454429 to 0.564652), with sulfate (0.564652) receiving marginally higher importance. This more balanced feature weighting may partially explain the FTTransformer’s lower overall performance, as it might not sufficiently prioritize the most discriminative parameters.
The lower importance of features such as turbidity, total dissolved solids (TDS), and organic carbon across models suggests that these parameters may have less discriminatory power in this dataset. This could be attributed to their relatively narrow range of variation (e.g., turbidity: 1.45–6.49 NTU,
Table 5) or their indirect relationship to potability compared to chloramines and trihalomethanes, which are directly linked to health risks. These insights can guide sensor prioritization in water quality monitoring systems, focusing resources on measuring high-impact parameters to optimize cost and efficiency. Unfortunately, feature importance values could not be extracted for the TAPE architecture due to its complex autoencoder structure, which does not contain a suitable layer for direct weight interpretation. This highlights a limitation in model interpretability for certain deep learning architectures, particularly those employing unsupervised pretraining methodologies.
4.3. Performance with Feature Subsets
The comparative analysis using different feature subsets (
Table 6) provides critical insights into model robustness and the predictive power of specific parameter combinations. All models performed best when utilizing the full set of nine features (configuration 1*), confirming that comprehensive water quality assessment benefits from considering the full spectrum of physicochemical parameters. However, the performance degradation observed across different subset configurations varied significantly between models, revealing interesting patterns in architectural robustness.
The EnhancedTabTransformer maintained the highest accuracy across most subset configurations, with its performance dropping from 95.04% with all features to 72.95% in configuration 5* (pH, hardness, chloramines, and sulfate). This relatively smaller performance decline compared to other models suggests superior feature extraction capabilities that can maintain discriminative power even with reduced input dimensionality.
The TAPE architecture demonstrated remarkable resilience in configuration 5*, achieving the highest accuracy (75.93%) among all models for this specific feature subset. This indicates TAPE’s effective representation learning capabilities for these particular parameters, possibly attributable to its autoencoder-based pretraining that captures intrinsic structural relationships between these specific water quality indicators.
Reducing the feature set to subsets such as configuration 2* or configuration 5* led to significant performance degradation, particularly for the SAINT and FTTransformer models. This highlights the importance of diverse feature representation in capturing complex relationships within water quality data. The SAINT exhibited dramatic performance deterioration across all subset configurations, with accuracy dropping from 92.31% with all features to as low as 41.44% in configuration 4* (pH, trihalomethanes, and turbidity). This suggests that SAINT’s dual-attention mechanism might be optimized for higher-dimensional input spaces where complex feature interactions can be leveraged more effectively. The FTTransformer displayed moderate performance degradation across subset configurations, maintaining relatively consistent behavior but at lower overall accuracy levels. This indicates that while its feature tokenization approach provides stable performance characteristics, it may not extract sufficiently discriminative representations from the available water quality parameters compared to other architectures.
4.4. Statistical Analysis of Dataset Characteristics
The detailed statistical analysis of the water potability dataset (
Table 7) reveals considerable variability across all measured parameters. pH values range from highly acidic (0.23) to strongly alkaline (14.00), with a mean of 7.09 approximating neutral conditions. This variability reflects the diverse sources and conditions under which water samples were collected.
Total dissolved solids (TDS) demonstrate particularly high variability (standard deviation of 8642.24 ppm), ranging from 320.94 ppm to 56,488.67 ppm, indicating that the dataset encompasses water samples from diverse sources with varying mineral content. Chloramines, identified as the most important feature by the EnhancedTabTransformer, show concentrations ranging from 1.39 ppm to 13.13 ppm (mean: 7.13 ppm), with several samples exceeding regulatory limits for drinking water in many jurisdictions. Similarly, trihalomethanes, byproducts of water chlorination associated with potential health risks, range from 8.58 µg/L to 124.00 µg/L, with approximately 25% of samples exceeding the 80 µg/L threshold established by some regulatory agencies.
