1. Introduction
In the five years between 2019 and 2023, there were 28,109 geologic disasters in China, 16,209 of which were landslide disasters, according to statistical data from the China Statistical Yearbook 2024 edition. Since landslides are one of the most damaging geologic disasters and result in a significant number of fatalities and financial losses each year, landslide prediction is crucial for minimizing these losses [
1].
Landslide prediction techniques include machine learning model prediction, conventional statistical prediction, and physical mechanics-based prediction. Prediction techniques based on physical mechanics necessitate additional geomechanical characteristics, which are difficult to gather. Additionally, physical mechanics techniques have more computing complexity and more stringent usage requirements [
2]. In the subject of landslide prediction, machine learning model prediction techniques and conventional statistical prediction techniques are currently gaining traction [
3,
4,
5]. Weight of evidence (WOE), logistic regression, generalized linear models (GLM), generalized additive models (GAM), and multivariate statistical analysis are examples of traditional statistical prediction models that rely on historical data and preset thresholds [
6,
7]. While these models are simple to use, they are unable to capture the complex dependencies and nonlinear relationships present in landslide data [
8]. The shortcomings of traditional statistical prediction models in capturing complex dependencies and nonlinear relationships have been addressed by machine learning techniques like decision trees [
9], support vector machines (SVMs) [
10], and random forests [
11,
12]. However, these techniques still have difficulty handling the high dimensionality and temporal dynamics of the data, and while their predictive ability is superior to that of traditional statistical models, it has demonstrated very little difference in predictive performance in a number of real-world projects [
13,
14,
15].
Deep learning techniques, known for their ability to automatically extract significant features from large and complex datasets, have become increasingly prevalent in landslide prediction models in recent years. Various studies have demonstrated the effectiveness of deep learning in enhancing prediction accuracy by handling both spatial and temporal data. For instance, Liu et al. (2022) compared the performance of convolutional neural networks (CNNs) and conventional machine learning methods in landslide susceptibility mapping, showing that CNN models outperform traditional approaches due to their ability to capture intricate spatial patterns [
16,
17,
18]. Similarly, Nguyen et al. (2022) explored the potential of recurrent neural networks (RNNs), particularly Long Short-Term Memory (LSTM) networks, in modeling temporal dependencies and forecasting landslide occurrences triggered by rainfall and earthquakes. Additionally, hybrid models combining CNN and LSTM have been proposed to address the spatiotemporal complexity of landslide data, with promising results in both spatial feature extraction and temporal dependency modeling [
17,
18,
19,
20,
21].
Long Short-Term Memory (LSTM) networks have shown notable advantages in modeling and forecasting landslide displacement due to their capability to capture long-term temporal dependencies and nonlinear relationships in sequential data. Unlike traditional neural networks, LSTM can retain and selectively forget past information, making it highly suitable for analyzing complex hydrometeorological conditions leading to landslides. Fang et al. (2021) applied LSTM to flood susceptibility prediction and found it outperformed traditional machine learning models in both sensitivity and specificity, thanks to its sequential data modeling capacity [
22]. Similarly, Liu et al. (2025) used LSTM to predict landslide displacement in the Italian Alps by incorporating rainfall, temperature, humidity, and snowmelt data. The results showed that LSTM models effectively captured the delayed and cumulative effects of snowmelt and precipitation, outperforming other configurations in both early-stage and long-term prediction scenarios [
23]. Overall, LSTM’s ability to model time-series data makes it a powerful tool for landslide forecasting, especially in environments where landslide movement is influenced by multiple interrelated factors such as rainfall, snow cover, and seasonal temperature variations.
Convolutional Neural Networks (CNNs) have gained prominence in landslide susceptibility mapping due to their powerful capabilities in spatial feature extraction and image interpretation. CNNs can automatically learn and extract complex features from satellite imagery and digital elevation models (DEMs), making them highly effective in capturing nonlinear and spatially heterogeneous triggering factors such as topographic curvature, slope, aspect, weathering, and hydrological conditions. For example, in the Gorzineh-khil region of Iran, a 15-layer CNN model integrating both topographic and hydrological factors achieved superior predictive performance—79% accuracy, 73% precision, 75% recall, and 77% F1-score—significantly outperforming conventional models such as SVM (70%), k-NN (65%), and decision trees (60%) [
24]. Similarly, in a study conducted in Icheon, South Korea, CNNs combined with metaheuristic optimization algorithms like Grey Wolf Optimizer (GWO) and Imperialist Competitive Algorithm (ICA) demonstrated enhanced performance in susceptibility mapping by improving both spatial generalization and predictive precision [
25]. These findings underline CNN’s robustness in processing high-dimensional data and modeling complex spatial patterns, making it a powerful deep learning approach for landslide prediction, particularly in regions with diverse geomorphological and hydrometeorological conditions.
Spatial Attention Mechanism (SAM) have shown notable benefits in landslide detection and prediction by enhancing feature focus, reducing background noise, and improving boundary precision. Amankwah et al. (2022) demonstrated that attention-based models like STANet and SNUNet outperform traditional CNNs in segmentation accuracy [
26]. Moghimi et al. (2024) combined SAM with LSTM, improving landslide susceptibility mapping in complex terrains [
27]. Wei et al. (2022) proposed OC-ACNN, integrating statistical knowledge and attention to boost spatial prediction accuracy [
28]. Zhang et al. (2022) introduced a multi-head self-attention LSTM model that captured abrupt displacement patterns more effectively [
29]. Overall, SAM enhances landslide modeling by capturing key spatial-temporal features and improving generalization in varied and complex environments.
However, a critical limitation persists in existing studies: they predominantly apply CNN and LSTM in isolation, thereby failing to adequately capture and model the essential dynamic coupling mechanism of spatiotemporal features that drive landslide initiation [
30,
31,
32]. Landslide triggering is frequently caused by complex multi-factor spatiotemporal interactions, including geological activity, rainwater penetration, and terrain stability, which demand integrated spatiotemporal analysis. Landslide triggering is frequently caused by multi-factor spatiotemporal interactions, including geological activity, rainwater penetration, and terrain stability. To directly address this limitation of isolated spatiotemporal modeling, this study proposes a CNN–LSTM–SAM–Attention landslide prediction model. This integrated architecture explicitly captures the dynamic coupling of spatiotemporal features by synergistically combining spatial feature extraction (CNN), temporal dependency modeling (LSTM), and dynamic feature weighting (SAM-Attention mechanism) within a cohesive spatio-temporal analytic framework [
30,
31,
32]. In order to identify long-term dependencies in time-series data, the model first uses a CNN to extract important characteristics from the original data. Lastly, the self-attention mechanism highlights the important spatiotemporal aspects by weighting the LSTM’s output [
33,
34].
This study’s primary contributions: (1) The novel integration of CNN, LSTM, and SAM self-attention mechanism within a single, end-to-end architecture. This specifically overcomes the key limitation of existing methods identified above—their inability to model the dynamic coupling of spatiotemporal features—by enabling simultaneous and synergistic extraction of spatial patterns, modeling of temporal dependencies, and dynamic weighting of salient features. (2) Compile information about the 2020 Kumamoto Prefecture landslide, build a database, and use the model suggested in this research to train and forecast. (3) Train and predict using conventional machine learning models on the same datasets and then compare the model evaluation index with the model suggested in this paper. It is demonstrated that the CNN–LSTM–SAM–Attention model can successfully capture the spatio-temporal characteristics of the data, deal with the complex and nonlinear relationships in geospatial and temporal data, and then improve the accuracy of landslide prediction by comparing evaluation indices like accuracy, precision, recall, F1 score, ROC–AUC, and PR–AUC [
35,
36].
This is how the remainder of the paper is structured.
Section 2 presents the CNN–LSTM–SAM–Attention model’s process framework and each module’s underlying principles.
Section 3 creates a database of landslide samples and describes the engineering background of the landslides in Kumamoto Prefecture. The model’s training procedure and actual outcomes are detailed in
Section 4, which also analyzes and assesses the model in light of the findings. In
Section 5, a traditional machine learning model is used to predict landslides on the same landslide sample database. The performance differences between the CNN–LSTM–SAM–Attention model suggested in this paper and the traditional machine learning model are compared. The conclusion and prospects for further study are presented in
Section 6.
2. Research Methodology (CNN–LSTM–SAM–Attention Model)
By integrating spatial feature extraction, time series modeling, and an attention-weighting mechanism, the CNN–LSTM–SAM–Attention model presented in this paper aims to increase the accuracy of landslide prediction. It consists of a convolutional neural network (CNN), a long short-term memory network (LSTM), and a spatial attention mechanism (SAM). With the help of the spatial attention mechanism, the model can better forecast outcomes by highlighting significant aspects and accurately capturing the intricate spatial and temporal connections found in landslide data.
2.1. Principles of Convolutional Neural Networks (CNN)
One deep learning model that is particularly good at handling images and spatiotemporal data is the Convolutional Neural Network (CNN). Fundamentally, it uses convolutional procedures to extract local characteristics from the input data. The input layer, convolutional layer, pooling layer, fully connected layer, and output layer are the components of a basic CNN. Each element of the input layer’s a m × n matrix has a feature value, and the input data is shown as a 2D feature map. The three main parts of a CNN are the convolutional layer, the pooling layer, and the fully connected layer. Multiple convolutional kernels are present in the convolutional layer. A set of convolutional kernels can be used to capture local representations between slippery-slope feature vectors, and additional convolutional layers can be employed to represent more complex features and iteratively learn from low-level features. In contrast, the pooling layer uses downsampling to reduce the quantity of feature information and the dimensions of the feature map, which enhances the model’s computational efficiency and lowers the possibility of overfitting. The final classification or regression operation is carried out by the fully connected layer, which combines the local features extracted by the convolutional and pooling layers into a global feature representation. The fully connected layer enhances the model’s performance by capturing the intricate patterns and correlations of the input data through the learning of weights and biases.
Rich spatial information, including topography, climate, soil characteristics, etc., is typically present in the raw data used for landslide prediction. CNN uses a convolution technique to extract valuable spatial characteristics from the raw data. Let
be the input data, where H, W, and C stand for the data’s height, width, and number of channels, respectively. The following formula can be used to define the output feature map of the convolution operation
:
where
is the output features following the convolution process,
is the convolution kernel, and
is the bias term. The CNN can efficiently capture the local spatial properties of the input data and produce more insightful inputs for time series modeling by using multi-layer convolution and pooling operations.
2.2. Principles of Long and Short-Term Memory Networks (LSTM)
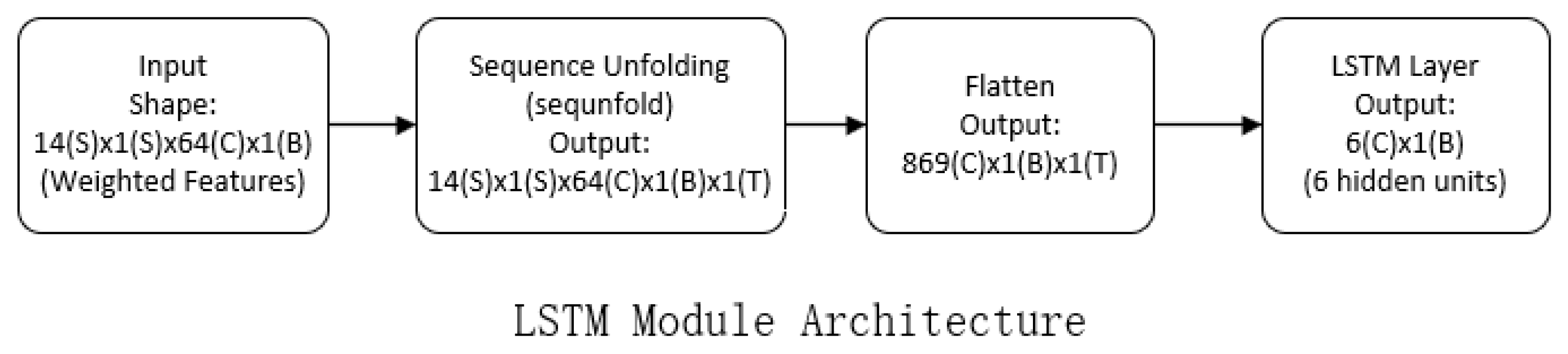
Long Short-Term Memory Network (LSTM) is a special kind of Recurrent Neural Network (RNN). RNN has the advantage of being able to relate the information from past data to the current data; nevertheless, it faces the issue of gradient vanishing or gradient expanding when the data length exceeds a particular point. To efficiently capture the long-term dependencies in time series data, the LSTM regulates the information flow by introducing three gate control units (Input Gate, Oblivious Gate, and Output Gate). It also resolves the gradient vanishing and gradient explosion issues of RNN in lengthy sequences and preserves the hidden state or memory of previous inputs.
The cell states
and hidden states
make up the LSTM’s basic structure. Through three gates, each LSTM cell regulates the output and updating of data. In particular, the output gate determines the output information at present, the forgetting gate determines the extent to which the cell state has been forgotten, and the input gate determines the impact of the current input on the cell state. The following equation represents the LSTM’s updating process:
where
,
,
are forgetting gate, input gate and output gate, respectively,
is cell state,
is hidden state,
is sigmoid activation function and
denotes element by element multiplication.