The substantial variability in water quality parameters underscores the complexity of the classification task and highlights the value of advanced machine learning approaches in capturing non-linear relationships between multiple physicochemical parameters and water potability.
4.5. Implications and Applications
The superior performance of transformer-based architectures, particularly the ETT and SAINT, demonstrates the efficacy of attention mechanisms in capturing complex relationships between water quality parameters. ETT, in particular, offers to achieve 95.04% of predictive accuracy, computational efficiency, and interpretability, making it suitable for deployment in diverse settings where comprehensive laboratory testing is challenging. Its ability to highlight key physicochemical parameters such as chloramines and conductivity can inform the design of targeted sensor arrays, reducing the complexity and cost of monitoring infrastructure. SAINT’s dual-attention mechanism, while computationally intensive, provides a unique advantage in capturing population-level patterns, which could be leveraged in large-scale environmental studies involving multiple water sources.
TAPE’s efficiency and competitive accuracy make it an appealing choice for scenarios with limited computational resources or unlabeled data, such as preliminary water quality assessments in developing regions. However, its lower F1 score suggests that further optimization, potentially through hybrid pretraining strategies, is needed to match ETT’s precision. Although FTTransformer is theoretically promising, its relatively poor performance in this study highlights the difficulty of applying transformer models to tabular data without careful hyperparameter tuning. This finding aligns with prior research indicating that transformer models can be sensitive to dataset characteristics and tuning [
4].
The feature importance analysis provides valuable insights for practical applications in water quality monitoring. The identification of chloramines, pH, and sulfate as highly influential parameters across multiple models suggests these could serve as priority indicators in rapid screening protocols. This could inform the development of more targeted and cost-effective monitoring approaches, particularly in regions where comprehensive water quality assessment resources are limited.
Comparative analysis using feature subsets further supports this application potential, demonstrating that even with reduced parameter sets, transformer-based models can maintain reasonable classification accuracy. Configuration 5* (pH, hardness, chloramines, and sulfate) yielded the highest accuracy among all subset configurations across models, suggesting this combination of parameters might offer an optimal balance between measurement simplicity and predictive power for field deployment scenarios.
4.6. Limitations and Future Research Directions
Despite the promising results, several limitations and challenges deserve careful consideration. For example, groundwater in dry regions may exhibit different physicochemical characteristics than surface water in temperate zones. Future studies should validate these architectures across diverse water quality datasets representing multi-regional and contamination scenarios.
The interpretability challenges encountered with the TAPE architecture highlight ongoing limitations in translating complex deep learning models into actionable water quality management insights. Developing more transparent autoencoder-based approaches could enhance the utility of these models in regulatory and public health contexts where decision justifications are critical.
Additionally, while the current study focused on binary potability classification, future work could explore multi-class approaches that differentiate between various treatment requirements (e.g., no treatment, conventional treatment, and advanced treatment) or specific contamination types, providing more nuanced guidance for water resource management. The study did not account for temporal dynamics in water quality, which are critical for detecting seasonal variations or event-driven contamination (e.g., heavy rainfall or industrial spills).
5. Conclusions
This comparative study focused on four advanced transformer-based deep learning models aimed at classifying water potability from physicochemical features. The experimental results indicate clear performance differences between the architectures, with enhanced tabular transformers (ETT) showing the best performance. The ETT achieved a test accuracy of nearly 95%, significantly outperforming the other models (SAINT: ~92%, TAPE: ~89%, and FTTransformer: ~83%). The F1-score of ETT (≈0.94) was likewise the highest among these, which points to its excellent precision–recall balance for drinkable and non-drinkable inferences.