By efficiently transferring time information backward and capturing long-term temporal dependencies, the LSTM model’s strong memory capacity allows it to handle time-series data in landslide prediction tasks. This helps the model comprehend the data change trend over time, increasing prediction accuracy.
2.3. Spatial Attention Mechanism (SAM) Principles
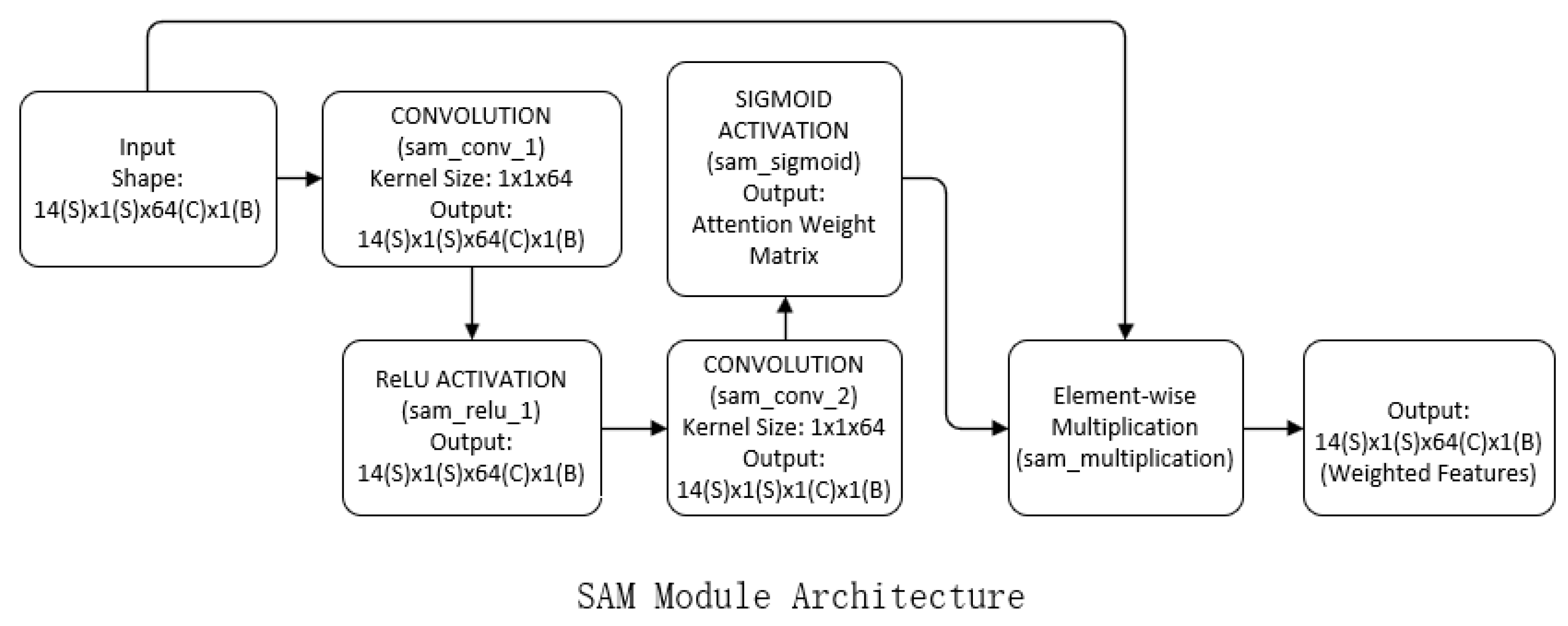
The Spatial Attention Mechanism (SAM) is an adaptive mechanism that improves the model’s capacity to represent features at significant spatial locations by giving various features in the model varying weights to emphasize significant information and suppress unimportant ones. The following is the spatial attention mechanism’s concept and implementation:
The input feature map: Assume that the input feature map is F∈R^(H × W × C), where H is the height, W is the width, and C is the number of channels.
Pooling activities:
To create a feature map with a size of 1 × 1 × C, Global Max Pooling (GMP) is applied to the input feature map in the channel dimension.
To create a new feature map with dimensions of 1 × 1 × C, the input feature map is subjected to Global Average Pooling (GAP) in the channel dimension.
- (1)
Fusion Pooling Result: To obtain a complete feature representation, fuse and together. This can be achieved by concatenating (splicing) or performing an additive operation.
- (2)
Attention weight computation: To create a spatial attention weight map , the fused features are run through a convolutional layer or another transformation function.
- (3)
Applying Attention Weights: The computed attention weight map A is applied to the original feature map to weigh the features at each spatial location. This can be achieved by element-by-element multiplication, i.e., , where · denotes element-by-element multiplication.
- (4)
Output weighted feature map: The weighted feature map will be used as an input to the subsequent network modules for subsequent tasks such as classification, detection, etc.
Specifically, given an input feature map
, the spatial attention mechanism generates an attention weight matrix
by a convolution operation indicating the importance of each spatial location. The computational process can be represented as
where
is a 2D convolution operation,
is the sigmoid activation function, and
is the generated attention weight matrix.
Following the procedures mentioned above, the Spatial Attention Mechanism Pass (SAM) may draw attention to crucial regions and highlight the characteristics of significant spatial locations in the input feature maps, enhancing the model’s prediction performance.
2.4. Process Framework
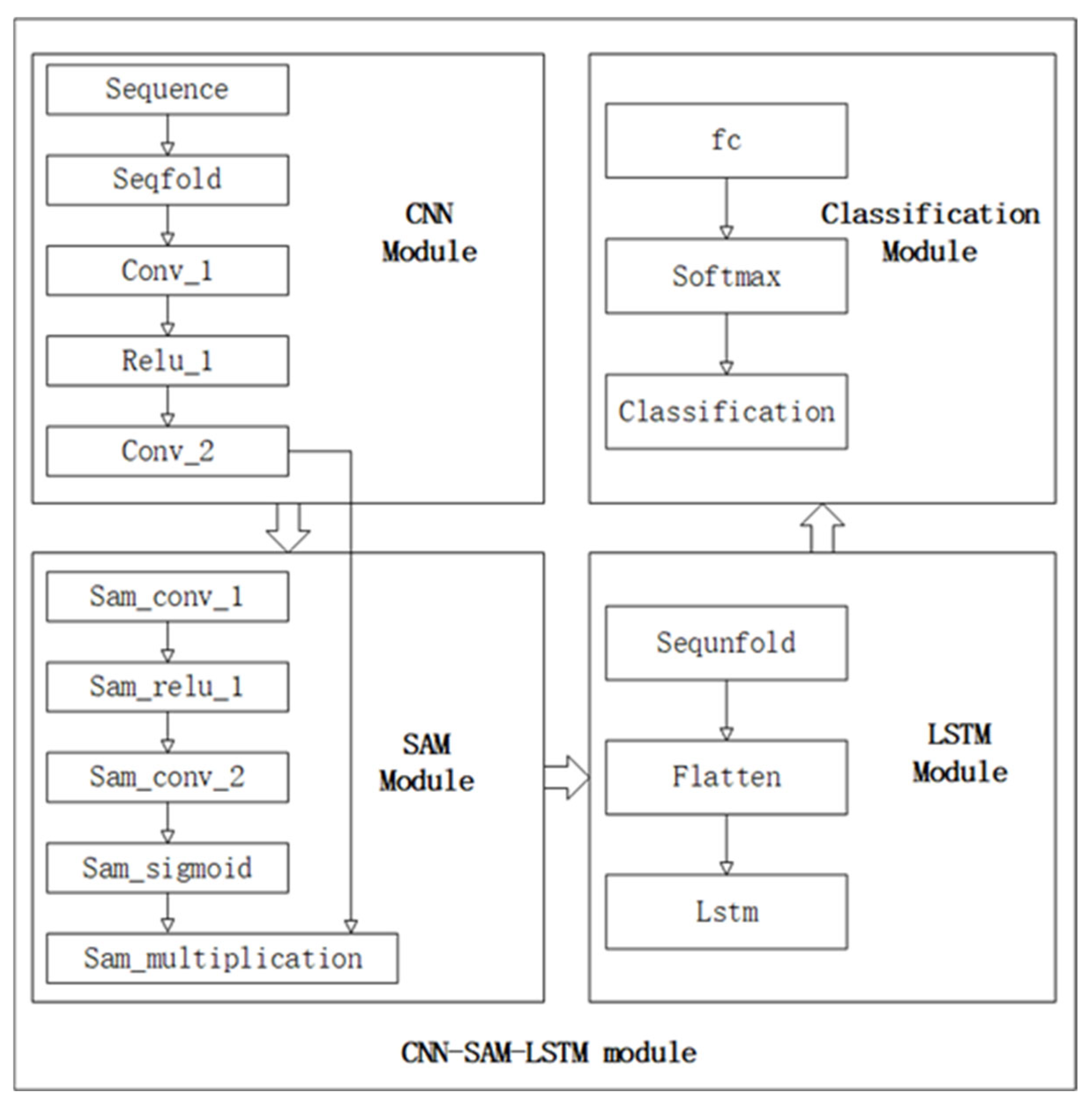
The proposed CNN–LSTM–SAM–Attention framework for landslide prediction integrates four modules: CNN (feature extraction), SAM (spatial attention), LSTM (temporal modeling), and Classification. The overall workflow is depicted in
Figure 1. Each module is detailed in subsequent subsections.
2.4.1. CNN Module
As illustrated in
Figure 2, the CNN module architecture is designed to extract hierarchical features from raw sequences.
Function: Hierarchical feature extraction from raw sequences.
Selection justification: Convolutional layers efficiently capture local spatial patterns in sensor data. The multi-scale design (progressively increasing receptive fields) models both short- and mid-range dependencies critical for early landslide indicators.
2.4.2. SAM Module
Figure 3 provides a visual representation of the SAM module architecture, demonstrating the dynamic feature weighting mechanism based on spatial significance.
Function: Dynamic feature weighting based on spatial significance.
Selection justification: Attention mechanisms suppress noise in geospatial data by focusing computational resources on critical regions (e.g., unstable slopes). This adaptive weighting improves robustness against irrelevant terrain variations.
2.4.3. LSTM Module
The LSTM module architecture, shown in
Figure 4, focuses on modeling long-term temporal dependencies critical for landslide prediction.
Function: Long-term temporal dependency modeling.
Selection justification: The LSTM module effectively models precursor event sequences where timing is critical. Its state compression mechanism balances memory retention with overfitting prevention by reducing dimensionality while preserving essential temporal patterns.
2.4.4. Classification Module
Figure 5 depicts the classification module, which maps risk probability, using a softmax classifier to provide probabilistic outputs for decision-making.
Function: Risk probability mapping.
Selection justification: A minimal classifier prevents overfitting given limited landslide event data. Softmax provides probabilistic outputs essential for risk-tiered decision making.
3. Engineering Background and Database Construction
In this paper, a database for landslide prediction is constructed using the landslide disaster data of Kumamoto Prefecture in 2020, combined with the actual geographic and meteorological data, as the input data for the CNN–LSTM–SAM–Attention model. The process of database construction and processing includes data cleaning, normalization, dimensionality reduction, and sample equalization to improve the predictive ability of the model.
3.1. Introduction to the Background of the Project
In July 2020, Kumamoto Prefecture was hit by a historically rare persistent rainstorm. The disaster was triggered by the stagnation of the Ume rain front, with cumulative rainfall exceeding 800 mm in 72 h, locally reaching the extreme rainfall standard of “once in decades” as defined by the Japan Meteorological Agency (JMA). The heavy rainfall triggered large-scale landslides and flooding, resulting in more than 50 deaths and 20 missing people, as well as the destruction of more than 2000 houses and severe damage to infrastructure (e.g., roads and bridges). Kumamoto Prefecture is located in the central part of Kyushu, with a predominantly mountainous and hilly topography, and complex geologic conditions, which have been the cause of many landslides in the past, due to both typhoons and torrential rainfalls. The large amount of multidimensional data on topography, meteorology, soil, and human activities from this disaster provides a valuable resource for landslide disaster prediction and research. Based on these data, this study processes the data and constructs a comprehensive sample database to provide rich input for model training.
3.2. Data Structure and Type
The dataset used in this study consists of tabular data, with each row representing a unique geographical location and time point, and each column representing a feature relevant to landslide prediction. The features include topographical, meteorological, and geological data, such as slope, distance from fault lines, and soil properties. This tabular structure was chosen for ease of processing and compatibility with machine learning algorithms.
A sample of the dataset, as shown in
Table 1 below, is provided to illustrate the structure and format of the data used in the model. The data includes 16 features, such as slope and proximity to fault lines, which are key factors in landslide prediction.
3.3. Data Processing and Dataset Construction
To ensure data quality, consistency, and suitability for model training, the raw data underwent a structured preprocessing pipeline before the final training dataset was assembled. The primary goal was to create a well-structured, standardized, balanced, and optimized dataset ready for input into the landslide prediction model. The resulting training dataset consists of 19,898 samples, each characterized by 16 optimized features, with balanced representation of landslide (positive) and non-landslide (negative) classes.