Specifically, multi-head self-attention and efficient feature embeddings combined within the enhanced tabular transformer proved very beneficial for the binary classification task. The strong performance of the SAINT continues to resonate with previous reports touting its strengths, emphasizing the importance of its dual-attention mechanism, although it ranked just short of ETT in our evaluations. The TAPE model achieved competitive results aided by an unsupervised autoencoder pre-training phase, suggesting this pre-training helped, although it certainly could not rival ETT’s fully supervised approach.
Meanwhile, the FTTransformer—albeit easy and theoretically powerful on some benchmarks, was the underperformer in this study, perhaps owing to extensive hyperparameter tuning or difficulties associated with the water potability data that are very highly imbalanced. All in all, the study establishes that transformer-based deep learning frameworks are not only feasible but are among the most effective for water quality classification. The enhanced tabular transformer could be a strong basis for the development of intelligent water monitoring systems due to the state-of-the-art results it achieved on the dataset tested. Such findings serve to motivate the further embrace of advanced deep learning in environmental informatics, especially in high-risk applications such as the drinking water safety assessment. Concurrently, the study indicated that one model cannot be simply the best across the board; architecture selection must be relevant to the characteristics of the dataset and constraints in computational resources (for example, SAINT took longer to train due to its elaborate attention, whereas TAPE trained relatively fast but was a bit less accurate).
Future Directions
Multimodal data integration with temporal modeling: Future research may focus on the integration of temporal sensor data (e.g., hourly turbidity, and hourly temperature trends) through sequence-aware architecture designs, such as hybrid models wherein LSTM and transformers are mixed or through temporal fusion transformers (TFT). These models, being capable of addressing time-dependent procedural changes in water quality, will also become useful for appraising very dynamic environmental prediction scenarios. Real-life effectiveness can be checked through benchmarking on time-stamped datasets.
Recent computer vision research indicates that transformer variants may boast the ability to generalize across domains. Hwang et al. (2025) [
25] implemented transformer-compatible data augmentation and instance-based segmentation methods in estimating the dimensions of buildings in urban scenes; Park et al. (2025) [
27] incorporated advanced image enhancement techniques into transformer models of YOLOv8 to detect PPEs at construction sites. Though stemming from visual realms, the transformer-based approaches have much to offer in cross-domain adaptability and robustness, thereby implying that analog methods may also come in handy for environmental forecast studies such as water quality modeling.
Cross-domain generalization with meta-learning: To tackle the regional variability for the water sources, meta-learning algorithms (for example, MAML or Reptile) can be exercised to enhance cross-site adaptability. Fine-tuning transformer models from a few-shot samples from new locations may enforce robust generalization. The performance should be tested on a dataset from geologically different regions, for example, urban vs. rural vs. coastal settings.
Feature attribution via SHAP and integrated gradients: Whereas the interpretation of attention weights shed some light on the issue, the next steps should apply other model-agnostic interpretation methods, such as SHAP and integrated gradients to ETT and SAINT. These methods should then be able to uncover both global and local feature influences in artifacts as they would help clarify end-users the way parameters, such as pH, turbidity, or TDS, come into play in potable decisions. A comparison of interpretability methods could yield valuable insights as well.
Model compression and edge deployment: Since monitoring water might eventually occur in remote or resource-starved locales, research would also develop model-compression techniques, including pruning, quantization, and knowledge distillation, for deploying these models onto edge devices with low power. Experiments may focus on the trade-offs between inference speed and model size, and predictive accuracy.
Resistance to sensor interference and data loss: Deep models should also be examined in terms of the presence of noise, drops, and time delays in adding sensor data. Dropout methods, robust objectives, or possible Bayesian transformers (e.g., BERT with uncertainty estimation) could be applied to such conditions. Testing such under-constrained noise conditions will highlight the boundaries in operation.
Open-source benchmark and standardized evaluation: Prior work also recommended that future research focus on the creation of open-source benchmarks for the classification of water quality. The opening up of the datasets, model implementations, and evaluation pipelines will go a long way toward enhancing experiment reproducibility and more consistent comparisons across studies.



 ,
, 

{kind=link}