3.3.1. Data Cleaning
Missing values within the raw data were addressed using appropriate techniques such as mean-filling or interpolation. Outliers were identified and corrected or filtered based on predefined, physically reasonable thresholds for each variable (e.g., maximum plausible slope angle, rainfall intensity).
This step is crucial for maintaining data integrity and preventing spurious results caused by incomplete or erroneous entries. Handling missing values ensures all samples can be used, while outlier treatment prevents extreme, potentially unrepresentative values from unduly influencing model training.
3.3.2. Data Standardization
All numerical features (e.g., distance from river, slope angle, rainfall amount) were transformed using Z-score standardization. This technique rescales each feature to have a mean (μ) of 0 and a standard deviation (σ) of 1.
Features naturally exhibit different units and scales (e.g., meters for distance, degrees for slope, mm for rainfall). Standardization eliminates these magnitude disparities. This prevents features with larger native ranges from dominating the model’s learning process solely due to their scale, leading to more stable and efficient training, and ensuring all features contribute proportionally to the model’s objective function.
3.3.3. Feature Optimization
The Minimum Redundancy Maximum Relevance (mRMR) algorithm was employed to rigorously evaluate feature importance for landslide prediction. mRMR quantifies both the relevance of each feature to landslide occurrence and the redundancy among features. Analysis confirmed that all 16 original features exhibited significant predictive relevance and acceptably low mutual redundancy. Consequently, the complete feature set was retained for model training.
3.3.4. Sample Equalization (Class Balancing)
Landslide prediction inherently presents a severe class imbalance problem, with significantly fewer landslide occurrences (positive samples) compared to non-occurrences (negative samples). To address this, the SMOTE (Synthetic Minority Over-sampling Technique) algorithm was applied exclusively to the training set. SMOTE generates synthetic examples for the minority landslide class by interpolating between existing real minority samples.
This process structures the training dataset to have an approximately equal proportion of landslide and non-landslide samples. Severe class imbalance biases models towards predicting the majority class (non-landslide), as simply predicting “no landslide” yields high accuracy but fails the core prediction task. By balancing the classes within the training set using SMOTE, the model is exposed to sufficient examples of landslides during learning, enabling it to learn the characteristics of both classes effectively and reducing prediction bias towards the majority class.
After the above steps, the finally constructed database contains multi-dimensional and multi-temporal landslide prediction data, covering a variety of factors such as topography, meteorology, soil, etc., which provides high-quality data support for model training and prediction. The reasonable construction and preprocessing steps of this database lay the foundation for improving the performance of the CNN–LSTM–SAM–Attention model in landslide prediction.
5. Discussion
5.1. Results of Landslide Prediction Based on Conventional Models
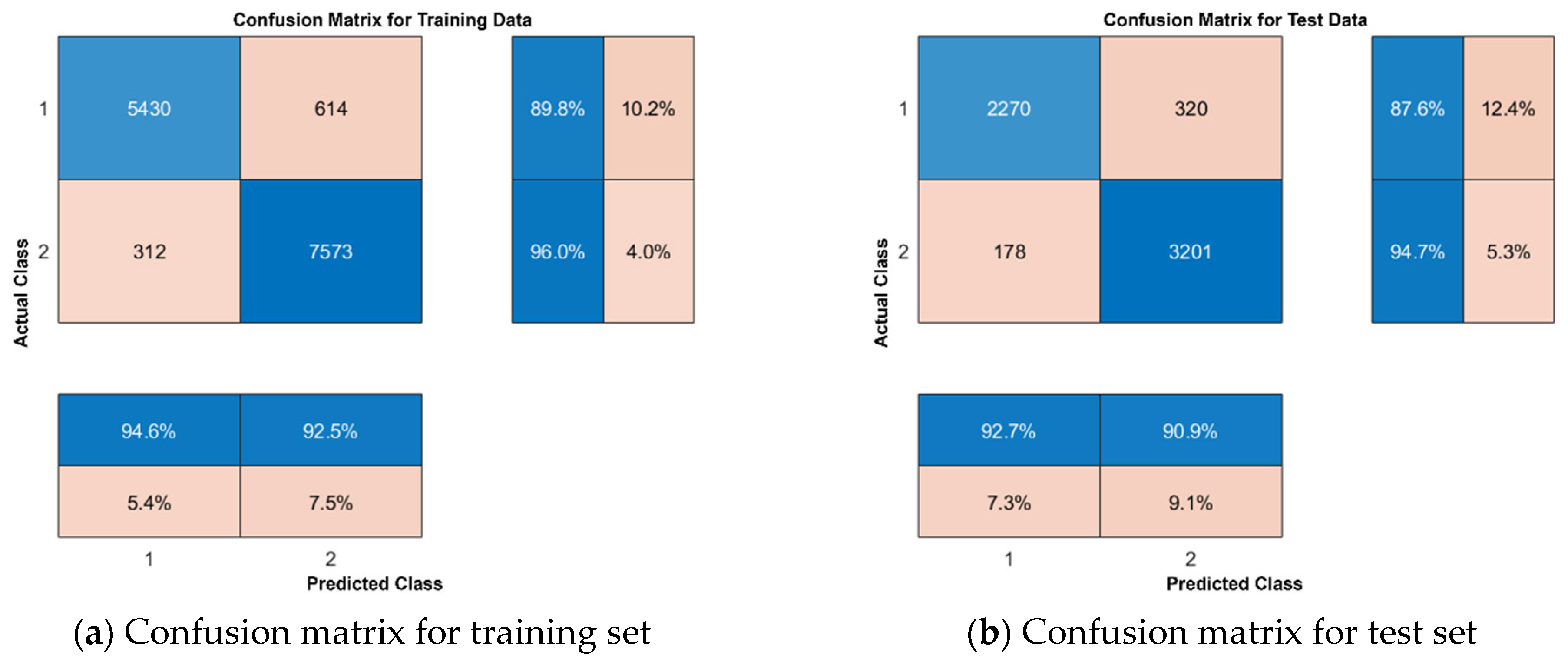
In order to verify the optimization performance of the CNN–LSTM–SAM–Attention model in the landslide prediction task, this study compares it with traditional models such as Random Forest (RF), Support Vector Machine (SVM), Logistic Regression (LR), and CNN. All models use the same training set (2020 landslide data from Kumamoto Prefecture, Japan), feature inputs, and evaluation metrics (accuracy, precision, recall, F1 score, ROC–AUC, and PR–AUC) to ensure comparable results.
The performance metrics of the Random Forest (RF), Support Vector Machine (SVM), Logistic Regression (LR), and Convolutional Neural Network (CNN) models are summarized in
Table 3:
The logistic regression (LR) model demonstrates substantially lower predictive accuracy (81.07%) compared to other models, suggesting that its linear assumption struggles to capture the nonlinear interactions among landslide-contributing factors such as slope gradient and rainfall patterns. With the lowest recall rate (70.90%) among conventional models, this approach exhibits critical deficiencies in identifying positive-class instances (landslides), potentially leading to systematic underreporting of disaster risks. The model’s comprehensive performance metrics further reveal limitations: both the F1-score (0.7624) and ROC–AUC (0.8809) remain suboptimal, particularly when handling datasets with moderate class imbalance (60% negative-class instances).
The support vector machine (SVM) achieves the highest precision (90.12%) among conventional models, demonstrating its enhanced capacity to process nonlinear features through kernel function optimization compared to logistic regression. Nevertheless, while its recall rate (79.58%) exceeds that of logistic regression, a persistent 20.42% detection gap persists, fundamentally compromising its suitability for high-reliability early-warning systems requiring near-complete landslide identification.
The random forest (RF) model demonstrates superior comprehensive performance with accuracy (88.88%), ROC–AUC (0.9535), and PR–AUC (0.8917) outperforming both SVM and logistic regression, confirming its ensemble learning mechanism effectively captures complex nonlinear relationships. A critical limitation persists: the F1-score (0.8655) reveals systematic deficiencies in precision-recall harmonization (91.01% vs. 82.51%), likely attributable to inherent decision tree overfitting tendencies or feature importance distribution imbalances within the ensemble architecture.
The convolutional neural network (CNN) demonstrates superior performance over logistic regression and SVM in both accuracy (88.14%) and recall (84.94%), confirming its efficacy in capturing localized spatial patterns within geospatial data. While achieving precision (87.37%) and ROC–AUC (0.952) comparable to Random Forest, the model’s F1-score (0.709) remains substantially lower than its counterparts, revealing systemic deficiencies in optimizing precision-recall equilibrium. Regarding class imbalance sensitivity, despite attaining an elevated PR–AUC (0.9562), the recall rate (84.94%) underperforms the integrated CNN-LSTM-SAM framework (87.64%) proposed in this work, highlighting the constrained capacity of standalone CNN architectures to sufficiently represent positive-class instances.
Core limitations of conventional modeling approaches:
Spatiotemporal feature integration deficit: No existing implementations systematically integrate multidimensional predictors (terrain rasters and rainfall sequences), failing to capture dynamic interlocking mechanisms governing landslide triggering in geological processes.
Class imbalance vulnerability: Consistently sub-85% recall rates expose systemic bias toward conservative prediction paradigms prioritizing specificity over sensitivity, compromising early-warning efficacy through underdetection risks.
These findings collectively reveal inherent performance constraints in traditional landslide prediction frameworks, necessitating architectural innovation with dynamic feature recalibration mechanisms for enhancing operational viability through holistic framework redesign.
While deep learning models like CNN often demonstrate superior capability in complex domains such as image recognition or sequential data modeling, its performance relative to the Random Forest (RF) model in this specific task warrants clarification, particularly given the introductory premise of deep learning’s potential advantages. The observed underperformance of the standalone CNN model (Accuracy: 88.14%, F1-Score: 0.7090) compared to RF (Accuracy: 88.88%, F1-Score: 0.8655) can be primarily attributed to the nature of our input data and the core operational principles of each model. Crucially, our landslide prediction task utilizes tabular data (Excel format), where each sample is represented by a fixed set of 16 distinct geospatial and climatic features per location point. This structure differs fundamentally from the dense, spatially correlated grids (e.g., images, rasters) where CNNs excel through local feature extraction via convolutional filters. Applying CNNs directly to tabular data, where explicit spatial locality between adjacent features is often absent or less meaningful, can be suboptimal. The convolutional operations may struggle to capture the complex, potentially non-local interactions between heterogeneous features (e.g., slope angle vs. antecedent rainfall) as effectively as RF’s ensemble of decision trees, which inherently perform robust feature selection and interaction modeling. Furthermore, RF’s bagging mechanism inherently mitigates overfitting, which can be a challenge for CNNs, especially with datasets of limited size relative to model complexity (as is common in geospatial applications). The CNN’s significantly lower F1-score starkly illustrates its difficulty in achieving a balanced trade-off between precision and recall on this tabular classification task under class imbalance. This highlights a key nuance: different deep learning architectures are specialized for distinct data modalities and tasks. While CNNs dominate spatially structured data, their direct application to conventional tabular feature vectors might not always yield benefits over well-tuned ensemble methods like RF for that specific data type. This limitation underscores the rationale behind our proposed CNN–LSTM–SAM–Attention model, which strategically fuses deep learning components (CNN for potential spatial patterns within derived representations, LSTM for temporal sequences) and attention mechanisms to transcend the limitations of both standalone classical models and monolithic deep learning architectures applied to heterogeneous data.
5.2. Comparative Analysis of the CNN–LSTM–SAM–Attention Model and Traditional Models
The key metrics of the CNN–LSTM–SAM–Attention model compared with traditional models are shown in
Table 3, and the following
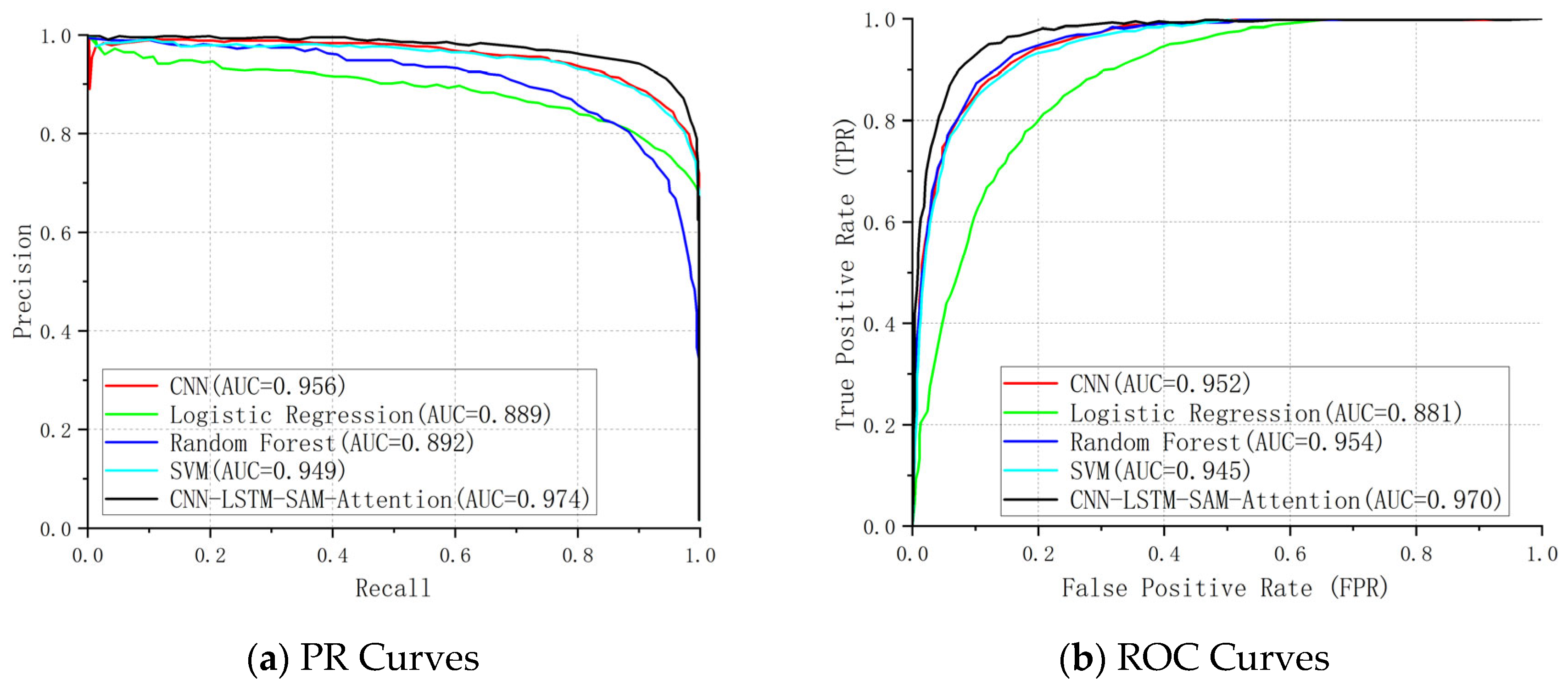
Figure 9 compares the PR curve and ROC curve graphs of each model.
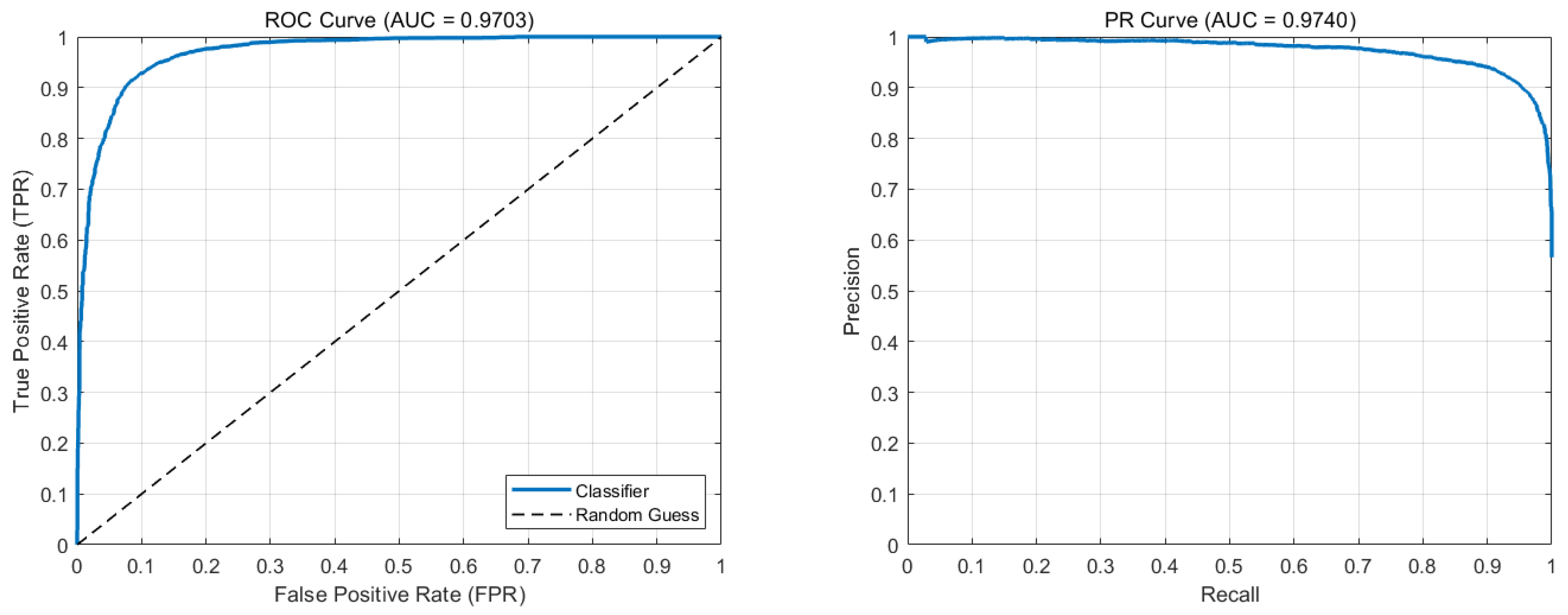
According to the comparison, the CNN–LSTM–SAM–Attention model put forth in this study outperforms the traditional models in the landslide prediction task by a considerable margin. Its strong discriminant in high-dimensional feature spaces is confirmed by the fact that both ROC–AUC (0.9703) and PR–AUC (0.9740) are substantially higher than the conventional models and near the theoretical maximum (1.0) capability.
Beginning with the fundamental metrics, including accuracy, recall, F1 value, AUC value of PR curve, and ROC curve, we compare the CNN–LSTM–SAM–Attention model’s performance to that of conventional models. The analysis is as follows:
Accuracy: The CNN–LSTM–SAM–Attention framework achieves superior accuracy (91.66%), outperforming all conventional models by 2.78–10.59 percentage points, with a 2.78% improvement over the suboptimal Random Forest (88.88%). While Random Forest (88.88%) and CNN (88.14%) demonstrate competency in static spatial feature extraction, their exclusion of temporal dynamics critically compromises adaptability to evolving landslide conditions. Similarly, SVM (87.35%) and logistic regression (81.07%) exhibit fundamental constraints in modeling complex nonlinear interactions due to inherent architectural limitations. This performance hierarchy conclusively validates the proposed model’s enhanced predictive capacity through spatiotemporal fusion (CNN-LSTM) and adaptive attention mechanisms (SAM).
Recall: 87.64% for CNN–LSTM–SAM–Attention, a 5.13% improvement over the optimal traditional model (Random Forest, 82.51%), covering more real landslide events. Logistic regression (70.90%) is only applicable to linearly divisible scenarios due to the simplicity of the model, and the risk of underreporting is extremely high.SVM (79.58%) and CNN (84.94%) do not explicitly enhance the ortho-classical sample response, although they partially alleviate the problem through nonlinear modeling. It can be seen that the SAM module of the model in this paper significantly reduces underreporting by dynamically adjusting the feature weights.
F1-score: The CNN–LSTM–SAM–Attention model achieves a superior F1-score of 0.9012, outperforming the best traditional model (Random Forest: 0.8655) by 4.1 percentage points. This demonstrates enhanced precision-recall balance (92.73% precision vs. 87.64% recall) compared to conventional approaches. Traditional models exhibit limitations: Random Forest (0.8655 F1) and SVM (0.8452 F1) show inadequate coordination between false alarms and missed detections due to unmodeled temporal dependencies, while CNN’s single spatial feature extraction results in substantially lower performance (0.709 F1). Our model’s high F1-score (>0.9) confirms its effectiveness in maintaining safety-economic equilibrium for disaster prevention applications.
PR–AUC: The CNN–LSTM–SAM–Attention model achieves a superior PR–AUC of 0.9740, substantially exceeding conventional methods (logistic regression: 0.8885; SVM: 0.9487). Notably, our solution maintains precision >90% in high-recall regimes (Recall > 0.8) (
Figure 8), demonstrating effective coverage of landslide events with minimal false positives while preserving operational reliability.
ROC–AUC: The CNN–LSTM–SAM–Attention model achieves a near-optimal ROC–AUC of 0.9703, significantly outperforming conventional approaches (e.g., logistic regression: 0.8809; SVM: 0.9453). While Random Forest (0.9535) and CNN (0.9520) demonstrate relatively strong performance, their inability to model temporal features results in compromised dynamic event discrimination. Notably, our model maintains a true positive rate (TPR) > 0.9 at a low false positive rate (FPR = 0.2) (
Figure 8), demonstrating precise differentiation between landslide and non-landslide events while effectively preventing unnecessary emergency response activations.
Comparison results show that the CNN–LSTM–SAM–Attention model comprehensively surpasses traditional models in five indices: accuracy, recall, F1 value, PR–AUC, and ROC–AUC, and provides a high-precision and high-reliability solution for landslide prediction tasks, which can be applied to disaster warning under complex terrain and dynamic climate conditions.
5.3. Model Component Contribution Analysis
The proposed CNN-LSTM-SAM framework integrates three core modules to address the limitations of conventional landslide prediction models. Based on the experimental results and architectural mechanisms, the specific contributions of each component are analyzed as follows:
The CNN module processes the 16-dimensional tabular feature vectors by reorganizing them into spatial representations through feature embedding layers. This transformation enables convolutional operations to extract local feature interactions and nonlinear patterns within the 16 geospatial factors. As shown in
Table 3, the standalone CNN achieves 88.14% accuracy and 84.94% recall—significantly outperforming logistic regression and SVM models. This demonstrates CNN’s capacity to capture complex relationships within tabular data, particularly for terrain-related features like slope gradient and soil composition.
The LSTM module handles sequential dependencies within the feature set. By processing any inherent temporal patterns or ordered dependencies within the 16 feature dimensions, it captures dynamic interactions and temporal evolution patterns among factors such as vegetation index changes and soil moisture variations. The 3.52% accuracy gain of the full framework (91.66%) over standalone CNN (88.14%) validates LSTM’s critical role in modeling feature dynamics, which is further evidenced by the 2.13% recall improvement (87.64% vs. 85.51% for RF).
The SAM (Spatial Attention Module) dynamically recalibrates feature importance across the spatial dimensions derived from CNN outputs. This mechanism focuses computational resources on the most discriminative features while suppressing noise from less relevant factors. As demonstrated in
Figure 9a, the framework maintains precision >90% across recall levels >0.8—a capability directly attributable to SAM’s selective weighting of high-impact spatial patterns in complex terrain environments.
Collectively, these components establish a synergistic processing chain: CNN extracts localized feature representations, LSTM models dynamic interactions, and SAM optimizes feature weighting. This integrated architecture overcomes the feature integration limitations of conventional approaches while achieving state-of-the-art performance.
5.4. Model Limitations
While the CNN–LSTM–SAM–Attention model provides significant improvements over traditional machine learning models, it is not without limitations. One of the primary constraints is the model’s reliance on a comprehensive dataset of landslide occurrences and related factors. The performance of the model is directly tied to the quality and quantity of the input data. Although we have taken extensive measures to clean, standardize, and balance the dataset, any inconsistencies or biases in the dataset could affect the model’s accuracy and generalizability.
Furthermore, the model assumes that spatial and temporal relationships remain relatively consistent within the training data’s geographic region. This assumption may limit the model’s ability to predict landslide susceptibility accurately in areas with significantly different environmental, climatic, or geological conditions. The CNN and LSTM components, while powerful, may also struggle with spatial data that does not exhibit clear local patterns or temporal sequences. In such cases, the convolutional layers may not extract meaningful features, and the LSTM may fail to capture temporal dependencies.
Additionally, despite the integration of the Spatial Attention Mechanism (SAM), which helps focus on relevant spatial regions, the model may still be sensitive to background noise and less significant features in certain cases. This can lead to occasional misclassifications in complex terrains where multiple variables interact in unpredictable ways.
5.5. Transferability to Other Regions
The transferability of the CNN–LSTM–SAM–Attention model to regions beyond Kumamoto Prefecture remains a critical area for future exploration. While the model has demonstrated excellent performance on the Kumamoto dataset, its success in other regions would depend on the availability of high-quality data and the similarity of spatial and temporal patterns. Landslide susceptibility is highly context-dependent, and factors such as topography, rainfall patterns, soil composition, and human activities can vary significantly from region to region.
In order to apply the model to other areas, additional data collection would be required to ensure that the model can adapt to different geographical conditions. It may be necessary to fine-tune the model or retrain it using region-specific datasets to achieve optimal performance. Future work should focus on testing the model in various regions, including regions with differing climatic and geological conditions, to assess its robustness and adaptability. Techniques like transfer learning may also be explored to improve the model’s ability to generalize across diverse environments.
In conclusion, while the CNN–LSTM–SAM–Attention model shows promising results in Kumamoto Prefecture, further validation and adaptation to different regions are essential to fully assess its transferability. A more in-depth analysis of model limitations and its ability to predict landslide susceptibility in diverse regions will help enhance the model’s robustness and reliability in real-world applications.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}